Refine search
Actions for selected content:
181 results
Speech pause and speech rate for evaluating Alzheimer’s and mild cognitive impairment: A meta-analysis
-
- Journal:
- Journal of the International Neuropsychological Society , First View
- Published online by Cambridge University Press:
- 11 December 2025, pp. 1-8
-
- Article
- Export citation
Deformation dynamics of biconcave red blood cells in viscous fluid driven by ultrasound
-
- Journal:
- Journal of Fluid Mechanics / Volume 1023 / 25 November 2025
- Published online by Cambridge University Press:
- 20 November 2025, A22
-
- Article
- Export citation
Modelling the dynamics of an oil drop driven by a surface acoustic wave in the underlying substrate
-
- Journal:
- Journal of Fluid Mechanics / Volume 1022 / 10 November 2025
- Published online by Cambridge University Press:
- 10 November 2025, A49
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Role of convecting disturbances and acoustic standing waves in supersonic impinging jet
-
- Journal:
- Journal of Fluid Mechanics / Volume 1021 / 25 October 2025
- Published online by Cambridge University Press:
- 16 October 2025, A29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Acoustic-gravity quantum tunnelling analogy
-
- Journal:
- Journal of Fluid Mechanics / Volume 1018 / 10 September 2025
- Published online by Cambridge University Press:
- 19 September 2025, A18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Kierkegaard and Phenomenology
-
- Published online:
- 16 August 2025
- Print publication:
- 11 September 2025
-
- Element
- Export citation
Vortex modes in acoustofluidic cylindrical resonators
-
- Journal:
- Journal of Fluid Mechanics / Volume 1015 / 25 July 2025
- Published online by Cambridge University Press:
- 17 July 2025, A34
-
- Article
- Export citation
Acoustic disambiguation of homophonous morphs is exceptional
-
- Journal:
- Journal of Linguistics , First View
- Published online by Cambridge University Press:
- 10 July 2025, pp. 1-33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Acoustic characteristics of stop consonants in Vietnamese children and adults
-
- Journal:
- Journal of Child Language , First View
- Published online by Cambridge University Press:
- 10 July 2025, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Acoustic study of vowel quality in Ghanaian English
-
- Journal:
- English Today , First View
- Published online by Cambridge University Press:
- 27 June 2025, pp. 1-8
-
- Article
- Export citation
Acoustothermal effect: mechanism and quantification of the heat source
-
- Journal:
- Journal of Fluid Mechanics / Volume 1012 / 10 June 2025
- Published online by Cambridge University Press:
- 04 June 2025, A11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Resonant triad interactions of two acoustic modes and a gravity wave
-
- Journal:
- Journal of Fluid Mechanics / Volume 1008 / 10 April 2025
- Published online by Cambridge University Press:
- 07 April 2025, A15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Unified limit-cycle amplitude prediction and symmetry-breaking analysis of combustion instabilities
-
- Journal:
- Journal of Fluid Mechanics / Volume 1007 / 25 March 2025
- Published online by Cambridge University Press:
- 17 March 2025, A66
-
- Article
- Export citation
5 - Note, Sharpness, and Heaviness
- from Part II - Texts
-
- Book:
- The Science of Music
- Published online:
- 19 December 2024
- Print publication:
- 02 January 2025, pp 121-144
-
- Chapter
- Export citation
Introduction - Whispers in the Roar
-
- Book:
- Acoustics in Nineteenth-Century Literature and Science
- Published online:
- 13 December 2024
- Print publication:
- 19 December 2024, pp 1-16
-
- Chapter
- Export citation
16 - The Art of Counterpoint in Performance
- from Part IV - The Art in Action
-
- Book:
- The Art of Counterpoint from Du Fay to Josquin
- Published online:
- 05 December 2024
- Print publication:
- 12 December 2024, pp 293-318
-
- Chapter
- Export citation
An acoustic exploration of sibilant contrasts and sibilant merger in Mixean Basque
-
- Journal:
- Journal of the International Phonetic Association / Volume 54 / Issue 2 / August 2024
- Published online by Cambridge University Press:
- 16 May 2024, pp. 677-706
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Experiments on symmetry breaking of azimuthal combustion instabilities and their analysis combining acoustic energy balance and flame describing functions
-
- Journal:
- Journal of Fluid Mechanics / Volume 985 / 25 April 2024
- Published online by Cambridge University Press:
- 23 April 2024, A31
-
- Article
- Export citation
-
Combustion instabilities in annular systems raise fundamental issues that are also of practical importance to aircraft engines and ground-based gas turbine combustors. Recent studies indicate that the injector plays a significant role in the stability of combustors by defining the flame dynamical response and setting the inlet impedance of the system. The present investigation examines the effects of combinations of injectors of two different types (
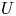 $U$ and
$U$ and 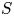 $S$) on thermoacoustic instabilities in a laboratory-scale annular combustor and compares different circumferential staging strategies. The combustor operates in a stable fashion when all injection units belong to the
$S$) on thermoacoustic instabilities in a laboratory-scale annular combustor and compares different circumferential staging strategies. The combustor operates in a stable fashion when all injection units belong to the 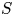 $S$-family, but exhibits large amplitude pressure oscillations when all these units are of the
$S$-family, but exhibits large amplitude pressure oscillations when all these units are of the 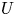 $U$-type. When the system comprises a mix of
$U$-type. When the system comprises a mix of 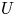 $U$- and
$U$- and 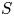 $S$-injectors, it is possible to determine the number of
$S$-injectors, it is possible to determine the number of 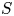 $S$-injectors leading to stable operation. For a fixed proportion of
$S$-injectors leading to stable operation. For a fixed proportion of 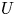 $U$- and
$U$- and 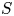 $S$-injectors, some arrangements give rise to stable operation while others do not. Results also show that introducing symmetry-breaking elements affects the system's modal dynamics. These experimental observations are interpreted in an acoustic energy balance framework used to derive an expression for the growth rate as a function of the describing functions of the flames formed by the different injectors and their respective azimuthal locations. Growth rates are determined for the different configurations and used to explain the various observations, estimate the system damping rate and predict the location of the nodal line when the standing mode prevails.
$S$-injectors, some arrangements give rise to stable operation while others do not. Results also show that introducing symmetry-breaking elements affects the system's modal dynamics. These experimental observations are interpreted in an acoustic energy balance framework used to derive an expression for the growth rate as a function of the describing functions of the flames formed by the different injectors and their respective azimuthal locations. Growth rates are determined for the different configurations and used to explain the various observations, estimate the system damping rate and predict the location of the nodal line when the standing mode prevails.
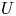
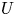
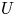
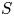
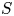
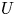
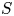
Characterizing Clay Mineral Suspensions using Acoustic and Electroacoustic Spectroscopy — A Review
-
- Journal:
- Clays and Clay Minerals / Volume 52 / Issue 2 / April 2004
- Published online by Cambridge University Press:
- 01 January 2024, pp. 145-157
-
- Article
- Export citation
Eleven vowels of Imilike Igbo including ATR and RTR schwa
-
- Journal:
- Journal of the International Phonetic Association / Volume 54 / Issue 1 / April 2024
- Published online by Cambridge University Press:
- 20 December 2023, pp. 294-317
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
