Refine search
Actions for selected content:
229 results
Chapter 3 - The 1960s
- from Part I - The Dream of Imperial Ruins
-
-
- Book:
- The Cambridge Companion to British Utopian Literature and Culture since 1945
- Print publication:
- 31 December 2025, pp 55-72
-
- Chapter
- Export citation
9 - Prediction in Language Processing
- from Part III - Language and Cognitive Plasticity and Processing
-
-
- Book:
- The Cambridge Handbook of Language and Brain
- Published online:
- 12 December 2025
- Print publication:
- 09 October 2025, pp 214-236
-
- Chapter
- Export citation
Shadowing, sensitivity, and entropy points
- Part of
-
- Journal:
- Canadian Mathematical Bulletin , First View
- Published online by Cambridge University Press:
- 18 September 2025, pp. 1-17
-
- Article
- Export citation
Bargaining Complexity Beyond Arithmetic
-
- Journal:
- British Journal of Political Science / Volume 55 / 2025
- Published online by Cambridge University Press:
- 27 August 2025, e114
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
4 - Connecting Thermodynamics with Statistical Mechanics
-
- Book:
- Statistical Mechanics for Physicists and Mathematicians
- Published online:
- 28 July 2025
- Print publication:
- 14 August 2025, pp 111-167
-
- Chapter
- Export citation
On the impact of exposure to different languages on Theory of Mind in neurotypical and autistic children
-
- Journal:
- Bilingualism: Language and Cognition , First View
- Published online by Cambridge University Press:
- 01 August 2025, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Probability Theory for Quantitative Scientists
-
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025
Chapter 7 - Naturalism’s Financial Sublime
- from Part II - Histories
-
-
- Book:
- Money and American Literature
- Published online:
- 03 July 2025
- Print publication:
- 17 July 2025, pp 125-141
-
- Chapter
- Export citation
Chapter 8 - Entropy and synthesis
-
- Book:
- The Pattern of Change
- Published online:
- 17 June 2025
- Print publication:
- 03 July 2025, pp 212-269
-
- Chapter
- Export citation
2 - Canonical Distribution
-
- Book:
- Stochastic Thermodynamics
- Published online:
- 09 June 2025
- Print publication:
- 19 June 2025, pp 23-37
-
- Chapter
- Export citation
8 - Dynamics of a Compressible Flow Field
-
- Book:
- Aerodynamics for Engineers
- Published online:
- 12 June 2025
- Print publication:
- 12 June 2025, pp 504-578
-
- Chapter
- Export citation

Quantum Resource Theories
-
- Published online:
- 03 May 2025
- Print publication:
- 10 April 2025
6 - Entropies and Relative Entropies
- from Part II - Tools and Methods
-
- Book:
- Quantum Resource Theories
- Published online:
- 03 May 2025
- Print publication:
- 10 April 2025, pp 266-307
-
- Chapter
- Export citation
Directional behavioral spillover and cognitive load effects in multiple repeated games
-
- Journal:
- Experimental Economics / Volume 22 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 14 March 2025, pp. 705-734
-
- Article
- Export citation
Chapter 15 - Reducing Surprisal and Entropy
- from Part III - Mathematical Theories
-
- Book:
- Looking Ahead
- Published online:
- 20 March 2025
- Print publication:
- 06 March 2025, pp 163-173
-
- Chapter
- Export citation
6 - Equilibrium Thermodynamics
- from Part I - Continuum Physics
-
- Book:
- An Introduction to Continuum Physics
- Published online:
- 06 February 2025
- Print publication:
- 13 February 2025, pp 313-392
-
- Chapter
- Export citation
Delusions as 'wrong beliefs': a conceptual history: commentary, Ghalib
-
- Journal:
- The British Journal of Psychiatry / Volume 226 / Issue 2 / February 2025
- Published online by Cambridge University Press:
- 17 March 2025, p. 117
- Print publication:
- February 2025
-
- Article
- Export citation
4 - Digital Information Sources
-
- Book:
- Fundamentals of Digital Communication Systems
- Published online:
- 10 March 2025
- Print publication:
- 23 January 2025, pp 138-161
-
- Chapter
- Export citation
An Entropy Approach to the Scaling of Ordinal Categorical Data
-
- Journal:
- Psychometrika / Volume 54 / Issue 2 / June 1989
- Published online by Cambridge University Press:
- 01 January 2025, pp. 203-215
-
- Article
- Export citation
Generating Multivariate Ordinal Data via Entropy Principles
-
- Journal:
- Psychometrika / Volume 83 / Issue 1 / March 2018
- Published online by Cambridge University Press:
- 01 January 2025, pp. 156-181
-
- Article
- Export citation
-
When conducting robustness research where the focus of attention is on the impact of non-normality, the marginal skewness and kurtosis are often used to set the degree of non-normality. Monte Carlo methods are commonly applied to conduct this type of research by simulating data from distributions with skewness and kurtosis constrained to pre-specified values. Although several procedures have been proposed to simulate data from distributions with these constraints, no corresponding procedures have been applied for discrete distributions. In this paper, we present two procedures based on the principles of maximum entropy and minimum cross-entropy to estimate the multivariate observed ordinal distributions with constraints on skewness and kurtosis. For these procedures, the correlation matrix of the observed variables is not specified but depends on the relationships between the latent response variables. With the estimated distributions, researchers can study robustness not only focusing on the levels of non-normality but also on the variations in the distribution shapes. A simulation study demonstrates that these procedures yield excellent agreement between specified parameters and those of estimated distributions. A robustness study concerning the effect of distribution shape in the context of confirmatory factor analysis shows that shape can affect the robust \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\chi ^2$$\end{document}
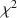 and robust fit indices, especially when the sample size is small, the data are severely non-normal, and the fitted model is complex.
and robust fit indices, especially when the sample size is small, the data are severely non-normal, and the fitted model is complex.