Refine search
Actions for selected content:
33 results
Non-parametric estimation of the generalized past entropy function under α-mixing sample
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 05 November 2025, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Measure of uncertainty in past lifetime distribution plays an important role in the context of information theory, forensic science and other related fields. In the present work, we propose non-parametric kernel type estimator for generalized past entropy function, which was introduced by Gupta and Nanda [9], under
 $\alpha$-mixing sample. The resulting estimator is shown to be weak and strong consistent and asymptotically normally distributed under certain regularity conditions. The performance of the estimator is validated through simulation study and a real data set.
$\alpha$-mixing sample. The resulting estimator is shown to be weak and strong consistent and asymptotically normally distributed under certain regularity conditions. The performance of the estimator is validated through simulation study and a real data set.

Introducing and applying varinaccuracy: a measure for doubly truncated random variables in reliability analysis
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 05 September 2025, pp. 1-27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Relative entropy bounds for sampling with and without replacement
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 28 July 2025, pp. 1578-1593
- Print publication:
- December 2025
-
- Article
- Export citation
-
Sharp, nonasymptotic bounds are obtained for the relative entropy between the distributions of sampling with and without replacement from an urn with balls of
 $c\geq 2$ colors. Our bounds are asymptotically tight in certain regimes and, unlike previous results, they depend on the number of balls of each color in the urn. The connection of these results with finite de Finetti-style theorems is explored, and it is observed that a sampling bound due to Stam (1978) combined with the convexity of relative entropy yield a new finite de Finetti bound in relative entropy, which achieves the optimal asymptotic convergence rate.
$c\geq 2$ colors. Our bounds are asymptotically tight in certain regimes and, unlike previous results, they depend on the number of balls of each color in the urn. The connection of these results with finite de Finetti-style theorems is explored, and it is observed that a sampling bound due to Stam (1978) combined with the convexity of relative entropy yield a new finite de Finetti bound in relative entropy, which achieves the optimal asymptotic convergence rate.

Sharp estimates for Gowers norms on discrete cubes
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics , First View
- Published online by Cambridge University Press:
- 16 June 2025, pp. 1-27
-
- Article
- Export citation
-
We study optimal dimensionless inequalities
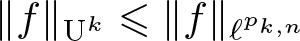 \begin{equation*} \|f\|_{\textrm{U}^k} \leqslant \|f\|_{\ell^{p_{k,n}}} \end{equation*}
\begin{equation*} \|f\|_{\textrm{U}^k} \leqslant \|f\|_{\ell^{p_{k,n}}} \end{equation*}that hold for all functions
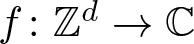 $f\colon\mathbb{Z}^d\to\mathbb{C}$ supported in
$f\colon\mathbb{Z}^d\to\mathbb{C}$ supported in 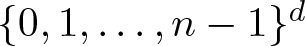 $\{0,1,\ldots,n-1\}^d$ and estimates
$\{0,1,\ldots,n-1\}^d$ and estimates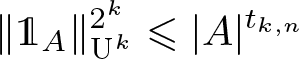 \begin{equation*} \|\mathbb{1}_A\|_{\textrm{U}^k}^{2^k}\leqslant |A|^{t_{k,n}} \end{equation*}
\begin{equation*} \|\mathbb{1}_A\|_{\textrm{U}^k}^{2^k}\leqslant |A|^{t_{k,n}} \end{equation*}that hold for all subsets A of the same discrete cubes. A general theory, analogous to the work of de Dios Pont, Greenfeld, Ivanisvili, and Madrid, is developed to show that the critical exponents are related by
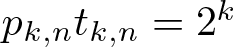 $p_{k,n} t_{k,n} = 2^k$. This is used to prove the three main results of the article:
$p_{k,n} t_{k,n} = 2^k$. This is used to prove the three main results of the article:• an explicit formula for
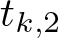 $t_{k,2}$, which generalizes a theorem by Kane and Tao,
$t_{k,2}$, which generalizes a theorem by Kane and Tao,• two-sided asymptotic estimates for
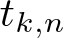 $t_{k,n}$ as
$t_{k,n}$ as 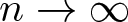 $n\to\infty$ for a fixed
$n\to\infty$ for a fixed 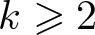 $k\geqslant2$, which generalize a theorem by Shao, and
$k\geqslant2$, which generalize a theorem by Shao, and• a precise asymptotic formula for
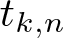 $t_{k,n}$ as
$t_{k,n}$ as 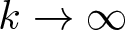 $k\to\infty$ for a fixed
$k\to\infty$ for a fixed 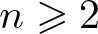 $n\geqslant2$.
$n\geqslant2$.
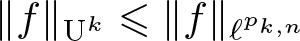
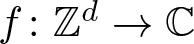
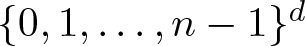
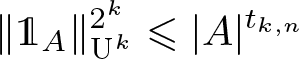
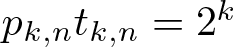
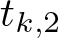
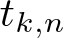
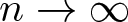
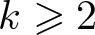
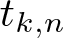
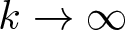
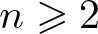
Extropy-based dynamic cumulative residual inaccuracy measure: properties and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 4 / October 2025
- Published online by Cambridge University Press:
- 26 February 2025, pp. 461-485
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Some generalized information and divergence generating functions: properties, estimation, validation, and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 25 February 2025, pp. 397-430
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal experimental design: Formulations and computations
- Part of
-
- Journal:
- Acta Numerica / Volume 33 / July 2024
- Published online by Cambridge University Press:
- 04 September 2024, pp. 715-840
-
- Article
-
- You have access
- Open access
- Export citation
Quantile-based information generating functions and their properties and uses
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 4 / October 2024
- Published online by Cambridge University Press:
- 22 May 2024, pp. 733-751
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Convergence rate of entropy-regularized multi-marginal optimal transport costs
- Part of
-
- Journal:
- Canadian Journal of Mathematics / Volume 77 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 15 March 2024, pp. 1072-1092
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We investigate the convergence rate of multi-marginal optimal transport costs that are regularized with the Boltzmann–Shannon entropy, as the noise parameter
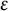 $\varepsilon $ tends to
$\varepsilon $ tends to 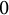 $0$. We establish lower and upper bounds on the difference with the unregularized cost of the form
$0$. We establish lower and upper bounds on the difference with the unregularized cost of the form 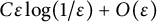 $C\varepsilon \log (1/\varepsilon )+O(\varepsilon )$ for some explicit dimensional constants C depending on the marginals and on the ground cost, but not on the optimal transport plans themselves. Upper bounds are obtained for Lipschitz costs or locally semiconcave costs for a finer estimate, and lower bounds for
$C\varepsilon \log (1/\varepsilon )+O(\varepsilon )$ for some explicit dimensional constants C depending on the marginals and on the ground cost, but not on the optimal transport plans themselves. Upper bounds are obtained for Lipschitz costs or locally semiconcave costs for a finer estimate, and lower bounds for 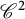 $\mathscr {C}^2$ costs satisfying some signature condition on the mixed second derivatives that may include degenerate costs, thus generalizing results previously in the two marginals case and for nondegenerate costs. We obtain in particular matching bounds in some typical situations where the optimal plan is deterministic.
$\mathscr {C}^2$ costs satisfying some signature condition on the mixed second derivatives that may include degenerate costs, thus generalizing results previously in the two marginals case and for nondegenerate costs. We obtain in particular matching bounds in some typical situations where the optimal plan is deterministic.
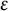
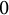
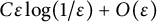
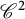
On the Ziv–Merhav theorem beyond Markovianity I
- Part of
-
- Journal:
- Canadian Journal of Mathematics / Volume 77 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 07 March 2024, pp. 891-915
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Approximate discrete entropy monotonicity for log-concave sums
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 13 November 2023, pp. 196-209
-
- Article
- Export citation
-
It is proven that a conjecture of Tao (2010) holds true for log-concave random variables on the integers: For every
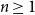 $n \geq 1$, if
$n \geq 1$, if 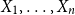 $X_1,\ldots,X_n$ are i.i.d. integer-valued, log-concave random variables, thenas
$X_1,\ldots,X_n$ are i.i.d. integer-valued, log-concave random variables, thenas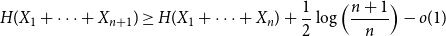 \begin{equation*} H(X_1+\cdots +X_{n+1}) \geq H(X_1+\cdots +X_{n}) + \frac {1}{2}\log {\Bigl (\frac {n+1}{n}\Bigr )} - o(1) \end{equation*}
\begin{equation*} H(X_1+\cdots +X_{n+1}) \geq H(X_1+\cdots +X_{n}) + \frac {1}{2}\log {\Bigl (\frac {n+1}{n}\Bigr )} - o(1) \end{equation*}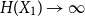 $H(X_1) \to \infty$, where
$H(X_1) \to \infty$, where 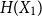 $H(X_1)$ denotes the (discrete) Shannon entropy. The problem is reduced to the continuous setting by showing that if
$H(X_1)$ denotes the (discrete) Shannon entropy. The problem is reduced to the continuous setting by showing that if 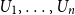 $U_1,\ldots,U_n$ are independent continuous uniforms on
$U_1,\ldots,U_n$ are independent continuous uniforms on 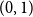 $(0,1)$, thenas
$(0,1)$, thenas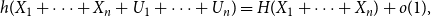 \begin{equation*} h(X_1+\cdots +X_n + U_1+\cdots +U_n) = H(X_1+\cdots +X_n) + o(1), \end{equation*}
\begin{equation*} h(X_1+\cdots +X_n + U_1+\cdots +U_n) = H(X_1+\cdots +X_n) + o(1), \end{equation*}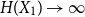 $H(X_1) \to \infty$, where
$H(X_1) \to \infty$, where 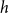 $h$ stands for the differential entropy. Explicit bounds for the
$h$ stands for the differential entropy. Explicit bounds for the 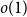 $o(1)$-terms are provided.
$o(1)$-terms are provided.
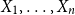
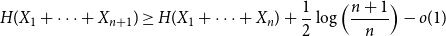
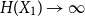
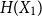
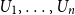
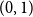
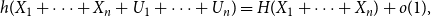
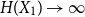
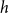
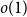
The unified extropy and its versions in classical and Dempster–Shafer theories
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 23 October 2023, pp. 685-696
- Print publication:
- June 2024
-
- Article
- Export citation
Costa’s concavity inequality for dependent variables based on the multivariate Gaussian copula
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 12 April 2023, pp. 1136-1156
- Print publication:
- December 2023
-
- Article
- Export citation
A new lifetime distribution by maximizing entropy: properties and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 28 February 2023, pp. 189-206
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Varentropy of doubly truncated random variable
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 3 / July 2023
- Published online by Cambridge University Press:
- 08 July 2022, pp. 852-871
-
- Article
- Export citation
On reconsidering entropies and divergences and their cumulative counterparts: Csiszár's, DPD's and Fisher's type cumulative and survival measures
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 21 February 2022, pp. 294-321
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Concentration functions and entropy bounds for discrete log-concave distributions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 27 May 2021, pp. 54-72
-
- Article
- Export citation
PROBABILISTIC STABILITY, AGM REVISION OPERATORS AND MAXIMUM ENTROPY
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 21 October 2020, pp. 553-590
- Print publication:
- September 2022
-
- Article
- Export citation
Orlicz Addition for Measures and an Optimization Problem for the
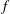 $f$-divergence
$f$-divergence
- Part of
-
- Journal:
- Canadian Journal of Mathematics / Volume 72 / Issue 2 / April 2020
- Published online by Cambridge University Press:
- 16 July 2019, pp. 455-479
- Print publication:
- April 2020
-
- Article
-
- You have access
- Export citation
-
This paper provides a functional analogue of the recently initiated dual Orlicz–Brunn–Minkowski theory for star bodies. We first propose the Orlicz addition of measures, and establish the dual functional Orlicz–Brunn–Minkowski inequality. Based on a family of linear Orlicz additions of two measures, we provide an interpretation for the famous
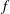 $f$-divergence. Jensen’s inequality for integrals is also proved to be equivalent to the newly established dual functional Orlicz–Brunn–Minkowski inequality. An optimization problem for the
$f$-divergence. Jensen’s inequality for integrals is also proved to be equivalent to the newly established dual functional Orlicz–Brunn–Minkowski inequality. An optimization problem for the 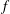 $f$-divergence is proposed, and related functional affine isoperimetric inequalities are established.
$f$-divergence is proposed, and related functional affine isoperimetric inequalities are established.
CONVEXITY OF PARAMETER EXTENSIONS OF SOME RELATIVE OPERATOR ENTROPIES WITH A PERSPECTIVE APPROACH
- Part of
-
- Journal:
- Glasgow Mathematical Journal / Volume 62 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 06 June 2019, pp. 737-744
- Print publication:
- September 2020
-
- Article
-
- You have access
- Export citation
