Refine search
Actions for selected content:
3312 results in Artificial Intelligence and Natural Language Processing
A survey of methods for revealing and overcoming weaknesses of data-driven Natural Language Understanding
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 22 April 2022, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Creating a More Transparent Internet
-
- Published online:
- 21 April 2022
- Print publication:
- 05 May 2022
NLE volume 28 issue 3 Cover and Front matter
-
- Journal:
- Natural Language Engineering / Volume 28 / Issue 3 / May 2022
- Published online by Cambridge University Press:
- 08 April 2022, pp. f1-f2
-
- Article
-
- You have access
- Export citation
NLE volume 28 issue 3 Cover and Back matter
-
- Journal:
- Natural Language Engineering / Volume 28 / Issue 3 / May 2022
- Published online by Cambridge University Press:
- 08 April 2022, pp. b1-b2
-
- Article
-
- You have access
- Export citation
The voice synthesis business: 2022 update
-
- Journal:
- Natural Language Engineering / Volume 28 / Issue 3 / May 2022
- Published online by Cambridge University Press:
- 08 April 2022, pp. 401-408
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Real-world sentence boundary detection using multitask learning: A case study on French
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 06 April 2022, pp. 150-170
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Gender bias in legal corpora and debiasing it
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 30 March 2022, pp. 449-482
-
- Article
- Export citation
Generating Arabic TAG for syntax-semantics analysis
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 24 March 2022, pp. 386-424
-
- Article
- Export citation
In-depth analysis of the impact of OCR errors on named entity recognition and linking
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 18 March 2022, pp. 425-448
-
- Article
- Export citation
Explainable lexical entailment with semantic graphs
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 28 February 2022, pp. 1223-1246
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
MHeTRep: A multilingual semantically tagged health terms repository
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 25 February 2022, pp. 1364-1401
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Enhancing deep neural networks with morphological information
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 21 February 2022, pp. 360-385
-
- Article
- Export citation
An empirical study of cyclical learning rate on neural machine translation
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 09 February 2022, pp. 316-336
-
- Article
- Export citation
NLE volume 28 issue 2 Cover and Back matter
-
- Journal:
- Natural Language Engineering / Volume 28 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 08 February 2022, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Emerging Trends: SOTA-Chasing
-
- Journal:
- Natural Language Engineering / Volume 28 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 08 February 2022, pp. 249-269
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NLE volume 28 issue 2 Cover and Front matter
-
- Journal:
- Natural Language Engineering / Volume 28 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 08 February 2022, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Towards improving the robustness of sequential labeling models against typographical adversarial examples using triplet loss
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 04 February 2022, pp. 287-315
-
- Article
- Export citation
SoundexGR: An algorithm for phonetic matching for the Greek language
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 04 February 2022, pp. 1305-1340
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Text usually suffers from typos which can negatively affect various Information Retrieval and Natural Language Processing tasks. Although there is a wide variety of choices for tackling this issue in the English language, this is not the case for other languages. For the Greek language, most of the existing phonetic algorithms provide rather insufficient support. For this reason, in this paper, we introduce an algorithm for phonetic matching designed for the Greek language: we start from the original Soundex and we redesign and extend it for accommodating the Greek language’s phonetic rules, ending up to a family of algorithms, that we call
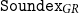 ${\tt Soundex}_{GR}$. Then, we report various experimental results showcasing how the algorithm behaves in different scenarios, and we provide comparative results for various parameters of the algorithm for revealing the trade-off between precision and recall in datasets with different kinds of errors. We also provide comparative results with matching using stemming, full phonemic transcription, and edit distance, that demonstrate that
${\tt Soundex}_{GR}$. Then, we report various experimental results showcasing how the algorithm behaves in different scenarios, and we provide comparative results for various parameters of the algorithm for revealing the trade-off between precision and recall in datasets with different kinds of errors. We also provide comparative results with matching using stemming, full phonemic transcription, and edit distance, that demonstrate that 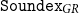 ${\tt Soundex}_{GR}$ performs better (indicatively, it achieves F-Score over 95% in collections of similar-sounded words). The simplicity, efficiency, and effectiveness of the proposed algorithm make it applicable and adaptable to a wide range of tasks.
${\tt Soundex}_{GR}$ performs better (indicatively, it achieves F-Score over 95% in collections of similar-sounded words). The simplicity, efficiency, and effectiveness of the proposed algorithm make it applicable and adaptable to a wide range of tasks.
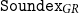
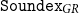
Towards improving coherence and diversity of slogan generation
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 04 February 2022, pp. 254-286
-
- Article
- Export citation
-
Previouswork in slogan generation focused on utilising slogan skeletons mined from existing slogans. While some generated slogans can be catchy, they are often not coherent with the company’s focus or style across their marketing communications because the skeletons are mined from other companies’ slogans. We propose a sequence-to-sequence (seq2seq) Transformer model to generate slogans from a brief company description. A naïve seq2seq model fine-tuned for slogan generation is prone to introducing false information. We use company name delexicalisation and entity masking to alleviate this problem and improve the generated slogans’ quality and truthfulness. Furthermore, we apply conditional training based on the first words’ part-of-speech tag to generate syntactically diverse slogans. Our best model achieved a ROUGE-1/-2/-L
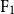 $\mathrm{F}_1$ score of 35.58/18.47/33.32. Besides, automatic and human evaluations indicate that our method generates significantly more factual, diverse and catchy slogans than strong long short-term memory and Transformer seq2seq baselines.
$\mathrm{F}_1$ score of 35.58/18.47/33.32. Besides, automatic and human evaluations indicate that our method generates significantly more factual, diverse and catchy slogans than strong long short-term memory and Transformer seq2seq baselines.
Topical language generation using transformers
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 04 February 2022, pp. 337-359
-
- Article
- Export citation
