




1 Introduction
A matrix A is called normal if it commutes with its conjugate transpose:
 $AA^\ast = A^\ast A$
. The set of
$AA^\ast = A^\ast A$
. The set of
 $d \times d$
complex normal matrices, which we denote as
$d \times d$
complex normal matrices, which we denote as
 $\mathcal {N}_d \subset \mathbb {C}^{d \times d}$
, is a fundamental object in linear algebra; for example, the Spectral Theorem characterizes
$\mathcal {N}_d \subset \mathbb {C}^{d \times d}$
, is a fundamental object in linear algebra; for example, the Spectral Theorem characterizes
 $\mathcal {N}_d$
as the set of unitarily diagonalizable matrices:
$\mathcal {N}_d$
as the set of unitarily diagonalizable matrices:
 $$\begin{align*}\mathcal{N}_d = \{UDU^\ast \mid D \in \mathcal{D}_d, \, U \in \operatorname{U}(d)\}, \end{align*}$$
$$\begin{align*}\mathcal{N}_d = \{UDU^\ast \mid D \in \mathcal{D}_d, \, U \in \operatorname{U}(d)\}, \end{align*}$$
where
 $\mathcal {D}_d \subset \mathbb {C}^{d \times d}$
is the set of diagonal matrices and
$\mathcal {D}_d \subset \mathbb {C}^{d \times d}$
is the set of diagonal matrices and
 $\operatorname {U}(d)$
is the group of unitary matrices. Moreover, normal matrices are especially well-behaved from a numerical analysis perspective. Indeed, the Bauer–Fike Theorem [Reference Bauer and Fike5] implies that the eigenvalues of a normal matrix are Lipschitz stable under perturbations, which motivates the approximation of transfer matrices by normal matrices in classical control theory [Reference Daniel and Kouvaritakis15, Reference Daniel and Kouvaritakis16]. In the literature on dynamics on complex networks, it has also been observed that directed networks whose weighted adjacency matrices are not normal exhibit distinctive dynamical features which can confound classical spectral methods [Reference Asllani and Carletti2, Reference Asllani, Lambiotte and Carletti3, Reference Muolo, Asllani, Fanelli, Maini and Carletti45]. Based on these considerations, the closest normal matrix problem – that is, the problem of finding a closest point in
$\operatorname {U}(d)$
is the group of unitary matrices. Moreover, normal matrices are especially well-behaved from a numerical analysis perspective. Indeed, the Bauer–Fike Theorem [Reference Bauer and Fike5] implies that the eigenvalues of a normal matrix are Lipschitz stable under perturbations, which motivates the approximation of transfer matrices by normal matrices in classical control theory [Reference Daniel and Kouvaritakis15, Reference Daniel and Kouvaritakis16]. In the literature on dynamics on complex networks, it has also been observed that directed networks whose weighted adjacency matrices are not normal exhibit distinctive dynamical features which can confound classical spectral methods [Reference Asllani and Carletti2, Reference Asllani, Lambiotte and Carletti3, Reference Muolo, Asllani, Fanelli, Maini and Carletti45]. Based on these considerations, the closest normal matrix problem – that is, the problem of finding a closest point in
 $\mathcal {N}_d$
to an arbitrary matrix in
$\mathcal {N}_d$
to an arbitrary matrix in
 $\mathbb {C}^{d \times d}$
– has been thoroughly studied [Reference Gabriel22, Reference Guglielmi and Scalone25, Reference Noschese and Reichel50, Reference Ruhe52].
$\mathbb {C}^{d \times d}$
– has been thoroughly studied [Reference Gabriel22, Reference Guglielmi and Scalone25, Reference Noschese and Reichel50, Reference Ruhe52].
This paper studies
 $\mathcal {N}_d$
from a geometric perspective, with a view toward optimization tasks such as the closest normal matrix problem. Our results are largely derived from the simple observation that
$\mathcal {N}_d$
from a geometric perspective, with a view toward optimization tasks such as the closest normal matrix problem. Our results are largely derived from the simple observation that
 $\mathcal {N}_d$
is the set of global minima of the function
$\mathcal {N}_d$
is the set of global minima of the function
 $$ \begin{align} \operatorname{E}:\mathbb{C}^{d \times d} \to \mathbb{R}, \quad \mbox{defined by} \quad \operatorname{E}(A) = \|AA^\ast - A^\ast A\|^2, \end{align} $$
$$ \begin{align} \operatorname{E}:\mathbb{C}^{d \times d} \to \mathbb{R}, \quad \mbox{defined by} \quad \operatorname{E}(A) = \|AA^\ast - A^\ast A\|^2, \end{align} $$
where
 $\|\cdot \|$
is the Frobenius norm; that is,
$\|\cdot \|$
is the Frobenius norm; that is,
 $$\begin{align*}\|B\|^2 = \sum_{i,j = 1}^d b_{ij}^2, \quad \mbox{for } \quad B = \big(b_{ij}\big)_{i,j = 1}^d \in \mathbb{C}^{d \times d}. \end{align*}$$
$$\begin{align*}\|B\|^2 = \sum_{i,j = 1}^d b_{ij}^2, \quad \mbox{for } \quad B = \big(b_{ij}\big)_{i,j = 1}^d \in \mathbb{C}^{d \times d}. \end{align*}$$
Despite the fact that the function
 $\operatorname {E}$
, which we refer to as the non-normal energy, is not quasiconvex (see Remark 2.5), it is surprisingly well-behaved from an optimization perspective: we prove in Theorem 2.3 that the only critical points of
$\operatorname {E}$
, which we refer to as the non-normal energy, is not quasiconvex (see Remark 2.5), it is surprisingly well-behaved from an optimization perspective: we prove in Theorem 2.3 that the only critical points of
 $\operatorname {E}$
are normal matrices, hence gradient descent along
$\operatorname {E}$
are normal matrices, hence gradient descent along
 $\operatorname {E}$
gives an approximate solution to the closest normal matrix problem. We derive several related results, which are described in more detail below in Section 1.1; in short, we show that gradient descent preserves interesting features of the initializing matrix, such as its spectrum or the realness of its entries. We also consider the restriction of non-normal energy to the space of matrices with unit Frobenius norm and show that its gradient flow is also quite well-behaved. This has immediate topological implications, as we explain in more detail in Section 1.1.
$\operatorname {E}$
gives an approximate solution to the closest normal matrix problem. We derive several related results, which are described in more detail below in Section 1.1; in short, we show that gradient descent preserves interesting features of the initializing matrix, such as its spectrum or the realness of its entries. We also consider the restriction of non-normal energy to the space of matrices with unit Frobenius norm and show that its gradient flow is also quite well-behaved. This has immediate topological implications, as we explain in more detail in Section 1.1.
The properties of the non-normal energy which we exploit in this paper are predictable from a high-level perspective:
 $\operatorname {E}$
is the squared norm of a momentum map associated to a Hamiltonian action of
$\operatorname {E}$
is the squared norm of a momentum map associated to a Hamiltonian action of
 $\mathrm {SU}(d)$
on
$\mathrm {SU}(d)$
on
 $\mathbb {C}^{d \times d}$
(see Proposition 2.2). This terminology comes from the field of symplectic geometry, where the behavior of functions of this form is well-understood [Reference Kirwan37, Reference Lerman40]. Our work in this paper is heavily inspired by Mumford’s Geometric Invariant Theory (GIT) [Reference Mumford, Fogarty and Kirwan44] (see [Reference Thomas55] for a nice introduction or [Reference Mixon, Needham, Shonkwiler, Villar, Casey, Dodson, Ferreira and Zayed43] for applications to similar matrix optimization problems) and Kirwan’s work relating GIT and symplectic geometry [Reference Kirwan37]; there are also strong connections to Ness’s paper [Reference Ness49]. One of our goals in writing this paper was to make our arguments – especially the fundamentally elementary ones – as accessible as possible, so we have mostly avoided explicitly invoking GIT in what follows, but it was very much on our minds as we were working on this paper. Connections to GIT and symplectic ideas are explained throughout.
$\mathbb {C}^{d \times d}$
(see Proposition 2.2). This terminology comes from the field of symplectic geometry, where the behavior of functions of this form is well-understood [Reference Kirwan37, Reference Lerman40]. Our work in this paper is heavily inspired by Mumford’s Geometric Invariant Theory (GIT) [Reference Mumford, Fogarty and Kirwan44] (see [Reference Thomas55] for a nice introduction or [Reference Mixon, Needham, Shonkwiler, Villar, Casey, Dodson, Ferreira and Zayed43] for applications to similar matrix optimization problems) and Kirwan’s work relating GIT and symplectic geometry [Reference Kirwan37]; there are also strong connections to Ness’s paper [Reference Ness49]. One of our goals in writing this paper was to make our arguments – especially the fundamentally elementary ones – as accessible as possible, so we have mostly avoided explicitly invoking GIT in what follows, but it was very much on our minds as we were working on this paper. Connections to GIT and symplectic ideas are explained throughout.
As our results on
 $\mathcal {N}_d$
are rooted in powerful general theory, it should not be surprising that our techniques are more broadly applicable. Indeed, we also apply our geometric approach to the graph balancing problem: given a weighted, directed graph
$\mathcal {N}_d$
are rooted in powerful general theory, it should not be surprising that our techniques are more broadly applicable. Indeed, we also apply our geometric approach to the graph balancing problem: given a weighted, directed graph
 $\mathcal {G}$
, one wishes to determine a new set of edge weights which balances the graph in the sense that the weighted in-degree is the same as the weighted out-degree at each node. If the latter condition is met, we say that the graph is balanced. An example of our gradient flow-based approached to graph balancing, as is described below, is shown in Figure 1. This problem is natural from an applications perspective; for example, in the case that the underlying graph represents a road network and that the weights are roadway capacities, that the graph is balanced corresponds to the feasibility of traffic flow through all intersections. As such, the graph balancing problem is well-studied in the operations research literature [Reference Hadjicostis and Rikos26, Reference Loh33, Reference Rikos, Charalambous and Hadjicostis51].
$\mathcal {G}$
, one wishes to determine a new set of edge weights which balances the graph in the sense that the weighted in-degree is the same as the weighted out-degree at each node. If the latter condition is met, we say that the graph is balanced. An example of our gradient flow-based approached to graph balancing, as is described below, is shown in Figure 1. This problem is natural from an applications perspective; for example, in the case that the underlying graph represents a road network and that the weights are roadway capacities, that the graph is balanced corresponds to the feasibility of traffic flow through all intersections. As such, the graph balancing problem is well-studied in the operations research literature [Reference Hadjicostis and Rikos26, Reference Loh33, Reference Rikos, Charalambous and Hadjicostis51].

Figure 1 Balancing a graph, starting at top left with a random weighted, directed multigraph with 6 vertices and 15 edges and ending with a balanced graph with the same edges and vertices on the bottom right. The thickness of each edge is proportional to its weight and the time parameter is logarithmic in the number of iterations of gradient descent. Two features of interest: different edges have activity in different timeframes (compare the two edges connecting the bottom-right vertex to the top-center vertex), and the weight of an edge can be nonmonotone as a function of time (e.g., the left-most edge or the edge connecting the top-right vertex to the central vertex).
Representing a graph
 $\mathcal {G}$
on d nodes by a matrix
$\mathcal {G}$
on d nodes by a matrix
 $A \in \mathbb {C}^{d \times d}$
containing the square roots of the entries of the weighted adjacency matrix of
$A \in \mathbb {C}^{d \times d}$
containing the square roots of the entries of the weighted adjacency matrix of
 $\mathcal {G}$
, the balanced graphs are exactly the global minima of the unbalanced energy function,
$\mathcal {G}$
, the balanced graphs are exactly the global minima of the unbalanced energy function,
 $$ \begin{align} \operatorname{B}:\mathbb{C}^{d \times d} \to \mathbb{R}, \quad \mbox{defined by} \quad A \mapsto \|\operatorname{diag}(AA^\ast - A^\ast A)\|^2, \end{align} $$
$$ \begin{align} \operatorname{B}:\mathbb{C}^{d \times d} \to \mathbb{R}, \quad \mbox{defined by} \quad A \mapsto \|\operatorname{diag}(AA^\ast - A^\ast A)\|^2, \end{align} $$
where
 $\operatorname {diag}$
is the linear map which zeros out all off-diagonal entries. The unbalanced energy is similar in structure to the non-normal energy – in fact, it is also the squared norm of a momentum map – and we derive similar results regarding its gradient flow. We show in Theorem 4.1 that the critical points of
$\operatorname {diag}$
is the linear map which zeros out all off-diagonal entries. The unbalanced energy is similar in structure to the non-normal energy – in fact, it is also the squared norm of a momentum map – and we derive similar results regarding its gradient flow. We show in Theorem 4.1 that the critical points of
 $\operatorname {B}$
are exactly the balanced matrices and refine this result to show that gradient flow preserves geometric features of the underlying graph. We describe these results more precisely in the following subsection.
$\operatorname {B}$
are exactly the balanced matrices and refine this result to show that gradient flow preserves geometric features of the underlying graph. We describe these results more precisely in the following subsection.
1.1 Main contributions and outline
We now summarize our main results in more detail.
-
• Gradient flow of non-normal energy: Section 2 considers properties of the non-normal energy (1.1), with a focus on properties of its gradient descent dynamics in relation to normal matrices. Although the non-normal energy is not convex (Remark 2.5), we show in Theorem 2.3 that the only critical points of
 $\operatorname {E}$
are normal matrices; that is, its global minima. It follows easily that its gradient descent has a well-defined limiting normal matrix for every choice of initial conditions; we additionally show in Theorem 2.6 that the gradient descent trajectories of the non-normal entries preserve spectra and realness of matrix entries. We derive estimates of the distance traveled under gradient flow, which give new interpretations of concepts in the literature on the closest normal matrix problem (Corollary 2.9 and Proposition 2.11).
$\operatorname {E}$
are normal matrices; that is, its global minima. It follows easily that its gradient descent has a well-defined limiting normal matrix for every choice of initial conditions; we additionally show in Theorem 2.6 that the gradient descent trajectories of the non-normal entries preserve spectra and realness of matrix entries. We derive estimates of the distance traveled under gradient flow, which give new interpretations of concepts in the literature on the closest normal matrix problem (Corollary 2.9 and Proposition 2.11). -
• Restriction to unit norm matrices and topological consequences: In Section 3, we consider the restriction of the non-normal energy to the space of matrices with unit Frobenius norm. We prove in Theorem 3.1 that if gradient descent is initialized at a non-nilpotent unit norm matrix, then it converges to a normal matrix, and that if the initialization has real entries then so does its limit. As an application, we show that the low-dimension homotopy groups of the spaces of complex and real unit norm normal matrices vanish in Theorem 3.9 and Theorem 3.13, respectively. In particular, the space of
$d \times d$
unit norm complex normal matrices is connected for all d and simply connected for
$d\geq 2$
, whereas the space of unit norm real normal matrices is connected for
$d \geq 2$
and simply connected for
$d \geq 3$
. -
• Graph balancing via unbalanced energy: The unbalanced energy (1.2) and its applications to graph balancing are studied in Section 4. Theorem 4.1 shows that the only critical points of the unbalanced energy are its global minima; that is, matrices representing balanced digraphs. Gradient descent converges to a balanced digraph representation, and we show in Theorem 4.3 that it preserves spectra and realness of entries. Moreover, this theorem shows that if the entries of a real matrix are positive then this property is also preserved, and that if an entry in the initial matrix is zero then it stays zero along the gradient descent path – in terms of graphs, gradient descent does not create any edges that were not present at initialization. We also consider the restriction of the unbalanced energy to unit norm matrices (which represent digraphs with a fixed total edge capacity) and derive similar useful properties of its gradient flow in Theorem 4.5. Finally, we observe in Theorem 4.10 that the spaces of complex and real balanced unit norm matrices are homotopy equivalent to spaces of real and complex normal matrices, respectively.





2 Normal matrices and optimization
Recall from the introduction that the non-normal energy
 $\operatorname {E}:\mathbb {C}^{d \times d} \to \mathbb {R}$
is the function
$\operatorname {E}:\mathbb {C}^{d \times d} \to \mathbb {R}$
is the function
 $$\begin{align*}\operatorname{E}(A) = \|AA^\ast - A^\ast A\|^2 = \|[A,A^\ast]\|^2. \end{align*}$$
$$\begin{align*}\operatorname{E}(A) = \|AA^\ast - A^\ast A\|^2 = \|[A,A^\ast]\|^2. \end{align*}$$
Throughout this paper we use
 $[\cdot , \cdot ]$
to denote the matrix commutator:
$[\cdot , \cdot ]$
to denote the matrix commutator:
 $[A,B]=AB-BA$
.
$[A,B]=AB-BA$
.
The goal of this section is to derive properties of the gradient descent dynamics of
 $\operatorname {E}$
. In particular, we will show that we can normalize any square matrix by sending it to its limit under the negative gradient flow of
$\operatorname {E}$
. In particular, we will show that we can normalize any square matrix by sending it to its limit under the negative gradient flow of
 $\operatorname {E}$
.
$\operatorname {E}$
.
2.1 Background
The map
 $\operatorname {E}$
has a long history in the problem of finding the closest normal matrix to a given matrix, going back at least to Henrici [Reference Henrici30], who proved the following:
$\operatorname {E}$
has a long history in the problem of finding the closest normal matrix to a given matrix, going back at least to Henrici [Reference Henrici30], who proved the following:
Proposition 2.1 (Henrici [Reference Henrici30]).
For any
 $A \in \mathbb {C}^{d \times d}$
,
$A \in \mathbb {C}^{d \times d}$
,
 $$\begin{align*}\inf_{M \in \mathcal{N}_d} \|A - M\| \leq \left(\frac{d^3-d}{12}\operatorname{E}(A)\right)^{1/4}. \end{align*}$$
$$\begin{align*}\inf_{M \in \mathcal{N}_d} \|A - M\| \leq \left(\frac{d^3-d}{12}\operatorname{E}(A)\right)^{1/4}. \end{align*}$$
In other words, the distance from A to
 $\mathcal {N}_d$
is bounded above by a quantity proportional to
$\mathcal {N}_d$
is bounded above by a quantity proportional to
 $\operatorname {E}(A)^{1/4}$
. One virtue of this estimate is that
$\operatorname {E}(A)^{1/4}$
. One virtue of this estimate is that
 $\operatorname {E}(A)$
is relatively easy to compute.
$\operatorname {E}(A)$
is relatively easy to compute.
We now give an interpretation of
 $\operatorname {E}$
in terms of symplectic geometry, where we consider
$\operatorname {E}$
in terms of symplectic geometry, where we consider
 $\mathbb {C}^{d \times d} \approx \mathbb {C}^{d^2}$
as a symplectic manifold with its standard symplectic structure. This interpretation is not necessary for most of the paper, and is mainly included for context. As such, we give a somewhat informal treatment and avoid explicit definitions of any of the standard terminology from symplectic geometry. In our previous papers, we give short and elementary overviews of the necessary concepts from symplectic geometry, with a view toward understanding similar spaces of structured matrices (e.g., spaces consisting of unit norm tight frames); we refer the reader to [Reference Needham and Shonkwiler46, Section 2] and [Reference Needham and Shonkwiler47, Section 2.1] for more in-depth exposition.
$\mathbb {C}^{d \times d} \approx \mathbb {C}^{d^2}$
as a symplectic manifold with its standard symplectic structure. This interpretation is not necessary for most of the paper, and is mainly included for context. As such, we give a somewhat informal treatment and avoid explicit definitions of any of the standard terminology from symplectic geometry. In our previous papers, we give short and elementary overviews of the necessary concepts from symplectic geometry, with a view toward understanding similar spaces of structured matrices (e.g., spaces consisting of unit norm tight frames); we refer the reader to [Reference Needham and Shonkwiler46, Section 2] and [Reference Needham and Shonkwiler47, Section 2.1] for more in-depth exposition.
Consider the action of the unitary group
 $\operatorname {SU}(d)$
on
$\operatorname {SU}(d)$
on
 $\mathbb {C}^{d \times d}$
by conjugation. Let
$\mathbb {C}^{d \times d}$
by conjugation. Let
 $\mathfrak {su}(d)$
denote the Lie algebra of
$\mathfrak {su}(d)$
denote the Lie algebra of
 $\operatorname {SU}(d)$
– that is, the traceless, skew-Hermitian
$\operatorname {SU}(d)$
– that is, the traceless, skew-Hermitian
 $d\times d$
matrices – and let
$d\times d$
matrices – and let
 $\mathfrak {su}(d)^\ast $
denote its dual. It will be convenient to identify
$\mathfrak {su}(d)^\ast $
denote its dual. It will be convenient to identify
 $\mathfrak {su}(d)^\ast $
with the space
$\mathfrak {su}(d)^\ast $
with the space
 $\mathscr {H}_0(d)$
of
$\mathscr {H}_0(d)$
of
 $d \times d$
traceless Hermitian matrices via the isomorphism
$d \times d$
traceless Hermitian matrices via the isomorphism
 $$ \begin{align*} \mathscr{H}_0(d) &\to \mathfrak{su}(d)^\ast \\ Y &\mapsto \big(X \mapsto \frac{i}{2}\mathrm{Tr}(XY)\big). \end{align*} $$
$$ \begin{align*} \mathscr{H}_0(d) &\to \mathfrak{su}(d)^\ast \\ Y &\mapsto \big(X \mapsto \frac{i}{2}\mathrm{Tr}(XY)\big). \end{align*} $$
Then we have the following interpretation of
 $\operatorname {E}$
.
$\operatorname {E}$
.
Proposition 2.2. The conjugation action of
 $\operatorname {SU}(d)$
on
$\operatorname {SU}(d)$
on
 $\mathbb {C}^{d \times d}$
is Hamiltonian, with momentum map
$\mathbb {C}^{d \times d}$
is Hamiltonian, with momentum map
 $$ \begin{align} \mu: \mathbb{C}^{d \times d} &\to \mathscr{H}_0(d) \approx \mathfrak{su}(d)^\ast \end{align} $$
$$ \begin{align} \mu: \mathbb{C}^{d \times d} &\to \mathscr{H}_0(d) \approx \mathfrak{su}(d)^\ast \end{align} $$
 $$ \begin{align}\kern-5pt A &\mapsto [A,A^\ast]. \end{align} $$
$$ \begin{align}\kern-5pt A &\mapsto [A,A^\ast]. \end{align} $$
The non-normal energy
 $\operatorname {E}$
is therefore the squared norm of a momentum map.
$\operatorname {E}$
is therefore the squared norm of a momentum map.
We omit the proof of Proposition 2.2, which is a straightforward calculation. In light of this result, one should expect the non-normal energy to have nice properties – see, for example, work of Kirwan [Reference Kirwan37] and Lerman [Reference Lerman40]. However, the specific properties of
 $\operatorname {E}$
(and related functions) that we derive below do not follow directly from the general theory.
$\operatorname {E}$
(and related functions) that we derive below do not follow directly from the general theory.
2.2 Critical points of non-normal energy
Obviously, the global minima of the non-normal energy
 $\operatorname {E}$
are exactly the normal matrices. In fact, we now show that these are the only critical points. Throughout the paper, we use
$\operatorname {E}$
are exactly the normal matrices. In fact, we now show that these are the only critical points. Throughout the paper, we use
 $\langle \cdot , \cdot \rangle $
to denote the real part of the Frobenius inner product on
$\langle \cdot , \cdot \rangle $
to denote the real part of the Frobenius inner product on
 $\mathbb {C}^{d \times d}$
,
$\mathbb {C}^{d \times d}$
,
and we use
 $D\mathrm {F}(A)$
to denote the derivative of a map
$D\mathrm {F}(A)$
to denote the derivative of a map
 $\mathrm {F}:\mathbb {C}^{d \times d} \to \mathbb {R}$
at
$\mathrm {F}:\mathbb {C}^{d \times d} \to \mathbb {R}$
at
 $A \in \mathbb {C}^{d \times d}$
.
$A \in \mathbb {C}^{d \times d}$
.
Theorem 2.3. The only critical points of
 $\operatorname {E}$
are the global minima; that is, the normal matrices.
$\operatorname {E}$
are the global minima; that is, the normal matrices.
Proof. We claim that
 $$ \begin{align} \nabla \operatorname{E}(A) = -4[A,[A,A^\ast]]. \end{align} $$
$$ \begin{align} \nabla \operatorname{E}(A) = -4[A,[A,A^\ast]]. \end{align} $$
Indeed, since
 $\operatorname {E}$
is the square of a momentum map (Proposition 2.2), this follows by general principles of symplectic geometry – see, for example, [Reference Kirwan37, Lemma 6.6] or [Reference Ness49, Lemma 6.1]. Let us additionally give an elementary derivation of this fact. Writing
$\operatorname {E}$
is the square of a momentum map (Proposition 2.2), this follows by general principles of symplectic geometry – see, for example, [Reference Kirwan37, Lemma 6.6] or [Reference Ness49, Lemma 6.1]. Let us additionally give an elementary derivation of this fact. Writing
 $\operatorname {E} = N \circ \mu $
, where
$\operatorname {E} = N \circ \mu $
, where
 $\mu $
is the momentum map (2.1) and
$\mu $
is the momentum map (2.1) and
 $N:\mathbb {C}^{d \times d} \to \mathbb {R}$
is the norm-squared map
$N:\mathbb {C}^{d \times d} \to \mathbb {R}$
is the norm-squared map
 $N(A) = \|A\|^2$
, we have, for any
$N(A) = \|A\|^2$
, we have, for any
 $A,B \in \mathbb {C}^{d \times d}$
,
$A,B \in \mathbb {C}^{d \times d}$
,
 $$ \begin{align*} &\langle \nabla \operatorname{E}(A), B\rangle = D\operatorname{E}(A)(B) = DN(\mu(A)) \circ D\mu(A) (B) \\ &\quad= \langle \nabla N (\mu(A)), D\mu(A)(B)\rangle = \langle D\mu(A)^\vee \nabla N (\mu(A)), B\rangle, \end{align*} $$
$$ \begin{align*} &\langle \nabla \operatorname{E}(A), B\rangle = D\operatorname{E}(A)(B) = DN(\mu(A)) \circ D\mu(A) (B) \\ &\quad= \langle \nabla N (\mu(A)), D\mu(A)(B)\rangle = \langle D\mu(A)^\vee \nabla N (\mu(A)), B\rangle, \end{align*} $$
where we use
 $D\mu (A)^\vee $
to denote the adjoint of
$D\mu (A)^\vee $
to denote the adjoint of
 $D\mu (A)$
with respect to the inner product
$D\mu (A)$
with respect to the inner product
 $\langle \cdot , \cdot \rangle $
. It follows that
$\langle \cdot , \cdot \rangle $
. It follows that
 $$\begin{align*}\nabla \operatorname{E} (A) = D\mu(A)^\vee \nabla N (\mu(A)). \end{align*}$$
$$\begin{align*}\nabla \operatorname{E} (A) = D\mu(A)^\vee \nabla N (\mu(A)). \end{align*}$$
A straightforward calculation then shows that the adjoint is given by the formula
 $$ \begin{align} D\mu(A)^\vee(C) = [C + C^\ast, A]. \end{align} $$
$$ \begin{align} D\mu(A)^\vee(C) = [C + C^\ast, A]. \end{align} $$
It is also easy to show that
 $\nabla N(C) = 2C$
, so we conclude that
$\nabla N(C) = 2C$
, so we conclude that
 $$\begin{align*}\nabla \operatorname{E} (A) = [2\mu(A) + 2\mu(A)^\ast, A] = -4[A,[A,A^\ast]]. \end{align*}$$
$$\begin{align*}\nabla \operatorname{E} (A) = [2\mu(A) + 2\mu(A)^\ast, A] = -4[A,[A,A^\ast]]. \end{align*}$$
Therefore, we have a critical point of
 $\operatorname {E}$
exactly when
$\operatorname {E}$
exactly when
 $$\begin{align*}0 = [A,[A,A^\ast]]; \end{align*}$$
$$\begin{align*}0 = [A,[A,A^\ast]]; \end{align*}$$
that is, when A and
 $[A,A^\ast ]$
commute. By Jacobson’s Lemma (stated below as Lemma 2.4), this implies that
$[A,A^\ast ]$
commute. By Jacobson’s Lemma (stated below as Lemma 2.4), this implies that
 $[A,A^\ast ]$
is nilpotent. But
$[A,A^\ast ]$
is nilpotent. But
 $[A,A^\ast ]$
is Hermitian, so it is nilpotent if and only if it is the zero matrix, which happens precisely when A is normal.Footnote 1
$[A,A^\ast ]$
is Hermitian, so it is nilpotent if and only if it is the zero matrix, which happens precisely when A is normal.Footnote 1
Lemma 2.4 (Jacobson [Reference Jacobson34]; see also [Reference Kaplansky36]).
If A and B are
 $d \times d$
matrices over a field of characteristic 0 and A commutes with
$d \times d$
matrices over a field of characteristic 0 and A commutes with
 $[A,B]$
, then
$[A,B]$
, then
 $[A,B]$
is nilpotent.
$[A,B]$
is nilpotent.
Remark 2.5. Theorem 2.3 might lead one to suspect that
 $\operatorname {E}$
is convex, but it is not. To see this, consider the normal matrices
$\operatorname {E}$
is convex, but it is not. To see this, consider the normal matrices
 $$\begin{align*}A_0 = \begin{bmatrix}0 & 1 \\ -1 & 0\end{bmatrix} \qquad \mbox{and} \qquad A_1 = \begin{bmatrix} 0 & 1 \\ 1 & 0 \end{bmatrix}. \end{align*}$$
$$\begin{align*}A_0 = \begin{bmatrix}0 & 1 \\ -1 & 0\end{bmatrix} \qquad \mbox{and} \qquad A_1 = \begin{bmatrix} 0 & 1 \\ 1 & 0 \end{bmatrix}. \end{align*}$$
Since they are normal,
 $\operatorname {E}(A_0) = 0 = \operatorname {E}(A_1)$
. However,
$\operatorname {E}(A_0) = 0 = \operatorname {E}(A_1)$
. However,
 $$\begin{align*}\operatorname{E}((1-t)A_0 + tA_1) = 32t^2(1-t)^2> 0 \end{align*}$$
$$\begin{align*}\operatorname{E}((1-t)A_0 + tA_1) = 32t^2(1-t)^2> 0 \end{align*}$$
for all
 $0<t<1$
, so the interior of the line segment connecting
$0<t<1$
, so the interior of the line segment connecting
 $A_0$
and
$A_0$
and
 $A_1$
consists entirely of non-normal matrices, and hence
$A_1$
consists entirely of non-normal matrices, and hence
 $\operatorname {E}$
is not even quasiconvex, let alone convex. See Figure 2. Of course, we can pad
$\operatorname {E}$
is not even quasiconvex, let alone convex. See Figure 2. Of course, we can pad
 $A_0$
and
$A_0$
and
 $A_1$
by zeros to get an analogous example for any
$A_1$
by zeros to get an analogous example for any
 $d> 2$
.
$d> 2$
.

Figure 2 The graph of
 $\operatorname {E}$
restricted to the collection of real matrices of the form
$\operatorname {E}$
restricted to the collection of real matrices of the form
 $\begin{bmatrix} 0 & x \\ y & 0 \end{bmatrix}$
.
$\begin{bmatrix} 0 & x \\ y & 0 \end{bmatrix}$
.
On the other hand, Theorem 2.3 shows that
 $\operatorname {E}$
is an invex function. Recall that, as first defined by Hanson [Reference Hanson27] (later named by Craven [Reference Craven, Schaible and Ziemba13]), a function
$\operatorname {E}$
is an invex function. Recall that, as first defined by Hanson [Reference Hanson27] (later named by Craven [Reference Craven, Schaible and Ziemba13]), a function
 $f:\mathbb {R}^n \to \mathbb {R}$
is invex if there exists a function
$f:\mathbb {R}^n \to \mathbb {R}$
is invex if there exists a function
 $\eta :\mathbb {R}^{n} \times \mathbb {R}^n \to \mathbb {R}^n$
such that
$\eta :\mathbb {R}^{n} \times \mathbb {R}^n \to \mathbb {R}^n$
such that
 $$\begin{align*}f(x) - f(u) \geq \langle \eta(x,u), \nabla f(u) \rangle \qquad x,u \in \mathbb{R}^n. \end{align*}$$
$$\begin{align*}f(x) - f(u) \geq \langle \eta(x,u), \nabla f(u) \rangle \qquad x,u \in \mathbb{R}^n. \end{align*}$$
A theorem of Craven and Glover [Reference Craven and Glover14] (see also [Reference Ben-Israel and Mond6]) says that a function is invex if and only if its critical points are all global minima; hence,
 $\operatorname {E}$
is invex.
$\operatorname {E}$
is invex.
2.3 Gradient flow of non-normal energy
Consider the negative gradient flow
 $\mathcal {F}: \mathbb {C}^{d \times d} \times [0,\infty ) \to \mathbb {C}^{d \times d}$
defined by
$\mathcal {F}: \mathbb {C}^{d \times d} \times [0,\infty ) \to \mathbb {C}^{d \times d}$
defined by
 $$ \begin{align} \mathcal{F}(A_0,0) = A_0, \qquad \frac{d}{dt}\mathcal{F}(A_0,t) = -\nabla\operatorname{E}(\mathcal{F}(A_0,t)). \end{align} $$
$$ \begin{align} \mathcal{F}(A_0,0) = A_0, \qquad \frac{d}{dt}\mathcal{F}(A_0,t) = -\nabla\operatorname{E}(\mathcal{F}(A_0,t)). \end{align} $$
We pause here to note that there is a substantial history of applying flows like (2.5) to problems in numerical linear algebra, going back at least to Rutishauer’s work on the LU decomposition [Reference Rutishauser53, Section 11]. See Chu’s survey [Reference Chu12] for an introduction to this circle of ideas.
Since
 $\operatorname {E}$
is a real polynomial function on the real vector space
$\operatorname {E}$
is a real polynomial function on the real vector space
 $\mathbb {C}^{d \times d}$
, the gradient flow cannot have limit cycles or other bad behavior [Reference Łojasiewicz41], so Theorem 2.3 implies that, for any
$\mathbb {C}^{d \times d}$
, the gradient flow cannot have limit cycles or other bad behavior [Reference Łojasiewicz41], so Theorem 2.3 implies that, for any
 $A_0 \in \mathbb {C}^{d \times d}$
, the limit
$A_0 \in \mathbb {C}^{d \times d}$
, the limit ![]() of the gradient flow is well-defined and normal.
of the gradient flow is well-defined and normal.
From (2.3), we see that
 $$ \begin{align} \nabla \operatorname{E}(A) &= -4[A,[A,A^\ast]] = -4(A[A,A^\ast]-[A,A^\ast]A) \nonumber\\ &= 4 \left( \left. \frac{d}{d\epsilon}\right|{}_{\epsilon = 0} e^{\epsilon[A,A^\ast]}A e^{-\epsilon[A,A^\ast]}\right) = 4 \left( \left. \frac{d}{d\epsilon}\right|{}_{\epsilon = 0} e^{\epsilon[A,A^\ast]} \cdot A \right). \end{align} $$
$$ \begin{align} \nabla \operatorname{E}(A) &= -4[A,[A,A^\ast]] = -4(A[A,A^\ast]-[A,A^\ast]A) \nonumber\\ &= 4 \left( \left. \frac{d}{d\epsilon}\right|{}_{\epsilon = 0} e^{\epsilon[A,A^\ast]}A e^{-\epsilon[A,A^\ast]}\right) = 4 \left( \left. \frac{d}{d\epsilon}\right|{}_{\epsilon = 0} e^{\epsilon[A,A^\ast]} \cdot A \right). \end{align} $$
Since
 $[A,A^\ast ]$
is traceless,
$[A,A^\ast ]$
is traceless,
 $e^{\epsilon [A,A^\ast ]} \in \operatorname {SL}_d(\mathbb {C})$
for any
$e^{\epsilon [A,A^\ast ]} \in \operatorname {SL}_d(\mathbb {C})$
for any
 $\epsilon $
, so the negative gradient flow lines
$\epsilon $
, so the negative gradient flow lines
 $\mathcal {F}(A_0,t)$
produced by any
$\mathcal {F}(A_0,t)$
produced by any
 $A_0$
stay within the conjugation orbit of
$A_0$
stay within the conjugation orbit of
 $A_0$
. In particular,
$A_0$
. In particular,
 $A_\infty $
must have the same eigenvalues as
$A_\infty $
must have the same eigenvalues as
 $A_0$
. Since real matrices are invariant under gradient flow, we have thus proved:
$A_0$
. Since real matrices are invariant under gradient flow, we have thus proved:
Theorem 2.6. For any
 $A_0 \in \mathbb {C}^{d \times d}$
, the matrix
$A_0 \in \mathbb {C}^{d \times d}$
, the matrix
 $A_\infty = \displaystyle \lim _{t \to \infty } \mathcal {F}(A_0,t)$
exists, is normal, and has the same eigenvalues as
$A_\infty = \displaystyle \lim _{t \to \infty } \mathcal {F}(A_0,t)$
exists, is normal, and has the same eigenvalues as
 $A_0$
. Moreover, if
$A_0$
. Moreover, if
 $A_0$
is real, then so is
$A_0$
is real, then so is
 $A_\infty $
.
$A_\infty $
.
Remark 2.7. This theorem implies that the gradient flow (2.5) is an isospectral flow [Reference Deift, Nanda and Tomei17, Reference Tomei56, Reference Watkins57, Reference Watkins and Elsner58]. While it does not quite fit into the classical framework of isospectral flows except in the trivial case that
 $A_0$
is Hermitian, we caution readers interested in implementing (2.5) that standard numerical ODE methods fail in the classical case [Reference Calvo, Iserles and Zanna10], and there is no reason to think that our flow won’t pose similar numerical issues.
$A_0$
is Hermitian, we caution readers interested in implementing (2.5) that standard numerical ODE methods fail in the classical case [Reference Calvo, Iserles and Zanna10], and there is no reason to think that our flow won’t pose similar numerical issues.
If
 $A_0$
and
$A_0$
and
 $A_\infty $
are as in Theorem 2.6 and
$A_\infty $
are as in Theorem 2.6 and
 $\lambda _1, \dots , \lambda _d$
are their common eigenvalues, then the normality of
$\lambda _1, \dots , \lambda _d$
are their common eigenvalues, then the normality of
 $A_\infty $
implies that
$A_\infty $
implies that
 $$\begin{align*}\|A_\infty\|^2 = \sum_{i=1}^d |\lambda_i|^2. \end{align*}$$
$$\begin{align*}\|A_\infty\|^2 = \sum_{i=1}^d |\lambda_i|^2. \end{align*}$$
This immediately implies the following corollary.
Corollary 2.8. If
 $A_0$
is non-nilpotent, then its gradient flow (2.5) is bounded away from zero. On the other hand, if
$A_0$
is non-nilpotent, then its gradient flow (2.5) is bounded away from zero. On the other hand, if
 $A_0$
is nilpotent, then the limit of gradient flow
$A_0$
is nilpotent, then the limit of gradient flow
 $A_\infty $
is the zero matrix.
$A_\infty $
is the zero matrix.
A widely used statistic for describing the extent to which a matrix is non-normal is the Henrici departure from normality [Reference Henrici30]. For a matrix
 $A \in \mathbb {C}^{d \times d}$
with eigenvalues
$A \in \mathbb {C}^{d \times d}$
with eigenvalues
 $\lambda _i$
, this is the quantityFootnote 2
$\lambda _i$
, this is the quantityFootnote 2
 $$\begin{align*}\mathrm{Hen}(A) = \|A\|^2 - \sum_{i=1}^d |\lambda_i|^2. \end{align*}$$
$$\begin{align*}\mathrm{Hen}(A) = \|A\|^2 - \sum_{i=1}^d |\lambda_i|^2. \end{align*}$$
Corollary 2.9. Let
 $A_0 \in \mathbb {C}^{d \times d}$
and let
$A_0 \in \mathbb {C}^{d \times d}$
and let
 $A_\infty $
be its limit under the gradient flow (2.5). The change in scale along gradient flow is equal to Henrici departure from normality,
$A_\infty $
be its limit under the gradient flow (2.5). The change in scale along gradient flow is equal to Henrici departure from normality,
 $$\begin{align*}\|A_0\|^2 - \|A_\infty\|^2 = \mathrm{Hen}(A_0). \end{align*}$$
$$\begin{align*}\|A_0\|^2 - \|A_\infty\|^2 = \mathrm{Hen}(A_0). \end{align*}$$
2.4 Bound on the distance to the limit of gradient flow
We now show that
 $A_\infty $
is not too much further from
$A_\infty $
is not too much further from
 $A_0$
than the closest normal matrix, despite the fact that
$A_0$
than the closest normal matrix, despite the fact that
 $A_\infty $
preserves features (spectrum, realness) that the closest normal matrix may not. We do so by a standard argument starting from a Łojasiewicz inequality.
$A_\infty $
preserves features (spectrum, realness) that the closest normal matrix may not. We do so by a standard argument starting from a Łojasiewicz inequality.
Since
 $\operatorname {E}$
is the squared norm of a momentum map (Proposition 2.2), a result of Fisher [Reference Fisher20] gives us the desired inequalityFootnote 3:
$\operatorname {E}$
is the squared norm of a momentum map (Proposition 2.2), a result of Fisher [Reference Fisher20] gives us the desired inequalityFootnote 3:
Proposition 2.10 (Fisher [Reference Fisher20, Theorem 4.7]).
There exist constants
 $\epsilon , c> 0$
so that for all
$\epsilon , c> 0$
so that for all
 $A \in \mathbb {C}^{d \times d}$
with
$A \in \mathbb {C}^{d \times d}$
with
 $\operatorname {E}(A) < \epsilon $
,
$\operatorname {E}(A) < \epsilon $
,
 $$\begin{align*}\|\nabla \operatorname{E}(A)\| \geq c \operatorname{E}(A)^{3/4}. \end{align*}$$
$$\begin{align*}\|\nabla \operatorname{E}(A)\| \geq c \operatorname{E}(A)^{3/4}. \end{align*}$$
Now we follow a standard argument (see, e.g., Lerman [Reference Lerman40]) to get bounds on the distance from
 $A_0$
to
$A_0$
to
 $A_\infty $
. Certainly this distance is no larger than the length of the gradient flow path:
$A_\infty $
. Certainly this distance is no larger than the length of the gradient flow path:
 $$ \begin{align} \|A_0 - A_\infty\| \leq \int_0^\infty \left\|\frac{d}{dt} \mathcal{F}(A_0,t)\right\|dt = \int_0^\infty \|\nabla \operatorname{E}(\mathcal{F}(A_0,t))\|dt. \end{align} $$
$$ \begin{align} \|A_0 - A_\infty\| \leq \int_0^\infty \left\|\frac{d}{dt} \mathcal{F}(A_0,t)\right\|dt = \int_0^\infty \|\nabla \operatorname{E}(\mathcal{F}(A_0,t))\|dt. \end{align} $$
So long as
 $\operatorname {E}(\mathcal {F}(A_0,t)) < \epsilon $
,
$\operatorname {E}(\mathcal {F}(A_0,t)) < \epsilon $
,
 $$ \begin{align*} -\frac{d}{dt} (\operatorname{E}(\mathcal{F}(A_0,t)))^{1/4} &= -\frac{1}{4} \operatorname{E}(\mathcal{F}(A_0,t))^{-3/4} D\operatorname{E}(\mathcal{F}(A_0,t)))(-\nabla \operatorname{E}(\mathcal{F}(A_0,t))) \\ &= \frac{1}{4} \operatorname{E}(\mathcal{F}(A_0,t))^{-3/4}\|\nabla \operatorname{E}(\mathcal{F}(A_0,t))\|^2 \geq \frac{c}{4}\|\nabla\operatorname{E}(\mathcal{F}(A_0,t))\|, \end{align*} $$
$$ \begin{align*} -\frac{d}{dt} (\operatorname{E}(\mathcal{F}(A_0,t)))^{1/4} &= -\frac{1}{4} \operatorname{E}(\mathcal{F}(A_0,t))^{-3/4} D\operatorname{E}(\mathcal{F}(A_0,t)))(-\nabla \operatorname{E}(\mathcal{F}(A_0,t))) \\ &= \frac{1}{4} \operatorname{E}(\mathcal{F}(A_0,t))^{-3/4}\|\nabla \operatorname{E}(\mathcal{F}(A_0,t))\|^2 \geq \frac{c}{4}\|\nabla\operatorname{E}(\mathcal{F}(A_0,t))\|, \end{align*} $$
where the last inequality follows since Proposition 2.10 implies
 $\operatorname {E}(\mathcal {F}(A_0,t))^{-3/4}\|\nabla \operatorname {E}(\mathcal {F}(A_0,t))\| \geq c$
.
$\operatorname {E}(\mathcal {F}(A_0,t))^{-3/4}\|\nabla \operatorname {E}(\mathcal {F}(A_0,t))\| \geq c$
.
Combining this with (2.7) yields:
 $$\begin{align*}\|A_0 - A_\infty\| \leq \int_0^\infty \|\nabla \operatorname{E}(\mathcal{F}(A_0,t))\|dt \leq -\frac{4}{c} \int_0^\infty \frac{d}{dt}(\operatorname{E}(\mathcal{F}(A_0,t)))^{1/4} dt = \frac{4}{c} \operatorname{E}(A_0)^{1/4}. \end{align*}$$
$$\begin{align*}\|A_0 - A_\infty\| \leq \int_0^\infty \|\nabla \operatorname{E}(\mathcal{F}(A_0,t))\|dt \leq -\frac{4}{c} \int_0^\infty \frac{d}{dt}(\operatorname{E}(\mathcal{F}(A_0,t)))^{1/4} dt = \frac{4}{c} \operatorname{E}(A_0)^{1/4}. \end{align*}$$
Therefore, we have proved:
Proposition 2.11. There exist constants
 $\epsilon , c> 0$
so that, if
$\epsilon , c> 0$
so that, if
 $\operatorname {E}(A_0) < \epsilon $
, then
$\operatorname {E}(A_0) < \epsilon $
, then
 $$\begin{align*}\|A_0 - A_\infty\| \leq \frac{4}{c} \operatorname{E}(A_0)^{1/4}. \end{align*}$$
$$\begin{align*}\|A_0 - A_\infty\| \leq \frac{4}{c} \operatorname{E}(A_0)^{1/4}. \end{align*}$$
Comparing to the Henrici estimate (Proposition 2.1), we see that, at least when
 $\operatorname {E}(A_0)$
is small, the normal matrix
$\operatorname {E}(A_0)$
is small, the normal matrix
 $A_\infty $
we get by doing gradient descent is not much further from
$A_\infty $
we get by doing gradient descent is not much further from
 $A_0$
than the closest normal matrix is, even though
$A_0$
than the closest normal matrix is, even though
 $A_\infty $
has the same spectrum as
$A_\infty $
has the same spectrum as
 $A_0$
and is real if
$A_0$
and is real if
 $A_0$
is.
$A_0$
is.
Remark 2.12. The closest normal matrix to a given
 $A_0 \in \mathbb {C}^{d \times d}$
can be computed explicitly by Ruhe’s algorithm [Reference Ruhe52],Footnote 4 but the actual closest normal matrix does not have the same spectrum as
$A_0 \in \mathbb {C}^{d \times d}$
can be computed explicitly by Ruhe’s algorithm [Reference Ruhe52],Footnote 4 but the actual closest normal matrix does not have the same spectrum as
 $A_0$
and may be complex even if
$A_0$
and may be complex even if
 $A_0$
is real (see discussion in Chu [Reference Chu11] and Guglielmi and Scalone [Reference Guglielmi and Scalone25]). This suggests that the gradient descent approach to finding a nearby normal matrix may be useful in situations where one is interested in preserving structural properties of the initialization. These observations are borne out by numerical experiments, and indeed
$A_0$
is real (see discussion in Chu [Reference Chu11] and Guglielmi and Scalone [Reference Guglielmi and Scalone25]). This suggests that the gradient descent approach to finding a nearby normal matrix may be useful in situations where one is interested in preserving structural properties of the initialization. These observations are borne out by numerical experiments, and indeed
 $A_\infty $
gets relatively closer to the closest normal matrix when
$A_\infty $
gets relatively closer to the closest normal matrix when
 $A_0$
is almost normal to begin with: see Figure 3.
$A_0$
is almost normal to begin with: see Figure 3.

Figure 3 Left: We generated 10,000 initial matrices
 $A_0 \in \mathbb {C}^{20 \times 20}$
by letting the real and imaginary parts of each entry be drawn from a standard Gaussian and then normalizing so that
$A_0 \in \mathbb {C}^{20 \times 20}$
by letting the real and imaginary parts of each entry be drawn from a standard Gaussian and then normalizing so that
 $A_0$
has Frobenius norm 1. We computed the closest normal matrix
$A_0$
has Frobenius norm 1. We computed the closest normal matrix
 $\widehat {A}$
using Ruhe’s algorithm [Reference Ruhe52] and
$\widehat {A}$
using Ruhe’s algorithm [Reference Ruhe52] and
 $A_\infty = \displaystyle \lim _{t \to \infty } \mathcal {F}(A_0,t)$
using a very simple gradient descent with fixed step sizes, and then plotted the point
$A_\infty = \displaystyle \lim _{t \to \infty } \mathcal {F}(A_0,t)$
using a very simple gradient descent with fixed step sizes, and then plotted the point
 $(\|\widehat {A}-A_0\|^2, \|A_\infty - A_0\|^2)$
. The ratios
$(\|\widehat {A}-A_0\|^2, \|A_\infty - A_0\|^2)$
. The ratios
 $\frac {\|A_\infty - A_0\|^2}{\|\widehat {A}-A_0\|^2}$
were all in the interval
$\frac {\|A_\infty - A_0\|^2}{\|\widehat {A}-A_0\|^2}$
were all in the interval
 $[1.028,1.161]$
. Center: The same computations and visualization, except the initial matrices
$[1.028,1.161]$
. Center: The same computations and visualization, except the initial matrices
 $A_0$
were all
$A_0$
were all
 $20 \times 20$
real matrices. In this case the
$20 \times 20$
real matrices. In this case the
 $\frac {\|A_\infty - A_0\|^2}{\|\widehat {A}-A_0\|^2}$
were all in the interval
$\frac {\|A_\infty - A_0\|^2}{\|\widehat {A}-A_0\|^2}$
were all in the interval
 $[1.023,1.196]$
. Right: The same computations and visualization, but with nearly normal initial matrices
$[1.023,1.196]$
. Right: The same computations and visualization, but with nearly normal initial matrices
 $A_0 \in \mathbb {C}^{20 \times 20}$
. More precisely, we generated
$A_0 \in \mathbb {C}^{20 \times 20}$
. More precisely, we generated
 $B \in \mathbb {C}^{20 \times 20}$
by normalizing a matrix of standard complex Gaussians, found the closest normal matrix
$B \in \mathbb {C}^{20 \times 20}$
by normalizing a matrix of standard complex Gaussians, found the closest normal matrix
 $\widehat {B}$
, then added an
$\widehat {B}$
, then added an
 $\mathcal {N}(0,0.0075)$
random variate to the real and complex parts of each entry of
$\mathcal {N}(0,0.0075)$
random variate to the real and complex parts of each entry of
 $\widehat {B}$
, and let
$\widehat {B}$
, and let
 $A_0$
be the normalization of this matrix, so that
$A_0$
be the normalization of this matrix, so that
 $A_0$
has Frobenius norm 1 and is already close to being normal. In this case the
$A_0$
has Frobenius norm 1 and is already close to being normal. In this case the
 $\frac {\|A_\infty - A_0\|^2}{\|\widehat {A}-A_0\|^2}$
were all in the interval
$\frac {\|A_\infty - A_0\|^2}{\|\widehat {A}-A_0\|^2}$
were all in the interval
 $[1.009,1.036]$
. In all three plots, the solid line has slope 1 and the dashed line has slope
$[1.009,1.036]$
. In all three plots, the solid line has slope 1 and the dashed line has slope
 $1.3$
. Code for these experiments is available on GitHub [Reference Shonkwiler54].
$1.3$
. Code for these experiments is available on GitHub [Reference Shonkwiler54].
3 Unit norm normal matrices
We have seen in Corollary 2.9 that the gradient flow of
 $\operatorname {E}$
does not preserve the Frobenius norm. If we want a flow that preserves the norm, we should consider the restriction of
$\operatorname {E}$
does not preserve the Frobenius norm. If we want a flow that preserves the norm, we should consider the restriction of
 $\operatorname {E}$
to the space
$\operatorname {E}$
to the space
 $\mathcal {U}_d$
of
$\mathcal {U}_d$
of
 $d \times d$
matrices with Frobenius norm 1. Geometrically,
$d \times d$
matrices with Frobenius norm 1. Geometrically,
 $\mathcal {U}_d$
is just the
$\mathcal {U}_d$
is just the
 $(2d^2-1)$
-dimensional unit sphere in
$(2d^2-1)$
-dimensional unit sphere in
 $\mathbb {C}^{d \times d}$
.
$\mathbb {C}^{d \times d}$
.
Let
 $\overline {\operatorname {E}}: \mathcal {U}_d \to \mathbb {R}$
be the restriction of
$\overline {\operatorname {E}}: \mathcal {U}_d \to \mathbb {R}$
be the restriction of
 $\operatorname {E}$
to
$\operatorname {E}$
to
 $\mathcal {U}_d$
and let
$\mathcal {U}_d$
and let
 $\overline {\mathcal {F}}:\mathcal {U}_d \times [0,\infty ) \to \mathcal {U}_d$
be the associated gradient flow; that is,
$\overline {\mathcal {F}}:\mathcal {U}_d \times [0,\infty ) \to \mathcal {U}_d$
be the associated gradient flow; that is,
 $$\begin{align*}\overline{\mathcal{F}}(A_0,0) = A_0 \qquad \frac{d}{dt} \overline{\mathcal{F}}(A_0,t) = -\operatorname{grad} \overline{\operatorname{E}}(\overline{\mathcal{F}}(A_0,t)), \end{align*}$$
$$\begin{align*}\overline{\mathcal{F}}(A_0,0) = A_0 \qquad \frac{d}{dt} \overline{\mathcal{F}}(A_0,t) = -\operatorname{grad} \overline{\operatorname{E}}(\overline{\mathcal{F}}(A_0,t)), \end{align*}$$
where
 $\operatorname {grad}$
is the Riemannian gradient on
$\operatorname {grad}$
is the Riemannian gradient on
 $\mathcal {U}_d$
.
$\mathcal {U}_d$
.
3.1 Gradient flow of restricted non-normal energy
The normal matrices in
 $\mathcal {U}_d$
are exactly the global minima of
$\mathcal {U}_d$
are exactly the global minima of
 $\overline {\operatorname {E}}$
; the goal is to show that almost every matrix in
$\overline {\operatorname {E}}$
; the goal is to show that almost every matrix in
 $\mathcal {U}_d$
flows to a normal matrix under the gradient flow:
$\mathcal {U}_d$
flows to a normal matrix under the gradient flow:
Theorem 3.1. For any non-nilpotent
 $A_0 \in \mathcal {U}_d$
, the matrix
$A_0 \in \mathcal {U}_d$
, the matrix ![]() exists, is normal, and has Frobenius norm 1. Moreover, if
exists, is normal, and has Frobenius norm 1. Moreover, if
 $A_0$
is real, then so is
$A_0$
is real, then so is
 $A_\infty $
.
$A_\infty $
.
Remark 3.2. In GIT terms, we are looking at (a linearization of) the projective adjoint action of
 $\operatorname {SL}(d)$
on
$\operatorname {SL}(d)$
on
 $\mathbb {P}(\mathfrak {sl}(d)^\ast )$
, and the fact that we have to assume
$\mathbb {P}(\mathfrak {sl}(d)^\ast )$
, and the fact that we have to assume
 $A_0$
is non-nilpotent in Theorem 3.1 is equivalent to the fact that the non-nilpotent matrices are exactly the semistable points with respect to this action [Reference Kostant38] (see [Reference Mumford, Fogarty and Kirwan44, Proposition 4.4]).
$A_0$
is non-nilpotent in Theorem 3.1 is equivalent to the fact that the non-nilpotent matrices are exactly the semistable points with respect to this action [Reference Kostant38] (see [Reference Mumford, Fogarty and Kirwan44, Proposition 4.4]).
Since
 $\overline {\operatorname {E}}$
is a polynomial function defined on a real-analytic submanifold of Euclidean space, it will have a Łojasiewicz exponent (cf. [Reference Bodmann and Haas7, Corollary 4.2]), and hence the gradient flow will have a single limit point [Reference Łojasiewicz41], proving the existence of
$\overline {\operatorname {E}}$
is a polynomial function defined on a real-analytic submanifold of Euclidean space, it will have a Łojasiewicz exponent (cf. [Reference Bodmann and Haas7, Corollary 4.2]), and hence the gradient flow will have a single limit point [Reference Łojasiewicz41], proving the existence of
 $A_\infty $
.
$A_\infty $
.
Since the non-nilpotent matrices form an open, dense subset of
 $\mathcal {U}_d$
, Theorem 3.1 implies that almost every member of any neighborhood of a nonminimizing critical point will flow to a normal matrix; that is, a global minimum of
$\mathcal {U}_d$
, Theorem 3.1 implies that almost every member of any neighborhood of a nonminimizing critical point will flow to a normal matrix; that is, a global minimum of
 $\overline {\operatorname {E}}$
. Hence, the nonminimizing critical points of
$\overline {\operatorname {E}}$
. Hence, the nonminimizing critical points of
 $\overline {\operatorname {E}}$
cannot be basins of attraction. Since
$\overline {\operatorname {E}}$
cannot be basins of attraction. Since
 $\overline {\operatorname {E}}$
has a Łojasiewicz exponent, an argument analogous to [Reference Absil and Kurdyka1, Theorem 3] shows that all local minima must be basins of attraction. Hence we have the following corollary.
$\overline {\operatorname {E}}$
has a Łojasiewicz exponent, an argument analogous to [Reference Absil and Kurdyka1, Theorem 3] shows that all local minima must be basins of attraction. Hence we have the following corollary.
Corollary 3.3. Every local minimum of
 $\overline {\operatorname {E}}$
must be a global minimum; that is, a normal matrix.
$\overline {\operatorname {E}}$
must be a global minimum; that is, a normal matrix.
We have already shown that the gradient flow of
 $\overline {\operatorname {E}}$
converges to a single limit point
$\overline {\operatorname {E}}$
converges to a single limit point
 $A_\infty $
. The remainder of this subsection will be devoted to proving the remaining statements of Theorem 3.1 through several supporting results. The strategy for proving the rest of the first sentence of Theorem 3.1 is to show that the gradient flow preserves non-nilpotency and that all nonminimizing critical points must be nilpotent. As with Theorem 2.6, the last sentence will follow because the real submanifold of
$A_\infty $
. The remainder of this subsection will be devoted to proving the remaining statements of Theorem 3.1 through several supporting results. The strategy for proving the rest of the first sentence of Theorem 3.1 is to show that the gradient flow preserves non-nilpotency and that all nonminimizing critical points must be nilpotent. As with Theorem 2.6, the last sentence will follow because the real submanifold of
 $\mathcal {U}_d$
is invariant under the gradient flow.
$\mathcal {U}_d$
is invariant under the gradient flow.
Proposition 3.4. The intrinsic gradient of
 $\overline {\operatorname {E}}$
on
$\overline {\operatorname {E}}$
on
 $\mathcal {U}_d$
is
$\mathcal {U}_d$
is
 $$\begin{align*}\operatorname{grad} \overline{\operatorname{E}}(A) = -4([A,[A,A^\ast]] + \overline{\operatorname{E}}(A) A). \end{align*}$$
$$\begin{align*}\operatorname{grad} \overline{\operatorname{E}}(A) = -4([A,[A,A^\ast]] + \overline{\operatorname{E}}(A) A). \end{align*}$$
Proof. Geometrically,
 $\operatorname {grad} \overline {\operatorname {E}}(A)$
is the projection of the Euclidean gradient
$\operatorname {grad} \overline {\operatorname {E}}(A)$
is the projection of the Euclidean gradient
 $\nabla \operatorname {E}(A)$
onto the tangent space
$\nabla \operatorname {E}(A)$
onto the tangent space
 $T_A \mathcal {U}_d = \mathrm {span}(\{A\})^\bot $
:
$T_A \mathcal {U}_d = \mathrm {span}(\{A\})^\bot $
:
 $$\begin{align*}\operatorname{grad} \overline{\operatorname{E}}(A) = \nabla \operatorname{E}(A) - \langle \nabla \operatorname{E}(A), A\rangle A. \end{align*}$$
$$\begin{align*}\operatorname{grad} \overline{\operatorname{E}}(A) = \nabla \operatorname{E}(A) - \langle \nabla \operatorname{E}(A), A\rangle A. \end{align*}$$
We know from (2.3) that
 $\nabla \operatorname {E}(A) = -4[A,[A,A^\ast ]]$
, so the fact that
$\nabla \operatorname {E}(A) = -4[A,[A,A^\ast ]]$
, so the fact that
 $[A,A^\ast ]$
is Hermitian implies
$[A,A^\ast ]$
is Hermitian implies
 $$ \begin{align} \langle \nabla \operatorname{E}(A), A\rangle &= -4\mathrm{Re}\operatorname{tr}([A,[A,A^\ast]]^\ast A) = -4\mathrm{Re}\operatorname{tr}([A,A^\ast]A^\ast A - A^\ast [A,A^\ast]A) \nonumber\\ &= 4\mathrm{Re}\operatorname{tr}([A,A^\ast][A,A^\ast]) = 4\|[A,A^\ast]\|^2 = 4 \overline{\operatorname{E}}(A) \end{align} $$
$$ \begin{align} \langle \nabla \operatorname{E}(A), A\rangle &= -4\mathrm{Re}\operatorname{tr}([A,[A,A^\ast]]^\ast A) = -4\mathrm{Re}\operatorname{tr}([A,A^\ast]A^\ast A - A^\ast [A,A^\ast]A) \nonumber\\ &= 4\mathrm{Re}\operatorname{tr}([A,A^\ast][A,A^\ast]) = 4\|[A,A^\ast]\|^2 = 4 \overline{\operatorname{E}}(A) \end{align} $$
by the linearity and cyclic invariance of trace, and the result follows.
Since
 $[A,A^\ast ]$
is traceless, notice that
$[A,A^\ast ]$
is traceless, notice that
 $$\begin{align*}\operatorname{grad} \overline{\operatorname{E}}(A) = 4\left. \frac{d}{dt}\right|{}_{t=0} e^{-t \overline{\operatorname{E}}(A)} e^{t[A,A^\ast]} A e^{-t[A,A^\ast]} = 4\left. \frac{d}{dt}\right|{}_{t=0} (e^{t[A,A^\ast]},e^{-t \overline{\operatorname{E}}(A)}) \cdot A \end{align*}$$
$$\begin{align*}\operatorname{grad} \overline{\operatorname{E}}(A) = 4\left. \frac{d}{dt}\right|{}_{t=0} e^{-t \overline{\operatorname{E}}(A)} e^{t[A,A^\ast]} A e^{-t[A,A^\ast]} = 4\left. \frac{d}{dt}\right|{}_{t=0} (e^{t[A,A^\ast]},e^{-t \overline{\operatorname{E}}(A)}) \cdot A \end{align*}$$
is tangent to the
 $\operatorname {SL}_d(\mathbb {C}) \times \mathbb {C}^\times $
-orbit of A, where the action of
$\operatorname {SL}_d(\mathbb {C}) \times \mathbb {C}^\times $
-orbit of A, where the action of
 $\operatorname {SL}_d(\mathbb {C}) \times \mathbb {C}^\times $
on
$\operatorname {SL}_d(\mathbb {C}) \times \mathbb {C}^\times $
on
 $\mathbb {C}^{d \times d}$
is defined by
$\mathbb {C}^{d \times d}$
is defined by ![]() .
.
We could use this to show that the negative gradient flow preserves non-nilpotency, but extending to the limit poses challenges, so we adopt a different approach. For
 $A \in \mathbb {C}^{d \times d}$
, define
$A \in \mathbb {C}^{d \times d}$
, define

where
 $\lambda _1, \dots , \lambda _d$
are the eigenvalues of A. The nilpotent matrices are precisely the vanishing locus of s.
$\lambda _1, \dots , \lambda _d$
are the eigenvalues of A. The nilpotent matrices are precisely the vanishing locus of s.
Lemma 3.5. For any
 $A \in \mathcal {U}_d$
,
$A \in \mathcal {U}_d$
,
 $$\begin{align*}\langle -\operatorname{grad} \overline{\operatorname{E}}(A), \operatorname{grad} s(A) \rangle = 8 s(A) \overline{\operatorname{E}}(A), \end{align*}$$
$$\begin{align*}\langle -\operatorname{grad} \overline{\operatorname{E}}(A), \operatorname{grad} s(A) \rangle = 8 s(A) \overline{\operatorname{E}}(A), \end{align*}$$
where
 $\operatorname {grad} s(A)$
is the intrinsic gradient of s in
$\operatorname {grad} s(A)$
is the intrinsic gradient of s in
 $\mathcal {U}_d$
.
$\mathcal {U}_d$
.
Proof. Note, first of all, that
 $\langle A, \operatorname {grad} s(A) \rangle = 0$
, since
$\langle A, \operatorname {grad} s(A) \rangle = 0$
, since
 $\operatorname {grad} s(A) \in T_A \mathcal {U}_d = \mathrm {span}(\{A\})^\bot $
. Therefore,
$\operatorname {grad} s(A) \in T_A \mathcal {U}_d = \mathrm {span}(\{A\})^\bot $
. Therefore,
 $$ \begin{align*} \langle -\operatorname{grad} \overline{\operatorname{E}}(A), \operatorname{grad} s(A) \rangle & = \langle -\nabla \operatorname{E}(A) + 4\overline{\operatorname{E}}(A) A, \operatorname{grad} s(A) \rangle \\ & = \langle -\nabla \operatorname{E}(A), \operatorname{grad} s(A) \rangle \\ & = \langle -\nabla \operatorname{E}(A), \nabla s(A) - \langle \nabla s(A), A \rangle A\rangle \\ & = -\langle \nabla \operatorname{E}(A), \nabla s(A)\rangle + \langle \nabla s(A),A \rangle \langle \nabla \operatorname{E}(A), A \rangle \\ & = -\langle \nabla \operatorname{E}(A), \nabla s(A) \rangle + 4 \langle \nabla s(A), A \rangle \overline{\operatorname{E}}(A), \end{align*} $$
$$ \begin{align*} \langle -\operatorname{grad} \overline{\operatorname{E}}(A), \operatorname{grad} s(A) \rangle & = \langle -\nabla \operatorname{E}(A) + 4\overline{\operatorname{E}}(A) A, \operatorname{grad} s(A) \rangle \\ & = \langle -\nabla \operatorname{E}(A), \operatorname{grad} s(A) \rangle \\ & = \langle -\nabla \operatorname{E}(A), \nabla s(A) - \langle \nabla s(A), A \rangle A\rangle \\ & = -\langle \nabla \operatorname{E}(A), \nabla s(A)\rangle + \langle \nabla s(A),A \rangle \langle \nabla \operatorname{E}(A), A \rangle \\ & = -\langle \nabla \operatorname{E}(A), \nabla s(A) \rangle + 4 \langle \nabla s(A), A \rangle \overline{\operatorname{E}}(A), \end{align*} $$
using (3.1) in the first and last equalities.
We know from (2.6) and the following sentence that
 $\nabla \operatorname {E}(A)$
lies in the conjugation orbit of A. But this means that
$\nabla \operatorname {E}(A)$
lies in the conjugation orbit of A. But this means that
 $\nabla \operatorname {E}(A)$
must be tangent to the level set of s passing through A, since conjugation preserves eigenvalues, and hence fixes s. Therefore,
$\nabla \operatorname {E}(A)$
must be tangent to the level set of s passing through A, since conjugation preserves eigenvalues, and hence fixes s. Therefore,
 $\langle \nabla \operatorname {E}(A), \nabla s(A) \rangle = 0$
and we have shown that
$\langle \nabla \operatorname {E}(A), \nabla s(A) \rangle = 0$
and we have shown that
 $$\begin{align*}\langle -\operatorname{grad} \overline{\operatorname{E}}(A), \operatorname{grad} s(A) \rangle = 4 \langle \nabla s(A), A \rangle \overline{\operatorname{E}}(A). \end{align*}$$
$$\begin{align*}\langle -\operatorname{grad} \overline{\operatorname{E}}(A), \operatorname{grad} s(A) \rangle = 4 \langle \nabla s(A), A \rangle \overline{\operatorname{E}}(A). \end{align*}$$
By definition of the gradient, the inner product is a directional derivative,
 $$\begin{align*}\langle \nabla s(A), A \rangle = D s(A)(A) = \lim_{t \to 0} \frac{s(A + t A) - s(A)}{t} = \lim_{t \to 0} \frac{(1+t)^2 s(A) - s(A)}{t} = 2s(A), \end{align*}$$
$$\begin{align*}\langle \nabla s(A), A \rangle = D s(A)(A) = \lim_{t \to 0} \frac{s(A + t A) - s(A)}{t} = \lim_{t \to 0} \frac{(1+t)^2 s(A) - s(A)}{t} = 2s(A), \end{align*}$$
completing the proof.
Proposition 3.6. If
 $A_0 \in \mathcal {U}_d$
is non-nilpotent, then so is
$A_0 \in \mathcal {U}_d$
is non-nilpotent, then so is ![]() for all
for all
 $t \in [0,\infty )$
and so is
$t \in [0,\infty )$
and so is ![]() .
.
Proof. For any
 $A \in \mathcal {U}_d$
, Lemma 3.5 implies that
$A \in \mathcal {U}_d$
, Lemma 3.5 implies that
 $$\begin{align*}\langle -\operatorname{grad} \overline{\operatorname{E}}(A), \operatorname{grad} s(A) \rangle = 8 s(A) \overline{\operatorname{E}}(A) \geq 0. \end{align*}$$
$$\begin{align*}\langle -\operatorname{grad} \overline{\operatorname{E}}(A), \operatorname{grad} s(A) \rangle = 8 s(A) \overline{\operatorname{E}}(A) \geq 0. \end{align*}$$
Therefore,
 $s(A)$
must be nondecreasing along the negative gradient flow lines of
$s(A)$
must be nondecreasing along the negative gradient flow lines of
 $\overline {\operatorname {E}}$
, so
$\overline {\operatorname {E}}$
, so
 $s(A_t) \geq s(A_0)> 0$
for all
$s(A_t) \geq s(A_0)> 0$
for all
 $t \in [0, \infty )$
, and in the limit we also have
$t \in [0, \infty )$
, and in the limit we also have
 $s(A_\infty ) \geq s(A_0)> 0$
. Hence,
$s(A_\infty ) \geq s(A_0)> 0$
. Hence,
 $A_t$
and
$A_t$
and
 $A_\infty $
must be non-nilpotent.
$A_\infty $
must be non-nilpotent.
In other words, gradient flow preserves non-nilpotency, including in the limit, so we have completed the first step in our strategy for proving Theorem 3.1. We now proceed with the second step.
Proposition 3.7. All nonminimizing critical points of
 $\overline {\operatorname {E}}$
are nilpotent.
$\overline {\operatorname {E}}$
are nilpotent.
Proof. By Proposition 3.4, A is a critical point of
 $\overline {\operatorname {E}}$
if and only if
$\overline {\operatorname {E}}$
if and only if
 $$\begin{align*}0 = [A,[A,A^\ast]] + \overline{\operatorname{E}}(A)A. \end{align*}$$
$$\begin{align*}0 = [A,[A,A^\ast]] + \overline{\operatorname{E}}(A)A. \end{align*}$$
If A is a nonminimizing critical point, then A is not normal, so
 $\overline {\operatorname {E}}(A) \neq 0$
and
$\overline {\operatorname {E}}(A) \neq 0$
and
 $$\begin{align*}A = -\frac{1}{\overline{\operatorname{E}}(A)}[A,[A,A^\ast]]. \end{align*}$$
$$\begin{align*}A = -\frac{1}{\overline{\operatorname{E}}(A)}[A,[A,A^\ast]]. \end{align*}$$
In other words,
 $A = [A,B]$
with
$A = [A,B]$
with
 $B = -\frac {1}{\overline {\operatorname {E}}(A)}[A,A^\ast ]$
. But then A certainly commutes with
$B = -\frac {1}{\overline {\operatorname {E}}(A)}[A,A^\ast ]$
. But then A certainly commutes with
 $[A,B]$
, so Jacobson’s Lemma (Lemma 2.4) implies that
$[A,B]$
, so Jacobson’s Lemma (Lemma 2.4) implies that
 $[A,B]$
is nilpotent. Since
$[A,B]$
is nilpotent. Since
 $A=[A,B]$
, we conclude that A is nilpotent.
$A=[A,B]$
, we conclude that A is nilpotent.
Proof of Theorem 3.1.
If
 $A_0 \in \mathcal {U}_d$
is not nilpotent, then the limit
$A_0 \in \mathcal {U}_d$
is not nilpotent, then the limit
 $A_\infty = \displaystyle \lim _{t \to \infty } \overline {\mathcal {F}}(A_0,t)$
exists and, by Proposition 3.6, is not nilpotent.
$A_\infty = \displaystyle \lim _{t \to \infty } \overline {\mathcal {F}}(A_0,t)$
exists and, by Proposition 3.6, is not nilpotent.
 $A_\infty $
must be a critical point of
$A_\infty $
must be a critical point of
 $\overline {\operatorname {E}}$
and, by Proposition 3.7, must be a global minimum, and hence normal.
$\overline {\operatorname {E}}$
and, by Proposition 3.7, must be a global minimum, and hence normal.
It is possible to prove an analogous statement to Proposition 2.11 in this setting as well, so gradient descent of
 $\overline {\operatorname {E}}$
, even though it preserves norms and (when applicable) realness, produces a limiting normal matrix
$\overline {\operatorname {E}}$
, even though it preserves norms and (when applicable) realness, produces a limiting normal matrix
 $A_\infty $
which is not much further from
$A_\infty $
which is not much further from
 $A_0$
than the closest normal matrix. Again, this conclusion is supported by numerical experiments: see Figure 4.
$A_0$
than the closest normal matrix. Again, this conclusion is supported by numerical experiments: see Figure 4.

Figure 4 This is the same experimental setup as in Figure 3, except that now
 $A_\infty = \displaystyle \lim _{t \to \infty } \overline {\mathcal {F}}(A_0,t)$
. Left:
$A_\infty = \displaystyle \lim _{t \to \infty } \overline {\mathcal {F}}(A_0,t)$
. Left:
 $A_0 \in \mathbb {C}^{20 \times 20}$
; all
$A_0 \in \mathbb {C}^{20 \times 20}$
; all
 $\frac {\|A_\infty - A_0\|^2}{\|\widehat {A}-A_0\|^2} \in [1.060,1.198]$
. Center:
$\frac {\|A_\infty - A_0\|^2}{\|\widehat {A}-A_0\|^2} \in [1.060,1.198]$
. Center:
 $A_0 \in \mathbb {R}^{20 \times 20}$
; all
$A_0 \in \mathbb {R}^{20 \times 20}$
; all
 $\frac {\|A_\infty - A_0\|^2}{\|\widehat {A}-A_0\|^2} \in [1.046,1.253]$
. Right:
$\frac {\|A_\infty - A_0\|^2}{\|\widehat {A}-A_0\|^2} \in [1.046,1.253]$
. Right:
 $A_0 \in \mathbb {C}^{20 \times 20}$
is a small perturbation of a normal matrix; all
$A_0 \in \mathbb {C}^{20 \times 20}$
is a small perturbation of a normal matrix; all
 $\frac {\|A_\infty - A_0\|^2}{\|\widehat {A}-A_0\|^2} \in [1.010,1.031]$
. In all three plots, the solid line has slope 1 and the dashed line has slope
$\frac {\|A_\infty - A_0\|^2}{\|\widehat {A}-A_0\|^2} \in [1.010,1.031]$
. In all three plots, the solid line has slope 1 and the dashed line has slope
 $1.3$
. Code for these experiments is available on GitHub [Reference Shonkwiler54].
$1.3$
. Code for these experiments is available on GitHub [Reference Shonkwiler54].
3.2 Topology of unit norm normal matrices
The space of normal matrices
 $\mathcal {N}_d$
is a cone in
$\mathcal {N}_d$
is a cone in
 $\mathbb {C}^{d \times d}$
and hence topologically trivial. However, the space
$\mathbb {C}^{d \times d}$
and hence topologically trivial. However, the space
 $\mathcal {U}\mathcal {N}_d$
can potentially have interesting topology. Friedland [Reference Friedland21] argues that
$\mathcal {U}\mathcal {N}_d$
can potentially have interesting topology. Friedland [Reference Friedland21] argues that
 $\mathcal {U}\mathcal {N}_d$
is irreducible and the quasi-variety of its smooth points is connected. However, this is not quite enough to imply that
$\mathcal {U}\mathcal {N}_d$
is irreducible and the quasi-variety of its smooth points is connected. However, this is not quite enough to imply that
 $\mathcal {U}\mathcal {N}_d$
is connected, since irreducible real varieties can have connected components consisting entirely of nonsmooth points (see, e.g., [Reference Cahill, Mixon and Strawn9, Figure 2]). In this subsection, we show that
$\mathcal {U}\mathcal {N}_d$
is connected, since irreducible real varieties can have connected components consisting entirely of nonsmooth points (see, e.g., [Reference Cahill, Mixon and Strawn9, Figure 2]). In this subsection, we show that
 $\mathcal {U}\mathcal {N}_d$
is connected and, in fact, that many of its low-dimensional homotopy groups vanish.
$\mathcal {U}\mathcal {N}_d$
is connected and, in fact, that many of its low-dimensional homotopy groups vanish.
The key fact that we use when studying the topology of
 $\mathcal {U}\mathcal {N}_d$
is that it is closely related to the topology of the space of all non-nilpotent matrices in
$\mathcal {U}\mathcal {N}_d$
is that it is closely related to the topology of the space of all non-nilpotent matrices in
 $\mathbb {C}^{d \times d}$
. For the rest of this subsection, we use
$\mathbb {C}^{d \times d}$
. For the rest of this subsection, we use
 $\mathcal {P}_d$
to denote the space of nilpotent matrices in
$\mathcal {P}_d$
to denote the space of nilpotent matrices in
 $\mathbb {C}^{d \times d}$
and we let
$\mathbb {C}^{d \times d}$
and we let
 $\mathcal {M}_d = \mathbb {C}^{d \times d} \setminus \mathcal {P}_d$
. The relationship between the topologies of
$\mathcal {M}_d = \mathbb {C}^{d \times d} \setminus \mathcal {P}_d$
. The relationship between the topologies of
 $\mathcal {U}\mathcal {N}_d$
and
$\mathcal {U}\mathcal {N}_d$
and
 $\mathcal {M}_d$
is made precise by the following result.
$\mathcal {M}_d$
is made precise by the following result.
Corollary 3.8. The space
 $\mathcal {U}\mathcal {N}_d$
is a strong deformation retract of
$\mathcal {U}\mathcal {N}_d$
is a strong deformation retract of
 $\mathcal {M}_d$
.
$\mathcal {M}_d$
.
Proof. As the function
 $\mu :A \mapsto \|[A,A^\ast ]\|^2$
is the norm squared of a momentum map (Proposition 2.2), with set of critical points exactly equal to
$\mu :A \mapsto \|[A,A^\ast ]\|^2$
is the norm squared of a momentum map (Proposition 2.2), with set of critical points exactly equal to
 $\mathcal {N}_d$
(Theorem 2.3), it follows by a more general result of Duistermaat (see the expository work of Lerman [Reference Lerman40]) that gradient descent gives a strong deformation retract of
$\mathcal {N}_d$
(Theorem 2.3), it follows by a more general result of Duistermaat (see the expository work of Lerman [Reference Lerman40]) that gradient descent gives a strong deformation retract of
 $\mathbb {C}^{d \times d}$
onto
$\mathbb {C}^{d \times d}$
onto
 $\mathcal {N}_d$
. One can also deduce this from the work above: by Theorem 2.6, we have a well-defined function
$\mathcal {N}_d$
. One can also deduce this from the work above: by Theorem 2.6, we have a well-defined function
 $\mathcal {F}:\mathbb {C}^{d \times d} \times [0,\infty ] \to \mathcal {N}_d$
induced by gradient descent, which obviously fixes
$\mathcal {F}:\mathbb {C}^{d \times d} \times [0,\infty ] \to \mathcal {N}_d$
induced by gradient descent, which obviously fixes
 $\mathcal {N}_d$
, and the arguments in [Reference Lerman40] show that the map is continuous. Moreover, this restricts to a strong deformation retract
$\mathcal {N}_d$
, and the arguments in [Reference Lerman40] show that the map is continuous. Moreover, this restricts to a strong deformation retract
 $\mathcal {M}_d \times [0,\infty ] \to \mathcal {N}_d \setminus \{0\}$
, by Corollary 2.8. As
$\mathcal {M}_d \times [0,\infty ] \to \mathcal {N}_d \setminus \{0\}$
, by Corollary 2.8. As
 $\mathcal {N}_d \setminus \{0\}$
is a cone over
$\mathcal {N}_d \setminus \{0\}$
is a cone over
 $\mathcal {U}\mathcal {N}_d$
, the former also strong deformation retracts onto the latter. Concatenating these two strong deformation retracts gives a strong deformation retract
$\mathcal {U}\mathcal {N}_d$
, the former also strong deformation retracts onto the latter. Concatenating these two strong deformation retracts gives a strong deformation retract
 $\mathcal {M}_d \to \mathcal {U}\mathcal {N}_d$
.
$\mathcal {M}_d \to \mathcal {U}\mathcal {N}_d$
.
In particular,
 $\mathcal {U}\mathcal {N}_d$
is homotopy equivalent to
$\mathcal {U}\mathcal {N}_d$
is homotopy equivalent to
 $\mathcal {M}_d$
, so our goal of characterizing the topology of the former space reduces to understanding that of the latter space. From such an understanding, we will deduce the main theorem of this subsection, stated below. In the following, we use
$\mathcal {M}_d$
, so our goal of characterizing the topology of the former space reduces to understanding that of the latter space. From such an understanding, we will deduce the main theorem of this subsection, stated below. In the following, we use
 $\pi _k(\mathcal {X},x_0)$
to denote the kth homotopy group of a space
$\pi _k(\mathcal {X},x_0)$
to denote the kth homotopy group of a space
 $\mathcal {X}$
with respect to a basepoint
$\mathcal {X}$
with respect to a basepoint
 $x_0 \in \mathcal {X}$
, and write
$x_0 \in \mathcal {X}$
, and write
 $\pi _k(\mathcal {X})$
in the case that
$\pi _k(\mathcal {X})$
in the case that
 $\mathcal {X}$
is path connected (in which case the result is independent of basepoint, up to isomorphism) – we refer the reader to [Reference Hatcher28, Chapter 4] for basic terminology and properties. We say that
$\mathcal {X}$
is path connected (in which case the result is independent of basepoint, up to isomorphism) – we refer the reader to [Reference Hatcher28, Chapter 4] for basic terminology and properties. We say that
 $\mathcal {X}$
is k-connected if
$\mathcal {X}$
is k-connected if
 $\pi _k(\mathcal {X},x_0)$
is the trivial group.
$\pi _k(\mathcal {X},x_0)$
is the trivial group.
Theorem 3.9. The space
 $\mathcal {U}\mathcal {N}_d$
is k-connected for all
$\mathcal {U}\mathcal {N}_d$
is k-connected for all
 $k \leq 2d-2$
.
$k \leq 2d-2$
.
Remark 3.10. In particular,
 $\mathcal {U}\mathcal {N}_d$
is connected for all d. Moreover,
$\mathcal {U}\mathcal {N}_d$
is connected for all d. Moreover,
 $\mathcal {U}\mathcal {N}_d$
is simply connected (i.e.,
$\mathcal {U}\mathcal {N}_d$
is simply connected (i.e.,
 $\pi _1(\mathcal {U}\mathcal {N}_d)$
is also trivial) for all
$\pi _1(\mathcal {U}\mathcal {N}_d)$
is also trivial) for all
 $d \geq 2$
.
$d \geq 2$
.
The proof will use two auxiliary topological results. The first follows from more general results on nilpotent cones, which are classical. We use [Reference Jantzen, Anker and Orsted35] as a general reference and explain how to deduce this particular result from the general results therein.
Lemma 3.11. The space
 $\mathcal {P}_d$
of nilpotent matrices in
$\mathcal {P}_d$
of nilpotent matrices in
 $\mathbb {C}^{d \times d}$
is an irreducible variety of complex dimension
$\mathbb {C}^{d \times d}$
is an irreducible variety of complex dimension
 $d(d-1)$
.
$d(d-1)$
.
Proof. We apply the general nilpotent cone theory to the Lie group of invertible matrices
 $\mathrm {GL}_d(\mathbb {C})$
, in which case the nilpotent cone is exactly
$\mathrm {GL}_d(\mathbb {C})$
, in which case the nilpotent cone is exactly
 $\mathcal {P}_d$
. Then the fact that
$\mathcal {P}_d$
. Then the fact that
 $\mathcal {P}_d$
is an irreducible variety is [Reference Jantzen, Anker and Orsted35, Lemma 6.2]. By [Reference Jantzen, Anker and Orsted35, Theorem 6.4], the dimension of
$\mathcal {P}_d$
is an irreducible variety is [Reference Jantzen, Anker and Orsted35, Lemma 6.2]. By [Reference Jantzen, Anker and Orsted35, Theorem 6.4], the dimension of
 $\mathcal {P}_d$
is twice the dimension of the maximal unipotent subalgebra of the Lie algebra
$\mathcal {P}_d$
is twice the dimension of the maximal unipotent subalgebra of the Lie algebra
 $\mathbb {C}^{d \times d}$
, namely the subalgebra of strictly upper triangular matrices (i.e., with zeros on the diagonal). This subalgebra has complex dimension
$\mathbb {C}^{d \times d}$
, namely the subalgebra of strictly upper triangular matrices (i.e., with zeros on the diagonal). This subalgebra has complex dimension
 $1 + 2 + \cdots + (d-1) = \frac {1}{2}d(d-1)$
.
$1 + 2 + \cdots + (d-1) = \frac {1}{2}d(d-1)$
.
The following is a standard application of transversality (see [Reference Lee39, Chapter 6] and [Reference Hirsch32, Chapter 3]). Special cases of the result appear in, for example, [Reference Godbillon23, Theorem 2.3] and [Reference Ebert18, Theorem 1.1.4]. We give a proof sketch here for the sake of convenience.
Lemma 3.12. Let
 $\mathcal {X}$
be a connected smooth manifold and let
$\mathcal {X}$
be a connected smooth manifold and let
 $\mathcal {Y} \subset \mathcal {X}$
be a union of smooth submanifolds,
$\mathcal {Y} \subset \mathcal {X}$
be a union of smooth submanifolds,
 $\mathcal {Y} = \mathcal {Y}_1 \cup \cdots \cup \mathcal {Y}_\ell $
, such that each
$\mathcal {Y} = \mathcal {Y}_1 \cup \cdots \cup \mathcal {Y}_\ell $
, such that each
 $\mathcal {Y}_j$
has codimension greater than or equal to m in
$\mathcal {Y}_j$
has codimension greater than or equal to m in
 $\mathcal {X}$
. Then
$\mathcal {X}$
. Then
 $\pi _k(\mathcal {X} \setminus \mathcal {Y})$
is isomorphic to
$\pi _k(\mathcal {X} \setminus \mathcal {Y})$
is isomorphic to
 $\pi _k(\mathcal {X})$
for all
$\pi _k(\mathcal {X})$
for all
 $k \leq m-2$
.
$k \leq m-2$
.
Proof. We will show that the inclusion map
 $\iota : \mathcal {X} \setminus \mathcal {Y} \hookrightarrow \mathcal {X}$
induces a bijection between homotopy groups.
$\iota : \mathcal {X} \setminus \mathcal {Y} \hookrightarrow \mathcal {X}$
induces a bijection between homotopy groups.
To establish surjectivity, we will show that any map
 $f:S^k \to \mathcal {X}$
is homotopic to a map
$f:S^k \to \mathcal {X}$
is homotopic to a map
 $S^k \to \mathcal {X} \setminus \mathcal {Y}$
. To do so, we apply the Whitney Approximation Theorem [Reference Lee39, Theorem 6.26] to homotope f to a smooth map. By the version of the corollary of the Transversality Theorem given in [Reference Hirsch32, Theorem 2.5], together with the argument in the proof of the Transversality Homotopy Theorem [Reference Lee39, Theorem 6.36], the resulting map is then homotopic to a map
$S^k \to \mathcal {X} \setminus \mathcal {Y}$
. To do so, we apply the Whitney Approximation Theorem [Reference Lee39, Theorem 6.26] to homotope f to a smooth map. By the version of the corollary of the Transversality Theorem given in [Reference Hirsch32, Theorem 2.5], together with the argument in the proof of the Transversality Homotopy Theorem [Reference Lee39, Theorem 6.36], the resulting map is then homotopic to a map
 $S^k \to \mathcal {X}$
which is transverse to each submanifold
$S^k \to \mathcal {X}$
which is transverse to each submanifold
 $\mathcal {Y}_j$
. By the codimensionality constraint, this is only possible if the image of
$\mathcal {Y}_j$
. By the codimensionality constraint, this is only possible if the image of
 $S^k$
is disjoint from each
$S^k$
is disjoint from each
 $\mathcal {Y}_j$
. This shows that f is homotopic to a map whose image is disjoint from
$\mathcal {Y}_j$
. This shows that f is homotopic to a map whose image is disjoint from
 $\mathcal {Y}$
.
$\mathcal {Y}$
.
Next, we show that the map induced by
 $\iota $
is injective. That is, if maps
$\iota $
is injective. That is, if maps
 $f_0,f_1:S^k \to \mathcal {X}$
are homotopic, and, without loss of generality (by the above),
$f_0,f_1:S^k \to \mathcal {X}$
are homotopic, and, without loss of generality (by the above),
 $f_0(S^k) \cap \mathcal {Y} = f_1(S^k) \cap \mathcal {Y} = \emptyset $
, then they are homotopic in
$f_0(S^k) \cap \mathcal {Y} = f_1(S^k) \cap \mathcal {Y} = \emptyset $
, then they are homotopic in
 $\mathcal {X} \setminus \mathcal {Y}$
. This is done by applying similar arguments to the above to the homotopy
$\mathcal {X} \setminus \mathcal {Y}$
. This is done by applying similar arguments to the above to the homotopy
 $f:S^k \times [0,1] \to \mathcal {X}$
; in particular, this map may be homotoped without destroying transversality at the boundary
$f:S^k \times [0,1] \to \mathcal {X}$
; in particular, this map may be homotoped without destroying transversality at the boundary
 $S^k \times \{0,1\}$
[Reference Hirsch32, Ch. 3, Theorem 2.1].
$S^k \times \{0,1\}$
[Reference Hirsch32, Ch. 3, Theorem 2.1].
Proof of Theorem 3.9.
By Corollary 3.8, it suffices to show that
 $\mathcal {M}_d$
is k-connected for all
$\mathcal {M}_d$
is k-connected for all
 $2d-2$
. By a theorem of Whitney, the algebraic variety
$2d-2$
. By a theorem of Whitney, the algebraic variety
 $\mathcal {P}_d$
can be expressed as a disjoint union of smooth manifolds [Reference Whitney59, Theorem 2], and, by Lemma 3.11, each of these has real codimension at least
$\mathcal {P}_d$
can be expressed as a disjoint union of smooth manifolds [Reference Whitney59, Theorem 2], and, by Lemma 3.11, each of these has real codimension at least
 $$\begin{align*}\mathrm{dim}(\mathbb{C}^{d \times d}) - \mathrm{dim}(\mathcal{P}_d) = 2d^2 - 2d(d-1) = 2d. \end{align*}$$
$$\begin{align*}\mathrm{dim}(\mathbb{C}^{d \times d}) - \mathrm{dim}(\mathcal{P}_d) = 2d^2 - 2d(d-1) = 2d. \end{align*}$$
The theorem then follows from Lemma 3.12, since
 $\mathbb {C}^{d \times d}$
is k-connected for all k.
$\mathbb {C}^{d \times d}$
is k-connected for all k.
3.3 Topology of real unit norm normal matrices
Let
 $\mathcal {U}\mathcal {N}_d^{\mathbb {R}}$
denote the space of real, normal
$\mathcal {U}\mathcal {N}_d^{\mathbb {R}}$
denote the space of real, normal
 $d\times d$
matrices with Frobenius norm equal to one (so
$d\times d$
matrices with Frobenius norm equal to one (so
 $\mathcal {UN}_{d}^{\mathbb {R}} \subset \mathcal {U}\mathcal {N}_d$
). Adapting the arguments from the previous subsection, we will show the following.
$\mathcal {UN}_{d}^{\mathbb {R}} \subset \mathcal {U}\mathcal {N}_d$
). Adapting the arguments from the previous subsection, we will show the following.
Theorem 3.13. The space
 $\mathcal {UN}_d^{\mathbb {R}}$
is k-connected for all
$\mathcal {UN}_d^{\mathbb {R}}$
is k-connected for all
 $k \leq d-2$
.
$k \leq d-2$
.
Remark 3.14. It follows from the theorem that
 $\mathcal {UN}_d^{\mathbb {R}}$
is path connected for
$\mathcal {UN}_d^{\mathbb {R}}$
is path connected for
 $d \geq 2$
and simply connected for
$d \geq 2$
and simply connected for
 $d \geq 3$
. These results are tight:
$d \geq 3$
. These results are tight:
-
•
$\mathcal {UN}_1^{\mathbb {R}} \approx \{\pm 1\}$
is not path connected. -
•
$\mathcal {UN}_2^{\mathbb {R}}$
is not simply connected. This is illustrated in Figure 5.Figure 5 Consider the space
$\mathcal {U}_2^{\mathbb {R}}$
of
$2 \times 2$
real matrices with Frobenius norm 1. Since
$\mathcal {U}_2^{\mathbb {R}}$
is a copy of the 3-sphere, we can stereographically project to
$\mathbb {R}^3$
. The image under this projection of the unit-norm nilpotent matrices is shown in blue, and the image of
$\kern1pt\mathcal {UN}_2^{\mathbb {R}}$
is shown in pink. Specifically, the pink plane (which is the
$y=z$
plane) is the image of the symmetric matrices and the pink loop is the image of the normal matrices of the form
$\begin{bmatrix}a & b \\ -b & a\end{bmatrix}$
.










The proof of the theorem follows the same general steps as that of Theorem 3.9. Let
 $\mathcal {P}_d^{\mathbb {R}}$
denote the
$\mathcal {P}_d^{\mathbb {R}}$
denote the
 $d \times d$
real nilpotent matrices, and let
$d \times d$
real nilpotent matrices, and let
 $\mathcal {M}_d^{\mathbb {R}} = \mathbb {R}^{d \times d} \setminus \mathcal {P}_d^{\mathbb {R}}$
denote the set of non-nilpotent matrices. By the same arguments used in the previous subsection,
$\mathcal {M}_d^{\mathbb {R}} = \mathbb {R}^{d \times d} \setminus \mathcal {P}_d^{\mathbb {R}}$
denote the set of non-nilpotent matrices. By the same arguments used in the previous subsection,
 $\mathcal {M}_d^{\mathbb {R}}$
deformation retracts onto
$\mathcal {M}_d^{\mathbb {R}}$
deformation retracts onto
 $\mathcal {UN}_d^{\mathbb {R}}$
, so it suffices to prove that
$\mathcal {UN}_d^{\mathbb {R}}$
, so it suffices to prove that
 $\mathcal {M}_d^{\mathbb {R}}$
is k-connected for all
$\mathcal {M}_d^{\mathbb {R}}$
is k-connected for all
 $k \leq d-2$
.
$k \leq d-2$
.
The main difference in the real case is that an analogue of Lemma 3.11 does not follow from general facts of nilpotent cones described in [Reference Jantzen, Anker and Orsted35], as the results therein are valid over algebraically closed fields. We obtain a decomposition of
 $\mathcal {P}_d^{\mathbb {R}}$
in analogy with the Whitney decomposition used in the proof of Theorem 3.9 from results of [Reference Heinzner, Schwarz and Stötzel29] and [Reference Böhm, Lafuente, Dearricott, Tuschmann, Nikolayevsky, Leistner and Crowley8].
$\mathcal {P}_d^{\mathbb {R}}$
in analogy with the Whitney decomposition used in the proof of Theorem 3.9 from results of [Reference Heinzner, Schwarz and Stötzel29] and [Reference Böhm, Lafuente, Dearricott, Tuschmann, Nikolayevsky, Leistner and Crowley8].
Lemma 3.15. The set of nilpotent matrices
 $\mathcal {P}_d^{\mathbb {R}}$
is a union of smooth submanifolds of
$\mathcal {P}_d^{\mathbb {R}}$
is a union of smooth submanifolds of
 $\mathbb {R}^{d \times d}$
, each of which has codimension at least d.
$\mathbb {R}^{d \times d}$
, each of which has codimension at least d.
Proof. It follows from a general theory of real reductive Lie group actions developed in [Reference Heinzner, Schwarz and Stötzel29] that
 $\mathbb {R}^{d \times d} \setminus \{0\}$
decomposes as a union of
$\mathbb {R}^{d \times d} \setminus \{0\}$
decomposes as a union of
 $\mathrm {GL}_d(\mathbb {R})$
-invariant (with respect to the conjugation action) smooth submanifolds
$\mathrm {GL}_d(\mathbb {R})$
-invariant (with respect to the conjugation action) smooth submanifolds
 $S_0 \cup S_1 \cup \cdots \cup S_k$
, where
$S_0 \cup S_1 \cup \cdots \cup S_k$
, where
 $S_0$
is exactly the open submanifold
$S_0$
is exactly the open submanifold
 $\mathcal {M}_d^{\mathbb {R}}$
– see also [Reference Böhm, Lafuente, Dearricott, Tuschmann, Nikolayevsky, Leistner and Crowley8, Section 1] for a short exposition of these ideas. It is shown in [Reference Böhm, Lafuente, Dearricott, Tuschmann, Nikolayevsky, Leistner and Crowley8, Section 1.2] that (for the specific example of the conjugation action on
$\mathcal {M}_d^{\mathbb {R}}$
– see also [Reference Böhm, Lafuente, Dearricott, Tuschmann, Nikolayevsky, Leistner and Crowley8, Section 1] for a short exposition of these ideas. It is shown in [Reference Böhm, Lafuente, Dearricott, Tuschmann, Nikolayevsky, Leistner and Crowley8, Section 1.2] that (for the specific example of the conjugation action on
 $\mathbb {R}^{d \times d}$
) the remaining submanifolds
$\mathbb {R}^{d \times d}$
) the remaining submanifolds
 $S_i$
,
$S_i$
,
 $i> 0$
, are parameterized by Jordan canonical forms of nilpotent matrices. That is, fixing such a Jordan matrix J, we consider the corresponding set of nilpotent matrices as the homogeneous space
$i> 0$
, are parameterized by Jordan canonical forms of nilpotent matrices. That is, fixing such a Jordan matrix J, we consider the corresponding set of nilpotent matrices as the homogeneous space
 $\mathrm {GL}_d(\mathbb {R})/\mathrm {stab}(J)$
, where
$\mathrm {GL}_d(\mathbb {R})/\mathrm {stab}(J)$
, where
 $\mathrm {stab}(J)$
is the stabilizer of J under the conjugation action. To complete the proof, it suffices to show that the dimension of such a homogeneous space is at most
$\mathrm {stab}(J)$
is the stabilizer of J under the conjugation action. To complete the proof, it suffices to show that the dimension of such a homogeneous space is at most
 $d^2-d$
, that is, to show that the stabilizer of any such Jordan matrix is at least of dimension d.
$d^2-d$
, that is, to show that the stabilizer of any such Jordan matrix is at least of dimension d.
Let us now establish the claim made above. A nilpotent Jordan matrix J necessarily has all zeros on its diagonal, and is therefore characterized by the pattern of ones in the super diagonal (i.e., by the size of its Jordan blocks). An invertible real matrix
 $A = (a_{ij})_{i,j=1}^d$
lies in the stabilizer of J if and only if
$A = (a_{ij})_{i,j=1}^d$
lies in the stabilizer of J if and only if
 $AJ = JA$
. This matrix equation gives several constraints in the entries of A, and the number of independent constraints determines the dimension of the stabilizer.
$AJ = JA$
. This matrix equation gives several constraints in the entries of A, and the number of independent constraints determines the dimension of the stabilizer.
In particular, since we aim to determine a lower bound on codimension, it suffices to consider the Jordan matrix which produces the largest number of constraints: that is, when J is the matrix whose superdiagonal consists of all ones (i.e., it has a single Jordan block). It is a standard fact (see, e.g., [Reference Gohberg, Lancaster and Rodman24, Theorem 9.1.1]) that, for this J, solutions of the equation
 $AJ = JA$
must be upper triangular Toeplitz matrices. In other words, elements of
$AJ = JA$
must be upper triangular Toeplitz matrices. In other words, elements of
 $\mathrm {stab}(J)$
are of the form
$\mathrm {stab}(J)$
are of the form
 $$\begin{align*}\begin{bmatrix} a_1 & a_2 & a_3 & \cdots & a_{d-1} & a_d \\ 0 & a_1 & a_2 & \cdots & a_{d-2} & a_{d-1} \\ 0 & 0 & a_1 & \cdots & a_{d-3} & a_{d-2} \\ \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & \cdots & a_1 & a_2 \\ 0 & 0 & 0 & \cdots & 0 & a_1 \end{bmatrix}. \end{align*}$$
$$\begin{align*}\begin{bmatrix} a_1 & a_2 & a_3 & \cdots & a_{d-1} & a_d \\ 0 & a_1 & a_2 & \cdots & a_{d-2} & a_{d-1} \\ 0 & 0 & a_1 & \cdots & a_{d-3} & a_{d-2} \\ \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & \cdots & a_1 & a_2 \\ 0 & 0 & 0 & \cdots & 0 & a_1 \end{bmatrix}. \end{align*}$$
Clearly, then,
 $\dim (\mathrm {stab}(J)) = d$
. This implies that the codimension of the associated submanifold is d. Since this is the submanifold of smallest codimension, this completes the proof.
$\dim (\mathrm {stab}(J)) = d$
. This implies that the codimension of the associated submanifold is d. Since this is the submanifold of smallest codimension, this completes the proof.


4 Balanced matrices and weighted digraphs
As was described in the introduction, the techniques and results that we have developed for normal matrices can be adapted to the setting of weighted digraphs. The naturality of such an application follows from the following observation. Notice that the diagonal entries of
 $\mu (A) = [A,A^\ast ]$
are of the form
$\mu (A) = [A,A^\ast ]$
are of the form
 $\|A_i\|^2 - \|A^i\|^2$
, where
$\|A_i\|^2 - \|A^i\|^2$
, where
 $A_i$
is the ith row of A and
$A_i$
is the ith row of A and
 $A^i$
is the ith column. Hence, if
$A^i$
is the ith column. Hence, if
 $A \in \mathbb {C}^{d \times d}$
is normal, then
$A \in \mathbb {C}^{d \times d}$
is normal, then
 $\|A_i\|^2 = \|A^i\|^2$
for all
$\|A_i\|^2 = \|A^i\|^2$
for all
 $i=1, \dots , d$
. This suggests a certain balancing condition, as we expand on below.
$i=1, \dots , d$
. This suggests a certain balancing condition, as we expand on below.
Suppose that
 $\mathcal {G}$
is a weighted, directed graph and
$\mathcal {G}$
is a weighted, directed graph and
 $\widehat {A}$
is its associated adjacency matrix; that is, the
$\widehat {A}$
is its associated adjacency matrix; that is, the
 $(i,j)$
entry of
$(i,j)$
entry of
 $\widehat {A}$
is the (non-negative) weight of the directed edge from vertex i to vertex j if such an edge exists, and zero if there is no such edge. In particular, the entries of
$\widehat {A}$
is the (non-negative) weight of the directed edge from vertex i to vertex j if such an edge exists, and zero if there is no such edge. In particular, the entries of
 $\widehat {A}$
are non-negative real numbers. If A is the matrix whose entries are the square roots of the entries of
$\widehat {A}$
are non-negative real numbers. If A is the matrix whose entries are the square roots of the entries of
 $\widehat {A}$
, then
$\widehat {A}$
, then
 $\|A_i\|^2 = \|A^i\|^2$
says that the ith vertex
$\|A_i\|^2 = \|A^i\|^2$
says that the ith vertex
 $v_i$
of
$v_i$
of
 $\mathcal {G}$
is balanced: the sum of the weights of the edges coming into
$\mathcal {G}$
is balanced: the sum of the weights of the edges coming into
 $v_i$
equals the sum of the weights of the edges leaving
$v_i$
equals the sum of the weights of the edges leaving
 $v_i$
. In other words, every real normal matrix A corresponds to a balanced, weighted, directed (multi-)graphFootnote 5
$v_i$
. In other words, every real normal matrix A corresponds to a balanced, weighted, directed (multi-)graphFootnote 5
 $\mathcal {G}$
by interpreting the component-wise square of A as the adjacency matrix of
$\mathcal {G}$
by interpreting the component-wise square of A as the adjacency matrix of
 $\mathcal {G}$
. Moreover, the gradient descent procedures described in the previous sections give ways of balancing a given weighted, directed graph.
$\mathcal {G}$
. Moreover, the gradient descent procedures described in the previous sections give ways of balancing a given weighted, directed graph.
However, balancing a graph by gradient descent of
 $\operatorname {E}$
or
$\operatorname {E}$
or
 $\overline {\operatorname {E}}$
has some undesirable features. First, the condition that A is normal is stronger than the condition that
$\overline {\operatorname {E}}$
has some undesirable features. First, the condition that A is normal is stronger than the condition that
 $\mathcal {G}$
is balanced;Footnote 6 second, the gradient flow is not guaranteed to ensure that a zero entry in the adjacency matrix will stay zero, so the limiting balanced graph may have sprouted new edges (and even loop edges) not present in the initial graph.
$\mathcal {G}$
is balanced;Footnote 6 second, the gradient flow is not guaranteed to ensure that a zero entry in the adjacency matrix will stay zero, so the limiting balanced graph may have sprouted new edges (and even loop edges) not present in the initial graph.
For applications to balancing graphs, then, the natural energy to consider is not the non-normal energy
 $\operatorname {E}$
, but rather the unbalanced energy
$\operatorname {E}$
, but rather the unbalanced energy
 $\operatorname {B}: \mathbb {C}^{d \times d} \to \mathbb {R}$
defined by
$\operatorname {B}: \mathbb {C}^{d \times d} \to \mathbb {R}$
defined by
 $$\begin{align*}\operatorname{B}(A) = \|\operatorname{diag}(AA^\ast - A^\ast A)\|^2 = \sum_{i=1}^d \left(\|A_i\|^2 - \|A^i\|^2\right)^2, \end{align*}$$
$$\begin{align*}\operatorname{B}(A) = \|\operatorname{diag}(AA^\ast - A^\ast A)\|^2 = \sum_{i=1}^d \left(\|A_i\|^2 - \|A^i\|^2\right)^2, \end{align*}$$
where we use
 $A_i$
for the ith row of A and
$A_i$
for the ith row of A and
 $A^i$
for the ith column. We will say that A is balanced if
$A^i$
for the ith column. We will say that A is balanced if
 $\operatorname {B}(A) = 0$
.
$\operatorname {B}(A) = 0$
.
We now describe this function from the perspective of symplectic geometry and GIT. Following a general theme of the paper, these observations are not really essential in what follows, but they provided inspiration, especially in light of Kirwan’s fundamental work [Reference Kirwan37]. Let
 $\operatorname {DSU}(d)$
be the subgroup of
$\operatorname {DSU}(d)$
be the subgroup of
 $\operatorname {SU}(d)$
consisting of diagonal matrices. Then
$\operatorname {SU}(d)$
consisting of diagonal matrices. Then
 $\operatorname {DSU}(d) \approx \operatorname {U}(1)^{d-1}$
is the standard maximal torus of
$\operatorname {DSU}(d) \approx \operatorname {U}(1)^{d-1}$
is the standard maximal torus of
 $\operatorname {SU}(d)$
. The restriction of the conjugation action of
$\operatorname {SU}(d)$
. The restriction of the conjugation action of
 $\operatorname {SU}(d)$
on
$\operatorname {SU}(d)$
on
 $\mathbb {C}^{d \times d}$
gives a Hamiltonian action of
$\mathbb {C}^{d \times d}$
gives a Hamiltonian action of
 $\operatorname {DSU}(d)$
on
$\operatorname {DSU}(d)$
on
 $\mathbb {C}^{d \times d}$
with momentum map
$\mathbb {C}^{d \times d}$
with momentum map
 $\mu _\Delta : \mathbb {C}^{d \times d} \to \mathbb {R}^d$
given by composing the momentum map
$\mu _\Delta : \mathbb {C}^{d \times d} \to \mathbb {R}^d$
given by composing the momentum map
 $\mu $
of the
$\mu $
of the
 $\operatorname {SU}(d)$
action with orthogonal projection to
$\operatorname {SU}(d)$
action with orthogonal projection to
 $\mathfrak {dsu}(d)^\ast \subset \mathfrak {su}(d)^\ast $
(see, e.g., [Reference Audin4, Proposition III.1.10]). Under the identification of
$\mathfrak {dsu}(d)^\ast \subset \mathfrak {su}(d)^\ast $
(see, e.g., [Reference Audin4, Proposition III.1.10]). Under the identification of
 $\mathfrak {su}(d)^\ast $
with the traceless Hermitian matrices,
$\mathfrak {su}(d)^\ast $
with the traceless Hermitian matrices,
 $\mathfrak {dsu}(d)^\ast $
corresponds to the traceless, diagonal, real matrices, so we have
$\mathfrak {dsu}(d)^\ast $
corresponds to the traceless, diagonal, real matrices, so we have
 $$\begin{align*}\mu_\Delta(A) = \operatorname{diag}(\mu(A)) = \operatorname{diag}([A,A^\ast]) \end{align*}$$
$$\begin{align*}\mu_\Delta(A) = \operatorname{diag}(\mu(A)) = \operatorname{diag}([A,A^\ast]) \end{align*}$$
and
 $\operatorname {B}(A) = \|\mu _\Delta (A)\|^2$
. The GIT version of the foregoing is that the diagonal subgroup
$\operatorname {B}(A) = \|\mu _\Delta (A)\|^2$
. The GIT version of the foregoing is that the diagonal subgroup
 $\operatorname {DSL}_d(\mathbb {C}) \subset \operatorname {SL}_d(\mathbb {C})$
has an algebraic action by conjugation on
$\operatorname {DSL}_d(\mathbb {C}) \subset \operatorname {SL}_d(\mathbb {C})$
has an algebraic action by conjugation on
 $\mathbb {C}^{d \times d}$
(or, in Section 4.2, on
$\mathbb {C}^{d \times d}$
(or, in Section 4.2, on
 $\mathbb {P}(\mathbb {C}^{d \times d})$
).
$\mathbb {P}(\mathbb {C}^{d \times d})$
).
4.1 Balancing matrices by gradient descent
As in the case of
 $\operatorname {E}$
, all critical points of
$\operatorname {E}$
, all critical points of
 $\operatorname {B}$
are global minima:
$\operatorname {B}$
are global minima:
Theorem 4.1. The only critical points of
 $\operatorname {B}$
are the global minima; that is, the balanced matrices.
$\operatorname {B}$
are the global minima; that is, the balanced matrices.
Proof. We first show that the gradient of the balanced energy is given by
 $$ \begin{align} \nabla \operatorname{B}(A) = -4[A,\operatorname{diag}([A,A^\ast])]. \end{align} $$
$$ \begin{align} \nabla \operatorname{B}(A) = -4[A,\operatorname{diag}([A,A^\ast])]. \end{align} $$
We write
 $\operatorname {B} = N \circ \mathrm {diag} \circ \mu $
, where
$\operatorname {B} = N \circ \mathrm {diag} \circ \mu $
, where
 $\mu $
is the momentum map (2.1), we consider the diagonalization operator as a linear map
$\mu $
is the momentum map (2.1), we consider the diagonalization operator as a linear map
 $\mathrm {diag}:\mathbb {C}^{d \times d} \to \mathbb {C}^{d \times d}$
, and N is the norm-squared map, as in the proof of Theorem 2.3. Following the logic of that proof, we then have that
$\mathrm {diag}:\mathbb {C}^{d \times d} \to \mathbb {C}^{d \times d}$
, and N is the norm-squared map, as in the proof of Theorem 2.3. Following the logic of that proof, we then have that
 $$\begin{align*}\nabla \operatorname{B}(A) = D\mu(A)^\vee \mathrm{diag}^\vee \nabla N (\mathrm{diag} \circ \mu(A)), \end{align*}$$
$$\begin{align*}\nabla \operatorname{B}(A) = D\mu(A)^\vee \mathrm{diag}^\vee \nabla N (\mathrm{diag} \circ \mu(A)), \end{align*}$$
where the superscripts once again denote adjoints with respect to
 $\langle \cdot , \cdot \rangle $
. It is not hard to show that the map
$\langle \cdot , \cdot \rangle $
. It is not hard to show that the map
 $\mathrm {diag}$
is self-adjoint and idempotent. Then
$\mathrm {diag}$
is self-adjoint and idempotent. Then
 $$ \begin{align*} \nabla \operatorname{B}(A) &= D\mu(A)^\vee \mathrm{diag} (2 \cdot \mathrm{diag} \circ \mu(A)) = 2 D\mu(A)^\vee \mathrm{diag}(\mu(A)) \\ &= 2 [\mathrm{diag}(\mu(A)) + \mathrm{diag}(\mu(A))^\ast, A] = -4 [A, \mathrm{diag}([A,A^\ast])]. \end{align*} $$
$$ \begin{align*} \nabla \operatorname{B}(A) &= D\mu(A)^\vee \mathrm{diag} (2 \cdot \mathrm{diag} \circ \mu(A)) = 2 D\mu(A)^\vee \mathrm{diag}(\mu(A)) \\ &= 2 [\mathrm{diag}(\mu(A)) + \mathrm{diag}(\mu(A))^\ast, A] = -4 [A, \mathrm{diag}([A,A^\ast])]. \end{align*} $$
The above shows that we have a critical point of
 $\operatorname {B}$
exactly when
$\operatorname {B}$
exactly when
 $$\begin{align*}0 = [A,\operatorname{diag}([A,A^\ast])]. \end{align*}$$
$$\begin{align*}0 = [A,\operatorname{diag}([A,A^\ast])]. \end{align*}$$
Since the entries of
 $[A,\operatorname {diag}([A,A^\ast ])]$
are of the form
$[A,\operatorname {diag}([A,A^\ast ])]$
are of the form
 $$ \begin{align} a_{ij}\left((\|A_i\|^2 - \|A^i\|^2) - (\|A_j\|^2 - \|A^j\|^2)\right), \end{align} $$
$$ \begin{align} a_{ij}\left((\|A_i\|^2 - \|A^i\|^2) - (\|A_j\|^2 - \|A^j\|^2)\right), \end{align} $$
this means that
 $\|A_i\|^2 - \|A^i\|^2 = \|A_j\|^2 - \|A^j\|^2$
for all i and j such that
$\|A_i\|^2 - \|A^i\|^2 = \|A_j\|^2 - \|A^j\|^2$
for all i and j such that
 $a_{ij} \neq 0$
.
$a_{ij} \neq 0$
.
In other words, A is a critical point of
 $\operatorname {B}$
if and only if
$\operatorname {B}$
if and only if
 $\|A_i\|^2 - \|A^i\|^2$
is independent of i. However, since
$\|A_i\|^2 - \|A^i\|^2$
is independent of i. However, since
 $$\begin{align*}\sum_{i=1}^d \left(\|A_i\|^2 - \|A^i\|^2\right) = \sum_{i=1}^d\|A_i\|^2 - \sum_{i=1}^d\|A^i\|^2 = \|A\|^2 - \|A\|^2 = 0, \end{align*}$$
$$\begin{align*}\sum_{i=1}^d \left(\|A_i\|^2 - \|A^i\|^2\right) = \sum_{i=1}^d\|A_i\|^2 - \sum_{i=1}^d\|A^i\|^2 = \|A\|^2 - \|A\|^2 = 0, \end{align*}$$
this can only happen if all
 $\|A_i\|^2 - \|A^i\|^2 = 0$
; that is, if A is balanced.
$\|A_i\|^2 - \|A^i\|^2 = 0$
; that is, if A is balanced.
Remark 4.2. Theorem 4.1 shows that
 $\operatorname {B}$
is an invex function, but it is not quasiconvex. To see this, consider the matrices
$\operatorname {B}$
is an invex function, but it is not quasiconvex. To see this, consider the matrices
 $$\begin{align*}A_0 = \begin{bmatrix} 0 & 1 & 0 \\ 0 & 0 & 1 \\ 1 & 0 & 0 \end{bmatrix} \qquad \text{and} \qquad A_1 = \begin{bmatrix} 0 & 0 & 0 \\ 0 & 0 & 1 \\ 0 & 1 & 0 \end{bmatrix}, \end{align*}$$
$$\begin{align*}A_0 = \begin{bmatrix} 0 & 1 & 0 \\ 0 & 0 & 1 \\ 1 & 0 & 0 \end{bmatrix} \qquad \text{and} \qquad A_1 = \begin{bmatrix} 0 & 0 & 0 \\ 0 & 0 & 1 \\ 0 & 1 & 0 \end{bmatrix}, \end{align*}$$
which are the (entrywise square roots of the) adjacency matrices of the balanced graphs

respectively. Then
 $\operatorname {B}(A_0) = 0 = \operatorname {B}(A_1)$
, but
$\operatorname {B}(A_0) = 0 = \operatorname {B}(A_1)$
, but
 $\operatorname {B}\left ((1-t)A_0 + t A_1\right ) = 8t^2(1-t)^2> 0$
for all
$\operatorname {B}\left ((1-t)A_0 + t A_1\right ) = 8t^2(1-t)^2> 0$
for all
 $0 < t < 1$
.
$0 < t < 1$
.
As in the case of
 $\operatorname {E}$
, we can find global minima of
$\operatorname {E}$
, we can find global minima of
 $\operatorname {B}$
by gradient descent. Specifically, let
$\operatorname {B}$
by gradient descent. Specifically, let
 $\mathscr {F}: \mathbb {C}^{d \times d} \times [0,\infty ) \to \mathbb {C}^{d \times d}$
be the negative gradient flow of
$\mathscr {F}: \mathbb {C}^{d \times d} \times [0,\infty ) \to \mathbb {C}^{d \times d}$
be the negative gradient flow of
 $\operatorname {B}$
:
$\operatorname {B}$
:
 $$\begin{align*}\mathscr{F}(A_0,0) = A_0 \qquad \frac{d}{dt} \mathscr{F}(A_0, t) = -\nabla \operatorname{B}(\mathscr{F}(A_0,t)). \end{align*}$$
$$\begin{align*}\mathscr{F}(A_0,0) = A_0 \qquad \frac{d}{dt} \mathscr{F}(A_0, t) = -\nabla \operatorname{B}(\mathscr{F}(A_0,t)). \end{align*}$$
Since
 $\operatorname {B}$
is a real polynomial function on
$\operatorname {B}$
is a real polynomial function on
 $\mathbb {C}^{d \times d}$
, Theorem 4.1 implies that
$\mathbb {C}^{d \times d}$
, Theorem 4.1 implies that
 $\lim _{t \to \infty } \mathscr {F}(A_0,t)$
is always well-defined and normal. Since the real matrices stay real under gradient flow, this limit will be real whenever
$\lim _{t \to \infty } \mathscr {F}(A_0,t)$
is always well-defined and normal. Since the real matrices stay real under gradient flow, this limit will be real whenever
 $A_0$
is.
$A_0$
is.
Moreover,
 $$ \begin{align} \nabla \operatorname{B}(A) = -4[A,\operatorname{diag}([A,A^\ast])] = 4\left(\left. \frac{d}{d\epsilon}\right|{}_{\epsilon = 0} e^{\epsilon \operatorname{diag}([A,A^\ast])} \cdot A\right) \end{align} $$
$$ \begin{align} \nabla \operatorname{B}(A) = -4[A,\operatorname{diag}([A,A^\ast])] = 4\left(\left. \frac{d}{d\epsilon}\right|{}_{\epsilon = 0} e^{\epsilon \operatorname{diag}([A,A^\ast])} \cdot A\right) \end{align} $$
is tangent to the orbit of the diagonal subgroup
 $\operatorname {DSL}_d(\mathbb {C}) \leq \operatorname {SL}_d(\mathbb {C})$
acting by conjugation on
$\operatorname {DSL}_d(\mathbb {C}) \leq \operatorname {SL}_d(\mathbb {C})$
acting by conjugation on
 $\mathbb {C}^{d \times d}$
. In particular, flowing
$\mathbb {C}^{d \times d}$
. In particular, flowing
 $A_0$
by the gradient flow of
$A_0$
by the gradient flow of
 $\operatorname {B}$
preserves not just the eigenvalues of
$\operatorname {B}$
preserves not just the eigenvalues of
 $A_0$
, but also all principal minors of
$A_0$
, but also all principal minors of
 $A_0$
, including the diagonal entries of
$A_0$
, including the diagonal entries of
 $A_0$
.
$A_0$
.
From the expression (4.2) for the entries of
 $-\frac {1}{4}\nabla \operatorname {B}(A)$
we see that, if there is
$-\frac {1}{4}\nabla \operatorname {B}(A)$
we see that, if there is
 $t_0 \geq 0$
so that the
$t_0 \geq 0$
so that the
 $(i,j)$
entry in
$(i,j)$
entry in
 $\mathscr {F}(A_0,t_0)$
vanishes, then the
$\mathscr {F}(A_0,t_0)$
vanishes, then the
 $(i,j)$
entry of
$(i,j)$
entry of
 $\mathscr {F}(A_0, t)$
will vanish for all
$\mathscr {F}(A_0, t)$
will vanish for all
 $t \geq t_0$
. In graph terms, the gradient flow of
$t \geq t_0$
. In graph terms, the gradient flow of
 $\operatorname {B}$
cannot sprout new edges in the graph. This also means that if
$\operatorname {B}$
cannot sprout new edges in the graph. This also means that if
 $A_0$
is real, its entries cannot change sign under gradient descent of
$A_0$
is real, its entries cannot change sign under gradient descent of
 $\operatorname {B}$
. Thus, we have proved:
$\operatorname {B}$
. Thus, we have proved:
Theorem 4.3. For any
 $A_0 \in \mathbb {C}^{d \times d}$
, the matrix
$A_0 \in \mathbb {C}^{d \times d}$
, the matrix ![]() exists, is balanced, has the same eigenvalues and principal minors as
exists, is balanced, has the same eigenvalues and principal minors as
 $A_0$
, and has zero entries wherever
$A_0$
, and has zero entries wherever
 $A_0$
does. If
$A_0$
does. If
 $A_0$
is real, then so is
$A_0$
is real, then so is
 $A_\infty $
, and if
$A_\infty $
, and if
 $A_0$
has all non-negative entries, then so does
$A_0$
has all non-negative entries, then so does
 $A_\infty $
.
$A_\infty $
.
When we take
 $A_0$
to be the entrywise square root of the adjacency matrix of some weighted, directed graph
$A_0$
to be the entrywise square root of the adjacency matrix of some weighted, directed graph
 $\mathcal {G}_0 = (\mathcal {V}_0, \mathcal {E}_0,w_0)$
, then we can sensibly interpret
$\mathcal {G}_0 = (\mathcal {V}_0, \mathcal {E}_0,w_0)$
, then we can sensibly interpret
 $A_\infty = \displaystyle \lim _{t \to \infty } \mathscr {F}(A_0,t)$
as the entrywise square root of the adjacency matrix of some balanced, weighted, directed graph
$A_\infty = \displaystyle \lim _{t \to \infty } \mathscr {F}(A_0,t)$
as the entrywise square root of the adjacency matrix of some balanced, weighted, directed graph
 $\mathcal {G}_\infty = (\mathcal {V}_\infty , \mathcal {E}_\infty ,w_\infty )$
with
$\mathcal {G}_\infty = (\mathcal {V}_\infty , \mathcal {E}_\infty ,w_\infty )$
with
 $\mathcal {V}_\infty = \mathcal {V}_0$
and
$\mathcal {V}_\infty = \mathcal {V}_0$
and
 $\mathcal {E}_\infty \subseteq \mathcal {E}_0$
. In other words, gradient descent of
$\mathcal {E}_\infty \subseteq \mathcal {E}_0$
. In other words, gradient descent of
 $\operatorname {B}$
balances
$\operatorname {B}$
balances
 $\mathcal {G}_0$
without introducing any new edges.
$\mathcal {G}_0$
without introducing any new edges.
Remark 4.4. An important consideration in the applied literature on graph balancing is that algorithms are local, in the sense that iterative updates are only performed based on node-level information [Reference Rikos, Charalambous and Hadjicostis51, Reference Loh33, Reference Hadjicostis and Rikos26]. This is due both to practical constraints on data acquisition, as well as the need for parallelizability in computation. Observe from the structure of the gradient of the unbalanced energy that the gradient descent approach to graph balancing is not local in the sense described above, but is semilocal in the sense that updates only depend on edge-level information. While this paper is concerned with theory and makes no claims to efficiency or practicality of the algorithm, the useful properties of the gradient flow of
 $\mathrm {B}$
suggest that it may be interesting to explore its viability in real-world applications.
$\mathrm {B}$
suggest that it may be interesting to explore its viability in real-world applications.
In the case of gradient descent of
 $\operatorname {E}$
, we saw that all nilpotent matrices flowed to the zero matrix. We see the same phenomenon here: if
$\operatorname {E}$
, we saw that all nilpotent matrices flowed to the zero matrix. We see the same phenomenon here: if
 $\mathcal {G}_0$
is a weighted, directed, acyclic graph (DAG), then its adjacency matrix is nilpotent, as is the entrywise square root
$\mathcal {G}_0$
is a weighted, directed, acyclic graph (DAG), then its adjacency matrix is nilpotent, as is the entrywise square root
 $A_0$
. The gradient flow
$A_0$
. The gradient flow
 $\mathscr {F}(A_0,t)$
will limit to the zero matrix, which makes sense: the only way to balance a weighted DAG is by driving all the weights to zero.
$\mathscr {F}(A_0,t)$
will limit to the zero matrix, which makes sense: the only way to balance a weighted DAG is by driving all the weights to zero.
4.2 Preserving weights
Weighted DAGs provide an extreme example of the general phenomenon that gradient descent of
 $\operatorname {B}$
decreases the Frobenius norm. In graph terms, if
$\operatorname {B}$
decreases the Frobenius norm. In graph terms, if
 $A_0$
is the entrywise square root of the adjacency matrix of a weighted, directed graph
$A_0$
is the entrywise square root of the adjacency matrix of a weighted, directed graph
 $\mathcal {G}_0$
, then the squared Frobenius norm
$\mathcal {G}_0$
, then the squared Frobenius norm
 $$\begin{align*}\|A_0\|^2 = \sum_{i,j} |a_{ij}|^2 = \sum_{i,j} a_{ij}^2 \end{align*}$$
$$\begin{align*}\|A_0\|^2 = \sum_{i,j} |a_{ij}|^2 = \sum_{i,j} a_{ij}^2 \end{align*}$$
is precisely the sum of the weights in
 $\mathcal {G}_0$
. If the weights correspond to, for example, mass traversing between nodes in a network, then it may not make sense to balance the flows in the network by reducing the total mass in the system.
$\mathcal {G}_0$
. If the weights correspond to, for example, mass traversing between nodes in a network, then it may not make sense to balance the flows in the network by reducing the total mass in the system.
In order to preserve the sum of weights on
 $\mathcal {G}_0$
, we consider
$\mathcal {G}_0$
, we consider
 $\overline {\operatorname {B}}: \mathcal {U}_d \to \mathbb {R}$
, the restriction of
$\overline {\operatorname {B}}: \mathcal {U}_d \to \mathbb {R}$
, the restriction of
 $\operatorname {B}$
to
$\operatorname {B}$
to
 $\mathcal {U}_d$
, and its gradient descent
$\mathcal {U}_d$
, and its gradient descent
 $\overline {\mathscr {F}}: \mathcal {U}_d \times [0, \infty ) \to \mathcal {U}_d$
given by
$\overline {\mathscr {F}}: \mathcal {U}_d \times [0, \infty ) \to \mathcal {U}_d$
given by
 $$\begin{align*}\overline{\mathscr{F}}(A_0,0) = A_0 \qquad \frac{d}{dt} \overline{\mathscr{F}}(A_0,t) = -\operatorname{grad} \overline{\operatorname{B}}(\overline{\mathscr{F}}(A_0,t)). \end{align*}$$
$$\begin{align*}\overline{\mathscr{F}}(A_0,0) = A_0 \qquad \frac{d}{dt} \overline{\mathscr{F}}(A_0,t) = -\operatorname{grad} \overline{\operatorname{B}}(\overline{\mathscr{F}}(A_0,t)). \end{align*}$$
Theorem 4.5. For any non-nilpotent
 $A_0 \in \mathcal {U}_d$
, the matrix
$A_0 \in \mathcal {U}_d$
, the matrix ![]() exists, is balanced, has Frobenius norm 1, and has zero entries wherever
exists, is balanced, has Frobenius norm 1, and has zero entries wherever
 $A_0$
does. If
$A_0$
does. If
 $A_0$
is real, so is
$A_0$
is real, so is
 $A_\infty $
, and if
$A_\infty $
, and if
 $A_0$
has all non-negative entries, then so does
$A_0$
has all non-negative entries, then so does
 $A_\infty $
.
$A_\infty $
.
In graph terms, if
 $A_0$
is the entrywise square root of an adjacency matrix for
$A_0$
is the entrywise square root of an adjacency matrix for
 $\mathcal {G}_0$
with total weight 1, then
$\mathcal {G}_0$
with total weight 1, then
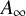 $A_\infty $
is the entrywise square root of the adjacency matrix for a balanced graph
$A_\infty $
is the entrywise square root of the adjacency matrix for a balanced graph
 $\mathcal {G}_\infty $
with total weight 1 whose vertices are the same as the vertices of
$\mathcal {G}_\infty $
with total weight 1 whose vertices are the same as the vertices of
 $\mathcal {G}_0$
and whose edges are a subset of the edges of
$\mathcal {G}_0$
and whose edges are a subset of the edges of
 $\mathcal {G}_0$
. That is, gradient descent of
$\mathcal {G}_0$
. That is, gradient descent of
 $\overline {\operatorname {B}}$
balances
$\overline {\operatorname {B}}$
balances
 $\mathcal {G}_0$
without introducing any new edges and without losing any overall weight.
$\mathcal {G}_0$
without introducing any new edges and without losing any overall weight.
The strategy for proving Theorem 4.5 is the same as for Theorem 3.1. The existence of a unique limit point
 $A_\infty $
follows from the fact that
$A_\infty $
follows from the fact that
 $\overline {\operatorname {B}}$
is a polynomial function on
$\overline {\operatorname {B}}$
is a polynomial function on
 $\mathcal {U}_d$
, and hence has a Łojasiewicz exponent. The bulk of the argument is in showing that the gradient flow preserves non-nilpotency and that the nonminimizing critical points are nilpotent. The rest of the theorem will follow from the structure of
$\mathcal {U}_d$
, and hence has a Łojasiewicz exponent. The bulk of the argument is in showing that the gradient flow preserves non-nilpotency and that the nonminimizing critical points are nilpotent. The rest of the theorem will follow from the structure of
 $\operatorname {grad} \overline {\operatorname {B}}$
and the fact that the real submanifold of
$\operatorname {grad} \overline {\operatorname {B}}$
and the fact that the real submanifold of
 $\mathcal {U}_d$
is invariant under gradient flow.
$\mathcal {U}_d$
is invariant under gradient flow.
First, we compute the intrinsic gradient of
 $\overline {\operatorname {B}}$
, which follows the same pattern as
$\overline {\operatorname {B}}$
, which follows the same pattern as
 $\operatorname {grad} \overline {\operatorname {E}}$
:
$\operatorname {grad} \overline {\operatorname {E}}$
:
Proposition 4.6. The intrinsic gradient of
 $\overline {\operatorname {B}}$
on
$\overline {\operatorname {B}}$
on
 $\mathcal {U}_d$
is
$\mathcal {U}_d$
is
 $$\begin{align*}\operatorname{grad} \overline{\operatorname{B}}(A) = -4([A,\operatorname{diag}([A,A^\ast])]+\overline{\operatorname{B}}(A)A). \end{align*}$$
$$\begin{align*}\operatorname{grad} \overline{\operatorname{B}}(A) = -4([A,\operatorname{diag}([A,A^\ast])]+\overline{\operatorname{B}}(A)A). \end{align*}$$
Proof. We know that
 $$\begin{align*}\operatorname{grad} \overline{\operatorname{B}}(A) = \nabla \operatorname{B}(A) - \langle \nabla \operatorname{B}(A),A\rangle A, \end{align*}$$
$$\begin{align*}\operatorname{grad} \overline{\operatorname{B}}(A) = \nabla \operatorname{B}(A) - \langle \nabla \operatorname{B}(A),A\rangle A, \end{align*}$$
so the key is to use (4.1) and the fact that the diagonal of
 $[A,A^\ast ]$
is real to compute
$[A,A^\ast ]$
is real to compute
 $$ \begin{align*} \langle \nabla \operatorname{B}(A),A\rangle & = -4\mathrm{Re}\operatorname{tr}([A,\operatorname{diag}([A,A^\ast])]^\ast A) \\ & = -4\mathrm{Re}\operatorname{tr}(\operatorname{diag}([A,A^\ast])A^\ast A - A^\ast \operatorname{diag}([A,A^\ast])A) \\ & = 4\mathrm{Re}\operatorname{tr}(\operatorname{diag}([A,A^\ast])[A,A^\ast]) \\ & = 4\mathrm{Re}\operatorname{tr}(\operatorname{diag}([A,A^\ast])\operatorname{diag}([A,A^\ast])) \\ & = 4\|\operatorname{diag}([A,A^\ast])\|^2 \\ & = 4\overline{\operatorname{B}}(A) \end{align*} $$
$$ \begin{align*} \langle \nabla \operatorname{B}(A),A\rangle & = -4\mathrm{Re}\operatorname{tr}([A,\operatorname{diag}([A,A^\ast])]^\ast A) \\ & = -4\mathrm{Re}\operatorname{tr}(\operatorname{diag}([A,A^\ast])A^\ast A - A^\ast \operatorname{diag}([A,A^\ast])A) \\ & = 4\mathrm{Re}\operatorname{tr}(\operatorname{diag}([A,A^\ast])[A,A^\ast]) \\ & = 4\mathrm{Re}\operatorname{tr}(\operatorname{diag}([A,A^\ast])\operatorname{diag}([A,A^\ast])) \\ & = 4\|\operatorname{diag}([A,A^\ast])\|^2 \\ & = 4\overline{\operatorname{B}}(A) \end{align*} $$
using the linearity and cyclic invariance of trace.
Each entry of
 $\operatorname {grad} \overline {\operatorname {B}}(A)$
is a scalar multiple of the corresponding entry of A, so the fact that the negative gradient flow
$\operatorname {grad} \overline {\operatorname {B}}(A)$
is a scalar multiple of the corresponding entry of A, so the fact that the negative gradient flow
 $\overline {\mathscr {F}}$
preserves zero entries and cannot change the sign of real entries follows immediately.
$\overline {\mathscr {F}}$
preserves zero entries and cannot change the sign of real entries follows immediately.
Next, we prove an analog of Lemma 3.5. Recall that
 $s(A) = \sum |\lambda _i|^2$
is the sum of the squares of the absolute values of the eigenvalues of A.
$s(A) = \sum |\lambda _i|^2$
is the sum of the squares of the absolute values of the eigenvalues of A.
Lemma 4.7. For any
 $A \in \mathcal {U}_d$
,
$A \in \mathcal {U}_d$
,
 $$\begin{align*}\langle -\operatorname{grad} \overline{\operatorname{B}}(A),\operatorname{grad} s(A)\rangle = 8s(A)\overline{\operatorname{B}}(A). \end{align*}$$
$$\begin{align*}\langle -\operatorname{grad} \overline{\operatorname{B}}(A),\operatorname{grad} s(A)\rangle = 8s(A)\overline{\operatorname{B}}(A). \end{align*}$$
Proof. The proof exactly parallels the proof of Lemma 3.5 by substituting
 $\operatorname {B}$
,
$\operatorname {B}$
,
 $\overline {\operatorname {B}}$
, and (4.3) for
$\overline {\operatorname {B}}$
, and (4.3) for
 $\operatorname {E}$
,
$\operatorname {E}$
,
 $\overline {\operatorname {E}}$
, and (2.6), respectively.
$\overline {\operatorname {E}}$
, and (2.6), respectively.
Since
 $\langle -\operatorname {grad} \overline {\operatorname {B}}(A), \operatorname {grad} s(A) \rangle = 8s(A)\overline {\operatorname {B}}(A) \geq 0$
,
$\langle -\operatorname {grad} \overline {\operatorname {B}}(A), \operatorname {grad} s(A) \rangle = 8s(A)\overline {\operatorname {B}}(A) \geq 0$
,
 $s(A)$
must be nondecreasing along the negative gradient flow lines of
$s(A)$
must be nondecreasing along the negative gradient flow lines of
 $\overline {\operatorname {B}}$
, so we have proved:
$\overline {\operatorname {B}}$
, so we have proved:
Proposition 4.8. If
 $A_0 \in \mathcal {U}_d$
is non-nilpotent, then so is
$A_0 \in \mathcal {U}_d$
is non-nilpotent, then so is ![]() and so is
and so is ![]() .
.
We know the balanced matrices are exactly the global minima of
 $\overline {\operatorname {B}}$
. Proposition 4.6 implies that A is a critical point of
$\overline {\operatorname {B}}$
. Proposition 4.6 implies that A is a critical point of
 $\overline {\operatorname {B}}$
if and only if
$\overline {\operatorname {B}}$
if and only if
 $$\begin{align*}0 = [A,\operatorname{diag}([A,A^\ast])] + \overline{\operatorname{B}}(A)A. \end{align*}$$
$$\begin{align*}0 = [A,\operatorname{diag}([A,A^\ast])] + \overline{\operatorname{B}}(A)A. \end{align*}$$
When A is a non-minimizing critical point,
 $\overline {\operatorname {B}}(A) \neq 0$
and the same Jacobson’s Lemma argument as in Proposition 3.7 shows that A is nilpotent, proving:
$\overline {\operatorname {B}}(A) \neq 0$
and the same Jacobson’s Lemma argument as in Proposition 3.7 shows that A is nilpotent, proving:
Proposition 4.9. All non-minimizing critical points of
 $\overline {\operatorname {B}}$
are nilpotent.
$\overline {\operatorname {B}}$
are nilpotent.
This completes the proof of Theorem 4.5.
Figure 1 shows an application of this approach to balancing graphs, and Figure 6 shows a much larger example. In both cases, up to an overall normalization to ensure
 $\|A_0\| = 1$
, the non-zero entries in the starting matrix
$\|A_0\| = 1$
, the non-zero entries in the starting matrix
 $A_0$
were populated by the absolute values of standard Gaussians.
$A_0$
were populated by the absolute values of standard Gaussians.

Figure 6 Balancing a larger graph by the flow
 $\overline {\mathscr {F}}$
, with
$\overline {\mathscr {F}}$
, with
 $A_0$
on the left and
$A_0$
on the left and
 $A_\infty = \displaystyle \lim _{t \to \infty } \overline {\mathscr {F}}(A_0,t)$
on the right. The thickness of each edge is proportional to its weight. The underlying graph is a random planar graph with 100 vertices and 284 edges, constructed as the 1-skeleton of the Delaunay triangulation of 100 random points in the square; to make the visualization more comprehensible, the graph that is shown is a spring embedding, so the vertices are not at the locations of the original random points in the square.
$A_\infty = \displaystyle \lim _{t \to \infty } \overline {\mathscr {F}}(A_0,t)$
on the right. The thickness of each edge is proportional to its weight. The underlying graph is a random planar graph with 100 vertices and 284 edges, constructed as the 1-skeleton of the Delaunay triangulation of 100 random points in the square; to make the visualization more comprehensible, the graph that is shown is a spring embedding, so the vertices are not at the locations of the original random points in the square.
4.3 Topology of unit norm balanced graphs
Let
 $\mathcal {UB}_d$
denote the space of balanced
$\mathcal {UB}_d$
denote the space of balanced
 $d \times d$
matrices of unit Frobenius norm, and let
$d \times d$
matrices of unit Frobenius norm, and let
 $\mathcal {UB}_d^{\mathbb {R}}$
denote the subspace of balanced matrices with real entries. The topology of these spaces is tied to the topology of the relevant spaces of normal matrices, as we record in the following theorem.
$\mathcal {UB}_d^{\mathbb {R}}$
denote the subspace of balanced matrices with real entries. The topology of these spaces is tied to the topology of the relevant spaces of normal matrices, as we record in the following theorem.
Theorem 4.10. The spaces
 $\mathcal {U}\mathcal {N}_d$
and
$\mathcal {U}\mathcal {N}_d$
and
 $\mathcal {UB}_d$
are homotopy equivalent. Similarly, the spaces
$\mathcal {UB}_d$
are homotopy equivalent. Similarly, the spaces
 $\mathcal {UN}_d^{\mathbb {R}}$
and
$\mathcal {UN}_d^{\mathbb {R}}$
and
 $\mathcal {UB}_d^{\mathbb {R}}$
are homotopy equivalent.
$\mathcal {UB}_d^{\mathbb {R}}$
are homotopy equivalent.


Acknowledgments
We are grateful to Malbor Asllani for catalyzing this line of inquiry, to Chris Peterson for enlightening conversations, and to the anonymous referees for their careful reading and thoughtful comments which have made this a better paper. We would like to thank the Isaac Newton Institute for Mathematical Sciences, Cambridge, for support and hospitality during the program New equivariant methods in algebraic and differential geometry, where some of the work on this paper was undertaken.
Competing interest
The authors have no competing interests to declare.
Funding statement
This work was supported by EPSRC grant EP/R014604/1 and by grants from the National Science Foundation (DMS–2107808 and DMS–2324962, Tom Needham; DMS–2107700, Clayton Shonkwiler).


















































 Open access
Open access