





Impact Statement
In many low-income countries, air quality monitors are few and far between. Even with the development of an air quality monitoring network, many locations remain unmonitored, resulting in unknown air quality due to the absence of air quality sensors. The methodology in this study provides an approach to understanding exposure to particulate matter in a given geographical area with a sparse distribution of air quality sensors. This study is especially important because very limited studies have so far been done in this geographic area, and it can be replicated in other areas with similar conditions. Additionally, it provides insightful information that has a broader impact on health, environmental sustainability, and government policy in the region.
1. Introduction
Air pollution is one of the world’s biggest environmental health problems (Ritchie and Roser, Reference Ritchie and Roser2017), and ambient (outdoor) air pollution is estimated to account for around 4.2 million annual deaths worldwide (World Health Organization, 2022). It has also been shown that low- and middle-income countries are disproportionately affected by the effects of air pollution (OECD iLibrary, 2017), and yet, in many of these countries, air quality monitoring networks are sparse or nonexistent. For example, in sub-Saharan Africa, only a handful of countries, for example, South Africa (The World Air Quality Index Project, 2008), Uganda (AIRQO Africa, 2018), Kenya (Nairobi City County, 2023), and Rwanda (Rwanda Air Quality, 2021), have established continuous air quality networks, and mostly driven by research-led initiatives in recent years. Many African urban areas exhibit significant variations in pollution profiles (Dobson et al., Reference Dobson, Siddiqi, Ferdous, Huque, Lesosky, Balmes and Semple2021; Green et al., Reference Green, Okure, Adong, Sserunjogi and Bainomugisha2022), which necessitates high-resolution monitoring, yet the resource constraints prohibit establishing continuous monitoring networks. Spatial predictions have the potential to close the data gaps in areas with limited monitoring networks.
In this article, we present a novel case study of spatial prediction of two cities (Kampala and Jinja) in Uganda, a country in Eastern Africa. We selected Uganda primarily due to the presence of a recently established continuous air quality network of PM
 $ {}_{2.5} $
and PM
$ {}_{2.5} $
and PM
 $ {}_{10} $
sensors, developed and managed by AirQo (Sserunjogi et al., Reference Sserunjogi, Ssematimba, Okure, Ogenrwot, Adong, Muyama, Nsimbe, Bbaale and Bainomugisha2022; AIRQO Africa 2018). This network employs calibrated low-cost sensors (Adong et al., Reference Adong, Bainomugisha, Okure and Sserunjogi2022) to contribute to a more precise understanding of the air quality in the country. This information could, in turn, be used to inform decision-making and policy. In addition, Uganda is a low-income sub-Saharan African country with a highly variable pollution profile (Kirenga et al., Reference Kirenga, Meng, Van Gemert, Aanyu-Tukamuhebwa, Chavannes, Katamba, Obai, Van der Molen, Schwander and Mohsenin2015; Okure et al., Reference Okure, Ssematimba, Sserunjogi, Gracia, Soppelsa and Bainomugisha2022), which may be due to differences in activity rates, population levels, and traffic levels, among others. Since urban centers are more polluted than rural areas, we chose the two most populated and highly urbanised cities in the country for this study. Kampala is Uganda’s capital city, while Jinja is a historically large industrial hub in the country (Uganda Investment Authority, 2022). In our study, we specifically look at particulate matter (PM) with a diameter ≤2.5 μm, that is, PM
$ {}_{10} $
sensors, developed and managed by AirQo (Sserunjogi et al., Reference Sserunjogi, Ssematimba, Okure, Ogenrwot, Adong, Muyama, Nsimbe, Bbaale and Bainomugisha2022; AIRQO Africa 2018). This network employs calibrated low-cost sensors (Adong et al., Reference Adong, Bainomugisha, Okure and Sserunjogi2022) to contribute to a more precise understanding of the air quality in the country. This information could, in turn, be used to inform decision-making and policy. In addition, Uganda is a low-income sub-Saharan African country with a highly variable pollution profile (Kirenga et al., Reference Kirenga, Meng, Van Gemert, Aanyu-Tukamuhebwa, Chavannes, Katamba, Obai, Van der Molen, Schwander and Mohsenin2015; Okure et al., Reference Okure, Ssematimba, Sserunjogi, Gracia, Soppelsa and Bainomugisha2022), which may be due to differences in activity rates, population levels, and traffic levels, among others. Since urban centers are more polluted than rural areas, we chose the two most populated and highly urbanised cities in the country for this study. Kampala is Uganda’s capital city, while Jinja is a historically large industrial hub in the country (Uganda Investment Authority, 2022). In our study, we specifically look at particulate matter (PM) with a diameter ≤2.5 μm, that is, PM
 $ {}_{2.5} $
, because it has been shown to have adverse health effects (Curtis et al., Reference Curtis, Rea, Smith-Willis, Fenyves and Pan2006; Laumbach, Reference Laumbach2010; Zheng et al., Reference Zheng, Pozzer, Cao and Lelieveld2015). We utilize the existing network to predict PM
$ {}_{2.5} $
, because it has been shown to have adverse health effects (Curtis et al., Reference Curtis, Rea, Smith-Willis, Fenyves and Pan2006; Laumbach, Reference Laumbach2010; Zheng et al., Reference Zheng, Pozzer, Cao and Lelieveld2015). We utilize the existing network to predict PM
 $ {}_{2.5} $
concentrations in locations without sensors and demonstrate the potential to use spatial predictions to close the data gaps in other low- and middle-income countries.
$ {}_{2.5} $
concentrations in locations without sensors and demonstrate the potential to use spatial predictions to close the data gaps in other low- and middle-income countries.
Previous work has largely focused on forecasting the air quality of a location by relying on historical data from the same location (Vong et al., Reference Vong, Ip, Wong and Yang2012; Petelin et al., Reference Petelin, Grancharova and Kocijan2013; Jaiswal et al., Reference Jaiswal, Samuel and Kadabgaon2018; Lei et al., Reference Lei, Monjardino, Mendes, Gonçalves and Ferreira2019), or by employing weather parameters to predict the air quality of an area (Yu et al., Reference Yu, Yang, Yang, Han and Move2016; Athira et al., Reference Athira, Geetha, Vinayakumar and Soman2018; Liu et al., Reference Liu, Yang, Huang, Wang and Yoo2018; Wang and Song, Reference Wang and Song2018; Khurram and Lim, Reference Khurram and Lim2024; Lim et al., Reference Lim, Owusu, Thongrod, Khurram, Pongsiri, Ingviya and Buya2024). These studies employ a range of approaches, encompassing deterministic approaches, such as chemical transport models (CTMs), which are known for their computational intensity and substantial data requirements. Machine learning (ML) techniques, such as decision trees, support vector machines, and neural networks, have also been leveraged. For instance, long short-term memory (LSTM) is used in (Mao et al., Reference Mao, Wang, Jiao, Zhao and Liu2021) to predict the future air quality of an area based on previous air quality readings, while (Khurram and Lim, Reference Khurram and Lim2024) used lag-dependent Gaussian process (GP) models to predict and forecast PM
 $ {}_{2.5} $
, PM
$ {}_{2.5} $
, PM
 $ {}_{10} $
, O
$ {}_{10} $
, O
 $ {}_3 $
, NO
$ {}_3 $
, NO
 $ {}_2 $
, and CO. Additional approaches that are used in previous works are more extensively discussed in Section 2.
$ {}_2 $
, and CO. Additional approaches that are used in previous works are more extensively discussed in Section 2.
In contrast to the above works, this article aims to investigate whether historical data from multiple air quality sensors can be used to accurately predict the air quality in another location. Consequently, this method is more applicable in areas lacking an air quality sensor or historical air quality data. This is a somewhat different task from the previous studies. We therefore propose to use GPs because of their non-linearity and their ability to provide uncertainty estimates. Additionally, the nature of the data, which is time-dependent and periodic, makes GPs the most appropriate solution for this problem.
The main contributions of this article include:
-
• We propose an air quality prediction approach for a location based on using only historical air quality observations from other locations in two urban settings in sub-Saharan Africa. We consider the similarity of air quality levels that are closer distance-wise and/or time-wise.
-
• We demonstrate the use of GP Regression (GPR) for PM
 $ {}_{2.5} $
prediction, and we show that there is a relationship between the quality of the prediction and the rate of change in PM
$ {}_{2.5} $
concentration, regardless of distance and time.
$ {}_{2.5} $
prediction, and we show that there is a relationship between the quality of the prediction and the rate of change in PM
$ {}_{2.5} $
concentration, regardless of distance and time. -
• We evaluate our approach using leave-one-out cross-validation, whereby we predict PM
$ {}_{2.5} $
levels of a location using data from the rest of the locations. Our approach performed well in both use cases, providing useful predictions that may be used to guide interventions and policy.



The rest of the article is structured as follows: Section 2 presents the previous studies that are related to this work; Section 3 introduces the methods that were used to conduct the study; and Section 4 shows the results of these methods. In Section 5, the implication of these results and the challenges faced are discussed, while Section 6 presents the conclusions made and the direction of future works.
2. Related work
Previous approaches to the problem of air quality prediction can be divided into two broad categories, that is, deterministic and statistical approaches. One such deterministic approach is the operational street pollution model (OSPM) (Hertel et al., Reference Hertel, Berkowicz, Larssen, van Dop and Steyn1991), which has been used to model air pollution in various cities. Hung et al. (Reference Hung, Ketzel, Jensen and Oanh2010) used OSPM to estimate the air pollution levels for five streets in Hanoi, Vietnam. In addition to existing pollutants including various nitrogen oxides, carbon monoxide, sulfur dioxide, and benzene, the OSPM model also requires, as part of its input, the street and building configuration, hourly traffic emissions data, hourly meteorological data, hourly urban background concentration data, and so forth All these data are subsequently used to calculate the street pollution level. Similarly, Ketzel et al. (Reference Ketzel, Jensen, Brandt, Ellermann, Olesen, Berkowicz and Hertel2012) used OSPM to predict air quality measurements over a multiyear period in Copenhagen, Denmark. They used measurements of various nitrogen oxides as well as PM
 $ {}_{2.5} $
and PM
$ {}_{2.5} $
and PM
 $ {}_{10} $
, in conjunction with traffic emission data and the street and building configurations. However, this model is specific to traffic-based emissions. It also requires various nontrivial input data that may be complicated to obtain, especially at an hourly time resolution, and is therefore difficult to use.
$ {}_{10} $
, in conjunction with traffic emission data and the street and building configurations. However, this model is specific to traffic-based emissions. It also requires various nontrivial input data that may be complicated to obtain, especially at an hourly time resolution, and is therefore difficult to use.
CTMs (Seigneur and Dennis, Reference Seigneur, Dennis, Hidy, Brook, Demerjian, Molina, Pennell and Scheffe2011) are another type of deterministic approach for air quality prediction. Uno et al. (Reference Uno, Carmichael, Streets, Tang, Yienger, Satake, Wang, Woo, Guttikunda, Uematsu, Matsumoto, Tanimoto, Yoshioka and Iida2003) provided a detailed description of a CTM, that is, Chemical Weather Forecast System, which was used in the prediction of several pollutants such as carbon monoxide, sulfate radon, and mineral dust. Finardi et al. (Reference Finardi, De Maria, D’Allura, Cascone, Calori and Lollobrigida2008) developed a forecasting system for the prevention and management of air pollution episodes for PM
 $ {}_{10} $
, NO
$ {}_{10} $
, NO
 $ {}_2 $
, and O
$ {}_2 $
, and O
 $ {}_3 $
partially based on a CTM simulation. Likewise, Stroud et al. (Reference Stroud, Moran, Makar, Gong, Gong, Zhang, Slowik, Abbatt, Lu, Brook, Mihele, Li, Sills, Strawbridge, McGuire and Evans2012) used a CTM to make predictions of primary organic aerosol, black carbon, and carbon monoxide. In a study by Roozitalab et al. (Reference Roozitalab, Carmichael and Guttikunda2021), a CTM was used in the prediction of an extreme pollution event in the Indo-Gangetic Plain. However, these models are very computationally expensive. They also require updated current emissions data of the area for which the prediction is to be made, which data are not always readily available, and which in turn can affect the accuracy of the results.
$ {}_3 $
partially based on a CTM simulation. Likewise, Stroud et al. (Reference Stroud, Moran, Makar, Gong, Gong, Zhang, Slowik, Abbatt, Lu, Brook, Mihele, Li, Sills, Strawbridge, McGuire and Evans2012) used a CTM to make predictions of primary organic aerosol, black carbon, and carbon monoxide. In a study by Roozitalab et al. (Reference Roozitalab, Carmichael and Guttikunda2021), a CTM was used in the prediction of an extreme pollution event in the Indo-Gangetic Plain. However, these models are very computationally expensive. They also require updated current emissions data of the area for which the prediction is to be made, which data are not always readily available, and which in turn can affect the accuracy of the results.
Statistical approaches have also been utilized in the prediction of air quality levels. Lei et al. (Reference Lei, Monjardino, Mendes, Gonçalves and Ferreira2019) predicted air quality levels for the next day using multiple linear regression, and classification and regression trees. Historical air quality data over a 5-year period, as well as meteorological data, were utilized in this study. Similarly, using annual concentration levels of various pollutants, Jaiswal et al. (Reference Jaiswal, Samuel and Kadabgaon2018) applied the autoregressive integrated moving average model to predict future annual concentrations. This was done for CO, NO
 $ {}_2 $
, SO
$ {}_2 $
, SO
 $ {}_2 $
, and PM.
$ {}_2 $
, and PM.
Traditional ML methods (Mitchell, Reference Mitchell1997) have been applied to the air quality prediction task as well. Vong et al. (Reference Vong, Ip, Wong and Yang2012) used support vector machine (SVM) to forecast daily ambient air pollution using meteorological (temperature, humidity, rainfall, wind direction, wind speed, and precipitation) and pollutant (NO
 $ {}_2 $
, SO
$ {}_2 $
, SO
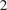 $ {}_2 $
, suspended PM, and O
$ {}_2 $
, suspended PM, and O
 $ {}_3 $
) features. Data from the previous day and the current day were used to forecast the pollution level of the different pollutants for the next day. Similarly, Song et al. (\ Reference Song, Pang, Longley, Olivares and Sarrafzadeh2014) used support vector regression for PM
$ {}_3 $
) features. Data from the previous day and the current day were used to forecast the pollution level of the different pollutants for the next day. Similarly, Song et al. (\ Reference Song, Pang, Longley, Olivares and Sarrafzadeh2014) used support vector regression for PM
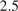 $ {}_{2.5} $
prediction. Likewise, Yu et al. (Reference Yu, Yang, Yang, Han and Move2016) employed random forest (RF) to predict the air quality concentration given meteorological data (temperature, humidity, barometric pressure, wind speed visibility), the length of the road, the traffic congestion status of the road and point of interest distribution which shows the land use of the area. By applying RF to these hourly data, they were able to predict the Air Quality Index (AQI) level of specific locations. In a study by Zhang et al. (Reference Zhang, Wang, Gao, Ma, Zhao, Zhang, Wang and Huang2019), light gradient-boosting machine (LightGBM) was used to predict PM
$ {}_{2.5} $
prediction. Likewise, Yu et al. (Reference Yu, Yang, Yang, Han and Move2016) employed random forest (RF) to predict the air quality concentration given meteorological data (temperature, humidity, barometric pressure, wind speed visibility), the length of the road, the traffic congestion status of the road and point of interest distribution which shows the land use of the area. By applying RF to these hourly data, they were able to predict the Air Quality Index (AQI) level of specific locations. In a study by Zhang et al. (Reference Zhang, Wang, Gao, Ma, Zhao, Zhang, Wang and Huang2019), light gradient-boosting machine (LightGBM) was used to predict PM
 $ {}_{2.5} $
levels in Beijing over the next 24 hours. They used meteorological data such as temperature and humidity, temporal features such as the day of the week and the hour of day, air quality data from other pollutants, namely, CO, SO
$ {}_{2.5} $
levels in Beijing over the next 24 hours. They used meteorological data such as temperature and humidity, temporal features such as the day of the week and the hour of day, air quality data from other pollutants, namely, CO, SO
 $ {}_2 $
, NO
$ {}_2 $
, NO
 $ {}_2 $
, O
$ {}_2 $
, O
 $ {}_3 $
, and PM
$ {}_3 $
, and PM
 $ {}_{10} $
, as well as the weather forecast for the next 24 hours. Additional studies have also analyzed and compared the performance of various ML methods for this problem (Doreswamy et al., Reference Doreswamy, Harishkumar, Yogesh and Gad2020; Liang et al., Reference Liang, Maimury, Chen and Juarez2020).
$ {}_{10} $
, as well as the weather forecast for the next 24 hours. Additional studies have also analyzed and compared the performance of various ML methods for this problem (Doreswamy et al., Reference Doreswamy, Harishkumar, Yogesh and Gad2020; Liang et al., Reference Liang, Maimury, Chen and Juarez2020).
More recently, with the exponential increase in data available, there has been a resurgence in the usage of deep learning methods (LeCun et al., Reference LeCun, Bengio and Hinton2015) to accomplish a multitude of tasks. Wang and Wang (Reference Wang and Song2018) built an ensemble model comprised of three components to predict air quality. The predictor component was based on LSTM, and the features considered were meteorological as well as spatial–temporal features. Similarly, Mao et al. (Reference Mao, Wang, Jiao, Zhao and Liu2021) used deep learning to predict the air quality for the next 24 hours using historical hourly air quality measurements. Likewise, using meteorological data such as temperature and humidity as well as spatial features, Athira et al. (Reference Athira, Geetha, Vinayakumar and Soman2018) forecast PM
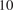 $ {}_{10} $
values utilizing three deep learning architectures, namely, recurrent neural network (RNN), LSTM, and gated recurrent unit. Other papers that use LSTM include (Kim et al., Reference Kim, Park, Song, Lee, Yun, Kim, Jeon, Lee and Han2019; Qin et al., Reference Qin, Yu, Zou, Yong, Zhao and Zhang2019; Kalajdjieski et al., Reference Kalajdjieski, Mirceva and Kalajdziski2020; Lin et al., Reference Lin, Chen, Yang, Xu and Fang2020). However, these studies are all mainly based on historical air quality and weather data, and/or features of a specific location, and yet in many cases, such data are not readily available due to a multitude of reasons such as the absence of an air quality monitoring station.
$ {}_{10} $
values utilizing three deep learning architectures, namely, recurrent neural network (RNN), LSTM, and gated recurrent unit. Other papers that use LSTM include (Kim et al., Reference Kim, Park, Song, Lee, Yun, Kim, Jeon, Lee and Han2019; Qin et al., Reference Qin, Yu, Zou, Yong, Zhao and Zhang2019; Kalajdjieski et al., Reference Kalajdjieski, Mirceva and Kalajdziski2020; Lin et al., Reference Lin, Chen, Yang, Xu and Fang2020). However, these studies are all mainly based on historical air quality and weather data, and/or features of a specific location, and yet in many cases, such data are not readily available due to a multitude of reasons such as the absence of an air quality monitoring station.
Iyer et al. (Reference Iyer, Balashankar, Aeberhard, Bhattacharyya, Rusconi, Jose, Soans, Sudarshan, Pande and Subramanian2022) used message-passing RNNs (MPRNNs) to model air pollution maps for Delhi, India, using a network of 60 air quality monitors, including both low cost and reference grade air quality monitors. PM
 $ {}_{2.5} $
data collected at an hourly resolution over a two-year period were used to train the models and make predictions up to an hour in advance. However, in our study, we aim to use readings from only low-cost air quality monitors. Also, Delhi may have a different air quality profile from the two Ugandan cities because of different climatic conditions and different sources of air pollution, among other reasons.
$ {}_{2.5} $
data collected at an hourly resolution over a two-year period were used to train the models and make predictions up to an hour in advance. However, in our study, we aim to use readings from only low-cost air quality monitors. Also, Delhi may have a different air quality profile from the two Ugandan cities because of different climatic conditions and different sources of air pollution, among other reasons.
In addition, a few studies have employed GPs (Rasmussen, Reference Rasmussen, Bousquet, von Luxburg and Rätsch2003), such as in Liu et al. (Reference Liu, Yang, Huang, Wang and Yoo2018) where a GPR model was used to model the indoor air quality of a subway. Seven indoor pollutants and two meteorological variables, that is, temperature and humidity, were used in this study. Similarly, in Petelin et al. (Reference Petelin, Grancharova and Kocijan2013), various first and high-order GP models were used to predict the ozone concentration in the air of Bourgas in Bulgaria, utilizing hourly measurements of ozone, sulfur dioxide, nitrogen dioxide, phenol, and benzene plus several meteorological parameters. In our study, we focus on PM
 $ {}_{2.5} $
prediction while using only air quality measurements from a network of low-cost monitoring devices.
$ {}_{2.5} $
prediction while using only air quality measurements from a network of low-cost monitoring devices.
In this study, we propose to use GPR to predict the outdoor PM
 $ {}_{2.5} $
concentration of a geographical location without any historical or current air quality information using only the PM
$ {}_{2.5} $
concentration of a geographical location without any historical or current air quality information using only the PM
 $ {}_{2.5} $
data collected from air quality monitoring devices in other areas, as well as the spatial (latitude and longitude) and temporal (time) features of those readings.
$ {}_{2.5} $
data collected from air quality monitoring devices in other areas, as well as the spatial (latitude and longitude) and temporal (time) features of those readings.
3. Methodology
3.1. Study areas
This study considered two cities in Uganda, namely Kampala and Jinja, which are located in the Central and Eastern regions of the country. Figure 1 depicts a map of Uganda showing the location of the two cities. We focused on two cities because it is demonstrated in Cross (Reference Cross2021) that air quality levels are generally worse in urban areas than in rural areas. It is also shown in Mcdonald (Reference Mcdonald2012) that areas with high commercial activity experience higher pollution.

Figure 1. A map of Uganda showing the locations of Kampala and Jinja cities.
Kampala is the capital city of Uganda and is situated in the central region of the country, just North of Lake Victoria, at an average altitude of about 1190 m (The Editors of Encyclopaedia Britannica, 2024). Over the past years, Kampala’s air quality has been found to be up to 11 times the World Health Organization (WHO) health guidelines (Adong et al., Reference Adong, Bainomugisha, Okure and Sserunjogi2022; Okure et al., Reference Okure, Ssematimba, Sserunjogi, Gracia, Soppelsa and Bainomugisha2022). This is to be expected given the high population density as the Kampala metropolitan area is estimated to be home to around 10% of the entire country’s population (The World Bank, 2018).
On the other hand, Jinja, which has the second largest economy, lies about 81 km to the East of Kampala along the Northern shore of Lake Victoria. It lies at an estimated altitude of about 1140 meters (The Editors of Encyclopaedia Britannica, 2023) and also hosts the Nile River. Since Jinja only acquired its city status in 2020, the total population is uncertain, but estimates put it at about 300,000 (Kazungu, Reference Kazungu2020). It is also a big industrial hub hosting over 100 manufacturing industries (Uganda Investment Authority, 2022). Maps showing some of the locations of the air quality monitors used in this study for Kampala and Jinja are shown in Figures 2 and 3, respectively. More contextual details on Kampala and Jinja can be found in Vermeiren et al. (Reference Vermeiren, Van Rompaey, Loopmans, Serwajja and Mukwaya2012) and McQuaid et al. (Reference McQuaid, Vanderbeck, Valentine, Liu, Chen, Zhang and Diprose2018) respectively.

Figure 2. A map of Kampala showing some of the sensor locations.

Figure 3. A map of Jinja showing the sensor locations used in this study.
3.2. Dataset description
We consider a dataset from a distributed network of low-cost air quality sensors (Sserunjogi et al., Reference Sserunjogi, Ssematimba, Okure, Ogenrwot, Adong, Muyama, Nsimbe, Bbaale and Bainomugisha2022), which currently has over 100 devices installed in Uganda. With the aim of providing air quality data for locations with diverse features, the sites in which these devices are installed are, therefore, selected based on various factors, such as, population density, land use, traffic levels, and nearness to known pollution sources such as dusty roads. The devices primarily measure PM
 $ {}_{2.5} $
and PM
$ {}_{2.5} $
and PM
 $ {}_{10} $
. However, as shown in Figures 2 and 3, there exist several locations that do not have an air quality monitor. To understand the air quality in these areas, we use the data from the existing network devices to predict what the air quality is in these areas.
$ {}_{10} $
. However, as shown in Figures 2 and 3, there exist several locations that do not have an air quality monitor. To understand the air quality in these areas, we use the data from the existing network devices to predict what the air quality is in these areas.
In addition, for our experiments, we use calibrated data because low-cost sensors can be affected by weather conditions, notably, temperature and relative humidity, such that there may be some inconsistency between their measurements and the ground truth (Adong et al., Reference Adong, Bainomugisha, Okure and Sserunjogi2022; Davda, Reference Davda2023). Low-cost sensors are portable and affordable air quality monitors usually costing between $100 and $2000 USD that provide high temporal and spatial resolution data, though they often require calibration to ensure measurement accuracy and reliability (Adong et al., Reference Adong, Bainomugisha, Okure and Sserunjogi2022; Bainomugisha et al., Reference Bainomugisha, Ssematimba, Okedi, Nsubuga, Banda, Settala and Lubisia2023). Therefore, device calibration ensures that our results are more reliable and accurate. The calibration function is derived using data from reference-grade air quality monitors, which in our case are Met One Beta Attenuation Monitors Model 1022 (Met One Instruments, 2023), as well as data from low-cost monitors that are collocated with these reference monitors (Adong et al., Reference Adong, Bainomugisha, Okure and Sserunjogi2022).
We considered the data for a three-month period, that is, from 1 September 2021 to 30 November 2021. We chose this time period because, although both cities had established air quality networks at that point, several areas within the cities still lacked air quality monitors, and thus were not well covered by the networks. The data were collected from 34 and 10 air quality monitors for Kampala and Jinja, respectively, and a total of 48,112 and 13,653 records were used for the two locations. The data were recorded at an hourly interval. The features considered were latitude, longitude, and time. Meteorological features were considered, that is, temperature, relative humidity, wind speed, and wind direction, but these did not have any significant effect on the model performance hence why they are not included in the final results. During the study period, the average meteorological conditions in Kampala and Jinja were generally warm and humid. Kampala exhibited a mean temperature of 22.09 °C, mean relative humidity of 82.16%, and a modest mean wind speed of 0.81 m/s. In contrast, Jinja experienced slightly higher temperatures, averaging 22.57 °C, slightly lower mean relative humidity at 77.34%, and stronger wind speeds averaging 3.42 m/s. Comparable observations are reported in a 3-year study (Alaran et al., Reference Alaran, Natasha, Lambed, Sserunjogi and Okello2024), which explored seasonal and spatial PM
 $ {}_{2.5} $
and the meteorological influence on it across Kampala and Jinja. A summary of the meteorological conditions during this period is provided in Appendix A.
$ {}_{2.5} $
and the meteorological influence on it across Kampala and Jinja. A summary of the meteorological conditions during this period is provided in Appendix A.
During data preprocessing, all rows containing missing PM
 $ {}_{2.5} $
values were dropped. Additionally, the datetime column was converted to a timestamp and divided by 3600, which is the number of seconds in an hour.
$ {}_{2.5} $
values were dropped. Additionally, the datetime column was converted to a timestamp and divided by 3600, which is the number of seconds in an hour.
3.3. Methods
For this task, we propose to use GPR because it is an efficient nonparametric method for modeling nonlinear problems, which, in addition to providing the predictions, also provides uncertainty estimates over those predictions and hence is useful for quantifying their reliability. GPR models also have a variety of kernels which are able to model almost any task and are thus very flexible (Rasmussen, Reference Rasmussen, Bousquet, von Luxburg and Rätsch2003; Seeger, Reference Seeger2004).
In (Rasmussen, Reference Rasmussen, Bousquet, von Luxburg and Rätsch2003), a GP is defined as a collection of random variables, any finite number of which have (consistent) joint Gaussian distributions. A GP is defined by its mean and covariance function as shown in Equation 3.1, where
 $ \mu $
and
$ \mu $
and
 $ \Sigma $
denote the mean and covariance function or kernel, respectively.
$ \Sigma $
denote the mean and covariance function or kernel, respectively.
 $$ f\sim \mathcal{N}\left(\mu, \Sigma \right)\hskip0.1em $$
$$ f\sim \mathcal{N}\left(\mu, \Sigma \right)\hskip0.1em $$
In GPR, it is assumed that the observations are drawn from a noisy function as shown in Equation 3.2, where the additive noise,
 $ \unicode{x025B} $
, is defined by a mean of 0 and a variance of
$ \unicode{x025B} $
, is defined by a mean of 0 and a variance of
 $ {\sigma}_n^2 $
.
$ {\sigma}_n^2 $
.
 $$ y=f(X)+\unicode{x025B}, \unicode{x025B} \sim \mathcal{N}\left(0,{\sigma}_n^2\right) $$
$$ y=f(X)+\unicode{x025B}, \unicode{x025B} \sim \mathcal{N}\left(0,{\sigma}_n^2\right) $$
Consider a dataset,
 $ D=\left(X,y\right) $
, whereby
$ D=\left(X,y\right) $
, whereby
 $ X={\left\{{x}_1,{x}_2,\dots, {x}_n\right\}}^m $
and
$ X={\left\{{x}_1,{x}_2,\dots, {x}_n\right\}}^m $
and
 $ y=\left\{{y}_1,{y}_2,\dots, {y}_n\right\} $
where
$ y=\left\{{y}_1,{y}_2,\dots, {y}_n\right\} $
where
 $ m $
and
$ m $
and
 $ n $
represent the number of features and the number of samples in the dataset, respectively. Assuming a mean of 0 for our prior distribution, to predict
$ n $
represent the number of features and the number of samples in the dataset, respectively. Assuming a mean of 0 for our prior distribution, to predict
 $ {y}_{\ast}\in R $
for a new input dataset
$ {y}_{\ast}\in R $
for a new input dataset
 $ {X}_{\ast}\in {R}^m $
using GPR, we need to learn the nonlinear mapping between
$ {X}_{\ast}\in {R}^m $
using GPR, we need to learn the nonlinear mapping between
 $ X $
and
$ X $
and
 $ y $
as shown in Equation 3.3. The covariance matrix
$ y $
as shown in Equation 3.3. The covariance matrix
 $ k $
is an
$ k $
is an
 $ n $
×
$ n $
×
 $ n $
matrix, which defines the correlation between the input data points.
$ n $
matrix, which defines the correlation between the input data points.
 $$ y\sim \mathcal{N}\left(0,k\left(x,{x}^{\prime}\right)\right)\hskip0.1em $$
$$ y\sim \mathcal{N}\left(0,k\left(x,{x}^{\prime}\right)\right)\hskip0.1em $$
For this study, we used the radial basis function (RBF) kernel, which is defined as shown in Equation 3.4, where
 $ {\sigma}_f^2 $
is the signal variance and
$ {\sigma}_f^2 $
is the signal variance and
 $ \mathrm{\ell} $
is the lengthscale parameter. The RBF kernel is also sometimes known as the Gaussian kernel or the squared exponential kernel.
$ \mathrm{\ell} $
is the lengthscale parameter. The RBF kernel is also sometimes known as the Gaussian kernel or the squared exponential kernel.
 $$ k\left(x,{x}^{\prime}\right)={\sigma}_f^2\exp \left(-\frac{\parallel x-{x}^{\prime }{\parallel}^2}{2{\mathrm{\ell}}^2}\right) $$
$$ k\left(x,{x}^{\prime}\right)={\sigma}_f^2\exp \left(-\frac{\parallel x-{x}^{\prime }{\parallel}^2}{2{\mathrm{\ell}}^2}\right) $$
Model training involves minimizing the negative log likelihood shown in Equation 3.5, where
 $ K $
is the covariance matrix of size N × N,
$ K $
is the covariance matrix of size N × N,
 $ I $
is the identity matrix, and
$ I $
is the identity matrix, and
 $ {\sigma}_n $
is the noise variance.
$ {\sigma}_n $
is the noise variance.
 $$ \mathrm{\mathcal{L}}=\frac{-N}{2}\log 2\pi -\frac{1}{2}\log \mid K+{\sigma}_n^2I\mid -\frac{1}{2}{y}^T{\left(K+{\sigma}_n^2I\right)}^{-1}y $$
$$ \mathrm{\mathcal{L}}=\frac{-N}{2}\log 2\pi -\frac{1}{2}\log \mid K+{\sigma}_n^2I\mid -\frac{1}{2}{y}^T{\left(K+{\sigma}_n^2I\right)}^{-1}y $$
Thus, after training, for our new input data matrix,
 $ {X}_{\ast } $
, the predictive Gaussian distribution
$ {X}_{\ast } $
, the predictive Gaussian distribution
 $ N\Big({\mu}_{\ast },{\Sigma}_{\ast } $
) is defined as shown in Equations 3.6 and 3.7, respectively.
$ N\Big({\mu}_{\ast },{\Sigma}_{\ast } $
) is defined as shown in Equations 3.6 and 3.7, respectively.
 $$ {\mu}_{\ast }=K\left({X}_{\ast },X\right){\left(K\left(X,X\right)+{\sigma}_n^2I\right)}^{-1}y $$
$$ {\mu}_{\ast }=K\left({X}_{\ast },X\right){\left(K\left(X,X\right)+{\sigma}_n^2I\right)}^{-1}y $$
 $$ {\Sigma}_{\ast }=K\left({X}_{\ast },{X}_{\ast}\right)-K\left({X}_{\ast },X\right){\left(K\left(X,X\right)+{\sigma}_n^2I\right)}^{-1}K\left(X,{X}_{\ast}\right) $$
$$ {\Sigma}_{\ast }=K\left({X}_{\ast },{X}_{\ast}\right)-K\left({X}_{\ast },X\right){\left(K\left(X,X\right)+{\sigma}_n^2I\right)}^{-1}K\left(X,{X}_{\ast}\right) $$
In this work, we used a full GPR model from the Gpflow Python package (Matthews et al., Reference Matthews, van der Wilk, Nickson, Fujii, Boukouvalas, León-Villagrá, Ghahramani and Hensman2017) to predict the PM
 $ {}_{2.5} $
levels in the locations of interest. The model hyperparameters were optimized using a random search strategy. For Kampala, the lengthscales were set to 0.08°, 0.08° and 1 hour for longitude, latitude, and time, respectively, and were fixed during the training process. The signal variance and likelihood variance were initialized to 625 and 400, respectively. For Jinja, the likelihood variance was fixed to 400, and the lengthscales were initialized to 0.008°, 0.008° and 2 hours for longitude, latitude, and time, respectively. Due to the model’s computational complexity, we sampled only a subset of rows from the training dataset for some device locations.
$ {}_{2.5} $
levels in the locations of interest. The model hyperparameters were optimized using a random search strategy. For Kampala, the lengthscales were set to 0.08°, 0.08° and 1 hour for longitude, latitude, and time, respectively, and were fixed during the training process. The signal variance and likelihood variance were initialized to 625 and 400, respectively. For Jinja, the likelihood variance was fixed to 400, and the lengthscales were initialized to 0.008°, 0.008° and 2 hours for longitude, latitude, and time, respectively. Due to the model’s computational complexity, we sampled only a subset of rows from the training dataset for some device locations.
3.4. Experiment setup and evaluation
For each city, the model was trained using data from all devices in that city except one, which we call the hold-out device. The data from this hold-out device served as the test set to evaluate the model’s performance. Thereafter, various performance metrics were computed by comparing the model’s predicted PM
 $ {}_{2.5} $
concentration with the actual measurements from the test data. This process was repeated across multiple experiments, each time selecting a different device in the city as the hold-out device. Take Jinja, for instance, where 10 air quality monitors were used. A total of 10 experiments were conducted, whereby for each experiment, a different device was used as the hold-out device, while data from the 9 remaining devices were used to train the model.
$ {}_{2.5} $
concentration with the actual measurements from the test data. This process was repeated across multiple experiments, each time selecting a different device in the city as the hold-out device. Take Jinja, for instance, where 10 air quality monitors were used. A total of 10 experiments were conducted, whereby for each experiment, a different device was used as the hold-out device, while data from the 9 remaining devices were used to train the model.
For model evaluation, we used the root-mean-square error (RMSE) as our primary metric, which we calculated as shown in Equation 3.8, where
 $ {y}_{\mathrm{actual}} $
represents the actual (test) PM
$ {y}_{\mathrm{actual}} $
represents the actual (test) PM
 $ {}_{2.5} $
concentration, and
$ {}_{2.5} $
concentration, and
 $ {y}_{\mathrm{predicted}} $
represents the predicted PM
$ {y}_{\mathrm{predicted}} $
represents the predicted PM
 $ {}_{2.5} $
concentration.
$ {}_{2.5} $
concentration.
 $$ \mathrm{RMSE}=\sqrt{\frac{1}{n}\sum \limits_{i=1}^n{\left({y}_{\mathrm{actual}}-{y}_{\mathrm{predicted}}\right)}^2} $$
$$ \mathrm{RMSE}=\sqrt{\frac{1}{n}\sum \limits_{i=1}^n{\left({y}_{\mathrm{actual}}-{y}_{\mathrm{predicted}}\right)}^2} $$
Additionally, we computed the normalized RMSE (nRMSE), which was derived as shown in Equation 3.9, the coefficient of determination (R2), and the prediction bias to provide a more comprehensive assessment of model performance.
 $$ \mathrm{nRMSE}=\frac{RMSE}{{\overline{y}}_{\mathrm{actual}}}\times 100 $$
$$ \mathrm{nRMSE}=\frac{RMSE}{{\overline{y}}_{\mathrm{actual}}}\times 100 $$
4. Results
4.1. Model predictions
Our aim is to provide predictions for the PM
 $ {}_{2.5} $
concentration in locations where there is no air quality monitor available using data from the monitors installed elsewhere. For each experiment, the performance metrics were computed as described in Section 3.4, and as a result, we obtained multiple values for each metric. For instance, we had 10 and 34 different RMSEs for Jinja and Kampala, respectively. The mean and standard deviation values of the RMSE, nRMSE, R2, and bias for both cities are shown in Table 1.
$ {}_{2.5} $
concentration in locations where there is no air quality monitor available using data from the monitors installed elsewhere. For each experiment, the performance metrics were computed as described in Section 3.4, and as a result, we obtained multiple values for each metric. For instance, we had 10 and 34 different RMSEs for Jinja and Kampala, respectively. The mean and standard deviation values of the RMSE, nRMSE, R2, and bias for both cities are shown in Table 1.
Table 1. Table showing the summary of model performance for the two cities

Graphs from sample locations in Kampala and Jinja, that is, Civic center and Jinja Main Street, showing the actual PM
 $ {}_{2.5} $
concentration versus the predicted PM
$ {}_{2.5} $
concentration versus the predicted PM
 $ {}_{2.5} $
concentration are represented in Figures 4 and 5, respectively. Figure 4 shows the predictions for when the hold-out device is the one installed at a location known as Civic center. The blue line plot shows the actual PM
$ {}_{2.5} $
concentration are represented in Figures 4 and 5, respectively. Figure 4 shows the predictions for when the hold-out device is the one installed at a location known as Civic center. The blue line plot shows the actual PM
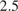 $ {}_{2.5} $
concentration during this period, while the orange plot shows the predictions made by a model trained using data from the other devices (besides the one at Civic center). It can be seen that the plots follow a similar trend, and the overall RMSE for this experiment was 15.84 μg/m3. Similarly, Figure 5 shows the results of an experiment where the test data is from a device installed at a location, here called Jinja Main Street. The RMSE for this experiment was 12.64 μg/m3. The shaded region in both figures represents the 95% confidence interval of the model’s predictions.
$ {}_{2.5} $
concentration during this period, while the orange plot shows the predictions made by a model trained using data from the other devices (besides the one at Civic center). It can be seen that the plots follow a similar trend, and the overall RMSE for this experiment was 15.84 μg/m3. Similarly, Figure 5 shows the results of an experiment where the test data is from a device installed at a location, here called Jinja Main Street. The RMSE for this experiment was 12.64 μg/m3. The shaded region in both figures represents the 95% confidence interval of the model’s predictions.

Figure 4. A graph plot showing actual vs predicted PM
 $ {}_{2.5} $
concentration for the Civic Center device location in Kampala.
$ {}_{2.5} $
concentration for the Civic Center device location in Kampala.

Figure 5. A graph plot showing actual vs predicted PM
 $ {}_{2.5} $
concentration for the Jinja Main Street device location in Jinja.
$ {}_{2.5} $
concentration for the Jinja Main Street device location in Jinja.
4.2. Comparison with other methods
We aimed to compare our model’s performance with that of well-known state-of-the-art algorithms used in the prediction of time-series data, namely, kriging, support vector machine, RF, eXtreme Gradient Boosting (XGBoost), a feed-forward neural network (FFNN), an LSTM network, a Bayesian neural network (BNN), and a deep GPR (DGPR) model. We incorporated dropout regularization as appropriate for the neural network-based models. We specifically chose these models because of their utilization in previous studies and their good performance on the task. Additionally, we included DGPR because it extends GPR by incorporating deep neural networks into the GP framework. We used the same approach as described in Section 4.1 and the results were also summarized in a similar fashion. Table 2 shows the results for Kampala, while Table 3 shows the ones for Jinja. The individual RMSEs for all the locations in Kampala and Jinja are shown in Figures B1 and B2 in Appendix B.
Table 2. Summary of performance metrics for various models in predicting PM
 $ {}_{2.5} $
concentration across different locations in Kampala. Bold values indicate the best-performing model for each metric.
$ {}_{2.5} $
concentration across different locations in Kampala. Bold values indicate the best-performing model for each metric.

The values represent the mean and standard deviation computed from individual location-specific results.
Table 3. Summary of performance metrics for various models in predicting PM
 $ {}_{2.5} $
concentration across different locations in Jinja. Bold values indicate the best-performing model for each metric.
$ {}_{2.5} $
concentration across different locations in Jinja. Bold values indicate the best-performing model for each metric.

The values represent the mean and standard deviation computed from individual location-specific results.
For Kampala, our model had the lowest mean RMSE, nRMSE, and the highest R2 value, although this was still low. XGBoost had the second best performance after GPR. The neural network-based models, along with SVM and Kriging exhibited worse performance, along with having a negative R2 value. This may be due to the fact that they were not able to adequately capture the nonlinear relationships in the data. Also, the size of the dataset may have affected the performance of the neural network-based models.
Similarly, for Jinja, our GPR model had the best value for the mean RMSE, nRMSE, and R2. Again, all the other models had a negative R2 value.
5. Discussion
In this article, we presented the prediction of PM
 $ {}_{2.5} $
levels for a geographical location using air quality data from sensors that are installed elsewhere in two major Ugandan cities. We also showed the uncertainty over the predictions made and demonstrated that GPR is the most appropriate method for such a task.
$ {}_{2.5} $
levels for a geographical location using air quality data from sensors that are installed elsewhere in two major Ugandan cities. We also showed the uncertainty over the predictions made and demonstrated that GPR is the most appropriate method for such a task.
On the whole, it can clearly be seen that there is a remarkable difference between the performance of the two GPR models, that is, the one for Kampala and the one for Jinja. While the mean error rates are not so incredibly different, the Jinja model’s average error rate (16.88 μg/m3) is lower than that of the Kampala model, which is 18.32 μg/m3. However, as shown by the standard deviation of the RMSEs, the Kampala results are more varied than those of Jinja. Additionally, we see that the highest RMSE for a Kampala experiment (40.32 μg/m3) is almost twice the highest RMSE got for a Jinja experiment (23.04 μg/m3). Looking at the performance summaries of the two cities, it can be inferred that in general, Kampala has a higher and more variable PM
 $ {}_{2.5} $
concentration level than Jinja. This can be attributed to many factors, such as population density, traffic levels, and level of commercial activity, all of which are at a higher level in Kampala than in Jinja.
$ {}_{2.5} $
concentration level than Jinja. This can be attributed to many factors, such as population density, traffic levels, and level of commercial activity, all of which are at a higher level in Kampala than in Jinja.
Additionally, from our study, we deduced that a location with more “spikes” in its data will have a higher RMSE. Here, we define a spike as a sharp increase in the PM
 $ {}_{2.5} $
concentration of an area between two consecutive time points. A graph of the location with the second highest RMSE in Kampala (36.94 μg/m3) is shown in Figure 6, and the sharp peaks in the graph are the “spikes.” Evidently, while the model is able to predict the general trend of the air quality, it is not able to convincingly predict the spikes in the location, therefore leading to a higher error rate in the predictions. It should also be noted that the location of the device whose data and predictions are shown in Figure 6 is next to a roadside with heavy traffic concentration in a busy commercial area. We believe that these spikes are due to air pollution from local sources in the area and, hence, the difficulty in predicting these PM
$ {}_{2.5} $
concentration of an area between two consecutive time points. A graph of the location with the second highest RMSE in Kampala (36.94 μg/m3) is shown in Figure 6, and the sharp peaks in the graph are the “spikes.” Evidently, while the model is able to predict the general trend of the air quality, it is not able to convincingly predict the spikes in the location, therefore leading to a higher error rate in the predictions. It should also be noted that the location of the device whose data and predictions are shown in Figure 6 is next to a roadside with heavy traffic concentration in a busy commercial area. We believe that these spikes are due to air pollution from local sources in the area and, hence, the difficulty in predicting these PM
 $ {}_{2.5} $
concentrations. Addressing this challenge will be pivotal in the further improvement of our model’s performance.
$ {}_{2.5} $
concentrations. Addressing this challenge will be pivotal in the further improvement of our model’s performance.

Figure 6. A graph plot showing actual vs predicted PM
 $ {}_{2.5} $
concentration for the location with the highest RMSE (Kiwatule) in Kampala as well as the spikes in the location. It should be noted that data are missing for most of the month of September.
$ {}_{2.5} $
concentration for the location with the highest RMSE (Kiwatule) in Kampala as well as the spikes in the location. It should be noted that data are missing for most of the month of September.
Furthermore, we believe that the GPR models perform better than any of the other models because they are uniquely suited to this task. With the lengthscale parameter in the RBF kernel, we are able to control how strongly features at the different locations correlate with those at the location of interest. Therefore, data from locations nearer in latitude and longitude to the location of interest will be more relevant to the prediction as well as data from timestamps closer to the timestamp of interest. This is not possible with most of the other models. LSTM’s ability to model long-term dependencies, and hence why it is used with sequential data such as time-series data, is more helpful if the features of the data are changing with time. In this case, other than the time feature, the other two features are latitude and longitude, which are time-invariant. This explains why LSTM performs poorly on this task as well as the other models. The ability of GPs to learn a distribution of the data and also model the model’s uncertainty are also very powerful features that make GPR the most suitable method for this study.
5.1. Challenges and limitations
However, GPs have their own challenges, the most significant of which is their computational complexity. GPR has
 $ \mathcal{O}\left({n}^3\right) $
training computational complexity, and
$ \mathcal{O}\left({n}^3\right) $
training computational complexity, and
 $ \mathcal{O}\left({n}^2\right) $
memory complexity, where
$ \mathcal{O}\left({n}^2\right) $
memory complexity, where
 $ n $
is the number of samples in the training dataset. This computational complexity is primarily due to the Cholesky decomposition, which involves the inversion of the covariance matrix (Rasmussen, Reference Rasmussen, Bousquet, von Luxburg and Rätsch2003). During our experiments, we had to manually reduce the size of the training datasets in order to optimize computational resources. As such, a significant amount of data were left out of the training process, and this could have impacted performance. Nonetheless, even with the implementation of this measure, the GP models had the second longest training time as shown in Table 4. This is reasonable because GPR has a higher computational complexity than all the other models (Rasmussen, Reference Rasmussen, Bousquet, von Luxburg and Rätsch2003) besides DGPR, which has a higher complexity due to its multi-layered neural network architecture (Damianou and Lawrence, Reference Damianou and Lawrence2013).
$ n $
is the number of samples in the training dataset. This computational complexity is primarily due to the Cholesky decomposition, which involves the inversion of the covariance matrix (Rasmussen, Reference Rasmussen, Bousquet, von Luxburg and Rätsch2003). During our experiments, we had to manually reduce the size of the training datasets in order to optimize computational resources. As such, a significant amount of data were left out of the training process, and this could have impacted performance. Nonetheless, even with the implementation of this measure, the GP models had the second longest training time as shown in Table 4. This is reasonable because GPR has a higher computational complexity than all the other models (Rasmussen, Reference Rasmussen, Bousquet, von Luxburg and Rätsch2003) besides DGPR, which has a higher complexity due to its multi-layered neural network architecture (Damianou and Lawrence, Reference Damianou and Lawrence2013).
Table 4. The duration of training and testing processes for the different algorithms for one location (Jinja Main Street in Jinja city)

We show the mean
 $ \pm $
standard deviation of 7 runs. It should be noted that all algorithms were run on the same computer except DGPR because it was unable to run on that particular machine. The training and testing times shown for the DGPR are therefore from another computer.
$ \pm $
standard deviation of 7 runs. It should be noted that all algorithms were run on the same computer except DGPR because it was unable to run on that particular machine. The training and testing times shown for the DGPR are therefore from another computer.
Additionally, some of the locations whose data were used had a few gaps, which may have affected the performance of our models. However, given the limited size of these gaps, their impact is assumed to be minimal. Moreover, the study period spanned only 3 months, which is insufficient to capture full annual seasonal trends and variations, as well as their effect on PM
 $ {}_{2.5} $
concentrations and model predictions.
$ {}_{2.5} $
concentrations and model predictions.
6. Conclusion and future work
In this study, we developed air quality prediction models for two cities in Uganda, namely, Kampala and Jinja. We utilized data from devices installed elsewhere to predict the air quality of a particular location at a given time. This is vital to predict air quality in areas without air quality sensors. In sub-Saharan Africa especially, where there is a scarcity on the air quality information readily available, this model could help in providing timely information to inform decisions. For instance, in a region with devices installed in a few locations, these data can then be used to create an air quality prediction heatmap over the entire region. Additionally, we demonstrated the aptness of GPs for this problem and we believe that this solution can be replicated across different cities on the continent. The main limitations in the study include a few gaps in the data where the air quality monitors did not record the relevant measurements, and also the computational complexity of GPs, which meant that some of the data available were not used.
For future work, we intend to leverage sparse approximation in our methodology to optimize resource utilization and be able to use data from a multiyear period to capture seasonal changes and trends. Additionally, we shall work on incorporating spike detection in the model since spikes have a significant effect on the error rate. The assumption is that improving the ability of the model to predict spikes will positively affect the quality of the predictions made. Moreover, instead of eliminating data with missing values, the missing values can also be imputed using GPR. Furthermore, GPR could be used to aid in the optimal placement of air quality sensors based on model uncertainty.
Open peer review
To view the open peer review materials for this article, please visit http://doi.org/10.1017/eds.2025.10026.
Acknowledgements
We would like to thank Michael T. Smith, for his invaluable insights that helped advance this work.
Author contribution
Conceptualization: E.B. and L.M. Project administration: E.B. and D.O. Funding acquisition: E.B. Data curation: R.S. and L.M. Methodology: L.M. Software: L.M. and R.S. Data visualization: L.M. Writing – original draft: L.M. Writing – review & editing: L.M., R.S., D.O., and E.B. Supervision: E.B. All authors approved the final submitted draft.
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Data availability statement
Replication data and code can be found at https://doi.org/10.5281/zenodo.17607881.
Ethics statement
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.
Funding statement
This research was supported by grants from Google.org; the Global Challenges Research Fund; the Kingdom of Belgium through the Wehubit program implemented by Enabel.
A. Appendix. Meteorological summary of Kampala and Jinja
Table A1. Descriptive statistics for weather parameters in Kampala during the study period

Table A2. Monthly weather summary for Kampala during the study period

Table A3. Descriptive statistics for weather parameters in Jinja during the study period

Table A4. Monthly weather summary for Jinja during the study period

B. Appendix. More results
Figures B1 and B2 show the device locations in Kampala and Jinja that were used in this study alongside their individual RMSE values.

Figure B1. The device locations in Kampala with their respective RMSE values.

Figure B2. The device locations in Jinja and their respective RMSE values.






















 Open access
Open access