Refine search
Actions for selected content:
48917 results in Computer Science

Crises at Work
- Economy, Climate and Pandemic
-
- Published by:
- Bristol University Press
- Published online:
- 27 December 2024
- Print publication:
- 06 September 2024
Vortex gust mitigation from onboard measurements using deep reinforcement learning
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 27 December 2024, e47
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper proposes to solve the vortex gust mitigation problem on a 2D, thin flat plate using onboard measurements. The objective is to solve the discrete-time optimal control problem of finding the pitch rate sequence that minimizes the lift perturbation, that is, the criterion
 where
where 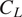 is the lift coefficient obtained by the unsteady vortex lattice method. The controller is modeled as an artificial neural network, and it is trained to minimize
is the lift coefficient obtained by the unsteady vortex lattice method. The controller is modeled as an artificial neural network, and it is trained to minimize 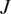 using deep reinforcement learning (DRL). To be optimal, we show that the controller must take as inputs the locations and circulations of the gust vortices, but these quantities are not directly observable from the onboard sensors. We therefore propose to use a Kalman particle filter (KPF) to estimate the gust vortices online from the onboard measurements. The reconstructed input is then used by the controller to calculate the appropriate pitch rate. We evaluate the performance of this method for gusts composed of one to five vortices. Our results show that (i) controllers deployed with full knowledge of the vortices are able to mitigate efficiently the lift disturbance induced by the gusts, (ii) the KPF performs well in reconstructing gusts composed of less than three vortices, but shows more contrasted results in the reconstruction of gusts composed of more vortices, and (iii) adding a KPF to the controller recovers a significant part of the performance loss due to the unobservable gust vortices.
using deep reinforcement learning (DRL). To be optimal, we show that the controller must take as inputs the locations and circulations of the gust vortices, but these quantities are not directly observable from the onboard sensors. We therefore propose to use a Kalman particle filter (KPF) to estimate the gust vortices online from the onboard measurements. The reconstructed input is then used by the controller to calculate the appropriate pitch rate. We evaluate the performance of this method for gusts composed of one to five vortices. Our results show that (i) controllers deployed with full knowledge of the vortices are able to mitigate efficiently the lift disturbance induced by the gusts, (ii) the KPF performs well in reconstructing gusts composed of less than three vortices, but shows more contrasted results in the reconstruction of gusts composed of more vortices, and (iii) adding a KPF to the controller recovers a significant part of the performance loss due to the unobservable gust vortices.

Meta-models for transfer learning in source localization
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 27 December 2024, e48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Batch sojourn and delivery times in polling systems on a circle
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 27 December 2024, pp. 217-242
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A simple blame calculus for explicit nulls
-
- Journal:
- Journal of Functional Programming / Volume 34 / 2024
- Published online by Cambridge University Press:
- 27 December 2024, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exploring AI governance in the Middle East and North Africa (MENA) region: gaps, efforts, and initiatives
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 27 December 2024, e83
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
COMPLIANCE AND COMMAND III: CONDITIONAL IMPERATIVES
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 27 December 2024, pp. 52-98
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
THE GENERIC MULTIVERSE IS NOT GOING AWAY
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 27 December 2024, pp. 671-703
- Print publication:
- September 2025
-
- Article
- Export citation
-
The generic multiverse was introduced in [74] and [81] to explicate the portion of mathematics which is immune to our independence techniques. It consists, roughly speaking, of all universes of sets obtainable from a given universe by forcing extension. Usuba recently showed that the generic multiverse contains a unique definable universe, assuming strong large cardinal hypotheses. On the basis of this theorem, a non-pluralist about set theory could dismiss the generic multiverse as irrelevant to what set theory is really about, namely that unique definable universe. Whatever one’s attitude towards the generic multiverse, we argue that certain impure proofs ensure its ongoing relevance to the foundations of set theory. The proofs use forcing-fragile theories and absoluteness to prove
 ${\mathrm {ZFC}}$ theorems about simple “concrete” objects.
${\mathrm {ZFC}}$ theorems about simple “concrete” objects.

Honest Computing: achieving demonstrable data lineage and provenance for driving data and process-sensitive policies
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 26 December 2024, e84
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Big data acquisition for underground infrastructure condition assessment
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 26 December 2024, e49
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
WHAT STANDS BETWEEN GROUNDING RULES AND LOGICAL RULES IS THE EXCLUDED MIDDLE
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 23 December 2024, pp. 1-27
- Print publication:
- March 2025
-
- Article
- Export citation
Structural convergence and algebraic roots
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 23 December 2024, pp. 392-400
-
- Article
- Export citation
-
Structural convergence is a framework for the convergence of graphs by Nešetřil and Ossona de Mendez that unifies the dense (left) graph convergence and Benjamini-Schramm convergence. They posed a problem asking whether for a given sequence of graphs
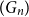 $(G_n)$ converging to a limit
$(G_n)$ converging to a limit 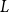 $L$ and a vertex
$L$ and a vertex  $r$ of
$r$ of 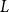 $L$, it is possible to find a sequence of vertices
$L$, it is possible to find a sequence of vertices 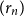 $(r_n)$ such that
$(r_n)$ such that 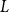 $L$ rooted at
$L$ rooted at  $r$ is the limit of the graphs
$r$ is the limit of the graphs 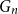 $G_n$ rooted at
$G_n$ rooted at 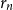 $r_n$. A counterexample was found by Christofides and Král’, but they showed that the statement holds for almost all vertices
$r_n$. A counterexample was found by Christofides and Král’, but they showed that the statement holds for almost all vertices  $r$ of
$r$ of 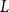 $L$. We offer another perspective on the original problem by considering the size of definable sets to which the root
$L$. We offer another perspective on the original problem by considering the size of definable sets to which the root  $r$ belongs. We prove that if
$r$ belongs. We prove that if  $r$ is an algebraic vertex (i.e. belongs to a finite definable set), the sequence of roots
$r$ is an algebraic vertex (i.e. belongs to a finite definable set), the sequence of roots 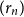 $(r_n)$ always exists.
$(r_n)$ always exists.
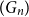
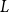

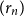
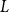

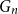
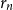

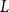


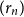
Measuring design mindset: developing the Design Mindset Inventory through its relationship with ambiguity tolerance, self-efficacy and sensation-seeking
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 23 December 2024, e48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Completion times of jobs on two-state service processes and their asymptotic behavior
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 23 December 2024, pp. 188-216
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider the task completion time of a repairable server system in which a server experiences randomly occurring service interruptions during which the server works slowly. Every service-state change preempts the task that is being processed. The server may then resume the interrupted task, it may replace the task with a different one, or it may restart the same task from the beginning, under the new service-state. The total time that the server takes to complete a task of random size including interruptions is called completion time. We study the completion time of a task under the last two cases as a function of the task size distribution, the service interruption frequency/severity, and the repair frequency. We derive closed form expressions for the completion time distribution in Laplace domain under replace and restart recovery disciplines and present their asymptotic behavior. In general, the heavy tailed behavior of completion times arises due to the heavy tailedness of the task time. However, in the preempt-restart service discipline, even in the case that the server still serves during interruptions albeit at a slower rate, completion times may demonstrate power tail behavior for exponential tail task time distributions. Furthermore, we present an
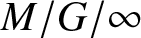 $M/G/\infty$ queue with exponential service time and Markovian service interruptions. Our results reveal that the stationary first order moments, that is, expected system time and expected number in the system are insensitive to the way the service modulation affects the servers; system-wide modulation affecting every server simultaneously vs identical modulation affecting each server independently.
$M/G/\infty$ queue with exponential service time and Markovian service interruptions. Our results reveal that the stationary first order moments, that is, expected system time and expected number in the system are insensitive to the way the service modulation affects the servers; system-wide modulation affecting every server simultaneously vs identical modulation affecting each server independently.
On dual risk models with proportional gains and dependencies
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 23 December 2024, pp. 156-187
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the development of a practical Bayesian optimization algorithm for expensive experiments and simulations with changing environmental conditions
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 23 December 2024, e45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
