In this paper we develop a collection of results associated to the analysis of the sequential Monte Carlo (SMC) samplers algorithm, in the context of high-dimensional independent and identically distributed target probabilities. The SMC samplers algorithm can be designed to sample from a single probability distribution, using Monte Carlo to approximate expectations with respect to this law. Given a target density in d dimensions our results are concerned with d → ∞, while the number of Monte Carlo samples, N, remains fixed. We deduce an explicit bound on the Monte-Carlo error for estimates derived using the SMC sampler and the exact asymptotic relative 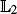 -error of the estimate of the normalising constant associated to the target. We also establish marginal propagation of chaos properties of the algorithm. These results are deduced when the cost of the algorithm is O(Nd2).
-error of the estimate of the normalising constant associated to the target. We also establish marginal propagation of chaos properties of the algorithm. These results are deduced when the cost of the algorithm is O(Nd2).

