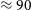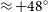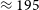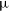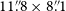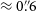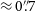Refine search
Actions for selected content:
719 results
3 - Introduction to Methods
- from Part One - Breakthrough Astrophysics
-
- Book:
- Quasar Absorption Lines
- Published online:
- 10 December 2025
- Print publication:
- 18 December 2025, pp 55-82
-
- Chapter
- Export citation
Lawyers, Career Goals, and the Gender Gap in Political Ambition
-
- Journal:
- Journal of Law and Courts ,
- Published online by Cambridge University Press:
- 28 November 2025, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
GLEAM-300: The GaLactic and Extragalactic All-sky Murchison Widefield Array (GLEAM) survey at 300 MHz
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 17 November 2025, e158
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper we present a wide-field radio survey at 300 MHz covering the sky from
 $-90^{\circ} \leq \delta_{\text{J2000}} \lesssim {+40}^{\circ}$ using the Murchison Widefield Array (MWA). This 300-MHz survey follows the Galactic and Extragalactic All-sky MWA (GLEAM) survey and provides an additional comparatively high-frequency data point to existing multi-frequency (72–231 MHz) data. With this data release we provide mosaic images and a catalogue of compact source components. We use two-minute snapshot observations covering 2015–2016, combining overlapping two-minute snapshot images to provide full-sensitivity mosaic images with a median root-mean-square noise of
$-90^{\circ} \leq \delta_{\text{J2000}} \lesssim {+40}^{\circ}$ using the Murchison Widefield Array (MWA). This 300-MHz survey follows the Galactic and Extragalactic All-sky MWA (GLEAM) survey and provides an additional comparatively high-frequency data point to existing multi-frequency (72–231 MHz) data. With this data release we provide mosaic images and a catalogue of compact source components. We use two-minute snapshot observations covering 2015–2016, combining overlapping two-minute snapshot images to provide full-sensitivity mosaic images with a median root-mean-square noise of  ${9.1_{-2.8}^{+5.5}}$ mJy beam
${9.1_{-2.8}^{+5.5}}$ mJy beam $^{-1}$ and median angular resolution of
$^{-1}$ and median angular resolution of  ${128^{\prime\prime}8} \times {112^{\prime\prime}5}$, with some position-dependent variation. We find a total of 338 080 unique Gaussian components across the mosaic images. The survey is the first at 300 MHz from the MWA covering the whole Southern Hemisphere. It provides a unique spectral data point that complements the existing GLEAM survey and the ongoing GLEAM-eXtended survey and points towards results from the upcoming SKA-Low surveys.
${128^{\prime\prime}8} \times {112^{\prime\prime}5}$, with some position-dependent variation. We find a total of 338 080 unique Gaussian components across the mosaic images. The survey is the first at 300 MHz from the MWA covering the whole Southern Hemisphere. It provides a unique spectral data point that complements the existing GLEAM survey and the ongoing GLEAM-eXtended survey and points towards results from the upcoming SKA-Low surveys.




GaLactic and extragalactic all-sky Murchison Widefield Array survey eXtended (GLEAM-X) III: Galactic plane
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 28 October 2025, e137
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We present the third data release for the Galactic and Extragalactic All-Sky Murchison Widefield Array eXtended (GLEAM-X) survey, covering
 $\approx 3\,800$ deg
$\approx 3\,800$ deg $^2$ of the southern Galactic Plane (GP) with
$^2$ of the southern Galactic Plane (GP) with  ${233}^{\circ} \lt l \lt {44}^{\circ}$ and
${233}^{\circ} \lt l \lt {44}^{\circ}$ and  $|b| \lt {11}^{\circ}$ across a frequency range of 72–231 MHz divided into 20 sub-bands. GLEAM-X observations were taken using the ‘extended’ Phase-ii configuration of the Murchison Widefield Array (MWA), which features baselines ranging from approximately 12 m to 5 km. This configuration limits sensitivity to the diffuse structure of the GP, with an angular resolution range of about
$|b| \lt {11}^{\circ}$ across a frequency range of 72–231 MHz divided into 20 sub-bands. GLEAM-X observations were taken using the ‘extended’ Phase-ii configuration of the Murchison Widefield Array (MWA), which features baselines ranging from approximately 12 m to 5 km. This configuration limits sensitivity to the diffuse structure of the GP, with an angular resolution range of about  $45^{''}$ to
$45^{''}$ to  $2^{'}$. To achieve lower noise levels while being sensitive to a wide range of spatial scales (
$2^{'}$. To achieve lower noise levels while being sensitive to a wide range of spatial scales ( $45^{''} - {15}^{\circ}$), we combined these observations with the previous Galactic and Extragalactic All-Sky Murchison Widefield Array (GLEAM) survey. For the area covered, we provide images spanning the whole frequency range. A wide-band image over 170–231 MHz, with RMS noise of
$45^{''} - {15}^{\circ}$), we combined these observations with the previous Galactic and Extragalactic All-Sky Murchison Widefield Array (GLEAM) survey. For the area covered, we provide images spanning the whole frequency range. A wide-band image over 170–231 MHz, with RMS noise of  $\approx\;$3–6 mJy beam
$\approx\;$3–6 mJy beam $^{-1}$ and source position accuracy within 1 arcsec, is then used to perform source-finding, which yields 98 207 elements measured across
$^{-1}$ and source position accuracy within 1 arcsec, is then used to perform source-finding, which yields 98 207 elements measured across  $20 \times 7.68$ MHz frequency bands. The catalogue is 90
$20 \times 7.68$ MHz frequency bands. The catalogue is 90 $\%$ complete at 50 mJy within
$\%$ complete at 50 mJy within  ${233}^{\circ} \lt l \lt {324}^{\circ}$ and at 125 mJy in
${233}^{\circ} \lt l \lt {324}^{\circ}$ and at 125 mJy in  ${290}^{\circ} \lt l \lt {44}^{\circ}$, while it is
${290}^{\circ} \lt l \lt {44}^{\circ}$, while it is  $99.3\%$ reliable overall. All the images and the catalogue are available online for download.
$99.3\%$ reliable overall. All the images and the catalogue are available online for download.














5 - Big Experiments
-
- Book:
- Big Data in the Psychological Sciences
- Published online:
- 23 October 2025
- Print publication:
- 23 October 2025, pp 70-91
-
- Chapter
- Export citation
3 - Experimental vs. Correlational Studies, Measuring Constructs, and Internal Consistency Reliability
-
- Book:
- Research Methods and Applied Statistics
- Published online:
- 17 December 2025
- Print publication:
- 02 October 2025, pp 70-93
-
- Chapter
- Export citation
A long period transient search method for the Murchison Widefield Array
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 15 September 2025, e129
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Awareness of animal welfare among primary stakeholders during transport and in livestock markets in Nigeria
-
- Journal:
- Animal Welfare / Volume 34 / 2025
- Published online by Cambridge University Press:
- 26 August 2025, e61
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
4 - What is the relationship between oracy edcuation and confidence for students and teachers?
- from Part I - Debating Oracy in the UK
-
-
- Book:
- Oracy
- Published online:
- 23 September 2025
- Print publication:
- 31 July 2025, pp 46-65
-
- Chapter
- Export citation
Marine park monitoring informs productivity potential of a southern rock lobster resource in South Australia
-
- Journal:
- Journal of the Marine Biological Association of the United Kingdom / Volume 105 / 2025
- Published online by Cambridge University Press:
- 16 July 2025, e81
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 10 - Evaluating Emergency Risk Communication and Engaging in Public Education for the Next Emergency
- from Part III - Communicating and Planning after a Health Emergency
-
- Book:
- Risk Communication in Public Health Emergencies
- Published online:
- 05 June 2025
- Print publication:
- 19 June 2025, pp 257-280
-
- Chapter
- Export citation
Invitation Letters Increase Response Rates in Elite Surveys: Evidence from Germany and the United Kingdom
-
- Journal:
- Journal of Experimental Political Science , First View
- Published online by Cambridge University Press:
- 10 June 2025, pp. 1-6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The first large absorption survey in H i (FLASH): II. Pilot survey data release and first results
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 09 June 2025, e088
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The First Large Absorption Survey in H i (FLASH) is a large-area radio survey for neutral hydrogen in and around galaxies in the intermediate redshift range
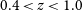 $0.4\lt z\lt1.0$, using the 21-cm H i absorption line as a probe of cold neutral gas. The survey uses the ASKAP radio telescope and will cover 24,000 deg
$0.4\lt z\lt1.0$, using the 21-cm H i absorption line as a probe of cold neutral gas. The survey uses the ASKAP radio telescope and will cover 24,000 deg $^2$ of sky over the next five years. FLASH breaks new ground in two ways – it is the first large H i absorption survey to be carried out without any optical preselection of targets, and we use an automated Bayesian line-finding tool to search through large datasets and assign a statistical significance to potential line detections. Two Pilot Surveys, covering around 3000 deg
$^2$ of sky over the next five years. FLASH breaks new ground in two ways – it is the first large H i absorption survey to be carried out without any optical preselection of targets, and we use an automated Bayesian line-finding tool to search through large datasets and assign a statistical significance to potential line detections. Two Pilot Surveys, covering around 3000 deg $^2$ of sky, were carried out in 2019-22 to test and verify the strategy for the full FLASH survey. The processed data products from these Pilot Surveys (spectral-line cubes, continuum images, and catalogues) are public and available online. In this paper, we describe the FLASH spectral-line and continuum data products and discuss the quality of the H i spectra and the completeness of our automated line search. Finally, we present a set of 30 new H i absorption lines that were robustly detected in the Pilot Surveys, almost doubling the number of known H i absorption systems at
$^2$ of sky, were carried out in 2019-22 to test and verify the strategy for the full FLASH survey. The processed data products from these Pilot Surveys (spectral-line cubes, continuum images, and catalogues) are public and available online. In this paper, we describe the FLASH spectral-line and continuum data products and discuss the quality of the H i spectra and the completeness of our automated line search. Finally, we present a set of 30 new H i absorption lines that were robustly detected in the Pilot Surveys, almost doubling the number of known H i absorption systems at 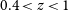 $0.4\lt z\lt1$. The detected lines span a wide range in H i optical depth, including three lines with a peak optical depth
$0.4\lt z\lt1$. The detected lines span a wide range in H i optical depth, including three lines with a peak optical depth 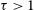 $\tau\gt1$, and appear to be a mixture of intervening and associated systems. Interestingly, around two-thirds of the lines found in this untargeted sample are detected against sources with a peaked-spectrum radio continuum, which are only a minor (5–20%) fraction of the overall radio-source population. The detection rate for H i absorption lines in the Pilot Surveys (0.3 to 0.5 lines per 40 deg
$\tau\gt1$, and appear to be a mixture of intervening and associated systems. Interestingly, around two-thirds of the lines found in this untargeted sample are detected against sources with a peaked-spectrum radio continuum, which are only a minor (5–20%) fraction of the overall radio-source population. The detection rate for H i absorption lines in the Pilot Surveys (0.3 to 0.5 lines per 40 deg $^2$ ASKAP field) is a factor of two below the expected value. One possible reason for this is the presence of a range of spectral-line artefacts in the Pilot Survey data that have now been mitigated and are not expected to recur in the full FLASH survey. A future paper in this series will discuss the host galaxies of the H i absorption systems identified here.
$^2$ ASKAP field) is a factor of two below the expected value. One possible reason for this is the presence of a range of spectral-line artefacts in the Pilot Survey data that have now been mitigated and are not expected to recur in the full FLASH survey. A future paper in this series will discuss the host galaxies of the H i absorption systems identified here.
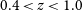


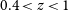
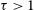

The Polarisation Sky Survey of the Universe’s Magnetism (POSSUM): Science goals and survey description
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 09 June 2025, e091
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The Australian SKA Pathfinder (ASKAP) offers powerful new capabilities for studying the polarised and magnetised Universe at radio wavelengths. In this paper, we introduce the Polarisation Sky Survey of the Universe’s Magnetism (POSSUM), a groundbreaking survey with three primary objectives: (1) to create a comprehensive Faraday rotation measure (RM) grid of up to one million compact extragalactic sources across the southern
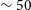 $\sim50$% of the sky (20,630 deg
$\sim50$% of the sky (20,630 deg $^2$); (2) to map the intrinsic polarisation and RM properties of a wide range of discrete extragalactic and Galactic objects over the same area; and (3) to contribute interferometric data with excellent surface brightness sensitivity, which can be combined with single-dish data to study the diffuse Galactic interstellar medium. Observations for the full POSSUM survey commenced in May 2023 and are expected to conclude by mid-2028. POSSUM will achieve an RM grid density of around 30–50 RMs per square degree with a median measurement uncertainty of
$^2$); (2) to map the intrinsic polarisation and RM properties of a wide range of discrete extragalactic and Galactic objects over the same area; and (3) to contribute interferometric data with excellent surface brightness sensitivity, which can be combined with single-dish data to study the diffuse Galactic interstellar medium. Observations for the full POSSUM survey commenced in May 2023 and are expected to conclude by mid-2028. POSSUM will achieve an RM grid density of around 30–50 RMs per square degree with a median measurement uncertainty of 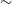 $\sim$1 rad m
$\sim$1 rad m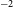 $^{-2}$. The survey operates primarily over a frequency range of 800–1088 MHz, with an angular resolution of 20” and a typical RMS sensitivity in Stokes Q or U of 18
$^{-2}$. The survey operates primarily over a frequency range of 800–1088 MHz, with an angular resolution of 20” and a typical RMS sensitivity in Stokes Q or U of 18 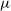 $\mu$Jy beam
$\mu$Jy beam $^{-1}$. Additionally, the survey will be supplemented by similar observations covering 1296–1440 MHz over 38% of the sky. POSSUM will enable the discovery and detailed investigation of magnetised phenomena in a wide range of cosmic environments, including the intergalactic medium and cosmic web, galaxy clusters and groups, active galactic nuclei and radio galaxies, the Magellanic System and other nearby galaxies, galaxy halos and the circumgalactic medium, and the magnetic structure of the Milky Way across a very wide range of scales, as well as the interplay between these components. This paper reviews the current science case developed by the POSSUM Collaboration and provides an overview of POSSUM’s observations, data processing, outputs, and its complementarity with other radio and multi-wavelength surveys, including future work with the SKA.
$^{-1}$. Additionally, the survey will be supplemented by similar observations covering 1296–1440 MHz over 38% of the sky. POSSUM will enable the discovery and detailed investigation of magnetised phenomena in a wide range of cosmic environments, including the intergalactic medium and cosmic web, galaxy clusters and groups, active galactic nuclei and radio galaxies, the Magellanic System and other nearby galaxies, galaxy halos and the circumgalactic medium, and the magnetic structure of the Milky Way across a very wide range of scales, as well as the interplay between these components. This paper reviews the current science case developed by the POSSUM Collaboration and provides an overview of POSSUM’s observations, data processing, outputs, and its complementarity with other radio and multi-wavelength surveys, including future work with the SKA.

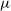

Navigating the Lexis+ UK Migration: Insights and Lessons Learned
-
- Journal:
- Legal Information Management / Volume 25 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 29 August 2025, pp. 116-119
- Print publication:
- June 2025
-
- Article
- Export citation
The GALAH survey: Data release 4
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 27 May 2025, e051
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The field-ready tea-box adaptometer: colonial nutrition science and/in imperial economies in Malawi
-
- Journal:
- Medical History , First View
- Published online by Cambridge University Press:
- 15 May 2025, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
BIALL/SLS Academic Law Library Survey 2022/23
-
- Journal:
- Legal Information Management / Volume 25 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 10 June 2025, pp. 8-11
- Print publication:
- March 2025
-
- Article
- Export citation
WALLABY Pilot Survey: HI source-finding with a machine learning framework
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e033
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The data volumes generated by theWidefield ASKAP L-band Legacy All-sky Blind surveY atomic hydrogen (Hi) survey using the Australian Square Kilometre Array Pathfinder (ASKAP) necessitate greater automation and reliable automation in the task of source finding and cataloguing. To this end, we introduce and explore a novel deep learning framework for detecting low signal-to-noise ratio (SNR) Hi sources in an automated fashion. Specifically, our proposed method provides an automated process for separating true Hi detections from false positives when used in combination with the source finding application output candidate catalogues. Leveraging the spatial and depth capabilities of 3D convolutional neural networks, our method is specifically designed to recognize patterns and features in three-dimensional space, making it uniquely suited for rejecting false-positive sources in low SNR scenarios generated by conventional linear methods. As a result, our approach is significantly more accurate in source detection and results in considerably fewer false detections compared to previous linear statistics-based source finding algorithms. Performance tests using mock galaxies injected into real ASKAP data cubes reveal our method’s capability to achieve near-100% completeness and reliability at a relatively low integrated SNR
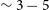 $\sim3-5$. An at-scale version of this tool will greatly maximise the science output from the upcoming widefield Hi surveys.
$\sim3-5$. An at-scale version of this tool will greatly maximise the science output from the upcoming widefield Hi surveys.
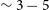
The Rapid ASKAP Continuum Survey (RACS) VI: The RACS-high 1 655.5 MHz images and catalogue
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 03 February 2025, e038
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We have conducted a widefield, wideband, snapshot survey using the Australian SKA Pathfinder (ASKAP) referred to as the Rapid ASKAP Continuum Survey (RACS). RACS covers
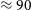 $\approx 90$% of the sky, with multiple observing epochs in three frequency bands sampling the ASKAP frequency range of 700–1 800 MHz. This paper describes the third major epoch at 1 655.5 MHz, RACS-high, and the subsequent imaging and catalogue data release. The RACS-high observations at 1 655.5 MHz are otherwise similar to the previously released RACS-mid (at 1 367.5 MHz) and were calibrated and imaged with minimal changes. From the 1 493 images covering the sky up to declination
$\approx 90$% of the sky, with multiple observing epochs in three frequency bands sampling the ASKAP frequency range of 700–1 800 MHz. This paper describes the third major epoch at 1 655.5 MHz, RACS-high, and the subsequent imaging and catalogue data release. The RACS-high observations at 1 655.5 MHz are otherwise similar to the previously released RACS-mid (at 1 367.5 MHz) and were calibrated and imaged with minimal changes. From the 1 493 images covering the sky up to declination 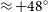 $\approx +48^\circ$, we present a catalogue of 2 677 509 radio sources. The catalogue is constructed from images with a median root-mean-square noise of
$\approx +48^\circ$, we present a catalogue of 2 677 509 radio sources. The catalogue is constructed from images with a median root-mean-square noise of 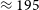 $\approx 195$
$\approx 195$ 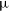 $\unicode{x03BC}$Jy PSF
$\unicode{x03BC}$Jy PSF $^{-1}$ (point-spread function) and a median angular resolution of
$^{-1}$ (point-spread function) and a median angular resolution of 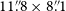 $11{\stackrel{\prime\prime}{\raise-0pt\hbox{.}}}8 \times 8{\stackrel{\prime\prime}{\raise-0pt\hbox{.}}}1$. The overall reliability of the catalogue is estimated to be 99.18%, and we find a decrease in reliability as angular resolution improves. We estimate the brightness scale to be accurate to 10%, and the astrometric accuracy to be within
$11{\stackrel{\prime\prime}{\raise-0pt\hbox{.}}}8 \times 8{\stackrel{\prime\prime}{\raise-0pt\hbox{.}}}1$. The overall reliability of the catalogue is estimated to be 99.18%, and we find a decrease in reliability as angular resolution improves. We estimate the brightness scale to be accurate to 10%, and the astrometric accuracy to be within 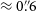 $\approx 0{\stackrel{\prime\prime}{\raise-0pt\hbox{.}}}6$ in right ascension and
$\approx 0{\stackrel{\prime\prime}{\raise-0pt\hbox{.}}}6$ in right ascension and 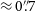 $\approx 0{\stackrel{\prime\prime}{\raise-0pt\hbox{.}}}7$ in declination after correction of a systematic declination-dependent offset. All data products from RACS-high, including calibrated visibility datasets, images from individual observations, full-sensitivity mosaics, and the all-sky catalogue are available at the CSIRO ASKAP Science Data Archive.
$\approx 0{\stackrel{\prime\prime}{\raise-0pt\hbox{.}}}7$ in declination after correction of a systematic declination-dependent offset. All data products from RACS-high, including calibrated visibility datasets, images from individual observations, full-sensitivity mosaics, and the all-sky catalogue are available at the CSIRO ASKAP Science Data Archive.