Refine search
Actions for selected content:
311 results

A Hands-On Introduction to Data Science with Python
- Coming soon
-
- Expected online publication date:
- January 2026
- Print publication:
- 22 January 2026
-
- Textbook
- Export citation

A Hands-On Introduction to Data Science with R
- Coming soon
-
- Expected online publication date:
- January 2026
- Print publication:
- 22 January 2026
-
- Textbook
- Export citation
Using optimal transport aligned latent embeddings for separated flow analysis
-
- Journal:
- Journal of Fluid Mechanics / Volume 1027 / 25 January 2026
- Published online by Cambridge University Press:
- 16 January 2026, A24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Quantifying differences between flow fields is a key challenge in fluid mechanics, particularly when evaluating the effectiveness of flow control or other problem parameters. Traditional vector metrics, such as the Euclidean distance, provide straightforward pointwise comparisons but can fail to distinguish distributional changes in flow fields. To address this limitation, we employ optimal transport (OT) theory, which is a mathematical framework built on probability and measure theory. By aligning Euclidean distances between flow fields in a latent space learned by an autoencoder with the corresponding OT geodesics, we seek to learn low-dimensional representations of flow fields that are interpretable from the perspective of unbalanced OT. As a demonstration, we utilise this OT-based analysis on separated flows past a NACA 0012 airfoil with periodic heat flux actuation near the leading edge. The cases considered are at a chord-based Reynolds number of 23 000 and a free-stream Mach number of 0.3 for two angles of attack (AoA) of
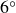 $6^\circ$ and
$6^\circ$ and 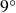 $9^\circ$. For each angle of attack, we identify a two-dimensional embedding that succinctly captures the different effective regimes of flow responses and control performance, characterised by the degree of suppression of the separation bubble and secondary effects from laminarisation and trailing-edge separation. The interpretation of the latent representation was found to be consistent across the two AoA, suggesting that the OT-based latent encoding was capable of extracting physical relationships that are common across the different suites of cases. This study demonstrates the potential utility of optimal transport in the analysis and interpretation of complex flow fields.
$9^\circ$. For each angle of attack, we identify a two-dimensional embedding that succinctly captures the different effective regimes of flow responses and control performance, characterised by the degree of suppression of the separation bubble and secondary effects from laminarisation and trailing-edge separation. The interpretation of the latent representation was found to be consistent across the two AoA, suggesting that the OT-based latent encoding was capable of extracting physical relationships that are common across the different suites of cases. This study demonstrates the potential utility of optimal transport in the analysis and interpretation of complex flow fields.
The Marginalized Democracies of the World
-
- Journal:
- Democratic Theory / Volume 8 / Issue 2 / December 2021
- Published online by Cambridge University Press:
- 01 January 2026, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Who Gives, Who Gets, and How do We Know? The Promises and Limitations of Administrative Data for Cross-border Philanthropy Tracking
-
- Journal:
- Voluntas: International Journal of Voluntary and Nonprofit Organizations / Volume 34 / Issue 1 / February 2023
- Published online by Cambridge University Press:
- 01 January 2026, pp. 91-99
-
- Article
- Export citation
Re-envisioning the Role of “Big Data” in the Nonprofit Sector: A Data Feminist Perspective
-
- Journal:
- Voluntas: International Journal of Voluntary and Nonprofit Organizations / Volume 34 / Issue 5 / October 2023
- Published online by Cambridge University Press:
- 01 January 2026, pp. 1094-1105
-
- Article
- Export citation
2,234 Descriptions of Democracy: An Update to Democracy’s Ontological Pluralism
-
- Journal:
- Democratic Theory / Volume 5 / Issue 1 / June 2018
- Published online by Cambridge University Press:
- 01 January 2026, pp. 92-113
-
- Article
- Export citation
Big data meets open political science: an empirical assessment of transparency standards 2008–2019
-
- Journal:
- European Political Science / Volume 22 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 01 January 2026, pp. 182-201
-
- Article
- Export citation
Chapter 2 - What Big Data Tells Us about American English Phonetics
-
-
- Book:
- Data-Intensive Investigations of English
- Published online:
- 03 December 2025
- Print publication:
- 18 December 2025, pp 20-47
-
- Chapter
- Export citation

Chilling Effects
- Repression, Conformity, and Power in the Digital Age
-
- Published online:
- 20 November 2025
- Print publication:
- 20 November 2025
2 - Medical Progress as Biomedical Knowledge Gains
-
- Book:
- Making Medical Progress
- Published online:
- 12 December 2025
- Print publication:
- 20 November 2025, pp 66-103
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
New Technology and OB/HRM in China: Digital Methods for Organizational Research
-
- Journal:
- Management and Organization Review / Volume 21 / Issue 4 / August 2025
- Published online by Cambridge University Press:
- 07 November 2025, pp. 728-733
-
- Article
- Export citation
7 - Technology, Nudges, Reputation, and Voluntary Compliance
-
- Book:
- Can the Public be Trusted?
- Published online:
- 11 October 2025
- Print publication:
- 30 October 2025, pp 165-185
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation

Big Data in the Psychological Sciences
-
- Published online:
- 23 October 2025
- Print publication:
- 23 October 2025
-
- Textbook
- Export citation
1 - What Is Big Data?
-
- Book:
- Big Data in the Psychological Sciences
- Published online:
- 23 October 2025
- Print publication:
- 23 October 2025, pp 1-12
-
- Chapter
- Export citation

Satellite Remote Sensing for Water Management
-
- Published online:
- 10 October 2025
- Print publication:
- 04 September 2025
-
- Textbook
- Export citation
3 - The Data War
-
- Book:
- Killing the Messenger
- Published online:
- 05 September 2025
- Print publication:
- 25 September 2025, pp 51-61
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
7 - Privacy, Big Data, and Free Speech
-
- Book:
- Killing the Messenger
- Published online:
- 05 September 2025
- Print publication:
- 25 September 2025, pp 146-163
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
The current state of paediatric publishing utilising high-fidelity physiologic data streaming with sickbay or etiometry: a systematic review
-
- Journal:
- Cardiology in the Young / Volume 35 / Issue 9 / September 2025
- Published online by Cambridge University Press:
- 05 September 2025, pp. 1809-1814
-
- Article
- Export citation
4 - Introduction to Cloud Computing
-
- Book:
- Satellite Remote Sensing for Water Management
- Published online:
- 10 October 2025
- Print publication:
- 04 September 2025, pp 59-84
-
- Chapter
- Export citation
