






1. Introduction
The theory of backward stochastic differential equations (BSDEs), initiated by Bismut [Reference Bismut7] and Pardoux and Peng [Reference Pardoux and Peng32], has been extensively studied over the past three decades, particularly in relation to stochastic control, finance, and insurance (see e.g. [Reference Delong17, Reference Zhang39]). Important applications include dynamic risk measures [Reference Barrieu and El Karoui4] and g-expectations [Reference Coquet, Hu, Memin and Peng16, Reference Peng33], which generalize classical expectations and martingales to nonlinear settings. Recent applications to financial economics include [Reference Beissner, Lin and Riedel6], [Reference Bouchard, Fukasawa, Herdegen and Muhle-Karbe8], [Reference Gonon, Muhle-Karbe and Shi20], [Reference Herdegen, Muhle-Karbe and Possamaï24], [Reference Kardaras, Xing and Žitkovi28], and [Reference Muhle-Karbe, Nutz and Tan30].
While BSDEs are powerful theoretical tools, their solutions are typically implicit and require discretization for numerical implementation. As discrete analogs, backward stochastic difference equations (BS
 $\Delta$
Es) have been widely studied, falling into two main categories. The first focuses on BS
$\Delta$
Es) have been widely studied, falling into two main categories. The first focuses on BS
 $\Delta$
Es as weak approximations of BSDEs [Reference Briand, Delyon and Mémin9, Reference Briand, Delyon and Mémin10, Reference Briand, Geiss, Geiss and Labart11, Reference Cheridito and Stadje12, Reference Ma, Protter, Martín and Torres29, Reference Nakayama31, Reference Stadje35, Reference Tanaka37]. The second explores the structure of BS
$\Delta$
Es as weak approximations of BSDEs [Reference Briand, Delyon and Mémin9, Reference Briand, Delyon and Mémin10, Reference Briand, Geiss, Geiss and Labart11, Reference Cheridito and Stadje12, Reference Ma, Protter, Martín and Torres29, Reference Nakayama31, Reference Stadje35, Reference Tanaka37]. The second explores the structure of BS
 $\Delta$
Es themselves. A general framework is provided in [Reference Cohen and Elliot15], while specific cases involving driving martingales with the predictable representation property are studied in [Reference Cohen and Elliott14] and [Reference Elliott, Siu and Cohen19].
$\Delta$
Es themselves. A general framework is provided in [Reference Cohen and Elliot15], while specific cases involving driving martingales with the predictable representation property are studied in [Reference Cohen and Elliott14] and [Reference Elliott, Siu and Cohen19].
This paper falls into the second category and studies a class of BS
 $\Delta$
Es including the one introduced in [Reference Nakayama31] and [Reference Tanaka37], where a d-dimensional scaled random walk – whose increments take only
$\Delta$
Es including the one introduced in [Reference Nakayama31] and [Reference Tanaka37], where a d-dimensional scaled random walk – whose increments take only
 $d+1$
values – is used to approximate Brownian motion in BSDEs. Such a random walk is minimal among discrete-time processes that converge to d-dimensional Brownian motions. The weak convergence of this BS
$d+1$
values – is used to approximate Brownian motion in BSDEs. Such a random walk is minimal among discrete-time processes that converge to d-dimensional Brownian motions. The weak convergence of this BS
 $\Delta$
E to the BSDE was proved in [Reference Nakayama31], and the convergence rate in a Markovian setting was given in [Reference Tanaka37], generalizing the one-dimensional case in [Reference Briand, Geiss, Geiss and Labart11].
$\Delta$
E to the BSDE was proved in [Reference Nakayama31], and the convergence rate in a Markovian setting was given in [Reference Tanaka37], generalizing the one-dimensional case in [Reference Briand, Geiss, Geiss and Labart11].
This minimal BS
 $\Delta$
E is computationally efficient, as it involves only a
$\Delta$
E is computationally efficient, as it involves only a
 $(d + 1)$
-dimensional problem, in contrast to a
$(d + 1)$
-dimensional problem, in contrast to a
 $2^d$
-dimensional problem required when using d-dimensional Bernoulli random walks [Reference Cheridito and Stadje12]. Although Cohen and Elliott [Reference Cohen and Elliot15] have developed a general BS
$2^d$
-dimensional problem required when using d-dimensional Bernoulli random walks [Reference Cheridito and Stadje12]. Although Cohen and Elliott [Reference Cohen and Elliot15] have developed a general BS
 $\Delta$
E theory, we focus on the specific structure of this minimal BS
$\Delta$
E theory, we focus on the specific structure of this minimal BS
 $\Delta$
E, which exhibits properties not covered in their general framework. In the one-dimensional case, it reduces to a BS
$\Delta$
E, which exhibits properties not covered in their general framework. In the one-dimensional case, it reduces to a BS
 $\Delta$
E on a binomial tree, studied in [Reference Elliott, Siu and Cohen19] in the context of dynamic risk measures. We treat the general multi-dimensional setting here.
$\Delta$
E on a binomial tree, studied in [Reference Elliott, Siu and Cohen19] in the context of dynamic risk measures. We treat the general multi-dimensional setting here.
Our key contribution is to identify a gradient constraint on the BS
 $\Delta$
E driver, which endows the solution with certain properties as a generalized conditional expectation. This allows us to link the driver to a measure change for the driving random walk, and apply these insights to market equilibrium analysis.
$\Delta$
E driver, which endows the solution with certain properties as a generalized conditional expectation. This allows us to link the driver to a measure change for the driving random walk, and apply these insights to market equilibrium analysis.
The g-expectation is part of the solution of a BSDE or BS
 $\Delta$
E, and generalizes the expectation and the certainty equivalent of an expected utility. A subclass of them with concavity and translation invariance has been employed as the utility functional for market equilibrium analyses in [Reference Antar and Dempster3], [Reference Cheridito, Horst, Kupper and Pirvu13], [Reference Horst, Pirvu and Dos Reis25], and [Reference Kardaras, Xing and Žitkovi28]. In this paper, we also apply our BS
$\Delta$
E, and generalizes the expectation and the certainty equivalent of an expected utility. A subclass of them with concavity and translation invariance has been employed as the utility functional for market equilibrium analyses in [Reference Antar and Dempster3], [Reference Cheridito, Horst, Kupper and Pirvu13], [Reference Horst, Pirvu and Dos Reis25], and [Reference Kardaras, Xing and Žitkovi28]. In this paper, we also apply our BS
 $\Delta$
E to a market equilibrium analysis. In contrast to the preceding studies, which place an emphasis on incomplete markets, we are interested in explicit computations in a dynamically complete market.
$\Delta$
E to a market equilibrium analysis. In contrast to the preceding studies, which place an emphasis on incomplete markets, we are interested in explicit computations in a dynamically complete market.
Anderson and Raimondo [Reference Anderson and Raimondo2] proved the existence of equilibrium in a continuous-time dynamically complete market by means of non-standard analysis, where an approximation to a Brownian motion by a minimal random walk played a key role. We consider a simpler dynamically complete market to derive explicit conditions for market equilibrium.
Under a unique equivalent martingale measure, our asset price model is a multi-dimensional extension of the recombining binomial tree. In our approach, an asset price process is given as a stochastic process taking values on a lattice. We do not argue the existence of an equilibrium price but characterize the agents’ utilities under which the given discrete (in both time and space) price process is to be in general equilibrium. This feature is in contrast to the preceding studies [Reference Antar and Dempster3], [Reference Cheridito, Horst, Kupper and Pirvu13], and [Reference Horst, Pirvu and Dos Reis25] and similar to [Reference Bouchard, Fukasawa, Herdegen and Muhle-Karbe8], [Reference He and Leland23], [Reference Kardaras, Xing and Žitkovi28], and [Reference Sekine34] in continuous time.
Our framework includes heterogeneous agents with exponential utilities under heterogeneous beliefs. Their risk-aversion coefficients may be stochastic and time-varying. We observe in particular that under equilibrium with heterogeneous beliefs, agents trade with each other, even in the absence of random endowments to hedge, complementing earlier studies of heterogeneous beliefs [Reference Basak5, Reference Hara21, Reference Harris and Raviv22, Reference Jouini and Napp26, Reference Muhle-Karbe, Nutz and Tan30, Reference Varian38].
In Section 2.1 we describe a lattice in
 $\mathbb{R}^d$
where a stochastic process
$\mathbb{R}^d$
where a stochastic process
 $\{X_n\}$
takes values, and give some elementary linear algebraic lemmas as a preliminary. In Section 2.2 we introduce the process
$\{X_n\}$
takes values, and give some elementary linear algebraic lemmas as a preliminary. In Section 2.2 we introduce the process
 $\{X_n\}$
that is the source of randomness in this paper and generates a filtration. It is minimal in the sense that the increment
$\{X_n\}$
that is the source of randomness in this paper and generates a filtration. It is minimal in the sense that the increment
 $\Delta X_n$
takes values in a set
$\Delta X_n$
takes values in a set
 $\{v_0,\ldots,v_d\}$
of
$\{v_0,\ldots,v_d\}$
of
 $d+1$
points in
$d+1$
points in
 $\mathbb{R}^d$
. Some elementary measure change formulas are also given as a preliminary.
$\mathbb{R}^d$
. Some elementary measure change formulas are also given as a preliminary.
In Section 2.3 our BS
 $\Delta$
E
$\Delta$
E
 \begin{equation*} \Delta Y_n = -g_n(Z_n) + Z_n^\top \Delta X_n,\quad Y_N = Y,\end{equation*}
\begin{equation*} \Delta Y_n = -g_n(Z_n) + Z_n^\top \Delta X_n,\quad Y_N = Y,\end{equation*}
is formulated. Due to the minimality of
 $\{X_n\}$
, there exists a unique solution
$\{X_n\}$
, there exists a unique solution
 $\{(Y_n,Z_n)\}$
to the above equation, without orthogonal martingale terms needed in [Reference Briand, Delyon and Mémin10] and [Reference Cheridito and Stadje12]. The process
$\{(Y_n,Z_n)\}$
to the above equation, without orthogonal martingale terms needed in [Reference Briand, Delyon and Mémin10] and [Reference Cheridito and Stadje12]. The process
 $\{X_n\}$
itself takes more than
$\{X_n\}$
itself takes more than
 $d+1$
points, so this BS
$d+1$
points, so this BS
 $\Delta$
E is different from the one studied in [Reference Cohen and Elliott14]. The g-expectation
$\Delta$
E is different from the one studied in [Reference Cohen and Elliott14]. The g-expectation
 $\mathcal{E}^g_n$
for
$\mathcal{E}^g_n$
for
 $g = \{g_n\}$
is defined by
$g = \{g_n\}$
is defined by
 $\mathcal{E}^g_n(Y) = Y_n$
. Proposition 2.1 concerns the case
$\mathcal{E}^g_n(Y) = Y_n$
. Proposition 2.1 concerns the case
 $g_n(z) = f_n(X_{n-1},z)$
and
$g_n(z) = f_n(X_{n-1},z)$
and
 $Y_N = h(X_N)$
for deterministic functions
$Y_N = h(X_N)$
for deterministic functions
 $f_n$
and h to provide a nonlinear Feynman–Kac-type formula, which is a computationally efficient recurrence equation on the lattice for a deterministic function
$f_n$
and h to provide a nonlinear Feynman–Kac-type formula, which is a computationally efficient recurrence equation on the lattice for a deterministic function
 $u_n$
such that
$u_n$
such that
 $Y_n = u_n(X_n)$
.
$Y_n = u_n(X_n)$
.
Section 2.4 is about the aforementioned gradient constraint. First we observe that the g-expectation is a conditional expectation when
 $g_n$
are linear with slope coefficients included in the convex hull
$g_n$
are linear with slope coefficients included in the convex hull
 $\Theta$
of the set
$\Theta$
of the set
 $\{v_0,\ldots,v_d\}$
. The importance of this constraint on the slope is a special feature of our BS
$\{v_0,\ldots,v_d\}$
. The importance of this constraint on the slope is a special feature of our BS
 $\Delta$
E, and to the best of our knowledge has not been recognized in the preceding studies of multi-dimensional BS
$\Delta$
E, and to the best of our knowledge has not been recognized in the preceding studies of multi-dimensional BS
 $\Delta$
Es. A balance condition introduced by Cohen and Elliot [Reference Cohen and Elliot15] for a comparison theorem to hold is translated in terms of
$\Delta$
Es. A balance condition introduced by Cohen and Elliot [Reference Cohen and Elliot15] for a comparison theorem to hold is translated in terms of
 $\Theta$
for our BS
$\Theta$
for our BS
 $\Delta$
E. We also prove a robust representation when
$\Delta$
E. We also prove a robust representation when
 $g_n$
are concave, where the set
$g_n$
are concave, where the set
 $\Theta$
again plays an important role. In Section 2.5 we show that a translation-invariant filtration-consistent nonlinear expectation is a g-expectation.
$\Theta$
again plays an important role. In Section 2.5 we show that a translation-invariant filtration-consistent nonlinear expectation is a g-expectation.
In Section 3 we regard
 $\{X_n\}$
as a d-dimensional asset price process. In Section 3.1 we consider an optimal investment strategy which maximizes the g-expectation of terminal wealth. By the minimality, the market is complete, extending the well-known binomial tree model for a one-dimensional asset. Our asset price model can be seen as a discrete approximation of the multi-dimensional Bachelier model with constant covariance and general stochastic drift. An advantage of our use of the minimal process as an approximation is that the completeness of the Bachelier model is preserved. Further, the minimality property naturally arises in a variance swap pricing model as illustrated in Example 3.2. In Sections 3.2–3.4 we give a market equilibrium analysis. We consider agents whose utility functionals are g expectations and seek conditions on those g expectations under which
$\{X_n\}$
as a d-dimensional asset price process. In Section 3.1 we consider an optimal investment strategy which maximizes the g-expectation of terminal wealth. By the minimality, the market is complete, extending the well-known binomial tree model for a one-dimensional asset. Our asset price model can be seen as a discrete approximation of the multi-dimensional Bachelier model with constant covariance and general stochastic drift. An advantage of our use of the minimal process as an approximation is that the completeness of the Bachelier model is preserved. Further, the minimality property naturally arises in a variance swap pricing model as illustrated in Example 3.2. In Sections 3.2–3.4 we give a market equilibrium analysis. We consider agents whose utility functionals are g expectations and seek conditions on those g expectations under which
 $\{X_n\}$
is an equilibrium price process.
$\{X_n\}$
is an equilibrium price process.
Throughout our financial application, we have short maturity problems in mind, and so, for brevity, assume interest rates, dividend rates, and consumption rates to be zero as in [Reference Antar and Dempster3], [Reference Cheridito, Horst, Kupper and Pirvu13], [Reference Horst, Pirvu and Dos Reis25], and [Reference Kardaras, Xing and Žitkovi28].
We use the convention that
 \begin{equation*} \sum_{i=m}^n a_i= 0\end{equation*}
\begin{equation*} \sum_{i=m}^n a_i= 0\end{equation*}
for any sequence
 $\{a_i\}$
if
$\{a_i\}$
if
 $m \gt n$
.
$m \gt n$
.
2. BS
 $\Delta$
E on a lattice
$\Delta$
E on a lattice

2.1. Lattice
We start by describing a lattice. Let
 $\{v_1,\ldots, v_d\}$
be a basis of
$\{v_1,\ldots, v_d\}$
be a basis of
 $\mathbb{R}^d$
. The subset
$\mathbb{R}^d$
. The subset
 \begin{equation*} L = \Biggl\{\sum_{i=1}^d z_i v_i, \ ; \ z_i \in \mathbb{Z}, i=1,\ldots, d\Biggr\}\end{equation*}
\begin{equation*} L = \Biggl\{\sum_{i=1}^d z_i v_i, \ ; \ z_i \in \mathbb{Z}, i=1,\ldots, d\Biggr\}\end{equation*}
of
 $\mathbb{R}^d$
is a d-dimensional lattice generated by the basis. Notice that L admits an alternative expression
$\mathbb{R}^d$
is a d-dimensional lattice generated by the basis. Notice that L admits an alternative expression
 \begin{equation} L = \Biggl\{\sum_{i=0}^d n_i v_i, \ ; \ n_i \in \mathbb{N}, i=0,1,\ldots, d\Biggr\},\end{equation}
\begin{equation} L = \Biggl\{\sum_{i=0}^d n_i v_i, \ ; \ n_i \in \mathbb{N}, i=0,1,\ldots, d\Biggr\},\end{equation}
where
 $v_0 = -v_1 - \cdots - v_d$
and
$v_0 = -v_1 - \cdots - v_d$
and
 $\mathbb{N}$
is the set of the non-negative integers. Let
$\mathbb{N}$
is the set of the non-negative integers. Let
 \begin{equation*} \mathbf{v} = [v_0,v_1,\ldots,v_d]\end{equation*}
\begin{equation*} \mathbf{v} = [v_0,v_1,\ldots,v_d]\end{equation*}
be the
 $d \times (d+1)$
matrix with
$d \times (d+1)$
matrix with
 $v_i$
,
$v_i$
,
 $i=0,\ldots, d$
as its column vectors. Put
$i=0,\ldots, d$
as its column vectors. Put
 \begin{equation*} \mathbf{1} = (1,\ldots,1)^\top \in \mathbb{R}^{d+1}.\end{equation*}
\begin{equation*} \mathbf{1} = (1,\ldots,1)^\top \in \mathbb{R}^{d+1}.\end{equation*}
The following lemmas will be of repeated use in this paper.
Lemma 2.1. The
 $(d+1)\times (d+1)$
matrix
$(d+1)\times (d+1)$
matrix
 $(\mathbf{1},\mathbf{v}^\top)$
is invertible.
$(\mathbf{1},\mathbf{v}^\top)$
is invertible.
Proof. We show that the row vectors of
 $(\mathbf{1},\mathbf{v}^\top)$
are linearly independent. Suppose
$(\mathbf{1},\mathbf{v}^\top)$
are linearly independent. Suppose
 \begin{equation*} (\alpha_0,\ldots,\alpha_d)(\mathbf{1},\mathbf{v}^\top) = 0,\end{equation*}
\begin{equation*} (\alpha_0,\ldots,\alpha_d)(\mathbf{1},\mathbf{v}^\top) = 0,\end{equation*}
or equivalently
 \begin{equation*} \sum_{j=0}^d \alpha_j = 0,\quad \sum_{j=0}^d \alpha_j v_j = 0\end{equation*}
\begin{equation*} \sum_{j=0}^d \alpha_j = 0,\quad \sum_{j=0}^d \alpha_j v_j = 0\end{equation*}
for scalars
 $\alpha_j$
. By the second equation and the definition of
$\alpha_j$
. By the second equation and the definition of
 $v_0$
, we have
$v_0$
, we have
 \begin{equation*} \sum_{j=1}^d (\alpha_j -\alpha_0) v_j = 0,\end{equation*}
\begin{equation*} \sum_{j=1}^d (\alpha_j -\alpha_0) v_j = 0,\end{equation*}
from which we can conclude
 $\alpha_j = \alpha_0 $
for all j because
$\alpha_j = \alpha_0 $
for all j because
 $\{v_1,\ldots,v_d\}$
is a basis. Together with the first equation, we then conclude
$\{v_1,\ldots,v_d\}$
is a basis. Together with the first equation, we then conclude
 $\alpha_j = 0$
for all j.
$\alpha_j = 0$
for all j.
Lemma 2.2. Let
 $y \in \mathbb{R}^{d+1}$
. The unique solution to the equation
$y \in \mathbb{R}^{d+1}$
. The unique solution to the equation
 \begin{equation} y = (\mathbf{1}, \mathbf{v}^\top) z, \quad z = (z_0,z_1,\ldots,z_d)^\top \in \mathbb{R}^{d+1}\end{equation}
\begin{equation} y = (\mathbf{1}, \mathbf{v}^\top) z, \quad z = (z_0,z_1,\ldots,z_d)^\top \in \mathbb{R}^{d+1}\end{equation}
is given by
 \begin{equation} z_0 = a(y) \,:\!=\, \frac{1}{d+1} \mathbf{1}^\top y, \quad (z_1,\ldots,z_d)^\top = b(y) \,:\!=\, (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v}y. \end{equation}
\begin{equation} z_0 = a(y) \,:\!=\, \frac{1}{d+1} \mathbf{1}^\top y, \quad (z_1,\ldots,z_d)^\top = b(y) \,:\!=\, (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v}y. \end{equation}
Proof. By Lemma 2.1, there exists a unique
 $z \in \mathbb{R}^{d+1}$
such that (2.2) holds. Since
$z \in \mathbb{R}^{d+1}$
such that (2.2) holds. Since
 $\mathbf{v}\mathbf{1} = 0$
, multiplying both sides of (2.2) by
$\mathbf{v}\mathbf{1} = 0$
, multiplying both sides of (2.2) by
 $\mathbf{1}^\top$
, we obtain the first equation of (2.3). Also, multiplying both sides of (2.2) by
$\mathbf{1}^\top$
, we obtain the first equation of (2.3). Also, multiplying both sides of (2.2) by
 $\mathbf{v}$
and again using
$\mathbf{v}$
and again using
 $\mathbf{v}\mathbf{1} = 0$
, we have
$\mathbf{v}\mathbf{1} = 0$
, we have
 $\mathbf{v}y = \mathbf{v}\mathbf{v}^\top (z_1,\ldots,z_d)^\top$
. Since
$\mathbf{v}y = \mathbf{v}\mathbf{v}^\top (z_1,\ldots,z_d)^\top$
. Since
 $\{v_1,\ldots,v_d\}$
is a basis,
$\{v_1,\ldots,v_d\}$
is a basis,
 $\mathbf{v}$
has rank d. Therefore
$\mathbf{v}$
has rank d. Therefore
 $\mathbf{v}^\top$
has rank d and so, for any
$\mathbf{v}^\top$
has rank d and so, for any
 $x \in \mathbb{R}^d\setminus\{0\}$
,
$x \in \mathbb{R}^d\setminus\{0\}$
,
 $x^\top \mathbf{v}\mathbf{v}^\top x = | \mathbf{v}^\top x|^2 \neq 0$
. This implies that the
$x^\top \mathbf{v}\mathbf{v}^\top x = | \mathbf{v}^\top x|^2 \neq 0$
. This implies that the
 $d\times d$
matrix
$d\times d$
matrix
 $\mathbf{v}\mathbf{v}^\top$
is invertible and, in turn, the second equation of (2.3) is valid.
$\mathbf{v}\mathbf{v}^\top$
is invertible and, in turn, the second equation of (2.3) is valid.
2.2. Probability space
Let
 $(\Omega,\mathscr{F},\mathbb{P})$
be a probability space. For a stochastic process
$(\Omega,\mathscr{F},\mathbb{P})$
be a probability space. For a stochastic process
 $\{X_n\}_{n \in \mathbb{N}}$
, we put
$\{X_n\}_{n \in \mathbb{N}}$
, we put
 $\Delta X_n = X_n - X_{n-1}$
. Let
$\Delta X_n = X_n - X_{n-1}$
. Let
 $\{X_n\}$
be a d-dimensional stochastic process with
$\{X_n\}$
be a d-dimensional stochastic process with
 $\Delta X_n$
taking values in
$\Delta X_n$
taking values in
 $\{v_0,v_1,\ldots,v_d\}$
for all
$\{v_0,v_1,\ldots,v_d\}$
for all
 $n \geq 1$
and
$n \geq 1$
and
 $X_0 = 0$
. By (2.1),
$X_0 = 0$
. By (2.1),
 $X_n$
takes values in L for all
$X_n$
takes values in L for all
 $n \in \mathbb{N}$
. Let
$n \in \mathbb{N}$
. Let
 $\mathscr{F}_n = \sigma(X_0,\ldots,X_n)$
,
$\mathscr{F}_n = \sigma(X_0,\ldots,X_n)$
,
 $ n\in \mathbb{N}$
, be the natural filtration generated by
$ n\in \mathbb{N}$
, be the natural filtration generated by
 $\{X_n\}$
, and put
$\{X_n\}$
, and put
 $P_n = (P_{n,0},\ldots, P_{n,d})^\top$
for
$P_n = (P_{n,0},\ldots, P_{n,d})^\top$
for
 $n\geq 1$
, where
$n\geq 1$
, where
 \begin{equation*} P_{n,j} = \mathbb{P}(\Delta X_n = v_j \mid \mathscr{F}_{n-1}), \quad j=0,\ldots, d.\end{equation*}
\begin{equation*} P_{n,j} = \mathbb{P}(\Delta X_n = v_j \mid \mathscr{F}_{n-1}), \quad j=0,\ldots, d.\end{equation*}
Note that
 $\{P_n\}$
is a
$\{P_n\}$
is a
 $\Delta_d$
-valued predictable process, where
$\Delta_d$
-valued predictable process, where
 \begin{equation*} \Delta_d = \bigl\{p \in \mathbb{R}^{d+1}\ ; \ \mathbf{1}^\top p = 1, \ p \geq 0\bigr\}.\end{equation*}
\begin{equation*} \Delta_d = \bigl\{p \in \mathbb{R}^{d+1}\ ; \ \mathbf{1}^\top p = 1, \ p \geq 0\bigr\}.\end{equation*}
We assume
 $P_{n,j}$
is positive for all
$P_{n,j}$
is positive for all
 $n \geq 1$
and
$n \geq 1$
and
 $j = 0,\ldots, d$
. Let
$j = 0,\ldots, d$
. Let
 $N \in \mathbb{N}\setminus\{0\}$
. The following lemma will be of repeated use in this paper.
$N \in \mathbb{N}\setminus\{0\}$
. The following lemma will be of repeated use in this paper.
Lemma 2.3. For any
 $\Delta_d$
-valued predictable process
$\Delta_d$
-valued predictable process
 $\{\hat{P}_n\}$
, there exists a probability measure
$\{\hat{P}_n\}$
, there exists a probability measure
 $\hat{\mathbb{P}}$
on
$\hat{\mathbb{P}}$
on
 $(\Omega,\mathscr{F}_N)$
such that
$(\Omega,\mathscr{F}_N)$
such that
 $\hat{P}_n = (\hat{P}_{n,0},\ldots, \hat{P}_{n,d})^\top$
, where
$\hat{P}_n = (\hat{P}_{n,0},\ldots, \hat{P}_{n,d})^\top$
, where
 \begin{equation} \hat{P}_{n,j} = \hat{\mathbb{P}}(\Delta X_n = v_j \mid \mathscr{F}_{n-1}), \quad j=0,\ldots, d, \ n=1,\ldots, N.\end{equation}
\begin{equation} \hat{P}_{n,j} = \hat{\mathbb{P}}(\Delta X_n = v_j \mid \mathscr{F}_{n-1}), \quad j=0,\ldots, d, \ n=1,\ldots, N.\end{equation}
Proof. Define
 $\hat{\mathbb{P}}$
by
$\hat{\mathbb{P}}$
by
 \begin{equation} \hat{\mathbb{P}}(A) = \mathbb{E}[L_N1_A],\quad L_n = \prod_{k=1}^n \Biggl(\sum_{j=0}^d\frac{\hat{P}_{k,j}}{P_{k,j}}1_{\{\Delta X_k = v_j \}} \Biggr) \end{equation}
\begin{equation} \hat{\mathbb{P}}(A) = \mathbb{E}[L_N1_A],\quad L_n = \prod_{k=1}^n \Biggl(\sum_{j=0}^d\frac{\hat{P}_{k,j}}{P_{k,j}}1_{\{\Delta X_k = v_j \}} \Biggr) \end{equation}
for
 $A \in \mathscr{F}_N$
. The measure
$A \in \mathscr{F}_N$
. The measure
 $\hat{\mathbb{P}}$
is a probability measure because
$\hat{\mathbb{P}}$
is a probability measure because
 \begin{equation*} \mathbb{E}\Biggl[ \sum_{j=0}^d\frac{\hat{P}_{n,j}}{P_{n,j}}1_{\{\Delta X_n = v_j \}} \bigg| \mathscr{F}_{n-1}\Biggr] = \sum_{j=0}^d\frac{\hat{P}_{n,j}}{P_{n,j}} P_{n,j} = 1\end{equation*}
\begin{equation*} \mathbb{E}\Biggl[ \sum_{j=0}^d\frac{\hat{P}_{n,j}}{P_{n,j}}1_{\{\Delta X_n = v_j \}} \bigg| \mathscr{F}_{n-1}\Biggr] = \sum_{j=0}^d\frac{\hat{P}_{n,j}}{P_{n,j}} P_{n,j} = 1\end{equation*}
and so
 $L_n$
is a martingale with
$L_n$
is a martingale with
 $L_0 = 1$
. Using Bayes’ formula, we derive
$L_0 = 1$
. Using Bayes’ formula, we derive
 \begin{equation*} \hat{\mathbb{P}}(\Delta X_n =v_j \mid \mathscr{F}_{n-1}) = \frac{\mathbb{E}[L_N1_{\{\Delta X_n = v_j\}}\mid \mathscr{F}_{n-1}]}{\mathbb{E}[L_N \mid \mathscr{F}_{n-1}]} = \mathbb{E}\biggl[ \frac{\hat{P}_{n,j}}{P_{n,j}}1_{\{\Delta X_n = v_j \}} \bigg| \mathscr{F}_{n-1}\biggr] = \hat{P}_{n,j},\end{equation*}
\begin{equation*} \hat{\mathbb{P}}(\Delta X_n =v_j \mid \mathscr{F}_{n-1}) = \frac{\mathbb{E}[L_N1_{\{\Delta X_n = v_j\}}\mid \mathscr{F}_{n-1}]}{\mathbb{E}[L_N \mid \mathscr{F}_{n-1}]} = \mathbb{E}\biggl[ \frac{\hat{P}_{n,j}}{P_{n,j}}1_{\{\Delta X_n = v_j \}} \bigg| \mathscr{F}_{n-1}\biggr] = \hat{P}_{n,j},\end{equation*}
by the martingale property of
 $L_n$
.
$L_n$
.
Define a measure
 $\mathbb{Q}$
on
$\mathbb{Q}$
on
 $\mathscr{F}_N$
by
$\mathscr{F}_N$
by
 \begin{equation*} \mathbb{Q}(A) = \mathbb{E}[L_N1_A],\quad L_N = \prod_{n=1}^N \Biggl( \frac{1}{d+1} \sum_{j=0}^d\frac{1}{P_{n,j}}1_{\{\Delta X_n = v_j \}} \Biggr). \end{equation*}
\begin{equation*} \mathbb{Q}(A) = \mathbb{E}[L_N1_A],\quad L_N = \prod_{n=1}^N \Biggl( \frac{1}{d+1} \sum_{j=0}^d\frac{1}{P_{n,j}}1_{\{\Delta X_n = v_j \}} \Biggr). \end{equation*}
Let
 $\mathbb{E}_\mathbb{Q}$
denote the integration under
$\mathbb{E}_\mathbb{Q}$
denote the integration under
 $\mathbb{Q}$
.
$\mathbb{Q}$
.
Lemma 2.4. The measure
 $\mathbb{Q}$
is the unique probability measure on
$\mathbb{Q}$
is the unique probability measure on
 $\mathscr{F}_N$
under which
$\mathscr{F}_N$
under which
 $\{X_n\}$
is a martingale. Under
$\{X_n\}$
is a martingale. Under
 $\mathbb{Q}$
,
$\mathbb{Q}$
,
 $\{\Delta X_n\}$
is i.i.d. with
$\{\Delta X_n\}$
is i.i.d. with
 \begin{equation*} \mathbb{Q}(\Delta X_n = v_j ) = \mathbb{Q}(\Delta X_n =v_j \mid \mathscr{F}_{n-1}) = \frac{1}{d+1}\end{equation*}
\begin{equation*} \mathbb{Q}(\Delta X_n = v_j ) = \mathbb{Q}(\Delta X_n =v_j \mid \mathscr{F}_{n-1}) = \frac{1}{d+1}\end{equation*}
for all
 $n =1,\ldots, N$
and
$n =1,\ldots, N$
and
 $j=0,\ldots, d$
. We also have
$j=0,\ldots, d$
. We also have
 \begin{equation}\mathbb{E}_\mathbb{Q}[\Delta X_n \mid\mathscr{F}_{n-1}] = 0,\quad \mathbb{E}_\mathbb{Q}[\Delta X_n (\Delta X_n)^\top \mid\mathscr{F}_{n-1}] = \frac{1}{d+1} \mathbf{v}\mathbf{v}^\top.\end{equation}
\begin{equation}\mathbb{E}_\mathbb{Q}[\Delta X_n \mid\mathscr{F}_{n-1}] = 0,\quad \mathbb{E}_\mathbb{Q}[\Delta X_n (\Delta X_n)^\top \mid\mathscr{F}_{n-1}] = \frac{1}{d+1} \mathbf{v}\mathbf{v}^\top.\end{equation}
Proof. By Lemma 2.3,
 $\mathbb{Q}$
is a probability measure with
$\mathbb{Q}$
is a probability measure with
 $ \mathbb{Q}(\Delta X_n =v_j \mid \mathscr{F}_{n-1}) = 1/(d+1)$
, which implies
$ \mathbb{Q}(\Delta X_n =v_j \mid \mathscr{F}_{n-1}) = 1/(d+1)$
, which implies
 \begin{equation*} \mathbb{E}_\mathbb{Q}[\Delta X_n \mid\mathscr{F}_{n-1}] = \frac{1}{d+1} \mathbf{v}\mathbf{1} = 0.\end{equation*}
\begin{equation*} \mathbb{E}_\mathbb{Q}[\Delta X_n \mid\mathscr{F}_{n-1}] = \frac{1}{d+1} \mathbf{v}\mathbf{1} = 0.\end{equation*}
Therefore
 $\{X_n\}$
is a martingale with (2.6). There is no other such measure because
$\{X_n\}$
is a martingale with (2.6). There is no other such measure because
 \begin{equation*} \sum_{j=0}^d \alpha_j = 1, \quad \sum_{j=0}^d \alpha_j v_j = 0\end{equation*}
\begin{equation*} \sum_{j=0}^d \alpha_j = 1, \quad \sum_{j=0}^d \alpha_j v_j = 0\end{equation*}
implies
 $\alpha_j = 1/(d+1)$
as in the proof of Lemma 2.1. Since the conditional law of
$\alpha_j = 1/(d+1)$
as in the proof of Lemma 2.1. Since the conditional law of
 $\Delta X_n$
given
$\Delta X_n$
given
 $\mathscr{F}_{n-1}$
is deterministic for every n,
$\mathscr{F}_{n-1}$
is deterministic for every n,
 $\{\Delta X_n\}$
is i.i.d.
$\{\Delta X_n\}$
is i.i.d.
Remark 2.1. For any positive definite
 $d\times d$
matrix
$d\times d$
matrix
 $\Sigma$
, we can construct such a lattice L that
$\Sigma$
, we can construct such a lattice L that
 $\mathbf{v}\mathbf{v}^\top = \Sigma$
. Indeed, starting with an arbitrary basis, say,
$\mathbf{v}\mathbf{v}^\top = \Sigma$
. Indeed, starting with an arbitrary basis, say,
 $\bar{v}_j = e_j$
(the standard basis of
$\bar{v}_j = e_j$
(the standard basis of
 $\mathbb{R}^d)$
with
$\mathbb{R}^d)$
with
 $\bar{v}_0 = -\bar{v}_1 - \cdots - \bar{v}_d$
and
$\bar{v}_0 = -\bar{v}_1 - \cdots - \bar{v}_d$
and
 $\bar{\mathbf{v}} = [\bar{v}_0, \ldots, \bar{v}_d]$
, using the Cholesky decomposition
$\bar{\mathbf{v}} = [\bar{v}_0, \ldots, \bar{v}_d]$
, using the Cholesky decomposition
 $\Sigma = CC^\top$
and
$\Sigma = CC^\top$
and
 $\bar{\mathbf{v}}\bar{\mathbf{v}}^\top= \bar{C}\bar{C}^\top$
, if we take
$\bar{\mathbf{v}}\bar{\mathbf{v}}^\top= \bar{C}\bar{C}^\top$
, if we take
 $v_j = C\bar{C}^{-1}\bar{v}_j$
,
$v_j = C\bar{C}^{-1}\bar{v}_j$
,
 $j=0,\ldots, d$
, then
$j=0,\ldots, d$
, then
 $\mathbf{v} = C\bar{C}^{-1}\bar{\mathbf{v}}$
and so we get
$\mathbf{v} = C\bar{C}^{-1}\bar{\mathbf{v}}$
and so we get
 $\mathbf{vv}^\top = C\bar{C}^{-1}\bar{\mathbf{v}}\bar{\mathbf{v}}^\top (\bar{C}^\top)^{-1}C^\top = \Sigma$
. In particular, we can construct such
$\mathbf{vv}^\top = C\bar{C}^{-1}\bar{\mathbf{v}}\bar{\mathbf{v}}^\top (\bar{C}^\top)^{-1}C^\top = \Sigma$
. In particular, we can construct such
 $v_j$
that
$v_j$
that
 $\mathbf{vv}^\top$
is the identity matrix. In this case a scaling limit of
$\mathbf{vv}^\top$
is the identity matrix. In this case a scaling limit of
 $\{X_n\}$
under
$\{X_n\}$
under
 $\mathbb{Q}$
is the d-dimensional standard Brownian motion. Such a set of vectors played an essential role in proving the existence of continuous-time market equilibrium in Anderson and Raimondo [Reference Anderson and Raimondo2] by means of non-standard analysis, where the existence of the vectors was proved in a recursive manner. It is also the building block of a d-dimensional diamond in topological crystallography [Reference Sunada36].
$\mathbb{Q}$
is the d-dimensional standard Brownian motion. Such a set of vectors played an essential role in proving the existence of continuous-time market equilibrium in Anderson and Raimondo [Reference Anderson and Raimondo2] by means of non-standard analysis, where the existence of the vectors was proved in a recursive manner. It is also the building block of a d-dimensional diamond in topological crystallography [Reference Sunada36].
2.3. Existence, uniqueness and representation
Here we introduce our BS
 $\Delta$
E. Let
$\Delta$
E. Let
 $\mathcal{A}$
denote the set of the sequences
$\mathcal{A}$
denote the set of the sequences
 $g = \{g_n\}_{n=1}^N$
of
$g = \{g_n\}_{n=1}^N$
of
 $\mathscr{F}_{n-1}\otimes \mathscr{B}(\mathbb{R}^d)$
measurable functions
$\mathscr{F}_{n-1}\otimes \mathscr{B}(\mathbb{R}^d)$
measurable functions
 $g_n\colon \Omega \times \mathbb{R}^d \to \mathbb{R}$
. Now we state an elementary but fundamental result.
$g_n\colon \Omega \times \mathbb{R}^d \to \mathbb{R}$
. Now we state an elementary but fundamental result.
Theorem 2.1. Let
 $Y_N$
be an
$Y_N$
be an
 $\mathscr{F}_N$
-measurable random variable, and let
$\mathscr{F}_N$
-measurable random variable, and let
 $g = \{g_n\} \in \mathcal{A}$
. Then there exist uniquely an adapted process
$g = \{g_n\} \in \mathcal{A}$
. Then there exist uniquely an adapted process
 $\{Y_n\}_{n=0,\ldots,N-1}$
and an
$\{Y_n\}_{n=0,\ldots,N-1}$
and an
 $\mathbb{R}^d$
-valued predictable process
$\mathbb{R}^d$
-valued predictable process
 $\{Z_n\}_{n=1,\ldots,N}$
such that
$\{Z_n\}_{n=1,\ldots,N}$
such that
 \begin{equation} \Delta Y_n = -g_n(Z_n) + Z_n^\top \Delta X_n,\quad n=1,\ldots, N.\end{equation}
\begin{equation} \Delta Y_n = -g_n(Z_n) + Z_n^\top \Delta X_n,\quad n=1,\ldots, N.\end{equation}
Further, they admit the following representation:
 \begin{align*}Y_{n-1}& = \mathbb{E}_\mathbb{Q}[Y_n\mid\mathscr{F}_{n-1}] + g_n(Z_n),\\*Z_n& = (d+1) (\mathbf{v}\mathbf{v}^\top)^{-1} \mathbb{E}_\mathbb{Q}[Y_n \Delta X_n\mid \mathscr{F}_{n-1}]= (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v}\bar{Y}_n,\end{align*}
\begin{align*}Y_{n-1}& = \mathbb{E}_\mathbb{Q}[Y_n\mid\mathscr{F}_{n-1}] + g_n(Z_n),\\*Z_n& = (d+1) (\mathbf{v}\mathbf{v}^\top)^{-1} \mathbb{E}_\mathbb{Q}[Y_n \Delta X_n\mid \mathscr{F}_{n-1}]= (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v}\bar{Y}_n,\end{align*}
where
 $\bar{Y}_n = (\bar{Y}_{n,0}, \ldots, \bar{Y}_{n,d})^\top$
and
$\bar{Y}_n = (\bar{Y}_{n,0}, \ldots, \bar{Y}_{n,d})^\top$
and
 \begin{equation*} \bar{Y}_{n,j} = \mathbb{E}_\mathbb{Q}[Y_n\mid\mathscr{F}_{n-1}, \Delta X_n = v_j] = (d+1) \mathbb{E}_\mathbb{Q}[Y_n1_{\{\Delta X_n = v_j\}}\mid \mathscr{F}_{n-1}].\end{equation*}
\begin{equation*} \bar{Y}_{n,j} = \mathbb{E}_\mathbb{Q}[Y_n\mid\mathscr{F}_{n-1}, \Delta X_n = v_j] = (d+1) \mathbb{E}_\mathbb{Q}[Y_n1_{\{\Delta X_n = v_j\}}\mid \mathscr{F}_{n-1}].\end{equation*}
Proof. Since
 $Y_N$
is
$Y_N$
is
 $\mathscr{F}_N$
-measurable, there exists a function
$\mathscr{F}_N$
-measurable, there exists a function
 $f\colon L^N \to \mathbb{R}$
such that
$f\colon L^N \to \mathbb{R}$
such that
 $Y_N = f(X_1,\ldots,X_N)$
. Since
$Y_N = f(X_1,\ldots,X_N)$
. Since
 $\mathbb{P}_{N,j}$
are positive by the assumption, (2.7) for
$\mathbb{P}_{N,j}$
are positive by the assumption, (2.7) for
 $n=N$
is equivalent to the system of equations for
$n=N$
is equivalent to the system of equations for
 $\mathscr{F}_{N-1}$
-measurable random variables
$\mathscr{F}_{N-1}$
-measurable random variables
 \begin{equation*}Y\,:\!=\,\begin{bmatrix}f(X_1,\ldots,X_{N-1},X_{N-1} + v_0) \\ \vdots\\f(X_1,\ldots,X_{N-1},X_{N-1} + v_d)\end{bmatrix}= (\mathbf{1},\mathbf{v}^\top)\begin{bmatrix} Y_{N-1} - g_N(Z_N) \\ Z_N\end{bmatrix}\!.\end{equation*}
\begin{equation*}Y\,:\!=\,\begin{bmatrix}f(X_1,\ldots,X_{N-1},X_{N-1} + v_0) \\ \vdots\\f(X_1,\ldots,X_{N-1},X_{N-1} + v_d)\end{bmatrix}= (\mathbf{1},\mathbf{v}^\top)\begin{bmatrix} Y_{N-1} - g_N(Z_N) \\ Z_N\end{bmatrix}\!.\end{equation*}
Applying Lemma 2.2, we obtain (2.7) for
 $n=N$
with
$n=N$
with
 \begin{equation*} Z_N = b(Y), \quad Y_{N-1} = a(Y)+g_N(Z_N),\end{equation*}
\begin{equation*} Z_N = b(Y), \quad Y_{N-1} = a(Y)+g_N(Z_N),\end{equation*}
where a(y) and b(y) are defined by (2.3). It is clear that both
 $Z_N$
and
$Z_N$
and
 $Y_{N-1}$
are
$Y_{N-1}$
are
 $\mathscr{F}_{N-1}$
-measurable. By backward induction, we obtain
$\mathscr{F}_{N-1}$
-measurable. By backward induction, we obtain
 $\{Y_n\}$
and
$\{Y_n\}$
and
 $\{Z_n\}$
. The representation follows from (2.7) and (2.6) by taking the conditional expectation under
$\{Z_n\}$
. The representation follows from (2.7) and (2.6) by taking the conditional expectation under
 $\mathbb{Q}$
.
$\mathbb{Q}$
.
For
 $g = \{g_n\} \in \mathcal{A}$
fixed, the
$g = \{g_n\} \in \mathcal{A}$
fixed, the
 $\mathscr{F}_n$
-measurable random variable
$\mathscr{F}_n$
-measurable random variable
 $Y_n$
given by Theorem 2.1 is uniquely determined by the
$Y_n$
given by Theorem 2.1 is uniquely determined by the
 $\mathscr{F}_N$
-measurable random variable
$\mathscr{F}_N$
-measurable random variable
 $Y_N$
. We write this mapping as
$Y_N$
. We write this mapping as
 $Y_n = \mathcal{E}^g_n(Y_N)$
and call it the g-expectation of
$Y_n = \mathcal{E}^g_n(Y_N)$
and call it the g-expectation of
 $Y_N$
(with respect to
$Y_N$
(with respect to
 $\mathscr{F}_n$
). The stochastic process
$\mathscr{F}_n$
). The stochastic process
 $\{(Y_n,Z_n)\}$
given by Theorem 2.1 is called the solution of the BS
$\{(Y_n,Z_n)\}$
given by Theorem 2.1 is called the solution of the BS
 $\Delta$
E (2.7).
$\Delta$
E (2.7).
Remark 2.2. In the literature, say, in [Reference Cohen and Elliot15], BS
 $\Delta$
E is formulated by decomposing
$\Delta$
E is formulated by decomposing
 $\Delta Y_n$
into a predictable part and a martingale difference part. In our formulation (2.7),
$\Delta Y_n$
into a predictable part and a martingale difference part. In our formulation (2.7),
 $\Delta X_n$
is not necessarily a martingale difference. It is a minor reparametrization because (2.7) can be rewritten as
$\Delta X_n$
is not necessarily a martingale difference. It is a minor reparametrization because (2.7) can be rewritten as
 \begin{equation*} \Delta Y_n = - \hat{g}_n(Z_n) + Z_n^\top(\Delta X_n - A_n)\end{equation*}
\begin{equation*} \Delta Y_n = - \hat{g}_n(Z_n) + Z_n^\top(\Delta X_n - A_n)\end{equation*}
with
 $\hat{g}_n(z) = g_n(z) - z^\top A_n$
,
$\hat{g}_n(z) = g_n(z) - z^\top A_n$
,
 $A_n = \mathbb{E}[\Delta X_n \mid \mathscr{F}_{n-1}]$
.
$A_n = \mathbb{E}[\Delta X_n \mid \mathscr{F}_{n-1}]$
.
Example 2.1. Let
 $\gamma \gt 0$
,
$\gamma \gt 0$
,
 $\{(\hat{P}_{n,0},\ldots,\hat{P}_{n,d})^\top\}$
be a
$\{(\hat{P}_{n,0},\ldots,\hat{P}_{n,d})^\top\}$
be a
 $\Delta_d$
-valued predictable process, and
$\Delta_d$
-valued predictable process, and
 \begin{equation} g_n(z) = -\frac{1}{\gamma} \log \Biggl(\sum_{j=0}^{d} \,{\mathrm{e}}^{-\gamma z^\top v_j} {\hat{P}}_{n,j}\Biggr).\end{equation}
\begin{equation} g_n(z) = -\frac{1}{\gamma} \log \Biggl(\sum_{j=0}^{d} \,{\mathrm{e}}^{-\gamma z^\top v_j} {\hat{P}}_{n,j}\Biggr).\end{equation}
Then
 \begin{equation} \mathcal{E}^g_n(Y) = -\frac{1}{\gamma} \log \hat{\mathbb{E}}\big[{\mathrm{e}}^{-\gamma Y}\mid \mathscr{F}_n\big], \quad n=0,1,\ldots, N ,\end{equation}
\begin{equation} \mathcal{E}^g_n(Y) = -\frac{1}{\gamma} \log \hat{\mathbb{E}}\big[{\mathrm{e}}^{-\gamma Y}\mid \mathscr{F}_n\big], \quad n=0,1,\ldots, N ,\end{equation}
for any
 $\mathscr{F}_N$
-measurable random variable Y, where
$\mathscr{F}_N$
-measurable random variable Y, where
 $\hat{\mathbb{E}}$
is the expectation under the measure
$\hat{\mathbb{E}}$
is the expectation under the measure
 $\hat{\mathbb{P}}$
on
$\hat{\mathbb{P}}$
on
 $\mathscr{F}_N$
defined by (2.5). To see this, note that by Lemma 2.3,
$\mathscr{F}_N$
defined by (2.5). To see this, note that by Lemma 2.3,
 \begin{equation*}g_n(z) = -\frac{1}{\gamma} \log \hat{\mathbb{E}}\bigl[{\mathrm{e}}^{-\gamma z^\top \Delta X_n}\mid \mathscr{F}_{n-1}\bigr]. \end{equation*}
\begin{equation*}g_n(z) = -\frac{1}{\gamma} \log \hat{\mathbb{E}}\bigl[{\mathrm{e}}^{-\gamma z^\top \Delta X_n}\mid \mathscr{F}_{n-1}\bigr]. \end{equation*}
Substituting
 $Y_n= Y_{n-1}- g_n (Z_n) + Z_n ^\top \Delta X_n $
, we have
$Y_n= Y_{n-1}- g_n (Z_n) + Z_n ^\top \Delta X_n $
, we have
 \begin{equation*} -\frac{1}{\gamma} \log \hat{\mathbb{E}}\big[{\mathrm{e}}^{-\gamma Y_n}\mid \mathscr{F}_{n-1}\big]= Y_{n-1} - g_n(Z_n)-\frac{1}{\gamma} \log \hat{\mathbb{E}}\bigl[{\mathrm{e}}^{-\gamma Z_n^\top \Delta X_n }\mid \mathscr{F}_{n-1}\bigr] =Y_{n-1}\end{equation*}
\begin{equation*} -\frac{1}{\gamma} \log \hat{\mathbb{E}}\big[{\mathrm{e}}^{-\gamma Y_n}\mid \mathscr{F}_{n-1}\big]= Y_{n-1} - g_n(Z_n)-\frac{1}{\gamma} \log \hat{\mathbb{E}}\bigl[{\mathrm{e}}^{-\gamma Z_n^\top \Delta X_n }\mid \mathscr{F}_{n-1}\bigr] =Y_{n-1}\end{equation*}
which implies (2.9) for
 $n=N-1$
. The general case follows by backward induction.
$n=N-1$
. The general case follows by backward induction.
Next we give a discrete analog of the nonlinear Feynman–Kac formula, which is computationally efficient when dealing with large N.
Proposition 2.1. Let
 $f_n \colon L \times \mathbb{R}^d \to \mathbb{R}$
,
$f_n \colon L \times \mathbb{R}^d \to \mathbb{R}$
,
 $n=1,\ldots, N$
and
$n=1,\ldots, N$
and
 $h \colon L \to \mathbb{R}$
. Define
$h \colon L \to \mathbb{R}$
. Define
 $u_n \colon L \to \mathbb{R}$
,
$u_n \colon L \to \mathbb{R}$
,
 $n=0,1,\ldots, N$
backward inductively by
$n=0,1,\ldots, N$
backward inductively by
 \begin{equation*} u_{n-1}(x) = u_n(x) + \mathcal{L} u_n(x) + f_n(x, (\mathbf{vv}^\top)^{-1}\mathbf{v}\mathcal{N} u_n(x))\end{equation*}
\begin{equation*} u_{n-1}(x) = u_n(x) + \mathcal{L} u_n(x) + f_n(x, (\mathbf{vv}^\top)^{-1}\mathbf{v}\mathcal{N} u_n(x))\end{equation*}
with
 $u_N = h$
, where
$u_N = h$
, where
 \begin{align*} \mathcal{L} u_n(x) & = \frac{1}{d+1} \sum_{j=0}^d (u_n(x+v_j)-u_n(x)), \\* \mathcal{N} u_n(x) & = (u_n(x+v_0)-u_n(x), \ldots, u_n(x+v_d)-u_n(x))^\top.\end{align*}
\begin{align*} \mathcal{L} u_n(x) & = \frac{1}{d+1} \sum_{j=0}^d (u_n(x+v_j)-u_n(x)), \\* \mathcal{N} u_n(x) & = (u_n(x+v_0)-u_n(x), \ldots, u_n(x+v_d)-u_n(x))^\top.\end{align*}
Then the unique solution to (2.7) with
 $g_n = f_n(X_{n-1},\cdot)$
and
$g_n = f_n(X_{n-1},\cdot)$
and
 $Y_N = h(X_N)$
is given by
$Y_N = h(X_N)$
is given by
 \begin{equation*} Y_{n-1} = u_{n-1}(X_{n-1}), \quad Z_{n} = (\mathbf{vv}^\top)^{-1}\mathbf{v}\mathcal{N} u_{n}(X_{n-1}), \quad n= 1,\ldots, N. \end{equation*}
\begin{equation*} Y_{n-1} = u_{n-1}(X_{n-1}), \quad Z_{n} = (\mathbf{vv}^\top)^{-1}\mathbf{v}\mathcal{N} u_{n}(X_{n-1}), \quad n= 1,\ldots, N. \end{equation*}
Proof. By definition,
 $Y_N = h(X_N) = u_N(X_N)$
. Suppose
$Y_N = h(X_N) = u_N(X_N)$
. Suppose
 $Y_n = u_n(X_n)$
. Then, by Theorem 2.1,
$Y_n = u_n(X_n)$
. Then, by Theorem 2.1,
 $Z_n = (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v}\bar{Y}_n$
, where
$Z_n = (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v}\bar{Y}_n$
, where
 \begin{equation*}\bar{Y}_{n,j} = \mathbb{E}_\mathbb{Q}[Y_n\mid \mathscr{F}_{n-1}, \Delta X_n = v_j] = u_n(X_{n-1} + v_j).\end{equation*}
\begin{equation*}\bar{Y}_{n,j} = \mathbb{E}_\mathbb{Q}[Y_n\mid \mathscr{F}_{n-1}, \Delta X_n = v_j] = u_n(X_{n-1} + v_j).\end{equation*}
Using
 $\mathbf{v1} = 0$
, we conclude
$\mathbf{v1} = 0$
, we conclude
 $Z_n = (\mathbf{vv}^\top)^{-1}\mathbf{v}\mathcal{N} u_n(X_{n-1})$
. Further, again by Theorem 2.1,
$Z_n = (\mathbf{vv}^\top)^{-1}\mathbf{v}\mathcal{N} u_n(X_{n-1})$
. Further, again by Theorem 2.1,
 \begin{equation*} Y_{n-1} =\mathbb{E}_\mathbb{Q}[Y_n\mid \mathscr{F}_{n-1}] + g_n(Z_n)= u_n(X_{n-1}) + \mathcal{L} u_n(X_{n-1})+ g_n(Z_n) = u_{n-1}(X_{n-1}),\end{equation*}
\begin{equation*} Y_{n-1} =\mathbb{E}_\mathbb{Q}[Y_n\mid \mathscr{F}_{n-1}] + g_n(Z_n)= u_n(X_{n-1}) + \mathcal{L} u_n(X_{n-1})+ g_n(Z_n) = u_{n-1}(X_{n-1}),\end{equation*}
which concludes the proof.
2.4. A gradient constraint
Let
 $\Theta$
be the closed convex hull spanned by
$\Theta$
be the closed convex hull spanned by
 $\{v_0,v_1,\ldots,v_d\}$
, or equivalently
$\{v_0,v_1,\ldots,v_d\}$
, or equivalently
 \begin{equation*} \Theta = \{\mathbf{v}p \ ; \ p \in \Delta_d\}.\end{equation*}
\begin{equation*} \Theta = \{\mathbf{v}p \ ; \ p \in \Delta_d\}.\end{equation*}
In this section we study BS
 $\Delta$
Es with the gradient of g being constrained in
$\Delta$
Es with the gradient of g being constrained in
 $\Theta$
.
$\Theta$
.
Example 2.2. The triangular lattice of
 $\mathbb{R}^2$
is generated by
$\mathbb{R}^2$
is generated by
 \begin{equation*} v_1 =\frac{1}{\sqrt{6}} \begin{pmatrix} 0\\-2 \end{pmatrix}\!, \quad v_2 = \frac{1}{\sqrt{6}} \begin{pmatrix} \sqrt{3} \\ 1 \end{pmatrix}\!.\end{equation*}
\begin{equation*} v_1 =\frac{1}{\sqrt{6}} \begin{pmatrix} 0\\-2 \end{pmatrix}\!, \quad v_2 = \frac{1}{\sqrt{6}} \begin{pmatrix} \sqrt{3} \\ 1 \end{pmatrix}\!.\end{equation*}
In this case,
 $\mathbf{v}\mathbf{v}^\top = I$
and
$\mathbf{v}\mathbf{v}^\top = I$
and
 $\Theta$
is an equilateral triangle.
$\Theta$
is an equilateral triangle.
Proposition 2.2. Let
 $g_n(z) = A_n^\top z + B_n$
for a
$g_n(z) = A_n^\top z + B_n$
for a
 $\Theta$
-valued predictable process
$\Theta$
-valued predictable process
 $\{A_n\}$
and a predictable process
$\{A_n\}$
and a predictable process
 $\{B_n\}$
,
$\{B_n\}$
,
 $n=1,\ldots,N$
. Then
$n=1,\ldots,N$
. Then
 \begin{equation*} \mathcal{E}^g_n (Y) = \hat{\mathbb{E}}\Biggl[Y +\sum_{i=n+1}^N B_i \bigg|\mathscr{F}_n\Biggr], \quad n=0,1,\ldots,N, \end{equation*}
\begin{equation*} \mathcal{E}^g_n (Y) = \hat{\mathbb{E}}\Biggl[Y +\sum_{i=n+1}^N B_i \bigg|\mathscr{F}_n\Biggr], \quad n=0,1,\ldots,N, \end{equation*}
for any
 $\mathcal{F}_N$
-measurable random variable Y, where
$\mathcal{F}_N$
-measurable random variable Y, where
 $\hat{\mathbb{E}}$
is the expectation under the measure
$\hat{\mathbb{E}}$
is the expectation under the measure
 $\hat{\mathbb{P}}$
on
$\hat{\mathbb{P}}$
on
 $\mathscr{F}_N$
defined by (2.5) with
$\mathscr{F}_N$
defined by (2.5) with
 $\hat{P}_n = (\hat{P}_{n,0},\ldots, \hat{P}_{n,d})^\top$
such that
$\hat{P}_n = (\hat{P}_{n,0},\ldots, \hat{P}_{n,d})^\top$
such that
 $A_n = \mathbf{v}\hat{P}_n$
.
$A_n = \mathbf{v}\hat{P}_n$
.
Proof. By Lemma 2.3,
 \begin{equation*} \hat{\mathbb{E}}[\Delta X_n \mid \mathcal{F}_{n-1}] = \frac{\mathbb{E}[L_N \Delta X_n \mid \mathcal{F}_{n-1}]}{\mathbb{E}[L_N \mid \mathcal{F}_{n-1}]}= \sum_{j=0}^d v_j \hat{P}_{n,j}= \mathbf{v}\hat{P}_n = A_n\end{equation*}
\begin{equation*} \hat{\mathbb{E}}[\Delta X_n \mid \mathcal{F}_{n-1}] = \frac{\mathbb{E}[L_N \Delta X_n \mid \mathcal{F}_{n-1}]}{\mathbb{E}[L_N \mid \mathcal{F}_{n-1}]}= \sum_{j=0}^d v_j \hat{P}_{n,j}= \mathbf{v}\hat{P}_n = A_n\end{equation*}
for all n. On the other hand, from (2.7), we have
 \begin{equation*} Y= Y_N = Y_n + \sum_{i=n+1}^N \big({-}g_i(Z_i) + Z_i^\top \Delta X_i\big) = Y_n + \sum_{i=n+1}^N \big({-}B_i + Z_i^{\top}(\Delta X_i - A_i)\big).\end{equation*}
\begin{equation*} Y= Y_N = Y_n + \sum_{i=n+1}^N \big({-}g_i(Z_i) + Z_i^\top \Delta X_i\big) = Y_n + \sum_{i=n+1}^N \big({-}B_i + Z_i^{\top}(\Delta X_i - A_i)\big).\end{equation*}
Taking the conditional expectation under
 $\hat{\mathbb{P}}$
, we get the conclusion.
$\hat{\mathbb{P}}$
, we get the conclusion.
Example 2.3. Let
 $N=1$
,
$N=1$
,
 $d=1$
,
$d=1$
,
 $\Omega = \{+,-\}$
,
$\Omega = \{+,-\}$
,
 $v_0 = -1, v_1 = 1$
, and
$v_0 = -1, v_1 = 1$
, and
 $\Delta X_1(\pm) = \pm 1$
. Then
$\Delta X_1(\pm) = \pm 1$
. Then
 $L = \mathbb{Z}$
,
$L = \mathbb{Z}$
,
 $\mathbf{v} = ({-}1,1)$
,
$\mathbf{v} = ({-}1,1)$
,
 $\Theta = [-1,1]$
and
$\Theta = [-1,1]$
and
 $\mathbf{vv}^\top = 2$
. Following the proof of Theorem 2.1, the solution of the linear BS
$\mathbf{vv}^\top = 2$
. Following the proof of Theorem 2.1, the solution of the linear BS
 $\Delta$
E
$\Delta$
E
 $\Delta Y_1 = -AZ_1 + Z_1\Delta X_1$
can be constructed as
$\Delta Y_1 = -AZ_1 + Z_1\Delta X_1$
can be constructed as
 \begin{equation*} Y_0 = \frac{Y_1(+) + Y_1({-})}{2} + A \frac{Y_1(+)-Y_1({-})}{2} = \frac{1+A}{2} Y_1(+) + \frac{1-A}{2} Y_1({-})\end{equation*}
\begin{equation*} Y_0 = \frac{Y_1(+) + Y_1({-})}{2} + A \frac{Y_1(+)-Y_1({-})}{2} = \frac{1+A}{2} Y_1(+) + \frac{1-A}{2} Y_1({-})\end{equation*}
for any
 $A \in \mathbb{R}$
. The expression given by Proposition 2.2 is
$A \in \mathbb{R}$
. The expression given by Proposition 2.2 is
 $Y_0 = \hat{E}[Y_1]$
, which can be directly seen with
$Y_0 = \hat{E}[Y_1]$
, which can be directly seen with
 $\hat{P}_1 = ((1-A)/2, (1+A)/2)^\top$
for
$\hat{P}_1 = ((1-A)/2, (1+A)/2)^\top$
for
 $A \in \Theta = [-1,1]$
. For
$A \in \Theta = [-1,1]$
. For
 $A \notin \Theta$
, we observe that
$A \notin \Theta$
, we observe that
 $Y_0$
is not increasing in either
$Y_0$
is not increasing in either
 $Y_1(+)$
or
$Y_1(+)$
or
 $Y_1({-})$
. In particular,
$Y_1({-})$
. In particular,
 $Y_0$
cannot be represented as an expectation in this case.
$Y_0$
cannot be represented as an expectation in this case.
The set
 $\Theta$
plays a key role also for a comparison theorem. Let
$\Theta$
plays a key role also for a comparison theorem. Let
 $\mathcal{B}$
denote the set of the sequence
$\mathcal{B}$
denote the set of the sequence
 $g = \{g_n\}_{n=1}^N \in \mathcal{A}$
with
$g = \{g_n\}_{n=1}^N \in \mathcal{A}$
with
 \begin{equation} g_n(z_2) - g_n(z_1) \geq \min_{\theta\in\Theta}\theta^\top(z_2-z_1) \end{equation}
\begin{equation} g_n(z_2) - g_n(z_1) \geq \min_{\theta\in\Theta}\theta^\top(z_2-z_1) \end{equation}
for all
 $z_1, z_2 \in \mathbb{R}^d$
.
$z_1, z_2 \in \mathbb{R}^d$
.
Proposition 2.3. (Comparison theorem.) For
 $i=1,2$
, let
$i=1,2$
, let
 $Y^{(i)}$
be
$Y^{(i)}$
be
 $\mathscr{F}_N$
-measurable random variables with
$\mathscr{F}_N$
-measurable random variables with
 $Y^{(1)} \geq Y^{(2)}$
, and
$Y^{(1)} \geq Y^{(2)}$
, and
 $g^{(i)} = \{g^{(i)}_n\} \in \mathcal{A}$
with
$g^{(i)} = \{g^{(i)}_n\} \in \mathcal{A}$
with
 $g^{(1)}_n \geq g^{(2)}_n$
. Let
$g^{(1)}_n \geq g^{(2)}_n$
. Let
 $\mathcal{E}^{(i)}_n(Y^{(i)})$
denote
$\mathcal{E}^{(i)}_n(Y^{(i)})$
denote
 $\mathcal{E}^g_n(Y^{(i)})$
for
$\mathcal{E}^g_n(Y^{(i)})$
for
 $g = g^{(i)}$
,
$g = g^{(i)}$
,
 $i=1,2$
respectively. Assume also
$i=1,2$
respectively. Assume also
 $g^{(i)} \in \mathcal{B}$
for either
$g^{(i)} \in \mathcal{B}$
for either
 $i=1$
or
$i=1$
or
 $i=2$
. Then
$i=2$
. Then
 \begin{equation*} \mathcal{E}^{(1)}_n(Y^{(1)}) \geq \mathcal{E}^{(2)}_n(Y^{(2)}), \quad n=0,1,\ldots, N.\end{equation*}
\begin{equation*} \mathcal{E}^{(1)}_n(Y^{(1)}) \geq \mathcal{E}^{(2)}_n(Y^{(2)}), \quad n=0,1,\ldots, N.\end{equation*}
Proof. Note first that
 \begin{equation} \min_{\omega \in \Omega} z^\top \Delta X_n(\omega) = \min_{p \in \Delta_d} z^\top \mathbf{v}p = \min_{\theta \in \Theta}z^\top \theta\end{equation}
\begin{equation} \min_{\omega \in \Omega} z^\top \Delta X_n(\omega) = \min_{p \in \Delta_d} z^\top \mathbf{v}p = \min_{\theta \in \Theta}z^\top \theta\end{equation}
for any
 $z \in \mathbb{R}^d$
and n. Therefore, under (2.10) for
$z \in \mathbb{R}^d$
and n. Therefore, under (2.10) for
 $g= g^{(i)}$
,
$g= g^{(i)}$
,
 $g^{(i)}$
is balanced in the terminology of [Reference Cohen and Elliot15], so the result follows from Theorem 3.2 of [Reference Cohen and Elliot15]. Here we repeat essentially the same proof for the readers’ convenience. Let
$g^{(i)}$
is balanced in the terminology of [Reference Cohen and Elliot15], so the result follows from Theorem 3.2 of [Reference Cohen and Elliot15]. Here we repeat essentially the same proof for the readers’ convenience. Let
 $\bigl\{\bigl(Y^{(i)}_n,Z^{(i)}_n\bigr)\bigr\}$
be the solution of (2.7) with
$\bigl\{\bigl(Y^{(i)}_n,Z^{(i)}_n\bigr)\bigr\}$
be the solution of (2.7) with
 $g = g^{(i)}$
and
$g = g^{(i)}$
and
 $Y_N = Y^{(i)}$
. We have
$Y_N = Y^{(i)}$
. We have
 $Y^{(1)}_N \geq Y^{(2)}_N$
by assumption. Suppose
$Y^{(1)}_N \geq Y^{(2)}_N$
by assumption. Suppose
 $Y^{(1)}_k \geq Y^{(2)}_k$
for some k. Then
$Y^{(1)}_k \geq Y^{(2)}_k$
for some k. Then
 \begin{equation*}0 \leq Y^{(1)}_k - Y^{(2)}_k = Y^{(1)}_{k-1} - Y^{(2)}_{k-1}- g^{(1)}_k\bigl(Z^{(1)}_k\bigr) + g^{(2)}_k\bigl(Z^{(2)}_k\bigr) + \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr)^\top \Delta X_k\end{equation*}
\begin{equation*}0 \leq Y^{(1)}_k - Y^{(2)}_k = Y^{(1)}_{k-1} - Y^{(2)}_{k-1}- g^{(1)}_k\bigl(Z^{(1)}_k\bigr) + g^{(2)}_k\bigl(Z^{(2)}_k\bigr) + \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr)^\top \Delta X_k\end{equation*}
and so
 \begin{equation*} \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr)^\top \Delta X_k \geq - Y^{(1)}_{k-1} + Y^{(2)}_{k-1} + g^{(1)}_k\bigl(Z^{(1)}_k\bigr) - g^{(2)}_k\bigl(Z^{(2)}_k\bigr).\end{equation*}
\begin{equation*} \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr)^\top \Delta X_k \geq - Y^{(1)}_{k-1} + Y^{(2)}_{k-1} + g^{(1)}_k\bigl(Z^{(1)}_k\bigr) - g^{(2)}_k\bigl(Z^{(2)}_k\bigr).\end{equation*}
Since the right-hand side is
 $\mathscr{F}_{k-1}$
-measurable, this implies further
$\mathscr{F}_{k-1}$
-measurable, this implies further
 \begin{equation*} \min_{\theta \in \Theta} \theta^\top \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr) \geq - Y^{(1)}_{k-1} + Y^{(2)}_{k-1} + g^{(1)}_k\bigl(Z^{(1)}_k\bigr) - g^{(2)}_k\bigl(Z^{(2)}_k\bigr)\end{equation*}
\begin{equation*} \min_{\theta \in \Theta} \theta^\top \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr) \geq - Y^{(1)}_{k-1} + Y^{(2)}_{k-1} + g^{(1)}_k\bigl(Z^{(1)}_k\bigr) - g^{(2)}_k\bigl(Z^{(2)}_k\bigr)\end{equation*}
by (2.11). Therefore
 \begin{align*} Y^{(1)}_{k-1} - Y^{(2)}_{k-1} & \geq g^{(1)}_k\bigl(Z^{(1)}_k\bigr) - g^{(2)}_k\bigl(Z^{(2)}_k\bigr) - \min_{\theta \in \Theta} \theta^\top \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr) \\* & = g^{(1)}_k\bigl(Z^{(2)}_k\bigr) - g^{(2)}_k\bigl(Z^{(2)}_k\bigr) +g^{(1)}_k\bigl(Z^{(1)}_k\bigr) - g^{(1)}_k\bigl(Z^{(2)}_k\bigr) - \min_{\theta \in \Theta} \theta^\top \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr) \\* & \geq 0 \end{align*}
\begin{align*} Y^{(1)}_{k-1} - Y^{(2)}_{k-1} & \geq g^{(1)}_k\bigl(Z^{(1)}_k\bigr) - g^{(2)}_k\bigl(Z^{(2)}_k\bigr) - \min_{\theta \in \Theta} \theta^\top \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr) \\* & = g^{(1)}_k\bigl(Z^{(2)}_k\bigr) - g^{(2)}_k\bigl(Z^{(2)}_k\bigr) +g^{(1)}_k\bigl(Z^{(1)}_k\bigr) - g^{(1)}_k\bigl(Z^{(2)}_k\bigr) - \min_{\theta \in \Theta} \theta^\top \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr) \\* & \geq 0 \end{align*}
under (2.10) for
 $g_n = g^{(1)}_n$
, and also
$g_n = g^{(1)}_n$
, and also
 \begin{align*} Y^{(1)}_{k-1} - Y^{(2)}_{k-1} & \geq g^{(1)}_k\bigl(Z^{(1)}_k\bigr) - g^{(2)}_k\bigl(Z^{(2)}_k\bigr) - \min_{\theta \in \Theta} \theta^\top \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr) \\* & = g^{(1)}_k\bigl(Z^{(1)}_k\bigr) - g^{(2)}_k\bigl(Z^{(1)}_k\bigr) +g^{(2)}_k\bigl(Z^{(1)}_k\bigr) - g^{(2)}_k\bigl(Z^{(2)}_k\bigr) - \min_{\theta \in \Theta} \theta^\top \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr) \\* & \geq 0 \end{align*}
\begin{align*} Y^{(1)}_{k-1} - Y^{(2)}_{k-1} & \geq g^{(1)}_k\bigl(Z^{(1)}_k\bigr) - g^{(2)}_k\bigl(Z^{(2)}_k\bigr) - \min_{\theta \in \Theta} \theta^\top \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr) \\* & = g^{(1)}_k\bigl(Z^{(1)}_k\bigr) - g^{(2)}_k\bigl(Z^{(1)}_k\bigr) +g^{(2)}_k\bigl(Z^{(1)}_k\bigr) - g^{(2)}_k\bigl(Z^{(2)}_k\bigr) - \min_{\theta \in \Theta} \theta^\top \bigl(Z^{(1)}_k- Z^{(2)}_k\bigr) \\* & \geq 0 \end{align*}
under (2.10) for
 $g_n = g^{(2)}_n$
. The result then follows by induction.
$g_n = g^{(2)}_n$
. The result then follows by induction.
Remark 2.3. A sufficient condition for
 $g_n$
to meet (2.10) is that
$g_n$
to meet (2.10) is that
 $g_n(z)$
is continuously differentiable in z with
$g_n(z)$
is continuously differentiable in z with
 $\nabla g_n(z)$
taking values in
$\nabla g_n(z)$
taking values in
 $\Theta$
. Indeed, by Taylor’s theorem,
$\Theta$
. Indeed, by Taylor’s theorem,
 \begin{equation*} g_n(z_1) - g_n(z_2) = A_n^\top (z_1-z_2),\quad A_n = \int_0^1 \nabla g_n(z_2 + t(z_1 -z_2))\,\mathrm{d}t,\end{equation*}
\begin{equation*} g_n(z_1) - g_n(z_2) = A_n^\top (z_1-z_2),\quad A_n = \int_0^1 \nabla g_n(z_2 + t(z_1 -z_2))\,\mathrm{d}t,\end{equation*}
and then notice that
 $A_n$
is
$A_n$
is
 $\Theta$
-valued because
$\Theta$
-valued because
 $\Theta$
is a convex set.
$\Theta$
is a convex set.
Example 2.4.
(
Locally entropic monetary utility.) Let
 $\{(\hat{P}_{n,0},\ldots,\hat{P}_{n,d})^\top\}$
be a
$\{(\hat{P}_{n,0},\ldots,\hat{P}_{n,d})^\top\}$
be a
 $\Delta_d$
-valued predictable process, let
$\Delta_d$
-valued predictable process, let
 $\{B_n\}$
and
$\{B_n\}$
and
 $\{\Gamma_n\}$
be positive predictable processes, and
$\{\Gamma_n\}$
be positive predictable processes, and
 \begin{equation} g_n(z) = -\frac{1}{\Gamma_n} \log \Biggl(\sum_{j=0}^{d} \,{\mathrm{e}}^{-\Gamma_n z^\top v_j} \hat{P}_{n,j}\Biggr) - \frac{1}{\Gamma_n}\log B_n.\end{equation}
\begin{equation} g_n(z) = -\frac{1}{\Gamma_n} \log \Biggl(\sum_{j=0}^{d} \,{\mathrm{e}}^{-\Gamma_n z^\top v_j} \hat{P}_{n,j}\Biggr) - \frac{1}{\Gamma_n}\log B_n.\end{equation}
Using a similar calculation to Example 2.1, we deduce the relation
 \[Y_{n-1}=-\frac{1}{\Gamma_n}\{\log \hat{\mathbb{E}}[ {\mathrm{e}}^{-\Gamma_n Y_n} \mid {\mathcal F}_{n-1}]+\log B_n\}, \quad n=N,\ldots, 1.\]
\[Y_{n-1}=-\frac{1}{\Gamma_n}\{\log \hat{\mathbb{E}}[ {\mathrm{e}}^{-\Gamma_n Y_n} \mid {\mathcal F}_{n-1}]+\log B_n\}, \quad n=N,\ldots, 1.\]
In particular, when
 $B_n=1$
,
$B_n=1$
,
 ${\mathcal E}_{n-1}^g$
is locally the minus of the entropic risk measure with risk-aversion parameter
${\mathcal E}_{n-1}^g$
is locally the minus of the entropic risk measure with risk-aversion parameter
 $\Gamma_n$
extending (2.9). In contrast to the dynamic entropic risk measure studied in [Reference Acciaio and Penner1], we have the time-consistency property
$\Gamma_n$
extending (2.9). In contrast to the dynamic entropic risk measure studied in [Reference Acciaio and Penner1], we have the time-consistency property
 $\mathcal{E}_m^g(\mathcal{E}_n^g(Y))=\mathcal{E}_m^g(Y)$
for any
$\mathcal{E}_m^g(\mathcal{E}_n^g(Y))=\mathcal{E}_m^g(Y)$
for any
 $m \leq n$
when
$m \leq n$
when
 $B_n = 1$
for all n even if the process
$B_n = 1$
for all n even if the process
 $\{\Gamma_n\}$
is not constant. We allow
$\{\Gamma_n\}$
is not constant. We allow
 $B_n \neq 1$
in order to include an example in Section 3. We call
$B_n \neq 1$
in order to include an example in Section 3. We call
 $\mathcal{E}^g_n$
a locally entropic monetary utility. A brief numerical study for this utility is provided in Appendix B. We have
$\mathcal{E}^g_n$
a locally entropic monetary utility. A brief numerical study for this utility is provided in Appendix B. We have
 \begin{equation*} \nabla g_n(z) = \frac{\hat{\mathbb{E}}[\Delta X_n \,{\mathrm{e}}^{-\Gamma_n z^\top \Delta X_n}\mid \mathscr{F}_{n-1}]}{\hat{\mathbb{E}}[{\mathrm{e}}^{-\Gamma_n z^\top \Delta X_n}\mid \mathscr{F}_{n-1}]} = \mathbf{v}\hat{P}_n(z), \end{equation*}
\begin{equation*} \nabla g_n(z) = \frac{\hat{\mathbb{E}}[\Delta X_n \,{\mathrm{e}}^{-\Gamma_n z^\top \Delta X_n}\mid \mathscr{F}_{n-1}]}{\hat{\mathbb{E}}[{\mathrm{e}}^{-\Gamma_n z^\top \Delta X_n}\mid \mathscr{F}_{n-1}]} = \mathbf{v}\hat{P}_n(z), \end{equation*}
where
 $\hat{P}_n(z) = (\hat{P}_{n,0}(z),\ldots,\hat{P}_{n,d}(z))^\top$
and
$\hat{P}_n(z) = (\hat{P}_{n,0}(z),\ldots,\hat{P}_{n,d}(z))^\top$
and
 \begin{equation*} \hat{P}_{n,j}(z)= \frac{{\mathrm{e}}^{-\Gamma_n z^\top v_j} \hat{P}_{n,j}}{\sum_{k=0}^d \,{\mathrm{e}}^{-\Gamma_n z^\top v_k} \hat{P}_{n,k}}. \end{equation*}
\begin{equation*} \hat{P}_{n,j}(z)= \frac{{\mathrm{e}}^{-\Gamma_n z^\top v_j} \hat{P}_{n,j}}{\sum_{k=0}^d \,{\mathrm{e}}^{-\Gamma_n z^\top v_k} \hat{P}_{n,k}}. \end{equation*}
Since
 $\hat{P}_n(z)$
is continuous in z and
$\hat{P}_n(z)$
is continuous in z and
 $\Delta_d$
-valued for all n, by Remark 2.3, the assumptions of Proposition 2.3 on
$\Delta_d$
-valued for all n, by Remark 2.3, the assumptions of Proposition 2.3 on
 $g^{(i)}_n$
are satisfied.
$g^{(i)}_n$
are satisfied.
Next, we seek a robust representation of
 $\mathcal{E}^g$
when g is concave. Let
$\mathcal{E}^g$
when g is concave. Let
 $\mathcal{C}$
denote the set of
$\mathcal{C}$
denote the set of
 $g = \{g_n\} \in \mathcal{B}$
with
$g = \{g_n\} \in \mathcal{B}$
with
 $g_n(z)$
being concave in z for all n.
$g_n(z)$
being concave in z for all n.
Lemma 2.5. Let
 $g = \{g_n\} \in \mathcal{A}$
. Then
$g = \{g_n\} \in \mathcal{A}$
. Then
 $g \in \mathcal{C}$
if and only if
$g \in \mathcal{C}$
if and only if
 \begin{equation} g_n(z) = \min_{\theta \in \Theta} \{z^\top \theta + b_n(\theta)\}, \end{equation}
\begin{equation} g_n(z) = \min_{\theta \in \Theta} \{z^\top \theta + b_n(\theta)\}, \end{equation}
where
 \begin{equation*} b_n(\theta) = \sup_{z \in \mathbb{R}^d} \{g_n(z)-z^\top \theta\}. \end{equation*}
\begin{equation*} b_n(\theta) = \sup_{z \in \mathbb{R}^d} \{g_n(z)-z^\top \theta\}. \end{equation*}
Proof. If
 $g_n$
is concave, then it is continuous on the interior of its domain that is
$g_n$
is concave, then it is continuous on the interior of its domain that is
 $\mathbb{R}^d$
. Therefore by a well-known fact on the Legendre transform, we have
$\mathbb{R}^d$
. Therefore by a well-known fact on the Legendre transform, we have
 \begin{equation*} g_n(z) = \inf_{x \in \mathbb{R}^d} \{z^\top x + b_n(x)\}. \end{equation*}
\begin{equation*} g_n(z) = \inf_{x \in \mathbb{R}^d} \{z^\top x + b_n(x)\}. \end{equation*}
Let
 $x \notin \Theta$
. Since
$x \notin \Theta$
. Since
 $\Theta$
is a closed convex set of
$\Theta$
is a closed convex set of
 $\mathbb{R}^d$
, by the Hahn–Banach theorem (or the separating hyperplane theorem), there exists
$\mathbb{R}^d$
, by the Hahn–Banach theorem (or the separating hyperplane theorem), there exists
 $z_0 \in \mathbb{R}^d$
such that
$z_0 \in \mathbb{R}^d$
such that
 \begin{equation*} \min_{\theta \in \Theta}z_0^\top \theta > z_0^\top x.\end{equation*}
\begin{equation*} \min_{\theta \in \Theta}z_0^\top \theta > z_0^\top x.\end{equation*}
Using (2.10), for
 $z = \alpha z_0$
,
$z = \alpha z_0$
,
 $\alpha \gt 0$
,
$\alpha \gt 0$
,
 \begin{equation*} g_n(z) - z^\top x \geq g_n(0) + \min_{\theta \in \Theta} \theta^\top z -z^\top x = g_n(0)+ \alpha \min_{\theta \in \Theta} z_0^\top(\theta -x).\end{equation*}
\begin{equation*} g_n(z) - z^\top x \geq g_n(0) + \min_{\theta \in \Theta} \theta^\top z -z^\top x = g_n(0)+ \alpha \min_{\theta \in \Theta} z_0^\top(\theta -x).\end{equation*}
Since the last term is positive, letting
 $\alpha \to \infty$
, we conclude
$\alpha \to \infty$
, we conclude
 $b_n(x)=\infty$
. This implies
$b_n(x)=\infty$
. This implies
 \begin{equation*} g_n(z) = \inf_{\theta \in \Theta} \{z^\top \theta + b_n(\theta)\} = \inf_{(\theta,b) \in A_n} \{z^\top \theta + b\}, \end{equation*}
\begin{equation*} g_n(z) = \inf_{\theta \in \Theta} \{z^\top \theta + b_n(\theta)\} = \inf_{(\theta,b) \in A_n} \{z^\top \theta + b\}, \end{equation*}
where
 $A_n = \{(\theta,b) \in \Theta \times \mathbb{R} \, ; \, g_n(w) \leq w^\top \theta + b \text{ for all } w \in \mathbb{R}^d\}$
. Fix n and z and then take a sequence
$A_n = \{(\theta,b) \in \Theta \times \mathbb{R} \, ; \, g_n(w) \leq w^\top \theta + b \text{ for all } w \in \mathbb{R}^d\}$
. Fix n and z and then take a sequence
 $\{(\theta_k,b_k)\} \subset A_n$
such that
$\{(\theta_k,b_k)\} \subset A_n$
such that
 $z^\top \theta_k + b_k \to g_n(z)$
. Since
$z^\top \theta_k + b_k \to g_n(z)$
. Since
 $\Theta$
is compact, there exists a converging subsequence
$\Theta$
is compact, there exists a converging subsequence
 $\{\theta_{k_j}\}$
with limit
$\{\theta_{k_j}\}$
with limit
 $\theta_\ast \in \Theta$
. We have
$\theta_\ast \in \Theta$
. We have
 $b_{k_j} = z^\top\theta_{k_j} + b_{k_j} - z^\top \theta_{k_j} \to g_n(z) - z^\top \theta_\ast = \! : \, b_\ast$
. Also,
$b_{k_j} = z^\top\theta_{k_j} + b_{k_j} - z^\top \theta_{k_j} \to g_n(z) - z^\top \theta_\ast = \! : \, b_\ast$
. Also,
 $w^\top \theta_{k_j} + b_{k_j} \geq g_n(w)$
for all w implies
$w^\top \theta_{k_j} + b_{k_j} \geq g_n(w)$
for all w implies
 $w^\top \theta_\ast + b_\ast \geq g_n(w)$
for all w, hence
$w^\top \theta_\ast + b_\ast \geq g_n(w)$
for all w, hence
 $(\theta_\ast,b_\ast) \in A_n$
. Thus we obtain (2.13). Conversely, if (2.13) is true, then
$(\theta_\ast,b_\ast) \in A_n$
. Thus we obtain (2.13). Conversely, if (2.13) is true, then
 $g_n(z)$
is concave, being the minimum of concave (affine) functions. Since
$g_n(z)$
is concave, being the minimum of concave (affine) functions. Since
 \begin{equation*} z_1^\top \theta + b_n(\theta) = z_2^\top \theta + b_n(\theta) + \theta^\top(z_1-z_2) \geq z_2^\top \theta + b_n(\theta) + \min_{\theta \in \Theta} \theta^\top(z_1-z_2), \end{equation*}
\begin{equation*} z_1^\top \theta + b_n(\theta) = z_2^\top \theta + b_n(\theta) + \theta^\top(z_1-z_2) \geq z_2^\top \theta + b_n(\theta) + \min_{\theta \in \Theta} \theta^\top(z_1-z_2), \end{equation*}
Let
 $\mathcal{P}_N$
denote the set of the probability measures on
$\mathcal{P}_N$
denote the set of the probability measures on
 $(\Omega,\mathscr{F}_N)$
absolutely continuous with respect to
$(\Omega,\mathscr{F}_N)$
absolutely continuous with respect to
 $\mathbb{P}$
. For
$\mathbb{P}$
. For
 $\hat{\mathbb{P}} \in \mathcal{P}_N$
, there corresponds a
$\hat{\mathbb{P}} \in \mathcal{P}_N$
, there corresponds a
 $\Delta_d$
-valued predictable process
$\Delta_d$
-valued predictable process
 $\{\hat{P}_n\}$
by (2.4). The measure
$\{\hat{P}_n\}$
by (2.4). The measure
 $\hat{\mathbb{P}}$
is recovered from
$\hat{\mathbb{P}}$
is recovered from
 $\{\hat{P}_n\}$
by (2.5). Let
$\{\hat{P}_n\}$
by (2.5). Let
 $\hat{\mathbb{E}}$
denote the expectation under
$\hat{\mathbb{E}}$
denote the expectation under
 $\hat{\mathbb{P}}$
and define
$\hat{\mathbb{P}}$
and define
 \begin{equation*} c^g_n(\hat{\mathbb{P}}) = \hat{\mathbb{E}}\Biggl[\sum_{i=n+1}^N b_i(\mathbf{v}\hat{P}_i)\bigg|\mathscr{F}_n\Biggr],\end{equation*}
\begin{equation*} c^g_n(\hat{\mathbb{P}}) = \hat{\mathbb{E}}\Biggl[\sum_{i=n+1}^N b_i(\mathbf{v}\hat{P}_i)\bigg|\mathscr{F}_n\Biggr],\end{equation*}
where
 $b_i$
is associated with
$b_i$
is associated with
 $g = \{g_n\} \in \mathcal{C}$
via (2.13). The following theorem shows the nature of the g-expectation with the gradient constraint as a nonlinear expectation, taking care of Knightian uncertainty, refining a general convex duality result in [Reference Detlefsen and Scandolo18] for an explicit representation of a penalty function.
$g = \{g_n\} \in \mathcal{C}$
via (2.13). The following theorem shows the nature of the g-expectation with the gradient constraint as a nonlinear expectation, taking care of Knightian uncertainty, refining a general convex duality result in [Reference Detlefsen and Scandolo18] for an explicit representation of a penalty function.
Theorem 2.2. Let
 $g \in \mathcal{C}$
. Then, for any
$g \in \mathcal{C}$
. Then, for any
 $\mathscr{F}_N$
-measurable random variable Y,
$\mathscr{F}_N$
-measurable random variable Y,
 \begin{equation} \mathcal{E}^g_n(Y) = \min_{\hat{\mathbb{P}}\in \mathcal{P}_N} \big\{ \hat{\mathbb{E}}[Y\mid \mathscr{F}_n] + c^g_n(\hat{\mathbb{P}}) \big\}, \quad n=0,1,\ldots, N.\end{equation}
\begin{equation} \mathcal{E}^g_n(Y) = \min_{\hat{\mathbb{P}}\in \mathcal{P}_N} \big\{ \hat{\mathbb{E}}[Y\mid \mathscr{F}_n] + c^g_n(\hat{\mathbb{P}}) \big\}, \quad n=0,1,\ldots, N.\end{equation}
Proof. By (2.13), we have
 \begin{equation*} g_n(z) \leq z^\top \mathbf{v}\hat{P}_n + b_n(\mathbf{v}\hat{P}_n)\end{equation*}
\begin{equation*} g_n(z) \leq z^\top \mathbf{v}\hat{P}_n + b_n(\mathbf{v}\hat{P}_n)\end{equation*}
for any
 $\hat{\mathbb{P}} \in \mathcal{P}_N$
. Therefore, by Propositions 2.2 and 2.3, we have
$\hat{\mathbb{P}} \in \mathcal{P}_N$
. Therefore, by Propositions 2.2 and 2.3, we have
 \begin{equation*} \mathcal{E}^g_n(Y) \leq \hat{\mathbb{E}}[Y\mid \mathscr{F}_n] + c^g_n(\hat{\mathbb{P}})\end{equation*}
\begin{equation*} \mathcal{E}^g_n(Y) \leq \hat{\mathbb{E}}[Y\mid \mathscr{F}_n] + c^g_n(\hat{\mathbb{P}})\end{equation*}
for any
 $\hat{\mathbb{P}} \in \mathcal{P}_N$
. On the other hand, for any
$\hat{\mathbb{P}} \in \mathcal{P}_N$
. On the other hand, for any
 $Y \in \mathscr{F}_N$
, there exists the solution
$Y \in \mathscr{F}_N$
, there exists the solution
 $\{(Y_n,Z_n)\}$
of (2.7) with
$\{(Y_n,Z_n)\}$
of (2.7) with
 $Y_N= Y$
. By (2.13), there exists
$Y_N= Y$
. By (2.13), there exists
 $\hat{P}_n$
such that
$\hat{P}_n$
such that
 \begin{equation*} g_n(Z_n) = Z_n^\top \mathbf{v}\hat{P}_n + b_n(\mathbf{v}\hat{P}_n)\end{equation*}
\begin{equation*} g_n(Z_n) = Z_n^\top \mathbf{v}\hat{P}_n + b_n(\mathbf{v}\hat{P}_n)\end{equation*}
for each n. Since
 $\{g_n\}$
and
$\{g_n\}$
and
 $\{Z_n\}$
are predictable,
$\{Z_n\}$
are predictable,
 $\{\hat{P}_n\}$
is a
$\{\hat{P}_n\}$
is a
 $\Delta_d$
-valued predictable process. Let
$\Delta_d$
-valued predictable process. Let
 $\hat{\mathbb{P}} \in \mathcal{P}_N$
be associated with
$\hat{\mathbb{P}} \in \mathcal{P}_N$
be associated with
 $\{\hat{P}_n\}$
. Then
$\{\hat{P}_n\}$
. Then
 $\{(Y_n,Z_n)\}$
solves the BSDE with
$\{(Y_n,Z_n)\}$
solves the BSDE with
 $\hat{g}_n(z) = z^\top \mathbf{v}\hat{P}_n + b_n(\mathbf{v}\hat{P}_n)$
as well, and so by Proposition 2.2,
$\hat{g}_n(z) = z^\top \mathbf{v}\hat{P}_n + b_n(\mathbf{v}\hat{P}_n)$
as well, and so by Proposition 2.2,
 \begin{equation*} \mathcal{E}^g_n(Y) = Y_n= \hat{\mathbb{E}}[Y\mid \mathscr{F}_n] + c^g_n(\hat{\mathbb{P}}),\end{equation*}
\begin{equation*} \mathcal{E}^g_n(Y) = Y_n= \hat{\mathbb{E}}[Y\mid \mathscr{F}_n] + c^g_n(\hat{\mathbb{P}}),\end{equation*}
which implies (2.14).
Corollary 2.1. Let
 $g \in \mathcal{C}$
. Let Y and
$g \in \mathcal{C}$
. Let Y and
 $Y^\prime$
be
$Y^\prime$
be
 $\mathscr{F}_N$
-measurable random variables.
$\mathscr{F}_N$
-measurable random variables.
-
(i) If
$Y \geq Y^\prime$
, then
$\mathcal{E}^g_n(Y) \geq \mathcal{E}^g_n(Y^\prime)$
,
$n=0,1,\ldots, N$
. -
(ii) For any
$\mathscr{F}_n$
-measurable [0,1]-valued random variable
$\lambda$
,
\begin{equation*} \mathcal{E}^g_n(\lambda Y + (1-\lambda)Y^\prime) \geq \lambda\mathcal{E}^g_n(Y) + (1-\lambda) \mathcal{E}^g_n(Y^\prime), \quad n=0,1,\ldots, N. \end{equation*}






Example 2.5. Let
 $\Theta_n \subset \Theta$
and
$\Theta_n \subset \Theta$
and
 \begin{equation*} g_n(z) = \inf_{\theta \in \Theta_n} z^\top \theta, \quad n= 1,\ldots, N.\end{equation*}
\begin{equation*} g_n(z) = \inf_{\theta \in \Theta_n} z^\top \theta, \quad n= 1,\ldots, N.\end{equation*}
Here, the set
 $\Theta_n$
can be random in such a way that
$\Theta_n$
can be random in such a way that
 $g_n$
is
$g_n$
is
 $\mathscr{F}_{n-1}\otimes \mathscr{B}(\mathbb{R}^d)$
-measurable. Then we have (2.13) with
$\mathscr{F}_{n-1}\otimes \mathscr{B}(\mathbb{R}^d)$
-measurable. Then we have (2.13) with
 $b_n$
such that
$b_n$
such that
 $b_n(\theta) = 0$
if
$b_n(\theta) = 0$
if
 $\theta \in \bar{\Theta}_n$
while
$\theta \in \bar{\Theta}_n$
while
 $b_n(\theta) = \infty$
otherwise, where
$b_n(\theta) = \infty$
otherwise, where
 $\bar{\Theta}_n$
is the closure of
$\bar{\Theta}_n$
is the closure of
 $\Theta_n$
. In particular when
$\Theta_n$
. In particular when
 $\Theta_n = \Theta$
, by Theorem 2.2,
$\Theta_n = \Theta$
, by Theorem 2.2,
 \begin{equation*} \mathcal{E}^g_n(Y) = \min_{\hat{\mathbb{P}} \in \mathcal{P}_N} \hat{\mathbb{E}}[Y \mid \mathscr{F}_n],\quad n= 1,\ldots, N,\end{equation*}
\begin{equation*} \mathcal{E}^g_n(Y) = \min_{\hat{\mathbb{P}} \in \mathcal{P}_N} \hat{\mathbb{E}}[Y \mid \mathscr{F}_n],\quad n= 1,\ldots, N,\end{equation*}
for any
 $\mathscr{F}_N$
-measurable random variable Y. Note also that
$\mathscr{F}_N$
-measurable random variable Y. Note also that
 \begin{equation*} \mathcal{E}^g_0(Y) = \min_{\hat{\mathbb{P}} \in \mathcal{P}_N} \hat{\mathbb{E}}[Y] = \min_{\omega \in \Omega} Y(\omega).\end{equation*}
\begin{equation*} \mathcal{E}^g_0(Y) = \min_{\hat{\mathbb{P}} \in \mathcal{P}_N} \hat{\mathbb{E}}[Y] = \min_{\omega \in \Omega} Y(\omega).\end{equation*}
When
 $\Theta_n = \{\mathbf{v}P_n^{(1)}, \ldots, \mathbf{v}P^{(m)}_n\}$
for a
$\Theta_n = \{\mathbf{v}P_n^{(1)}, \ldots, \mathbf{v}P^{(m)}_n\}$
for a
 $\Delta_d$
-valued predictable process
$\Delta_d$
-valued predictable process
 $\{P^{(i)}_n\}$
, letting
$\{P^{(i)}_n\}$
, letting
 $\mathbb{E}^{(x)}$
denote the expectation under the measure determined by
$\mathbb{E}^{(x)}$
denote the expectation under the measure determined by
 $\{P^{(x_n)}_n\}$
for
$\{P^{(x_n)}_n\}$
for
 $x = (x_1,\ldots,x_N) \in \{1,\ldots,m\}^N$
, by Theorem 2.2, we have
$x = (x_1,\ldots,x_N) \in \{1,\ldots,m\}^N$
, by Theorem 2.2, we have
 \begin{equation*} \mathcal{E}^g_n(Y) = \min_x \mathbb{E}^{(x)}[Y \mid \mathscr{F}_n],\quad n= 1,\ldots, N.\end{equation*}
\begin{equation*} \mathcal{E}^g_n(Y) = \min_x \mathbb{E}^{(x)}[Y \mid \mathscr{F}_n],\quad n= 1,\ldots, N.\end{equation*}
2.5. Filtration consistent nonlinear expectations
Inspired by Coquet et al. [Reference Coquet, Hu, Memin and Peng16], we call
 $\mathcal{E}\colon L^0(\Omega,\mathscr{F}_N,\mathbb{P}) \to \mathbb{R}$
a filtration consistent nonlinear expectation if:
$\mathcal{E}\colon L^0(\Omega,\mathscr{F}_N,\mathbb{P}) \to \mathbb{R}$
a filtration consistent nonlinear expectation if:
-
(i)
$Y \geq Y^\prime \Rightarrow \mathcal{E}(Y) \geq \mathcal{E}(Y^\prime)$
, -
(ii)
$Y \geq Y^\prime$
and
$ \mathcal{E}(Y) = \mathcal{E}(Y^\prime) \Rightarrow Y = Y^\prime$
, -
(iii)
$\mathcal{E}(c) = c$
for any constant
$c \in \mathbb{R}$
, and -
(iv) for any
$n=1,\ldots,N$
and Y, there exists an
$\mathscr{F}_n$
-measurable
$\eta$
such that
$\mathcal{E}(Y1_A) = \mathcal{E}(\eta 1_A)$
for any
$A \in \mathscr{F}_n$
.










Further,
 $\eta$
is uniquely determined as shown in [Reference Coquet, Hu, Memin and Peng16]. Let it be denoted by
$\eta$
is uniquely determined as shown in [Reference Coquet, Hu, Memin and Peng16]. Let it be denoted by
 $\mathcal{E}_n(Y)$
. It follows that
$\mathcal{E}_n(Y)$
. It follows that
 \begin{equation} \mathcal{E}_n(\mathcal{E}_m(Y)) = \mathcal{E}_n(Y)\end{equation}
\begin{equation} \mathcal{E}_n(\mathcal{E}_m(Y)) = \mathcal{E}_n(Y)\end{equation}
for any
 $m \geq n$
, and
$m \geq n$
, and
 \begin{equation} \mathcal{E}_n(Y)1_A = \mathcal{E}_n(Y1_A)\end{equation}
\begin{equation} \mathcal{E}_n(Y)1_A = \mathcal{E}_n(Y1_A)\end{equation}
for any
 $A \in \mathscr{F}_n$
.
$A \in \mathscr{F}_n$
.
Proposition 2.4. Let
 $g = \{g_n \} \in \mathcal{A}$
, and assume that for
$g = \{g_n \} \in \mathcal{A}$
, and assume that for
 $n = 1,\ldots, N$
,
$n = 1,\ldots, N$
,
-
(i)
$g_n(0) = 0$
and -
(ii) for any
$z_1, z_2 \in \mathbb{R}^d$
with equality holding only if
\begin{equation*} g_n(z_1) -g_n(z_2) \geq \min_{\theta \in \Theta} \theta^\top (z_1-z_2),\end{equation*}
$z_1 = z_2$
.




Then
 $\mathcal{E}^g_0$
is a filtration consistent nonlinear expectation with
$\mathcal{E}^g_0$
is a filtration consistent nonlinear expectation with
 $\mathcal{E}_n = \mathcal{E}^g_n$
and a translation invariance property,
$\mathcal{E}_n = \mathcal{E}^g_n$
and a translation invariance property,
 \begin{equation} \mathcal{E}_n(Y + \eta) = \mathcal{E}_n(Y) + \eta,\end{equation}
\begin{equation} \mathcal{E}_n(Y + \eta) = \mathcal{E}_n(Y) + \eta,\end{equation}
for any
 $\mathscr{F}_N$
-measurable random variable Y,
$\mathscr{F}_N$
-measurable random variable Y,
 $\mathscr{F}_n$
-measurable random variable
$\mathscr{F}_n$
-measurable random variable
 $\eta$
, and
$\eta$
, and
 $n=1,\ldots, N$
.
$n=1,\ldots, N$
.
Proof. From Proposition 2.3 and its proof, we observe the first two properties of filtration consistent nonlinear expectation. By
 $g_n(0) = 0$
we derive (2.15) and (2.16), from which the other properties follow.
$g_n(0) = 0$
we derive (2.15) and (2.16), from which the other properties follow.
The following theorem is a discrete analog of Theorem 7.1 of [Reference Coquet, Hu, Memin and Peng16].
Proposition 2.5. Let
 $\mathcal{E}$
be a filtration consistent nonlinear expectation with the translation invariance property (2.17). Let
$\mathcal{E}$
be a filtration consistent nonlinear expectation with the translation invariance property (2.17). Let
 $g_n(z) = \mathcal{E}_{n-1}(z^\top \Delta X_n)$
. Then
$g_n(z) = \mathcal{E}_{n-1}(z^\top \Delta X_n)$
. Then
 $\mathcal{E}_n = \mathcal{E}^g_n$
.
$\mathcal{E}_n = \mathcal{E}^g_n$
.
Proof. We have
 $\mathcal{E}_N(Y) = Y$
for any Y, so the claim is true for
$\mathcal{E}_N(Y) = Y$
for any Y, so the claim is true for
 $n=N$
. Assume
$n=N$
. Assume
 $\mathcal{E}_k(Y) = \mathcal{E}^g_k(Y)$
for
$\mathcal{E}_k(Y) = \mathcal{E}^g_k(Y)$
for
 $k \geq n$
. Then, by (2.2), there exists
$k \geq n$
. Then, by (2.2), there exists
 $\mathscr{F}_{n-1}$
-measurable
$\mathscr{F}_{n-1}$
-measurable
 $A_n$
and
$A_n$
and
 $Z_n$
such that
$Z_n$
such that
 \begin{equation*} \mathcal{E}_n(Y) = A_n + Z_n^\top \Delta X_n.\end{equation*}
\begin{equation*} \mathcal{E}_n(Y) = A_n + Z_n^\top \Delta X_n.\end{equation*}
 \begin{equation*} \mathcal{E}_{n-1}(Y) = A_n + \mathcal{E}_{n-1}(Z_n^\top \Delta X_n).\end{equation*}
\begin{equation*} \mathcal{E}_{n-1}(Y) = A_n + \mathcal{E}_{n-1}(Z_n^\top \Delta X_n).\end{equation*}
The last term is
 $g_n(Z_n)$
by (2.16). Therefore
$g_n(Z_n)$
by (2.16). Therefore
 \begin{equation*}\mathcal{E}_n(Y)- \mathcal{E}_{n-1}(Y) = - g_n(Z_n) + Z_n^\top \Delta X_n,\end{equation*}
\begin{equation*}\mathcal{E}_n(Y)- \mathcal{E}_{n-1}(Y) = - g_n(Z_n) + Z_n^\top \Delta X_n,\end{equation*}
which implies that
 $\mathcal{E}_{n-1}(Y) = \mathcal{E}_{n-1}^g(Y)$
. The result follows by induction.
$\mathcal{E}_{n-1}(Y) = \mathcal{E}_{n-1}^g(Y)$
. The result follows by induction.
3. Market equilibrium analysis
3.1. Monetary utility maximization
Now we consider
 $\{X_n\}$
to be a d-dimensional asset price process. The lattice L is then understood as the price grid. For any
$\{X_n\}$
to be a d-dimensional asset price process. The lattice L is then understood as the price grid. For any
 $\{\mathscr{F}_n\}$
-predictable
$\{\mathscr{F}_n\}$
-predictable
 $\mathbb{R}^d$
-valued process
$\mathbb{R}^d$
-valued process
 $Z = \{Z_n\}$
and
$Z = \{Z_n\}$
and
 $w \in \mathbb{R}$
,
$w \in \mathbb{R}$
,
 \begin{equation*} W_n(w,Z) \,:\!=\, w + \sum_{i=1}^n Z_i^\top \Delta X_i\end{equation*}
\begin{equation*} W_n(w,Z) \,:\!=\, w + \sum_{i=1}^n Z_i^\top \Delta X_i\end{equation*}
represents the wealth process associated with the portfolio strategy Z and the initial wealth w. Applying Theorem 2.1 with
 $g_n = 0$
,
$g_n = 0$
,
 $n=1,\ldots, N$
, we observe that the market is complete, that is, for any
$n=1,\ldots, N$
, we observe that the market is complete, that is, for any
 $\mathscr{F}_N$
-measurable random variable Y, there exists a predictable process Z and
$\mathscr{F}_N$
-measurable random variable Y, there exists a predictable process Z and
 $w \in \mathbb{R}$
such that
$w \in \mathbb{R}$
such that
 $Y = W_N( w,Z)$
.
$Y = W_N( w,Z)$
.
Consider an agent whose utility functional is
 $\mathcal{E}^g_0$
for
$\mathcal{E}^g_0$
for
 $g \in \mathcal{C}$
. This utility is monetary in the sense that for all
$g \in \mathcal{C}$
. This utility is monetary in the sense that for all
 $n = 0, \ldots, N$
,
$n = 0, \ldots, N$
,
 $\mathcal{E}_n^g(Y+A) = \mathcal{E}_n^g(Y)+A$
for any
$\mathcal{E}_n^g(Y+A) = \mathcal{E}_n^g(Y)+A$
for any
 $\mathscr{F}_N$
-measurable random variable Y and
$\mathscr{F}_N$
-measurable random variable Y and
 $\mathscr{F}_n$
-measurable random variable A. When assuming
$\mathscr{F}_n$
-measurable random variable A. When assuming
 $g_n(0) = 0$
for all n in addition, the utility is normalized in the sense that
$g_n(0) = 0$
for all n in addition, the utility is normalized in the sense that
 $\mathcal{E}^g_n(0)=0$
,
$\mathcal{E}^g_n(0)=0$
,
 $n =0,\ldots, N$
, and it is time-consistent in the sense that
$n =0,\ldots, N$
, and it is time-consistent in the sense that
 $\mathcal{E}_m^g(\mathcal{E}_n^g(Y))=\mathcal{E}_m^g(Y)$
for any
$\mathcal{E}_m^g(\mathcal{E}_n^g(Y))=\mathcal{E}_m^g(Y)$
for any
 $m \leq n$
and for any
$m \leq n$
and for any
 $\mathscr{F}_N$
-measurable random variable Y. The simplest example is
$\mathscr{F}_N$
-measurable random variable Y. The simplest example is
 $\mathcal{E}^g_n(Y) = \mathbb{E}[Y\mid \mathscr{F}_n]$
corresponding to
$\mathcal{E}^g_n(Y) = \mathbb{E}[Y\mid \mathscr{F}_n]$
corresponding to
 $g_n(z) = z^\top \mathbb{E}[\Delta X_n \mid \mathscr{F}_{n-1}]$
. More generally,
$g_n(z) = z^\top \mathbb{E}[\Delta X_n \mid \mathscr{F}_{n-1}]$
. More generally,
 $\mathcal{E}^g_n(Y)$
is a conditional expectation with respect to a probability measure when
$\mathcal{E}^g_n(Y)$
is a conditional expectation with respect to a probability measure when
 $g_n$
are linear for all n by Proposition 2.2. The driver
$g_n$
are linear for all n by Proposition 2.2. The driver
 $\{g_n\}$
should reflect the agent’s belief in the distribution of the price process
$\{g_n\}$
should reflect the agent’s belief in the distribution of the price process
 $\{X_n\}$
. For example, if
$\{X_n\}$
. For example, if
 $g_n = 0$
for all n, then
$g_n = 0$
for all n, then
 $\mathcal{E}^g_n(Y) = \mathbb{E}_\mathbb{Q}[Y\mid \mathscr{F}_n]$
irrespective of
$\mathcal{E}^g_n(Y) = \mathbb{E}_\mathbb{Q}[Y\mid \mathscr{F}_n]$
irrespective of
 $\mathbb{P}$
. The choice of nonlinear
$\mathbb{P}$
. The choice of nonlinear
 $\{g_n\}$
accommodates a nonlinear evaluation of risk, extending the exponential utility (2.9). In light of Theorem 2.2, our problem can be interpreted as a robust utility maximization.
$\{g_n\}$
accommodates a nonlinear evaluation of risk, extending the exponential utility (2.9). In light of Theorem 2.2, our problem can be interpreted as a robust utility maximization.
The agent’s objective is to maximize
 $\mathcal{E}^g_0(H + W_N(w,\pi))$
among the predictable process
$\mathcal{E}^g_0(H + W_N(w,\pi))$
among the predictable process
 $\pi = \{\pi_n\}$
, where H is a given
$\pi = \{\pi_n\}$
, where H is a given
 $\mathscr{F}_N$
-measurable random variable representing an initial endowment of the agent, i.e. an initially endowed asset or a scheduled random cashflow. Since the utility is monetary, it suffices to treat the case
$\mathscr{F}_N$
-measurable random variable representing an initial endowment of the agent, i.e. an initially endowed asset or a scheduled random cashflow. Since the utility is monetary, it suffices to treat the case
 $w = 0$
. Let
$w = 0$
. Let
 \begin{equation} Y^\pi_n =\mathcal{E}^g_n(H + W_N(0,\pi)- W_n(0,\pi) ) =\mathcal{E}^g_n(H + W_N(0,\pi))- W_n(0,\pi).\end{equation}
\begin{equation} Y^\pi_n =\mathcal{E}^g_n(H + W_N(0,\pi)- W_n(0,\pi) ) =\mathcal{E}^g_n(H + W_N(0,\pi))- W_n(0,\pi).\end{equation}
Then the problem is equivalent to maximizing
 $Y^\pi_0$
among
$Y^\pi_0$
among
 $\pi$
. The following theorem characterizes the maximizer.
$\pi$
. The following theorem characterizes the maximizer.
Theorem 3.1. Assume that there exists a predictable process
 $\{Z^\dagger_n\}$
such that
$\{Z^\dagger_n\}$
such that
 \begin{equation} g_n(Z^\dagger_n) = \sup_{z \in \mathbb{R}^d} g_n(z), \quad n=1,\ldots, N.\end{equation}
\begin{equation} g_n(Z^\dagger_n) = \sup_{z \in \mathbb{R}^d} g_n(z), \quad n=1,\ldots, N.\end{equation}
Then
 \begin{equation*} \max_{\pi} Y^\pi_0 = \max_{\pi}\mathcal{E}^g_0(H + W_{N} (0,\pi)) = \mathcal{E}^g_0(H + W_{N}(0,\pi^\ast)),\end{equation*}
\begin{equation*} \max_{\pi} Y^\pi_0 = \max_{\pi}\mathcal{E}^g_0(H + W_{N} (0,\pi)) = \mathcal{E}^g_0(H + W_{N}(0,\pi^\ast)),\end{equation*}
where
 $\pi^\ast_n = Z^\dagger_n - Z^\ast_n$
,
$\pi^\ast_n = Z^\dagger_n - Z^\ast_n$
,
 $ Z^\ast_n = Z^H_n + Z^g_n$
,
$ Z^\ast_n = Z^H_n + Z^g_n$
,
 \begin{align} Z^H_n& =(d+1) (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbb{E}_\mathbb{Q}[H\Delta X_n \mid \mathscr{F}_{n-1}],\nonumber\\Z^g_n & =(d+1) (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbb{E}_\mathbb{Q}[G_n \Delta X_n \mid \mathscr{F}_{n-1}],\end{align}
\begin{align} Z^H_n& =(d+1) (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbb{E}_\mathbb{Q}[H\Delta X_n \mid \mathscr{F}_{n-1}],\nonumber\\Z^g_n & =(d+1) (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbb{E}_\mathbb{Q}[G_n \Delta X_n \mid \mathscr{F}_{n-1}],\end{align}
and
 \begin{equation*} G_n = \sum_{i=n+1}^N \mathbb{E}_\mathbb{Q}[ g_i(Z_i^\dagger) \mid \mathscr{F}_n]\end{equation*}
\begin{equation*} G_n = \sum_{i=n+1}^N \mathbb{E}_\mathbb{Q}[ g_i(Z_i^\dagger) \mid \mathscr{F}_n]\end{equation*}
for
 $n=1,\ldots, N$
. Moreover,
$n=1,\ldots, N$
. Moreover,
 \begin{equation}Y^{\pi^\ast}_n = \mathbb{E}_\mathbb{Q}[ H \mid \mathscr{F}_n]+ G_n\end{equation}
\begin{equation}Y^{\pi^\ast}_n = \mathbb{E}_\mathbb{Q}[ H \mid \mathscr{F}_n]+ G_n\end{equation}
for
 $n=0,1,\ldots, N$
. If in addition
$n=0,1,\ldots, N$
. If in addition
 $Z^\dagger_n$
is unique, then
$Z^\dagger_n$
is unique, then
 $\pi^\ast_n$
is the unique maximizer.
$\pi^\ast_n$
is the unique maximizer.
Proof. Let
 $Y^\ast_n$
denote the right-hand side of (3.4). Then
$Y^\ast_n$
denote the right-hand side of (3.4). Then
 $\{(Y^\ast_n,Z^\ast_n)\}$
is the solution of the BS
$\{(Y^\ast_n,Z^\ast_n)\}$
is the solution of the BS
 $\Delta$
E
$\Delta$
E
 \begin{equation} \Delta Y^\ast_n = - g_n(Z_n^\dagger) + (Z^\ast_n)^\top \Delta X_n, \quad Y^\ast_N = H ,\end{equation}
\begin{equation} \Delta Y^\ast_n = - g_n(Z_n^\dagger) + (Z^\ast_n)^\top \Delta X_n, \quad Y^\ast_N = H ,\end{equation}
by Theorem 2.1. Note that
 \begin{equation*} \Delta Y^\pi_n = -g_n(Z_n) + Z_n^\top \Delta X_n - \pi_n^\top \Delta X_n,\quad Y^\pi_N = H ,\end{equation*}
\begin{equation*} \Delta Y^\pi_n = -g_n(Z_n) + Z_n^\top \Delta X_n - \pi_n^\top \Delta X_n,\quad Y^\pi_N = H ,\end{equation*}
for a predictable process
 $\{Z_n\}$
by (3.1). This means
$\{Z_n\}$
by (3.1). This means
 $\{(Y^\pi_n,Z^\pi_n)\}$
,
$\{(Y^\pi_n,Z^\pi_n)\}$
,
 $Z^\pi_n = Z_n -\pi_n$
solves the BS
$Z^\pi_n = Z_n -\pi_n$
solves the BS
 $\Delta$
E
$\Delta$
E
 \begin{equation*}\Delta Y^\pi_n = -h^\pi_n(Z^\pi_n) + (Z_n^\pi)^\top \Delta X_n,\quad Y^\pi_N = H,\end{equation*}
\begin{equation*}\Delta Y^\pi_n = -h^\pi_n(Z^\pi_n) + (Z_n^\pi)^\top \Delta X_n,\quad Y^\pi_N = H,\end{equation*}
where
 $h^\pi_n(z) = g_n(z+ \pi_n)$
. For any predictable process
$h^\pi_n(z) = g_n(z+ \pi_n)$
. For any predictable process
 $\pi$
, we have
$\pi$
, we have
 $h^\pi_n \leq g_n(Z^\dagger_n)$
. Therefore
$h^\pi_n \leq g_n(Z^\dagger_n)$
. Therefore
 $Y^\pi_n \leq Y^\ast_n$
by Proposition 2.3. Notice also that by choosing
$Y^\pi_n \leq Y^\ast_n$
by Proposition 2.3. Notice also that by choosing
 $\pi^\ast_n = Z^\dagger_n -Z^\ast_n$
we have
$\pi^\ast_n = Z^\dagger_n -Z^\ast_n$
we have
 $g_n(Z^\dagger) = h_n^{\pi^\ast}(Z^\ast_n)$
, so that
$g_n(Z^\dagger) = h_n^{\pi^\ast}(Z^\ast_n)$
, so that
 $\{(Y^\ast_n,Z^\ast_n)\}$
satisfies the same BS
$\{(Y^\ast_n,Z^\ast_n)\}$
satisfies the same BS
 $\Delta$
E as
$\Delta$
E as
 $\{(Y^{\pi^\ast}_n,Z^{\pi^\ast}_n)\}$
. Hence
$\{(Y^{\pi^\ast}_n,Z^{\pi^\ast}_n)\}$
. Hence
 $Y^\ast_n = Y^{\pi^\ast}_n$
.
$Y^\ast_n = Y^{\pi^\ast}_n$
.
Remark 3.1. Applying Theorem 2.1 to
 $g_n = 0$
and
$g_n = 0$
and
 $Y_N = H$
, we have
$Y_N = H$
, we have
 \begin{equation*} H = \mathbb{E}_\mathbb{Q}[H] + \sum_{n=1}^N Z^H_n \Delta X_n \end{equation*}
\begin{equation*} H = \mathbb{E}_\mathbb{Q}[H] + \sum_{n=1}^N Z^H_n \Delta X_n \end{equation*}
with
 $\{Z^H_n\}$
defined by (3.3). Therefore the optimal strategy
$\{Z^H_n\}$
defined by (3.3). Therefore the optimal strategy
 $\pi^\ast = Z^\dagger_n - Z^\ast_n = -Z^H_n + Z^\dagger_n - Z^g_n$
of Theorem 3.1 is decomposed into the hedging part
$\pi^\ast = Z^\dagger_n - Z^\ast_n = -Z^H_n + Z^\dagger_n - Z^g_n$
of Theorem 3.1 is decomposed into the hedging part
 $-Z^H_n$
and the optimal investment part
$-Z^H_n$
and the optimal investment part
 $Z^\dagger_n - Z^g_n$
.
$Z^\dagger_n - Z^g_n$
.
Example 3.1. (Locally entropic monetary utility.) Consider (2.12). Let
 $\Delta_d^\circ$
denote the interior of
$\Delta_d^\circ$
denote the interior of
 $\Delta_d$
and assume
$\Delta_d$
and assume
 $\{(\hat{P}_{n,1},\ldots, \hat{P}_{n,d})^\top\}$
to be
$\{(\hat{P}_{n,1},\ldots, \hat{P}_{n,d})^\top\}$
to be
 $\Delta_d^\circ$
-valued. Then the map
$\Delta_d^\circ$
-valued. Then the map
 $z \mapsto g_n(z)$
is strictly concave and its unique maximizer is given by
$z \mapsto g_n(z)$
is strictly concave and its unique maximizer is given by
 $Z^\dagger_n = b(y)$
of (2.3) for
$Z^\dagger_n = b(y)$
of (2.3) for
 \begin{equation*} y = \frac{1}{\Gamma_n} \log \hat{P}_n \,:\!=\, \frac{1}{\Gamma_n} \big( \log \hat{P}_{n,1}, \ldots, \log \hat{P}_{n,d}\big)^\top, \end{equation*}
\begin{equation*} y = \frac{1}{\Gamma_n} \log \hat{P}_n \,:\!=\, \frac{1}{\Gamma_n} \big( \log \hat{P}_{n,1}, \ldots, \log \hat{P}_{n,d}\big)^\top, \end{equation*}
or equivalently
 \begin{equation} Z^\dagger_n = \frac{1}{\Gamma_n} (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v} \log \hat{P}_n. \end{equation}
\begin{equation} Z^\dagger_n = \frac{1}{\Gamma_n} (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v} \log \hat{P}_n. \end{equation}
Indeed,
 $v_j^\top Z^\dagger_n = \Gamma_n^{-1}\log \hat{P}_{n,j} - a(y)$
implies
$v_j^\top Z^\dagger_n = \Gamma_n^{-1}\log \hat{P}_{n,j} - a(y)$
implies
 \begin{equation*} \sum_{j=0}^d v_j \,{\mathrm{e}}^{-\Gamma_n v_j^\top Z^\dagger_n} \hat{P}_{n,j}= 0, \end{equation*}
\begin{equation*} \sum_{j=0}^d v_j \,{\mathrm{e}}^{-\Gamma_n v_j^\top Z^\dagger_n} \hat{P}_{n,j}= 0, \end{equation*}
and thus
 $\nabla g_n(Z^\dagger_n) =0$
for all n. We also have
$\nabla g_n(Z^\dagger_n) =0$
for all n. We also have
 \begin{align} \frac{1}{\Gamma_n}\log B_n + g_n(Z^\dagger_n) &= -\frac{1}{\Gamma_n} \log \Biggl( \sum_{j=0}^d \,{\mathrm{e}}^{-\Gamma_n v_j^\top Z^\dagger_n} \hat{P}_{n,j}\Biggr)\notag \\*& =-\frac{1}{\Gamma_n} \log \Bigl((d+1) \,{\mathrm{e}}^{\frac{1}{d+1}\mathbf{1}^\top \log \hat{P}_n }\Bigr)\notag \\ &= \frac{1}{\Gamma_n} \frac{1}{d+1}\sum_{j=0}^d \log \frac{1}{(d+1)\hat{P}_{n,j}} \notag \\*&= \frac{1}{\Gamma_n}D_{\mathrm{KL}}(Q_n ||\hat{P}_n) \notag \\*&\geq 0, \end{align}
\begin{align} \frac{1}{\Gamma_n}\log B_n + g_n(Z^\dagger_n) &= -\frac{1}{\Gamma_n} \log \Biggl( \sum_{j=0}^d \,{\mathrm{e}}^{-\Gamma_n v_j^\top Z^\dagger_n} \hat{P}_{n,j}\Biggr)\notag \\*& =-\frac{1}{\Gamma_n} \log \Bigl((d+1) \,{\mathrm{e}}^{\frac{1}{d+1}\mathbf{1}^\top \log \hat{P}_n }\Bigr)\notag \\ &= \frac{1}{\Gamma_n} \frac{1}{d+1}\sum_{j=0}^d \log \frac{1}{(d+1)\hat{P}_{n,j}} \notag \\*&= \frac{1}{\Gamma_n}D_{\mathrm{KL}}(Q_n ||\hat{P}_n) \notag \\*&\geq 0, \end{align}
where
 $D_{\mathrm{KL}}$
denotes the Kullback–Leibler divergence on
$D_{\mathrm{KL}}$
denotes the Kullback–Leibler divergence on
 $\Delta_d$
and
$\Delta_d$
and
 $Q_n = \mathbf{1}/(d+1)$
. By (3.3) and (3.6),
$Q_n = \mathbf{1}/(d+1)$
. By (3.3) and (3.6),
 \begin{equation*} \pi^\ast_n = Z^\dagger_n - Z^g_n - Z^H_n= - Z^H_n + (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v} \biggl( \frac{\log \hat{P}_n}{\Gamma_n} - \hat{Y}_n \biggr), \end{equation*}
\begin{equation*} \pi^\ast_n = Z^\dagger_n - Z^g_n - Z^H_n= - Z^H_n + (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v} \biggl( \frac{\log \hat{P}_n}{\Gamma_n} - \hat{Y}_n \biggr), \end{equation*}
where
 $\hat{Y}_n = (\hat{Y}_{n,0},\ldots, \hat{Y}_{n,d})^\top$
and
$\hat{Y}_n = (\hat{Y}_{n,0},\ldots, \hat{Y}_{n,d})^\top$
and
 $ \hat{Y}_{n,j} = \mathbb{E}_\mathbb{Q}[G_n \mid \mathscr{F}_{n-1}, \Delta X_n = v_j]$
. The first term
$ \hat{Y}_{n,j} = \mathbb{E}_\mathbb{Q}[G_n \mid \mathscr{F}_{n-1}, \Delta X_n = v_j]$
. The first term
 $-Z^H_n$
is the hedging term as noted in Remark 3.1. The term
$-Z^H_n$
is the hedging term as noted in Remark 3.1. The term
 \begin{equation*} Z^\dagger_n = (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v} \frac{\log \hat{P}_n}{\Gamma_n} \approx (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v} \frac{\hat{P}_n - \mathbf{1}}{\Gamma_n} = \frac{1}{\Gamma_n} (\mathbf{v}\mathbf{v}^\top)^{-1}\hat{\mathbb{E}}[\Delta X_n \mid \mathscr{F}_{n-1}] \end{equation*}
\begin{equation*} Z^\dagger_n = (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v} \frac{\log \hat{P}_n}{\Gamma_n} \approx (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v} \frac{\hat{P}_n - \mathbf{1}}{\Gamma_n} = \frac{1}{\Gamma_n} (\mathbf{v}\mathbf{v}^\top)^{-1}\hat{\mathbb{E}}[\Delta X_n \mid \mathscr{F}_{n-1}] \end{equation*}
can be interpreted as the discrete counterpart of the Merton portfolio (see e.g. Remark 8.9 of [Reference Karatzas and Shreve27]). The term
 $\hat{Y}_n$
adjusts the expected return depending on the stochastic dynamics of
$\hat{Y}_n$
adjusts the expected return depending on the stochastic dynamics of
 $D_{\mathrm{KL}}(Q_i ||\hat{P}_i)$
for
$D_{\mathrm{KL}}(Q_i ||\hat{P}_i)$
for
 $i \geq n+1$
. Indeed, when
$i \geq n+1$
. Indeed, when
 $B_n = 1$
and
$B_n = 1$
and
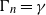 $\Gamma_n = \gamma$
for all n and a constant
$\Gamma_n = \gamma$
for all n and a constant
 $\gamma \gt 0$
as in (2.8), we have
$\gamma \gt 0$
as in (2.8), we have
 \begin{align*} G_n &= \sum_{i=n+1}^n \mathbb{E}_\mathbb{Q}[g_i(Z^\dagger_i) \mid \mathscr{F}_n]\\ &= \frac{1}{\gamma}\sum_{i=n+1}^n \mathbb{E}_\mathbb{Q}[D_{\mathrm{KL}}(Q_i||\hat{P}_i) | \mathscr{F}_n]\\ &= \frac{1}{\gamma} \mathbb{E}_\mathbb{Q}\biggl[ \log \frac{\mathrm{d}\mathbb{Q}}{\mathrm{d}\hat{\mathbb{P}}} - \log \mathbb{E}_\mathbb{Q}\biggl[ \frac{\mathrm{d}\mathbb{Q}}{\mathrm{d}\hat{\mathbb{P}}}\,\bigg|\, \mathscr{F}_n\biggr]\, \bigg|\, \mathscr{F}_n\biggr]\end{align*}
\begin{align*} G_n &= \sum_{i=n+1}^n \mathbb{E}_\mathbb{Q}[g_i(Z^\dagger_i) \mid \mathscr{F}_n]\\ &= \frac{1}{\gamma}\sum_{i=n+1}^n \mathbb{E}_\mathbb{Q}[D_{\mathrm{KL}}(Q_i||\hat{P}_i) | \mathscr{F}_n]\\ &= \frac{1}{\gamma} \mathbb{E}_\mathbb{Q}\biggl[ \log \frac{\mathrm{d}\mathbb{Q}}{\mathrm{d}\hat{\mathbb{P}}} - \log \mathbb{E}_\mathbb{Q}\biggl[ \frac{\mathrm{d}\mathbb{Q}}{\mathrm{d}\hat{\mathbb{P}}}\,\bigg|\, \mathscr{F}_n\biggr]\, \bigg|\, \mathscr{F}_n\biggr]\end{align*}
by (3.7), where
 $\hat{\mathbb{P}}$
is associated with
$\hat{\mathbb{P}}$
is associated with
 $\{\hat{P}_n\}$
by (2.5). Note also that
$\{\hat{P}_n\}$
by (2.5). Note also that
 $Z^g_n = 0$
if
$Z^g_n = 0$
if
 $G_n$
is deterministic, which is the case when
$G_n$
is deterministic, which is the case when
 $\{\hat{P}_n\}$
,
$\{\hat{P}_n\}$
,
 $\{\Gamma_n\}$
, and
$\{\Gamma_n\}$
, and
 $\{B_n\}$
are deterministic.
$\{B_n\}$
are deterministic.
Example 3.2. Let
 $d=2$
and
$d=2$
and
 \begin{equation*} \mathbf{v} = \begin{pmatrix} 0 & \quad 1 & \quad -1 \\ -2c & \quad c & \quad c \end{pmatrix}\!, \end{equation*}
\begin{equation*} \mathbf{v} = \begin{pmatrix} 0 & \quad 1 & \quad -1 \\ -2c & \quad c & \quad c \end{pmatrix}\!, \end{equation*}
where
 $c \in \mathbb{R}$
. Then we have
$c \in \mathbb{R}$
. Then we have
 \begin{equation*} X_{n,2} = c\Biggl(3 \sum_{k=1}^n |\Delta X_{k,1}|^2 - 2n\Biggr).\end{equation*}
\begin{equation*} X_{n,2} = c\Biggl(3 \sum_{k=1}^n |\Delta X_{k,1}|^2 - 2n\Biggr).\end{equation*}
Indeed, if
 $X_n = (n-a-b)v_0 + av_1 + bv_2$
for
$X_n = (n-a-b)v_0 + av_1 + bv_2$
for
 $(a,b) \in \mathbb{N}^2$
, then
$(a,b) \in \mathbb{N}^2$
, then
 \begin{equation*} a + b = \sum_{k=1}^n |\Delta X_{k,1}|^2, \quad X_{n,2} = -2c(n-a-b) + c(a+b) = c(3(a+b)-2n).\end{equation*}
\begin{equation*} a + b = \sum_{k=1}^n |\Delta X_{k,1}|^2, \quad X_{n,2} = -2c(n-a-b) + c(a+b) = c(3(a+b)-2n).\end{equation*}
Regarding
 $\{X_{n,1}\}$
as a price process of an asset, the above identity allows us to interpret
$\{X_{n,1}\}$
as a price process of an asset, the above identity allows us to interpret
 $X_{N,2}$
as an affine transform of the variance swap payoff of the asset. Further, regarding
$X_{N,2}$
as an affine transform of the variance swap payoff of the asset. Further, regarding
 $\mathbb{Q}$
as the pricing measure,
$\mathbb{Q}$
as the pricing measure,
 $\{X_{n,2}\}$
corresponds to the price process of the variance swap payoff. Note that
$\{X_{n,2}\}$
corresponds to the price process of the variance swap payoff. Note that
 $\{X_{n,1}\}$
describes a trinomial model for the asset, which is not complete. The variance swap trading makes the two-dimensional market
$\{X_{n,1}\}$
describes a trinomial model for the asset, which is not complete. The variance swap trading makes the two-dimensional market
 $\{X_n\}$
complete.
$\{X_n\}$
complete.
3.2. General equilibrium
Consider m agents who maximize respective utilities
 $\mathcal{E}_0^{(i)}(H^{(i)} + W_N(0,\pi^{(i)}))$
,
$\mathcal{E}_0^{(i)}(H^{(i)} + W_N(0,\pi^{(i)}))$
,
 $i=1,\ldots, m$
through trading strategies
$i=1,\ldots, m$
through trading strategies
 $\pi^{(i)}$
of the d-dimensional asset
$\pi^{(i)}$
of the d-dimensional asset
 $\{X_n\}$
, where
$\{X_n\}$
, where
 $\mathcal{E}^{(i)}$
is the solution map of the BS
$\mathcal{E}^{(i)}$
is the solution map of the BS
 $\Delta$
E (2.7) with
$\Delta$
E (2.7) with
 $g = g^{(i)} \in \mathcal{C}$
, and
$g = g^{(i)} \in \mathcal{C}$
, and
 $H^{(i)}$
is an
$H^{(i)}$
is an
 $\mathscr{F}_N$
-measurable random variable representing an endowment for the agent i,
$\mathscr{F}_N$
-measurable random variable representing an endowment for the agent i,
 $i=1,\ldots,m$
. Let
$i=1,\ldots,m$
. Let
 $H_n$
denote the total supply vector of the asset vector
$H_n$
denote the total supply vector of the asset vector
 $X_n$
and assume
$X_n$
and assume
 $\{H_n\}$
to be an
$\{H_n\}$
to be an
 $\mathbb{R}^d$
-valued predictable process. We say the market is in general equilibrium if there exist predictable processes
$\mathbb{R}^d$
-valued predictable process. We say the market is in general equilibrium if there exist predictable processes
 $\pi^{(i)} = \{\pi^{(i)}_n\}$
,
$\pi^{(i)} = \{\pi^{(i)}_n\}$
,
 $i=1,\ldots, m$
such that
$i=1,\ldots, m$
such that
-
(i)
$\mathcal{E}_0^{(i)}(H^{(i)} + W_N(0,\pi^{(i)})) = \max_\pi \mathcal{E}_0^{(i)}(H^{(i)} + W_N(0,\pi))$
for all
$i=1,\ldots, m$
, and -
(ii)
$\sum_{i=1}^m \pi^{(i)}_n = H_n $
for all
$n=1,\ldots, N$
,




where the maximum is among all predictable processes
 $\pi$
.
$\pi$
.
Proposition 3.1. Let
 $H^{(i)}$
and
$H^{(i)}$
and
 $\tilde{H}^{(i)}$
,
$\tilde{H}^{(i)}$
,
 $i=1,\ldots,m$
be
$i=1,\ldots,m$
be
 $\mathscr{F}_N$
-measurable random variables, and let
$\mathscr{F}_N$
-measurable random variables, and let
 $\{H_n\}$
and
$\{H_n\}$
and
 $\{\tilde{H}_n\}$
be
$\{\tilde{H}_n\}$
be
 $\mathbb{R}^d$
-valued predictable processes satisfying
$\mathbb{R}^d$
-valued predictable processes satisfying
 \begin{equation*} \sum_{i=1}^m H^{(i)} + \sum_{n=1}^N H_n^\top \Delta X_n = \sum_{i=1}^m \tilde{H}^{(i)} + \sum_{n=1}^N \tilde{H}_n^\top \Delta X_n. \end{equation*}
\begin{equation*} \sum_{i=1}^m H^{(i)} + \sum_{n=1}^N H_n^\top \Delta X_n = \sum_{i=1}^m \tilde{H}^{(i)} + \sum_{n=1}^N \tilde{H}_n^\top \Delta X_n. \end{equation*}
Then the market with the endowments
 $H^{(i)}$
and the total supply
$H^{(i)}$
and the total supply
 $\{H_n\}$
is in general equilibrium if and only if the market with the endowments
$\{H_n\}$
is in general equilibrium if and only if the market with the endowments
 $\tilde{H}^{(i)}$
and total supply
$\tilde{H}^{(i)}$
and total supply
 $\{\tilde{H}_n\}$
is in general equilibrium.
$\{\tilde{H}_n\}$
is in general equilibrium.
Proof. Let
 $Z^{\dagger(i)}$
,
$Z^{\dagger(i)}$
,
 $Z^{H(i)}$
, and
$Z^{H(i)}$
, and
 $Z^{g(i)}$
, respectively, denote
$Z^{g(i)}$
, respectively, denote
 $Z^{\dagger}$
,
$Z^{\dagger}$
,
 $Z^{H}$
, and
$Z^{H}$
, and
 $Z^{g}$
in Theorem 3.1 with
$Z^{g}$
in Theorem 3.1 with
 $g = g^{(i)}$
and
$g = g^{(i)}$
and
 $H = H^{(i)}$
. Then, by Theorem 3.1,
$H = H^{(i)}$
. Then, by Theorem 3.1,
 \begin{equation*}-H_n + \sum_{i=1}^m \pi^{(i)}_n = -H_n - \sum_{i=1}^m Z^{H(i)} + \sum_{i=1}^m \big(Z^{\dagger(i)} - Z^{g(i)}\big) =- Z^H + \sum_{i=1}^m \big(Z^{\dagger(i)} - Z^{g(i)}\big),\end{equation*}
\begin{equation*}-H_n + \sum_{i=1}^m \pi^{(i)}_n = -H_n - \sum_{i=1}^m Z^{H(i)} + \sum_{i=1}^m \big(Z^{\dagger(i)} - Z^{g(i)}\big) =- Z^H + \sum_{i=1}^m \big(Z^{\dagger(i)} - Z^{g(i)}\big),\end{equation*}
where
 $Z^H$
is defined by (3.3) with
$Z^H$
is defined by (3.3) with
 \begin{equation*} H = \sum_{i=1}^m H^{(i)} + \sum_{n=1}^N H_n^\top \Delta X_n.\end{equation*}
\begin{equation*} H = \sum_{i=1}^m H^{(i)} + \sum_{n=1}^N H_n^\top \Delta X_n.\end{equation*}
Therefore, whether or not
 $\sum_{i=1}^m \pi^{(i)}_n =H_n$
depends on
$\sum_{i=1}^m \pi^{(i)}_n =H_n$
depends on
 $H^{(i)}$
and
$H^{(i)}$
and
 $\{H_n\}$
only through H.
$\{H_n\}$
only through H.
We are interested in conditions on
 $g^{(i)}$
for the market to be in general equilibrium. In light of Proposition 3.1, we assume hereafter
$g^{(i)}$
for the market to be in general equilibrium. In light of Proposition 3.1, we assume hereafter
 $H^{(i)}=0$
(
$H^{(i)}=0$
(
 $i \geq 2)$
and
$i \geq 2)$
and
 $H_n =0$
(
$H_n =0$
(
 $n\geq 1$
), without loss of generality. Let H denote
$n\geq 1$
), without loss of generality. Let H denote
 $H^{(1)}$
.
$H^{(1)}$
.
For functions
 $f^{(1)}$
and
$f^{(1)}$
and
 $f^{(2)}$
on
$f^{(2)}$
on
 $\mathbb{R}^d$
, define the sup-convolution
$\mathbb{R}^d$
, define the sup-convolution
 $f^{(1)} \square f^{(2)}$
by
$f^{(1)} \square f^{(2)}$
by
 \begin{equation*} f^{(1)}\square \, f^{(2)}(z) = \sup_{x \in \mathbb{R}^d} \{\, f^{(1)}(x) + f^{(2)}(z-x)\}.\end{equation*}
\begin{equation*} f^{(1)}\square \, f^{(2)}(z) = \sup_{x \in \mathbb{R}^d} \{\, f^{(1)}(x) + f^{(2)}(z-x)\}.\end{equation*}
For the drivers
 $g^{(i)} = \{g^{(i)}_n\}$
,
$g^{(i)} = \{g^{(i)}_n\}$
,
 $i=1,\ldots,m$
of the m agents’ utilities, let
$i=1,\ldots,m$
of the m agents’ utilities, let
 \begin{equation} g_n(z) = g^{(1)}_n \square \cdots \square g^{(m)}_n(z).\end{equation}
\begin{equation} g_n(z) = g^{(1)}_n \square \cdots \square g^{(m)}_n(z).\end{equation}
Lemma 3.1. For all n,
 \begin{equation} \sup_{z \in \mathbb{R}^d} g_n(z) = \sum_{i=1}^m \sup_{z \in \mathbb{R}^d} g_n^{(i)}(z).\end{equation}
\begin{equation} \sup_{z \in \mathbb{R}^d} g_n(z) = \sum_{i=1}^m \sup_{z \in \mathbb{R}^d} g_n^{(i)}(z).\end{equation}
Proof. It is trivial that
 $g_n(z)$
is upper-bounded by the right-hand side sum for any z, and hence its supremum is upper-bounded. Conversely, let
$g_n(z)$
is upper-bounded by the right-hand side sum for any z, and hence its supremum is upper-bounded. Conversely, let
 $\bigl\{z^{(i)}_k\bigr\}$
be a sequence for which
$\bigl\{z^{(i)}_k\bigr\}$
be a sequence for which
 $ \lim_{k \to \infty} g_n^{(i)}\bigl(z^{(i)}_k\bigr) = \sup_{z \in \mathbb{R}^d} g_n^{(i)}(z)$
for each i. Then
$ \lim_{k \to \infty} g_n^{(i)}\bigl(z^{(i)}_k\bigr) = \sup_{z \in \mathbb{R}^d} g_n^{(i)}(z)$
for each i. Then
 \begin{equation*} \sum_{i=1}^m g_n^{(i)}\bigl(z^{(i)}_k\bigr) \leq g_n\Biggl(\sum_{i=1}^m z^{(i)}_k \Biggr) \leq \sup_{z \in \mathbb{R}^d} g_n(z)\end{equation*}
\begin{equation*} \sum_{i=1}^m g_n^{(i)}\bigl(z^{(i)}_k\bigr) \leq g_n\Biggl(\sum_{i=1}^m z^{(i)}_k \Biggr) \leq \sup_{z \in \mathbb{R}^d} g_n(z)\end{equation*}
for any k, and the limit is similarly bounded.
A single agent whose utility is
 $\mathcal{E}^g_0$
with
$\mathcal{E}^g_0$
with
 $g = \{g_n\}$
defined by (3.8) and whose endowment is H is called the representative agent of the market. The following theorem reduces the general equilibrium problem for the multi-agent market to the one for a single agent market. This extends the idea of the well-known Gorman aggregation theorem.
$g = \{g_n\}$
defined by (3.8) and whose endowment is H is called the representative agent of the market. The following theorem reduces the general equilibrium problem for the multi-agent market to the one for a single agent market. This extends the idea of the well-known Gorman aggregation theorem.
Proposition 3.2. Assume that there exists a unique predictable process
 $\{Z^{\dagger(i)}_n\}$
for each
$\{Z^{\dagger(i)}_n\}$
for each
 $i=1,\ldots,m$
such that
$i=1,\ldots,m$
such that
 \begin{equation*} g^{(i)}_n(Z^{\dagger(i)}_n) = \sup_{z \in \mathbb{R}^d}g^{(i)}_n(z)\end{equation*}
\begin{equation*} g^{(i)}_n(Z^{\dagger(i)}_n) = \sup_{z \in \mathbb{R}^d}g^{(i)}_n(z)\end{equation*}
for all
 $n = 1,\ldots, N$
. Assume further that the maximizer of the map
$n = 1,\ldots, N$
. Assume further that the maximizer of the map
 $z \mapsto g_n(z)(\omega)$
is unique for each n and
$z \mapsto g_n(z)(\omega)$
is unique for each n and
 $\omega \in \Omega$
. The market for the m agents is in general equilibrium if and only the market for the representative agent is in general equilibrium.
$\omega \in \Omega$
. The market for the m agents is in general equilibrium if and only the market for the representative agent is in general equilibrium.
Proof. Let
 $\{(Y^{\ast(i)}_n,Z^{\ast(i)}_n)\}$
be the solution of
$\{(Y^{\ast(i)}_n,Z^{\ast(i)}_n)\}$
be the solution of
 \begin{equation*} \Delta Y^{\ast (i)}_n = -g^{(i)}_n(Z^{\dagger (i)}_n) + (Z^{\ast (i)}_n)^\top \Delta X_n,\end{equation*}
\begin{equation*} \Delta Y^{\ast (i)}_n = -g^{(i)}_n(Z^{\dagger (i)}_n) + (Z^{\ast (i)}_n)^\top \Delta X_n,\end{equation*}
with
 $Y^{\ast (1)}_N = H$
and
$Y^{\ast (1)}_N = H$
and
 $Y^{\ast (i)}_N = 0$
for
$Y^{\ast (i)}_N = 0$
for
 $i \geq 2$
. By Theorem 3.1, the unique optimal strategy
$i \geq 2$
. By Theorem 3.1, the unique optimal strategy
 $\pi^{(i)}$
for the agent i is given by
$\pi^{(i)}$
for the agent i is given by
 $\pi^{(i)}_n = Z^{\dagger (i)}_n -Z^{\ast(i)}_n $
. By (3.9), we have
$\pi^{(i)}_n = Z^{\dagger (i)}_n -Z^{\ast(i)}_n $
. By (3.9), we have
 \begin{equation*} \sum_{i=1}^m g^{(i)}_n(Z^{\dagger(i)}_n) = \sup_{z \in \mathbb{R}^d}g_n(z) = g_n(Z^\dagger_n), \quad Z^\dagger_n \,:\!=\, \sum_{i=1}^m Z^{\dagger(i)}_n.\end{equation*}
\begin{equation*} \sum_{i=1}^m g^{(i)}_n(Z^{\dagger(i)}_n) = \sup_{z \in \mathbb{R}^d}g_n(z) = g_n(Z^\dagger_n), \quad Z^\dagger_n \,:\!=\, \sum_{i=1}^m Z^{\dagger(i)}_n.\end{equation*}
Therefore
 \begin{equation*} Y^\ast_n \,:\!=\, \sum_{i=1}^m Y^{\ast(i)}_n, \quad Z^\ast_n \,:\!=\, \sum_{i=1}^m Z^{\ast (i)}_n\end{equation*}
\begin{equation*} Y^\ast_n \,:\!=\, \sum_{i=1}^m Y^{\ast(i)}_n, \quad Z^\ast_n \,:\!=\, \sum_{i=1}^m Z^{\ast (i)}_n\end{equation*}
solves
 \begin{equation*} \Delta Y^\ast_n = -g_n(Z^\dagger_n) + (Z^\ast_n)^\top \Delta X_n, \quad Y^\ast_N = H.\end{equation*}
\begin{equation*} \Delta Y^\ast_n = -g_n(Z^\dagger_n) + (Z^\ast_n)^\top \Delta X_n, \quad Y^\ast_N = H.\end{equation*}
Since
 $Z^\dagger_n$
is the unique maximizer of
$Z^\dagger_n$
is the unique maximizer of
 $g_n$
, the unique optimal strategy for the representative agent is
$g_n$
, the unique optimal strategy for the representative agent is
 $\pi^\ast_n = Z^\dagger_n - Z^\ast_n$
, again by Theorem 3.1. Hence
$\pi^\ast_n = Z^\dagger_n - Z^\ast_n$
, again by Theorem 3.1. Hence
 \begin{equation*} \sum_{i=1}^m \pi^i_n = \sum_{i=1}^m Z^{\ast (i)}_n - \sum_{i=1}^m Z^{\dagger (i)}_n = Z^\ast_n - Z^\dagger_n = \pi^\ast_n.\end{equation*}
\begin{equation*} \sum_{i=1}^m \pi^i_n = \sum_{i=1}^m Z^{\ast (i)}_n - \sum_{i=1}^m Z^{\dagger (i)}_n = Z^\ast_n - Z^\dagger_n = \pi^\ast_n.\end{equation*}
Therefore
 $\sum_{i=1}^m \pi^i_n = 0$
if and only if
$\sum_{i=1}^m \pi^i_n = 0$
if and only if
 $\pi^\ast_n = 0$
.
$\pi^\ast_n = 0$
.
3.3. Equilibrium in a single agent market
By Proposition 3.2, it suffices to consider the case
 $m=1$
in order to characterize the general equilibrium. Let
$m=1$
in order to characterize the general equilibrium. Let
 $m=1$
, and put
$m=1$
, and put
 $g_n = g^{(1)}_n$
and
$g_n = g^{(1)}_n$
and
 $\pi_n = \pi^{(1)}_n$
. The market is in general equilibrium if and only if
$\pi_n = \pi^{(1)}_n$
. The market is in general equilibrium if and only if
 $\mathcal{E}_0^g (H) = \max_\pi \mathcal{E}_0^{g}(H + W_N(0,\pi))$
, that is,
$\mathcal{E}_0^g (H) = \max_\pi \mathcal{E}_0^{g}(H + W_N(0,\pi))$
, that is,
 $\pi^\ast_n \equiv 0$
is the maximizer. The following theorems characterize the general equilibrium by a backward recurrence relation for the BS
$\pi^\ast_n \equiv 0$
is the maximizer. The following theorems characterize the general equilibrium by a backward recurrence relation for the BS
 $\Delta$
E driver
$\Delta$
E driver
 $\{g_n\}$
.
$\{g_n\}$
.
Theorem 3.2. The market is in general equilibrium if (3.2) holds with
 \begin{equation}Z^\dagger_n = (d+1)(\mathbf{v}\mathbf{v}^\top)^{-1} \mathbb{E}_\mathbb{Q}[(H+G_n)\Delta X_n \mid \mathscr{F}_{n-1}],\quad n=1,\ldots, N,\end{equation}
\begin{equation}Z^\dagger_n = (d+1)(\mathbf{v}\mathbf{v}^\top)^{-1} \mathbb{E}_\mathbb{Q}[(H+G_n)\Delta X_n \mid \mathscr{F}_{n-1}],\quad n=1,\ldots, N,\end{equation}
where
 \begin{equation*} G_n =\mathbb{E}_\mathbb{Q}\Biggl[ \sum_{i=n+1}^N \sup_{z\in \mathbb{R}^d} g_i(z) \bigg| \mathscr{F}_n\Biggr].\end{equation*}
\begin{equation*} G_n =\mathbb{E}_\mathbb{Q}\Biggl[ \sum_{i=n+1}^N \sup_{z\in \mathbb{R}^d} g_i(z) \bigg| \mathscr{F}_n\Biggr].\end{equation*}
Conversely, if the market is in general equilibrium and there exist sequences of maximizers
 $\{Z^\dagger_n\}$
of
$\{Z^\dagger_n\}$
of
 $\{g_n\}$
, then (3.10) is one of them.
$\{g_n\}$
, then (3.10) is one of them.
Proof. Notice that the right-hand side of (3.10) coincides with
 $Z^\ast_n$
defined in Theorem 3.1. If (3.2) holds with (3.10), then we conclude that
$Z^\ast_n$
defined in Theorem 3.1. If (3.2) holds with (3.10), then we conclude that
 $\pi^\ast_n = 0$
is optimal by Theorem 3.1, which means that the market is in general equilibrium. Conversely, if the market is in general equilibrium, then by Theorem 3.1,
$\pi^\ast_n = 0$
is optimal by Theorem 3.1, which means that the market is in general equilibrium. Conversely, if the market is in general equilibrium, then by Theorem 3.1,
 $Z^\ast_n$
should coincide with a maximizer of
$Z^\ast_n$
should coincide with a maximizer of
 $g_n$
if any.
$g_n$
if any.
Proposition 3.3. Let
 $f_n\colon \Omega \times \mathbb{R}^d \times \Delta_d \to \mathbb{R}$
be
$f_n\colon \Omega \times \mathbb{R}^d \times \Delta_d \to \mathbb{R}$
be
 $\mathscr{F}_{n-1}\otimes \mathscr{B}(\mathbb{R}^d \times \Delta_d)$
-measurable, concave on
$\mathscr{F}_{n-1}\otimes \mathscr{B}(\mathbb{R}^d \times \Delta_d)$
-measurable, concave on
 $\mathbb{R}^d$
and continuously differentiable on
$\mathbb{R}^d$
and continuously differentiable on
 $\mathbb{R}^d$
with
$\mathbb{R}^d$
with
 $\nabla f_n$
taking values in
$\nabla f_n$
taking values in
 $\Theta$
, and
$\Theta$
, and
 $0 \in \nabla f_n(z,\Delta_d)$
for all
$0 \in \nabla f_n(z,\Delta_d)$
for all
 $z \in \mathbb{R}^d$
,
$z \in \mathbb{R}^d$
,
 $n=1,\ldots, N$
. Then there exists a
$n=1,\ldots, N$
. Then there exists a
 $\Delta_d$
-valued predictable process
$\Delta_d$
-valued predictable process
 $\{\hat{P}_n\}$
such that the market with
$\{\hat{P}_n\}$
such that the market with
 $g =\{g_n\}$
,
$g =\{g_n\}$
,
 $g_n(z) = f_n(z,\hat{P}_n)$
, is in general equilibrium.
$g_n(z) = f_n(z,\hat{P}_n)$
, is in general equilibrium.
Proof. Note first that
 $g \in \mathcal{C}$
by Remark 2.3. We construct
$g \in \mathcal{C}$
by Remark 2.3. We construct
 $\{\hat{P}_n\}$
inductively. By the assumption, there exists
$\{\hat{P}_n\}$
inductively. By the assumption, there exists
 $\hat{P}_N$
such that
$\hat{P}_N$
such that
 $\nabla f_N(Z^\dagger_N,\hat{P}_N) = 0$
for
$\nabla f_N(Z^\dagger_N,\hat{P}_N) = 0$
for
 $Z^\dagger_N$
defined by (3.10) for
$Z^\dagger_N$
defined by (3.10) for
 $n=N$
. Given
$n=N$
. Given
 $\hat{P}_k$
for
$\hat{P}_k$
for
 $k \geq n+1 $
, let
$k \geq n+1 $
, let
 $Z^\dagger_n$
be defined by (3.10) with
$Z^\dagger_n$
be defined by (3.10) with
 $g_k(z) = f_k\bigr(z,\hat{P}_k\bigr)$
. By the assumption, there exists
$g_k(z) = f_k\bigr(z,\hat{P}_k\bigr)$
. By the assumption, there exists
 $\hat{P}_n$
such that
$\hat{P}_n$
such that
 $\nabla f_n(Z^\dagger_n,\hat{P}_n) = 0$
. Since
$\nabla f_n(Z^\dagger_n,\hat{P}_n) = 0$
. Since
 $z \mapsto f_n(z,\hat{P}_n)$
is concave,
$z \mapsto f_n(z,\hat{P}_n)$
is concave,
 $Z^\dagger_n$
is a maximizer of
$Z^\dagger_n$
is a maximizer of
 $g_n(z) = f_n(z,\hat{P}_n)$
. The result then follows from Theorem 3.2.
$g_n(z) = f_n(z,\hat{P}_n)$
. The result then follows from Theorem 3.2.
Example 3.3.
(
Locally entropic monetary utility.) We consider (2.12) again with
 $\{\hat{P}_n\}$
,
$\{\hat{P}_n\}$
,
 $\hat{P}_n = (\hat{P}_{n,1},\ldots, \hat{P}_{n,d})^\top$
, being
$\hat{P}_n = (\hat{P}_{n,1},\ldots, \hat{P}_{n,d})^\top$
, being
 $\Delta_d^\circ$
-valued. The driver
$\Delta_d^\circ$
-valued. The driver
 $g_n$
is of the form
$g_n$
is of the form
 $g_n(z) = (f(\Gamma_nz,\hat{P}_n) -\log B_n)/\Gamma_n $
, where
$g_n(z) = (f(\Gamma_nz,\hat{P}_n) -\log B_n)/\Gamma_n $
, where
 \begin{equation} f(z,p) = -\log \sum_{j=0}^d \,{\mathrm{e}}^{-z^\top v_j}p_j,\quad z \in \mathbb{R}^d, \quad p = (p_0,\ldots,p_d)^\top \in \Delta_d. \end{equation}
\begin{equation} f(z,p) = -\log \sum_{j=0}^d \,{\mathrm{e}}^{-z^\top v_j}p_j,\quad z \in \mathbb{R}^d, \quad p = (p_0,\ldots,p_d)^\top \in \Delta_d. \end{equation}
By (3.6), we have
 $\nabla f_n(Z_n,\hat{P}_n) = 0$
if and only if
$\nabla f_n(Z_n,\hat{P}_n) = 0$
if and only if
 \begin{equation*} Z_n = \frac{1}{\Gamma_n} (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v} \log \hat{P}_n. \end{equation*}
\begin{equation*} Z_n = \frac{1}{\Gamma_n} (\mathbf{v}\mathbf{v}^\top)^{-1}\mathbf{v} \log \hat{P}_n. \end{equation*}
By Theorem 3.2, the market is in general equilibrium if and only if
 \begin{equation*} \mathbf{v}\log \hat{P}_n = (d+1)\Gamma_n \mathbb{E}_\mathbb{Q}[(H+G_n) \Delta X_n\mid \mathscr{F}_{n-1}], \quad n=1,\ldots, N.\end{equation*}
\begin{equation*} \mathbf{v}\log \hat{P}_n = (d+1)\Gamma_n \mathbb{E}_\mathbb{Q}[(H+G_n) \Delta X_n\mid \mathscr{F}_{n-1}], \quad n=1,\ldots, N.\end{equation*}
This is a backward recurrence equation for
 $\{\hat{P}_n\}$
because
$\{\hat{P}_n\}$
because
 \begin{equation*} G_n = \mathbb{E}_\mathbb{Q}\Biggl[ \sum_{i=n+1}^N \frac{1}{\Gamma_i} ( D_{\mathrm{KL}}(Q_i||\hat{P}_i) - \log B_i )\, \bigg|\, \mathscr{F}_n \Biggr]\end{equation*}
\begin{equation*} G_n = \mathbb{E}_\mathbb{Q}\Biggl[ \sum_{i=n+1}^N \frac{1}{\Gamma_i} ( D_{\mathrm{KL}}(Q_i||\hat{P}_i) - \log B_i )\, \bigg|\, \mathscr{F}_n \Biggr]\end{equation*}
by (3.7). Since
 $\mathbf{v}$
has rank d and
$\mathbf{v}$
has rank d and
 $\mathbf{v}\mathbf{1} = 0$
, an equivalent condition is that
$\mathbf{v}\mathbf{1} = 0$
, an equivalent condition is that
 \begin{equation} \hat{P}_{n,j} = \frac{{\mathrm{e}}^{\Gamma_n\bar{Y}_{n,j}}}{\sum_{k=0}^d\,{\mathrm{e}}^{\Gamma_n\bar{Y}_{n,k}} }, \quad \bar{Y}_{n,j} = \mathbb{E}_\mathbb{Q}[H+G_n \mid \mathscr{F}_{n-1},\Delta X_n = v_j], \quad j=0,\ldots, d, \end{equation}
\begin{equation} \hat{P}_{n,j} = \frac{{\mathrm{e}}^{\Gamma_n\bar{Y}_{n,j}}}{\sum_{k=0}^d\,{\mathrm{e}}^{\Gamma_n\bar{Y}_{n,k}} }, \quad \bar{Y}_{n,j} = \mathbb{E}_\mathbb{Q}[H+G_n \mid \mathscr{F}_{n-1},\Delta X_n = v_j], \quad j=0,\ldots, d, \end{equation}
for
 $n=1,\ldots, N$
. Let
$n=1,\ldots, N$
. Let
 $ Y^\ast_n = \mathbb{E}_\mathbb{Q}[H\mid \mathscr{F}_n] + G_n$
. Then
$ Y^\ast_n = \mathbb{E}_\mathbb{Q}[H\mid \mathscr{F}_n] + G_n$
. Then
 \begin{equation*}Y_n = \mathbb{E}_\mathbb{Q}[Y_n\mid \mathscr{F}_{n-1},\Delta X_n] = \sum_{j=0}^d \bar{Y}_{n,j} 1_{\{\Delta X_n = v_j\}}, \end{equation*}
\begin{equation*}Y_n = \mathbb{E}_\mathbb{Q}[Y_n\mid \mathscr{F}_{n-1},\Delta X_n] = \sum_{j=0}^d \bar{Y}_{n,j} 1_{\{\Delta X_n = v_j\}}, \end{equation*}
which implies
 \begin{equation*} \hat{P}_{n,j}1_{\{\Delta X_n = v_j\}} = \frac{{\mathrm{e}}^{\Gamma_nY^\ast_n}}{(d+1)\mathbb{E}_\mathbb{Q}[{\mathrm{e}}^{\Gamma_nY^\ast_n}\mid \mathscr{F}_{n-1}]}1_{\{\Delta X_n=v_j\}},\quad j=0,\ldots,d, \end{equation*}
\begin{equation*} \hat{P}_{n,j}1_{\{\Delta X_n = v_j\}} = \frac{{\mathrm{e}}^{\Gamma_nY^\ast_n}}{(d+1)\mathbb{E}_\mathbb{Q}[{\mathrm{e}}^{\Gamma_nY^\ast_n}\mid \mathscr{F}_{n-1}]}1_{\{\Delta X_n=v_j\}},\quad j=0,\ldots,d, \end{equation*}
under (3.12). Therefore the market is in general equilibrium if and only if
 \begin{equation*} \frac{\mathrm{d}\hat{\mathbb{P}}}{\mathrm{d}\mathbb{Q}}=\prod_{n=1}^N\frac{{\mathrm{e}}^{\Gamma_nY^\ast_n}}{\mathbb{E}_{\mathbb{Q}}[{\mathrm{e}}^{\Gamma_nY^\ast_n}\mid \mathscr{F}_{n-1}]}, \end{equation*}
\begin{equation*} \frac{\mathrm{d}\hat{\mathbb{P}}}{\mathrm{d}\mathbb{Q}}=\prod_{n=1}^N\frac{{\mathrm{e}}^{\Gamma_nY^\ast_n}}{\mathbb{E}_{\mathbb{Q}}[{\mathrm{e}}^{\Gamma_nY^\ast_n}\mid \mathscr{F}_{n-1}]}, \end{equation*}
where
 $\hat{\mathbb{P}}$
is defined by (2.5). Further, by (3.5), we have
$\hat{\mathbb{P}}$
is defined by (2.5). Further, by (3.5), we have
 \begin{align*} \log \hat{\mathbb{E}}[{\mathrm{e}}^{-\Gamma_n Y^\ast_n}\mid \mathscr{F}_{n-1}]& = -\Gamma_n(Y^\ast_{n-1} - g_n(Z^\dagger_n)) +\log \hat{\mathbb{E}}[{\mathrm{e}}^{-\Gamma_n(\Delta X_n)^\top Z^\dagger_n}\mid \mathscr{F}_{n-1}] \\*&=-\Gamma_n(Y^\ast_{n-1} - g_n(Z^\dagger_n)) -f_n(\Gamma_n Z^\dagger_n, \hat{P}_n) \\*& =-\Gamma_nY^\ast_{n-1} - \log B_n. \end{align*}
\begin{align*} \log \hat{\mathbb{E}}[{\mathrm{e}}^{-\Gamma_n Y^\ast_n}\mid \mathscr{F}_{n-1}]& = -\Gamma_n(Y^\ast_{n-1} - g_n(Z^\dagger_n)) +\log \hat{\mathbb{E}}[{\mathrm{e}}^{-\Gamma_n(\Delta X_n)^\top Z^\dagger_n}\mid \mathscr{F}_{n-1}] \\*&=-\Gamma_n(Y^\ast_{n-1} - g_n(Z^\dagger_n)) -f_n(\Gamma_n Z^\dagger_n, \hat{P}_n) \\*& =-\Gamma_nY^\ast_{n-1} - \log B_n. \end{align*}
This implies
 \begin{equation} \frac{\mathrm{d}\mathbb{Q}}{\mathrm{d}\hat{\mathbb{P}}}=\prod_{n=1}^N\frac{{\mathrm{e}}^{-\Gamma_nY^\ast_n}}{\hat{\mathbb{E}}[{\mathrm{e}}^{-\Gamma_n Y^\ast_n}\mid \mathscr{F}_{n-1}]}= \exp\Biggl\{\sum_{n=1}^N -\Gamma_n \Delta Y^\ast_n \Biggr\} \prod_{n=1}^N B_n. \end{equation}
\begin{equation} \frac{\mathrm{d}\mathbb{Q}}{\mathrm{d}\hat{\mathbb{P}}}=\prod_{n=1}^N\frac{{\mathrm{e}}^{-\Gamma_nY^\ast_n}}{\hat{\mathbb{E}}[{\mathrm{e}}^{-\Gamma_n Y^\ast_n}\mid \mathscr{F}_{n-1}]}= \exp\Biggl\{\sum_{n=1}^N -\Gamma_n \Delta Y^\ast_n \Biggr\} \prod_{n=1}^N B_n. \end{equation}
In particular, when
 $B_n = 1$
and
$B_n = 1$
and
 $\Gamma_n = \gamma$
for all n and a constant
$\Gamma_n = \gamma$
for all n and a constant
 $\gamma \gt 0$
as in (2.8), we have
$\gamma \gt 0$
as in (2.8), we have
 \begin{equation}\frac{\mathrm{d}\mathbb{Q}}{\mathrm{d}\hat{\mathbb{P}}}=\frac{{\mathrm{e}}^{-\gamma H}}{\hat{\mathbb{E}}[{\mathrm{e}}^{-\gamma H}]},\end{equation}
\begin{equation}\frac{\mathrm{d}\mathbb{Q}}{\mathrm{d}\hat{\mathbb{P}}}=\frac{{\mathrm{e}}^{-\gamma H}}{\hat{\mathbb{E}}[{\mathrm{e}}^{-\gamma H}]},\end{equation}
which characterizes the equilibrium probability measure
 $\hat{\mathbb{P}}$
and is consistent with the well-known computation under exponential utility.
$\hat{\mathbb{P}}$
and is consistent with the well-known computation under exponential utility.
Remark 3.2. In addition to the conditions of Proposition 3.3, if
 $f_n$
is of the form
$f_n$
is of the form
 $f_n(z,p) = f(\Gamma_n z,p)/\Gamma_n$
for a smooth function
$f_n(z,p) = f(\Gamma_n z,p)/\Gamma_n$
for a smooth function
 $f\colon \mathbb{R}^d \times \Delta_d \to \mathbb{R}$
with
$f\colon \mathbb{R}^d \times \Delta_d \to \mathbb{R}$
with
 $\nabla f(0,p) = p$
and a positive predictable process
$\nabla f(0,p) = p$
and a positive predictable process
 $\{\Gamma_n\}$
as in Example 3.3 with
$\{\Gamma_n\}$
as in Example 3.3 with
 $B_n = 1$
, then we have
$B_n = 1$
, then we have
 \begin{equation*} g_n(z) = f_n(z,\hat{P}_n) \approx z^\top \hat{P}_n \end{equation*}
\begin{equation*} g_n(z) = f_n(z,\hat{P}_n) \approx z^\top \hat{P}_n \end{equation*}
considering
 $\Gamma_n$
to be small. This approximation implies in turn
$\Gamma_n$
to be small. This approximation implies in turn
 \begin{equation*} \mathcal{E}^g_n(Y) \approx \hat{\mathbb{E}}[Y \mid \mathscr{F}_n] \end{equation*}
\begin{equation*} \mathcal{E}^g_n(Y) \approx \hat{\mathbb{E}}[Y \mid \mathscr{F}_n] \end{equation*}
in light of Proposition 2.2, where
 $\hat{\mathbb{E}}$
is the expectation under
$\hat{\mathbb{E}}$
is the expectation under
 $\hat{\mathbb{P}}$
defined by (2.5). Therefore, in this case, extending Example 3.3, we can interpret
$\hat{\mathbb{P}}$
defined by (2.5). Therefore, in this case, extending Example 3.3, we can interpret
 $\Gamma_n$
as a risk-aversion parameter and
$\Gamma_n$
as a risk-aversion parameter and
 $\hat{\mathbb{P}}$
as the belief of the agent. If the market is in general equilibrium,
$\hat{\mathbb{P}}$
as the belief of the agent. If the market is in general equilibrium,
 \begin{equation*} \hat{\mathbb{E}}[\Delta X_n \mid \mathscr{F}_{n-1}] = \mathbf{v}\hat{P}_n \end{equation*}
\begin{equation*} \hat{\mathbb{E}}[\Delta X_n \mid \mathscr{F}_{n-1}] = \mathbf{v}\hat{P}_n \end{equation*}
is interpreted as an equilibrium return.
Example 3.4. If
 $H = h(X_N)$
and
$H = h(X_N)$
and
 $g_n(z) = f_n(X_{n-1},z)$
for deterministic functions h and
$g_n(z) = f_n(X_{n-1},z)$
for deterministic functions h and
 $f_n$
, as in Proposition 2.1, and if f(x,z) is strictly concave and continuously differentiable in z, then the condition (3.10) follows from the deterministic identity
$f_n$
, as in Proposition 2.1, and if f(x,z) is strictly concave and continuously differentiable in z, then the condition (3.10) follows from the deterministic identity
 \begin{equation*} \nabla_z f_n(x,(\mathbf{vv}^\top)^{-1}\mathbf{v}\mathcal{N}u_n(x)) = 0,\quad x \in L, \ n=1,\ldots, N, \end{equation*}
\begin{equation*} \nabla_z f_n(x,(\mathbf{vv}^\top)^{-1}\mathbf{v}\mathcal{N}u_n(x)) = 0,\quad x \in L, \ n=1,\ldots, N, \end{equation*}
where
 $\mathcal{N}u_n$
is as in Proposition 2.1. For example, for the market with no random endowments (
$\mathcal{N}u_n$
is as in Proposition 2.1. For example, for the market with no random endowments (
 $H^{(i)}=0$
) and unit total supply (
$H^{(i)}=0$
) and unit total supply (
 $H_n = \mathbf{1}$
), we have
$H_n = \mathbf{1}$
), we have
 $H = \mathbf{1}^\top X_N$
.
$H = \mathbf{1}^\top X_N$
.
Example 3.5. Consider (2.12) with
 $B_n = 1$
,
$B_n = 1$
,
 $\Gamma_n = \gamma_n(X_{n-1})$
and
$\Gamma_n = \gamma_n(X_{n-1})$
and
 $\hat{P}_n = p_n(X_{n-1})$
for deterministic functions
$\hat{P}_n = p_n(X_{n-1})$
for deterministic functions
 $\gamma_n\colon L \to (0,\infty)$
and
$\gamma_n\colon L \to (0,\infty)$
and
 $p_n\colon L \to \Delta_d^\circ$
. Assume also
$p_n\colon L \to \Delta_d^\circ$
. Assume also
 $H = h (X_N)$
as in Example 3.4. Then, from Examples 3.3 and 3.4, the market is in general equilibrium if
$H = h (X_N)$
as in Example 3.4. Then, from Examples 3.3 and 3.4, the market is in general equilibrium if
 \begin{equation*} \mathbf{v}\log p_n(x) = \gamma_n(x) \mathbf{v} \mathcal{N}u_n(x), \quad x \in L, \ n=1,\ldots, N. \end{equation*}
\begin{equation*} \mathbf{v}\log p_n(x) = \gamma_n(x) \mathbf{v} \mathcal{N}u_n(x), \quad x \in L, \ n=1,\ldots, N. \end{equation*}
The function
 $u_n(x)$
is computed backward inductively without using
$u_n(x)$
is computed backward inductively without using
 $p_n(x)$
. For a given function
$p_n(x)$
. For a given function
 $\gamma_n(x)$
, there exists a unique
$\gamma_n(x)$
, there exists a unique
 $p_n(x) \in \Delta_d^\circ$
satisfying this equation for each
$p_n(x) \in \Delta_d^\circ$
satisfying this equation for each
 $x \in L$
. For the sequence of such functions
$x \in L$
. For the sequence of such functions
 $p_n(x)$
obtained in the backward manner, the
$p_n(x)$
obtained in the backward manner, the
 $\Delta_d$
-valued sequence
$\Delta_d$
-valued sequence
 $\hat{P}_n = p_n(X_{n-1})$
defines a unique equilibrium probability
$\hat{P}_n = p_n(X_{n-1})$
defines a unique equilibrium probability
 $\hat{\mathbb{P}}$
by (2.5) associated with the sequence
$\hat{\mathbb{P}}$
by (2.5) associated with the sequence
 $\Gamma_n = \gamma_n(X_{n-1})$
. The equilibrium return is approximated as
$\Gamma_n = \gamma_n(X_{n-1})$
. The equilibrium return is approximated as
 \begin{equation*} \hat{\mathbb{E}}[\Delta X_n \mid \mathscr{F}_{n-1}] = \mathbf{v} \hat{P}_n\approx \mathbf{v}\log \hat{P}_n = \gamma_n(X_{n-1})\mathbf{v} \mathcal{N}u_n(X_{n-1}) \end{equation*}
\begin{equation*} \hat{\mathbb{E}}[\Delta X_n \mid \mathscr{F}_{n-1}] = \mathbf{v} \hat{P}_n\approx \mathbf{v}\log \hat{P}_n = \gamma_n(X_{n-1})\mathbf{v} \mathcal{N}u_n(X_{n-1}) \end{equation*}
using
 $\mathbf{v1} = 0$
.
$\mathbf{v1} = 0$
.
3.4. Equilibrium under heterogeneous beliefs
Here we assume
 $m>1$
again and give more explicit computations of the sup-convolution in special cases. First, we consider a homogeneous case, i.e. the case where all of the drivers
$m>1$
again and give more explicit computations of the sup-convolution in special cases. First, we consider a homogeneous case, i.e. the case where all of the drivers
 $g^{(i)}$
have the same functional form determined by a common
$g^{(i)}$
have the same functional form determined by a common
 $\Delta_d$
-valued predictable process
$\Delta_d$
-valued predictable process
 $\{\hat{P}_n\}$
as
$\{\hat{P}_n\}$
as
 \begin{equation} g^{(i)}_n(z) = \frac{1}{\Gamma^{(i)}_n}f_n(\Gamma^{(i)}_nz,\hat{P}_n),\end{equation}
\begin{equation} g^{(i)}_n(z) = \frac{1}{\Gamma^{(i)}_n}f_n(\Gamma^{(i)}_nz,\hat{P}_n),\end{equation}
where
 $f_n\colon \Omega \times \mathbb{R}^d \times \Delta_d \to \mathbb{R}$
is as in Proposition 3.3 and
$f_n\colon \Omega \times \mathbb{R}^d \times \Delta_d \to \mathbb{R}$
is as in Proposition 3.3 and
 $\{\Gamma^{(i)}_n\}$
,
$\{\Gamma^{(i)}_n\}$
,
 $i=1,\ldots,m$
are positive predictable processes quantifying each agent’s risk preference; see Remark 3.2. By induction, we can show that
$i=1,\ldots,m$
are positive predictable processes quantifying each agent’s risk preference; see Remark 3.2. By induction, we can show that
 \begin{equation*}g_n(z) \,:\!=\, g^{(1)}_n \square \cdots \square g^{(m)}_n(z)= \frac{1}{\Gamma_n} f_n(\Gamma_nz,\hat{P}_n),\end{equation*}
\begin{equation*}g_n(z) \,:\!=\, g^{(1)}_n \square \cdots \square g^{(m)}_n(z)= \frac{1}{\Gamma_n} f_n(\Gamma_nz,\hat{P}_n),\end{equation*}
with
 \begin{equation} \frac{1}{\Gamma_n} = \sum_{i=1}^m \frac{1}{\Gamma^{(i)}_n}.\end{equation}
\begin{equation} \frac{1}{\Gamma_n} = \sum_{i=1}^m \frac{1}{\Gamma^{(i)}_n}.\end{equation}
Proposition 3.4. Under (3.15), there exists a
 $\Delta_d$
-valued predictable process
$\Delta_d$
-valued predictable process
 $\{\hat{P}_n\}$
such that the market is in general equilibrium.
$\{\hat{P}_n\}$
such that the market is in general equilibrium.
Example 3.6.
(
Locally entropic monetary utility.) Let
 $f_n(z,p) = f(z,p)$
defined by (3.11). The predictable processes
$f_n(z,p) = f(z,p)$
defined by (3.11). The predictable processes
 $\{\Gamma^{(i)}_n\}$
and
$\{\Gamma^{(i)}_n\}$
and
 $\{\Gamma_n\}$
are then interpreted as the local risk-aversion parameter for the agent i and for the representative agent respectively. Then (3.12) defines the unique sequence
$\{\Gamma_n\}$
are then interpreted as the local risk-aversion parameter for the agent i and for the representative agent respectively. Then (3.12) defines the unique sequence
 $\{\hat{P}_n\}$
such that the market is in general equilibrium. The equilibrium probability measure
$\{\hat{P}_n\}$
such that the market is in general equilibrium. The equilibrium probability measure
 $\hat{\mathbb{P}}$
satisfies (3.13) with
$\hat{\mathbb{P}}$
satisfies (3.13) with
 $B_n = 1$
. When
$B_n = 1$
. When
 $\Gamma_n = \gamma$
for all n for a constant
$\Gamma_n = \gamma$
for all n for a constant
 $\gamma \gt 0$
, then the representative agent has the exponential utility (2.9) and the equilibrium probability measure
$\gamma \gt 0$
, then the representative agent has the exponential utility (2.9) and the equilibrium probability measure
 $\hat{\mathbb{P}}$
is characterized by (3.14).
$\hat{\mathbb{P}}$
is characterized by (3.14).
Now we consider a heterogeneous case. We assume locally entropic monetary utilities
 $g^{(i)}_n(z) = f(\Gamma^{(i)}_nz,\hat{P}^{(i)}_n)/\Gamma^{(i)}_n$
, where f is defined by (3.11), and
$g^{(i)}_n(z) = f(\Gamma^{(i)}_nz,\hat{P}^{(i)}_n)/\Gamma^{(i)}_n$
, where f is defined by (3.11), and
 $\{\Gamma^{(i)}_n\}$
and
$\{\Gamma^{(i)}_n\}$
and
 \[\big\{\hat{P}^{(i)}_n\big\} =\Bigl\{\bigl(\hat{P}^{(i)}_{n,0},\ldots,\hat{P}^{(i)}_{n,d}\bigr)^\top \Bigr\} ,\]
\[\big\{\hat{P}^{(i)}_n\big\} =\Bigl\{\bigl(\hat{P}^{(i)}_{n,0},\ldots,\hat{P}^{(i)}_{n,d}\bigr)^\top \Bigr\} ,\]
respectively, are
 $(0,\infty)$
-valued and
$(0,\infty)$
-valued and
 $\Delta_d^\circ$
-valued predictable processes for each
$\Delta_d^\circ$
-valued predictable processes for each
 $i=1,\ldots,m$
. Each sequence
$i=1,\ldots,m$
. Each sequence
 $\{\hat{P}^{(i)}_n\}$
determines a probability measure
$\{\hat{P}^{(i)}_n\}$
determines a probability measure
 $\hat{P}^{(i)}$
on
$\hat{P}^{(i)}$
on
 $\mathscr{F}_N$
by (2.5), which is interpreted as the agent i’s belief in the law of
$\mathscr{F}_N$
by (2.5), which is interpreted as the agent i’s belief in the law of
 $\{X_n\}$
.
$\{X_n\}$
.
Proposition 3.5. Define
 $\{\Gamma_n\}$
by (3.16). Then
$\{\Gamma_n\}$
by (3.16). Then
 \begin{equation*} g^{(1)}_n \square \cdots \square g^{(m)}_n(z) = \frac{1}{\Gamma_n}f(\Gamma_nz,\tilde{P}_n) - \frac{1}{\Gamma_n}\log B_n, \end{equation*}
\begin{equation*} g^{(1)}_n \square \cdots \square g^{(m)}_n(z) = \frac{1}{\Gamma_n}f(\Gamma_nz,\tilde{P}_n) - \frac{1}{\Gamma_n}\log B_n, \end{equation*}
where
 $ \tilde{P}_n = ( \tilde{P}_{n,0},\ldots, \tilde{P}_{n,d})^\top$
and
$ \tilde{P}_n = ( \tilde{P}_{n,0},\ldots, \tilde{P}_{n,d})^\top$
and
 \begin{equation*} \tilde{P}_{n,j} = \frac{1}{B_n}\prod_{i=1}^m \bigl(\hat{P}^{(i)}_{n,j}\bigr)^{\Gamma_n/\Gamma_n^{(i)}}, \quad B_n = \sum_{j=0}^d \prod_{i=1}^m \bigl(\hat{P}^{(i)}_{n,j}\bigr)^{\Gamma_n/\Gamma_n^{(i)}}. \end{equation*}
\begin{equation*} \tilde{P}_{n,j} = \frac{1}{B_n}\prod_{i=1}^m \bigl(\hat{P}^{(i)}_{n,j}\bigr)^{\Gamma_n/\Gamma_n^{(i)}}, \quad B_n = \sum_{j=0}^d \prod_{i=1}^m \bigl(\hat{P}^{(i)}_{n,j}\bigr)^{\Gamma_n/\Gamma_n^{(i)}}. \end{equation*}
Proof. The case
 $m=2$
follows by solving the equation
$m=2$
follows by solving the equation
 \begin{equation*} \nabla f\bigl(\Gamma^{(1)}_nx,\hat{P}^{(1)}_n\bigr) = \nabla f\bigl(\Gamma^{(2)}_n(z-x),\hat{P}^{(2)}_n\bigr)\end{equation*}
\begin{equation*} \nabla f\bigl(\Gamma^{(1)}_nx,\hat{P}^{(1)}_n\bigr) = \nabla f\bigl(\Gamma^{(2)}_n(z-x),\hat{P}^{(2)}_n\bigr)\end{equation*}
in
 $x \in \mathbb{R}^d$
; see Lemma A.1. The general case then follows by induction.
$x \in \mathbb{R}^d$
; see Lemma A.1. The general case then follows by induction.
Remark 3.3. By Lemma A.2 we have
 $B_n \leq 1$
, with equality holding if and only if
$B_n \leq 1$
, with equality holding if and only if
 $\hat{P}^{(i)}_n =\hat{P}^{(1)}_n$
for all i.
$\hat{P}^{(i)}_n =\hat{P}^{(1)}_n$
for all i.
By Proposition 3.5, the representative agent’s market falls into Example 3.3. In particular, when
 $\Gamma_n = \gamma>0$
(a constant), the market is in general equilibrium if and only if
$\Gamma_n = \gamma>0$
(a constant), the market is in general equilibrium if and only if
 $\tilde{P}_n =\hat{P}_n$
, where
$\tilde{P}_n =\hat{P}_n$
, where
 \begin{equation*} \frac{\mathrm{d}\mathbb{Q}}{\mathrm{d}\hat{\mathbb{P}}}= \frac{{\mathrm{e}}^{-\gamma H} \prod_{n=1}^N B_n }{\hat{\mathbb{E}}[{\mathrm{e}}^{-\gamma H} \prod_{n=1}^N B_n ]}. \end{equation*}
\begin{equation*} \frac{\mathrm{d}\mathbb{Q}}{\mathrm{d}\hat{\mathbb{P}}}= \frac{{\mathrm{e}}^{-\gamma H} \prod_{n=1}^N B_n }{\hat{\mathbb{E}}[{\mathrm{e}}^{-\gamma H} \prod_{n=1}^N B_n ]}. \end{equation*}
To highlight the outcome of heterogeneous beliefs, let us further assume there are only two agents (
 $m=2$
) with constant risk aversion
$m=2$
) with constant risk aversion
 $\Gamma^{(i)}_n = \gamma_i>0$
and with no endowment (
$\Gamma^{(i)}_n = \gamma_i>0$
and with no endowment (
 $H=0$
). In this case,
$H=0$
). In this case,
 $\nabla g^{(i)}(0,\mathbb{Q}) = 0$
, and so, if the two agents have a common belief
$\nabla g^{(i)}(0,\mathbb{Q}) = 0$
, and so, if the two agents have a common belief
 $\hat{\mathbb{P}}$
, we need
$\hat{\mathbb{P}}$
, we need
 $\hat{\mathbb{P}}=\mathbb{Q}$
for the market to be in general equilibrium. The optimal strategies are simply
$\hat{\mathbb{P}}=\mathbb{Q}$
for the market to be in general equilibrium. The optimal strategies are simply
 $\pi^{(1)}_n = \pi^{(2)}_n = 0$
. On the other hand, for any
$\pi^{(1)}_n = \pi^{(2)}_n = 0$
. On the other hand, for any
 $\Delta_d^\circ$
-valued deterministic sequence
$\Delta_d^\circ$
-valued deterministic sequence
 $\{\hat{P}^{(1)}_n\}$
, by choosing
$\{\hat{P}^{(1)}_n\}$
, by choosing
 $\hat{P}^{(2)}_n$
as
$\hat{P}^{(2)}_n$
as
 \begin{equation*}\hat{P}^{(2)}_{n,j} = \frac{(\hat{P}^{(1)}_{n,j})^{-\gamma_2/\gamma_1}}{\sum_{k=0}^d (\hat{P}^{(1)}_{n,k})^{-\gamma_2/\gamma_1}},\end{equation*}
\begin{equation*}\hat{P}^{(2)}_{n,j} = \frac{(\hat{P}^{(1)}_{n,j})^{-\gamma_2/\gamma_1}}{\sum_{k=0}^d (\hat{P}^{(1)}_{n,k})^{-\gamma_2/\gamma_1}},\end{equation*}
we have
 $\tilde{P}_{n,j} = 1/(d+1)$
for all n and j, which makes this market with heterogeneous beliefs be in general equilibrium. The individual optimal strategies
$\tilde{P}_{n,j} = 1/(d+1)$
for all n and j, which makes this market with heterogeneous beliefs be in general equilibrium. The individual optimal strategies
 $\pi^{(1)}_n = - \pi^{(2)}_n$
are non-zero; the agents bet on their beliefs.
$\pi^{(1)}_n = - \pi^{(2)}_n$
are non-zero; the agents bet on their beliefs.
Another observation is that the equilibrium return is mostly affected by the belief of the least risk-averse agent. Indeed, if
 $\Gamma^{(1)}_n \ll \Gamma^{(i)}_n$
for
$\Gamma^{(1)}_n \ll \Gamma^{(i)}_n$
for
 $i \geq 2$
, we have
$i \geq 2$
, we have
 $\Gamma_n/\Gamma_n^{(1)} \approx 1$
, while
$\Gamma_n/\Gamma_n^{(1)} \approx 1$
, while
 $\Gamma_n/\Gamma_n^{(i)} \approx 0$
for
$\Gamma_n/\Gamma_n^{(i)} \approx 0$
for
 $i \geq 2$
. Therefore
$i \geq 2$
. Therefore
 $\tilde{P}_n \approx \hat{P}^{(1)}_n$
.
$\tilde{P}_n \approx \hat{P}^{(1)}_n$
.
Remark 3.4. The product
 $\prod_n B_n$
corresponds to the consensus characteristic introduced in a continuous-time framework [Reference Jouini and Napp26] of heterogeneous beliefs. It can be interpreted as a discounting factor, and was further investigated in [Reference Hara21].
$\prod_n B_n$
corresponds to the consensus characteristic introduced in a continuous-time framework [Reference Jouini and Napp26] of heterogeneous beliefs. It can be interpreted as a discounting factor, and was further investigated in [Reference Hara21].
Appendix A. Computation of sup-convolution
Lemma A.1. Let
 $\alpha \gt 0$
,
$\alpha \gt 0$
,
 $\beta \gt 0$
,
$\beta \gt 0$
,
 $p_j > 0$
,
$p_j > 0$
,
 $q_j > 0$
,
$q_j > 0$
,
 $j=0,\ldots,d$
, and
$j=0,\ldots,d$
, and
 $z \in \mathbb{R}^d$
. Then
$z \in \mathbb{R}^d$
. Then
 \begin{align*} & \sup_{x \in \mathbb{R}^d}\Biggl\{-\frac{1}{\alpha}\log \sum_{j=0}^d \,{\mathrm{e}}^{-\alpha x^\top v_j}p_j-\frac{1}{\beta}\log \sum_{j=0}^d \,{\mathrm{e}}^{-\beta (z-x)^\top v_j}q_j\Biggr\}\\* &\quad = -\frac{1}{\gamma} \log \sum_{j=0}^d \,{\mathrm{e}}^{-\gamma z^\top v_j} p_j^{\gamma/\alpha}q_j^{\gamma/\beta},\end{align*}
\begin{align*} & \sup_{x \in \mathbb{R}^d}\Biggl\{-\frac{1}{\alpha}\log \sum_{j=0}^d \,{\mathrm{e}}^{-\alpha x^\top v_j}p_j-\frac{1}{\beta}\log \sum_{j=0}^d \,{\mathrm{e}}^{-\beta (z-x)^\top v_j}q_j\Biggr\}\\* &\quad = -\frac{1}{\gamma} \log \sum_{j=0}^d \,{\mathrm{e}}^{-\gamma z^\top v_j} p_j^{\gamma/\alpha}q_j^{\gamma/\beta},\end{align*}
where
 $\gamma = 1/(1/\alpha + 1/\beta)$
.
$\gamma = 1/(1/\alpha + 1/\beta)$
.
Proof. The first-order condition is
 \begin{equation*} \sum_{j=0}^d v_j \biggl(\frac{{\mathrm{e}}^{-\alpha x^\top v_j} p_j}{S(x,\alpha,\{p_k\})} - \frac{{\mathrm{e}}^{-\beta (z-x)^\top v_j}q_j}{S(z-x,\beta,\{q_k\})}\biggr) = 0,\end{equation*}
\begin{equation*} \sum_{j=0}^d v_j \biggl(\frac{{\mathrm{e}}^{-\alpha x^\top v_j} p_j}{S(x,\alpha,\{p_k\})} - \frac{{\mathrm{e}}^{-\beta (z-x)^\top v_j}q_j}{S(z-x,\beta,\{q_k\})}\biggr) = 0,\end{equation*}
where
 \begin{equation*} S(x,\alpha,\{p_k\}) = \sum_{j=0}^d \,{\mathrm{e}}^{-\alpha x^\top v_j}p_j.\end{equation*}
\begin{equation*} S(x,\alpha,\{p_k\}) = \sum_{j=0}^d \,{\mathrm{e}}^{-\alpha x^\top v_j}p_j.\end{equation*}
Since
 $\mathbf{v}\mathbf{1}= 0$
and
$\mathbf{v}\mathbf{1}= 0$
and
 $\mathrm{rank}\, \mathbf{v} = d$
, the first-order condition is met if and only if
$\mathrm{rank}\, \mathbf{v} = d$
, the first-order condition is met if and only if
 \begin{equation*} -\alpha x^\top v_j + \log p_j = -\beta(z-x)^\top v_j + \log q_j + c(x),\quad j=0,\ldots,d ,\end{equation*}
\begin{equation*} -\alpha x^\top v_j + \log p_j = -\beta(z-x)^\top v_j + \log q_j + c(x),\quad j=0,\ldots,d ,\end{equation*}
for a function c. Substituting
 \begin{equation*} x^\top v_j = \frac{\beta}{\alpha + \beta}z^\top v_j + \frac{\log p_j - \log q_j -c(x)}{\alpha + \beta},\end{equation*}
\begin{equation*} x^\top v_j = \frac{\beta}{\alpha + \beta}z^\top v_j + \frac{\log p_j - \log q_j -c(x)}{\alpha + \beta},\end{equation*}
we obtain
 \begin{align*} -\frac{1}{\alpha}\log \sum_{j=0}^d \,{\mathrm{e}}^{-\alpha x^\top v_j}p_j & = -\frac{1}{\alpha}\log \sum_{j=0}^d \,{\mathrm{e}}^{-\gamma z^\top v_j}p_j^{\gamma/\alpha}q_j^{\gamma/\beta} - \frac{c(x)}{\alpha + \beta}, \\*-\frac{1}{\beta}\log \sum_{j=0}^d \,{\mathrm{e}}^{-\beta (z-x)^\top v_j}q_j& = -\frac{1}{\beta}\log \sum_{j=0}^d \,{\mathrm{e}}^{-\gamma z^\top v_j}p_j^{\gamma/\alpha}q_j^{\gamma/\beta} + \frac{c(x)}{\alpha + \beta},\end{align*}
\begin{align*} -\frac{1}{\alpha}\log \sum_{j=0}^d \,{\mathrm{e}}^{-\alpha x^\top v_j}p_j & = -\frac{1}{\alpha}\log \sum_{j=0}^d \,{\mathrm{e}}^{-\gamma z^\top v_j}p_j^{\gamma/\alpha}q_j^{\gamma/\beta} - \frac{c(x)}{\alpha + \beta}, \\*-\frac{1}{\beta}\log \sum_{j=0}^d \,{\mathrm{e}}^{-\beta (z-x)^\top v_j}q_j& = -\frac{1}{\beta}\log \sum_{j=0}^d \,{\mathrm{e}}^{-\gamma z^\top v_j}p_j^{\gamma/\alpha}q_j^{\gamma/\beta} + \frac{c(x)}{\alpha + \beta},\end{align*}
hence the result.
Lemma A.2. Let
 $(p_{i,0},\ldots,p_{i,d})^\top$
,
$(p_{i,0},\ldots,p_{i,d})^\top$
,
 $i=1,\ldots,m$
be m points in
$i=1,\ldots,m$
be m points in
 $\Delta_d^\circ$
. Let
$\Delta_d^\circ$
. Let
 $\gamma_i \gt 0$
for
$\gamma_i \gt 0$
for
 $i=1,\ldots,m$
and
$i=1,\ldots,m$
and
 \begin{equation*} \gamma = \Biggl(\sum_{i=1}^m \frac{1}{\gamma_i}\Biggr)^{-1}. \end{equation*}
\begin{equation*} \gamma = \Biggl(\sum_{i=1}^m \frac{1}{\gamma_i}\Biggr)^{-1}. \end{equation*}
Then
 \begin{equation*} \sum_{j=0}^d \prod_{i=1}^m p_{i,j}^{\gamma/\gamma_i} \leq 1. \end{equation*}
\begin{equation*} \sum_{j=0}^d \prod_{i=1}^m p_{i,j}^{\gamma/\gamma_i} \leq 1. \end{equation*}
Proof. The case
 $m=1$
is trivial. Let
$m=1$
is trivial. Let
 \begin{equation*} \hat\gamma_k = \Biggl(\sum_{i=1}^k \frac{1}{\gamma_i}\Biggr)^{-1}, \quad k=1,\ldots,m. \end{equation*}
\begin{equation*} \hat\gamma_k = \Biggl(\sum_{i=1}^k \frac{1}{\gamma_i}\Biggr)^{-1}, \quad k=1,\ldots,m. \end{equation*}
If the inequality is true when
 $m=k$
, then
$m=k$
, then
 \begin{equation*} \sum_{j=0}^d \prod_{i=1}^{k+1} p_{i,j}^{\hat\gamma_{k+1}/\gamma_i} = \sum_{j=0}^d p_{k+1,j} \biggl(\frac{\prod_{i=1}^{k} p_{i,j}^{\hat\gamma_k/\gamma_i} }{p_{k+1,j}}\biggr)^{\hat\gamma_{k+1}/\hat\gamma_k} \leq \Biggl( \sum_{j=0}^d \prod_{i=1}^{k} p_{i,j}^{\hat\gamma_{k}/\gamma_i} \Biggr)^{\hat\gamma_{k+1}/\hat\gamma_k} \leq 1\end{equation*}
\begin{equation*} \sum_{j=0}^d \prod_{i=1}^{k+1} p_{i,j}^{\hat\gamma_{k+1}/\gamma_i} = \sum_{j=0}^d p_{k+1,j} \biggl(\frac{\prod_{i=1}^{k} p_{i,j}^{\hat\gamma_k/\gamma_i} }{p_{k+1,j}}\biggr)^{\hat\gamma_{k+1}/\hat\gamma_k} \leq \Biggl( \sum_{j=0}^d \prod_{i=1}^{k} p_{i,j}^{\hat\gamma_{k}/\gamma_i} \Biggr)^{\hat\gamma_{k+1}/\hat\gamma_k} \leq 1\end{equation*}
by Jensen’s inequality. We obtain the result by induction.
Appendix B. Numerical experiment
Here we give a brief numerical experiment on the locally entropic monetary utility defined by (2.12). We focus on the case
 $B_n=1$
and
$B_n=1$
and
 $\hat{P}_{n,j} = 1/(d+1)$
for all n and j. The purpose here is to examine numerically the effect of the local risk-aversion process
$\hat{P}_{n,j} = 1/(d+1)$
for all n and j. The purpose here is to examine numerically the effect of the local risk-aversion process
 $\{\Gamma_n\}$
. More specifically, we consider an auto-regressive structure
$\{\Gamma_n\}$
. More specifically, we consider an auto-regressive structure
 \begin{equation*} \log \frac{\Gamma_{n+1}}{\gamma} = \alpha \log \frac{\Gamma_n}{\gamma} + \frac{\beta}{\sqrt{N}} \mathbf{1}^\top \Delta X_n\end{equation*}
\begin{equation*} \log \frac{\Gamma_{n+1}}{\gamma} = \alpha \log \frac{\Gamma_n}{\gamma} + \frac{\beta}{\sqrt{N}} \mathbf{1}^\top \Delta X_n\end{equation*}
with constants
 $\gamma \gt 0$
,
$\gamma \gt 0$
,
 $\alpha \in [0,1]$
and
$\alpha \in [0,1]$
and
 $\beta \in \mathbb{R}$
, and compute the g-expectation
$\beta \in \mathbb{R}$
, and compute the g-expectation
 $\mathcal{E}^g_0(Y_N)$
for
$\mathcal{E}^g_0(Y_N)$
for
 $Y_N = (Nd)^{-1/2}\mathbf{1}^\top X_N$
. When
$Y_N = (Nd)^{-1/2}\mathbf{1}^\top X_N$
. When
 $\beta$
is negative, the negative values of
$\beta$
is negative, the negative values of
 $\mathbf{1}^\top \Delta X_n$
push
$\mathbf{1}^\top \Delta X_n$
push
 $\Gamma_n$
up, that is, the utility becomes more risk-averse when
$\Gamma_n$
up, that is, the utility becomes more risk-averse when
 $\mathbf{1}^\top \Delta X_n$
is negative. We are interested in how such dynamics affects the initial utility value
$\mathbf{1}^\top \Delta X_n$
is negative. We are interested in how such dynamics affects the initial utility value
 $Y_0 = \mathcal{E}^g_0(Y_N)$
.
$Y_0 = \mathcal{E}^g_0(Y_N)$
.
For example, for
 $d=100$
,
$d=100$
,
 $N=3$
,
$N=3$
,
 $\gamma=1$
, and
$\gamma=1$
, and
 $\Sigma/(d+1)$
being the identity matrix, Figure 1 shows the shapes of
$\Sigma/(d+1)$
being the identity matrix, Figure 1 shows the shapes of
 $Y_0=\mathcal{E}^g_0(Y_N)$
as a function of
$Y_0=\mathcal{E}^g_0(Y_N)$
as a function of
 $\beta \in ({-}0.1,0.1)$
for
$\beta \in ({-}0.1,0.1)$
for
 $\alpha = 0$
,
$\alpha = 0$
,
 $0.5$
, and 1. For the negative region of
$0.5$
, and 1. For the negative region of
 $\beta$
, we have monotone shapes, which means that the larger the variance of the process
$\beta$
, we have monotone shapes, which means that the larger the variance of the process
 $\{\Gamma_n\}$
, the less the initial utility. This monotonicity is lost in the positive region of
$\{\Gamma_n\}$
, the less the initial utility. This monotonicity is lost in the positive region of
 $\beta$
.
$\beta$
.

Figure 1.
 $Y_0=\mathcal{E}^g_0(Y_N)$
as a function of
$Y_0=\mathcal{E}^g_0(Y_N)$
as a function of
 $\beta \in ({-}0.1, 0.1)$
for
$\beta \in ({-}0.1, 0.1)$
for
 $\alpha = 0, 0.5$
and 1.
$\alpha = 0, 0.5$
and 1.
Acknowledgements
The authors are grateful to Professor Chiaki Hara for his helpful comments.
Funding information
Jun Sekine acknowledges Grant-in-Aid for Scientific Research (C), 23K01450.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.






 Open access
Open access