We investigate some aspects of the problem of the estimation of birth distributions (BDs) in multi-type Galton–Watson trees (MGWs) with unobserved types. More precisely, we consider two-type MGWs called spinal-structured trees. This kind of tree is characterized by a spine of special individuals whose BD  $\nu$ is different from the other individuals in the tree (called normal, and whose BD is denoted by
$\nu$ is different from the other individuals in the tree (called normal, and whose BD is denoted by 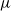 $\mu$). In this work, we show that even in such a very structured two-type population, our ability to distinguish the two types and estimate
$\mu$). In this work, we show that even in such a very structured two-type population, our ability to distinguish the two types and estimate 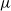 $\mu$ and
$\mu$ and  $\nu$ is constrained by a trade-off between the growth-rate of the population and the similarity of
$\nu$ is constrained by a trade-off between the growth-rate of the population and the similarity of 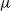 $\mu$ and
$\mu$ and  $\nu$. Indeed, if the growth-rate is too large, large deviation events are likely to be observed in the sampling of the normal individuals, preventing us from distinguishing them from special ones. Roughly speaking, our approach succeeds if
$\nu$. Indeed, if the growth-rate is too large, large deviation events are likely to be observed in the sampling of the normal individuals, preventing us from distinguishing them from special ones. Roughly speaking, our approach succeeds if 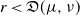 $r\lt \mathfrak{D}(\mu,\nu)$, where r is the exponential growth-rate of the population and
$r\lt \mathfrak{D}(\mu,\nu)$, where r is the exponential growth-rate of the population and 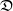 $\mathfrak{D}$ is a divergence measuring the dissimilarity between
$\mathfrak{D}$ is a divergence measuring the dissimilarity between 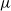 $\mu$ and
$\mu$ and  $\nu$.
$\nu$.
We study the community detection problem on a Gaussian mixture model, in which vertices are divided into  $k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.
$k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.
Let 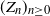 $(Z_n)_{n\geq0}$ be a supercritical Galton–Watson process. Consider the Lotka–Nagaev estimator for the offspring mean. In this paper we establish self-normalized Cramér-type moderate deviations and Berry–Esseen bounds for the Lotka–Nagaev estimator. The results are believed to be optimal or near-optimal.
$(Z_n)_{n\geq0}$ be a supercritical Galton–Watson process. Consider the Lotka–Nagaev estimator for the offspring mean. In this paper we establish self-normalized Cramér-type moderate deviations and Berry–Esseen bounds for the Lotka–Nagaev estimator. The results are believed to be optimal or near-optimal.
Consider the problem of determining the Bayesian credibility mean 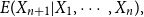 $E(X_{n+1}|X_1,\cdots, X_n),$ whenever the random claims
$E(X_{n+1}|X_1,\cdots, X_n),$ whenever the random claims 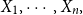 $X_1,\cdots, X_n,$ given parameter vector
$X_1,\cdots, X_n,$ given parameter vector 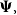 $\boldsymbol{\Psi},$ are sampled from the K-component mixture family of distributions, whose members are the union of different families of distributions. This article begins by deriving a recursive formula for such a Bayesian credibility mean. Moreover, under the assumption that using additional information
$\boldsymbol{\Psi},$ are sampled from the K-component mixture family of distributions, whose members are the union of different families of distributions. This article begins by deriving a recursive formula for such a Bayesian credibility mean. Moreover, under the assumption that using additional information 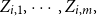 $Z_{i,1},\cdots,Z_{i,m},$ one may probabilistically determine a random claim
$Z_{i,1},\cdots,Z_{i,m},$ one may probabilistically determine a random claim 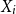 $X_i$ belongs to a given population (or a distribution), the above recursive formula simplifies to an exact Bayesian credibility mean whenever all components of the mixture distribution belong to the exponential families of distributions. For a situation where a 2-component mixture family of distributions is an appropriate choice for data modelling, using the logistic regression model, it shows that: how one may employ such additional information to derive the Bayesian credibility model, say Logistic Regression Credibility model, for a finite mixture of distributions. A comparison between the Logistic Regression Credibility (LRC) model and its competitor, the Regression Tree Credibility (RTC) model, has been given. More precisely, it shows that under the squared error loss function, it shows the LRC’s risk function dominates the RTC’s risk function at least in an interval which about
$X_i$ belongs to a given population (or a distribution), the above recursive formula simplifies to an exact Bayesian credibility mean whenever all components of the mixture distribution belong to the exponential families of distributions. For a situation where a 2-component mixture family of distributions is an appropriate choice for data modelling, using the logistic regression model, it shows that: how one may employ such additional information to derive the Bayesian credibility model, say Logistic Regression Credibility model, for a finite mixture of distributions. A comparison between the Logistic Regression Credibility (LRC) model and its competitor, the Regression Tree Credibility (RTC) model, has been given. More precisely, it shows that under the squared error loss function, it shows the LRC’s risk function dominates the RTC’s risk function at least in an interval which about 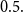 $0.5.$ Several examples have been given to illustrate the practical application of our findings.
$0.5.$ Several examples have been given to illustrate the practical application of our findings.
Let 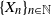 $\{X_n\}_{n\in{\mathbb{N}}}$ be an
$\{X_n\}_{n\in{\mathbb{N}}}$ be an 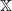 ${\mathbb{X}}$-valued iterated function system (IFS) of Lipschitz maps defined as
${\mathbb{X}}$-valued iterated function system (IFS) of Lipschitz maps defined as 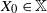 $X_0 \in {\mathbb{X}}$ and for
$X_0 \in {\mathbb{X}}$ and for 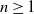 $n\geq 1$,
$n\geq 1$, 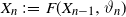 $X_n\;:\!=\;F(X_{n-1},\vartheta_n)$, where
$X_n\;:\!=\;F(X_{n-1},\vartheta_n)$, where 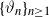 $\{\vartheta_n\}_{n \ge 1}$ are independent and identically distributed random variables with common probability distribution
$\{\vartheta_n\}_{n \ge 1}$ are independent and identically distributed random variables with common probability distribution 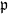 $\mathfrak{p}$,
$\mathfrak{p}$, 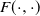 $F(\cdot,\cdot)$ is Lipschitz continuous in the first variable, and
$F(\cdot,\cdot)$ is Lipschitz continuous in the first variable, and 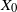 $X_0$ is independent of
$X_0$ is independent of 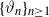 $\{\vartheta_n\}_{n \ge 1}$. Under parametric perturbation of both F and
$\{\vartheta_n\}_{n \ge 1}$. Under parametric perturbation of both F and 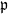 $\mathfrak{p}$, we are interested in the robustness of the V-geometrical ergodicity property of
$\mathfrak{p}$, we are interested in the robustness of the V-geometrical ergodicity property of 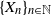 $\{X_n\}_{n\in{\mathbb{N}}}$, of its invariant probability measure, and finally of the probability distribution of
$\{X_n\}_{n\in{\mathbb{N}}}$, of its invariant probability measure, and finally of the probability distribution of 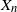 $X_n$. Specifically, we propose a pattern of assumptions for studying such robustness properties for an IFS. This pattern is implemented for the autoregressive processes with autoregressive conditional heteroscedastic errors, and for IFS under roundoff error or under thresholding/truncation. Moreover, we provide a general set of assumptions covering the classical Feller-type hypotheses for an IFS to be a V-geometrical ergodic process. An accurate bound for the rate of convergence is also provided.
$X_n$. Specifically, we propose a pattern of assumptions for studying such robustness properties for an IFS. This pattern is implemented for the autoregressive processes with autoregressive conditional heteroscedastic errors, and for IFS under roundoff error or under thresholding/truncation. Moreover, we provide a general set of assumptions covering the classical Feller-type hypotheses for an IFS to be a V-geometrical ergodic process. An accurate bound for the rate of convergence is also provided.
Bifurcating Markov chains (BMCs) are Markov chains indexed by a full binary tree representing the evolution of a trait along a population where each individual has two children. We provide a central limit theorem for additive functionals of BMCs under 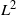 $L^2$
-ergodic conditions with three different regimes. This completes the pointwise approach developed in a previous work. As an application, we study the elementary case of a symmetric bifurcating autoregressive process, which justifies the nontrivial hypothesis considered on the kernel transition of the BMCs. We illustrate in this example the phase transition observed in the fluctuations.
$L^2$
-ergodic conditions with three different regimes. This completes the pointwise approach developed in a previous work. As an application, we study the elementary case of a symmetric bifurcating autoregressive process, which justifies the nontrivial hypothesis considered on the kernel transition of the BMCs. We illustrate in this example the phase transition observed in the fluctuations.

