


1 Introduction
Peer grading, also known as peer assessment, is a system of formative assessment in education whereby students assess and give feedback on one another’s work. It substantially reduces teachers’ burden for grading and improves students’ understanding of the subject and critical thinking (Panadero & Alqassab, Reference Panadero and Alqassab2019; Yin et al., Reference Yin, Chen and Chang2022). Consequently, it is widely used in many educational settings, including massive open online courses (MOOCs; Gamage et al., Reference Gamage, Staubitz and Whiting2021), large university courses (Double et al., Reference Double, Mcgrane and Hopfenbeck2020), and small classroom settings (Sanchez et al., Reference Sanchez, Atkinson, Koenka, Moshontz and Cooper2017). In a peer grading system, each student’s work is assigned, often randomly, among several other students who act as graders or raters. Due to the design of this system, peer grading data have a different structure from traditional rating data, which also consists of students’ grades from graders. For traditional rating data, the students whose work is evaluated cannot serve as graders, which leads to a relatively simple data structure. On the other hand, peer grading data have a network structure where all the peer grades may be dependent. Each student can be viewed as a network vertex, and each peer grade serves as an edge connecting two students—a grader and an examinee (see Figure 1 for a visual illustration of such a network structure).
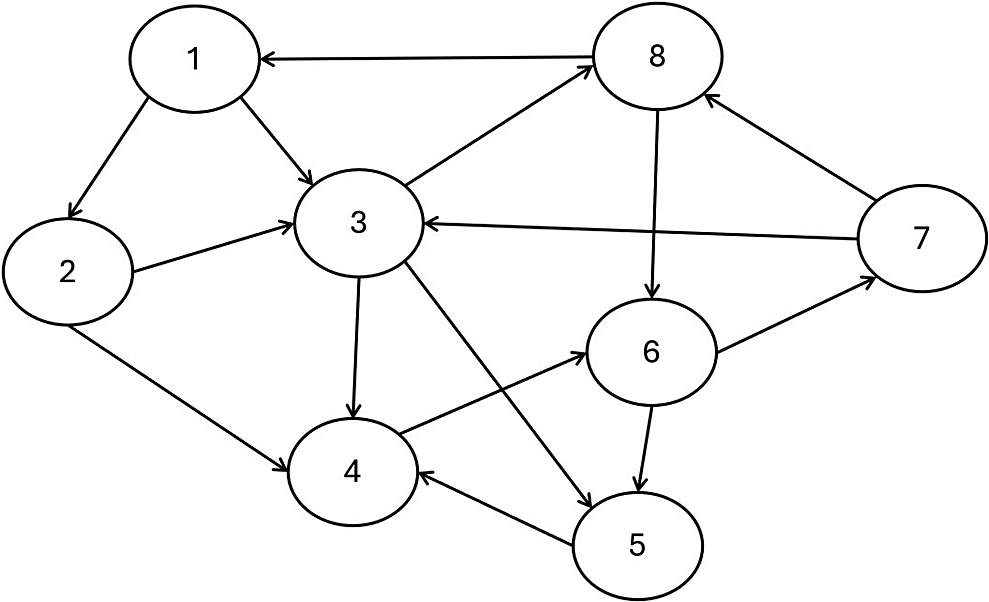
Figure 1 Network diagram representing the network structure of peer grading data. Note: Each circle is a vertex of the network and represents a student. The arrows are the peer grades, which serve as edges connecting two students; their direction indicates whether the student receives or gives the grade.
A simple peer grading system aggregates the peer grades using a straightforward method like the mean or median to derive a final grade for each student’s work (Reily et al., Reference Reily, Finnerty, Terveen, Teasley, Havn, Prinz and Lutters2009; Sajjadi et al., Reference Sajjadi, Alamgir and Luxburg2016). This conventional method does not consider the heterogeneity among the graders. Some graders may exhibit systematic biases and tend to assign higher or lower grades than their peers when assessing the same work. Graders may also exhibit varying levels of reliability; while some maintain consistent grading standards, others may give erratic grades that lack a consistent standard. Furthermore, when the data involve multiple formative assessments for each student, a more accurate grade may be derived by borrowing information across assessments. Finally, monitoring how students perform as graders is often helpful, as it provides an opportunity to reward the best-performing graders and offer feedback to help those who need improvement. Different methods have been developed to mitigate grader bias and improve peer assessment reliability (see Alqassab et al., Reference Alqassab, Strijbos, Panadero, Ruiz, Warrens and To2023 for a review). Depending on whether instructors’ scores are needed in method training, they can be classified as supervised and unsupervised learning methods. Supervised learning methods utilize instructors’ scores to train a function that maps multiple peer grades to an aggregated grade that mimics the instructor’s score (Namanloo et al., Reference Namanloo, Thorpe, Salehi-Abari, Mitrovic and Bosch2022; Xiao et al., Reference Xiao, Zingle, Jia, Shah, Zhang, Li, Gehringer, Rafferty, Whitehill, Romero and Cavalli-Sforza2020). For instance, Namanloo et al. (Reference Namanloo, Thorpe, Salehi-Abari, Mitrovic and Bosch2022) proposed a graph convolutional network method that uses peer grades and behaviors of peers to predict the respective instructors’ scores.
On the other hand, unsupervised learning methods try to find an aggregation rule based only on peer grades without access to instructors’ scores. Unsupervised learning is typically performed by employing latent-variable-based measurement models (e.g., Han, Reference Han2018; Piech et al., Reference Piech, Huang, Chen, Do, Ng, Koller, D’Mello, Calvo and Olney2013; Xu et al., Reference Xu, Li, Liu, Lv and Yu2021), which are closely related to models for traditional rating data in which each individual is either a student or a grader. As explained in the sequel, they make an independence assumption that is also adopted in the latent variable models for traditional rating data. However, as peer grading data have a complex network structure, this independence assumption is likely oversimplified, leading to suboptimal performance.
Many latent variable models have been proposed for traditional rating data, including the facet model (Linacre, Reference Linacre1989) and its extensions (Uto & Ueno, Reference Uto and Ueno2020; Uto, Reference Uto2021), the hierarchical rater models (Casabianca et al., Reference Casabianca, Junker and Patz2016; DeCarlo et al., Reference DeCarlo, Kim and Johnson2011; Molenaar et al., Reference Molenaar, Uluman, Tavşanc and De Boeck2021; Nieto & Casabianca, Reference Nieto and Casabianca2019; Patz et al., Reference Patz, Junker, Johnson and Mariano2002), the rater bundle model (Wilson & Hoskens, Reference Wilson and Hoskens2001), and the generalized rater model (Wang et al., Reference Wang, Su and Qiu2014). These models introduce rater-specific parameters to model the rater effects in the data. With many raters, these rater-specific parameters are treated as random effects (i.e., latent variables) and further assumed to be independent of the examinee-specific latent variables used to model examinee performance. These assumptions are also made in the existing latent variable models for peer grading data (Han, Reference Han2018; Piech et al., Reference Piech, Huang, Chen, Do, Ng, Koller, D’Mello, Calvo and Olney2013; Xu et al., Reference Xu, Li, Liu, Lv and Yu2021). However, we note that the assumption about the independence between the rater-specific latent variables and examinee-specific latent variables does not hold for peer grading data, as the same students are both examinees and raters, and the characteristics of the same student as a rater and those as an examinee are naturally correlated. Ignoring such dependence can result in model misspecification and substantial information loss. To the best of our knowledge, no rater model in the literature accounts for such a dependence structure.
We fill this gap by proposing an unsupervised latent variable model for peer grading data. The proposed model jointly analyzes peer grades for multiple assessments and produces more accurate aggregated grades. It models the student effects with correlated latent variables that capture a student’s characteristics as an examinee and a grader, respectively. Unlike the existing latent variable models for peer grading data, the proposed model captures the dependence in data brought by the network structure of peer grades and the dual roles of each student as an examinee and a rater.
Due to the complex dependence structure under the proposed model, its marginal likelihood involves a very high-dimensional integral with respect to all the student-specific latent variables that can hardly be simplified. Thus, solving the maximum likelihood estimator is computationally infeasible, and consequently, frequentist inference based on the marginal likelihood is a challenge. We develop a fully Bayesian approach for drawing statistical inferences to overcome the computational challenge. With this approach, uncertainty quantification is straightforward when inferring the student-specific latent variables as well as the structural parameters of the model. However, its computation is still non-trivial due to the presence of a large number of latent variables and a complex network structure. To solve this, we use a No-U-Turn Hamiltonian Monte Carlo (HMC) sampler (Hoffman & Gelman, Reference Hoffman and Gelman2014), which produces efficient approximate samples from the posterior distribution.
Besides the traditional rater models, the proposed framework is closely related to cross-classified random effects models (Goldstein, Reference Goldstein1994; Rasbash & Goldstein, Reference Rasbash and Goldstein1994; Raudenbush, Reference Raudenbush1993), an extension of standard multilevel models for non-hierarchical data that have cross-classified structures. These models have received wide applications for evaluating measurement reliability, including in generalizability theory (Brennan, Reference Brennan2001, Reference Brennan2010). Our data involve three crossed factors—the examinees, the graders, and the assessments—and the proposed model decomposes each peer grade based on these three factors. However, our model allows the latent variables (i.e., random effects) associated with the crossed factors (examinees and raters) to be correlated to account for the special design of peer grading. In contrast, a standard cross-classified random effects model assumes the random effects associated with different crossed factors to be independent. Introducing such dependence among the latent variables substantially increases the complexity of the model and its inferences. Our model also has close connections with several latent variable models concerning dyadic data, including social relations models (e.g., Kenny & La Voie, Reference Kenny and La Voie1984; Nestler, Reference Nestler2016; Nestler et al., Reference Nestler, Geukes, Hutteman and Back2017; Nestler et al., Reference Nestler, Lüdtke and Robitzsch2020; Warner et al., Reference Warner, Kenny and Stoto1979) and the dyadic item response theory (IRT) model (Gin et al., Reference Gin, Sim, Skrondal and Rabe-Hesketh2020), where the dyadic IRT model extends the social relations models by incorporating an IRT measurement model. Peer grading data can be viewed as a special type of dyadic data, where each dyad involves an examinee and a grader, and the dyads are formed by random assignment. However, our model differs substantially from the existing social relations models in how latent variables are modeled and interpreted. The traditional social relations models focus on inferring the causes and consequences of interpersonal perceptions and judgments. In contrast, the current analysis focuses on measuring latent traits concerned with applying peer grading (e.g., examinee performance and rater reliability). As a result, the existing social relations models are unsuitable for the current application.
The rest of the article is organized as follows. Section 2 proposes a latent variable model framework for peer grading data, within which specific models are discussed. Two real data applications are given in Section 3. Section 4 discusses advantages, limitations, and future directions. The appendix includes extensions of the proposed model, technical details, and additional simulated examples. The Online Supplementary Material include further results from simulation studies and real data analysis.
2 Proposed model
2.1 Problem setup
Consider N students who receive T assessments. Each student i’s work on assessment t is randomly assigned to a small subset of other students to grade their work. We denote this subset as
 $S_{it}$
, which is a subset of
$S_{it}$
, which is a subset of
 $\{1, \dots , i-1, i+1, \dots , N\}$
. Each grader
$\{1, \dots , i-1, i+1, \dots , N\}$
. Each grader
 $g \in S_{it}$
gives this work a grade
$g \in S_{it}$
gives this work a grade
 $Y_{igt}$
, following certain scoring rubrics. For simplicity, we consider the case when
$Y_{igt}$
, following certain scoring rubrics. For simplicity, we consider the case when
 $Y_{igt}$
is continuous. It is common, but not required, for the number of graders
$Y_{igt}$
is continuous. It is common, but not required, for the number of graders
 $|S_{it}|$
to be the same for all students and assessments. An aggregated score is then computed as a measure of student i’s performance on the tth assessment, often by taking the mean or the median of the peer grades
$|S_{it}|$
to be the same for all students and assessments. An aggregated score is then computed as a measure of student i’s performance on the tth assessment, often by taking the mean or the median of the peer grades
 $Y_{igt}, g \in S_{it}$
. We note that a simple aggregation rule, such as the mean and the median of the peer grades, fails to account for the grader effect and, thus, may not be accurate enough.
$Y_{igt}, g \in S_{it}$
. We note that a simple aggregation rule, such as the mean and the median of the peer grades, fails to account for the grader effect and, thus, may not be accurate enough.
2.2 Proposed model
2.2.1 Modeling peer grade
 $Y_{igt}$
$Y_{igt}$

We assume the following decomposition for the peer grade
 $Y_{igt}$
:
$Y_{igt}$
:
 $$ \begin{align} Y_{igt} = \theta_{it} + \tau_{igt} - \delta_t, \quad i = 1, \dots, N, \quad t= 1,\dots, T, \quad g\in S_{it}. \end{align} $$
$$ \begin{align} Y_{igt} = \theta_{it} + \tau_{igt} - \delta_t, \quad i = 1, \dots, N, \quad t= 1,\dots, T, \quad g\in S_{it}. \end{align} $$
Here,
 $\delta _t$
captures the difficulty level of assessment t. A larger value of
$\delta _t$
captures the difficulty level of assessment t. A larger value of
 $\delta _t$
corresponds to a more difficult assessment. In addition,
$\delta _t$
corresponds to a more difficult assessment. In addition,
 $\theta _{it}$
represents student i’s true score for assessment t, and
$\theta _{it}$
represents student i’s true score for assessment t, and
 $\tau _{igt}$
is an error attributed to the grader. We assume
$\tau _{igt}$
is an error attributed to the grader. We assume
 $\theta _{it}$
,
$\theta _{it}$
,
 $\tau _{igt}$
and
$\tau _{igt}$
and
 $\delta _t$
to be independent.
$\delta _t$
to be independent.
2.2.2 Modeling true score
$\theta _{it}$

For each student i, we assume that their true scores for different assessments
 $\theta _{it}, \; t = 1,\dots , T$
, are independent and identically distributed (i.i.d.), following a normal distribution
$\theta _{it}, \; t = 1,\dots , T$
, are independent and identically distributed (i.i.d.), following a normal distribution
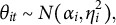 $$ \begin{align} \theta_{it} \sim N(\alpha_{i}, \eta_{i}^2), \end{align} $$
$$ \begin{align} \theta_{it} \sim N(\alpha_{i}, \eta_{i}^2), \end{align} $$
where the mean and variance are student-specific latent variables. The latent variable
 $\alpha _{i}$
captures the student’s average performance over the assessments, and the latent variable
$\alpha _{i}$
captures the student’s average performance over the assessments, and the latent variable
 $\eta _{i}^2$
measures their performance consistency (i.e., the extent to which students’ proficiency varies across assessments). This model assumes the true scores fluctuate randomly around the average score
$\eta _{i}^2$
measures their performance consistency (i.e., the extent to which students’ proficiency varies across assessments). This model assumes the true scores fluctuate randomly around the average score
 $\alpha _{i}$
without a trend. This assumption can be relaxed if we are interested in assessing students’ growth over time (see Appendix B to relax this assumption).
$\alpha _{i}$
without a trend. This assumption can be relaxed if we are interested in assessing students’ growth over time (see Appendix B to relax this assumption).
2.2.3 Modeling grader effect
$\tau _{igt}$

Each student g grades multiple assessments from multiple students. We let
 $H_g = \{(i,t): g \in S_{it}, t = 1, \dots , T\}$
be all the work student g grades. For each student g, we assume that
$H_g = \{(i,t): g \in S_{it}, t = 1, \dots , T\}$
be all the work student g grades. For each student g, we assume that
 $\tau _{igt}$
, for all
$\tau _{igt}$
, for all
 $(i,t) \in H_g$
, are i.i.d., following a normal distribution
$(i,t) \in H_g$
, are i.i.d., following a normal distribution
 $N(\beta _{g}, \phi _{g}^2)$
, where the mean and variance are student-specific latent variables. The latent variable
$N(\beta _{g}, \phi _{g}^2)$
, where the mean and variance are student-specific latent variables. The latent variable
 $\beta _{g}$
may be interpreted as the bias of student g as a grader. For two students g and
$\beta _{g}$
may be interpreted as the bias of student g as a grader. For two students g and
 $g'$
satisfying
$g'$
satisfying
 $\beta _g> \beta _{g'}$
, student g will give a higher grade on average than student
$\beta _g> \beta _{g'}$
, student g will give a higher grade on average than student
 $g'$
when grading the same work. We say grader g is unbiased when
$g'$
when grading the same work. We say grader g is unbiased when
 $\beta _g = 0$
. Moreover, the latent variable
$\beta _g = 0$
. Moreover, the latent variable
 $\phi _{g}^2$
measures the grader’s reliability. A smaller value of
$\phi _{g}^2$
measures the grader’s reliability. A smaller value of
 $\phi _{g}^2$
implies that the grader provides consistent grades to similar quality assessments, while a larger value suggests the opposite. In other words, when grading multiple pieces of work with the same true score and assessment difficulty (so that, ideally, they should receive the same grade), a grader with a small
$\phi _{g}^2$
implies that the grader provides consistent grades to similar quality assessments, while a larger value suggests the opposite. In other words, when grading multiple pieces of work with the same true score and assessment difficulty (so that, ideally, they should receive the same grade), a grader with a small
 $\phi _g^2$
tends to give similar grades, and thus, the grades are more reliable. In contrast, a grader with a large
$\phi _g^2$
tends to give similar grades, and thus, the grades are more reliable. In contrast, a grader with a large
 $\phi _g^2$
tends to give noisy grades that lack consistency. We remark that the grader effects
$\phi _g^2$
tends to give noisy grades that lack consistency. We remark that the grader effects
 $\tau _{igt}$
,
$\tau _{igt}$
,
 $t = 1, \dots , T$
, are assumed to be i.i.d. in the current setting, which means the grading quality remains the same across assignments.
$t = 1, \dots , T$
, are assumed to be i.i.d. in the current setting, which means the grading quality remains the same across assignments.
2.2.4 Joint modeling of student-specific latent variables
The model specification above introduces four latent variables, namely
 $\alpha _{i}$
,
$\alpha _{i}$
,
 $\beta _{i}$
,
$\beta _{i}$
,
 $\eta _{i}^2$
, and
$\eta _{i}^2$
, and
 $\phi _{i}^2$
, for each student i. These variables allow us to account for the relationship between a student’s performance data and grading data as an examinee and a grader. By allowing for dependence between these variables, we can share information and make more informed evaluations of their performance. We assume that
$\phi _{i}^2$
, for each student i. These variables allow us to account for the relationship between a student’s performance data and grading data as an examinee and a grader. By allowing for dependence between these variables, we can share information and make more informed evaluations of their performance. We assume that
 $(\alpha _{i}, \beta _{i}, \eta _{i}^2, \phi _{i}^2)$
, where
$(\alpha _{i}, \beta _{i}, \eta _{i}^2, \phi _{i}^2)$
, where
 $i = 1, \dots , N$
are i.i.d.; we also assume that
$i = 1, \dots , N$
are i.i.d.; we also assume that
 $(\alpha _{i}, \beta _{i}, \log (\eta _{i}^2), \log (\phi _{i}^2))$
follows a multivariate normal distribution
$(\alpha _{i}, \beta _{i}, \log (\eta _{i}^2), \log (\phi _{i}^2))$
follows a multivariate normal distribution ![]() , where
, where ![]() and
and ![]() . To ensure parameter identifiability, we set
. To ensure parameter identifiability, we set
 $\mu _1 = \mu _2 =0$
so that the average score of each assessment (averaged across students and graders) is completely captured by the difficulty parameter
$\mu _1 = \mu _2 =0$
so that the average score of each assessment (averaged across students and graders) is completely captured by the difficulty parameter
 $\delta _t$
. There are no constraints on
$\delta _t$
. There are no constraints on
 $\mu _3$
and
$\mu _3$
and
 $\mu _4$
.
$\mu _4$
.
2.2.5 Remarks
Figure 2 shows an illustrative path diagram for the proposed model under a simplified setting with
 $N=4$
students and
$N=4$
students and
 $T=2$
assessments. Compared with many traditional latent variable models, the current path diagram shows a network structure where the latent variables of different individuals interact with each other. This phenomenon is due to the network structure of peer grading data, where each grade involves two students- one as the examinee and the other as the grader.
$T=2$
assessments. Compared with many traditional latent variable models, the current path diagram shows a network structure where the latent variables of different individuals interact with each other. This phenomenon is due to the network structure of peer grading data, where each grade involves two students- one as the examinee and the other as the grader.
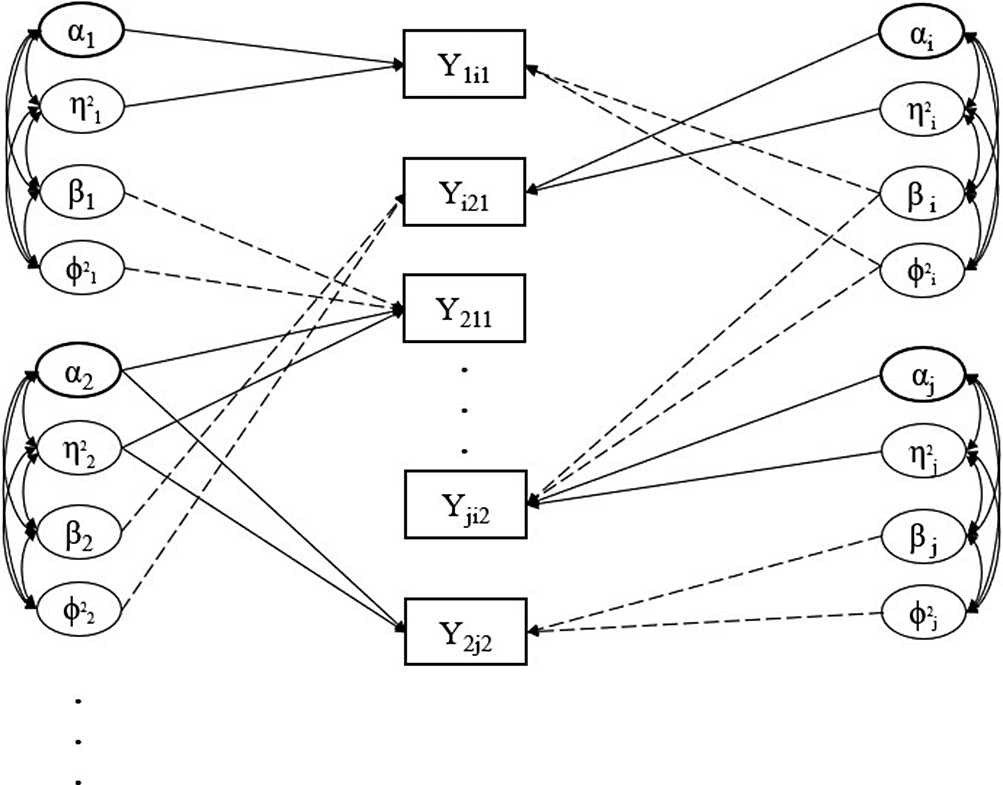
Figure 2 Path diagram representing the network structure of peer grading data. Note: The latent variables of four independent students are represented as an example. Students’ grades, reported in the squared box, refer to two assessments, as the subscripts indicated. The curve double-arrows stand for correlation; the straight (solid and dotted) lines represent the effect of the respective latent variable. For the sake of readability, we prefer to adopt the solid lines for the effect of variables referring to the role of the examinee (i.e.,
 $\alpha , \eta ^2$
), whereas the dotted lines refer to the effect of the latent variables associated with the role of grader (i.e.,
$\alpha , \eta ^2$
), whereas the dotted lines refer to the effect of the latent variables associated with the role of grader (i.e.,
 $\beta , \phi ^2$
).
$\beta , \phi ^2$
).
The proposed model is useful in different ways. First, the model provides a measurement model for the true score of each student i’s assessment t. By inferring each latent variable,
 $\theta _{it}$
, whose technical details will be discussed in Section 2.3, the grader and assessment effects will be adjusted. Thus, a more accurate aggregated score may be obtained. Second, it allows us to further assess each student’s overall performance and consistency as an examinee by inferring
$\theta _{it}$
, whose technical details will be discussed in Section 2.3, the grader and assessment effects will be adjusted. Thus, a more accurate aggregated score may be obtained. Second, it allows us to further assess each student’s overall performance and consistency as an examinee by inferring
 $\alpha _{i}$
and
$\alpha _{i}$
and
 $\eta _{i}^2$
. Third, the model also provides a measurement model for the characteristics of each student as a grader. Specifically, the bias and reliability of each grader can be assessed by inferring
$\eta _{i}^2$
. Third, the model also provides a measurement model for the characteristics of each student as a grader. Specifically, the bias and reliability of each grader can be assessed by inferring
 $\beta _{i}$
and
$\beta _{i}$
and
 $\phi _{i}^2$
. Such results can be used to reward the best-performing graders and offer feedback to help those who need improvement. Finally, the statistical inference of the structural parameters in
$\phi _{i}^2$
. Such results can be used to reward the best-performing graders and offer feedback to help those who need improvement. Finally, the statistical inference of the structural parameters in
 $\boldsymbol {\Sigma }$
allows us to address substantive questions, such as whether a student who performs better in the coursework tends to be a more reliable grader.
$\boldsymbol {\Sigma }$
allows us to address substantive questions, such as whether a student who performs better in the coursework tends to be a more reliable grader.
2.3 Bayesian inference
We adopt a fully Bayesian procedure for drawing statistical inference under the proposed model.
2.3.1 Prior specification
We first specify the prior for the assessment difficulty parameters
 $\delta _1,\dots ,\delta _T$
. When T is large, we can get reliable estimates of the assessments’ population parameters (e.g., the mean and the variance, Cao & Stokes, Reference Cao and Stokes2008; De Boeck, Reference De Boeck2008; Fox & Glas, Reference Fox and Glas2001; Gelman, Reference Gelman2006). In such cases, we can use a hierarchical prior specification and assume that
$\delta _1,\dots ,\delta _T$
. When T is large, we can get reliable estimates of the assessments’ population parameters (e.g., the mean and the variance, Cao & Stokes, Reference Cao and Stokes2008; De Boeck, Reference De Boeck2008; Fox & Glas, Reference Fox and Glas2001; Gelman, Reference Gelman2006). In such cases, we can use a hierarchical prior specification and assume that
 $\delta _1,\dots ,\delta _T$
are i.i.d. following a specific prior distribution (e.g., a normal distribution) with some hyper-parameters. Then, we set a hyper-prior distribution for the hyper-parameters. When T is small, it is not reasonable to assume to observe a representative sample of assessments, and the estimates at the population level might be very unreliable (De Boeck, Reference De Boeck2008). Therefore, we let each
$\delta _1,\dots ,\delta _T$
are i.i.d. following a specific prior distribution (e.g., a normal distribution) with some hyper-parameters. Then, we set a hyper-prior distribution for the hyper-parameters. When T is small, it is not reasonable to assume to observe a representative sample of assessments, and the estimates at the population level might be very unreliable (De Boeck, Reference De Boeck2008). Therefore, we let each
 $\delta _t$
have a weakly informative prior distribution of
$\delta _t$
have a weakly informative prior distribution of
 $N(0, 25)$
. However, tailored considerations must be made depending on the specific dataset, and different prior specifications might be specified (Gelman et al., Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin2013).
$N(0, 25)$
. However, tailored considerations must be made depending on the specific dataset, and different prior specifications might be specified (Gelman et al., Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin2013).
We specify a prior for the parameters ![]() and
and ![]() in the joint distribution for the student-specific latent variables. Recall that
in the joint distribution for the student-specific latent variables. Recall that
 $\mu _1$
and
$\mu _1$
and
 $\mu _2$
are constrained to zero, so no prior is required. As for
$\mu _2$
are constrained to zero, so no prior is required. As for
 $\mu _3$
and
$\mu _3$
and
 $\mu _4$
, they are assumed to be independent, and each follows a weakly informative normal prior
$\mu _4$
, they are assumed to be independent, and each follows a weakly informative normal prior
 $N(0, 25)$
. Finally, for the covariance matrix
$N(0, 25)$
. Finally, for the covariance matrix ![]() , we reparameterize it as
, we reparameterize it as
where
 $\textbf {S}=\mbox {diag}(\sqrt {\sigma _{11}},\dots ,\sqrt {\sigma _{44}})$
is a
$\textbf {S}=\mbox {diag}(\sqrt {\sigma _{11}},\dots ,\sqrt {\sigma _{44}})$
is a
 $4 \times 4$
diagonal matrix with diagonal entries the standard deviations of
$4 \times 4$
diagonal matrix with diagonal entries the standard deviations of
 $(\alpha _{i}, \beta _{i}, \log (\eta _{i}^2), \log (\phi _{i}^2))$
, and
$(\alpha _{i}, \beta _{i}, \log (\eta _{i}^2), \log (\phi _{i}^2))$
, and ![]() is the correlation matrix of
is the correlation matrix of
 $(\alpha _{i}, \beta _{i}, \log (\eta _{i}^2), \log (\phi _{i}^2))$
. The prior distribution on
$(\alpha _{i}, \beta _{i}, \log (\eta _{i}^2), \log (\phi _{i}^2))$
. The prior distribution on ![]() is imposed through the priors on
is imposed through the priors on
 $\textbf {S}$
and
$\textbf {S}$
and ![]() . For
. For
 $\textbf {S}$
, we assume
$\textbf {S}$
, we assume
 $\sqrt {\sigma _{11}},\dots ,\sqrt {\sigma _{44}}$
to be i.i.d., each following a half-Cauchy distribution with location
$\sqrt {\sigma _{11}},\dots ,\sqrt {\sigma _{44}}$
to be i.i.d., each following a half-Cauchy distribution with location
 $0$
and scale
$0$
and scale
 $5$
. For the correlation matrix
$5$
. For the correlation matrix ![]() , we assume a Lewandowski–Kurowicka–Joe (LKJ) prior distribution with shape parameter 1 (Lewandowski et al., Reference Lewandowski, Kurowicka and Joe2009) that corresponds to the uniform distribution over the space of all correlation matrices.
, we assume a Lewandowski–Kurowicka–Joe (LKJ) prior distribution with shape parameter 1 (Lewandowski et al., Reference Lewandowski, Kurowicka and Joe2009) that corresponds to the uniform distribution over the space of all correlation matrices.
2.3.2 Model comparison
Several reduced models can be derived under the proposed framework as special cases. For instance, a reduced model may be obtained by constraining
 $\eta _1^2 = \cdots = \eta _N^2 = \eta ^2$
, that is, students’ performance consistency as examinee is constant across individuals. Another reduced model may be derived by constraining
$\eta _1^2 = \cdots = \eta _N^2 = \eta ^2$
, that is, students’ performance consistency as examinee is constant across individuals. Another reduced model may be derived by constraining
 $\phi _1^2 = \cdots = \phi _N^2 = \phi ^2$
. An even more simplified model can be obtained by imposing both sets of constraints. Given a dataset, Bayesian model comparison methods may be used to find the best-performing model among the full and the reduced models and, thus, provide insights into the peer grading system and yield more accurate aggregated grades.
$\phi _1^2 = \cdots = \phi _N^2 = \phi ^2$
. An even more simplified model can be obtained by imposing both sets of constraints. Given a dataset, Bayesian model comparison methods may be used to find the best-performing model among the full and the reduced models and, thus, provide insights into the peer grading system and yield more accurate aggregated grades.
We consider a Bayesian leave-one-out (LOO) cross-validation procedure for model comparison, which concerns the model’s prediction performance. For a given dataset and a given model, this procedure computes the expected log point-wise predictive density (elpd; Vehtari et al., Reference Vehtari, Gelman and Gabry2017) to measure the overall accuracy in predicting each data point (i.e., peer grade) based on the rest of the data. More precisely, we define the Bayesian LOO estimate of out-of-sample predictive fit as
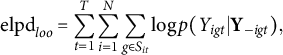 $$ \begin{align*} \mbox{elpd}_{loo} = \sum_{t=1}^{T} \sum_{i=1}^{N} \sum_{g \in S_{it}} \log p(Y_{igt}|\textbf{Y}_{-igt}), \end{align*} $$
$$ \begin{align*} \mbox{elpd}_{loo} = \sum_{t=1}^{T} \sum_{i=1}^{N} \sum_{g \in S_{it}} \log p(Y_{igt}|\textbf{Y}_{-igt}), \end{align*} $$
where
 $\textbf {Y}_{-igt}$
denotes all the observed peer grades except for
$\textbf {Y}_{-igt}$
denotes all the observed peer grades except for
 $Y_{igt}$
, and
$Y_{igt}$
, and
 $p(Y_{igt}|\textbf {Y}_{-igt})$
denotes the conditional probability mass function of
$p(Y_{igt}|\textbf {Y}_{-igt})$
denotes the conditional probability mass function of
 $Y_{igt}$
given
$Y_{igt}$
given
 $\textbf {Y}_{-igt}$
under the fitted Bayesian model. A model with a higher value of
$\textbf {Y}_{-igt}$
under the fitted Bayesian model. A model with a higher value of
 $\mbox {elpd}_{loo}$
is regarded to have better prediction power and, thus, is preferred. In Section 3, we also report the Watanabe–Akaike information criterion (WAIC), which corrects the expected log point-wise predictive density by adding a penalty term for the effective number of parameters (Vehtari et al., Reference Vehtari, Gelman and Gabry2017).
$\mbox {elpd}_{loo}$
is regarded to have better prediction power and, thus, is preferred. In Section 3, we also report the Watanabe–Akaike information criterion (WAIC), which corrects the expected log point-wise predictive density by adding a penalty term for the effective number of parameters (Vehtari et al., Reference Vehtari, Gelman and Gabry2017).
2.3.4 Computation
As illustrated in Figure 2, the proposed model involves a latent space with dimension
 $4N$
and a complex dependence structure between the observed data and the latent variables. This complex model structure makes its statistical inference computationally a challenge. We use a Markov Chain Monte Carlo (MCMC) algorithm for statistical inference. More specifically, we adopt the No-U-Turn HMC sampler (Hoffman & Gelman, Reference Hoffman and Gelman2014), a computationally efficient MCMC sampler, and implement it under the Stan programming language. Compared with classical MCMC samplers, such as the Gibbs and Metropolis–Hastings samplers, the No-U-Turn HMC sampler uses geometric properties of the target distribution to propose posterior samples. It thus converges faster to high-dimensional target distributions (Hoffman & Gelman, Reference Hoffman and Gelman2014). Further computational details are given in the appendix.
$4N$
and a complex dependence structure between the observed data and the latent variables. This complex model structure makes its statistical inference computationally a challenge. We use a Markov Chain Monte Carlo (MCMC) algorithm for statistical inference. More specifically, we adopt the No-U-Turn HMC sampler (Hoffman & Gelman, Reference Hoffman and Gelman2014), a computationally efficient MCMC sampler, and implement it under the Stan programming language. Compared with classical MCMC samplers, such as the Gibbs and Metropolis–Hastings samplers, the No-U-Turn HMC sampler uses geometric properties of the target distribution to propose posterior samples. It thus converges faster to high-dimensional target distributions (Hoffman & Gelman, Reference Hoffman and Gelman2014). Further computational details are given in the appendix.
Regarding the implementation, we use the CmdStan interface (Stan Development Team, 2023) for posterior sampling, which is a command-line interface to Stan that is considerably more efficient than using R as the interface. For all the models, four HMC chains are run in parallel for 2,000 iterations, of which the first 1,000 iterations were specified as the burn-in period. We use the rstan R package to analyze the resulting posterior samples, more specifically, it enables us to merge the MCMCs, compute the summary statistics of the posteriors and check the MCMC mixing and convergence. Moreover, the R package loo (Vehtari et al., Reference Vehtari, Gelman and Gabry2017) and Bayesplot (Gabry et al., Reference Gabry, Simpson, Vehtari, Betancourt and Gelman2019) are used separately for model comparisons and to plot the results, respectively. The computation code used in our analysis, the computational time, and other details on model diagnostics are publically available online.Footnote 1
2.4 A related model
One of the most well-known approaches to latent variable modeling of peer grading data was proposed by Piech et al. (Reference Piech, Huang, Chen, Do, Ng, Koller, D’Mello, Calvo and Olney2013). They present three models of increasing complexity, in which the observed score is assumed to be a function of two independent variables: the student’s ability (also known as the true score) and the effect of the grader (often considered the error part). This type of decomposition is very common in rater effects models (Gwet, Reference Gwet2008; Martinková et al., Reference Martinková, Bartoš and Brabec2023) and is also assumed in our framework. For comparison purposes, we briefly discuss their more complex model, which is also considered in Section 3 and compared with the one we present in Section 2.2. The notation we adopt in presenting their model is consistent with our framework. They assume that the observed score
 $Y_{ig}$
is normally distributed with the mean parameter given by the sum of the true score
$Y_{ig}$
is normally distributed with the mean parameter given by the sum of the true score
 $\theta _i$
and the grader bias
$\theta _i$
and the grader bias
 $\beta _g$
, and the precision parameter being a linear function of the true score of student g:
$\beta _g$
, and the precision parameter being a linear function of the true score of student g:
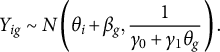 $$ \begin{align*} Y_{ig} \sim N\left( \theta_i + \beta_g, \frac{1}{\gamma_0+\gamma_1 \theta_g}\right). \end{align*} $$
$$ \begin{align*} Y_{ig} \sim N\left( \theta_i + \beta_g, \frac{1}{\gamma_0+\gamma_1 \theta_g}\right). \end{align*} $$
The model assumes that the true scores of students, denoted by
 $\theta _i$
, are independently and identically normally distributed,
$\theta _i$
, are independently and identically normally distributed,
 $\theta _i \sim N(\mu _0, 1/\gamma _2)$
,
$\theta _i \sim N(\mu _0, 1/\gamma _2)$
,
 $i=1,\dots ,N$
. In addition, the model assumes that graders’ biases denoted by
$i=1,\dots ,N$
. In addition, the model assumes that graders’ biases denoted by
 $\beta _g$
, are i.i.d. normally distributed,
$\beta _g$
, are i.i.d. normally distributed,
 $\beta _g \sim N(0,1/\gamma _3)$
,
$\beta _g \sim N(0,1/\gamma _3)$
,
 $g=1,\dots ,N$
.
$g=1,\dots ,N$
.
While this model relates to the proposed method, the two have several differences. For example, the model proposed by the authors does not account for the difficulty level of the assignment. Even if they propose to use normalized grades (z-scores) to remove any assignment effects, it may still be useful to estimate the difficulty level of the assignment. Furthermore, the model assumes that the parameters
 $\theta _i$
and
$\theta _i$
and
 $\beta _i$
, which are the same student indexes, are independent. It also imposes a strict constraint on the precision parameter of the observed score. Specifically, it does not allow the precision to vary given the same value of
$\beta _i$
, which are the same student indexes, are independent. It also imposes a strict constraint on the precision parameter of the observed score. Specifically, it does not allow the precision to vary given the same value of
 $\theta _g$
, and it assumes that the precision is independent of the grader bias
$\theta _g$
, and it assumes that the precision is independent of the grader bias
 $\beta _g$
. Finally, the model does not account for the temporal dependency in the presence of multiple assessments. This model, denoted in Section 3 as PM (i.e., Piech’s Model), is compared against the proposed one using real data from multiple and single assessment contexts.
$\beta _g$
. Finally, the model does not account for the temporal dependency in the presence of multiple assessments. This model, denoted in Section 3 as PM (i.e., Piech’s Model), is compared against the proposed one using real data from multiple and single assessment contexts.
2.5 Reduced model for a single assessment
Some peer grading data only involve a single assessment, as the case for one of our real data examples in Section 3. The proposed model can still be applied in that situation, but certain constraints must be imposed for model identification. Details of the Bayesian inference for this model are given in the appendix.
2.5.1 Modeling peer grade
$Y_{ig}$

With only one assessment, the notation for peer grade simplifies to
 $Y_{ig} = Y_{ig1}$
, and its decomposition simplifies to
$Y_{ig} = Y_{ig1}$
, and its decomposition simplifies to
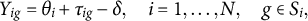 $$ \begin{align} Y_{ig} = \theta_{i} + \tau_{ig} - \delta, \quad i = 1, \dots, N, \quad g\in S_{i}, \end{align} $$
$$ \begin{align} Y_{ig} = \theta_{i} + \tau_{ig} - \delta, \quad i = 1, \dots, N, \quad g\in S_{i}, \end{align} $$
where the subscript t is removed from all the notations in (1), and the interpretation of the variables remains the same. Due to the lack of multiple assessments, the examinee parameters
 $\alpha _{i}$
and
$\alpha _{i}$
and
 $\eta _{i}^2$
in the main model, Equation (2), can no longer be identified and, thus, are not introduced here.
$\eta _{i}^2$
in the main model, Equation (2), can no longer be identified and, thus, are not introduced here.
2.5.2 Modeling grader effect
$\tau _{ig}$

Each student g grades the assessment of multiple peers. Let
 $H_g = \{i: g \in S_i\}$
be the peers whose work is graded by student g. It is assumed that
$H_g = \{i: g \in S_i\}$
be the peers whose work is graded by student g. It is assumed that
 $\tau _{ig}$
,
$\tau _{ig}$
,
 $i \in H_g$
, are i.i.d., following a normal distribution
$i \in H_g$
, are i.i.d., following a normal distribution
 $N(\beta _{g}, \phi _{g}^2)$
. The interpretation of these parameters is the same as in the primary model (see Section 2.2).
$N(\beta _{g}, \phi _{g}^2)$
. The interpretation of these parameters is the same as in the primary model (see Section 2.2).
2.5.3 Joint modeling of student specific latent variables
The reduced model involves three student-specific latent variables
 $(\theta _i,\beta _{i},\phi _{i}^2)$
. Similar to the main model, we assume that
$(\theta _i,\beta _{i},\phi _{i}^2)$
. Similar to the main model, we assume that
 $(\theta _i,\beta _{i},\log (\phi _{i}^2))$
,
$(\theta _i,\beta _{i},\log (\phi _{i}^2))$
,
 $i=1, \dots , N$
, are i.i.d., each following a multivariate normal distribution
$i=1, \dots , N$
, are i.i.d., each following a multivariate normal distribution ![]() , where
, where ![]() and
and ![]() . Similar to the main model, we constrain
. Similar to the main model, we constrain
 $\mu _1 = \mu _2 = 0$
, while keep
$\mu _1 = \mu _2 = 0$
, while keep
 $\mu _3$
freely estimated. Figure 3 gives an illustrative path diagram for this reduced model with
$\mu _3$
freely estimated. Figure 3 gives an illustrative path diagram for this reduced model with
 $N=3$
students.
$N=3$
students.
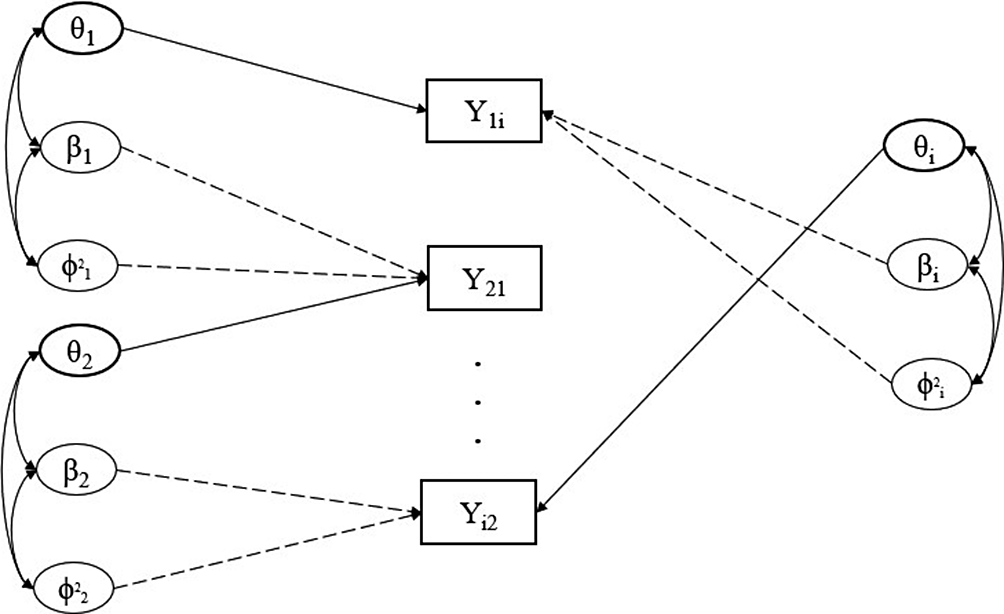
Figure 3 Path diagram representing the network structure of peer grading data for a single assessment. Note: The latent variables of three independent students are represented as an example. The box indicates the students’ grades for a single assessment. The double arrows represent correlation, while the straight (solid and dotted) lines represent the effect of the respective latent variable. The meaning of the arrows is consistent with those of Figure 2. The solid line represents the effect of the latent variable related to the role of the examinee (i.e.,
 $\theta $
). The dotted lines refer to the effect of the latent variables associated with the grader role (i.e.,
$\theta $
). The dotted lines refer to the effect of the latent variables associated with the grader role (i.e.,
 $\beta , \phi ^2$
).
$\beta , \phi ^2$
).
3 Real data examples
Two real-world applications referring to single- and multiple-assessments settings are considered here. Various models are compared for each dataset, and the one that exhibits the best predictive performance is used for inference.
3.1 Multiple-assessments setting
The peer grading data are from Zong et al. (Reference Zong, Schunn and Wang2021). In this data, 274 American undergraduate students taking a Biology course completed four double-blind peer gradings throughout the course (
 $N=274, T=4$
). The assessments had a similar format, and the online peer reviewing system managed the submission and peer grading procedures SWoRD/Peerceptiv (Patchan et al., Reference Patchan, Schunn and Correnti2016). Students’ mean age was
$N=274, T=4$
). The assessments had a similar format, and the online peer reviewing system managed the submission and peer grading procedures SWoRD/Peerceptiv (Patchan et al., Reference Patchan, Schunn and Correnti2016). Students’ mean age was
 $20$
, and
$20$
, and
 $59\%$
were female. Students’ ethnicity was quite heterogeneous,
$59\%$
were female. Students’ ethnicity was quite heterogeneous,
 $69\%$
were Asian,
$69\%$
were Asian,
 $2\%$
Black,
$2\%$
Black,
 $14\%$
Latinx, and
$14\%$
Latinx, and
 $15\%$
White. On average, each work was graded by a random set of five other students. Zong et al. (Reference Zong, Schunn and Wang2021) produced the peer grading score as the average across different rubrics. As a result, gradings are on a 1–7 continuous scale. The minimum and the maximum observed values were, respectively, 1 and 7. The mean and the median grades were 5.414 and 5.500, respectively, which suggest that data are slightly negatively skewed. To implement the main model, only students who completed at least three assessments were included in the analysis, which resulted in a sample size of 212 students.
$15\%$
White. On average, each work was graded by a random set of five other students. Zong et al. (Reference Zong, Schunn and Wang2021) produced the peer grading score as the average across different rubrics. As a result, gradings are on a 1–7 continuous scale. The minimum and the maximum observed values were, respectively, 1 and 7. The mean and the median grades were 5.414 and 5.500, respectively, which suggest that data are slightly negatively skewed. To implement the main model, only students who completed at least three assessments were included in the analysis, which resulted in a sample size of 212 students.
3.1.1 Model comparison
Four different models of increased complexity are fitted and compared. In the first model (M1), we only accounted for one student-specific latent variable: the ability and the assessment difficulty level. This model did not consider the effects of graders, such as their systematic biases and reliability levels. Additionally, M1 assumed that the student’s ability was equal across all assessments. This is the more constrained model. In the second model (M2), we relax our assumptions and consider the graders’ effects, such as their systematic bias and reliability levels. To do this, we use a three-dimensional multivariate normal distribution to jointly model the student-specific latent variables, including
 $\theta _i$
,
$\theta _i$
,
 $\beta _i$
and
$\beta _i$
and
 $\phi ^2_i$
,
$\phi ^2_i$
,
 $i=1,\dots , N$
. It is worth noting that fitting M2 is like fitting the reduced model for a single assessment separately (see Section 2.5), except that students are assumed to have the same ability level across assessments, that is,
$i=1,\dots , N$
. It is worth noting that fitting M2 is like fitting the reduced model for a single assessment separately (see Section 2.5), except that students are assumed to have the same ability level across assessments, that is,
 $\theta _{it}=\theta _i$
,
$\theta _{it}=\theta _i$
,
 $i=1,\dots , N$
. In the third model (M3), we relax this assumption and allow for variations in students’ abilities across assessments by introducing a fourth student-specific latent variable,
$i=1,\dots , N$
. In the third model (M3), we relax this assumption and allow for variations in students’ abilities across assessments by introducing a fourth student-specific latent variable,
 $\eta ^2_i$
,
$\eta ^2_i$
,
 $i=1,\dots , N$
. Under this model, examinee- and grader-specific latent variables, respectively,
$i=1,\dots , N$
. Under this model, examinee- and grader-specific latent variables, respectively,
 $(\theta _i, \eta ^2_i)$
and
$(\theta _i, \eta ^2_i)$
and
 $(\beta _i, \phi ^2_i)$
are assumed to be independent. This assumption is relaxed in the fourth model (M4) in which the latent variables
$(\beta _i, \phi ^2_i)$
are assumed to be independent. This assumption is relaxed in the fourth model (M4) in which the latent variables
 $\theta _i,\beta _i, \log (\eta ^2_i), \log (\phi ^2_i)$
,
$\theta _i,\beta _i, \log (\eta ^2_i), \log (\phi ^2_i)$
,
 $i=1,\dots , N$
, are allowed to be correlated. M4 is the main model introduced in Section 2.2. We also compare these models with the one proposed by Piech et al. (Reference Piech, Huang, Chen, Do, Ng, Koller, D’Mello, Calvo and Olney2013) and detailed in Section 2.4. Under this multiple-assessments setting, we let the difficulty parameter vary across assessments for comparison purposes.
$i=1,\dots , N$
, are allowed to be correlated. M4 is the main model introduced in Section 2.2. We also compare these models with the one proposed by Piech et al. (Reference Piech, Huang, Chen, Do, Ng, Koller, D’Mello, Calvo and Olney2013) and detailed in Section 2.4. Under this multiple-assessments setting, we let the difficulty parameter vary across assessments for comparison purposes.
Model comparison is based on the predictive performance criteria discussed in Section 2.3. The models are fitted using the prior specifications and posterior procedure discussed in Section 2.3. Grades are on a continuous 1–7 scale, with the midpoint considered the average assessment difficulty. Therefore, we have set the prior distribution for
 $\delta _1,\dots ,\delta _4 \stackrel {iid}{\sim } N(4,25)$
. The students are then given an estimate of the true score for each work and a reliability estimate as a grader.
$\delta _1,\dots ,\delta _4 \stackrel {iid}{\sim } N(4,25)$
. The students are then given an estimate of the true score for each work and a reliability estimate as a grader.
3.1.2 Results from the selected model
Upon graphical inspection of the MCMCs, no mixing or convergence issues were detected, as indicated by
 $\hat {R}$
values being less than 1.01. The Number of Effective Sample Size was above the cut-off
$\hat {R}$
values being less than 1.01. The Number of Effective Sample Size was above the cut-off
 $\hat {N}_{eff}>0.10$
for all the structural parameters (Gelman et al., Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin2013). The average computational time per chain varies from
$\hat {N}_{eff}>0.10$
for all the structural parameters (Gelman et al., Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin2013). The average computational time per chain varies from
 $64.445$
to
$64.445$
to
 $1,594.02$
s (seconds), respectively, recorded for models M1 and M4. Further details on model diagnostics (e.g., trace plot,
$1,594.02$
s (seconds), respectively, recorded for models M1 and M4. Further details on model diagnostics (e.g., trace plot,
 $\hat {R}$
,
$\hat {R}$
,
 $\hat {N}_{eff}$
, convergence diagnostic plots), as well as computational time, can be found in Supplementary Material.Footnote
2
$\hat {N}_{eff}$
, convergence diagnostic plots), as well as computational time, can be found in Supplementary Material.Footnote
2
Table 1 gives the value of the LOO expected log point-wise density elpd
 $_{loo}$
and the relative standard error for each model fitted, including the pairwise difference in terms of elpd
$_{loo}$
and the relative standard error for each model fitted, including the pairwise difference in terms of elpd
 $_{loo}$
between M4 and each of the other models; in the last column we also report the WAIC (Gelman et al., Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin2013). The procedure for model comparison showed that M4 provides the best predictive performance. The slightly better performance of M4 over M3 in terms of these criteria supports our assumption of the examinee- and grader-specific latent variables being correlated.
$_{loo}$
between M4 and each of the other models; in the last column we also report the WAIC (Gelman et al., Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin2013). The procedure for model comparison showed that M4 provides the best predictive performance. The slightly better performance of M4 over M3 in terms of these criteria supports our assumption of the examinee- and grader-specific latent variables being correlated.
Table 1 Multiple-assessments example: Four model specifications are compared using a leave-one-out cross-validation approach
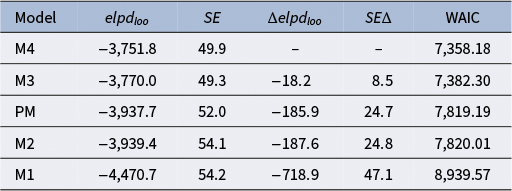
Note: The expected log point-wise density value (elpd
 $_{loo}$
) and its respective standard error (
$_{loo}$
) and its respective standard error (
 $SE$
) are reported. The models are given in descending order based on their elpd
$SE$
) are reported. The models are given in descending order based on their elpd
 $_{loo}$
values.
$_{loo}$
values.
 $\Delta elpd_{loo}$
gives the pairwise comparisons between each model and the model with the largest elpd
$\Delta elpd_{loo}$
gives the pairwise comparisons between each model and the model with the largest elpd
 $_{loo}$
(M4), and
$_{loo}$
(M4), and
 $SE \Delta $
is the standard error of the difference. The Watanabe–Akaike information criterion (WAIC) is given in the last column for each model.
$SE \Delta $
is the standard error of the difference. The Watanabe–Akaike information criterion (WAIC) is given in the last column for each model.
Table 2 shows that the difficulty levels of the assessments are increasing throughout the course. The
 $95\%$
quantile-based credible intervals of the assessment difficulty parameters are moderately narrow, indicating a low level of uncertainty for these parameters.
$95\%$
quantile-based credible intervals of the assessment difficulty parameters are moderately narrow, indicating a low level of uncertainty for these parameters.
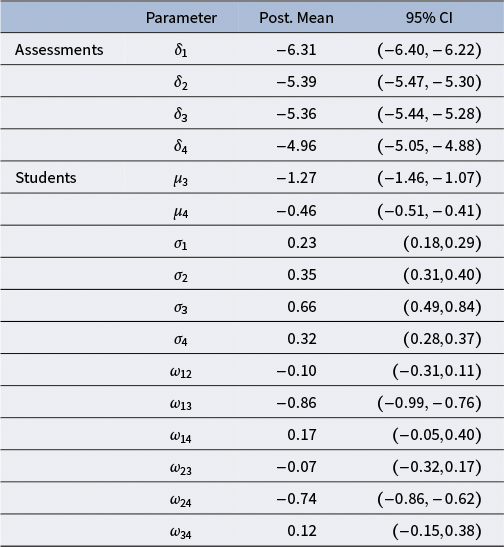
Table 2 Multiple-assessments example: Model M4 estimated structural parameters
Note: The posterior mean (Post. Mean) and the
 $95\%$
quantile-based credible interval (CI) are reported for each parameter. The parameter
$95\%$
quantile-based credible interval (CI) are reported for each parameter. The parameter
 $\delta _t$
represents the difficulty level of the assessment t;
$\delta _t$
represents the difficulty level of the assessment t;
 $\mu _3$
and
$\mu _3$
and
 $\mu _4$
are the location parameters of the third and the fourth latent variable, respectively;
$\mu _4$
are the location parameters of the third and the fourth latent variable, respectively;
 $\sigma _1,\dots ,\sigma _4$
are the standard deviations of the latent variables;
$\sigma _1,\dots ,\sigma _4$
are the standard deviations of the latent variables;
 $\omega _{mn}$
is the correlation parameter between the latent variables m and n.
$\omega _{mn}$
is the correlation parameter between the latent variables m and n.
The posterior means for the latent variable variances are
 $\hat {\mu }_3=-1.27$
with a
$\hat {\mu }_3=-1.27$
with a
 $95\%$
credible interval of
$95\%$
credible interval of
 $(-1.46,-1.07)$
and
$(-1.46,-1.07)$
and
 $\hat {\mu }_4=-0.46$
with a 95% credible interval of
$\hat {\mu }_4=-0.46$
with a 95% credible interval of
 $(-0.51,-0.41)$
. This implies that, on average, the variance of the student’s ability is smaller than the error variance of the grades they give. In other words, they are more consistent as an examinee than a grader. This seems reasonable, considering that they are not grader experts. Note that these parameters are expressed on a logarithmic scale, meaning that the average variance of the students’ proficiency across different assessments is
$(-0.51,-0.41)$
. This implies that, on average, the variance of the student’s ability is smaller than the error variance of the grades they give. In other words, they are more consistent as an examinee than a grader. This seems reasonable, considering that they are not grader experts. Note that these parameters are expressed on a logarithmic scale, meaning that the average variance of the students’ proficiency across different assessments is
 $\exp (\hat {\mu }_3)=0.28$
, and, on average, their reliability parameter is
$\exp (\hat {\mu }_3)=0.28$
, and, on average, their reliability parameter is
 $\exp (\hat {\mu }_4)=0.63$
.
$\exp (\hat {\mu }_4)=0.63$
.
Students are moderately homogeneous regarding their mean abilities, as suggested by
 $\hat {\sigma }_1=0.23$
. In contrast, they are more variable in their systematic bias,
$\hat {\sigma }_1=0.23$
. In contrast, they are more variable in their systematic bias,
 $\hat {\sigma }_2=0.35$
. In other words, they are, on average, more similar as examinees than as graders. Moreover, students are widely different concerning their consistency across assessments,
$\hat {\sigma }_2=0.35$
. In other words, they are, on average, more similar as examinees than as graders. Moreover, students are widely different concerning their consistency across assessments,
 $\hat {\sigma }_3=0.66$
. Finally, they have slightly less variability concerning the reliability parameters as indicated by
$\hat {\sigma }_3=0.66$
. Finally, they have slightly less variability concerning the reliability parameters as indicated by
 $\hat {\sigma }_4=0.32$
.
$\hat {\sigma }_4=0.32$
.
Regarding the dependencies among the latent variables, higher values of students’ proficiency are associated with higher consistency values. Indeed, there is evidence of a strong correlation between the first and the second student-specific latent variable, respectively,
 $\alpha _i$
and
$\alpha _i$
and
 $\log (\eta _i^2)$
, as suggested by
$\log (\eta _i^2)$
, as suggested by
 $\hat {\omega }_{13}=-0.86$
and the
$\hat {\omega }_{13}=-0.86$
and the
 $95\%$
credible interval of and
$95\%$
credible interval of and
 $(-0.99,-0.76)$
. In addition, higher mean bias values are associated with higher reliability levels. This is evidenced by
$(-0.99,-0.76)$
. In addition, higher mean bias values are associated with higher reliability levels. This is evidenced by
 $\hat {\omega }_{24}=-0.74$
and the
$\hat {\omega }_{24}=-0.74$
and the
 $95\%$
credible interval of
$95\%$
credible interval of
 $(-0.86,-0.62)$
. The estimates of the other correlation parameters do not provide clear evidence about any other dependencies. The grader’s effect explains, on average,
$(-0.86,-0.62)$
. The estimates of the other correlation parameters do not provide clear evidence about any other dependencies. The grader’s effect explains, on average,
 $26.1\%$
of the grading variance, conditioning on the assessment difficulties.
$26.1\%$
of the grading variance, conditioning on the assessment difficulties.
At the student-specific level, a score estimate and a
 $95\%$
quantile-based credible interval may be provided for each assessment to measure the uncertainty. For students’ scores, the posterior mean of
$95\%$
quantile-based credible interval may be provided for each assessment to measure the uncertainty. For students’ scores, the posterior mean of
 $\hat {\theta }_{it} - \hat {\delta }_t$
can be used as a point estimate. Additionally, the posterior distributions for both the average bias and the reliability of each grader can be useful in assessing their grading behavior. If a grader is accurate and reliable, their
$\hat {\theta }_{it} - \hat {\delta }_t$
can be used as a point estimate. Additionally, the posterior distributions for both the average bias and the reliability of each grader can be useful in assessing their grading behavior. If a grader is accurate and reliable, their
 $\beta _i$
and
$\beta _i$
and
 $\eta _i^2$
values should be close to zero. Conversely, values far from zero indicate biased and unreliable grading behavior. Both parameters are provided with a
$\eta _i^2$
values should be close to zero. Conversely, values far from zero indicate biased and unreliable grading behavior. Both parameters are provided with a
 $95\%$
quantile-based credible interval. For illustrative purposes, the posterior estimates of the true score
$95\%$
quantile-based credible interval. For illustrative purposes, the posterior estimates of the true score
 $\hat {\theta }_{11} - \hat {\delta }_1$
, the mean bias
$\hat {\theta }_{11} - \hat {\delta }_1$
, the mean bias
 $\beta _1$
and the reliability
$\beta _1$
and the reliability
 $\phi _1$
of student
$\phi _1$
of student
 $i=1$
are reported in Figure 4. On the examinee side, the posterior estimates of the true score suggest that for the first assessment
$i=1$
are reported in Figure 4. On the examinee side, the posterior estimates of the true score suggest that for the first assessment
 $t=1$
, the proficiency level of this student is slightly larger than the average. On the grader side, based on the posterior estimates of
$t=1$
, the proficiency level of this student is slightly larger than the average. On the grader side, based on the posterior estimates of
 $\beta _1$
and
$\beta _1$
and
 $\phi _1^2$
, this student is more severe and moderately less reliable than the average (note that
$\phi _1^2$
, this student is more severe and moderately less reliable than the average (note that
 $\mu _2=0$
and the posterior mean of
$\mu _2=0$
and the posterior mean of
 $\mu _4$
is
$\mu _4$
is
 $-0.46$
on the log scale). Additional results about the posterior mean estimates of the student-specific latent variables, including their density plots, pairwise scatter plots, and Pearson correlations between latent variables, are presented in Supplementary Material. According to these results, the posterior mean estimates seem well-behaved, based on which the multivariate normality assumption of the latent variables does not seem to be severely violated.
$-0.46$
on the log scale). Additional results about the posterior mean estimates of the student-specific latent variables, including their density plots, pairwise scatter plots, and Pearson correlations between latent variables, are presented in Supplementary Material. According to these results, the posterior mean estimates seem well-behaved, based on which the multivariate normality assumption of the latent variables does not seem to be severely violated.
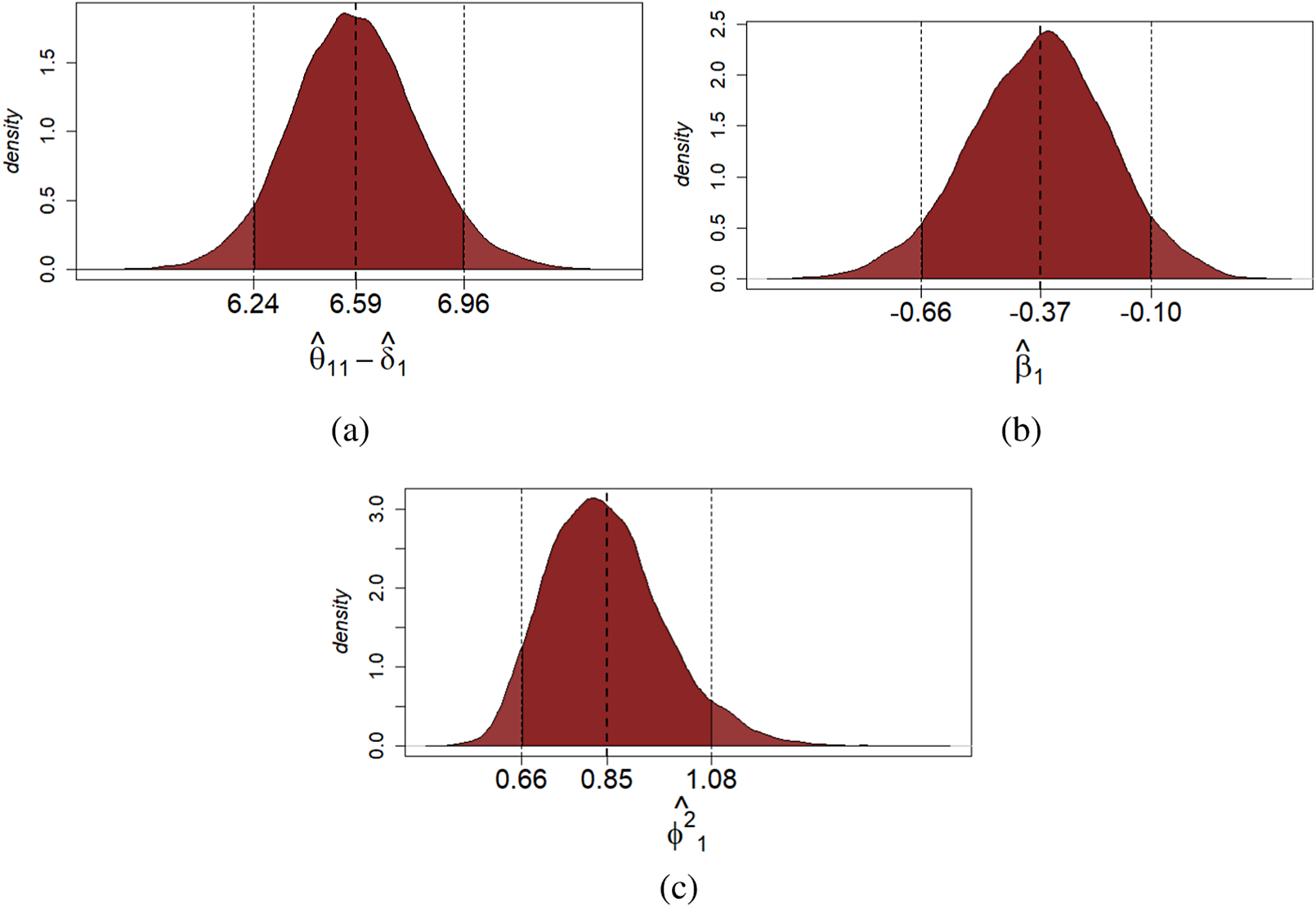
Figure 4 Multiple-assessments example: Posterior distribution of the true score of the first assessment (a), mean bias (b), and reliability (c) of student
 $i=1$
. Note: The black dotted lines indicate the
$i=1$
. Note: The black dotted lines indicate the
 $95\%$
quantile-based credible interval and the posterior mean of each estimated parameter.
$95\%$
quantile-based credible interval and the posterior mean of each estimated parameter.
3.2 Single assessment setting
The data used for the cross-sectional analysis were obtained from an applied economics undergraduate course at the University of Oviedo, as reported by Luaces et al., (Reference Luaces, Díez and Bahamonde2018). The sample consisted of 108 students who participated in a double-blind individual peer assessment on an online platform provided by the university. Each coursework was an open-response assessment rated by ten students according to different rubrics on Likert scales of various lengths. For the present analysis, we consider the sum of the ratings given on these other aspects as the final grade. The observed grades ranged from 0 to 12, with a mean of 7.526 and a median of 8.000. Further information on the grading procedure might be found in Luaces et al. (Reference Luaces, Díez and Bahamonde2018).
3.2.1 Model comparison
Four models are fitted and compared. Three are nested models, and the fourth is the model provided by Piech et al. (Reference Piech, Huang, Chen, Do, Ng, Koller, D’Mello, Calvo and Olney2013) and discussed in Section 2.4. In the first model (M1), we specify one single student-specific latent variable: the student ability and the assessment difficulty parameter. This model did not consider the effects of graders, such as their systematic biases and reliability levels. In other words, graders’ mean bias is fixed to zero, and they are assumed to be equally reliable. This model is the same as the (M1) model detailed in Section 3.1, but only with one assessment. In the second model (M2), we let the graders’ mean biases be freely estimated. Moreover, we let this second student-specific latent variable correlate with the first one. Indeed, they are assumed to be i.i.d. across students, following a bivariate normal distribution. In the third model (M3), we relax the assumption of equal reliability across different graders. However, the latent ability
 $\theta _i$
is assumed to be independent of the other features of the student as a grader (i.e.,
$\theta _i$
is assumed to be independent of the other features of the student as a grader (i.e.,
 $\beta _i$
and
$\beta _i$
and
 $\phi ^2_i$
), for
$\phi ^2_i$
), for
 $i=1,\dots , N$
. This independence assumption is relaxed in the fourth model (M4) and we allow them to be correlated. M4 is the model presented in Section 2.5. The models are fitted using the prior specifications and the posterior procedure discussed in Section 2.3. As with the multiple-assessments example, the prior distribution for the difficulty parameters is set to
$i=1,\dots , N$
. This independence assumption is relaxed in the fourth model (M4) and we allow them to be correlated. M4 is the model presented in Section 2.5. The models are fitted using the prior specifications and the posterior procedure discussed in Section 2.3. As with the multiple-assessments example, the prior distribution for the difficulty parameters is set to
 $N(5.5,25)$
. The students are then given an estimate of the true score for each assessment and a reliability estimate as a grader.
$N(5.5,25)$
. The students are then given an estimate of the true score for each assessment and a reliability estimate as a grader.
3.2.2 Results for the selected model
As with the multiple-assessments example, no mixing or convergence issues were detected, as indicated by
 $\hat {R}$
values less than 1.01. The average computational time per chain ranges from
$\hat {R}$
values less than 1.01. The average computational time per chain ranges from
 $2.7$
to
$2.7$
to
 $44.772$
s, respectively, recorded from Models M1 and M4. Further details on Model diagnostics (e.g., trace plot,
$44.772$
s, respectively, recorded from Models M1 and M4. Further details on Model diagnostics (e.g., trace plot,
 $\hat {R}$
), as well as computational time, can be found in the Appendix and an online repository.Footnote
3
$\hat {R}$
), as well as computational time, can be found in the Appendix and an online repository.Footnote
3
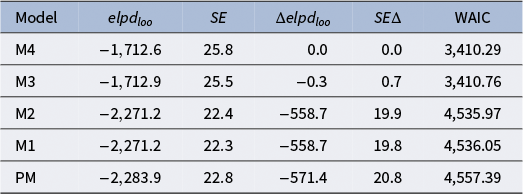
Table 3 indicates that model M4 has the best predictive performance, though its advantage over M3 is very small.
 $\hat {\mu }_3=0.10$
gives the mean graders’ reliability level (i.e., the posterior mean of
$\hat {\mu }_3=0.10$
gives the mean graders’ reliability level (i.e., the posterior mean of
 $\eta _i$
), and there is considerable variability among them as indicated by
$\eta _i$
), and there is considerable variability among them as indicated by
 $\sigma _3$
. Indeed, the estimates of
$\sigma _3$
. Indeed, the estimates of
 $\sigma _3$
on a log scale imply a posterior standard deviation of
$\sigma _3$
on a log scale imply a posterior standard deviation of
 $\eta _i$
larger than one on the original rating scale.
$\eta _i$
larger than one on the original rating scale.
Table 3 Single assessment example: Four model specifications are compared using a leave-one-out cross-validation approach
Note: The expected log point-wise density value (elpd
 $_{loo}$
) and its respective standard error (
$_{loo}$
) and its respective standard error (
 $SE$
) are reported. The models are given in descending order based on their elpd
$SE$
) are reported. The models are given in descending order based on their elpd
 $_{loo}$
values.
$_{loo}$
values.
 $\Delta elpd_{loo}$
gives the pairwise comparisons between each model and the model with the largest elpd
$\Delta elpd_{loo}$
gives the pairwise comparisons between each model and the model with the largest elpd
 $_{loo}$
(M4), and
$_{loo}$
(M4), and
 $SE \Delta $
is the standard error of the difference. The Watanabe–Akaike information criterion (WAIC) is given in the last column for each model.
$SE \Delta $
is the standard error of the difference. The Watanabe–Akaike information criterion (WAIC) is given in the last column for each model.
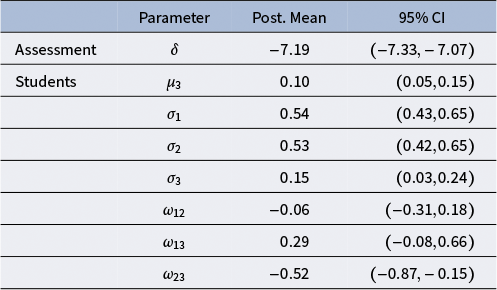
Table 4 Single assessment example: Model M4 estimated structural parameters
Note: The posterior mean (Post. Mean) and the
 $95\%$
quantile-based credible interval (CI) are reported for each parameter. The parameter
$95\%$
quantile-based credible interval (CI) are reported for each parameter. The parameter
 $\delta $
represents the difficulty level of the assessment;
$\delta $
represents the difficulty level of the assessment;
 $\mu _3$
is the location parameter of the third latent variable;
$\mu _3$
is the location parameter of the third latent variable;
 $\sigma _1,\dots ,\sigma _3$
are the standard deviations of the latent variables;
$\sigma _1,\dots ,\sigma _3$
are the standard deviations of the latent variables;
 $\omega _{mn}$
is the correlation parameter between the latent variables m and n.
$\omega _{mn}$
is the correlation parameter between the latent variables m and n.
Students are very similar in their latent ability, as suggested by the small values of the posterior standard deviation of their abilities, that is,
 $\sigma _1$
(see Table 4). The same extent of variability is estimated concerning their mean biases
$\sigma _1$
(see Table 4). The same extent of variability is estimated concerning their mean biases
 $\sigma _2$
. This implies that students are pretty homogeneous regarding proficiency in doing the assessment and severity in grading their peers. The
$\sigma _2$
. This implies that students are pretty homogeneous regarding proficiency in doing the assessment and severity in grading their peers. The
 $95\%$
CI for the correlation parameters
$95\%$
CI for the correlation parameters
 $\omega _1$
and
$\omega _1$
and
 $\omega _2$
do not suggest a clear relation between the respective latent variables. A positive correlation between graders’ bias and their reliability is highlighted by the estimate of
$\omega _2$
do not suggest a clear relation between the respective latent variables. A positive correlation between graders’ bias and their reliability is highlighted by the estimate of
 $\omega _{23}$
. Nonetheless, the relative credible interval is quite large, implying uncertainty about the correlation size. Grader’s effects explain, on average, the
$\omega _{23}$
. Nonetheless, the relative credible interval is quite large, implying uncertainty about the correlation size. Grader’s effects explain, on average, the
 $16.3\%$
of the grading variance.
$16.3\%$
of the grading variance.
Each student might receive a true score estimate at the individual level. The posterior mean of
 $\hat {\theta }_{i} - \hat {\delta }$
might be used as a point estimate for students’ true scores. Moreover, the posterior distributions of both the mean bias and the reliability of each grader might be helpful information to assess their grading behavior. As an illustration, the posterior estimates of the true score
$\hat {\theta }_{i} - \hat {\delta }$
might be used as a point estimate for students’ true scores. Moreover, the posterior distributions of both the mean bias and the reliability of each grader might be helpful information to assess their grading behavior. As an illustration, the posterior estimates of the true score
 $\hat {\theta }_{11} - \hat {\delta }$
, the mean bias
$\hat {\theta }_{11} - \hat {\delta }$
, the mean bias
 $\hat \beta _1$
and the reliability
$\hat \beta _1$
and the reliability
 $\hat \phi _1$
of student
$\hat \phi _1$
of student
 $i=1$
are reported in Figure 5. On the examinee side, the true score’s posterior estimates suggest that this student’s proficiency level is slightly larger than the average. On the grader side, the posterior estimates of
$i=1$
are reported in Figure 5. On the examinee side, the true score’s posterior estimates suggest that this student’s proficiency level is slightly larger than the average. On the grader side, the posterior estimates of
 $\beta _1$
and
$\beta _1$
and
 $\phi _1^2$
suggest that this student is moderately more severe than the average in terms of mean bias but average in terms of reliability level (note that
$\phi _1^2$
suggest that this student is moderately more severe than the average in terms of mean bias but average in terms of reliability level (note that
 $\mu _2=0$
and the posterior mean of
$\mu _2=0$
and the posterior mean of
 $\mu _3$
is
$\mu _3$
is
 $0.10$
on the log scale).
$0.10$
on the log scale).
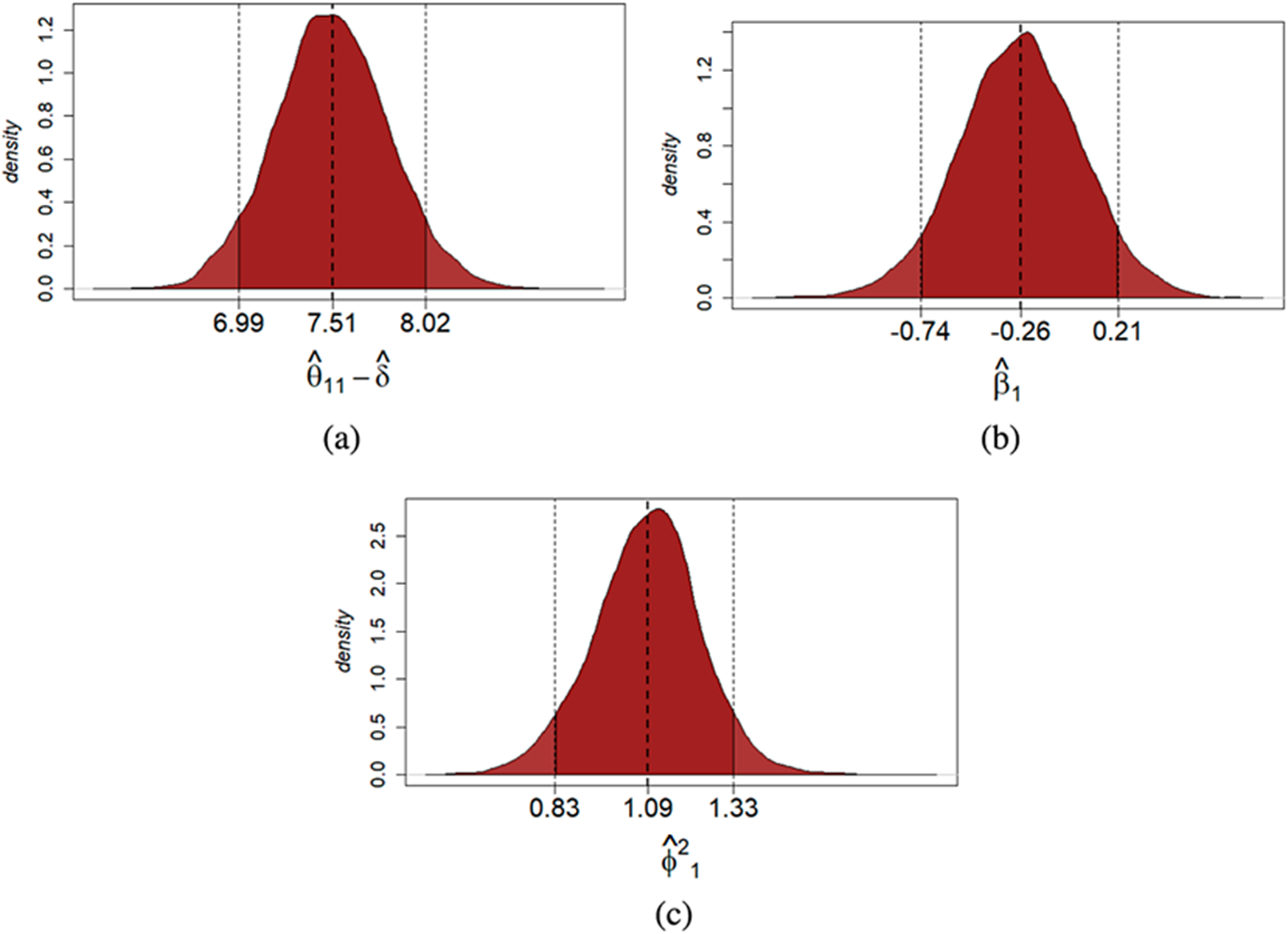
Figure 5 Single assessment example: Posterior distribution of the true score (a), mean bias (b), reliability (c) of student
 $i=1$
. Note: The black dotted lines indicate the
$i=1$
. Note: The black dotted lines indicate the
 $95\%$
quantile-based credible interval and the posterior mean of each estimated parameter.
$95\%$
quantile-based credible interval and the posterior mean of each estimated parameter.
4 Discussions
This article presents a new modeling framework for peer grading data, which introduces latent variables to capture the dependencies in the data from the network structure of peer grades and the dual role of each student as an examinee and a grader. The statistical inference uses a Bayesian method, and an algorithm based on the No-U-Turn HMC sampler was developed. The proposed model was applied to two real-world peer grading datasets, one with a single assessment and the other with four. The results showed that the proposed model had superior prediction performance in real-world applications and that the MCMC did not suffer from mixing or convergence issues.
The current work also has some limitations. First, the peer grades in the applications in Section 3 are bounded, which may cause ceiling and floor effects, as the variability of student performance is no longer measurable when they receive a very high or low score. However, the proposed model is based on several normal assumptions, which fail to capture such phenomena. To model bounded grades, we may add a nonlinear transformation to the right-hand side of (1) to ensure
 $Y_{ig}$
to be bounded.
$Y_{ig}$
to be bounded.
Second, it is not easy to verify the assumptions about the latent variables in our model and further validate their interpretation as we cannot observe the latent variables. Specifically, the multivariate normality assumption about the student-specific latent variables may be quite strong for many real-world settings. As pointed out by Ma & Genton (Reference Ma and Genton2010), severe violation of this assumption can lead to substantially biased estimates. Nevertheless, our sensitivity analysis in the Supplementary Material shows that the model estimates are still reasonably accurate under mild deviations from the normality assumption. Without additional information, it is hard to disentangle different assumptions about the latent variables and verify them separately. We can only check whether the model-implied distribution for the observed data fits its empirical distribution (e.g., using Bayesian LOO and WAIC) and use it to compare different models. Using this approach, we can only tell that the assumptions of one model are more sensible than those of the other. To further verify our model’s assumptions, we may collect data with both peer and instructor grades. The instructor’s grades may be used as the underlying truth to check some specific assumptions in our model.
The current work can be further extended in several directions. First, in formative assessment settings, people are often interested in the growth of students over multiple assessments during a course. Therefore, extending the proposed model to a longitudinal setting and developing a latent growth curve model for peer grading may be helpful. To explore this direction, we have considered a simple extension of the proposed model and performed a small simulation study in Appendix B. This model assumes the true score
 $\theta _{it}$
to follow a latent growth curve model. While this model performed well in the simulation, it may be oversimplified for real-world settings. In practice, student characteristics as a rater and the difficulty levels of the assessments may also change over time. Simultaneously modeling all these changes may result in model identification issues. We leave this problem for future investigation.
$\theta _{it}$
to follow a latent growth curve model. While this model performed well in the simulation, it may be oversimplified for real-world settings. In practice, student characteristics as a rater and the difficulty levels of the assessments may also change over time. Simultaneously modeling all these changes may result in model identification issues. We leave this problem for future investigation.
Second, additional context information, such as student- and classroom-related factors, is often available in formative assessment settings. Such information is useful in explaining and predicting each student’s performance both as an examinee and a rater. In this regard, we believe extending the framework of explanatory item response models (Kim & Wilson, Reference Kim and Wilson2020; Wilson & De Boeck, Reference Wilson and De Boeck2004) to the current setting to include context information as covariates is useful.
Third, the reliability of the peer grading system based on the proposed model is worth investigating. This may be done by adapting the generalizability theory (Brennan, Reference Brennan2001, Reference Brennan2010), originally established under the traditional cross-classified random effects models, to the current model. With the new generalizability theory, we may evaluate the reliability of the system from different perspectives (e.g., examinees, raters, and assessments). Moreover, while the average reliability level of graders might affect the accuracy of the score estimates, a larger number of graders per student’s assignment might mitigate this effect and improve their accuracy (see the Supplementary Material for additional simulation results about these aspects).
Fourth, many real-world peer grading systems involve ordinal peer grades. The proposed model may be extended to ordinal data by replacing the linear model (1) with a generalized linear model. One possible formulation is given in Appendix D, which still mimics the proposed model but replaces (1) with a partial credit model form (Masters, Reference Masters1982). Alternative models also may be available, such as one based on the graded response model (Samejima, Reference Samejima1969). The suitability of these models for peer grading remains to be studied through a theoretical investigation and numerical studies based on simulated and real data. We leave it for future investigation.
Finally, it should be noted that although the Bayesian approach allows for statistical inferences, it can be time-consuming to compute. The high computational cost is due to the proposed model’s high dimensionality, which depends on the number of students and assessments. To make the proposed method scalable for large-scale applications, like MOOC data, advanced computational methods for Bayesian inference, such as stochastic gradient MCMC algorithms, should be explored (Nemeth & Fearnhead, Reference Nemeth and Fearnhead2021).
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/psy.2025.10021.
Acknowledgements
We are sincerely grateful to Professors Oscar Luaces and Christian Schunn for sharing the datasets in Section 3.
Funding statement
The authors declare that no specific funding has been received for this article.
Competing interests
The authors declare no competing interests.
Appendix
A Computational details
To resolve the convergence issue and make the MCMC mix well, we used a non-centred reparametrization for the multivariate normal distribution (Betancourt & Girolami, Reference Betancourt, Girolami, Upadhyay, Singh, Dey and Loganathan2015; Gelman et al., Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin2013; Papaspiliopoulos et al., Reference Papaspiliopoulos, Roberts and Sköld2007). We express the distribution of the vector of student-specific latent variables through an affine transformation, such that
Here,
 $\textbf {L}$
is the Cholesky factor of the correlation matrix
$\textbf {L}$
is the Cholesky factor of the correlation matrix ![]() and
and ![]() is the diagonal matrix of the standard deviation of the latent variables,
is the diagonal matrix of the standard deviation of the latent variables, ![]() ,
,
 $j=1,\dots ,4$
; note that
$j=1,\dots ,4$
; note that ![]() . The element of the four-dimensional vector
. The element of the four-dimensional vector ![]() are i.i.d. following a standard normal distribution,
are i.i.d. following a standard normal distribution,
 $\gamma _{i,1},\dots ,\gamma _{i,4}\stackrel {iid}{\sim }N(0,1)$
,
$\gamma _{i,1},\dots ,\gamma _{i,4}\stackrel {iid}{\sim }N(0,1)$
,
 $i=1,\dots ,N$
. Notice that, as stated above,
$i=1,\dots ,N$
. Notice that, as stated above,
 $\mu _1=\mu _2=0$
for identifiability purposes.
$\mu _1=\mu _2=0$
for identifiability purposes.
Under this inference procedure, each parameter and student-specific latent variables might be provided with a posterior point estimate, for example, the posterior mean, and an interval estimate, for example, a
 $95\%$
quantile-based credible interval. The latter might be seen as an uncertainty measure of the estimated parameter; broader intervals suggest more uncertainty about the values of the parameters, whereas narrower intervals reflect less uncertainty about their values.
$95\%$
quantile-based credible interval. The latter might be seen as an uncertainty measure of the estimated parameter; broader intervals suggest more uncertainty about the values of the parameters, whereas narrower intervals reflect less uncertainty about their values.
B Extension to latent growth curve model
B.1 Model specification
When sufficient assessments are given over time, evaluating students’ growth during that period may be interesting. This can be done using Latent Growth Curve (LGC) modeling (Bollen & Curran, Reference Bollen and Curran2006). For example, a linear latent curve unconditional model can expand the structural model (2) for true score
 $\theta _{it}$
by assuming
$\theta _{it}$
by assuming
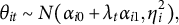 $$ \begin{align} \theta_{it} \sim N(\alpha_{i0} + \lambda_t \alpha_{i1}, \eta_i^2), \end{align} $$
$$ \begin{align} \theta_{it} \sim N(\alpha_{i0} + \lambda_t \alpha_{i1}, \eta_i^2), \end{align} $$
where
 $\alpha _{i0}$
,
$\alpha _{i0}$
,
 $\alpha _{i1}$
, and
$\alpha _{i1}$
, and
 $\eta _i^2$
are student-specific latent variables, and
$\eta _i^2$
are student-specific latent variables, and
 $\lambda _t$
,
$\lambda _t$
,
 $t=1, \dots , T$
are a pre-specified coding of time. The linear function
$t=1, \dots , T$
are a pre-specified coding of time. The linear function
 $\alpha _{i0} + \lambda _t \alpha _{i1}$
can be interpreted as the latent trajectory of student i. The coding of time can be chosen based on the time when the assessments are given. In the special case when the assessments are given at equally spaced intervals, we can set
$\alpha _{i0} + \lambda _t \alpha _{i1}$
can be interpreted as the latent trajectory of student i. The coding of time can be chosen based on the time when the assessments are given. In the special case when the assessments are given at equally spaced intervals, we can set
 $\lambda _t = t-1, t=1, 2, \dots , T$
. We keep the model for
$\lambda _t = t-1, t=1, 2, \dots , T$
. We keep the model for
 $\tau _{igt}$
unchanged. The student-specific latent variables now include
$\tau _{igt}$
unchanged. The student-specific latent variables now include
 $(\alpha _{i0}, \alpha _{i1}, \beta _{i}, \eta _{i}^2, \phi _{i}^2)$
. In line with our assumptions in the main model, we assume that
$(\alpha _{i0}, \alpha _{i1}, \beta _{i}, \eta _{i}^2, \phi _{i}^2)$
. In line with our assumptions in the main model, we assume that
 $(\alpha _{i0}, \alpha _{i1}, \beta _{i}, \log (\eta _{i}^2), \log (\phi _{i}^2))$
,
$(\alpha _{i0}, \alpha _{i1}, \beta _{i}, \log (\eta _{i}^2), \log (\phi _{i}^2))$
,
 $i=1, \dots , N$
are i.i.d., and follow a multivariate normal distribution.
$i=1, \dots , N$
are i.i.d., and follow a multivariate normal distribution.
This model can be further extended to capture nonlinear trajectories. For example, a quadratic latent curve model may be assumed for
 $\theta _{it}$
by assuming
$\theta _{it}$
by assuming
 $$ \begin{align} \theta_{it} \sim N(\alpha_{i0} + \lambda_t \alpha_{i1} +\lambda_t^2 \alpha_{i2}, \eta_i^2), \end{align} $$
$$ \begin{align} \theta_{it} \sim N(\alpha_{i0} + \lambda_t \alpha_{i1} +\lambda_t^2 \alpha_{i2}, \eta_i^2), \end{align} $$
where
 $\alpha _{i0}$
,
$\alpha _{i0}$
,
 $\alpha _{i1}$
,
$\alpha _{i1}$
,
 $\alpha _{i2}$
, and
$\alpha _{i2}$
, and
 $\eta _i^2$
are student-specific latent variables, and
$\eta _i^2$
are student-specific latent variables, and
 $\lambda _t$
,
$\lambda _t$
,
 $t=1, \dots , T$
are still a pre-specified coding of time. The random second-order coefficient
$t=1, \dots , T$
are still a pre-specified coding of time. The random second-order coefficient
 $\alpha _{i2}$
is the rate of change in the linear component along time and represents the acceleration in growth for student i’ ability (Biesanz et al., Reference Biesanz, Deeb-Sossa, Papadakis, Bollen and Curran2004; Bollen & Curran, Reference Bollen and Curran2006). The joint model for student-specific latent variables can be extended accordingly.
$\alpha _{i2}$
is the rate of change in the linear component along time and represents the acceleration in growth for student i’ ability (Biesanz et al., Reference Biesanz, Deeb-Sossa, Papadakis, Bollen and Curran2004; Bollen & Curran, Reference Bollen and Curran2006). The joint model for student-specific latent variables can be extended accordingly.
Figure B1 Estimated linear latent growth of a random sample of four students. Note: The red and the black dotted lines are the true linear growth and the estimated one, respectively; the red bands are the
 $95\%$
credible intervals of this trend.
$95\%$
credible intervals of this trend.
The prior specifications discussed in Section 2 for the unknown parameters,
 $\delta _1,\dots ,\delta _T$
and
$\delta _1,\dots ,\delta _T$
and ![]() , might be consistently adopted for the current model. The same procedures and reparametrization used for the posterior computation introduced above might be freely applied here for the multivariate normal distribution. The Bayesian model comparison procedure discussed in Section 2 might be used to compare the models under the main and LGC frameworks. As for the previous models, each parameter and student-specific latent variables might be provided with a posterior point estimate, for example, the posterior mean, and an interval estimate, for example, a
, might be consistently adopted for the current model. The same procedures and reparametrization used for the posterior computation introduced above might be freely applied here for the multivariate normal distribution. The Bayesian model comparison procedure discussed in Section 2 might be used to compare the models under the main and LGC frameworks. As for the previous models, each parameter and student-specific latent variables might be provided with a posterior point estimate, for example, the posterior mean, and an interval estimate, for example, a
 $95\%$
quantile-based credible interval. Indeed, it might be seen as an uncertainty measure of the relative estimated parameter.
$95\%$
quantile-based credible interval. Indeed, it might be seen as an uncertainty measure of the relative estimated parameter.
B.2 A simulation under the LGC model
Homoscedastic LGC models typically require at least three time-points per individual (e.g., Curran et al., Reference Curran, Obeidat and Losardo2010), whereas, our proposal concerns a heteroscedastic setting that allows some variance terms to be individual-specific and implies a larger number of parameters. Given the relatively small number of assignments per student (at most four) and the rather small sample size
 $N=212$
, the LGC model might not be suitable for the real data analyzed in Section 3.1. We provide a simulated example based on the above LGC model an illustrative example.
$N=212$
, the LGC model might not be suitable for the real data analyzed in Section 3.1. We provide a simulated example based on the above LGC model an illustrative example.
B.2.1 Data generation
We generated a dataset from the linear LGC model in which a sample of
 $N=100$
students are assigned
$N=100$
students are assigned
 $T=6$
assessments. For each assessment, each student’s work is graded by a random subset of other
$T=6$
assessments. For each assessment, each student’s work is graded by a random subset of other
 $|S_{it}|=3$
students. The following values are fixed for the structural parameters of the model:
$|S_{it}|=3$
students. The following values are fixed for the structural parameters of the model:
 $\mu _\delta =0$
,
$\mu _\delta =0$
,
 $\sigma _\delta =1$
,
$\sigma _\delta =1$
, ![]() ,
, ![]() is a five-dimensional identity matrix,
is a five-dimensional identity matrix, ![]() , see Table C2.
, see Table C2.
Table C2 Estimated structural parameters
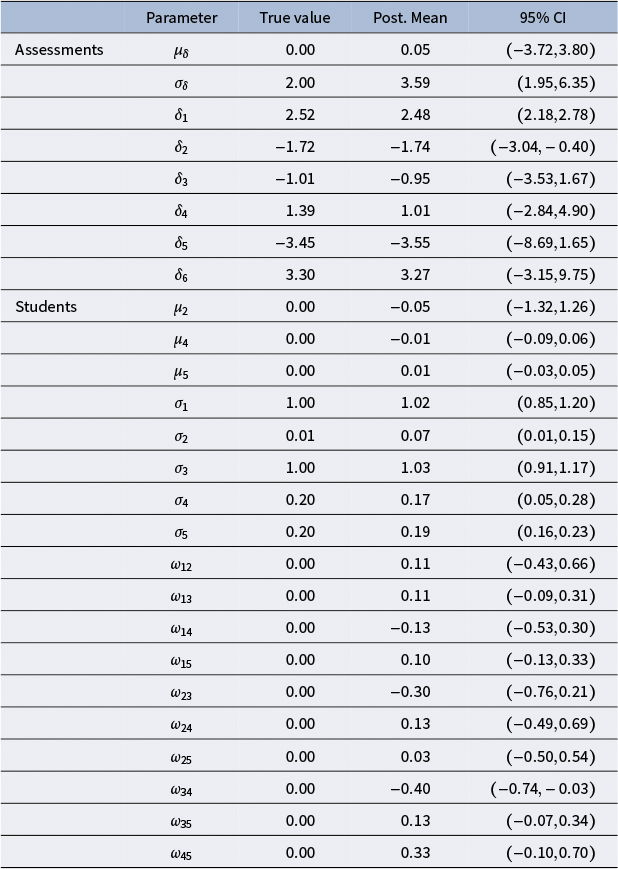
Note: The true value, the posterior mean (Post. Mean) and the
 $95\%$
quantile-based credible interval (CI) are reported for each parameter. The parameter
$95\%$
quantile-based credible interval (CI) are reported for each parameter. The parameter
 $\delta $
is the difficulty level of the assessment;
$\delta $
is the difficulty level of the assessment;
 $\mu _2$
,
$\mu _2$
,
 $\mu _4$
, and
$\mu _4$
, and
 $\mu _5$
are the location parameters of the second, the fourth and the fifth latent variable, respectively;
$\mu _5$
are the location parameters of the second, the fourth and the fifth latent variable, respectively;
 $\sigma _1,\dots ,\sigma _5$
are the standard deviations of the latent variables;
$\sigma _1,\dots ,\sigma _5$
are the standard deviations of the latent variables;
 $\omega _{mn}$
is the correlation parameter between the latent variables m and n.
$\omega _{mn}$
is the correlation parameter between the latent variables m and n.
B.2.2 Estimated parameters
All the considerations on the prior and computational aspects discussed in the main text are consistently followed here. The graphical inspection of the MCMCs does not suggest any mixing or convergence issues, which is consistent with the low values of
 $\hat {R}<1.01$
. The average computational time per chain recorded is
$\hat {R}<1.01$
. The average computational time per chain recorded is
 $5,293.08$
s.Footnote
4
$5,293.08$
s.Footnote
4
The estimates of the structural parameters are reported in Table C2. All the true values are included in the
 $95\%$
credible intervals, even though these posterior intervals are considerably large. This uncertainty might be due to the small sample size
$95\%$
credible intervals, even though these posterior intervals are considerably large. This uncertainty might be due to the small sample size
 $N=100$
. The only exception is the correlation parameter
$N=100$
. The only exception is the correlation parameter
 $\omega _{34}$
, whose
$\omega _{34}$
, whose
 $95\%$
credible interval does not include the true value (even if it is the difference between the upper bound of the interval and the true value is practically negligible). More replications might shed light on these aspects.
$95\%$
credible interval does not include the true value (even if it is the difference between the upper bound of the interval and the true value is practically negligible). More replications might shed light on these aspects.
Under this model, along with the estimates of the true grade and the grader’s effects (i.e., the mean bias and the reliability), each student might be provided with the estimate of his/her latent linear growth trend. For illustrative purposes, we plot the estimated growth of four students in Figure B1. Note that the
 $95\%$
credible intervals of the student-specific trend
$95\%$
credible intervals of the student-specific trend
 $\alpha _{0i}+\alpha _{1i}(t-1)$
are proportional to the values of t. This is because the
$\alpha _{0i}+\alpha _{1i}(t-1)$
are proportional to the values of t. This is because the
 $0.05$
and the
$0.05$
and the
 $0.95$
quantiles of the posterior of
$0.95$
quantiles of the posterior of
 $\alpha _{1i}$
are multiplied by this covariate.
$\alpha _{1i}$
are multiplied by this covariate.
C Prior sensitivity analysis
We performed a prior sensitivity analysis to investigate the impact of the prior on final model estimates (Gelman et al., Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin2013). As discussed by Gelman (Reference Gelman2006), inferences might be very sensitive to the choice of the prior distribution for hierarchical variance parameters, and valuable information might come from tailored stimulative studies. As a preliminary analysis, we fit the main model on different generated datasets comparable to the real dataset analyzed in Section 3.1. For each dataset, we alternatively fit the main model under three prior specifications, resulting in three different scenarios. We compare the respective estimates through the root mean square error (RMSE) and the mean absolute error (MAE).
C.1 Data generation
We generated
 $R=10$
independent datasets from the main model in which a sample of
$R=10$
independent datasets from the main model in which a sample of
 $N=100$
students are assigned
$N=100$
students are assigned
 $T=4$
assessments. Each student’s work is graded by a random subset of other
$T=4$
assessments. Each student’s work is graded by a random subset of other
 $|S_{it}|=3$
students for each assessment. The following values are fixed for the structural parameters of the model:
$|S_{it}|=3$
students for each assessment. The following values are fixed for the structural parameters of the model:
 $\mu _\delta =0$
,
$\mu _\delta =0$
,
 $\sigma _\delta =1$
,
$\sigma _\delta =1$
, ![]() ,
, ![]() is a four-dimensional identity matrix,
is a four-dimensional identity matrix, ![]() .
.
Figure C2 Priors placed under different scenarios on
 $\sigma _1, \dots ,\sigma _4, \mu _3,\mu _4$
. Note: The blue, orange, and green solid lines indicate, respectively, the half-Cauchy, the inverse-gamma and the exponential priors.
$\sigma _1, \dots ,\sigma _4, \mu _3,\mu _4$
. Note: The blue, orange, and green solid lines indicate, respectively, the half-Cauchy, the inverse-gamma and the exponential priors.
Table C3 Root mean square error (RMSE) and mean absolute error (MAE) related to students’ true scores and structural parameters under different scenarios across 10 independent datasets
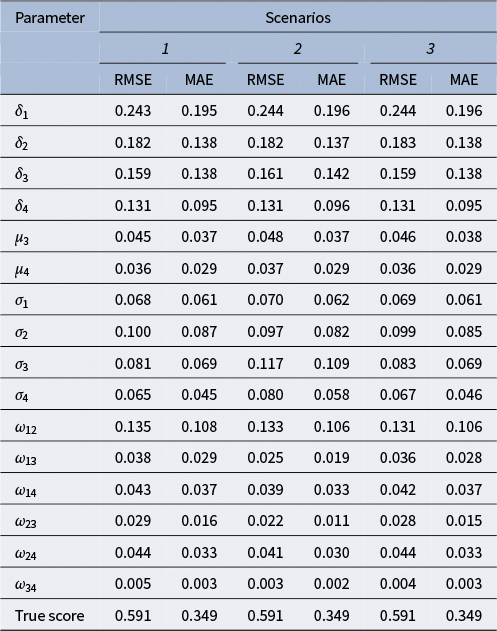
C.2 Scenarios and priors
We place three different priors on the scale parameters
 $\sigma _1, \dots ,\sigma _4$
and on the means
$\sigma _1, \dots ,\sigma _4$
and on the means
 $\mu _3,\mu _4$
. Under the first scenario, they are assigned a half-Cauchy as recommended by Gelman et al. (Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin2013),
$\mu _3,\mu _4$
. Under the first scenario, they are assigned a half-Cauchy as recommended by Gelman et al. (Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin2013),
 $\sigma _1, \dots ,\sigma _4 \stackrel {iid}{\sim } half-Cauchy(0,5)$
and
$\sigma _1, \dots ,\sigma _4 \stackrel {iid}{\sim } half-Cauchy(0,5)$
and
 $\mu _3,\mu _4 \stackrel {iid}{\sim } half-Cauchy(0,5)$
. This class of priors are referred to as “weekly informative” by Gelman (Reference Gelman2006) because of the gentle slope of their tails, which can let the data dominate the posterior if the likelihood is strong in that region. In the second scenario, we place an inverse-gamma on those parameters,
$\mu _3,\mu _4 \stackrel {iid}{\sim } half-Cauchy(0,5)$
. This class of priors are referred to as “weekly informative” by Gelman (Reference Gelman2006) because of the gentle slope of their tails, which can let the data dominate the posterior if the likelihood is strong in that region. In the second scenario, we place an inverse-gamma on those parameters,
 $\sigma _1, \dots ,\sigma _4 \stackrel {iid}{\sim } InvGamma(0.5,0.5)$
and
$\sigma _1, \dots ,\sigma _4 \stackrel {iid}{\sim } InvGamma(0.5,0.5)$
and
 $\mu _3,\mu _4 \stackrel {iid}{\sim } InvGamma(0.5,0.5)$
. Under the third scenario, they are assigned an exponential prior,
$\mu _3,\mu _4 \stackrel {iid}{\sim } InvGamma(0.5,0.5)$
. Under the third scenario, they are assigned an exponential prior,
 $\sigma _1, \dots ,\sigma _4 \stackrel {iid}{\sim } \exp (0.5)$
and
$\sigma _1, \dots ,\sigma _4 \stackrel {iid}{\sim } \exp (0.5)$
and
 $\mu _3,\mu _4 \stackrel {iid}{\sim } \exp (0.5)$
. As shown by Figure C2, the probability density is more spread and diffused under the first scenario as a result of the half-Cauchy prior specification.
$\mu _3,\mu _4 \stackrel {iid}{\sim } \exp (0.5)$
. As shown by Figure C2, the probability density is more spread and diffused under the first scenario as a result of the half-Cauchy prior specification.
C.3 Results
Inferences are the same across different scenarios, suggesting a robustness of the model to different prior specifications for the scale parameters. Table C3 gives the RMSE and the MAE for the structural parameters and the true scores (i.e.,
 $\theta _{it}-\delta _t$
). The RMSE and the MAE of the estimates of the true scores are, on average, 0.59 and 0.34 under all the scenarios. The RMSE and the MAE of the aggregated score using the mean to derive the final grade for each student’s work (Reily et al., Reference Reily, Finnerty, Terveen, Teasley, Havn, Prinz and Lutters2009; Sajjadi et al., Reference Sajjadi, Alamgir and Luxburg2016) are, respectively, 2.46 and 1.98. This suggests that our proposal might consistently mitigate graders’ systematic bias and unreliability.
$\theta _{it}-\delta _t$
). The RMSE and the MAE of the estimates of the true scores are, on average, 0.59 and 0.34 under all the scenarios. The RMSE and the MAE of the aggregated score using the mean to derive the final grade for each student’s work (Reily et al., Reference Reily, Finnerty, Terveen, Teasley, Havn, Prinz and Lutters2009; Sajjadi et al., Reference Sajjadi, Alamgir and Luxburg2016) are, respectively, 2.46 and 1.98. This suggests that our proposal might consistently mitigate graders’ systematic bias and unreliability.
D An extension to ordinal peer grades
The models in this article are for continuous grades, while grades in many peer grading systems are on an ordinal scale. In what follows, we discuss how the proposed model may be extended to ordinal grades. We consider a formulation based on the partial credit model (Masters, Reference Masters1982) under the same setting as our main model in Section 2.2 except for the ordinal grades. More specifically, suppose that
 $Y_{igt} \in \{1,\dots ,K\}$
. For each
$Y_{igt} \in \{1,\dots ,K\}$
. For each
 $k = 2, \dots , K$
, we assume that
$k = 2, \dots , K$
, we assume that
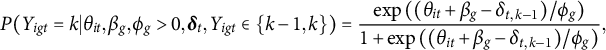 $$ \begin{align} P(Y_{igt} = k | \theta_{it},\beta_g,\phi_g> 0,\boldsymbol{\delta}_t, Y_{igt} \in \{k-1, k\}) = \frac{\exp{((\theta_{it} + \beta_g - \delta_{t,k-1})/\phi_{g})}}{1+\exp{((\theta_{it} + \beta_g - \delta_{t,k-1})/\phi_g)}}, \end{align} $$
$$ \begin{align} P(Y_{igt} = k | \theta_{it},\beta_g,\phi_g> 0,\boldsymbol{\delta}_t, Y_{igt} \in \{k-1, k\}) = \frac{\exp{((\theta_{it} + \beta_g - \delta_{t,k-1})/\phi_{g})}}{1+\exp{((\theta_{it} + \beta_g - \delta_{t,k-1})/\phi_g)}}, \end{align} $$
where
 $\boldsymbol {\delta }_t=(\delta _{t1},\dots , \delta _{t, K-1})^\top $
contains the item-specific parameters and the rest of the variables can be interpreted similarly as in Section 2.2. More specifically,
$\boldsymbol {\delta }_t=(\delta _{t1},\dots , \delta _{t, K-1})^\top $
contains the item-specific parameters and the rest of the variables can be interpreted similarly as in Section 2.2. More specifically,
 $\theta _{it}$
may be interpreted as student i’s true score for assessment t. The larger the value of
$\theta _{it}$
may be interpreted as student i’s true score for assessment t. The larger the value of
 $\theta _{it}$
, the more likely it is that
$\theta _{it}$
, the more likely it is that
 $Y_{igt}$
takes a value in a higher category. The variable
$Y_{igt}$
takes a value in a higher category. The variable
 $\beta _g$
can still be interpreted as rater g’s bias, as raters with a larger
$\beta _g$
can still be interpreted as rater g’s bias, as raters with a larger
 $\beta _g$
value tend to give a higher grade on average. In addition,
$\beta _g$
value tend to give a higher grade on average. In addition,
 $\phi _g$
still indicates rater g’s reliability. When
$\phi _g$
still indicates rater g’s reliability. When
 $\phi _g$
goes to infinity and the rest of the parameters remain fixed, the probability in (D.1) will converge to 0.5, and thus, the probability of
$\phi _g$
goes to infinity and the rest of the parameters remain fixed, the probability in (D.1) will converge to 0.5, and thus, the probability of
 $Y_{igt} = k$
will converge to
$Y_{igt} = k$
will converge to
 $1/K$
, for each category k, regardless what the true score
$1/K$
, for each category k, regardless what the true score
 $\theta _{it}$
is. In other words, the grade
$\theta _{it}$
is. In other words, the grade
 $Y_{igt}$
becomes a purely random guess. On the other hand, when
$Y_{igt}$
becomes a purely random guess. On the other hand, when
 $\phi _g$
goes to zero, the distribution of
$\phi _g$
goes to zero, the distribution of
 $Y_{igt}$
will concentrate on one of the categories.
$Y_{igt}$
will concentrate on one of the categories.
Similar to the model in Section 2.2, we can assume
 $\theta _{it}$
to follow (2) and further set priors for the student-specific latent variables, as well as the rest of the model parameters. Bayesian inference can then be performed.
$\theta _{it}$
to follow (2) and further set priors for the student-specific latent variables, as well as the rest of the model parameters. Bayesian inference can then be performed.


























 Open access
Open access