


1. Introduction
Markov chain Monte Carlo (MCMC) provides a means to estimate integrals with respect to a target probability measure from the empirical average of a Markov chain. Many Markov chains require a delicate choice of tuning parameters to explore the state space properly, such as Metropolis–Hastings [Reference Roberts and Rosenthal31] and discretized Langevin diffusions [Reference Roberts and Rosenthal30, Reference Roberts and Tweedie35]. The optimal tuning parameter choice often depends on properties of the target probability measure, which may be challenging to compute precisely. At the same time, a poor tuning parameter choice may lead to unreliable estimation and diagnostics from the Markov chain. This motivates adaptive MCMC processes that automatically learn or adapt the tuning parameters of the Markov chain as the process progresses in time [Reference Haario, Saksman and Tamminen18, Reference Roberts and Rosenthal32].
The general theory for adaptive MCMC processes is accomplished through a convergence guarantee on the non-adapted Markov chain in the total variation distance combined with diminishing conditions on the adaptation of the tuning parameters [Reference Roberts and Rosenthal32]. Numerous adaptation strategies are possible such as stochastic approximation [Reference Robbins and Monro29] or specifically designed strategies to rapidly decrease the adaptation as time progresses [Reference Chimisov, Latuszynski and Roberts9]. The existing general theory results in the ability to approximate arbitrary bounded functions through a weak law of large numbers. However, there has been increasing evidence that convergence in total variation is inadequate for many high-dimensional target probability measures compared to convergence in Wasserstein distances from optimal transportation [Reference Durmus and Moulines15, Reference Hairer, Mattingly and Scheutzow20, Reference Qin and Hobert27, Reference Qin and Hobert28]. The issues with analyzing convergence with total variation are not limited to high dimensions and may appear for certain diffusion processes in any dimension [Reference Hairer, Mattingly and Scheutzow20], and even for toy examples [Reference Butkovsky8, Reference Tweedie39].
Since the introduction of adaptive MCMC [Reference Haario, Saksman and Tamminen18], many advancements have been made based upon convergence in total variation [Reference Atchadé and Rosenthal2, Reference Haario, Saksman and Tamminen19, Reference Roberts and Rosenthal33], but weak convergence appears less explored. For example, convergence theory for adaptive MCMC has been extended to handle augmented target distributions that may depend on the adaptation to target multi-modal distributions [Reference Pompe, Holmes and Latuszyński26]. Under specific adaptation strategies based on stochastic approximation, convergence theory under stronger assumptions can lead to a central limit theorem [Reference Andrieu and Moulines1]. However, each of these theoretical results and guarantees is based on convergence of the non-adapted Markov chain in total variation.
This article’s main contribution is the weak convergence of adaptive MCMC processes under general conditions using Wasserstein distances that metrize the weak convergence of probability measures [Reference Gibbs17, Reference Villani41]. Section 2 introduces the general adaptive MCMC regime, and Section 3 reviews the existing theory and some motivating examples that emphasize the inadequacy of the existing convergence theory. Section 5 extends the traditional convergence framework in total variation for adaptive MCMC [Reference Roberts and Rosenthal32] to a framework based on weak convergence. While the convergence result is weaker than total variation, it provides theoretical guarantees for approximations of bounded Lipschitz functions and arbitrary closed sets via Strassen’s theorem [Reference Strassen37]. Section 6 develops general conditions for a weak law of large numbers applied to bounded Lipschitz functions based on weak convergence.
Some examples and applications are explored in Section 5 with adapted autoregressive processes, adaptive unadjusted Langevin processes, adaptive Langevin diffusions, and adaptive Metropolis–Hastings. Beyond the examples studied here, the weak convergence theory for adaptive MCMC can be used to develop new adaptive algorithms for Bayesian inverse problems popular in physics that involve sampling posterior distributions on infinite-dimensional spaces where total variation can be problematic [Reference Cotter, Roberts, Stuart and White10]. Another potentially useful application of the theory developed here is demonstrated in the adaptive Langevin diffusion example where using Wasserstein distances to show weak convergence can yield simpler proofs of the required conditions in comparison to proofs needed to show convergence in total variation.
Weak convergence and the law of large numbers are further extended to general Wasserstein distances under stronger conditions. The main application of this extension is a law of large numbers for unbounded Lipschitz functions in Section 6 and is of practical relevance in statistics. In particular, this extends the weak law of large numbers for Lipschitz functions for adaptive MCMC processes [Reference Roberts and Rosenthal32] and for Markov chains [Reference Sandrić36]. Recently, a law of large numbers for bounded Lipschitz functions has been developed under strong contraction conditions in Wasserstein distances combined with strong limitations on the adaptation [Reference Hofstadler, Latuszynski, Roberts and Rudolf21]. The law of large numbers developed here holds under more general conditions and can apply to unbounded Lipschitz functions under suitable conditions. Section 9 discusses our theoretical results along with limitations and potential extensions of the newly developed theory.
2. Background: Adaptive Markov chain Monte Carlo processes
Let
 ${\mathbb{Z}}_+$
denote the positive integers and denote the minimum and maximum of
${\mathbb{Z}}_+$
denote the positive integers and denote the minimum and maximum of
 $a, b \in {\mathbb{R}}$
by
$a, b \in {\mathbb{R}}$
by
 $a \wedge b$
and
$a \wedge b$
and
 $a \vee b$
respectively. For a Borel measurable space S, let
$a \vee b$
respectively. For a Borel measurable space S, let
 ${\mathcal{B}}(S)$
denote its Borel sigma field. The Euclidean norm is denoted by
${\mathcal{B}}(S)$
denote its Borel sigma field. The Euclidean norm is denoted by ![]() and, for a measure
and, for a measure
 $\mu$
, Lebesgue spaces are denoted by
$\mu$
, Lebesgue spaces are denoted by
 $L^p(\mu)$
. For a real-valued function f, denote the optimal Lipschitz constant with respect to a metric d by
$L^p(\mu)$
. For a real-valued function f, denote the optimal Lipschitz constant with respect to a metric d by ![]() .
.
We follow closely to the adaptive MCMC process framework of [Reference Roberts and Rosenthal32]. Let
 $( \Omega, {\mathcal{B}}(\Omega) )$
be a Borel measurable space and let
$( \Omega, {\mathcal{B}}(\Omega) )$
be a Borel measurable space and let
 ${\mathcal{X}}$
and
${\mathcal{X}}$
and
 ${\mathcal{Y}}$
be complete separable metric spaces with respect to some metrics, with
${\mathcal{Y}}$
be complete separable metric spaces with respect to some metrics, with
 ${\mathcal{B}}({\mathcal{X}})$
and
${\mathcal{B}}({\mathcal{X}})$
and
 ${\mathcal{B}}({\mathcal{Y}})$
their respective Borel sigma fields. Let
${\mathcal{B}}({\mathcal{Y}})$
their respective Borel sigma fields. Let
 $\pi$
be a target Borel probability measure on
$\pi$
be a target Borel probability measure on
 ${\mathcal{X}}$
. For a discrete time index
${\mathcal{X}}$
. For a discrete time index
 $t \in {\mathbb{Z}}_+$
, the adaptive process updates a random tuning parameter
$t \in {\mathbb{Z}}_+$
, the adaptive process updates a random tuning parameter
 $\Gamma_t \colon \Omega \mapsto {\mathcal{Y}}$
as the process progresses using the entire history to improve the distribution of
$\Gamma_t \colon \Omega \mapsto {\mathcal{Y}}$
as the process progresses using the entire history to improve the distribution of
 $X_t \colon \Omega \mapsto {\mathcal{X}}$
. The result is for the marginal distribution of
$X_t \colon \Omega \mapsto {\mathcal{X}}$
. The result is for the marginal distribution of
 $X_t$
to approximate the target distribution
$X_t$
to approximate the target distribution
 $\pi$
.
$\pi$
.
We define generalized Borel measurable probability transition kernels
 $({\mathcal{Q}}_{t})_{t \ge 0}$
with
$({\mathcal{Q}}_{t})_{t \ge 0}$
with
 ${\mathcal{Q}}_t \colon ({\mathcal{Y}} \times {\mathcal{X}})^t \times {\mathcal{B}}({\mathcal{Y}}) \mapsto [0, 1]$
and a family of Borel measurable Markov transition kernels
${\mathcal{Q}}_t \colon ({\mathcal{Y}} \times {\mathcal{X}})^t \times {\mathcal{B}}({\mathcal{Y}}) \mapsto [0, 1]$
and a family of Borel measurable Markov transition kernels
 $({\mathcal{P}}_{\gamma})_{\gamma \in {\mathcal{Y}}}$
with
$({\mathcal{P}}_{\gamma})_{\gamma \in {\mathcal{Y}}}$
with
 ${\mathcal{P}}_\gamma \colon {\mathcal{X}} \times {\mathcal{B}}({\mathcal{X}}) \mapsto [0, 1]$
to prescribe the adaptive process by the relations
${\mathcal{P}}_\gamma \colon {\mathcal{X}} \times {\mathcal{B}}({\mathcal{X}}) \mapsto [0, 1]$
to prescribe the adaptive process by the relations
 \begin{equation*} {\mathbb{P}}(\Gamma_t \in {\mathrm{d}}\gamma \mid H_{t-1} ) = {\mathcal{Q}}_{t}(H_{t-1}, {\mathrm{d}}\gamma), \qquad {\mathbb{P}}(X_t \in {\mathrm{d}} x \mid \Gamma_t, X_s, H_{t-1} ) = {\mathcal{P}}_{\Gamma_t}(X_s, {\mathrm{d}} x),\end{equation*}
\begin{equation*} {\mathbb{P}}(\Gamma_t \in {\mathrm{d}}\gamma \mid H_{t-1} ) = {\mathcal{Q}}_{t}(H_{t-1}, {\mathrm{d}}\gamma), \qquad {\mathbb{P}}(X_t \in {\mathrm{d}} x \mid \Gamma_t, X_s, H_{t-1} ) = {\mathcal{P}}_{\Gamma_t}(X_s, {\mathrm{d}} x),\end{equation*}
where
 $H_{t} = (\Gamma_0, X_0, \ldots, \Gamma_{t}, X_{t})$
denotes the history at time t. This prescribes the finite-dimensional distributions so that
$H_{t} = (\Gamma_0, X_0, \ldots, \Gamma_{t}, X_{t})$
denotes the history at time t. This prescribes the finite-dimensional distributions so that
 $(\Gamma_0, X_0, \ldots, \Gamma_t, X_t)$
for fixed
$(\Gamma_0, X_0, \ldots, \Gamma_t, X_t)$
for fixed
 $\Gamma_0, X_0$
has joint distribution
$\Gamma_0, X_0$
has joint distribution
 \begin{equation*} {\mathcal{A}}^{(0, \ldots, t)}((\gamma_0, x_0), {\mathrm{d}}\gamma_1, {\mathrm{d}} x_1, \ldots, {\mathrm{d}}\gamma_t, {\mathrm{d}} x_t) = \prod_{k = 1}^{t} {\mathcal{Q}}_{k}(h_{k - 1}, {\mathrm{d}}\gamma_{k}) {\mathcal{P}}_{\gamma_{k}}(x_{k - 1}, {\mathrm{d}} x_{k})\end{equation*}
\begin{equation*} {\mathcal{A}}^{(0, \ldots, t)}((\gamma_0, x_0), {\mathrm{d}}\gamma_1, {\mathrm{d}} x_1, \ldots, {\mathrm{d}}\gamma_t, {\mathrm{d}} x_t) = \prod_{k = 1}^{t} {\mathcal{Q}}_{k}(h_{k - 1}, {\mathrm{d}}\gamma_{k}) {\mathcal{P}}_{\gamma_{k}}(x_{k - 1}, {\mathrm{d}} x_{k})\end{equation*}
with history
 $h_{k} = ( \gamma_{0}, x_{0}, \ldots, \gamma_{k}, x_{k} )$
. This defines an adaptive process
$h_{k} = ( \gamma_{0}, x_{0}, \ldots, \gamma_{k}, x_{k} )$
. This defines an adaptive process
 $(\Gamma_t, X_t)_{t \ge 0}$
adapted to the filtration
$(\Gamma_t, X_t)_{t \ge 0}$
adapted to the filtration
 ${\mathcal{H}}_t = {\mathcal{B}}(\Gamma_s, X_s \colon 0 \le s \le t)$
and initialized at any probability measure
${\mathcal{H}}_t = {\mathcal{B}}(\Gamma_s, X_s \colon 0 \le s \le t)$
and initialized at any probability measure
 $\mu$
on
$\mu$
on
 $( {\mathcal{Y}} \times {\mathcal{X}}, {\mathcal{B}}({\mathcal{Y}} \times {\mathcal{X}}) )$
by the Ionescu–Tulcea extension theorem [Reference Tulcea38].
$( {\mathcal{Y}} \times {\mathcal{X}}, {\mathcal{B}}({\mathcal{Y}} \times {\mathcal{X}}) )$
by the Ionescu–Tulcea extension theorem [Reference Tulcea38].
We will mostly be concerned with the marginal distribution
 $X_t$
from fixed initialization points
$X_t$
from fixed initialization points
 $\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
and general initializations
$\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
and general initializations
 $\mu$
on
$\mu$
on
 $( {\mathcal{Y}} \times {\mathcal{X}}, {\mathcal{B}}({\mathcal{Y}} \times {\mathcal{X}}) )$
, defined by
$( {\mathcal{Y}} \times {\mathcal{X}}, {\mathcal{B}}({\mathcal{Y}} \times {\mathcal{X}}) )$
, defined by
 \begin{equation} X_t \mid \Gamma_0, X_0 = \gamma, x \sim {\mathcal{A}}^{(t)}((\gamma, x), \cdot), \qquad X_t \sim \mu{\mathcal{A}}^{(t)}(\cdot) = \int_{{\mathcal{Y}} \times {\mathcal{X}}} {\mathcal{A}}^{(t)}((\gamma, x), \cdot)\,\mu({\mathrm{d}}\gamma, {\mathrm{d}} x).\end{equation}
\begin{equation} X_t \mid \Gamma_0, X_0 = \gamma, x \sim {\mathcal{A}}^{(t)}((\gamma, x), \cdot), \qquad X_t \sim \mu{\mathcal{A}}^{(t)}(\cdot) = \int_{{\mathcal{Y}} \times {\mathcal{X}}} {\mathcal{A}}^{(t)}((\gamma, x), \cdot)\,\mu({\mathrm{d}}\gamma, {\mathrm{d}} x).\end{equation}
3. Background: Wasserstein distances
Let
 $d \colon {\mathcal{X}} \times {\mathcal{X}} \to [0, \infty)$
be a lower semicontinuous metric. Define the Wasserstein distance or transportation distance of order
$d \colon {\mathcal{X}} \times {\mathcal{X}} \to [0, \infty)$
be a lower semicontinuous metric. Define the Wasserstein distance or transportation distance of order
 $p \in {\mathbb{Z}}_+$
between two arbitrary Borel probability measures
$p \in {\mathbb{Z}}_+$
between two arbitrary Borel probability measures
 $\mu$
and
$\mu$
and
 $\nu$
on
$\nu$
on
 $({\mathcal{X}}, {\mathcal{B}}({\mathcal{X}}))$
by
$({\mathcal{X}}, {\mathcal{B}}({\mathcal{X}}))$
by
 \[{\mathcal{W}}_{d, p}(\mu, \nu)= \bigg( \inf_{\xi \in {\mathcal{C}}(\mu, \nu)} \int_{{\mathcal{X}} \times {\mathcal{X}}} d(x, y)^p\,\xi({\mathrm{d}} x, {\mathrm{d}} y) \bigg)^{1/p},\]
\[{\mathcal{W}}_{d, p}(\mu, \nu)= \bigg( \inf_{\xi \in {\mathcal{C}}(\mu, \nu)} \int_{{\mathcal{X}} \times {\mathcal{X}}} d(x, y)^p\,\xi({\mathrm{d}} x, {\mathrm{d}} y) \bigg)^{1/p},\]
where
 ${\mathcal{C}}(\mu, \nu)$
is the set of all joint probability measures
${\mathcal{C}}(\mu, \nu)$
is the set of all joint probability measures
 $\xi$
such that
$\xi$
such that
 $\xi(\,\cdot\times {\mathcal{X}}) = \mu(\cdot)$
and
$\xi(\,\cdot\times {\mathcal{X}}) = \mu(\cdot)$
and
 $\xi({\mathcal{X}} \times\,\cdot\,) = \nu(\cdot)$
. We generally suppress the 1 in the
$\xi({\mathcal{X}} \times\,\cdot\,) = \nu(\cdot)$
. We generally suppress the 1 in the
 $L^1$
metric and write
$L^1$
metric and write
 ${\mathcal{W}}_{d}(\mu, \nu) := {\mathcal{W}}_{d, 1}(\mu, \nu)$
.
${\mathcal{W}}_{d}(\mu, \nu) := {\mathcal{W}}_{d, 1}(\mu, \nu)$
.
The total variation distance denoted by
 ${\mathcal{W}}_{\text{TV}}(\cdot, \cdot)$
between probability measures can be seen as a special case of a Wasserstein distance when the metric is defined by
${\mathcal{W}}_{\text{TV}}(\cdot, \cdot)$
between probability measures can be seen as a special case of a Wasserstein distance when the metric is defined by
 $I_{D^\mathrm{c}}(\cdot, \cdot)$
with the off-diagonal set
$I_{D^\mathrm{c}}(\cdot, \cdot)$
with the off-diagonal set
 $D^\mathrm{c} = \{ x, y \in {\mathcal{X}} \times {\mathcal{X}} \colon x \not= y \}$
. If
$D^\mathrm{c} = \{ x, y \in {\mathcal{X}} \times {\mathcal{X}} \colon x \not= y \}$
. If
 $({\mathcal{X}}, d)$
is a complete separable metric space, then the standard bounded metric
$({\mathcal{X}}, d)$
is a complete separable metric space, then the standard bounded metric
 $d(\cdot, \cdot) \wedge 1$
defines a Wasserstein distance
$d(\cdot, \cdot) \wedge 1$
defines a Wasserstein distance
 ${\mathcal{W}}_{d \wedge 1}(\cdot, \cdot)$
. This Wasserstein distance metrizes the weak convergence of probability measures through the bounded Lipschitz metric [Reference Dudley13, Theorem 11.3.3] and is equivalent up to a constant to the bounded Lipschitz metric by Kantovorich–Rubinstein duality [Reference Villani40, Theorem 1.4].
${\mathcal{W}}_{d \wedge 1}(\cdot, \cdot)$
. This Wasserstein distance metrizes the weak convergence of probability measures through the bounded Lipschitz metric [Reference Dudley13, Theorem 11.3.3] and is equivalent up to a constant to the bounded Lipschitz metric by Kantovorich–Rubinstein duality [Reference Villani40, Theorem 1.4].
Traditional theory of adaptive MCMC considers an adaptive process
 $(\Gamma_t, X_t)_{t \ge 0}$
initialized at
$(\Gamma_t, X_t)_{t \ge 0}$
initialized at
 $\Gamma_0, X_0 = \gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
satisfying a (strong) diminishing adaptation condition
$\Gamma_0, X_0 = \gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
satisfying a (strong) diminishing adaptation condition
 \begin{equation} \lim_{t \to \infty} \sup_{x \in {\mathcal{X}}} {\mathcal{W}}_{\text{TV}}({\mathcal{P}}_{\Gamma_{t + 1}}(x, \cdot), {\mathcal{P}}_{\Gamma_{t}}(x, \cdot)) = 0\end{equation}
\begin{equation} \lim_{t \to \infty} \sup_{x \in {\mathcal{X}}} {\mathcal{W}}_{\text{TV}}({\mathcal{P}}_{\Gamma_{t + 1}}(x, \cdot), {\mathcal{P}}_{\Gamma_{t}}(x, \cdot)) = 0\end{equation}
in probability with the supremum assumed Borel measurable and a (strong) containment condition, which is to show that, for any
 $\varepsilon \in (0, 1)$
, the sequence
$\varepsilon \in (0, 1)$
, the sequence
 \begin{equation} M_{\varepsilon}(\Gamma_t,X_t) = \inf\big\{N\in{\mathbb{Z}}_+\colon{\mathcal{W}}_{\text{TV}}\big({\mathcal{P}}_{\Gamma_t}^n(X_t,\cdot),\pi\big) \le \varepsilon \text{ for all } n \ge N \big\}\end{equation}
\begin{equation} M_{\varepsilon}(\Gamma_t,X_t) = \inf\big\{N\in{\mathbb{Z}}_+\colon{\mathcal{W}}_{\text{TV}}\big({\mathcal{P}}_{\Gamma_t}^n(X_t,\cdot),\pi\big) \le \varepsilon \text{ for all } n \ge N \big\}\end{equation}
is bounded in probability, that is,
 $\lim_{N \to \infty} \sup_{t \ge 0} {\mathbb{P}}( M_{\varepsilon}(\Gamma_t, X_t) > N ) = 0$
. The (strong) diminishing adaptation restricts the adaptation plan for
$\lim_{N \to \infty} \sup_{t \ge 0} {\mathbb{P}}( M_{\varepsilon}(\Gamma_t, X_t) > N ) = 0$
. The (strong) diminishing adaptation restricts the adaptation plan for
 $(\Gamma_t)_t$
and (strong) containment is a uniform convergence requirement on the non-adapted Markov chain.
$(\Gamma_t)_t$
and (strong) containment is a uniform convergence requirement on the non-adapted Markov chain.
Under these two conditions, we have the guarantee [Reference Roberts and Rosenthal32] that for every fixed initialization
 $\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
and for every bounded Borel measurable function
$\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
and for every bounded Borel measurable function
 $\varphi \colon {\mathcal{X}} \to {\mathbb{R}}$
,
$\varphi \colon {\mathcal{X}} \to {\mathbb{R}}$
,
 \begin{equation*} \lim_{t \to \infty} {\mathcal{W}}_{\text{TV}}\big( {\mathcal{A}}^{(t)}( (\gamma, x), \cdot), \pi \big) = 0 \quad\text{and}\quad \frac{1}{t} \sum_{s = 1}^t \varphi(X_s) \to \int_{\mathcal{X}} \varphi \,{\mathrm{d}}\pi \ \text{in probability as $t \to \infty$}.\end{equation*}
\begin{equation*} \lim_{t \to \infty} {\mathcal{W}}_{\text{TV}}\big( {\mathcal{A}}^{(t)}( (\gamma, x), \cdot), \pi \big) = 0 \quad\text{and}\quad \frac{1}{t} \sum_{s = 1}^t \varphi(X_s) \to \int_{\mathcal{X}} \varphi \,{\mathrm{d}}\pi \ \text{in probability as $t \to \infty$}.\end{equation*}
Both of these guarantees have many practical applications in the reliability of Monte Carlo simulations in Bayesian statistics. General conditions for (strong) containment (3) to hold have also been developed [Reference Bai, Roberts and Rosenthal3, Reference Latuszynski and Rosenthal23].
The (strong) containment condition (3) is often established via simultaneous drift and minorization conditions [Reference Bai, Roberts and Rosenthal3, Reference Roberts and Rosenthal32]. This requires a drift function
 $V \colon {\mathcal{X}} \to [0, \infty)$
and identification of a small set
$V \colon {\mathcal{X}} \to [0, \infty)$
and identification of a small set
 $S = \{ x \in {\mathcal{X}} \colon V(x) \le R \}$
such that there are constants
$S = \{ x \in {\mathcal{X}} \colon V(x) \le R \}$
such that there are constants
 $\lambda, \alpha \in (0, 1)$
and
$\lambda, \alpha \in (0, 1)$
and
 $L \in (0, \infty)$
where
$L \in (0, \infty)$
where
 $R > 2 L / (1 - \lambda)$
is required and, for every
$R > 2 L / (1 - \lambda)$
is required and, for every
 $\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
, there is a Borel probability measure
$\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
, there is a Borel probability measure
 $\nu_\gamma$
on
$\nu_\gamma$
on
 ${\mathcal{X}}$
such that
${\mathcal{X}}$
such that
 \begin{equation} \inf_{y \in S} {\mathcal{P}}_{\gamma}(y, \cdot) \ge \alpha \nu_\gamma(\cdot) \quad\text{and}\quad ({\mathcal{P}}_\gamma V) (x) \le \lambda V(x) + L.\end{equation}
\begin{equation} \inf_{y \in S} {\mathcal{P}}_{\gamma}(y, \cdot) \ge \alpha \nu_\gamma(\cdot) \quad\text{and}\quad ({\mathcal{P}}_\gamma V) (x) \le \lambda V(x) + L.\end{equation}
These techniques yield (strong) containment (3) through a geometric rate
 $r \in (0, 1)$
and constant
$r \in (0, 1)$
and constant
 $M_0 > 0$
such that, for
$M_0 > 0$
such that, for
 $t, n \in {\mathbb{Z}}_+$
,
$t, n \in {\mathbb{Z}}_+$
,
 ${\mathcal{W}}_{\text{TV}}\big( {\mathcal{P}}_{\Gamma_t}^n(X_t, \cdot), \pi \big) \le M_0 r^n V(X_t)$
and
${\mathcal{W}}_{\text{TV}}\big( {\mathcal{P}}_{\Gamma_t}^n(X_t, \cdot), \pi \big) \le M_0 r^n V(X_t)$
and
 $( V(X_t) )_{t \ge 0}$
is bounded in probability [Reference Roberts and Rosenthal32, Theorem 18].
$( V(X_t) )_{t \ge 0}$
is bounded in probability [Reference Roberts and Rosenthal32, Theorem 18].
The identification of such a small set S and drift function V as in (4) often becomes problematic in large dimensions as probability measures often tend towards mutual singularity. Even in low dimensions, a small set may not exist as a non-adapted Markov kernel may fail to be irreducible, meaning that, for each
 $\gamma \in {\mathcal{Y}}$
, there is no Borel probability measure
$\gamma \in {\mathcal{Y}}$
, there is no Borel probability measure
 $\varphi_\gamma$
on
$\varphi_\gamma$
on
 ${\mathcal{X}}$
such that
${\mathcal{X}}$
such that
 $\varphi_\gamma(\cdot) > 0$
implies
$\varphi_\gamma(\cdot) > 0$
implies
 ${\mathcal{P}}_\gamma(x, \cdot) > 0$
for all
${\mathcal{P}}_\gamma(x, \cdot) > 0$
for all
 $x \in {\mathcal{X}}$
. In this case, it is not possible to find such a small set regardless of the dimension [Reference Meyn and Tweedie24, Theorem 5.2.2].
$x \in {\mathcal{X}}$
. In this case, it is not possible to find such a small set regardless of the dimension [Reference Meyn and Tweedie24, Theorem 5.2.2].
4. Motivating examples
The following running examples illustrate problematic points with analysis in total variation for adapting the tuning parameters of Markov chains compared to their alternative weak convergence properties. In particular, (strong) containment (3) may fail. Stark differences in the convergence characteristics may even appear when adapting a discrete Markov chain, as the following example illustrates.
Example 1. (Discrete autoregressive process.) Let
 $\gamma \in {\mathbb{Z}}_+$
with
$\gamma \in {\mathbb{Z}}_+$
with
 $\gamma \ge 2$
and
$\gamma \ge 2$
and
 $(\xi^{\gamma}_t)_{t \ge 0}$
be independent uniformly distributed discrete random variables on
$(\xi^{\gamma}_t)_{t \ge 0}$
be independent uniformly distributed discrete random variables on
 $\{ 0, 1/\gamma, 2/\gamma, \ldots, (\gamma - 1)/\gamma \}$
. With
$\{ 0, 1/\gamma, 2/\gamma, \ldots, (\gamma - 1)/\gamma \}$
. With
 $X_0 = x \in [0, 1)$
, define the autoregressive process for
$X_0 = x \in [0, 1)$
, define the autoregressive process for
 $t \in {\mathbb{Z}}_+$
by
$t \in {\mathbb{Z}}_+$
by
 $X^{\gamma}_{t} = ({1}/{\gamma}) X^{\gamma}_{t-1} + \xi^{\gamma}_{t}$
. For each fixed
$X^{\gamma}_{t} = ({1}/{\gamma}) X^{\gamma}_{t-1} + \xi^{\gamma}_{t}$
. For each fixed
 $\gamma \ge 2$
, this defines a Markov chain with Markov transition kernel denoted by
$\gamma \ge 2$
, this defines a Markov chain with Markov transition kernel denoted by
 ${\mathcal{P}}_\gamma$
. It can be shown that the invariant probability measure
${\mathcal{P}}_\gamma$
. It can be shown that the invariant probability measure
 $\pi \equiv \text{Unif}(0, 1)$
is a Lebesgue measure on [0, 1).
$\pi \equiv \text{Unif}(0, 1)$
is a Lebesgue measure on [0, 1).
For any adaptive process
 $(\Gamma_t, X_t)_{t \ge 0}$
using these Markov kernels
$(\Gamma_t, X_t)_{t \ge 0}$
using these Markov kernels
 $({\mathcal{P}}_\gamma)_{\gamma}$
, traditional convergence theory in total variation [Reference Roberts and Rosenthal32, Theorem 13] is inadequate. Indeed, it can be shown that
$({\mathcal{P}}_\gamma)_{\gamma}$
, traditional convergence theory in total variation [Reference Roberts and Rosenthal32, Theorem 13] is inadequate. Indeed, it can be shown that
 ${\mathcal{W}}_{\text{TV}}\big( {\mathcal{P}}^t_\gamma(x, \cdot), \text{Unif}(0, 1) \big) = 1$
and (strong) containment (3) fails under any adaptive strategy. On the other hand, weak convergence is exponentially fast. For
${\mathcal{W}}_{\text{TV}}\big( {\mathcal{P}}^t_\gamma(x, \cdot), \text{Unif}(0, 1) \big) = 1$
and (strong) containment (3) fails under any adaptive strategy. On the other hand, weak convergence is exponentially fast. For
 $t \in {\mathbb{Z}}_+$
and any fixed
$t \in {\mathbb{Z}}_+$
and any fixed
 $\gamma$
, starting from
$\gamma$
, starting from
 $X_0 = x \in [0, 1)$
and
$X_0 = x \in [0, 1)$
and
 $Y_0 = y \in [0, 1)$
, define
$Y_0 = y \in [0, 1)$
, define
 $X^{\gamma}_{t} = ({1}/{\gamma}) X^{\gamma}_{t-1} + \xi^{\gamma}_{t}$
and
$X^{\gamma}_{t} = ({1}/{\gamma}) X^{\gamma}_{t-1} + \xi^{\gamma}_{t}$
and
 $Y^{\gamma}_{t} = ({1}/{\gamma}) Y^{\gamma}_{t-1} + \xi^{\gamma}_{t}$
with shared discrete uniformly distributed random variable
$Y^{\gamma}_{t} = ({1}/{\gamma}) Y^{\gamma}_{t-1} + \xi^{\gamma}_{t}$
with shared discrete uniformly distributed random variable
 $\xi^{\gamma}_{t}$
. These random variables
$\xi^{\gamma}_{t}$
. These random variables
 $(X^{\gamma}_{t}, Y^{\gamma}_{t})$
define a coupling such that, for any
$(X^{\gamma}_{t}, Y^{\gamma}_{t})$
define a coupling such that, for any
 $x \in [0, 1)$
and
$x \in [0, 1)$
and
 $\gamma \ge 2$
,
$\gamma \ge 2$
,
 \begin{equation*} {\mathcal{W}}_{ |\cdot|}\big( {\mathcal{P}}^t_\gamma(x, \cdot), \text{Unif}(0, 1) \big) \le \int_{[0, 1)}{\mathbb{E}}\big[|X^{\gamma}_{t} - Y^{\gamma}_{t}|X_0 = x, Y_0 = y \big]\,{\mathrm{d}} y \le 2^{-t}. \end{equation*}
\begin{equation*} {\mathcal{W}}_{ |\cdot|}\big( {\mathcal{P}}^t_\gamma(x, \cdot), \text{Unif}(0, 1) \big) \le \int_{[0, 1)}{\mathbb{E}}\big[|X^{\gamma}_{t} - Y^{\gamma}_{t}|X_0 = x, Y_0 = y \big]\,{\mathrm{d}} y \le 2^{-t}. \end{equation*}
In particular, we will show later that under a suitable adaptation strategy, the adaptive process converges weakly using this Wasserstein distance.
The next example shows how problems appear in infinite dimensions. Although the example is somewhat abstract, poor scaling properties in infinite dimensions can also appear in practical high-dimensional scenarios in statistics.
Example 2. (Infinite-dimensional autoregressive process.) Consider a Hilbert space H separable with infinite dimension and inner product ![]() . Let
. Let
 ${\mathcal{N}}(0, C)$
be a Gaussian Borel probability measure on H with mean
${\mathcal{N}}(0, C)$
be a Gaussian Borel probability measure on H with mean
 $0 \in H$
and symmetric positive covariance operator
$0 \in H$
and symmetric positive covariance operator
 $C \colon H \to H$
such that
$C \colon H \to H$
such that
 ${\text{tr}}(C) = \sum_{k = 1}^{\infty} \langle C u_k, u_k \rangle < \infty$
, where
${\text{tr}}(C) = \sum_{k = 1}^{\infty} \langle C u_k, u_k \rangle < \infty$
, where
 $(u_k)_k$
is any orthonormal basis of H. We will further assume that C is non-degenerate so that, for every
$(u_k)_k$
is any orthonormal basis of H. We will further assume that C is non-degenerate so that, for every
 $x, y \in H$
,
$x, y \in H$
,
 $C x \equiv 0 \in H$
implies
$C x \equiv 0 \in H$
implies
 $x \equiv 0 \in H$
. For some
$x \equiv 0 \in H$
. For some
 $\gamma^* < 1$
, consider the family of Markov transition kernels
$\gamma^* < 1$
, consider the family of Markov transition kernels
 $({\mathcal{P}}_{\gamma})_{\gamma\in (0, \gamma^*)}$
for the autoregressive process
$({\mathcal{P}}_{\gamma})_{\gamma\in (0, \gamma^*)}$
for the autoregressive process
 $(X^{\gamma}_t)_{t \ge 0}$
where the
$(X^{\gamma}_t)_{t \ge 0}$
where the
 $(\xi_{t})_t$
are independent with
$(\xi_{t})_t$
are independent with
 $\xi_{t} \sim {\mathcal{N}}(0, C)$
and
$\xi_{t} \sim {\mathcal{N}}(0, C)$
and
 \begin{equation*} X^{\gamma}_t = \gamma X^{\gamma}_{t-1} + \sqrt{1 - \gamma^2} \xi_{t}, \quad t \in {\mathbb{Z}}_+. \end{equation*}
\begin{equation*} X^{\gamma}_t = \gamma X^{\gamma}_{t-1} + \sqrt{1 - \gamma^2} \xi_{t}, \quad t \in {\mathbb{Z}}_+. \end{equation*}
For any fixed
 $\gamma \in (0, \gamma^*)$
, if
$\gamma \in (0, \gamma^*)$
, if
 $X^{\gamma}_{t-1} \sim {\mathcal{N}}(0, C)$
, then
$X^{\gamma}_{t-1} \sim {\mathcal{N}}(0, C)$
, then
 $X^{\gamma}_{t} \sim {\mathcal{N}}(0, C)$
and the invariant probability measure is
$X^{\gamma}_{t} \sim {\mathcal{N}}(0, C)$
and the invariant probability measure is
 ${\mathcal{N}}(0, C)$
.
${\mathcal{N}}(0, C)$
.
For an adaptive autoregressive process
 $(\Gamma_t, X_t)_{t \ge 0}$
defined by (2), convergence theory in total variation [Reference Roberts and Rosenthal32, Theorem 13] fails to provide a convergence guarantee. For each
$(\Gamma_t, X_t)_{t \ge 0}$
defined by (2), convergence theory in total variation [Reference Roberts and Rosenthal32, Theorem 13] fails to provide a convergence guarantee. For each
 $x \in H$
and
$x \in H$
and
 $\gamma \in (0, 1)$
,
$\gamma \in (0, 1)$
,
 ${\mathcal{W}}_{\text{TV}}( {\mathcal{P}}_{\gamma}(x, \cdot), {\mathcal{N}}(0, C) ) = 1$
due to the covariances differing and the Feldman–Hajeck theorem [Reference Da Prato and Zabczyk12, Theorem 2.25]. It follows that (strong) containment (3) cannot hold under any adaptation strategy (2). However, convergence in
${\mathcal{W}}_{\text{TV}}( {\mathcal{P}}_{\gamma}(x, \cdot), {\mathcal{N}}(0, C) ) = 1$
due to the covariances differing and the Feldman–Hajeck theorem [Reference Da Prato and Zabczyk12, Theorem 2.25]. It follows that (strong) containment (3) cannot hold under any adaptation strategy (2). However, convergence in
 $L^2$
-Wasserstein distances is exponentially fast. Initialized with
$L^2$
-Wasserstein distances is exponentially fast. Initialized with
 $X_0 = x \in H$
and
$X_0 = x \in H$
and
 $Y_0 = y \in H$
, define
$Y_0 = y \in H$
, define
 $X^{\gamma}_t = \gamma X^{\gamma}_{t-1} + \sqrt{1 - \gamma^2} \xi_{t}$
and
$X^{\gamma}_t = \gamma X^{\gamma}_{t-1} + \sqrt{1 - \gamma^2} \xi_{t}$
and
 $Y^{\gamma}_t = \gamma Y^{\gamma}_{t-1} + \sqrt{1 - \gamma^2} \xi_{t}$
using the common random variable
$Y^{\gamma}_t = \gamma Y^{\gamma}_{t-1} + \sqrt{1 - \gamma^2} \xi_{t}$
using the common random variable
 $\xi_t \sim N(0, C)$
. This defines a coupling such that the
$\xi_t \sim N(0, C)$
. This defines a coupling such that the
 $L^2$
-Wasserstein distance is upper bounded with
$L^2$
-Wasserstein distance is upper bounded with
5. Main results
This section extends previous results on convergence in total variation of adaptive MCMC processes to weak convergence and general Wasserstein distances [Reference Roberts and Rosenthal32, Theorems 5 and 13]. Let
 $\rho(\cdot, \cdot)$
be a lower semicontinuous metric on
$\rho(\cdot, \cdot)$
be a lower semicontinuous metric on
 ${\mathcal{X}}$
, so
${\mathcal{X}}$
, so
 ${\mathcal{W}}_{\rho \wedge 1}(\cdot, \cdot)$
defines a Wasserstein distance. If
${\mathcal{W}}_{\rho \wedge 1}(\cdot, \cdot)$
defines a Wasserstein distance. If
 $(X, \rho)$
, is a complete separable metric space, then
$(X, \rho)$
, is a complete separable metric space, then
 ${\mathcal{W}}_{\rho \wedge 1}(\cdot, \cdot)$
metrizes weak convergence [Reference Dudley13, Theorem 11.3.3]. A motivation for this convergence is Strassen’s theorem, which gives approximations to arbitrary closed sets [Reference Villani40, Corollary 1.28]. However,
${\mathcal{W}}_{\rho \wedge 1}(\cdot, \cdot)$
metrizes weak convergence [Reference Dudley13, Theorem 11.3.3]. A motivation for this convergence is Strassen’s theorem, which gives approximations to arbitrary closed sets [Reference Villani40, Corollary 1.28]. However,
 $\rho(\cdot, \cdot)$
need only satisfy the axioms of a metric and
$\rho(\cdot, \cdot)$
need only satisfy the axioms of a metric and
 ${\mathcal{W}}_{\rho \wedge 1}(\cdot, \cdot)$
is defined more generally.
${\mathcal{W}}_{\rho \wedge 1}(\cdot, \cdot)$
is defined more generally.
The first simple situation is to introduce a stopping time T such that the adaptation terminates and
 $\Gamma_T = \Gamma_t$
for all
$\Gamma_T = \Gamma_t$
for all
 $t \ge T$
. For any
$t \ge T$
. For any
 $T \ge 1$
determining a stopping point of adaptation, we can construct a finite adaptation process
$T \ge 1$
determining a stopping point of adaptation, we can construct a finite adaptation process
 $(Y_t, \Gamma_t)_{t = 0}^{\infty}$
adapted to the filtration
$(Y_t, \Gamma_t)_{t = 0}^{\infty}$
adapted to the filtration
 ${\mathcal{H}}'_t = {\mathcal{B}}(Y_s, \Gamma_s \colon 0 \le s \le t)$
initialized at
${\mathcal{H}}'_t = {\mathcal{B}}(Y_s, \Gamma_s \colon 0 \le s \le t)$
initialized at
 $\Gamma_0, Y_0, = \gamma, x$
such that
$\Gamma_0, Y_0, = \gamma, x$
such that
 $Y_t = X_t$
for
$Y_t = X_t$
for
 $0 \le t \le T$
and is a Markov chain further out, that is,
$0 \le t \le T$
and is a Markov chain further out, that is,
 $Y_{t + 1} \mid {\mathcal{H}}'_{t}, Y_{t} = y \sim {\mathcal{P}}_{\Gamma_{T}}(y, \cdot)$
for
$Y_{t + 1} \mid {\mathcal{H}}'_{t}, Y_{t} = y \sim {\mathcal{P}}_{\Gamma_{T}}(y, \cdot)$
for
 $t \ge T$
. Denote the marginal distribution as
$t \ge T$
. Denote the marginal distribution as
 $B^{(T, t - T)}((\gamma, x), \cdot) = {\mathbb{P}}(Y_t \in \cdot \mid \Gamma_0, Y_0 = \gamma, x)$
.
$B^{(T, t - T)}((\gamma, x), \cdot) = {\mathbb{P}}(Y_t \in \cdot \mid \Gamma_0, Y_0 = \gamma, x)$
.
Proposition 1. Let
 $\rho(\cdot, \cdot)$
be a lower semicontinuous metric on
$\rho(\cdot, \cdot)$
be a lower semicontinuous metric on
 ${\mathcal{X}}$
and let
${\mathcal{X}}$
and let
 $(\Gamma_t, X_t)_{t \ge 0}$
be a finite adaptive process with initialization probability measure
$(\Gamma_t, X_t)_{t \ge 0}$
be a finite adaptive process with initialization probability measure
 $\mu$
as in (1). If, for every initialization
$\mu$
as in (1). If, for every initialization
 $x \in {\mathcal{X}}$
and every
$x \in {\mathcal{X}}$
and every
 $\gamma \in {\mathcal{Y}}$
,
$\gamma \in {\mathcal{Y}}$
,
 $\lim_{t \to \infty} {\mathcal{W}}_{\rho \wedge 1}\big({\mathcal{P}}_{\gamma}^t(x, \cdot), \pi\big) = 0$
, then
$\lim_{t \to \infty} {\mathcal{W}}_{\rho \wedge 1}\big({\mathcal{P}}_{\gamma}^t(x, \cdot), \pi\big) = 0$
, then
 $\lim_{t \to \infty} {\mathcal{W}}_{\rho \wedge 1}\big(\mu B^{(T, t - T)}, \pi\big) = 0$
.
$\lim_{t \to \infty} {\mathcal{W}}_{\rho \wedge 1}\big(\mu B^{(T, t - T)}, \pi\big) = 0$
.
Proof. Since the optimal coupling exists [Reference Villani41, Theorem 4.1] and is Borel measurable [Reference Villani41, Corollary 5.22],
 ${\mathcal{W}}_{\rho\wedge 1}\big(\mu B^{(T, t - T)},\pi\big) \le {\mathbb{E}}\big[{\mathcal{W}}_{\rho\wedge 1}({\mathcal{P}}_{\Gamma_{T}}^{t - T}(X_T,\cdot),\pi)\big]$
. The conclusion follows by dominated convergence.
${\mathcal{W}}_{\rho\wedge 1}\big(\mu B^{(T, t - T)},\pi\big) \le {\mathbb{E}}\big[{\mathcal{W}}_{\rho\wedge 1}({\mathcal{P}}_{\Gamma_{T}}^{t - T}(X_T,\cdot),\pi)\big]$
. The conclusion follows by dominated convergence.
While finite adaptation may be a safe strategy, infinite adaptation where the process continually learns tuning parameters is often of greater interest in applications [Reference Roberts and Rosenthal32]. Consider now the following two weakened assumptions, both generalized from [Reference Roberts and Rosenthal32]. The first assumption is a weak restriction on the adaptation and the second is a weak containment condition on convergence of the non-adapted Markov chain.
Assumption 1. Let
 $(\Gamma_t, X_t)_{t \ge 0}$
be an adaptive process with initialization probability measure
$(\Gamma_t, X_t)_{t \ge 0}$
be an adaptive process with initialization probability measure
 $\mu$
as in (1). Let
$\mu$
as in (1). Let
 $\rho(\cdot, \cdot)$
and
$\rho(\cdot, \cdot)$
and
 $\tilde{\rho}(\cdot, \cdot)$
be lower semicontinuous metrics on
$\tilde{\rho}(\cdot, \cdot)$
be lower semicontinuous metrics on
 ${\mathcal{X}}$
such that
${\mathcal{X}}$
such that
 $\rho(\cdot,\cdot)\wedge 1 \le \tilde{\rho}(\cdot,\cdot)\wedge 1$
. We make the following assumptions.
$\rho(\cdot,\cdot)\wedge 1 \le \tilde{\rho}(\cdot,\cdot)\wedge 1$
. We make the following assumptions.
-
(i) (Weak containment.) Suppose, for any
 $\varepsilon \in (0, 1)$
, the sequence is bounded in probability, that is,
\[ M_{\varepsilon,\rho}(\Gamma_t,X_t) := \inf\big\{N \ge 0 \colon {\mathcal{W}}_{\rho\wedge 1}\big[{\mathcal{P}}_{\Gamma_t}^n(X_t,\cdot),\pi\big] \le \varepsilon \text{ for all $n \ge N$} \big\} \]
(5)
\begin{equation} \lim_{T \to \infty} \sup_{t \ge 0}{\mathbb{P}}(M_{\varepsilon, \rho}(\Gamma_t, X_t) \ge T) = 0. \end{equation}
$\varepsilon \in (0, 1)$
, the sequence is bounded in probability, that is,
\[ M_{\varepsilon,\rho}(\Gamma_t,X_t) := \inf\big\{N \ge 0 \colon {\mathcal{W}}_{\rho\wedge 1}\big[{\mathcal{P}}_{\Gamma_t}^n(X_t,\cdot),\pi\big] \le \varepsilon \text{ for all $n \ge N$} \big\} \]
(5)
\begin{equation} \lim_{T \to \infty} \sup_{t \ge 0}{\mathbb{P}}(M_{\varepsilon, \rho}(\Gamma_t, X_t) \ge T) = 0. \end{equation}
-
(ii) (Weak diminishing adaptation.) Suppose there is a conditional coupling
$x,y,\gamma,\gamma' \mapsto \xi_{x,y,\gamma',\gamma} \in {\mathcal{C}}[{\mathcal{P}}_{\gamma'}(x,\cdot),{\mathcal{P}}_{\gamma}(y,\cdot)]$
and a non-negative real-valued sequence
$(\delta_k)_{k \ge 0}$
with
$\lim_{k \to \infty} \delta_k = 0$
such that (6)is
\begin{equation} D_{\tilde{\rho}}(\Gamma_{t + 1}, \Gamma_t) := \lim_{k\to\infty}\sup_{\{x,y\in{\mathcal{X}}\times{\mathcal{X}}:\tilde\rho(x,y)\le\delta_k\}} \int_{{\mathcal{X}}\times{\mathcal{X}}}\tilde\rho(x',y') \wedge 1\,\xi_{x,y,\Gamma_{t+1},\Gamma_{t}}({\mathrm{d}} x',{\mathrm{d}} y') \end{equation}
${\mathcal{H}}_{t + 1}$
-measurable and
$D_{\tilde{\rho}}(\Gamma_{t+1},\Gamma_t) \to 0$
in probability as
$t \to \infty$
.










There are existing results to bound the convergence rate of non-adapted Markov chains that can be modified to satisfy the weak containment condition using drift and coupling techniques [Reference Durmus and Moulines15, Reference Hairer, Mattingly and Scheutzow20]. Note that
 $\rho(\cdot, \cdot) \wedge 1 \le I_{ \{ x \not= y \} }(\cdot, \cdot)$
and (strong) diminishing adaptation [Reference Roberts and Rosenthal32] implies weak diminishing adaptation (6). We then immediately have Proposition 2. In certain cases it may be simpler to show (strong) diminishing adaptation where only weak containment (5) holds; the implications of Proposition 2 are visualized in Figure 1.
$\rho(\cdot, \cdot) \wedge 1 \le I_{ \{ x \not= y \} }(\cdot, \cdot)$
and (strong) diminishing adaptation [Reference Roberts and Rosenthal32] implies weak diminishing adaptation (6). We then immediately have Proposition 2. In certain cases it may be simpler to show (strong) diminishing adaptation where only weak containment (5) holds; the implications of Proposition 2 are visualized in Figure 1.

Figure 1. Illustration of comparison of strong/weak containment and strong/weak diminishing adaptation conditions required to obtain weak convergence of adaptive MCMC.
Proposition 2. Let
 $(\Gamma_t, X_t)_{t \ge 0}$
be an adaptive process with initialization probability measure
$(\Gamma_t, X_t)_{t \ge 0}$
be an adaptive process with initialization probability measure
 $\mu$
as in (1). If the process satisfies (strong) containment (3), then weak containment (5) is satisfied. If the process satisfies (strong) diminishing adaptation (2), then weak diminishing adaptation (6) is satisfied.
$\mu$
as in (1). If the process satisfies (strong) containment (3), then weak containment (5) is satisfied. If the process satisfies (strong) diminishing adaptation (2), then weak diminishing adaptation (6) is satisfied.
The following result shows weak convergence of the adaptive MCMC process.
Theorem 1. Let
 $(\Gamma_t, X_t)_{t \ge 0}$
be an adaptive process with initialization probability measure
$(\Gamma_t, X_t)_{t \ge 0}$
be an adaptive process with initialization probability measure
 $\mu$
as in (1). If weak containment (5) holds and weak diminishing adaptation (6) holds, then
$\mu$
as in (1). If weak containment (5) holds and weak diminishing adaptation (6) holds, then
 $\lim_{t\to\infty} {\mathcal{W}}_{\rho \wedge 1}( \mu{\mathcal{A}}^{(t)}, \pi ) = 0$
.
$\lim_{t\to\infty} {\mathcal{W}}_{\rho \wedge 1}( \mu{\mathcal{A}}^{(t)}, \pi ) = 0$
.
We will prove Theorem 1 through the subsequent lemmas by comparing the adaptive process to an adaptive process where adaptation stops at a finite time. The first result shows that weak containment ensures the convergence of the finite adaptation process to the target measure uniformly in the finite adaptation stopping time.
Lemma 1. If weak containment holds (5), then, for any
 $\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
,
$\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
,
 \[ \lim_{n\to\infty}\sup_{T \ge n}{\mathcal{W}}_{\rho \wedge 1}\big[B^{(T, n - T)}((\gamma, x),\cdot),\pi\big] = 0. \]
\[ \lim_{n\to\infty}\sup_{T \ge n}{\mathcal{W}}_{\rho \wedge 1}\big[B^{(T, n - T)}((\gamma, x),\cdot),\pi\big] = 0. \]
Proof. Fix
 $\varepsilon \in(0, 1)$
. For any
$\varepsilon \in(0, 1)$
. For any
 $\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
and each
$\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
and each
 $n \in {\mathbb{Z}}_+$
, the infimum is attained at an optimal coupling
$n \in {\mathbb{Z}}_+$
, the infimum is attained at an optimal coupling
 $\xi_{x,\gamma}^{(n)} \in {\mathcal{C}}[{\mathcal{P}}_{\gamma}^n(x,\cdot),\pi]$
[Reference Villani41, Theorem 4.1] so that
$\xi_{x,\gamma}^{(n)} \in {\mathcal{C}}[{\mathcal{P}}_{\gamma}^n(x,\cdot),\pi]$
[Reference Villani41, Theorem 4.1] so that
 \begin{equation*} {\mathcal{W}}_{\rho \wedge 1}\big[{\mathcal{P}}_{\gamma}^n(x,\cdot),\pi\big] = \int_{{\mathcal{X}}^2}\rho(x',y') \wedge 1\,\xi^{(n)}_{\gamma,x}({\mathrm{d}} x',{\mathrm{d}} y'). \end{equation*}
\begin{equation*} {\mathcal{W}}_{\rho \wedge 1}\big[{\mathcal{P}}_{\gamma}^n(x,\cdot),\pi\big] = \int_{{\mathcal{X}}^2}\rho(x',y') \wedge 1\,\xi^{(n)}_{\gamma,x}({\mathrm{d}} x',{\mathrm{d}} y'). \end{equation*}
The coupling is Borel measurable due to
 $\rho(\cdot, \cdot) \wedge 1$
being lower semicontinuous, and can be approximated by a non-decreasing sequence of bounded Lipschitz functions so we can choose a measurable selection [Reference Villani41, Corollary 5.22] such that the limit is Borel measurable using the approximation techniques in [Reference Villani40, Theorem 1.3]. Define the set
$\rho(\cdot, \cdot) \wedge 1$
being lower semicontinuous, and can be approximated by a non-decreasing sequence of bounded Lipschitz functions so we can choose a measurable selection [Reference Villani41, Corollary 5.22] such that the limit is Borel measurable using the approximation techniques in [Reference Villani40, Theorem 1.3]. Define the set
 $A_{\varepsilon} = \{\gamma,x \in {\mathcal{Y}} \times {\mathcal{X}} \colon M_{\varepsilon,\rho}(\gamma, x) \le N \}$
. For all
$A_{\varepsilon} = \{\gamma,x \in {\mathcal{Y}} \times {\mathcal{X}} \colon M_{\varepsilon,\rho}(\gamma, x) \le N \}$
. For all
 $\gamma,x \in A_{\varepsilon}$
and for all
$\gamma,x \in A_{\varepsilon}$
and for all
 $n \ge N$
,
$n \ge N$
,
 \begin{equation} {\mathcal{W}}_{\rho \wedge 1}\big[{\mathcal{P}}_{\gamma}^n(x, \cdot), \pi \big] \le \varepsilon. \end{equation}
\begin{equation} {\mathcal{W}}_{\rho \wedge 1}\big[{\mathcal{P}}_{\gamma}^n(x, \cdot), \pi \big] \le \varepsilon. \end{equation}
Let
 $\nu_{\gamma, x}^{(T)}$
denote the probability measure for
$\nu_{\gamma, x}^{(T)}$
denote the probability measure for
 $(X_{T},\Gamma_{T})$
given
$(X_{T},\Gamma_{T})$
given
 $\Gamma_0, X_0 = \gamma, x$
. Then
$\Gamma_0, X_0 = \gamma, x$
. Then
 \[ \hat{\xi}^{(T + n)}_{\gamma, x}({\mathrm{d}} x_{T + n},{\mathrm{d}} y) = \int_{{\mathcal{Y}}\times{\mathcal{X}}}\xi_{\gamma_{T}, y_{T}}^{(n)}({\mathrm{d}} x',{\mathrm{d}} y')\nu^{(T)}_{\gamma,x}(\gamma_{T},y_{T}) \]
\[ \hat{\xi}^{(T + n)}_{\gamma, x}({\mathrm{d}} x_{T + n},{\mathrm{d}} y) = \int_{{\mathcal{Y}}\times{\mathcal{X}}}\xi_{\gamma_{T}, y_{T}}^{(n)}({\mathrm{d}} x',{\mathrm{d}} y')\nu^{(T)}_{\gamma,x}(\gamma_{T},y_{T}) \]
defines a coupling for the finite adaptation process
 $Y_{T + n} \sim B^{(T, n)}((\gamma, x), \cdot)$
and
$Y_{T + n} \sim B^{(T, n)}((\gamma, x), \cdot)$
and
 $Y \sim \pi$
[Reference Villani41, Theorem 4.8]. By the weak containment assumption (5), there is an N depending on
$Y \sim \pi$
[Reference Villani41, Theorem 4.8]. By the weak containment assumption (5), there is an N depending on
 $\varepsilon$
such that, uniformly in
$\varepsilon$
such that, uniformly in
 $T \ge 0$
,
$T \ge 0$
,
 $\nu^{(T)}_{\gamma, x}(A_{\varepsilon}^\mathrm{c}) = {\mathbb{P}}(M_{\varepsilon,\rho}(\Gamma_T,X_T) > N) \le \varepsilon$
. Using (7), uniformly in
$\nu^{(T)}_{\gamma, x}(A_{\varepsilon}^\mathrm{c}) = {\mathbb{P}}(M_{\varepsilon,\rho}(\Gamma_T,X_T) > N) \le \varepsilon$
. Using (7), uniformly in
 $T \ge n$
,
$T \ge n$
,
 \begin{align*} {\mathcal{W}}_{\rho \wedge 1}\big[ B^{(T, n - T)}( (\gamma, x), \cdot), \pi \big] & \le \int_{{\mathcal{X}}^2}\rho(x', y') \wedge 1\,\hat\xi_{\gamma, x}^{(T + n)}({\mathrm{d}} x',{\mathrm{d}} y') \\ & \le \int_{{\mathcal{X}}^2}\int_{A_\varepsilon}\rho(y_{T + n}, y) \wedge 1\,\xi_{\gamma_{T}, y_{T}}^{(n)}({\mathrm{d}} x',{\mathrm{d}} y') \nu^{(T)}_{\gamma, x}(\gamma_{T}, y_{T}) \\ & \quad + \sup_{T' \ge 0} \nu^{(T')}_{\gamma, x}(A_{\varepsilon}^\mathrm{c}) \le 2\varepsilon. \end{align*}
\begin{align*} {\mathcal{W}}_{\rho \wedge 1}\big[ B^{(T, n - T)}( (\gamma, x), \cdot), \pi \big] & \le \int_{{\mathcal{X}}^2}\rho(x', y') \wedge 1\,\hat\xi_{\gamma, x}^{(T + n)}({\mathrm{d}} x',{\mathrm{d}} y') \\ & \le \int_{{\mathcal{X}}^2}\int_{A_\varepsilon}\rho(y_{T + n}, y) \wedge 1\,\xi_{\gamma_{T}, y_{T}}^{(n)}({\mathrm{d}} x',{\mathrm{d}} y') \nu^{(T)}_{\gamma, x}(\gamma_{T}, y_{T}) \\ & \quad + \sup_{T' \ge 0} \nu^{(T')}_{\gamma, x}(A_{\varepsilon}^\mathrm{c}) \le 2\varepsilon. \end{align*}
The weak diminishing adaptation condition will ensure our next goal, which is to have the adaptive MCMC process converge to the finite adaptation process.
Lemma 2. If weak diminishing adaptation (6) holds, then, for any
 $\gamma,x \in {\mathcal{Y}}\times{\mathcal{X}}$
and any
$\gamma,x \in {\mathcal{Y}}\times{\mathcal{X}}$
and any
 $N \ge 0$
,
$N \ge 0$
,
 $\lim_{T\to\infty}{\mathcal{W}}_{\tilde{\rho}\wedge 1}\big({\mathcal{A}}^{(T+N)}((\gamma,x),\cdot), B^{(T,N)}((\gamma,x),\cdot)\big) = 0$
.
$\lim_{T\to\infty}{\mathcal{W}}_{\tilde{\rho}\wedge 1}\big({\mathcal{A}}^{(T+N)}((\gamma,x),\cdot), B^{(T,N)}((\gamma,x),\cdot)\big) = 0$
.
Proof. It will suffice to assume that
 $\tilde\rho = \rho$
and the optimal coupling in the weak diminishing adaptation assumption (6). Fix
$\tilde\rho = \rho$
and the optimal coupling in the weak diminishing adaptation assumption (6). Fix
 $N \ge 1$
and
$N \ge 1$
and
 $\varepsilon \in(0, 1)$
. For each
$\varepsilon \in(0, 1)$
. For each
 $\gamma,\gamma'$
and each x, y, there exists a Borel measurable optimal coupling
$\gamma,\gamma'$
and each x, y, there exists a Borel measurable optimal coupling
 $\xi_{x, y, \gamma', \gamma}^*$
such that
$\xi_{x, y, \gamma', \gamma}^*$
such that
 \[ {\mathcal{W}}_{\rho \wedge 1}[{\mathcal{P}}_{\gamma'}(x, \cdot), {\mathcal{P}}_{\gamma}(y, \cdot)] = \int_{{\mathcal{X}}^2}\rho(x',y') \wedge 1\,\xi_{x,y,\gamma',\gamma}^*({\mathrm{d}} x',{\mathrm{d}} y'). \]
\[ {\mathcal{W}}_{\rho \wedge 1}[{\mathcal{P}}_{\gamma'}(x, \cdot), {\mathcal{P}}_{\gamma}(y, \cdot)] = \int_{{\mathcal{X}}^2}\rho(x',y') \wedge 1\,\xi_{x,y,\gamma',\gamma}^*({\mathrm{d}} x',{\mathrm{d}} y'). \]
Using these conditional couplings, we define a joint probability measure
 $\zeta_{\gamma_0, x_0}$
by
$\zeta_{\gamma_0, x_0}$
by
 \begin{align*} & \zeta_{\gamma_0, x_0}({\mathrm{d}} x_{1},{\mathrm{d}}\gamma_1,{\mathrm{d}} y_{1},\ldots,{\mathrm{d}} x_{T+N},{\mathrm{d}}\gamma_{T+N},{\mathrm{d}} y_{T+N}) \\ & \qquad = \prod_{s=1}^{T}{\mathcal{P}}_{\gamma_s}(x_{s-1},{\mathrm{d}} x_s){\mathcal{Q}}_{s}(h_{s-1},{\mathrm{d}}\gamma_s) \delta_{x_1,\ldots,x_s}({\mathrm{d}} y_1,\ldots,{\mathrm{d}} y_{s}) \\ & \qquad\quad \times \prod_{s=T+1}^{T+N}\xi_{x_{s-1},y_{s-1},\gamma_s,\gamma_T}^*({\mathrm{d}} x_{s},{\mathrm{d}} y_{s}){\mathcal{Q}}_{s}(h_{s-1},{\mathrm{d}}\gamma_s), \end{align*}
\begin{align*} & \zeta_{\gamma_0, x_0}({\mathrm{d}} x_{1},{\mathrm{d}}\gamma_1,{\mathrm{d}} y_{1},\ldots,{\mathrm{d}} x_{T+N},{\mathrm{d}}\gamma_{T+N},{\mathrm{d}} y_{T+N}) \\ & \qquad = \prod_{s=1}^{T}{\mathcal{P}}_{\gamma_s}(x_{s-1},{\mathrm{d}} x_s){\mathcal{Q}}_{s}(h_{s-1},{\mathrm{d}}\gamma_s) \delta_{x_1,\ldots,x_s}({\mathrm{d}} y_1,\ldots,{\mathrm{d}} y_{s}) \\ & \qquad\quad \times \prod_{s=T+1}^{T+N}\xi_{x_{s-1},y_{s-1},\gamma_s,\gamma_T}^*({\mathrm{d}} x_{s},{\mathrm{d}} y_{s}){\mathcal{Q}}_{s}(h_{s-1},{\mathrm{d}}\gamma_s), \end{align*}
where, for
 $0 \le s \le t$
, the history
$0 \le s \le t$
, the history
 $h_s = (\gamma_0, x_0, \ldots, \gamma_s, x_s)$
. The marginal is a coupling
$h_s = (\gamma_0, x_0, \ldots, \gamma_s, x_s)$
. The marginal is a coupling
 $\zeta_{\gamma_0, x_0}({\mathrm{d}} x_{t}, {\mathrm{d}} y_{t})$
for the adaptive process
$\zeta_{\gamma_0, x_0}({\mathrm{d}} x_{t}, {\mathrm{d}} y_{t})$
for the adaptive process
 $X_t\mid\Gamma_0,X_{0} = \gamma,x$
and the finite adaptation process
$X_t\mid\Gamma_0,X_{0} = \gamma,x$
and the finite adaptation process
 $Y_t \mid \Gamma_0,Y_{0} = \gamma,x$
initialized so that they are identical up to time T and use conditional couplings thereafter.
$Y_t \mid \Gamma_0,Y_{0} = \gamma,x$
initialized so that they are identical up to time T and use conditional couplings thereafter.
For
 $\gamma',\gamma \in {\mathcal{Y}}$
and
$\gamma',\gamma \in {\mathcal{Y}}$
and
 $\delta \in (0,1)$
, define
$\delta \in (0,1)$
, define
 $D_{\rho,\delta}(\gamma',\gamma) = \sup_{\{x,y:\rho(x,y)\le\delta\}}{\mathcal{W}}_{\rho\wedge1}({\mathcal{P}}_{\gamma'}(x,\cdot),{\mathcal{P}}_{\gamma}(y,\cdot))$
. For any
$D_{\rho,\delta}(\gamma',\gamma) = \sup_{\{x,y:\rho(x,y)\le\delta\}}{\mathcal{W}}_{\rho\wedge1}({\mathcal{P}}_{\gamma'}(x,\cdot),{\mathcal{P}}_{\gamma}(y,\cdot))$
. For any
 $\varepsilon', \delta' \in (0, 1)$
and
$\varepsilon', \delta' \in (0, 1)$
and
 $k \in {\mathbb{Z}}_+$
, define the set
$k \in {\mathbb{Z}}_+$
, define the set
 \[ E^{(T,N)}_{\varepsilon',\delta'} = \{\gamma_{T+1},\ldots,\gamma_{T+N}\colon D_{\rho,\delta'}(\gamma_{t+1},\gamma_{t}) \le \varepsilon'/N^2, T+1 \le t \le T+N-1\}. \]
\[ E^{(T,N)}_{\varepsilon',\delta'} = \{\gamma_{T+1},\ldots,\gamma_{T+N}\colon D_{\rho,\delta'}(\gamma_{t+1},\gamma_{t}) \le \varepsilon'/N^2, T+1 \le t \le T+N-1\}. \]
Starting with
 $\delta_N = r \in (0, 1)$
, for each
$\delta_N = r \in (0, 1)$
, for each
 $1 \le k \le N$
, given
$1 \le k \le N$
, given
 $\delta_k \in (0, 1)$
, by weak diminishing adaptation (6) we can choose T large enough depending on
$\delta_k \in (0, 1)$
, by weak diminishing adaptation (6) we can choose T large enough depending on
 $\varepsilon, N, \delta_k$
and
$\varepsilon, N, \delta_k$
and
 $\delta_{k - 1}$
sufficiently small such that, for all
$\delta_{k - 1}$
sufficiently small such that, for all
 $t \ge T$
,
$t \ge T$
,
 $D_{\rho,\delta}(\Gamma_{t+1},\Gamma_t)$
is
$D_{\rho,\delta}(\Gamma_{t+1},\Gamma_t)$
is
 ${\mathcal{H}}_{t + 1}$
-measurable and
${\mathcal{H}}_{t + 1}$
-measurable and
 \[ {\mathbb{P}}(D_{\rho, \delta_{k - 1}}(\Gamma_{t + 1}, \Gamma_{t}) > \delta_{k}\varepsilon/N^2) \le \varepsilon/N^2. \]
\[ {\mathbb{P}}(D_{\rho, \delta_{k - 1}}(\Gamma_{t + 1}, \Gamma_{t}) > \delta_{k}\varepsilon/N^2) \le \varepsilon/N^2. \]
This constructs
 $\delta_0, \ldots, \delta_N = r$
such that, using a union probability bound, we can choose T sufficiently large depending on
$\delta_0, \ldots, \delta_N = r$
such that, using a union probability bound, we can choose T sufficiently large depending on
 $\varepsilon, N, \delta_1, \ldots, \delta_N$
that, for each
$\varepsilon, N, \delta_1, \ldots, \delta_N$
that, for each
 $1 \le k \le N$
, we have
$1 \le k \le N$
, we have
 ${\mathbb{P}}\big(E^{(T, N)}_{\varepsilon \delta_k, \delta_{k - 1}} \big) \ge 1 - \varepsilon/N$
. Define
${\mathbb{P}}\big(E^{(T, N)}_{\varepsilon \delta_k, \delta_{k - 1}} \big) \ge 1 - \varepsilon/N$
. Define
 $E = \bigcap_{k = 1}^N E^{(T, N)}_{\delta_k \varepsilon, \delta_{k - 1}}$
; a union probability bound then implies that
$E = \bigcap_{k = 1}^N E^{(T, N)}_{\delta_k \varepsilon, \delta_{k - 1}}$
; a union probability bound then implies that
 \[ {\mathbb{P}}(E) = {\mathbb{P}}\Bigg(\bigcap_{k = 1}^N E^{(T, N)}_{\delta_k \varepsilon, \delta_{k - 1}}\Bigg) \ge 1 - \varepsilon. \]
\[ {\mathbb{P}}(E) = {\mathbb{P}}\Bigg(\bigcap_{k = 1}^N E^{(T, N)}_{\delta_k \varepsilon, \delta_{k - 1}}\Bigg) \ge 1 - \varepsilon. \]
The triangle inequality for the Wasserstein distance [Reference Villani40, Lemma 7.6] holds for every
 $1 \le k \le N$
with
$1 \le k \le N$
with
 \begin{align*} {\mathcal{W}}_{\rho \wedge 1}[{\mathcal{P}}_{\gamma_{T + k}}(x, \cdot), {\mathcal{P}}_{\gamma_{T}}(y, \cdot)] & \le {\mathcal{W}}_{\rho \wedge 1}[{\mathcal{P}}_{\gamma_{T + 1}}(x, \cdot), {\mathcal{P}}_{\gamma_{T}}(y, \cdot)] \\ & \quad + \sum_{s = 1}^{N - 1}{\mathcal{W}}_{\rho \wedge 1}[{\mathcal{P}}_{\gamma_{T + s + 1}}(x, \cdot), {\mathcal{P}}_{\gamma_{T} + s}(x, \cdot)]. \end{align*}
\begin{align*} {\mathcal{W}}_{\rho \wedge 1}[{\mathcal{P}}_{\gamma_{T + k}}(x, \cdot), {\mathcal{P}}_{\gamma_{T}}(y, \cdot)] & \le {\mathcal{W}}_{\rho \wedge 1}[{\mathcal{P}}_{\gamma_{T + 1}}(x, \cdot), {\mathcal{P}}_{\gamma_{T}}(y, \cdot)] \\ & \quad + \sum_{s = 1}^{N - 1}{\mathcal{W}}_{\rho \wedge 1}[{\mathcal{P}}_{\gamma_{T + s + 1}}(x, \cdot), {\mathcal{P}}_{\gamma_{T} + s}(x, \cdot)]. \end{align*}
For each k, if
 $\gamma_{T + 1}, \ldots, \gamma_{T + k} \in E^{(T, N)}_{\varepsilon \delta_{k}, \delta_{k - 1} }$
, then by the previous inequality and Markov’s inequality,
$\gamma_{T + 1}, \ldots, \gamma_{T + k} \in E^{(T, N)}_{\varepsilon \delta_{k}, \delta_{k - 1} }$
, then by the previous inequality and Markov’s inequality,
 \[ \inf_{\{\rho(x,y)\le\delta_{k-1}\}}{\mathcal{W}}_{\{\rho(x',y')\le\delta_{k}\}}[{\mathcal{P}}_{\gamma_{T+k}}(x,\cdot),{\mathcal{P}}_{\gamma_{T}}(y,\cdot)] \ge 1 - \frac{\varepsilon}{N}. \]
\[ \inf_{\{\rho(x,y)\le\delta_{k-1}\}}{\mathcal{W}}_{\{\rho(x',y')\le\delta_{k}\}}[{\mathcal{P}}_{\gamma_{T+k}}(x,\cdot),{\mathcal{P}}_{\gamma_{T}}(y,\cdot)] \ge 1 - \frac{\varepsilon}{N}. \]
By the construction of the distribution
 $\zeta$
,
$\zeta$
,
 $\rho(x_T, y_T) \le \delta_0$
regardless of how small
$\rho(x_T, y_T) \le \delta_0$
regardless of how small
 $\delta_0$
is, and we have the lower bound
$\delta_0$
is, and we have the lower bound
 \begin{equation*} \zeta\Bigg(\bigcap_{k=1}^{N}\{\rho(x_{T+k},y_{T+k}) \le \delta_k\} \mid E\Bigg) \ge \bigg(1 - \frac{\varepsilon}{N}\bigg)^{N} \ge 1 - \varepsilon. \end{equation*}
\begin{equation*} \zeta\Bigg(\bigcap_{k=1}^{N}\{\rho(x_{T+k},y_{T+k}) \le \delta_k\} \mid E\Bigg) \ge \bigg(1 - \frac{\varepsilon}{N}\bigg)^{N} \ge 1 - \varepsilon. \end{equation*}
Combining these results, we have
 \begin{align*} {\mathcal{W}}_{I_{\{x',y':\rho(x',y')>r\}}}\big({\mathcal{A}}^{(T+N)}((\gamma,x),\cdot),B^{(T,N)}((\gamma,x),\cdot)\big) & \le \zeta(\{\rho(x_{T + N}, y_{T + N}) > r \}) \\ & \le \zeta(\{\rho(x_{T + N}, y_{T + N}) > \delta_N\} \mid E) + {\mathbb{P}}(E) \\ & \le 2\varepsilon. \end{align*}
\begin{align*} {\mathcal{W}}_{I_{\{x',y':\rho(x',y')>r\}}}\big({\mathcal{A}}^{(T+N)}((\gamma,x),\cdot),B^{(T,N)}((\gamma,x),\cdot)\big) & \le \zeta(\{\rho(x_{T + N}, y_{T + N}) > r \}) \\ & \le \zeta(\{\rho(x_{T + N}, y_{T + N}) > \delta_N\} \mid E) + {\mathbb{P}}(E) \\ & \le 2\varepsilon. \end{align*}
Since this holds for any
 $r, \varepsilon$
,
$r, \varepsilon$
,
 ${\mathcal{W}}_{\rho\wedge1}\big({\mathcal{A}}^{(T+N)}((\gamma,x),\cdot),B^{(T,N)}((\gamma,x),\cdot)\big) \le r + 2\varepsilon$
and the conclusion follows.
${\mathcal{W}}_{\rho\wedge1}\big({\mathcal{A}}^{(T+N)}((\gamma,x),\cdot),B^{(T,N)}((\gamma,x),\cdot)\big) \le r + 2\varepsilon$
and the conclusion follows.
Combining these lemmas, we may now prove Theorem 1.
Proof of Theorem 1. Fix
 $\varepsilon \in(0, 1)$
. From Lemma 1, we can choose
$\varepsilon \in(0, 1)$
. From Lemma 1, we can choose
 $N_\varepsilon$
sufficiently large that, for all
$N_\varepsilon$
sufficiently large that, for all
 $n \ge N_\varepsilon$
with a particular adaptation stopping time
$n \ge N_\varepsilon$
with a particular adaptation stopping time
 $T_n = n - N_\varepsilon \ge 0$
,
$T_n = n - N_\varepsilon \ge 0$
,
 \begin{equation*} {\mathcal{W}}_{\rho \wedge 1}\big[ B^{(T_n, N_\varepsilon)}( (\gamma, x), \cdot), \pi\big] \le \varepsilon/2. \end{equation*}
\begin{equation*} {\mathcal{W}}_{\rho \wedge 1}\big[ B^{(T_n, N_\varepsilon)}( (\gamma, x), \cdot), \pi\big] \le \varepsilon/2. \end{equation*}
Given this
 $N_\varepsilon$
and using Lemma 2, we can choose
$N_\varepsilon$
and using Lemma 2, we can choose
 $n_\varepsilon$
sufficiently large that, for all
$n_\varepsilon$
sufficiently large that, for all
 $n \ge n_\varepsilon$
,
$n \ge n_\varepsilon$
,
 ${\mathcal{W}}_{\rho\wedge1}\big[{\mathcal{A}}^{(T_n+N_\varepsilon)}((\gamma,x),\cdot),B^{(T_n,N_\varepsilon)}((\gamma,x),\cdot)\big] \le \varepsilon/2$
. The triangle inequality holds by [Reference Villani40, Lemma 7.6], so that
${\mathcal{W}}_{\rho\wedge1}\big[{\mathcal{A}}^{(T_n+N_\varepsilon)}((\gamma,x),\cdot),B^{(T_n,N_\varepsilon)}((\gamma,x),\cdot)\big] \le \varepsilon/2$
. The triangle inequality holds by [Reference Villani40, Lemma 7.6], so that
 \begin{align*} {\mathcal{W}}_{\rho \wedge 1}\big[ {\mathcal{A}}^{(n)}( (\gamma, x), \cdot), \pi \big] & \le {\mathcal{W}}_{\rho \wedge 1}\big[{\mathcal{A}}^{(T_n + N_\varepsilon)}( (\gamma, x), \cdot), B^{(T_n, N_\varepsilon)}( (\gamma, x), \cdot) \big] \\ & \quad + {\mathcal{W}}_{\rho \wedge 1}\big[ B^{(T_n, N_\varepsilon)}( (\gamma, x), \cdot), \pi \big] \le \varepsilon. \end{align*}
\begin{align*} {\mathcal{W}}_{\rho \wedge 1}\big[ {\mathcal{A}}^{(n)}( (\gamma, x), \cdot), \pi \big] & \le {\mathcal{W}}_{\rho \wedge 1}\big[{\mathcal{A}}^{(T_n + N_\varepsilon)}( (\gamma, x), \cdot), B^{(T_n, N_\varepsilon)}( (\gamma, x), \cdot) \big] \\ & \quad + {\mathcal{W}}_{\rho \wedge 1}\big[ B^{(T_n, N_\varepsilon)}( (\gamma, x), \cdot), \pi \big] \le \varepsilon. \end{align*}
Since the conditional optimal coupling is attained and is Borel measurable [Reference Villani41, Theorem 4.8], we have, by dominated convergence,
 \begin{equation*} \lim_{t\to\infty}{\mathcal{W}}_{\rho\wedge1}[\mu{\mathcal{A}}^{(n)},\pi] \le \lim_{t\to\infty}\int_{{\mathcal{Y}}\times{\mathcal{X}}}{\mathcal{W}}_{\rho\wedge1}[{\mathcal{A}}^{(n)}((\gamma,x),\cdot),\pi]\,\mu({\mathrm{d}}\gamma,{\mathrm{d}} x) = 0. \end{equation*}
\begin{equation*} \lim_{t\to\infty}{\mathcal{W}}_{\rho\wedge1}[\mu{\mathcal{A}}^{(n)},\pi] \le \lim_{t\to\infty}\int_{{\mathcal{Y}}\times{\mathcal{X}}}{\mathcal{W}}_{\rho\wedge1}[{\mathcal{A}}^{(n)}((\gamma,x),\cdot),\pi]\,\mu({\mathrm{d}}\gamma,{\mathrm{d}} x) = 0. \end{equation*}
Interestingly, we do not assume that
 $\pi$
is invariant. Denote the distance to a closed set
$\pi$
is invariant. Denote the distance to a closed set
 $C \subseteq {\mathcal{X}}$
by
$C \subseteq {\mathcal{X}}$
by
 $\rho(x, C) = \inf_{y \in C} \rho(x, y)$
and the
$\rho(x, C) = \inf_{y \in C} \rho(x, y)$
and the
 $\varepsilon$
-inflation of the set by
$\varepsilon$
-inflation of the set by
 $C^\varepsilon = \{ x \in X \colon \rho(x, C) \le \varepsilon \}$
. Theorem 1 and Strassen’s theorem [Reference Strassen37] ensures, uniformly for any closed Borel measurable set
$C^\varepsilon = \{ x \in X \colon \rho(x, C) \le \varepsilon \}$
. Theorem 1 and Strassen’s theorem [Reference Strassen37] ensures, uniformly for any closed Borel measurable set
 $C \subseteq {\mathcal{X}}$
, that
$C \subseteq {\mathcal{X}}$
, that
 $\mu{\mathcal{A}}^{(t)}(C)\to \pi(C^\varepsilon)$
. Theorem 1 also ensures that, for every bounded
$\mu{\mathcal{A}}^{(t)}(C)\to \pi(C^\varepsilon)$
. Theorem 1 also ensures that, for every bounded
 $\rho$
-Lipschitz Borel measurable function
$\rho$
-Lipschitz Borel measurable function
 $\varphi \colon {\mathcal{X}} \to {\mathbb{R}}$
,
$\varphi \colon {\mathcal{X}} \to {\mathbb{R}}$
,
 $\int_{{\mathcal{X}}} \varphi\,{\mathrm{d}}\mu{\mathcal{A}}^{(t)} \to \int_{{\mathcal{X}}} \varphi\,{\mathrm{d}}\pi$
.
$\int_{{\mathcal{X}}} \varphi\,{\mathrm{d}}\mu{\mathcal{A}}^{(t)} \to \int_{{\mathcal{X}}} \varphi\,{\mathrm{d}}\pi$
.
The following extends Theorem 1 to
 $L^p$
-Wasserstein distances with unbounded metrics.
$L^p$
-Wasserstein distances with unbounded metrics.
Proposition 3. Suppose an adaptive process
 $(\Gamma_t, X_t)_{t \ge 0}$
with initialization probability measure
$(\Gamma_t, X_t)_{t \ge 0}$
with initialization probability measure
 $\mu$
(1) satisfies weak containment (5) and weak diminishing adaptation (6). Suppose further that, for some
$\mu$
(1) satisfies weak containment (5) and weak diminishing adaptation (6). Suppose further that, for some
 $x_0 \in {\mathcal{X}}$
and
$x_0 \in {\mathcal{X}}$
and
 $p \in {\mathbb{Z}}_+$
,
$p \in {\mathbb{Z}}_+$
,
 $\int \rho(x, x_0)^p\,\pi({\mathrm{d}} x) < \infty$
. Then the following are equivalent:
$\int \rho(x, x_0)^p\,\pi({\mathrm{d}} x) < \infty$
. Then the following are equivalent:
-
(i) Convergence in the
$L^p$
-Wasserstein distance holds:
$\lim_{t \to \infty}{\mathcal{W}}_{\rho, p}(\mu{\mathcal{A}}^{(t)}, \pi) = 0$
. -
(ii) The sequence
$( \rho(X_t, x_0)^p )_{t \ge 0}$
is uniformly integrable:
\[ \lim_{R\to\infty}\sup_{t\ge0}\int_{\rho(x,x_0)>R}\rho(x,x_0)^p\mu{\mathcal{A}}^{(t)}({\mathrm{d}} x) = 0. \]
-
(iii) If
$({\mathcal{X}},\rho)$
is a complete separable metric space, then the following are also equivalent to (i): -
(iv)
$\lim_{t \to \infty} \int_{{\mathcal{X}}} \rho(x, x_0)^p \mu{\mathcal{A}}^{(t)}({\mathrm{d}} x) = \int_{{\mathcal{X}}} \rho(x, x_0)^p\,\pi({\mathrm{d}} x)$
. -
(v)
$\limsup_{t \to \infty} \int_{{\mathcal{X}}} \rho(x, x_0)^p \mu{\mathcal{A}}^{(t)}({\mathrm{d}} x) \le \int_{{\mathcal{X}}} \rho(x, x_0)^p\,\pi({\mathrm{d}} x)$
.







Proof. By Theorem 1 and Markov’s inequality,
 $\inf_{\xi \in {\mathcal{C}}(\mu{\mathcal{A}}^{(t)}, \pi)} \xi( \{ \rho(u, v) > \varepsilon \} ) \to 0$
for any
$\inf_{\xi \in {\mathcal{C}}(\mu{\mathcal{A}}^{(t)}, \pi)} \xi( \{ \rho(u, v) > \varepsilon \} ) \to 0$
for any
 $\varepsilon > 0$
. Let
$\varepsilon > 0$
. Let
 $\xi^{(t)}$
be the attained optimal coupling for each t [Reference Villani41, Theorem 4.1].
$\xi^{(t)}$
be the attained optimal coupling for each t [Reference Villani41, Theorem 4.1].
Assume (i) holds. For any
 $\varepsilon \in (0 , 1)$
,
$\varepsilon \in (0 , 1)$
,
 $\lim_{t\to\infty}\xi^{(t)}(|\rho(x,x_0) - \rho(y,x_0)| \ge \varepsilon) = 0$
. By Young’s inequality, for any
$\lim_{t\to\infty}\xi^{(t)}(|\rho(x,x_0) - \rho(y,x_0)| \ge \varepsilon) = 0$
. By Young’s inequality, for any
 $\varepsilon \in (0, 1)$
there is a constant
$\varepsilon \in (0, 1)$
there is a constant
 $C_{\varepsilon, p}$
depending on
$C_{\varepsilon, p}$
depending on
 $p, \varepsilon$
such that
$p, \varepsilon$
such that
 \[ \rho(x, x_0)^p \le (1 + \varepsilon) \rho(y, x_0)^p + C_{\varepsilon, p} \rho(x, y)^p. \]
\[ \rho(x, x_0)^p \le (1 + \varepsilon) \rho(y, x_0)^p + C_{\varepsilon, p} \rho(x, y)^p. \]
Integrating with the coupling implies that
 \[ \limsup_{t \to \infty} \int_{\mathcal{X}} \rho(x, x_0)^p \mu {\mathcal{A}}^{(t)}({\mathrm{d}} x) \le \int_{\mathcal{X}} \rho(y, x_0)^p\,\pi({\mathrm{d}} y). \]
\[ \limsup_{t \to \infty} \int_{\mathcal{X}} \rho(x, x_0)^p \mu {\mathcal{A}}^{(t)}({\mathrm{d}} x) \le \int_{\mathcal{X}} \rho(y, x_0)^p\,\pi({\mathrm{d}} y). \]
By [Reference Kallenberg22, Theorem 5.11], (ii) holds.
Now assume (ii) holds. By convexity,
 \begin{align*} \lim\sup_{t}\int_{\rho(x,y)>R}\rho(x,y)^p\,\xi^{(t)}({\mathrm{d}} x,{\mathrm{d}} y) & \le 2^{p-1}\lim\sup_{t}\int_{\rho(x,y)>R}\rho(x,x_0)^p\mu{\mathcal{A}}^{(t)}({\mathrm{d}} x) \\ & \quad + 2^{p-1}\lim\sup_{t}\int_{\rho(x,y)>R}\rho(y,x_0)^p\,\xi^{(t)}({\mathrm{d}} x,{\mathrm{d}} y). \end{align*}
\begin{align*} \lim\sup_{t}\int_{\rho(x,y)>R}\rho(x,y)^p\,\xi^{(t)}({\mathrm{d}} x,{\mathrm{d}} y) & \le 2^{p-1}\lim\sup_{t}\int_{\rho(x,y)>R}\rho(x,x_0)^p\mu{\mathcal{A}}^{(t)}({\mathrm{d}} x) \\ & \quad + 2^{p-1}\lim\sup_{t}\int_{\rho(x,y)>R}\rho(y,x_0)^p\,\xi^{(t)}({\mathrm{d}} x,{\mathrm{d}} y). \end{align*}
By the characterization of uniform integrability [Reference Kallenberg22, Theorem 5.11] and dominated convergence, this bound tends to 0 as
 $R \to 0$
. This implies that
$R \to 0$
. This implies that
 \[ \lim_{t\to\infty}{\mathcal{W}}_{\rho,p}^p\big[\mu{\mathcal{A}}^{(t)},\pi\big] = \lim_{t\to\infty}\int_{{\mathcal{X}}^2}\rho(x_t,y)^p\,\xi^{(t)}({\mathrm{d}} x',{\mathrm{d}} y') = 0. \]
\[ \lim_{t\to\infty}{\mathcal{W}}_{\rho,p}^p\big[\mu{\mathcal{A}}^{(t)},\pi\big] = \lim_{t\to\infty}\int_{{\mathcal{X}}^2}\rho(x_t,y)^p\,\xi^{(t)}({\mathrm{d}} x',{\mathrm{d}} y') = 0. \]
The remaining equivalences follow from [Reference Kallenberg22, Lemma 5.11].
Proposition 3 has many interesting applications to extend weak convergence of adaptive MCMC, and also extending convergence in total variation of adaptive MCMC. For example, if
 ${\mathcal{X}} = {\mathbb{R}}^d$
, then weak convergence from Theorem 1 can be used to extend the convergence to the
${\mathcal{X}} = {\mathbb{R}}^d$
, then weak convergence from Theorem 1 can be used to extend the convergence to the
 $L^2$
Wasserstein distance
$L^2$
Wasserstein distance ![]() . Another possibility is to extend traditional convergence of adaptive MCMC to stronger convergence [Reference Roberts and Rosenthal32, Theorem 13] in the case when (strong) containment and (strong) diminishing adaptation hold. The following corollary extends convergence in total variation to a stronger Wasserstein distance under similar conditions [Reference Roberts and Rosenthal32, Theorem 18].
. Another possibility is to extend traditional convergence of adaptive MCMC to stronger convergence [Reference Roberts and Rosenthal32, Theorem 13] in the case when (strong) containment and (strong) diminishing adaptation hold. The following corollary extends convergence in total variation to a stronger Wasserstein distance under similar conditions [Reference Roberts and Rosenthal32, Theorem 18].
Corollary 1. Suppose an adaptive process
 $(\Gamma_t, X_t)_{t \ge 0}$
with initialization probability measure
$(\Gamma_t, X_t)_{t \ge 0}$
with initialization probability measure
 $\mu$
as in (1) satisfies (strong) containment (3) and (strong) diminishing adaptation (2). Suppose there is a lower semicontinuous function
$\mu$
as in (1) satisfies (strong) containment (3) and (strong) diminishing adaptation (2). Suppose there is a lower semicontinuous function
 $V\colon {\mathcal{X}} \to [0,\infty)$
and constants
$V\colon {\mathcal{X}} \to [0,\infty)$
and constants
 $\lambda \in (0,1)$
and
$\lambda \in (0,1)$
and
 $L \in (0,\infty)$
such that, for all
$L \in (0,\infty)$
such that, for all
 $\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
,
$\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
,
 $({\mathcal{P}}_\gamma V) (x) \le \lambda V(x) + L$
. If
$({\mathcal{P}}_\gamma V) (x) \le \lambda V(x) + L$
. If
 $\int_{{\mathcal{X}}} V\,{\mathrm{d}}\mu < \infty$
, then
$\int_{{\mathcal{X}}} V\,{\mathrm{d}}\mu < \infty$
, then
 $\lim_{t \to \infty} {\mathcal{W}}_{\bar{\rho}}\big(\mu{\mathcal{A}}^{(t)}, \pi\big) = 0$
, where
$\lim_{t \to \infty} {\mathcal{W}}_{\bar{\rho}}\big(\mu{\mathcal{A}}^{(t)}, \pi\big) = 0$
, where
 $\bar{\rho}(x, y) = [(1 + V(x) + V(y))]^{1/2}$
if
$\bar{\rho}(x, y) = [(1 + V(x) + V(y))]^{1/2}$
if
 $x \not= y$
and 0 otherwise.
$x \not= y$
and 0 otherwise.
Proof. The drift condition and assumption on
 $\mu$
imply that
$\mu$
imply that
 $(\sqrt{V(X_t)})_{t \ge 0}$
is uniformly integrable, and Proposition 3 implies the conclusion.
$(\sqrt{V(X_t)})_{t \ge 0}$
is uniformly integrable, and Proposition 3 implies the conclusion.
Remark 1. An alternative way to extend weak convergence to a stronger convergence in total variation convergence is through addition of an independent random variable [Reference Bogachev6]. Consider
 ${\mathcal{X}} = {\mathbb{R}}^d$
for some
${\mathcal{X}} = {\mathbb{R}}^d$
for some
 $d \in {\mathbb{Z}}_+$
, and an adaptive process
$d \in {\mathbb{Z}}_+$
, and an adaptive process
 $(\Gamma_t, X_t)_{t \ge 0}$
with initialization probability measure
$(\Gamma_t, X_t)_{t \ge 0}$
with initialization probability measure
 $\mu$
(1) that satisfies weak containment (5) and weak diminishing adaptation (6), both with metric
$\mu$
(1) that satisfies weak containment (5) and weak diminishing adaptation (6), both with metric ![]() . Let
. Let
 $h \in (0, 1)$
and let
$h \in (0, 1)$
and let
 $\sigma_h$
be a Gaussian distribution on
$\sigma_h$
be a Gaussian distribution on
 ${\mathbb{R}}^d$
, N(0, h I). Then
${\mathbb{R}}^d$
, N(0, h I). Then
 $\lim_{t\to\infty}{\mathcal{W}}_{\text{TV}}\big(\mu{\mathcal{A}}^{(t)} * \sigma_h,\pi * \sigma_h\big) = 0$
, where
$\lim_{t\to\infty}{\mathcal{W}}_{\text{TV}}\big(\mu{\mathcal{A}}^{(t)} * \sigma_h,\pi * \sigma_h\big) = 0$
, where
 $*$
denotes convolution.
$*$
denotes convolution.
The following is a useful coupling technique to show weak containment (5).
Lemma 3. Let
 $(\Gamma_t, X_t)_{t \ge 0}$
be an adaptive process with initialization probability measure
$(\Gamma_t, X_t)_{t \ge 0}$
be an adaptive process with initialization probability measure
 $\mu$
as in (1). Suppose
$\mu$
as in (1). Suppose
 $\pi {\mathcal{P}}_\gamma = \pi$
for every
$\pi {\mathcal{P}}_\gamma = \pi$
for every
 $\gamma \in {\mathcal{Y}}$
. Assume, for some
$\gamma \in {\mathcal{Y}}$
. Assume, for some
 $x_0 \in {\mathcal{X}}$
and some
$x_0 \in {\mathcal{X}}$
and some
 $p \in {\mathbb{Z}}_+$
, that
$p \in {\mathbb{Z}}_+$
, that
 $L = \int_{\mathcal{X}} \rho(x, x_0)^p\,\pi({\mathrm{d}} x) < \infty$
and, for every
$L = \int_{\mathcal{X}} \rho(x, x_0)^p\,\pi({\mathrm{d}} x) < \infty$
and, for every
 $\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
,
$\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
,
 $\int_{\mathcal{X}} \rho(y, x_0)^p\,{\mathcal{P}}_{\gamma}(x,{\mathrm{d}} y) < \infty$
. Suppose there is an
$\int_{\mathcal{X}} \rho(y, x_0)^p\,{\mathcal{P}}_{\gamma}(x,{\mathrm{d}} y) < \infty$
. Suppose there is an
 $\alpha \in (0, 1)$
such that, for all
$\alpha \in (0, 1)$
such that, for all
 $x, y \in {\mathcal{X}}$
and
$x, y \in {\mathcal{X}}$
and
 $\gamma \in {\mathcal{Y}}$
,
$\gamma \in {\mathcal{Y}}$
,
 \[ {\mathcal{W}}_{\rho, p}({\mathcal{P}}_\gamma(x, \cdot), {\mathcal{P}}_\gamma(y, \cdot)) \le (1 - \alpha) \rho(x, y). \]
\[ {\mathcal{W}}_{\rho, p}({\mathcal{P}}_\gamma(x, \cdot), {\mathcal{P}}_\gamma(y, \cdot)) \le (1 - \alpha) \rho(x, y). \]
Then, for every
 $t \in {\mathbb{Z}}_+$
and
$t \in {\mathbb{Z}}_+$
and
 $x \in {\mathcal{X}}$
,
$x \in {\mathcal{X}}$
,
 ${\mathcal{W}}_{\rho,p}\big({\mathcal{P}}^t_{\gamma}(x,\cdot),\pi\big) \le (1-\alpha)^t[\rho(x,x_0) + L]$
. Further,
${\mathcal{W}}_{\rho,p}\big({\mathcal{P}}^t_{\gamma}(x,\cdot),\pi\big) \le (1-\alpha)^t[\rho(x,x_0) + L]$
. Further,
 $\sup_{t\ge0}{\mathbb{E}}[\rho(X_t,x_0)^p] < \infty$
and
$\sup_{t\ge0}{\mathbb{E}}[\rho(X_t,x_0)^p] < \infty$
and
 $(\rho(X_t, x_0))_{t \ge 0}$
is bounded in probability.
$(\rho(X_t, x_0))_{t \ge 0}$
is bounded in probability.
Proof. For each
 $t \in Z_+$
and each
$t \in Z_+$
and each
 $x, y \in {\mathcal{X}}$
,
$x, y \in {\mathcal{X}}$
,
 ${\mathcal{W}}_{\rho, p}\big({\mathcal{P}}^t_\gamma(x, \cdot), {\mathcal{P}}^t_\gamma(y, \cdot)\big)^p \le (1 - \alpha)^{t p} \rho(x, y)^p$
. The optimal coupling is attained [Reference Villani41, Theorem 4.1] at some conditional coupling
${\mathcal{W}}_{\rho, p}\big({\mathcal{P}}^t_\gamma(x, \cdot), {\mathcal{P}}^t_\gamma(y, \cdot)\big)^p \le (1 - \alpha)^{t p} \rho(x, y)^p$
. The optimal coupling is attained [Reference Villani41, Theorem 4.1] at some conditional coupling
 $\xi_{x,y}$
and is Borel measurable [Reference Villani41, Corollary 5.22]. Since
$\xi_{x,y}$
and is Borel measurable [Reference Villani41, Corollary 5.22]. Since
 $\int_{\mathcal{X}} \xi_{x, y}(\cdot,\cdot)\,\pi({\mathrm{d}} y) \in {\mathcal{C}}[{\mathcal{P}}_\gamma^t, \pi]$
,
$\int_{\mathcal{X}} \xi_{x, y}(\cdot,\cdot)\,\pi({\mathrm{d}} y) \in {\mathcal{C}}[{\mathcal{P}}_\gamma^t, \pi]$
,
 \begin{equation*} {\mathcal{W}}_{\rho,p}({\mathcal{P}}^t_\gamma(x,\cdot),\pi)^p \le \int_{\mathcal{X}}\int_{{\mathcal{X}}^2}\rho(x',y')^p\,\xi_{x,y}({\mathrm{d}} x',{\mathrm{d}} y')\,\pi({\mathrm{d}} y) \le (1 - \alpha)^{t p} \int_{\mathcal{X}} \rho(x, y)^p\,\pi({\mathrm{d}} y). \end{equation*}
\begin{equation*} {\mathcal{W}}_{\rho,p}({\mathcal{P}}^t_\gamma(x,\cdot),\pi)^p \le \int_{\mathcal{X}}\int_{{\mathcal{X}}^2}\rho(x',y')^p\,\xi_{x,y}({\mathrm{d}} x',{\mathrm{d}} y')\,\pi({\mathrm{d}} y) \le (1 - \alpha)^{t p} \int_{\mathcal{X}} \rho(x, y)^p\,\pi({\mathrm{d}} y). \end{equation*}
By Young’s inequality, for any
 $\varepsilon > 0$
there is a constant
$\varepsilon > 0$
there is a constant
 $C_\varepsilon > 0$
such that, for any
$C_\varepsilon > 0$
such that, for any
 $a, b \ge 0$
,
$a, b \ge 0$
,
 $(a + b)^p \le (1 + \varepsilon) a^p + C_\varepsilon b^p$
. For any
$(a + b)^p \le (1 + \varepsilon) a^p + C_\varepsilon b^p$
. For any
 $x_0 \in {\mathcal{X}}$
, we can choose
$x_0 \in {\mathcal{X}}$
, we can choose
 $\varepsilon$
sufficiently small that
$\varepsilon$
sufficiently small that
 $(1 + \varepsilon)(1 - \alpha)^{p} < 1$
, and a constant
$(1 + \varepsilon)(1 - \alpha)^{p} < 1$
, and a constant
 $C_{\varepsilon, p}$
such that
$C_{\varepsilon, p}$
such that
 \begin{equation*} \int_{\mathcal{X}}\rho(x',x_0)^p\,{\mathcal{P}}_\gamma(x,{\mathrm{d}} x') \le [(1-\alpha)\rho(x,x_0) + 2L^{1/p}]^p \le (1 + \varepsilon) (1 - \alpha)^{p} \rho(x, x_0)^p + C_{\varepsilon, p} L. \end{equation*}
\begin{equation*} \int_{\mathcal{X}}\rho(x',x_0)^p\,{\mathcal{P}}_\gamma(x,{\mathrm{d}} x') \le [(1-\alpha)\rho(x,x_0) + 2L^{1/p}]^p \le (1 + \varepsilon) (1 - \alpha)^{p} \rho(x, x_0)^p + C_{\varepsilon, p} L. \end{equation*}
By [Reference Roberts and Rosenthal32, Lemma 15], this simultaneous geometric drift condition implies that
 $( \rho(X_t, x_0) )_{t}$
is bounded in probability.
$( \rho(X_t, x_0) )_{t}$
is bounded in probability.
6. A weak law of large numbers
The point of this section is to develop convergence in probability of the empirical average of the adaptive MCMC process or weak law of large numbers. The convergence theory developed so far in Wasserstein distances provides estimation accuracy for the marginal distribution of
 $X_t$
but this generally has a large variability. Estimation from the entire adaptive process
$X_t$
but this generally has a large variability. Estimation from the entire adaptive process
 $X_s \sim \mu {\mathcal{A}}^{(s)}$
for
$X_s \sim \mu {\mathcal{A}}^{(s)}$
for
 $s \le t$
requires theory for the empirical average. It is then of interest for reliable estimation to develop conditions such that, for bounded
$s \le t$
requires theory for the empirical average. It is then of interest for reliable estimation to develop conditions such that, for bounded
 $\rho$
-Lipschitz functions,
$\rho$
-Lipschitz functions,
 $({1}/{t}) \sum_{s = 1}^t \varphi(X_s)\to \int_{{\mathcal{X}}} \varphi\,{\mathrm{d}}\pi$
in probability.
$({1}/{t}) \sum_{s = 1}^t \varphi(X_s)\to \int_{{\mathcal{X}}} \varphi\,{\mathrm{d}}\pi$
in probability.
The law of large numbers for non-adapted Markov chains is well studied under convergence in total variation. On the other hand, convergence in Wasserstein distances and its connection to the law of large numbers is less understood [Reference Sandrić36, Theorem 1.2]. The first result is general and relies on the convergence of the adaptive process, but may even apply the law of large numbers to unbounded functions if the conditions are satisfied.
Theorem 2. Let
 $(\Gamma_t, X_t)_{t \ge 0}$
be an adaptive process with initialization probability measure
$(\Gamma_t, X_t)_{t \ge 0}$
be an adaptive process with initialization probability measure
 $\mu$
such that
$\mu$
such that
 $X_t \sim \mu {\mathcal{A}}^{(t)}$
(1). Let
$X_t \sim \mu {\mathcal{A}}^{(t)}$
(1). Let
 $d(\cdot, \cdot)$
be a lower semicontinuous metric and suppose, for some
$d(\cdot, \cdot)$
be a lower semicontinuous metric and suppose, for some
 $x_0 \in {\mathcal{X}}$
and for each
$x_0 \in {\mathcal{X}}$
and for each
 $t \in {\mathbb{Z}}_+$
,
$t \in {\mathbb{Z}}_+$
,
 $\int d(x, x_0)^2 \mu {\mathcal{A}}^{(t)}({\mathrm{d}} x) < \infty$
and
$\int d(x, x_0)^2 \mu {\mathcal{A}}^{(t)}({\mathrm{d}} x) < \infty$
and
 $\int d(x, x_0)^2\,\pi({\mathrm{d}} x) < \infty$
. If
$\int d(x, x_0)^2\,\pi({\mathrm{d}} x) < \infty$
. If
 \[ \lim_{t \to \infty} {\mathcal{W}}_{d, 2}(\mu{\mathcal{A}}^{(t)}, \pi) = 0, \]
\[ \lim_{t \to \infty} {\mathcal{W}}_{d, 2}(\mu{\mathcal{A}}^{(t)}, \pi) = 0, \]
then for every Borel measurable
 $\varphi \colon {\mathcal{X}} \to {\mathbb{R}}$
with
$\varphi \colon {\mathcal{X}} \to {\mathbb{R}}$
with ![]() ,
,
 \begin{equation} \lim_{t\to\infty}{\mathbb{E}}\Bigg[\Bigg(\frac{1}{t}\sum_{s=1}^t\varphi(X_s) - \int_{\mathcal{X}}\varphi\,{\mathrm{d}}\pi\Bigg)^2\Bigg] = 0. \end{equation}
\begin{equation} \lim_{t\to\infty}{\mathbb{E}}\Bigg[\Bigg(\frac{1}{t}\sum_{s=1}^t\varphi(X_s) - \int_{\mathcal{X}}\varphi\,{\mathrm{d}}\pi\Bigg)^2\Bigg] = 0. \end{equation}
In particular, the weak law of large numbers holds, that is,
 $({1}/{t})\sum_{s=1}^t\varphi(X_s) \to \int_{{\mathcal{X}}}\varphi\,{\mathrm{d}}\pi$
in probability.
$({1}/{t})\sum_{s=1}^t\varphi(X_s) \to \int_{{\mathcal{X}}}\varphi\,{\mathrm{d}}\pi$
in probability.
Proof. We can assume that ![]() since we may normalize
since we may normalize
 $\varphi$
. We may also assume that
$\varphi$
. We may also assume that
 $\int\varphi\,{\mathrm{d}}\pi = 0$
since
$\int\varphi\,{\mathrm{d}}\pi = 0$
since
 $\psi = \varphi - \int\varphi\,{\mathrm{d}}\pi$
is also d-Lipschitz. We can assume there is an
$\psi = \varphi - \int\varphi\,{\mathrm{d}}\pi$
is also d-Lipschitz. We can assume there is an
 $x_0 \in {\mathcal{X}}$
such that
$x_0 \in {\mathcal{X}}$
such that
 $\varphi(x_0) = 0$
. Let
$\varphi(x_0) = 0$
. Let
 $\Gamma$
be a coupling of
$\Gamma$
be a coupling of
 $X_t \sim \mu {\mathcal{A}}^{(t)}$
and
$X_t \sim \mu {\mathcal{A}}^{(t)}$
and
 $Y \sim \pi$
. By disintegration [Reference Kallenberg22, Theorem 3.4], there is a Borel measurable conditional probability measure
$Y \sim \pi$
. By disintegration [Reference Kallenberg22, Theorem 3.4], there is a Borel measurable conditional probability measure
 $\Gamma_{h_s}({\mathrm{d}} x_t, {\mathrm{d}} y)$
with
$\Gamma_{h_s}({\mathrm{d}} x_t, {\mathrm{d}} y)$
with
 $h_s = (\gamma_1, x_1, \ldots, \gamma_s, x_s)$
such that
$h_s = (\gamma_1, x_1, \ldots, \gamma_s, x_s)$
such that
 $\Gamma({\mathrm{d}} x_t,{\mathrm{d}} y) = \int_{{\mathcal{X}}^s}\Gamma_{h_s}({\mathrm{d}} x_t,{\mathrm{d}} y)\mu{\mathcal{A}}^{(1,\ldots,s)}({\mathrm{d}} h_s)$
. With the history
$\Gamma({\mathrm{d}} x_t,{\mathrm{d}} y) = \int_{{\mathcal{X}}^s}\Gamma_{h_s}({\mathrm{d}} x_t,{\mathrm{d}} y)\mu{\mathcal{A}}^{(1,\ldots,s)}({\mathrm{d}} h_s)$
. With the history
 $H_s = (\Gamma_k, X_k)_{k = 1}^s$
and since
$H_s = (\Gamma_k, X_k)_{k = 1}^s$
and since
 $\varphi$
is d-Lipschitz, for
$\varphi$
is d-Lipschitz, for
 $t \ge s$
,
$t \ge s$
,
 \[ \bigg|{\mathbb{E}}[\varphi(X_{t}) \mid {\mathcal{H}}_s] - \int_{{\mathcal{X}}}\varphi\,{\mathrm{d}}\pi\bigg| \le \int_{{\mathcal{X}}^2}d(x_{t},y)\,\Gamma_{H_s}({\mathrm{d}} x_{t},{\mathrm{d}} y). \]
\[ \bigg|{\mathbb{E}}[\varphi(X_{t}) \mid {\mathcal{H}}_s] - \int_{{\mathcal{X}}}\varphi\,{\mathrm{d}}\pi\bigg| \le \int_{{\mathcal{X}}^2}d(x_{t},y)\,\Gamma_{H_s}({\mathrm{d}} x_{t},{\mathrm{d}} y). \]
For
 $T \in {\mathbb{Z}}_+$
, we have the upper bound
$T \in {\mathbb{Z}}_+$
, we have the upper bound
 \begin{align*} {\mathbb{E}}\Bigg[\Bigg(\sum_{t=1}^T\varphi(X_t)\Bigg)^2 \Bigg] & = \sum_{t=1}^T\sum_{s=1}^T{\mathbb{E}}[\varphi(X_t)\varphi(X_s)] \\ & = \sum_{t=1}^T{\mathbb{E}}[\varphi(X_t)^2] + 2\sum_{t=2}^T\sum_{s=1}^{t-1}{\mathbb{E}}[{\mathbb{E}}[\varphi(X_t) \mid {\mathcal{H}}_s]\varphi(X_s)] \\ & \le T\sup_{t\ge0}\int_{\mathcal{X}} d(x,x_0)^2\mu{\mathcal{A}}^{(t)}({\mathrm{d}} x) \\ & \quad + 2 \sum_{t=2}^T\sum_{s=1}^{t-1} {\mathbb{E}}\bigg[\int_{{\mathcal{X}}^2}d(x_{t},y)\,\Gamma_{H_s}({\mathrm{d}} x_{t},{\mathrm{d}} y)d(X_s, x_0) \bigg]. \end{align*}
\begin{align*} {\mathbb{E}}\Bigg[\Bigg(\sum_{t=1}^T\varphi(X_t)\Bigg)^2 \Bigg] & = \sum_{t=1}^T\sum_{s=1}^T{\mathbb{E}}[\varphi(X_t)\varphi(X_s)] \\ & = \sum_{t=1}^T{\mathbb{E}}[\varphi(X_t)^2] + 2\sum_{t=2}^T\sum_{s=1}^{t-1}{\mathbb{E}}[{\mathbb{E}}[\varphi(X_t) \mid {\mathcal{H}}_s]\varphi(X_s)] \\ & \le T\sup_{t\ge0}\int_{\mathcal{X}} d(x,x_0)^2\mu{\mathcal{A}}^{(t)}({\mathrm{d}} x) \\ & \quad + 2 \sum_{t=2}^T\sum_{s=1}^{t-1} {\mathbb{E}}\bigg[\int_{{\mathcal{X}}^2}d(x_{t},y)\,\Gamma_{H_s}({\mathrm{d}} x_{t},{\mathrm{d}} y)d(X_s, x_0) \bigg]. \end{align*}
Using Cauchy–Schwarz and Jensen’s inequality,
 \begin{align*} & {\mathbb{E}}\bigg[\int_{{\mathcal{X}}^2}d(x_{t},y)\,\Gamma_{H_s}({\mathrm{d}} x_{t},{\mathrm{d}} y)d(X_s, x_0) \bigg] \\ & \qquad \le \sqrt{{\mathbb{E}}\bigg[\bigg(\int_{{\mathcal{X}}^2}d(x_{t},y)\,\Gamma_{H_s}({\mathrm{d}} x_{t},{\mathrm{d}} y)\bigg)^2\bigg]} \sqrt{{\mathbb{E}}[d(X_s,x_0)^2]} \\ & \qquad \le \sqrt{\int_{{\mathcal{X}}\times{\mathcal{X}}}d(x_{t},y)^2\,\Gamma({\mathrm{d}} x_{t},{\mathrm{d}} y)} \sqrt{\sup_{t \ge 0}\int_{\mathcal{X}} d(x,x_0)^2 \mu{\mathcal{A}}^{(t)}({\mathrm{d}} x)}. \end{align*}
\begin{align*} & {\mathbb{E}}\bigg[\int_{{\mathcal{X}}^2}d(x_{t},y)\,\Gamma_{H_s}({\mathrm{d}} x_{t},{\mathrm{d}} y)d(X_s, x_0) \bigg] \\ & \qquad \le \sqrt{{\mathbb{E}}\bigg[\bigg(\int_{{\mathcal{X}}^2}d(x_{t},y)\,\Gamma_{H_s}({\mathrm{d}} x_{t},{\mathrm{d}} y)\bigg)^2\bigg]} \sqrt{{\mathbb{E}}[d(X_s,x_0)^2]} \\ & \qquad \le \sqrt{\int_{{\mathcal{X}}\times{\mathcal{X}}}d(x_{t},y)^2\,\Gamma({\mathrm{d}} x_{t},{\mathrm{d}} y)} \sqrt{\sup_{t \ge 0}\int_{\mathcal{X}} d(x,x_0)^2 \mu{\mathcal{A}}^{(t)}({\mathrm{d}} x)}. \end{align*}
By assumption, we can choose a
 $T_\varepsilon$
depending on
$T_\varepsilon$
depending on
 $\varepsilon$
such that, for all
$\varepsilon$
such that, for all
 $t \ge T_\varepsilon$
,
$t \ge T_\varepsilon$
,
 ${\mathcal{W}}_{d,2}(\mu{\mathcal{A}}^{(t)},\pi) \le \varepsilon$
. By assumption,
${\mathcal{W}}_{d,2}(\mu{\mathcal{A}}^{(t)},\pi) \le \varepsilon$
. By assumption,
 $\max_{0\le t\le T_\varepsilon}{\mathbb{E}}[d(X_t,x_0)^2] < \infty$
and it follows by the triangle inequality [Reference Villani40, Lemma 7.6] that there is an
$\max_{0\le t\le T_\varepsilon}{\mathbb{E}}[d(X_t,x_0)^2] < \infty$
and it follows by the triangle inequality [Reference Villani40, Lemma 7.6] that there is an
 $R \in (0, \infty)$
such that
$R \in (0, \infty)$
such that
 \begin{equation*} \sup_{t\ge0}{\mathcal{W}}_{d,2}(\mu{\mathcal{A}}^{(t)},\pi) \le \sqrt{\sup_{t\ge0}{\mathbb{E}}(d(X_t,x_0)^2)} + \sqrt{\int d(x,x_0)^2\,\pi({\mathrm{d}} x)} \le R. \end{equation*}
\begin{equation*} \sup_{t\ge0}{\mathcal{W}}_{d,2}(\mu{\mathcal{A}}^{(t)},\pi) \le \sqrt{\sup_{t\ge0}{\mathbb{E}}(d(X_t,x_0)^2)} + \sqrt{\int d(x,x_0)^2\,\pi({\mathrm{d}} x)} \le R. \end{equation*}
Since the coupling
 $\Gamma$
is arbitrary, we have the upper bound for every
$\Gamma$
is arbitrary, we have the upper bound for every
 $T \ge T_\varepsilon + 1$
:
$T \ge T_\varepsilon + 1$
:
 \begin{align*} {\mathbb{E}}\Bigg[\Bigg(\frac{1}{T}\sum_{t=1}^T\varphi(X_t)\Bigg)^2\Bigg] & \le \frac{R^2}{T} + \frac{2R}{T^2}\sum_{t=2}^T(t-1){\mathcal{W}}_{d,2}(\mu{\mathcal{A}}^{(t)},\pi) \\ & \le \frac{R^2}{T} + \frac{2R^2}{T^2}\sum_{t=2}^{T_\varepsilon}(t-1) + \frac{2R}{T^2}\sum_{t=T_{\varepsilon}+1}^T(t-1)\varepsilon \\ & \le \frac{R^2}{T} + \frac{R^2T_{\varepsilon}(T_{\varepsilon}-1)}{T^2} + \frac{R\varepsilon(T - T_\varepsilon)(T + T_\varepsilon - 1)}{T^2}. \end{align*}
\begin{align*} {\mathbb{E}}\Bigg[\Bigg(\frac{1}{T}\sum_{t=1}^T\varphi(X_t)\Bigg)^2\Bigg] & \le \frac{R^2}{T} + \frac{2R}{T^2}\sum_{t=2}^T(t-1){\mathcal{W}}_{d,2}(\mu{\mathcal{A}}^{(t)},\pi) \\ & \le \frac{R^2}{T} + \frac{2R^2}{T^2}\sum_{t=2}^{T_\varepsilon}(t-1) + \frac{2R}{T^2}\sum_{t=T_{\varepsilon}+1}^T(t-1)\varepsilon \\ & \le \frac{R^2}{T} + \frac{R^2T_{\varepsilon}(T_{\varepsilon}-1)}{T^2} + \frac{R\varepsilon(T - T_\varepsilon)(T + T_\varepsilon - 1)}{T^2}. \end{align*}
The conclusion follows since we can choose T sufficiently large and
 $\varepsilon$
sufficiently small.
$\varepsilon$
sufficiently small.
Theorem 2 also provides general conditions for weakly converging Markov chains [Reference Sandrić36, Theorem 1.2]. We may now show that the conditions of Theorem 1 are sufficient for a weak law of large numbers for bounded
 $\rho-$
Lipschitz functions.
$\rho-$
Lipschitz functions.
Corollary 2. Suppose an adaptive process
 $(\Gamma_t, X_t)_{t \ge 0}$
with initialization probability measure
$(\Gamma_t, X_t)_{t \ge 0}$
with initialization probability measure
 $\mu$
(1) satisfies weak containment (5) and weak diminishing adaptation (6). Then, for every bounded Borel measurable
$\mu$
(1) satisfies weak containment (5) and weak diminishing adaptation (6). Then, for every bounded Borel measurable
 $\varphi \colon {\mathcal{X}} \to {\mathbb{R}}$
with
$\varphi \colon {\mathcal{X}} \to {\mathbb{R}}$
with ![]() and any
and any
 $p \in {\mathbb{Z}}_+$
,
$p \in {\mathbb{Z}}_+$
,
 \begin{equation} \lim_{t\to\infty}{\mathbb{E}}\Bigg[\bigg|\frac{1}{t}\sum_{s=1}^t\varphi(X_s) - \int_{\mathcal{X}}\varphi\,{\mathrm{d}}\pi\bigg|^p\Bigg] = 0. \end{equation}
\begin{equation} \lim_{t\to\infty}{\mathbb{E}}\Bigg[\bigg|\frac{1}{t}\sum_{s=1}^t\varphi(X_s) - \int_{\mathcal{X}}\varphi\,{\mathrm{d}}\pi\bigg|^p\Bigg] = 0. \end{equation}
If, in addition, for some
 $x_0 \in {\mathcal{X}}$
,
$x_0 \in {\mathcal{X}}$
,
 $( \rho(X_t, x_0)^2 )_{t \ge 0}$
is uniformly integrable and also
$( \rho(X_t, x_0)^2 )_{t \ge 0}$
is uniformly integrable and also
 $\int \rho(x, x_0)\,\pi({\mathrm{d}} x) < \infty$
, then (9) holds with
$\int \rho(x, x_0)\,\pi({\mathrm{d}} x) < \infty$
, then (9) holds with
 $p = 2$
and for all
$p = 2$
and for all ![]() .
.
Proof. For Borel measurable
 $\varphi \colon {\mathcal{X}} \to {\mathbb{R}}$
with
$\varphi \colon {\mathcal{X}} \to {\mathbb{R}}$
with ![]() , apply Theorems 1 and 2 and it follows that (8) holds. Since
, apply Theorems 1 and 2 and it follows that (8) holds. Since
 $\varphi$
is bounded and (8) holds,
$\varphi$
is bounded and (8) holds,
 $L^p$
convergence follows for
$L^p$
convergence follows for
 $p \in {\mathbb{Z}}_+$
. To remove the bounded assumption on
$p \in {\mathbb{Z}}_+$
. To remove the bounded assumption on
 $\varphi$
, since it is assumed that
$\varphi$
, since it is assumed that
 $( \rho(X_t, x_0)^2 )_{t \ge 0}$
is uniformly integrable,
$( \rho(X_t, x_0)^2 )_{t \ge 0}$
is uniformly integrable,
 ${\mathbb{E}}(\rho(X_t, x_0)^2) < \infty$
for each
${\mathbb{E}}(\rho(X_t, x_0)^2) < \infty$
for each
 $t \in {\mathbb{Z}}_+$
and
$t \in {\mathbb{Z}}_+$
and
 $\int\rho(x,x_0)\,\pi({\mathrm{d}} x) < \infty$
then we can apply Proposition 3.
$\int\rho(x,x_0)\,\pi({\mathrm{d}} x) < \infty$
then we can apply Proposition 3.
7. Examples and applications
Let us now revisit constructing adaptive processes for the running examples of Markov chains (Example 1) and Example 2, where (strong) containment (3) fails to hold.
7.1. Example: Discrete adaptive autoregressive process
Consider an adaptive process
 $(\Gamma_t, X_t)_{t \ge 0}$
using the Markov kernels
$(\Gamma_t, X_t)_{t \ge 0}$
using the Markov kernels
 $({\mathcal{P}}_\gamma)_\gamma$
for the discrete autoregressive process defined in Example 1, which fails to satisfy (strong) containment (3). Assume the adaptation satisfies
$({\mathcal{P}}_\gamma)_\gamma$
for the discrete autoregressive process defined in Example 1, which fails to satisfy (strong) containment (3). Assume the adaptation satisfies
 $|\Gamma_{t + 1} - \Gamma_{t}| \to 0$
in probability as
$|\Gamma_{t + 1} - \Gamma_{t}| \to 0$
in probability as
 $t \to \infty$
. For any
$t \to \infty$
. For any
 $\gamma \in {\mathbb{Z}}_+$
with
$\gamma \in {\mathbb{Z}}_+$
with
 $\gamma \ge 2$
and
$\gamma \ge 2$
and
 $x \in [0, 1)$
, we showed previously in Example 1 that, for any
$x \in [0, 1)$
, we showed previously in Example 1 that, for any
 $t \in {\mathbb{Z}}_+$
,
$t \in {\mathbb{Z}}_+$
,
 \[ {\mathcal{W}}_{ |\cdot|}\big( {\mathcal{P}}^t_\gamma(x, \cdot), \text{Unif}(0, 1) \big) \le 2^{-t},\]
\[ {\mathcal{W}}_{ |\cdot|}\big( {\mathcal{P}}^t_\gamma(x, \cdot), \text{Unif}(0, 1) \big) \le 2^{-t},\]
where
 $\text{Unif}([0, 1)$
is Lebesgue measure on [0, 1) and so weak containment holds (5). For every
$\text{Unif}([0, 1)$
is Lebesgue measure on [0, 1) and so weak containment holds (5). For every
 $x, y \in [0, 1)$
define
$x, y \in [0, 1)$
define
 $X^{\Gamma_{t}}_1 = x/\Gamma_t + \xi^{\Gamma_t}_1$
and
$X^{\Gamma_{t}}_1 = x/\Gamma_t + \xi^{\Gamma_t}_1$
and
 $Y^{\Gamma_{t}}_1 = y/\Gamma_t + \xi^{\Gamma_t}_1$
with common discrete random variable
$Y^{\Gamma_{t}}_1 = y/\Gamma_t + \xi^{\Gamma_t}_1$
with common discrete random variable
 $\xi^{\Gamma_t}_1$
defined previously in Example 1. The random variables
$\xi^{\Gamma_t}_1$
defined previously in Example 1. The random variables
 $\big(X^{\Gamma_{t + 1}}_1, Y^{\Gamma_{t}}_1\big)$
define a coupling and since, for sufficiently large t,
$\big(X^{\Gamma_{t + 1}}_1, Y^{\Gamma_{t}}_1\big)$
define a coupling and since, for sufficiently large t,
 $\Gamma_{t + 1} = \Gamma_t$
with high probability, then
$\Gamma_{t + 1} = \Gamma_t$
with high probability, then
 \begin{equation*} \sup_{|x-y|\le\delta}{\mathcal{W}}_{|\cdot|}({\mathcal{P}}_{\Gamma_{t+1}}(x,\cdot),{\mathcal{P}}_{\Gamma_{t}}(y,\cdot)) \le \sup_{|x-y|\le\delta}{\mathbb{E}}\big[\big|X^{\Gamma_{t+1}}_1 - Y^{\Gamma_{t}}_1\big| \mid X_0 = x, Y_0 = y\big] \le \frac{\delta}{2}\end{equation*}
\begin{equation*} \sup_{|x-y|\le\delta}{\mathcal{W}}_{|\cdot|}({\mathcal{P}}_{\Gamma_{t+1}}(x,\cdot),{\mathcal{P}}_{\Gamma_{t}}(y,\cdot)) \le \sup_{|x-y|\le\delta}{\mathbb{E}}\big[\big|X^{\Gamma_{t+1}}_1 - Y^{\Gamma_{t}}_1\big| \mid X_0 = x, Y_0 = y\big] \le \frac{\delta}{2}\end{equation*}
holds with high probability. Then this bound tends to 0 as
 $\delta \to 0$
and we conclude that weak diminishing adaptation (6) holds. By Theorem 1, for every
$\delta \to 0$
and we conclude that weak diminishing adaptation (6) holds. By Theorem 1, for every
 $\gamma \ge 2$
and
$\gamma \ge 2$
and
 $x \in [0, 1)$
,
$x \in [0, 1)$
,
 \[ \lim_{t\to\infty} {\mathcal{W}}_{|\cdot|}[ {\mathcal{A}}^{(t)}( (\gamma, x) , \cdot), \text{Unif}(0, 1) ] = 0\]
\[ \lim_{t\to\infty} {\mathcal{W}}_{|\cdot|}[ {\mathcal{A}}^{(t)}( (\gamma, x) , \cdot), \text{Unif}(0, 1) ] = 0\]
and this discrete autoregressive adaptive process converges weakly. Corollary 2 then implies a weak law of large numbers for all bounded Lipschitz continuous functions.
7.2. Example: Infinite-dimensional adaptive autoregressive process
Consider an adaptive process
 $(\Gamma_t, X_t)_{t \ge 0}$
using Markov kernels
$(\Gamma_t, X_t)_{t \ge 0}$
using Markov kernels
 $({\mathcal{P}}_\gamma)_\gamma$
for the infinite-dimensional autoregressive process (2), which cannot satisfy (strong) containment (3). Assume the adaptation is restricted to a bounded set, that is, for some
$({\mathcal{P}}_\gamma)_\gamma$
for the infinite-dimensional autoregressive process (2), which cannot satisfy (strong) containment (3). Assume the adaptation is restricted to a bounded set, that is, for some
 $R \in (0, \infty)$
, if
$R \in (0, \infty)$
, if ![]() then
then
 $\Gamma_{t + 1}= \Gamma_{t}$
and
$\Gamma_{t + 1}= \Gamma_{t}$
and
 $|\Gamma_t - \Gamma_{t + 1}| \to 0$
in probability as
$|\Gamma_t - \Gamma_{t + 1}| \to 0$
in probability as
 $t \to \infty$
.
$t \to \infty$
.
We showed previously (2) that for any
 $\gamma \in (0, \gamma^*)$
and any
$\gamma \in (0, \gamma^*)$
and any
 $x, y \in H$
,
$x, y \in H$
,
combined with Lemma 3. this implies that weak containment (5) holds. For
 $x, y \in H$
, let
$x, y \in H$
, let
 $Y_t = \Gamma_{t + 1} x + \sqrt{1 - {\Gamma_{t + 1}}^2} \xi_{t}$
and
$Y_t = \Gamma_{t + 1} x + \sqrt{1 - {\Gamma_{t + 1}}^2} \xi_{t}$
and
 $Y'_t = \Gamma_{t} y + \sqrt{1 - {\Gamma_{t}}^2} \xi_{t}$
with common independent random variable
$Y'_t = \Gamma_{t} y + \sqrt{1 - {\Gamma_{t}}^2} \xi_{t}$
with common independent random variable
 $\xi_t \sim {\mathcal{N}}(0, C)$
. We have the upper bound, for any
$\xi_t \sim {\mathcal{N}}(0, C)$
. We have the upper bound, for any
 $t \in {\mathbb{Z}}_+$
,
$t \in {\mathbb{Z}}_+$
,

If ![]() and
and ![]() , then
, then ![]() Otherwise, if
Otherwise, if ![]() and
and ![]() ,
,
In either case, weak diminishing adaptation (6) holds.
For any
 $p \in {\mathbb{Z}}_+$
, Young’s inequality and Fernique’s theorem [Reference Bogachev5, Theorem 2.8.5] imply we can choose
$p \in {\mathbb{Z}}_+$
, Young’s inequality and Fernique’s theorem [Reference Bogachev5, Theorem 2.8.5] imply we can choose
 $\varepsilon >0$
such that
$\varepsilon >0$
such that
 $(1 + \varepsilon) {\gamma^*}^p < 1$
and a constant
$(1 + \varepsilon) {\gamma^*}^p < 1$
and a constant
 $C_{\varepsilon} > 0$
depending on
$C_{\varepsilon} > 0$
depending on
 $\varepsilon$
such that, for every
$\varepsilon$
such that, for every
 $\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
,
$\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
, ![]() . This implies that
. This implies that ![]() is uniformly integrable. From Theorem 1 and Proposition 3, for every
is uniformly integrable. From Theorem 1 and Proposition 3, for every
 $\gamma, x \in (0, \gamma^*] \times H$
and every
$\gamma, x \in (0, \gamma^*] \times H$
and every
 $p \in {\mathbb{Z}}_+$
,
$p \in {\mathbb{Z}}_+$
, ![]() and Corollary 2 implies a weak law of large numbers for all Lipschitz continuous functions.
and Corollary 2 implies a weak law of large numbers for all Lipschitz continuous functions.
7.3. Example: Adaptive random-walk Metropolis–Hastings
We look at a discrete version of the adaptive random-walk Metropolis–Hastings algorithm [Reference Haario, Saksman and Tamminen18], which adapts the covariance of the proposal towards the covariance of the target probability measure. This concrete example illustrates an issue in practical applications since current computers only produce floating-point approximations to real numbers. As a result, convergence theory in total variation corresponding to an adaptive Markov chain Monte Carlo simulation targeting a continuous target probability measure is infeasible and has other issues that have been studied previously through perturbation theory [Reference Breyer, Roberts and Rosenthal7, Reference Roberts, Rosenthal and Schwartz34]. This is not necessarily the case in alternative distances which metrize weak convergence.
Let
 $\pi$
be a target Borel probability measure on
$\pi$
be a target Borel probability measure on
 ${\mathbb{R}}^d$
with
${\mathbb{R}}^d$
with
 $d \in {\mathbb{Z}}_+$
and Lebesgue density f. Let
$d \in {\mathbb{Z}}_+$
and Lebesgue density f. Let
 $D = (x_k)_{k = 1}^{\infty} \subset {\mathbb{R}}^d$
be a dense subset in
$D = (x_k)_{k = 1}^{\infty} \subset {\mathbb{R}}^d$
be a dense subset in
 ${\mathbb{R}}^d$
,
${\mathbb{R}}^d$
,
 $\Sigma$
be a symmetric, positive-definite matrix,
$\Sigma$
be a symmetric, positive-definite matrix,
 $\mu \in {\mathbb{R}}^d$
, and let
$\mu \in {\mathbb{R}}^d$
, and let
 ${\mathcal{N}}_{D}(\mu, \Sigma)$
denote the discrete Gaussian with probability mass function
${\mathcal{N}}_{D}(\mu, \Sigma)$
denote the discrete Gaussian with probability mass function
 \[g_{\Sigma}(\mu, x) = \frac{\exp\big({-}\frac{1}{2} ( x - \mu )^\top \Sigma^{-1} ( x - \mu ) \big)}{\sum_{j = 1}^{\infty} \exp\big({-}\frac{1}{2} ( x_j - \mu )^\top \Sigma^{-1} ( x_j - \mu ) \big) }.\]
\[g_{\Sigma}(\mu, x) = \frac{\exp\big({-}\frac{1}{2} ( x - \mu )^\top \Sigma^{-1} ( x - \mu ) \big)}{\sum_{j = 1}^{\infty} \exp\big({-}\frac{1}{2} ( x_j - \mu )^\top \Sigma^{-1} ( x_j - \mu ) \big) }.\]
When
 $\mu \in D$
,
$\mu \in D$
,
 $g_{\Sigma}(\mu, x) = g_{\Sigma}(x, \mu)$
and it is symmetric. Let
$g_{\Sigma}(\mu, x) = g_{\Sigma}(x, \mu)$
and it is symmetric. Let
 $(M(\gamma))_{\gamma \in {\mathcal{Y}}}$
be a family of symmetric, positive-definite matrices on
$(M(\gamma))_{\gamma \in {\mathcal{Y}}}$
be a family of symmetric, positive-definite matrices on
 ${\mathbb{R}}^d$
. We define a discrete Markov chain
${\mathbb{R}}^d$
. We define a discrete Markov chain
 $\big( X^{\gamma}_{t} \big)_{t \ge 0}$
using a discrete random-walk Metropolis–Hastings kernel
$\big( X^{\gamma}_{t} \big)_{t \ge 0}$
using a discrete random-walk Metropolis–Hastings kernel
 ${\mathcal{P}}_{\Sigma}$
with discrete Gaussian proposal, where the proposal X
′ given the previous state x is
${\mathcal{P}}_{\Sigma}$
with discrete Gaussian proposal, where the proposal X
′ given the previous state x is
 $X' \sim {\mathcal{N}}_{D}(x, M(\gamma))$
. The Markov kernel is defined for each
$X' \sim {\mathcal{N}}_{D}(x, M(\gamma))$
. The Markov kernel is defined for each
 $x_l, x_k \in D$
by
$x_l, x_k \in D$
by
 \begin{equation*} {\mathcal{P}}_{\gamma}(x_l,x_k) = \bigg[1\wedge\frac{f(x_k)}{f(x_l)}\bigg]g_{M(\gamma)}(x_l x_k) + \delta_{x_l}(\{x_k\})\Bigg(1-\sum_{j=1}^{\infty}\bigg[1\wedge\frac{f(x_j)}{f(x_l)}\bigg]g_{M(\gamma)}(x_l,x_j)\Bigg).\end{equation*}
\begin{equation*} {\mathcal{P}}_{\gamma}(x_l,x_k) = \bigg[1\wedge\frac{f(x_k)}{f(x_l)}\bigg]g_{M(\gamma)}(x_l x_k) + \delta_{x_l}(\{x_k\})\Bigg(1-\sum_{j=1}^{\infty}\bigg[1\wedge\frac{f(x_j)}{f(x_l)}\bigg]g_{M(\gamma)}(x_l,x_j)\Bigg).\end{equation*}
We will assume that f is continuous with compact support
 $K \subset {\mathbb{R}}^d$
. Further, we will assume that the set of
$K \subset {\mathbb{R}}^d$
. Further, we will assume that the set of
 $\Sigma$
is compact and so the eigenvalues of
$\Sigma$
is compact and so the eigenvalues of
 $\Sigma$
are uniformly bounded, so there are constants
$\Sigma$
are uniformly bounded, so there are constants
 $\lambda_*, \lambda^* \in (0, \infty)$
such that
$\lambda_*, \lambda^* \in (0, \infty)$
such that
 $\lambda_* \le \lambda_{i}(\Sigma) \le \lambda^*$
for all
$\lambda_* \le \lambda_{i}(\Sigma) \le \lambda^*$
for all
 $i = 1, \ldots, d$
. It follows by a minorization argument over K that there is an
$i = 1, \ldots, d$
. It follows by a minorization argument over K that there is an
 $\alpha \in (0, 1)$
such that, for any
$\alpha \in (0, 1)$
such that, for any
 $\gamma \in {\mathcal{Y}}$
, any
$\gamma \in {\mathcal{Y}}$
, any
 $x_i, x_j \in D$
, and any bounded Lipschitz continuous function
$x_i, x_j \in D$
, and any bounded Lipschitz continuous function
 $\varphi \colon {\mathbb{R}}^d \to {\mathbb{R}}$
,
$\varphi \colon {\mathbb{R}}^d \to {\mathbb{R}}$
,
 $|{\mathcal{P}}_\gamma^t\varphi(x_i) - {\mathcal{P}}_\gamma^t\varphi(x_j)| \le (1 - \alpha)^t$
. By the density of D and continuity of
$|{\mathcal{P}}_\gamma^t\varphi(x_i) - {\mathcal{P}}_\gamma^t\varphi(x_j)| \le (1 - \alpha)^t$
. By the density of D and continuity of
 ${\mathcal{P}} \varphi(\cdot)$
,
${\mathcal{P}} \varphi(\cdot)$
,
 $\big|{\mathcal{P}}_\gamma^t\varphi(x_i) - \int_K\varphi\,{\mathrm{d}}\pi\big| \le (1 - \alpha)^t$
. Weak containment (5) holds since it follows by Kantorovich–Rubinstein duality [Reference Villani40, Theorem 1.14] that
$\big|{\mathcal{P}}_\gamma^t\varphi(x_i) - \int_K\varphi\,{\mathrm{d}}\pi\big| \le (1 - \alpha)^t$
. Weak containment (5) holds since it follows by Kantorovich–Rubinstein duality [Reference Villani40, Theorem 1.14] that ![]() .
.
Now let
 $\gamma, x \in {\mathcal{Y}} \times D$
and let
$\gamma, x \in {\mathcal{Y}} \times D$
and let
 $(\Gamma_t, X_t)_{t \ge 0}$
where
$(\Gamma_t, X_t)_{t \ge 0}$
where
 $X_t \sim {\mathcal{A}}^{(t)}( (\gamma, x), \cdot)$
be the adaptive process using these Metropolis–Hastings kernels. Under any valid weak diminishing adaptation strategy satisfying (6), we have
$X_t \sim {\mathcal{A}}^{(t)}( (\gamma, x), \cdot)$
be the adaptive process using these Metropolis–Hastings kernels. Under any valid weak diminishing adaptation strategy satisfying (6), we have ![]() . Corollary 2 then implies a weak law of large numbers for bounded Lipschitz continuous functions. On the other hand, it can be shown that
. Corollary 2 then implies a weak law of large numbers for bounded Lipschitz continuous functions. On the other hand, it can be shown that
 ${\mathcal{W}}_{\text{TV}}({\mathcal{A}}^{(t)}( (\gamma, x), \cdot), \pi ) = 1$
and fails to converge in total variation under any adaptation plan.
${\mathcal{W}}_{\text{TV}}({\mathcal{A}}^{(t)}( (\gamma, x), \cdot), \pi ) = 1$
and fails to converge in total variation under any adaptation plan.
7.4. Example: Adaptive unadjusted Langevin process
In certain cases, it has been observed [Reference Villani41, p. 21] that Wasserstein distances can be simpler to prove convergence results than total variation; the following example provides a concrete illustration. Consider the Euclidean space
 ${\mathbb{R}}^d$
where
${\mathbb{R}}^d$
where
 $d \in {\mathbb{Z}}_+$
with Euclidean norm
$d \in {\mathbb{Z}}_+$
with Euclidean norm ![]() . Let the potential
. Let the potential
 $V \colon {\mathbb{R}}^d \to {\mathbb{R}}$
have gradient
$V \colon {\mathbb{R}}^d \to {\mathbb{R}}$
have gradient
 $\nabla V(\cdot)$
with constants
$\nabla V(\cdot)$
with constants
 $\alpha, \beta > 0$
such that, for every
$\alpha, \beta > 0$
such that, for every
 $x, y \in {\mathbb{R}}^d$
,
$x, y \in {\mathbb{R}}^d$
,
Let
 $({\mathcal{Y}}, d)$
be a complete separable metric space and, for each
$({\mathcal{Y}}, d)$
be a complete separable metric space and, for each
 $\gamma \in {\mathcal{Y}}$
, let
$\gamma \in {\mathcal{Y}}$
, let
 $M(\gamma)$
define a symmetric positive-definite matrix. Let
$M(\gamma)$
define a symmetric positive-definite matrix. Let
 $h \in (0, 1)$
be a fixed discretization size and consider the unadjusted Langevin process
$h \in (0, 1)$
be a fixed discretization size and consider the unadjusted Langevin process
 \[ X^{\gamma, h}_{t + 1} = X^{\gamma, h}_t - h M(\gamma) \nabla V\big(M(\gamma) X^{\gamma, h}_t\big) + \sqrt{2 h} Z_{t + 1},\]
\[ X^{\gamma, h}_{t + 1} = X^{\gamma, h}_t - h M(\gamma) \nabla V\big(M(\gamma) X^{\gamma, h}_t\big) + \sqrt{2 h} Z_{t + 1},\]
where
 $(Z_t)_{t \ge 0}$
are independent and identically distributed
$(Z_t)_{t \ge 0}$
are independent and identically distributed
 ${\mathcal{N}}(0, I_d)$
. We can define a family of Markov kernels
${\mathcal{N}}(0, I_d)$
. We can define a family of Markov kernels
 $( {\mathcal{P}}_{\gamma, h} )_{\gamma, h}$
prescribing the conditional distributions
$( {\mathcal{P}}_{\gamma, h} )_{\gamma, h}$
prescribing the conditional distributions
 $X^{\gamma, h}_{t + 1} \mid X^{\gamma, h}_{t} = x \sim {\mathcal{P}}_{\gamma, h}(x, \cdot)$
. For an adaptive strategy
$X^{\gamma, h}_{t + 1} \mid X^{\gamma, h}_{t} = x \sim {\mathcal{P}}_{\gamma, h}(x, \cdot)$
. For an adaptive strategy
 $(\Gamma_t, h_t)_{t \ge 0}$
, we define the adaptive process
$(\Gamma_t, h_t)_{t \ge 0}$
, we define the adaptive process
 $X_t := M(\Gamma_t) X^{\Gamma_t, h_t}_t$
for
$X_t := M(\Gamma_t) X^{\Gamma_t, h_t}_t$
for
 $t \ge 0$
. For example,
$t \ge 0$
. For example,
 $M(\Gamma_t)$
can estimate the inverse covariance matrix using the entire history of the process as in adaptive Metropolis–Hastings [Reference Haario, Saksman and Tamminen18] and adaptive piecewise-deterministic Markov processes [Reference Bertazzi and Bierkens4]. We make the following assumption on the adaptation of the matrix
$M(\Gamma_t)$
can estimate the inverse covariance matrix using the entire history of the process as in adaptive Metropolis–Hastings [Reference Haario, Saksman and Tamminen18] and adaptive piecewise-deterministic Markov processes [Reference Bertazzi and Bierkens4]. We make the following assumption on the adaptation of the matrix
 $M(\gamma)$
.
$M(\gamma)$
.
Assumption 2. Assume
 $M(\cdot)$
is continuous and, for each
$M(\cdot)$
is continuous and, for each
 $\gamma \in {\mathcal{Y}}$
and
$\gamma \in {\mathcal{Y}}$
and
 $x \in {\mathbb{R}}^d$
, there is a constant
$x \in {\mathbb{R}}^d$
, there is a constant
 $\lambda_* \in (0, \infty)$
such that, for every
$\lambda_* \in (0, \infty)$
such that, for every
 $v \in {\mathbb{R}}^d\setminus \{0\}$
with
$v \in {\mathbb{R}}^d\setminus \{0\}$
with ![]() ,
, ![]() . Assume
. Assume
 $d(\Gamma_{t + 1}, \Gamma_t) \to 0$
in probability and
$d(\Gamma_{t + 1}, \Gamma_t) \to 0$
in probability and
 $\Gamma_{t + 1} = \Gamma_t$
if
$\Gamma_{t + 1} = \Gamma_t$
if ![]() for some
for some
 $R > 0$
.
$R > 0$
.
We have the following convergence result.
Proposition 4. Assume the adaptation plan satisfies Assumption 2 and, for some
 $h_* \in (0, 1)$
, let
$h_* \in (0, 1)$
, let
 $H = [h_*, 1/(\alpha + \beta) ]$
and assume
$H = [h_*, 1/(\alpha + \beta) ]$
and assume
 $(h_t)_{t \ge 0}$
is a deterministic sequence with
$(h_t)_{t \ge 0}$
is a deterministic sequence with
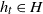 $h_t \in H$
. Further, assume there is a limit
$h_t \in H$
. Further, assume there is a limit
 $h^* \in H$
such that
$h^* \in H$
such that
 $\lim_{t \to \infty}|h_t - h^*| = 0$
. Then the adaptive unadjusted Langevin process converges in the
$\lim_{t \to \infty}|h_t - h^*| = 0$
. Then the adaptive unadjusted Langevin process converges in the
 $L^1$
-Wasserstein distance for every
$L^1$
-Wasserstein distance for every
 $\gamma, h, x \in {\mathcal{Y}} \times H \times {\mathbb{R}}^d$
to some probability measure
$\gamma, h, x \in {\mathcal{Y}} \times H \times {\mathbb{R}}^d$
to some probability measure
 $\pi_{h^*}$
, that is,
$\pi_{h^*}$
, that is, ![]() , and a weak law of large numbers holds for all bounded Lipschitz continuous functions.
, and a weak law of large numbers holds for all bounded Lipschitz continuous functions.
Proof. It can be shown that
 $M(\gamma) \nabla V(M(\gamma) \cdot )$
is
$M(\gamma) \nabla V(M(\gamma) \cdot )$
is
 $\beta$
Lipschitz and
$\beta$
Lipschitz and
 $\alpha$
strongly convex. For
$\alpha$
strongly convex. For
 $x, y \in {\mathbb{R}}^d$
and
$x, y \in {\mathbb{R}}^d$
and
 $\gamma, \gamma' \in {\mathcal{Y}}$
, let
$\gamma, \gamma' \in {\mathcal{Y}}$
, let
 \begin{equation*} X^{\gamma}_{1} = x - h M(\gamma) \nabla V(M(\gamma) x) + \sqrt{2 h} Z_{1}, \qquad Y^{\gamma'}_{1} = y - h M(\gamma') \nabla V(M(\gamma') y) + \sqrt{2 h} Z_{1} \end{equation*}
\begin{equation*} X^{\gamma}_{1} = x - h M(\gamma) \nabla V(M(\gamma) x) + \sqrt{2 h} Z_{1}, \qquad Y^{\gamma'}_{1} = y - h M(\gamma') \nabla V(M(\gamma') y) + \sqrt{2 h} Z_{1} \end{equation*}
with shared Gaussian random variable
 $Z_1 \sim N(0, I)$
. By [Reference Nesterov25, Theorem 2.1.12],
$Z_1 \sim N(0, I)$
. By [Reference Nesterov25, Theorem 2.1.12],

For each adapted discretization size h, h
′, ![]() . Along with the assumed adaptation strategy, these imply that there exists an invariant measure
. Along with the assumed adaptation strategy, these imply that there exists an invariant measure
 $\pi_{h^*}$
with finite second moment. By Lemma 3, weak containment (5) holds.
$\pi_{h^*}$
with finite second moment. By Lemma 3, weak containment (5) holds.
For each adapted discretization size h, h
′ and each adaptation parameter
 $\gamma,\gamma' \in {\mathcal{Y}}$
,
$\gamma,\gamma' \in {\mathcal{Y}}$
,

This upper bound implies weak diminishing adaptation (6) under this adaptation strategy. Therefore, this adaptive process converges weakly by Theorem 1. Lemma 3 implies ![]() is uniformly integrable and then, by Proposition 3, the Wasserstein convergence follows. Corollary 2 implies a weak law of large numbers for all bounded Lipschitz functions.
is uniformly integrable and then, by Proposition 3, the Wasserstein convergence follows. Corollary 2 implies a weak law of large numbers for all bounded Lipschitz functions.
7.5. Example: Adaptive diffusion process
Let the potential
 $V \colon {\mathbb{R}}^d \to {\mathbb{R}}$
satisfy (10). Let
$V \colon {\mathbb{R}}^d \to {\mathbb{R}}$
satisfy (10). Let
 $( M(\gamma) )_{\gamma \in {\mathcal{Y}}}$
be defined as in Section 7.4 and consider adapting a stochastic differential equation with
$( M(\gamma) )_{\gamma \in {\mathcal{Y}}}$
be defined as in Section 7.4 and consider adapting a stochastic differential equation with
 $M(\gamma)$
defined for
$M(\gamma)$
defined for
 $t \in [0, 1]$
by
$t \in [0, 1]$
by
 \[ {\mathrm{d}} X^{\gamma}_t = - M(\gamma)\nabla V(M(\gamma)X^{\gamma}_t)\,{\mathrm{d}} t + \sqrt{2}\,{\mathrm{d}} W_t,\]
\[ {\mathrm{d}} X^{\gamma}_t = - M(\gamma)\nabla V(M(\gamma)X^{\gamma}_t)\,{\mathrm{d}} t + \sqrt{2}\,{\mathrm{d}} W_t,\]
where
 $(W_t)_{t \ge 0}$
is standard Brownian motion in
$(W_t)_{t \ge 0}$
is standard Brownian motion in
 ${\mathbb{R}}^d$
. Then, for any
${\mathbb{R}}^d$
. Then, for any
 $\gamma \in {\mathcal{Y}}$
and
$\gamma \in {\mathcal{Y}}$
and
 $x \in {\mathbb{R}}^d$
, there exists a strong solution
$x \in {\mathbb{R}}^d$
, there exists a strong solution
 $(X^{\gamma}_t)_{t \ge 0}$
that is a Markov process with kernel
$(X^{\gamma}_t)_{t \ge 0}$
that is a Markov process with kernel
 $\tilde{\mathcal{P}}^t_{\gamma}$
. Using the solution at
$\tilde{\mathcal{P}}^t_{\gamma}$
. Using the solution at
 $t = 1$
, we can define a new Markov chain
$t = 1$
, we can define a new Markov chain
 $X^{\gamma}_{n} \mid X_0 = x$
with Markov transition kernel
$X^{\gamma}_{n} \mid X_0 = x$
with Markov transition kernel
 $\tilde{P}^1_{\gamma}$
. We can define an adaptive process
$\tilde{P}^1_{\gamma}$
. We can define an adaptive process
 $(\Gamma_n, X_n)_{n \ge 0}$
with
$(\Gamma_n, X_n)_{n \ge 0}$
with
 $X_n = M(\Gamma_n) X_n^{\Gamma_n}$
so that
$X_n = M(\Gamma_n) X_n^{\Gamma_n}$
so that
 $X_n \mid \Gamma_n = \gamma$
,
$X_n \mid \Gamma_n = \gamma$
,
 $X_{n - 1} = x$
has Markov transition
$X_{n - 1} = x$
has Markov transition
 ${\mathcal{P}}_{\gamma}(x, \cdot)$
with invariant measure
${\mathcal{P}}_{\gamma}(x, \cdot)$
with invariant measure
 $\pi({\mathrm{d}} x) = Z^{-1} \exp(-V(x))\,{\mathrm{d}} x$
, where
$\pi({\mathrm{d}} x) = Z^{-1} \exp(-V(x))\,{\mathrm{d}} x$
, where
 $Z = \int \exp({-}V(x))\,{\mathrm{d}} x$
. This type of adaptive scheme using matrices has been successful in piecewise-deterministic Markov processes [Reference Bertazzi and Bierkens4].
$Z = \int \exp({-}V(x))\,{\mathrm{d}} x$
. This type of adaptive scheme using matrices has been successful in piecewise-deterministic Markov processes [Reference Bertazzi and Bierkens4].
Proposition 5. Assume the adaptation plan satisfies Assumption 2 and assume the potential
 $V \colon {\mathbb{R}}^d \to {\mathbb{R}}$
satisfies (10) and (11). Then, for every
$V \colon {\mathbb{R}}^d \to {\mathbb{R}}$
satisfies (10) and (11). Then, for every
 $\gamma, x \in {\mathcal{Y}} \times {\mathbb{R}}^d$
, the adaptive diffusion process converges in the
$\gamma, x \in {\mathcal{Y}} \times {\mathbb{R}}^d$
, the adaptive diffusion process converges in the
 $L^1$
-Wasserstein distance
$L^1$
-Wasserstein distance ![]() and a weak law of large numbers holds for all bounded Lipschitz continuous functions.
and a weak law of large numbers holds for all bounded Lipschitz continuous functions.
Proof. For
 $\gamma, \gamma' \in {\mathcal{Y}}$
and
$\gamma, \gamma' \in {\mathcal{Y}}$
and
 $x, y \in {\mathbb{R}}^d$
, let
$x, y \in {\mathbb{R}}^d$
, let
 $X^{\gamma}_t \mid X_0 = x$
and
$X^{\gamma}_t \mid X_0 = x$
and
 $Y^{\gamma'}_t \mid Y_0 = y$
,
$Y^{\gamma'}_t \mid Y_0 = y$
,
 $Y_0 = y$
, share the same Brownian motion so that these random variables define a coupling. By strong convexity, for every
$Y_0 = y$
, share the same Brownian motion so that these random variables define a coupling. By strong convexity, for every
 $x, y \in {\mathbb{R}}^d$
,
$x, y \in {\mathbb{R}}^d$
, ![]() . Define
. Define ![]() ; it follows that
; it follows that

By Gronwall’s inequality, ![]() . We have the upper bound
. We have the upper bound
By [Reference Durmus and Moulines16, Proposition 1], ![]() is finite, and by Lemma 3, weak containment (5) holds. Lemma 3 then implies weak containment (5) and
is finite, and by Lemma 3, weak containment (5) holds. Lemma 3 then implies weak containment (5) and ![]() is uniformly integrable. A similar argument as in Example 7.4 shows weak diminishing adaptation (6). By Proposition 3, the convergence in Wasserstein follows and Corollary 2 implies a weak law of large numbers for all bounded Lipschitz functions.
is uniformly integrable. A similar argument as in Example 7.4 shows weak diminishing adaptation (6). By Proposition 3, the convergence in Wasserstein follows and Corollary 2 implies a weak law of large numbers for all bounded Lipschitz functions.
8. Connections to geometric drift and coupling conditions
A general approach to satisfy the containment condition (5) is through a simultaneous version of the weak Harris theorem [Reference Hairer, Mattingly and Scheutzow20, Theorem 4.8]. Other similar convergence bounds for non-adapted Markov chains could be modified to simultaneous versions as well [Reference Durmus and Moulines15, Reference Qin and Hobert28].
Theorem 3. (Simultaneous weak Harris theorem). Let
 $({\mathcal{P}}_\gamma)_{\gamma \in {\mathcal{Y}}}$
be a family of Markov kernels on
$({\mathcal{P}}_\gamma)_{\gamma \in {\mathcal{Y}}}$
be a family of Markov kernels on
 ${\mathcal{X}}$
with invariant probability measure
${\mathcal{X}}$
with invariant probability measure
 $\pi$
.
$\pi$
.
-
• (Simultaneous geometric drift.) Suppose there is a Borel drift function
$V \colon {\mathcal{Y}} \times {\mathcal{X}} \to [0, \infty)$
and constants
$\lambda \in (0, 1)$
,
$K \in (0, \infty)$
such that, for every
$\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
,
\[ \int_{{\mathcal{X}}} V(\gamma, x') {\mathcal{P}}_{\gamma}(x, {\mathrm{d}} x') \le \lambda V(\gamma, x) + K. \]
-
• (
$\rho$
-contracting.) Suppose there is a
$\kappa \in (0, 1)$
such that, for every
$x, y \in {\mathcal{X}}$
with
$\rho(x, y) < 1$
and every
$\gamma \in {\mathcal{Y}}$
,
${\mathcal{W}}_{\rho \wedge 1}({\mathcal{P}}_{\gamma}(x, \cdot), {\mathcal{P}}_{\gamma}(y, \cdot)) \le (1-\kappa) \rho(x, y)$
. -
• (
$\rho$
-small.) Suppose, for some constants
$\alpha, \delta \in (0, 1)$
and every
$\gamma \in {\mathcal{Y}}$
, where
\[ \sup_{x, y \in C_{\gamma}} {\mathcal{W}}_{\rho \wedge 1}({\mathcal{P}}_{\gamma}(x, \cdot), {\mathcal{P}}_{\gamma}(y, \cdot)) \le 1 - \alpha, \]
$C_{\gamma} = \{ x \in {\mathcal{X}} \colon V(\gamma, x) \le (1 + \delta) 2 K /(1 - \lambda) \}$
.
















Then there is an explicit
 $\alpha^* \in (0, 1)$
depending on
$\alpha^* \in (0, 1)$
depending on
 $\alpha, \kappa, \lambda$
such that, for every
$\alpha, \kappa, \lambda$
such that, for every
 $t \in {\mathbb{Z}}_+$
and every
$t \in {\mathbb{Z}}_+$
and every
 $\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
,
$\gamma, x \in {\mathcal{Y}} \times {\mathcal{X}}$
,
 $\alpha^* \in (0, 1)$
,
$\alpha^* \in (0, 1)$
,
 \[ {\mathcal{W}}_{\rho_{\gamma}}({\mathcal{P}}^{t}_{\gamma}(x, \cdot), \pi) \le (1 - \alpha^*)^{t} \sqrt{(1 + \beta^* V(\gamma, x) + (\alpha \wedge \kappa)/ [ 4(1 - \lambda)) ]}, \]
\[ {\mathcal{W}}_{\rho_{\gamma}}({\mathcal{P}}^{t}_{\gamma}(x, \cdot), \pi) \le (1 - \alpha^*)^{t} \sqrt{(1 + \beta^* V(\gamma, x) + (\alpha \wedge \kappa)/ [ 4(1 - \lambda)) ]}, \]
where
 $\rho_\gamma(u,v) = \sqrt{(\rho(u,v) \wedge 1)[1 + \beta^*V(\gamma,u) + \beta^*V(\gamma,v)]}$
and
$\rho_\gamma(u,v) = \sqrt{(\rho(u,v) \wedge 1)[1 + \beta^*V(\gamma,u) + \beta^*V(\gamma,v)]}$
and
 $\beta^* = ( \alpha \wedge \kappa )/(4K)$
.
$\beta^* = ( \alpha \wedge \kappa )/(4K)$
.
Proof. The argument is inspired by [Reference Hairer, Mattingly and Scheutzow20, Theorem 4.8]. Fix
 $\gamma \in {\mathcal{Y}}$
. For
$\gamma \in {\mathcal{Y}}$
. For
 $\beta > 0$
, define
$\beta > 0$
, define
 $\rho_{\beta,\gamma}(x,y) = \sqrt{(\rho(x,y) \wedge 1)(1 + \beta(V(\gamma,x) + V(\gamma,y))}$
. First, assume for
$\rho_{\beta,\gamma}(x,y) = \sqrt{(\rho(x,y) \wedge 1)(1 + \beta(V(\gamma,x) + V(\gamma,y))}$
. First, assume for
 $x, y \in {\mathcal{X}}$
that
$x, y \in {\mathcal{X}}$
that
 $\rho(x, y) \ge 1$
and
$\rho(x, y) \ge 1$
and
 $V(\gamma, x) + V(\gamma, y) > R$
. Now, for
$V(\gamma, x) + V(\gamma, y) > R$
. Now, for
 $\delta > 0$
, choose
$\delta > 0$
, choose
 $R = (1 + \delta) 2 K /(1 - \lambda)$
. Then, using the simultaneous drift condition,
$R = (1 + \delta) 2 K /(1 - \lambda)$
. Then, using the simultaneous drift condition,
 \begin{align*} {\mathcal{W}}_{\rho_{\beta, \gamma}}( {\mathcal{P}}_{\gamma}(x, \cdot), {\mathcal{P}}_{\gamma}(x, \cdot) )^2 & \le 1 + \beta {\mathcal{P}}_\gamma V(\gamma, x) + \beta {\mathcal{P}}_\gamma V(\gamma, y) \\ & \le 1 - \lambda + \lambda ( 1 + \beta V(\gamma, x) + \beta V(\gamma, y) ) + \beta 2 K \\ & \le \bigg[(1-\lambda)\frac{1+\beta2K/(1-\lambda)}{1+\beta R} + \lambda\bigg]\rho_{\beta,\gamma}(x,y)^2. \end{align*}
\begin{align*} {\mathcal{W}}_{\rho_{\beta, \gamma}}( {\mathcal{P}}_{\gamma}(x, \cdot), {\mathcal{P}}_{\gamma}(x, \cdot) )^2 & \le 1 + \beta {\mathcal{P}}_\gamma V(\gamma, x) + \beta {\mathcal{P}}_\gamma V(\gamma, y) \\ & \le 1 - \lambda + \lambda ( 1 + \beta V(\gamma, x) + \beta V(\gamma, y) ) + \beta 2 K \\ & \le \bigg[(1-\lambda)\frac{1+\beta2K/(1-\lambda)}{1+\beta R} + \lambda\bigg]\rho_{\beta,\gamma}(x,y)^2. \end{align*}
Now assume for
 $x, y \in {\mathcal{X}}$
that
$x, y \in {\mathcal{X}}$
that
 $\rho(x, y) \ge 1$
and
$\rho(x, y) \ge 1$
and
 $V(\gamma, x) + V(\gamma, y) \le R$
. Then, using that
$V(\gamma, x) + V(\gamma, y) \le R$
. Then, using that
 $C_\gamma$
is
$C_\gamma$
is
 $\rho$
-small and the simultaneous drift condition, and choosing
$\rho$
-small and the simultaneous drift condition, and choosing
 $\beta \le \alpha/(4K)$
,
$\beta \le \alpha/(4K)$
,
 \begin{align*} {\mathcal{W}}_{\rho_{\beta, \gamma}}( {\mathcal{P}}_{\gamma}(x, \cdot), {\mathcal{P}}_{\gamma}(x, \cdot) )^2 & \le (1 - \alpha)[1 + \beta {\mathcal{P}}_\gamma V(\gamma, x) + \beta {\mathcal{P}}_\gamma V(\gamma, y)] \\ & \le (1 - \alpha)\rho(x,y) \wedge 1[1 + \lambda\beta(V(x) + V(y)) + \beta 2 K] \\ & \le (1-\alpha/2) \rho_{\beta, \gamma}(x, y)^2. \end{align*}
\begin{align*} {\mathcal{W}}_{\rho_{\beta, \gamma}}( {\mathcal{P}}_{\gamma}(x, \cdot), {\mathcal{P}}_{\gamma}(x, \cdot) )^2 & \le (1 - \alpha)[1 + \beta {\mathcal{P}}_\gamma V(\gamma, x) + \beta {\mathcal{P}}_\gamma V(\gamma, y)] \\ & \le (1 - \alpha)\rho(x,y) \wedge 1[1 + \lambda\beta(V(x) + V(y)) + \beta 2 K] \\ & \le (1-\alpha/2) \rho_{\beta, \gamma}(x, y)^2. \end{align*}
Next, assume for
 $x, y \in {\mathcal{X}}$
that
$x, y \in {\mathcal{X}}$
that
 $\rho(x, y) < 1$
. Then, using
$\rho(x, y) < 1$
. Then, using
 $\rho$
-contracting and the simultaneous drift condition with
$\rho$
-contracting and the simultaneous drift condition with
 $\beta \le \kappa/(4 K)$
,
$\beta \le \kappa/(4 K)$
,
 \begin{align*} {\mathcal{W}}_{\rho_{\beta, \gamma}}( {\mathcal{P}}_{\gamma}(x, \cdot), {\mathcal{P}}_{\gamma}(x, \cdot) )^2 & \le (1 - \kappa)\rho(x,y)[1 + \beta{\mathcal{P}}_\gamma V(\gamma, x) + \beta{\mathcal{P}}_\gamma V(\gamma, y)] \\ & \le \rho(x, y) \wedge 1[1 - \kappa + \beta2K + (1 - \kappa)\lambda\beta(V(\gamma,x) + V(\gamma,y))] \\ & \le (1 - \kappa/2) \rho_{\beta, \gamma}(x, y)^2. \end{align*}
\begin{align*} {\mathcal{W}}_{\rho_{\beta, \gamma}}( {\mathcal{P}}_{\gamma}(x, \cdot), {\mathcal{P}}_{\gamma}(x, \cdot) )^2 & \le (1 - \kappa)\rho(x,y)[1 + \beta{\mathcal{P}}_\gamma V(\gamma, x) + \beta{\mathcal{P}}_\gamma V(\gamma, y)] \\ & \le \rho(x, y) \wedge 1[1 - \kappa + \beta2K + (1 - \kappa)\lambda\beta(V(\gamma,x) + V(\gamma,y))] \\ & \le (1 - \kappa/2) \rho_{\beta, \gamma}(x, y)^2. \end{align*}
Theorem 3 can be seen as an extension of the simultaneous geometric drift and minorization conditions [Reference Roberts and Rosenthal32, Theorem 18]. We allow the drift function to depend on the adapted tuning parameter and the metric
 $\rho$
is not restricted to the Hamming metric. For drift functions V constant in
$\rho$
is not restricted to the Hamming metric. For drift functions V constant in
 $\gamma \in {\mathcal{Y}}$
so that we can write
$\gamma \in {\mathcal{Y}}$
so that we can write
 $V \colon {\mathcal{X}} \to [0, \infty)$
, we have the following result for the adaptive process if the conditions of Theorem 3 hold.
$V \colon {\mathcal{X}} \to [0, \infty)$
, we have the following result for the adaptive process if the conditions of Theorem 3 hold.
Theorem 4. Suppose the adaptive process
 $(\Gamma_t, X_t)_{t \ge 0}$
with initialization probability measure
$(\Gamma_t, X_t)_{t \ge 0}$
with initialization probability measure
 $\mu$
as in (1) constructed with Markov kernels
$\mu$
as in (1) constructed with Markov kernels
 $({\mathcal{P}}_\gamma)_{\gamma \in {\mathcal{Y}}}$
satisfies weak diminishing adaptation (6). Suppose the conditions of Theorem 3 are satisfied for
$({\mathcal{P}}_\gamma)_{\gamma \in {\mathcal{Y}}}$
satisfies weak diminishing adaptation (6). Suppose the conditions of Theorem 3 are satisfied for
 $({\mathcal{P}}_\gamma)_{\gamma \in {\mathcal{Y}}}$
with a drift function V constant in
$({\mathcal{P}}_\gamma)_{\gamma \in {\mathcal{Y}}}$
with a drift function V constant in
 $\gamma \in {\mathcal{Y}}$
. Then
$\gamma \in {\mathcal{Y}}$
. Then
 $\lim_{t\to\infty}{\mathcal{W}}_{\rho \wedge 1}(\mu{\mathcal{A}}^{(t)}, \pi) = 0$
.
$\lim_{t\to\infty}{\mathcal{W}}_{\rho \wedge 1}(\mu{\mathcal{A}}^{(t)}, \pi) = 0$
.
Proof. Since
 $\rho \wedge 1$
is bounded, it will suffice to assume that the adaptive process
$\rho \wedge 1$
is bounded, it will suffice to assume that the adaptive process
 $(\Gamma_t, X_t)_t$
is initialized at
$(\Gamma_t, X_t)_t$
is initialized at
 $\gamma_0, x_0 \in {\mathcal{Y}} \times {\mathcal{X}}$
. The conclusion follows from Theorem 1 if we verify weak containment (5). The conditions of Theorem 3 imply that, in order to satisfy weak containment, it suffices to show that
$\gamma_0, x_0 \in {\mathcal{Y}} \times {\mathcal{X}}$
. The conclusion follows from Theorem 1 if we verify weak containment (5). The conditions of Theorem 3 imply that, in order to satisfy weak containment, it suffices to show that
 $( V(X_t) )_t$
is bounded in probability. The geometric drift condition implies
$( V(X_t) )_t$
is bounded in probability. The geometric drift condition implies
 $( V(X_t) )_{t \ge 0}$
is bounded in probability by [Reference Roberts and Rosenthal32, Lemma 15] since it is constant in
$( V(X_t) )_{t \ge 0}$
is bounded in probability by [Reference Roberts and Rosenthal32, Lemma 15] since it is constant in
 $\gamma \in {\mathcal{Y}}$
.
$\gamma \in {\mathcal{Y}}$
.
To satisfy weak containment (5), Theorem 4 can be weakened to subgeometric rates of convergence. If there is a constant
 $M_0 > 0$
, a Borel measurable function
$M_0 > 0$
, a Borel measurable function
 $V \colon {\mathcal{X}} \to [0, \infty)$
such that
$V \colon {\mathcal{X}} \to [0, \infty)$
such that
 $( V(X_t) )_{t \ge 0}$
is bounded in probability, and a rate function
$( V(X_t) )_{t \ge 0}$
is bounded in probability, and a rate function
 $r \colon {\mathbb{Z}}_+ \to [0, 1]$
with
$r \colon {\mathbb{Z}}_+ \to [0, 1]$
with
 $\lim_{n \to \infty} r(n) = 0$
such that, for all
$\lim_{n \to \infty} r(n) = 0$
such that, for all
 $n, t \in {\mathbb{Z}}_+$
,
$n, t \in {\mathbb{Z}}_+$
,
 ${\mathcal{W}}_{\rho \wedge 1}\big( {\mathcal{P}}_{\Gamma_t}^n( X_t, \cdot ), \pi \big) \le M_0 r(n) V(X_t)$
, then weak containment (5) holds. For example, a polynomial drift condition is sufficient for
${\mathcal{W}}_{\rho \wedge 1}\big( {\mathcal{P}}_{\Gamma_t}^n( X_t, \cdot ), \pi \big) \le M_0 r(n) V(X_t)$
, then weak containment (5) holds. For example, a polynomial drift condition is sufficient for
 $( V(X_t) )_{t \ge 0}$
to be bounded in probability [Reference Bai, Roberts and Rosenthal3] and existing subgeometric rates of convergence for non-adapted Markov chains in Wasserstein distances can be modified to simultaneous versions [Reference Butkovsky8, Reference Durmus, Fort and Moulines14].
$( V(X_t) )_{t \ge 0}$
to be bounded in probability [Reference Bai, Roberts and Rosenthal3] and existing subgeometric rates of convergence for non-adapted Markov chains in Wasserstein distances can be modified to simultaneous versions [Reference Butkovsky8, Reference Durmus, Fort and Moulines14].
In certain cases, it can be difficult to find a drift function that does not change with
 $\gamma \in {\mathcal{Y}}$
and alternative techniques can be used to show (strong) containment. One successful strategy here is to only apply adaptation on a compact or bounded set of the state space [Reference Craiu, Gray, Latuszyński, Madras, Roberts and Rosenthal11, Theorem 21]. We will say adaptation is restricted to a Borel set
$\gamma \in {\mathcal{Y}}$
and alternative techniques can be used to show (strong) containment. One successful strategy here is to only apply adaptation on a compact or bounded set of the state space [Reference Craiu, Gray, Latuszyński, Madras, Roberts and Rosenthal11, Theorem 21]. We will say adaptation is restricted to a Borel set
 $S \subset {\mathcal{X}}$
for the adaptive process
$S \subset {\mathcal{X}}$
for the adaptive process
 $(\Gamma_t, X_t)_{t \ge 0}$
if, for all
$(\Gamma_t, X_t)_{t \ge 0}$
if, for all
 $t \in {\mathbb{Z}}_+$
,
$t \in {\mathbb{Z}}_+$
,
 $X_{t-1} \not\in S$
,
$X_{t-1} \not\in S$
,
 $\Gamma_t = \Gamma_{t-1}$
.
$\Gamma_t = \Gamma_{t-1}$
.
Our next result shows the benefit of Theorem 3 with drift functions depending on the adapted tuning parameter if adaptation is restricted to a set.
Proposition 6. Suppose the adaptive process
 $(\Gamma_t, X_t)_{t \ge 0}$
with initialization probability measure
$(\Gamma_t, X_t)_{t \ge 0}$
with initialization probability measure
 $\mu$
as in (1) constructed with Markov kernels
$\mu$
as in (1) constructed with Markov kernels
 $({\mathcal{P}}_\gamma)_{\gamma \in {\mathcal{Y}}}$
satisfies weak diminishing adaptation (6). Suppose the conditions of Theorem 3 are satisfied with Markov kernels
$({\mathcal{P}}_\gamma)_{\gamma \in {\mathcal{Y}}}$
satisfies weak diminishing adaptation (6). Suppose the conditions of Theorem 3 are satisfied with Markov kernels
 $({\mathcal{P}}_\gamma)_{\gamma \in {\mathcal{Y}}}$
and drift function
$({\mathcal{P}}_\gamma)_{\gamma \in {\mathcal{Y}}}$
and drift function
 $V(\cdot, \cdot)$
. Additionally, assume
$V(\cdot, \cdot)$
. Additionally, assume
 $(\Gamma_t, X_t)_{t \ge 0}$
has adaptation restricted to the Borel set
$(\Gamma_t, X_t)_{t \ge 0}$
has adaptation restricted to the Borel set
 $S \subset {\mathcal{X}}$
and
$S \subset {\mathcal{X}}$
and
 $\sup_{x \in S}\sup_{t \in {\mathbb{Z}}_+}{\mathbb{E}}[V(\Gamma_{t + 1}, X_{t + 1}) \mid {\mathcal{H}}_{t}, X_{t} = x] < \infty$
. Then
$\sup_{x \in S}\sup_{t \in {\mathbb{Z}}_+}{\mathbb{E}}[V(\Gamma_{t + 1}, X_{t + 1}) \mid {\mathcal{H}}_{t}, X_{t} = x] < \infty$
. Then
 $\lim_{t\to\infty}{\mathcal{W}}_{\rho \wedge 1}(\mu{\mathcal{A}}^{(t)}, \pi) = 0$
.
$\lim_{t\to\infty}{\mathcal{W}}_{\rho \wedge 1}(\mu{\mathcal{A}}^{(t)}, \pi) = 0$
.
Proof. It will suffice to assume the adaptive process
 $(\Gamma_t, X_t)_t$
is initialized at
$(\Gamma_t, X_t)_t$
is initialized at
 $\gamma_0, x_0 \in {\mathcal{Y}} \times {\mathcal{X}}$
, and by Theorem 1 we may show that
$\gamma_0, x_0 \in {\mathcal{Y}} \times {\mathcal{X}}$
, and by Theorem 1 we may show that
 $(V(\Gamma_t, X_t))_t$
is bounded in probability. By the assumptions, we can assume that
$(V(\Gamma_t, X_t))_t$
is bounded in probability. By the assumptions, we can assume that
 ${\mathbb{E}}[ V(\Gamma_t, X_t) I_{S}(X_{t-1}) ] \le K$
. We have the upper bound
${\mathbb{E}}[ V(\Gamma_t, X_t) I_{S}(X_{t-1}) ] \le K$
. We have the upper bound
 \begin{align*} {\mathbb{E}}[V(\Gamma_t, X_t)] & \le {\mathbb{E}}[V(\Gamma_t, X_t)I_{S}(X_{t-1})] + {\mathbb{E}}[V(\Gamma_t, X_t)I_{S^\mathrm{c}}(X_{t-1})] \\ & \le K + {\mathbb{E}}[V(\Gamma_{t-1}, X_t)I_{S^\mathrm{c}}(X_{t-1})] \\ & \le 2K + \lambda{\mathbb{E}}[V(\Gamma_{t-1}, X_{t-1})] \le 2K/(1 - \lambda) + V(\gamma_0, x_0). \end{align*}
\begin{align*} {\mathbb{E}}[V(\Gamma_t, X_t)] & \le {\mathbb{E}}[V(\Gamma_t, X_t)I_{S}(X_{t-1})] + {\mathbb{E}}[V(\Gamma_t, X_t)I_{S^\mathrm{c}}(X_{t-1})] \\ & \le K + {\mathbb{E}}[V(\Gamma_{t-1}, X_t)I_{S^\mathrm{c}}(X_{t-1})] \\ & \le 2K + \lambda{\mathbb{E}}[V(\Gamma_{t-1}, X_{t-1})] \le 2K/(1 - \lambda) + V(\gamma_0, x_0). \end{align*}
Therefore,
 $( V(\Gamma_t, X_t) )_t$
is bounded in probability by Markov’s inequality.
$( V(\Gamma_t, X_t) )_t$
is bounded in probability by Markov’s inequality.
9. Concluding remarks
This article developed weak convergence of adaptive MCMC processes under general conditions that is suited to situations where convergence in total variation is inadequate. One motivation is adapting the tuning parameters of reducible Markov chains where the traditional theory of adaptive MCMC may not be applied. Another application of the developed theory can be used to analyze adaptive MCMC processes where (strong) containment is difficult to show but weak containment may be more tractable. The weak law of large numbers developed here can be seen as an extension of [Reference Roberts and Rosenthal32, Theorem 23] and appears of practical interest for the reliability and stability of adaptive MCMC simulations widely used in statistics and machine learning.
There are many future research directions worthy of pursuit. While the developed theory for weak convergence allows a Markov process in continuous time to be adapted at discrete times, the proof techniques do not appear limited to discrete-time adaptive processes. In particular, a precise formulation of an adaptive MCMC process in continuous time with similar convergence results appears feasible. It also appears that some techniques for the convergence results developed here might be extended to develop quantitative convergence rates in Wasserstein distances or mixing times for adaptive MCMC, but would require stronger assumptions on the adaptation plan. Another interesting direction is to try to generalize Theorem 1 to hold for general, possibly unbounded, Wassserstein distances by adapting weak containment and weak diminishing adaptation to hold using general Wasserstein distances.
Acknowledgements
The authors would like to thank the Associate Editor and the two anonymous referees for their insightful comments in helping to improve this article.
Funding information
This work was partially funded by NSERC Discovery Grant RGPIN-2019-04142, and by a postdoctoral fellowship at the University of Toronto.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.


 Open access
Open access