Refine search
Actions for selected content:
116 results
2 - Methods of Empirical Paleoclimatology
-
- Book:
- Quaternary Climate Dynamics
- Published online:
- 17 December 2025
- Print publication:
- 22 January 2026, pp 40-65
-
- Chapter
- Export citation
Chapter 8 - An Allometry for Rhythmic Pulse
-
- Book:
- The Psychology of Human Temporality
- Published online:
- 24 October 2025
- Print publication:
- 13 November 2025, pp 117-135
-
- Chapter
- Export citation
11 - Integration of InSAR and GNSS
-
- Book:
- Satellite Radar Interferometry
- Published online:
- 13 September 2025
- Print publication:
- 04 September 2025, pp 166-183
-
- Chapter
-
- You have access
- Open access
- Export citation
What moves (spending) mood? The nature and origins of parallel public preferences
-
- Journal:
- Political Science Research and Methods , First View
- Published online by Cambridge University Press:
- 15 August 2025, pp. 1-17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Formulating and evaluating time series algorithms to forecast daily asthma hospital admissions
-
- Journal:
- Journal of Clinical and Translational Science / Volume 9 / Issue 1 / 2025
- Published online by Cambridge University Press:
- 30 July 2025, e185
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tree semantic segmentation from aerial image time series
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 29 July 2025, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A temporal stochastic bias correction using a machine learning attention model
- Part of
-
- Journal:
- Environmental Data Science / Volume 3 / 2024
- Published online by Cambridge University Press:
- 02 January 2025, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Models for the Analysis of Alternative Sources of Growth in Correlated Stochastic Variables
-
- Journal:
- Psychometrika / Volume 39 / Issue 2 / June 1974
- Published online by Cambridge University Press:
- 01 January 2025, pp. 223-245
-
- Article
- Export citation
Pursuing Collective Synchrony in Teams: A Regime-Switching Dynamic Factor Model of Speed Similarity in Soccer
-
- Journal:
- Psychometrika / Volume 86 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1016-1038
-
- Article
- Export citation
OpenMx 2.0: Extended Structural Equation and Statistical Modeling
-
- Journal:
- Psychometrika / Volume 81 / Issue 2 / June 2016
- Published online by Cambridge University Press:
- 01 January 2025, pp. 535-549
-
- Article
- Export citation
Connect: A Novel Network Approach for Investigating the Co-occurrence of Binary Psychopathological Symptoms Over Time
-
- Journal:
- Psychometrika / Volume 87 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 107-132
-
- Article
- Export citation
A General Model for the Analysis of Multilevel Data
-
- Journal:
- Psychometrika / Volume 53 / Issue 4 / December 1988
- Published online by Cambridge University Press:
- 01 January 2025, pp. 455-467
-
- Article
- Export citation
Penalized Estimation and Forecasting of Multiple Subject Intensive Longitudinal Data
-
- Journal:
- Psychometrika / Volume 87 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 403-431
-
- Article
- Export citation
Modeling Noisy Data with Differential Equations Using Observed and Expected Matrices
-
- Journal:
- Psychometrika / Volume 75 / Issue 3 / September 2010
- Published online by Cambridge University Press:
- 01 January 2025, pp. 420-437
-
- Article
- Export citation
Two Filtering Methods of Forecasting Linear and Nonlinear Dynamics of Intensive Longitudinal Data
-
- Journal:
- Psychometrika / Volume 87 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 477-505
-
- Article
- Export citation
Using State-Space Model with Regime Switching to Represent the Dynamics of Facial Electromyography (EMG) Data
-
- Journal:
- Psychometrika / Volume 75 / Issue 4 / December 2010
- Published online by Cambridge University Press:
- 01 January 2025, pp. 744-771
-
- Article
- Export citation
A Network Approach for Evaluating Coherence in Multivariate Systems: An Application to Psychophysiological Emotion Data
-
- Journal:
- Psychometrika / Volume 76 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 01 January 2025, pp. 124-152
-
- Article
- Export citation
Possible Futures for Network Psychometrics
-
- Journal:
- Psychometrika / Volume 87 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 253-265
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Forecasting Intra-individual Changes of Affective States Taking into Account Inter-individual Differences Using Intensive Longitudinal Data from a University Student Dropout Study in Math
-
- Journal:
- Psychometrika / Volume 87 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 533-558
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The longitudinal process that leads to university student dropout in STEM subjects can be described by referring to (a) inter-individual differences (e.g., cognitive abilities) as well as (b) intra-individual changes (e.g., affective states), (c) (unobserved) heterogeneity of trajectories, and d) time-dependent variables. Large dynamic latent variable model frameworks for intensive longitudinal data (ILD) have been proposed which are (partially) capable of simultaneously separating the complex data structures (e.g., DLCA; Asparouhov et al. in Struct Equ Model 24:257–269, 2017; DSEM; Asparouhov et al. in Struct Equ Model 25:359–388, 2018; NDLC-SEM, Kelava and Brandt in Struct Equ Model 26:509–528, 2019). From a methodological perspective, forecasting in dynamic frameworks allowing for real-time inferences on latent or observed variables based on ongoing data collection has not been an extensive research topic. From a practical perspective, there has been no empirical study on student dropout in math that integrates ILD, dynamic frameworks, and forecasting of critical states of the individuals allowing for real-time interventions. In this paper, we show how Bayesian forecasting of multivariate intra-individual variables and time-dependent class membership of individuals (affective states) can be performed in these dynamic frameworks using a Forward Filtering Backward Sampling method. To illustrate our approach, we use an empirical example where we apply the proposed forecasting method to ILD from a large university student dropout study in math with multivariate observations collected over 50 measurement occasions from multiple students (\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$N = 122$$\end{document}
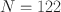 ). More specifically, we forecast emotions and behavior related to dropout. This allows us to predict emerging critical dynamic states (e.g., critical stress levels or pre-decisional states) 8 weeks before the actual dropout occurs.
). More specifically, we forecast emotions and behavior related to dropout. This allows us to predict emerging critical dynamic states (e.g., critical stress levels or pre-decisional states) 8 weeks before the actual dropout occurs.
Time series analysis of GSS bonds Part 2 – further univariate analysis of S&P Green Bond Index
-
- Journal:
- British Actuarial Journal / Volume 29 / 2024
- Published online by Cambridge University Press:
- 20 December 2024, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
