


1. Introduction
In many cultures around the world, young children are frequently exposed to songs; this includes during the preschool years when children are preparing to start school. Often, these songs are meant to help teach new information (e.g., the letters in the alphabet, the colors of the rainbow, etc.). While preschoolers appear to enjoy songs, there is little empirical data supporting whether presenting new concepts (and specifically words) in melodies, as opposed to spoken sentences, leads to better learning.
Speech and song are features of human communication (e.g., Brandt et al., Reference Brandt, Gebrian and Slevc2012; Trehub, Reference Trehub2019). The similarity between speaking and singing is noteworthy; both require the same structural components (e.g., vocal folds, respiration), and have the ability to express feeling and emotion through shared acoustic properties (i.e., prosody, pitch) (Juslin & Laukka, Reference Juslin and Laukka2003; Poeppel & Assaneo, Reference Poeppel and Assaneo2020; Quinto et al., Reference Quinto, Thompson and Keating2013; Thompson et al., Reference Thompson, Schellenberg and Husain2004). The ability to process speech and song has been proposed to rely on a shared set of cognitive and neural abilities (e.g., Fedorenko et al., Reference Fedorenko, Patel, Casasanto, Winawer and Gibson2009; Fiveash et al., Reference Fiveash, Bedoin, Gordon and Tillmann2021; Thompson et al., Reference Thompson, Marin and Stewart2012). Further, exposure to songs has been suggested to lead to advantages in neural processing that are related to language development (Brandt et al., Reference Brandt, Gebrian and Slevc2012; Dehaene-Lambertz et al., Reference Dehaene-Lambertz, Montavont, Jobert, Allirol, Dubois, Hertz-Pannier and Dehaene2010; Zhao & Kuhl, Reference Zhao and Kuhl2016). Moreover, song has been proposed to play a role in social and emotional development (see Smith & Kong, Reference Smith and Kong2024, for review). Thus, speech and song are tools used to convey meaning. It is perhaps for this reason that there has been a rise in popularity of word learning through song programs (Debreceny, Reference Debreceny2015; Governor et al., Reference Governor, Hall and Jackson2013; gymbobuzz, 2021), and a consistent use of song in school curricula (Kirby et al., Reference Kirby, Dahbi, Surrain, Rowe and Luk2023; Rajan, Reference Rajan2017).
The idea that song may benefit learning likely stems from research that has shown that children prefer, and learn more, from speech registers that are more “musical,” such as child-directed speech (CDS). CDS is characterized by a slower rate of speech, higher pitch, elongation of vowels, and its increased rhythmicity compared to adult-directed speech (ADS) (Fernald & Simon, Reference Fernald and Simon1984; Stern et al., Reference Stern, Spieker and MacKain1982), making it appear more melodic or song-like (Fernald et al., Reference Fernald, Papoušek, Jürgens and Papoušek1992). Young children show a preference for CDS compared to ADS (Frank et al., Reference Frank, Alcock, Arias-Trejo, Aschersleben, Baldwin, Barbu, Bergelson, Bergmann, Black, Blything, Böhland, Bolitho, Borovsky, Brady, Braun, Brown, Byers-Heinlein, Campbell, Cashon and Davies2020), and research has suggested that CDS facilitates word learning in comparison to ADS (Ma et al., Reference Ma, Golinkoff, Houston and Hirsh-Pasek2011; Singh et al., Reference Singh, Nestor, Parikh and Yull2009; Thiessen et al., Reference Thiessen, Hill and Saffran2005). Very often, songs, particularly child-directed songs, share similarities with CDS, such as a slower tempo, higher pitch, and repetition (Trainor et al., Reference Trainor, Clark, Huntley and Adams1997; Trehub et al., Reference Trehub, Unyk, Kamenetsky, Hill, Trainor, Henderson and Saraza1997). These shared characteristics would suggest that children’s songs, like CDS, might facilitate vocabulary learning.
Studies exploring learning in song in the first language have primarily been conducted with infants or older school-age children. While word learning in song likely takes place in classrooms of both first and second language learning, we focus on first language development in the present study and subsequent literature review. However, it should be noted that prior work has found little difference between different types of rhythmic input on the depth of word learning between first and second language learners (e.g., Lawson-Adams et al., Reference Lawson-Adams, Dickenson and Donner2022).
One study with 6.5–8-month-old infants found that infants were able to recognize a familiar number sequence when it was sung, but not when it was spoken (Thiessen & Saffran, Reference Thiessen and Saffran2009). Another study with 11-month-olds tested infants’ ability to detect changes in a sequence of notes or speech sounds (Lebedeva & Kuhl, Reference Lebedeva and Kuhl2010). This study found a facilitatory effect of song, with changes in the note sequence being detected but not changes to the speech sequence. These findings are supported by physiological evidence, which used event-related potentials (ERPs) to examine word segmentation in 10-month-old infants (Snijders et al., Reference Snijders, Benders and Fikkert2020). This paper found that when familiarized with speech versus song, infants demonstrated similar levels of recognition for words in both conditions. Though these findings demonstrate some effect of song on sequence learning and segmentation, they have been conducted with infants and have not directly assessed the creation of a word-item link.
Studies with school-age children have produced conflicting data. On the one hand, there appears to be a facilitatory effect of songs compared to speech during word learning (Chou, Reference Chou2014; Davis & Fan, Reference Davis and Fan2016; Good et al., Reference Good, Russo and Sullivan2015; Zhou & Li, Reference Zhou and Li2017). However, other studies report a null effect of songs during word learning compared to speech alone (Albaladejo et al., Reference Albaladejo, Coyle and De Larios2018; Heidari & Araghi, Reference Heidari and Araghi2015; Leśniewska & Pichette, Reference Leśniewska and Pichette2016). Thus, the role of song during word learning is unclear for school-age children.
To our knowledge, only two studies have explored word-learning in song in a population of toddlers and preschool-age children. One study explored word learning through the presentation of novel objects in children from 1 to 5 years old. The novel items were presented and named either in song or in ADS (Ma et al., Reference Ma, Bowers, Behrend, Hellmuth Margulis and Forde Thompson2023). The authors found that the novel words were learned better in song than in ADS, and that the words learned in song were retained at a delayed testing measure, whereas words learned in ADS were not. However, this work did not provide information as to whether song necessarily leads to better learning compared to other types of speech, particularly CDS. This is important, given that young children are mostly spoken to in CDS rather than in ADS.
We explored this question in a prior study (Morini & Blair, Reference Morini and Blair2021), in which children were taught novel word-object relations in song and in spoken sentences (using CDS prosody). This study utilized a Preferential Looking Paradigm (PLP) and was conducted with toddlers between the ages of 29–32 months and preschoolers between 47 and 50 months. Both groups of learners demonstrated the ability to learn novel words in both song and CDS. Critically, the 29–32-month-olds showed no statistical difference in learning between speech and song, whereas the 47–50-month-olds learned the novel words better in the spoken condition compared to the song condition. One important limitation of this prior work was that the tune that was used for the song condition (“Old MacDonald Had a Farm”) had minimal pitch contrast when the target words were introduced in the song, while the spoken (CDS) condition had prosodic variation that emphasized the target word within the sentence. This prosodic variation may have facilitated the ability to segment and attend to the novel word (Song et al., Reference Song, Demuth and Morgan2010). Additionally, presenting children with a familiar melody that was matched with an unexpected lyric change may have made the task more difficult due to the stimuli not aligning with the child’s expectation. In the present study, we address these limitations by (i) using an unfamiliar melody, and (ii) controlling for pitch variation between the spoken and song stimuli.
2. Experiment
We examined the role of song during the acquisition of novel word-object relations in preschool-age children using a within-subjects design. Specifically, we wanted to understand whether controlling for pitch differences would lead to better or equivalent word learning in song compared to CDS in preschool-age children. We chose to only run the 47–50-month-olds, as in the prior study (Morini & Blair, Reference Morini and Blair2021), this age group displayed learning differences between the song and CDS conditions, whereas the younger children did not. The design of the present study was identical to that of Morini and Blair (Reference Morini and Blair2021), with the key difference being the melody used to teach the novel words in the song condition.
3. Methods
3.1. Participants
A total of 32 children (14 female, 17 male, 1 other), between the ages of 47–50 months (M = 48.6 SD = .85) participated. A sensitivity analysis revealed that this sample is large enough to detect differences of a medium effect size as found in the Morini and Blair (Reference Morini and Blair2021) paper. Of the participants, 22 were White, 3 were Black/African American, 1 was Hispanic/Latino, 2 were Asian, 3 were Mixed Race, and 1 declined to answer. Socioeconomic status was determined via maternal education, and on average, mothers had 18 years of education (SD = 1.77), the equivalent of a master’s degree. Data from an additional 28 children were dropped due to technical issues (N = 12), child fussiness/inattention (N = 13), side bias (N = 1) and ineligibility for the study that was not discovered until the time of study running (N = 2). This dropout rate is not unusual for work using the PLP (Schmale et al., Reference Schmale, Cristia and Seidl2012), and matches that of prior work Morini and Blair (Reference Morini and Blair2021). Moreover, there were no differences in dropout rate based on condition (i.e., speech versus song). Children were raised in monolingual English-speaking homes and did not have any diagnosed disabilities or language disorders based on parental report. Children completed the study virtually from their own home via a synchronous Zoom appointment and needed to have access to a computer with at least a 12-inch screen and a webcam, and a reliable internet connection.
3.2. Stimuli
Four videos of novel objects were used as the visual stimuli. In the videos, the objects were slowly moved from side to side to maintain visual attention. The four objects were paired up, all objects were made of the same material (i.e., wood), were similar sizes, and had equivalent anticipated salience. Each object was notably different from the others, as they were all different solid colours.
The auditory stimuli were recorded by a female native speaker of American English. Training sentences were either spoken using CDS or sung to a tune that matched the pitch of the CDS sentence (see Figure 1).

Figure 1. The melody used in the prior study (Morini & Blair, Reference Morini and Blair2021) (A), and in the current study (B).
The training sentences were comprised of the carrier phrase (“Look! It’s a ___. Wow it’s a _____. Do you see it? A ____.”). The target word was embedded into the carrier phrase. The four novel target words were one syllable in length and were created following English phonotactic rules (i.e., “doop,” “neff,” “shoon,” “fim”). The carrier phrase in testing sentences provided a directive for children to look at one of the two items on the screen. (“Look at the _____! Do you see the _____? Where is that _____? _____!”). All test phrases were produced in spoken sentences using CDS prosody. In both testing and training trials, the onset of the first instance of the target word was 1.4 seconds after the onset of speech. All trials had a duration of 7.5 seconds. For more information, see Morini and Blair (Reference Morini and Blair2021).
3.3. Procedure
The study paradigm was comprised of four testing blocks, two in the song condition and two in the spoken (CDS) training condition. Blocks 1 and 2 taught and tested a new word: one in the song condition, and one in the CDS condition. Blocks 3 and 4 were repetitions of the first two blocks (i.e., Block 1 = Block 3, Block 2 = Block 4). Each block began with a silent trial where an object pair was shown on the screen to examine any object or side biases. Next, three identical training trials were presented. In training trials, a single item was presented on the screen and was accompanied by a training sentence either in song or CDS (Figure 2). Testing took place immediately after training trials. Children were tested on the trained item and on the second untrained item, which was given an unfamiliar name. These untrained trials were included, as if children learned the trained item, they should look longer at the new item when a novel name was presented, due to the principle of mutual exclusivity (Markman & Wachtel, Reference Markman and Wachtel1988). The assumption of mutual exclusivity is that children assume that each item has only one label and will assign a novel label to the untrained item. Both the trained and untrained test trials assessed learning of the trained word-object pair via direct recall and mutual exclusivity testing, respectively. Additionally, this approach controls for trained object preferences that may arise due to repeated familiarization of the trained item. In between all trial types, an 8-second attention getter with a black background was presented (Figure 2).

Figure 2. An example study block.
For participants to be included in the final sample, children needed to have had complete, analysable data for at least one block in each of the training conditions. We counterbalanced for the following parameters across participants (i) which words were trained versus untrained words, (ii) whether trained or untrained testing trials were presented first, (iii) whether trials in the song condition were presented in blocks 1 and 3 or blocks 2 and 4, (iv) which object was assigned which label, and (v) the position of the items on the screen (i.e., if the items were presented on the left or right at testing). See Tables S1 and S2 in Supplemental Materials for confirmation of null effects of the counterbalanced items on the study results.
During the study appointment, caregivers were asked to find a quiet room and eliminate any possible distractors during the appointment (i.e., turning off the TV/music). All experimenters followed a written testing protocol. The appointment began with a check of the lighting, the webcam, and the audio of the participating family’s computer, utilizing a 30-second video of a spinning whale, which was sent to the family in the Zoom chat. In this video, music played, and the background changed from black to white. This background change allowed the experimenter to note if changes in brightness were visible on the child’s face when the screen went from black to white from the webcam. This video was additionally used to test the audio level, as the music was at the same intensity level as the stimuli in the word learning task. Caregivers were asked to adjust their computer’s volume so that the music could be heard at a comfortable listening level.
After completing the checks, experimenters turned off their cameras and muted themselves not to be seen or heard during the study appointment. A link to the study video, which contained all training and testing trials as well as attention getters, was sent to the parents through the chat in Zoom. Parents were instructed to record the session locally on their computer using pre-installed software (e.g., Quicktime for Mac and Camera for Windows). After beginning their recording, caregivers played the study video and closed their eyes for the duration of the video. The children completed the task seated on their caregiver’s lap. Once the video had finished playing, the experimenters turned their audio and camera’s back on, and guided the caregivers through uploading their video of the testing session through a secure link.
3.4. Data coding
All participant videos were coded offline, frame by frame, by two trained coders utilizing the Datavyu coding software (Datavyu Team, 2014). All coded files were checked for coder reliability, and any trials where there were discrepancies of over 0.5 seconds were recoded by a trained third coder, which is common practice for hand-coded data (e.g., Newman et al., Reference Newman, Morini, Kozlovsky and Panza2018). In this study, 16.1% of trials required a third coder, which is not uncommon in data coded from young children (Newman et al., Reference Newman, Morini, Kozlovsky and Panza2018), or online studies (Morini & Blair, Reference Morini and Blair2021).
4. Results
We began by looking for outliers in the data using a z-score method, in which values that were over or under 2 standard deviations from the mean were dropped (e.g., Venkataanusha et al., Reference Venkataanusha, Anuradha, Chandra Murty and Chebrolu2019). After removing the 8 outlier data points, the remaining data included 244 data points from 32 children. Of these data points, 122 of these observations were from the song condition, and the other 122 were from the spoken condition.
Next, we examined the children’s looking patterns during the baseline trials to ensure that there were no pre-existing side or item biases. We found that children looked to the item on the left side of the screen 49% of the time (SD = .11) and to the item on the right side 51% of the time (SD = .11). As children were given no looking instructions during baseline trials, these looking patterns suggest that there were no overall side biases. We then calculated accuracy based on the proportion of time the participants looked toward the target object compared to the competitor item during testing (i.e., accuracy), over a time window of 367–5100 ms after the onset of the target word, across all trials of the same condition (Morini & Blair, Reference Morini and Blair2021). Target items varied across testing conditions and included the trained object and the untrained object, depending on the type of testing trial and the item that was requested. Each of these objects was the “correct” object on one of the two test trials, and if the children adequately learned the trained word, they should be able to look toward the target item in both test trials (e.g., Markman & Wachtel, Reference Markman and Wachtel1988).
Further exploration of the data utilized two-tailed single-sample t-tests comparing child performance in speech and in song to chance (in this case, 50%), to determine whether children had been able to learn the novel words in each condition. These t-tests demonstrated that both training in speech (t(31) = 8.36, Cohen’s d = 1.48, p < .001) and in song (t(31) = 5.58, Cohen’s d = .99, p < .001) led to learning above chance. This indicated that children were able to successfully learn the novel words in both training conditions. While children demonstrated learning in both conditions, on average, children looked longer at the target item for words trained in IDS (M = .69, SD = .20), compared to song (M = .63, SD = .22) (Figure 3). For further visualization of the data, see Figure 1 in Supplemental Materials.
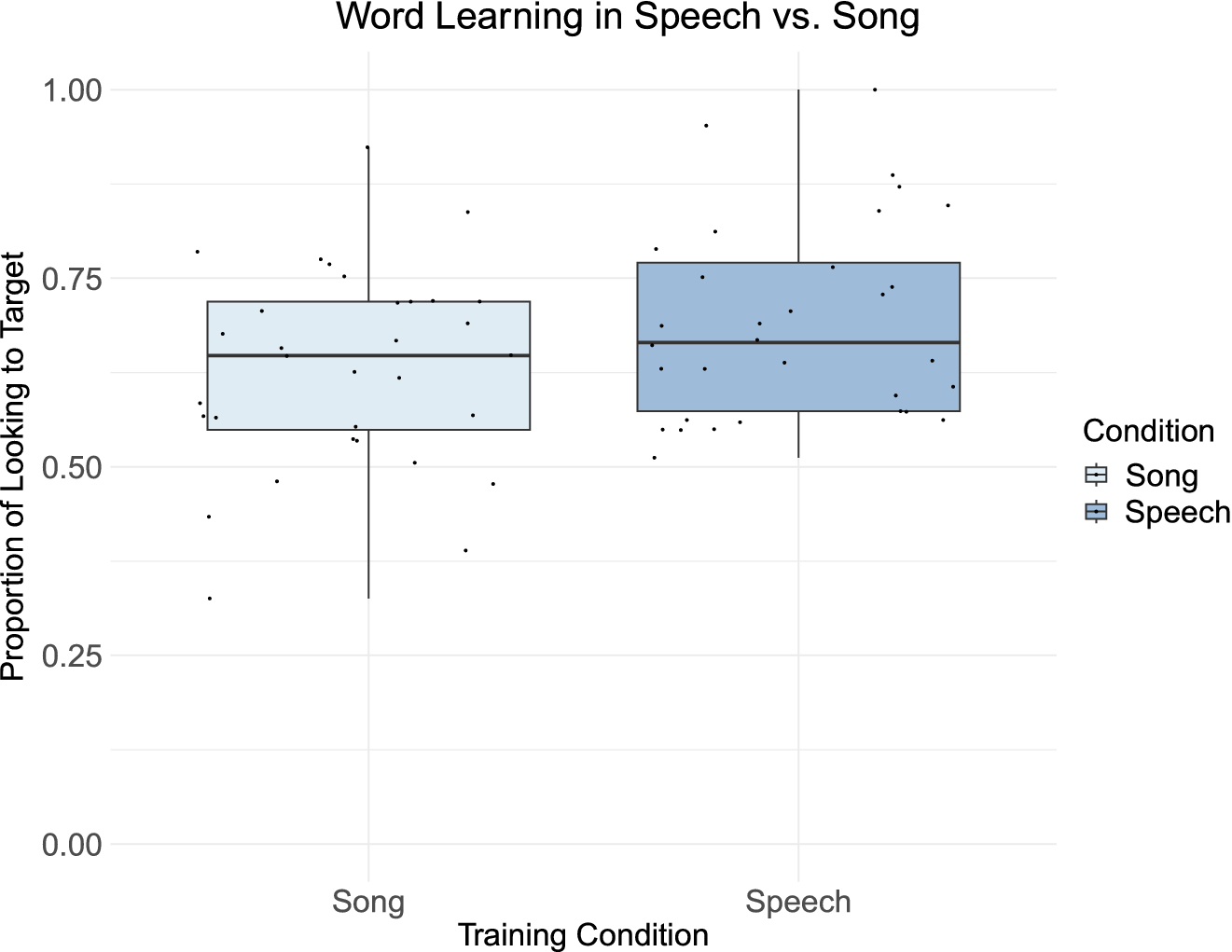
Figure 3. A graph of accuracy in word learning in speech and in song.
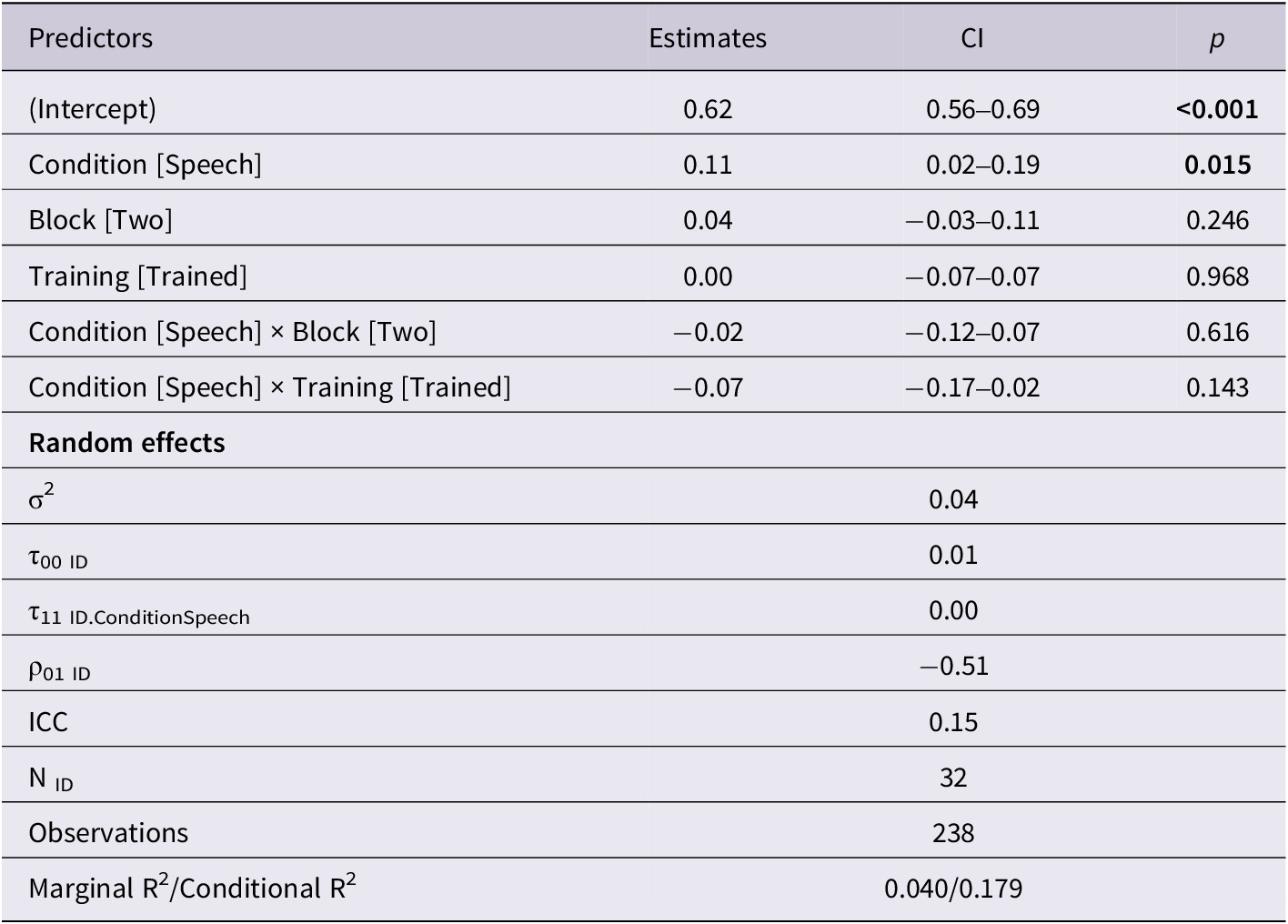
To examine the role of song during novel word learning, we ran a mixed-effects model using the lme4 package in R (Bates et al., Reference Bates, Mächler, Bolker and Walker2015). The mixed-effects model compared accuracy across both learning conditions (speech versus song). The type of test trial (trained versus untrained), and whether the testing block (i.e., the first instance versus the second instance of learning in song/speech) were included in the model as interactions (formula = Accuracy~Condition*(Training+Block) + (Condition|ID)). All factor items were deviation coded within the model. Within the model, the following factors were coded as 0: Training in Song, Testing in Block 1, Untrained Testing, and these factors were coded as 1: Training in Speech, Testing in Block 2, Trained Testing. Additionally, random slopes were included for condition by participant to take into account individual differences related to both the condition of learning and the child. A complete random effects structure could not be run due to convergence issues, which is further acknowledged in the discussion.
The mixed effects model showed a significant main effect of training condition, with child performance in the spoken condition leading to higher accuracy at test than when the novel word was learned in the song condition (β = .11, ηp 2 = .14, p < .05). No other comparisons were significant, suggesting that the type of testing condition (i.e., trained versus untrained words) and the block did not significantly affect performance on the task (see Table 1). Further, a comparison of the data from the present study and the 2021 paper demonstrated no significant differences in performance between the two studies by group (β = .00, ηp 2 = .00, p > .05)., or group by condition interactions (β = .00, ηp2 = .00, p > .05). This suggests that even with pitch changes, learning in song was essentially the same between song conditions in the present and past data sets (see Table S3 in Supplemental Materials).
Table 1. Model of performance in speech versus song (bolded items are statistically significant p < .05)
5. Discussion
This study expanded on prior work examining the role of song on word learning in preschool-age children. Furthermore, we evaluated whether prior findings suggesting that preschoolers learned new words better in speech than in song were due to pitch differences in the stimuli. The present work indicated that even when matching pitch, preschoolers demonstrated better learning of novel words in speech compared to song, as seen in the initial study (Morini & Blair, Reference Morini and Blair2021). This suggests that differences in learning between speech and song are found in the Morini and Blair (Reference Morini and Blair2021) study were not caused by an enhanced identification of the novel word due to the variation in pitch between the spoken and song conditions. This aligns with prior findings which suggest that prosodic cues, while important for speech segmentation, appear to be most influential for infants under 12 months old (Männel & Friederici, Reference Männel and Friederici2013). Further, Snijders et al. (Reference Snijders, Benders and Fikkert2020) posed that pitch changes were not critical for segmenting familiar words from spoken sentences, nor from song. Thus, other factors may be leading to the differences seen in learning between speech and song.
One possibility is that the variability seen between learning in speech versus song may be related to theories of deep learning (e.g., Calvert, Reference Calvert2001). Calvert (Reference Calvert2001) proposed that learning takes place in levels. Some of these levels are more superficial, such as verbatim memory; however, other levels of learning are deeper, such as the ability to encode and retrieve information about prior events. For vocabulary learning, superficial learning may lead to recalling the sound sequence, but not necessarily the word-object link. Deeper learning, in contrast, would be not only creating a word-object link, but also encoding greater meaning about that object. While a song may appear to be “catchy,” the listener is not only hearing the content of the utterance, but now a melody and a cadence that differ from typical CDS. Because of this, during song, children may not as easily attend to the content, or the words being sung, as they are also attending to other qualities of the song. Future work could explore whether children are attending to and learning about other properties of song (e.g., the melody) more than the novel word being presented by teaching the names of novel objects with different melodies. At the test, they could be instructed to identify the previously taught item with the same melody used at training, or with a new melody that was not present at training. If children attach the melody more to the object rather than the name, their performance in the same melody condition would be expected to be higher than in the different melody testing condition. It should be noted, however, that in the present study, both song and speech conditions led to learning above chance. Therefore, while learning in song was more difficult than in speech, it did not prevent learning.
Another possibility is that children may have had difficulty generalizing the information learned in the song condition, as all testing took place in CDS. The rationale for this methodology was that even if children learned new words in song, they need to be able to then successfully recognize the word in other speech contexts. While it is unlikely, given that it has been shown that even infants are able to recognize words across different registers (e.g., happy voices versus neutral voices) (e.g., Singh, Reference Singh2008), it is possible that the mismatch between training and testing may have made testing in the song condition more difficult than in the speech condition. Future work should explore novel word learning in speech and song with testing conditions that match the conditions of the training.
Additionally, there are some limitations that are worth discussing. First, all our participants were within a tight age range. Older children or younger children may respond differently to speech and song for word learning, and therefore, these populations should also be tested in future work. Additionally, our population was not very diverse in race, socioeconomic status, or in their language background (all were monolingual). Future work in this space should aim to work with more racially, ethnically, and linguistically diverse populations, as well as with participants from varied socioeconomic backgrounds. Moreover, our sample size and number of items did not allow for a complete random structure to be included in our analyses, meaning that we were unable to account for random slopes due to the within participant factors of testing Block, and Trained versus Untrained testing. Additional studies should be conducted with larger sample sizes and a wider range of items tested.
Second, the methodology of the study could be made more naturalistic. In our design, children rapidly learned the name of an item over 3 identical training trials and then immediately went into testing. This is not often how children learn the names of items in a real-world context, where they instead may learn the name of an item slowly over days and then have no formal testing. Future studies should explore how children are able to learn the novel names of items in speech and in song in scenarios that are more ecologically valid.
Third, our data only measures immediate learning and does not examine retention effects. It is possible that consolidation of the word-object relations may be affected by training in the spoken or song conditions, as prior work has found differences in the retention of newly learned words when they were taught in song or in speech (ADS) (Ma et al., Reference Ma, Bowers, Behrend, Hellmuth Margulis and Forde Thompson2023). Therefore, more work is needed to determine if there are retention effects of learning in song versus in spoken (CDS) language.
Finally, our study had a high drop-out rate, with data from 28 children being lost due to technical issues or fussiness. While not necessarily atypical in work with preschool-age children, this high drop-out rate may affect the generalizability of our findings, as many children were unable to provide sufficient data for the study. Future work should aim for less data loss, perhaps by modifying the design of the study.
6. Conclusion
The present work explored whether matching pitch and prosodic cues would affect how well preschool-age children were able to learn novel word-object relations in speech and in song. It was found that children learned the novel words better when they were trained in speech rather than in song, which aligns with prior work. These findings suggest that when aiming to teach children new words, using song may not be the most beneficial tool, compared to CDS (at least not for initial learning). This is increasingly relevant with the rise of “learning through song” programs, and can inform parent and teacher practices when approaching vocabulary learning. More research is still needed in this space and should examine learning in speech and song with different populations, different testing measures, and more naturalistic training. Further, future work should examine the role of learning in song on retention of newly learned word-object relations, rather than only immediate testing.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S0305000925100081.
Acknowledgements
We are grateful for the support of the entire Speech Language Acquisition and Multilingualism Lab and their help with contacting families, running study appointments, and coding data. Particularly, we want to thank Meli R. Ayala and Karla Marie Mercedes for their help scheduling participants.
Competing interests
The authors declare none.







 Open access
Open access