Refine search
Actions for selected content:
279 results
7 - Neuromorphic Algorithms
-
- Book:
- Introduction to Neuromorphic Computing
- Published online:
- 01 January 2026
- Print publication:
- 22 January 2026, pp 145-168
-
- Chapter
- Export citation
2 - Principles of Artificial Neural Networks
-
- Book:
- Introduction to Neuromorphic Computing
- Published online:
- 01 January 2026
- Print publication:
- 22 January 2026, pp 15-26
-
- Chapter
- Export citation

Introduction to Machine Learning
- From Math to Code
- Coming soon
-
- Expected online publication date:
- January 2026
- Print publication:
- 18 December 2025
-
- Textbook
- Export citation
Chasing the authoritarian spectre: Detecting authoritarian discourse with large language models
-
- Journal:
- European Journal of Political Research / Volume 64 / Issue 3 / August 2025
- Published online by Cambridge University Press:
- 02 January 2026, pp. 1304-1325
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prediction of calving to conception interval (days open) in dairy cows using recurrent neural networks
-
- Journal:
- Journal of Dairy Research , First View
- Published online by Cambridge University Press:
- 23 December 2025, pp. 1-9
-
- Article
- Export citation
Uncertainty quantification for deep learning
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 17 December 2025, e53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Fine-grained mortality forecasting with deep learning
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 12 December 2025, pp. 1-27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Instability in deep learning – when algorithms cannot compute uncertainty quantifications for neural networks
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 37 / Issue 1 / February 2026
- Published online by Cambridge University Press:
- 20 November 2025, pp. 290-312
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In deep learning, interval neural networks are used to quantify the uncertainty of a pre-trained neural network. Suppose we are given a computational problem
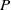 $P$ and a pre-trained neural network
$P$ and a pre-trained neural network 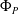 $\Phi _P$ that aims to solve
$\Phi _P$ that aims to solve 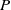 $P$. An interval neural network is then a pair of neural networks
$P$. An interval neural network is then a pair of neural networks 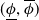 $(\underline {\phi }, \overline {\phi })$, with the property that
$(\underline {\phi }, \overline {\phi })$, with the property that 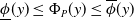 $\underline {\phi }(y) \leq \Phi _P(y) \leq \overline {\phi }(y)$ for all inputs
$\underline {\phi }(y) \leq \Phi _P(y) \leq \overline {\phi }(y)$ for all inputs 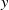 $y$, where the inequalities are meant componentwise.
$y$, where the inequalities are meant componentwise. 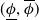 $(\underline {\phi }, \overline {\phi })$ are specifically trained to quantify the uncertainty of
$(\underline {\phi }, \overline {\phi })$ are specifically trained to quantify the uncertainty of 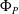 $\Phi _P$, in the sense that the size of the interval
$\Phi _P$, in the sense that the size of the interval 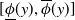 $[\underline {\phi }(y),\overline {\phi }(y)]$ quantifies the uncertainty of the prediction
$[\underline {\phi }(y),\overline {\phi }(y)]$ quantifies the uncertainty of the prediction 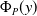 $\Phi _P(y)$. In this paper, we investigate the phenomenon when algorithms cannot compute interval neural networks in the setting of inverse problems. We show that in the typical setting of a linear inverse problem, the problem of constructing an optimal pair of interval neural networks is non-computable, even with the assumption that the pre-trained neural network
$\Phi _P(y)$. In this paper, we investigate the phenomenon when algorithms cannot compute interval neural networks in the setting of inverse problems. We show that in the typical setting of a linear inverse problem, the problem of constructing an optimal pair of interval neural networks is non-computable, even with the assumption that the pre-trained neural network 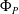 $\Phi _P$ is an optimal solution. In other words, there exist classes of training sets
$\Phi _P$ is an optimal solution. In other words, there exist classes of training sets  $\Omega$, such that there is no algorithm, even randomised (with probability
$\Omega$, such that there is no algorithm, even randomised (with probability 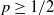 $p \geq 1/2$), that computes an optimal pair of interval neural networks for each training set
$p \geq 1/2$), that computes an optimal pair of interval neural networks for each training set 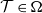 ${\mathcal{T}} \in \Omega$. This phenomenon happens even when we are given a pre-trained neural network
${\mathcal{T}} \in \Omega$. This phenomenon happens even when we are given a pre-trained neural network 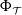 $\Phi _{{\mathcal{T}}}$ that is optimal for
$\Phi _{{\mathcal{T}}}$ that is optimal for 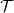 $\mathcal{T}$. This phenomenon is intimately linked to instability in deep learning.
$\mathcal{T}$. This phenomenon is intimately linked to instability in deep learning.
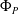
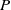
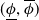
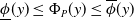
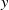
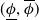
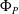
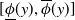
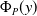
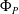

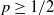
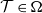
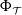
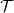
Generative Adversarial Networks for High-Dimensional Item Factor Analysis: A Deep Adversarial Learning Algorithm
-
- Journal:
- Psychometrika / Volume 90 / Issue 5 / December 2025
- Published online by Cambridge University Press:
- 11 November 2025, pp. 1765-1788
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Can artificial intelligence support Bactrian camel conservation? Testing machine learning on aerial imagery in Mongolia’s Gobi Desert – CORRIGENDUM
-
- Journal:
- Environmental Conservation , First View
- Published online by Cambridge University Press:
- 05 November 2025, pp. 1-2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
2 - Artificial Intelligence and Machine Learning
-
- Book:
- Insight-Driven Problem Solving
- Published online:
- 21 October 2025
- Print publication:
- 30 October 2025, pp 53-110
-
- Chapter
- Export citation
1 - What Is AI?
-
- Book:
- Artificial Intelligence in Schools
- Published online:
- 24 December 2025
- Print publication:
- 30 October 2025, pp 4-23
-
- Chapter
- Export citation
6 - Big Artificial Intelligence
-
- Book:
- Big Data in the Psychological Sciences
- Published online:
- 23 October 2025
- Print publication:
- 23 October 2025, pp 92-116
-
- Chapter
- Export citation
Graph neural networks for hourly precipitation projections at the convection permitting scale with a novel hybrid imperfect framework
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 13 October 2025, e47
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Extreme precipitation events are projected to increase both in frequency and intensity due to climate change. High-resolution climate projections are essential to effectively model the convective phenomena responsible for severe precipitation and to plan any adaptation and mitigation action. Existing numerical methods struggle with either insufficient accuracy in capturing the evolution of convective dynamical systems, due to the low resolution, or are limited by the excessive computational demands required to achieve kilometre-scale resolution. To fill this gap, we propose a novel deep learning regional climate model (RCM) emulator called graph neural networks for climate downscaling (GNN4CD) to estimate high-resolution precipitation. The emulator is innovative in architecture and training strategy, using graph neural networks (GNNs) to learn the downscaling function through a novel hybrid imperfect framework. GNN4CD is initially trained to perform reanalysis to observation downscaling and then used for RCM emulation during the inference phase. The emulator is able to estimate precipitation at very high resolution both in space (
 $ 3 $km) and time (
$ 3 $km) and time ( $ 1 $h), starting from lower-resolution atmospheric data (
$ 1 $h), starting from lower-resolution atmospheric data ( $ \sim 25 $km). Leveraging the flexibility of GNNs, we tested its spatial transferability in regions unseen during training. The model trained on northern Italy effectively reproduces the precipitation distribution, seasonal diurnal cycles, and spatial patterns of extreme percentiles across all of Italy. When used as an RCM emulator for the historical, mid-century, and end-of-century time slices, GNN4CD shows the remarkable ability to capture the shifts in precipitation distribution, especially in the tail, where changes are most pronounced.
$ \sim 25 $km). Leveraging the flexibility of GNNs, we tested its spatial transferability in regions unseen during training. The model trained on northern Italy effectively reproduces the precipitation distribution, seasonal diurnal cycles, and spatial patterns of extreme percentiles across all of Italy. When used as an RCM emulator for the historical, mid-century, and end-of-century time slices, GNN4CD shows the remarkable ability to capture the shifts in precipitation distribution, especially in the tail, where changes are most pronounced.



7 - AI for Human and Misinformation Interactions
-
-
- Book:
- Human-AI Interaction and Collaboration
- Published online:
- 19 September 2025
- Print publication:
- 09 October 2025, pp 153-174
-
- Chapter
- Export citation

Deep Learning in Quantitative Trading
-
- Published online:
- 03 October 2025
- Print publication:
- 30 October 2025
-
- Element
- Export citation
