Refine search
Actions for selected content:
54 results
Chapter 22 - Twenty Questions about Employment Testing Bias and Unfairness in Türkiye
-
-
- Book:
- Global Perspectives on the Definition, Assessment, and Reduction of Bias and Unfairness in Employment Testing
- Published online:
- 04 November 2025
- Print publication:
- 20 November 2025, pp 439-460
-
- Chapter
- Export citation
A Novel Method for Detecting Intersectional DIF: Multilevel Random Item Effects Model with Regularized Gaussian Variational Estimation
-
- Journal:
- Psychometrika ,
- Published online by Cambridge University Press:
- 15 September 2025, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Detecting Differential Item Functioning across Multiple Groups Using Group Pairwise Penalty
-
- Journal:
- Psychometrika ,
- Published online by Cambridge University Press:
- 11 August 2025, pp. 1-28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We introduce a novel regularization method for detecting differential item functioning (DIF) in two-parameter logistic (2PL) models. Existing regularization methods require choosing a reference group and using an
 $L_1$ penalty (LP) to shrink the item parameters of focal groups toward those of the reference. This approach has two key limitations: (1) shrinking all focal groups toward a reference is inherently unfair, as results are affected by the choice of reference and direct comparison among focal groups is unavailable and (2) the LP leads to biased estimates because it overly shrinks large nonzero parameters toward zero. These limitations are particularly problematic for intersectional DIF, where various identity aspects intersect to create multiple smaller groups. Our method addresses these issues by penalizing item parameter differences between all pairs of groups using a truncated LP, thereby treating groups equally and avoiding excessive penalization of large differences. Simulations demonstrate that the proposed method outperforms existing approaches by accurately identifying items exhibiting DIF even with multiple small groups. Application to two real-world datasets further illustrates its utility. We recommend this method as a more equitable and precise tool for DIF detection. The proposed method is available as D2PL_pair_em() in the R package VEMIRT (https://map-lab-uw.github.io/VEMIRT).
$L_1$ penalty (LP) to shrink the item parameters of focal groups toward those of the reference. This approach has two key limitations: (1) shrinking all focal groups toward a reference is inherently unfair, as results are affected by the choice of reference and direct comparison among focal groups is unavailable and (2) the LP leads to biased estimates because it overly shrinks large nonzero parameters toward zero. These limitations are particularly problematic for intersectional DIF, where various identity aspects intersect to create multiple smaller groups. Our method addresses these issues by penalizing item parameter differences between all pairs of groups using a truncated LP, thereby treating groups equally and avoiding excessive penalization of large differences. Simulations demonstrate that the proposed method outperforms existing approaches by accurately identifying items exhibiting DIF even with multiple small groups. Application to two real-world datasets further illustrates its utility. We recommend this method as a more equitable and precise tool for DIF detection. The proposed method is available as D2PL_pair_em() in the R package VEMIRT (https://map-lab-uw.github.io/VEMIRT).

Multi-Group Regularized Gaussian Variational Estimation: Fast Detection of DIF
-
- Journal:
- Psychometrika / Volume 90 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 January 2025, pp. 2-23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Differential Item Functioning Analysis Without A Priori Information on Anchor Items: QQ Plots and Graphical Test
-
- Journal:
- Psychometrika / Volume 86 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 345-377
-
- Article
- Export citation
Differential Item Functioning Analyses of the Patient-Reported Outcomes Measurement Information System (PROMIS®) Measures: Methods, Challenges, Advances, and Future Directions
-
- Journal:
- Psychometrika / Volume 86 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 674-711
-
- Article
- Export citation
Unifying Differential Item Functioning in Factor Analysis for Categorical Data Under a Discretization of a Normal Variant
-
- Journal:
- Psychometrika / Volume 82 / Issue 2 / June 2017
- Published online by Cambridge University Press:
- 01 January 2025, pp. 382-406
-
- Article
- Export citation
Psychometrics: from Practice to Theory and Back: 15 Years of nonparametric multidimensional IRT, DIF/test equity, and skills diagnostic assessment
-
- Journal:
- Psychometrika / Volume 67 / Issue 4 / December 2002
- Published online by Cambridge University Press:
- 01 January 2025, pp. 485-518
-
- Article
- Export citation
Score-Based Tests of Differential Item Functioning via Pairwise Maximum Likelihood Estimation
-
- Journal:
- Psychometrika / Volume 83 / Issue 1 / March 2018
- Published online by Cambridge University Press:
- 01 January 2025, pp. 132-155
-
- Article
- Export citation
Not all DIF is shaped similarly
-
- Journal:
- Psychometrika / Volume 86 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 712-716
-
- Article
- Export citation
Testing for DIF in a Model with Single Peaked Item Characteristic Curves: The Parella Model
-
- Journal:
- Psychometrika / Volume 57 / Issue 3 / September 1992
- Published online by Cambridge University Press:
- 01 January 2025, pp. 383-397
-
- Article
- Export citation
Item Screening in Graphical Loglinear Rasch Models
-
- Journal:
- Psychometrika / Volume 76 / Issue 2 / April 2011
- Published online by Cambridge University Press:
- 01 January 2025, pp. 228-256
-
- Article
- Export citation
A Penalty Approach to Differential Item Functioning in Rasch Models
-
- Journal:
- Psychometrika / Volume 80 / Issue 1 / March 2015
- Published online by Cambridge University Press:
- 01 January 2025, pp. 21-43
-
- Article
- Export citation
Model-Based Measures for Detecting and Quantifying Response Bias
-
- Journal:
- Psychometrika / Volume 83 / Issue 3 / September 2018
- Published online by Cambridge University Press:
- 01 January 2025, pp. 696-732
-
- Article
- Export citation
Finite Mixture Multilevel Multidimensional Ordinal IRT Models for Large Scale Cross-Cultural Research
-
- Journal:
- Psychometrika / Volume 75 / Issue 1 / March 2010
- Published online by Cambridge University Press:
- 01 January 2025, pp. 3-32
-
- Article
-
- You have access
- Open access
- Export citation
DIF Statistical Inference Without Knowing Anchoring Items
-
- Journal:
- Psychometrika / Volume 88 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1097-1122
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Establishing the invariance property of an instrument (e.g., a questionnaire or test) is a key step for establishing its measurement validity. Measurement invariance is typically assessed by differential item functioning (DIF) analysis, i.e., detecting DIF items whose response distribution depends not only on the latent trait measured by the instrument but also on the group membership. DIF analysis is confounded by the group difference in the latent trait distributions. Many DIF analyses require knowing several anchor items that are DIF-free in order to draw inferences on whether each of the rest is a DIF item, where the anchor items are used to identify the latent trait distributions. When no prior information on anchor items is available, or some anchor items are misspecified, item purification methods and regularized estimation methods can be used. The former iteratively purifies the anchor set by a stepwise model selection procedure, and the latter selects the DIF-free items by a LASSO-type regularization approach. Unfortunately, unlike the methods based on a correctly specified anchor set, these methods are not guaranteed to provide valid statistical inference (e.g., confidence intervals and p-values). In this paper, we propose a new method for DIF analysis under a multiple indicators and multiple causes (MIMIC) model for DIF. This method adopts a minimal \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L_1$$\end{document}
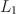 norm condition for identifying the latent trait distributions. Without requiring prior knowledge about an anchor set, it can accurately estimate the DIF effects of individual items and further draw valid statistical inferences for quantifying the uncertainty. Specifically, the inference results allow us to control the type-I error for DIF detection, which may not be possible with item purification and regularized estimation methods. We conduct simulation studies to evaluate the performance of the proposed method and compare it with the anchor-set-based likelihood ratio test approach and the LASSO approach. The proposed method is applied to analysing the three personality scales of the Eysenck personality questionnaire-revised (EPQ-R).
norm condition for identifying the latent trait distributions. Without requiring prior knowledge about an anchor set, it can accurately estimate the DIF effects of individual items and further draw valid statistical inferences for quantifying the uncertainty. Specifically, the inference results allow us to control the type-I error for DIF detection, which may not be possible with item purification and regularized estimation methods. We conduct simulation studies to evaluate the performance of the proposed method and compare it with the anchor-set-based likelihood ratio test approach and the LASSO approach. The proposed method is applied to analysing the three personality scales of the Eysenck personality questionnaire-revised (EPQ-R).
Analyses of Model Fit and Robustness. A New Look at the PISA Scaling Model Underlying Ranking of Countries According to Reading Literacy
-
- Journal:
- Psychometrika / Volume 79 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 01 January 2025, pp. 210-231
-
- Article
- Export citation
Differential Item Functioning via Robust Scaling
-
- Journal:
- Psychometrika / Volume 89 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 796-821
-
- Article
- Export citation
Contextual Responses to Affirmative and/or Reversed-Worded Items
-
- Journal:
- Psychometrika / Volume 84 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 01 January 2025, pp. 986-999
-
- Article
- Export citation
Examining Differential Item Functioning from a Multidimensional IRT Perspective
-
- Journal:
- Psychometrika / Volume 89 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 4-41
-
- Article
- Export citation
