Pitman (2003), and subsequently Gnedin and Pitman (2006), showed that a large class of random partitions of the integers derived from a stable subordinator of index 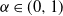 $\alpha\in(0,1)$ have infinite Gibbs (product) structure as a characterizing feature. The most notable case are random partitions derived from the two-parameter Poisson–Dirichlet distribution,
$\alpha\in(0,1)$ have infinite Gibbs (product) structure as a characterizing feature. The most notable case are random partitions derived from the two-parameter Poisson–Dirichlet distribution, 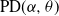 $\textrm{PD}(\alpha,\theta)$, whose corresponding
$\textrm{PD}(\alpha,\theta)$, whose corresponding  $\alpha$-diversity/local time have generalized Mittag–Leffler distributions, denoted by
$\alpha$-diversity/local time have generalized Mittag–Leffler distributions, denoted by 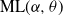 $\textrm{ML}(\alpha,\theta)$. Our aim in this work is to provide indications on the utility of the wider class of Gibbs partitions as it relates to a study of Riemann–Liouville fractional integrals and size-biased sampling, and in decompositions of special functions, and its potential use in the understanding of various constructions of more exotic processes. We provide characterizations of general laws associated with nested families of
$\textrm{ML}(\alpha,\theta)$. Our aim in this work is to provide indications on the utility of the wider class of Gibbs partitions as it relates to a study of Riemann–Liouville fractional integrals and size-biased sampling, and in decompositions of special functions, and its potential use in the understanding of various constructions of more exotic processes. We provide characterizations of general laws associated with nested families of 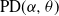 $\textrm{PD}(\alpha,\theta)$ mass partitions that are constructed from fragmentation operations described in Dong et al. (2014). These operations are known to be related in distribution to various constructions of discrete random trees/graphs in [n], and their scaling limits. A centerpiece of our work is results related to Mittag–Leffler functions, which play a key role in fractional calculus and are otherwise Laplace transforms of the
$\textrm{PD}(\alpha,\theta)$ mass partitions that are constructed from fragmentation operations described in Dong et al. (2014). These operations are known to be related in distribution to various constructions of discrete random trees/graphs in [n], and their scaling limits. A centerpiece of our work is results related to Mittag–Leffler functions, which play a key role in fractional calculus and are otherwise Laplace transforms of the 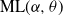 $\textrm{ML}(\alpha,\theta)$ variables. Notably, this leads to an interpretation within the context of
$\textrm{ML}(\alpha,\theta)$ variables. Notably, this leads to an interpretation within the context of 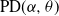 $\textrm{PD}(\alpha,\theta)$ laws conditioned on Poisson point process counts over intervals of scaled lengths of the
$\textrm{PD}(\alpha,\theta)$ laws conditioned on Poisson point process counts over intervals of scaled lengths of the  $\alpha$-diversity.
$\alpha$-diversity.
In this article we prove new central limit theorems (CLTs) for several coupled particle filters (CPFs). CPFs are used for the sequential estimation of the difference of expectations with respect to filters which are in some sense close. Examples include the estimation of the filtering distribution associated to different parameters (finite difference estimation) and filters associated to partially observed discretized diffusion processes (PODDP) and the implementation of the multilevel Monte Carlo (MLMC) identity. We develop new theory for CPFs, and based upon several results, we propose a new CPF which approximates the maximal coupling (MCPF) of a pair of predictor distributions. In the context of ML estimation associated to PODDP with time-discretization 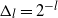 $\Delta_l=2^{-l}$
,
$\Delta_l=2^{-l}$
, 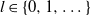 $l\in\{0,1,\dots\}$
, we show that the MCPF and the approach of Jasra, Ballesio, et al. (2018) have, under certain assumptions, an asymptotic variance that is bounded above by an expression that is of (almost) the order of
$l\in\{0,1,\dots\}$
, we show that the MCPF and the approach of Jasra, Ballesio, et al. (2018) have, under certain assumptions, an asymptotic variance that is bounded above by an expression that is of (almost) the order of 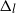 $\Delta_l$
(
$\Delta_l$
(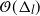 $\mathcal{O}(\Delta_l)$
), uniformly in time. The
$\mathcal{O}(\Delta_l)$
), uniformly in time. The 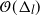 $\mathcal{O}(\Delta_l)$
bound preserves the so-called forward rate of the diffusion in some scenarios, which is not the case for the CPF in Jasra et al. (2017).
$\mathcal{O}(\Delta_l)$
bound preserves the so-called forward rate of the diffusion in some scenarios, which is not the case for the CPF in Jasra et al. (2017).
Both sequential Monte Carlo (SMC) methods (a.k.a. ‘particle filters’) and sequential Markov chain Monte Carlo (sequential MCMC) methods constitute classes of algorithms which can be used to approximate expectations with respect to (a sequence of) probability distributions and their normalising constants. While SMC methods sample particles conditionally independently at each time step, sequential MCMC methods sample particles according to a Markov chain Monte Carlo (MCMC) kernel. Introduced over twenty years ago in [6], sequential MCMC methods have attracted renewed interest recently as they empirically outperform SMC methods in some applications. We establish an 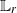 $\mathbb{L}_r$
-inequality (which implies a strong law of large numbers) and a central limit theorem for sequential MCMC methods and provide conditions under which errors can be controlled uniformly in time. In the context of state-space models, we also provide conditions under which sequential MCMC methods can indeed outperform standard SMC methods in terms of asymptotic variance of the corresponding Monte Carlo estimators.
$\mathbb{L}_r$
-inequality (which implies a strong law of large numbers) and a central limit theorem for sequential MCMC methods and provide conditions under which errors can be controlled uniformly in time. In the context of state-space models, we also provide conditions under which sequential MCMC methods can indeed outperform standard SMC methods in terms of asymptotic variance of the corresponding Monte Carlo estimators.
Let  $X_1, X_2,\dots$
be a short-memory linear process of random variables. For
$X_1, X_2,\dots$
be a short-memory linear process of random variables. For 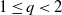 $1\leq q<2$
, let
$1\leq q<2$
, let 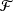 ${\mathcal{F}}$
be a bounded set of real-valued functions on [0, 1] with finite q-variation. It is proved that
${\mathcal{F}}$
be a bounded set of real-valued functions on [0, 1] with finite q-variation. It is proved that 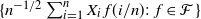 $\{n^{-1/2}\sum_{i=1}^nX_i\,f(i/n)\colon f\in{\mathcal{F}}\}$
converges in outer distribution in the Banach space of bounded functions on
$\{n^{-1/2}\sum_{i=1}^nX_i\,f(i/n)\colon f\in{\mathcal{F}}\}$
converges in outer distribution in the Banach space of bounded functions on 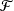 ${\mathcal{F}}$
as
${\mathcal{F}}$
as  $n\to\infty$
. Several applications to a regression model and a multiple change point model are given.
$n\to\infty$
. Several applications to a regression model and a multiple change point model are given.
We consider a class of correlated Bernoulli variables, which have the following form: for some 0 < p < 1,
where 0 ≤ θj ≤ 1, 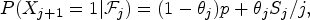 $$\begin{align}{P(X_{j+1}=1 \vert {\cal F}_{j})= (1-\theta_j)p+\theta_jS_j/j,}\end{align}$$
$$\begin{align}{P(X_{j+1}=1 \vert {\cal F}_{j})= (1-\theta_j)p+\theta_jS_j/j,}\end{align}$$ $S_n=\sum _{j=1}^nX_j$ and
$S_n=\sum _{j=1}^nX_j$ and 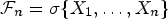 ${\cal F}_n=\sigma \{X_1,\ldots , X_n\}$. The aim of this paper is to establish the strong law of large numbers which extend some known results, and prove the moderate deviation principle for the correlated Bernoulli model.
${\cal F}_n=\sigma \{X_1,\ldots , X_n\}$. The aim of this paper is to establish the strong law of large numbers which extend some known results, and prove the moderate deviation principle for the correlated Bernoulli model.

