Refine search
Actions for selected content:
90 results
The unpredictable role of language distance in bilingual cognition: A systematic review from brain to behavior
-
- Journal:
- Bilingualism: Language and Cognition , First View
- Published online by Cambridge University Press:
- 11 November 2025, pp. 1-14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A unified Bayesian framework for mortality model selection
-
- Journal:
- Annals of Actuarial Science / Volume 19 / Issue 3 / November 2025
- Published online by Cambridge University Press:
- 17 October 2025, pp. 462-481
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
5 - Estimation for Structural Models
- from Part II - Intermediate Concepts
-
- Book:
- Statistics for Chemical Engineers
- Published online:
- 12 December 2025
- Print publication:
- 25 September 2025, pp 210-286
-
- Chapter
- Export citation
Humility and Complexity
-
- Journal:
- Canadian Journal of Philosophy , FirstView
- Published online by Cambridge University Press:
- 20 August 2025, pp. 1-12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Placebo and nocebo phenomena in schizophrenia spectrum disorders: a narrative review on current knowledge and potential future directions
-
- Journal:
- Psychological Medicine / Volume 55 / 2025
- Published online by Cambridge University Press:
- 18 July 2025, e199
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
9 - Predictive Coding Models of Attention
-
- Book:
- Neuroscience of Attention
- Published online:
- 02 May 2025
- Print publication:
- 22 May 2025, pp 315-348
-
- Chapter
- Export citation
Meta-analysis with Jeffreys priors: Empirical frequentist properties
-
- Journal:
- Research Synthesis Methods / Volume 16 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 12 March 2025, pp. 87-122
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
9 - Methods for Estimating Discrete-Time Stochastic Volatility Models
- from Part III - Bayesian Estimation and Inferences
-
- Book:
- Financial Econometrics
- Published online:
- 20 February 2025
- Print publication:
- 27 February 2025, pp 271-305
-
- Chapter
- Export citation
Estimating the Cognitive Diagnosis Q\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{Q}$$\end{document}
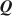 Matrix with Expert Knowledge: Application to the Fraction-Subtraction Dataset
Matrix with Expert Knowledge: Application to the Fraction-Subtraction Dataset
-
- Journal:
- Psychometrika / Volume 84 / Issue 2 / June 2019
- Published online by Cambridge University Press:
- 01 January 2025, pp. 333-357
-
- Article
- Export citation
-
Cognitive diagnosis models (CDMs) are an important psychometric framework for classifying students in terms of attribute and/or skill mastery. The \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{Q}$$\end{document}
 matrix, which specifies the required attributes for each item, is central to implementing CDMs. The general unavailability of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{Q}$$\end{document}
matrix, which specifies the required attributes for each item, is central to implementing CDMs. The general unavailability of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{Q}$$\end{document} for most content areas and datasets poses a barrier to widespread applications of CDMs, and recent research accordingly developed fully exploratory methods to estimate Q. However, current methods do not always offer clear interpretations of the uncovered skills and existing exploratory methods do not use expert knowledge to estimate Q. We consider Bayesian estimation of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{Q}$$\end{document}
for most content areas and datasets poses a barrier to widespread applications of CDMs, and recent research accordingly developed fully exploratory methods to estimate Q. However, current methods do not always offer clear interpretations of the uncovered skills and existing exploratory methods do not use expert knowledge to estimate Q. We consider Bayesian estimation of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{Q}$$\end{document}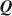 using a prior based upon expert knowledge using a fully Bayesian formulation for a general diagnostic model. The developed method can be used to validate which of the underlying attributes are predicted by experts and to identify residual attributes that remain unexplained by expert knowledge. We report Monte Carlo evidence about the accuracy of selecting active expert-predictors and present an application using Tatsuoka’s fraction-subtraction dataset.
using a prior based upon expert knowledge using a fully Bayesian formulation for a general diagnostic model. The developed method can be used to validate which of the underlying attributes are predicted by experts and to identify residual attributes that remain unexplained by expert knowledge. We report Monte Carlo evidence about the accuracy of selecting active expert-predictors and present an application using Tatsuoka’s fraction-subtraction dataset.
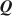


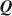
Gibbs Samplers for Logistic Item Response Models via the Pólya–Gamma Distribution: A Computationally Efficient Data-Augmentation Strategy
-
- Journal:
- Psychometrika / Volume 84 / Issue 2 / June 2019
- Published online by Cambridge University Press:
- 01 January 2025, pp. 358-374
-
- Article
- Export citation
Revisiting the 4-Parameter Item Response Model: Bayesian Estimation and Application
-
- Journal:
- Psychometrika / Volume 81 / Issue 4 / December 2016
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1142-1163
-
- Article
- Export citation
-
There has been renewed interest in Barton and Lord’s (An upper asymptote for the three-parameter logistic item response model (Tech. Rep. No. 80-20). Educational Testing Service, 1981) four-parameter item response model. This paper presents a Bayesian formulation that extends Béguin and Glas (MCMC estimation and some model fit analysis of multidimensional IRT models. Psychometrika, 66 (4):541–561, 2001) and proposes a model for the four-parameter normal ogive (4PNO) model. Monte Carlo evidence is presented concerning the accuracy of parameter recovery. The simulation results support the use of less informative uniform priors for the lower and upper asymptotes, which is an advantage to prior research. Monte Carlo results provide some support for using the deviance information criterion and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\chi ^{2}$$\end{document}
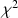 index to choose among models with two, three, and four parameters. The 4PNO is applied to 7491 adolescents’ responses to a bullying scale collected under the 2005–2006 Health Behavior in School-Aged Children study. The results support the value of the 4PNO to estimate lower and upper asymptotes in large-scale surveys.
index to choose among models with two, three, and four parameters. The 4PNO is applied to 7491 adolescents’ responses to a bullying scale collected under the 2005–2006 Health Behavior in School-Aged Children study. The results support the value of the 4PNO to estimate lower and upper asymptotes in large-scale surveys.
Bayesian Mixture Model of Extended Redundancy Analysis
-
- Journal:
- Psychometrika / Volume 87 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 946-966
-
- Article
- Export citation
The Reliability Factor: Modeling Individual Reliability with Multiple Items from a Single Assessment
-
- Journal:
- Psychometrika / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1318-1342
-
- Article
- Export citation
A Hierarchical Ornstein–Uhlenbeck Model for Continuous Repeated Measurement Data
-
- Journal:
- Psychometrika / Volume 74 / Issue 3 / September 2009
- Published online by Cambridge University Press:
- 01 January 2025, pp. 395-418
-
- Article
- Export citation
Inferring the Number of Attributes for the Exploratory DINA Model
-
- Journal:
- Psychometrika / Volume 86 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 30-64
-
- Article
- Export citation
-
Diagnostic classification models (DCMs) are widely used for providing fine-grained classification of a multidimensional collection of discrete attributes. The application of DCMs requires the specification of the latent structure in what is known as the \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
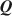 matrix. Expert-specified \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
matrix. Expert-specified \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}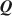 matrices might be biased and result in incorrect diagnostic classifications, so a critical issue is developing methods to estimate \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
matrices might be biased and result in incorrect diagnostic classifications, so a critical issue is developing methods to estimate \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}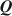 in order to infer the relationship between latent attributes and items. Existing exploratory methods for estimating \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
in order to infer the relationship between latent attributes and items. Existing exploratory methods for estimating \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}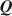 must pre-specify the number of attributes, K. We present a Bayesian framework to jointly infer the number of attributes K and the elements of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
must pre-specify the number of attributes, K. We present a Bayesian framework to jointly infer the number of attributes K and the elements of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document} . We propose the crimp sampling algorithm to transit between different dimensions of K and estimate the underlying \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
. We propose the crimp sampling algorithm to transit between different dimensions of K and estimate the underlying \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}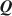 and model parameters while enforcing model identifiability constraints. We also adapt the Indian buffet process and reversible-jump Markov chain Monte Carlo methods to estimate \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
and model parameters while enforcing model identifiability constraints. We also adapt the Indian buffet process and reversible-jump Markov chain Monte Carlo methods to estimate \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document} . We report evidence that the crimp sampler performs the best among the three methods. We apply the developed methodology to two data sets and discuss the implications of the findings for future research.
. We report evidence that the crimp sampler performs the best among the three methods. We apply the developed methodology to two data sets and discuss the implications of the findings for future research.


A Latent Space Network Model for Social Influence
-
- Journal:
- Psychometrika / Volume 85 / Issue 2 / June 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 251-274
-
- Article
- Export citation
Bayesian Hierarchical Classes Analysis
-
- Journal:
- Psychometrika / Volume 73 / Issue 1 / March 2008
- Published online by Cambridge University Press:
- 01 January 2025, pp. 39-64
-
- Article
- Export citation
Detecting Multiple Random Changepoints in Bayesian Piecewise Growth Mixture Models
-
- Journal:
- Psychometrika / Volume 83 / Issue 3 / September 2018
- Published online by Cambridge University Press:
- 01 January 2025, pp. 733-750
-
- Article
- Export citation
Forecasting Intra-individual Changes of Affective States Taking into Account Inter-individual Differences Using Intensive Longitudinal Data from a University Student Dropout Study in Math
-
- Journal:
- Psychometrika / Volume 87 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 533-558
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The longitudinal process that leads to university student dropout in STEM subjects can be described by referring to (a) inter-individual differences (e.g., cognitive abilities) as well as (b) intra-individual changes (e.g., affective states), (c) (unobserved) heterogeneity of trajectories, and d) time-dependent variables. Large dynamic latent variable model frameworks for intensive longitudinal data (ILD) have been proposed which are (partially) capable of simultaneously separating the complex data structures (e.g., DLCA; Asparouhov et al. in Struct Equ Model 24:257–269, 2017; DSEM; Asparouhov et al. in Struct Equ Model 25:359–388, 2018; NDLC-SEM, Kelava and Brandt in Struct Equ Model 26:509–528, 2019). From a methodological perspective, forecasting in dynamic frameworks allowing for real-time inferences on latent or observed variables based on ongoing data collection has not been an extensive research topic. From a practical perspective, there has been no empirical study on student dropout in math that integrates ILD, dynamic frameworks, and forecasting of critical states of the individuals allowing for real-time interventions. In this paper, we show how Bayesian forecasting of multivariate intra-individual variables and time-dependent class membership of individuals (affective states) can be performed in these dynamic frameworks using a Forward Filtering Backward Sampling method. To illustrate our approach, we use an empirical example where we apply the proposed forecasting method to ILD from a large university student dropout study in math with multivariate observations collected over 50 measurement occasions from multiple students (\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$N = 122$$\end{document}
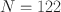 ). More specifically, we forecast emotions and behavior related to dropout. This allows us to predict emerging critical dynamic states (e.g., critical stress levels or pre-decisional states) 8 weeks before the actual dropout occurs.
). More specifically, we forecast emotions and behavior related to dropout. This allows us to predict emerging critical dynamic states (e.g., critical stress levels or pre-decisional states) 8 weeks before the actual dropout occurs.
Comparing Bayesian Variable Selection to Lasso Approaches for Applications in Psychology
-
- Journal:
- Psychometrika / Volume 88 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1032-1055
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
