Refine search
Actions for selected content:
62 results
Host-Country Identification Among Early Modern Immigrants: A Case Study of the Late Eighteenth-Century Dutch Republic
-
- Journal:
- Social Science History , First View
- Published online by Cambridge University Press:
- 14 October 2025, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Economic Change in the Mediterranean between the Principate and Late Antiquity
-
- Journal:
- European Journal of Archaeology , First View
- Published online by Cambridge University Press:
- 29 September 2025, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Identifying dietary patterns related to metabolic syndrome using the 7th Korea National Health and Nutrition Examination Survey
-
- Journal:
- British Journal of Nutrition / Volume 134 / Issue 2 / 28 July 2025
- Published online by Cambridge University Press:
- 14 July 2025, pp. 147-155
- Print publication:
- 28 July 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
5 - Data and Methods for Modeling Climate-Related Migration
-
- Book:
- Migration and Displacement in a Changing Climate
- Published online:
- 10 April 2025
- Print publication:
- 17 April 2025, pp 162-188
-
- Chapter
- Export citation
Chapter 3 - The Price of Slaves in New York and New Jersey, 1700–1830
-
- Book:
- The Slow Death of Slavery in Dutch New York
- Published online:
- 20 December 2024
- Print publication:
- 09 January 2025, pp 88-114
-
- Chapter
- Export citation
A Simulated Annealing Methodology for Clusterwise Linear Regression
-
- Journal:
- Psychometrika / Volume 54 / Issue 4 / December 1989
- Published online by Cambridge University Press:
- 01 January 2025, pp. 707-736
-
- Article
- Export citation
Assessing the Stability of Principal Components Using Regression
-
- Journal:
- Psychometrika / Volume 60 / Issue 3 / September 1995
- Published online by Cambridge University Press:
- 01 January 2025, pp. 355-369
-
- Article
- Export citation
Convergence Theory for Partial Images and Revision of the Definition of Total Images
-
- Journal:
- Psychometrika / Volume 44 / Issue 3 / September 1979
- Published online by Cambridge University Press:
- 01 January 2025, pp. 315-328
-
- Article
- Export citation
Standardized Regression Coefficients and Newly Proposed Estimators for R2\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${R}^{{2}}$$\end{document}
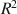 in Multiply Imputed Data
in Multiply Imputed Data
-
- Journal:
- Psychometrika / Volume 85 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 185-205
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Whenever statistical analyses are applied to multiply imputed datasets, specific formulas are needed to combine the results into one overall analysis, also called combination rules. In the context of regression analysis, combination rules for the unstandardized regression coefficients, the t-tests of the regression coefficients, and the F-tests for testing \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document}
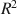 for significance have long been established. However, there is still no general agreement on how to combine the point estimators of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document}
for significance have long been established. However, there is still no general agreement on how to combine the point estimators of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document}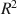 in multiple regression applied to multiply imputed datasets. Additionally, no combination rules for standardized regression coefficients and their confidence intervals seem to have been developed at all. In the current article, two sets of combination rules for the standardized regression coefficients and their confidence intervals are proposed, and their statistical properties are discussed. Additionally, two improved point estimators of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document}
in multiple regression applied to multiply imputed datasets. Additionally, no combination rules for standardized regression coefficients and their confidence intervals seem to have been developed at all. In the current article, two sets of combination rules for the standardized regression coefficients and their confidence intervals are proposed, and their statistical properties are discussed. Additionally, two improved point estimators of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document}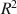 in multiply imputed data are proposed, which in their computation use the pooled standardized regression coefficients. Simulations show that the proposed pooled standardized coefficients produce only small bias and that their 95% confidence intervals produce coverage close to the theoretical 95%. Furthermore, the simulations show that the newly proposed pooled estimates for \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document}
in multiply imputed data are proposed, which in their computation use the pooled standardized regression coefficients. Simulations show that the proposed pooled standardized coefficients produce only small bias and that their 95% confidence intervals produce coverage close to the theoretical 95%. Furthermore, the simulations show that the newly proposed pooled estimates for \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document} are less biased than two earlier proposed pooled estimates.
are less biased than two earlier proposed pooled estimates.
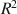
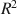
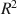
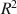

4 - Cross-National Evidence, 1945–2017
-
- Book:
- Guilt by Location
- Published online:
- 12 December 2024
- Print publication:
- 19 December 2024, pp 88-118
-
- Chapter
- Export citation
Association between age of paediatric index cases and household SARS-CoV-2 transmission
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 20 November 2024, e145
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
8 - Chekists and Secret Informants: Post-Stalinist Transitions, Elite Cohesion, and Coercive Capacity
- from Part III - Cross-national Quantitative Analysis
-
- Book:
- Watching the Watchers
- Published online:
- 22 February 2024
- Print publication:
- 29 February 2024, pp 223-252
-
- Chapter
- Export citation
9 - Empirical Methods
- from Part I - Methods of Comparative Law
-
-
- Book:
- The Cambridge Handbook of Comparative Law
- Published online:
- 26 January 2024
- Print publication:
- 01 February 2024, pp 157-176
-
- Chapter
- Export citation
An EEG-based method to decode cognitive factors in creative processes
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The effect of clinical and haemodynamic variables on post-operative length of stay immediately upon admission after biventricular repair with Yasui operation following an earlier Norwood operation
-
- Journal:
- Cardiology in the Young / Volume 33 / Issue 10 / October 2023
- Published online by Cambridge University Press:
- 20 December 2022, pp. 2066-2071
-
- Article
- Export citation
8 - Cost Estimation
- from Part III - Production and Cost Analysis
-
- Book:
- Managerial Economics
- Published online:
- 09 February 2022
- Print publication:
- 13 January 2022, pp 369-406
-
- Chapter
- Export citation
Interrogating the validity of cumulative indices of environmental and genetic risk for negative developmental outcomes
-
- Journal:
- Development and Psychopathology / Volume 35 / Issue 3 / August 2023
- Published online by Cambridge University Press:
- 13 December 2021, pp. 1171-1187
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How to understand diversity in citizens’ care attitudes: an exploratory study in the Netherlands
-
- Journal:
- Ageing & Society / Volume 43 / Issue 5 / May 2023
- Published online by Cambridge University Press:
- 02 August 2021, pp. 1164-1183
- Print publication:
- May 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
1 - The Origins of Douglas’s Production Function Research Program and His Initial Time Series Studies
- from Part I - Paul Douglas and His Regression, 1927–1948
-
- Book:
- Progress through Regression
- Published online:
- 30 October 2020
- Print publication:
- 12 November 2020, pp 13-58
-
- Chapter
- Export citation
3 - Regime-Contingent Biases and Sovereign Default, 1960–2009
-
- Book:
- Democracy, Dictatorship, and Default
- Published online:
- 31 July 2020
- Print publication:
- 13 August 2020, pp 55-79
-
- Chapter
- Export citation
