


1. Introduction
Our article proposes the typological approach to research on child language to correct the pervasive focus on the acquisition of individual languages. Unlike the restricted-language approach of current acquisition research (e.g., Bloom, Reference Bloom1973; Braine, Reference Braine1963), the typological approach uses information on all languages as a framework for acquisition research. It draws insights from linguistic typology, the comparative study of language form, and structure (Beck, Reference Beck2016; Haspelmath, Reference Haspelmath2010, Reference Haspelmath, Van Olmen, Mortelmans and Brisard2018; Plank, Reference Plank2016; Song, Reference Song2011). Previous scholars have used typological research to inform acquisition studies (e.g., Andersen, Reference Andersen, Greenberg, Ferguson and Moravcsik1978 on body parts; Bowerman, Reference Bowerman and Song2011; Bowerman & Choi, Reference Bowerman, Choi, Bowerman and Levinson2001 on space; Pye, Reference Pye1990 on ergativity), but none suggest making linguistic typology the foundation for all research on language acquisition.
Child language research typically takes an iterative approach; so, theories advanced to explain results for one language (often English) are gradually extended to successive languages. The iterative approach leads to comparisons of results between languages A and B, and languages A and C, but rarely between languages B and C. The languages are selected for convenience rather than their typological features. The iterative approach privileges research on language A by imposing the methods and theories devised for A on other languages (Singh, Reference Singh2022). David Crystal (Reference Crystal1974, p. 300) observed this phenomenon for Brown’s (Reference Brown1973) mean length of utterance (MLU) warning that “Many researchers will try to apply the Brown model, and they will be faced with a large number of problems, both of principle and of analytic detail, which (the danger is) they will ‘solve’ by arbitrary means.”
In contrast to the iterative approach, the typological approach uses the accumulated knowledge of linguistic typologists to avoid making ad hoc adjustments in successive languages. It first surveys how the feature of interest is realised crosslinguistically, which provides the comparative basis for a cumulative analysis of all languages.
Sounds, words, and meanings have language-specific realisations that complicate comparative studies between languages (Amberber et al., Reference Amberber, Baker and Harvey2010; Mithun, Reference Mithun and Genetti2014; Port & Leary, Reference Port and Leary2005; Siewierska, Reference Siewierska2004). This variation occurs at the phonological, morphosyntactic, and semantic levels (Evans & Levinson, Reference Evans and Levinson2009). Phonologically, a ‘word’ in the Mbyá variety of Guaraní must be multisyllabic (Guedes, Reference Guedes1991, p. 44, p. 49), while Mandarin words can be monosyllabic (Chao, Reference Chao1946), and some words in Tashlhiyt lack vowels (Ridouane, Reference Ridouane2008). Unlike, accusative languages, ergative languages use different markers for the subjects of transitive and intransitive verbs, while subject marking in stative-active languages cross-references properties of the event (Dixon, Reference Dixon1994). Semantically, verbs may conflate motion and manner as in English, motion and path as in Spanish, or motion and figure as in Navajo (Talmy, Reference Talmy and Shopen1985).
In this article, we use the typological approach to generalise Ingram’s (Reference Ingram2002) whole-word measures of phonological complexity (PMLU) and proximity (PWP). We first demonstrate how we convert Ingram’s language-specific measures into generally applicable measures with typological validity. We derive a procedure for calculating lexical complexity based on generalised properties of words and syllables. We show that phonemic differences lead to differences in what counts as a correct consonant between languages.
Subsequently, we present statistical analyses using the generalised complexity and proximity measures for children’s words in six languages. As in previous studies, we find significant crosslinguistic differences in the children’s whole-word complexity measures, but unlike some studies, we find no significant crosslinguistic differences in the children’s whole-word proximity measures. We discuss the properties of the proximity measure that minimise its crosslinguistic differences. We end by considering the broader implications of the typological approach to research on child language.
2. Deriving comparative measures of whole-word phonology
Research on whole-word phonological complexity is theoretically motivated by investigations showing that children’s productions are based on word-size holistic representations (e.g., Ferguson & Farwell, Reference Ferguson and Farwell1975; Menn, Reference Menn1976; Vihman & Croft, Reference Vihman and Croft2007; Waterson, Reference Waterson1971; Vihman, Reference Vihman2019 summarises this research). At 1;8, for example, Waterson’s son’s finger [ɲẽ:ɲẽ ~ ɲi:ɲɪ] and window [ɲe:ɲe:] match the overall adult target shape in terms of its syllables and a consonant, but change the target structure by segment reordering and syllable repetition to match the child’s production template. Such templates become more frequent “toward the middle or end of the single-word period – but then fade thereafter, as the child comes to master … the more complex sequences of the adult language…” (Vihman & Keren-Portnoy, Reference Vihman, Keren-Portnoy, Vihman and Keren-Portnoy2013, p. 3).
These observations inspired researchers to develop measures that systematically assess children’s whole-word complexity and variation (Ingram, Reference Ingram2002; Ingram & Ingram, Reference Ingram and Ingram2001; Jalieski, Reference Jalieski2000; Masterson & Kamhi, Reference Masterson and Kamhi1992). Waterson (Reference Waterson1971) states that only 48 of her son’s 155 words at 1;8 were disyllabic. Ingram and Ingram (Reference Ingram and Ingram2001) proposed the whole-word measures of phonological complexity (PMLU), proximity (PWP), correctness (PWC), and variation (PWV). Analogous to Brown’s MLU measure of sentence complexity, phonological mean length of utterance (PMLU) provides a preliminary assessment of a child’s phonological development. The PMLU measure awards one point for each segment in a child’s word, and an extra point for correct consonants, i.e., dog has a PMLU score of 5, 1 point for each segment and two extra points for the two correct consonants. The whole-word proximity measure (PWP) is derived by dividing the PMLU score for the child’s words by the PMLU score for the target words.
Subsequent investigations have used Ingram’s PMLU and PWP measures to examine language samples from monolingual and bilingual children (Beers et al., Reference Beers, Rodenburg-Van Wee and Gerrits2019; Bunta et al., Reference Bunta, Fabiano-Smith, Goldstein and Ingram2009; Burrows & Goldstein, Reference Burrows and Goldstein2010; Ingram, Reference Ingram2002; Loatman, Reference Loatman2001; Saaristo-Helin et al., Reference Saaristo-Helin, Savinainen-Makkonen and Kunnari2006; Sosa & Stoel-Gammon, Reference Sosa and Stoel-Gammon2012). The clinical relevance of PMLU has been demonstrated in studies of children with speech and language disorders (Burrows & Goldstein, Reference Burrows and Goldstein2010; Ingram & Ingram, Reference Ingram and Ingram2001; MacLeod & McCauley, Reference MacLeod and McCauley2003; Newbold et al., Reference Newbold, Stackhouse and Wells2013), children with low birth weight (van Noort-van der Spek et al., Reference van Noort-van der Spek, Franken, Wieringa and Weisglas-Kuperus2009), and children with cochlear implants (Schauwers, Reference Schauwers2006; Schauwers et al., Reference Schauwers, Taelman, Gillis, Govaerts, Kern, Gayraud and Marsico2008).
Several PMLU studies raise the issue of iteratively adjusting the procedure for particular languages (Beers et al., Reference Beers, Rodenburg-Van Wee and Gerrits2019; Bunta et al., Reference Bunta, Fabiano-Smith, Goldstein and Ingram2009; Ingram, Reference Ingram2002; Saaristo-Helin et al., Reference Saaristo-Helin, Savinainen-Makkonen and Kunnari2006; Taelman et al., Reference Taelman, Durieux and Gillis2005). In his original article, Ingram (Reference Ingram2002) proposed adjusting the PMLU calculation for Cantonese by adding points for correct vowels and tones. Bunta et al. (Reference Bunta, Fabiano-Smith, Goldstein and Ingram2009) selected comparable target words in English and Spanish in terms of length and phonological complexity. Saaristo-Helin et al. (Reference Saaristo-Helin, Savinainen-Makkonen and Kunnari2006) adjusted PMLU for child Finnish by collapsing the Finnish long-short consonant contrast. Bunta et al. (Reference Bunta, Fabiano-Smith, Goldstein and Ingram2009, p. 158) assert that Ingram’s whole-word measures “are adaptable to different settings and can be modified as demanded by the particular linguistic environment…”
While such modifications may be appropriate for individual investigations, they are fatal to crosslinguistic comparisons of PMLU. As Crystal (Reference Crystal1974) warned, they lead to the danger of arbitrary adjustments, and do not produce cumulative results that can be integrated within a single framework. Ingram’s adjustments for Cantonese tones would be inappropriate for Finnish, while Saaristo-Helin et al.’s adjustments for Finnish geminates would be inappropriate for Spanish. It is impossible to control the effects of such modifications because researchers seldom publish the children’s words.
Our study is the first to suggest a typologically informed procedure for child language research. We illustrate this approach by showing how we generalise Ingram’s measures of whole-word complexity and proximity in order to apply them consistently across languages. In particular, we generalise the word concept in light of the diverse variety of word forms across languages. The typological approach provides the foundation for an index of whole-word phonological complexity in children’s words.
2.1. Generalising Ingram’s lexical complexity measure
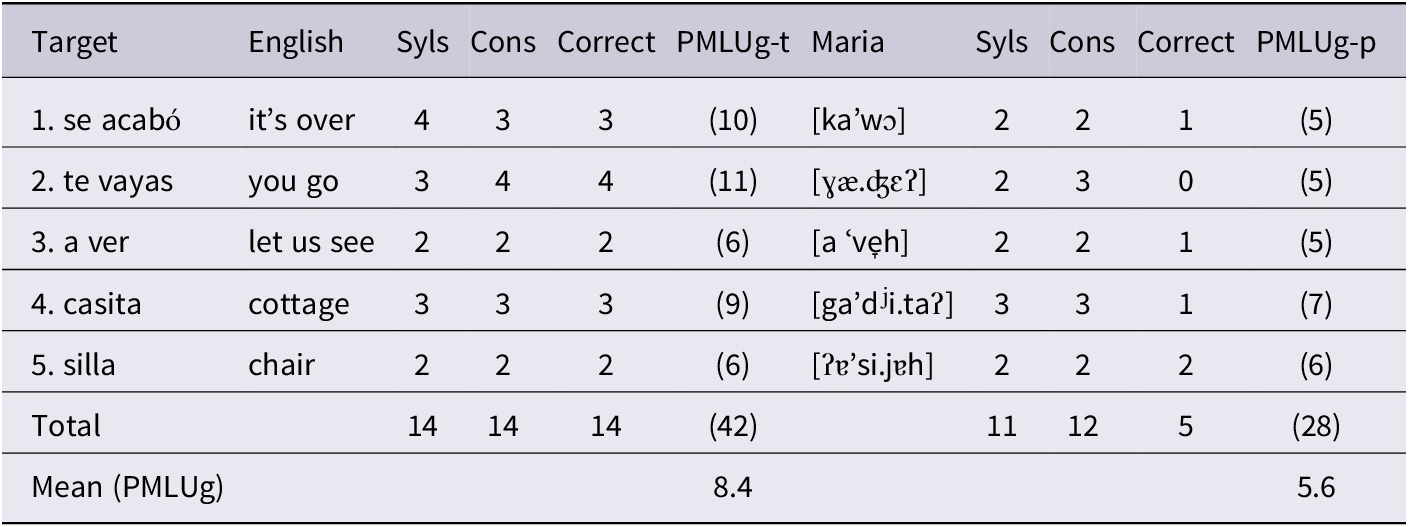
We derive a generalised measure of lexical complexity by eliminating references in Ingram’s rules to language-particular, distributional features thereby making each rule as general as possible. We list Ingram’s rules for calculating PMLU in Table 1, and then discuss how we modify the individual rules to derive a generalised measure of whole-word complexity.
Table 1. Ingram’s (Reference Ingram2002) rules for calculating the phonological mean length of utterance (PMLU)

2.2. Sample-size rule (Rule 1)
Rule 1 establishes a consistent basis for measuring PMLU. Sample size is one of four variables affecting children’s PMLU measurement. Other variables for typically developing (TD) children include the language (Beers et al., Reference Beers, Rodenburg-Van Wee and Gerrits2019; Ingram, Reference Ingram2002; Saaristo-Helin et al., Reference Saaristo-Helin, Savinainen-Makkonen and Kunnari2006), age (Burrows & Goldstein, Reference Burrows and Goldstein2010; Ingram, Reference Ingram2002; Babatsouli et al., Reference Babatsouli, Ingram and Sotiropoulos2014; Watson & Terrell, Reference Watson and Terrell2012), gender, and sampling method (Faes et al., Reference Faes, Gillis and Gillis2016; Wren et al., Reference Wren, Titterington and White2021). Investigators should pay attention to each of these variables when designing their studies.
Sample size affects the precision of PMLU. Taelman et al. (Reference Taelman, Durieux and Gillis2005) calculated 95% confidence intervals of PMLU values for Dutch-speaking Robin in 25-word samples over a 9-month period. They report a decrease in PMLU precision with older children and smaller sample sizes. Taelman et al. proposed changing Ingram’s sample-size rule by using all word tokens; observing a minimum of 25 words for children with PMLU scores up to 4.5 (ages 1;3–1;11), a minimum of 50 words for children with PMLU scores between 4.5 and 5.5 (ages 2;0–3;5), and a minimum of 100 words for children with PMLU scores of 5.5 and higher. They encouraged investigators to report sample size and standard deviation in order to calculate measurement error.
Collecting a 25-word sample from 11-month-old children can be challenging. Joan’s (Velten, Reference Velten1945) 25-word sample that Ingram (Reference Ingram2002) analysed included seven words that named alphabet letters. Saaristo-Helin et al. (Reference Saaristo-Helin, Savinainen-Makkonen and Kunnari2006, p. 188) combined words from multiple sessions with the same child to increase sample sizes.
Sampling techniques vary according to the purpose of the investigations. Bunta et al. (Reference Bunta, Fabiano-Smith, Goldstein and Ingram2009, p. 162) collected children’s single-word and connected speech samples in English and Spanish, but only analysed the single-word data. A bilingual English-Spanish phonological assessment test was used for single-word elicitations, but words that were not comparable in length and phonological complexity between the languages were discarded. Such decisions miss words that children use in connected speech. Children’s conversational samples may be limited in size, but they document children’s word use in naturalistic contexts (Stoel-Gammon & Dunn, Reference Stoel-Gammon and Dunn1985; Wren et al., Reference Wren, Titterington and White2021). Shriberg (Reference Shriberg1993) found that conversational samples are linguistically and psychometrically robust. For consistency, we recommend analysing children’s words from conversational samples. This is especially important when little primary research is available for the language.
Investigations of PMLU should ideally assess the effect of gender. Sosa and Stoel-Gammon’s (Reference Sosa and Stoel-Gammon2012, p. 603) study of nine boys and six girls, aged 24 and 29 months, did not find a significant difference between the children’s PWP scores, but the study did not account for likely gender effects.
2.3. Lexical class rule (Rule 2)
Rule 2 establishes a basis for excluding words that might distort PMLU. Ingram references lexical classes that differ between languages (Evans & Levinson, Reference Evans and Levinson2009). The Mayan language Mam, for example, does not have prepositions or pronouns, but does have lexical classes for relational nouns and positional verbs (England, Reference England1983). Lao has no adjective class (Enfield, Reference Enfield, Dixon and Aikhenvald2004). Pronouns vary between independent words and phonologically dependent clitics (Siewierska, Reference Siewierska2004).
Ingram recommends excluding fillers (e.g., oh, huh, um) that would lower the child’s PMLU, and reduplicated words (e.g., mommy, daddy, byebye) that would inflate the child’s PMLU. The words hi and no are problematic in being frequently used in isolation. Beers et al. (Reference Beers, Rodenburg-Van Wee and Gerrits2019, p. 1154) included the first syllable of reduplicated words in their study.
Saaristo-Helin et al. (Reference Saaristo-Helin, Savinainen-Makkonen and Kunnari2006, p. 188) observed that excluding onomatopoeic and reduplicative words from PMLU analyses deserves further justification in that these are often children’s most accurately produced words. Excluding words from PMLU calculations severely impacts samples with few words and decreases the reliability of the results. Children’s phonology undergoes rapid structural changes when children acquire their first 25 words, so excluding such words will miss important dimensions of children’s lexical development. Excluding words increases the risk of making arbitrary decisions that lead to inconsistencies between studies.
There is also a cultural dimension to deciding what should count as a word. Taine (Reference Taine1877, p. 257) observed that he adopted his daughter’s innovated word [ham] for eating, commenting that “Originality and invention are so strong in a child that if it learns our language from us, we learn its from the child.” The mutual influence between children and their caretakers produces sizable differences in the prevalence of baby-talk words across cultures (Ferguson, Reference Ferguson1964). Ku waru- and Nungon-speaking caretakers in Papua New Guinea teach non-inflecting words to children that are replaced by inflecting words as the children grow older (Sarvasy, Reference Sarvasy2019; Sarvasy et al., Reference Sarvasy, Rumsey, Dahmen, Onga and YamUnder review). These baby-talk words have a systematic link to their contexts of use that is the same as the adult-like words.
For these reasons, we generalised Rule 2 by eliminating its reference to lexical classes and changing it to a rule for excluding a restricted set of expressions. We suggest including greetings (e.g., hi, bye, good morning), names (including mommy and daddy), and yes and no. Only fillers and exclamations (e.g., ah, oh, oof, ouch, ssh, um, etc.) should be excluded. Researchers should state the number and proportion of excluded words and list them.
2.4. Compound rule (Rule 3)
Rule 3 defines what counts as a single word in a child’s language sample, which varies with phonology, morphology, and orthography (Brookes et al., Reference Brookes, Makaure, Yalala, Danvers, Mossmer, Little, Ndhambi, Southwood and Ludidi2025; Dixon & Aikenhvald, Reference Dixon, Aikenhvald, Dixon and Aikenhvald2003; Hyman, Reference Hyman and Greenberg1978; Shopen, Reference Shopen1985). Words have phonological features (e.g., stress, vowel harmony) and grammatical features (e.g., inflexions) that coincide in prototypical words. Nevertheless, many languages have single phonological words containing several grammatical words (e.g., articles, clitics), while others have single grammatical words containing several phonological words (e.g., complex predicates).
Ingram’s rule references an English spelling convention that does not apply to other languages. Beers et al. (Reference Beers, Rodenburg-Van Wee and Gerrits2019, p. 1150) note that some Dutch compound words written as single words correspond to English compounds written as two words (e.g., voetbalspeler ‘football player,’ appeltaart ‘apple pie’).
Rule 3 also excludes particle verbs. Particle verbs do not fit the prototype of a word because other words can intervene between the verb and its particle, e.g., pick me up. Particle verbs in Dutch and German are spelt as single words when the particle precedes the verb in subordinate clauses (1a) and as separate words when the particle follows the verb in main clauses (1b). Ingram counts the verb and its particle as separate words.

Particle verbs are a type of complex predicate; these combine several semantic elements into a mono-clausal predicate that may or may not be written as a single word (Amberber et al., Reference Amberber, Baker and Harvey2010; Pye, Reference Pye2024). Sarvasy (Reference Sarvasy2021) describes the types of complex predicates that occur in Nungon, a Papuan language of the Finisterre grouping in northeastern Papua New Guinea. Nungon has multi-verb predicates that form a single clause. Person, number, and tense are marked on the last predicate in the construction. The Nungon complex predicate shown in (2) has the morpheme hak ‘clean’ that only appears in combination with the auxiliary to- ‘do.’

Clitics differ across languages in their degree of attachment to their host (Spencer & Luís, Reference Spencer and Luís2012). Spanish clitics are written apart from the verb in indicative clauses, e.g., le pone ‘s/he puts it,’ but are written together with the verb in imperative clauses ponle ‘put it.’
We generalised Rule 3 by eliminating references to language-specific features such as orthographic conventions for writing compounds and complex predicates. We count all clitics with their hosts as single words regardless of whether they were written as such. We treat all forms with non-compositional meanings as single words, including clitics, compounds, complex predicates, and idiomatic phrases such as Niagara Falls (Williams, Reference Williams1994). In this way, we derived a generalised concept of wordhood.
2.5. Variability rule (Rule 4)
Rule 4 selects a single token for words with multiple forms. This token represents the child’s token variation for each word. This is the same rule that Ingram (Reference Ingram1989) proposes for the analysis of child phonology, where he discusses the rationale for this procedure. The rule reduces the impact of frequent words such as is and mommy on the analysis and highlights common features across the child’s different words. This rule generalises the PMLU by reducing a potential source of crosslinguistic variation. Taelman et al. (Reference Taelman, Durieux and Gillis2005) and Beers et al. (Reference Beers, Rodenburg-Van Wee and Gerrits2019) included all word tokens in their PMLU analyses. Beers et al. report that they did not find significant differences between PMLU measures based on word tokens and word types. We retained the variability procedure described in Ingram (Reference Ingram1989), and base our PMLU calculations on word types because some of the samples we used only listed a single form for each word.
2.6. Production rule (Rule 5)
Ingram took a major step to generalising the production rule by referencing consonants in general terms rather than in terms of their language-specific features, e.g., manner and place of articulation. The diversity of consonant inventories in the world’s languages can be expected to impact the accuracy of consonant production. Rotokas (West Bougainville; Papua New Guinea) has six consonants, written as /p, t, k, b, d, g/, while the Southern Khoisan language!Xóõ, spoken in Botswana has 122 consonants with a large number of click sounds (Maddieson, Reference Maddieson, Dryer and Haspelmath2013). Ingram’s rule generalises across these consonant inventories by summing across a child’s produced consonants.
Ingram generalised Rule 5 further by not scoring vowel accuracy because vowel transcription is less accurate. Even so, we have to modify the production rule for languages like Tashlhiyt Berber that have words without vowels. In Tashlhiyt Berber, voiceless fricatives and stops can function as syllable peaks (Dell & Elmedlaoui, Reference Dell and Elmedlaoui1985; Ridouane, Reference Ridouane2008). The Tashlhiyt verb tk.kst ‘you took off’ has the syllable peaks /k/ and /s/ and no vowels (Ridouane, Reference Ridouane2008).
We propose modifying Rule 5 by counting syllable peaks instead of vowels to capture a prominent feature of prosodic structure (Demuth, Reference Demuth, Morgan and Demuth1996; Fikkert, Reference Fikkert1994). Scoring syllable peaks moves PMLU further towards a general measure. Hyman (Reference Hyman and Greenberg1978) notes that syllables share many phonological features with words. A PMLU that counts syllable peaks rather than vowels analyses tk.kst as two syllable peaks and five consonants.
Scoring syllable peaks leads to a more consistent treatment of syllabic consonants (Bell, Reference Bell and Greenberg1978). This decision analyses syllabic consonants as consonants on the segmental level and syllable peaks on the prosodic level. Ingram (Reference Ingram2002, p. 716) analysed syllabic consonants as single consonants rather than a combination of consonant and syllable. He aligned [o] in a child’s [bado] (bottle) with the final syllabic consonant [l]. We analyse the child’s [bado] as having two consonants and two syllables with a PMLU of 5 compared to the target PMLU of 8. The child’s production lacks the targeted word’s final consonant and has the incorrect medial consonant [d].Footnote 1 Counting syllable peaks rather than vowels makes the analysis of syllabic consonants and other consonants consistent. We describe the rules for aligning segments in Appendix A of the Supplementary Material.
Counting syllable peaks rather than vowels produces a consistent treatment of diphthongs as well. We counted diphthongs as a single syllable peak giving them 1 point. We further extended our treatment of diphthongs to glides. We counted glides in syllable onsets as consonants and as an offglide when in the same syllable with the preceding vowel. Accordingly, away has a PMLU score of 4 (2 syllables, 1 consonant). Onset glide /w/ counts as a consonant and gets two points, while offglide /j/ is part of a diphthong and does not contribute to the PMLU score.
There is another aspect of Rule 5 that makes it still more general. Ingram excludes produced sounds that are not part of the target. He discusses Joan Velten’s foot produced as /hwut/ (Velten, Reference Velten1945). Both the targeted word’s PMLU (two consonants, one syllable) and Joan’s produced PMLU is 5 unless we exclude the extra initial consonant in the child’s production. Excluding the child’s [h] reduces the produced PMLU to 4, indicating a non-targeted word production.Footnote 2
Excluding extra sounds from the PMLU calculation generalises the measure in that it ties the measure of the child’s word closer to its target. Phrasal prosody and articulatory constraints can lead to the production of additional sounds in children’s words and such processes vary crosslinguistically (Demuth, Reference Demuth, Ferris-Trimble and Barlow2014, p. 19). In keeping with a generalised measure, PMLU is best understood as an abstract measure of that portion of children’s words that align with the target.
2.7. Consonants correct rule (Rule 6)
Rule 6 adds an extra point for the correct consonants in the child’s production. We used a broad phonemic interpretation to code the transcriptions aiming to maximise scoring consistency across the languages. We did not code narrow phonetic features such as vowel offglides or aspiration if they were not contrastive for the language. Taelman et al. (Reference Taelman, Durieux and Gillis2005) reconciled the phonemic transcription from the MAARTEN-corpus data with the narrow phonetic transcription from the CLPF-corpus data for Dutch by reducing allophones to a single phonemic form. The child SR produced English splash as [phæs] with an aspirated stop in place of the targeted unaspirated stop (Stoel-Gammon & Dunn, Reference Stoel-Gammon and Dunn1985). We considered her initial stop production to be correct and added two points, resulting in a PMLU of 4. Aspiration is contrastive for stops in Xi’iùy (Berthiaume, Reference Berthiaume2012) so we considered substitutions between aspirated and unaspirated stops in Xi’iùy to be incorrect. For example, NP04 (NPJL1202), produced khuʔt ‘they come’ in Xi’iùy as [kut] with an unaspirated initial velar stop. We could only score his final consonant as correct, giving his production a PMLU of 4, instead of 5 had he produced the initial consonant correctly.
We summarise our rules for calculating a generalised lexical complexity score (PMLUg) in Table 2 and provide a sample analysis in Table 3. The PMLUg scores for the target and produced words in the sample are shown in parentheses. The five target words in this sample have a mean PMLUg of 8.4 and the child’s productions have a mean PMLUg of 5.6. We provide a full analysis for one child in Appendix B of the Supplementary Material.
Table 2. Rules for calculating the generalised phonological mean length of utterance (PMLUg)
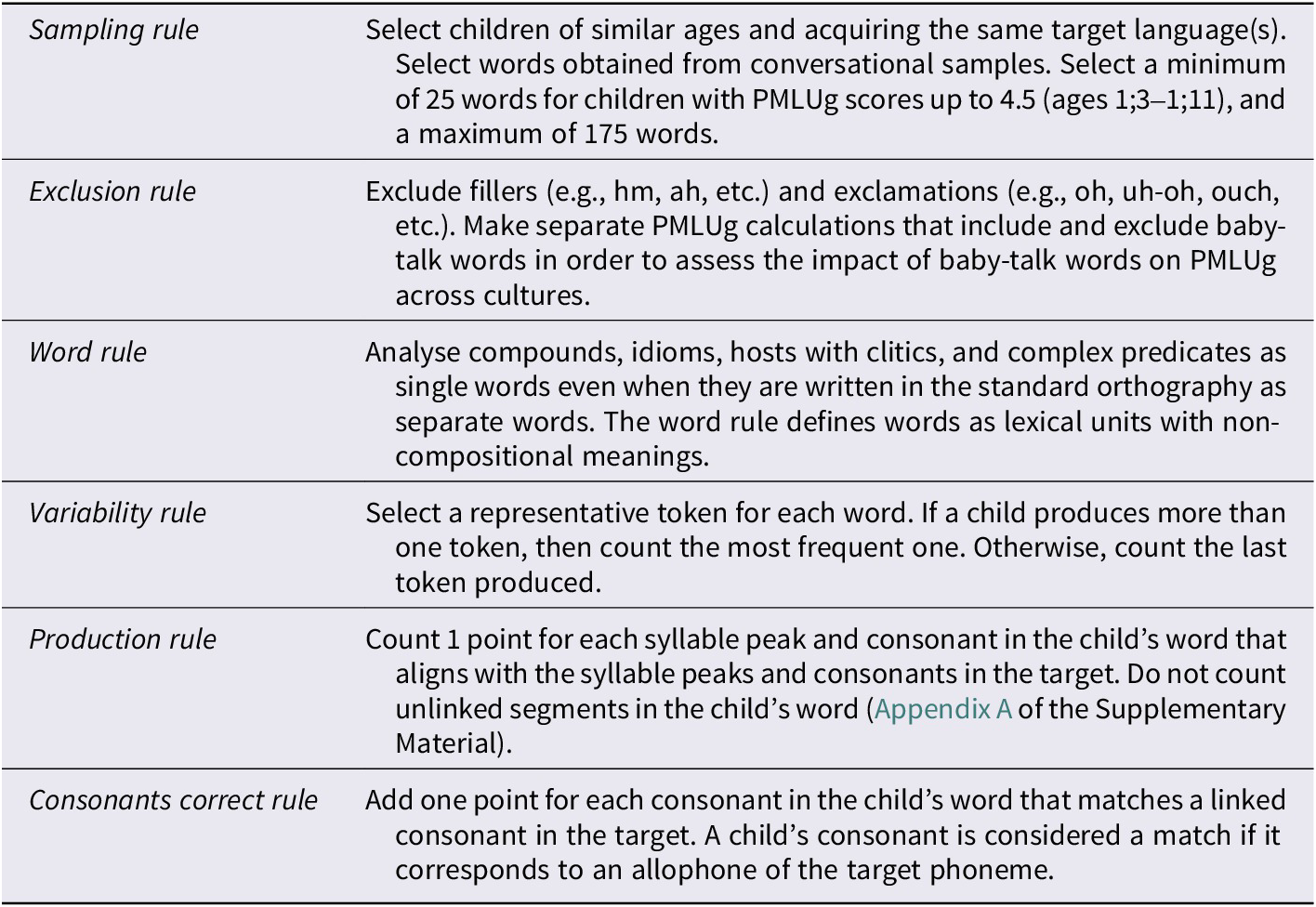
Table 3. PMLUg calculation for Maria (1;10, Lleó & Prinz, Reference Lleó and Prinz1996)
3. Complexity and proximity
The crosslinguistic validity of comparative measures can only be achieved by making the measures maximally general. Detailed analyses of segmental features and processes illuminate phonological development within individual languages, but the analyses do not generalise to phonological development crosslinguistically. Generalised measures, like PMLUg, can be used to rank world languages by the average phonological complexity of their words. We would then know how well existing studies of phonological development sample the full range of lexical complexity in the world’s languages.
The complexity measure is an absolute score in that it counts syllable peaks and consonants in target and produced words. Crosslinguistic differences in the syllable peaks and consonants in the target words that children attempt will lead to differences in the children’s lexical complexity scores (Bunta et al., Reference Bunta, Davidovich and Ingram2006, Reference Bunta, Fabiano-Smith, Goldstein and Ingram2009; Ingram, Reference Ingram2002; Loatman, Reference Loatman2001; Saaristo-Helin et al., Reference Saaristo-Helin, Savinainen-Makkonen and Kunnari2006). The generalised complexity measure will reflect such crosslinguistic differences unless restrictions on children’s articulation reduce the differences in the complexity of children’s words (MacNeilage et al., Reference MacNeilage, Davis and Matyear1997; McAllister Byun & Tessier, Reference McAllister Byun and Tessier2016).
Ingram’s (Reference Ingram2002) PWP however is a relative score as it calculates the proximity of the child’s words to the target word. The proximity score is the ratio of produced PMLUg to target PMLUg, found by summing the produced and target PMLUg for all words in a sample and then dividing the produced sum by the target sum. The proximity calculation converts an absolute score like PMLUg that counts the number of syllable peaks and consonants to a relative score that assesses the proportion of a child’s complexity measure relative to an adult target. It is possible that even though children differ between languages in their lexical complexity scores, they display similar developmental progress towards the target words. Children acquiring languages with longer words will produce longer words than children acquiring languages with shorter words, but children acquiring long-word languages and short-word languages may have similar proximity scores. If such is the case, the proximity score would provide a crosslinguistic basis for equating children at similar stages of phonological development regardless of average differences in lexical complexity across the languages. We test three research questions based on the difference between lexical complexity and proximity:
-
1. Do the target words that children attempt differ in lexical complexity between languages?
-
2. Do the words that children produce differ in lexical complexity between languages?
-
3. Do children at similar stages of development produce words that exhibit the same proximity to target words across languages?
4. A crosslinguistic study
We apply the generalised measures of lexical complexity and proximity to children’s words in six languages to address our research questions. We test for the following variables that may affect these measures: age, sex, the number of produced words, targeted syllables, and consonants per targeted syllable.
5. Method
We selected six languages based on their historical and typological features and the availability of data from a sufficient number of children to allow for statistical analysis. The datasets consist of words produced by 51 two-year-old children acquiring Dutch, English, Japanese, Portuguese, Spanish, and Xi’iùy (Northern Pame). Ingram’s study suggests that children’s PMLUg and PWPg scores will be higher for children acquiring Spanish than those acquiring English. Adding additional European languages allows us to test whether the differences in children’s PMLUg scores for English and Spanish extend to Dutch and Portuguese. Historical and phonological features of the languages are shown in Table 4.
Table 4. Historical and phonological features of the languages
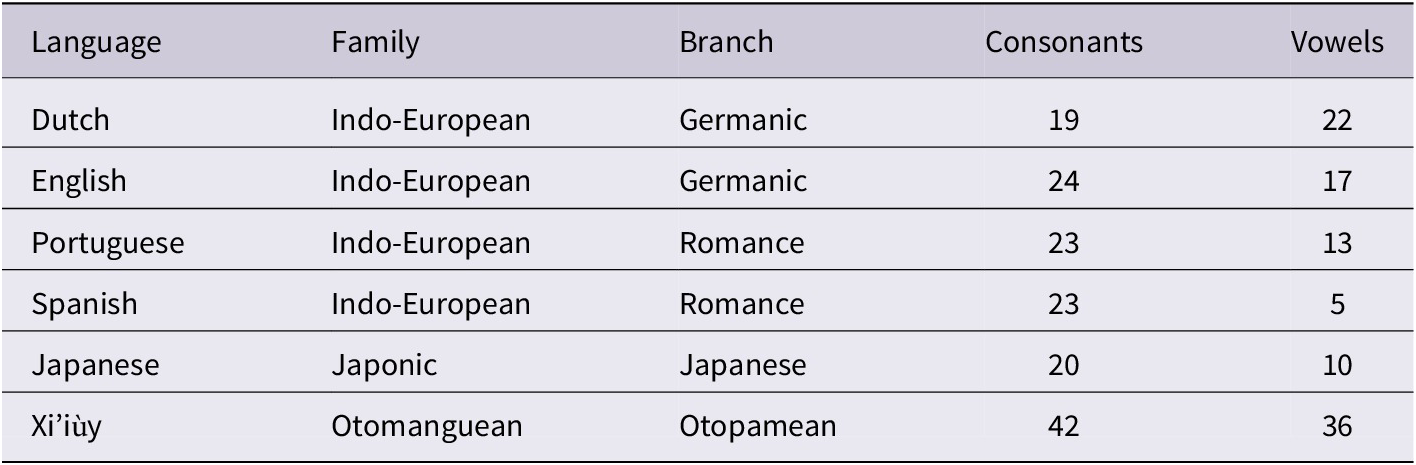
Japanese has many polysyllabic words with open syllables like the Romance languages, and we expect PMLUg and PWPg scores for Japanese to be similar to those for Portuguese and Spanish. Xi’iùy, an Otomanguean language spoken in Mexico, has roughly twice as many consonants and vowels as any of the other languages. Most consonants have a three-way contrast between plain, aspirated, and glottalised forms (e.g., m, mh, m’). Xi’iùy has six modal vowels (i, e, æ, ə, u, ɑ), and a four-way manner contrast between modal, nasal, creaky, and breathy vowels, with two tones: high and low, rising (Berthiaume, Reference Berthiaume2012).
Unlike the other languages in our study, a high proportion of Xi’iùy words have obligatory inflexions. Most Xi’iùy nouns have obligatory prefixes for noun class, while most Xi’iùy verbs have obligatory prefixes for person and aspect (Berthiaume, Reference Berthiaume2012). These inflectional prefixes often take the form of syllabic consonants. The syllabic consonantal prefixes increase the syllable count in Xi’iùy words, while consonant clusters occur in syllable onsets and codas. Xi’iùy is similar to Portuguese, Spanish, and Japanese in having many polysyllabic words, but resembles Germanic languages in having many consonants per syllable. Thus, we expect the PMLUg and PWPg scores for children acquiring Xi’iùy to be midway between those for children acquiring Germanic languages and children acquiring Japanese and Romance languages.
5.1. Data collection
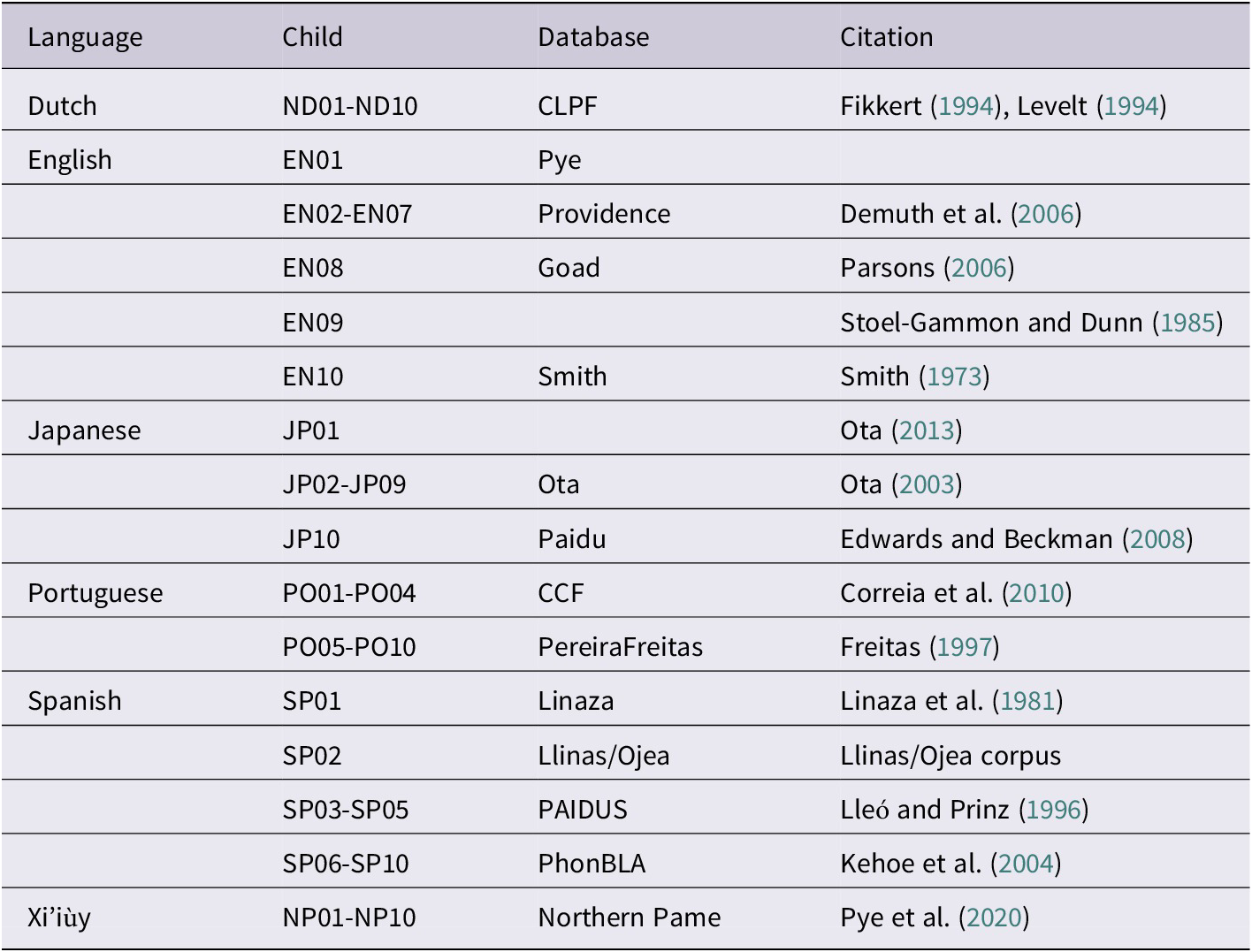
The data we analysed come from both published and unpublished sources. We searched for language samples with phonetic transcriptions that allowed us to assess the accuracy of the children’s consonant productions. The wordlist for EN01, Charlie, was extracted from recordings of play sessions made by Pye. The wordlist for EN09, SR, was published in Stoel-Gammon and Dunn (Reference Stoel-Gammon and Dunn1985). The wordlist for JP01, Tai, was published in Ota (Reference Ota, Vihman and Keren-Portnoy2013). The wordlists for the children acquiring Xi’iùy (Northern Pame) were extracted from transcripts in the AILLA archive (Pye et al., Reference Pye, Berthiaume and Pfeiler2020). We extracted words for the other children from the CHILDES and PhonBank archives (MacWhinney, Reference MacWhinney2000; Rose & MacWhinney, Reference Rose, MacWhinney, Durand, Gut and Kristoffersen2014). Table 5 shows the sources of the children’s data files.
Table 5. Data sources
We searched these sources for transcripts of children aged approximately 2;0. We used data from the same child recorded in different sessions when transcripts were not available for ten different children in each language. We did this for two Xi’iùy children, four Japanese children, one Portuguese child, and one Spanish child. The resulting dataset has samples from 51 children. In other cases, we combined the data from several sessions for a single child if that child did not produce many words in a single session. This was the case for two Xi’iùy children (NP01, NP06) and three Spanish children (SP06, SP07, SP08).
Table 6 shows the general measures for the children. All measures for the children are reported in Appendix C of the Supplementary Material. In the study, 44 of the 51 children were between 21 and 24 months old. The standard deviation in age across all children investigated was less than 1.5 months. Since most children had similar ages, the effect of age on the whole-word measures was not a focus of the study, but we included an age variable in some of our models to account for potential variation caused by some children falling outside the core age range. The children were fairly balanced for gender except for those in the Xi’iùy and Spanish groups. There were also large differences in the number of words produced ranging between a mean of 57.4 words for Japanese and 130.2 words for Xi’iùy.
Table 6. General measures for the children
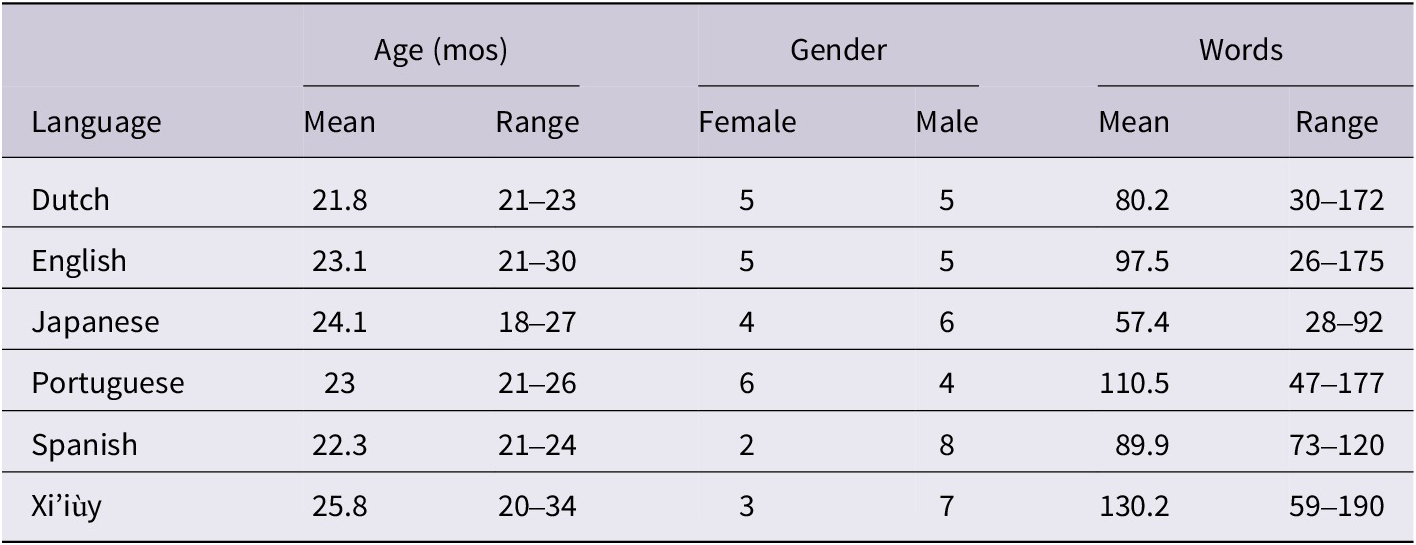
We could not find samples of connected speech for all children. Language samples for some children come from single-word elicitation sessions with a fixed word list. Such sessions elicited words with a greater variety of phonemes, but intra-language comparisons show that the elicitation sessions and conversations produced words with similar PMLUgs within each language subgroup. These comparisons suggest that PMLUg is fairly robust in profiling children’s lexical phonology across different data collection methods.
Some samples come from different varieties of the languages. Some children in the Providence dataset for English were acquiring the r-less variety of English found in New England. Amahl was acquiring the standard r-less variety of British English (Smith, Reference Smith1973, pp. 97–98). The transcriptions of the adult utterances do not indicate the r-less targets. We coded the target words with post-vocalic [r] as r-less in assessing PMLUg for children acquiring r-less varieties. The children in the Dutch subgroup were acquiring varieties of Dutch. These differ in the production of /n/ in the ‘-en’ suffix on plural nouns and verbs (Hanssen et al., Reference Hanssen, Banga, Neijt and Schreuder2012). The Dutch transcriptions show a variable realisation of final /n/ for some children and between different children. We used the Dutch transcriptions as a guide to assessing when the children omitted a final /n/ in their productions.
The data for Spanish come from the most varied sources. The children documented in the PhonBLA Corpus acquiring Spanish (Kehoe et al., Reference Kehoe, Lleó and Rakow2004) were bilingual speakers of Spanish (primary language) and German. We excluded the few German words the children produced from the analysis. The recordings of children acquiring Spanish in the PAIDUS Corpus (Lleó & Prinz, Reference Lleó and Prinz1996) elicited the animal names from a picture book. We used the Spanish transcriptions as a guide to assess the variety of Spanish the children targeted. The transcriptions in the CCF Corpus for Portuguese (Correia et al., Reference Correia, da Costa and Freitas2010) only have phonetic transcriptions of the children’s utterances.
We produced a lexical concordance for the samples of connected speech and selected a phonetic token as the representative phonetic type, following Ingram’s variability rule to select the child’s phonetic form with the most tokens as the phonetic type for each word (Ingram, Reference Ingram1989). The data for EN08, EN09, JP01 and others only list one form for each child word. We used the single tokens as the phonetic types for the transcripts that only recorded one token for each word.
5.2. Data analysis
We entered the children’s phonetic types with their targets in a spreadsheet and added columns for the forms of the children’s produced and target words coding consonants as ‘C’ and syllable peaks as ‘V.’ We counted onset glides as consonants but did not count coda glides if they formed a diphthong with a preceding vowel. We counted a VV vowel sequence as two syllables but counted diphthongs as one syllable. We coded syllabic consonants as syllable peaks at the prosodic level and consonants at the segmental level. We coded children’s words accordingly but only counted produced segments that aligned with targeted segments following Rule 5. We added columns for the target words that show the number of consonants and syllables per target and the target’s PMLUg value (PMLUg-t). We added columns for the children’s words that show the number of syllables, consonants and correct consonants, and the PMLUg value for the child’s word (PMLUg-p). Finally, we calculated the children’s PWPg scores by dividing their total PMLUg-produced by their total PMLUg-target scores. Appendix B of the Supplementary Material provides an example analysis for one child.
Babatsouli checked the PMLUg-target and PMLUg-produced scores that Pye calculated for the English-speaking children. Out of a total of 970 English words, Babatsouli identified a total of 18 errors (1.9%) in the PMLUg-target scores and 42 errors (4.3%) in the PMLUg-produced scores. Sarvasy checked the PMLUg-target and PMLUg-produced scores that Pye calculated for Dutch and Spanish. Out of a total of 802 Dutch words, Sarvasy identified a total of 90 errors (11.2%) in the PMLUg-target scores and 64 errors (8%) in the PMLUg-produced scores. Out of a total of 899 Spanish words, Sarvasy identified a total of 22 errors (2.4%) in the PMLUg-target scores and 53 errors (5.9%) in the PMLUg-produced scores. We reconciled these discrepancies before proceeding to the analyses.
We cross-checked the results to ensure that the number of syllables and consonants in the children’s words did not exceed those in the target following the alignment constraints. We cross-checked the PMLUg-produced scores for each child word with the PMLUg-target scores for the target words to ensure that the PMLUg-produced score for the child’s word did not exceed the PMLUg-target score for the target.
5.3. Predictor variables
Before modelling the PMLUg and PWPg scores, we investigated the inter-dependencies between four potential quantitative predictor variables: the number of children’s produced words, the number of syllables in the target words, the number of consonants per syllable in the target words, and the number of consonants in the target words. We used JMP Pro 16 for all statistical analyses. We converted these variables to language-relative z-scores to look for sources of variation in the children’s words outside of any variation due to language effects. The language-relative z-scores for the quantitative predictor variables are correlated to some degree, but the number of consonants in the target words was highly correlated with the number of syllables and consonants per syllable in the target words (Table 7). In order to reduce the risk of multicollinearity (Mertler & Vannatta, Reference Mertler and Vannatta2005), we replaced the number of consonants in the target words with the number of consonants per syllable in targeted words as that had a much lower correlation with the number of syllables per word.
Table 7. Pearson correlations for the language-relative z-scores of the predictor variables

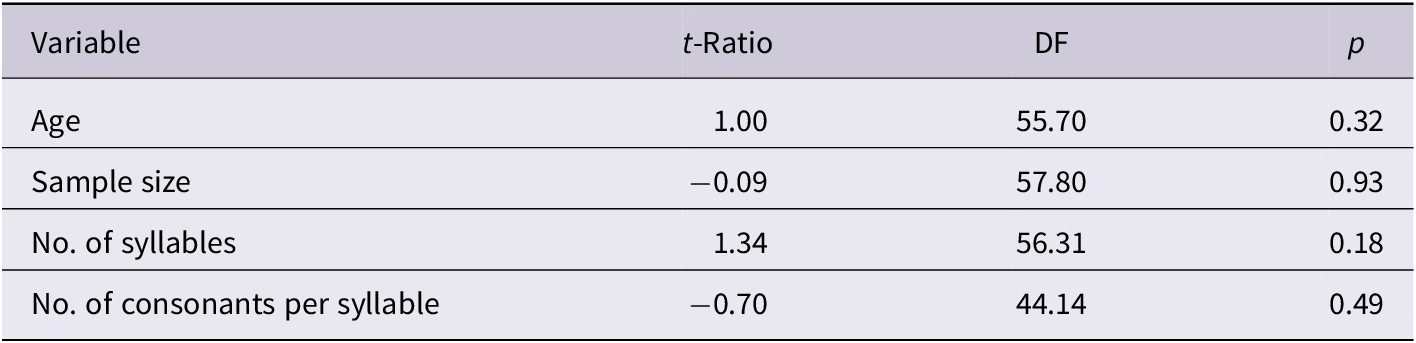
Due to the discrete nature of the gender variable, we used a series of t-tests to investigate how the other independent variables differed by gender. We tested for gender differences on the language-relative z-scores for the number of words, the number of syllables in the target words and the number of consonants per syllable in the target words. As shown in Table 8 none of the other four independent variables have significant differences for gender. These results confirm the independence of the predictor variables we used in modelling the PMLUg and PWPg scores.
Table 8. T-tests of differences by gender for the four predictor variables
To determine which variables, if any, were significant predictors of the PMLUg-target and PMLUg-produced scores and the children’s proximity scores (PWPg), we submitted three general measures of the children (gender, age, and number of words produced) and three language measures (the language, the number of syllables per target word, and the number of consonants per syllable in target words) to separate multivariate linear regression analyses. We converted the quantitative independent variables (number of words, number of syllables per word, and the number of consonants per syllable) to language-relative z-scores in order to analyse their effects within each language, that is, independently of the effect of language.
We modelled the dependent variables PMLUg-target, PMLUg-produced, and PWPg separately. The predictor variables were entered simultaneously in each analysis, allowing the significance of each variable’s effect to be determined independently of the effects of the other predictor variables. The language-relative variables in our models for number of words, number of syllables per target word, and the number of consonants per syllable per target word predict variation in the dependent variable within each language. For example, if the language-relative z-score for the number of words the children produce emerges as a significant predictor of the PMLUg-produced scores, it would indicate that the number of words predicts a significant amount of the residual variation of PMLUg-produced within each language. As these are multiple regression models, it is important to note that the significance of any predictor (independent) variable is measured in terms of the effectiveness of that variable in the model in explaining the variation of the target (dependent) variable that is not already explained by the other predictor variables.
6. Results
6.1. PMLUg-target
The first research question asks whether the target words that children attempt differ in lexical complexity between languages. The results from previous studies predict that the children will differ by language on PMLUg-target. Figure 1 plots the distribution of the children’s samples in the six languages by the mean number of syllables and consonants per syllable in the words targeted in each sample. The ellipses cover 90% of the area around the means based on a bivariate normal approximation of the distribution of the axis ratios for each language group. Languages with more syllables per word have fewer consonants per syllable, and vice versa. English samples are clustered at the upper left region and Japanese samples spread across the lower right region. The sample means for the target words in Dutch and English overlap as do those for Portuguese and Spanish. The sample means for target words in Xi’iùy fall midway between the sample means of the target words for the Germanic and Romance languages.

Figure 1. Distribution of the children’s samples plotted by the mean number of syllables per target word and the mean number of consonants per syllable per target.
We provide the group means and standard deviations for the PMLUg-target, the PMLUg-produced, and PWPg scores in each language in Table 9.
Table 9. Mean PMLUg-target and PMLUg-produced measures per word and PWPg
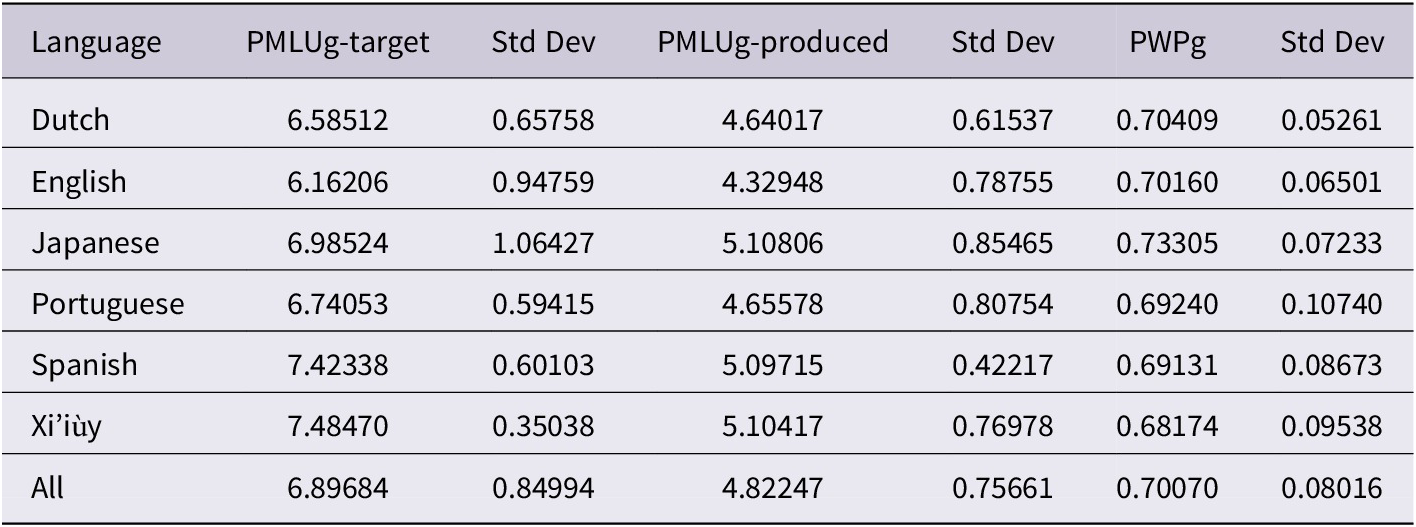
The multiple-regression model for the PMLUg-target scores was statistically significant (F[10,49] = 43.60, p < 0.0001, R 2 = 0.90). The root mean square error for the model was 0.30. The R 2 value indicates that the model explained 90% of the variation in target PMLU per word. The parameter estimates for the regression analysis are presented in Table 10. As expected language was a significant predictor of the PMLUg-target scores except for Japanese (F[5,5] = 30.22, p < 0.0001). As shown in Table 9, Xi’iùy and Spanish have mean PMLUg-target scores above 7, while Dutch and English have mean PMLUg-target scores below 6.6. Children acquiring Japanese, Xi’iùy, and Spanish targeted words with more complexity than children acquiring Dutch, English, and Portuguese. Independently of language, higher PMLUg-target scores within each language were predicted by the language-relative z-scores for the number of syllables and the number of consonants per syllable in the target words. Gender was also positively related to the PMLUg-target scores independently of language. Girls targeted fewer complex words than boys across the languages.
Table 10. Parameter estimates for the PMLUg-target scores*

* The statistical program JMP sets the parameters for the categorical variables so that they sum to zero. The estimate for Xi’iùy (0.61) is the negative of the sum of the parameters for the other language variables and the estimate for males (−0.08) is the negative of the parameter for females. The format of the full-regression model is presented in Appendix D of the Supplementary Material in algebraic form.
6.2. PMLUg-produced
Our second question asked whether the words that children produce differ in lexical complexity between languages. It is possible that children produce words with similar levels of complexity due to articulatory restrictions even though they target words with different levels of complexity (MacNeilage et al., Reference MacNeilage, Davis and Matyear1997; McAllister Byun & Tessier, Reference McAllister Byun and Tessier2016).
Figure 2 plots the distribution of the children’s samples by the mean number of syllables and consonants per syllable in the produced words in the sample. As in Figure 1, the ellipses cover 90% of the area around the means based on a bivariate normal approximation of the distribution of the axis ratios for each language group. The ellipses cluster together at the lower left corner of the plot as the words children produced have fewer syllables and consonants per syllable than the target words. The samples for the children’s words for each language do not group together as tightly as the target word samples, but they retain the general distribution of the target word samples, with the English samples at the upper left and Japanese samples spread across the lower right. The samples for the children’s words preserve the same inverse relation between the number of syllables and consonants per syllable as the samples for the target words.
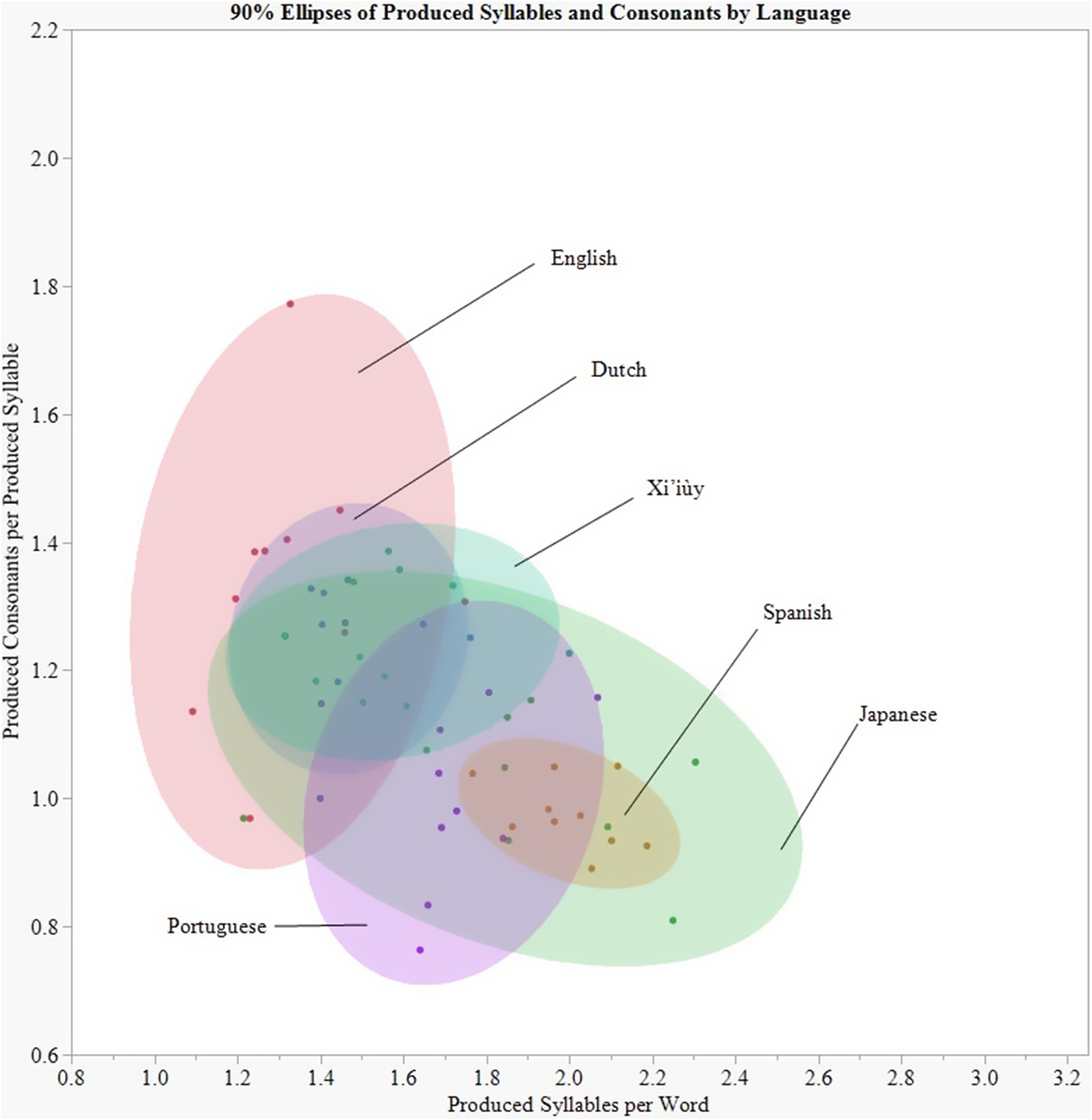
Figure 2. Distribution of the children’s samples plotted by the mean number of syllables per produced word and the mean number of consonants per syllable per produced word.
The multiple-regression model for the PMLUg-produced scores was also statistically significant (F[10,49] = 8.45, p < 0.0001, R 2 = 0.63). The root mean square error for the model was 0.50. The R 2 value indicates that the model explained 63% of the variation in the children’s PMLUgs per word. Results of the regression analysis for the PMLUg-produced scores are presented in Table 11. Language emerged again as a significant predictor of the PMLUg-produced scores for all languages except Dutch, Japanese, and Portuguese (F[5,5] = 5.49, p < 0.0004). As shown in Table 9, Japanese, Spanish, and Xi’iùy have mean PMLUg-produced scores above 5, while Dutch, English, and Portuguese have mean PMLUg-produced scores below 5. Children acquiring Japanese, Xi’iùy, and Spanish produced words with greater complexity than children acquiring Dutch, English, and Portuguese.
Table 11. Parameter estimates for the PMLUg-produced scores
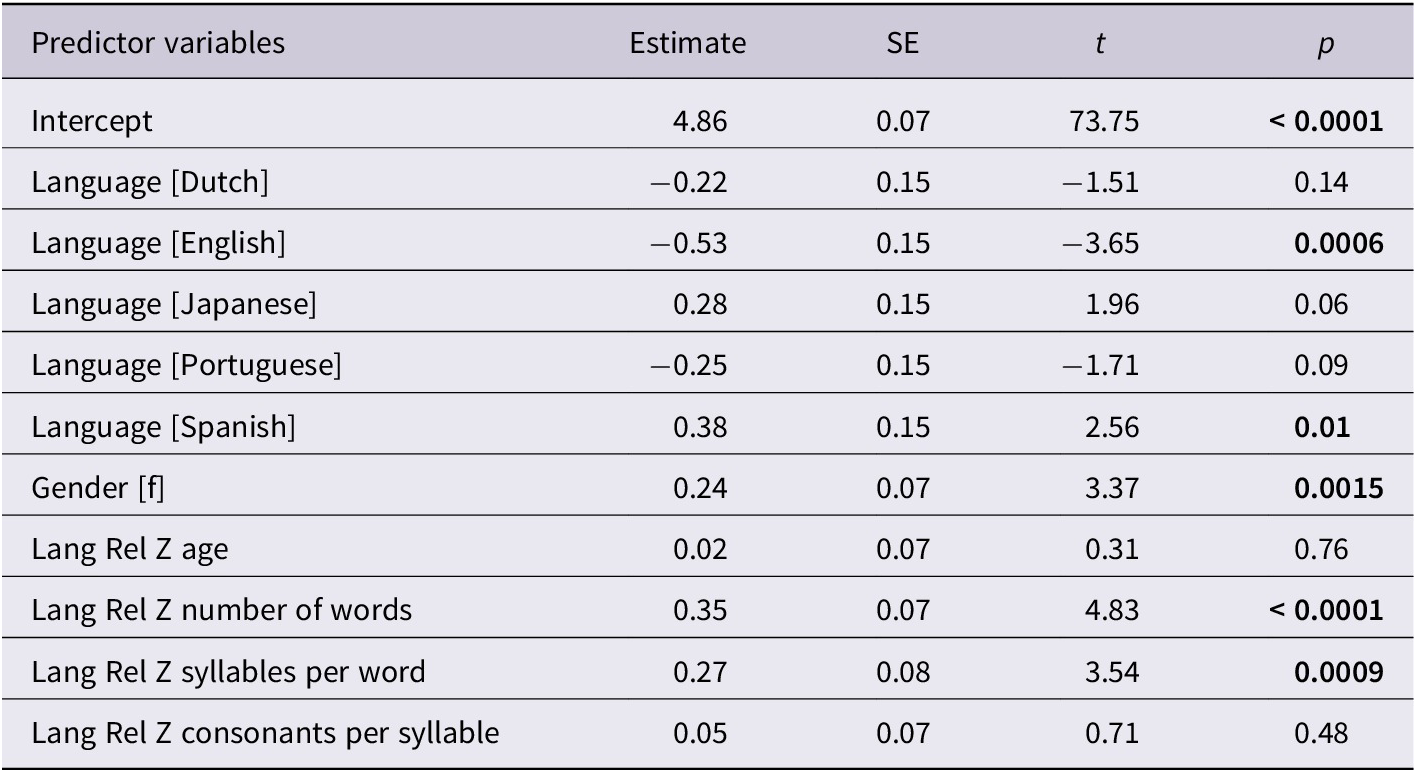
The language-relative z-score for the number of consonants per syllable in the target words was not a significant predictor of PMLUg-produced scores independently of the language. This result supports the hypothesis that PMLUg-produced scores differ significantly by language with the limitation that the number of consonants per syllable in the children’s words does not differ significantly within the languages in contrast to the words they targeted.
Gender, the number of words and the number of syllables per word were positive predictors of the PMLUg-produced scores independently of language. Girls produced words with greater complexity than boys across the languages. Within each language group, the number of words the children produced during the session and the average number of syllables per word relative to the other children in the language group were positively related to their PMLUg-produced scores.
6.3. PWPg
The third research question asks whether children at similar stages of development produce words that exhibit the same proximity to target words across languages. Proximity is a relative score so even though the children’s productions differ in complexity, they may exhibit a similar proximity to the adult targets across languages.
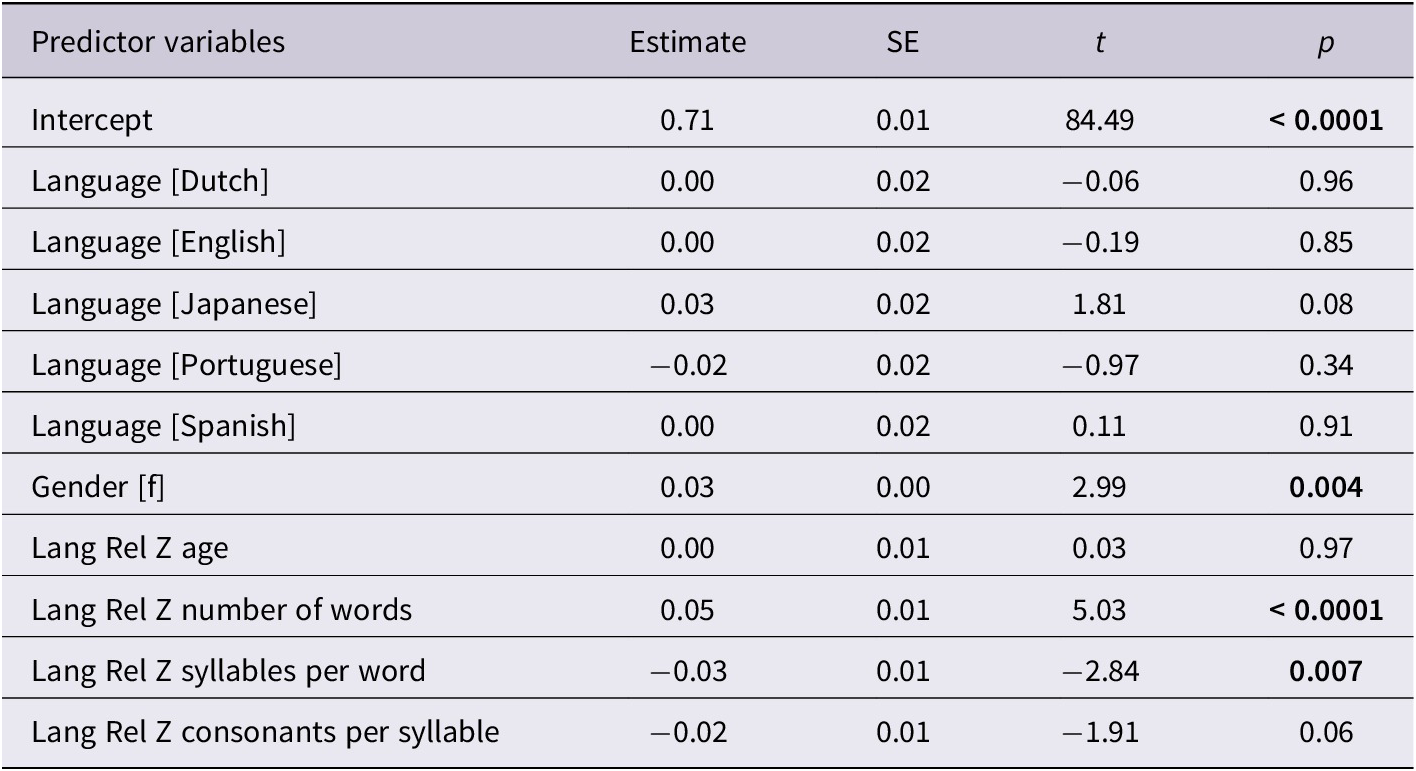
Results of the regression analysis for the children’s PWPg are presented in Table 12. The regression model for the children’s PWPg was statistically significant (F[10,49] = 4.47, p = 0.0002, R 2 = 0.48). The root mean square error for the model was 0.06. The model explained 48% of the variation in PWPg per word. Language was not a significant predictor of PWPg (F[5,5] = 0.79, p = 0.56). This result supports the hypothesis that there are no significant differences in mean PWPg across the six languages for children in this general age cohort. Gender, the number of words, and the number of syllables per target word emerged as significant predictors of the PWPg scores. The number of syllables per target word was inversely related to the children’s PWPg indicating that, after controlling for the other independent variables, the children produced short words more accurately than long words. The number of consonants per syllable in the target words was a marginally significant predictor of the children’s PWPg.
Table 12. Parameter estimates for the children’s PWPg scores
It is noteworthy that the PMLUg-t and PMLUg-p means differ significantly between language groups, but language group mean PWPg values (which use the ratio of PMLUg-p divided by PMLUg-t for each child session) did not. If the samples had indicated weak or no difference in PMLUg-t and PMLUg-p language means, it would have been of little surprise if PWPg ratios had similar means for the language groups. The fact that mean PMLUg-p seems to be in similar proportion to PMLUg-t across all six languages despite differences in mean PMLUg-p and mean PMLUg-t between languages is significant.
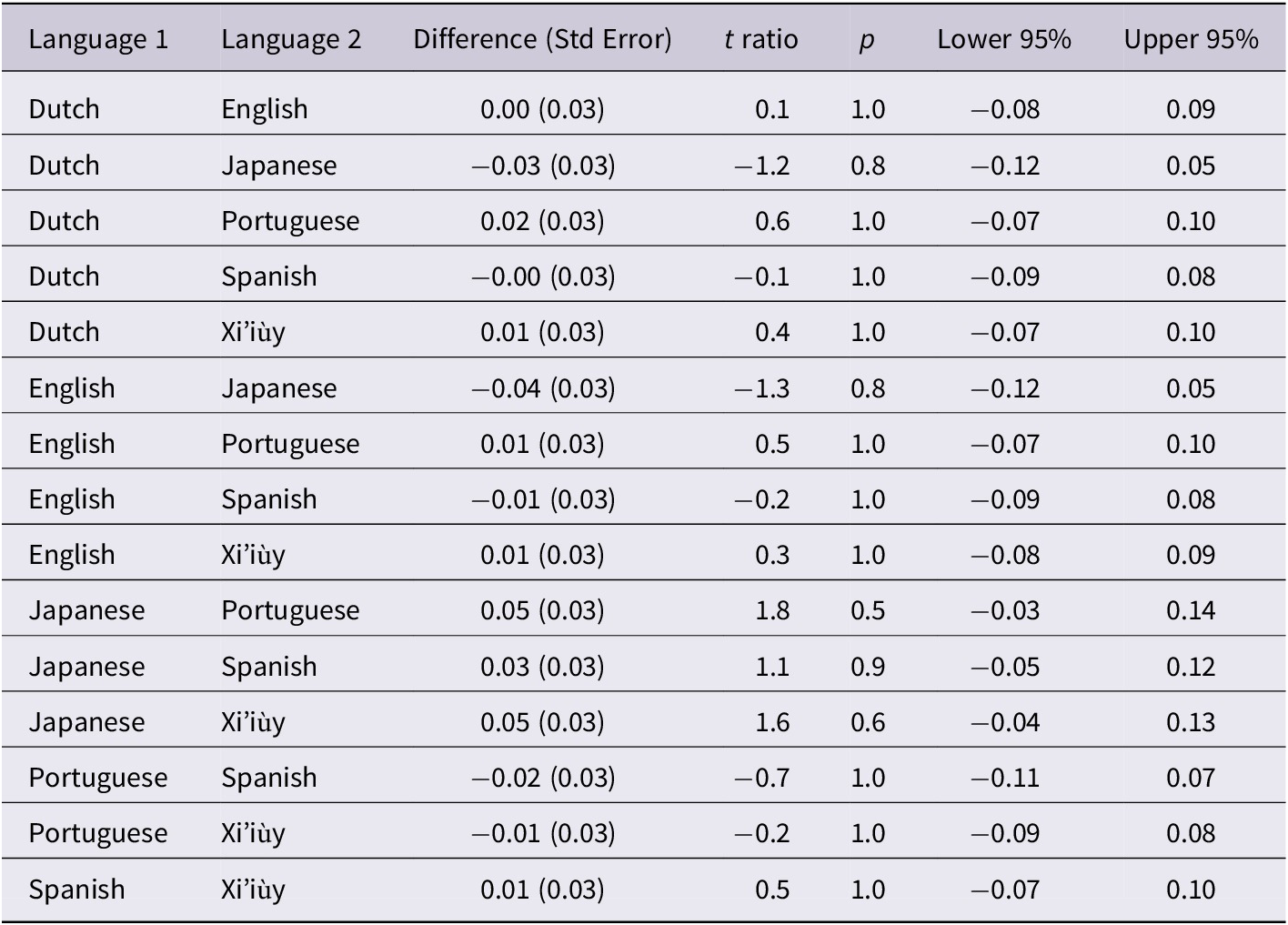
The multiple-regression models showed that language was a significant predictor for both the PMLUg-target and PMLUg-produced scores (calculated on a per-word basis from a child session), but not for the children’s PWPg scores. The 95% confidence intervals for the language mean PWPg values show considerable overlap (Table 13). A multiple comparison of pairwise differences between language group means in the regression equation that produced 95% Tukey–Kramer confidence intervals (15 of them for all possible pairings of languages) showed that a difference of zero falls decidedly within the interval in all cases (Table 14).Footnote 3 This evidence supports the null hypothesis that there are no significant differences in mean PWPg across the six languages for children in this general age cohort.
Table 13. 95% confidence intervals for the language mean PWPg values
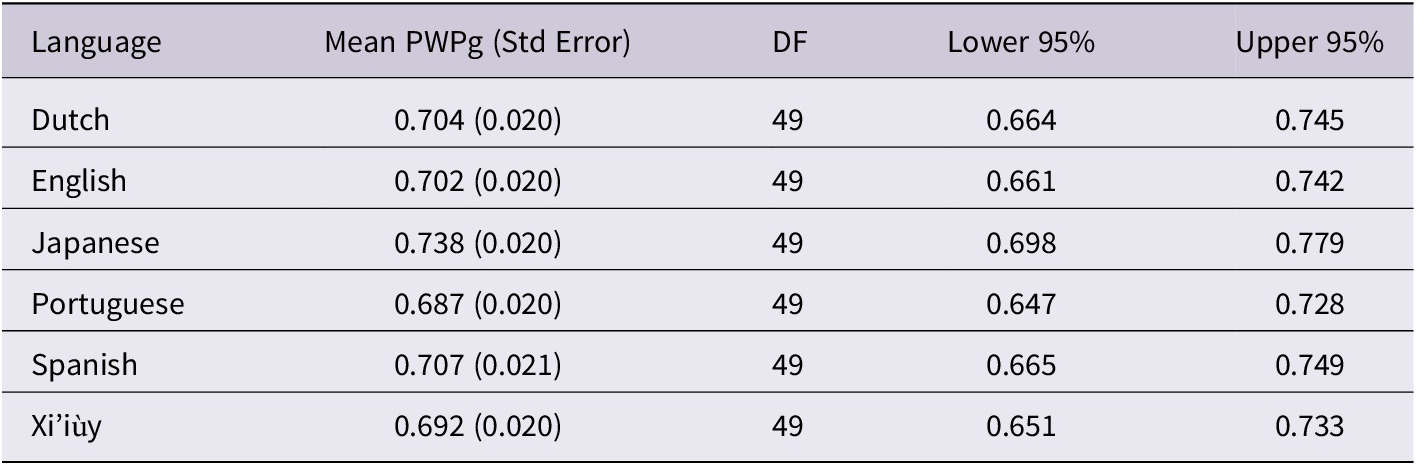
Table 14. Pairwise differences between language group PWPg means
The low F-ratio (0.79) and high p-value (0.56) for the language effect on PWPg, in the presence of considerable variation within language groups (within language groups standard deviations in PWPg in Table 9 ranged from 0.053 for the Dutch group to 0.107 for the Portuguese group), indicates there is a fair amount of variation in PWPg for the populations sampled, but that the variation between group means was not significantly larger than would be expected from the variation observed in PWPg within languages. In fact, the estimated variation in PWPg across all 60 samples based on variation between language group means was actually a little less than an estimate from variation within groups.
While we did not find significant differences in PWPg between language groups, we did find a significant difference in PWPg between children based on sample size. We divided the children’s samples into two groups based on whether or not the sample had more words than the mean number of words for all samples in the same language group. The samples with z-scores above the group mean produced an average of 125.62 words, while the group with z-scores at or below the group mean produced an average of 64.97 words. The mean PWPg score for the z-score above the group mean was 0.73, while the mean PWPg score for the z-score at or below the group mean was 0.67. A t-test showed the difference was significant (t = 3.49, df = 54.14, p = 0.0005 one-tailed).
6.4. Decomposing PWPg scores
The PWPg analysis here contrasts with previous evidence of crosslinguistic differences in PWP (Ingram, Reference Ingram2002; Saaristo-Helin et al., Reference Saaristo-Helin, Savinainen-Makkonen and Kunnari2006). To understand the PWPg measurement better we decomposed the children’s PWPg scores into three components:

A child’s PWPg score is the sum of these three components. Table 15 shows these component scores for each language and their rank orders. The rank orders show that the children’s syllable component is inversely related to their component for correct consonants. As the proportion of syllables in the children’s words increases, their proportion of correct consonants decreases. This relation results in a rough balance between the proportion of syllables in children’s words and the proportion of correct consonants. Adding the component scores together yields the similarity in the proximity (PWPg) scores we found in these languages.
Table 15. PWPg component scores

The difference between the children’s component productions per target PMLUg shown in Table 16 and the maximum possible productions per target PMLUg (if all words were produced correctly) indicates the growth potential for each component within each language. Figure 3 shows these potentials in the form of stacked columns for each language arranged in order of increasing growth potential for the syllable component. Because this chart shows the potential growth for each component, the total for each column is equal to 1 minus the children’s PWPg scores, that is, approximately 0.30.
Table 16. Matched pair t-tests (one-tailed) of PWPg component potentials
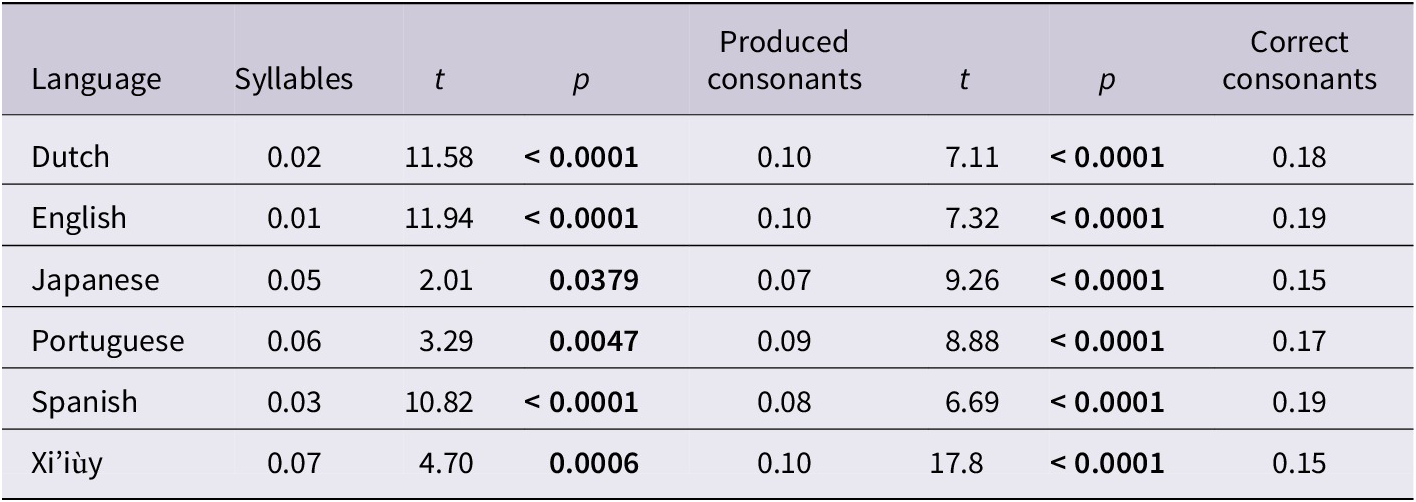
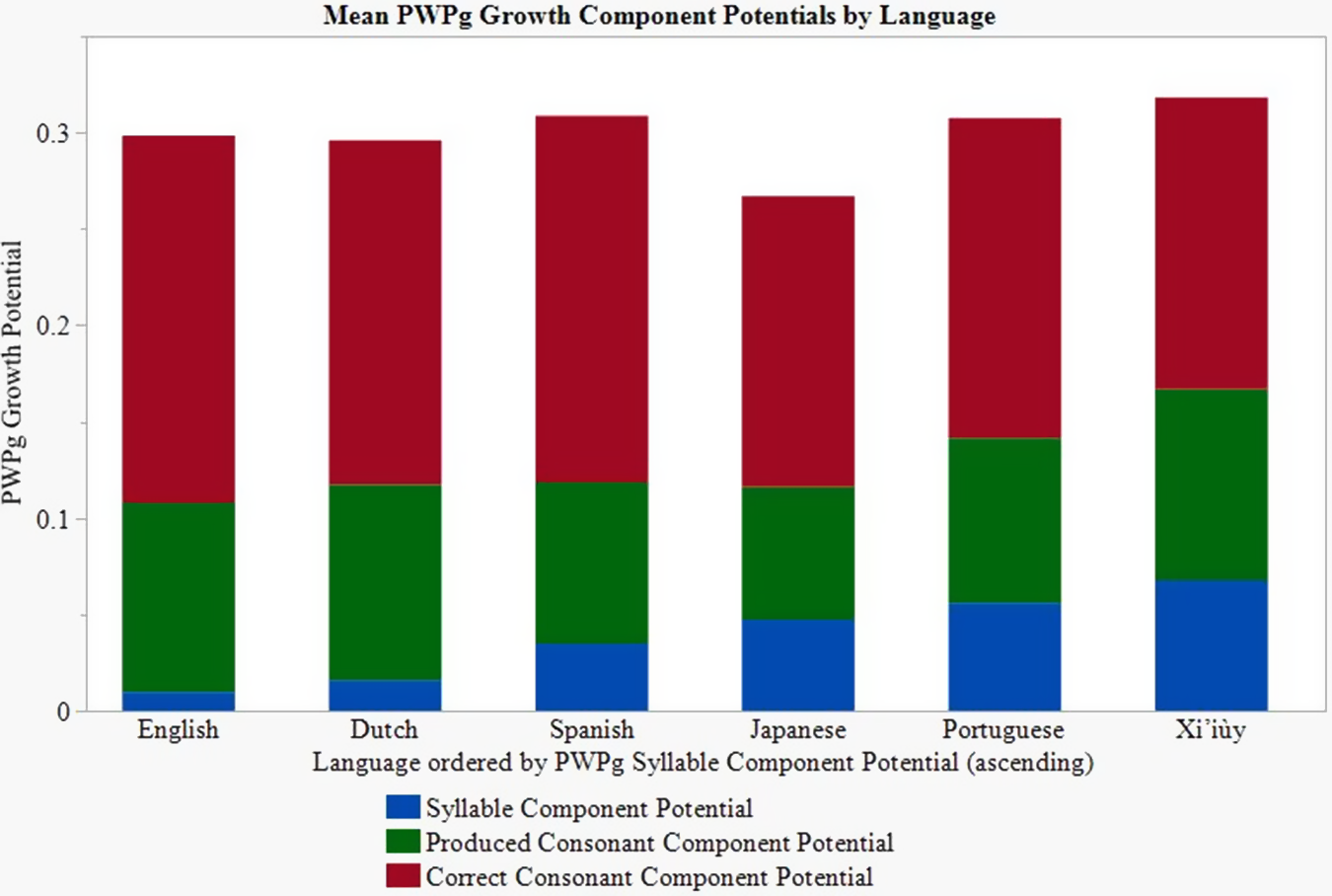
Figure 3. Growth potentials for each PWPg component in each language.
The syllable potentials are smaller than the produced consonant potentials, which in turn are smaller than the correct consonant potentials in each language. Children who omit syllables will necessarily omit the consonants in those syllables and so the potential for producing consonants reflects both the potential for producing more syllables and the potential for producing more consonants per syllable. Children can only produce correct consonants if they produce the syllable and the consonants in the syllable. This explains why the potential for producing correct consonants is greater than the potential for producing syllables and consonants across the languages.
We did two matched pair t-tests for each language group: one testing whether the mean difference between the syllable component and the produced consonant component potentials for the children in the group is greater than zero and the second testing whether the mean difference between the produced consonant component and the correct consonant component potentials for the children in the group is greater than zero. The component potentials and t-tests for each language group are shown in Table 16. The produced consonant component potential is significantly greater than the syllable component potential in each language group. The correct consonant component potential is significantly greater than the produced consonant component potential in all of the language groups.
As expected, children acquiring the languages with a high proportion of monosyllabic words (Dutch and English) had little potential for increasing the number of syllables in their words, while children acquiring the other languages had the greatest potential for adding syllables to their words due to the greater proportion of polysyllabic words in those languages. The children acquiring Dutch and English had to work on increasing the number of consonants in each syllable, while the children acquiring Japanese, Portuguese, and Xi’iùy produced fewer consonants per syllable but more correct consonants. Children acquiring Xi’iùy had a greater potential for adding consonants to their words than children acquiring Japanese because many of the omitted syllables in Xi’iùy were prefixes in the form of syllabic consonants.
6.5. Gender
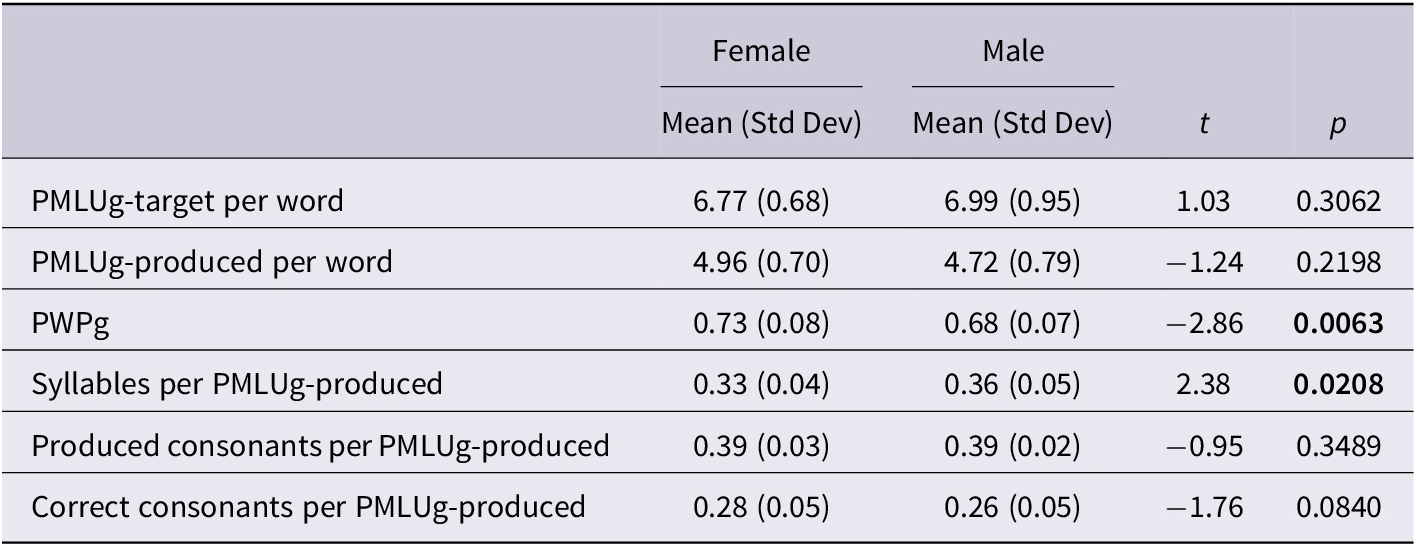
The multiple-regression models showed that the children’s gender was a significant predictor of their PMLUg-target (Table 10), PMLUg-produced (Table 11), and PWPg scores (Table 12). Boys had a slightly higher PMLUg-target per word, while girls had a higher PMLUg-produced score per word (Table 17). Although none of these gender differences were significant by themselves, the higher PMLUg-produced score per word for girls (increasing their PWPg numerator) and lower PMLUg-target per word for girls (decreasing their PWPg denominator) worked together to make the mean PWPg significantly higher for girls. The component scores for PMLUg-produced show that boys produced significantly more syllables per PMLUg-produced than girls, while girls produced more correct consonants per PMLUg-produced than boys. These differences deserve further investigation as some studies have not reported gender differences for PMLU (Sosa & Stoel-Gammon, Reference Sosa and Stoel-Gammon2012).
Table 17. Gender differences in PMLUg, PWPg, and component measures
6.6. Sample size
Independently of language and gender, the language-relative z-score for the number of produced words emerged as a significant predictor in two of the models. The number of words the children produced in their samples predicts the PMLUg scores of the children’s words within each language. The number of words was a significant within-language predictor of PWPg and the proportion of syllables and correct consonants per PMLUg-produced score. The number of words was a marginally significant within-language predictor of consonants per PMLUg-produced score (p = 0.0685).
Previous studies have not reported an effect of the number of words on children’s PMLUg and PWPg scores. Our finding is surprising in view of the heterogeneous nature of the children’s language samples, some of which included function words and others not. Some samples included words drawn from multiple recording sessions to maximise the number of words for each child.
In most data-based studies, a larger number of words primarily leads to a reduction of errors in estimating summary parameters of the variables in question for the population from which the elements were drawn (e.g., Taelman et al., Reference Taelman, Durieux and Gillis2005). This was the case for our results as well. From the perspective of statistical sampling, more words should reduce the sampling error. The variance of the sampling error should be inversely proportional to the sample size. We tested this prediction by dividing the children’s samples into two groups based on whether or not the sample had more words than the mean number of words for all samples in the same language group. The ratio of the mean sample size for the below-average-size group (64.97) to the mean sample size of the above-average-size group (125.62) yields an estimated ratio of variances in PWPg of 0.517 to 1. The variance in PWPg for the z-scores above average group was 0.00358 and the variance in PWPg for the z-scores at or below average group was 0.00714, yielding a ratio of 0.502 to 1. This result shows that the larger samples in our study reduced the error in the PWPg estimate.
The size of the word sample may reflect the size of the child’s vocabulary, and not just the estimated accuracy of the subsample recorded from that child. We assume that children with larger phonetic inventories and better phonotactic skills will speak more fluently than children with more restricted skills. As children’s interests expand, they encounter more words with low token frequencies and greater phonological complexity, e.g., spaghetti, elephant. In producing such words, they practice the language-specific phonotactic patterns embodied in the words. This practice would create synergy between an expanding vocabulary and more generalised phonotactic rules, accelerating lexical development. Stoel-Gammon (Reference Stoel-Gammon2011, p. 17) concluded that vocabulary size and articulation abilities are correlated among TD children (cf. Fletcher et al., Reference Fletcher, Chan, Wong, Stokes, Tardif and Leung2004; Smith et al., Reference Smith, McGregor and Demille2006). Our study suggests that the number of words a child produces in a language sample may be a robust measure of the child’s vocabulary across languages and warrants further investigation as a predictor of children’s phonological development.
6.7. Syllables per target word
The language-relative z-score for syllables per target word was a significant predictor for PMLUg-target (Table 10), PMLUg-produced (Table 11), and PWPg (Table 12). The number of syllables per target word was positively related to PMLUg-target and PMLUg-produced, but negatively related to PWPg. This result shows that within each language the number of syllables in the target words is tied to the whole-word complexity of the target words and the complexity of children’s produced words. The negative relation between PWPg and the number of syllables in the target words shows that the children’s words did not faithfully reproduce the number of syllables that differentiated the target words within each language.
6.8. Target consonants per syllable
The language-relative z-score for the number of target consonants per syllable was only a significant predictor for PMLUg-target within each language (Table 10). Nevertheless, we note that the p-value for this variable was low for the PWPg score (0.06) indicating that the number of target consonants per syllable had some effect on PWPg within each language. This result shows that the children’s words did not faithfully copy the number of consonants per syllable that differentiated the target words within each language.
7. Discussion
Few concepts play as central a role in acquisition research and yet remain as ill-defined as words. Spencer (Reference Spencer, Mairal and Gil2006, p. 129) notes that “There may be clear criteria for wordhood in individual languages, but we have no clear-cut set of criteria that can be applied to the totality of the world’s languages.” Over the course of a thousand centuries, languages have recombined the phonological, morphosyntactic, and semantic properties of words yielding the diversity of word forms in present-day languages. Differences in the ways that families and cultures adopt the words that children invent increase the diversity in child language. Research that does not recognise this diversity produces what Bowerman (Reference Bowerman and Song2011, p. 616) terms “parochial explanations of language acquisition.”
Our article proposes the typological approach to research on child language to correct the pervasive influences of research on individual languages. An understanding of typological variation is essential to a cumulative science that builds on research in all documented languages. We use the typological approach to derive generalised measures of phonological complexity and phonological proximity that extend the concept ‘word’ to complex predicates and words without vowels. We apply the generalised measures in a crosslinguistic study to address three primary questions:
-
1. Do the target words that children attempt differ in complexity between languages?
-
2. Do the words that children produce differ in complexity between languages?
-
3. Do children at similar stages of development produce words that exhibit the same proximity to target words across languages?
The analyses showed that language is a significant predictor of the complexity of the words that children target and produce as measured by PMLUg. The effects on the children’s PMLUg scores were robust despite the heterogeneous nature of the primary data derived from multiple sources using multiple collection techniques.
The target words we examined differ by language in their mean numbers of syllables and consonants per syllable. We found an inverse relation between the mean number of syllables and consonants per syllable in the target words such that monosyllabic words have more consonants per syllable than polysyllabic words (Figure 1). The children produced words with a similar relation between the number of syllables and consonants per syllable, although the differences between languages were more attenuated in the children’s words than in the target words as the children’s words contain fewer syllables and consonants than the target words (Figure 2). The significant crosslinguistic differences in PMLUg values for the child and target words confirm the findings of Ingram and others.
We found that language is not a significant predictor of the proximity of children’s words to their targets as measured by PWPg. We decomposed the children’s PWPg scores into their components for the number of syllables, consonants, and correct consonants per PMLU-target. This decomposition allowed us to track the contribution of each component and showed how the potentials for further development differed by language. The component PWPg scores show that children acquiring Spanish and Japanese produced words with more syllables but children acquiring Dutch and English produced words with more correct consonants. The results illustrate the multiple pathways that children take in negotiating the phonological terrain of the target languages.
8. Conclusion
The typological approach recognises the significance of all child languages before “many of them perish irrecoverably from the face of the earth, uncared for and unknown” (after Wallace, Reference Wallace1863). An understanding of typological variation promotes greater consistency in crosslinguistic comparisons of language development. Linguistic typology guards against parochial explanations of language acquisition based on unfounded assumptions. Comparing the complexity of the children’s words with the complexity of target words reveals their growth potentials along the syllable and consonant dimensions. Our study points the way towards a cumulative investigation of the features that determine whole-word phonological complexity and proximity crosslinguistically.
Abbreviations
- 1:
-
first person
- Cons:
-
consonants
- Correct:
-
correct consonants
- Lang Rel:
-
language-relative
- mos:
-
months
- No:
-
number
- PL:
-
plural
- PRÉS:
-
present tense
- SE:
-
standard estimate
- Std Dev:
-
standard deviation
- Syls:
-
syllables
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S0305000925100056.
Acknowledgements
We thank the children and families who made this research possible by allowing investigators to record their speech. Their words have not been forgotten. Our thanks also go to the investigators who recorded, transcribed, and made their work accessible. We thank the action editor, Dr. Titia Benders, the associate editor as well as the two anonymous reviewers of this article for helpful suggestions that have substantially improved the initial manuscript. We are responsible for any remaining errors. No AI tools were used for writing this article.
Funding statement
Data collection for Northern Pame was supported by a grant to Pye from the National Science Foundation (BCS-1360874). Sarvasy’s work was supported by the Australian Research Council (DE180101609).
Competing interests
The authors declare no competing interests exist.























 Open access
Open access