Refine search
Actions for selected content:
23 results
Political DEBATE: Efficient Zero-Shot and Few-Shot Classifiers for Political Text
-
- Journal:
- Political Analysis , First View
- Published online by Cambridge University Press:
- 15 December 2025, pp. 1-15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Partisan conflict in nonverbal communication
-
- Journal:
- Political Science Research and Methods , First View
- Published online by Cambridge University Press:
- 04 December 2025, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Codebook LLMs: Evaluating LLMs as Measurement Tools for Political Science Concepts
-
- Journal:
- Political Analysis , First View
- Published online by Cambridge University Press:
- 19 September 2025, pp. 1-17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Measuring Media Criticism with ALC Word Embeddings
-
- Journal:
- Political Analysis , First View
- Published online by Cambridge University Press:
- 26 August 2025, pp. 1-17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Positioning Political Texts with Large Language Models by Asking and Averaging
-
- Journal:
- Political Analysis / Volume 33 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 27 January 2025, pp. 274-282
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Categorizing Topics Versus Inferring Attitudes: A Theory and Method for Analyzing Open-ended Survey Responses
-
- Journal:
- Political Analysis / Volume 33 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 24 January 2025, pp. 231-251
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multilanguage Word Embeddings for Social Scientists: Estimation, Inference, and Validation Resources for 157 Languages
-
- Journal:
- Political Analysis / Volume 33 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 27 December 2024, pp. 156-163
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Linking datasets on organizations using half a billion open-collaborated records
-
- Journal:
- Political Science Research and Methods / Volume 13 / Issue 4 / October 2025
- Published online by Cambridge University Press:
- 16 October 2024, pp. 923-942
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stance detection: a practical guide to classifying political beliefs in text
-
- Journal:
- Political Science Research and Methods / Volume 13 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 19 September 2024, pp. 611-628
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Is industrial policy back in fashion? Text-as-data evidence from UK policy documents
-
- Journal:
- Business and Politics / Volume 26 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 15 February 2024, pp. 406-428
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Racial Tropes in the Foreign Policy Bureaucracy: A Computational Text Analysis
-
- Journal:
- International Organization / Volume 78 / Issue 2 / Spring 2024
- Published online by Cambridge University Press:
- 02 August 2024, pp. 189-223
- Print publication:
- Spring 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On Finetuning Large Language Models
-
- Journal:
- Political Analysis / Volume 32 / Issue 3 / July 2024
- Published online by Cambridge University Press:
- 28 November 2023, pp. 379-383
-
- Article
- Export citation
-
A recent paper by Häffner et al. (2023, Political Analysis 31, 481–499) introduces an interpretable deep learning approach for domain-specific dictionary creation, where it is claimed that the dictionary-based approach outperforms finetuned language models in predictive accuracy while retaining interpretability. We show that the dictionary-based approach’s reported superiority over large language models, BERT specifically, is due to the fact that most of the parameters in the language models are excluded from finetuning. In this letter, we first discuss the architecture of BERT models, then explain the limitations of finetuning only the top classification layer, and lastly we report results where finetuned language models outperform the newly proposed dictionary-based approach by 27% in terms of
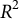 $R^2$ and 46% in terms of mean squared error once we allow these parameters to learn during finetuning. Researchers interested in large language models, text classification, and text regression should find our results useful. Our code and data are publicly available.
$R^2$ and 46% in terms of mean squared error once we allow these parameters to learn during finetuning. Researchers interested in large language models, text classification, and text regression should find our results useful. Our code and data are publicly available.
3 - A Global Dataset of Autocratic Propaganda
-
- Book:
- Propaganda in Autocracies
- Published online:
- 18 July 2023
- Print publication:
- 14 September 2023, pp 82-122
-
- Chapter
- Export citation
Less Annotating, More Classifying: Addressing the Data Scarcity Issue of Supervised Machine Learning with Deep Transfer Learning and BERT-NLI
-
- Journal:
- Political Analysis / Volume 32 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 09 June 2023, pp. 84-100
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
No Longer Conforming to Stereotypes? Gender, Political Style and Parliamentary Debate in the UK
-
- Journal:
- British Journal of Political Science / Volume 52 / Issue 4 / October 2022
- Published online by Cambridge University Press:
- 02 February 2022, pp. 1584-1601
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Going in circles? The influence of the electoral cycle on the party behaviour in parliament
-
- Journal:
- European Political Science Review / Volume 14 / Issue 1 / February 2022
- Published online by Cambridge University Press:
- 05 October 2021, pp. 36-55
-
- Article
- Export citation
Topics, Concepts, and Measurement: A Crowdsourced Procedure for Validating Topics as Measures
-
- Journal:
- Political Analysis / Volume 30 / Issue 4 / October 2022
- Published online by Cambridge University Press:
- 27 September 2021, pp. 570-589
-
- Article
- Export citation
The discursive construction of digitalization: a comparative analysis of national discourses on the digital future of work
-
- Journal:
- European Political Science Review / Volume 13 / Issue 3 / August 2021
- Published online by Cambridge University Press:
- 07 June 2021, pp. 391-409
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Countering Violent Extremism and Radical Rhetoric
-
- Journal:
- International Organization / Volume 76 / Issue 1 / Winter 2022
- Published online by Cambridge University Press:
- 06 May 2021, pp. 251-272
- Print publication:
- Winter 2022
-
- Article
- Export citation
A General Model of Author “Style” with Application to the UK House of Commons, 1935–2018
-
- Journal:
- Political Analysis / Volume 28 / Issue 3 / July 2020
- Published online by Cambridge University Press:
- 24 January 2020, pp. 412-434
-
- Article
- Export citation
