Stevens’ power law for the judgments of sensation has a long history in psychology and is used in many psychophysical investigations of the effects of predictors such as group or condition. Stevens’ formulation \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varPsi = {aP}^{n}$$\end{document}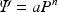 , where \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varPsi $$\end{document}
, where \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varPsi $$\end{document}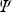 is the psychological judgment, P is the physical intensity, and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$n$$\end{document}
is the psychological judgment, P is the physical intensity, and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$n$$\end{document} is the power law exponent, is usually tested by plotting log \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(\varPsi )$$\end{document}
is the power law exponent, is usually tested by plotting log \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(\varPsi )$$\end{document}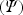 against log (P). In some, but by no means all, studies, effects on the scale parameter, \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$a$$\end{document}
against log (P). In some, but by no means all, studies, effects on the scale parameter, \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$a$$\end{document} , are also investigated. This two-parameter model is simple but known to be flawed, for at least some modalities. Specifically, three-parameter functions that include a threshold parameter produce a better fit for many data sets. In addition, direct non-linear computation of power laws often fit better than regressions of log-transformed variables. However, such potentially flawed methods continue to be used because of assumptions that the approximations are “close enough” as to not to make any difference to the conclusions drawn (or possibly through ignorance the errors in these assumptions). We investigate two modalities in detail: duration and roughness. We show that a three-parameter power law is the best fitting of several plausible models. Comparison between this model and the prevalent two parameter version of Stevens’ power law shows significant differences for the parameter estimates with at least medium effect sizes for duration.
, are also investigated. This two-parameter model is simple but known to be flawed, for at least some modalities. Specifically, three-parameter functions that include a threshold parameter produce a better fit for many data sets. In addition, direct non-linear computation of power laws often fit better than regressions of log-transformed variables. However, such potentially flawed methods continue to be used because of assumptions that the approximations are “close enough” as to not to make any difference to the conclusions drawn (or possibly through ignorance the errors in these assumptions). We investigate two modalities in detail: duration and roughness. We show that a three-parameter power law is the best fitting of several plausible models. Comparison between this model and the prevalent two parameter version of Stevens’ power law shows significant differences for the parameter estimates with at least medium effect sizes for duration.

