




Highlights
-
• We tested complex word processing in L1 and L2, focussing on positional encoding.
-
• We also explored how individual variability influenced morphological TL priming.
-
• L1 English speakers showed robust morphological and TL-within priming.
-
• TL-across priming varied as a function of critical bigram frequency and spelling.
-
• Only morphologically related primes facilitated the stem targets in L2 speakers.
Letter position encoding, morpho-orthographic decomposition, and morpho-semantic processing are crucial and closely intertwined processes involved in complex word recognition (e.g., Amenta & Crepaldi, Reference Amenta and Crepaldi2012). However, there is no consensus on how these components interact and function during the early stages of processing morphologically complex words. This study used a morphological transposed-letter (TL) priming paradigm in first-language (L1) and second-language (L2) speakers of English to shed new light on a long-standing debate about how orthographic and morphological information is encoded during the early stages of visual word recognition.
The masked priming paradigm is typically used within a lexical decision task to investigate the mechanisms of word recognition. In this procedure, a brief forward mask is followed by a prime, and then the target. This method allows for studying early word recognition processes as participants are often unaware of the manipulations due to the short prime presentation (usually for about 50 ms) that still affects participant responses based on their relation to the target word. A morphological priming effect is measured by comparing the morphological condition (e.g., braveness-BRAVE) to the unrelated condition (e.g., directness-BRAVE). In the transposed-letter (TL) priming paradigm, prime words contain transposed letters that could be either within a single morpheme (intra-morphemic) or across multiple morphemes (cross-morphemic). For example, for the target word BRAVE, the prime ‘braevness’ involves transposed letters within the morpheme boundary, whereas the prime ‘bravneess’ involves TL, cutting across the morpheme boundary. The transposed letter effect refers to less accurate and longer lexical decisions to targets preceded by substituted-letter (SL) primes, in which two letters are replaced by other letters (e.g., ‘braocness’) relative to primes that contain transposed letters.
Investigating how letters are positioned within a complex word may provide information about how the brain deals with the information at higher levels of cognitive processing. Such investigation involves the lexical organisation and representation of morphemic constituents and aims to answer the larger question of how the brain represents complex input such as ‘BRAVENESS’ and if morphological effects interact with TL effects. To address these questions, the present study investigated morphological TL effects to determine the relationship between letter position coding and morphological processing during first language (L1) and second language (L2) word recognition. TL effects were examined through transpositions that occurred both within and across morpheme boundaries to provide insights into the processing of morphologically complex words.
There has been a long-standing debate between decompositional and distributional theories of morphological processing, which provide different explanations for morphological TL-priming effects. Decompositional theories propose that morphologically complex words are stored and processed decompositionally as symbolic units of stems and affixes in the mental lexicon (e.g., Beyersmann & Grainger, Reference Beyersmann, Grainger and Crepaldi2023; Rastle et al., Reference Rastle, Davis and New2004; Taft & Forster, Reference Taft and Forster1975; Wei et al., Reference Wei, Niu, Taft and Carreiras2023). Some theories within this class posit a dual process whereby the complex word could be recognised either via representations of the word’s constituent morphemes or via its full-form lexical representation (e.g., Baayen et al., Reference Baayen, Lieber and Schreuder1997; Beyersmann et al., Reference Beyersmann, Coltheart and Castles2012; Beyersmann & Grainger, Reference Beyersmann, Grainger and Crepaldi2023; Diependaele et al., Reference Diependaele, Duñabeitia, Morris and Keuleers2011; Grainger & Beyersmann, Reference Grainger, Beyersmann and Ross2017; Grainger & Ziegler, Reference Grainger and Ziegler2011). These two contrasting theoretical streams provide convincing but distinct explanations for previously reported morphological priming effects (e.g., Beyersmann, Duñabeitia, et al., Reference Beyersmann, Duñabeitia, Carreiras, Coltheart and Castles2013; Taft, Reference Taft and Crepaldi2023). The decompositional models postulate that complex words are broken down into their constituent morphemes during processing. These models are supported by evidence from masked priming studies, which show that both semantically transparent (e.g., farmer-FARM) and opaque (e.g., department-DEPART) prime-target pairs facilitate target word recognition against the form condition (e.g., sandwich-SAND), suggesting an early morpho-orthographic decomposition. Hence, according to these models, morphological priming effects can be attributed to the early automatic decomposition of complex words into their constituent morphemes, which occurs regardless of the word’s semantic transparency (e.g., Beyersmann et al., Reference Beyersmann, Casalis, Ziegler and Grainger2015; Rastle et al., Reference Rastle, Davis and New2004). Morphological priming effects have been consistently observed across a diverse range of languages with different scripts and morphological structures, including Chinese (e.g., Wei et al., Reference Wei, Niu, Taft and Carreiras2023), Korean (e.g., Kim et al., Reference Kim, Wang and Taft2015), French (e.g., Coughlin & Tremblay, Reference Coughlin and Tremblay2015), and Turkish (e.g., Kırkıcı & Clahsen, Reference Kırkıcı and Clahsen2013). Morphological TL-priming effects can be explained by decompositional models that allow letter-position flexibility during word recognition. For example, the Word and Affix model (Beyersmann & Grainger, Reference Beyersmann, Grainger and Crepaldi2023), utilises the principles of position flexibility separately for stems and affixes. This concept builds upon Grainger and Ziegler’s orthographic dual-route model (2011), which introduced the difference between fine-grained and coarse-grained processing. Fine-grained processing involves a detailed and precise analysis of individual letters in a word. It requires exact position coding for each letter, which is crucial for recognising affixes and specific letter sequences. On the other hand, coarse-grained processing allows for greater flexibility in the arrangement of letters. It does not necessitate precise position coding, enabling the recognition of words even if some letters are transposed. This type of processing is less sensitive to the exact position of letters, facilitating the activation of an embedded word despite minor positional variations. Critically, the affix activation mechanism involves fine-grained processing and is associated with precise letter position coding for the affixes, while the embedded word activation mechanism is less sensitive to the precise position coding of letters and can activate a word even when its letters are transposed, due to its insensitivity to letter position encoding during embedded word identification.
Distributed models of morphology, on the other hand, assign a more complex role to morphology and propose that morphology is only captured between the systematic mapping of orthographic, phonological, and semantic representations and, therefore, has no explicit localist representations (e.g., Feldman, Reference Feldman2000; Gonnerman et al., Reference Gonnerman, Seidenberg and Andersen2007; Marelli et al., Reference Marelli, Traficante, Burani, Pirrelli, Plag and Dressler2020; Plaut & Gonnerman, Reference Plaut and Gonnerman2000; Stevens & Plaut, Reference Stevens and Plaut2022). Distributional models suggest that morphological priming effects arise from the statistical properties of the language, such as the co-occurrence of morphemes (e.g., Gonnerman et al., Reference Gonnerman, Seidenberg and Andersen2007), and are modulated by semantic transparency (e.g., Feldman et al., Reference Feldman, Soltano, Pastizzo and Francis2004). These models are also supported by findings that morphological processing is influenced by the transitional probability from stem to affix and that morphological processing is a gradient process, with both form and semantic effects contributing to priming (e.g., Hay & Baayen, Reference Hay and Baayen2005).
Morphological transposed-letter effects in L1 speakers
Over the past two decades, a whole series of visual word recognition studies have examined the interaction between letter transpositions and morphological processing in L1 speakers, using masked primed lexical decision tasks (LDT). The primary aim of these studies was to provide additional evidence of the early time-course of morpheme-based processing (e.g., Diependaele et al., Reference Diependaele, Morris, Serota, Bertrand and Grainger2013; Taft et al., Reference Taft, Li and Beyersmann2018). Specifically, if morphological priming co-occurred with sub-lexical letter position coding at very early stages of visual-word recognition, cross-morphemic letter transpositions would hinder recognising individual morphemes, resulting in no priming in this condition. However, if letter position encoding occurred before morphological facilitation, priming would occur. Hence, several studies have investigated morphological TL effects with morphologically complex words using both cross-morphemic and intra-morphemic transpositions (e.g., Christianson et al., Reference Christianson, Johnson and Rayner2005; Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2007, Reference Duñabeitia, Perea and Carreiras2014; Gu & Li, Reference Gu and Li2015; Rueckl & Rimzhim, Reference Rueckl and Rimzhim2011; Sánchez-Gutiérrez & Rastle, Reference Sánchez-Gutiérrez and Rastle2013; Taikh et al., Reference Taikh, Gagné and Spalding2024).
In English, a number of empirical studies have consistently reported facilitation in within-morpheme letter transpositions (Beyersmann et al., Reference Beyersmann, Castles and Coltheart2011, Reference Beyersmann, Coltheart and Castles2012; Beyersmann, Duñabeitia, et al., Reference Beyersmann, Duñabeitia, Carreiras, Coltheart and Castles2013; Beyersmann, McCormick, et al., Reference Beyersmann, McCormick and Rastle2013; Christianson et al., Reference Christianson, Johnson and Rayner2005; Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2007, Reference Duñabeitia, Perea and Carreiras2014; Rueckl & Rimzhim, Reference Rueckl and Rimzhim2011; Sánchez-Gutiérrez & Rastle, Reference Sánchez-Gutiérrez and Rastle2013). However, the results are less consistent for cross-morphemic transpositions (see Table 1 for a summary of studies).
Table 1. Summary of masked morphological TL-across priming studies in L1 speakers
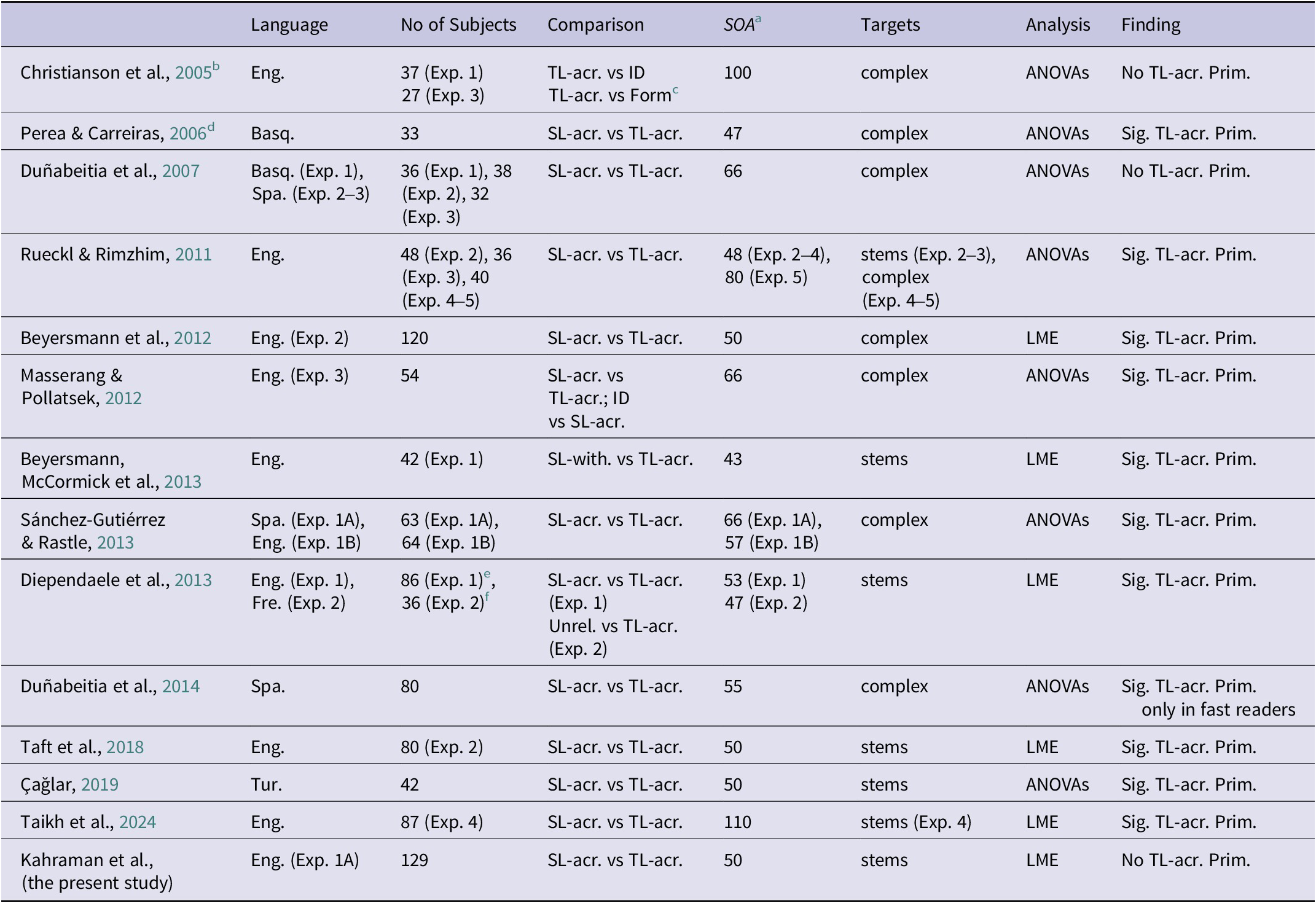
a All SOAs are in ms.
b All studies used a masked lexical decision task except Christianson et al. (Reference Christianson, Johnson and Rayner2005) that used a masked primed naming task.
c The form condition involved one substituted-letter (e.g., sifkworm-silkworm).
d This study used a nonadjacent transposed-letter manipulation (e.g., ortakila-ORKATILA, arbigide-ARGIBIDE) as opposed to other studies listed in Table 1.
e This experiment used transparent (e.g., farmer-farm) and opaque (e.g., corner-corn) word primes. Only transparent primes yielded significant priming effects.
f This experiment used affixed word and affixed nonword primes. Only affixed primes yielded significant priming effects.
In a masked primed naming task, priming effects disappeared when letter transpositions disrupted morpheme boundaries in English transparent and opaque compound words (Christianson et al., Reference Christianson, Johnson and Rayner2005). This finding suggests that the position of a transposition could be detrimental to morpho-orthographic segmentation. However, the study used a relatively long prime duration (100 ms), thereby giving readers time to thoroughly process the prime. The use of a longer prime duration raises questions about whether these results reflected early or later stages of morphological processing (see Taikh et al., Reference Taikh, Gagné and Spalding2024 for similar issues). The study also used an unusual orthographic control where only one of the two letters was replaced in the SL condition. Furthermore, the study was conducted with only 12 items, a total of 108 trials, which was significantly below the recommended number of 1,600 trials for repeated-measures analyses (Brysbaert & Stevens, Reference Brysbaert and Stevens2018). It is likely that these factors might have influenced the results.
Perea and Carreiras (Reference Perea and Carreiras2006) addressed this issue by using a shorter prime duration (47 ms) and increasing the number of trials per condition in their Basque experiment. Participants responded to compound and non-compound words preceded by identity, TL-across, or SL-across primes. With the SL-across baseline condition, significant transposed-letter effects were reported, contrasting earlier evidence reported by Christianson et al. (Reference Christianson, Johnson and Rayner2005). However, this study (Perea & Carreiras, Reference Perea and Carreiras2006) used compound stimuli consisting of the combination of at least two stem morphemes (e.g., blue [stem] + berry [stem]). Since affixes are bound morphemes that require more specialised and abstract knowledge compared to stems (e.g., Beyersmann et al., Reference Beyersmann, Grainger and Castles2019, Reference Beyersmann, Mousikou, Schroeder, Javourey-Drevet, Ziegler and Grainger2021), the TL-priming effects from compound words do not necessarily generalise to those with affixed words. Additionally, this study used complex targets and did not have a form condition to separate morphological effects from orthographic effects. Duñabeitia et al. (Reference Duñabeitia, Perea and Carreiras2007), using complex targets, found that transposing letters across morpheme boundaries hindered target word recognition and eliminated TL-priming effects. However, the authors reported in a subsequent study that TL-across priming was modulated by reading speed and that it was only present in slower readers (Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2014).
Rueckl and Rimzhim (Reference Rueckl and Rimzhim2011) aimed to replicate the findings of Christianson et al. (Reference Christianson, Johnson and Rayner2005) and Duñabeitia et al. (Reference Duñabeitia, Perea and Carreiras2007) through a series of masked primed LDT experiments with varying stimulus onset asynchronies (SOA; experiments 2–4, 48 ms; experiment 5, 80 ms). In experiments 2–3, with SL-across primes as the baseline condition, TL-across primes facilitated the recognition of simple word targets. Experiments 4 and 5 demonstrated similar priming effects with complex target words. However, upon closer look at their stimuli, there are at least three methodological issues. In studies of TL priming, the SL condition typically involves replacing two letters to match the number of letters being transposed. Rueckl and Rimzhim replaced three letters in their SL-across condition in experiments 3–5 (e.g., acceptable-acceghible), thereby introducing a possible confounding factor in the effect of letter position change across morpheme boundaries. Additionally, unlike previous TL studies, all stimuli in this study ended in consonants, and hence, it is not clear whether results will generalise to other words. Further inspection of their stimuli revealed significant differences in positional specific bigram frequency. Specifically, TL-across primes had a lower higher bigram frequency compared to the SL-across primes. Positional specific bigram frequency is a key variable affecting TL-priming effects (e.g., Frankish & Turner, Reference Frankish and Turner2007; Perea & Carreiras, Reference Perea and Carreiras2008). Perea and Carreiras (Reference Perea and Carreiras2008), for example, reported TL-priming effects only for illegal bigrams, which had lower bigram frequency, particularly at morpheme boundaries. Hence, it cannot be ruled out that these bigram units, rather than morphological influences, may be driving TL-across priming, suggesting that the results of Rueckl and Rimzhim could be entirely orthographic. For example, Masserang and Pollatsek (Reference Masserang and Pollatsek2012), using complex targets, obtained similar magnitudes of TL priming across prefixed and non-prefixed items, suggesting morphological decomposition did not take place at all in this study.
Beyersmann, McCormick et al. (Reference Beyersmann, Duñabeitia, Carreiras, Coltheart and Castles2013), using Rueckl and Rimzhim’s stimuli, further tested whether the position of letter transpositions (occurring at internal or external letters of the stem) would affect TL-across priming. However, they obtained similar magnitudes of TL-across priming. They also suggested neither the overall proportion of affixed trials nor the relative frequency between the prime and the target influenced the size of TL-across priming. Nevertheless, similar to Rueckl and Rimzhim’s study, their stimuli did not match in positional specific bigram frequency. Additionally, an unusual control condition was used, specifically comparing TL-across primes with SL-within controls, and the visual shape of their SL primes was not maintained (i.e., some transpositions involved the replacement of ascender letters by descender or middle letters, d vs c; also see Beyersmann et al., Reference Beyersmann, Coltheart and Castles2012; Masserang & Pollatsek, Reference Masserang and Pollatsek2012; Taikh et al., Reference Taikh, Gagné and Spalding2024 for similar issues). Hence, most SL primes used new letters of different perceptual saliency with different resemblances and heights as compared to the transposed letters. Diependaele et al. (Reference Diependaele, Morris, Serota, Bertrand and Grainger2013) and Taft et al. (Reference Taft, Li and Beyersmann2018) found facilitatory effects of TL-across priming in English for semantically transparent prime-target words (for similar results in L1 Turkish, see Çağlar, Reference Çağlar2019). However, the visual shape of their SL primes was not maintained, and they used an unusual control condition in which three or more letters of the primes were replaced with different letters, resulting in slower reaction times in this condition.
Some studies have additionally attempted to identify why cross-morphemic transpositions have not yielded TL-priming. For example, Rueckl and Rimzhim (Reference Rueckl and Rimzhim2011) tested whether the use of complex versus simplex word targets would influence the findings. Some studies used whole words as targets preceded by complex TL nonwords (e.g., accidenatl -ACCIDENTAL; Beyersmann et al., Reference Beyersmann, Coltheart and Castles2012; Christianson et al., Reference Christianson, Johnson and Rayner2005; Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2007, Reference Duñabeitia, Perea and Carreiras2014; Masserang & Pollatsek, Reference Masserang and Pollatsek2012; Perea & Carreiras, Reference Perea and Carreiras2006, Reference Perea and Carreiras2008; Sánchez-Gutiérrez & Rastle, Reference Sánchez-Gutiérrez and Rastle2013; Taikh et al., Reference Taikh, Gagné and Spalding2024). Rueckl and Rimzhim (Reference Rueckl and Rimzhim2011) concluded that the target word structure did not explain why there existed a difference in TL-across priming across the studies. Sánchez-Gutiérrez and Rastle (Reference Sánchez-Gutiérrez and Rastle2013) further examined whether different magnitudes of TL-across priming might be attributed to cross-language differences. They conducted two lexical decision experiments in English and Spanish using the same whole-word cognate targets (e.g., COOPERACIÓN-COOPERATION). TL-within and TL-across facilitated targets to the same extent in both languages, which was taken to support the hypothesis that TL-across priming effects in L1 were not influenced by cross-linguistic differences between Spanish and English.
In summary, we argue that there are at least four potential issues with existing TL-across studies. First, some studies did not use the (typical) substituted-letter condition as the baseline condition (Beyersmann, McCormick, et al., Reference Beyersmann, McCormick and Rastle2013; Christianson et al., Reference Christianson, Johnson and Rayner2005; Diependaele et al., Reference Diependaele, Morris, Serota, Bertrand and Grainger2013; Rueckl & Rimzhim, Reference Rueckl and Rimzhim2011). Relatedly, in some studies, the letter shapes across TL and SL primes were not maintained (Beyersmann et al., Reference Beyersmann, Coltheart and Castles2012; Beyersmann, McCormick, et al., Reference Beyersmann, McCormick and Rastle2013; Christianson et al., Reference Christianson, Johnson and Rayner2005; Diependaele et al., Reference Diependaele, Morris, Serota, Bertrand and Grainger2013; Masserang & Pollatsek, Reference Masserang and Pollatsek2012; Rueckl & Rimzhim, Reference Rueckl and Rimzhim2011; Taikh et al., Reference Taikh, Gagné and Spalding2024). Research has revealed that word recognition processes can tolerate minor changes in letter position coding, but they are highly sensitive to changes in letter identity (e.g., Frankish & Barnes, Reference Frankish and Barnes2008; Kinoshita et al., Reference Kinoshita, Castles and Davis2009; Marcet & Perea, Reference Marcet and Perea2017). For example, Marcet and Perea (Reference Marcet and Perea2017) found that primes with dissimilar letters (neztral-NEUTRAL) resulted in slower reaction times compared to primes with similar letters (nevtral-NEUTRAL). When the visual properties of the letters were not matched in the substituted-letter condition, it led to slower RTs in this condition, resulting in greater transposed-letter priming. Hence, it is critical for TL-across studies to carefully match the visual properties of the letters in the experimental and control primes.
Second, the majority of studies used complex targets (Beyersmann et al., Reference Beyersmann, Coltheart and Castles2012; Christianson et al., Reference Christianson, Johnson and Rayner2005; Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2007, Reference Duñabeitia, Perea and Carreiras2014; Masserang & Pollatsek, Reference Masserang and Pollatsek2012; Perea & Carreiras, Reference Perea and Carreiras2006; Rueckl & Rimzhim, Reference Rueckl and Rimzhim2011; Sánchez-Gutiérrez & Rastle, Reference Sánchez-Gutiérrez and Rastle2013). The use of complex targets raises the question of whether affixes were used as decision cues in those studies. Another significant concern with this design is that since affixes are very frequent word-initial and final bigrams and trigrams, their use in target words may potentially overwrite minor errors in position coding. In addition, it is not clear whether morphological decomposition occurred at all or whether any observed TL-across priming effect was merely a result of orthographic priming. To investigate whether morphological decomposition and orthographic processing co-occur during the initial stages of word identification, it is essential to use stem targets.
Moreover, only a handful of studies were adequately powered and employed robust statistical analysis techniques. These techniques account for random effects, consider trial sequencing, and handle missing data. Linear mixed effect (LME) models, in comparison to the analysis of variance (ANOVA), can accommodate variability across participants and items, which is a critical feature when dealing with repeated measures study design. It has been reported that item characteristics can significantly impact TL-priming effects (e.g., Lupker et al., Reference Lupker, Perea and Davis2008). Additionally, Duñabeitia et al. (Reference Duñabeitia, Perea and Carreiras2014) demonstrated the influence of participants' average reading speed on TL-across priming. LMEs offer precise control over numerous variables that have been suggested as potential moderators of transposed-letter effects. They incorporate random intercepts for each participant and item, accounting for the fact that some participants are faster, and some items are easier than others. They also include random slopes for each participant and item, considering the possibility that the priming effect may vary among participants and items. Hence, it is not clear if the results of the studies using ANOVAs might be influenced by these item- and participant-related characteristics.
We additionally pinpoint another key methodological difference that may explain why the TL-across priming effect was absent in some studies, whereas it was robust in others. The studies that showed TL-across priming did not control for the effects of orthographic properties, specifically, the critical bigram frequency. As it turned out, positional specific bigram frequency indeed modulates the TL-across priming in L1 speakers, as will be discussed later.
The methodological differences among studies raise concerns that priming effects yielded by TL and control primes may not be completely reliable since target facilitation in an LDT is influenced by the visual and orthographic similarity between the prime and target. We argue that the consideration of these factors at the methodological level can increase the reliability of TL-across priming. Accordingly, to avoid these methodological concerns in the present experiments, we carefully selected English stimuli that were comparable in several critical psycholinguistic characteristics.
Morphological transposed-letter effects in L2 speakers
As a large volume of empirical evidence has accumulated in regard to the processing of morphologically complex words in L1 visual word recognition literature, current models of morphological processing are mainly based on data from L1 speakers. This systematic selection of a very specific and homogenous L1 profile ignores data from L2 speakers and does not represent their experiences (see Arnett, Reference Arnett2008 for similar arguments). Current models may not be applicable to explaining the mechanisms involved in L2 processing since access to lexical representations in L2 speakers involves cross-language activation of lexical entries, which can affect orthographic coding in these readers (e.g., Dijkstra & van Heuven, Reference Dijkstra and van Heuven2002; Lin et al., Reference Lin, Bangert and Schwartz2015). Therefore, more research on L2 speakers is needed to provide a clearer and more thorough understanding of complex word processes during reading.
Recent research has explored how bilingual speakers process L2 words, with a specific focus on the flexibility of letter-position coding during sentence reading. For example, employing eye-tracking methodology, Cong and Chen (Reference Cong and Chen2022) and Man et al. (Reference Man, Parker and Taylor2024) investigated how adult native Chinese speakers read English sentences containing affixed words, transposed-letter nonwords, and substituted-letter nonwords. Their findings demonstrated that these bilingual readers exhibited flexible letter-position processing, as evidenced by longer reading times for substituted-letter nonwords compared to transposed-letter nonwords. Similar to the methodological issues addressed in L1 TL research, a closer examination of their stimuli revealed that TL and control primes were not matched on positional specific bigram frequency. Furthermore, while sentence-reading experiments provide a holistic view of L2 processing, the focus shifts to understanding how readers integrate words within sentences using contextual cues. In contrast, single-word tasks provide tight control over context, reducing potential interference from neighbouring words. Consequently, these single-word tasks, such as lexical decision experiments, offer detailed insights into early word recognition and morphological processing, while simultaneously reducing the influence of surrounding context – a goal central to the present study.
Compared with L1 speakers, there is little evidence on morphological TL-priming in L2 speakers. L2 derivational processing has been investigated in combination with the masked TL-priming paradigm with complex words (Kahraman & Kırkıcı, Reference Kahraman and Kırkıcı2021). Highly proficient unbalanced L1 Turkish-L2 English participants responded to English monomorphemic target words paired with primes in morphological, TL-within, SL-within, TL-across, or SL-across prime conditions using an SOA of 50 ms. Significant priming effects were reported only for the morphological (21 ms) condition relative to the unrelated control condition, with inhibitory TL-within priming (−3 ms, relative to SL-within condition) and TL-across priming (−7 ms, relative to SL-across condition). Similarly, Zeng et al. (Reference Zeng, Han, Zhai and Mu2019) used an English lexical decision task where L1 Chinese participants responded to stem targets preceded by five types of masked primes with a longer SOA of 800 ms: TL-across, TL-within, SL-across, SL-within, identical controls. For the derived word set, with the identity condition as the baseline condition, high-proficiency bilinguals showed statistically significant TL-within and TL-across priming, whereas there was only TL-across priming in low-proficiency bilinguals. However, TL-within priming effects were shaky, and since a long SOA of 800 ms was used in this study, it is not clear if the observed priming effects reflected early automatic processing or were free of strategic decision-making factors.
A factor that further complicates the investigation of TL-priming effects in bilinguals is that transposed-letter priming in L2 might be influenced by the cross-linguistic influences of one language over the other, as shown by the cognateness effect on L2 word processing (e.g., Comesaña et al., Reference Comesaña, Bertin, Oliveira, Soares, Hernández-Cabrera and Casalis2018). Velan and Frost’s (Reference Velan and Frost2009) research demonstrated that the effects of letter transpositions on word recognition could vary significantly depending on the morphological characteristics of the language. In alphabetic languages such as English and Spanish, transposed-letter priming effects are typically observed. However, Velan and Frost found that these effects were not present in Hebrew, a language characterised by its root-based morphology (e.g., the root k-t-b whose overall meaning is ‘to write’). This linguistic structure results in a high occurrence of anagrams in the Hebrew language with an orthographically dense writing system. The precise coding of letter positions is, therefore, essential to prevent the activation of the meaning of another word. Velan and Frost (Reference Velan and Frost2009; Experiment 3) used two types of masked primes that were presented for 40 ms: an existing TL-root, or a non-existing TL-root for derived target words. The results showed that TL nonword primes did not facilitate the recognition of targets in Hebrew. When the root letters embedded in TL nonwords formed a legal root morpheme, they produced inhibition. These findings indicate that Hebrew’s morphological structure, which is organised according to root families rather than orthographic structure, leads to different patterns of word recognition compared to alphabetic languages like English and Spanish.
Individual differences and priming
Research on individual variability has shown that priming effects are modulated by individual differences in reading (e.g., Andrews & Lo, Reference Andrews and Lo2013; Beyersmann et al., Reference Beyersmann, Cavalli, Casalis and Colé2016; Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2014; Medeiros & Duñabeitia, Reference Medeiros and Duñabeitia2016). Overall, these studies demonstrate that different reading profiles can influence the access to morphological information in a qualitatively different manner and that individual factors in reading determine the processing of complex words. The lexical quality hypothesis (Perfetti, Reference Perfetti2007; Perfetti & Hart, Reference Perfetti, Hart, Verhoeven, Elbro and Reitsma2002) provides a theoretical framework to interpret the impact of these individual differences. According to this framework, the quality of lexical representations significantly influences reading skills. High-quality lexical representations are well-specified and have well-integrated links between their orthographic, phonological and semantic properties. This integration allows for rapid and reliable word activation, facilitating word recognition tasks such as spelling, reading, vocabulary, and reading with speed (e.g., Andrews et al., Reference Andrews, Veldre and Clarke2020). Therefore, measures of spelling, vocabulary, and reading comprehension are often used as measures of lexical quality and are commonly used to investigate priming modulation.
Andrews and Lo (Reference Andrews and Lo2013), in their pioneering work, revealed that spelling and vocabulary proficiency influenced the processing of morphologically complex English words in skilled L1 readers. Beyersmann et al. (Reference Beyersmann, Cavalli, Casalis and Colé2016) also found that high-proficiency readers exhibited embedded stem priming effects, regardless of whether the stems occurred in combination with a real affix or a nonaffix. These readers likely had high-quality lexical representations, allowing them to rapidly and reliably extract the stems from complex nonwords. Duñabeitia et al. (Reference Duñabeitia, Perea and Carreiras2014) further explored the impact of individual differences on priming and found that the magnitude of the masked TL-priming across morphemes was influenced by participants’ reading speed in an LDT. Specifically, faster readers yielded greater TL priming for within- than for across-morpheme transpositions. Medeiros & Duñabeitia (Reference Medeiros and Duñabeitia2016) also explored the role of individual differences in complex word recognition and found that only slower participants showed significant masked suffix priming effects, whereas faster participants showed negligible priming.
In contrast to L1, there are only a few studies that have examined the modulation of morphological priming effects using a wide range of individual differences measures in L2. Viviani and Crepaldi (Reference Viviani and Crepaldi2022) investigated masked priming effects in semantically transparent, opaque, or orthographic prime-target pairs and found L2 phonemic fluency moderated the group-level priming patterns. Using a range of productive and receptive reading tests, Kahraman and Kırkıcı (Reference Kahraman and Kırkıcı2021) observed significant TL priming in L2 speakers who were less proficient in reading nonwords. They found robust TL-within and TL-across priming in individuals with low nonword reading proficiency, showcasing the contribution of individual skills to the TL priming effects in L2 speakers. Zeng et al. (Reference Zeng, Han, Zhai and Mu2019) also explored the influence of language proficiency on TL-within and TL-across priming. Their findings revealed that bilinguals with high proficiency demonstrated significant TL priming effects, both within and across morpheme boundaries, when the identity condition was used as the baseline. In contrast, bilinguals with low proficiency only showed TL-across priming.
Despite these findings, the modulation of priming effects is still not fully understood, particularly in L2 processing contexts. Therefore, the present study aimed to provide new and deeper insights into the moderation of L1 and L2 priming effects using tests of spelling, vocabulary, and reading. Additionally, the Language Experience and Proficiency Questionnaire (LEAP-Q; Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007) was used to collect comprehensive language profile data for L2 speakers, including language exposure in different settings, immersion duration, and age of L2 acquisition. These factors have been previously reported to influence word recognition in L2 (e.g., Kahraman et al., Reference Kahraman, de Wit and Beyersmann2024; Sabourin et al., Reference Sabourin, Brien and Burkholder2014). The questionnaire also included questions related to language proficiency in speaking, understanding, and reading, which were used to analyse L1 and L2 data. It is important to note that some studies have found self-reported proficiency correlated well with other proficiency measures, validating the use of self-reported proficiency in the present study (e.g., de Bruin, Reference de Bruin2019; De Bruin et al., Reference De Bruin, Carreiras and Duñabeitia2017).
The present study
Our review of TL-across research has revealed issues associated with choosing stimuli and designing TL-across priming experiments. To address these concerns at the methodological level, the present study investigated TL priming effects using carefully matched stimuli in terms of several key psycholinguistic properties including positional specific bigram frequency. We also adopted a robust experimental approach and employed sophisticated analysis techniques that incorporate random effects to simultaneously control for participant-specific and item-specific effects, accommodating individual differences and capturing item-specific patterns at the same time (e.g., Brown, Reference Brown2021; Li & Baron, Reference Li, Baron, Li and Baron2012). This investigation is crucial because, as previously noted, prior studies have yielded mixed results regarding TL-across priming effects. By controlling for potential interactions between orthographic characteristics and participant factors, we aimed to clarify the role of letter transpositions on morphological influences during visual word recognition.
Based on the limited number of studies reviewed above, there are inconsistencies in L2 transposed-letter research. Specifically, Kahraman and Kırkıcı (Reference Kahraman and Kırkıcı2021) found no morphological TL-priming at a 50 ms SOA with the SL baseline primes, whereas using identity primes as the baseline at an SOA of 800 ms, Zeng et al. (Reference Zeng, Han, Zhai and Mu2019) reported significant TL-across priming. Hence, it is not clear whether TL priming can be reliably obtained using a short SOA (e.g., 50 ms) with the typically used SL baseline condition. Also, questions remain about whether cross-linguistic differences between L1 and L2 might influence morphological transposed-letter priming effects using non-cognate complex word stimuli. This study addressed this gap by comparing early automatic processes involved in the recognition of derived word forms in L1 English speakers as well as in L2 English speakers with Chinese as their L1.
The use of English and Chinese languages in the present study provides important insights into visual word recognition since they represent two distinct language structures: English possesses complex grapheme-to-phoneme correspondences with an alphabetical language and relatively poor morphological complexity. Chinese, on the other hand, uses characters as morpho-syllables that are similar in form but do not necessarily have similar phonology or close meaning and represent an analytic type with the rich compounding morphology.
In summary, the present study examined the early automatic processes involved in the recognition of morphologically complex words in L1 English speakers and L2 English speakers of L1 Chinese by combining the widely used masked morphological priming paradigm with the transposed letter priming paradigm. It additionally explored whether priming effects were modulated by individual differences. It was hypothesised that a briefly presented morphologically related prime (e.g., braveness) would be decomposed in the early stages of word recognition consistent with its morphological structure (brave + ness), which would facilitate the target word identification (BRAVE) in both L1 and L2 speakers of English. Based on previous masked primed TL research in L1 speakers, it was expected that TL-within priming effects would arise. Empirical evidence suggests different magnitudes of morphological TL-across priming. If TL-priming effects were absent in the TL-across condition, the decompositional theories would be supported.
For TL priming in L2 speakers, given the differences between the two languages (Chinese vs English), it is possible that precise letter position coding could be more crucial in L2 English than in L1 Chinese (e.g., Gu et al., Reference Gu, Li and Liversedge2015; Lally et al., Reference Lally, Taylor, Lee and Rastle2020). For instance, Lally et al. (Reference Lally, Taylor, Lee and Rastle2020), employed an artificial language learning paradigm to train participants on two distinct writing systems: one orthographically sparse language devoid of anagrams, and another orthographically dense language where all words were anagrams of each other. Subsequent testing of participants’ orthographic knowledge through a series of tests revealed a larger TL effect in the orthographically sparse language. In dense orthography, the newly developing orthographic representations were encoded with greater precision for letter positioning. This effect could potentially be observed in readers who have acquired English as a second language at a later stage in their lives, as these individuals would be in the process of forming these emerging orthographic representations. Notably, the English writing system is more dense orthographically, with frequent anagrams compared to Chinese (e.g., Yang et al., Reference Yang, Taikh and Lupker2022). It was therefore predicted that if the decomposition process during L2 English reading were facilitated by the orthographic, and phonological effects of the prime, and neither TL-within nor TL-across priming effects would arise as the use of TL primes would reduce the similarity of prime to the target word orthographically and phonologically.
Finally, we explored whether and how the size of morphological and TL-priming priming was modulated by different indexes in L2 language proficiency and L2 profile. To this end, we first tested how L1 English readers process the stimuli, creating a baseline for our L2 English experiment.
Experiment 1A: L1 English speakers
Method
Participants
A hundred twenty-nine L1 speakers of English with normal or corrected-to-normal vision and no history of neurological disorders completed the first experiment for course credit or financial reimbursement.Footnote 1 The selection criteria for participants included individuals who were L1 speakers of English and were born and raised in English-speaking countries (e.g., Australia and the UK). Additionally, these individuals came from families where English was the primary language of communication. The eligibility criteria also specified the age range of 17–50 years. Participants who had acquired proficiency in another language before the age of 10 were excluded from the study.
According to the Language Experience and Proficiency Questionnaire (LEAP-Q; Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007) responses, 98 L1 speakers of English (mean age: 21.5, SD = 6.7, range:17–60, 74 females) reported English as their native language and hence were used in the analyses. The mean length of formal education they received was 13.8 years (SD = 2.7). The majority of participants (n = 37) completed high school or had a college education (n = 36). The mean age when participants began acquiring English was 0.9 (SD = 1.1) and the mean age when they became fluent in English was 5.0 years (SD = 2.6). Participant responses to the rest of the questions are presented in Table 2.
Table 2. Participant demographics in L1 and L2 groups
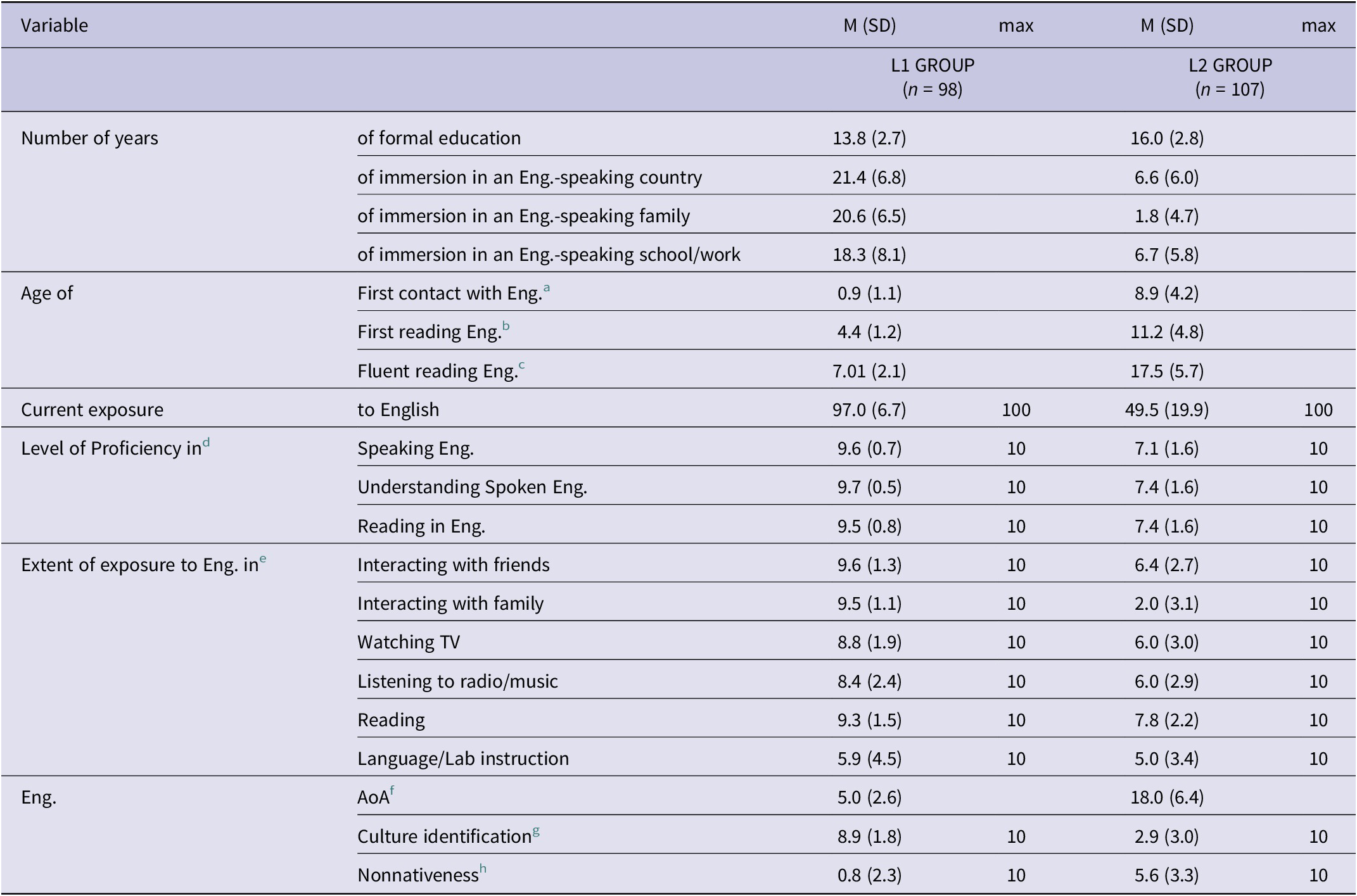
Note. Eng = English; AoA = Age of Acquisition.
a Age when participants began acquiring English.
b Age when participants began reading in English.
c Age when participants became fluent in reading English.
d Participants rated their proficiency on a rating scale from 0–10 on the domains of speaking, understanding spoken English, reading in English where 0 and 10 denoted to ‘none’ and ‘perfect’.
e Participants rated to which extent they were exposed to English on a rating scale from 0–10 in interacting with friends and family, watching TV and listening to radio/music, reading, and language-lab/self-instruction. 0 and 10 denoted to ‘none’ and ‘always’.
f Age at which participants became fluent in English. We believe that this definition is more realistic given that participants were not immersed in the foreign language at the time of the testing.
g Based on how much a participant identifies with English culture on a rating scale from 0–10.
h Based on how frequently others identify participants as a non-native speaker based on their accent in English.
Materials and design
Stimuli
For the masked primed lexical decision experiment, 54 English target words were selected from Kahraman and Kırkıcı (Reference Kahraman and Kırkıcı2021; see Appendix A for stimuli characteristics and Appendix B for the entire list of stimuli). All targets were the stems (e.g., BRAVE) of derived wordsFootnote 2, Footnote 3 and were preceded by six different primes: a morphological prime (braveness), a TL-within prime (braevness), an SL-within prime (braocness), a TL-across prime (bravneess), an SL-across prime (bravruess), or an unrelated prime (directness).
Unrelated primes were matched as closely as possible to related primes on ten psycholinguistic characteristics: stem length, stem frequency, stem bigram frequency, stem orthographic neighbourhood density (OLD20), word length, word frequency, word bigram frequency, position-specific bigram frequency, orthographic neighbourhood density (OLD20), and Coltheart’s N. We computed position-specific bigram frequency and OLD20 using the functions ‘ngramFreq’ and ‘old20’ from the‘vwr’ package (Keuleers, Reference Keuleers2015). This package utilises the CELEX database and is implemented in R Version 4.3.2 (RDevelopmentCoreTeam, 2019). The same derivational suffix was used in related and unrelated primes (e.g., braveness, directness) to avoid the potential effect of the suffix. The majority of letter transpositions contained a vowel and a consonant (Lupker et al., Reference Lupker, Perea and Davis2008), and none of the transpositions formed a real word. SL-control prime words included the two new letters of similar resemblance and height to the transposed letters (e.g., braevness, braocness). They were matched with their TL primes on length, bigram frequency, OLD20, and positional specific bigram frequency.
Fifty-four orthographically legal and pronounceable nonword filler targets were constructed for the purposes of the lexical decision task. The first and last letters of a real word were altered to create the nonword (e.g., frinp from bring). Nonword targets were matched with real word targets on length, bigram frequency, position-specific bigram frequency, orthographic neighbourhood, and OLD20 and preceded by primes that were constructed in the same manner as real word target primes. Six lists were created in a Latin square design so that each participant saw each target in a different priming condition. The order of target presentation within each list was randomised across participants.
Procedure
Participants were tested individually in a silent room. Stimulus presentation was randomised using DMDX (Forster & Forster, Reference Forster and Forster2003). We shifted in-person data collection to online due to the start of the COVID-19 outbreak when all in-person participant testing was paused. Using the same software package, LabDMDX and a web-delivered version of DMDX (webDMDX) were implemented (Forster & Forster, Reference Forster and Forster2003; Witzel et al., Reference Witzel, Cornelius, Witzel, Forster and Forster2013). Out of a total of 129 participants, 68 participants participated in the web-delivered version of the experiment. To run the experiments on participant computers locally, a zip file was formed to contain (1) the .rtf script to control the experiment, (2) the .bat file to execute the experiment, and (3) the poster.exe file to send off raw data over the web to a data repository at the University of Arizona. WebDMDX uses the host computer’s Windows operating system to accurately time the display of visual stimuli and therefore has yielded reliable masked repetition priming results (e.g., Witzel et al., Reference Witzel, Cornelius, Witzel, Forster and Forster2013).Footnote 4
Participants first saw the forward mask of hash marks for 500 ms, which was followed by the prime word for 50 ms. The target stimulus then appeared on the screen for a maximum of 3000 ms or until the participant responded. To prevent priming due to the mere physical similarity between the prime and target, primes were shown in lowercase, while targets were in uppercase letters. Participants were told to press the ‘right key’ on a keyboard if the visual target was a real English word or the ‘left key’ if it was a nonword as quickly and accurately as possible. The whole experiment lasted for about 8 minutes.
After the lexical decision task, language profiles of participants were collected using The Language Experience and Proficiency Questionnaire (LEAP-Q; Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007). Finally, participants completed a test battery composed of spelling, vocabulary, and reading tests for both lab and online experiments, which are described below in detail.
Individual differences measures for lab testing
Spelling test
Participants’ spelling proficiency was evaluated using a dictation test and a recognition test. The dictation test involved listening to 30 words and spelling them correctly. The score was the number of words correctly spelled. The recognition test required selecting the correctly spelled word from a list of 30 items. The items were taken from Kahraman and Kırkıcı (Reference Kahraman and Kırkıcı2021).Footnote 5 The score was the number of correct answers. Individual spelling proficiency scores were then calculated by summing the scores from both tests.Footnote 6
Vocabulary test
Participants demonstrated their vocabulary knowledge in context. They were given 16 target words (e.g., ‘essential’) with the first and last letters provided as clues. Additionally, a list of related words and sentences containing gaps for the target word was provided. The items were taken from Kahraman and Kırkıcı (Reference Kahraman and Kırkıcı2021). The score was the number of correct answers.
Reading fluency test
Participants read a passage within one minute. At intervals of approximately 60 words, they chose a word coherent with the passage or indicated whether a given statement was true or false. Scores were based on the number of words read and subtracting 50 words for every incorrect answer.
Individual differences measures for online testing
Spelling test
Participants were presented with a list of 60 items and asked to choose the correctly spelt option. The items were adapted from Kahraman and Kırkıcı (Reference Kahraman and Kırkıcı2021). The score was the number of correct responses.
Vocabulary test
Participants were shown individual words in uppercase letters and required to select the option that best corresponded to the uppercase word. The test consisted of 60 questions, and the score was the number of correct responses.
Reading comprehension test
Participants read 10 incomplete sentences and selected the answer that best completed each sentence. The score was the number of correct responses.
Results and discussion
One target word (i.e., PALATE) was excluded as it contained a pseudo-suffix. Linear mixed-effect (LME) modelling was used to analyse error rates (ERs) and reaction times (RTs) using the ‘glmer’ and ‘lmer’ functions, respectively, through the ‘lmerTest’ package (Version 3.1–3; Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017) in R (Version 4.3.1.; RDevelopmentCoreTeam, 2019). Both models employed the ‘bobyqa optimiser’ to optimise the model parameters. To assess if the testing modality (lab or online) influenced priming results, ‘testing modality’ was added as a factor in our analyses. The final model included two fixed effect factors (prime type: morphological, TL-within, SL-within, TL-across, SL-across, unrelated; testing modality: lab, online), their interactions, and two random effects factors (random intercepts and random slopes for subjects and items). Standardised trial order was included as a covariate in the models to statistically control for longitudinal task effects of fatigue or habituation and was kept in the analyses if it significantly improved the model, as measured by the ‘anova’ function. Post-hoc comparisons between experimental and control conditions (i.e., Morphological priming: unrelated vs morphological; TL-within priming: SL-within vs TL-within; TL-across priming: SL-across vs TL-across) were carried out using the ‘emmeans’ package (Version 1.8.8; Lenth, Reference Lenth2023), which automatically adjusted for multiple comparisons using the ‘holm’ method.
An additional analysis was conducted to further separate the influences of lower-level form overlap between the prime and target on morphological priming. To this end, the levels of SL-within and TL-within were merged, which both shared a mean proportion of 60% (SD = 0.1) orthographic overlap with the target, into a new combined level ‘intra-morpheme’. Similarly, the levels of SL-across and TL-across were combined, which had a mean proportion of 77% (SD = 0.1) orthographic overlap with the target, under the new variable ‘inter-morpheme’. These two new variables were then contrasted using ‘emmeans’. If the observed morphological effects were triggered by the orthographic similarity between the prime and target pairs, a difference between intra- and inter-morpheme levels would be expected.
Error rate analyses
Twenty generalised linear mixed models (GLMMs) with different random effect structures were fitted, including a maximal random effect structure (Barr et al., Reference Barr, Levy, Scheepers and Tily2013). The model with the smallest value of the Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) was selected as the final model (Matuschek et al., Reference Matuschek, Kliegl, Vasishth, Baayen and Bates2017). The random effects structure, including random slopes for the fixed effect ‘testing modality’ as in the by-subject random intercept led to a significant increase in model fit. The main effect of prime type was not significant (χ 2(5) = 9.71, p = .08). Trial order was a significant covariate (χ2(1) = 4.48, p = .03). Post-hoc analyses did not show any significant differences due to comparable error rates across conditions.
Reaction time analyses
Reaction time (RT) analyses were conducted on only correct trials after the omission of incorrect trials. Based on the distribution of the data, individual data points below 300 ms or above 3000 ms were treated as extreme values and hence omitted (1 datapoint; 0.02% of all data). Data points whose standardised residuals were greater than 2.5 in absolute value (Baayen, Reference Baayen2008) were removed (2.33% of all data). There were 4,847 data points remaining for the analysis. Table 3 shows mean RTs, error rates, and standard deviations across conditions.
Table 3 Mean RTs and ERs (SDs) across Conditions in L1 Speakers
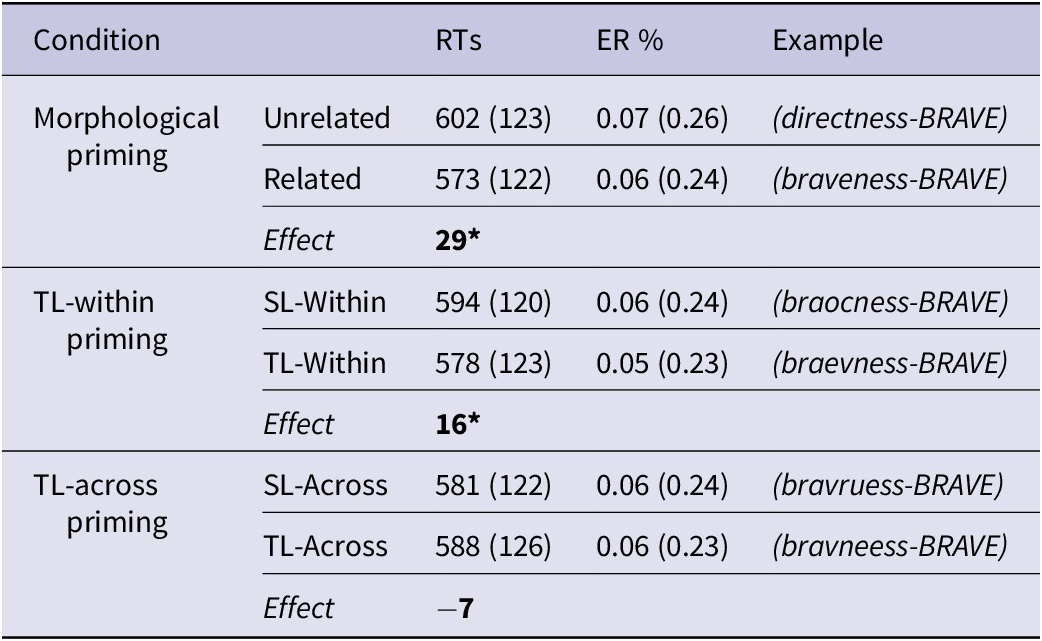
Note. Significant facilitation was obtained in the morphological and TL-within priming conditions. TL-priming effects were absent when the transpositions crossed morphemic boundaries.
a Standard deviations are presented in parentheses.
b RT = reaction time; ER% = error rate.
c An asterisk (*) indicates statistical significance.
d Results are averaged over the levels of factor ‘testing modality’.
RTs were inverse-transformed based on the Box-Cox transformation analysis (Box & Cox, Reference Box and Cox1964) and analysed through linear mixed-effect (LME) modelling. Out of 20 possible random effect structures, including a maximal random effect structure, the model with random slopes for the fixed effect ‘prime type’ and covariate ‘trial order’ in the by-subject and by-target random intercepts led to a significant increase in model fit and hence was used.
RT analyses revealed a robust main effect of prime type (χ2(5) = 42.89, p < .0001). Trial order was not a significant covariate (χ2(1) = 2.93, p = .08). The two-way interaction between prime type and testing modality was not significant (χ2(5) = 8.96, p = .11), showing that testing modality did not moderate priming effects. Post-hoc statistics for correct responses are shown in Appendix C. Responses to target words preceded by morphologically related primes (e.g., braveness-BRAVE) were significantly faster than targets preceded by unrelated primes (e.g., directness-BRAVE), yielding a 29-ms facilitation, β = −0.09, SE = 0.01, z = −4.81, p < .0001. There was not any statistically significant difference between the levels of intra- and inter-morpheme (β = −0.005, SE = 0.01, z = −0.52, p = .59), suggesting that the observed morphological facilitation cannot solely be attributed to orthographic overlap between the prime and target. The mean RT difference between TL-within and SL-within conditions was also significant (β = −0.05, SE = 0.01, z = −2.89, p = .003), due to faster responses to TL-within primes by 16 ms. However, there was no statistically significant difference between TL-across and SL-across conditions, β = 0.01, SE = 0.01, z = 0.91, p = .36.
We conducted additional exploratory analyses to test whether TL-across priming was modulated by positional specific bigram frequency. The two-way interaction between the ‘prime type’ and positional specific bigram frequency was significant, showing that TL-across priming varied as a function of positional specific bigram frequency (χ2(5) = 15.54, p < .001). Critically, nonwords with lower transposed-letter bigram frequencies did not exhibit any TL-across priming. Conversely, priming progressively increased when letter transpositions had higher bigram frequencies (as indicated by higher positional specific bigram frequency in Figure 1).
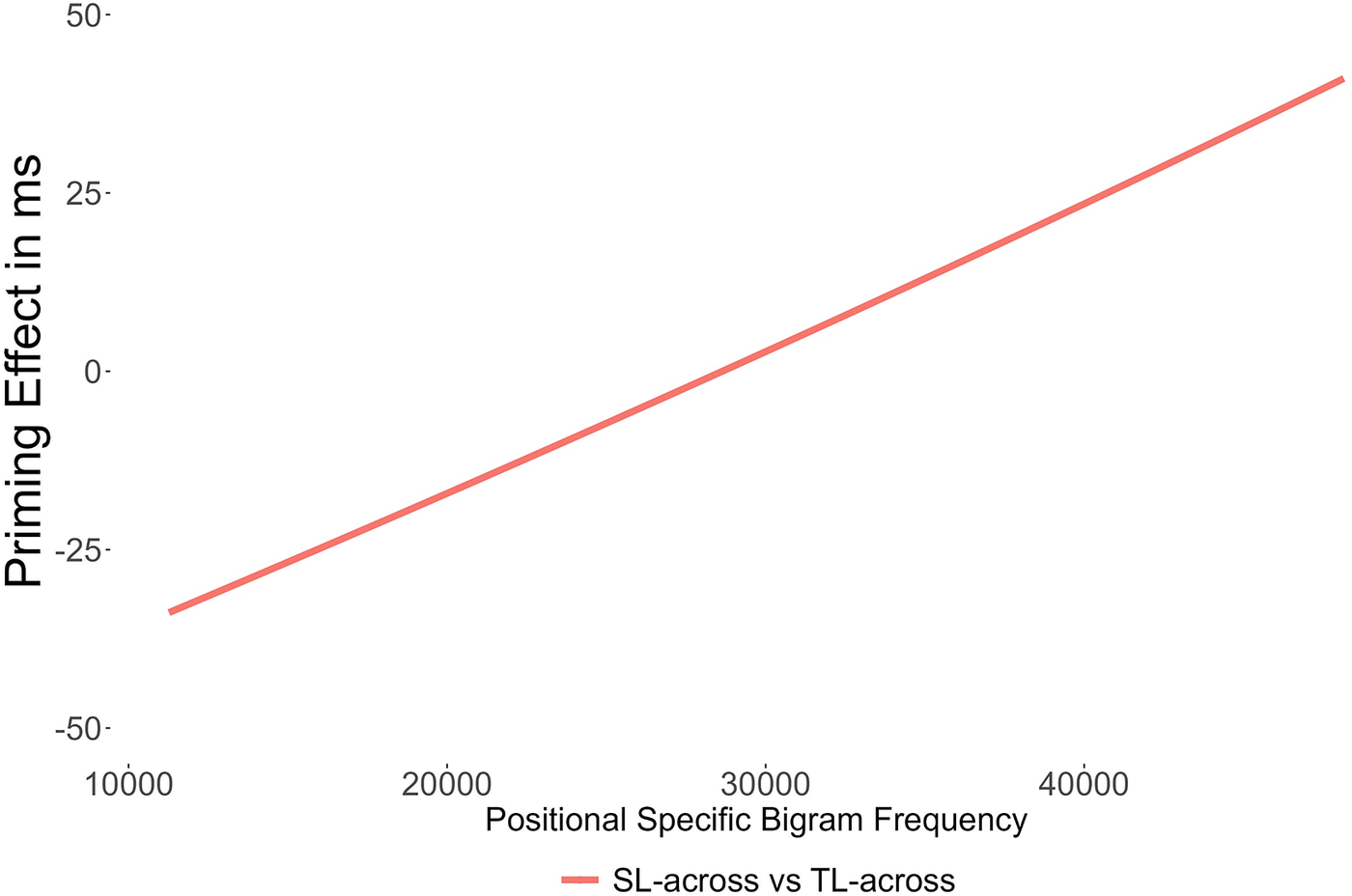
Figure 1. Modulation of transposed-letter priming across morpheme boundaries by positional specific bigram frequency in the first language.
Following RT analyses, we conducted a post-hoc power analysis based on 1000 simulations using the ‘simr’ package (Green & MacLeod, Reference Green and MacLeod2016) in R. The results indicated that the present study had a high power (> .93) to detect the true TL-across effect if it were as large as those observed in Rueckl and Rimzhim (Reference Rueckl and Rimzhim2011), Diependaele et al. (Reference Diependaele, Morris, Serota, Bertrand and Grainger2013), Beyersmann et al. (Reference Beyersmann, Coltheart and Castles2012), Perea and Carreiras (Reference Perea and Carreiras2006), Masserang and Pollatsek (Reference Masserang and Pollatsek2012), Sánchez-Gutiérrez and Rastle (Reference Sánchez-Gutiérrez and Rastle2013), Çağlar (Reference Çağlar2019), and Taikh et al. (Reference Taikh, Gagné and Spalding2024).Footnote 7 The power of 93% corresponded to an effect size of 0.022 (inverse RT) or approximately 14.1 ms. Therefore, the present study was well-powered to detect true effects larger than this size.
Individual differences analyses
For the individual differences analyses, test scores from the reading skills test battery were standardised and added to the LME model one at a time to assess if each significantly improved the model’s goodness of fit. Then, direct analysis of the interaction of each proficiency test with morphological priming (i.e., unrelated vs morphological), TL-within priming (i.e., SL-within vs TL-within), and TL-across priming (i.e., SL-across vs TL-across) was carried out through contrasts in the ‘emmeans’ package in R.
The reading skills battery
Significant interaction with TL-across priming was observed in spelling scores, β = −0.09, SE = 0.04, z = −2.40, p = .01. Figure 2 illustrates the impact of varying spelling proficiency levels on the extent of TL-across priming.
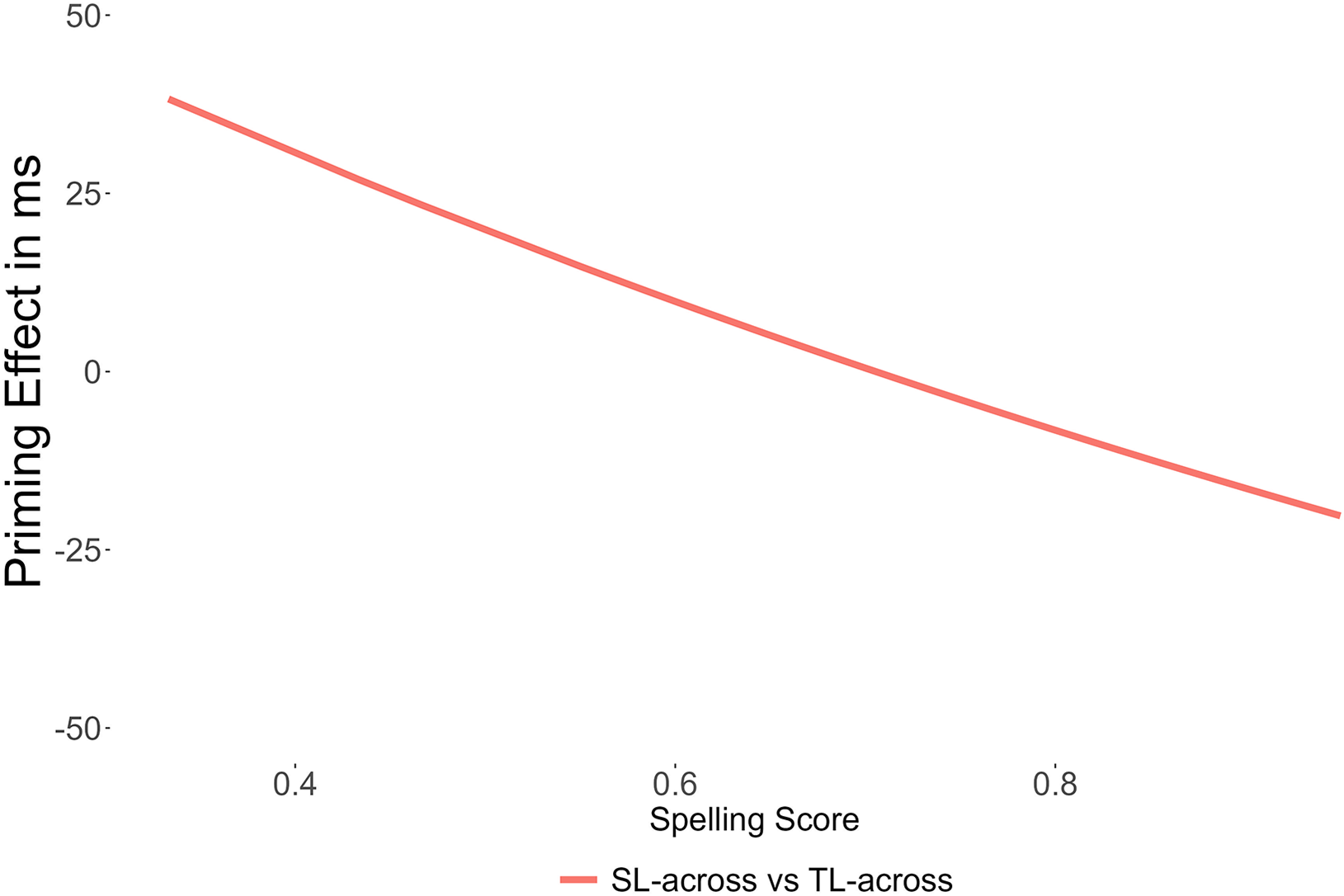
Figure 2. Modulation of transposed-letter priming across morpheme boundaries by spelling proficiency in the first language.
A comparison of L1 speakers with diverse spelling abilities revealed distinct differences in their language processing, suggesting that readers with higher spelling proficiency might experience inherent changes in their orthographic coding processes. Individuals with lower proficiency demonstrated a robust TL-across priming effect, which gradually decreased as the spelling ability improved.
The findings from Experiment 1A were in line with our hypothesis and consistent with existing literature on masked morphological priming in L1 speakers. As predicted, a robust facilitatory morphological priming effect of 29 ms was obtained relative to the unrelated priming condition. Notably, morphological TL primes within the morpheme boundary facilitated lexical decisions, while those that crossed the morpheme boundary did not. Furthermore, the results from individual differences analyses highlighted that cross-morphemic transpositions had a disruptive effect on lexical access for readers with advanced orthographic skills.
Experiment 1B: L2 English speakers
Method
Participants
A hundred twenty-six L2 speakers of English with normal or corrected-to-normal vision and no history of neurological disorders completed the experiment for course credit or financial reimbursement. Sixty-nine participants participated in the web-delivered version of the experiment. The selection criteria for our study included individuals who were L1 speakers of Chinese, including its varieties such as Mandarin and Cantonese. To be eligible for participation, these individuals were required to have been born and raised outside of Australia. Furthermore, we ensured that all participants were within the age range of 17–50 and had acquired English proficiency after the age of 10 years. Participants who had acquired English proficiency before the age of 10 were excluded from the study.
According to LEAP-Q responses, 107 (mean age: 26.1, SD = 7.6, range:18–51, 71 females) L2 speakers of English reported Chinese as their native language, and it was the dominant language for the majority of speakers. The mean length of formal education they received was 16.0 years (SD = 2.8). The majority of participants (n = 24) completed high school education and held a college (n = 30), or Master’s degree (n = 24). The mean age when participants began acquiring English was 8.9 (SD = 4.2) and when they became fluent in English was 18.0 years (SD = 6.4). The mean level of proficiency on a 10-point scale in speaking, understanding, and reading in English was 7.1 (SD = 1.6), 7.4 (SD = 1.6), and 7.4 (SD = 1.6), respectively (see Table 2 for responses to the rest of the LEAP-Q items).
Materials, design, and procedure
The same materials, design, and procedure as Experiment 1A.
Results and discussion
One target word (i.e., PALATE) was excluded as it contained a pseudo-suffix. One target word (i.e., LAMENT) and ten participants whose response accuracies were below 55% were also removed. The final model included ‘prime type’ (morphological, TL-within, SL-within, TL-across, SL-across, unrelated) and ‘testing modality’ (lab, online) as fixed effects, their interactions, and ‘subjects’ and ‘items’ as random effects factors (random intercepts and random slopes). Standardised trial order was included as a covariate in the model to statistically control for longitudinal task effects of fatigue or habituation and was kept in the analyses if it significantly improved the model, as measured by the ‘anova’ function. Similar to the L1 speakers, SL-within and TL-within levels were collapsed into ‘intra-morpheme’, and SL-across and TL-across into ‘inter-morpheme’ levels, which were then contrasted using the ‘emmeans’ package.
Error rate analyses
Twenty GLMMs with different random effects structures were fitted. Similar to the L1 group, the random effects structure, including random slopes for the fixed effect ‘testing modality’ as in the by-subject random intercept led to a significant increase in model fit. The main effect of prime type was not significant (χ2(5) = 4.66, p = .45). Trial order was a significant covariate (χ2(1) = 7.59, p = .005). There was a marginal two-way interaction between ‘prime type’ and ‘testing modality’ (χ2(5) = 10.72, p = .05), driven by significantly fewer errors to targets preceded by morphologically related primes (e.g., braveness-BRAVE) than targets preceded by unrelated primes in the online testing (e.g., directness-BRAVE), β = −0.52, SE = 0.16, z = −3.17, p = .001. No other post-hoc analyses yielded significant effects.
Reaction time analyses
Reaction time (RT) analyses were conducted on correct trials after the omission of incorrect trials. Based on the distribution of the data, individual data points below 300 ms or above 3000 ms were treated as extreme values and hence omitted (60 data points; 1.2% of all data). Data points whose standardised residuals were greater than 2.5 in absolute value (Baayen, Reference Baayen2008) were removed (3.22% of all data). There were 4,504 data points remaining for the analysis. Table 4 shows mean RTs, error rates, and standard deviations across conditions.
Table 4. Mean RTs and ERs (SDs) across conditions in L2 speakers
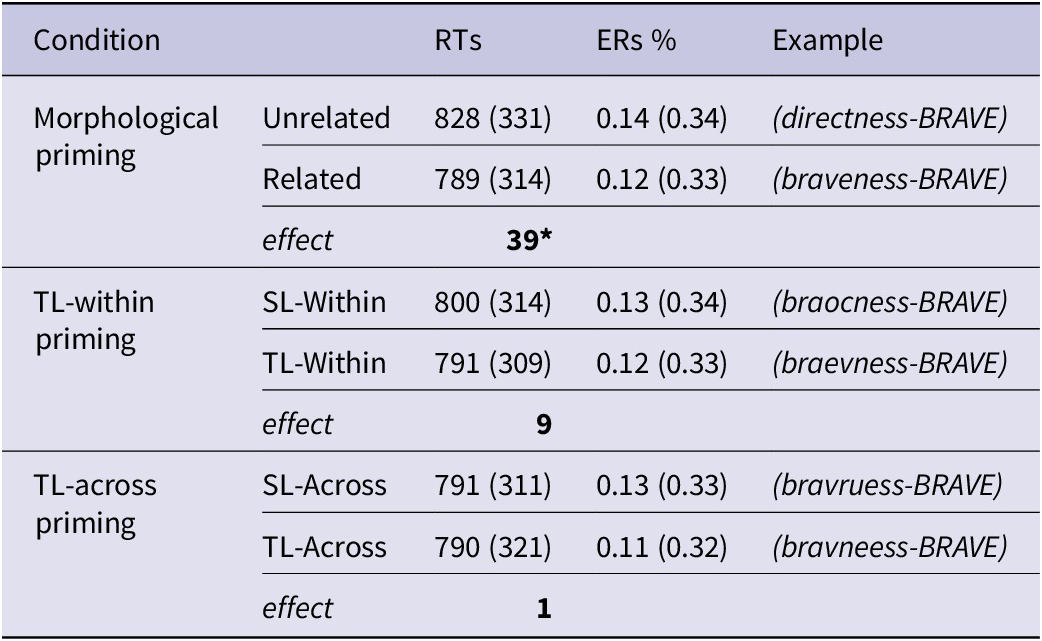
Note. Significant facilitation was only obtained in the morphological priming condition. TL-priming effects were absent irrespective of whether the transpositions crossed morphemic boundaries.
a Standard deviations are presented in parentheses.
b RT = reaction time; ER% = error rate.
c An asterisk (*) indicates statistical significance.
d Results are averaged over the levels of factor ‘testing modality’.
The Box-Cox transformation revealed that inverse transformation was the best approximation to normalise RTs. The trial order did not improve the model fit and hence not included in the analyses. Thirteen possible random effect structures were fitted, including a maximal random effect structure (Barr et al., Reference Barr, Levy, Scheepers and Tily2013). The random effects structure, including random slopes for the fixed effect ‘prime type’ in the by-item random intercept led to a significant increase in model fit. Inverse RT (−1000/RT) analysis revealed a main effect of ‘prime type’ (χ2(5) = 26.14, p < .0001). The two-way interaction between ‘prime type’ and ‘testing modality’ was not significant (χ2(5) = 0.63, p = .98), showing that testing modality did not influence priming effects.
Post-hoc tests for correct responses showed that responses to target words preceded by morphologically related primes (e.g., braveness-BRAVE) were significantly faster than targets preceded by unrelated primes (e.g., directness-BRAVE), yielding a 39-ms morphological facilitation, β = −0.06, SE = 0.01, z = −4.21, p < .0001. Intra-morpheme primes were statistically comparable to inter-morpheme primes (β = −0.01, SE = 0.01, z = −1.08, p = .27), suggesting that the observed morphological effects were not merely orthographic. Similar to Kahraman and Kırkıcı (Reference Kahraman and Kırkıcı2021), no significant difference was found between TL-within and SL-within conditions, β = −0.01, SE = 0.01, z = −0.76, p = .44, nor between TL-across and SL-across conditions, β = −0.01, SE = 0.01, z = −0.77, p = .43.
Individual differences analyses
Individual differences analyses were conducted using the same steps as in the L1 group except that responses from LEAP-Q were also standardised and added to the LME model one at a time to assess if each significantly improved the model’s goodness of fit.
The reading skills battery
None of the tests showed a significant interaction with prime type, χ2(1) = 2.61, p = .75 for spelling, χ2(1) = 4.39, p = .49 for vocabulary, χ2(1) = 8.61, p = .12 for reading comprehension. Following Andrews and Lo (Reference Andrews and Lo2013), summed and subtracted scores of standardised vocabulary and spelling were also calculated for each participant and then analysed in a similar manner. This variable also failed to yield any two-way interaction, χ2(5) = 4.35, p = 0.50 for composite scores, χ2(5) = 0.77, p = 0.97 for subtracted scores of vocabulary and spelling.
LEAP-Q Factor Analysis
Next, responses from the LEAP-Q were included in the mixed effects model. Only the questionnaire items that were relevant to the present study and with the strongest predictive power for word recognition (e.g., Luk & Bialystok, Reference Luk and Bialystok2013) were used in subsequent analyses. These were self-reported age milestones (i.e., age when a participant started to learn English, attained fluency in English, started reading in English, attained reading fluency in English), extent of current exposure to English, proficiency in understanding, speaking, and reading in English, immersion duration in an English-speaking country, family, and school, year of formal education, extent of exposure to English in interacting with family, friends, watching TV, listening to radio/music, reading, language-lab environment, self-reported culture identification and non-native perception (see Table 2 for variable descriptions and descriptive statistics).
In order to reduce the number of variables for LME models, where a large number of variables made it impractical to model all the measures individually, the exploratory factor analysis (EFA) was conducted to identify a smaller number of factors with a ‘promax’ rotation methodFootnote 8 within the R environment. Factor analysis was an appropriate statistical technique for the present research since it examined the interrelationships among a large set of variables and identified the underlying structure by explaining them in terms of a smaller number of common underlying factors.
The ‘scores’ parameter of the ‘factanal’ function was used to run EFA in base R with the extraction method of maximum likelihood. Variables with missing values were dropped prior to the factor analysis (i.e., culture identification, number of years of education, extent of exposure to English in interaction with friends). Based on the ‘promax’ rotated factor loadings, six factors were identified (see Table 5 for factor structure). Proficiency in understanding, speaking, reading and the level of English exposure loaded together on Factor 1; age when a participant began acquiring English and reading in English loaded on Factor 2; age of English acquisition and age when a participant became fluent in reading English loaded on Factor 3; years of immersion in an English-speaking country, and school/work loaded on Factor 4; the extent of exposure to English in listening to radio/music and watching TV loaded on Factor 5; years of immersion in an English-speaking family and extent of exposure to English in interacting with family loaded on Factor 6. None of the factors interacted with ‘prime type’, except for Factor 5, which represented exposure to L2 English through media and exhibited a trend towards interaction with TL-within priming, β = −0.09, SE = 0.05, z = 1.77, p = .07.
Table 5. Factor loadings for LEAP-Q variables in L2
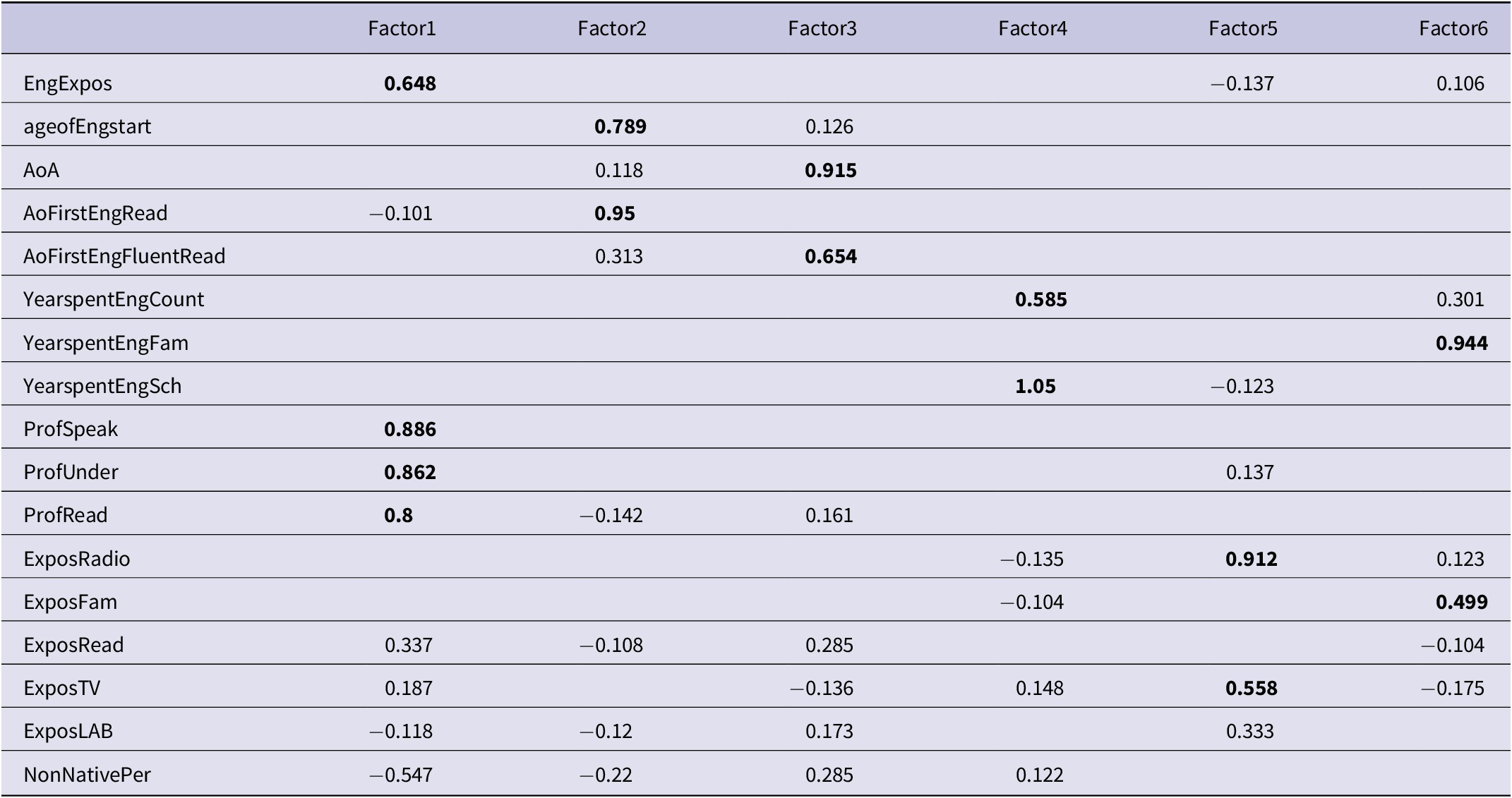
Note. Tests that load on a factor are in bold.
Not surprisingly, bilingual participants in Experiment 1B were overall slower and less accurate in responding to targets compared to monolinguals in Experiment 1A. Similar to Experiment 1A, a large facilitatory priming effect was observed for morphologically related prime words relative to unrelated prime words. A trend towards TL-within priming emerged with a 9-ms difference relative to the SL-within condition; however, TL conditions that involved both intra- and inter-morphemic transpositions did not yield a significant effect. These findings point to an L2 reading system that is sensitive to precise orthographic coding schemes.
Combined L1 and L2 analysis
In order to more directly compare differences in L1 and L2 morphological priming, the interaction of prime type (morphological, TL-within, SL-within, TL-across, SL-across, unrelated), group (L1, L2), and testing modality (lab, online) was assessed in the combined results of Experiments 1A and 1B. In error rate analyses, a set of generalised linear mixed effect models with different random effect structures was fitted, similar to the error rate analyses within the individual groups. The random effects structure, including random slopes for the fixed effects of ‘prime type’ and ‘testing modality’ as in the by-subject random intercept and the fixed effects of ‘prime type’, ‘testing modality’, and ‘group’ as in the by-item random intercept led to a significant increase in model fit. The main effects of ‘prime type’ (χ2(5) = 22.48) and ‘group’ (χ2(1) = 36.68) were robust (both ps < .0001), due to higher error rates in L2 speakers, but they did not yield a significant two-way interaction (χ2(5) = 2.77, p = .73). The trial number was a significant covariate, χ2(1) = 12.05, p < .0001. There was a three-way interaction between ‘prime type’, ‘group’, and ‘testing modality’, due to fewer errors in targets preceded by morphologically related primes than in targets preceded by unrelated primes in the online L2 testing.
RT analysis followed the same steps as the ER analyses. RT data showed a significant two-way interaction between the fixed effects of ‘prime type’ and ‘group’ (χ2(5) = 11.84, p = .03), showing that priming effects differed across L1 and L2 groups (see also Figure 3 for reaction times in L1 and L2 speaker groups). The main effects of ‘prime type’ (χ2(5) = 48.12) and ‘group’ (χ2(1) = 135.47) were significant (both ps < .0001), driven by higher RTs in the L2 group. Trial number was not significant (χ2(1) = 0.79, p = .37). Post-hoc comparisons showed that group difference was only found in TL-within priming effects (β = −0.03, SE = 0.01, z = −2.03, p = .04; see Appendix C for contrasts).
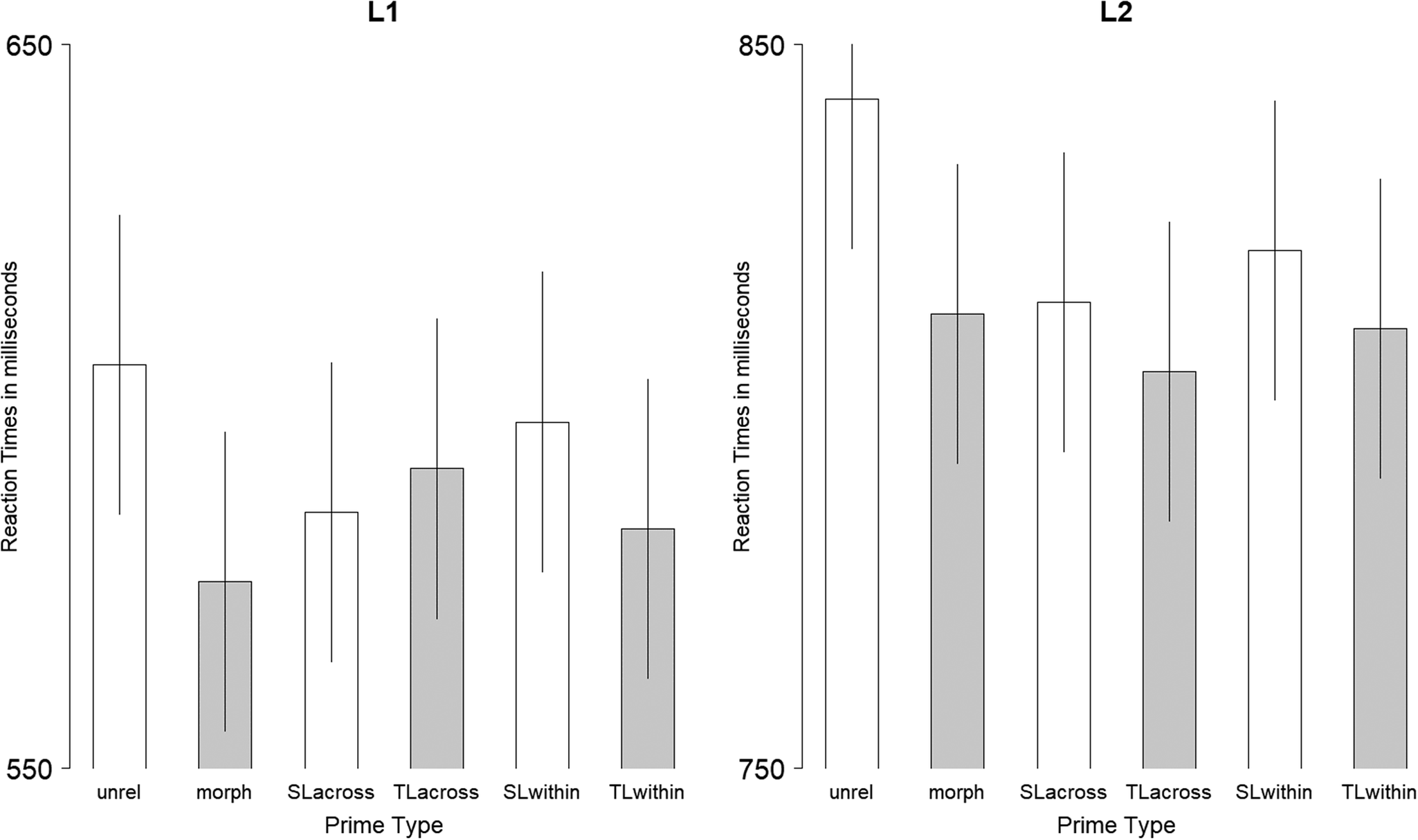
Figure 3. Model-based estimates of reaction times in the first language (left panel) and in the second language (right panel).
The aim of the combined analysis was to test whether there existed differences in the general mechanism(s) underlying language processing between L1 English and L2 English. Our findings support this hypothesis, as evidenced by a significant interaction between ‘prime type’ and ‘group’. Morphological primes yielded significant facilitative effects of 29 ms in Experiment 1A and 39 ms in Experiment 1B relative to unrelated primes. Critically, TL-within priming was significantly larger in L1 than the non-significant TL-priming observed in L2. Another piece of key finding was the absence of facilitation from TL-across primes in both L1 and L2 speakers, showing that morphological priming is sensitive to the place in which the letter manipulations take place.
General discussion
The present study described and reflected on existing studies employing cross-morphemic transposed-letter methodology. Using well-matched stimuli, the study then examined how skilled readers activate lexical representations from printed text using a combined methodology of masked transposed-letter (TL) priming and morphological priming. It explored the interplay between letter position encoding and morphological processing in L1 (Experiment 1A) and L2 (Experiment 1B). The experiments also investigated the potential influences of individual variability on priming. The study replicated the findings of Kahraman and Kırkıcı (Reference Kahraman and Kırkıcı2021) within a different L2 group and also included an L1 group. The same stem targets (e.g., BRAVE) were preceded by morphologically related (braveness), TL-within (braevness), SL-within (braocness), TL-across (bravneess), SL-across (bravruess), or unrelated primes (directness).
Morphological TL priming in L1 speakers
L1 English speakers showed robust morphological and TL-within priming. Critically, morphological priming was not driven by the mere orthographic overlap between the prime and the target (e.g., Rastle et al., Reference Rastle, Davis and New2004). This finding adds to the substantial body of research that has consistently reported the facilitatory effect of morphological TL primes (e.g., see Beyersmann et al., Reference Beyersmann, Castles and Coltheart2011 for evidence in English; Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2007 for evidence in Basque and Spanish). These results together suggest that the orthographic and morphological processes are intricately linked and operate simultaneously during the initial stages of reading. However, the transition to TL-across primes was marked by a loss in that effect, indicating that the reading process is relatively robust to letter transpositions within the morpheme boundaries of a complex word, but not to those that cross the morpheme boundaries. These findings highlight an important aspect of the reading process: intact words and words with intra-morphemic transpositions can provide a bottom-up activation, effectively facilitating lexical activation, while there is little role for possible top-down influences such as lexical meaning.
Morphological TL priming in L2 speakers
In our group of L2 speakers (Experiment 1B), RT analyses showed morphological facilitation with complex intact primes (39 ms; braveness-BRAVE). This finding is consistent with studies in the bilingual literature that have shown morphologically-based priming (see Table 1 in Kahraman & Beyersmann, Reference Kahraman, Beyersmann, Elgort, Siyanova-Chanturia and Brysbaert2023 for a review of studies comparing L1 and L2 derivational processing).
Present findings revealed that neither TL-within nor TL-across primes (braevness-BRAVE; bravneess-BRAVE) were facilitatory for L2 speakers. This result suggests that Chinese English late bilinguals may rely on the serial letter-by-letter reading strategy of phonological recoding to access L2 words. Furthermore, this sensitivity to the letter transpositions remained consistent regardless of the position of the transposed letters. While character position coding processes are generally considered more flexible in L1 Chinese readers (e.g., Gu et al., Reference Gu, Li and Liversedge2015; Yang et al., Reference Yang, Taikh and Lupker2022), morphological TL primes did not facilitate lexical decisions during late-acquired L2 reading. Instead, Chinese–English bilinguals seem to employ a precise position coding system when processing L2 words. Notably, the participants in the present study were unbalanced bilinguals, acquiring English after their L1. This late L2 acquisition might hinder their ability to develop flexible orthographic coding schemes. This pattern mirrors the observations made by Kahraman and Kırkıcı (Reference Kahraman and Kırkıcı2021) in L1 Turkish speakers of L2 English who acquired English proficiency at later ages. Using the same prime-target stimuli in a masked LDT as in the present study, the Turkish speakers did not show any significant transposed-letter priming effects in L2 English. The cross-linguistic differences between L1 and L2 may have played a role here. Turkish and Chinese differ typologically from English due to their frequent and extensive use of derivational processes and have a more morphologically complex structure compared to English. When coupled with late L2 acquisition, cross-language differences may impact the precision of orthographic coding for L2 speakers, potentially leading to precise letter position coding strategies.
One possible explanation for these findings, therefore, is that the impact of the first language (L1) on second language (L2) reading becomes pronounced when the L2 is typologically distinct from the L1. Chinese is a logographic language in which meaning-bearing characters represent morpho-syllables. Consequently, when primes are created by transposing characters of a target word, targets and their transposed-character primes continue to share morphemes, resulting in a Chinese character string that contains the same sound and meaning units as the original word, albeit fully transposed. Morphemes often correspond to individual characters with clear boundaries. For example, the word 总的来说 can be divided into four characters: ‘总’, ‘的’ ‘来’ and ‘说’ each representing a distinct morpheme. This clear segmentation makes it straightforward for Chinese readers to identify morphemes. In contrast, English features many pseudo-morphological words, such as ‘carpet’, where the apparent morphemes ‘car’ and ‘pet’ do not contribute to the word’s meaning. Additionally, other words like ‘cart’, ‘carp’ are embedded within ‘carpet’, further complicating morphological decomposition. This is not prevalent in Chinese, and hence, accurately recognising morphemes within words in alphabetic languages like English may be somewhat more challenging than in Chinese, as the segmentation is not as visually straightforward as in Chinese. Yang et al. (Reference Yang, Taikh and Lupker2022), using simple monomorphemic words (e.g., 哆嗦 [similar to the English word ‘practice’]), complex monomorphemic words (e.g., 烂漫 [similar to ‘carpet’ type words in English]), and multimorphemic words (e.g., 地震 [similar to ‘earthquake’ type words in English]) found that priming effects varied: simple monomorphemic words showed stronger priming effects than single morpheme complex words, while there was no difference between multimorphemic words and simple monomorphemic words.
In a transposed-character study, Yang et al. (Reference Yang, Chen, Spinelli and Lupker2019) revealed that L1 Chinese readers show transposed-character priming effects when processing four-character words (for related evidence from a backward priming task, see Yang et al., Reference Yang, Hino, Chen, Yoshihara, Nakayama, Xue and Lupker2020). These findings support the results of Gu and Li (Reference Gu and Li2015) who found a significant effect of morpheme boundaries on Chinese character-order encoding. The researchers used four-character stimuli that either constituted a single word or two separate words. In the one-word condition, the transposition of the middle two characters within a single word was classified as a within-word transposition, and in the two-word condition, as an across-word transposition. Critically, gaze durations in the transposed-character (TC) condition were shorter than those in the substituted-character (SC) condition for within-word transpositions (i.e., significant TL-within priming). However, gaze durations in the TC and SC conditions were found to be comparable for across-word transpositions (i.e., no TL-across priming), which suggests that the cognitive processing of character transpositions in reading might vary significantly between languages and word structures.
According to Zhang and Peng’s (Reference Zhang and Peng1992) Chinese word recognition model, the lexical representation at the word level is achieved through a separate morphemic processing level, which can explain the TC priming effect in L1 Chinese readers through the activation of morphological units relevant to the lexical decision-making process. Taft and Zhu (Reference Taft and Zhu1997) also proposed that recognising Chinese words involves activating sub-morphemic units, such as position-specific radicals. Their research showed that the frequency of radicals within a character impacts recognition speed, with more frequent radicals resulting in faster responses. The multilevel interactive-activation model they developed suggests that activation passes from the radical level, incorporating positional details to the character level and subsequently to the multiple-character level. L1 Chinese speakers have extensive experience processing characters based on position-specific radicals and sub-morphemic units due to their first language’s logographic nature. Therefore, their reading system is finely tuned to pay attention to the precise positioning of radicals within characters. When L1 Chinese speakers read in L2 English, which is an alphabetic language, the reading strategies they have developed for Chinese may not translate directly. Thus, in the case of Chinese-English readers, it is crucial for the reading system to ensure orthographic accuracy before morphological effects appear. This approach may guarantee a more effective and accurate reading process, especially using TL primes. For instance, Basnight-Brown et al. (Reference Basnight-Brown, Chen, Hua, Kostić and Feldman2007) found that the processing mechanisms differed in L1 and L2, a difference they attributed to the typological distance between the two languages (see also Portin et al., Reference Portin, Lehtonen, Harrer, Wande, Niemi and Laine2008).
The combined analysis of L1 and L2 data further highlighted a key distinction in the processing of morphologically complex TL words: the degree of facilitation from TL-within primes varied between English monolinguals and Chinese-English bilinguals. This finding shows that, unlike monolinguals, L2 readers of English did not exploit the partial orthographic or morphological similarity between the prime and target. We propose that individual letters could potentially play a significant role in L2 orthographic and morphological code. Hence, theoretical models should consider specific predictions regarding how letters are coded and positioned in the processing of complex visual stimuli across different language systems.
Implications for models of visual complex word recognition
The L1 results can be explained by reading models that assign relative flexibility to letter-position coding in the reading process. One such (decompositional) model is the Word and Affix model (Beyersmann & Grainger, Reference Beyersmann, Grainger and Crepaldi2023). The model predicts that the coarse-grained embedded word activation and fine-grained affix activation mechanisms operate in parallel, allowing intact words and intra-morphemic word transpositions to activate the lexical representations within the orthographic lexicon. For instance, for a TL-across prime (bravneess), both the embedded word ‘brave’ and the whole word ‘braveness’ are activated via the embedded word activation mechanism. Yet, the affix activation mechanism fails to activate the suffix _ness due to the distortion of the precise letter information of the affix through an inter-transposition, which is a prerequisite for the mechanism to function. The third mechanism, morpho-orthographic full decomposition, then fails to reduce the lexical competitionFootnote 9 between the embedded word (brave) and (braveness), resulting in the inhibition of the embedded target word (brave). In contrast, in the case of intra-transpositions where the letter positioning of the affix is not distorted, the morpho-orthographic full decomposition mechanism successfully identifies that the embedded word (brave) and whole word (braveness) are compatible, leading to strong activation of the embedded target stem (brave) and hence TL-within priming effects.
The relevant question then arises: could distributed models also account for the observed priming patterns in L1 speakers? Distributed models fundamentally rely on the orthographic (letter structure) and phonological (sound structure) properties of a language. According to these models, morphological structure is not explicitly represented in the reading system, and flexibility or inflexibility in letter position coding is determined by the statistical structure of the linguistic environment. In this case, one would expect all prime conditions to show comparable magnitudes of priming. If the language structure does not permit flexibility to letter transpositions, then facilitation should be uniformly reduced across TL-within and TL-across prime conditions. Such a scenario would effectively eliminate all TL priming effects, not just the TL-across prime, but also the TL-within prime condition. Therefore, any decrease in the effectiveness of TL primes at a morpheme boundary could be attributed to the application of a specific mechanism—specifically, the knowledge of flexible letter transpositions under different circumstances. Consequently, it becomes challenging for distributional models to explain the observed differences between the TL-within and TL-across priming effects.
Several other visual word recognition models consider the relative positioning of letters, contributing to our understanding of TL priming effects (e.g., Grainger & van Heuven, Reference Grainger, van Heuven and Bonin2003; Lupker et al., Reference Lupker, Zhang, Perry and Davis2015; Whitney, Reference Whitney2001). However, the influence of critical bigram frequency on cross-morphemic experiments remains unexplored. The present study made an attempt to explore if TL-across findings might be modulated by the critical bigram frequency of TL nonwords. While priming was absent in nonwords with lower positional specific bigram frequency scores, the size of TL-across priming gradually increased with higher values. This finding suggests that higher positional specific bigram frequency facilitates word recognition, likely due to the relatively more word-like structure of the nonwords. Furthermore, increased exposure to these familiar letter combinations may enhance the priming effect. Thus, bigram frequency appears to play a critical role in the effectiveness of TL priming. This is consistent with the work of Frankish and Turner (Reference Frankish and Turner2007) and Perea and Carreiras (Reference Perea and Carreiras2008), who found that TL-priming effects were affected by bigram frequency, particularly at morpheme boundaries. The empirical evidence straightforwardly demonstrated the complex interplay between orthographic properties and TL-across priming effects during the early stages of visual word recognition, highlighting the importance of considering positional specific bigram frequency in studies of TL-across priming.
Individual differences in morphological TL priming
To provide a comprehensive evaluation of language proficiency, both subjective and objective measures were used to thoroughly assess the impact of different aspects of language experience on reading processes. First, the reading skills test battery assessed different facets of reading in English, including spelling, vocabulary knowledge, and reading comprehension. Next, the LEAP-Q was used as a reliable tool that assessed various domains of L2 learners, including language acquisition history, context of acquisition and immersion, current language exposure, proficiency ratings as well as educational background.
A factor analysis examined the correlation among observed bilingual variables, aiming to model a smaller set of unobserved, latent factors in L2. These factors provided insights into the hidden abilities shared by tasks or, conversely, those that differed. Specifically, the extent of L2 exposure was associated with language proficiency, indicating that exposure plays a pivotal role in shaping linguistic abilities in L2 speakers. In addition, L2 exposure via media formed a distinct factor, separate from exposure to English in communicating with friends, reading, and self-directed learning. These findings highlight the multifaceted nature of L2 acquisition and underscores the varying impact of different exposure contexts on L2 speakers.
The novel finding from Experiment 1A is that the presence of TL-across priming in the average sample was due to averaging over participants who showed opposite patterns of priming for these items: participants with lower spelling proficiency scores showed significant TL-across priming, whereas those with higher proficiency did not. Cross-morphemic transpositions significantly impacted lexical access for readers with advanced orthographic skills—individuals who exhibited more sensitivity to the sequential arrangement of letters and relied on precise letter sequencing. In contrast, readers with lower sensitivity to word-level orthographic patterns were still able to activate the embedded stems within complex words, even when the morphemic structure was disturbed. This observation is consistent with Duñabeitia et al. (Reference Duñabeitia, Perea and Carreiras2014) who found that the size of the TL-across priming was sensitive to the general processing speed in that only slower participants showed significant TL-across priming. This finding also supports Andrews et al.’s (Reference Andrews, Veldre and Clarke2020) finding that spelling ability provided unique information, compared with the measures of reading comprehension and vocabulary and that it could serve as a measure of lexical precision.
The lexical quality hypothesis (Perfetti, Reference Perfetti2007; Perfetti & Hart, Reference Perfetti, Hart, Verhoeven, Elbro and Reitsma2002) provides a theoretical framework for understanding these findings. It emphasises the role of automatic and fluent access to high-quality lexical representations in skilled readers, suggesting that the precision of these representations directly influences reading. Given that lexical decision tasks require word identification, the observed individual differences in the impact of cross-morphemic transpositions on lexical access can be understood as variations in the quality of lexical representations. For less proficient spellers, these lexical representations may be less precise, as connections between phonological, orthographic, and semantic information are less integrated, which affects their ability to retrieve the word. In summary, the present study shows that the interplay between various individual factors significantly impacts visual word recognition in L1. Relations among a wide range of variables might influence reading in general and the processes of word recognition in particular.
Conclusion and future directions
This study examined the early automatic processes involved in processing complex words in L1 and L2 speaker groups with a joint investigation of positional encoding. Building on the work of Andrews and Lo (Reference Andrews and Lo2013), this study also examined if individual variability moderated the morphological TL priming effects, as measured by a set of reading skills and language profiles. Experiment 1A investigated early language processing mechanisms in L1 speakers of English, while Experiment 1B tested L2 speakers. The results from Experiments 1A and 1B showed robust morphological priming effects whereby brief exposure to a morphologically complex prime stimulus facilitated the monomorphemic target recognition in both groups. The L1 speaker cohort demonstrated significant TL-within priming, while TL primes within or across morpheme boundaries did not facilitate target decisions in L2 speakers. TL-across priming appeared to differ as a function of the positional specific bigram frequency and spelling ability in L1. At a methodological level, the present study shows that there is a clear need to use carefully-matched stimuli across several psycholinguistic variables, particularly positional specific bigram frequency, and robust methodologies since conclusions can differ substantially from those reached by non-robust methods.
The L2 data presented herein came from the speakers of L1 Chinese. These findings showcase how cross-linguistic characteristics can serve as a fruitful and fundamental property of reading in bilinguals, that may circumvent some of the experimental inconsistencies in theories of reading, especially their take on morphology. Further research into other languages will be critical to test the influences of cross-linguistic differences on morphological TL-priming.
Supplementary material
To view supplementary material for this article, please visit http://doi.org/10.1017/S1366728924001020.
Funding
This research was supported by a Discovery Early Career Researcher Award (DECRA) by the Australian Research Council (ARC) to EB (DE190100850) and International Macquarie University Research Excellence Scholarship (iMQRES) to HK.
Competing interest
The authors have no conflicts of interest to declare, and there is no financial interest to report.
Ethics approval
Ethics approval was granted by the Macquarie University Human Research Ethics Committee (Approval Code: 52021649924861).
Consent to participate
Participant consent was obtained prior to the experiments.
Open Practices Statement
The materials, the raw data, and analysis script for Experiments 1A and 1B are available at https://osf.io/gxhw6/?view_only=586ec38ed57149fcbc94b1fa65680478











 Open access
Open access