







1. Introduction
For any positive integer
 $n\in \mathbb{N}$
and any positive integer
$n\in \mathbb{N}$
and any positive integer
 $k\le n$
, a partition of
$k\le n$
, a partition of
 $[n]\,:\!=\, \{1, 2, \dots, n\}$
into k blocks, denoted by
$[n]\,:\!=\, \{1, 2, \dots, n\}$
into k blocks, denoted by
 $\{U_i\,:\, 1\leq i \leq k\}$
, is an unordered collection of nonempty disjoint sets whose union is [n]. Now, let
$\{U_i\,:\, 1\leq i \leq k\}$
, is an unordered collection of nonempty disjoint sets whose union is [n]. Now, let
 $\mathcal{P}_{n}^{k}$
be the set of all partitions of [n] into k blocks, and let
$\mathcal{P}_{n}^{k}$
be the set of all partitions of [n] into k blocks, and let
 $\mathcal{P}_n = \cup_{k=1}^{n} \mathcal{P}_{n}^{k}$
be the set of all partitions of [n]. Denoting by
$\mathcal{P}_n = \cup_{k=1}^{n} \mathcal{P}_{n}^{k}$
be the set of all partitions of [n]. Denoting by
 $\{U_i\,:\, i\ge 1\}$
the element in
$\{U_i\,:\, i\ge 1\}$
the element in
 $\mathcal{P}_n$
, the Ewens–Pitman partition is a distribution on
$\mathcal{P}_n$
, the Ewens–Pitman partition is a distribution on
 $\mathcal{P}_{n}$
with the following density parameterized by
$\mathcal{P}_{n}$
with the following density parameterized by
 $(\alpha, \theta)$
:
$(\alpha, \theta)$
:
 \begin{align}\frac{\prod_{i=1}^{K_n-1} (\theta + i\alpha)}{\prod_{i=1}^{n-1}(\theta + i)} \prod_{j=2}^{n} \left\{ \prod_{i=1}^{j-1} (\!-\alpha + i) \right\}^{S_{n,j}} \quad\text{for} \quad \begin{array}{l} S_{n,j} = \sum_{i\geq 1} \mathbb{1}\{|U_i| = j\}\\[6pt] K_n = \sum_{j=1}^n S_{n,j}. \end{array}\end{align}
\begin{align}\frac{\prod_{i=1}^{K_n-1} (\theta + i\alpha)}{\prod_{i=1}^{n-1}(\theta + i)} \prod_{j=2}^{n} \left\{ \prod_{i=1}^{j-1} (\!-\alpha + i) \right\}^{S_{n,j}} \quad\text{for} \quad \begin{array}{l} S_{n,j} = \sum_{i\geq 1} \mathbb{1}\{|U_i| = j\}\\[6pt] K_n = \sum_{j=1}^n S_{n,j}. \end{array}\end{align}
Note that
 $S_{n,j}$
is the number of blocks of size j and
$S_{n,j}$
is the number of blocks of size j and
 $K_n$
is the number of nonempty blocks. The likelihood formula (1.1) implies that
$K_n$
is the number of nonempty blocks. The likelihood formula (1.1) implies that
 $(S_{n,j})_{j=1}^n$
is a sufficient statistic.
$(S_{n,j})_{j=1}^n$
is a sufficient statistic.
Now we suppose that the true parameter
 $(\alpha, \theta)$
satisfies
$(\alpha, \theta)$
satisfies
 $0\lt\alpha\lt1$
and
$0\lt\alpha\lt1$
and
 $\theta\gt -\alpha$
. Then, the number of nonempty blocks
$\theta\gt -\alpha$
. Then, the number of nonempty blocks
 $K_n$
and the number of blocks of size j, denoted by
$K_n$
and the number of blocks of size j, denoted by
 $S_{n,j}$
, have the following asymptotics as
$S_{n,j}$
, have the following asymptotics as
 $n\to\infty$
(see Theorem 1):
$n\to\infty$
(see Theorem 1):
 \begin{align} \frac{K_n}{n^\alpha} &{\overset{\textrm{a.s.}}{\longrightarrow}} {\textsf{M}}_{\alpha, \theta} \ \text{(nondegenerate random variable)} \end{align}
\begin{align} \frac{K_n}{n^\alpha} &{\overset{\textrm{a.s.}}{\longrightarrow}} {\textsf{M}}_{\alpha, \theta} \ \text{(nondegenerate random variable)} \end{align}
 \begin{align} \forall j\in \mathbb{N}, \quad \frac{S_{n, j}}{K_n} &{\overset{\textrm{a.s.}}{\longrightarrow}} p_\alpha(\,j)\,:\!=\, \frac{\alpha \prod_{i=1}^{j-1}(i-\alpha)}{j!}.\end{align}
\begin{align} \forall j\in \mathbb{N}, \quad \frac{S_{n, j}}{K_n} &{\overset{\textrm{a.s.}}{\longrightarrow}} p_\alpha(\,j)\,:\!=\, \frac{\alpha \prod_{i=1}^{j-1}(i-\alpha)}{j!}.\end{align}
See Figure 1 for the illustration of the asymptotics (1.2)–(1.3). We emphasize that the almost sure limit
 ${\textsf{M}}_{\alpha, \theta} = \lim_{n\to\infty} {K_n}/{n^\alpha}$
is not a constant but a nondegenerate positive random variable. Furthermore,
${\textsf{M}}_{\alpha, \theta} = \lim_{n\to\infty} {K_n}/{n^\alpha}$
is not a constant but a nondegenerate positive random variable. Furthermore,
 $p_\alpha(\,j)$
in (1.3) is a probability mass function on integers
$p_\alpha(\,j)$
in (1.3) is a probability mass function on integers
 $\mathbb{N}$
, and thanks to Stirling’s formula
$\mathbb{N}$
, and thanks to Stirling’s formula
 $\Gamma(z) \sim \sqrt{{2\pi}/{z}} \left({z}/{e}\right)^z$
, we have
$\Gamma(z) \sim \sqrt{{2\pi}/{z}} \left({z}/{e}\right)^z$
, we have
 $$p_\alpha(\,j) \sim \frac{\alpha}{\Gamma(1-\alpha)} j^{-(\alpha+1)} \quad \text{as $j\to+\infty$}.$$
$$p_\alpha(\,j) \sim \frac{\alpha}{\Gamma(1-\alpha)} j^{-(\alpha+1)} \quad \text{as $j\to+\infty$}.$$
This implies that the ratio of blocks of particular sizes asymptotically follows a power law of exponents
 $(\alpha+1)$
, as illustrated by the right panel of Figure 1.
$(\alpha+1)$
, as illustrated by the right panel of Figure 1.

Figure 1. Asymptotic behavior of the Ewens–Pitman partition when
 $0\lt\alpha\lt1,\ \theta\gt -\alpha.$
$0\lt\alpha\lt1,\ \theta\gt -\alpha.$
The Ewens–Pitman partition has many applications in ecology [Reference Balocchi, Favaro and Naulet1, Reference Favaro, Lijoi, Mena and Prünster10, Reference Favaro and Naulet11, Reference Sibuya28], nonparametric Bayesian inference [Reference Caron, Neiswanger, Wood, Doucet and Davy2, Reference Dahl, Day and Tsai7], disclosure risk assessment [Reference Favaro, Panero and Rigon12, Reference Hoshino18], and network analysis [Reference Crane and Dempsey6, Reference Naulet, Rousseau and Caron22], as well as in forensic fields [Reference Cereda, Corradi and Viscardi3]. In those related studies, the estimation of
 $\alpha$
is of more interest than the estimation of
$\alpha$
is of more interest than the estimation of
 $\theta$
because
$\theta$
because
 $\alpha$
controls the asymptotic behavior mainly as we have shown in (1.2)–(1.3). Here, (1.2) implies that the naive estimator
$\alpha$
controls the asymptotic behavior mainly as we have shown in (1.2)–(1.3). Here, (1.2) implies that the naive estimator
 $\hat{{\alpha}}_n^{\text{naive}}\,:\!=\, \log K_n / \log n$
is
$\hat{{\alpha}}_n^{\text{naive}}\,:\!=\, \log K_n / \log n$
is
 $\log n$
-consistent, but it is not rate-optimal, owing to information loss from the sufficient statistic
$\log n$
-consistent, but it is not rate-optimal, owing to information loss from the sufficient statistic
 $(S_{n,j})_{j=1}^n$
to
$(S_{n,j})_{j=1}^n$
to
 $K_n(=\sum_{j=1}^{n} S_{n,j})$
. For the maximum-likelihood estimator (MLE)
$K_n(=\sum_{j=1}^{n} S_{n,j})$
. For the maximum-likelihood estimator (MLE)
 $(\hat{\alpha}_n,\hat{\theta}_n)$
, [Reference Favaro and Naulet11] shows
$(\hat{\alpha}_n,\hat{\theta}_n)$
, [Reference Favaro and Naulet11] shows
 $\hat{\alpha}_n = \alpha + O_p(n^{-\alpha/2}\log n)$
, but the exact asymptotic law is unknown. See Section 1.2 for a detailed review of prior literature.
$\hat{\alpha}_n = \alpha + O_p(n^{-\alpha/2}\log n)$
, but the exact asymptotic law is unknown. See Section 1.2 for a detailed review of prior literature.
1.1. Contribution
In this paper, we derive the exact asymptotic distribution of the MLE
 $(\hat{\alpha}_n, \hat{\theta}_n)$
. Here, let us introduce some notation. Let
$(\hat{\alpha}_n, \hat{\theta}_n)$
. Here, let us introduce some notation. Let
 $I_\alpha$
be the Fisher information of the heavy-tailed distribution with the probability mass function
$I_\alpha$
be the Fisher information of the heavy-tailed distribution with the probability mass function
 $p_\alpha(\,j)$
in (1.3), i.e.,
$p_\alpha(\,j)$
in (1.3), i.e.,
 \begin{align} I_\alpha\,:\!=\, - \sum_{j=1}^\infty p_\alpha(\,j) \cdot \partial_\alpha^2 \log p_\alpha(\,j) \quad \text{with }\quad p_\alpha(\,j)\,:\!=\, \frac{\alpha \prod_{i=1}^{j-1}(i-\alpha)}{j!},\end{align}
\begin{align} I_\alpha\,:\!=\, - \sum_{j=1}^\infty p_\alpha(\,j) \cdot \partial_\alpha^2 \log p_\alpha(\,j) \quad \text{with }\quad p_\alpha(\,j)\,:\!=\, \frac{\alpha \prod_{i=1}^{j-1}(i-\alpha)}{j!},\end{align}
and let
 $f_\alpha \,\colon ({-}1,\infty) \to \mathbb{R}$
be the function
$f_\alpha \,\colon ({-}1,\infty) \to \mathbb{R}$
be the function
 \begin{align} z\mapsto f_\alpha(z) = \psi(1+z)-\alpha\psi(1+\alpha z),\end{align}
\begin{align} z\mapsto f_\alpha(z) = \psi(1+z)-\alpha\psi(1+\alpha z),\end{align}
where
 $\psi(x)= \Gamma^{\prime}(x)/\Gamma(x)$
is the digamma function. Note that
$\psi(x)= \Gamma^{\prime}(x)/\Gamma(x)$
is the digamma function. Note that
 $f_\alpha$
is bijective (see Lemma 2). Furthermore, we denote by
$f_\alpha$
is bijective (see Lemma 2). Furthermore, we denote by
 ${\textsf{M}}_{\alpha, \theta}$
the limit of
${\textsf{M}}_{\alpha, \theta}$
the limit of
 $K_n/n^{\alpha}$
:
$K_n/n^{\alpha}$
:
 \begin{align} {\textsf{M}}_{\alpha, \theta}\,:\!=\, \lim_{n\to\infty} K_n/n^\alpha.\end{align}
\begin{align} {\textsf{M}}_{\alpha, \theta}\,:\!=\, \lim_{n\to\infty} K_n/n^\alpha.\end{align}
Recall that (1.2) implies
 ${\textsf{M}}_{\alpha, \theta}$
exists almost surely (a.s.) and
${\textsf{M}}_{\alpha, \theta}$
exists almost surely (a.s.) and
 ${\textsf{M}}_{\alpha, \theta}$
is a nondegenerate positive random variable. With the above notation, we show that the asymptotic distribution of the MLE
${\textsf{M}}_{\alpha, \theta}$
is a nondegenerate positive random variable. With the above notation, we show that the asymptotic distribution of the MLE
 $(\hat{\alpha}_n, \hat{\theta}_n)$
is characterized by (see Theorem 2)
$(\hat{\alpha}_n, \hat{\theta}_n)$
is characterized by (see Theorem 2)
 \begin{align} \sqrt{n^{\alpha} I_\alpha} \cdot (\hat{\alpha}_n - \alpha) &\to {N}/\sqrt{{\textsf{M}}_{\alpha, \theta}} \quad &&(\mathcal{F}_\infty \mbox{{-}stable}), \end{align}
\begin{align} \sqrt{n^{\alpha} I_\alpha} \cdot (\hat{\alpha}_n - \alpha) &\to {N}/\sqrt{{\textsf{M}}_{\alpha, \theta}} \quad &&(\mathcal{F}_\infty \mbox{{-}stable}), \end{align}
 \begin{align} \hat{\theta}_n &\to \alpha \cdot f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta}) \quad &&\,\,\,\,\,\,\,\,\,(\text{in probability}), \end{align}
\begin{align} \hat{\theta}_n &\to \alpha \cdot f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta}) \quad &&\,\,\,\,\,\,\,\,\,(\text{in probability}), \end{align}
where N is a random variable following the standard normal N(0,1), which is of
 ${\textsf{M}}_{\alpha, \theta}$
, and
${\textsf{M}}_{\alpha, \theta}$
, and
 $f_\alpha^{-1}$
is the inverse of the map
$f_\alpha^{-1}$
is the inverse of the map
 $f_\alpha$
in (1.5). Note the randomness of the limit distributions comes from the pair
$f_\alpha$
in (1.5). Note the randomness of the limit distributions comes from the pair
 $({N}, {\textsf{M}}_{\alpha, \theta})$
. Here,
$({N}, {\textsf{M}}_{\alpha, \theta})$
. Here,
 $(\mathcal{F}_\infty \mbox{{-}stable})$
in (1.7) is a notion of stochastic convergence stronger than the usual weak convergence (see Section 2.2). Equations (1.7) and (1.8) imply that
$(\mathcal{F}_\infty \mbox{{-}stable})$
in (1.7) is a notion of stochastic convergence stronger than the usual weak convergence (see Section 2.2). Equations (1.7) and (1.8) imply that
 $\hat{\alpha}_n$
is
$\hat{\alpha}_n$
is
 $n^{\alpha/2}$
-consistent while
$n^{\alpha/2}$
-consistent while
 $\hat{\theta}_n$
is not consistent since
$\hat{\theta}_n$
is not consistent since
 ${\textsf{M}}_{\alpha, \theta}$
is not constant.
${\textsf{M}}_{\alpha, \theta}$
is not constant.
It is important to emphasize that the limit law of
 $\hat{\alpha}_n$
,
$\hat{\alpha}_n$
,
 ${N}/\sqrt{{\textsf{M}}_{\alpha, \theta}}$
, is not normal but a variance mixture of normals. This type of asymptotics is referred to as asymptotic mixed normality, which is often observed in ‘nonergodic’ or ‘explosive’ stochastic processes (see [Reference Häusler and Luschgy17]). By contrast, if we normalize the error
${N}/\sqrt{{\textsf{M}}_{\alpha, \theta}}$
, is not normal but a variance mixture of normals. This type of asymptotics is referred to as asymptotic mixed normality, which is often observed in ‘nonergodic’ or ‘explosive’ stochastic processes (see [Reference Häusler and Luschgy17]). By contrast, if we normalize the error
 $\hat{\alpha}_n-\alpha$
by the random statistic
$\hat{\alpha}_n-\alpha$
by the random statistic
 $\sqrt{K_n I_\alpha }$
, where
$\sqrt{K_n I_\alpha }$
, where
 $K_n$
is the number of nonempty blocks and
$K_n$
is the number of nonempty blocks and
 $I_\alpha$
is the Fisher information in (1.4), the randomness of variance is canceled out, and the limit law becomes the standard normal:
$I_\alpha$
is the Fisher information in (1.4), the randomness of variance is canceled out, and the limit law becomes the standard normal:
 \begin{align*} \sqrt{K_n I_\alpha } (\hat{\alpha}_{n} - \alpha) = \sqrt{K_n/n^\alpha} \cdot \sqrt{n^\alpha I_\alpha} (\hat{\alpha}_{n} - \alpha)\to \sqrt{{\textsf{M}}_{\alpha, \theta}} \cdot {N}/\sqrt{{\textsf{M}}_{\alpha, \theta}} = {N},\end{align*}
\begin{align*} \sqrt{K_n I_\alpha } (\hat{\alpha}_{n} - \alpha) = \sqrt{K_n/n^\alpha} \cdot \sqrt{n^\alpha I_\alpha} (\hat{\alpha}_{n} - \alpha)\to \sqrt{{\textsf{M}}_{\alpha, \theta}} \cdot {N}/\sqrt{{\textsf{M}}_{\alpha, \theta}} = {N},\end{align*}
where we have used (1.6), (1.7), and (generalized) Slutsky’s lemma to stable convergence (see Lemma 1). Informally,
 $K_n$
(the number of blocks) corresponds to the sample size in typical parametric independent and identically distributed (i.i.d.) cases, and
$K_n$
(the number of blocks) corresponds to the sample size in typical parametric independent and identically distributed (i.i.d.) cases, and
 $I_\alpha$
quantifies the Fisher information per block. As an immediate application of this result, we get the approximate 95% confidence interval
$I_\alpha$
quantifies the Fisher information per block. As an immediate application of this result, we get the approximate 95% confidence interval
 $[\hat{\alpha}_n \pm 1.96/\sqrt{K_n I_{\hat{\alpha}_n}}]$
. We will apply the above result to a hypothesis testing of sparsity for network data (see Section 3.4).
$[\hat{\alpha}_n \pm 1.96/\sqrt{K_n I_{\hat{\alpha}_n}}]$
. We will apply the above result to a hypothesis testing of sparsity for network data (see Section 3.4).
1.2. Prior literature
Related papers consider the estimation of
 $\alpha$
under some misspecified settings. To compare them with our work, we introduce another representation of the Ewens–Pitman partition. Here, for a nonatomic measure G on
$\alpha$
under some misspecified settings. To compare them with our work, we introduce another representation of the Ewens–Pitman partition. Here, for a nonatomic measure G on
 $\mathbb{R}$
, e.g., N(0,1), the Pitman–Yor process
$\mathbb{R}$
, e.g., N(0,1), the Pitman–Yor process
 $(\alpha, \theta; G)$
is the discrete random measure P on
$(\alpha, \theta; G)$
is the discrete random measure P on
 $\mathbb{R}$
represented by
$\mathbb{R}$
represented by
 \begin{align*} P\,:\!=\, \sum_{i=1}^\infty p_i \delta_{y_i}, \quad (y_i)_{i=1}^\infty \overset{\textrm{i.i.d.}}{\sim} G, \quad p_i = v_i \prod_{j=1}^{i-1}(1-v_j) \text{ with } v_i \sim \text{Beta}(1-\alpha, \theta + i\alpha),\end{align*}
\begin{align*} P\,:\!=\, \sum_{i=1}^\infty p_i \delta_{y_i}, \quad (y_i)_{i=1}^\infty \overset{\textrm{i.i.d.}}{\sim} G, \quad p_i = v_i \prod_{j=1}^{i-1}(1-v_j) \text{ with } v_i \sim \text{Beta}(1-\alpha, \theta + i\alpha),\end{align*}
where
 $y_i$
and
$y_i$
and
 $v_i$
are independent. Since P is discrete with probability 1, conditional i.i.d. samples
$v_i$
are independent. Since P is discrete with probability 1, conditional i.i.d. samples
 $(X_i)_{i\geq 1} |P \overset{\textrm{i.i.d.}}{\sim} P$
induce a partition of [n] by the equivalence relation
$(X_i)_{i\geq 1} |P \overset{\textrm{i.i.d.}}{\sim} P$
induce a partition of [n] by the equivalence relation
 $i\sim j$
if and only if
$i\sim j$
if and only if
 $X_i = X_j$
. Then, with a nontrivial calculation, we can show that the random partition induced by the Pitman–Yor process
$X_i = X_j$
. Then, with a nontrivial calculation, we can show that the random partition induced by the Pitman–Yor process
 $(\alpha, \theta, G)$
has the same density as (1.1) of the Ewens–Pitman partition
$(\alpha, \theta, G)$
has the same density as (1.1) of the Ewens–Pitman partition
 $(\alpha, \theta)$
. In fact, any exchangeable partitions can be induced by a discrete measure (see [Reference Kingman20]).
$(\alpha, \theta)$
. In fact, any exchangeable partitions can be induced by a discrete measure (see [Reference Kingman20]).
Here, we define the function
 $L_P \,\colon (1, \infty) \to \mathbb{N}$
for any discrete measure P by
$L_P \,\colon (1, \infty) \to \mathbb{N}$
for any discrete measure P by
 \begin{align*}L_P(x)\,:\!=\, \# \left\{y\,:\,P(y)\gt x^{-1}\right\}.\end{align*}
\begin{align*}L_P(x)\,:\!=\, \# \left\{y\,:\,P(y)\gt x^{-1}\right\}.\end{align*}
Note that
 $L_P$
is an increasing function, and the order of
$L_P$
is an increasing function, and the order of
 $L_P(x)$
as
$L_P(x)$
as
 $x\to+\infty$
characterizes the tail behavior of P. In particular,
$x\to+\infty$
characterizes the tail behavior of P. In particular,
 $L_P(x) = O(x^\alpha)$
(almost everywhere) when P follows the Pitman–Yor process
$L_P(x) = O(x^\alpha)$
(almost everywhere) when P follows the Pitman–Yor process
 $(\alpha, \theta, G)$
, i.e., the Pitman–Yor process has a heavy tail of index
$(\alpha, \theta, G)$
, i.e., the Pitman–Yor process has a heavy tail of index
 $\alpha$
. More precisely,
$\alpha$
. More precisely,
 $x^{-\alpha} L_p(x)$
has a limit as
$x^{-\alpha} L_p(x)$
has a limit as
 $x\to\infty$
with probability 1, and the limit is given by
$x\to\infty$
with probability 1, and the limit is given by
 \begin{align} \lim_{x\to \infty} x^{-\alpha} L_P(x) =\frac{{\textsf{M}}_{\alpha, \theta}}{\Gamma(1-\alpha)} \quad \text{(with probability 1)},\end{align}
\begin{align} \lim_{x\to \infty} x^{-\alpha} L_P(x) =\frac{{\textsf{M}}_{\alpha, \theta}}{\Gamma(1-\alpha)} \quad \text{(with probability 1)},\end{align}
where
 ${\textsf{M}}_{\alpha, \theta}$
is a random variable following
${\textsf{M}}_{\alpha, \theta}$
is a random variable following
 $\textrm{GMtLf}(\alpha,\theta)$
(see [Reference Pitman24]).
$\textrm{GMtLf}(\alpha,\theta)$
(see [Reference Pitman24]).
Previous research has focused on estimating the tail index
 $\alpha$
of the unknown discrete measure P using the Pitman–Yor process
$\alpha$
of the unknown discrete measure P using the Pitman–Yor process
 $(\alpha,\theta, G)$
as a prior. Namely, they estimate the tail index
$(\alpha,\theta, G)$
as a prior. Namely, they estimate the tail index
 $\alpha$
by fitting the Ewens–Pitman partition
$\alpha$
by fitting the Ewens–Pitman partition
 $(\alpha, \theta)$
to partition data induced by i.i.d. samples from P, with
$(\alpha, \theta)$
to partition data induced by i.i.d. samples from P, with
 $\theta$
regarded as a nuisance parameter. Here, P is allowed to be misspecified and the assumption on P takes the following form:
$\theta$
regarded as a nuisance parameter. Here, P is allowed to be misspecified and the assumption on P takes the following form:
 \begin{align}\exists \, L(x) \text{ slowly varying}, \quad \exists \, r(x) = o(x^\alpha) \quad \text{such that} \quad|L_P(x) - L(x) x^{\alpha}| \leq r(x).\end{align}
\begin{align}\exists \, L(x) \text{ slowly varying}, \quad \exists \, r(x) = o(x^\alpha) \quad \text{such that} \quad|L_P(x) - L(x) x^{\alpha}| \leq r(x).\end{align}
Observe that (1.10) is motivated by (1.9): the Pitman–Yor process satisfies (1.10) with
 $L(x) = {\textsf{M}}_{\alpha, \theta}/\Gamma(1-\alpha)$
and
$L(x) = {\textsf{M}}_{\alpha, \theta}/\Gamma(1-\alpha)$
and
 $r(x) = O(x^{\alpha/2} \log x)$
, where
$r(x) = O(x^{\alpha/2} \log x)$
, where
 ${\textsf{M}}_{\alpha, \theta}$
is a positive random variable following
${\textsf{M}}_{\alpha, \theta}$
is a positive random variable following
 $\textrm{GMtLf}(\alpha,\theta)$
(see [Reference Balocchi, Favaro and Naulet1, Proposition 10]).
$\textrm{GMtLf}(\alpha,\theta)$
(see [Reference Balocchi, Favaro and Naulet1, Proposition 10]).
Recently, several papers have considered the asymptotics of the MLE
 $\hat{\alpha}_n$
by imposing assumptions on r(x) in (1.10); [Reference Favaro and Naulet11] show that
$\hat{\alpha}_n$
by imposing assumptions on r(x) in (1.10); [Reference Favaro and Naulet11] show that
 $\hat{\alpha}_n = \alpha + O_p(n^{-\alpha/2} \sqrt{\log n})$
and
$\hat{\alpha}_n = \alpha + O_p(n^{-\alpha/2} \sqrt{\log n})$
and
 $\hat{\alpha}_n$
is minimax near optimal, under the assumption of (1.10) with L being constant and
$\hat{\alpha}_n$
is minimax near optimal, under the assumption of (1.10) with L being constant and
 $r(x) = O(x^{\alpha/2} \log x)$
. Comparing it with our rate
$r(x) = O(x^{\alpha/2} \log x)$
. Comparing it with our rate
 $\hat{\alpha}_n - \alpha = O_p(n^{-\alpha/2})$
in Theorem 2, we observe that the price for such a misspecification is just
$\hat{\alpha}_n - \alpha = O_p(n^{-\alpha/2})$
in Theorem 2, we observe that the price for such a misspecification is just
 $\log n$
factors.
$\log n$
factors.
In contrast, [Reference Balocchi, Favaro and Naulet1] discuss the asymptotics of
 $(\hat{\alpha}_n, \hat{\theta}_n)$
under the assumption of (1.10) with
$(\hat{\alpha}_n, \hat{\theta}_n)$
under the assumption of (1.10) with
 $L(x) = L$
(a constant) and
$L(x) = L$
(a constant) and
 $r(x) = o(x^\alpha/\log x)$
, which is weaker than
$r(x) = o(x^\alpha/\log x)$
, which is weaker than
 $r(x) = O(x^{\alpha/2} \log x)$
in the previous assumption by [Reference Favaro and Naulet11]. They show that
$r(x) = O(x^{\alpha/2} \log x)$
in the previous assumption by [Reference Favaro and Naulet11]. They show that
 $(\hat{\alpha}_n, \hat{\theta}_n) \to ^p (\alpha, \Theta)$
where
$(\hat{\alpha}_n, \hat{\theta}_n) \to ^p (\alpha, \Theta)$
where
 $\Theta$
is a solution to the nonlinear equation
$\Theta$
is a solution to the nonlinear equation
 \begin{align*}L \cdot \Gamma(1-\alpha) = \exp(\psi(\Theta/\alpha+1)-\alpha \psi(\Theta + 1)).\end{align*}
\begin{align*}L \cdot \Gamma(1-\alpha) = \exp(\psi(\Theta/\alpha+1)-\alpha \psi(\Theta + 1)).\end{align*}
If P follows the Pitman–Yor process, we know
 $L= {\textsf{M}}_{\alpha, \theta}/\Gamma(1-\alpha)$
by (1.9). Combined with the definition
$L= {\textsf{M}}_{\alpha, \theta}/\Gamma(1-\alpha)$
by (1.9). Combined with the definition
 $f_\alpha(x) = \psi(x + 1)-\alpha \psi(\alpha x + 1)$
in (3.2), we have
$f_\alpha(x) = \psi(x + 1)-\alpha \psi(\alpha x + 1)$
in (3.2), we have
 \begin{align*} &\log {\textsf{M}}_{\alpha, \theta} = \psi(\Theta/{\alpha} + 1) - \alpha \psi(\Theta + 1) = f_\alpha(\Theta/\alpha)\end{align*}
\begin{align*} &\log {\textsf{M}}_{\alpha, \theta} = \psi(\Theta/{\alpha} + 1) - \alpha \psi(\Theta + 1) = f_\alpha(\Theta/\alpha)\end{align*}
and
 $\Theta = \alpha f_\alpha^{-1} (\log {\textsf{M}}_{\alpha, \theta})$
, which recover the asymptotics
$\Theta = \alpha f_\alpha^{-1} (\log {\textsf{M}}_{\alpha, \theta})$
, which recover the asymptotics
 $\hat{\theta}_n\to^p \alpha f_{\alpha}^{-1}(\log{\textsf{M}}_{\alpha, \theta})$
in Theorem 2.
$\hat{\theta}_n\to^p \alpha f_{\alpha}^{-1}(\log{\textsf{M}}_{\alpha, \theta})$
in Theorem 2.
After our paper was originally posted, [Reference Franssen and van der Vaart13] derived the asymptotic distribution of
 $\hat{\alpha}_n$
under the assumption (1.10) with
$\hat{\alpha}_n$
under the assumption (1.10) with
 $r(x) = O( x^{\beta})$
for some
$r(x) = O( x^{\beta})$
for some
 $\beta \lt \alpha/2$
. They show that
$\beta \lt \alpha/2$
. They show that
 \begin{align*} \sqrt{L_p(n)} (\hat{\alpha}_n - \alpha) \to {N}(0, \tau_1^2/\tau_2^4) \text{ as $n\to\infty$},\end{align*}
\begin{align*} \sqrt{L_p(n)} (\hat{\alpha}_n - \alpha) \to {N}(0, \tau_1^2/\tau_2^4) \text{ as $n\to\infty$},\end{align*}
where
 $\tau_1$
and
$\tau_1$
and
 $\tau_2$
are positive constants. Using our notation,
$\tau_2$
are positive constants. Using our notation,
 $\tau_1$
can be written by
$\tau_1$
can be written by
 $\tau_2^2 = \Gamma(1-\alpha) I_\alpha$
with
$\tau_2^2 = \Gamma(1-\alpha) I_\alpha$
with
 $I_\alpha$
being the Fisher information of the discrete distribution defined by (3.1), so
$I_\alpha$
being the Fisher information of the discrete distribution defined by (3.1), so
 $\tau_1$
is interpretable. Combining this with the tail asymptotics
$\tau_1$
is interpretable. Combining this with the tail asymptotics
 $L_p(n) \sim {\textsf{M}}_{\alpha, \theta} n^\alpha/\Gamma(1-\alpha) \sim K_n/\Gamma(1-\alpha)$
when P follows the Pitman–Yor process (see (1.9)), we obtain
$L_p(n) \sim {\textsf{M}}_{\alpha, \theta} n^\alpha/\Gamma(1-\alpha) \sim K_n/\Gamma(1-\alpha)$
when P follows the Pitman–Yor process (see (1.9)), we obtain
 $$\begin{align}\sqrt{K_n I_\alpha} (\hat{\alpha}_n - \alpha) &= \sqrt{\frac{K_n I_\alpha}{L_p(n)}} \sqrt{L_p(n)} (\hat{\alpha}_n - \alpha) \to {N} \left(0, \frac{\tau_1^2}{ I_\alpha \Gamma(1-\alpha)}\right).\end{align}$$
$$\begin{align}\sqrt{K_n I_\alpha} (\hat{\alpha}_n - \alpha) &= \sqrt{\frac{K_n I_\alpha}{L_p(n)}} \sqrt{L_p(n)} (\hat{\alpha}_n - \alpha) \to {N} \left(0, \frac{\tau_1^2}{ I_\alpha \Gamma(1-\alpha)}\right).\end{align}$$
Thus, if
 $\tau_1^2 =\Gamma(1-\alpha) I_\alpha$
holds, the above display coincides with our result in Corollary 1. However,
$\tau_1^2 =\Gamma(1-\alpha) I_\alpha$
holds, the above display coincides with our result in Corollary 1. However,
 $\tau_2$
is an involved quantity, so we couldn’t check
$\tau_2$
is an involved quantity, so we couldn’t check
 $\tau_1^2 =\Gamma(1-\alpha) I_\alpha$
. Furthermore, their assumption
$\tau_1^2 =\Gamma(1-\alpha) I_\alpha$
. Furthermore, their assumption
 $r(x) = o(x^{\beta})$
with
$r(x) = o(x^{\beta})$
with
 $\beta \lt\alpha/2$
is not satisfied by the Pitman–Yor process, and hence their result does not imply ours.
$\beta \lt\alpha/2$
is not satisfied by the Pitman–Yor process, and hence their result does not imply ours.
In summary, previous papers studied the estimation of the tail index of the underlying discrete measure by using the Pitman–Yor process as a prior, but to the best of our knowledge, the exact asymptotic distribution of the MLE was unknown. Considering the arguments in the previous section, the novelty of this paper is the exact asymptotic distribution of the MLE and the confidence interval of
 $\alpha$
. In our proof, as highlighted in Section 5, we avoid the representation of the Ewens–Pitman partition by the Pitman–Yor process. Instead, we exploit the sequential definition of the Ewens–Pitman partition and its martingale property.
$\alpha$
. In our proof, as highlighted in Section 5, we avoid the representation of the Ewens–Pitman partition by the Pitman–Yor process. Instead, we exploit the sequential definition of the Ewens–Pitman partition and its martingale property.
1.3. Organization
The remainder of this paper is organized as follows. Section 2 reviews the parameter dependency of the Ewens–Pitman partition and introduces the concept of stable convergence. In Section 3, we present the main theorem along with its applications to network analysis. Numerical simulations supporting the main theorem are provided in Section 4. The proof strategy is outlined in Section 5, and Section 6 concludes with a potential direction for future research. All proofs are given in the supplementary material.
2. Notation and Preliminaries
2.1. Parameter dependency of the Ewens–Pitman partition
In Section 1, we introduced the Ewens–Pitman partition as a distribution on the set of partitions of [n], denoted by
 $\mathcal{P}_n$
. Here, we introduce an alternative representation of the Ewens–Pitman partition; the Ewens–Pitman partition is a stochastic process over
$\mathcal{P}_n$
. Here, we introduce an alternative representation of the Ewens–Pitman partition; the Ewens–Pitman partition is a stochastic process over
 $(\mathcal{P}_n)_{n\geq 1}$
that randomly assigns integers (balls) into blocks (urns) in the following sequential manner:
$(\mathcal{P}_n)_{n\geq 1}$
that randomly assigns integers (balls) into blocks (urns) in the following sequential manner:
-
(i) The first ball belongs to urn
 $U_1$
with probability one.
$U_1$
with probability one. -
(ii) Suppose that
$n \, (\geq 1)$
balls are partitioned into
$K_n$
occupied urns
$\{U_1, \dots, U_{K_n}\}$
, and let
$|U_i|$
be the number of balls in
$U_i$
. Then, the
$(n+1)$
th ball is randomly assigned to the existing urns
$\{U_1,\dots, U_{K_n}\}$
or a new (empty) urn as follows:
\begin{align*} \text{$(n+1)$th ball} \in \left\{\begin{array}{ll} U_i & \text{with prob. $\frac{|U_i| -\alpha}{\theta + n}$} \ (\forall \, i=1, 2, \dots, K_n) \\[6pt] \text{Empty urn} & \text{with prob. $\frac{\theta+K_n\alpha}{\theta + n}$.} \end{array}\right. \end{align*}









Then, it follows from simple algebra that the probability of obtaining the partition
 $\{U_1, \dots, U_{K_n}\}$
of [n] coincides with the likelihood formula (1.1).
$\{U_1, \dots, U_{K_n}\}$
of [n] coincides with the likelihood formula (1.1).
Note that the Ewens–Pitman partition has three parameter spaces:
 $(\textrm{i})\ \alpha=0, \theta\gt0$
,
$(\textrm{i})\ \alpha=0, \theta\gt0$
,
 $(\textrm{ii})\ \alpha\lt0, \exists \, k \in \mathbb{N}\ \text{such that} \ \theta = -k\alpha$
, and
$(\textrm{ii})\ \alpha\lt0, \exists \, k \in \mathbb{N}\ \text{such that} \ \theta = -k\alpha$
, and
 $(\textrm{iii})\ 0\lt\alpha\lt1, \theta\gt-\alpha$
. In the following, we briefly explain the parameter dependency.
$(\textrm{iii})\ 0\lt\alpha\lt1, \theta\gt-\alpha$
. In the following, we briefly explain the parameter dependency.
When
 $\alpha=0, \, \theta\gt0$
: This is referred to as the Ewens partition or the standard Chinese restaurant process. By substituting
$\alpha=0, \, \theta\gt0$
: This is referred to as the Ewens partition or the standard Chinese restaurant process. By substituting
 $\alpha=0$
into the likelihood formula (1.1), we observe that the likelihood is proportional to
$\alpha=0$
into the likelihood formula (1.1), we observe that the likelihood is proportional to
 $\theta^{K_n}/\big(\prod_{i=0}^{n-1}(\theta + i)\big)$
, so that
$\theta^{K_n}/\big(\prod_{i=0}^{n-1}(\theta + i)\big)$
, so that
 $K_n$
is a sufficient statistic for
$K_n$
is a sufficient statistic for
 $\theta$
. Now we define the estimator
$\theta$
. Now we define the estimator
 $\theta^\star_n\,:\!=\, K_n/\log n$
. Then, we claim that
$\theta^\star_n\,:\!=\, K_n/\log n$
. Then, we claim that
 $\theta^\star_n$
is
$\theta^\star_n$
is
 $\sqrt{\log n}$
-consistent and asymptotically normal as follows:
$\sqrt{\log n}$
-consistent and asymptotically normal as follows:
 $$(\theta^{-1}\log n)^{1/2} (\theta^\star_n- \theta)\rightarrow {N}(0,1).$$
$$(\theta^{-1}\log n)^{1/2} (\theta^\star_n- \theta)\rightarrow {N}(0,1).$$
This follows from the following arguments. By the sequential definition above,
 $K_n$
can be expressed as independent sum of the Bernoulli random variables
$K_n$
can be expressed as independent sum of the Bernoulli random variables
 $K_n = \sum_{i=1}^{n} \zeta_i$
where
$K_n = \sum_{i=1}^{n} \zeta_i$
where
 $\zeta_i \sim \textrm{Bernoulli} \big(\frac{\theta}{\theta + i-1}\big)$
. Then, the Lindeberg–Feller theorem (cf. [Reference Durrett9, p. 128]) gives the asymptotic normality.
$\zeta_i \sim \textrm{Bernoulli} \big(\frac{\theta}{\theta + i-1}\big)$
. Then, the Lindeberg–Feller theorem (cf. [Reference Durrett9, p. 128]) gives the asymptotic normality.
When
 ${\alpha\lt0, \, \theta = -k\alpha}$
for some
${\alpha\lt0, \, \theta = -k\alpha}$
for some
 $k\in \mathbb{N}$
: In this case, the number of occupied urns
$k\in \mathbb{N}$
: In this case, the number of occupied urns
 $K_n$
is finite, i.e.,
$K_n$
is finite, i.e.,
 $K_n \rightarrow k$
a.s., since the probability of observing a new urn is proportional to
$K_n \rightarrow k$
a.s., since the probability of observing a new urn is proportional to
 $(\!-\alpha)(k-K_n)$
, which is strictly positive until
$(\!-\alpha)(k-K_n)$
, which is strictly positive until
 $K_n$
reaches k.
$K_n$
reaches k.
When
 $0\lt\alpha\lt1, \, \theta\gt - \alpha$
: In this regime, nonstandard asymptotics hold. Before its introduction, let us define some distributions appearing in the asymptotics.
$0\lt\alpha\lt1, \, \theta\gt - \alpha$
: In this regime, nonstandard asymptotics hold. Before its introduction, let us define some distributions appearing in the asymptotics.
Definition 1. (Sibuya distribution.) The Sibuya distribution of parameter
 $\alpha \in (0,1)$
[Reference Sibuya27], which is also called the Karlin–Rouault distribution [Reference Karlin19, Reference Rouault26], is a discrete distribution on
$\alpha \in (0,1)$
[Reference Sibuya27], which is also called the Karlin–Rouault distribution [Reference Karlin19, Reference Rouault26], is a discrete distribution on
 $\mathbb{N}$
with its density
$\mathbb{N}$
with its density
 $p_\alpha(\,j)$
defined by
$p_\alpha(\,j)$
defined by
 \begin{align} \forall \, j\in \mathbb{N}, \quad p_\alpha(\,j)\,:\!=\, \frac{\alpha \prod_{i=1}^{j-1}(i-\alpha)}{j!}.\end{align}
\begin{align} \forall \, j\in \mathbb{N}, \quad p_\alpha(\,j)\,:\!=\, \frac{\alpha \prod_{i=1}^{j-1}(i-\alpha)}{j!}.\end{align}
Here, Stirling’s formula
 $\Gamma(z) \sim \sqrt{{2\pi}/{z}} \left({z}/{e}\right)^z$
implies that the Sibuya distribution is heavy-tailed in the following sense:
$\Gamma(z) \sim \sqrt{{2\pi}/{z}} \left({z}/{e}\right)^z$
implies that the Sibuya distribution is heavy-tailed in the following sense:
 $$p_\alpha(\,j) \sim \frac{\alpha}{\Gamma(1-\alpha)}\cdot j^{-(1+\alpha)} \quad \text{as } j\to\infty.$$
$$p_\alpha(\,j) \sim \frac{\alpha}{\Gamma(1-\alpha)}\cdot j^{-(1+\alpha)} \quad \text{as } j\to\infty.$$
Readers may refer to [Reference Resnick25] for its important role in the extreme value theory.
Definition 2. (Generalized Mittag-Leffler distribution.) Let
 ${\textsf{S}_\alpha}$
be a positive random variable of parameter
${\textsf{S}_\alpha}$
be a positive random variable of parameter
 $\alpha\in(0,1)$
with its Laplace transform given by
$\alpha\in(0,1)$
with its Laplace transform given by
 $\mathbb{E}\big[{\rm e}^{-\lambda {\textsf{S}_\alpha}}\big] = {\rm e}^{-\lambda^\alpha} (\lambda\geq 0)$
. Then, the law of
$\mathbb{E}\big[{\rm e}^{-\lambda {\textsf{S}_\alpha}}\big] = {\rm e}^{-\lambda^\alpha} (\lambda\geq 0)$
. Then, the law of
 ${\textsf{M}_\alpha = \textsf{S}_{\alpha}^{-\alpha}}$
is referred to as the Mittag-Leffler distribution
${\textsf{M}_\alpha = \textsf{S}_{\alpha}^{-\alpha}}$
is referred to as the Mittag-Leffler distribution
 $(\alpha)$
. Moreover, for each
$(\alpha)$
. Moreover, for each
 $\theta\gt-\alpha$
, the generalized Mittag-Leffler distribution
$\theta\gt-\alpha$
, the generalized Mittag-Leffler distribution
 $(\alpha, \theta)$
, denoted by
$(\alpha, \theta)$
, denoted by
 $\textrm{GMtLf}(\alpha,\theta)$
, is a tilted distribution with its density
$\textrm{GMtLf}(\alpha,\theta)$
, is a tilted distribution with its density
 ${g_{\alpha, \theta}(x)}$
proportional to
${g_{\alpha, \theta}(x)}$
proportional to
 $x^{\theta/\alpha} g_\alpha(x)$
, where
$x^{\theta/\alpha} g_\alpha(x)$
, where
 $g_\alpha(x)$
is the density of the Mittag-Leffler distribution
$g_\alpha(x)$
is the density of the Mittag-Leffler distribution
 $(\alpha)$
.
$(\alpha)$
.
Remark 1. The density
 $g_\alpha(x)$
of the Mittag-Leffler distribution is characterized by the moment
$g_\alpha(x)$
of the Mittag-Leffler distribution is characterized by the moment
 $\int_0^\infty x^p g_\alpha(x) \mathop{}\!\textrm{d} x =\Gamma(p + 1)/\Gamma(p\alpha + 1)$
for all
$\int_0^\infty x^p g_\alpha(x) \mathop{}\!\textrm{d} x =\Gamma(p + 1)/\Gamma(p\alpha + 1)$
for all
 $p\gt -1$
. Then it easily follows from the definition
$p\gt -1$
. Then it easily follows from the definition
 $g_{{\alpha, \theta}}(x) \propto x^{\theta/\alpha} g(x)$
that the moment of
$g_{{\alpha, \theta}}(x) \propto x^{\theta/\alpha} g(x)$
that the moment of
 ${\textsf{M}}_{\alpha, \theta} \sim \textrm{GMtLf}(\alpha,\theta)$
is given by
${\textsf{M}}_{\alpha, \theta} \sim \textrm{GMtLf}(\alpha,\theta)$
is given by
 \begin{align} \forall \, p\gt-(1 + \theta/\alpha), \quad \mathbb{E}[({\textsf{M}}_{\alpha, \theta})^p] = \frac{\Gamma(\theta + 1)}{\Gamma(\theta/\alpha + 1)} \frac{\Gamma(\theta/\alpha + p + 1)}{\Gamma(\theta + p\alpha + 1)}.\end{align}
\begin{align} \forall \, p\gt-(1 + \theta/\alpha), \quad \mathbb{E}[({\textsf{M}}_{\alpha, \theta})^p] = \frac{\Gamma(\theta + 1)}{\Gamma(\theta/\alpha + 1)} \frac{\Gamma(\theta/\alpha + p + 1)}{\Gamma(\theta + p\alpha + 1)}.\end{align}
Finally, we introduce the nonstandard asymptotics of the Ewens–Pitman partition when
 $0\lt\alpha\lt1,\ \theta\gt-\alpha$
.
$0\lt\alpha\lt1,\ \theta\gt-\alpha$
.
Theorem 1.
We assume
 $0\lt\alpha\lt1, \theta\gt- \alpha$
. Let
$0\lt\alpha\lt1, \theta\gt- \alpha$
. Let
 $S_{n,j}$
be the number of blocks with size j, and let
$S_{n,j}$
be the number of blocks with size j, and let
 $K_n = \sum_{j\geq 1} S_{n,j}$
be the number of nonempty blocks. Then, we have:
$K_n = \sum_{j\geq 1} S_{n,j}$
be the number of nonempty blocks. Then, we have:
-
(A)
$K_n/n^\alpha \rightarrow {\textsf{M}}_{\alpha, \theta} $
a.s. and in the pth moment for all
$p\gt 0$
, where
${\textsf{M}}_{\alpha, \theta} \sim \textrm{GMtLf}(\alpha,\theta)$
(see Definition 2 for the definition of the law
$\textrm{GMtLf}(\alpha,\theta)$
);
-
(B)
${S_{n, j}}/{K_n} \rightarrow p_\alpha(\,j)$
a.s. for all
$j \in \mathbb{N}$
, where
$p_\alpha (\,j)$
is the density of the Sibuya distribution given by Definition 1.







Sketch of proof. Let
 $\mathbb{P}_{\alpha, \theta}$
denote the law of the Ewens–Pitman partition with parameter
$\mathbb{P}_{\alpha, \theta}$
denote the law of the Ewens–Pitman partition with parameter
 $(\alpha,\theta)$
. Then, (A) can be proved by applying the martingale convergence theorem to the likelihood ratio
$(\alpha,\theta)$
. Then, (A) can be proved by applying the martingale convergence theorem to the likelihood ratio
 $(\!\mathop{}\!\textrm{d} \mathbb{P}_{\alpha, \theta}/\mathop{}\!\textrm{d} {\mathbb{P}_{\alpha, 0}})|_{\mathcal{F}_n}$
under
$(\!\mathop{}\!\textrm{d} \mathbb{P}_{\alpha, \theta}/\mathop{}\!\textrm{d} {\mathbb{P}_{\alpha, 0}})|_{\mathcal{F}_n}$
under
 ${\mathbb{P}_{\alpha, 0}}$
, where
${\mathbb{P}_{\alpha, 0}}$
, where
 $\mathcal{F}_n$
is the
$\mathcal{F}_n$
is the
 $\sigma$
-field generated by the partition of n balls. For (B), Kingman’s representation theorem implies that the Ewens–Pitman partition can be expressed as the tied observation of conditional i.i.d. samples from the Pitman–Yor process (see Section 1.2 or [Reference Ghosal and van der Vaart14, p. 440]). Then, we can analyze
$\sigma$
-field generated by the partition of n balls. For (B), Kingman’s representation theorem implies that the Ewens–Pitman partition can be expressed as the tied observation of conditional i.i.d. samples from the Pitman–Yor process (see Section 1.2 or [Reference Ghosal and van der Vaart14, p. 440]). Then, we can analyze
 $S_{n,j}/K_n$
in the setting of a classical occupancy problem. Readers may refer to [Reference Pitman24, Theorem 3.8] for the detailed proof of (A) and [Reference Pitman24, Lemma 3.11], [Reference Gnedin, Hansen and Pitman15] for the proof of (B).
$S_{n,j}/K_n$
in the setting of a classical occupancy problem. Readers may refer to [Reference Pitman24, Theorem 3.8] for the detailed proof of (A) and [Reference Pitman24, Lemma 3.11], [Reference Gnedin, Hansen and Pitman15] for the proof of (B).
Remark 2. ([Reference Pitman24, p. 71].)
 ${\mathbb{P}_{\alpha, \theta}}$
are absolutely mutual continuous for each
${\mathbb{P}_{\alpha, \theta}}$
are absolutely mutual continuous for each
 $\theta (\!\gt -\alpha)$
: the Radon–Nikodym density is given by
$\theta (\!\gt -\alpha)$
: the Radon–Nikodym density is given by
 $\mathop{}\!\textrm{d} \mathbb{P}_{\alpha, \theta}/\mathop{}\!\textrm{d} {\mathbb{P}_{\alpha, 0}} = ({\textsf{M}_\alpha})^{\theta/\alpha} {\Gamma(\theta + 1)}/{\Gamma(\theta/\alpha + 1)}$
(
$\mathop{}\!\textrm{d} \mathbb{P}_{\alpha, \theta}/\mathop{}\!\textrm{d} {\mathbb{P}_{\alpha, 0}} = ({\textsf{M}_\alpha})^{\theta/\alpha} {\Gamma(\theta + 1)}/{\Gamma(\theta/\alpha + 1)}$
(
 ${\mathbb{P}_{\alpha, 0}}\text{-a.s.}$
), where
${\mathbb{P}_{\alpha, 0}}\text{-a.s.}$
), where
 ${\textsf{M}_{\alpha}}$
is the almost sure limit of
${\textsf{M}_{\alpha}}$
is the almost sure limit of
 $n^{-\alpha}K_n$
under
$n^{-\alpha}K_n$
under
 ${\mathbb{P}_{\alpha, 0}}$
. This is consistent with Proposition 2 below in the sense that the Fisher information about
${\mathbb{P}_{\alpha, 0}}$
. This is consistent with Proposition 2 below in the sense that the Fisher information about
 $\theta$
is bounded as n increases. Roughly speaking, this result implies that we cannot consistently estimate
$\theta$
is bounded as n increases. Roughly speaking, this result implies that we cannot consistently estimate
 $\theta$
.
$\theta$
.
2.2. Stable convergence
Our main theorem on the asymptotic law of the MLE (Theorem 2) involves a stable convergence, which is a notion of stochastic convergence stronger than the usual weak convergence. In this section, we introduce it in a general format. Let
 $(\Omega, \mathcal{F}, P)$
denote a probability space, and let
$(\Omega, \mathcal{F}, P)$
denote a probability space, and let
 $\mathcal{X}$
be a separable metrizable topological space equipped with its Borel
$\mathcal{X}$
be a separable metrizable topological space equipped with its Borel
 $\sigma$
-field
$\sigma$
-field
 $\mathcal{B}(\mathcal{X})$
. Furthermore, let
$\mathcal{B}(\mathcal{X})$
. Furthermore, let
 $\mathcal{L}^1(\Omega, \mathcal{F}, P) = \mathcal{L}^1$
be the set of
$\mathcal{L}^1(\Omega, \mathcal{F}, P) = \mathcal{L}^1$
be the set of
 $\mathcal{F}$
-measurable functions that satisfy
$\mathcal{F}$
-measurable functions that satisfy
 $\int |\,f| \,{\rm d}P \lt+ \infty$
, and let
$\int |\,f| \,{\rm d}P \lt+ \infty$
, and let
 $C_b(\mathcal{X})$
be the set of continuous bounded functions on
$C_b(\mathcal{X})$
be the set of continuous bounded functions on
 $\mathcal{X}$
. With the above notation, the stable convergence is defined as follows.
$\mathcal{X}$
. With the above notation, the stable convergence is defined as follows.
Definition 3. For a sub-
 $\sigma$
-field
$\sigma$
-field
 $\mathcal{G} \subset \mathcal{F}$
, a sequence of
$\mathcal{G} \subset \mathcal{F}$
, a sequence of
 $(\mathcal{X}, \mathcal{B}(\mathcal{X}))$
-valued random variables
$(\mathcal{X}, \mathcal{B}(\mathcal{X}))$
-valued random variables
 $(X_n)_{n\geq 1}$
is said to converge
$(X_n)_{n\geq 1}$
is said to converge
 $\mathcal{G}$
-stably to X, denoted by
$\mathcal{G}$
-stably to X, denoted by
 $X_n \rightarrow X$
$X_n \rightarrow X$
 $\mathcal{G}$
-stably, if and only if
$\mathcal{G}$
-stably, if and only if
 \begin{align} \forall \, f \in \mathcal{L}^1,\quad \forall \, h \in C_b(\mathcal{X}), \quad \lim_{n\rightarrow\infty} \mathbb{E}[\,f\mathbb{E}[h(X_n)|\mathcal{G}]] = \mathbb{E}[\,f\mathbb{E}[h(X)|\mathcal{G}]].\end{align}
\begin{align} \forall \, f \in \mathcal{L}^1,\quad \forall \, h \in C_b(\mathcal{X}), \quad \lim_{n\rightarrow\infty} \mathbb{E}[\,f\mathbb{E}[h(X_n)|\mathcal{G}]] = \mathbb{E}[\,f\mathbb{E}[h(X)|\mathcal{G}]].\end{align}
If the limit X is independent of
 $\mathcal{G}$
,
$\mathcal{G}$
,
 $(X_n)_{n\geq 1}$
is said to converge
$(X_n)_{n\geq 1}$
is said to converge
 $\mathcal{G}$
-mixing, denoted by
$\mathcal{G}$
-mixing, denoted by
 $X_n \rightarrow X$
$X_n \rightarrow X$
 $\mathcal{G}$
-mixing.
$\mathcal{G}$
-mixing.
Note that stable convergence implies the weak convergence, as the condition (2.3) with
 $f=1$
is identical to the definition of weak convergence. By contrast, if
$f=1$
is identical to the definition of weak convergence. By contrast, if
 $\mathcal{G}$
is a trivial
$\mathcal{G}$
is a trivial
 $\sigma$
-field
$\sigma$
-field
 $\{\emptyset, \Omega\}$
, then we have
$\{\emptyset, \Omega\}$
, then we have
 $\mathbb{E}[\,f\mathbb{E}[h(X_n)|\mathcal{G}]] = \int f \mathop{}\!\textrm{d} P \cdot \mathbb{E}[h(X_n)]$
for all
$\mathbb{E}[\,f\mathbb{E}[h(X_n)|\mathcal{G}]] = \int f \mathop{}\!\textrm{d} P \cdot \mathbb{E}[h(X_n)]$
for all
 $f\in \mathcal{L}^1$
. Thus,
$f\in \mathcal{L}^1$
. Thus,
 $X_n \rightarrow X $
$X_n \rightarrow X $
 $\mathcal{G}$
-stably coincides with the usual weak convergence
$\mathcal{G}$
-stably coincides with the usual weak convergence
 $X_n \to^d X$
in the trivial case
$X_n \to^d X$
in the trivial case
 $\mathcal{G}=\{\emptyset, \Omega\}$
.
$\mathcal{G}=\{\emptyset, \Omega\}$
.
The next lemma states that the well-known theorem for weak convergence holds for stable convergence. More precisely, Slutsky’s lemma holds in a stronger sense.
Lemma 1. ([Reference Häusler and Luschgy17, p. 34].) For a pair of separable metrizable spaces
 $(\mathcal{X}, \mathcal{B}(\mathcal{X})), (\mathcal{Y}, \mathcal{B}(\mathcal{Y}))$
with metric d, let
$(\mathcal{X}, \mathcal{B}(\mathcal{X})), (\mathcal{Y}, \mathcal{B}(\mathcal{Y}))$
with metric d, let
 $(X_n)_{n\geq 1}$
be a sequence of
$(X_n)_{n\geq 1}$
be a sequence of
 $(\mathcal{X}, \mathcal{B}(\mathcal{X}))$
-valued random variables, and let
$(\mathcal{X}, \mathcal{B}(\mathcal{X}))$
-valued random variables, and let
 $(Y_n)_{n\geq 1}$
be a sequence of
$(Y_n)_{n\geq 1}$
be a sequence of
 $(\mathcal{Y}, \mathcal{B}(\mathcal{Y}))$
-valued random variables. Assuming that a certain random variable X exists such that
$(\mathcal{Y}, \mathcal{B}(\mathcal{Y}))$
-valued random variables. Assuming that a certain random variable X exists such that
 $X_n \rightarrow X$
$X_n \rightarrow X$
 $\mathcal{G}$
-stably, the following statements hold.
$\mathcal{G}$
-stably, the following statements hold.
-
(A) Let
$\mathcal{X} = \mathcal{Y}$
. If
$d (X_n, Y_n) \rightarrow 0$
in probability,
$Y_n \rightarrow X\ \mathcal{G}\mbox{-}stably.$
-
(B) If
$Y_n \rightarrow Y$
in probability, and Y is
$\mathcal{G}$
-measurable,
$(X_n, Y_n) \rightarrow (X, Y) \ \mathcal{G}\mbox{-}stably$
. -
(C) If
$g \,\colon \mathcal{X} \rightarrow \mathcal{Y}$
is
$(\mathcal{B}(\mathcal{X}), \mathcal{B}(\mathcal{Y}))$
-measurable and continuous
$P^{X}$
-a.s.,
$g(X_n) \rightarrow g(X) \mathcal{G}\mbox{-}stably.$










If
 $\mathcal{G}$
is a tribal
$\mathcal{G}$
is a tribal
 $\sigma$
-field
$\sigma$
-field
 $\{\emptyset, \Omega\}$
, the above assertions are the well-known results for weak convergence. Importantly, (B) allows Y to be any
$\{\emptyset, \Omega\}$
, the above assertions are the well-known results for weak convergence. Importantly, (B) allows Y to be any
 $\mathcal{G}$
-measurable random variable and not just a constant. In this sense, Slutsky’s lemma holds strongly for stable convergence. In our theorem, we will set
$\mathcal{G}$
-measurable random variable and not just a constant. In this sense, Slutsky’s lemma holds strongly for stable convergence. In our theorem, we will set
 $\mathcal{G}$
as the limit of the sigma fields generated by the sequential partition generated by the Ewens–Pitman partition.
$\mathcal{G}$
as the limit of the sigma fields generated by the sequential partition generated by the Ewens–Pitman partition.
3. Main Result
3.1. Fisher information
In the following we will assume
 $0\lt\alpha\lt1,\ \theta\gt -\alpha$
. Before introducing our main theorem, let us discuss the asymptotic analysis of Fisher information to acquire insights into the parameter estimation of the Ewens–Pitman partition.
$0\lt\alpha\lt1,\ \theta\gt -\alpha$
. Before introducing our main theorem, let us discuss the asymptotic analysis of Fisher information to acquire insights into the parameter estimation of the Ewens–Pitman partition.
Let
 $I_\alpha$
be the Fisher information of the Sibuya distribution
$I_\alpha$
be the Fisher information of the Sibuya distribution
 \begin{align}I_\alpha\,:\!=\, -\sum_{j=1}^\infty p_\alpha(\,j)\cdot \partial_\alpha^2 \log p_\alpha(\,j) \quad \text{with } p_\alpha(\,j) = \frac{\alpha \prod_{i=1}^{j-1}(i-\alpha)}{j!},\end{align}
\begin{align}I_\alpha\,:\!=\, -\sum_{j=1}^\infty p_\alpha(\,j)\cdot \partial_\alpha^2 \log p_\alpha(\,j) \quad \text{with } p_\alpha(\,j) = \frac{\alpha \prod_{i=1}^{j-1}(i-\alpha)}{j!},\end{align}
for all
 $\alpha\in(0,1)$
. The next proposition provides two formulas for
$\alpha\in(0,1)$
. The next proposition provides two formulas for
 $I_\alpha$
.
$I_\alpha$
.
Proposition 1.
 $I_\alpha$
is continuous in
$I_\alpha$
is continuous in
 $\alpha\in (0,1)$
and can be written by
$\alpha\in (0,1)$
and can be written by
 \begin{align*} I_\alpha \overset{(A)}{=} \frac{1}{\alpha^2}+ \sum_{j=1}^\infty p_\alpha(\,j) \sum_{i=1}^{j-1} \frac{1}{(i-\alpha)^{2}} \overset{(B)}{=} \frac{1}{\alpha^2} + \sum_{j=1}^\infty \frac{p_\alpha(\,j)}{\alpha(\,j-\alpha)}\gt 0.\end{align*}
\begin{align*} I_\alpha \overset{(A)}{=} \frac{1}{\alpha^2}+ \sum_{j=1}^\infty p_\alpha(\,j) \sum_{i=1}^{j-1} \frac{1}{(i-\alpha)^{2}} \overset{(B)}{=} \frac{1}{\alpha^2} + \sum_{j=1}^\infty \frac{p_\alpha(\,j)}{\alpha(\,j-\alpha)}\gt 0.\end{align*}
We will use the two formulas in the proof of our main results. In particular, (A) will appear in the limit of the second derivative of the log-likelihood of the Ewens–Pitman partition, while (B) will be used in the limit of the variance of the first derivative of the log-likelihood. Furthermore, we will see later that our proposed confidence interval of
 $\alpha$
(see Corollary 1) requires the computation of
$\alpha$
(see Corollary 1) requires the computation of
 $I_\alpha$
. In this situation, we recommend (B) in terms of numerical errors:
$I_\alpha$
. In this situation, we recommend (B) in terms of numerical errors:
 $p_\alpha(\,j) = O(\,j^{-\alpha-1})$
by Stirling’s formula implies that the numerical error caused by truncating the infinite series of (A) at n is
$p_\alpha(\,j) = O(\,j^{-\alpha-1})$
by Stirling’s formula implies that the numerical error caused by truncating the infinite series of (A) at n is
 $\sum_{j=n}^\infty p_\alpha(\,j) \sum_{i=1}^{j-1} (i-\alpha)^{-2} = O(n^{-\alpha})$
, while
$\sum_{j=n}^\infty p_\alpha(\,j) \sum_{i=1}^{j-1} (i-\alpha)^{-2} = O(n^{-\alpha})$
, while
 $\sum_{j=n}^\infty p_\alpha(\,j) ({\alpha(\,j-\alpha)})^{-1} = O(n^{-\alpha - 1})$
for (B), where the error in (B) decays faster than that in (A). We plot
$\sum_{j=n}^\infty p_\alpha(\,j) ({\alpha(\,j-\alpha)})^{-1} = O(n^{-\alpha - 1})$
for (B), where the error in (B) decays faster than that in (A). We plot
 $I_\alpha$
in Figure 2 using the formula (B) with j truncated at
$I_\alpha$
in Figure 2 using the formula (B) with j truncated at
 $10^5$
for each
$10^5$
for each
 $\alpha$
. Figure 2 suggests that
$\alpha$
. Figure 2 suggests that
 $\alpha\mapsto I_\alpha$
is log-convex.
$\alpha\mapsto I_\alpha$
is log-convex.

Figure 2. Plot of
 $I_\alpha = I(\alpha)$
.
$I_\alpha = I(\alpha)$
.
For the asymptotic analysis of the Fisher information of the Ewens–Pitman partition ahead, we define the function
 $f_\alpha \,\colon ({-}1,\infty) \rightarrow \mathbb{R}$
for each
$f_\alpha \,\colon ({-}1,\infty) \rightarrow \mathbb{R}$
for each
 $\alpha\in (0,1)$
by
$\alpha\in (0,1)$
by
 \begin{align} \forall \, z\in ({-}1,\infty), \quad f_\alpha(z)\,:\!=\, \psi(1 + z) - \alpha \psi( 1 + \alpha z),\end{align}
\begin{align} \forall \, z\in ({-}1,\infty), \quad f_\alpha(z)\,:\!=\, \psi(1 + z) - \alpha \psi( 1 + \alpha z),\end{align}
where
 $\psi(x) = \Gamma^{\prime}(x)/\Gamma(x)$
is the digamma function. The next lemma claims some basic properties of
$\psi(x) = \Gamma^{\prime}(x)/\Gamma(x)$
is the digamma function. The next lemma claims some basic properties of
 $f_\alpha$
.
$f_\alpha$
.
Lemma 2.
The map
 $f_\alpha \,\colon ({-}1,\infty) \rightarrow \mathbb{R}$
defined by (3.2) is bijective and satisfies
$f_\alpha \,\colon ({-}1,\infty) \rightarrow \mathbb{R}$
defined by (3.2) is bijective and satisfies
 $f^{\prime}_\alpha(z)\gt 0$
and
$f^{\prime}_\alpha(z)\gt 0$
and
 $f^{\prime\prime}_\alpha(z) \lt 0$
for all
$f^{\prime\prime}_\alpha(z) \lt 0$
for all
 $z\in({-}1,\infty)$
.
$z\in({-}1,\infty)$
.
Here, it is important to emphasize that
 $f_\alpha$
is bijective. We will see later that
$f_\alpha$
is bijective. We will see later that
 $f_\alpha$
also appears in the asymptotics of the MLE for
$f_\alpha$
also appears in the asymptotics of the MLE for
 $\theta$
through its inverse function
$\theta$
through its inverse function
 $f_\alpha^{-1}$
.
$f_\alpha^{-1}$
.
Finally, we discuss the Fisher information of the Ewens–Pitman partition. We denote the logarithm of the likelihood (1.1) by
 $\ell_n(\alpha, \theta)$
, and we define
$\ell_n(\alpha, \theta)$
, and we define
 $I_{{\alpha,\alpha}}^{(n)}$
,
$I_{{\alpha,\alpha}}^{(n)}$
,
 $I_{{\alpha, \theta}}^{(n)}$
, and
$I_{{\alpha, \theta}}^{(n)}$
, and
 $I_{{\theta,\theta}}^{(n)}$
by
$I_{{\theta,\theta}}^{(n)}$
by
 \begin{align}\begin{split} I_{{\alpha,\alpha}}^{(n)} &\,:\!=\, \mathbb{E}[(\partial_\alpha \ell_n(\alpha, \theta))^2], \\ I_{{\alpha, \theta}}^{(n)} &\,:\!=\, \mathbb{E}[\partial_{\alpha} \ell_n(\alpha, \theta)\cdot \partial_{\theta} \ell_n(\alpha, \theta)], \\ I_{{\theta,\theta}}^{(n)} &\,:\!=\, \mathbb{E}[(\partial_\theta \ell_n(\alpha, \theta))^2],\end{split}\end{align}
\begin{align}\begin{split} I_{{\alpha,\alpha}}^{(n)} &\,:\!=\, \mathbb{E}[(\partial_\alpha \ell_n(\alpha, \theta))^2], \\ I_{{\alpha, \theta}}^{(n)} &\,:\!=\, \mathbb{E}[\partial_{\alpha} \ell_n(\alpha, \theta)\cdot \partial_{\theta} \ell_n(\alpha, \theta)], \\ I_{{\theta,\theta}}^{(n)} &\,:\!=\, \mathbb{E}[(\partial_\theta \ell_n(\alpha, \theta))^2],\end{split}\end{align}
i.e., they are the Fisher information obtained after n balls are partitioned according to the Ewens–Pitman partition
 $(\alpha,\theta)$
. The next proposition derives the leading terms as
$(\alpha,\theta)$
. The next proposition derives the leading terms as
 $n\to \infty$
.
$n\to \infty$
.
Proposition 2.
Let
 $I_\alpha$
be the Fisher information of the Sibuya distribution (3.1), and let
$I_\alpha$
be the Fisher information of the Sibuya distribution (3.1), and let
 $f^{\prime}_\alpha$
be the derivative of
$f^{\prime}_\alpha$
be the derivative of
 $f_\alpha$
defined by (3.2). Then the leading terms of the Fisher information are given by
$f_\alpha$
defined by (3.2). Then the leading terms of the Fisher information are given by
 \begin{align*} I_{{\alpha,\alpha}}^{(n)} \sim {n^\alpha} \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha, \quad I_{{\alpha, \theta}}^{(n)} \sim \alpha^{-1} \log n, \quad I_{{\theta,\theta}}^{(n)} \rightarrow \alpha^{-2} f^{\prime}_\alpha(\theta/\alpha) \lt+\infty,\end{align*}
\begin{align*} I_{{\alpha,\alpha}}^{(n)} \sim {n^\alpha} \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha, \quad I_{{\alpha, \theta}}^{(n)} \sim \alpha^{-1} \log n, \quad I_{{\theta,\theta}}^{(n)} \rightarrow \alpha^{-2} f^{\prime}_\alpha(\theta/\alpha) \lt+\infty,\end{align*}
where
 $\mathbb{E}[{\textsf{M}}_{\alpha, \theta}]$
is the moment of
$\mathbb{E}[{\textsf{M}}_{\alpha, \theta}]$
is the moment of
 $\textrm{GMtLf}(\alpha,\theta)$
given by (2.2).
$\textrm{GMtLf}(\alpha,\theta)$
given by (2.2).
We observe that the Fisher information of
 $\theta$
is finite, which means that
$\theta$
is finite, which means that
 $\theta$
can not be consistently estimated no matter how large n is. This agrees with the absolute mutual continuity given by Remark 2. On the other hand, the optimal convergence rate of estimators for
$\theta$
can not be consistently estimated no matter how large n is. This agrees with the absolute mutual continuity given by Remark 2. On the other hand, the optimal convergence rate of estimators for
 $\alpha$
is at most
$\alpha$
is at most
 $n^{-\alpha/2}$
, which is slower than the typical rate
$n^{-\alpha/2}$
, which is slower than the typical rate
 $n^{-1/2}$
in typical i.i.d. cases. Note in passing that the cross-term of the Fisher information matrix
$n^{-1/2}$
in typical i.i.d. cases. Note in passing that the cross-term of the Fisher information matrix
 $I_{{\alpha, \theta}}^{(n)}$
is negligible compared to
$I_{{\alpha, \theta}}^{(n)}$
is negligible compared to
 $I_{{\alpha,\alpha}}^{(n)}$
, which implies that
$I_{{\alpha,\alpha}}^{(n)}$
, which implies that
 $\alpha$
and
$\alpha$
and
 $\theta$
are asymptotically orthogonal (see Figure 3). This supports the well-known fact that the inference of
$\theta$
are asymptotically orthogonal (see Figure 3). This supports the well-known fact that the inference of
 $\theta$
has less effect on
$\theta$
has less effect on
 $\alpha$
as n increases (see [Reference Balocchi, Favaro and Naulet1, Reference Franssen and van der Vaart13]).
$\alpha$
as n increases (see [Reference Balocchi, Favaro and Naulet1, Reference Franssen and van der Vaart13]).

Figure 3. Asymptotic orthogonality of
 $\alpha$
and
$\alpha$
and
 $\theta$
$\theta$
3.2. MLE
In this section, we derive the exact asymptotic distribution of the MLE. Recall that
 $\ell_n(\alpha,\theta)$
is the logarithm of the likelihood (1.1), which can be written as
$\ell_n(\alpha,\theta)$
is the logarithm of the likelihood (1.1), which can be written as
 \begin{align} &\ell_n(\alpha, \theta) = \sum_{i=1}^{K_n-1}\log (\theta + i\alpha) - \sum_{i=1}^{n-1}\log (\theta+i) + \sum_{j=2}^n S_{n,j} \sum_{i=1}^{j-1}\log (i-\alpha).\end{align}
\begin{align} &\ell_n(\alpha, \theta) = \sum_{i=1}^{K_n-1}\log (\theta + i\alpha) - \sum_{i=1}^{n-1}\log (\theta+i) + \sum_{j=2}^n S_{n,j} \sum_{i=1}^{j-1}\log (i-\alpha).\end{align}
Then, the MLE
 $(\hat{\alpha}_n, \hat{\theta}_n)$
is defined as the maxima of
$(\hat{\alpha}_n, \hat{\theta}_n)$
is defined as the maxima of
 $\ell_n$
.
$\ell_n$
.
Definition 4. Define the MLE
 $(\hat{\alpha}_n,\hat{\theta}_n)$
by
$(\hat{\alpha}_n,\hat{\theta}_n)$
by
 \begin{align*} (\hat{\alpha}_n,\hat{\theta}_n) &\in \textrm{arg max}_{\alpha\in {(0,1)}, \theta\gt-\alpha} \ell_n(\alpha, \theta).\end{align*}
\begin{align*} (\hat{\alpha}_n,\hat{\theta}_n) &\in \textrm{arg max}_{\alpha\in {(0,1)}, \theta\gt-\alpha} \ell_n(\alpha, \theta).\end{align*}
As the parameter space
 $\{(\alpha, \theta): \alpha \in {(0,1)}, \theta\gt-\alpha\}$
is not compact, the existence and uniqueness of the MLE are not obvious. The following theorem verifies the existence and uniqueness rigorously.
$\{(\alpha, \theta): \alpha \in {(0,1)}, \theta\gt-\alpha\}$
is not compact, the existence and uniqueness of the MLE are not obvious. The following theorem verifies the existence and uniqueness rigorously.
Proposition 3.
With probability
 $1-o(1)$
, the MLE uniquely exists.
$1-o(1)$
, the MLE uniquely exists.
Now, let us define the
 $\sigma$
-field
$\sigma$
-field
 $\mathcal{F}_\infty\,:\!=\, \sigma (\cup_{n=1}^\infty \mathcal{F}_n)$
where
$\mathcal{F}_\infty\,:\!=\, \sigma (\cup_{n=1}^\infty \mathcal{F}_n)$
where
 $\mathcal{F}_n$
is the
$\mathcal{F}_n$
is the
 $\sigma$
-field generated by the partition of n balls following the Ewens–Pitman partition (see Section 2.1). Then, the exact asymptotic distribution of the MLE
$\sigma$
-field generated by the partition of n balls following the Ewens–Pitman partition (see Section 2.1). Then, the exact asymptotic distribution of the MLE
 $(\hat{\alpha}_n, \hat{\theta}_n)$
is characterized as follows.
$(\hat{\alpha}_n, \hat{\theta}_n)$
is characterized as follows.
Theorem 2.
Let
 $I_\alpha$
be the Fisher information of the Sibuya distribution defined by (3.1), and let
$I_\alpha$
be the Fisher information of the Sibuya distribution defined by (3.1), and let
 $f_\alpha^{-1}$
be the inverse of the bijective function
$f_\alpha^{-1}$
be the inverse of the bijective function
 $f_\alpha$
defined by (3.2). Then the asymptotics of
$f_\alpha$
defined by (3.2). Then the asymptotics of
 $(\hat{\alpha}_n, \hat{\theta}_n)$
is given by
$(\hat{\alpha}_n, \hat{\theta}_n)$
is given by
 \begin{align} n^{\alpha/2}(\hat{\alpha}_n - \alpha) &\to (I_\alpha {\textsf{M}}_{\alpha, \theta})^{-1/2} \cdot {N} &&(\mathcal{F}_\infty\mbox{-}stable),\end{align}
\begin{align} n^{\alpha/2}(\hat{\alpha}_n - \alpha) &\to (I_\alpha {\textsf{M}}_{\alpha, \theta})^{-1/2} \cdot {N} &&(\mathcal{F}_\infty\mbox{-}stable),\end{align}
 \begin{align} \hat{\theta}_n &\to \alpha \cdot f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta}) &&\quad\quad\,\,\,\,\,\,\,\,\, (in probability), \end{align}
\begin{align} \hat{\theta}_n &\to \alpha \cdot f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta}) &&\quad\quad\,\,\,\,\,\,\,\,\, (in probability), \end{align}
where
 ${N}\sim {N}(0,1)$
is independent of
${N}\sim {N}(0,1)$
is independent of
 $\mathcal{F}_\infty$
, and
$\mathcal{F}_\infty$
, and
 ${\textsf{M}}_{\alpha, \theta} = \lim_{n\to \infty} n^{-\alpha} K_n$
is a nondegenerate positive random variable following
${\textsf{M}}_{\alpha, \theta} = \lim_{n\to \infty} n^{-\alpha} K_n$
is a nondegenerate positive random variable following
 $\textrm{GMtLf}(\alpha,\theta)$
(see Definition 2).
$\textrm{GMtLf}(\alpha,\theta)$
(see Definition 2).
Noting that the leading term of the Fisher information about
 $\alpha$
, denoted by
$\alpha$
, denoted by
 $I_{{\alpha,\alpha}}^{(n)}$
, is given by
$I_{{\alpha,\alpha}}^{(n)}$
, is given by
 ${n^\alpha} \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha$
(see Proposition 2), (3.5) gives
${n^\alpha} \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha$
(see Proposition 2), (3.5) gives
 \begin{align} \sqrt{I_{{\alpha,\alpha}}^{(n)}} (\hat{\alpha}_{n} - \alpha) = \sqrt{I_{{\alpha,\alpha}}^{(n)}/n^\alpha} \cdot n^{\alpha/2} (\hat{\alpha}_{n} - \alpha) \to \sqrt{\mathbb{E}[{\textsf{M}}_{\alpha, \theta}]/{\textsf{M}}_{\alpha, \theta}}\cdot {N}.\end{align}
\begin{align} \sqrt{I_{{\alpha,\alpha}}^{(n)}} (\hat{\alpha}_{n} - \alpha) = \sqrt{I_{{\alpha,\alpha}}^{(n)}/n^\alpha} \cdot n^{\alpha/2} (\hat{\alpha}_{n} - \alpha) \to \sqrt{\mathbb{E}[{\textsf{M}}_{\alpha, \theta}]/{\textsf{M}}_{\alpha, \theta}}\cdot {N}.\end{align}
As
 ${\textsf{M}}_{\alpha, \theta}$
is a nondegenerate random variable, (3.7) implies that the error of the MLE normalized by the Fisher information does not converge to the standard normal but a variance mixture of centered normals. This type of asymptotics is referred to as asymptotic mixed normality, which is often observed in ‘nonergodic’ or ‘explosive’ stochastic processes (cf. [Reference Häusler and Luschgy17]).
${\textsf{M}}_{\alpha, \theta}$
is a nondegenerate random variable, (3.7) implies that the error of the MLE normalized by the Fisher information does not converge to the standard normal but a variance mixture of centered normals. This type of asymptotics is referred to as asymptotic mixed normality, which is often observed in ‘nonergodic’ or ‘explosive’ stochastic processes (cf. [Reference Häusler and Luschgy17]).
By contrast, Slutsky’s lemma for stable convergence (more precisely, (B) of Lemma 1 with
 $X_n = \sqrt{n^{\alpha}I_\alpha}(\hat{\alpha}_{n} - \alpha)$
and
$X_n = \sqrt{n^{\alpha}I_\alpha}(\hat{\alpha}_{n} - \alpha)$
and
 $Y_n = \sqrt{K_n/n^\alpha}$
) results in
$Y_n = \sqrt{K_n/n^\alpha}$
) results in
 \begin{align*} \sqrt{K_n I_\alpha } (\hat{\alpha}_{n} - \alpha) = \sqrt{K_n/n^\alpha} \cdot \sqrt{n^\alpha I_\alpha} (\hat{\alpha}_{n} - \alpha) \to \sqrt{{\textsf{M}}_{\alpha, \theta}} \cdot {N}/\sqrt{{\textsf{M}}_{\alpha, \theta}} = {N}.\end{align*}
\begin{align*} \sqrt{K_n I_\alpha } (\hat{\alpha}_{n} - \alpha) = \sqrt{K_n/n^\alpha} \cdot \sqrt{n^\alpha I_\alpha} (\hat{\alpha}_{n} - \alpha) \to \sqrt{{\textsf{M}}_{\alpha, \theta}} \cdot {N}/\sqrt{{\textsf{M}}_{\alpha, \theta}} = {N}.\end{align*}
We observe that the randomness of the variance is now canceled out, and the limit is the standard normal. Here, the number of blocks
 $K_n$
corresponds to the sample size in typical i.i.d. cases and
$K_n$
corresponds to the sample size in typical i.i.d. cases and
 $I_\alpha$
plays the role of the Fisher information per block. Furthermore, it immediately follows that
$I_\alpha$
plays the role of the Fisher information per block. Furthermore, it immediately follows that
 $\big[\hat{\alpha}_n \pm {1.96}/{\sqrt{I_{\hat{\alpha}_n} K_n}}\,\big]$
is an approximate 95% confidence interval for
$\big[\hat{\alpha}_n \pm {1.96}/{\sqrt{I_{\hat{\alpha}_n} K_n}}\,\big]$
is an approximate 95% confidence interval for
 $\alpha$
. We reiterate these observations as a corollary.
$\alpha$
. We reiterate these observations as a corollary.
Corollary 1.
Let
 $I_\alpha$
be the Fisher information of the Sibuya distribution defined by (3.1), and let
$I_\alpha$
be the Fisher information of the Sibuya distribution defined by (3.1), and let
 $K_n$
be the number of blocks generated after n balls are partitioned. Then, in the same setting as Theorem 2, the following mixing convergence holds:
$K_n$
be the number of blocks generated after n balls are partitioned. Then, in the same setting as Theorem 2, the following mixing convergence holds:
 \begin{align} \sqrt{I_\alpha K_n} \cdot (\hat{\alpha}_{n} - \alpha) \rightarrow {N} \quad (\mathcal{F}_\infty-mixing).\end{align}
\begin{align} \sqrt{I_\alpha K_n} \cdot (\hat{\alpha}_{n} - \alpha) \rightarrow {N} \quad (\mathcal{F}_\infty-mixing).\end{align}
Therefore, for any
 $p\in (0,1)$
, letting
$p\in (0,1)$
, letting
 $ \tau_{1-p/2}$
be the
$ \tau_{1-p/2}$
be the
 $(1-p/2)$
-quantile of standard normal, the interval
$(1-p/2)$
-quantile of standard normal, the interval
 $\hat{I}_n\,:\!=\, \big[\hat{\alpha}_n \pm \tau_{1-p/2}/{\sqrt{I_{\hat{\alpha}_n} K_n}}\,\big]$
is an approximate
$\hat{I}_n\,:\!=\, \big[\hat{\alpha}_n \pm \tau_{1-p/2}/{\sqrt{I_{\hat{\alpha}_n} K_n}}\,\big]$
is an approximate
 $100(1-p)\%$
confidence interval in the sense of
$100(1-p)\%$
confidence interval in the sense of
 $\lim_{n\to+\infty} \Pr\bigl(\alpha\in \hat{I}_n \bigr) = 1-p$
.
$\lim_{n\to+\infty} \Pr\bigl(\alpha\in \hat{I}_n \bigr) = 1-p$
.
Finally, we discuss the limit law
 $\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
of
$\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
of
 $\hat{\theta}_n$
in Theorem 2. We claim that the limit distribution of the MLE
$\hat{\theta}_n$
in Theorem 2. We claim that the limit distribution of the MLE
 $\hat{\theta}_n$
of
$\hat{\theta}_n$
of
 $\theta$
is positively biased. The key observation is the strict convexity of
$\theta$
is positively biased. The key observation is the strict convexity of
 $f_\alpha^{-1}$
. Indeed,
$f_\alpha^{-1}$
. Indeed,
 $f_\alpha$
is strictly concave and strictly increasing (see Lemma 2), so
$f_\alpha$
is strictly concave and strictly increasing (see Lemma 2), so
 $f_\alpha^{-1}$
is strictly convex. Since
$f_\alpha^{-1}$
is strictly convex. Since
 ${\textsf{M}}_{\alpha, \theta}\sim \textrm{GMtLf}(\alpha,\theta)$
is not constant, Jensen’s inequality gives the strict inequality:
${\textsf{M}}_{\alpha, \theta}\sim \textrm{GMtLf}(\alpha,\theta)$
is not constant, Jensen’s inequality gives the strict inequality:
 $$ \mathbb{E}\big[\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})\big] \gt \alpha f_\alpha^{-1} (\mathbb{E}[\log {\textsf{M}}_{\alpha, \theta}]), $$
$$ \mathbb{E}\big[\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})\big] \gt \alpha f_\alpha^{-1} (\mathbb{E}[\log {\textsf{M}}_{\alpha, \theta}]), $$
where
 $\mathbb{E}$
is the expectation with respect to
$\mathbb{E}$
is the expectation with respect to
 ${\textsf{M}}_{\alpha, \theta}\sim \textrm{GMtLf}(\alpha,\theta)$
. Since
${\textsf{M}}_{\alpha, \theta}\sim \textrm{GMtLf}(\alpha,\theta)$
. Since
 $\epsilon \mapsto (c^\epsilon-1)/\epsilon$
is increasing for any
$\epsilon \mapsto (c^\epsilon-1)/\epsilon$
is increasing for any
 $c\gt 0$
, the monotone convergence theorem yields
$c\gt 0$
, the monotone convergence theorem yields
 \begin{align} \mathbb{E}[\log {\textsf{M}}_{\alpha, \theta}] =\mathbb{E}\big[\lim_{\epsilon\rightarrow 0} \epsilon^{-1} (({\textsf{M}}_{\alpha, \theta})^\epsilon - 1)\big] = \lim_{\epsilon\rightarrow 0} \mathbb{E}\big[\epsilon^{-1}(({\textsf{M}}_{\alpha, \theta})^\epsilon-1)\big]. \end{align}
\begin{align} \mathbb{E}[\log {\textsf{M}}_{\alpha, \theta}] =\mathbb{E}\big[\lim_{\epsilon\rightarrow 0} \epsilon^{-1} (({\textsf{M}}_{\alpha, \theta})^\epsilon - 1)\big] = \lim_{\epsilon\rightarrow 0} \mathbb{E}\big[\epsilon^{-1}(({\textsf{M}}_{\alpha, \theta})^\epsilon-1)\big]. \end{align}
By the moment formula of
 ${\textsf{M}}_{\alpha, \theta}\sim \textrm{GMtLf}(\alpha,\theta)$
in (2.2), we have that
${\textsf{M}}_{\alpha, \theta}\sim \textrm{GMtLf}(\alpha,\theta)$
in (2.2), we have that

Combining the above display together, we are left with
 \begin{align*} \mathbb{E}\big[\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})\big] &\gt\alpha f_\alpha^{-1} (\mathbb{E}[\log {\textsf{M}}_{\alpha, \theta}])\\ &= \alpha f_\alpha^{-1} \Big(\lim_{\epsilon\rightarrow 0}\mathbb{E}\big[\epsilon^{-1}(({\textsf{M}}_{\alpha, \theta})^\epsilon-1)\big]\Big)\\ &= \alpha f_\alpha^{-1} (\,f_\alpha(\theta/\alpha))\\ &= \theta. \end{align*}
\begin{align*} \mathbb{E}\big[\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})\big] &\gt\alpha f_\alpha^{-1} (\mathbb{E}[\log {\textsf{M}}_{\alpha, \theta}])\\ &= \alpha f_\alpha^{-1} \Big(\lim_{\epsilon\rightarrow 0}\mathbb{E}\big[\epsilon^{-1}(({\textsf{M}}_{\alpha, \theta})^\epsilon-1)\big]\Big)\\ &= \alpha f_\alpha^{-1} (\,f_\alpha(\theta/\alpha))\\ &= \theta. \end{align*}
We present the result obtained above in the following proposition.
Proposition 4.
The limit distribution of
 $\hat{\theta}_n$
is biased, i.e.,
$\hat{\theta}_n$
is biased, i.e.,
 $\mathbb{E}\big[\alpha \cdot f_{\alpha}^{-1}(\log{\textsf{M}}_{\alpha, \theta})\big]\gt \theta$
.
$\mathbb{E}\big[\alpha \cdot f_{\alpha}^{-1}(\log{\textsf{M}}_{\alpha, \theta})\big]\gt \theta$
.
In Section 4, we will plot the histogram
 $\alpha f_{\alpha}^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
by sampling
$\alpha f_{\alpha}^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
by sampling
 ${\textsf{M}}_{\alpha, \theta} \sim \textrm{GMtLf}(\alpha,\theta)$
and confirm the positive bias
${\textsf{M}}_{\alpha, \theta} \sim \textrm{GMtLf}(\alpha,\theta)$
and confirm the positive bias
 $\mathbb{E}\big[\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})\big]\gt \theta$
.
$\mathbb{E}\big[\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})\big]\gt \theta$
.
3.3. Quasi-maximum-likelihood estimator
In the previous section, we considered the simultaneous estimation of
 $\alpha$
and
$\alpha$
and
 $\theta$
. However, as we mentioned in Section 1, the estimation of
$\theta$
. However, as we mentioned in Section 1, the estimation of
 $\alpha$
is of more interest than that of
$\alpha$
is of more interest than that of
 $\theta$
, and
$\theta$
, and
 $\theta$
is sometimes regarded as a nuisance parameter in practice. In this section, we consider the MLE of
$\theta$
is sometimes regarded as a nuisance parameter in practice. In this section, we consider the MLE of
 $\alpha$
with
$\alpha$
with
 $\theta$
being misspecified. Considering the asymptotic orthogonality of
$\theta$
being misspecified. Considering the asymptotic orthogonality of
 $(\alpha, \theta)$
(recall Proposition 2), the MLE of
$(\alpha, \theta)$
(recall Proposition 2), the MLE of
 $\alpha$
with
$\alpha$
with
 $\theta$
misspecified is expected to have the same asymptotic law as the MLE with
$\theta$
misspecified is expected to have the same asymptotic law as the MLE with
 $\theta$
jointly estimated. In this section, we make these arguments more rigorous: we claim that they are identical up to the order of
$\theta$
jointly estimated. In this section, we make these arguments more rigorous: we claim that they are identical up to the order of
 $n^{-\alpha/2}$
, but they differ in higher order (see Figure 3). Furthermore, we demonstrate that the MLE with
$n^{-\alpha/2}$
, but they differ in higher order (see Figure 3). Furthermore, we demonstrate that the MLE with
 $\theta$
jointly estimated is adaptive to the scale of the nuisance
$\theta$
jointly estimated is adaptive to the scale of the nuisance
 $\theta$
.
$\theta$
.
First, we define the quasi-maximum-likelihood estimator (QMLE) as the MLE of
 $\alpha$
with
$\alpha$
with
 $\theta$
being misspecified.
$\theta$
being misspecified.
Definition 5. (QMLE.) For each
 $\theta_{\textsf{plug}}\in(\!-\alpha,\infty)$
, we define the QMLE with plug-in
$\theta_{\textsf{plug}}\in(\!-\alpha,\infty)$
, we define the QMLE with plug-in
 $\theta_{\textsf{plug}}$
, denoted by
$\theta_{\textsf{plug}}$
, denoted by
 $\hat{\alpha}_{n,\theta_{\textsf{plug}}}$
, as
$\hat{\alpha}_{n,\theta_{\textsf{plug}}}$
, as
 \begin{align} \hat{\alpha}_{n,\theta_{\textsf{plug}}} &\in \underset{\alpha \in ((\!-\theta_{\textsf{plug}}) \vee 0, 1)}{\textrm{arg max}} \ \ell_n(\alpha, \theta_{\textsf{plug}}), \end{align}
\begin{align} \hat{\alpha}_{n,\theta_{\textsf{plug}}} &\in \underset{\alpha \in ((\!-\theta_{\textsf{plug}}) \vee 0, 1)}{\textrm{arg max}} \ \ell_n(\alpha, \theta_{\textsf{plug}}), \end{align}
where
 $\ell_n$
is the function defined by (3.4).
$\ell_n$
is the function defined by (3.4).
Note that the true parameter
 $(\alpha, \theta)$
must satisfy
$(\alpha, \theta)$
must satisfy
 $\alpha\in (0,1)$
and
$\alpha\in (0,1)$
and
 $\theta+\alpha\gt 0$
, so for each
$\theta+\alpha\gt 0$
, so for each
 $\theta\gt-1$
,
$\theta\gt-1$
,
 $\alpha$
belongs to the subset
$\alpha$
belongs to the subset
 $((\!-\theta)\vee 0, 1)$
of (0,1). Thus, the definition of the QMLE, i.e.,
$((\!-\theta)\vee 0, 1)$
of (0,1). Thus, the definition of the QMLE, i.e.,
 $\textrm{arg max}_{\alpha\in (\!-(\theta_{\textsf{plug}})\vee 0, 1)}$
, is natural, and it contains the true
$\textrm{arg max}_{\alpha\in (\!-(\theta_{\textsf{plug}})\vee 0, 1)}$
, is natural, and it contains the true
 $\alpha$
as long as we set
$\alpha$
as long as we set
 $\theta_{\textsf{plug}}\ge 0$
.
$\theta_{\textsf{plug}}\ge 0$
.
We emphasize that the QMLE
 $\hat{\alpha}_{n, \theta} = \hat{\alpha}_{n,\theta_{\textsf{plug}}=\theta}$
with
$\hat{\alpha}_{n, \theta} = \hat{\alpha}_{n,\theta_{\textsf{plug}}=\theta}$
with
 $\theta_{\textsf{plug}}$
being the true
$\theta_{\textsf{plug}}$
being the true
 $\theta$
is just the MLE of
$\theta$
is just the MLE of
 $\alpha$
with
$\alpha$
with
 $\theta$
known. From now on, we regard this as an oracle estimator of
$\theta$
known. From now on, we regard this as an oracle estimator of
 $\alpha$
, and we will compare the QMLE
$\alpha$
, and we will compare the QMLE
 $\hat{\alpha}_{n, \theta_{\textsf{plug}}}$
(with
$\hat{\alpha}_{n, \theta_{\textsf{plug}}}$
(with
 $\theta_{\textsf{plug}} \neq \theta$
) and the MLE
$\theta_{\textsf{plug}} \neq \theta$
) and the MLE
 $\hat{\alpha}_n$
in Definition 4 (where
$\hat{\alpha}_n$
in Definition 4 (where
 $\theta$
is jointly estimated) based on their error to the oracle
$\theta$
is jointly estimated) based on their error to the oracle
 $\hat{\alpha}_{n, \theta}$
.
$\hat{\alpha}_{n, \theta}$
.
The following propositions claim that
 $\hat{\alpha}_{n,\theta_{\textsf{plug}}}$
uniquely exists and has the same asymptotic distribution as
$\hat{\alpha}_{n,\theta_{\textsf{plug}}}$
uniquely exists and has the same asymptotic distribution as
 $\hat{\alpha}_n$
.
$\hat{\alpha}_n$
.
Proposition 5.
For any
 $\theta_{\textsf{plug}}\gt-\alpha$
, with probability
$\theta_{\textsf{plug}}\gt-\alpha$
, with probability
 $1-o(1)$
, the QMLE
$1-o(1)$
, the QMLE
 $\hat{\alpha}_{n,\theta_{\textsf{plug}}}$
uniquely exists.
$\hat{\alpha}_{n,\theta_{\textsf{plug}}}$
uniquely exists.
Proposition 6.
Equation (3.5) of Theorem 2 holds for QMLE
 $\hat{\alpha}_{n, \theta_{\textsf{plug}}}$
, i.e.,
$\hat{\alpha}_{n, \theta_{\textsf{plug}}}$
, i.e.,
 \begin{align*} n^{\alpha/2}(\hat{\alpha}_{n, \theta_{\textsf{plug}}} - \alpha) &\to (I_\alpha {\textsf{M}}_{\alpha, \theta})^{-1/2} \cdot {N} \quad (\mathcal{F}_\infty\mbox{-}stable).\end{align*}
\begin{align*} n^{\alpha/2}(\hat{\alpha}_{n, \theta_{\textsf{plug}}} - \alpha) &\to (I_\alpha {\textsf{M}}_{\alpha, \theta})^{-1/2} \cdot {N} \quad (\mathcal{F}_\infty\mbox{-}stable).\end{align*}
Proposition 6 implies that the QMLE
 $\hat{\alpha}_{n, \theta_{\textsf{plug}}}$
and
$\hat{\alpha}_{n, \theta_{\textsf{plug}}}$
and
 $\hat{\alpha}_{n}$
are asymptotically equivalent on the scale of
$\hat{\alpha}_{n}$
are asymptotically equivalent on the scale of
 $n^{-\alpha/2}$
. With this, it appears that jointly estimating
$n^{-\alpha/2}$
. With this, it appears that jointly estimating
 $\alpha$
and
$\alpha$
and
 $\theta$
is of no use. However, the next proposition implies that they differ on the order of
$\theta$
is of no use. However, the next proposition implies that they differ on the order of
 $n^{-\alpha} \log n$
, and that
$n^{-\alpha} \log n$
, and that
 $\hat{\alpha}_n$
is close to the oracle
$\hat{\alpha}_n$
is close to the oracle
 $\hat{\alpha}_{n, \theta}$
regardless of the scale of
$\hat{\alpha}_{n, \theta}$
regardless of the scale of
 $\theta$
.
$\theta$
.
Proposition 7.
For the QMLE
 $\hat{\alpha}_{n,\theta_{\textsf{plug}}}$
and the MLE
$\hat{\alpha}_{n,\theta_{\textsf{plug}}}$
and the MLE
 $\hat{\alpha}_n$
, their asymptotic errors to the oracle
$\hat{\alpha}_n$
, their asymptotic errors to the oracle
 $\hat{\alpha}_{n,\theta_{\textsf{plug}}=\theta}$
are given by
$\hat{\alpha}_{n,\theta_{\textsf{plug}}=\theta}$
are given by
 \begin{align} \frac{n^\alpha}{\log n}(\hat{\alpha}_{n,\theta_{\textsf{plug}}} - \hat{\alpha}_{n, \theta}) &\to^p -\frac{\theta_{\textsf{plug}}- \theta}{\alpha I_\alpha {\textsf{M}}_{\alpha, \theta}} \qquad \text{for all $\theta_{\textsf{plug}} \in (\!-\alpha, \infty)$},\end{align}
\begin{align} \frac{n^\alpha}{\log n}(\hat{\alpha}_{n,\theta_{\textsf{plug}}} - \hat{\alpha}_{n, \theta}) &\to^p -\frac{\theta_{\textsf{plug}}- \theta}{\alpha I_\alpha {\textsf{M}}_{\alpha, \theta}} \qquad \text{for all $\theta_{\textsf{plug}} \in (\!-\alpha, \infty)$},\end{align}
 \begin{align} \frac{n^\alpha}{\log n}(\hat{\alpha}_n - \hat{\alpha}_{n,\theta}) &\to^p -\frac{\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta}) - \theta}{\alpha I_\alpha {\textsf{M}}_{\alpha, \theta}}, \end{align}
\begin{align} \frac{n^\alpha}{\log n}(\hat{\alpha}_n - \hat{\alpha}_{n,\theta}) &\to^p -\frac{\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta}) - \theta}{\alpha I_\alpha {\textsf{M}}_{\alpha, \theta}}, \end{align}
where
 ${\textsf{M}}_{\alpha, \theta}=\lim_{n\to\infty} n^{-\alpha}K_n$
,
${\textsf{M}}_{\alpha, \theta}=\lim_{n\to\infty} n^{-\alpha}K_n$
,
 $I_\alpha$
is defined by (3.1), and
$I_\alpha$
is defined by (3.1), and
 $f_\alpha^{-1}$
is the inverse of
$f_\alpha^{-1}$
is the inverse of
 $f_\alpha$
defined by (3.2).
$f_\alpha$
defined by (3.2).
We observe that the limit error in (3.11) depends on the ‘misspecification error’
 $\theta_{\textsf{plug}}- \theta$
, while the corresponding term in (3.12) is replaced by
$\theta_{\textsf{plug}}- \theta$
, while the corresponding term in (3.12) is replaced by
 $\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})-\theta$
. Considering that
$\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})-\theta$
. Considering that
 $\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
is distributed around
$\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
is distributed around
 $\theta$
as in Figure 4, we expect that the error of
$\theta$
as in Figure 4, we expect that the error of
 $\hat{\alpha}_{n, \theta_{\textsf{plug}}}$
is larger than
$\hat{\alpha}_{n, \theta_{\textsf{plug}}}$
is larger than
 $\hat{\alpha}_{n}$
if the plug-in
$\hat{\alpha}_{n}$
if the plug-in
 $\theta_{\textsf{plug}}$
is taken far away from the true value
$\theta_{\textsf{plug}}$
is taken far away from the true value
 $\theta$
by the users. We prove in Section 4 that these errors significantly affect coverage and mean squared error (MSE).
$\theta$
by the users. We prove in Section 4 that these errors significantly affect coverage and mean squared error (MSE).

Figure 4. Histogram of
 $\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
with a sample size of
$\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
with a sample size of
 $10^6$
. The solid line is the probability density function of
$10^6$
. The solid line is the probability density function of
 ${N}(\theta, \alpha^2 /f_\alpha^{\prime}(\theta/\alpha))$
, where the variance is the inverse of the asymptotic Fisher information; that is,
${N}(\theta, \alpha^2 /f_\alpha^{\prime}(\theta/\alpha))$
, where the variance is the inverse of the asymptotic Fisher information; that is,
 $\alpha^{-2} f_\alpha^{\prime}(\theta/\alpha) = \lim_{n\to+\infty}\mathbb{E}[(\partial_{\theta} \ell_n(\alpha,\theta))^2]$
$\alpha^{-2} f_\alpha^{\prime}(\theta/\alpha) = \lim_{n\to+\infty}\mathbb{E}[(\partial_{\theta} \ell_n(\alpha,\theta))^2]$
3.4. Application to network data analysis
Here, we discuss the application of Corollary 1 to network data analysis. In [Reference Crane5, Reference Crane and Dempsey6], the authors propose the ‘Hollywood process’, a statistical model for network data. This is a stochastic process over growing networks that sequentially attach edges to vertices in the same manner as the Ewens–Pitman partition, where n is the total degree,
 $K_n$
is the number of vertices, and
$K_n$
is the number of vertices, and
 $S_{n,j}$
is the number of vertices with degree j. They define that a growing network has sparsity if and only if
$S_{n,j}$
is the number of vertices with degree j. They define that a growing network has sparsity if and only if
 $\lim_{n\to\infty} n K_n^{-\mu} = 0$
, where
$\lim_{n\to\infty} n K_n^{-\mu} = 0$
, where
 $\mu$
is the degree per vertex, e.g.,
$\mu$
is the degree per vertex, e.g.,
 $\mu = 2$
when the network is bivariate. Using the asymptotics
$\mu = 2$
when the network is bivariate. Using the asymptotics
 $n^{-\alpha} K_n\to {\textsf{M}}_{\alpha, \theta}\gt 0$
(a.s.) by Theorem 1, the authors claim that the Hollywood process has sparsity if and only if
$n^{-\alpha} K_n\to {\textsf{M}}_{\alpha, \theta}\gt 0$
(a.s.) by Theorem 1, the authors claim that the Hollywood process has sparsity if and only if
 $\mu^{-1} \lt \alpha \lt1$
.
$\mu^{-1} \lt \alpha \lt1$
.
Now, we construct a hypothesis testing of the sparsity based on Corollary 1. We define the null hypothesis
 $H_0$
and the alternative hypothesis
$H_0$
and the alternative hypothesis
 $H_1$
by
$H_1$
by
 \begin{align*} \text{(not sparse) } H_0: 0\lt\alpha\leq \mu^{-1}, \quad \text{(sparse) } H_1: \mu^{-1} \lt \alpha \lt 1.\end{align*}
\begin{align*} \text{(not sparse) } H_0: 0\lt\alpha\leq \mu^{-1}, \quad \text{(sparse) } H_1: \mu^{-1} \lt \alpha \lt 1.\end{align*}
For a constant
 $\delta \in (0, 1)$
, we reject the null
$\delta \in (0, 1)$
, we reject the null
 $H_0$
if
$H_0$
if
 \begin{align*}\sqrt{I_{\hat{\alpha}_n} K_n} (\hat{\alpha}_n - \mu^{-1})\gt \Phi^{-1}(1-\delta),\end{align*}
\begin{align*}\sqrt{I_{\hat{\alpha}_n} K_n} (\hat{\alpha}_n - \mu^{-1})\gt \Phi^{-1}(1-\delta),\end{align*}
where
 $\Phi$
is the cumulative distribution function (CDF) of the standard normal. Then the significance level of this testing is
$\Phi$
is the cumulative distribution function (CDF) of the standard normal. Then the significance level of this testing is
 $\delta$
, since the probability of rejecting the null when
$\delta$
, since the probability of rejecting the null when
 $\alpha \leq \mu^{-1}$
is upper bounded by
$\alpha \leq \mu^{-1}$
is upper bounded by
 $\Pr\big(\sqrt{I_{\hat{\alpha}_n} K_n} (\hat{\alpha}_n - \alpha)\gt \Phi^{-1}(1-\delta)\big)$
, which converges to
$\Pr\big(\sqrt{I_{\hat{\alpha}_n} K_n} (\hat{\alpha}_n - \alpha)\gt \Phi^{-1}(1-\delta)\big)$
, which converges to
 $\delta$
from Corollary 1.
$\delta$
from Corollary 1.
4. Numerical Simulation
First, we visualize the limit law
 $\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
of the MLE
$\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
of the MLE
 $\hat{\theta}_n$
. We sample
$\hat{\theta}_n$
. We sample
 ${\textsf{M}}_{\alpha, \theta} \sim \textrm{GMtLf}(\alpha,\theta)$
using the rejection algorithm proposed by [Reference Devroye8] with a sample size of
${\textsf{M}}_{\alpha, \theta} \sim \textrm{GMtLf}(\alpha,\theta)$
using the rejection algorithm proposed by [Reference Devroye8] with a sample size of
 $10^6$
and plot the histogram of
$10^6$
and plot the histogram of
 $\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
in Figure 4. We observe that the mean of
$\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
in Figure 4. We observe that the mean of
 $\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
is larger than
$\alpha f_\alpha^{-1}(\log {\textsf{M}}_{\alpha, \theta})$
is larger than
 $\theta$
, which verifies Proposition 4. We also plot the probability density function of
$\theta$
, which verifies Proposition 4. We also plot the probability density function of
 ${N}(\theta, \alpha^2 /f_\alpha^{\prime}(\theta/\alpha))$
, where the variance
${N}(\theta, \alpha^2 /f_\alpha^{\prime}(\theta/\alpha))$
, where the variance
 $\alpha^2/f_\alpha^{\prime}(\theta/\alpha)$
is the inverse of
$\alpha^2/f_\alpha^{\prime}(\theta/\alpha)$
is the inverse of
 $\lim_{n\to+\infty} \mathbb{E}[(\partial_{\theta} \ell_n(\alpha,\theta))^2]$
, i.e., the limit of the Fisher information about
$\lim_{n\to+\infty} \mathbb{E}[(\partial_{\theta} \ell_n(\alpha,\theta))^2]$
, i.e., the limit of the Fisher information about
 $\theta$
(see Proposition 2). Note that this normal distribution is a naive guess by standard asymptotic statistics. We observe that the limit law is close to the normal distribution
$\theta$
(see Proposition 2). Note that this normal distribution is a naive guess by standard asymptotic statistics. We observe that the limit law is close to the normal distribution
 ${N}(\theta, \alpha^2 /f_\alpha^{\prime}(\theta/\alpha))$
when
${N}(\theta, \alpha^2 /f_\alpha^{\prime}(\theta/\alpha))$
when
 $\alpha$
is small or
$\alpha$
is small or
 $\theta$
is large.
$\theta$
is large.
Next, we visualize the asymptotic mixed normality of the MLE
 $\hat\alpha_{n}$
by plotting the empirical CDF. Here, we plot two CDFs using different normalization; the CDF of
$\hat\alpha_{n}$
by plotting the empirical CDF. Here, we plot two CDFs using different normalization; the CDF of
 $\sqrt{n^\alpha \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha} (\hat\alpha_{n}-\alpha)$
and the CDF of
$\sqrt{n^\alpha \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha} (\hat\alpha_{n}-\alpha)$
and the CDF of
 $\sqrt{K_n I_\alpha} (\hat\alpha_{n}-\alpha)$
. Note that
$\sqrt{K_n I_\alpha} (\hat\alpha_{n}-\alpha)$
. Note that
 $n^\alpha \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha$
is the leading term of the Fisher information about
$n^\alpha \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha$
is the leading term of the Fisher information about
 $\alpha$
, i.e.,
$\alpha$
, i.e.,
 $\mathbb{E}[(\partial_{\alpha} \ell_n(\alpha,\theta))^2] = n^\alpha \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha + o(n^\alpha)$
(see Proposition 2). These empirical CDFs are computed from
$\mathbb{E}[(\partial_{\alpha} \ell_n(\alpha,\theta))^2] = n^\alpha \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha + o(n^\alpha)$
(see Proposition 2). These empirical CDFs are computed from
 $10^5$
Monte Carlo simulations and are plotted after subtracting the CDF of N(0,1). Figure 5 implies that the CDF of
$10^5$
Monte Carlo simulations and are plotted after subtracting the CDF of N(0,1). Figure 5 implies that the CDF of
 $\sqrt{n^\alpha \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha} (\hat\alpha_{n}-\alpha)$
does not converge to the CDF of N(0,1), while the CDF of
$\sqrt{n^\alpha \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha} (\hat\alpha_{n}-\alpha)$
does not converge to the CDF of N(0,1), while the CDF of
 $\sqrt{K_n I_\alpha} (\hat\alpha_{n}-\alpha)$
does converge to the CDF of N(0,1). These numerical simulations support Theorem 2 and Corollary 1.
$\sqrt{K_n I_\alpha} (\hat\alpha_{n}-\alpha)$
does converge to the CDF of N(0,1). These numerical simulations support Theorem 2 and Corollary 1.

Figure 5. The visualization of the asymptotic mixed normality. Left panel: Plot of the difference between the CDF of
 $\sqrt{n^\alpha \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha}(\hat{\alpha_{n}}-\alpha)$
to the CDF of N(0,1). Right panel: Plot of the difference between the CDF of
$\sqrt{n^\alpha \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] I_\alpha}(\hat{\alpha_{n}}-\alpha)$
to the CDF of N(0,1). Right panel: Plot of the difference between the CDF of
 $\sqrt{K_n I_\alpha}(\hat{\alpha}_n-\alpha)$
to the CDF of N(0,1). Simulation setting:
$\sqrt{K_n I_\alpha}(\hat{\alpha}_n-\alpha)$
to the CDF of N(0,1). Simulation setting:
 $\alpha=0.8$
,
$\alpha=0.8$
,
 $\theta=0$
,
$\theta=0$
,
 $10^5$
Monte Carlo simulations.
$10^5$
Monte Carlo simulations.
Finally, we compare
 $\hat{\alpha}_{n, \theta}$
(the MLE with
$\hat{\alpha}_{n, \theta}$
(the MLE with
 $\theta$
known),
$\theta$
known),
 $\hat{\alpha}_{n,0}$
(the QMLE with
$\hat{\alpha}_{n,0}$
(the QMLE with
 $\theta_{\textsf{plug}} = 0$
), and
$\theta_{\textsf{plug}} = 0$
), and
 $\hat{\alpha}_n$
(the MLE with
$\hat{\alpha}_n$
(the MLE with
 $\theta$
jointly estimated) based on the MSE and the coverage. Here, we sequentially generate the random partition and compute these estimators as n increases from
$\theta$
jointly estimated) based on the MSE and the coverage. Here, we sequentially generate the random partition and compute these estimators as n increases from
 $n=2^7$
to
$n=2^7$
to
 $2^{17}$
. This process is replicated
$2^{17}$
. This process is replicated
 $10^4$
times, and we calculate the MSE and the coverage of confidence interval
$10^4$
times, and we calculate the MSE and the coverage of confidence interval
 $\big[\bar{\alpha}_n + \frac{1.96}{\sqrt{K_n I_{\bar{\alpha}_n}}}\big]$
for each
$\big[\bar{\alpha}_n + \frac{1.96}{\sqrt{K_n I_{\bar{\alpha}_n}}}\big]$
for each
 $\bar{\alpha}_n = \hat{\alpha}_{n, \theta}, \hat{\alpha}_{n, 0}, \hat{\alpha}_n$
. The results are plotted in Figures 6 and 7. As n increases, the MSE decreases, and the coverage converges to
$\bar{\alpha}_n = \hat{\alpha}_{n, \theta}, \hat{\alpha}_{n, 0}, \hat{\alpha}_n$
. The results are plotted in Figures 6 and 7. As n increases, the MSE decreases, and the coverage converges to
 $0.95$
. When n is small and the plugin error
$0.95$
. When n is small and the plugin error
 $|0 - \theta| = |\theta|$
is large, the MSE and the coverage of the QMLE
$|0 - \theta| = |\theta|$
is large, the MSE and the coverage of the QMLE
 $\hat{\alpha}_{n, 0}$
are significantly large and small, respectively. In contrast,
$\hat{\alpha}_{n, 0}$
are significantly large and small, respectively. In contrast,
 $\hat{\alpha}_n$
is robust to the scale of
$\hat{\alpha}_n$
is robust to the scale of
 $\theta$
. These observations support Proposition 7.
$\theta$
. These observations support Proposition 7.

Figure 6. Plots of the MSE of the MLE with
 $\theta$
known, the MLE with
$\theta$
known, the MLE with
 $\theta$
unknown (estimated), and the QMLE with
$\theta$
unknown (estimated), and the QMLE with
 $\theta_{\textsf{plug}}=0$
. We fixed
$\theta_{\textsf{plug}}=0$
. We fixed
 $\alpha$
to
$\alpha$
to
 $0.6$
and ran
$0.6$
and ran
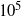 $10^5$
Monte Carlo simulations. Note that when
$10^5$
Monte Carlo simulations. Note that when
 $\theta=0$
, the QMLE with
$\theta=0$
, the QMLE with
 $\theta_{\textsf{plug}}=0$
coincides with the MLE with
$\theta_{\textsf{plug}}=0$
coincides with the MLE with
 $\theta$
known
$\theta$
known

Figure 7. Plots of the coverage of the MLE with
 $\theta$
known, the MLE with
$\theta$
known, the MLE with
 $\theta$
unknown (estimated), and the QMLE with
$\theta$
unknown (estimated), and the QMLE with
 $\theta_{\textsf{plug}}=0$
. We fixed
$\theta_{\textsf{plug}}=0$
. We fixed
 $\alpha$
to
$\alpha$
to
 $0.6$
and ran
$0.6$
and ran
 $10^5$
Monte Carlo simulations. Note that when
$10^5$
Monte Carlo simulations. Note that when
 $\theta=0$
, the QMLE with
$\theta=0$
, the QMLE with
 $\theta_{\textsf{plug}}=0$
coincides with the MLE with
$\theta_{\textsf{plug}}=0$
coincides with the MLE with
 $\theta$
known
$\theta$
known
5. Proof Highlights
In this section, we outline the fundamental idea behind the proofs of theorems in Section 3. First, we consider the QMLE
 $\hat{\alpha}_{n,0}$
with
$\hat{\alpha}_{n,0}$
with
 $\theta_{\textsf{plug}}=0$
for simplicity. Equation (3.4) with
$\theta_{\textsf{plug}}=0$
for simplicity. Equation (3.4) with
 $\theta=0$
implies that the log-likelihood with parameter
$\theta=0$
implies that the log-likelihood with parameter
 $(\alpha,\theta)=(\alpha,0)$
is given by
$(\alpha,\theta)=(\alpha,0)$
is given by
 \begin{align*}\ell_n(\alpha, 0) = (K_n-1) \log \alpha + \sum_{j=1}^n S_{n,j} \sum_{i=1}^{j-1}\log (i-\alpha) \quad \text{for all $\alpha\gt 0$},\end{align*}
\begin{align*}\ell_n(\alpha, 0) = (K_n-1) \log \alpha + \sum_{j=1}^n S_{n,j} \sum_{i=1}^{j-1}\log (i-\alpha) \quad \text{for all $\alpha\gt 0$},\end{align*}
where
 $S_{n,j}$
is the number of blocks of size j and
$S_{n,j}$
is the number of blocks of size j and
 $K_n$
is the number of nonempty blocks. Then, the score function
$K_n$
is the number of nonempty blocks. Then, the score function
 $\partial_\alpha\ell_n(\alpha, 0)$
is given by
$\partial_\alpha\ell_n(\alpha, 0)$
is given by
 $\partial_\alpha \ell_n(\alpha, 0) = \frac{K_n-1}{\alpha} - \sum_{j=1}^{n} S_{n,j} \sum_{i=1}^{j-1}\frac{1}{i-\alpha}.$
Here, we define the random measure
$\partial_\alpha \ell_n(\alpha, 0) = \frac{K_n-1}{\alpha} - \sum_{j=1}^{n} S_{n,j} \sum_{i=1}^{j-1}\frac{1}{i-\alpha}.$
Here, we define the random measure
 $\mathbb{P}_n$
on
$\mathbb{P}_n$
on
 $\mathbb{N}$
as the ratio of blocks of size j:
$\mathbb{N}$
as the ratio of blocks of size j:
 \begin{align*}\forall \, j \in \mathbb{N}, \quad \mathbb{P}_n(\,j)\,:\!=\, \frac{S_{n,j}}{\sum_{j^{\prime}=1}^\infty S_{n,j^{\prime}}} = \frac{S_{n,j}}{K_n}.\end{align*}
\begin{align*}\forall \, j \in \mathbb{N}, \quad \mathbb{P}_n(\,j)\,:\!=\, \frac{S_{n,j}}{\sum_{j^{\prime}=1}^\infty S_{n,j^{\prime}}} = \frac{S_{n,j}}{K_n}.\end{align*}
Note that
 $\mathbb{P}_n(\,j) = 0$
for all
$\mathbb{P}_n(\,j) = 0$
for all
 $j\gt n$
, as the total number of partitioned balls is n. In our proof, we denote
$j\gt n$
, as the total number of partitioned balls is n. In our proof, we denote
 $\sum_{j=1}^\infty \mathbb{P}_n(\,j) f(\,j)$
by
$\sum_{j=1}^\infty \mathbb{P}_n(\,j) f(\,j)$
by
 $\mathbb{P}_n\,f$
for any function f on
$\mathbb{P}_n\,f$
for any function f on
 $\mathbb{N}$
. Now we define the random function
$\mathbb{N}$
. Now we define the random function
 $\hat{\Psi}_{n,0}(x)=K_n^{-1} \partial_\alpha\ell_n(\alpha, 0)\mid_{\alpha=x}$
, which is the score function normalized by
$\hat{\Psi}_{n,0}(x)=K_n^{-1} \partial_\alpha\ell_n(\alpha, 0)\mid_{\alpha=x}$
, which is the score function normalized by
 $K_n$
. Then, the above displays give
$K_n$
. Then, the above displays give
 \begin{align*} \hat{\Psi}_{n,0}(x) &= \frac{1}{x} -\frac{1}{x K_n} - \sum_{j=1}^n \mathbb{P}_n(\,j) \sum_{i=1}^{j-1}\frac{1}{i-x} = \frac{1}{x}-\frac{1}{x K_n} - \mathbb{P}_n g_x,\end{align*}
\begin{align*} \hat{\Psi}_{n,0}(x) &= \frac{1}{x} -\frac{1}{x K_n} - \sum_{j=1}^n \mathbb{P}_n(\,j) \sum_{i=1}^{j-1}\frac{1}{i-x} = \frac{1}{x}-\frac{1}{x K_n} - \mathbb{P}_n g_x,\end{align*}
where
 $g_x$
is the function on
$g_x$
is the function on
 $\mathbb{N}$
defined by
$\mathbb{N}$
defined by
 $g_x(\,j) = \sum_{i=1}^{j-1} (i-x)^{-1}$
. We observe that
$g_x(\,j) = \sum_{i=1}^{j-1} (i-x)^{-1}$
. We observe that
 $\hat{\Psi}_{n,0}(x)$
is an expectation with respect to the empirical measure
$\hat{\Psi}_{n,0}(x)$
is an expectation with respect to the empirical measure
 $\mathbb{P}_n$
, and hence, the asymptotic behavior of the random function
$\mathbb{P}_n$
, and hence, the asymptotic behavior of the random function
 $\hat{\Psi}_{n,0}$
is characterized by a suitable convergence of
$\hat{\Psi}_{n,0}$
is characterized by a suitable convergence of
 $\mathbb{P}_n$
. Here, the convergence
$\mathbb{P}_n$
. Here, the convergence
 $S_{n,j}/K_n \to p_\alpha(\,j)$
(a.s.) by Theorem 1 implies
$S_{n,j}/K_n \to p_\alpha(\,j)$
(a.s.) by Theorem 1 implies
 \begin{align*} \forall \, j \in \mathbb{N}, \quad \mathbb{P}_n (\,j) {\overset{\textrm{a.s.}}{\longrightarrow}} \mathbb{P} (\,j)\,:\!=\, p_\alpha(\,j) = \frac{\alpha \prod_{i=1}^{j-1}(i-\alpha)}{j!},\end{align*}
\begin{align*} \forall \, j \in \mathbb{N}, \quad \mathbb{P}_n (\,j) {\overset{\textrm{a.s.}}{\longrightarrow}} \mathbb{P} (\,j)\,:\!=\, p_\alpha(\,j) = \frac{\alpha \prod_{i=1}^{j-1}(i-\alpha)}{j!},\end{align*}
i.e., the empirical measure
 $\mathbb{P}_n$
converges to the deterministic measure
$\mathbb{P}_n$
converges to the deterministic measure
 $\mathbb{P}$
pointwisely. Collectively, we expect that
$\mathbb{P}$
pointwisely. Collectively, we expect that
 $\hat{\Psi}_{n,0}$
converges to the deterministic function
$\hat{\Psi}_{n,0}$
converges to the deterministic function
 $\Psi$
as follows:
$\Psi$
as follows:
 \begin{align*} \forall \, x\in (0,1), \quad \hat{\Psi}_{n,0}(x) = \frac{1}{x} - \frac{1}{xK_n} - \mathbb{P}_n g_x \underset{\text{in prob.}}{\to}\frac{1}{x} - \mathbb{P} g_x =:\Psi(x)\end{align*}
\begin{align*} \forall \, x\in (0,1), \quad \hat{\Psi}_{n,0}(x) = \frac{1}{x} - \frac{1}{xK_n} - \mathbb{P}_n g_x \underset{\text{in prob.}}{\to}\frac{1}{x} - \mathbb{P} g_x =:\Psi(x)\end{align*}
Here, we emphasize that the above convergence does not follow directly from the pointwise convergence
 $\mathbb{P}_n(\,j) \to \mathbb{P}(\,j)$
because
$\mathbb{P}_n(\,j) \to \mathbb{P}(\,j)$
because
 $g_x(\,j) = \sum_{i=1}^{j-1} (i-x)^{-1}$
is not a bounded function. To make the arguments more rigorous, we prove the convergence of
$g_x(\,j) = \sum_{i=1}^{j-1} (i-x)^{-1}$
is not a bounded function. To make the arguments more rigorous, we prove the convergence of
 $\mathbb{P}_n$
for a suitable set of functions
$\mathbb{P}_n$
for a suitable set of functions
 $\mathcal{F}$
, i.e.,
$\mathcal{F}$
, i.e.,
 $| \mathbb{P}_n f - \mathbb{P} f| \to^p 0$
for all
$| \mathbb{P}_n f - \mathbb{P} f| \to^p 0$
for all
 $f\in \mathcal{F}$
(see Lemma 4 in the supplementary material). Using this lemma, we show the convergence of
$f\in \mathcal{F}$
(see Lemma 4 in the supplementary material). Using this lemma, we show the convergence of
 $\hat{\Psi}_{n,0}\to \Psi$
and
$\hat{\Psi}_{n,0}\to \Psi$
and
 $\hat{\Psi}^{\prime}_{n,0}\to \Psi^{\prime}$
in a suitable sense. Furthermore, we will argue that
$\hat{\Psi}^{\prime}_{n,0}\to \Psi^{\prime}$
in a suitable sense. Furthermore, we will argue that
 $\Psi(\alpha)=0$
and
$\Psi(\alpha)=0$
and
 $\Psi^{\prime}(\alpha) = -I_\alpha \lt 0$
with
$\Psi^{\prime}(\alpha) = -I_\alpha \lt 0$
with
 $I_\alpha$
being the Fisher information of the Sibuya distribution. Combining all of this, we obtain the consistency of
$I_\alpha$
being the Fisher information of the Sibuya distribution. Combining all of this, we obtain the consistency of
 $\hat{\alpha}_n$
. For the asymptotic mixed normality, we use a suitable Martingale central limit theorem for the score function (see Lemma 11 in the supplementary material). See Table 1 for rough comparisons with typical i.i.d. cases.
$\hat{\alpha}_n$
. For the asymptotic mixed normality, we use a suitable Martingale central limit theorem for the score function (see Lemma 11 in the supplementary material). See Table 1 for rough comparisons with typical i.i.d. cases.
Table 1. Comparison with typical i.i.d. parametric models.

We have discussed the QMLE so far, where the unknown
 $\theta$
is fixed. Now we consider the MLE
$\theta$
is fixed. Now we consider the MLE
 $(\hat{\alpha}_n, \hat{\theta}_n)$
that simultaneously estimates
$(\hat{\alpha}_n, \hat{\theta}_n)$
that simultaneously estimates
 $(\alpha, \theta)$
. The main difficulty here is that
$(\alpha, \theta)$
. The main difficulty here is that
 $\hat{\theta}_n$
does not converge to a fixed value, which requires technical arguments. The first step is to reduce the dimension of the parameters that we have to consider; we define the function
$\hat{\theta}_n$
does not converge to a fixed value, which requires technical arguments. The first step is to reduce the dimension of the parameters that we have to consider; we define the function
 $\hat{y}_n \,\colon (0,1) \to ({-}1, \infty)$
by
$\hat{y}_n \,\colon (0,1) \to ({-}1, \infty)$
by
 $\hat{y}_n(x)\,:\!=\, \textrm{arg max}_{y\gt -x} \ell_n(x, y)$
for all
$\hat{y}_n(x)\,:\!=\, \textrm{arg max}_{y\gt -x} \ell_n(x, y)$
for all
 $x\in(0,1)$
, where
$x\in(0,1)$
, where
 $\ell_n(x, y)$
is the log-likelihood (3.4) with
$\ell_n(x, y)$
is the log-likelihood (3.4) with
 $(\alpha,\theta)=(x,y)$
. Here we claim that
$(\alpha,\theta)=(x,y)$
. Here we claim that
 $\hat{y}_n$
is well defined with a high probability. The gain of introducing
$\hat{y}_n$
is well defined with a high probability. The gain of introducing
 $\hat{y}_n$
is that the MLE
$\hat{y}_n$
is that the MLE
 $(\hat{\alpha}_n, \hat{\theta}_n)$
can be rewritten as the solution of the one-dimensional maximization problem
$(\hat{\alpha}_n, \hat{\theta}_n)$
can be rewritten as the solution of the one-dimensional maximization problem
 \begin{align*} \hat{\alpha}_n \in \textrm{arg max}_{x\in {(0,1)}} \ell_n(x, \hat{y}_n(x)), \qquad \hat{\theta}_n = \hat{y}_n(\hat{\alpha}_n).\end{align*}
\begin{align*} \hat{\alpha}_n \in \textrm{arg max}_{x\in {(0,1)}} \ell_n(x, \hat{y}_n(x)), \qquad \hat{\theta}_n = \hat{y}_n(\hat{\alpha}_n).\end{align*}
Here, similarly to
 $\hat{\Psi}_{n, 0}$
, we define the random function
$\hat{\Psi}_{n, 0}$
, we define the random function
 $\hat{\Psi}_n$
by
$\hat{\Psi}_n$
by
 $\hat{\Psi}_n(x)\,:\!=\, K_n^{-1} \cdot\frac{\mathop{}\!\textrm{d}}{\mathop{}\!\textrm{d} x} \ell_n(x, \hat{y}_n(x))$
for all
$\hat{\Psi}_n(x)\,:\!=\, K_n^{-1} \cdot\frac{\mathop{}\!\textrm{d}}{\mathop{}\!\textrm{d} x} \ell_n(x, \hat{y}_n(x))$
for all
 $x\in (0,1)$
. Then, for the deterministic function
$x\in (0,1)$
. Then, for the deterministic function
 $\Psi(x) = x^{-1} - \mathbb{P} g_x$
, we again show the convergence of
$\Psi(x) = x^{-1} - \mathbb{P} g_x$
, we again show the convergence of
 $\hat{\Psi}_{n}\to \Psi$
and
$\hat{\Psi}_{n}\to \Psi$
and
 $\hat{\Psi}^{\prime}_n\to \Psi^{\prime}$
in a suitable sense.
$\hat{\Psi}^{\prime}_n\to \Psi^{\prime}$
in a suitable sense.
6. Discussion
In this paper, we investigated the MLE for the Ewens–Pitman partition and derived its exact asymptotic distribution. Specifically, we established the asymptotic mixed normality of the MLE for
 $\alpha$
and proposed a confidence interval. Below, we outline several promising directions for future research.
$\alpha$
and proposed a confidence interval. Below, we outline several promising directions for future research.
6.1. Quantitative martingale CLT
From Figure 7, we observe that the actual coverage of the confidence interval depends on n. To investigate the asymptotic behavior of coverage, we aim to identify a rate
 $c_n\to 0$
such that
$c_n\to 0$
such that
 $$ \operatorname{d}_{\textsf{Kol}}\Bigl(\sqrt{K_n I_{\hat{\alpha}_n}}(\hat\alpha_n - \alpha), N \Bigr) \le c_n, \quad c_n \to 0, $$
$$ \operatorname{d}_{\textsf{Kol}}\Bigl(\sqrt{K_n I_{\hat{\alpha}_n}}(\hat\alpha_n - \alpha), N \Bigr) \le c_n, \quad c_n \to 0, $$
where
 $\operatorname{d}_{\textsf{Kol}}(\cdot, \cdot)$
denotes the Kolmogorov distance, and
$\operatorname{d}_{\textsf{Kol}}(\cdot, \cdot)$
denotes the Kolmogorov distance, and
 $N\sim N(0,1)$
. Based on the Taylor expansion arguments in our proof, deriving this rate requires establishing a convergence rate for the martingale CLT as follows:
$N\sim N(0,1)$
. Based on the Taylor expansion arguments in our proof, deriving this rate requires establishing a convergence rate for the martingale CLT as follows:
 $$ \operatorname{d}_{\textsf{Kol}} \left(\frac{\sum_{m=1}^n X_m}{\sqrt{\sum_{m=1}^n\mathbb{E}\left[X_{m}^2| \mathcal{F}_{m-1}\right]}}, N \right) \le c_n, \quad c_n \to 0, $$
$$ \operatorname{d}_{\textsf{Kol}} \left(\frac{\sum_{m=1}^n X_m}{\sqrt{\sum_{m=1}^n\mathbb{E}\left[X_{m}^2| \mathcal{F}_{m-1}\right]}}, N \right) \le c_n, \quad c_n \to 0, $$
where
 $X_m$
is a martingale difference sequence. In our case,
$X_m$
is a martingale difference sequence. In our case,
 $X_m$
represents the increments of the score function
$X_m$
represents the increments of the score function
 $\partial_\alpha \ell_n(\alpha,\theta)$
.
$\partial_\alpha \ell_n(\alpha,\theta)$
.
If
 $X_m$
are i.i.d. random variables with finite third moment, the Berry–Esseen theorem (cf. [Reference Chen, Goldstein and Shao4, Chapter 3]) provides
$X_m$
are i.i.d. random variables with finite third moment, the Berry–Esseen theorem (cf. [Reference Chen, Goldstein and Shao4, Chapter 3]) provides
 $c_n = O(n^{-1/2})$
. More generally, if the quadratic variation
$c_n = O(n^{-1/2})$
. More generally, if the quadratic variation
 ${\sum_{m=1}^n\mathbb{E}[X_{m}^2| \mathcal{F}_{m-1}]}$
concentrates around the unconditional variance
${\sum_{m=1}^n\mathbb{E}[X_{m}^2| \mathcal{F}_{m-1}]}$
concentrates around the unconditional variance
 $\sum_{m=1}^n\mathbb{E}[X_{m}^2]$
, then previous results on quantitative martingale CLT (see [Reference Mourrat21] and references therein) can be used to estimate the rate
$\sum_{m=1}^n\mathbb{E}[X_{m}^2]$
, then previous results on quantitative martingale CLT (see [Reference Mourrat21] and references therein) can be used to estimate the rate
 $c_n$
. However, these results cannot be directly applied to our setting due to the lack of concentration of the quadratic variation around the unconditional variance. Indeed, Lemma 12 in the supplementary material and Proposition 2 give
$c_n$
. However, these results cannot be directly applied to our setting due to the lack of concentration of the quadratic variation around the unconditional variance. Indeed, Lemma 12 in the supplementary material and Proposition 2 give
 $${\sum_{m=1}^n\mathbb{E}[X_{m}^2| \mathcal{F}_{m-1}]} = n^\alpha I_\alpha {\textsf{M}}_{\alpha, \theta} + o_p(n^\alpha), \quad \sum_{m=1}^n \mathbb{E}[X_m^2] = n^\alpha I_\alpha \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] + o(n^\alpha)$$
$${\sum_{m=1}^n\mathbb{E}[X_{m}^2| \mathcal{F}_{m-1}]} = n^\alpha I_\alpha {\textsf{M}}_{\alpha, \theta} + o_p(n^\alpha), \quad \sum_{m=1}^n \mathbb{E}[X_m^2] = n^\alpha I_\alpha \mathbb{E}[{\textsf{M}}_{\alpha, \theta}] + o(n^\alpha)$$
and
 $\Pr({\textsf{M}}_{\alpha, \theta} \ne\mathbb{E}[{\textsf{M}}_{\alpha, \theta}])=1$
since
$\Pr({\textsf{M}}_{\alpha, \theta} \ne\mathbb{E}[{\textsf{M}}_{\alpha, \theta}])=1$
since
 ${\textsf{M}}_{\alpha, \theta}=\lim_{n\to+\infty} K_n/n^\alpha$
follows
${\textsf{M}}_{\alpha, \theta}=\lim_{n\to+\infty} K_n/n^\alpha$
follows
 $\textrm{GMtLf}(\alpha,\theta)$
.
$\textrm{GMtLf}(\alpha,\theta)$
.
We can nevertheless hypothesize the convergence rate
 $c_n$
by empirically estimating the distance via the empirical measure (see Figure 8). We conjecture from this figure that
$c_n$
by empirically estimating the distance via the empirical measure (see Figure 8). We conjecture from this figure that
 $c_n$
scales as
$c_n$
scales as
 $n^{-c}$
for some constant
$n^{-c}$
for some constant
 $c\gt 0$
.
$c\gt 0$
.

Figure 8. Left panel: Illustration of the pointwise convergence of the empirical CDF of
 $\sqrt{K_n I_\alpha}(\hat\alpha_n-\alpha)$
to the CDF of N(0,1). Right panel: Plot of the Kolmogorov distance as n increases. Simulation setting:
$\sqrt{K_n I_\alpha}(\hat\alpha_n-\alpha)$
to the CDF of N(0,1). Right panel: Plot of the Kolmogorov distance as n increases. Simulation setting:
 $\alpha=0,8$
,
$\alpha=0,8$
,
 $\theta=0$
,
$\theta=0$
,
 $10^5$
Monte Carlo simulations.
$10^5$
Monte Carlo simulations.
6.2. Extension to the Gibbs partitions
We are also interested in extending our results to the Gibbs partition [Reference Gnedin and Pitman16], which is a class of exchangeable random partitions characterized by the following likelihood:
 \begin{align} v_{n,K_n}(\alpha) \cdot \prod_{j=2}^n \left\{ \prod_{i=1}^{j-1} (\!-\alpha + i) \right\}^{S_{n,j}},\end{align}
\begin{align} v_{n,K_n}(\alpha) \cdot \prod_{j=2}^n \left\{ \prod_{i=1}^{j-1} (\!-\alpha + i) \right\}^{S_{n,j}},\end{align}
where
 $\alpha$
is a parameter in
$\alpha$
is a parameter in
 $(\!-\infty, 1)$
and
$(\!-\infty, 1)$
and
 $v_{n,k}(\alpha)$
for
$v_{n,k}(\alpha)$
for
 $1\le k\le n$
is a nonnegative sequence satisfying the backward recursion
$1\le k\le n$
is a nonnegative sequence satisfying the backward recursion
 \begin{align} v_{n, k}(\alpha) = (n-\alpha k) \cdot v_{n+1, k}(\alpha) + v_{n+1,k+1}(\alpha) \quad \text{with} \quad v_{1,1}(\alpha)=1. \end{align}
\begin{align} v_{n, k}(\alpha) = (n-\alpha k) \cdot v_{n+1, k}(\alpha) + v_{n+1,k+1}(\alpha) \quad \text{with} \quad v_{1,1}(\alpha)=1. \end{align}
Equivalently, (6.1) can be viewed as the marginal likelihood of a random partition generated sequentially, as follows:
 \begin{align*} \text{$(n+1)$th ball} \in\! \begin{cases} \text{an existing set $U_i$} & \!\!\text{with probability $\frac{v_{n+1, K_n}(\alpha)}{v_{n,K_n}(\alpha)} \cdot (|U_i|-\alpha)$}, \ \ \forall \, i=1, 2, \dots, K_n \\[6pt] \text{a new set} & \!\!\text{with probability $\frac{v_{n+1, K_n +1}(\alpha)}{v_{n, K_n}(\alpha)}$}. \end{cases} \end{align*}
\begin{align*} \text{$(n+1)$th ball} \in\! \begin{cases} \text{an existing set $U_i$} & \!\!\text{with probability $\frac{v_{n+1, K_n}(\alpha)}{v_{n,K_n}(\alpha)} \cdot (|U_i|-\alpha)$}, \ \ \forall \, i=1, 2, \dots, K_n \\[6pt] \text{a new set} & \!\!\text{with probability $\frac{v_{n+1, K_n +1}(\alpha)}{v_{n, K_n}(\alpha)}$}. \end{cases} \end{align*}
The recursion in (6.2) ensures that the probabilities above sum to 1. Within this framework, the Ewens–Pitman partition with parameter
 $(\alpha,\theta)$
emerges as a special class of the Gibbs partitions, where
$(\alpha,\theta)$
emerges as a special class of the Gibbs partitions, where
 $v_{n,k}$
is explicitly given by
$v_{n,k}$
is explicitly given by
 $ v_{n,k} (\alpha;\theta)\,:\!=\, \frac{\prod_{i=0}^{k-1} (\theta+i\alpha)}{\prod_{i=0}^{n-1}(\theta + i)}$
with
$ v_{n,k} (\alpha;\theta)\,:\!=\, \frac{\prod_{i=0}^{k-1} (\theta+i\alpha)}{\prod_{i=0}^{n-1}(\theta + i)}$
with
 $\theta\gt-\alpha$
and
$\theta\gt-\alpha$
and
 $\alpha\in (0,1)$
.
$\alpha\in (0,1)$
.
Importantly, the asymptotic properties of
 $(K_n, S_{n,j})$
in Theorem 1 extend to the Gibbs partition; that is, if
$(K_n, S_{n,j})$
in Theorem 1 extend to the Gibbs partition; that is, if
 $\alpha \in (0,1)$
, there exists a positive random variable
$\alpha \in (0,1)$
, there exists a positive random variable
 $\textsf{M}$
, referred to as the
$\textsf{M}$
, referred to as the
 $\alpha$
-diversity, such that
$\alpha$
-diversity, such that
 \begin{align} \frac{K_n}{n^\alpha} \to \textsf{M} \quad \text{and} \quad \frac{S_{n,j}}{K_n} \to p_\alpha(\,j) = \frac{\alpha \prod_{i=1}^{j-1}(i-\alpha)}{j!} \quad \text{for each $j\in\mathbb{N}$} \end{align}
\begin{align} \frac{K_n}{n^\alpha} \to \textsf{M} \quad \text{and} \quad \frac{S_{n,j}}{K_n} \to p_\alpha(\,j) = \frac{\alpha \prod_{i=1}^{j-1}(i-\alpha)}{j!} \quad \text{for each $j\in\mathbb{N}$} \end{align}
a.s. (see [Reference Pitman23, Section 6.1] and [Reference Pitman24, Lemma 3.11]).
Suppose that a random partition is generated by the Gibbs partition with an unknown parameter
 $\alpha\in (0,1)$
and
$\alpha\in (0,1)$
and
 $\{v_{n,k}(\alpha)\}$
satisfying the backward recursion (6.2). Let us denote the log-likelihood by
$\{v_{n,k}(\alpha)\}$
satisfying the backward recursion (6.2). Let us denote the log-likelihood by
 $\ell_n^{\text{gibbs}}(\alpha)$
:
$\ell_n^{\text{gibbs}}(\alpha)$
:
 $$ \ell_{n}^{\text{gibbs}}(\alpha)\,:\!=\, \log \bigl(v_{n,K_n}(\alpha)\bigr) + \sum_{j=2}^n S_{n,j} \sum_{i=1}^{j-1} \log(i-\alpha). $$
$$ \ell_{n}^{\text{gibbs}}(\alpha)\,:\!=\, \log \bigl(v_{n,K_n}(\alpha)\bigr) + \sum_{j=2}^n S_{n,j} \sum_{i=1}^{j-1} \log(i-\alpha). $$
We aim to estimate
 $\alpha$
by the QMLE
$\alpha$
by the QMLE
 $\hat{\alpha}_{n,0} \in \textrm{arg max}_{\alpha\in (0,1)} \ell_n(\alpha, 0)$
with
$\hat{\alpha}_{n,0} \in \textrm{arg max}_{\alpha\in (0,1)} \ell_n(\alpha, 0)$
with
 $$ \ell_n(\alpha, 0) = (K_n-1) \log \alpha + \sum_{j=1}^n S_{n,j} \sum_{i=1}^{j-1}\log (i-\alpha). $$
$$ \ell_n(\alpha, 0) = (K_n-1) \log \alpha + \sum_{j=1}^n S_{n,j} \sum_{i=1}^{j-1}\log (i-\alpha). $$
Based on the Taylor expansion argument in Appendix C of the supplementary material, the asymptotic distribution of the QMLE
 $\hat{\alpha}_{n,0}$
is determined by the asymptotics of
$\hat{\alpha}_{n,0}$
is determined by the asymptotics of
 $\partial_\alpha \ell_n(\alpha,0)$
and
$\partial_\alpha \ell_n(\alpha,0)$
and
 $ \partial_\alpha^2 \ell_n(\alpha, 0)$
. For
$ \partial_\alpha^2 \ell_n(\alpha, 0)$
. For
 $\partial_\alpha^2 \ell_n(\alpha, 0)$
, applying (6.3), we obtain the
$\partial_\alpha^2 \ell_n(\alpha, 0)$
, applying (6.3), we obtain the
 $\partial_\alpha^2 \ell_n(\alpha, 0)/K_n \to -I_\alpha$
as established in Lemma 7 of the supplementary material. For
$\partial_\alpha^2 \ell_n(\alpha, 0)/K_n \to -I_\alpha$
as established in Lemma 7 of the supplementary material. For
 $\partial_\alpha \ell_n(\alpha, 0)$
, we decompose it as
$\partial_\alpha \ell_n(\alpha, 0)$
, we decompose it as
 \begin{align*} \partial_{\alpha} \ell_n(\alpha, 0) &= \partial_{\alpha} \ell_{n}^{\text{gibbs}}(\alpha) + \partial_{\alpha} \ell_n(\alpha, 0) - \partial_{\alpha} \ell_{n}^{\text{gibbs}}(\alpha)\\ &= \partial_{\alpha} \ell_{n}^{\text{gibbs}}(\alpha) + \left(\frac{K_n-1}{\alpha} - \frac{v_{n,K_n}^{\prime}(\alpha)}{v_{n, K_n}(\alpha)}\right). \end{align*}
\begin{align*} \partial_{\alpha} \ell_n(\alpha, 0) &= \partial_{\alpha} \ell_{n}^{\text{gibbs}}(\alpha) + \partial_{\alpha} \ell_n(\alpha, 0) - \partial_{\alpha} \ell_{n}^{\text{gibbs}}(\alpha)\\ &= \partial_{\alpha} \ell_{n}^{\text{gibbs}}(\alpha) + \left(\frac{K_n-1}{\alpha} - \frac{v_{n,K_n}^{\prime}(\alpha)}{v_{n, K_n}(\alpha)}\right). \end{align*}
Here,
 $\partial_{\alpha} \ell_{n}^{\text{gibbs}}(\alpha) $
is the score function, which is martingale since the model is well specified. Thus, its asymptotic distribution can be derived from the martingale CLT as in Lemma 12 of the supplementary material, under suitable conditions on
$\partial_{\alpha} \ell_{n}^{\text{gibbs}}(\alpha) $
is the score function, which is martingale since the model is well specified. Thus, its asymptotic distribution can be derived from the martingale CLT as in Lemma 12 of the supplementary material, under suitable conditions on
 $\{v_{n,k}\}$
.
$\{v_{n,k}\}$
.
To establish the asymptotic distribution of the QMLE, it remains to verify that
 $\Bigl(\frac{K_n-1}{\alpha} - \frac{v_{n,K_n}^{\prime}(\alpha)}{v_{n, K_n}(\alpha)}\Bigr)$
is asymptotically negligible compared with the score function. This requires additional assumptions on
$\Bigl(\frac{K_n-1}{\alpha} - \frac{v_{n,K_n}^{\prime}(\alpha)}{v_{n, K_n}(\alpha)}\Bigr)$
is asymptotically negligible compared with the score function. This requires additional assumptions on
 $\{v_{n,k}\}$
, and formalizing these conditions is left for future research.
$\{v_{n,k}\}$
, and formalizing these conditions is left for future research.
Funding information
T. Matsuda was supported by JSPS KAKENHI Grant Numbers 19K20220, 21H05205, and 22K17865 and JST Moonshot Grant Number JPMJMS2024. F. Komaki was supported by MEXT KAKENHI Grant Number 16H06533, JST CREST Grant Number JPMJCR1763, and AMED Grant Numbers JP21dm0207001 and JP21dm0307009.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/apr.2025.10020.















































 Open access
Open access