Refine search
Actions for selected content:
60 results
Chapter 72 - Eating Pathology Symptoms Inventory (EPSI)
-
-
- Book:
- Handbook of Body Image-Related Measures
- Published online:
- 21 November 2025
- Print publication:
- 20 November 2025, pp 219-221
-
- Chapter
- Export citation
The (mis)measure of misbehavior: Cross-national invariance of the Youth Externalizing Problems Screener across 32 countries
-
- Journal:
- Development and Psychopathology / Volume 37 / Issue 5 / December 2025
- Published online by Cambridge University Press:
- 07 October 2025, pp. 2827-2840
-
- Article
- Export citation
Restricted Recalibration of Item Response Theory Models
-
- Journal:
- Psychometrika / Volume 84 / Issue 2 / June 2019
- Published online by Cambridge University Press:
- 01 January 2025, pp. 529-553
-
- Article
- Export citation
Single- and Multiple-Group Penalized Factor Analysis: A Trust-Region Algorithm Approach with Integrated Automatic Multiple Tuning Parameter Selection
-
- Journal:
- Psychometrika / Volume 86 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 65-95
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An autoregressive growth model for longitudinal item analysis
-
- Journal:
- Psychometrika / Volume 81 / Issue 3 / September 2016
- Published online by Cambridge University Press:
- 01 January 2025, pp. 830-850
-
- Article
- Export citation
Comparing Latent Means Without Mean Structure Models: A Projection-Based Approach
-
- Journal:
- Psychometrika / Volume 81 / Issue 3 / September 2016
- Published online by Cambridge University Press:
- 01 January 2025, pp. 802-829
-
- Article
- Export citation
Measurement Invariance, Factor Analysis and Factorial Invariance
-
- Journal:
- Psychometrika / Volume 58 / Issue 4 / December 1993
- Published online by Cambridge University Press:
- 01 January 2025, pp. 525-543
-
- Article
- Export citation
Assessing Growth in a Diagnostic Classification Model Framework
-
- Journal:
- Psychometrika / Volume 83 / Issue 4 / December 2018
- Published online by Cambridge University Press:
- 01 January 2025, pp. 963-990
-
- Article
- Export citation
Fitting and Testing Conditional Multinormal Partial Credit Models
-
- Journal:
- Psychometrika / Volume 77 / Issue 4 / October 2012
- Published online by Cambridge University Press:
- 01 January 2025, pp. 693-709
-
- Article
- Export citation
Finite Mixture Multilevel Multidimensional Ordinal IRT Models for Large Scale Cross-Cultural Research
-
- Journal:
- Psychometrika / Volume 75 / Issue 1 / March 2010
- Published online by Cambridge University Press:
- 01 January 2025, pp. 3-32
-
- Article
-
- You have access
- Open access
- Export citation
DIF Statistical Inference Without Knowing Anchoring Items
-
- Journal:
- Psychometrika / Volume 88 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1097-1122
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Establishing the invariance property of an instrument (e.g., a questionnaire or test) is a key step for establishing its measurement validity. Measurement invariance is typically assessed by differential item functioning (DIF) analysis, i.e., detecting DIF items whose response distribution depends not only on the latent trait measured by the instrument but also on the group membership. DIF analysis is confounded by the group difference in the latent trait distributions. Many DIF analyses require knowing several anchor items that are DIF-free in order to draw inferences on whether each of the rest is a DIF item, where the anchor items are used to identify the latent trait distributions. When no prior information on anchor items is available, or some anchor items are misspecified, item purification methods and regularized estimation methods can be used. The former iteratively purifies the anchor set by a stepwise model selection procedure, and the latter selects the DIF-free items by a LASSO-type regularization approach. Unfortunately, unlike the methods based on a correctly specified anchor set, these methods are not guaranteed to provide valid statistical inference (e.g., confidence intervals and p-values). In this paper, we propose a new method for DIF analysis under a multiple indicators and multiple causes (MIMIC) model for DIF. This method adopts a minimal \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L_1$$\end{document}
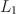 norm condition for identifying the latent trait distributions. Without requiring prior knowledge about an anchor set, it can accurately estimate the DIF effects of individual items and further draw valid statistical inferences for quantifying the uncertainty. Specifically, the inference results allow us to control the type-I error for DIF detection, which may not be possible with item purification and regularized estimation methods. We conduct simulation studies to evaluate the performance of the proposed method and compare it with the anchor-set-based likelihood ratio test approach and the LASSO approach. The proposed method is applied to analysing the three personality scales of the Eysenck personality questionnaire-revised (EPQ-R).
norm condition for identifying the latent trait distributions. Without requiring prior knowledge about an anchor set, it can accurately estimate the DIF effects of individual items and further draw valid statistical inferences for quantifying the uncertainty. Specifically, the inference results allow us to control the type-I error for DIF detection, which may not be possible with item purification and regularized estimation methods. We conduct simulation studies to evaluate the performance of the proposed method and compare it with the anchor-set-based likelihood ratio test approach and the LASSO approach. The proposed method is applied to analysing the three personality scales of the Eysenck personality questionnaire-revised (EPQ-R).
An Application of the LC-LSTM Framework to the Self-esteem Instability Case
-
- Journal:
- Psychometrika / Volume 78 / Issue 4 / October 2013
- Published online by Cambridge University Press:
- 01 January 2025, pp. 769-792
-
- Article
- Export citation
DIF Analysis with Unknown Groups and Anchor Items
-
- Journal:
- Psychometrika / Volume 89 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 267-295
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Ensuring fairness in instruments like survey questionnaires or educational tests is crucial. One way to address this is by a Differential Item Functioning (DIF) analysis, which examines if different subgroups respond differently to a particular item, controlling for their overall latent construct level. DIF analysis is typically conducted to assess measurement invariance at the item level. Traditional DIF analysis methods require knowing the comparison groups (reference and focal groups) and anchor items (a subset of DIF-free items). Such prior knowledge may not always be available, and psychometric methods have been proposed for DIF analysis when one piece of information is unknown. More specifically, when the comparison groups are unknown while anchor items are known, latent DIF analysis methods have been proposed that estimate the unknown groups by latent classes. When anchor items are unknown while comparison groups are known, methods have also been proposed, typically under a sparsity assumption – the number of DIF items is not too large. However, DIF analysis when both pieces of information are unknown has not received much attention. This paper proposes a general statistical framework under this setting. In the proposed framework, we model the unknown groups by latent classes and introduce item-specific DIF parameters to capture the DIF effects. Assuming the number of DIF items is relatively small, an \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L_1$$\end{document}
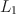 -regularised estimator is proposed to simultaneously identify the latent classes and the DIF items. A computationally efficient Expectation-Maximisation (EM) algorithm is developed to solve the non-smooth optimisation problem for the regularised estimator. The performance of the proposed method is evaluated by simulation studies and an application to item response data from a real-world educational test.
-regularised estimator is proposed to simultaneously identify the latent classes and the DIF items. A computationally efficient Expectation-Maximisation (EM) algorithm is developed to solve the non-smooth optimisation problem for the regularised estimator. The performance of the proposed method is evaluated by simulation studies and an application to item response data from a real-world educational test.
Rasch Trees: A New Method for Detecting Differential Item Functioning in the Rasch Model
-
- Journal:
- Psychometrika / Volume 80 / Issue 2 / June 2015
- Published online by Cambridge University Press:
- 01 January 2025, pp. 289-316
-
- Article
- Export citation
High-Stakes Testing Case Study: A Latent Variable Approach for Assessing Measurement and Prediction Invariance
-
- Journal:
- Psychometrika / Volume 84 / Issue 1 / 15 March 2019
- Published online by Cambridge University Press:
- 01 January 2025, pp. 285-309
-
- Article
- Export citation
Tests of Measurement Invariance Without Subgroups: A Generalization of Classical Methods
-
- Journal:
- Psychometrika / Volume 78 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 01 January 2025, pp. 59-82
-
- Article
- Export citation
Invariance in Measurement and Prediction Revisited
-
- Journal:
- Psychometrika / Volume 72 / Issue 4 / December 2007
- Published online by Cambridge University Press:
- 01 January 2025, pp. 461-473
-
- Article
- Export citation
Testing for Measurement Invariance with Respect to an Ordinal Variable
-
- Journal:
- Psychometrika / Volume 79 / Issue 4 / October 2014
- Published online by Cambridge University Press:
- 01 January 2025, pp. 569-584
-
- Article
- Export citation
The structure of the multidimensional scale of perceived social support: a meta-analytic confirmatory factor analysis
-
- Journal:
- Cambridge Prisms: Global Mental Health / Volume 11 / 2024
- Published online by Cambridge University Press:
- 25 December 2024, e126
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
23 - The Design and Analysis of Data from Dyads and Groups
- from Part IV - Understanding What Your Data Are Telling You About Psychological Processes
-
-
- Book:
- Handbook of Research Methods in Social and Personality Psychology
- Published online:
- 12 December 2024
- Print publication:
- 19 December 2024, pp 565-601
-
- Chapter
- Export citation
