


Introduction
Intuitively, learning a new language is easier if this language is similar to the language that one already speaks. Compared to a speaker of Mandarin, a speaker of Dutch will take less time and effort to reach the same level of proficiency in English because of a greater similarity in the orthographic, phonological, and morpho-syntactic systems of these two languages; a larger number of phonologically and semantically similar words (cognates); and the shared nature of the alphabetic Roman script. The literature on second language (L2) acquisition supports this intuitive notion and quantifies it using “language distance,” a measure of divergence between linguistic features of the first language (L1) and L2 (Appel & Muysken, Reference Appel and Muysken2005; Butler, Reference Butler, Bhatia and Ritchie2012; Jarvis & Pavlenko, Reference Jarvis and Pavlenko2008; Weinreich, Reference Weinreich1953). Specifically, the influential theoretical framework of contrastive analysis (Odlin, Reference Odlin, Doughty and Long2003; Ringbom & Jarvis, Reference Ringbom, Jarvis, Long and Doughty2009) argues that the L1–L2 language distance may modulate the magnitude of the group differences between speakers of different L1s in L2 reading comprehension and underlying skills (Melby-Lervåg & Lervåg, Reference Melby-Lervåg and Lervåg2014).
Even though the literature on the topic is rich, how exactly language distance influences reading proficiency in L2 is presently unclear. This paper aims to fill this gap by examining the effect of language distance on fluency and comprehension of reading in English as a second language among readers with 18 different L1 backgrounds. This introduction first reviews existing literature on language distance effects, then highlights the under-defined and vague theoretical status that language distance has in current-day accounts of L2 reading and finally outlines the logic of the present study.
Language distance effects
Many examples that language distance influences learnability of a new language emerge in the area of language proficiency testing. Consider, for instance, the guidelines of the United States Department of State Foreign Service Institute (https://www.state.gov/foreign-language-training/). For English-speaking diplomats to reach the General Professional Proficiency in a language, the following four categories are proposed, based on language distance from English. Category I includes languages similar to English (e.g., Dutch, Italian, and Spanish), which tend to take 24 weeks or 600 hr of instruction; category II (less similar languages, including German and Malay), 36 weeks; category III (even more distant languages, like Finnish, Greek, and Hebrew), 44 weeks; and category IV, “super-hard” languages (e.g., Mandarin and Arabic), 88 weeks. Another set of examples shows that language distance between the speaker’s L1 and Dutch predicts the speaker’s proficiency scores in the official state Dutch-as-a-second-language exam administered in the Netherlands for immigrants seeking admission to higher education. In the sample of over 33,000 test takers representing a diversity of L1 backgrounds, greater L1–Dutch L2 distance correlated with lower speaking proficiency scores, accounting for roughly 10% of total variance between speakers (Schepens, Van der Slik, & van Hout, Reference Schepens, Van der Slik, van Hout, Borin and Saxena2013) and so did the greater distance between the speaker’s L2 and Dutch as the third language (L3) (Schepens, Van der Slik, & van Hout, Reference Schepens, Van der Slik and van Hout2016). Similarly, a greater distance between the official language of the country and English predicts lower average national scores in the Test of English as a Foreign Language (TOEFL) (Snow, Reference Snow1998; Xinxin, Xiaolan, & Ahmed, Reference Xinxin, Xiaolan and Ahmed2022).
Several tightly controlled experimental studies corroborated the language distance effect on language learnability. Jiang (Reference Jiang2016) found that greater language distance between L1 and English predicted lower performance in oral reading fluency (including reading rate and accuracy) as well as lower reading comprehension in respective TOEFL tasks. Moreover, the longitudinal study of beginning readers in seven European countries (Lindgren & Muñoz, Reference Lindgren and Muñoz2013) observes lower reading and listening scores among children whose L1 was less similar to (i.e., was at a greater distance from) the L2 they learned. For additional demonstrations of the negative correlation between L1–L2 distance and L2 reading and language skills, see, among others, Jarvis and Pavlenko (Reference Jarvis and Pavlenko2008) and Vettori, Casado Ledesma, Tesone, and Tarchi (Reference Vettori, Casado Ledesma, Tesone and Tarchi2024). Finally, the eye-tracking study on English sentence reading with Finnish and German L2 participants and Canadian L1 readers of English (Nisbet, Bertram, Erlinghagen, Pieczykolan, & Kuperman, Reference Nisbet, Bertram, Erlinghagen, Pieczykolan and Kuperman2022) statistically controlled for the group difference in component skills and observed that the L1–L2 distance from English (greater for Finnish than German) exerted independent influence on eye-movement patterns over and above the component skills of reading, like spelling, vocabulary knowledge, and exposure to print.
Finally, meta-analyses of reading comprehension in L2 report mixed results regarding the roles of language distance and the related measure of script distance, (i.e., the degree of divergence in the writing systems of L1 and L2). For instance, Jeon and Yamashita (Reference Jeon and Yamashita2014) indicate a moderating role that the L1–L2 language and script distance play in the correlation between L2 decoding skill and L2 reading comprehension. Speakers of logographic languages showed a weaker correlation (e.g., Chinese and Japanese, r = .38; Koda, Reference Koda1998) than did speakers of alphabetic languages (e.g., Dutch and Spanish; r = .79; Koda, Reference Koda1998). In a similar vein, a shorter L1–L2 script distance—when both languages are alphabetic—led to stronger correlations between L2 vocabulary knowledge and reading comprehension compared to the case when one or both scripts were not alphabetic, r = .64 versus r = .52 (Zhang & Zhang, Reference Zhang and Zhang2022).
Conversely, the meta-analysis by Lee, Jung, and Lee (Reference Lee, Jung and Lee2022) considered but found no evidence for the moderating role of the L1–L2 distance in L2 reading comprehension. In their meta-analytic structural equation modeling of 81 experimental samples, with over 10,000 participants in total, Lee et al. (Reference Lee, Jung and Lee2022) estimated the effect of L2 comprehension abilities (i.e., listening comprehension, vocabulary knowledge, and grammar knowledge) and L2 decoding skills on L2 reading comprehension. The L1–L2 distance was incorporated into the model as a moderating variable. Analyses revealed no moderating effect of the L1–L2 distance on the functional relationship between L2 reading comprehension and L2 decoding skills and comprehension abilities. The proposed interpretation of the null effect is that language or script distances are confined in the scope of their influence to affecting component skills of L2 reading but not L2 comprehension (see also next section). The mixed findings across meta-analyses suggest that the effect of language distance on L2 reading comprehension may depend on the nature of the task, the complexity of reading materials, the proficiency level of readers, and the diversity of languages and scripts under comparison. To our knowledge, there has been no systematic study of the relationship between L1–L2 language distance and L2 reading fluency, to parallel the inquiry into reading comprehension.
Theoretical status of language distance
There is a consensus in the existing literature that reading fluency and comprehension in L2 are a result of the development and coordinated use of multiple component skills (Bernhardt, Reference Bernhardt2010; Eskey, Reference Eskey and Hinkel2005; Geva & Farnia, Reference Geva and Farnia2012). This consensus notwithstanding, the place that the L1–L2 distance occupies in theories of L2 reading is far from well understood or defined. It is clear from the language testing and much experimental literature (reviewed above) that this distance has influence on L2 acquisition and proficiency. Yet the literature does not give a clear answer to how exactly this influence is exerted. The main purpose of this paper is to shed light on this lacuna in the current body of knowledge. All relevant studies so far have considered the L1–L2 distance as a potential moderator of the functional relationship between L2 component skills and L2 reading comprehension or fluency. The evidence for this moderating role is mixed (see discussion above). Yet, the meta-analysis by Lee et al. (Reference Lee, Jung and Lee2022) introduces a different theoretical perspective, when interpreting the null moderating effect of the L1–L2 distance on the correlations between L2 reading comprehension and L2 component skills and L2 decoding. Specifically, Lee et al. propose that “the L1–L2 difference may exert effects only on sub-components, such as L2 language comprehension abilities and L2 decoding skills, but these effects do not extend beyond this level” (Lee et al., Reference Lee, Jung and Lee2022, pp. 600ff). In other words, they propose—but do not test—the possibility that the only way in which language distance can influence L2 reading comprehension is indirect: Language distance may affect component skills of L2 reading proficiency and these skills affect comprehension proper. L2 reading comprehension is proposed only to be sensitive to those component skills but not directly to the language distance.
We further illustrate the point of Lee et al.’s proposal through a hypothetical example. Suppose two speakers with different L1 backgrounds X and Y set out to study reading in language Z that is closer to X than Y. One would expect the speaker of Y to show lower performance in reading comprehension in Z, relative to the speaker of X. This lower performance may be observed because of greater difficulty of developing component skills of reading in Z (decoding, vocabulary, oral comprehension, etc.) for a speaker of Y. But would there be a difference in reading comprehension of Z between speakers of X and Y if they had identical proficiency in the component skills of reading in Z? The contrastive analysis framework appears to answer this question in the positive. It advocates for a direct effect of language distance on reading comprehension, over and above component skills. Lee et al. answer the question in the negative. Language distance only affects the development of component skills; if they are equally developed, no further effect of language distance on reading comprehension is expected.
The meta-analytical and interpretational knowledge base about reading fluency lags behind that available for reading comprehension. Thus, it is unclear whether the conflicting theoretical proposals can be generalized from reading comprehension to reading fluency. We examine the nature of the language distance effect on reading outcomes, fluency, and comprehension alike.
The present study
The questions we asked previously regarding the theoretical status of language distance fall within the area of statistical mediation analysis. Using the terminology of this analysis (fully spelled out in the Statistical Techniques section below), the questions can be rephrased as follows: Does language distance have a direct effect on reading fluency or comprehension in L2 and also on the component skills of L2 reading? Or is the influence of this distance fully mediated by proficiency in the component skills of reading in L2? We investigate these questions by reanalyzing data of the Multilingual Eye-movement Corpus (MECO), which presents the eye-movement record and reading comprehension scores in English text reading from 24 samples of participants with 18 different non-English L1 backgrounds (Kuperman et al., Reference Kuperman, Siegelman, Schroeder, Acartürk, Alexeeva, Amenta and Usal2023, Reference Kuperman, Schroeder, Acartürk, Agrawal, Bolliger and Siegelman2024). For simplicity, we label all participants L2 speakers of English, regardless of whether English is the L2, L3, fourth language, or fifth language they speak. We note that the MECO corpus and the present analyses are based on the performance of relatively advanced L2 readers of English (i.e., students at universities in which English proficiency is a selection criterion for admission). Thus, the present result may not readily generalize over less-proficient L2 readers of English.
In this study, we examine both reading fluency at the word level (indicated by eye movements), reading fluency at the text level (reading rate in words per minute), and reading comprehension (percent correct of comprehension questions). Moreover, the L2 component of MECO reports participant scores in several tests of component skills of English reading (decoding, vocabulary, spelling, etc.). These data enable us to estimate individual proficiency in component skills of reading in English. Finally, we use the state-of-the-art method and linguistic databases to define language distance (Chai & Bao, Reference Chai and Bao2023; Schepens et al., Reference Schepens, Van der Slik, van Hout, Borin and Saxena2013); see below. With this information at hand, we quantify the direct effect that language distance has on reading comprehension and fluency and its mediated (or indirect) effect on reading comprehension and fluency via component skills of reading. To reiterate, the research question of this paper is whether the L1–L2 distance influences both the component skills of English proficiency and English reading comprehension and reading fluency (i.e., it has both a direct and indirect effect on reading outcomes) or whether it only has an indirect effect on reading outcomes on reading comprehension and fluency, via mediation of component skills. These findings will enable adjudication between the conjecture formulated by Lee et al. (Reference Lee, Jung and Lee2022), who propose that the effect is indirect only, and viewpoints advocated in other literature on reading comprehension (reviewed above), which suggest that the effect can be both direct and indirect.
Methods
The paper reanalyzes data from the L2 component of the published MECO database of eye movements and skill tests, including its wave 1 release 1.1 (Kuperman et al., Reference Kuperman, Siegelman, Schroeder, Acartürk, Alexeeva, Amenta and Usal2023) and wave 2 release 1.0 (Kuperman et al., Reference Kuperman, Schroeder, Acartürk, Agrawal, Bolliger and Siegelman2024), both available at https://osf.io/q9h43/. This section provides a brief recap of relevant information on participants, data collection, and procedure as well as variables. For full details, we refer the reader to the papers cited above in this paragraph.
Participants
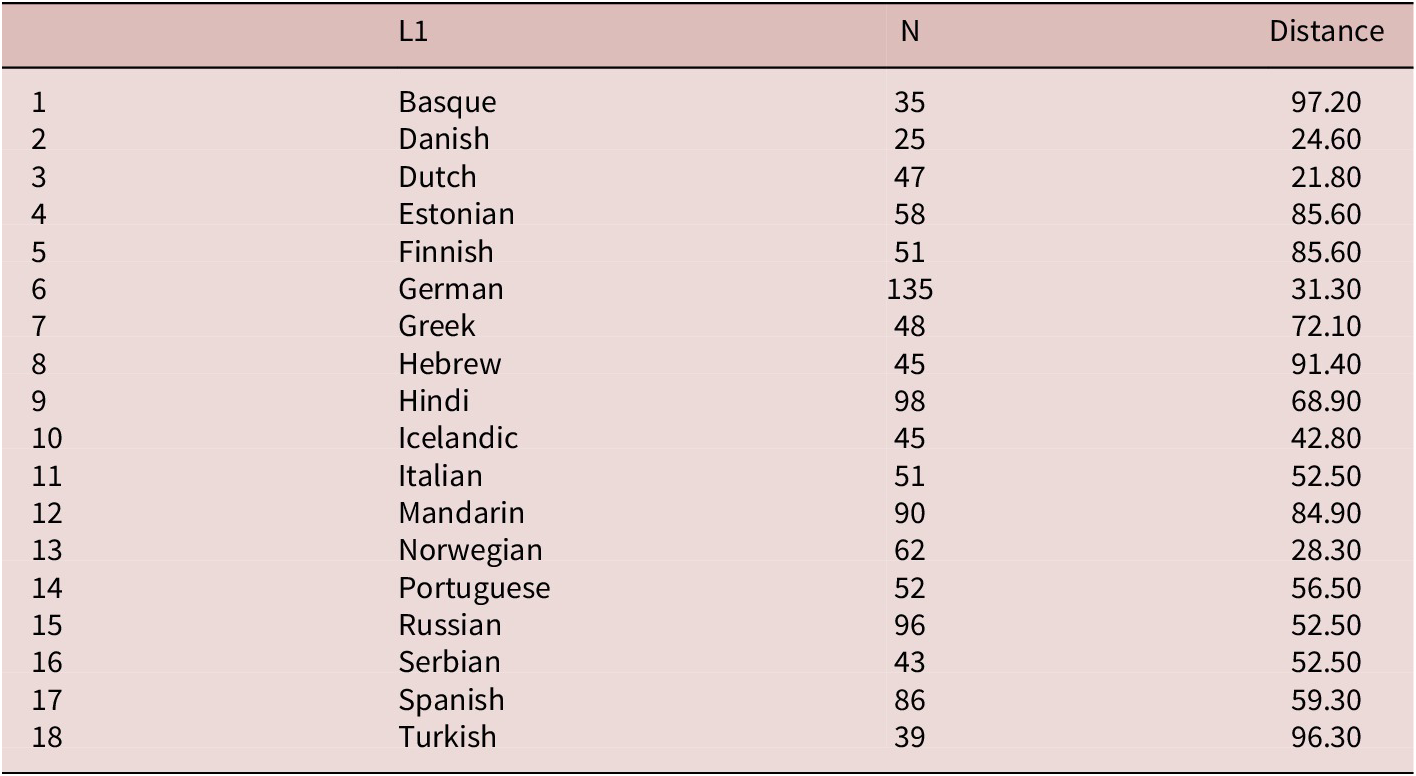
We analyze data from 1,105 participants who represent 24 university-based samples and 18 unique non-English L1 backgrounds (see Table 1 for details). All participants were undergraduate students or members of the university community and spoke as their L1 the official language(s) of the country in which the testing took place. Most if not all L2 participants were advanced learners of English: They had multiple years of training in the English language and passed examinations of English proficiency to be admitted to the university; see Kuperman et al. (Reference Kuperman, Siegelman, Schroeder, Acartürk, Alexeeva, Amenta and Usal2023, Reference Kuperman, Schroeder, Acartürk, Agrawal, Bolliger and Siegelman2024) for specifications of participating lab sites.
Table 1. Language distance between English and non-English L1s, along with the number of participants per L1
Materials
All participants in the MECO L2 component silently read a set of 12 English texts for comprehension. All texts were of expository nature and were adopted from the training materials of the college-level test of English reading comprehension ACCUPLACER. Texts range in length from 98 to 185 words, M = 137.8 (SD = 26.5). Their length in standard words—defined as a word of six characters, including punctuation and spaces (Carver, Reference Carver1992)—ranges from 92 to 183 words, M = 138.4 (SD = 27.1). The Flesch–Kincaid grade level readability ranged from 6.8 to 17.6, M = 10.6 (SD = 2.7). For a detailed breakdown, see Table 2 in Kuperman et al. (Reference Kuperman, Siegelman, Schroeder, Acartürk, Alexeeva, Amenta and Usal2023). Two multiple choice comprehension questions (one factual and one inferential) with four answer options followed each text, to a total of 24 questions. The readers’ eye movements were recorded during text reading; see relevant reliability estimates below.
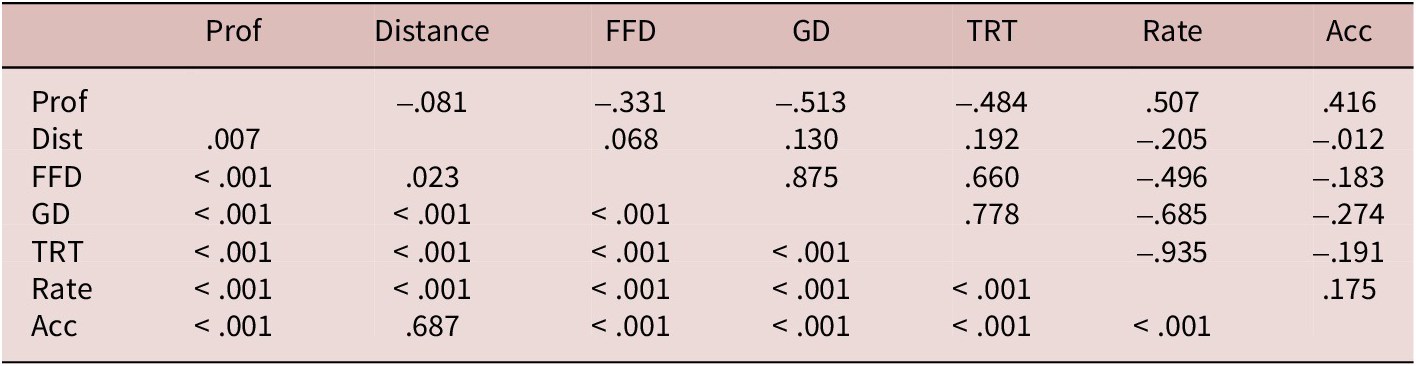
Table 2. Zero-order correlations between proficiency (Prof), language distance (Dist), and by participant mean first fixation duration (FFD), gaze duration (GD), total reading time (TRT), reading rate (Rate), and comprehension accuracy (Acc) are reported above the diagonal and respective p values below the diagonal
Note: N = 1,105.
Critically, participants also completed a battery of tests of component skills of English, including (a) a spelling recognition test (adapted from Andrews & Hersch [Reference Andrews and Hersch2010], split-half reliability with Brown-Spearman correction, r = .78); (b) a vocabulary knowledge test in which participants chose a correct word definition from four multiple choices (adapted from the vocabulary size test by Nation & Beglar [Reference Nation and Beglar2007], split-half reliability with Brown-Spearman correction, r = .74); and (c) a lexical knowledge test LexTALE, with yes/no forced choice decisions and reported split-half reliability ≥ .7 (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012). Tests (d) and (e) stemmed from the Test of Word Reading Efficiency (TOWRE) (Torgesen, Wagner, & Rashotte, Reference Torgesen, Wagner and Rashotte2012) with one subtest for word naming (sight word efficiency) and one subtest for pseudoword naming (phonemic decoding efficiency). Since the TOWRE tests are based on a single word and a single pseudoword list, their reliability could not be estimated. However, TOWRE scores are expected to be highly reliable, as reflected in previous reports of high test-retest reliability estimates (Torgesen et al., Reference Torgesen, Wagner and Rashotte2012). Reliability estimates above are given for 11 L1 backgrounds reported in the MECO wave 1 release (Kuperman et al., Reference Kuperman, Siegelman, Schroeder, Acartürk, Alexeeva, Amenta and Usal2023). Respective estimates for an additional seven L1 backgrounds reported in Kuperman et al. (Reference Kuperman, Schroeder, Acartürk, Agrawal, Bolliger and Siegelman2024) are virtually identical and not reported here in the interest of space. For full details regarding reliability and correlations between all test scores, see analysis 1 and supplementary materials S5 in Kuperman et al. (Reference Kuperman, Siegelman, Schroeder, Acartürk, Alexeeva, Amenta and Usal2023, Reference Kuperman, Schroeder, Acartürk, Agrawal, Bolliger and Siegelman2024).
Additional instruments included a non-verbal IQ test from the Culture Fair Intelligence Test-3 (Weiß, Reference Weiß2006) and an abridged version of the Language Experience and Proficiency Questionnaire (Marian, Blumenfeld, & Kaushanskaya, Reference Marian, Blumenfeld and Kaushanskaya2007). These instruments were not included in further calculations.
Procedure and apparatus
The experimental procedure was shared by the participating sites. Eye movements were recorded with EyeLink Portable Duo 1000 or 1000 plus eye-tracker (SR Research, Kanata, ON, Canada) with a sampling rate of 1,000 Hz and a chin rest used to minimize head movements. Each text appeared on a separate screen in 20- or 22-point mono-spaced font (the visual angle subtended by each character varied by the testing site) with 1.5 line spacing (see Kuperman et al., Reference Kuperman, Siegelman, Schroeder, Acartürk, Alexeeva, Amenta and Usal2023, Reference Kuperman, Schroeder, Acartürk, Agrawal, Bolliger and Siegelman2024, for a detailed description). The order of texts in the L2 component of MECO was the same for all participants, and each text was followed by two comprehension questions.
Variables
Dependent variables
Our goal is to examine the effect of language distance on all aspects of reading fluency and comprehension, namely, word reading fluency, text reading fluency, and comprehension accuracy. Three variables represent reading fluency at the word level. These are duration of the first fixation on the word, gaze duration (i.e., the summed duration of all fixations on the word before the eye leaves the word for the first time), and total reading time (the summed duration of all fixations on the word). First, fixation duration and gaze duration are considered early processing measures and tap into the cognitive effort of word recognition and decoding. Gaze duration may additionally indicate plausibility and predictability of the word in its context. Total reading time is a late and cumulative processing measure and taps into processes of the word’s semantic and syntactic integration into the sentence and discourse frame (Boston, Hale, Kliegl, Patil, & Vasishth, Reference Boston, Hale, Kliegl, Patil and Vasishth2008). Split-half by participant reliability for first fixation duration, gaze duration, and total reading time was extremely high: r > .94 for each of the 12 languages under consideration; see analysis 1 and supplementary materials S4 in Kuperman et al. (Reference Kuperman, Siegelman, Schroeder, Acartürk, Alexeeva, Amenta and Usal2023). As above, all reliability estimates are given for the 11 L2 samples in MECO wave 1 release (Kuperman et al., Reference Kuperman, Siegelman, Schroeder, Acartürk, Alexeeva, Amenta and Usal2023): Respective estimates for additional samples included in wave 2 of MECO were virtually identical; see Kuperman et al. (Reference Kuperman, Schroeder, Acartürk, Agrawal, Bolliger and Siegelman2024).
Text reading fluency is represented by reading rate, measured in words per minute and averaged across passages. Since text lengths measured in words and standard words correlate at r = .93, all analyses using these metrics produce very similar results. We only report analyses with words for comparability with the existing meta-analyses of reading rate (Brysbaert, Reference Brysbaert2019). When accounting for the genre and word length (Brysbaert, Sui, Duyck, & Dirix, Reference Brysbaert, Sui, Duyck and Dirix2021), the use of words rather than standard words per minute allows for a more flexible and specific characterization of variability in reading rate; but, see Kramer and McLean (Reference Kramer and McLean2013). Split-half by participant reliability for reading rate was extremely high: r > .94.
Comprehension accuracy was estimated as percent of correct responses to comprehension questions to the texts; see above. Split-half reliability of the reading comprehension accuracy was r = .68 with the Brown-Spearman correction, and Cronbach’s α was .69 (i.e., within the acceptable range). For 8 out of 12 languages, α is in the acceptable-to-good range; see supplementary materials S5 in Kuperman et al. (Reference Kuperman, Siegelman, Schroeder, Acartürk, Alexeeva, Amenta and Usal2023). For validity estimates of the reading comprehension test, see also (Mattern & Packman, Reference Mattern and Packman2009).
Independent variables
Two sets of variables critical for our analyses are language distance from the reader’s L1 to English and the reader’s proficiency in component skills of English reading. Literature proposes multiple ways of quantifying language distance (for an excellent overview, see Chai & Bao, Reference Chai and Bao2023; Schepens et al., Reference Schepens, Van der Slik, van Hout, Borin and Saxena2013). For the present study, we adopted the measure of genetic proximity between pairs of languages as the metric of their distance. Genetic proximity measures are made available via the online tool eLinguistics.net (Beaufils & Tomin, Reference Beaufils and Tomin2020). The tool operates on the set of 18 basic lexical items in each language, compiled from the relevant literature on comparative linguistics (body parts, personal pronouns, numerals, etc.). Consonants from each lexical item are compared both in quality (partially or fully matching consonant classes) and order in the word. The mathematical function of the consonant matching produces the proximity score. The greater the proximity between language, the larger the distance between them. Since the data used in these analyses are in open access, researchers can validate the present findings using other available metrics of language distance.
We also considered an alternative metric, which accounts jointly for language (dis)similarity by comparing words, morpho-syntactic features, and sounds of language pairs. van Hout and Van der Slik (Reference van Hout and Van der Slik2024) define three types of linguistic distance: lexical (the sum of branch lengths that connect two languages in a phylogenetic language tree for Indo-European languages and the fixed maximum value for non–Indo-European ones), morphological (differences in the morphological feature values as defined in Dryer & Haspelmath, Reference Dryer and Haspelmath2013), and phonological (the number of new phonological features in a target language based on complete sound and feature inventories). The principal component analysis applied to these three distance types by van Hout and Van der Slik (Reference van Hout and Van der Slik2024) determined that the first principal component is sufficiently representative of the linguistic distance between a given language and English. We did not adopt this measure because it is not defined for two of the languages for which we have data, Basque and Hebrew. However, for the remaining 15 languages, the linguistic distance metric used in the analyses below and the metric proposed by van Hout and Van der Slik (Reference van Hout and Van der Slik2024) correlated at r = .90, p < .001. We conclude that the analyses above are robust to different existing operationalizations of linguistic distance.
We acknowledge, in line with the literature reviewed in the Introduction, that script distance (between the writing system of L1 and the Roman script used by English) is a variable relevant for the ease of learning English as L2. Yet we opted out of using it in our calculations for two reasons. First, script distance does not allow for a similarly rigorous quantification as language distance. How far the Hindi abugida, the Hebrew abjad, and the logographic system of Cantonese and Mandarin are from the Roman alphabetic script of English is open for debate, and so is the question of whether the Greek alphabet or the Cyrillic alphabet of Russian and Serbian are equally far from the Roman script. The second reason to gloss over script distance is that all non-alphabetic systems in MECO are represented by one written language each (i.e., Chinese, Hebrew, and Hindi). Thus, consideration of the distance between each of these scripts and the Roman script of English is statistically conflated with the distance between the respective (oral) languages and English.
Proficiency in component skills of reading was defined here as the composite score based on tests (a)–(e), described in the Materials section above (i.e., the spelling recognition test, vocabulary knowledge test, LexTALE, and TOWRE sight word efficiency and decoding). The first step in the calculation was to standardize (Z-transform) the scores for each individual test across all participants. The composite proficiency score is the mean of those standardized scores, and its unit is 1 SD of the composite score. Figure 1 visualizes the distribution of the composite scores by testing site and L1 background. Composite proficiency scores among the top-performing sample of Hindi speakers are roughly 1.5 SDs higher, on average, than the scores in the lowest-performing sample of speakers of Icelandic. Thus, even if student participants in our dataset are relatively advanced learners of English—with years of English language training and successful completion of school- and university-level tests of English proficiency—they vary widely in their component skills of English reading.
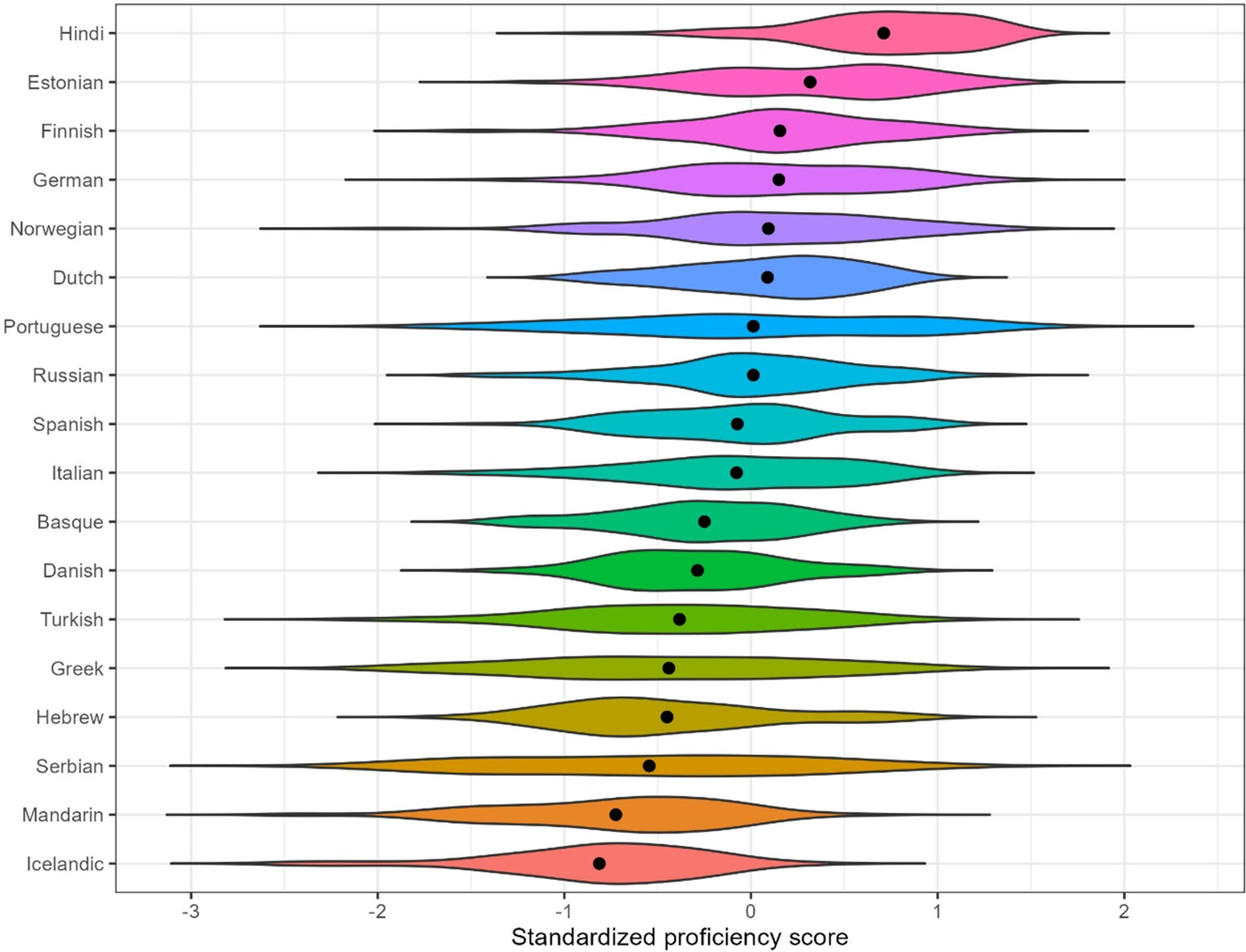
Figure 1. Violin plots of standardized scores of English proficiency in component skills, presented by L1 background. Black dots stand for mean scores.
Statistical techniques
All statistical analyses were conducted using statistical software platform R, version 4.2.2 (R Core Team, 2022). The mediation library (Tingley, Yamamoto, Hirose, Keele, & Imai, Reference Tingley, Yamamoto, Hirose, Keele and Imai2014) was used for mediation analyses. Mediation analysis consists of a system of two regression models. In one model, the mediator—component skill proficiency score—is predicted by language as the treatment variable. In the second model, language distance along with the mediating variable (proficiency), and other covariates where appropriate, serve as predictors of the outcome variable (e.g., reading comprehension). Mediation analysis considers the two models jointly and estimates the amounts of variance in the outcome variable that the treatment variable explains directly or through mediation of a third variable. The analysis estimates how strongly the direct effect of the treatment variable (language distance) on the outcome variable weakens when the mediating variable (proficiency score) is included in the model. Specifically, the models estimate how the total effect (the direct effect of the treatment on the outcome without mediation) changes when the mediator is introduced in the model. The amount of change in the total effect is assigned to the indirect effect of the treatment via the mediator. The difference between the total and the indirect effect is attributed to the direct effect of treatment in the presence of mediation.
The structure of the regression models that constitute the mediation analysis was constant for every dependent variable. The first model was a simple regression model in which language distance (treatment) predicts the reader’s composite proficiency score (mediator). The second linear multiple regression model had both language distance and proficiency scores as predictors of the given dependent variable (outcome). Since mediation analyses require zero-order correlations between all variables (treatment, mediator, and outcome) to be positive, in some models we used the inverse of the original values. For instance, proficiency scores were multiplied by –1 in models predicting eye-movement variables, so that the correlations between language distance and inverse proficiency scores and between fixation durations and inverse proficiency scores are positive. This step does not affect the estimation of the magnitudes of effects or the amount of variance they explain. The default setting of 1,000 simulations was used for the quasi-Bayesian Monte Carlo method based on normal approximation. Importantly, mediation analyses are only applicable when both (a) the treatment and the mediator and (b) the treatment and the outcome variable are significantly correlated. If either (a) or (b) does not hold, there is no statistical ground for mediation.
The estimates of the direct versus indirect effect that mediation models provide are critical for the present purposes. They indicate whether the reader’s proficiency in component skills of reading fully mediates the effect of language distance on reading behavior or whether both language distance and proficiency have unique effects on that behavior.
Results
The main question of this paper is whether the L1–L2 distance influences both the component skills of English proficiency and English reading comprehension and fluency or whether English proficiency fully mediates this influence. Mediation analyses below address this question for word-level reading fluency, represented by three eye-movement measures of real-time processing difficulty: (a) first fixation duration, (b) gaze duration, and (c) total fixation time; for text-level fluency represented by (d) reading rate; and for reading comprehension represented by (e) percent correct accuracy for comprehension questions. Since each mediation analysis requires a pair of regression models, a total of five model pairs were fitted to dependent variables (a–e). We report mediation analyses for word- and text-level fluency and reading comprehension in separate sections below. We precede these sections by outlining data processing steps common to all analyses.
The mediation models below take an individual participant as a unit of analysis. For this reason, we calculated the by participant means of each dependent variable (first fixation duration, gaze duration, total fixation time, reading rate, and comprehension accuracy) across all words and passages. We also calculated for each participant a value of the composite score representing their proficiency in component skills of English reading, and each L1 background is associated with the language distances between that L1 and English. Table 2 summarizes zero-order correlations between all independent and dependent variables of interest.
Table 2 reveals that a higher proficiency score correlates with shorter fixation times and a higher reading rate as well as higher accuracy of comprehension, e.g., greater fluency and comprehension accuracy, as expected. Greater language distance from English predicts the opposite, also as expected, e.g., longer fixation times, lower reading rate, and lower accuracy of comprehension. Moreover, greater language distance predicts lower proficiency in component skills of English reading, in line with prior studies (e.g., Schepens et al., Reference Schepens, Van der Slik, van Hout, Borin and Saxena2013, Reference Schepens, Van der Slik and van Hout2016; Snow, Reference Snow1998).
Word-level reading fluency
Mediation analyses reported in this section examine whether the L1–L2 distance has a direct effect or only an indirect effect on the early or late stages of word reading fluency, as indexed by eye-movement measures.
Prior to calculating the means for those measures, we removed from consideration words in which first fixation duration was either shorter than 80 ms or longer than 1,000 ms; total reading time was longer than 1,000 ms; more than five fixations were made to the word; or a blink was registered when reading the word. These cleaning procedures were based on reports of the minimal time of exposure to printed word required for its visual encoding and on removal of outliers based on the analysis of distributions of respective behavioral variables (as recommended by Baayen & Milin, Reference Baayen and Milin2010; Eskenazi, Reference Eskenazi2024; and Rayner, Reference Rayner1998). Table 3 summarizes the results of these mediation analyses.
Table 3. Mediation analyses of first fixation duration (FFD), gaze duration (GD), total reading time (TRT), and reading rate (Rate)
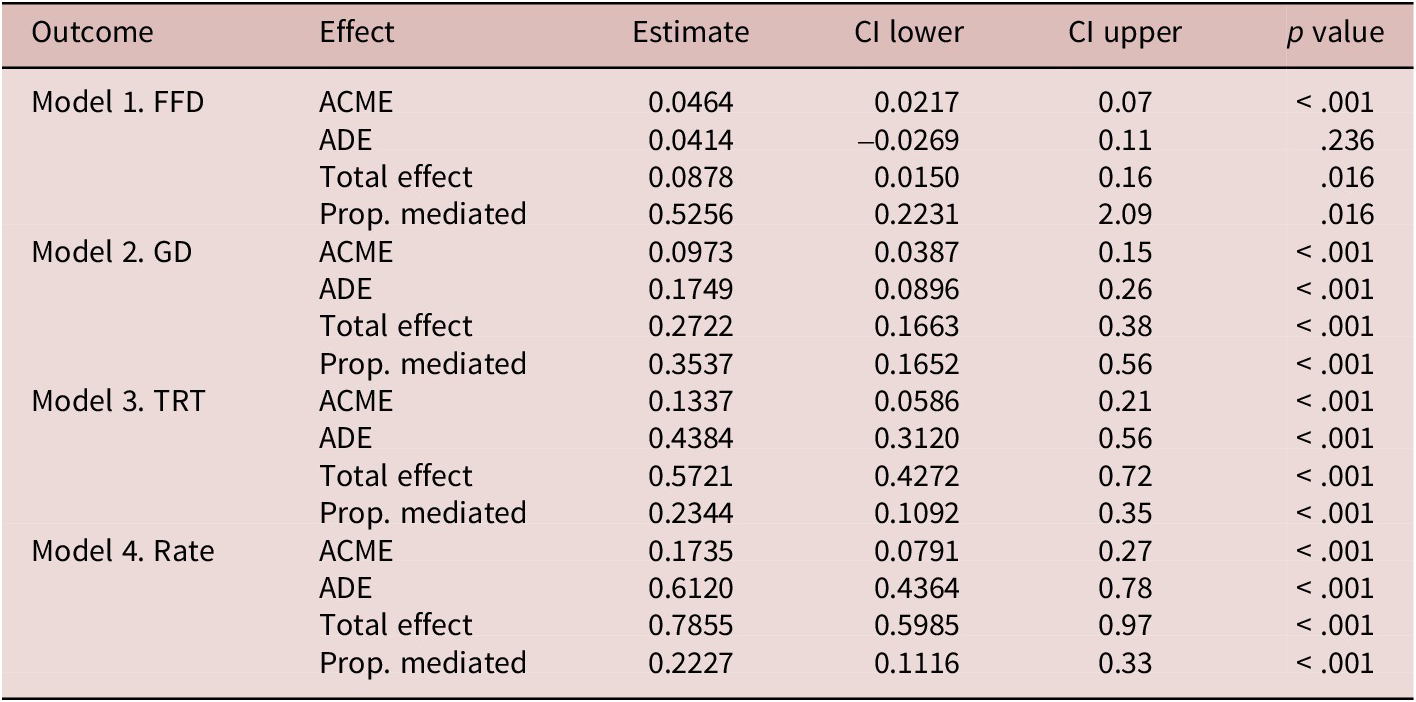
Note: ACME = average causal mediated effect; ADE = average direct effect; CI = confidence interval; Total effect = total effect on the dependent variable; Prop. = Proportion of variance. N = 1,105.
First fixation duration is a measure of difficulty during early stages of word processing and mostly represents decoding and word identification (Rayner, Reference Rayner1998). Model 1 in Table 3 reveals that the direct effect of language distance on this measure is not significant: β = .0414, p = .236. This finding suggests that the earliest stages of printed word decoding and identification gauged by first fixation duration in English as L2 are not affected by the L1–L2 distance per se. The indirect effect of language distance via mediation of proficiency scores is significant (β = .0464, p < .001) and accounts for 53% of the total effect. The presence of the significant indirect effect means that first fixation duration is sensitive to English proficiency, which in turn is affected by language distance.
Gaze duration is still an early eye-movement measure and tends to reflect both the effort of word identification and that of lexical integration with the sentence context. Model 2 in Table 3 estimates the direct effect of language distance on gaze duration as both strong and highly reliable (β = .1749, p < .001). The indirect effect is also significant and amounts to roughly one half of the direct effect in its magnitude (β = .0973, p < .001); it accounts for 35% of the total effect. Thus, language distance affects gaze duration in two ways, both directly and through the mediation of proficiency scores.
Total reading time is a late measure of word processing and represents the cumulative effort of identifying the word and integrating it into the syntactic and semantic structure of the sentence, including resolution of ambiguities and general comprehension difficulty (Boston et al., Reference Boston, Hale, Kliegl, Patil and Vasishth2008). As with gaze duration, language distance reliably demonstrated both direct and indirect effects on total reading time (both p values < .001); see Model 3 in Table 3. The indirect effect was weaker in magnitude than the direct one (β = .1337 versus .4384) and accounted for 23% of the total effect.
Text-level reading fluency
Reading rate reflects fluency at the passage level. Model 4 in Table 3 summarizes results of the respective mediation analysis. Language distance shows significant (p < .001) direct and indirect effects on reading rate. The indirect effect was smaller in magnitude than the direct one (β = .1735 versus .6120) and accounted for 22% of the total effect.
To summarize analyses of word- and text-level reading fluency, proficiency in component skills of English reading accounts for a substantial proportion of the effect that language distance has on reading outcomes. The proportion associated with this indirect effect appears to decrease as our consideration moves from earlier word processing stages (first fixation duration and gaze duration) to the cumulative effort of word and passage fluency (total reading time and reading rate), dwindling from over 50% to 22% of the total effect. Yet, with exception of first fixation duration, language distance has a reliable direct effect on reading fluency, which cannot be ascribed to proficiency scores. Since fluency is not often considered in research on language distance, these findings are novel. We return to them in the General Discussion section.
Reading comprehension
As indicated in the correlational analysis in Table 2, language distance did not produce a reliable effect on individual comprehension accuracy (r = –.012, p = .687). Since there is no evidence of a zero-order correlation, language distance can be safely assumed to have no direct or indirect effect on reading comprehension. In such cases, the mediation analysis is not applicable. This implies that the moderate positive correlation that proficiency scores demonstrate with comprehension accuracy (r = .416, p < .001) is independent of language distance.
General discussion
The motivation for this paper is the uncertain theoretical status of the L1–L2 distance in existing accounts of L2 reading. The conceptual framework of contrastive analysis (e.g., Odlin, Reference Odlin, Doughty and Long2003; Ringbom & Jarvis, Reference Ringbom, Jarvis, Long and Doughty2009) emphasizes the significance of language distance in the acquisition of L2 reading proficiency and its component skills. Empirical evidence also corroborates the notion that languages and scripts that are more remote from the learner’s language background are more difficult to learn (see the Introduction for a brief overview). Yet the mechanism through which L1–L2 language distance influences L2 learning is not well understood. So far, the literature has considered the L1–L2 distance as a possible moderator of the functional relationship between L2 reading comprehension and L2 decoding, vocabulary knowledge, and other L2 component skills of reading comprehension (e.g., Jeon & Yamashita, Reference Jeon and Yamashita2014; Lee et al., Reference Lee, Jung and Lee2022; Melby-Lervåg & Lervåg, Reference Melby-Lervåg and Lervåg2014; Zhang & Zhang, Reference Zhang and Zhang2022). The results of these studies of reading comprehension are mixed, with only a fraction confirming the moderating role of L1–L2 distance; see the Introduction. The status of the L1–L2 distance as a predictor of reading fluency is even less clear, because—to our knowledge—there is little systematic work on this topic; but, see relevant research on oral and written proficiency (Schepens et al., Reference Schepens, Van der Slik, van Hout, Borin and Saxena2013; van Hout & Van der Slik, Reference van Hout and Van der Slik2024).
This paper explores a theoretical possibility, introduced by Lee et al. (Reference Lee, Jung and Lee2022), to explain these mixed results. Specifically, Lee et al. theorize that the L1–L2 distance affects directly only the component skills of reading comprehension (orthographic knowledge, vocabulary, listening comprehension, spelling, etc.). On this account, language distance only exerts influence on reading outcomes indirectly. Namely, language distance explains variance in component skills of English proficiency, and component skills explain variance in reading comprehension or fluency; but without mediation of component skills, language distance does not explain variance in reading outcomes.
The theoretical stakes of the proposed alternatives for models of L2 acquisition are as follows. First, consider the full mediation hypothesis by Lee et al. (Reference Lee, Jung and Lee2022). On this account, readers of, say, Finnish and German (languages respectively remote and close to English) differ in the effort of acquiring those component skills. However, once a speaker of Finnish and a speaker of German reach the same proficiency in the English component skills—as they indeed do in our data (see Figure 1)—they are not predicted to differ in either comprehension or fluency of reading in English as L2. Conversely, if language distance has both a direct and an indirect effect on some reading outcomes, then speakers of Finnish will lag behind the German speakers in their respective performance in English even if their mastery of component skills is comparable (Nisbet et al., Reference Nisbet, Bertram, Erlinghagen, Pieczykolan and Kuperman2022). Logically, another alternative is possible—that proficiency in L2 component skills does not independently affect L2 reading performance. This possibility runs counter to decades of evidence from the L2 acquisition literature (see the Introduction). To our knowledge, the present paper is the first empirical test of these theoretical possibilities both for reading fluency at the word and text levels and for reading comprehension.
Specifically, we conducted mediation analyses to investigate whether and how language distance affects reading fluency at the word and text levels and reading comprehension, over and above the effect of component skills of English proficiency. To this end, the present inquiry makes use of the L2 component of the eye-tracking MECO data source (Kuperman et al., Reference Kuperman, Siegelman, Schroeder, Acartürk, Alexeeva, Amenta and Usal2023), featuring 1,105 readers with 18 distinct non-English first-language backgrounds reading the same set of English texts. English proficiency of these participants was estimated as the composite score of the spelling recognition test, LexTALE lexical decision test, vocabulary knowledge test, and TOWRE decoding and sight word efficiency tests.
The first key finding was the dissociation between reading comprehension and fluency. Language distance between the L1 background of the participants and English had no direct or indirect effect on reading comprehension, while their proficiency in component skills of English did. That is, the advantage in reading comprehension solely comes from the higher individual proficiency in vocabulary, decoding, spelling and other component skills of English reading. In agreement with Lee et al.’s (Reference Lee, Jung and Lee2022) full mediation account, the impact of language distance is confined to helping achieve better mastery of these component skills but does not influence reading comprehension. This finding provides evidence against the theoretical premises of the contrastive analysis model.
However, another reading outcome—reading fluency—exhibited the opposite pattern. Mediation analyses revealed a significant indirect effect of language distance, via mediation of proficiency in component skills, on all measures of word-level reading fluency (first fixation duration, gaze duration, and total reading time) and text-level reading fluency (reading rate). Learning a written language that is more remote from the learner’s background takes a toll on the acquisition of component skills of L2 reading: vocabulary, decoding, word identification, and others. This disadvantage in component skills partly explains why speakers with more remote L1 backgrounds lag in their L2 fluency. An even more compelling finding was the significant direct effect of language distance on gaze duration, total reading time, and reading rate. The direct effect implies that there is an additional “penalty” that the L1–L2 distance inflicts on reading fluency for learners of more remote languages. Even if they acquire a similar average level of component skills, like German and Finnish, or Danish and Turkish readers in our data (see Figure 1), the greater language distance would still cause lower fluency in English. This observation holds true both for early and late stages of word processing like word identification and integration of the word’s meaning within the semantic and syntactic sentence and discourse frame, indexed by eye movements. It also holds for reading rate as the global text-level measurement of reading fluency, which is additionally sensitive to the inferential and structural properties at the discourse level.
The findings for reading fluency are not compatible with the full-mediation hypothesis by Lee et al. (Reference Lee, Jung and Lee2022) formulated to L2 comprehension. They are, however, fully in line with the framework of contrastive analysis, originally proposed for reading comprehension (e.g., Odlin, Reference Odlin, Doughty and Long2003; Ringbom & Jarvis, Reference Ringbom, Jarvis, Long and Doughty2009). They are novel and contribute to a currently scarce body of work on language distance and reading fluency.
Limitations and future directions
While some of the measurements we use in our analyses show extremely high reliability (eye-movement measures and reading rate), others (e.g., reading comprehension and some of the component skills) are just within the conventional acceptable reliability range. This may have decreased the magnitude of respective effects. For this reason, additional studies with more precise instruments are necessary to validate the present findings.
We further acknowledge that our conclusions regarding the role of the L1–L2 distance may be specific to the higher range of L2 English proficiency. Most of the participants in this study are advanced university-level L2 readers of English. All universities from which the student participants were recruited have entrance requirements for English proficiency and many use reading materials in English in their curriculum. Expanding to less advanced ranges of proficiency may lead to different results and a greater role of L1–L2 distance. Similarly, one might expect the role of the L1–L2 distance may change in different tasks (text versus sentence reading versus word reading); see results in Nisbet et al., Reference Nisbet, Bertram, Erlinghagen, Pieczykolan and Kuperman2022. While the present study does not directly consider the role of script distance because of the difficulties in operationalizing this distance, it is clearly a relevant factor for written language learning. Future work is needed to come up with estimates of script distance for a broad variety of writing systems.
Overall, the contribution of the present results to the theories of L2 reading, including contrastive analysis, is in specifying the nature and the mechanism of the influence that language distance between the reader’s L1 and L2 have on L2 reading acquisition. We consider empirically the full landscape of logical possibilities in the causal and mediating relationships between the L1–L2 distance, component skills of reading, and reading outcomes. The findings highlight the diverging mechanisms of acquiring English reading comprehension versus fluency. They also adjudicate between and bring nuance to competing theoretical proposals. In sum, the observed data patterns demonstrated that both conflicting theoretical proposals hold true, but for different facets of reading. Language distance has no bearing on reading comprehension but affects reading fluency.





 Open access
Open access