Refine search
Actions for selected content:
70 results
Model weighting for ISMIP6-Greenland based on observations and similarity among models
- Part of
-
- Journal:
- Annals of Glaciology / Volume 66 / 2025
- Published online by Cambridge University Press:
- 26 June 2025, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The Ice Sheet Model Intercomparison Project for CMIP6 (ISMIP6) resulted in many ice-sheet simulations from multiple ice-sheet models. To date, no model weighting studies have analyzed or quantified the model performance, possible duplication of the ISMIP6 ice-sheet models and the effect on mass loss projections. In this study, we adopt a model weighting scheme for the ISMIP6-Greenland that accounts for both model performance compared to observation and model similarity due to possible duplication. We choose ice velocity and thickness for the measurement of model performance, and we use all suitable variables to compute similarity indexes. We update the sea level rise contribution from ISMIP6-Greenland by the end of this century with the weights, and we find that, although the multi-model mean is not considerably shifted (mostly within
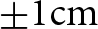 $ \pm 1{\text{cm}}$), the model spreads are reduced by 10–30% after applying the model weights. The magnitude of reduction varies largely among experiments and types of model weights applied. In general, we find that the model weighting scheme is skillful in producing model weights that effectively and reasonably quantify the model performance and inter-dependency, which can potentially benefit the future phase of the Ice Sheet Model Intercomparison Project, i.e. ISMIP7.
$ \pm 1{\text{cm}}$), the model spreads are reduced by 10–30% after applying the model weights. The magnitude of reduction varies largely among experiments and types of model weights applied. In general, we find that the model weighting scheme is skillful in producing model weights that effectively and reasonably quantify the model performance and inter-dependency, which can potentially benefit the future phase of the Ice Sheet Model Intercomparison Project, i.e. ISMIP7.
Equilibrium selection in similar repeated games: experimental evidence on the role of precedents
-
- Journal:
- Experimental Economics / Volume 21 / Issue 3 / September 2018
- Published online by Cambridge University Press:
- 14 March 2025, pp. 573-600
-
- Article
- Export citation
Conditional behavior and learning in similar stag hunt games
-
- Journal:
- Experimental Economics / Volume 21 / Issue 3 / September 2018
- Published online by Cambridge University Press:
- 14 March 2025, pp. 513-526
-
- Article
- Export citation
Feature-weighted categorized play across symmetric games
-
- Journal:
- Experimental Economics / Volume 25 / Issue 3 / June 2022
- Published online by Cambridge University Press:
- 14 March 2025, pp. 1052-1078
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Experimental game theory studies the behavior of agents who face a stream of one-shot games as a form of learning. Most literature focuses on a single recurring identical game. This paper embeds single-game learning in a broader perspective, where learning can take place across similar games. We posit that agents categorize games into a few classes and tend to play the same action within a class. The agent’s categories are generated by combining game features (payoffs) and individual motives. An individual categorization is experience-based, and may change over time. We demonstrate our approach by testing a robust (parameter-free) model over a large body of independent experimental evidence over
 symmetric games. The model provides a very good fit across games, performing remarkably better than standard learning models.
symmetric games. The model provides a very good fit across games, performing remarkably better than standard learning models.

5 - Fluid Dynamics
- from Part I - Continuum Physics
-
- Book:
- An Introduction to Continuum Physics
- Published online:
- 06 February 2025
- Print publication:
- 13 February 2025, pp 261-312
-
- Chapter
- Export citation
Pairwise Partitioning: A Nonmetric Algorithm for Identifying Feature-Based Similarity Structures
-
- Journal:
- Psychometrika / Volume 62 / Issue 1 / March 1997
- Published online by Cambridge University Press:
- 01 January 2025, pp. 85-117
-
- Article
- Export citation
Differential Ordering of Objects and Attributes
-
- Journal:
- Psychometrika / Volume 51 / Issue 2 / June 1986
- Published online by Cambridge University Press:
- 01 January 2025, pp. 209-240
-
- Article
- Export citation
Multivariate Stochastic Processes Compatible with “Aspect” Models of Similarity and Choice
-
- Journal:
- Psychometrika / Volume 46 / Issue 4 / December 1981
- Published online by Cambridge University Press:
- 01 January 2025, pp. 421-428
-
- Article
- Export citation
The Relative Sensitivities of Same-Different and Identification Judgment Models to Perceptual Dependence
-
- Journal:
- Psychometrika / Volume 58 / Issue 2 / June 1993
- Published online by Cambridge University Press:
- 01 January 2025, pp. 257-279
-
- Article
- Export citation
Colour-coded decisions: an experiment on case-based decision theory
-
- Journal:
- Journal of the Economic Science Association / Volume 10 / Issue 2 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 519-530
-
- Article
- Export citation
Netscal: A Network Scaling Algorithm for Nonsymmetric Proximity Data
-
- Journal:
- Psychometrika / Volume 54 / Issue 1 / March 1989
- Published online by Cambridge University Press:
- 01 January 2025, pp. 25-51
-
- Article
- Export citation
Similarities Derived from 3-d Nonlinear Psychophysics: Variance Distributions
-
- Journal:
- Psychometrika / Volume 59 / Issue 1 / March 1994
- Published online by Cambridge University Press:
- 01 January 2025, pp. 97-110
-
- Article
- Export citation
10 - The Ontogeny Phylogeny Model
- from Part II - Theoretical Models of Bilingual Phonetics and Phonology
-
-
- Book:
- The Cambridge Handbook of Bilingual Phonetics and Phonology
- Published online:
- 14 November 2024
- Print publication:
- 21 November 2024, pp 217-240
-
- Chapter
- Export citation
Dynamic semantic networks for exploration of creative thinking
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Identifying optimal decision-making strategies and determining effective messaging to maximize the expected outcomes of potential human–extraterrestrial encounters
-
- Journal:
- International Journal of Astrobiology / Volume 23 / 2024
- Published online by Cambridge University Press:
- 17 October 2024, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 9 - Epicureans on Preconceptions and Other Concepts
-
-
- Book:
- Conceptualising Concepts in Greek Philosophy
- Published online:
- 25 April 2024
- Print publication:
- 02 May 2024, pp 203-236
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Factors that promote the repulsion effect in preferential choice
-
- Journal:
- Judgment and Decision Making / Volume 19 / 2024
- Published online by Cambridge University Press:
- 01 April 2024, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Eye movements as a tool to investigate exemplar retrieval in judgments
-
- Journal:
- Judgment and Decision Making / Volume 19 / 2024
- Published online by Cambridge University Press:
- 26 February 2024, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 5 - Processing Components of Perspective Taking
-
- Book:
- The Analogical Reader
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp 122-150
-
- Chapter
- Export citation
4 - Romantic Attraction
- from Part II - Relationship Formation
-
- Book:
- The Science of Romantic Relationships
- Published online:
- 17 August 2023
- Print publication:
- 31 August 2023, pp 123-157
-
- Chapter
- Export citation
