Refine search
Actions for selected content:
63 results
Designing Learning Intervention Studies: Identifiability of Heterogeneous Hidden Markov Models
-
- Journal:
- Psychometrika ,
- Published online by Cambridge University Press:
- 22 July 2025, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Identifiability, as a Data Risk: Is a Uniform Approach to Anonymisation About to Emerge in the EU?
-
- Journal:
- European Journal of Risk Regulation , First View
- Published online by Cambridge University Press:
- 30 June 2025, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Causal Structural Modeling of Survey Questionnaires via a Bootstrapped Ordinal Bayesian Network Approach
-
- Journal:
- Psychometrika / Volume 90 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 January 2025, pp. 229-250
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Consistent Estimation in the Rasch Model based on Nonparametric Margins
-
- Journal:
- Psychometrika / Volume 53 / Issue 4 / December 1988
- Published online by Cambridge University Press:
- 01 January 2025, pp. 553-562
-
- Article
- Export citation
Remarks on the Identifiability of Thurstonian Ranking Models: Case V, Case III, or Neither?
-
- Journal:
- Psychometrika / Volume 65 / Issue 2 / June 2000
- Published online by Cambridge University Press:
- 01 January 2025, pp. 233-240
-
- Article
- Export citation
Unifying Differential Item Functioning in Factor Analysis for Categorical Data Under a Discretization of a Normal Variant
-
- Journal:
- Psychometrika / Volume 82 / Issue 2 / June 2017
- Published online by Cambridge University Press:
- 01 January 2025, pp. 382-406
-
- Article
- Export citation
A Note on Weaker Conditions for Identifying Restricted Latent Class Models for Binary Responses
-
- Journal:
- Psychometrika / Volume 88 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 158-174
-
- Article
- Export citation
Diagnostic Classification Models for Testlets: Methods and Theory
-
- Journal:
- Psychometrika / Volume 89 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 851-876
-
- Article
- Export citation
Thurstonian-Based Analyses: Past, Present, and Future Utilities
-
- Journal:
- Psychometrika / Volume 71 / Issue 4 / December 2006
- Published online by Cambridge University Press:
- 01 January 2025, pp. 615-629
-
- Article
- Export citation
New Paradigm of Identifiable General-response Cognitive Diagnostic Models: Beyond Categorical Data
-
- Journal:
- Psychometrika / Volume 89 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1304-1336
-
- Article
- Export citation
-
Cognitive diagnostic models (CDMs) are a popular family of discrete latent variable models that model students’ mastery or deficiency of multiple fine-grained skills. CDMs have been most widely used to model categorical item response data such as binary or polytomous responses. With advances in technology and the emergence of varying test formats in modern educational assessments, new response types, including continuous responses such as response times, and count-valued responses from tests with repetitive tasks or eye-tracking sensors, have also become available. Variants of CDMs have been proposed recently for modeling such responses. However, whether these extended CDMs are identifiable and estimable is entirely unknown. We propose a very general cognitive diagnostic modeling framework for arbitrary types of multivariate responses with minimal assumptions, and establish identifiability in this general setting. Surprisingly, we prove that our general-response CDMs are identifiable under \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\textbf{Q}}$$\end{document}
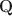 -matrix-based conditions similar to those for traditional categorical-response CDMs. Our conclusions set up a new paradigm of identifiable general-response CDMs. We propose an EM algorithm to efficiently estimate a broad class of exponential family-based general-response CDMs. We conduct simulation studies under various response types. The simulation results not only corroborate our identifiability theory, but also demonstrate the superior empirical performance of our estimation algorithms. We illustrate our methodology by applying it to a TIMSS 2019 response time dataset.
-matrix-based conditions similar to those for traditional categorical-response CDMs. Our conclusions set up a new paradigm of identifiable general-response CDMs. We propose an EM algorithm to efficiently estimate a broad class of exponential family-based general-response CDMs. We conduct simulation studies under various response types. The simulation results not only corroborate our identifiability theory, but also demonstrate the superior empirical performance of our estimation algorithms. We illustrate our methodology by applying it to a TIMSS 2019 response time dataset.
A Sparse Latent Class Model for Cognitive Diagnosis
-
- Journal:
- Psychometrika / Volume 85 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 121-153
-
- Article
- Export citation
Going Deep in Diagnostic Modeling: Deep Cognitive Diagnostic Models (DeepCDMs)
-
- Journal:
- Psychometrika / Volume 89 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 118-150
-
- Article
- Export citation
-
Cognitive diagnostic models (CDMs) are discrete latent variable models popular in educational and psychological measurement. In this work, motivated by the advantages of deep generative modeling and by identifiability considerations, we propose a new family of DeepCDMs, to hunt for deep discrete diagnostic information. The new class of models enjoys nice properties of identifiability, parsimony, and interpretability. Mathematically, DeepCDMs are entirely identifiable, including even fully exploratory settings and allowing to uniquely identify the parameters and discrete loading structures (the “\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{Q}$$\end{document}
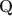 -matrices”) at all different depths in the generative model. Statistically, DeepCDMs are parsimonious, because they can use a relatively small number of parameters to expressively model data thanks to the depth. Practically, DeepCDMs are interpretable, because the shrinking-ladder-shaped deep architecture can capture cognitive concepts and provide multi-granularity skill diagnoses from coarse to fine grained and from high level to detailed. For identifiability, we establish transparent identifiability conditions for various DeepCDMs. Our conditions impose intuitive constraints on the structures of the multiple \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{Q}$$\end{document}
-matrices”) at all different depths in the generative model. Statistically, DeepCDMs are parsimonious, because they can use a relatively small number of parameters to expressively model data thanks to the depth. Practically, DeepCDMs are interpretable, because the shrinking-ladder-shaped deep architecture can capture cognitive concepts and provide multi-granularity skill diagnoses from coarse to fine grained and from high level to detailed. For identifiability, we establish transparent identifiability conditions for various DeepCDMs. Our conditions impose intuitive constraints on the structures of the multiple \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{Q}$$\end{document}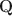 -matrices and inspire a generative graph with increasingly smaller latent layers when going deeper. For estimation and computation, we focus on the confirmatory setting with known \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{Q}$$\end{document}
-matrices and inspire a generative graph with increasingly smaller latent layers when going deeper. For estimation and computation, we focus on the confirmatory setting with known \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{Q}$$\end{document}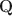 -matrices and develop Bayesian formulations and efficient Gibbs sampling algorithms. Simulation studies and an application to the TIMSS 2019 math assessment data demonstrate the usefulness of the proposed methodology.
-matrices and develop Bayesian formulations and efficient Gibbs sampling algorithms. Simulation studies and an application to the TIMSS 2019 math assessment data demonstrate the usefulness of the proposed methodology.
Asymptotic Identifiability of Nonparametric Item Response Models
-
- Journal:
- Psychometrika / Volume 66 / Issue 4 / December 2001
- Published online by Cambridge University Press:
- 01 January 2025, pp. 531-540
-
- Article
- Export citation
On the Identifiability of Diagnostic Classification Models
-
- Journal:
- Psychometrika / Volume 84 / Issue 1 / 15 March 2019
- Published online by Cambridge University Press:
- 01 January 2025, pp. 19-40
-
- Article
- Export citation
The Sufficient and Necessary Condition for the Identifiability and Estimability of the DINA Model
-
- Journal:
- Psychometrika / Volume 84 / Issue 2 / June 2019
- Published online by Cambridge University Press:
- 01 January 2025, pp. 468-483
-
- Article
- Export citation
Identifiability of Latent Class Models with Covariates
-
- Journal:
- Psychometrika / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1343-1360
-
- Article
- Export citation
On the Investigation of Local Identifiability: A Counterexample
-
- Journal:
- Psychometrika / Volume 48 / Issue 2 / June 1983
- Published online by Cambridge University Press:
- 01 January 2025, pp. 303-304
-
- Article
- Export citation
Latent Theme Dictionary Model for Finding Co-occurrent Patterns in Process Data
-
- Journal:
- Psychometrika / Volume 85 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 775-811
-
- Article
- Export citation
What can we Learn from the Path Equations?: Identifiability, Constraints, Equivalence
-
- Journal:
- Psychometrika / Volume 67 / Issue 2 / June 2002
- Published online by Cambridge University Press:
- 01 January 2025, pp. 225-249
-
- Article
- Export citation
Identifiability of Nonlinear Logistic Test Models
-
- Journal:
- Psychometrika / Volume 66 / Issue 3 / September 2001
- Published online by Cambridge University Press:
- 01 January 2025, pp. 357-371
-
- Article
- Export citation
