Refine search
Actions for selected content:
35 results
RaCE: A rank-clustering estimation method for network meta-analysis
-
- Journal:
- Research Synthesis Methods ,
- Published online by Cambridge University Press:
- 13 November 2025, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 8 - Competition Dynamics between North Korean Refugees and South Koreans
-
-
- Book:
- Questioning Conventional Assumptions of Competition Dynamics
- Published online:
- 07 May 2025
- Print publication:
- 21 August 2025, pp 195-224
-
- Chapter
- Export citation
Peer effects on risk behaviour: the importance of group identity
-
- Journal:
- Experimental Economics / Volume 20 / Issue 1 / March 2017
- Published online by Cambridge University Press:
- 14 March 2025, pp. 100-129
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Posterior Probabilities for a Consensus Ordering
-
- Journal:
- Psychometrika / Volume 55 / Issue 1 / March 1990
- Published online by Cambridge University Press:
- 01 January 2025, pp. 53-63
-
- Article
- Export citation
Analyses of Model Fit and Robustness. A New Look at the PISA Scaling Model Underlying Ranking of Countries According to Reading Literacy
-
- Journal:
- Psychometrika / Volume 79 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 01 January 2025, pp. 210-231
-
- Article
- Export citation
Information and Preference in Partial Orders: A Bimatrix Representation
-
- Journal:
- Psychometrika / Volume 51 / Issue 2 / June 1986
- Published online by Cambridge University Press:
- 01 January 2025, pp. 197-207
-
- Article
- Export citation
Monitoring Countries in a Changing World: A New Look at DIF in International Surveys
-
- Journal:
- Psychometrika / Volume 82 / Issue 1 / March 2017
- Published online by Cambridge University Press:
- 01 January 2025, pp. 210-232
-
- Article
- Export citation
6 - The State Capacity Ranking c. 1900
- from Part II - Region-Wide Analyses
-
- Book:
- Bringing War Back In
- Published online:
- 14 November 2024
- Print publication:
- 21 November 2024, pp 123-138
-
- Chapter
- Export citation
Has bitcoin been dethroned too quickly? The cryptocurrency return networks
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 07 November 2024, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Conclusion: Fourteen Wasted Years? The Verdict
-
-
- Book:
- The Conservative Effect, 2010–2024
- Published online:
- 24 July 2024
- Print publication:
- 27 June 2024, pp 508-525
-
- Chapter
- Export citation
Tasting and consumer demand for wine: do peers and experts matter?
-
- Journal:
- Agricultural and Resource Economics Review / Volume 53 / Issue 1 / April 2024
- Published online by Cambridge University Press:
- 13 October 2023, pp. 66-86
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Contextual effects in salary satisfaction
-
- Journal:
- Judgment and Decision Making / Volume 18 / 2023
- Published online by Cambridge University Press:
- 24 August 2023, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
5 - Classifying the Fine Arts
- from Part II - Genius and the Fine Arts
-
- Book:
- The Origins of Kant's Aesthetics
- Published online:
- 10 January 2024
- Print publication:
- 26 January 2023, pp 129-148
-
- Chapter
- Export citation
The tide that lifts all focal boats: Asymmetric predictions of ascent and descent in rankings
-
- Journal:
- Judgment and Decision Making / Volume 11 / Issue 1 / January 2016
- Published online by Cambridge University Press:
- 01 January 2023, pp. 7-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Attentional shifts and preference reversals: An eye-tracking study
-
- Journal:
- Judgment and Decision Making / Volume 16 / Issue 1 / January 2021
- Published online by Cambridge University Press:
- 01 January 2023, pp. 57-93
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Order effects in the results of song contests: Evidence from the Eurovision and the New Wave
-
- Journal:
- Judgment and Decision Making / Volume 12 / Issue 4 / July 2017
- Published online by Cambridge University Press:
- 01 January 2023, pp. 415-419
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
BRANCHING TECHNIQUE FOR A BI-OBJECTIVE TWO-STAGE ASSIGNMENT PROBLEM
-
- Journal:
- The ANZIAM Journal / Volume 64 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 15 August 2022, pp. 183-204
-
- Article
- Export citation
-
We discuss a bi-objective two-stage assignment problem (BiTSAP) that aims at minimizing two objective functions: one comprising a nonlinear cost function defined explicitly in terms of assignment variables and the other a total completion time. A two-stage assignment problem deals with the optimal allocation of n jobs to n agents in two stages, where
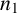 $n_1$ out of n jobs are primary jobs which constitute Stage-1 and the rest of the jobs are secondary jobs constituting Stage-2. The paper proposes an algorithm that seeks an optimal solution for a BiTSAP in terms of various efficient time-cost pairs. An algorithm for ranking all feasible assignments of a two-stage assignment problem in order of increasing total completion time is also presented. Theoretical justification and numerical illustrations are included to support the proposed algorithms.
$n_1$ out of n jobs are primary jobs which constitute Stage-1 and the rest of the jobs are secondary jobs constituting Stage-2. The paper proposes an algorithm that seeks an optimal solution for a BiTSAP in terms of various efficient time-cost pairs. An algorithm for ranking all feasible assignments of a two-stage assignment problem in order of increasing total completion time is also presented. Theoretical justification and numerical illustrations are included to support the proposed algorithms.
Development and initial validation of a multivariable predictive Early Adversity Scale for Schizophrenia (EAS-Sz) using register data to quantify environmental risk for adult schizophrenia diagnosis after childhood exposure to adversity
-
- Journal:
- Psychological Medicine / Volume 53 / Issue 11 / August 2023
- Published online by Cambridge University Press:
- 12 July 2022, pp. 4990-5000
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
4 - Vocabulary and listening and speaking
-
- Book:
- Learning Vocabulary in Another Language
- Published online:
- 02 June 2022
- Print publication:
- 09 June 2022, pp 156-193
-
- Chapter
- Export citation
8 - Computing Choice: Learning Distributions over Permutations
-
-
- Book:
- Information-Theoretic Methods in Data Science
- Published online:
- 22 March 2021
- Print publication:
- 08 April 2021, pp 229-262
-
- Chapter
- Export citation
