Refine search
Actions for selected content:
48900 results in Computer Science
Framework for a problem-solving educational program integrating medicine and design disciplines at a Japanese university
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 17 January 2025, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Pushing the boundaries of anticipatory action using machine learning
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 17 January 2025, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Moments to remember: The impact of mediated memory work on live event experiences
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 3 / 2024
- Published online by Cambridge University Press:
- 17 January 2025, e26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Improving the reproducibility in geoscientific papers: lessons learned from a Hackathon in climate science
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 16 January 2025, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Streamflow prediction using artificial neural networks and soil moisture proxies
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 16 January 2025, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Symbolic Parameter Learning in Probabilistic Answer Set Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 698-715
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Semantics of Metaprogramming in Prolog
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 885-900
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Early Validation of High-Level System Requirements with Event Calculus and Answer Set Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 844-862
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dominating Set Reconfiguration with Answer Set Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 755-771
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Introduction to the 40th International Conference On Logic Programming Special Issue
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 581-585
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Neurosymbolic Framework for Bias Correction in Convolutional Neural Networks
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 644-662
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Reliable Common-Sense Reasoning Socialbot Built Using LLMs and Goal-Directed ASP
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 606-627
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Fast Inference for Probabilistic Answer Set Programs Via the Residual Program
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 682-697
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Teachers’ articulations of digital resources in an upper secondary programme for newly arrived migrants
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Abstract Environment Trimming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 863-884
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On Lower Bounding Minimal Model Count
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 586-605
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Minimal models of a Boolean formula play a pivotal role in various reasoning tasks. While previous research has primarily focused on qualitative analysis over minimal models; our study concentrates on the quantitative aspect, specifically counting of minimal models. Exact counting of minimal models is strictly harder than
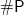 $\#\mathsf{P}$, prompting our investigation into establishing a lower bound for their quantity, which is often useful in related applications. In this paper, we introduce two novel techniques for counting minimal models, leveraging the expressive power of answer set programming: the first technique employs methods from knowledge compilation, while the second one draws on recent advancements in hashing-based approximate model counting. Through empirical evaluations, we demonstrate that our methods significantly improve the lower bound estimates of the number of minimal models, surpassing the performance of existing minimal model reasoning systems in terms of runtime.
$\#\mathsf{P}$, prompting our investigation into establishing a lower bound for their quantity, which is often useful in related applications. In this paper, we introduce two novel techniques for counting minimal models, leveraging the expressive power of answer set programming: the first technique employs methods from knowledge compilation, while the second one draws on recent advancements in hashing-based approximate model counting. Through empirical evaluations, we demonstrate that our methods significantly improve the lower bound estimates of the number of minimal models, surpassing the performance of existing minimal model reasoning systems in terms of runtime.
Reasoning About Study Regulations in Answer Set Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 790-804
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Stable Model Semantics for Higher-Order Logic Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 737-754
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Quantifying over Optimum Answer Sets
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 716-736
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Answer Set Programming with Quantifiers (ASP(Q)) has been introduced to provide a natural extension of ASP modeling to problems in the polynomial hierarchy (PH). However, ASP(Q) lacks a method for encoding in an elegant and compact way problems requiring a polynomial number of calls to an oracle in
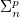 $\Sigma _n^p$ (that is, problems in
$\Sigma _n^p$ (that is, problems in 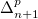 $\Delta _{n+1}^p$). Such problems include, in particular, optimization problems. In this paper, we propose an extension of ASP(Q), in which component programs may contain weak constraints. Weak constraints can be used both for expressing local optimization within quantified component programs and for modeling global optimization criteria. We showcase the modeling capabilities of the new formalism through various application scenarios. Further, we study its computational properties obtaining complexity results and unveiling non-obvious characteristics of ASP(Q) programs with weak constraints.
$\Delta _{n+1}^p$). Such problems include, in particular, optimization problems. In this paper, we propose an extension of ASP(Q), in which component programs may contain weak constraints. Weak constraints can be used both for expressing local optimization within quantified component programs and for modeling global optimization criteria. We showcase the modeling capabilities of the new formalism through various application scenarios. Further, we study its computational properties obtaining complexity results and unveiling non-obvious characteristics of ASP(Q) programs with weak constraints.
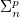
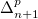
Modeling of spatial extremes in environmental data science: time to move away from max-stable processes
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 15 January 2025, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
