Refine search
Actions for selected content:
48 results
Part II - Separation Theorem, Extreme Points, Recessive Directions, and Geometry of Polyhedral Sets
-
- Book:
- Essential Mathematics for Convex Optimization
- Published online:
- 22 October 2025
- Print publication:
- 26 June 2025, pp 81-150
-
- Chapter
- Export citation
4 - Majorization
- from Part II - Tools and Methods
-
- Book:
- Quantum Resource Theories
- Published online:
- 03 May 2025
- Print publication:
- 10 April 2025, pp 135-207
-
- Chapter
- Export citation
12 - Pure-State Entanglement
- from Part IV - Entanglement Theory
-
- Book:
- Quantum Resource Theories
- Published online:
- 03 May 2025
- Print publication:
- 10 April 2025, pp 507-537
-
- Chapter
- Export citation
Robust Canonical Discriminant Analysis
-
- Journal:
- Psychometrika / Volume 59 / Issue 4 / December 1994
- Published online by Cambridge University Press:
- 01 January 2025, pp. 485-507
-
- Article
- Export citation
Weighted Least Squares Fitting Using Ordinary Least Squares Algorithms
-
- Journal:
- Psychometrika / Volume 62 / Issue 2 / June 1997
- Published online by Cambridge University Press:
- 01 January 2025, pp. 251-266
-
- Article
- Export citation
A Generalization of Takane's Algorithm for Dedicom
-
- Journal:
- Psychometrika / Volume 55 / Issue 1 / March 1990
- Published online by Cambridge University Press:
- 01 January 2025, pp. 151-158
-
- Article
- Export citation
The Integration of Multidimensional Scaling and Multivariate Analysis with Optimal Transformations
-
- Journal:
- Psychometrika / Volume 57 / Issue 4 / December 1992
- Published online by Cambridge University Press:
- 01 January 2025, pp. 539-565
-
- Article
- Export citation
Minimization of a Class of Matrix Trace Functions by means of Refined Majorization
-
- Journal:
- Psychometrika / Volume 57 / Issue 3 / September 1992
- Published online by Cambridge University Press:
- 01 January 2025, pp. 371-382
-
- Article
- Export citation
Majorization as a Tool for Optimizing a Class of Matrix Functions
-
- Journal:
- Psychometrika / Volume 55 / Issue 3 / September 1990
- Published online by Cambridge University Press:
- 01 January 2025, pp. 417-428
-
- Article
- Export citation
A Monotonically Convergent Algorithm for Orthogonal Congruence Rotation
-
- Journal:
- Psychometrika / Volume 61 / Issue 2 / June 1996
- Published online by Cambridge University Press:
- 01 January 2025, pp. 375-389
-
- Article
- Export citation
A Monotonically Convergent Algorithm for Factals
-
- Journal:
- Psychometrika / Volume 58 / Issue 4 / December 1993
- Published online by Cambridge University Press:
- 01 January 2025, pp. 567-574
-
- Article
- Export citation
Stochastic comparison on active redundancy allocation to K-out-of-N systems with statistically dependent component and redundancy lifetimes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 05 May 2023, pp. 1085-1115
- Print publication:
- December 2023
-
- Article
- Export citation
Optimal allocation of policy limits in layer reinsurance treaties
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 24 November 2022, pp. 546-566
-
- Article
- Export citation
8 - More on the Lieb–Thirring Constants
- from Part Three - Sharp Constants in Lieb–Thirring Inequalities
-
- Book:
- Schrödinger Operators: Eigenvalues and Lieb–Thirring Inequalities
- Published online:
- 03 November 2022
- Print publication:
- 17 November 2022, pp 451-470
-
- Chapter
- Export citation
On stochastic ordering among extreme shock models
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 28 October 2022, pp. 961-972
-
- Article
- Export citation
-
In the usual shock models, the shocks arrive from a single source. Bozbulut and Eryilmaz [(2020). Generalized extreme shock models and their applications. Communications in Statistics – Simulation and Computation 49(1): 110–120] introduced two types of extreme shock models when the shocks arrive from one of
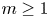 $m\geq 1$ possible sources. In Model 1, the shocks arrive from different sources over time. In Model 2, initially, the shocks randomly come from one of
$m\geq 1$ possible sources. In Model 1, the shocks arrive from different sources over time. In Model 2, initially, the shocks randomly come from one of 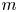 $m$ sources, and shocks continue to arrive from the same source. In this paper, we prove that the lifetime of Model 1 is less than Model 2 in the usual stochastic ordering. We further show that if the inter-arrival times of shocks have increasing failure rate distributions, then the usual stochastic ordering can be generalized to the hazard rate ordering. We study the stochastic behavior of the lifetime of Model 2 with respect to the severity of shocks using the notion of majorization. We apply the new stochastic ordering results to show that the age replacement policy under Model 1 is more costly than Model 2.
$m$ sources, and shocks continue to arrive from the same source. In this paper, we prove that the lifetime of Model 1 is less than Model 2 in the usual stochastic ordering. We further show that if the inter-arrival times of shocks have increasing failure rate distributions, then the usual stochastic ordering can be generalized to the hazard rate ordering. We study the stochastic behavior of the lifetime of Model 2 with respect to the severity of shocks using the notion of majorization. We apply the new stochastic ordering results to show that the age replacement policy under Model 1 is more costly than Model 2.
Dynamical fitness models: evidence of universality classes for preferential attachment graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 21 June 2022, pp. 609-630
- Print publication:
- September 2022
-
- Article
- Export citation
On transform orders for largest claim amounts
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 22 November 2021, pp. 1064-1085
- Print publication:
- December 2021
-
- Article
- Export citation
Stochastic properties of generalized finite α-mixtures
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 4 / October 2022
- Published online by Cambridge University Press:
- 15 July 2021, pp. 1055-1079
-
- Article
-
- You have access
- HTML
- Export citation
Derivatives of symplectic eigenvalues and a Lidskii type theorem
- Part of
-
- Journal:
- Canadian Journal of Mathematics / Volume 74 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 02 December 2020, pp. 457-485
- Print publication:
- April 2022
-
- Article
-
- You have access
- Export citation
-
Associated with every
 $2n\times 2n$ real positive definite matrix
$2n\times 2n$ real positive definite matrix 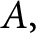 $A,$ there exist n positive numbers called the symplectic eigenvalues of
$A,$ there exist n positive numbers called the symplectic eigenvalues of 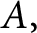 $A,$ and a basis of
$A,$ and a basis of 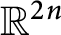 $\mathbb {R}^{2n}$ called the symplectic eigenbasis of A corresponding to these numbers. In this paper, we discuss differentiability and analyticity of the symplectic eigenvalues and corresponding symplectic eigenbasis and compute their derivatives. We then derive an analogue of Lidskii’s theorem for symplectic eigenvalues as an application.
$\mathbb {R}^{2n}$ called the symplectic eigenbasis of A corresponding to these numbers. In this paper, we discuss differentiability and analyticity of the symplectic eigenvalues and corresponding symplectic eigenbasis and compute their derivatives. We then derive an analogue of Lidskii’s theorem for symplectic eigenvalues as an application.

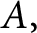
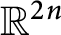
STOCHASTIC ORDERING OF LIFETIMES OF PARALLEL AND SERIES SYSTEMS COMPRISING HETEROGENEOUS DEPENDENT COMPONENTS WITH GENERALIZED BIRNBAUM-SAUNDERS DISTRIBUTIONS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 25 August 2020, pp. 49-65
-
- Article
- Export citation
