


Reading has been well established as a source of vocabulary learning, in both L1 (e.g., Nagy et al., Reference Nagy, Anderson and Herman1987; Nagy et al., Reference Nagy, Herman and Anderson1985) and L2 research (e.g., Alotaibi et al., Reference Alotaibi, Pellicer-Sánchez and Conklin2022; Elgort & Warren Reference Elgort and Warren2014; Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018; Reference Pellicer-Sanchez and SchmittPellicer-Sánchez & Schmitt, Reference Pellicer-Sanchez and Schmitt2010; Webb & Chang, Reference Webb and Chang2012). Although explicit teaching of new vocabulary is often recommended (Nation, Reference Nation1990, Reference Nation2001) and intentional learning is usually considered a more effective learning method (e.g., Laufer, Reference Laufer2005; Sonbul & Schmitt, Reference Sonbul and Schmitt2010), studies have found that learners of English require knowledge of at least 6,000–7,000 word families to understand spoken language and at least 8,000–9,000 in order to read authentic texts (Nation Reference Nation2001; Schmitt Reference Schmitt2008, Reference Schmitt2010). It is unlikely that a regular language classroom can provide this volume of knowledge through instruction alone (e.g., de Groot & van Hell, Reference de Groot, van Hell, Kroll and de Groot2005; Horst, Reference Horst2005) and explicit word-focused activities do not necessarily guarantee learning (Webb et al., Reference Webb, Yanagisawa and Uchihara2020), which makes it crucial to study the role of incidental learning in vocabulary acquisition (e.g., Chen & Truscott, Reference Chen and Truscott2010; Horst et al., Reference Horst, Cobb and Meara1998; Pigada & Schmitt, Reference Pigada and Schmitt2006; Pellicer-Sánchez, Reference Pellicer-Sánchez2016).
In order for incidental learning to take place, repeated exposure to the target words is required (Nation, Reference Nation2013; Uchihara et al., Reference Uchihara, Webb and Yanagisawa2019). Such repeated exposure to new vocabulary can be promoted by reading the same text multiple times or by reading different texts that include the same target words. Current evidence suggests that encountering new lexical items in a variety of contexts might be particularly beneficial for vocabulary learning (e.g., Adelman et al., Reference Adelman, Brown and Quesada2006; Bolger et al., Reference Bolger, Balass, Landen and Perfetti2008; Liu & Todd, Reference Liu and Todd2016; Pagán & Nation, Reference Pagán and Nation2019; Webb, Reference Webb2008). Contextual diversity appears to facilitate the encoding and retention of previously unknown words to a greater extent than frequency of exposure (Jones et al., Reference Jones, Dye and Johns2017), which suggests that this factor may have a greater influence on vocabulary learning than number of exposures alone. Notwithstanding, the effects of context remain understudied in comparison to investigations on the effects of frequency, a gap which our study aims to address.
In addition, a growing body of research incorporating eye tracking has shown the effect of repeated encounters on the processing of novel vocabulary, generally showing a decrease in reading times with repeated exposures (Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018; Elgort et al., Reference Elgort, Brysbaert, Stevens and Van Assche2018; Pellicer-Sánchez Reference Pellicer-Sánchez2016; Serrano & Pellicer-Sánchez, Reference Serrano and Pellicer-Sánchez2024). Recent studies have also suggested that reading times seem to be related to vocabulary gains from reading (Godfroid et al., Reference Godfroid, Boers and Housen2013; Koval, Reference Koval2019; Pellicer-Sánchez, Reference Pellicer-Sánchez2016). However, the role of contextual diversity on processing patterns has received little attention. Our study addresses this gap by being the first to explore the role of context in attention to unknown vocabulary in repeated reading of longer texts and its relation to vocabulary learning gains.
Literature review
Incidental vocabulary learning through reading
Although definitions of incidental learning vary, the process may be best understood as a “by-product of meaning-focused activities or tasks” (Webb, Reference Webb2020, p. 226). This implies that while completing an activity where the focus is to comprehend the content—whether reading, listening, or viewing—lexical knowledge can improve incidentally (e.g., Hulstijn, Reference Hulstijn and Robinson2001; Schmitt, Reference Schmitt2010). However, acquiring both breadth (Nation, Reference Nation2006a) and depth (Nation, Reference Nation2001) in L2 lexical knowledge requires extensive exposure to the target forms. Models of lexical access also assume that repeated encounters help fix an item in memory, making it both easier to access and process (Johns, Dye & Jones, Reference Johns, Dye and Jones2016).
The key prerequisites for incidental learning to occur via reading are repetition and the possibility of inferring meaning (Uchihara et al., Reference Uchihara, Webb and Yanagisawa2019; Webb, Reference Webb2020). Incidental lexical learning from reading therefore requires repeated and sufficient exposure to the target items (Pellicer-Sánchez & Schmitt, Reference Pellicer-Sanchez and Schmitt2010; Schmitt & Schmitt, Reference Schmitt and Schmitt2020), with figures ranging from six (Rott, Reference Rott1999), to eight (Horst et al., Reference Horst, Cobb and Meara1998), ten (Pellicer-Sánchez & Schmitt, Reference Pellicer-Sanchez and Schmitt2010) or even up to 20 (Waring & Takaki, Reference Waring and Takaki2003) exposures.
One reason for such discrepancies may be differences in how frequency (or word repetition) is operationalized in different studies (see Reynolds & Wible, Reference Reynolds and Wible2014, for a detailed analysis). Another reason could be that different frequencies are needed for learners at differing levels of proficiency (e.g., Horst Reference Horst2000; Zahar et al., Reference Zahar, Cobb and Spada2001) or for learning and retaining different aspects of lexical knowledge such as receptive versus productive knowledge (Peters, Reference Peters2020). As a result, while frequency of exposure remains a topic of interest, it is also crucial to focus on how frequency can be moderated by other factors that influence incidental vocabulary learning. Key among these are learner-related variables such as proficiency and text-related variables like the context in which target items appear (Beck et al., Reference Beck, McKeown and McCaslin1983; Uchihara et al., Reference Uchihara, Webb and Yanagisawa2019; Waring & Takaki, Reference Waring and Takaki2003; Webb & Chang, Reference Webb and Chang2015a).
The role of contextual diversity in incidental vocabulary learning
From a theoretical perspective, the positive effects of contextual diversity on vocabulary learning have been explained in different ways. An early explanation is the principle of “likely need” (Anderson & Milson, Reference Anderson and Milson1989; Anderson & Schooler, Reference Anderson and Schooler1991), which relates lexical access to contextual relevance and past access, suggesting that words encountered in a variety of contextual conditions are coded as more likely to be needed in an unknown future context, making them more readily accessible in lexical and semantic memory. Bolger et al. (Reference Bolger, Balass, Landen and Perfetti2008) explained the benefits of contextual diversity using an “instance-based resonance framework of incremental word learning model” (p. 144; based on Reichle & Perfetti’s Reference Reichle and Perfetti2003 episodic memory model), suggesting that contextual diversity allows words to be encoded in incremental resonant memory traces that include each different context, thereby allowing better consolidation and integration into semantic memory, and the eventual decontextualized encoding of meaning. Another explanation of the benefits of contextual diversity can be found in the semantic distinctiveness model or SDM (Johns & Jones, Reference Johns and Jones2008; Johns, Dye & Jones, Reference Johns, Dye and Jones2014; Jones, Johns & Recchia, Reference Jones, Johns and Recchia2012), which works on the assumption that when a word is encountered in a context that differs from those already encoded in memory, the word is consequently more strongly encoded (Jones et al., Reference Jones, Dye and Johns2017).
The role of context has been empirically analyzed from different perspectives, with some studies focusing on the number of distinct contexts in which novel words appear and others focusing on the quality of the contexts in terms of the information they provide: transparency of word meanings, imageability, etc. (see Jones et al., Reference Jones, Dye and Johns2017 for a comprehensive summary). The remaining of this section will focus on research into contextual diversity focusing on number of contexts, which are the most relevant for the present study.
One of the early studies on the influence of contextual diversity, operationalized as document count, was carried out by Adelman and colleagues in 2006. They compared the effects of word frequency and contextual diversity on the reaction times (RTs) in word naming and lexical decision tasks among English L1 speakers. They found that contextual diversity influenced item-based RTs to a greater extent than frequency. Results showed that even after accounting for the effects of semantic factors, greater contextual diversity led to faster RTs where frequency did not.
Bolger et al. (Reference Bolger, Balass, Landen and Perfetti2008) explored the role of context by presenting adult L1 speakers of English with rare words either in a single sentence repeated four times or in four different sentences, and either with or without a dictionary definition. They found an effect of contextual diversity on subsequent meaning generation and sentence completion tasks, with the provision of dictionary definitions reducing its effect. The authors conclude that encountering a word in a variety of contexts rather than a single repeated context aided the learning of word meanings, particularly in the absence of dictionary definitions. This would suggest that in situations that require meaning inference (i.e., with no dictionary definitions), contextual diversity has an important impact on vocabulary learning.
In a similar exploration of the effects of contextual variety, this time on L2 learners of English, Ferreira and Ellis (Reference Ferreira and Ellis2016) trained participants on real but obscure novel words in either two different sentences or 12 different sentences, while controlling for the frequency of exposures. Participants were subsequently tested on the novel items in a semantic decision task and a read-aloud task. The results indicated that greater contextual diversity led to greater accuracy and faster RTs, as well as faster naming latencies in the post test, indicating that, as reported in Adelman et al., Reference Adelman, Brown and Quesada2006, repeated exposures to novel items in a greater number of contexts facilitate faster processing.
Liu and Todd’s 2016 study extended the analysis of contextual diversity to longer texts in the context of repeated-reading practice, exploring the effects of encountering target items in either the same text read seven times (“repeated-reading-same”) or in seven different texts (“repeated-reading-different”). Their findings indicate that reading different texts one after the other may lead to more vocabulary gains—as assessed in a meaning recognition multiple-choice test—than reading the same text seven times. The authors suggest that this may be due to the variety of contextual clues provided by different texts benefitting the cognitive processes that lead to learning by “opening up a contextual need” (Zahar et al., Reference Zahar, Cobb and Spada2001, p. 556). They also make a connection between their findings and the observation that learners tend to process input primarily for meaning (VanPatten, Reference VanPatten, Piske and Young-Scholten2008), which may lead them to pay less attention to specific words when these words are repeated multiple times in the same context. Additionally, the high number of repetitions in the “repeated-reading-same” condition may have led learners to lose interest with the consequent decrease in attention, although the absence of processing data means that we can only speculate on this point.
Overall, the available studies generally indicate that greater variety of contexts facilitates vocabulary learning both among L1 and L2 speakers, as evidenced in greater accuracy and faster RTs in a number of different tasks (e.g., Adelman et al., Reference Adelman, Brown and Quesada2006; Bolger et al., Reference Bolger, Balass, Landen and Perfetti2008; Ferreira & Ellis, Reference Ferreira and Ellis2016; Liu & Todd, Reference Liu and Todd2016; Pagán & Nation, Reference Pagán and Nation2019), although this may be more beneficial for form recognition than for meaning recognition (Johns et al., Reference Johns, Dye and Jones2016). As Jones et al. (Reference Jones, Dye and Johns2017) suggest, while frequency and contextual diversity may be highly correlated (e.g., Adelman et al., Reference Adelman, Brown and Quesada2006), the number of diverse texts in which a word occurs may be better than just frequency at explaining how new words are learnt and remembered. Furthermore, a greater range of texts allows for a greater diversity of factors affecting learning such as motivation and interest in the text (Webb, Reference Webb2020). Notwithstanding these general trends, given the wide variety of participants’ L1s, input types, and methods used in previous studies, definitive claims about the benefits of contextual diversity for vocabulary learning cannot be made without further research.
In fact, conflicting findings have also been reported in the literature. When exploring the effects of contextual diversity on incidental vocabulary acquisition through reading, some of the existing studies manipulating semantic diversity have found faster RTs in form recognition tasks for “diverse” contexts, but a benefit of sameness on semantic representations on meaning recognition (e.g., Jones et al., Reference Jones, Johns and Recchia2012; Johns et al., Reference Johns, Dye and Jones2016). As a possible explanation, Johns et al., (Reference Johns, Dye and Jones2016) suggest that while semantic diversity aids the stronger encoding of novel forms, it may hinder comprehension and meaning inference, which is easier in semantically constant contexts. Similarly, other studies have also shown that contextual sameness may be more beneficial than diversity, especially for learners with lower comprehension skills or proficiency (e.g., Elgort et al., Reference Elgort, Perfetti, Rickles and Stafura2015; Elgort & Warren, Reference Elgort and Warren2014; Horvath & Arunachalam, Reference Horvath and Arunachalam2021; Zahar et al., Reference Zahar, Cobb and Spada2001). However, there are not enough studies to draw definitive conclusions on how context affects incidental vocabulary acquisition—especially among L2 learners—and thus the aim of the present study.
Online processing and vocabulary learning in SLA
The examination of eye movements is an important method to better understand the cognitive processes involved in reading and learning vocabulary under different conditions (Pellicer-Sánchez, Reference Pellicer-Sánchez2020), while coming as close as experimentally possible to capturing the natural processes of silent reading (Pagán & Nation, Reference Pagán and Nation2019). Studies on incidental learning emphasize the need to understand the amount and kind of attention novel items receive in order to better explain factors affecting vocabulary gains (e.g., Nassaji, Reference Nassaji2006; Pulido, Reference Pulido2007). The time spent processing a new linguistic element can be considered a measure of the amount of cognitive engagement with the material (Godfroid et al., Reference Godfroid, Boers and Housen2013, p. 486).
Previous eye-tracking studies have shown that readers spend more time looking at (i.e., show longer fixations on) novel words than words they already know (e.g., Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018; Pellicer-Sánchez, Reference Pellicer-Sánchez2016). Furthermore, within L2 reading research, eye-tracking has shown that reading times decrease across repetitions (e.g., Elgort et al., Reference Elgort, Brysbaert, Stevens and Van Assche2018; Mohamed, Reference Mohamed2018; Pellicer-Sánchez, Reference Pellicer-Sánchez2016, Pellicer-Sánchez et al., Reference Pellicer Sanchez, Siyanova-Chanturia and Parente2022), suggesting increasingly fluent processing of the text as a function of repeated encounters. In contrast, longer processing times on target vocabulary have been linked to better learning outcomes in some studies (Godfroid et al., Reference Godfroid, Boers and Housen2013; Koval, Reference Koval2019; Mohamed, Reference Mohamed2018; Pellicer-Sánchez, Reference Pellicer-Sánchez2016) but not in others (e.g., Wochna & Juhasz, Reference Wochna and Juhasz2013), calling for more research in this area.
Crucially, the patterns reported by the studies above are bound to be influenced by the context in which novel words appeared. Considering that learners tend to process textual input primarily for meaning (VanPatten, Reference VanPatten, Piske and Young-Scholten2008), encountering novel items in the same context repeatedly could lead to a decrease in reading times, since understanding a word may not be necessary to furthering global comprehension of the text (Liu & Todd, Reference Liu and Todd2016). Encountering the novel words in diverse contexts, however, would require learners to process them for meaning each time, potentially leading to increased attention and greater gains. However, to our knowledge, only one study has investigated the effect of contextual diversity on attention to novel words in reading.
Pagán and Nation (Reference Pagán and Nation2019) measured the eye movements of L1 speakers of English while encountering novel words in one repeated sentence (same context) against four different sentences (diverse context). Accurate responses to comprehension questions testing understanding of the target items were taken as evidence of vocabulary learning, as were faster processing times (measured by eye-movements to target items) in the post-task phase as compared to the experimental phase. Their findings showed that words read in the same context received shorter viewing times than words read in the diverse context—an effect that was visible in both early (first fixation and gaze duration) and late (go past and total time) processing measures. In the post-task testing phase, however, words that had appeared in the diverse condition received shorter fixations, indicating better learning and integration in the lexicon. The authors explain these patterns in terms of contextual diversity allowing representations of the words in the learners’ minds to become more context independent (Pagán & Nation, Reference Pagán and Nation2019). Crucially, similar investigations in the L2 context are yet to be conducted. Our study investigates whether similar processing patterns and learning outcomes may be observed when learners encounter target items embedded in longer texts, comparing the same text read multiple times with the reading of different texts. Moreover, apart from investigating processing during reading, our study also examines whether differences in processing are connected to differential lexical gains, as observed in vocabulary tests.
This study
As the review of the literature shows, besides the general scarcity of research on contextual diversity in the L2 context, research exploring the effects of contextual diversity on vocabulary learning (e.g., Bolger et al., Reference Bolger, Balass, Landen and Perfetti2008; Ferreira & Ellis, Reference Ferreira and Ellis2016) and studies exploring its effect on processing of new vocabulary (Pagán & Nation, Reference Pagán and Nation2019) have tended to focus on novel items embedded in single sentences. However, learners are often required to read longer texts for meaning, and it is important to understand what factors affect the learning as well as processing of novel words in longer texts. Therefore, in view of preliminary findings suggesting the benefits of contextual diversity for vocabulary learning in such conditions (e.g., Liu & Todd, Reference Liu and Todd2016), our aim is to investigate both processing and incidental vocabulary learning through the repeated reading of longer texts, comparing contextually same versus different conditions.
While several reading studies have used eye tracking to explore incidental vocabulary acquisition while reading longer texts (e.g., Godfroid et al., Reference Godfroid, Boers and Housen2013; Mohamed, Reference Mohamed2018; Pellicer-Sánchez et al., Reference Pellicer Sanchez, Siyanova-Chanturia and Parente2022), none, to our knowledge, have combined the study of processing and incidental learning through repeated reading of longer texts in the L2 while comparing same vs. different contexts. Understanding how externally manipulated conditions such as contextual diversity can affect how novel items are processed and to what extent they are learnt also has important pedagogical implications for the design of classroom reading tasks, for example. Finally, insights from processing may help explain the potential effects of contextual diversity on incidental vocabulary learning.
The present study therefore aims to investigate how contextual diversity (in the form of multiple texts) vs. contextual sameness (the same text read multiple times) affect the learning and processing of novel lexical items in L2 repeated reading and to what extent processing patterns may explain how well these items are learnt when the number of exposures (i.e., frequency of occurrence) is kept constant. To that end, our research questions are as follows:
-
1. Are there differences in the processing of novel vocabulary under same versus different repeated reading conditions?
-
2. Do vocabulary learning and retention differ when new words are repeated in the same text read multiple times versus different texts?
-
3. Do processing patterns explain vocabulary learning and retention under different contextual conditions?
Based on the existing literature, we can formulate certain hypotheses. In response to the first research question, we expect reading times to decrease across repetitions (e.g., Elgort et al., Reference Elgort, Brysbaert, Stevens and Van Assche2018; Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018; Mohamed, Reference Mohamed2018; Pellicer-Sánchez Reference Pellicer-Sánchez2016). We might also expect greater decreases in fixation times in the Same condition as opposed to the Different condition in line with episodic memory models (Bolger et al. Reference Bolger, Balass, Landen and Perfetti2008; Reichle & Perfetti’s Reference Reichle and Perfetti2003), the SDM and with Pagán and Nation’s (Reference Pagán and Nation2019) findings, since repetitions in the Different condition would require increased processing effort in order to be encoded in memory. Greater decreases in fixations in the Same condition would also be predicted by Liu and Todd’s (Reference Liu and Todd2016) theory of “input processing predilection” (p. 69).
In terms of vocabulary gains (RQ2), we might hypothesize greater vocabulary gains under the Different condition (Bolger et al., Reference Bolger, Balass, Landen and Perfetti2008, Ferreira & Ellis, Reference Ferreira and Ellis2016; Liu & Todd, Reference Liu and Todd2016; Pagán & Nation, Reference Pagán and Nation2019). Concerning the third research question, as indicated in the literature review, we can speculate that longer processing times might be indicative of greater cognitive processing of the items, which, in turn, might lead to more learning (e.g., Godfroid et al., Reference Godfroid, Boers and Housen2013; Mohamed, Reference Mohamed2018; Pellicer-Sánchez, Reference Pellicer-Sánchez2016).
Methods
Participants
The participants were 42 undergraduate students enrolled in the English Studies undergraduate degree at a university in Catalonia, Spain (five males and 37 females, aged between 19 and 23 years old). Twenty-seven were L1 Spanish/Catalan bilingual, 11 were multilingual (heritage speakers of another language along with Spanish/Catalan), and four were Erasmus exchange students from other parts of Europe (L1 Italian n = 2; German n = 1; Polish n = 1). All participants were enrolled in an Applied Linguistics class, and they received course credit for voluntarily taking part in the study. All participants had a vocabulary size above 4,000 according to V_YesNo Test (Meara & Miralpeix, Reference Meara and Miralpeix2017): M = 6661.86, SD = 1157.82. In addition, according to the Quick Oxford Placement Test (UCLES, 2001), the participants had an average score of 46.6/60 (SD = 6.05), indicating a B2 or upper intermediate proficiency level. As Table 1 illustrates, the scores of the vocabulary and grammar tests across L1 groups were very similar.
Table 1. Descriptive statistics for vocabulary size and proficiency by L1 group

Notes: Max. score for vocabulary size = 10000. Max score for OPT = 60
Reading materials
Four stories were designed for the purpose of this study. One story (henceforth Text 1) was read three times in the Same condition, while the other three stories (henceforth Texts 2–4) were read one after the other in the Different condition. Following the operationalization of contextual diversity as document count (e.g., Ferreira & Ellis, Reference Ferreira and Ellis2016; Jones et al., Reference Jones, Dye and Johns2017; Liu & Todd, Reference Liu and Todd2016; Pagán & Nation, Reference Pagán and Nation2019), in the present study, we considered target items to be in the same context when they appeared in the text that was read three times (Text 1) and in a different context when they appeared in Texts 2, 3, and 4, each of which were only read once. Each story consisted of 16 paragraphs and contained 10 pseudowords, with each word repeated twice within the text, resulting in a total of six repetitions, in line with the minimum recommended by Rott (Reference Rott1999). We decided to include two repetitions in each text and not just one occurrence in order to limit the number of re-readings of the entire text to three, considering the possibility that six repeated readings might lead to reduced attention due to boredom.
The text assigned to the Same condition (Text 1) was adapted from a text used in a previous study by Pellicer-Sánchez (Reference Pellicer-Sánchez2016). This text was shortened to include only two repetitions of the target items instead of the original eight, given that our participants read the text multiple times as opposed to one. The three texts used in the Different condition (Texts 2–4) were simple fictional narratives told in the past tense in a similar style to Text 1, taken from the website storynory.com and adapted to contain the same number of repetitions of the target items in each.
To ensure that the texts would be easily comprehensible to L2 participants and to facilitate noticing and processing of new lexical items, the words used in all four stories were high frequency words, mostly belonging to the first 2,000 most frequent English word families. Knowledge of the first 3,000 word families provided 98% lexical coverage. Given the average level of proficiency of participants (i.e., B2 or upper intermediate) and their overall vocabulary size (M = 6,572), we expected them to have no major issues comprehending the texts. The four texts all had a similar lexical profile and readability scores (see Table 2 for text characteristics and Appendix A in the supplementary materials for the complete texts).
Table 2. Text characteristics
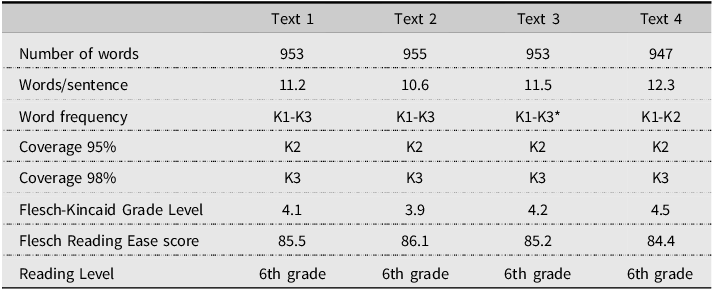
*There was one K5 word, jealous, which is a cognate with Catalan/Spanish gelós/celoso and was assumed to be known by the target participant.
The stories were presented on the desktop-based Tobii Pro Spectrum eye-tracking monitor (23.8″ diagonally, 1920 × 1080 pixel resolution) as black text on a white screen in Courier New font, size 18, with double line spacing. Each text was divided into sixteen screens, with one paragraph of the story and a maximum of 69 words per screen (M = 63.53). No more than two (different) target words were present on any one screen, and the target items were not placed at the beginning or end of a line or sentence since existing research indicates that the first fixation on a line may be longer (Rayner, Reference Rayner1977). All participants read all four texts, with half of them randomly assigned to either a Same-first or Different-first group, whereby approximately half read the text in the Same condition first, while the other half read the texts in the Different condition first.
Target items
The target items for the study were 20 nonwords chosen from the ARC Nonword Database (Rastle, Harrington, & Coltheart, Reference Rastle, Harrington and Coltheart2002) and used to replace 20 countable, high-frequency nouns from the texts (within the first 1K or 2K word families). They were selected based on the following criteria: neighborhood size (min = 1, max = 5), number of body neighbors (min = 1, max = 5), and number of phonological neighbors (min = 1, max = 5). In addition, no pseudo-homophones were used, and only orthographically existing onsets, orthographically existing bodies, and legal bigrams were extracted.
A pool of pseudowords was first piloted with L1 speakers of English, who were asked to rate 63 pseudowords intermixed with 12 low-frequency real words (e.g., burlap, scab, and churn) on a six-point Likert scale according to how English-like, or real word-like, their form was (1 = very unlikely to be an English word, and 6 = very likely to be an English word). Based on the scores provided, we selected 20 pseudowords whose mean rating was at least 4. We ensured that all the items that replaced plural nouns also finished with a regular plural morpheme (-s, -es), and that none of the items that replaced singular nouns ended in -s or -es. All were single syllable words (e.g., glabe, brald) and their lengths varied between 4 and 7 letters. For details of the pseudoword characteristics see Appendix B, and for pseudoword target meanings and distribution within the texts are see Appendix C (both included in the supplementary materials).
Even though we made sure the target pseudowords were similar with respect to features that might affect their processing and learning, as reported above, we also took a further step to control for the role of the target pseudowords. The 20 nonwords were divided into two sets of 10 words each, with approximately half of the participants being exposed to set 1 in Text 1 (Same condition) and set 2 in Texts 2–4 (Different condition) and the other half reading set 2 in Text 1 and set 1 in Texts 2–4 (see Appendix D in the supplementary materials for details of the experimental procedure, including the counterbalanced format). To control for the degree of informativeness of each specific context, 31 L1 speakers of English were asked to assess the likelihood of inferring the meaning of the target pseudowords by considering the two sentences in which they appeared using a 4-point rating scale similar to Webb’s (Reference Webb2008):
1 = Extremely unlikely that the target word can be guessed correctly.
2 = It is unlikely that the meaning of the target word can be inferred.
3 = It might be possible to infer the meaning of the target word.
4 = Readers have a good chance of guessing the meaning of the target word.
The mean score for all 20 pseudowords across the 31 raters was 3.31 (SD = .246), indicating that meanings were relatively easy to infer from all the contexts in which the items appeared. Crucially, no significant differences were found in contextual informativeness between words that appeared in the Same (Text 1) and Different (Texts 2–4) conditions (t(38) = .636, p = .528).
Vocabulary tests
To test different aspects of target item knowledge, we used three different vocabulary tests. First, in a form recognition test, participants were presented with a list of the 10 target items that appeared in each condition mixed with 10 distractor pseudowords and were told to choose any words they remembered seeing in the readings (no minimum or maximum limit was placed). The distractor pseudowords were also taken from the ARC Nonword Database (Rastle, Harrington, & Coltheart, Reference Rastle, Harrington and Coltheart2002), following the same criteria as the target pseudowords (see Appendix E in the supplementary materials for a list of the distractors). The form recognition was followed by a meaning recall test, in which participants were presented with the set of pseudowords and asked to provide a meaning (in the form of a synonym, short definition, or translation in Spanish/Catalan). Participants finally completed a multiple-choice meaning recognition test, which was expected to capture more learning gains than the meaning recall test (Waring & Takaki, Reference Waring and Takaki2003). The test contained three options: the target meaning, two distractors either taken from within the stories or that were plausibly semantically related to the content of the stories, and the option “I don’t know”. The three tests were completed in the same order via Google Forms (see Appendix F in the supplementary materials for the complete vocabulary tests).
Procedure
All participants were exposed to both contextual conditions and all 20 pseudowords in a counter-balanced, within-subjects design. The procedure consisted of three sessions, each lasting approximately half an hour to one hour. Prior to beginning the study, all participants were informed about the general aims of the study and signed an informed consent form. Additionally, participants filled in a language-background questionnaire which included questions on their L1(s) and experience learning and reading in English. In the first session, participants filled out the language background questionnaire, and then read three texts consecutively: either Text 1 three times or Texts 2–4, depending on whether they were in the Same-first (n = 23) or Different-first (n = 19) group. Since we were interested in incidental vocabulary learning and in order to ensure that participants were focusing on meaning, the texts were followed by 16 true-false questions about the main ideas in each paragraph of the text(s) (see Appendix G in the supplementary materials for complete comprehension tests). The participants were informed about these comprehension questions before they started reading, and they answered them on a different computer via Google Forms. None of the target items appeared in any of the questions.
Participants read the texts on a desktop-mounted Tobii Pro Spectrum monitor, which records eye movements at a maximum sample rate of 1200 Hz through the Tobii Pro Lab software (Tobii Pro AB, Reference Tobii Pro2014). Participants were seated 55–75 cm from the monitor, as recommended for optimal recording of eye movements. Before each session, accuracy was verified using a five-point calibration and validation. If calibration values were > 0.5º, the procedure was repeated. Participants read the texts silently and were told to minimize head movement. They navigated from one screen to the next by mouse-click and could therefore control their own pace. They were not allowed to go back to previously read screens. Participants took around 10–12 minutes to complete the readings in the Same condition and 15–18 in the Different condition.
Session 2 was held after a one-day gap. In this session, participants who had started with the Same condition read texts in the Different condition and vice versa. Once again, they were told to read for meaning, and the readings were followed by true/false comprehension questions. Overall, comprehension scores showed an average of 13.87/16 in the Same condition (86.69% correct responses) and 12.04/16 in the Different condition (75.25% correct responses) suggesting that participants did not have major comprehension difficulties. This session also included the vocabulary posttests of the words encountered in Session 2 readings, which were used to obtain a measure of participants’ immediate gains. In order to control for potential test effects, the immediate test was only conducted after the second session and included the items presented in that session. Before completing the immediate vocabulary posttests, participants did the V_YesNo Vocabulary size test (Meara & Miralpeix, Reference Meara and Miralpeix2017), which took approximately 10 minutes.
The final session, held a week after the first, consisted of delayed vocabulary posttests corresponding to the items encountered in the Session 1 readings. The tests were again completed in fixed order (1. form recognition. 2. meaning recall, and 3. meaning recognition). This was followed by the Quick OPT (UCLES, 2001), which was used to obtain a measure of participants’ English proficiency. As described in this section, and in line with some previous studies (e.g., Rogers & Cheung, Reference Rogers and Cheung2021), participants were only tested on each pseudoword once to avoid test repetition effects. Moreover, administering vocabulary tests after the first reading session would probably have increased participants’ focus on the new words during Session 2, affecting the incidental learning nature of the study. Figure 1 presents a summary of the experimental design.

Figure 1. Schematic layout of the experimental design.
Analyses
Processing measures
Areas of interest were created around each target item, with a uniform height of 100 pixels and a length varying between 105 and 150 pixels, depending on the length of the pseudoword. We then extracted fixation measures for each separate encounter with each pseudoword (six encounters over three readings for all pseudowords and conditions). Tobii’s I-VT fixation filter was applied to extract the data, which resulted in fixations lower than 60 ms being discarded.
The eye-tracking measures extracted were the following: total fixation duration (TFD), which is the sum of the durations of all fixations on an item; average fixation duration (AFD), which measures the average length of each fixation on the target area; first fixation duration (FFD), which is the initial or first fixation on the item; and fixation count (FC), which refers to the total number of fixations on the target item. FFD is considered an “early” measure that captures recognition and lexical access (Godfroid, Reference Godfroid2019), while TFD and FC are “later” measures that reflect lexical integration (Rayner, Reference Rayner2009), as well as the contextual- and discourse-level properties of what is being read (Conklin et al., Reference Conklin, Pellicer-Sánchez and Carrol2018). AFD, meanwhile, may indicate how eye movements evolve over time (Conklin et al., Reference Conklin, Pellicer-Sánchez and Carrol2018).
Vocabulary scores
The tests for vocabulary form and meaning recognition were scored dichotomously. On the form recognition test, one point was awarded for each target word accurately recognized; on the meaning recognition test, students received one point for each target pseudoword that was correctly matched to the original word from the texts it replaced. For meaning recall, answers were scored as 1 when students were able to either 1) provide the original words the target pseudo-words replaced or a synonym or word that was accurate in the target context (e.g., plates instead of bowls, or path instead of road), 2) provide a translation in Spanish/Catalan, and 3) or define the meaning of the target pseudowords. Answers that did not meet either criterion were scored as 0. Two raters scored the answers and reached 100% agreement on the scores.
Statistical analyses
Version 27.0 of the SPSS program (IBM Corp, 2020) was used for the statistical analyses. Since data from the eye-tracking measures were not normally distributed and were skewed toward higher values, a-priori cleaning was carried out by eliminating all values that were 2.5 SD above the mean (as recommended in Godfroid, Reference Godfroid2019). The resulting data loss were as follows: TFD 3.02%, AFD 1.47%, FFD 1.96%, and FC 2.58%. The remaining data were normally distributed according to the skewness and kurtosis values, which were between –2 and 2 (Godfroid, Reference Godfroid2019) for all four measures. In terms of the distribution of vocabulary scores, results for the form and meaning recognition tests also presented skewness and kurtosis values between –2 and 2 again indicating normal distribution (see Appendix H in the supplementary materials for normality all skewness and kurtosis values).
To examine processing (RQ1), we performed repeated measures linear mixed models (LMM) with participants as random factors, item number, and encounter time (1 and 2 for the two repetitions of each item in teach text) as repeated measures and the eye-tracking measures (TFD, AFD, FFD, and FC) as dependent measures. Initially, participants’ L1 was included as a fixed effect in the model but since it did not have a significant effect,Footnote 1 the factor was removed and the model was run again with only condition (Same vs. Different), reading time (1, 2, 3), and their interaction introduced as fixed effects. The SPSS model adjusted p-values for multiple comparisons using sequential Bonferroni. Standardized Pearson residuals were saved and were within the normal range for all the target factors (no absolute values greater than 2, as recommended in Godfroid, Reference Godfroid2019) reducing the likelihood of outliers affecting model fit.
In order to answer RQ2, generalized linear mixed models (GLMM) with repeated measures and participants as random factors were run, including the scores in the form and meaning recognition vocabulary tests as dependent measures. Condition (Same vs. Different) and time (immediate vs. delayed posttest) and their interaction were included as fixed effects. Finally, to examine the effects of processing on vocabulary learning (RQ3), the same model was re-run, this time with TFD added as a fixed effect. Only one eye-tracking measure was selected due to the strong correlation between them. TFD was chosen as it is the measure most strongly associated with learning in existing research (Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018) and the one that best captures global processing patterns (Godfroid, Reference Godfroid2019). Estimated marginal means were obtained for each categorical factor, with p-values of pairwise comparisons corrected using the sequential Bonferroni method. Fixed coefficients were obtained for continuous variables. Once again, standardized Pearson residuals were saved and found to be within the normal range for all of the target factors.
SPSS was unable to perform the GLMM analysis with the scores for meaning recall, due to the very high percentage of zeros in the results. From a total of 840 cases (20 target words x 42 participants), 738 (87.9%) were incorrect (0) and 102 (12.1%) were correct (1).
Results
RQ1. Processing patterns
The descriptive statistics of fixations on target items are presented in Table 3. These show a decrease in processing times and number of fixations from the first to the third reading, in both the Same and Different conditions, with a clearer decrease in the former.
Table 3. Descriptive statistics for fixation measures on target items across the three repeated readings by condition. Fixation durations in milliseconds

Notes: TFD = total fixation duration; AFD = average fixation duration; FFD = first fixation duration; FC = fixation count.
The results of the LMMs exploring the fixed effects of condition, reading times, and their interaction are presented in Table 4. The parameter estimates (SPSS fixed coefficients table) are included in Appendix I.
Table 4. LMMs. Fixed effects of condition, reading time, and condition*reading time on eye-movement measures

For TFD, there was a significant effect of condition (p = .030) and reading time (p < .001). Pairwise contrasts between Same and Different condition indicated that fixations were longer in the Different condition (t(4882) = –2.173, p = .030). When comparing processing patterns across the three reading times, pairwise contrasts showed that fixations were significantly shorter at Time 2 than Time 1 (p < .001), at Time 3 than at Time 2 (p = .037) and at Time 3 than at Time 1 (p < .001). There was a significant interaction between condition and reading time (p = .038). The pairwise comparisons suggest that, while changes in eye-movements across reading times were equivalent for the two conditions, showing a significant decrease (except for Times 2–3 [p = .140]), when comparing conditions across reading times, TFD was significantly higher in the Different condition at Time 2 (p = .016) and Time 3 (p = .012) but not at Time 1 (p = .395).
In terms of AFD, there was also a significant effect of condition (p < .001) and reading time (p < .001). Pairwise contrasts showed a similar pattern to TFD, with average fixations in the Different condition being longer than those in the Same condition (t(4960) = –4.016, p < .001). Pairwise contrasts across reading times showed a significant decrease in AFD from Times 1–2 (p = .001), Times 2–3 (p < .001), and Times 1–3 (p < .001). We again found a significant interaction between condition and reading time (p = .005). Subsequent pairwise contrasts revealed a significant decrease across all reading times for both conditions, except for Times 2–3 in the Same condition (p = .256). When comparing conditions across time, no significant differences were found at Time 1 (p = .822) and Time 3 (p = .051), although fixations were shorter in the Same condition at Time 2 (p < .001).
The results for FFD showed a significant main effect of condition (p < .001) and reading time (p < .001). Pairwise contrasts between Same and Different conditions again showed that initial fixations were longer in the Different condition than in the Same (t(4935) = –3.566, p < .001). In terms of processing across reading times, there was again a significant drop in FFDs from Times 1–2 (p < .001), Times 2–3 (p = .006), and Times 1–3 (p < .001). The interaction between the condition and reading time was not found to be significant (p = .196).
Finally, for FC, there was a significant effect of condition (p = .014), reading time (p < .001) and of the interaction between condition and reading time (p = .014). Pairwise contrasts, in line with the results for the other eye-tracking measures, indicated that the number of fixations was higher in the Different condition than in the Same condition (t(4904) = –2.394, p = .017). For reading times, pairwise contrasts indicated a significant drop in the number of fixations from Times 1–2 (p < .001), Times 2–3 (p = .038), and Times 1–3 (p < .001). There was a significant interaction between condition and reading time (p = .005). The pairwise comparisons showed that while changes across reading times were equivalent in both conditions (significant decrease between Times 1–2 and Times 1–3 but not Times 2-3), there were significantly fewer fixations in the Same condition at Time 2 (p = .011) and Time 3 (p = .003), although not at Time 1 (p = .314).
Details of all significant pairwise comparisons for all four processing measures can be found in Appendix I in the supplementary materials. Figure 2 presents a graphical representation of the interaction between reading time and condition for each of the processing measures.

Figure 2. Estimated marginal means for condition*reading time (see Appendix I for complete estimated marginal means tables).
RQ 2. Context and vocabulary scores
The descriptive statistics for vocabulary scores under the Same and Different conditions and by test time (immediate and delayed) are presented in Table 5. In the Same condition, higher mean scores were obtained at the immediate rather than delayed posttest for both form and meaning recognition. In the Different condition, form recognition scores were higher in the immediate posttest, although, interestingly, mean scores were slightly higher in the delayed posttest in the case of meaning recognition. Overall, the scores in the Same condition were higher than in the different condition in the immediate posttest, but this advantage disappears in the delayed posttest.
Table 5. Descriptive statistics for vocabulary scores in the immediate and delayed posttests by condition. Scores out of 1

Results for the GLMMs examining the fixed effects of condition, test time and the interaction between condition and test time are presented in Table 6.
Table 6. GLMMs. Fixed effects of condition, test time, and condition*test time on vocabulary test scores

For form recognition, there was a significant effect of test time (p < .001), but neither condition (p = .313) nor the interaction between test time and condition (p = .512) showed significant effects. Pairwise contrasts demonstrated that scores were significantly higher on the immediate posttest than on the delayed posttest (t(836) = 6.997, p < .001).
The results for meaning recognition showed a significant effect of both condition (p = .001) and test time (p = .003). Pairwise contrasts between the Same and Different conditions showed that participants who read the same text three times scored higher than those who read three different texts (t(836) = 3.446, p = .001). They also scored higher on the immediate than the delayed posttests (p = .003). There was a significant interaction between condition and test time (p < .001). Pairwise comparisons examining condition at each test time revealed significantly higher scores in the Same condition at the immediate posttest (p < .001), but no significant differences between conditions at the delayed posttest (p = .171). Further pairwise contrasts showed that in the Same condition, participants scored significantly higher on the immediate post-test (p < .001), although there was no significant difference between the two test times in the Different Condition (p = .191). Figure 3 shows a graphical representation of the interactions. See Appendix J in the supplementary materials for details of pairwise comparisons.

Figure 3. GLMMs: Estimated marginal means for condition*test time.
RQ3. Relationship between vocabulary and processing
In order to explore how processing relates to vocabulary learning, the GLMM model used for RQ2 was re-run to include processing (measured as TFD) as a fixed effect. We were especially interested in the interaction between TFD and condition (Same vs. Different) and also in the three-way interaction with testing time to examine differential effects between conditions for short- and long-term vocabulary learning. Initially, all fixed effects as well as possible two- and three-way interactions were included in the model. The results showed no interactions between TFD and condition (Same vs. Different), suggesting that the relationship between eye-movements and vocabulary learning were not different between Same and Different contexts (see Appendix K in the supplementary materials for all the results).
Another model was run in which these interactions were removed, for a better understanding of the results on how processing relates to vocabulary learning in repeated reading. Table 7 shows significant effects of TFD on form and meaning recognition scores.
Table 7. GLMMs. Fixed effects of TFD and TFD*test time on vocabulary test scores. Only significant results shown
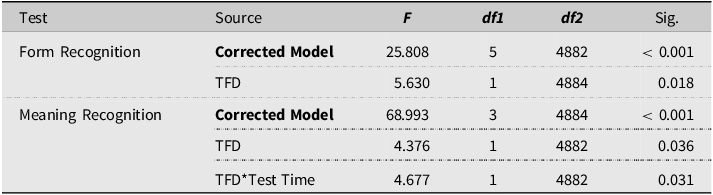
In terms of form recognition scores, TFD had a significant overall positive effect (OR = 1.24, 95% CI [1.04, 1.49]). This implies that, across conditions and test times, for each second more in TFD, the odds of correctly recognising the form of the target item went up by 24%.Footnote 2
For meaning recognition scores, results showed a significant overall effect of TFD (OR = 1.48, 95% CI [1.14, 1.92]) as well as a significant interaction between TFD and test time (p = .031). At immediate testing, the effect of TFD (OR = 1.48, 95% CI [1.04, 2.12]), was shown to be higher than at delayed testing (OR = 1.001, 95% CI [0.78, 1.29]). This indicates that one second longer in TFD resulted in 48% greater odds of correct meaning recognition at the immediate posttest, but only 0.1% greater odds at the delayed posttest (see Appendix K in the supplementary materials for complete parameter estimates).
Discussion
This study explored the effect of contextual diversity on the processing and learning of novel vocabulary through repeated reading. A group of undergraduate EFL learners encountered 20 pseudowords (10 per condition), each occurring six times across three readings of either the same or different English texts. Our results show that despite the difficulty of the task—completely unknown words, and only moderate frequency of exposure—participants managed to recognize the form and meaning of several of the target words with some even being able to produce an accurate translation or definition. This, by itself, is testament to the effectiveness of repeated reading for developing new lexical knowledge in the L2 (e.g., Liu & Todd, Reference Liu and Todd2016; Webb & Chang, Reference Webb and Chang2012).
When it comes to processing and reading patterns in the context of a repeated reading design that compares the same versus different texts, our findings show that the time spent processing novel items in repeated readings of the same text was significantly lower than when the texts were different. This is similar to Pagán and Nation’s (Reference Pagán and Nation2019) study, where target items read in the Same-condition sentences showed shorter fixations in both early and late measures of processing. Our data indicates that condition (Same vs. Different) had a significant fixed effect on processing patterns across all four processing measures, although certain differences were observed in each measure studied.
The interaction between condition and reading times was significant for three of the four processing measures (TFD, AFD, and FC). Despite a lack of statistically significant differences in eye movements between conditions during the first reading, the number and duration of fixations in subsequent readings (2 and 3) were significantly lower in the Same condition than in the Different condition. These findings suggest that the integration of contextual and discourse-level properties (Conklin et al., Reference Conklin, Pellicer-Sánchez and Carrol2018; Rayner, Reference Rayner2009) captured by a reduction in the number (FC) and length (TFD) of fixations across readings is slower when participants re-encounter novel items in contextually diverse texts. The significantly lower average processing time (AFD) in readings 2 and 3, along with the larger mean decreases in AFD from one reading to the next in the Same condition, indicate that overall processing evolves more slowly in the contextually Different condition, given that AFD is considered an evolutive measure (Conklin et al., Reference Conklin, Pellicer-Sánchez and Carrol2018). These results are also coherent with episodic memory models that suggest increasing contextual diversity would require more processing at each new encounter (Bolger et al. Reference Bolger, Balass, Landen and Perfetti2008; Reichle & Perfetti Reference Reichle and Perfetti2003). They also coincide with the theory of input processing predilection (Liu & Todd, Reference Liu and Todd2016; VanPatten, Reference VanPatten, Piske and Young-Scholten2008), whereby seeing the target items in a diverse context each time would lead learners to process them for meaning each time as well, leading to longer processing times in the Different condition.
In terms of early measures, we found significant fixed effects of both condition and reading time on FFD, which is said to represent aspects of processing such as recognition and lexical access (Godfroid, Reference Godfroid2019), although there was no significant interaction between the two. Our results indicate that encounters with novel items in the Different condition produced significantly longer initial fixations than in the Same condition, and that first fixation length decreased across the three readings overall. This appears consistent with the SDM (Semantic Distinctiveness Model, see Johns, Dye & Jones, Reference Johns, Dye and Jones2014 and Jones, Johns & Recchia, Reference Jones, Johns and Recchia2012), which may suggest that items encountered in diverse conditions would require more time to be encoded, given that the different contexts would not coincide with existing memory traces, although at each subsequent re-encounter, as the representation grows stronger, the time for lexical access would decrease. However, as the interaction between reading time and condition for FFD did not reach statistical significance in our case, further investigation would be needed to confirm this interpretation. Future studies could also incorporate posttest processing measures, as in Pagan and Nation (Reference Pagán and Nation2019), to further explore whether the different contextual conditions lead to processing differences that are also reflected in posttest processing tasks.
On exploring the effects of contextual diversity on incidental vocabulary learning, we found no significant effect of condition on participants’ ability to recognize the form of novel items. This may be because form recognition is one of the easiest components of vocabulary knowledge (Nation, Reference Nation2001), implying that contextual factors may not play a significant role in accuracy of form recognition. Previous research, however, has shown faster and more accurate form recognition under contextually diverse conditions (e.g., Johns et al., Reference Johns, Dye and Jones2016). This would also be predicted by the SDM (Johns, Dye & Jones, Reference Johns, Dye and Jones2014; Jones, Johns & Recchia, Reference Jones, Johns and Recchia2012) which would indicate an advantage for the Different condition, although this was not borne out in our study. This might be due to the fact that we operationalized contextual diversity as document count, rather than using the measure of “semantic distinctiveness” as in Johns et al. (Reference Johns, Dye and Jones2016), or because we studied L2 learners with upper-intermediate proficiency, who may be expected to process items differently to L1 speakers. Future studies would thus be required to confirm or elaborate on the effects of contextual diversity on form recognition under different experimental conditions.
Our participants’ ability to recall the meaning of the target was overall very low which is why the results could not be analysed using inferential statistics or LMM. The small gains in terms of meaning recall are in line with other studies on vocabulary learning through reading (e.g., Brown et al., Reference Brown, Waring and Donkaewbua2008; Pellicer-Sánchez & Schmitt, Reference Pellicer-Sanchez and Schmitt2010). These results are expected considering that reading is a receptive task and given the difficulty in acquiring this dimension of vocabulary knowledge (Gonzalez-fernandez & Schmitt, Reference Gonzalez-fernandez and Schmitt2020).
In terms of meaning recognition, gains were significantly higher in the immediate posttest for participants who encountered words in the Same contextual condition rather than across Different contexts. This is contrary to some existing research (e.g., Ferreira & Ellis, Reference Ferreira and Ellis2016; Liu & Todd, Reference Liu and Todd2016). Ferreira and Ellis (Reference Ferreira and Ellis2016) found that participants who had encountered obscure words in different sentences recognized their meaning faster and made fewer errors than those who had seen the targets in the same sentences repeated six times. However, since their study involved reading sentences rather than whole texts, as well as intentional learning (participants were told to try to infer the meaning of unknown words), the discrepancy in the results is not unexpected. Our results also contradict Liu and Todd’s (Reference Liu and Todd2016) study. We can speculate that the high number of repetitions of the same text (seven) in Liu and Todd (Reference Liu and Todd2016) probably contributed to a consequent loss of interest/attention and/or need to infer individual word meanings more clearly than in our study, which only included three repeated readings of the same text. This remains speculative as there was no processing information in Liu and Todd (Reference Liu and Todd2016).
In contrast, our findings regarding meaning recognition have been borne out by other studies that suggested that contextual uniformity may help build more stable semantic representations (e.g., Johns et al., Reference Johns, Dye and Jones2016). This can be explained by the fact that a stable or repeated context would make it easier for participants to first discern and subsequently confirm their guesses of the meaning of novel words from contextual clues. The changes in these clues inherent in the different context might make it more difficult to accurately infer meanings across the texts.
Furthermore, as posited by other researchers, the positive effects of contextual diversity may be linked to higher proficiency levels (e.g., Horvath & Arunachalam, Reference Horvath and Arunachalam2021; Zahar et al., Reference Zahar, Cobb and Spada2001) and have often been found among L1 rather than L2 learners (e.g., Adelman et al., Reference Adelman, Brown and Quesada2006; Bolger et al., Reference Bolger, Balass, Landen and Perfetti2008). The present study involved not only longer texts but also incidental learning of completely unknown pseudowords. We might reasonably assume that for participants of an upper-intermediate level (average B2 as per the Quick Oxford Placement), the difficulty of the task may account for the fact that the Same condition was more conducive to initial meaning recognition since it would allow readers to become more familiar with the contextual clues through repetition (Liu & Todd, Reference Liu and Todd2016), leading to a better chance of inferring meanings in that condition.
Notwithstanding these explanations, it is interesting to note that the difference between the two conditions is not present in the delayed posttest scores, indicating that while the Same condition may have led to immediately greater gains, it also led to a greater loss of knowledge in the delayed posttest. This seems to suggest that despite significantly lower immediate recognition, the Different condition appears to have fostered more stable long-term retention. This might be explained by the fact that contextual diversity allows for more context-independent encoding in the lexicon (Pagán & Nation, Reference Pagán and Nation2019) and easier future retrieval on the basis of “likely need” (Anderson & Milson, Reference Anderson and Milson1989; Anderson & Schooler, Reference Anderson and Schooler1991). It could also be explained with reference to the SDM or semantic distinctiveness model (Johns & Jones, Reference Johns and Jones2008; Johns, Dye & Jones, Reference Johns, Dye and Jones2014; Jones, Johns & Recchia, Reference Jones, Johns and Recchia2012), which posits that contextual diversity aids encoding items in the lexical memory at a “stronger magnitude” (Jones et al., Reference Jones, Dye and Johns2017, p. 270) than contextual repetition, which might imply better long-term retention. It could also be interpreted in light of the desirable difficulty framework (cf. Bjork, Reference Bjork1994; Suzuki, et al., Reference Suzuki, Nakata and DeKeyser2019). In this case, the Different condition constituted a “difficulty,” reflected in participants’ slower online processing across readings, but such difficulty was “desirable,” as it fostered long-term retention of knowledge. This is in line with other “desirable difficulties” in L2 practice conditions that have been shown to be more challenging during the learning phase, but which foster long-term knowledge (Suzuki et al., Reference Suzuki, Nakata and DeKeyser2019).
Finally, our results regarding the relationship between processing and vocabulary learning suggest that processing, as analysed by TFD, does not differentially affect vocabulary learning under Same vs. Different repeated reading conditions, as the interaction between TFD and context was not significant. However, our results do suggest a link between processing and overall vocabulary gains. Existing literature on the relationship between processing and vocabulary learning is divided: some studies have found a positive relationship between longer processing times and greater gains (Godfroid et al., Reference Godfroid, Boers and Housen2013; Pellicer-Sánchez, Reference Pellicer-Sánchez2016), while others have not (e.g., Elgort et al., Reference Elgort, Brysbaert, Stevens and Van Assche2018; Pellicer-Sánchez et al., Reference Pellicer Sanchez, Siyanova-Chanturia and Parente2022; Serrano & Pellicer-Sánchez, Reference Serrano and Pellicer-Sánchez2024), or have found inconclusive results (Wochna & Juhasz, Reference Wochna and Juhasz2013).
We found that longer TFD may be linked to higher scores in form recognition (irrespective of condition and test time). We also found a significant effect of processing on meaning recognition scores overall, with the effect being significantly greater at the immediate posttest than at the delayed posttest. These results are in line with previous studies that have found longer processing times to be related to greater gains (e.g., Koval, Reference Koval2019; Mohamed, Reference Mohamed2018; Pellicer-Sánchez, Reference Pellicer-Sánchez2016). This finding can be explained by considering longer processing times as an indication of greater cognitive engagement (Godfroid et al., Reference Godfroid, Boers and Housen2013), which could be expected to lead to greater learning. The results are also coherent with existing theories that suggest noticing and attention to target items are key to learning (e.g., Robinson Reference Robinson1995; Schmidt, Reference Schmidt2001). In terms of the interaction between test time and the effects of processing on meaning recognition scores, we could speculate that the benefits conferred by greater processing may diminish over time if there is no further exposure to the target words, thus leading to a much weaker effect at the delayed posttest. This would need to be tested and confirmed in future research.
Our study constitutes an initial exploration on how processing might predict different degrees of incidental vocabulary learning when new words are repeated in the same versus different texts. Future replication studies would be essential to reach more robust conclusions about the links between contextual diversity, processing, and long- and short-term vocabulary learning. Incorporating further vocabulary testing measures and using stimulated recalls or post-task questionnaires on engagement and learning strategies employed by participants might help better explain the links between processing patterns and vocabulary gains.
Limitations
This study was not without limitations, one of which may be the lack of ecological validity in the task, particularly under the Same condition. This is because learners are rarely asked to read a text three times consecutively in one sitting with general comprehension being the only focus. Future studies could perhaps devise other (non-vocabulary related) exercises to make this a more ecologically valid exercise for participants.
Another limitation is that, while our study focused on the role of contextual diversity, while trying to control for other potential factors, it is possible the role of contextual diversity in processing and learning of new words may be affected by such factors. Future studies should explore how the effects of contextual diversity may be affected by variables such as frequency, participant-, text-, and treatment-related variables including age, proficiency, engagement, modes of input, test format, and others (see Uchihara et al., Reference Uchihara, Webb and Yanagisawa2019) that may play a key role in vocabulary processing and learning. These are aspects that would be worth investigating in conjunction with contextual diversity.
In addition, triangulating a wider set of variables with more online and offline measures (the latter including stimulated recalls or further vocabulary tests, for example) might allow us to better understand the subprocesses involved in vocabulary acquisition through reading (Godfroid & Winke, Reference Godfroid, Winke and Rebuschat2015; Pellicer-Sánchez, Reference Pellicer-Sánchez2020) under different textual and experimental conditions.
Conclusion
This study explored the effects of contextual diversity versus sameness in a repeated reading design on the processing and incidental learning of novel vocabulary. Our findings suggest that while contextual sameness facilitates faster processing across subsequent readings and short-term learning of new words, it does not necessarily lead to better vocabulary learning long term. While initial encoding and lexical integration appear to take longer in the contextually Different condition, we did not find that these longer processing times were later reflected in higher vocabulary learning scores. This suggests that the role of context may depend on factors such as how diversity is conceptualized, the types of contexts new words are presented in, whether the target language is in the L1 or L2, and the proficiency of the participants, among others. Future studies should investigate other types of learners (differing in age, proficiency, etc.) as well as other types of texts or test formats, in order to generalize these results.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S0142716424000407
Acknowledgements
This research was funded by grants PID2019-110536GB-I00, from the Spanish Ministry of Science and Innovation, and 2023SGR00303, from the Catalan Agency for Management of University and Research Grants (AGAUR). We would like to thank the editor and the anonymous reviewers for their insightful comments.
Competing interests
The authors declare none.













 Open access
Open access