


I. Introduction
The concept of identifiability as a foundational criterion in European Union (EU) data protection law has attracted considerable criticism. Some scholars argue that the scope of identifiability is, on the one hand, too broad, making data protection law the “law of everything.”Footnote 1 In this view, data protection law risks becoming an overreaching framework that applies to virtually all forms of data, diluting its effectiveness and focus. On the other hand, some argue that the criterion is too narrow, leaving certain data practices, such as some forms of profiling, beyond the law’s reach.Footnote 2 Furthermore, some critique identifiability as a poor proxy for harm, suggesting that a focus on harm rather than identifiability would better address the underlying concerns privacy or data protection laws attempt to address.Footnote 3
With its third generation of data laws,Footnote 4 the EU confirms that identifiability remains a key risk factor for data sharing and reuse and, in an attempt to increase the level of data sharing and reuse within the EU data economy, promote anonymisation processes in different ways.Footnote 5 While data risks take various forms, identifiability is often one of the most talked about in practice.
Anonymisation, as a related EU data protection law concept, has thus been debated for many years, both under the Data Protection Directive (DPD)Footnote 6 and the General Data Protection Regulation (GDPR).Footnote 7 While national supervisory authorities (SAs) appear to converge in rejecting inadequate anonymisation practices,Footnote 8 determining when and if the anonymisation threshold is met remains a challenging task, which led a fair amount of consultants and practitioners taking the view that anonymisation under EU law can only be achieved when at least two conditions are met: the data is aggregated and the raw data, ie, the individual-level data, has been destroyed.
It is therefore not surprising that the European Data Protection Board (EDPB) has been delaying the release of its guidelines on anonymisation – intended to update its 2014 opinion – for several years.Footnote 9
Despite this delay, several recent trends are worth investigating, as they have direct implications for the EU approach to anonymisation. Recent case law of the Court of Justice of the European Union (CJEU) suggests that the concept of identifiability is gradually maturing, much like the assessment of anonymisation processes by national SAs. EDPB Opinion 28/2024, issued on 17 December 2024 and addressing implications of personal data processing in the context of Artificial Intelligence (AI) model training and deployment, also has direct consequences for the anonymisation of personal data,Footnote 10 which now seems to include AI model information when certain conditions are met.Footnote 11 In addition, EDPB Guidelines 01/2025 on pseudonymisation, while not directly tackling anonymisation practices, include important considerations related to risk assessment.Footnote 12
By exploring these trends, this paper aims to highlight how the EU approach to anonymisation has been evolving in the last few years. For this purpose, it unpacks the balance between over-inclusiveness and under-inclusiveness in CJEU case law and suggests that a functional definition of personal data is emerging, while making recommendations for refining the legal analysis and preserving the preventive goal pursued by EU data protection law.Footnote 13 This paper then stresses the importance of the burden of proof for assessing anonymisation processes and identifies ways to ensure consistency between the GDPR and newer data regulations.
This paper is structured as follows. Section II gives an overview of the identifiability test derived from the CJEU case law. Section III draws some lessons from national SA assessments of anonymisation processes and EDPB guidance. Section IV assesses the implications of the identifiability test for data sharing obligations stemming from recent data regulations. Section V concludes.
II. The CJEU’s approach to identifiability
The CJEU’s approach to identifiability is characterised by a focus upon anticipated uses of the data and does not expressly stress the importance of considering a wide range of stakeholders, including unintended recipients.
1. A focus upon anticipated uses
a. Breyer
For quite some time, the BreyerFootnote 14 case has been the main CJEU case touching upon the concept of identifiability. Let’s recall the facts, as they are important to shed light upon the effects of the CJEU’s holding. In Breyer, publicly accessible websites operated by German Federal institutions stored traffic data “on all access operations in logfiles.”Footnote 15 More specifically,
“[t]he information retained in the logfiles after those sites have been accessed include the name of the web page or file to which access was sought, the terms entered in the search fields, the time of access, the quantity of data transferred, an indication of whether access was successful, and the IP address of the computer from which access was sought.”Footnote 16
This browsing information was retained for cybersecurity purposes, ie, for “preventing attacks and making it possible to prosecute ‘pirates.’”Footnote 17
The first question posed to the CJEU in this case was whether “an internet protocol address (IP address) which an [online media] service provider stores when his website is accessed already constitutes personal data for the service provider if a third party (an access provider) has the additional knowledge required in order to identify the data subject”Footnote 18 under Article 2(a) of the Data Protection Directive. Said otherwise, the German Federal Court of Justice was essentially asking whether a (dynamic) IP addressFootnote 19 should be considered personal data when it is within the hands of an online service provider that is not an internet access service provider, ie, a provider that is able to combine IP addresses with subscriber information.
In Breyer, the CJEU easily admits that a dynamic IP address does not constitute data relating to an identified natural person. It states that
“a dynamic IP address does not constitute information relating to an ‘identified natural person’, since such an address does not directly reveal the identity of the natural person who owns the computer from which a website was accessed, or that of another person who might use that computer.”Footnote 20
The more difficult question to answer is whether a dynamic IP address constitutes data relating to an identifiable natural person.
The CJEU refers to Recital 26 of the Data Protection Directive and rightly states that “it is not necessary that that information alone allows the data subject to be identified”Footnote 21 to characterise it as personal data.
According to the CJEU, the applicable test in the case at hand to be able to determine whether a dynamic IP address amounts to personal data is “whether the possibility to combine a dynamic IP address with the additional data held by the internet service provider constitutes a means likely reasonably to be used to identify the data subject.”Footnote 22
The CJEU refers back to the opinion of its Advocate General and notes that “legal channels exist so that the online media services provider is able to contact the competent authority, so that the latter can take the steps necessary to obtain that information from the internet service provider and to bring criminal proceedings.”Footnote 23 Said otherwise, the CJEU refers to the purpose of the anticipated and subsequent use (ie, to bring criminal proceedings against attackers) to determine the relevant means likely reasonably to be used under Recital 26.
From a technical perspective, the CJEU’s solution can be explained through the concepts of distinguishability and availability, two core attributes of personal identifiers.Footnote 24 Distinguishability is the ability of a data point or a set of data points to distinguish or single out a data subject or closed group of data subjects within a broader open group. Availability is the ability of a data point or set of data points to be accessed by a situationally relevant entity who is said to be in a position to combine the data point or set of data points with additional personally identifying information, eg, official identification numbers of natural persons, full person names, home addresses…Footnote 25 A situationally relevant entity is an entity of which means should be taken into account for the purposes of the GDPR identifiability test. As a reminder, Recital 26 GDPR refers to the data controller as well as other persons.
In Breyer, the CJEU thus considers dynamic IP addresses as distinguishing references – data points capable of differentiating a natural person or a closed group of natural persons within a broader open group. To determine whether such a data point constitutes personal data, the CJEU also considers its availability, meaning whether additional personally identifying information exists and whether it is reasonably accessible to a situationally relevant entity, ie, the online service provider in this case, allowing the data point to be linked to the natural person it pertains to. As mentioned above, the anticipated and subsequent processing purpose is a key consideration for determining whether the data point is available.
b. Scania
ScaniaFootnote 26 is a 2023 CJEU judgment. It involved a vehicle manufacturer sharing vehicle, repair and maintenance information with independent repairers. Other independent operators brought a suit against a vehicle manufacturer and claimed access to vehicle, repair and maintenance information on the basis of Regulation 2018/858.Footnote 27 The Regional Court of Cologne decided to stay the proceedings and to refer three main questions to the CJEU for a preliminary ruling. The last question asked whether Article 61(1) of Regulation 2018/858 constitutes, for vehicle manufacturers, a legal obligation within the meaning of Article 6(1)(c) GDPR, which justifies the disclosure of vehicle identification numbers (VINs) or information linked to VINs to independent operators acting as controllers. To answer this question, the CJEU had to determine whether VINs, when within the hands of the vehicle manufacturer, amount to personal data.
Following its Advocate General, the CJEU holds in Scania that
“where independent operators may reasonably have at their disposal the means enabling them to link a VIN to an identified or identifiable natural person, which it is for the referring court to determine, that VIN constitutes personal data for them, within the meaning of Article 4(1) of the GDPR, and, indirectly, for the vehicle manufacturers making it available, even if the VIN is not, in itself, personal data for them, and is not personal data for them in particular where the vehicle to which the VIN has been assigned does not belong to a natural person.”Footnote 28
This sentence is relatively ambiguous and could mean two things: either the VIN is personal data within the hands of the vehicle manufacturer when the vehicle belongs to a natural person; or the VIN is personal data within the hands of the vehicle manufacturer the moment the independent operator submits a request to access the data. In both cases however, because the vehicle manufacturer does not know whether the vehicle has an owner and whether an access request will be made by independent operators, due diligence should imply treating all VINs as if they were personal data.
Just like what the CJEU did in Breyer, the court in Scania takes into consideration the purpose of the anticipated and subsequent use, ie, the offering of services to vehicle holders. To pursue such a purpose, independent operators will combine the data point at stake (the VIN) with additional information that is linked to a natural person, ie, the owner of the vehicle. The CJEU however goes further than in Breyer in that it considers two types of situationally relevant entities in which hands the data is indirectly personal or personal, ie, the initial data holder and the subsequent data recipients, that is to say the vehicle manufacturer and independent operators.
From a technical perspective, the CJEU’s solution in Scania can again be explained through the concepts of distinguishability and availability. The CJEU considers VINs as distinguishable references – data points capable of differentiating a natural person or a closed group of natural persons within a broader open group. To determine whether such a data point constitutes personal data, the CJEU assesses its availability, meaning whether additional personally identifying information exists and whether it is reasonably accessible to a situationally relevant entity, ie, the independent operator in this case, allowing the data point to be linked to the natural person it pertains to. This time the anticipated and subsequent processing purpose is a key consideration for determining whether the data point is available within the hands of both the initial data holder and the subsequent data recipient.
As a result, in both Breyer and Scania, the CJEU is dealing with a distinguishing reference, which is considered to be a personal identifier when it is considered available, ie, when it is reasonable to assume that additional personally identifying information will be associated with the reference. For the purposes of these two cases, a personal identifier is thus understood as a distinguishing and available reference to a natural person or a closed group of natural persons within a broader open group.
c. IAB Europe
IAB Europe,Footnote 29 a 2024 CJEU judgment, is even more interesting, as it marks a significant evolution. In IAB Europe, the data points at stake are not unique or closed group references. They are non-identifying user preferences, which can be shared across the whole population of users. When a user consults a website or application for the first time, a Consent Management Platform (‘CMP’) appears in a pop-up window to enable the user to consent or object to the subsequent processing of her personal data for pre-determined purposes, eg, for marketing or advertising. User preferences related to the subsequent processing of personal data are described as being “encoded and stored in a string composed of a combination of letters and characters.”Footnote 30 This Transparency and Consent String (‘the TC String’) is shared with data brokers and advertising platforms participating in the OpenRTB protocol, so that these stakeholders can adapt their processing on the basis of the TC String. When operating, the CMP places a cookie (euconsent-v2) on the user’s device. When combining the TC String with the euconsent-v2 cookie, the TC string can be linked to the user’s IP address.
The CJEU is asked two main questions in IAB Europe. The first one touches upon the test how to determine whether a string of preferences amounts to personal data. It is worth noting that the question is posed in the light of the roles played by two different stakeholders: IAB Europe, which is described as a “a sectoral organisation which makes available to its members a standard whereby it prescribes to them how that string should be generated, stored and/or distributed practically and technically,”Footnote 31 and participants to the OpenRTB protocol, ie, the parties that have implemented that standard on their websites or in their apps and thus have access to that string.
The CJEU initiates its reasoning by repeating a principle found in Breyer: “in order to treat information as personal data, it is not necessary that that information alone allows the data subject to be identified.”Footnote 32 The CJEU then adds that “it is not required that all the information enabling the identification of the data subject must be in the hands of one person.”Footnote 33
In IAB Europe, the CJEU expressly characterises an IP address as an identifier and states that this information “may make it possible to create a profile of that user and actually identify the person specifically concerned by such information.”Footnote 34 The CJEU is thus viewing IP addresses as distinguishing and thereby as tantamount to personal identifiers.
In IAB Europe, and contrary to Breyer although the CJEU refers to Breyer without distinguishing it from IAB Europe, the CJEU does not consider the availability of IP addresses, ie, whether it is reasonable to assume that IP addresses will be combined with additional personally identifying information. For the CJEU it is enough to consider whether it is reasonable to assume that the TC string could be combined with an IP address or other identifying information.Footnote 35 The CJEU finds that
it is apparent from the documents before the Court, and in particular from the decision of 2 February 2022, that the members of IAB Europe are required to provide that organisation, at its request, with all the information allowing it to identify the users whose data are the subject of a TC string.Footnote 36
The CJEU thus concludes that Recital 26 GDPR’s test is met and that IAB Europe has “reasonable means allowing it to identify a particular natural person from a TC String, on the basis of the information which its members and other organisations participating in the TCF are required to provide to it.”Footnote 37
Is the IAB Europe judgment departing from the Breyer judgment? It is not entirely clear, but the CJEU’s position is certainly evolving and maturing. The CJEU is now presuming or more radically mooting considerations related to the availability of the distinguishing reference, in particular for IP addresses, when the anticipated processing implies or enables the profiling of natural persons. The CJEU expressly refers to Recital 30 GDPR to justify its approach.Footnote 38
This solution should be welcome as profiling, even when there is no identity inference –the deducing of an individual’s identity based on available data – potentially jeopardises the autonomy of the natural person. Yet, autonomy is a fundamental value protected by the rights to privacy and data protection.Footnote 39 As a result, the anticipated processing purpose in IAB Europe is leveraged to set aside the criterion of availability.
d. Summary and implications for SRB
Table 1 compares the solutions adopted in Breyer, Scania and IAB Europe.
Table 1. Comparison between Breyer, Scania and IAB Europe
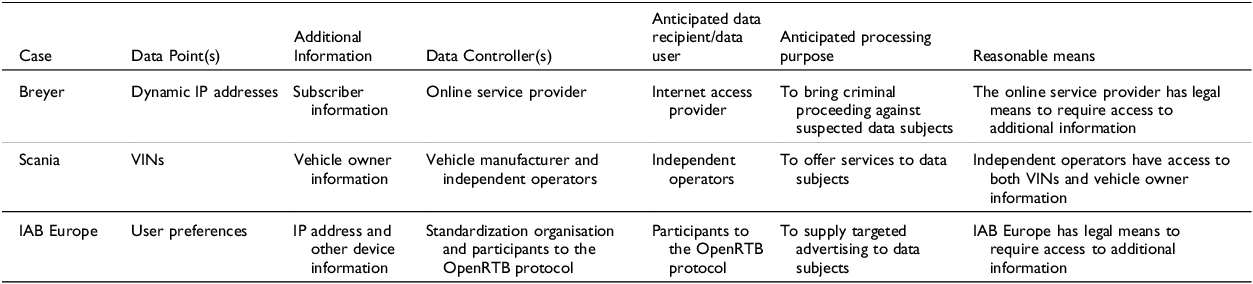
From Table 1, it appears that the data should be characterised personal in the following scenarios:
-
1. When the situationally relevant entity is in a position to process distinguishing and available information (Breyer).
-
2. When the situationally relevant entity is expected to share the data points at stake with other situationally relevant entities who are in a position to process distinguishing and available information (Scania).
-
3. When the situationally relevant entity is in a position to access distinguishing information if the anticipated processing performed by other situationally relevant entities implies or enables user profiling (IAB Europe).
How will the CJEU then manage upcoming cases? In SRB,Footnote 40 which will soon be decided by the CJEU in appeal, one key question to solve for the General Court was whether the data recipient (ie, Deloitte), with whom the data controller (ie, the Single Resolution Board) had shared key-coded individual-level data, held personal data, as Deloitte had alleged that it was not in a position to combine the data points at stake with additional personally identifiable information.Footnote 41
Applying the CJEU reasoning emerging from Breyer, Scania and IAB Europe, it is worth noting two things. First, the data recipient held data that is distinguishing. Second, the data provider was expected to learn from the data held by the data recipient to assess the situation of specific identified natural persons. To put it another way, there was a feedback loop.Footnote 42
Assuming the CJEU gives importance to this feedback loop, it should thus find that the data within the hands of the data recipient is personal data. It is with the feedback loop in mind that one could and should try to make sense of paragraph 105 of the General Court’s judgment.Footnote 43 Although the EDPS should have investigated whether Deloitte had legal means available to it to achieve re-identification, there is a reasonable argument that because the anticipated use implies re-identification the data held in the hands of Deloitte should remain personal data, or at the very least indirect personal data.
In his opinion delivered on 6 February 2025, the Advocate General Spielmann (AG) acknowledges that there is no reason to exclude that pseudonymisation could pave the way towards anonymisation.Footnote 44 Although he argues that there is no need to determine the status of the data held in Deloitte’s hand to characterise a transparency violation on the part of the SRB,Footnote 45 he opines that to determine the status of the data once it is in the hands of Deloitte, the EDPS should have demonstrated “for what reason, legal or technical, the pseudonymisation process (…) was not sufficient and should have led to the conclusion that [the data recipient] was processing personal data.”Footnote 46 The AG, however, does not seem to be viewing Deloitte’s processing as being ancillary to SRB’s processing and does not expressly point to the existence of a feedback loop. The AG’s interpretation is problematic for at least two other reasons, as explained below: unintended attackers seem to be ignored and it is on the EDPS to demonstrate that pseudonymisation is insufficient to achieve anonymisation.
2. The missing piece: unintended attackers
Although it is possible to present a relatively neat description of the CJEU case law by introducing the concepts of distinguishability and availability, the CJEU’s test remains too elliptic, as it seems to be only focusing (at least explicitly) upon anticipated uses to determine what the means reasonably likely to be used are in a particular case. In other words, in its case law the CJEU seems to focus either upon the situation of the initial data controller, ie, the online service provider in Breyer, the vehicle manufacturer in Scania, IAB Europe in IAB Europe, or the situation of the potential anticipated recipient of the data or anticipated provider of additional information, ie, the internet access providers in Breyer, the independent operators in Scania, the participants to the OpenRTB protocol in IAB Europe, to assess the means reasonably likely to be used to re-identify individuals.
Yet, if one adopts a robust approach to re-identification risks, the assessment should also take into account unintended attackers that are situationally relevant, which would need to be distinguished from the data controllers or anticipated recipients of the data or providers of additional information.
A situationally relevant attacker should be defined as an adversary whose capabilities, motivations and resources align with the specific context of the data and its environment, including its accessibility, sensitivity, and potential value. A situationally relevant attacker is thus an attacker that is plausibly positioned to exploit specific vulnerabilities of the data environment to access the data.
The Information Commissioner’s Office (ICO) conceptualises such an attacker through the prism of the test of the motivated intruder, which is a particular type of situationally relevant attacker with the following characteristics: the motivated intruder does not have prior knowledge but wishes to identify an individual within the data source and is relatively competent.Footnote 47 Depending upon the type of data at stake and the traits of its environment, it may make sense to use another model such, as the prosecutor model, and assume that the adversary knows that a target individual is in the data source.Footnote 48
As a consequence, to determine whether the identifiability test is met, the CJEU should ascertain two things:
-
1. Whether it is reasonable to expect that situationally relevant entities could combine the data points at stake and additional personally identifying information.
-
2. Whether data holders, both the initial data holder and the recipient of the data, have put in place appropriate measures to prevent situationally relevant attacks.
What is more, it is important to have a broad understanding of the concept of additional information and consider not only the additional information held or governed by a situationally relevant entity but also the additional information that is publicly available. What this means is that to determine whether the anticipated data user is in a position to combine the data points at stake with additional personally identifying information and whether data holders have put in place appropriate measures to prevent situationally relevant attacks, it is not sufficient to consider the data held by the entities sharing or governing the data.
For example, if it is reasonably likely that the data source contains demographic data points, which may be publicly available through public registries for example, a data recipient could be deemed to be in a position to re-identify even if it does not have access to the personally identifying information held by the data provider.
III. National supervisory authorities’ and the EDPB’s approaches to anonymisation
Just like the CJEU’s interpretation of the concept of personal data has been maturing over time, SA assessments of anonymisation processes have progressively become quite detailed, as illustrated by two recent SA decisions. EDPB Opinion 28/2024 is also rich in implications for the assessment of anonymisation processes, while EDPB 01/2025 Guidelines on pseudonymisation confirms the importance of a couple of key steps for risk assessment.
1. Doctissimo
Doctissimo is a 2023 decision from the French SA. Doctissimo operates a website that provides articles, tests, quizzes, and discussion forums related to health and well-being.
Privacy International had complained to the French SA regarding all personal data processing carried out by Doctissimo on its website, particularly the placement of cookies on users’ devices, the legal basis for processing personal data collected during health-related tests, transparency obligations, information provided to website users, and data security. The complaint led to a series of investigation missions performed by the French SA, acting as the lead SA in this case.
Since Doctissimo claimed that some of the retained data had been anonymised, the French SA needed to evaluate the robustness of the anonymisation process implemented. As regards personal data generated in the context of tests and quizzes, the SA finds that the anonymisation process is not good enough to meet the GDPR standard.Footnote 49 In particular, it notes that the anonymisation process performed by Doctissimo’s processor consists in transforming only two data elements: IP addresses, which are hashed without a hashing key,Footnote 50 and pseudonyms which are said to be replaced by a string of random numbers and letters.
The French SA therefore anticipates situationally relevant attacks by both the data controller and third parties and observes (1) Doctissimo was aware of the hashing parameters and, given the finite and known number of IP addresses, could use brute force to reasonably determine the IP addresses of individuals who completed the tests,Footnote 51 and (2) retained forum posts could include identifying information on their own as they had not been treated in any specific way.Footnote 52 To use the terminology developed in Section II, the information held by Doctissimo is therefore both distinguishing (each user is given a user ID) and available (forum posts may contain additional identifying information). Notably, Doctissimo’s practice amounts to profiling: profiles are organised by user IDs.
One key lesson from this case is that it is not enough for the data holder to claim that the possibility and risk of re-identifying individuals is not demonstrated to make a case for anonymisation.Footnote 53 Although this is not made explicit in the decision, as the data holder, ie, Doctissimo, had not established the implementation of a thorough evaluation of the identification risks,Footnote 54 the French SA had no choice but to limit its analysis to the re-identification risks mentioned in Opinion 05/2014 on Anonymisation Techniques issued by the EDPB’s predecessor.Footnote 55 This meant starting with an analysis of the risk of singling out, which is interpreted as requiring a determination as to whether the information at stake is distinguishable.Footnote 56
2. The THIN database
The Italian SA’s 2023 decision in the THIN database case is another interesting decision on the topic of anonymisation. The case was brought by a general practitioner (GP) who had reported an alleged violation of the GDPR by the company Thin S.r.l. in the context of the THIN project (the Project).
The Project aimed to improve patient care and clinical outcomes by analysing real-life anonymised data from GPs. This data was intended to help in understanding patient care pathways and driving advancements in healthcare. GPs using the “Medico 2000” software (developed by Mediatec Informatica S.r.l.) to manage patient data could leverage an add-on module that had been provided to automatically transform patient data from the software and transmit it to the company conducting the Project (Thin S.r.l.). Participating GPs received, in addition to monetary compensation to cover the expenses related to the installation of the software, additional services, including access to complete and updated information on their patients’ health conditions and prescriptions, a support tool to assist in their professional activities, and resources to help them become “researcher physicians” and contribute to medical knowledge.Footnote 57
The scientific value of the Project was said to be confirmed by the fact that the European Medicines Agency, following an open tenderFootnote 58 had selected, for the Italian territory, the THIN database for the development over the next six years of analyses on effectiveness and safety based on the population receiving primary care, presumably having assessed, both in terms of regulatory compliance and scientific adequacy, the creation methods, the level of anonymisation, and the data quality.
Thin S.r.l. thus alleged that the data transferred by the GPs was anonymised and stated that the anonymisation process was under the responsibility of GPSs acting as data controllers as per the contract concluded with GPs.
In regard to the anonymisation process, Thin S.r.l. stressed three points:
-
1) an independent and accredited third party, Edgewhere, acting as a processor for the GPs, operates at a centralised level to measure and ensure the effectiveness of the anonymisation process before the data is transmitted to Thin S.r.l., with the aim of eliminating any possible residual risk of singling out from the transformed dataset.Footnote 59
-
2) Records with a frequency lower than ten are systematically blocked, and therefore Thin S.r.l. will not have access to such records.Footnote 60
-
3) Edgewhere officially stated that it is impossible to proceed with the irreversible re-identification of the data contained in the Thin database.Footnote 61
Notably, Thin S.r.l. had produced a document titled “Results of the Anonymization Tests Conducted on the THIN Dataset” (prepared with the support of Bl4ckswan S.r.l.), containing the results of analyses conducted on three datasets created using the THIN Database as a source, with the goal of assessing the risk of re-identification following the application of a diversified set of de-identification techniques.Footnote 62
Despite the implementation of a compound set of organisational and technical measures and an allegation that the external guidance produced by the European Medicines Agency had been followed,Footnote 63 the Italian SA refused to consider that the data was anonymised to the GDPR standard once in the hands of Thin S.r.l. Referring to Opinion 05/2014 on Anonymisation Techniques, the SA considered that the risk of singling out, which requires a determination as to whether the information at stake is distinguishable, had not been properly mitigated.Footnote 64
Using the terminology developed in Section II, one reading of the SA’s decision would be to say that to determine whether the data at stake is personal, it is enough to find that the information is distinguishable.
What is peculiar about the setting of the THIN database case is that a feedback loop seems to be maintained between the data sent to Thin S.r.l. and the data held by GPs,Footnote 65 which would make it hard to argue that no profiling is happening. In fact, profiling would be an anticipated use if THIN data is intended to enrich patient data held by GPs.
3. EDPB Opinion 28/2024 on AI modelsFootnote 66
The EDPB adopted Opinion 28/2024 on 17 December 2024 on the basis of Article 64(2) GDPR. This opinion addresses data protection concerns related to AI models. Requested by the Irish SA in September 2024, the opinion offers non-exhaustive guidance on interpreting GDPR provisions when training and deploying AI models. It follows the Report of the work undertaken by the ChatGPT Taskforce adopted on 23 May 2024.Footnote 67
The Irish SA’s request raised four main questions: (1) When is an AI Model considered to be anonymous? (2) How can controllers demonstrate that they meet the test for the legitimate interest legal basis when they create, update and/or develop an AI Model? (3) How can controllers demonstrate that they meet the test for the legitimate interest legal basis when they deploy an AI Model? (4) What are the consequences of an unlawful processing of personal data during the development phase of an AI model upon subsequent phases, such as deployment?
In answering question 1, the EDPB draws two conclusions. First, adopting what seems to be a subjective approach and considering AI model designers’ intention, it states that for AI models that have been “specifically designed to provide personal data regarding individuals whose personal data were used to train the model, or in some way to make such data available,”Footnote 68 the models include personal data.
Second, and for other AI models, the EDPB stresses the possibility of an AI model memorising training data including personal data. Personal data in this case is said to be “absorbed in the parameters of the model, namely through mathematical objects.”Footnote 69 The EDPB’s conclusion is pretty clear: whenever memorisation may happen, the model may not be anonymous and therefore its storage may amount to the processing of personal data. The use of the auxiliary may is important. What this means is that ultimately the answer to question 1 is case specific.
What is this EDPB’s response telling us about its interpretation of the test for personal data anonymisation under the GDPR?
It is possible to draw five important observations from Opinion 28/2024.
First, the EDPB seems to confirm that Opinion 05/2014 on Anonymisation Techniques embeds a two-prong test and the prongs are actually alternative.Footnote 70 In other words, to determine whether anonymisation is achieved controllers have two options:
-
1) Option 1: to demonstrate that that three re-identification risks (singling out, linkability, and inference) are all mitigated.
-
2) Option 2: “whenever a proposal does not meet one of the [3] criteria, a thorough evaluation of the identification risks should be performed.”Footnote 71
To paraphrase one more time the EDPB, para. 40 seems to be saying that as a matter of principle it is not because singling out, linkability or inference risks are not all mitigated that anonymisation cannot be achieved under the GDPR.Footnote 72
Second, the EDPB stresses the importance of not focussing only upon the means available to the intended recipient of the information (or the model) to evaluate the risks of re-identification but of widening the net to consider unintended third parties as well.Footnote 73 This is particularly important in the light of the EU case law discussed in Section II.
Third, the EDPB draws an important distinction between information, including AI model information, that is publicly available and information that is not publicly available. The EDPB is thus saying that depending upon the release setting of the information at stake, (ie, open or closed settings) SAs will have to consider “different levels of testing and resistance to attacks.”Footnote 74 The EDPB thus indirectly confirms the relevance of context controls, ie, controls that do not transform the data as such, but impact its environment so that the likelihood of attacks is reduced. Notably, there is no mention in EDPB Opinion 28/2024 that the training data should be destroyed to be able to claim that the model is anonymised, which may suggest that data segmentation controls within the hands of a single controller could make it possible to effectively shield identifying data sources from non-identifying data sources.
Fourth, the EDPB makes it very clear that anonymisation processes are governed by data protection law and that the principle of accountabilityFootnote 75 is particularly relevant in this context. Appropriate documentation should therefore be produced to evidence the technical and organisational measures taken to reduce the likelihood of identification and demonstrate their effectiveness, which may include quantification of risks through the use of relevant metrics, as well as to describe the roles of the stakeholders involved in the data flows.
Notably, in the THIN database case such documentation had been produced but did not manage to convince the Italian SA. The Italian SA adopts a rather restrictive approach as it seems to reject option 2 when a k-anonymisation method is applied on the data and either progressive or randomized codes are used. The severity of the Italian SA could however be explained by the behaviour of THIN S.r.l., which had refused to bear any responsibility for the contentious anonymisation process.
Fifth, and this is probably the most contentious part, the EDPB seems to opine that if personal data is processed unlawfully and then successfully anonymised, the GDPR does not apply to the anonymised data.Footnote 76
4. EDPB Guidelines 01/2025 on pseudonymisation
EDPB Opinion 28/2024 has been followed by EDPB 01/2025 Guidelines on pseudonymisation, which have been adopted on 16 January 2025 and are expected to be revised after the consultation.Footnote 77
While these guidelines do not discuss CJEU case law, they attempt to unpack the main tenets of the GDPR definition of pseudonymisation and its implications for performing pseudonymisation on the ground. The EDPB does so by stressing that pseudonymisation under Article 4(5) GDPR does not simply mean removing or transforming direct identifiers into pseudonyms. It also entails developing and documenting a systematic approach to re-identification risks by clearly delineating a pseudonymisation domain. Such a stance should be welcome.Footnote 78
More specifically, the EDPB recalls that “information from publicly accessible sources, such as posts in a social media or an online forum” is relevant for assessing the strength of the data transformation process.Footnote 79
In addition, the EDPB confirms that the range of potentially relevant stakeholders for assessing the strength of the data transformation process includes both anticipated and unanticipated recipients.Footnote 80
The terminology used by the EDPB remains however confusing in that it does not distinguish between distinguishability and availability: pseudonyms seem to be categorised as direct identifiers although it is stated that “it is clear that direct identifiers need to be removed from data if those data are not to be attributed to individuals.”Footnote 81
Moreover, although a strict interpretation of these guidelines does not rule out the possibility that pseudonymised data could be considered anonymised under certain conditions, it is not clear what those conditions might be.Footnote 82
IV. Implications for new data sharing mandates
This section explores the implications of the trends discussed in Sections II and III for the new data-sharing mandates, following a deeper examination of the concept of profiling.
1. Profiling as a deal breaker
From Sections II and III, it should be possible to posit that if the anticipated use does not entail nor the profiling of data subjects nor the combination of the data points at stake with additional personally identifying information, these data points could be considered anonymised as long as appropriate controls have been in put in place to mitigate against situationally relevant attacks.
As a result, when data reuse does not involve data subject profiling, anonymisation through a risk-based approach remains possible. As mentioned in Section III(3), a risk-based approach to anonymisation had not been mooted by Article 29 Working Party (WP29). This seems to have been confirmed by the EDPB in Opinion 28/2024.Footnote 83
One key parameter to determine when anonymisation could be achieved is to properly delineate the concept of profiling. As mentioned in Section II(1), when profiling is anticipated, under IAB Europe, distinguishability appears to be the only relevant criterion for characterising personal data.
For the purposes of the GDPR, profiling covers “automated processing of personal data consisting of the use of personal data to evaluate certain personal aspects relating to a natural person, in particular to analyse or predict aspects concerning that natural person’s performance at work, economic situation, health, personal preferences, interests, reliability, behaviour, location or movements.”Footnote 84 Profiling therefore has the potential to have drastic consequences for individuals. By ignoring availability when profiling is anticipated, the CJEU is thus adopting a functional definition of personal data, which is guided by considerations related to potential harm.
When compared with other definitions of profiling such as Hildebrandt’s working definition,Footnote 85 the GDPR definition appears to kick in as early as the discovery phase. With this said, WP29 adopts a relatively narrow definition of profiling in its 2018 guidelines and states that a simple classification of natural persons does not necessarily lead to profiling.Footnote 86
The direct consequence of the CJEU approach in IAB Europe is that when profiling is anticipated, a risk-based approach to anonymisation should be mooted. What this implies is that the processing purpose ought to be a fundamental consideration for determining whether the anonymisation process is successful. The importance of purposes is confirmed by WP29 in its Opinion on Anonymisation Techniques.Footnote 87
Is this approach compatible with the framing of new data sharing mandates introduced by recent data regulations? Let’s look at two of them to better understand whether the overall jigsaw could make sense.
2. The Data Act
The Data Act (DA)Footnote 88 is intended to open up the pot of industrial data and stimulate its reuse.Footnote 89 The DA does not aim to derogate from the GDPR.Footnote 90 Building upon the Data Governance Act (DGA),Footnote 91 it acknowledges the relevance of anonymisation for sharing covered data, without suggesting that the raw data should be destroyed to achieve anonymisation.Footnote 92
Following the CJEU’s approach to identifiability, it seems reasonable to find that data access and sharing under Chapter II, which governs access to and sharing of IoT data, will often involve personal data or at the very least mixed data. This is because when product or related service data is granted access to natural persons or third parties permissioned by natural persons under Chapter II the data will often amount to a profile. Even if personally identifying information is not within the data source, the data is likely to contain very rich relational information.Footnote 93 In addition, the data user or third party is likely to have access to additional personally identifying information. In other words, the anticipated and subsequent processing purposes are likely to imply a combination of both non-personally identifying and personally identifying information.
Profiling by third parties is only partially prohibited by the DA: Article 6(2)(b) prohibits third parties from using the data received for profiling, “unless [profiling] is necessary to provide the service requested by the user.”Footnote 94
With this said, the drafters of the DA seem to have been well-aware of the functional definition of personal data and have therefore included within covered data both personal and non-personal data.Footnote 95
3. The European Health Data Space Regulation
Under the Health Data Space Regulation (EHDS) adopted on 8 January 2024,Footnote 96 two types of uses are distinguished: primary use and secondary use. Article 2(2)(e) defines secondary use of electronic health data by excluding the initial purposes for which the data was collected or produced and referring to the list of purposes found in Article 53. The introduction to the compromise text had a generic description of these purposes: “research, innovation, regulatory and public policy purposes across the EU.”Footnote 97
It is clear that the EHDS and the GDPR should be read together, as the data subject rights granted by the GDPR continue to apply when the EHDS applies.Footnote 98 The GDPR identifiability test should therefore be relevant for applying the EHDS and arguing that destroying the raw data is necessary to achieve anonymisation does not make sense in this context. With this said, interpreting Article 2(2)(b) EHDS in the light of Article 4(1) GDPR will require some agility. Indeed, it is not clear whether the category of personal electronic health data exhausts the category of personal data pertaining to a patient, although Recitals 6 and 7 seem relatively open.Footnote 99 Said otherwise Article 2(2)(b) should not be read as meaning that data that is not personal data concerning health or genetic data will always be non-personal.Footnote 100
Article 66 makes it clear that the secondary use of electronic health data is based on pseudonymised or anonymised data.Footnote 101 More specifically, Recital 65 seems to suggest that anonymisation of microdata sets is possible.Footnote 102
When considering the relationship between health data holders and health data users under the EHDS and within the context of secondary use, anticipated uses do not seem to cover the recombination of data held by data providers and data users.
Assuming there is no feedback loop and following the CJEU case law, SA assessment methods and the EDPB guidance, the data should be personal in two situations:
-
1. The data user is deemed profiling individuals.Footnote 103
-
2. The data user is in a position to distinguish data subjects and situationally relevant attacks have not been mitigated.
One last point should be stressed. When health data is kept at the individual level and is rich of relational information, it is hard to claim that the data is effectively anonymised without giving effect to contextual controls as defined by WP29,Footnote 104 which should combine both technical and organisational measures.
V. Conclusion
This paper has unpacked the identifiability test that is being progressively shaped by the CJEU and has described a sample of SA assessment methods deployed when evaluating the robustness of anonymisation processes.
It shows that profiling without the processing of personally identifying information is governed by the GDPR and that therefore the definition of personal data is functional. It also shows that it is on the data controller to prove the robustness of the anonymisation process, and the application of the accountability principle implies producing a detailed and rigorous documentation of such a process.
This paper has then assessed the implications of these emerging approaches to identifiability and anonymisation for recent data sharing mandates included in the Data Act and the Health Data Space Regulation.
It highlights that, in a data sharing context, a risk-based approach to anonymisation should remain workable outside of profiling scenarios but its effectiveness is dependent upon the richness of the relational information contained within the data source to be shared and the set of both data and context controls.
Assuming these interpretation and assessment trends are acknowledged and confirmed, a uniform approach to anonymisation may be on the verge of emerging within the EU. This approach does not entail that the raw data should be destroyed to achieve anonymisation and does not exclude that pseudonymisation could lead to anonymisation when additional conditions are met. There are also good reasons to be cautious about mere aggregation and not make it a conclusive consideration.Footnote 105 However, much will depend upon whether it is possible to generate consensus about what a thorough evaluation of identification risks should look like in case it is not possible to mitigate singling out, linkability and inference all together.
Competing interests
The author declares no competing interests related to this publication.


 Open access
Open access