Refine search
Actions for selected content:
109 results
Explaining Differences in Voting Patterns across Voting Domains Using Hierarchical Bayesian Models
-
- Journal:
- Political Analysis , First View
- Published online by Cambridge University Press:
- 27 August 2025, pp. 1-21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The chronology of the Early Neolithic Baraba culture, southwestern Siberia: New radiocarbon evidence
-
- Journal:
- Radiocarbon / Volume 67 / Issue 4 / August 2025
- Published online by Cambridge University Press:
- 22 August 2025, pp. 803-818
- Print publication:
- August 2025
-
- Article
- Export citation
12 - Closing Comments and Future Directions
-
- Book:
- Spatial Analysis
- Published online:
- 19 June 2025
- Print publication:
- 03 July 2025, pp 331-360
-
- Chapter
- Export citation
Investigating classical χ2 test methods for high-precision calibration of radiocarbon measurements
-
- Journal:
- Radiocarbon / Volume 67 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 27 March 2025, pp. 646-655
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Assessing the spatio-temporal pattern and determinants of child marriage in Nigeria
-
- Journal:
- Journal of Biosocial Science / Volume 57 / Issue 2 / March 2025
- Published online by Cambridge University Press:
- 17 March 2025, pp. 279-295
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Behavioral welfare economics and risk preferences: a Bayesian approach
-
- Journal:
- Experimental Economics / Volume 26 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 14 March 2025, pp. 273-303
-
- Article
- Export citation
Evolutionary Preference/Utility Functions: A Dynamic Perspective
-
- Journal:
- Psychometrika / Volume 70 / Issue 1 / March 2005
- Published online by Cambridge University Press:
- 01 January 2025, pp. 179-202
-
- Article
- Export citation
Confidence Regions for Multidimensional Scaling Analysis
-
- Journal:
- Psychometrika / Volume 43 / Issue 2 / June 1978
- Published online by Cambridge University Press:
- 01 January 2025, pp. 145-160
-
- Article
- Export citation
A Comment on ‘Some Standard Errors in Item Response Theory’
-
- Journal:
- Psychometrika / Volume 49 / Issue 2 / June 1984
- Published online by Cambridge University Press:
- 01 January 2025, pp. 269-272
-
- Article
- Export citation
A Bayesian Vector Multidimensional Scaling Procedure Incorporating Dimension Reparameterization with Variable Selection
-
- Journal:
- Psychometrika / Volume 80 / Issue 4 / December 2015
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1043-1065
-
- Article
- Export citation
A Taxonomy of Latent Structure Assumptions for Probability Matrix Decomposition Models
-
- Journal:
- Psychometrika / Volume 68 / Issue 1 / March 2003
- Published online by Cambridge University Press:
- 01 January 2025, pp. 61-77
-
- Article
- Export citation
A Bayesian Multinomial Probit Model for The Analysis of Panel Choice Data
-
- Journal:
- Psychometrika / Volume 81 / Issue 1 / March 2016
- Published online by Cambridge University Press:
- 01 January 2025, pp. 161-183
-
- Article
- Export citation
A Bayesian Analysis of Finite Mixtures in the LISREL Model
-
- Journal:
- Psychometrika / Volume 66 / Issue 1 / March 2001
- Published online by Cambridge University Press:
- 01 January 2025, pp. 133-152
-
- Article
- Export citation
A Hierarchical Bayesian Statistical Framework for Response Time Distributions
-
- Journal:
- Psychometrika / Volume 68 / Issue 4 / December 2003
- Published online by Cambridge University Press:
- 01 January 2025, pp. 589-606
-
- Article
- Export citation
Bayesian Inference for an Unknown Number of Attributes in Restricted Latent Class Models
-
- Journal:
- Psychometrika / Volume 88 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 613-635
-
- Article
- Export citation
-
The specification of the \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
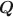 matrix in cognitive diagnosis models is important for correct classification of attribute profiles. Researchers have proposed many methods for estimation and validation of the data-driven \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
matrix in cognitive diagnosis models is important for correct classification of attribute profiles. Researchers have proposed many methods for estimation and validation of the data-driven \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}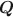 matrices. However, inference of the number of attributes in the general restricted latent class model remains an open question. We propose a Bayesian framework for general restricted latent class models and use the spike-and-slab prior to avoid the computation issues caused by the varying dimensions of model parameters associated with the number of attributes, K. We develop an efficient Metropolis-within-Gibbs algorithm to estimate K and the corresponding \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
matrices. However, inference of the number of attributes in the general restricted latent class model remains an open question. We propose a Bayesian framework for general restricted latent class models and use the spike-and-slab prior to avoid the computation issues caused by the varying dimensions of model parameters associated with the number of attributes, K. We develop an efficient Metropolis-within-Gibbs algorithm to estimate K and the corresponding \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}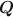 matrix simultaneously. The proposed algorithm uses the stick-breaking construction to mimic an Indian buffet process and employs a novel Metropolis–Hastings transition step to encourage exploring the sample space associated with different values of K. We evaluate the performance of the proposed method through a simulation study under different model specifications and apply the method to a real data set related to a fluid intelligence matrix reasoning test.
matrix simultaneously. The proposed algorithm uses the stick-breaking construction to mimic an Indian buffet process and employs a novel Metropolis–Hastings transition step to encourage exploring the sample space associated with different values of K. We evaluate the performance of the proposed method through a simulation study under different model specifications and apply the method to a real data set related to a fluid intelligence matrix reasoning test.
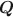
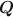
An Augmented Variable Dirichlet Process mixture model for the analysis of dependent lifetimes
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 02 December 2024, pp. 50-75
- Print publication:
- January 2025
-
- Article
- Export citation
Explaining Recruitment to Extremism: A Bayesian Hierarchical Case–Control Approach
-
- Journal:
- Political Analysis / Volume 32 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 16 November 2023, pp. 256-274
-
- Article
- Export citation
Global and local evolutionary dynamics of Dengue virus serotypes 1, 3, and 4
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 09 June 2023, e127
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
10 - Causal Process Tracing
- from Part III - What about Causality?
-
- Book:
- The Grammar of Time
- Published online:
- 11 May 2023
- Print publication:
- 25 May 2023, pp 164-182
-
- Chapter
- Export citation
8 - Approximate Bayesian Computation
-
-
- Book:
- New Handbook of Mathematical Psychology
- Published online:
- 20 April 2023
- Print publication:
- 27 April 2023, pp 357-384
-
- Chapter
- Export citation
