Refine search
Actions for selected content:
88 results
Chapter 3 - Truth, Falsity, and the Capacity to Judge
-
-
- Book:
- The Aristotelian Kant
- Published online:
- 15 December 2025
- Print publication:
- 22 January 2026, pp 65-91
-
- Chapter
- Export citation
9 - The Morphology of Verbs
-
- Book:
- Inventing Languages
- Published online:
- 27 November 2025
- Print publication:
- 04 December 2025, pp 171-188
-
- Chapter
- Export citation
10 - Word Order
-
- Book:
- Inventing Languages
- Published online:
- 27 November 2025
- Print publication:
- 04 December 2025, pp 189-203
-
- Chapter
- Export citation
On the licensing of complementizer agreement with nominals in the left periphery
-
- Journal:
- Journal of Linguistics , First View
- Published online by Cambridge University Press:
- 15 August 2025, pp. 1-27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
12 - The Conceptual Foundations of Contract Formation
- from Part III - Reinach and Legal Concepts
-
-
- Book:
- Reinach and the Foundations of Private Law
- Published online:
- 20 July 2025
- Print publication:
- 07 August 2025, pp 305-328
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Infants discover English suffixes allomorph by allomorph
-
- Journal:
- Journal of Child Language , First View
- Published online by Cambridge University Press:
- 01 August 2025, pp. 1-10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
3 - Relationship between the Investment Facilitation for Development and Other WTO Agreements
- from Part I - Investment Facilitation Rules in International and Domestic Law
-
-
- Book:
- The Making of an International Investment Facilitation Framework
- Published online:
- 13 March 2025
- Print publication:
- 20 March 2025, pp 83-106
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
On the Irish agreement pattern and its parallels: Asymmetric chains and defective goals
-
- Journal:
- Journal of Linguistics / Volume 61 / Issue 4 / November 2025
- Published online by Cambridge University Press:
- 10 March 2025, pp. 821-863
- Print publication:
- November 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper focuses on two phenomena in Irish agreement – namely, complementarity between overt in-situ arguments and agreement, and the obviation of this complementarity under A-movement. An analysis of these facts is offered in terms of the defective goal ‘incorporation’ (DGI) mechanism proposed by Roberts (2010), and applied to cases of complementarity in Bantu languages by Iorio (2014), and van der Wal (2015, 2020, 2022), as well as asymmetric chains under A-movement, consisting of a full copy and a pronominal
 $ \phi $-feature bundle; cf. similar configurations discussed by Takahashi & Hulsey (2009), Harizanov (2014), Kramer (2014), Baker & Kramer (2018), inter alios. It is shown that this approach accounts for the facts in Irish and that the same account can be extended to explain facts concerning participial agreement in, for example, Italian. Additional cross-linguistic implications are also considered, particularly with respect to French and Welsh.
$ \phi $-feature bundle; cf. similar configurations discussed by Takahashi & Hulsey (2009), Harizanov (2014), Kramer (2014), Baker & Kramer (2018), inter alios. It is shown that this approach accounts for the facts in Irish and that the same account can be extended to explain facts concerning participial agreement in, for example, Italian. Additional cross-linguistic implications are also considered, particularly with respect to French and Welsh.

Chapter 7 - Justice Springs Internal
-
- Book:
- Justice in Plato's <i>Republic</i>
- Published online:
- 24 January 2025
- Print publication:
- 16 January 2025, pp 181-193
-
- Chapter
- Export citation
11 - Testing the Predictions of Word Grammar, the Minimalist Programme and the Matrix Language Frame Model for German/English Mixed Determiner–Noun Constructions
-
-
- Book:
- Word Grammar, Cognition and Dependency
- Published online:
- 19 December 2024
- Print publication:
- 02 January 2025, pp 252-275
-
- Chapter
- Export citation
Reliability and Expected Loss: A Unifying Principle
-
- Journal:
- Psychometrika / Volume 59 / Issue 2 / June 1994
- Published online by Cambridge University Press:
- 01 January 2025, pp. 203-216
-
- Article
- Export citation
Agreement between Two Independent Groups of Raters
-
- Journal:
- Psychometrika / Volume 74 / Issue 3 / September 2009
- Published online by Cambridge University Press:
- 01 January 2025, pp. 477-491
-
- Article
- Export citation
Measuring Agreement Using Guessing Models and Knowledge Coefficients
-
- Journal:
- Psychometrika / Volume 88 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1002-1025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Several measures of agreement, such as the Perreault–Leigh coefficient, the \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textsc {AC}_{1}$$\end{document}
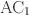 , and the recent coefficient of van Oest, are based on explicit models of how judges make their ratings. To handle such measures of agreement under a common umbrella, we propose a class of models called guessing models, which contains most models of how judges make their ratings. Every guessing model have an associated measure of agreement we call the knowledge coefficient. Under certain assumptions on the guessing models, the knowledge coefficient will be equal to the multi-rater Cohen’s kappa, Fleiss’ kappa, the Brennan–Prediger coefficient, or other less-established measures of agreement. We provide several sample estimators of the knowledge coefficient, valid under varying assumptions, and their asymptotic distributions. After a sensitivity analysis and a simulation study of confidence intervals, we find that the Brennan–Prediger coefficient typically outperforms the others, with much better coverage under unfavorable circumstances.
, and the recent coefficient of van Oest, are based on explicit models of how judges make their ratings. To handle such measures of agreement under a common umbrella, we propose a class of models called guessing models, which contains most models of how judges make their ratings. Every guessing model have an associated measure of agreement we call the knowledge coefficient. Under certain assumptions on the guessing models, the knowledge coefficient will be equal to the multi-rater Cohen’s kappa, Fleiss’ kappa, the Brennan–Prediger coefficient, or other less-established measures of agreement. We provide several sample estimators of the knowledge coefficient, valid under varying assumptions, and their asymptotic distributions. After a sensitivity analysis and a simulation study of confidence intervals, we find that the Brennan–Prediger coefficient typically outperforms the others, with much better coverage under unfavorable circumstances.
A New Interpretation of the Weighted Kappa Coefficients
-
- Journal:
- Psychometrika / Volume 81 / Issue 2 / June 2016
- Published online by Cambridge University Press:
- 01 January 2025, pp. 399-410
-
- Article
- Export citation
Nominal Scale Agreement Among Observers
-
- Journal:
- Psychometrika / Volume 51 / Issue 3 / September 1986
- Published online by Cambridge University Press:
- 01 January 2025, pp. 453-466
-
- Article
- Export citation
Measures of Agreement with Multiple Raters: Fréchet Variances and Inference
-
- Journal:
- Psychometrika / Volume 89 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 27 December 2024, pp. 517-541
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Non-agreeing degree constructions
-
- Journal:
- Journal of Linguistics / Volume 61 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 04 June 2024, pp. 265-300
- Print publication:
- April 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
16 - Numerals and Quantity Expressions
- from Part 3 - Syntax
-
-
- Book:
- The Cambridge Handbook of Slavic Linguistics
- Published online:
- 16 May 2024
- Print publication:
- 23 May 2024, pp 337-364
-
- Chapter
- Export citation
13 - Agreement
- from Part 3 - Syntax
-
-
- Book:
- The Cambridge Handbook of Slavic Linguistics
- Published online:
- 16 May 2024
- Print publication:
- 23 May 2024, pp 263-281
-
- Chapter
- Export citation
Morphosyntactic agreement in English: does it help the listener in noise?
-
- Journal:
- English Language & Linguistics / Volume 29 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 May 2024, pp. 80-101
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
