Refine search
Actions for selected content:
57 results
Keller–Segel type approximation for nonlocal Fokker–Planck equations in one-dimensional bounded domain
- Part of
-
- Journal:
- European Journal of Applied Mathematics , First View
- Published online by Cambridge University Press:
- 01 August 2025, pp. 1-37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Coupling results and Markovian structures for number representations of continuous random variables
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 28 April 2025, pp. 1340-1359
- Print publication:
- December 2025
-
- Article
- Export citation
-
Consider nested subdivisions of a bounded real set into intervals defining the digits
 $X_1,X_2,\ldots$ of a random variable X with a probability density function f. If f is almost everywhere lower semi-continuous, there is a non-negative integer-valued random variable N such that the distribution of
$X_1,X_2,\ldots$ of a random variable X with a probability density function f. If f is almost everywhere lower semi-continuous, there is a non-negative integer-valued random variable N such that the distribution of  $R=(X_{N+1},X_{N+2},\ldots)$ conditioned on
$R=(X_{N+1},X_{N+2},\ldots)$ conditioned on  $S=(X_1,\ldots,X_N)$ does not depend on f. If also the lengths of the intervals exhibit a Markovian structure,
$S=(X_1,\ldots,X_N)$ does not depend on f. If also the lengths of the intervals exhibit a Markovian structure,  $R\mid S$ becomes a Markov chain of a certain order
$R\mid S$ becomes a Markov chain of a certain order  $s\ge0$. If
$s\ge0$. If  $s=0$ then
$s=0$ then  $X_{N+1},X_{N+2},\ldots$ are independent and identically distributed with a known distribution. When
$X_{N+1},X_{N+2},\ldots$ are independent and identically distributed with a known distribution. When  $s>0$ and the Markov chain is uniformly geometric ergodic, there is a random time M such that the chain after time
$s>0$ and the Markov chain is uniformly geometric ergodic, there is a random time M such that the chain after time  $\max\{N,s\}+M-s$ is stationary and M follows a simple known distribution.
$\max\{N,s\}+M-s$ is stationary and M follows a simple known distribution.









On the smoothness of slowly varying functions
- Part of
-
- Journal:
- Proceedings of the Edinburgh Mathematical Society / Volume 67 / Issue 3 / August 2024
- Published online by Cambridge University Press:
- 16 May 2024, pp. 876-891
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
APPROXIMATION OF IRRATIONAL NUMBERS BY PAIRS OF INTEGERS FROM A LARGE SET
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 110 / Issue 3 / December 2024
- Published online by Cambridge University Press:
- 03 April 2024, pp. 439-447
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that there is a set
 $S \subseteq {\mathbb N}$ with lower density arbitrarily close to
$S \subseteq {\mathbb N}$ with lower density arbitrarily close to  $1$ such that, for each sufficiently large real number
$1$ such that, for each sufficiently large real number  $\alpha $, the inequality
$\alpha $, the inequality  $|m\alpha -n| \geq 1$ holds for every pair
$|m\alpha -n| \geq 1$ holds for every pair  $(m,n) \in S^2$. On the other hand, if
$(m,n) \in S^2$. On the other hand, if  $S \subseteq {\mathbb N}$ has density
$S \subseteq {\mathbb N}$ has density  $1$, then, for each irrational
$1$, then, for each irrational  $\alpha>0$ and any positive
$\alpha>0$ and any positive  $\varepsilon $, there exist
$\varepsilon $, there exist  $m,n \in S$ for which
$m,n \in S$ for which  $|m\alpha -n|<\varepsilon $.
$|m\alpha -n|<\varepsilon $.











Approximation and homotopy in regulous geometry
- Part of
-
- Journal:
- Compositio Mathematica / Volume 160 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 09 November 2023, pp. 1-20
- Print publication:
- January 2024
-
- Article
- Export citation
-
Let
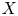 $X$,
$X$, 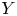 $Y$ be nonsingular real algebraic sets. A map
$Y$ be nonsingular real algebraic sets. A map 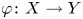 $\varphi \colon X \to Y$ is said to be
$\varphi \colon X \to Y$ is said to be 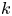 $k$-regulous, where
$k$-regulous, where 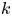 $k$ is a nonnegative integer, if it is of class
$k$ is a nonnegative integer, if it is of class 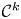 $\mathcal {C}^k$ and the restriction of
$\mathcal {C}^k$ and the restriction of 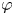 $\varphi$ to some Zariski open dense subset of
$\varphi$ to some Zariski open dense subset of 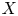 $X$ is a regular map. Assuming that
$X$ is a regular map. Assuming that 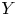 $Y$ is uniformly rational, and
$Y$ is uniformly rational, and 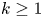 $k \geq 1$, we prove that a
$k \geq 1$, we prove that a 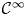 $\mathcal {C}^{\infty }$ map
$\mathcal {C}^{\infty }$ map 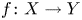 $f \colon X \to Y$ can be approximated by
$f \colon X \to Y$ can be approximated by 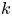 $k$-regulous maps in the
$k$-regulous maps in the 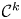 $\mathcal {C}^k$ topology if and only if
$\mathcal {C}^k$ topology if and only if 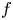 $f$ is homotopic to a
$f$ is homotopic to a 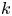 $k$-regulous map. The class of uniformly rational real algebraic varieties includes spheres, Grassmannians and rational nonsingular surfaces, and is stable under blowing up nonsingular centers. Furthermore, taking
$k$-regulous map. The class of uniformly rational real algebraic varieties includes spheres, Grassmannians and rational nonsingular surfaces, and is stable under blowing up nonsingular centers. Furthermore, taking  $Y=\mathbb {S}^p$ (the unit
$Y=\mathbb {S}^p$ (the unit 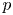 $p$-dimensional sphere), we obtain several new results on approximation of
$p$-dimensional sphere), we obtain several new results on approximation of 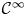 $\mathcal {C}^{\infty }$ maps from
$\mathcal {C}^{\infty }$ maps from 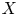 $X$ into
$X$ into 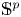 $\mathbb {S}^p$ by
$\mathbb {S}^p$ by 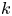 $k$-regulous maps in the
$k$-regulous maps in the 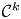 $\mathcal {C}^k$ topology, for
$\mathcal {C}^k$ topology, for 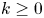 $k \geq 0$.
$k \geq 0$.
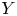
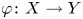
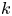
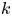
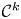
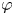
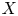
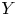
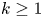
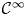
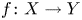
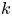
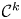
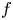
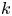

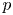
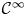
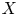
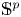
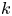
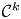
Chapter 20 - An Introduction to Psychologically Plausible Sampling Schemes for Approximating Bayesian Inference
- from Part VI - Computational Approaches
-
-
- Book:
- Sampling in Judgment and Decision Making
- Published online:
- 01 June 2023
- Print publication:
- 15 June 2023, pp 467-489
-
- Chapter
- Export citation
Chapter 21 - Approximating Bayesian Inference through Internal Sampling
- from Part VI - Computational Approaches
-
-
- Book:
- Sampling in Judgment and Decision Making
- Published online:
- 01 June 2023
- Print publication:
- 15 June 2023, pp 490-512
-
- Chapter
- Export citation
9 - Inexactness in Economic Theory
- from Part II - Theory Assessment
-
- Book:
- The Inexact and Separate Science of Economics
- Published online:
- 25 May 2023
- Print publication:
- 08 June 2023, pp 231-255
-
- Chapter
- Export citation

Idealizations in Physics
-
- Published online:
- 11 January 2023
- Print publication:
- 26 January 2023
-
- Element
- Export citation
3 - Expressivity of Deep Neural Networks
-
-
- Book:
- Mathematical Aspects of Deep Learning
- Published online:
- 29 November 2022
- Print publication:
- 22 December 2022, pp 149-199
-
- Chapter
- Export citation
12 - Infinite Orbits and Quitting Games
-
- Book:
- A Course in Stochastic Game Theory
- Published online:
- 05 May 2022
- Print publication:
- 26 May 2022, pp 211-235
-
- Chapter
- Export citation
Large very dense subgraphs in a stream of edges
-
- Journal:
- Network Science / Volume 9 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 25 January 2022, pp. 403-424
-
- Article
- Export citation
-
We study the detection and the reconstruction of a large very dense subgraph in a social graph with n nodes and m edges given as a stream of edges, when the graph follows a power law degree distribution, in the regime when
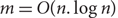 $m=O(n. \log n)$. A subgraph S is very dense if it has
$m=O(n. \log n)$. A subgraph S is very dense if it has 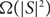 $\Omega(|S|^2)$ edges. We uniformly sample the edges with a Reservoir of size
$\Omega(|S|^2)$ edges. We uniformly sample the edges with a Reservoir of size 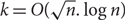 $k=O(\sqrt{n}.\log n)$. Our detection algorithm checks whether the Reservoir has a giant component. We show that if the graph contains a very dense subgraph of size
$k=O(\sqrt{n}.\log n)$. Our detection algorithm checks whether the Reservoir has a giant component. We show that if the graph contains a very dense subgraph of size 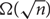 $\Omega(\sqrt{n})$, then the detection algorithm is almost surely correct. On the other hand, a random graph that follows a power law degree distribution almost surely has no large very dense subgraph, and the detection algorithm is almost surely correct. We define a new model of random graphs which follow a power law degree distribution and have large very dense subgraphs. We then show that on this class of random graphs we can reconstruct a good approximation of the very dense subgraph with high probability. We generalize these results to dynamic graphs defined by sliding windows in a stream of edges.
$\Omega(\sqrt{n})$, then the detection algorithm is almost surely correct. On the other hand, a random graph that follows a power law degree distribution almost surely has no large very dense subgraph, and the detection algorithm is almost surely correct. We define a new model of random graphs which follow a power law degree distribution and have large very dense subgraphs. We then show that on this class of random graphs we can reconstruct a good approximation of the very dense subgraph with high probability. We generalize these results to dynamic graphs defined by sliding windows in a stream of edges.
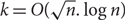
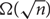
3 - Interpersonal Function and Intersubjectivity
-
- Book:
- General Extenders
- Published online:
- 20 August 2021
- Print publication:
- 02 September 2021, pp 43-59
-
- Chapter
- Export citation
11 - Multiperiod Blending
- from Part III - Advanced Methods
-
- Book:
- Chemical Production Scheduling
- Published online:
- 01 May 2021
- Print publication:
- 06 May 2021, pp 261-286
-
- Chapter
- Export citation
APPROXIMATION OF AND BY COMPLETELY MONOTONE FUNCTIONS
- Part of
-
- Journal:
- The ANZIAM Journal / Volume 61 / Issue 4 / October 2019
- Published online by Cambridge University Press:
- 06 March 2020, pp. 416-430
-
- Article
-
- You have access
- Export citation
Interaction of Poisson hyperplane processes and convex bodies
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 56 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 11 December 2019, pp. 1020-1032
- Print publication:
- December 2019
-
- Article
- Export citation
-
Given a stationary and isotropic Poisson hyperplane process and a convex body K in
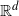 ${\mathbb R}^d$, we consider the random polytope defined by the intersection of all closed half-spaces containing K that are bounded by hyperplanes of the process not intersecting K. We investigate how well the expected mean width of this random polytope approximates the mean width of K if the intensity of the hyperplane process tends to infinity.
${\mathbb R}^d$, we consider the random polytope defined by the intersection of all closed half-spaces containing K that are bounded by hyperplanes of the process not intersecting K. We investigate how well the expected mean width of this random polytope approximates the mean width of K if the intensity of the hyperplane process tends to infinity.
Chapter 5 - Meaning-Shift Units in L2 Learning and Use: Usage vs. Exposure
-
- Book:
- Phraseology and the Advanced Language Learner
- Published online:
- 18 November 2019
- Print publication:
- 28 November 2019, pp 101-152
-
- Chapter
- Export citation
Chapter 7 - Towards the Bigger Picture
-
- Book:
- Phraseology and the Advanced Language Learner
- Published online:
- 18 November 2019
- Print publication:
- 28 November 2019, pp 206-219
-
- Chapter
- Export citation
Chapter 3 - L2 Use and Processing of Multi-Word Units
-
- Book:
- Phraseology and the Advanced Language Learner
- Published online:
- 18 November 2019
- Print publication:
- 28 November 2019, pp 38-65
-
- Chapter
- Export citation
The Korteweg–de Vries, Burgers and Whitham limits for a spatially periodic Boussinesq model
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 149 / Issue 1 / February 2019
- Published online by Cambridge University Press:
- 30 August 2018, pp. 191-217
- Print publication:
- February 2019
-
- Article
- Export citation
