Refine search
Actions for selected content:
55 results
Burden of anthropometric failures and concordance of mid-upper arm circumference with weight for length z score in identifying malnutrition among under two-year-old children in Southern India
-
- Journal:
- Public Health Nutrition / Accepted manuscript
- Published online by Cambridge University Press:
- 05 December 2025, pp. 1-20
-
- Article
-
- You have access
- Open access
- Export citation
The concordance between the Montreal cognitive assessment and the repeatable battery for the assessment of neuropsychological status as a cognitive screening tool in a south African community sample
-
- Journal:
- Cambridge Prisms: Global Mental Health / Volume 12 / 2025
- Published online by Cambridge University Press:
- 08 August 2025, e96
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The classification of links up to clasp-pass moves
-
- Journal:
- Canadian Journal of Mathematics , First View
- Published online by Cambridge University Press:
- 11 July 2025, pp. 1-30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We give a complete classification of links up to clasp-pass moves, which coincides with Habiro’s
 $C_3$-equivalence. We also classify links up to band-pass and band-
$C_3$-equivalence. We also classify links up to band-pass and band- $\#$ moves, which are versions of the usual pass- and
$\#$ moves, which are versions of the usual pass- and  $\#$-move, respectively, where each pair of parallel strands belong to the same component. This recovers and generalizes widely a number of partial results in the study of these local moves. The proofs make use of clasper theory.
$\#$-move, respectively, where each pair of parallel strands belong to the same component. This recovers and generalizes widely a number of partial results in the study of these local moves. The proofs make use of clasper theory.



Generalized Concordance
-
- Journal:
- Psychometrika / Volume 44 / Issue 2 / June 1979
- Published online by Cambridge University Press:
- 01 January 2025, pp. 135-142
-
- Article
- Export citation
Posterior Probabilities for a Consensus Ordering
-
- Journal:
- Psychometrika / Volume 55 / Issue 1 / March 1990
- Published online by Cambridge University Press:
- 01 January 2025, pp. 53-63
-
- Article
- Export citation
Salience or event-splitting? An experimental investigation of correlation sensitivity in risk-taking
-
- Journal:
- Journal of the Economic Science Association / Volume 10 / Issue 2 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 346-366
-
- Article
- Export citation
On Approximate Confidence Intervals for Measures of Concordance
-
- Journal:
- Psychometrika / Volume 49 / Issue 1 / March 1984
- Published online by Cambridge University Press:
- 01 January 2025, pp. 133-141
-
- Article
- Export citation
Statistical Applications of Linear Assignment
-
- Journal:
- Psychometrika / Volume 49 / Issue 4 / December 1984
- Published online by Cambridge University Press:
- 01 January 2025, pp. 449-473
-
- Article
- Export citation
An Ordinal Coefficient of Relational Agreement for Multiple Judges
-
- Journal:
- Psychometrika / Volume 59 / Issue 2 / June 1994
- Published online by Cambridge University Press:
- 01 January 2025, pp. 241-251
-
- Article
- Export citation
Chapter 1 - Literary Data
-
-
- Book:
- The Cambridge Companion to Literature in a Digital Age
- Published online:
- 29 November 2024
- Print publication:
- 14 November 2024, pp 12-33
-
- Chapter
- Export citation
Chapter 28 - Editing Dictionaries
- from Part V - The Business of Dictionaries
-
-
- Book:
- The Cambridge Handbook of the Dictionary
- Published online:
- 19 October 2024
- Print publication:
- 31 October 2024, pp 562-592
-
- Chapter
- Export citation
An exploratory qualitative study on factors influencing the level of agreement in symptom reports in child–caregiver dyads
-
- Journal:
- Palliative & Supportive Care / Volume 22 / Issue 6 / December 2024
- Published online by Cambridge University Press:
- 07 October 2024, pp. 2049-2059
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
2 - Rethinking Norm Change
- from Part I - Norm Strength, Collisions, and Conflicts
-
-
- Book:
- Contesting the World
- Published online:
- 01 November 2024
- Print publication:
- 06 June 2024, pp 29-42
-
- Chapter
- Export citation
1 - The Empirical Study of Language
-
- Book:
- English Corpus Linguistics
- Published online:
- 15 June 2023
- Print publication:
- 29 June 2023, pp 1-41
-
- Chapter
- Export citation
Concordance of spatial graphs
- Part of
-
- Journal:
- Canadian Mathematical Bulletin / Volume 66 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 15 March 2023, pp. 1091-1108
- Print publication:
- December 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We define smooth notions of concordance and sliceness for spatial graphs. We prove that sliceness of a spatial graph is equivalent to a condition on a set of linking numbers together with sliceness of a link associated with the graph. This generalizes the result of Taniyama for
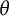 $\theta $-curves.
$\theta $-curves.
3 - Analytical Method 1
-
- Book:
- The Language of Mental Illness
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 47-67
-
- Chapter
- Export citation
9 - Promoting Concordance in Prescribing Interactions
-
-
- Book:
- Independent and Supplementary Prescribing
- Published online:
- 23 December 2021
- Print publication:
- 13 January 2022, pp 156-171
-
- Chapter
- Export citation
Measuring reciprocity: Double sampling, concordance, and network construction
-
- Journal:
- Network Science / Volume 9 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 12 September 2021, pp. 387-402
-
- Article
-
- You have access
- Open access
- Export citation
Mind the gap! the lack of concordance in diagnostic in liaison psychiatry in a portuguese hospital
-
- Journal:
- European Psychiatry / Volume 64 / Issue S1 / April 2021
- Published online by Cambridge University Press:
- 13 August 2021, pp. S653-S654
-
- Article
-
- You have access
- Open access
- Export citation
Chapter 3 - Technology and English Dictionaries
- from Part I - Issues in English Lexicography
-
-
- Book:
- The Cambridge Companion to English Dictionaries
- Published online:
- 18 September 2020
- Print publication:
- 24 September 2020, pp 18-30
-
- Chapter
- Export citation
