Refine search
Actions for selected content:
97 results
Asymptotics for a multidimensional risk model with a random number of delayed claims and multivariate regularly varying distribution
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 10 December 2025, pp. 1-30
-
- Article
- Export citation
A remark on the long-time asymptotics of global-in-time solutions for semilinear parabolic equations in
 ${\mathbb {R}^N}$
${\mathbb {R}^N}$
- Part of
-
- Journal:
- Canadian Journal of Mathematics , First View
- Published online by Cambridge University Press:
- 10 October 2025, pp. 1-21
-
- Article
- Export citation
-
We consider the asymptotics of long-time behavior of a solution u of the semilinear parabolic problem
 $\partial _tu=\Delta u-u+u|u|^{p-2}$ in
$\partial _tu=\Delta u-u+u|u|^{p-2}$ in  ${\mathbb {R}^N}\times (0,\infty )$,
${\mathbb {R}^N}\times (0,\infty )$,  $u(0)=u_0\in H^1({\mathbb {R}^N})\cap L^\infty ({\mathbb {R}^N})$. Since the spatial domain on which the problem is posed is noncompact, we cannot expect the relative compactness of the solution orbit, e.g., in
$u(0)=u_0\in H^1({\mathbb {R}^N})\cap L^\infty ({\mathbb {R}^N})$. Since the spatial domain on which the problem is posed is noncompact, we cannot expect the relative compactness of the solution orbit, e.g., in  $H^1({\mathbb {R}^N})$ in general. In this article, we prove that the compactness of the orbit holds up to the ground state energy level, namely, if
$H^1({\mathbb {R}^N})$ in general. In this article, we prove that the compactness of the orbit holds up to the ground state energy level, namely, if  $\lim _{t\to \infty }I(u(t))\leq d_\infty $, where I is the energy functional associated with (P) and
$\lim _{t\to \infty }I(u(t))\leq d_\infty $, where I is the energy functional associated with (P) and  $d_\infty $ its ground state energy, then the orbit of
$d_\infty $ its ground state energy, then the orbit of  $u(t)$ is compact in
$u(t)$ is compact in  $H^1({\mathbb {R}^N})$. Our result includes the previous results in [4, 5].
$H^1({\mathbb {R}^N})$. Our result includes the previous results in [4, 5].









Asymptotics for crank of overpartitions
- Part of
-
- Journal:
- Canadian Journal of Mathematics , First View
- Published online by Cambridge University Press:
- 09 January 2025, pp. 1-34
-
- Article
- Export citation
-
Let
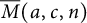 $\overline {M}(a,c,n)$ denote the number of overpartitions of n with first residual crank congruent to a modulo c with
$\overline {M}(a,c,n)$ denote the number of overpartitions of n with first residual crank congruent to a modulo c with  $c\geq 3$ being odd and
$c\geq 3$ being odd and  $0\leq a<c$. The central objective of this paper is twofold: firstly, to establish an asymptotic formula for the crank of overpartitions; and secondly, to establish several inequalities concerning
$0\leq a<c$. The central objective of this paper is twofold: firstly, to establish an asymptotic formula for the crank of overpartitions; and secondly, to establish several inequalities concerning  $\overline {M}(a,c,n)$ that encompasses crank differences, positivity, and strict log-subadditivity.
$\overline {M}(a,c,n)$ that encompasses crank differences, positivity, and strict log-subadditivity.



Modified Distribution-Free Goodness-of-Fit Test Statistic
-
- Journal:
- Psychometrika / Volume 83 / Issue 1 / March 2018
- Published online by Cambridge University Press:
- 01 January 2025, pp. 48-66
-
- Article
- Export citation
On Muthén’s Maximum Likelihood for Two-Level Covariance Structure Models
-
- Journal:
- Psychometrika / Volume 70 / Issue 1 / March 2005
- Published online by Cambridge University Press:
- 01 January 2025, pp. 147-167
-
- Article
- Export citation
On the Asymptotic Distributions of Two Statistics for Two-Level Covariance Structure Models within the Class of Elliptical Distributions
-
- Journal:
- Psychometrika / Volume 69 / Issue 3 / September 2004
- Published online by Cambridge University Press:
- 01 January 2025, pp. 437-457
-
- Article
- Export citation
Biases and Standard Errors of Standardized Regression Coefficients
-
- Journal:
- Psychometrika / Volume 76 / Issue 4 / October 2011
- Published online by Cambridge University Press:
- 01 January 2025, pp. 670-690
-
- Article
- Export citation
Comment on the Asymptotics of a Distribution-Free Goodness of Fit Test Statistic
-
- Journal:
- Psychometrika / Volume 80 / Issue 1 / March 2015
- Published online by Cambridge University Press:
- 01 January 2025, pp. 196-199
-
- Article
- Export citation
Asymptotically Corrected Person Fit Statistics for Multidimensional Constructs with Simple Structure and Mixed Item Types
-
- Journal:
- Psychometrika / Volume 86 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 464-488
-
- Article
- Export citation
-
Person fit statistics are frequently used to detect aberrant behavior when assuming an item response model generated the data. A common statistic, \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}
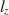 , has been shown in previous studies to perform well under a myriad of conditions. However, it is well-known that \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}
, has been shown in previous studies to perform well under a myriad of conditions. However, it is well-known that \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}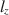 does not follow a standard normal distribution when using an estimated latent trait. As a result, corrections of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}
does not follow a standard normal distribution when using an estimated latent trait. As a result, corrections of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}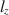 , called \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z^*$$\end{document}
, called \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z^*$$\end{document}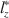 , have been proposed in the literature for specific item response models. We propose a more general correction that is applicable to many types of data, namely survey or tests with multiple item types and underlying latent constructs, which subsumes previous work done by others. In addition, we provide corrections for multiple estimators of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta $$\end{document}
, have been proposed in the literature for specific item response models. We propose a more general correction that is applicable to many types of data, namely survey or tests with multiple item types and underlying latent constructs, which subsumes previous work done by others. In addition, we provide corrections for multiple estimators of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta $$\end{document}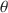 , the latent trait, including MLE, MAP and WLE. We provide analytical derivations that justifies our proposed correction, as well as simulation studies to examine the performance of the proposed correction with finite test lengths. An applied example is also provided to demonstrate proof of concept. We conclude with recommendations for practitioners when the asymptotic correction works well under different conditions and also future directions.
, the latent trait, including MLE, MAP and WLE. We provide analytical derivations that justifies our proposed correction, as well as simulation studies to examine the performance of the proposed correction with finite test lengths. An applied example is also provided to demonstrate proof of concept. We conclude with recommendations for practitioners when the asymptotic correction works well under different conditions and also future directions.
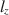
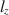
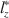
Rough multi-factor volatility for SPX and VIX options
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 16 December 2024, pp. 524-565
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tail variance and confidence of using tail conditional expectation: Analytical representation, capital adequacy, and asymptotics
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 31 July 2024, pp. 346-369
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multivariate regularly varying insurance and financial risks in multidimensional risk models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 13 May 2024, pp. 1319-1342
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Toeplitz determinants with a one-cut regular potential and Fisher–Hartwig singularities I. Equilibrium measure supported on the unit circle
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 5 / October 2024
- Published online by Cambridge University Press:
- 15 August 2023, pp. 1431-1472
- Print publication:
- October 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider Toeplitz determinants whose symbol has: (i) a one-cut regular potential $V$
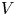 , (ii) Fisher–Hartwig singularities and (iii) a smooth function in the background. The potential $V$
, (ii) Fisher–Hartwig singularities and (iii) a smooth function in the background. The potential $V$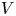 is associated with an equilibrium measure that is assumed to be supported on the whole unit circle. For constant potentials $V$
is associated with an equilibrium measure that is assumed to be supported on the whole unit circle. For constant potentials $V$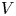 , the equilibrium measure is the uniform measure on the unit circle and our formulas reduce to well-known results for Toeplitz determinants with Fisher–Hartwig singularities. For non-constant $V$
, the equilibrium measure is the uniform measure on the unit circle and our formulas reduce to well-known results for Toeplitz determinants with Fisher–Hartwig singularities. For non-constant $V$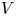 , our results appear to be new even in the case of no Fisher–Hartwig singularities. As applications of our results, we derive various statistical properties of a determinantal point process which generalizes the circular unitary ensemble.
, our results appear to be new even in the case of no Fisher–Hartwig singularities. As applications of our results, we derive various statistical properties of a determinantal point process which generalizes the circular unitary ensemble.
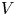
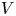
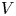
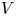
Exact formulae and Turán inequalities for Vafa–Witten invariants of
 $K3$ surfaces
$K3$ surfaces
- Part of
-
- Journal:
- Proceedings of the Edinburgh Mathematical Society / Volume 66 / Issue 3 / August 2023
- Published online by Cambridge University Press:
- 08 August 2023, pp. 845-861
-
- Article
- Export citation
-
We consider three different families of Vafa–Witten invariants of
 $K3$ surfaces. In each case, the partition function that encodes the Vafa–Witten invariants is given by combinations of twisted Dedekind η-functions. By utilizing known properties of these η-functions, we obtain exact formulae for each of the invariants and prove that they asymptotically satisfy all higher-order Turán inequalities.
$K3$ surfaces. In each case, the partition function that encodes the Vafa–Witten invariants is given by combinations of twisted Dedekind η-functions. By utilizing known properties of these η-functions, we obtain exact formulae for each of the invariants and prove that they asymptotically satisfy all higher-order Turán inequalities.
2 - Basic Tools
- from Part I - Preliminaries
-
- Book:
- Random Graphs and Networks: A First Course
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 8-26
-
- Chapter
- Export citation
Giant descendant trees, matchings, and independent sets in age-biased attachment graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 25 April 2022, pp. 299-324
- Print publication:
- June 2022
-
- Article
- Export citation
-
We study two models of an age-biased graph process: the
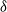 $\delta$-version of the preferential attachment graph model (PAM) and the uniform attachment graph model (UAM), with m attachments for each of the incoming vertices. We show that almost surely the scaled size of a breadth-first (descendant) tree rooted at a fixed vertex converges, for
$\delta$-version of the preferential attachment graph model (PAM) and the uniform attachment graph model (UAM), with m attachments for each of the incoming vertices. We show that almost surely the scaled size of a breadth-first (descendant) tree rooted at a fixed vertex converges, for 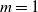 $m=1$, to a limit whose distribution is a mixture of two beta distributions and a single beta distribution respectively, and that for
$m=1$, to a limit whose distribution is a mixture of two beta distributions and a single beta distribution respectively, and that for 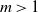 $m>1$ the limit is 1. We also analyze the likely performance of two greedy (online) algorithms, for a large matching set and a large independent set, and determine – for each model and each greedy algorithm – both a limiting fraction of vertices involved and an almost sure convergence rate.
$m>1$ the limit is 1. We also analyze the likely performance of two greedy (online) algorithms, for a large matching set and a large independent set, and determine – for each model and each greedy algorithm – both a limiting fraction of vertices involved and an almost sure convergence rate.
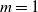
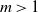
1 - Introduction
-
- Book:
- The Christoffel–Darboux Kernel for Data Analysis
- Published online:
- 31 March 2022
- Print publication:
- 07 April 2022, pp 1-6
-
- Chapter
- Export citation
Asymptotics for the number of standard tableaux of skew shape and for weighted lozenge tilings
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 4 / July 2022
- Published online by Cambridge University Press:
- 18 October 2021, pp. 550-573
-
- Article
- Export citation
-
We prove and generalise a conjecture in [MPP4] about the asymptotics of
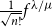 $\frac{1}{\sqrt{n!}} f^{\lambda/\mu}$, where
$\frac{1}{\sqrt{n!}} f^{\lambda/\mu}$, where 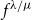 $f^{\lambda/\mu}$ is the number of standard Young tableaux of skew shape
$f^{\lambda/\mu}$ is the number of standard Young tableaux of skew shape 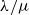 $\lambda/\mu$ which have stable limit shape under the
$\lambda/\mu$ which have stable limit shape under the 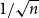 $1/\sqrt{n}$ scaling. The proof is based on the variational principle on the partition function of certain weighted lozenge tilings.
$1/\sqrt{n}$ scaling. The proof is based on the variational principle on the partition function of certain weighted lozenge tilings.
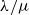
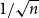
Pathwise large deviations for the rough Bergomi model: Corrigendum
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 16 September 2021, pp. 849-850
- Print publication:
- September 2021
-
- Article
-
- You have access
- HTML
- Export citation
ASYMPTOTICS FOR SYSTEMIC RISK WITH DEPENDENT HEAVY-TAILED LOSSES
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 2 / May 2021
- Published online by Cambridge University Press:
- 29 April 2021, pp. 571-605
- Print publication:
- May 2021
-
- Article
- Export citation
