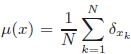Refine search
Actions for selected content:
43 results
Optimizing radiation patterns of mechanically reconfigurable phased arrays using flexible meta-gaps
-
- Journal:
- International Journal of Microwave and Wireless Technologies / Volume 16 / Issue 5 / June 2024
- Published online by Cambridge University Press:
- 02 January 2025, pp. 838-851
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Simulated Annealing Methodology for Clusterwise Linear Regression
-
- Journal:
- Psychometrika / Volume 54 / Issue 4 / December 1989
- Published online by Cambridge University Press:
- 01 January 2025, pp. 707-736
-
- Article
- Export citation
CLASSI: A classification model for the study of sequential processes and individual differences therein
-
- Journal:
- Psychometrika / Volume 73 / Issue 1 / March 2008
- Published online by Cambridge University Press:
- 01 January 2025, pp. 107-124
-
- Article
- Export citation
The Local Minima Problem in Hierarchical Classes Analysis: An Evaluation of a Simulated Annealing Algorithm and Various Multistart Procedures
-
- Journal:
- Psychometrika / Volume 72 / Issue 3 / September 2007
- Published online by Cambridge University Press:
- 01 January 2025, pp. 377-391
-
- Article
- Export citation
A Latent Class Multidimensional Scaling Model for Two-Way One-Mode Continuous Rating Dissimilarity Data
-
- Journal:
- Psychometrika / Volume 74 / Issue 2 / June 2009
- Published online by Cambridge University Press:
- 01 January 2025, pp. 297-315
-
- Article
- Export citation
Analysis of the Weighted Kappa and Its Maximum with Markov Moves
-
- Journal:
- Psychometrika / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1270-1289
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exemplar-Based Clustering via Simulated Annealing
-
- Journal:
- Psychometrika / Volume 74 / Issue 3 / September 2009
- Published online by Cambridge University Press:
- 01 January 2025, pp. 457-475
-
- Article
- Export citation
Clustering Qualitative Data Based on Binary Equivalence Relations: Neighborhood Search Heuristics for the Clique Partitioning Problem
-
- Journal:
- Psychometrika / Volume 74 / Issue 4 / December 2009
- Published online by Cambridge University Press:
- 01 January 2025, pp. 685-703
-
- Article
- Export citation
15 - Group Problem Solving: Harnessing the Wisdom of the Crowds
- from Part IV - Society
-
- Book:
- Behavioral Network Science
- Published online:
- 08 November 2024
- Print publication:
- 19 December 2024, pp 244-257
-
- Chapter
- Export citation
5 - Multivariate Feature Selection
- from Part I - Framework for Multivariate Biomarker Discovery
-
- Book:
- Multivariate Biomarker Discovery
- Published online:
- 30 May 2024
- Print publication:
- 06 June 2024, pp 76-98
-
- Chapter
- Export citation
Improved Metropolis–Hastings algorithms via landscape modification with applications to simulated annealing and the Curie–Weiss model
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 30 August 2023, pp. 587-620
- Print publication:
- June 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Large-time behaviour and the second eigenvalue problem for finite-state mean-field interacting particle systems
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 08 July 2022, pp. 85-125
- Print publication:
- March 2023
-
- Article
- Export citation
-
This article examines large-time behaviour of finite-state mean-field interacting particle systems. Our first main result is a sharp estimate (in the exponential scale) of the time required for convergence of the empirical measure process of the N-particle system to its invariant measure; we show that when time is of the order
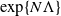 $\exp\{N\Lambda\}$ for a suitable constant
$\exp\{N\Lambda\}$ for a suitable constant 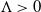 $\Lambda > 0$, the process has mixed well and it is close to its invariant measure. We then obtain large-N asymptotics of the second-largest eigenvalue of the generator associated with the empirical measure process when it is reversible with respect to its invariant measure. We show that its absolute value scales as
$\Lambda > 0$, the process has mixed well and it is close to its invariant measure. We then obtain large-N asymptotics of the second-largest eigenvalue of the generator associated with the empirical measure process when it is reversible with respect to its invariant measure. We show that its absolute value scales as 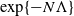 $\exp\{{-}N\Lambda\}$. The main tools used in establishing our results are the large deviation properties of the empirical measure process from its large-N limit. As an application of the study of large-time behaviour, we also show convergence of the empirical measure of the system of particles to a global minimum of a certain ‘entropy’ function when particles are added over time in a controlled fashion. The controlled addition of particles is analogous to the cooling schedule associated with the search for a global minimum of a function using the simulated annealing algorithm.
$\exp\{{-}N\Lambda\}$. The main tools used in establishing our results are the large deviation properties of the empirical measure process from its large-N limit. As an application of the study of large-time behaviour, we also show convergence of the empirical measure of the system of particles to a global minimum of a certain ‘entropy’ function when particles are added over time in a controlled fashion. The controlled addition of particles is analogous to the cooling schedule associated with the search for a global minimum of a function using the simulated annealing algorithm.
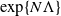
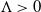
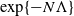
Aircraft sequencing and scheduling in TMAs under wind direction uncertainties
-
- Journal:
- The Aeronautical Journal / Volume 124 / Issue 1282 / December 2020
- Published online by Cambridge University Press:
- 13 August 2020, pp. 1896-1912
-
- Article
- Export citation
Predicting the flowering date of Portuguese grapevine varieties using temperature-based phenological models: a multi-site approach
-
- Journal:
- The Journal of Agricultural Science / Volume 156 / Issue 7 / September 2018
- Published online by Cambridge University Press:
- 24 October 2018, pp. 865-876
-
- Article
- Export citation
Automated statistical matching of multiple tephra records exemplified using five long maar sequences younger than 75 ka, Auckland, New Zealand
-
- Journal:
- Quaternary Research / Volume 82 / Issue 2 / September 2014
- Published online by Cambridge University Press:
- 20 January 2017, pp. 405-419
-
- Article
- Export citation
Designing efficient sampling schemes for reconnaissance surveys of contaminated bed sediments in water courses
-
- Journal:
- Netherlands Journal of Geosciences / Volume 79 / Issue 4 / December 2000
- Published online by Cambridge University Press:
- 01 April 2016, pp. 441-447
-
- Article
-
- You have access
- Export citation
Means in complete manifolds: uniqueness and approximation
-
- Journal:
- ESAIM: Probability and Statistics / Volume 18 / 2014
- Published online by Cambridge University Press:
- 27 March 2014, pp. 185-206
- Print publication:
- 2014
-
- Article
- Export citation
-
Let M be acomplete Riemannian manifold, M ∈ ℕ andp ≥ 1. Weprove that almost everywhere on x = (x1,...,xN) ∈ MNfor Lebesgue measure in MN, the measure \hbox{$\di \mu(x)=\f1N\sum_{k=1}^N\d_{x_k}$}
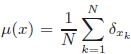 has a unique p–mean ep(x).As a consequence, if X = (X1,...,XN)is a MN-valued randomvariable with absolutely continuous law, then almost surely μ(X(ω)) has aunique p–mean. In particular if (Xn)n ≥ 1is an independent sample of an absolutely continuous law in M, then the processep,n(ω) = ep(X1(ω),...,Xn(ω))is well-defined. Assume M is compact and consider a probability measureν inM. Usingpartial simulated annealing, we define a continuous semimartingale which converges inprobability to the set of minimizers of the integral of distance at power p with respect toν. When theset is a singleton, it converges to the p–mean.
has a unique p–mean ep(x).As a consequence, if X = (X1,...,XN)is a MN-valued randomvariable with absolutely continuous law, then almost surely μ(X(ω)) has aunique p–mean. In particular if (Xn)n ≥ 1is an independent sample of an absolutely continuous law in M, then the processep,n(ω) = ep(X1(ω),...,Xn(ω))is well-defined. Assume M is compact and consider a probability measureν inM. Usingpartial simulated annealing, we define a continuous semimartingale which converges inprobability to the set of minimizers of the integral of distance at power p with respect toν. When theset is a singleton, it converges to the p–mean.