Refine search
Actions for selected content:
48786 results in Computer Science
Random embeddings of bounded-degree trees with optimal spread
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 13 October 2025, pp. 1-12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A seminal result of Komlós, Sárközy, and Szemerédi states that any
 $n$-vertex graph
$n$-vertex graph  $G$ with minimum degree at least
$G$ with minimum degree at least  $(1/2+\alpha )n$ contains every
$(1/2+\alpha )n$ contains every  $n$-vertex tree
$n$-vertex tree  $T$ of bounded degree. Recently, Pham, Sah, Sawhney, and Simkin extended this result to show that such graphs
$T$ of bounded degree. Recently, Pham, Sah, Sawhney, and Simkin extended this result to show that such graphs  $G$ in fact support an optimally spread distribution on copies of a given
$G$ in fact support an optimally spread distribution on copies of a given  $T$, which implies, using the recent breakthroughs on the Kahn-Kalai conjecture, the robustness result that
$T$, which implies, using the recent breakthroughs on the Kahn-Kalai conjecture, the robustness result that  $T$ is a subgraph of sparse random subgraphs of
$T$ is a subgraph of sparse random subgraphs of  $G$ as well. Pham, Sah, Sawhney, and Simkin construct their optimally spread distribution by following closely the original proof of the Komlós-Sárközy-Szemerédi theorem which uses the blow-up lemma and the Szemerédi regularity lemma. We give an alternative, regularity-free construction that instead uses the Komlós-Sárközy-Szemerédi theorem (which has a regularity-free proof due to Kathapurkar and Montgomery) as a black box. Our proof is based on the simple and general insight that, if
$G$ as well. Pham, Sah, Sawhney, and Simkin construct their optimally spread distribution by following closely the original proof of the Komlós-Sárközy-Szemerédi theorem which uses the blow-up lemma and the Szemerédi regularity lemma. We give an alternative, regularity-free construction that instead uses the Komlós-Sárközy-Szemerédi theorem (which has a regularity-free proof due to Kathapurkar and Montgomery) as a black box. Our proof is based on the simple and general insight that, if  $G$ has linear minimum degree, almost all constant-sized subgraphs of
$G$ has linear minimum degree, almost all constant-sized subgraphs of  $G$ inherit the same minimum degree condition that
$G$ inherit the same minimum degree condition that  $G$ has.
$G$ has.












Robust control based on Lyapunov stability theory for the joint modules in hip-assist exoskeleton robots
-
- Journal:
- Robotica , First View
- Published online by Cambridge University Press:
- 13 October 2025, pp. 1-17
-
- Article
- Export citation
Design and analysis of pipeline inspection robot based on generalized parallel mechanisms
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Synthetic afterlives: Deathbots as affective infrastructures of memory
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 4 / 2025
- Published online by Cambridge University Press:
- 13 October 2025, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Evaluating and benchmarking data-driven performance forecasting techniques for infrastructure asset management
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 13 October 2025, e49
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Algorithmic regulation at the city level in China—ERRATUM
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 10 October 2025, e68
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Beyond the broken tetrahedron
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 10 October 2025, pp. 1-12
-
- Article
- Export citation
-
Here we consider the hypergraph Turán problem in uniformly dense hypergraphs as was suggested by Erdős and Sós. Given a
 $3$-graph
$3$-graph  $F$, the uniform Turán density
$F$, the uniform Turán density  $\pi _{\boldsymbol{\therefore }}(F)$ of
$\pi _{\boldsymbol{\therefore }}(F)$ of  $F$ is defined as the supremum over all
$F$ is defined as the supremum over all  $d\in [0,1]$ for which there is an
$d\in [0,1]$ for which there is an  $F$-free uniformly
$F$-free uniformly  $d$-dense
$d$-dense  $3$-graph, where uniformly
$3$-graph, where uniformly  $d$-dense means that every linearly sized subhypergraph has density at least
$d$-dense means that every linearly sized subhypergraph has density at least  $d$. Recently, Glebov, Král’, and Volec and, independently, Reiher, Rödl, and Schacht proved that
$d$. Recently, Glebov, Král’, and Volec and, independently, Reiher, Rödl, and Schacht proved that  $\pi _{\boldsymbol{\therefore }}(K_4^{(3)-})=\frac {1}{4}$, solving a conjecture by Erdős and Sós. Despite substantial attention, the uniform Turán density is still only known for very few hypergraphs. In particular, the problem due to Erdős and Sós to determine
$\pi _{\boldsymbol{\therefore }}(K_4^{(3)-})=\frac {1}{4}$, solving a conjecture by Erdős and Sós. Despite substantial attention, the uniform Turán density is still only known for very few hypergraphs. In particular, the problem due to Erdős and Sós to determine  $\pi _{\boldsymbol{\therefore }}(K_4^{(3)})$ remains wide open.
$\pi _{\boldsymbol{\therefore }}(K_4^{(3)})$ remains wide open.In this work, we determine the uniform Turán density of the
 $3$-graph on five vertices that is obtained from
$3$-graph on five vertices that is obtained from  $K_4^{(3)-}$ by adding an additional vertex whose link forms a matching on the vertices of
$K_4^{(3)-}$ by adding an additional vertex whose link forms a matching on the vertices of 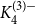 $K_4^{(3)-}$. Further, we point to two natural intermediate problems on the way to determining
$K_4^{(3)-}$. Further, we point to two natural intermediate problems on the way to determining  $\pi _{\boldsymbol{\therefore }}(K_4^{(3)})$, and solve the first of these.
$\pi _{\boldsymbol{\therefore }}(K_4^{(3)})$, and solve the first of these.















TPACK for corpus technology: TESOL student teachers’ growth and self-efficacy in independent language learning and teaching
-
- Journal:
- ReCALL , First View
- Published online by Cambridge University Press:
- 10 October 2025, pp. 1-17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cultural product design: an approach for identifying cultural carriers, transforming cultural elements and applying cultural features
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 10 October 2025, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
2 - User Interaction for Human–AI Interaction and Collaboration
-
-
- Book:
- Human-AI Interaction and Collaboration
- Published online:
- 19 September 2025
- Print publication:
- 09 October 2025, pp 14-42
-
- Chapter
- Export citation
1 - Introduction
-
-
- Book:
- Human-AI Interaction and Collaboration
- Published online:
- 19 September 2025
- Print publication:
- 09 October 2025, pp 1-13
-
- Chapter
- Export citation
Index
-
- Book:
- A Datafied Mind
- Published online:
- 27 September 2025
- Print publication:
- 09 October 2025, pp 215-217
-
- Chapter
- Export citation
Contents
-
- Book:
- Human-AI Interaction and Collaboration
- Published online:
- 19 September 2025
- Print publication:
- 09 October 2025, pp v-viii
-
- Chapter
- Export citation
Bibliography
-
- Book:
- A Datafied Mind
- Published online:
- 27 September 2025
- Print publication:
- 09 October 2025, pp 195-214
-
- Chapter
- Export citation
Epigraph
-
- Book:
- A Datafied Mind
- Published online:
- 27 September 2025
- Print publication:
- 09 October 2025, pp v-vi
-
- Chapter
- Export citation
6 - AI-supported Search Interaction for Enhancing Users’ Understanding
-
-
- Book:
- Human-AI Interaction and Collaboration
- Published online:
- 19 September 2025
- Print publication:
- 09 October 2025, pp 135-152
-
- Chapter
- Export citation
5 - AI-supported Crowdsourcing for Knowledge Sharing
-
-
- Book:
- Human-AI Interaction and Collaboration
- Published online:
- 19 September 2025
- Print publication:
- 09 October 2025, pp 110-134
-
- Chapter
- Export citation
Contributors
-
- Book:
- Human-AI Interaction and Collaboration
- Published online:
- 19 September 2025
- Print publication:
- 09 October 2025, pp ix-xiv
-
- Chapter
- Export citation
