












1 Introduction
Throughout this paper,
 $P \in \mathbb {Z}[\mathrm {n}]$
denotes a polynomial with integer coefficients of some degree
$P \in \mathbb {Z}[\mathrm {n}]$
denotes a polynomial with integer coefficients of some degree
 $d \geq 2$
in one indeterminate
$d \geq 2$
in one indeterminate
 $\mathrm {n}$
; a typical case to keep in mind is the quadratic polynomial
$\mathrm {n}$
; a typical case to keep in mind is the quadratic polynomial
 $P(\mathrm {n}) = \mathrm {n}^2$
.
$P(\mathrm {n}) = \mathrm {n}^2$
.
Define a measure-preserving system to be a triple
 $X = (X,\nu ,T)$
, where
$X = (X,\nu ,T)$
, where
 $X = (X,\nu )$
is a
$X = (X,\nu )$
is a
 $\sigma $
-finite measure space and
$\sigma $
-finite measure space and
 $T \colon X \to X$
is an invertible bimeasurable map which is measure-preserving in the sense that
$T \colon X \to X$
is an invertible bimeasurable map which is measure-preserving in the sense that
 $\nu (T^{-1}(E)) = \nu (E)$
for all measurable E. It is common in the literature to restrict to finite measure systems and to normalize
$\nu (T^{-1}(E)) = \nu (E)$
for all measurable E. It is common in the literature to restrict to finite measure systems and to normalize
 ${\nu (X)=1}$
; but our results will not require any hypothesis of finite measure. Given functions
${\nu (X)=1}$
; but our results will not require any hypothesis of finite measure. Given functions
 $f,g \colon X \to \mathbb {C}$
, a scale
$f,g \colon X \to \mathbb {C}$
, a scale
 $N \geq 1$
and a weight function
$N \geq 1$
and a weight function
 $w \colon \mathbb {N} \to \mathbb {C}$
, we can then define the non-conventional averaging operator
$w \colon \mathbb {N} \to \mathbb {C}$
, we can then define the non-conventional averaging operator
for any
 $x \in X$
(see §2 for our averaging notation).
$x \in X$
(see §2 for our averaging notation).
1.1 Unweighted ergodic averages
In the unweighted case
 $w=1$
, the following ergodic theorem was recently proven by two of the authors with Mirek.
$w=1$
, the following ergodic theorem was recently proven by two of the authors with Mirek.
Theorem 1.1. (Unweighted ergodic theorem [Reference Krause, Mirek and Tao13, Theorem 1.17])
Let
 $(X,\nu ,T)$
be a measure-preserving system and let
$(X,\nu ,T)$
be a measure-preserving system and let
 $f \in L^{p_1}(X)$
,
$f \in L^{p_1}(X)$
,
 $g \in L^{p_2}(X)$
for some
$g \in L^{p_2}(X)$
for some
 $1 < p_1,p_2 < \infty $
with
$1 < p_1,p_2 < \infty $
with
 $({1}/{p_1}) + ({1}/{p_2}) = ({1}/{p}) \leq 1$
.
$({1}/{p_1}) + ({1}/{p_2}) = ({1}/{p}) \leq 1$
.
-
(i) (Mean ergodic theorem) The averages
 $\mathrm {A}_{N,1;X}(f,g)$
converge in
$L^p(X)$
norm.
$\mathrm {A}_{N,1;X}(f,g)$
converge in
$L^p(X)$
norm. -
(ii) (Pointwise ergodic theorem) The averages
$\mathrm {A}_{N,1;X}(f,g)$
converge pointwise almost everywhere. -
(iii) (Maximal ergodic theorem) One has
(see §2.2 for our asymptotic notation conventions).
$$ \begin{align*} \| (\mathrm{A}_{N,1;X}(f,g))_{N \in \mathbb{Z}^+} \|_{L^p(X; \ell^\infty)} \lesssim_{p_1,p_2,P} \|f\|_{L^{p_1}(X)} \|g\|_{L^{p_2}(X)}\end{align*} $$
-
(iv) (Variational ergodic theorem) If
$r>2$
and
$\unicode{x3bb}>1$
, one has whenever
$$ \begin{align*} \| (\mathrm{A}_{N,1;X}(f,g))_{N \in \mathbb{D}} \|_{L^p(X; \mathbf{V}^r)} \lesssim_{p_1,p_2,r,P,\unicode{x3bb}} \|f\|_{L^{p_1}(X)} \|g\|_{L^{p_2}(X)}\end{align*} $$
$\mathbb {D} \subset [1,+\infty )$
is finite and
$\unicode{x3bb} $
-lacunary (see §2.6 for the definition of
$\unicode{x3bb} $
-lacunarity and the variational norm
$\mathbf {V}^r\!$
).











We very briefly review the main ingredients of the proof of Theorem 1.1. Case (iv) is the main estimate, which easily implies the other three claims. By some standard sparsification and transference arguments, as well as dyadic decompositions, it sufficed to prove the variant estimate
 $$ \begin{align*} \| (\tilde {\mathrm{A}}_{N,1}(f,g))_{N \in \mathbb{D}} \|_{\ell^p(\mathbb{Z}; \mathbf{V}^r)} \lesssim_{p_1,p_2,r,P,\unicode{x3bb}} \|f\|_{\ell^{p_1}(\mathbb{Z})} \|g\|_{\ell^{p_2}(\mathbb{Z})},\end{align*} $$
$$ \begin{align*} \| (\tilde {\mathrm{A}}_{N,1}(f,g))_{N \in \mathbb{D}} \|_{\ell^p(\mathbb{Z}; \mathbf{V}^r)} \lesssim_{p_1,p_2,r,P,\unicode{x3bb}} \|f\|_{\ell^{p_1}(\mathbb{Z})} \|g\|_{\ell^{p_2}(\mathbb{Z})},\end{align*} $$
where
is the ‘upper half’ of
 $\mathrm {A}_{N,w;X}$
when X is the integers
$\mathrm {A}_{N,w;X}$
when X is the integers
 $\mathbb {Z}$
with the usual shift
$\mathbb {Z}$
with the usual shift
 $T \colon n \mapsto n+1$
and counting measure
$T \colon n \mapsto n+1$
and counting measure
 $\nu $
.
$\nu $
.
A crucial observation was that the averages
 $\tilde {\mathrm {A}}_{N,1}$
are ‘complexity zero’ in the sense that they are small when the Fourier transform of f or g vanish on ‘major arcs’. Indeed, in [Reference Krause, Mirek and Tao13, Theorem 5.12], the single-scale minor arc estimate
$\tilde {\mathrm {A}}_{N,1}$
are ‘complexity zero’ in the sense that they are small when the Fourier transform of f or g vanish on ‘major arcs’. Indeed, in [Reference Krause, Mirek and Tao13, Theorem 5.12], the single-scale minor arc estimate
 $$ \begin{align} \| \tilde {\mathrm{A}}_{N,1}(f,g) \|_{\ell^1(\mathbb{Z})} \lesssim_{C_1} ( 2^{-cl} + \langle \operatorname{Log} N \rangle^{-cC_1} ) \|f\|_{\ell^2(\mathbb{Z})} \|g\|_{\ell^2(\mathbb{Z})} \end{align} $$
$$ \begin{align} \| \tilde {\mathrm{A}}_{N,1}(f,g) \|_{\ell^1(\mathbb{Z})} \lesssim_{C_1} ( 2^{-cl} + \langle \operatorname{Log} N \rangle^{-cC_1} ) \|f\|_{\ell^2(\mathbb{Z})} \|g\|_{\ell^2(\mathbb{Z})} \end{align} $$
was proven for
 $N \geq 1$
,
$N \geq 1$
,
 $l \in \mathbb {N}$
and
$l \in \mathbb {N}$
and
 $f,g \in \ell ^2(\mathbb {Z})$
with either the Fourier transform
$f,g \in \ell ^2(\mathbb {Z})$
with either the Fourier transform
 $\mathcal {F}_{\mathbb {Z}} f$
of f vanishing on the major arc set
$\mathcal {F}_{\mathbb {Z}} f$
of f vanishing on the major arc set
 $\mathcal {M}_{\leq l, \leq -\operatorname {Log} N + l}$
or the Fourier transform
$\mathcal {M}_{\leq l, \leq -\operatorname {Log} N + l}$
or the Fourier transform
 $\mathcal {F}_{\mathbb {Z}} g$
of g vanishing on the major arc set
$\mathcal {F}_{\mathbb {Z}} g$
of g vanishing on the major arc set
 $\mathcal {M}_{\leq l, \leq -d\operatorname {Log} N + dl}$
; we refer the reader to §2 for the definition of the various terms and symbols introduced here. This minor arc estimate was proven by combining Peluse–Prendiville estimates [Reference Peluse and Prendiville24] with a discrete
$\mathcal {M}_{\leq l, \leq -d\operatorname {Log} N + dl}$
; we refer the reader to §2 for the definition of the various terms and symbols introduced here. This minor arc estimate was proven by combining Peluse–Prendiville estimates [Reference Peluse and Prendiville24] with a discrete
 $\ell ^p$
improving inequality from [Reference Han, Kovač, Lacey, Madrid and Yang8], together with a Hahn–Banach argument.
$\ell ^p$
improving inequality from [Reference Han, Kovač, Lacey, Madrid and Yang8], together with a Hahn–Banach argument.
Using equation (1.2), one could now focus attention to major arcs. After some routine manipulations involving Ionescu–Wainger multiplier theory [Reference Ionescu and Wainger10], the task reduced to controlling the
 $\ell ^p(\mathbb {Z}; \mathbf {V}^r)$
norm of tuples of the form
$\ell ^p(\mathbb {Z}; \mathbf {V}^r)$
norm of tuples of the form
 $$ \begin{align} (\tilde {\mathrm{A}}_{N,1}(F_N, G_N))_{N \in \mathbb{I}}, \end{align} $$
$$ \begin{align} (\tilde {\mathrm{A}}_{N,1}(F_N, G_N))_{N \in \mathbb{I}}, \end{align} $$
where
 $\mathbb {I}$
is a certain
$\mathbb {I}$
is a certain
 $\unicode{x3bb} $
-lacunary set (bounded from below by certain bounds, but not from above) and
$\unicode{x3bb} $
-lacunary set (bounded from below by certain bounds, but not from above) and
 $F_N, G_N$
are various frequency localizations of
$F_N, G_N$
are various frequency localizations of
 $f,g$
, respectively, to major arcs (see [Reference Krause, Mirek and Tao13, Theorem 5.30] for a precise statement). By estimation of the bilinear symbol of the averaging operator
$f,g$
, respectively, to major arcs (see [Reference Krause, Mirek and Tao13, Theorem 5.30] for a precise statement). By estimation of the bilinear symbol of the averaging operator
 $\tilde {\mathrm {A}}_{N,1}$
, one could approximate this tuple by another tuple
$\tilde {\mathrm {A}}_{N,1}$
, one could approximate this tuple by another tuple
 $$ \begin{align} (\mathrm{B}^{l_1, l_2, m_{\hat {\mathbb{Z}}}}_{(\varphi_N \otimes \tilde \varphi_N) \tilde m_{N,\mathbb{R}}}(F,G) )_{N \in \mathbb{I}}, \end{align} $$
$$ \begin{align} (\mathrm{B}^{l_1, l_2, m_{\hat {\mathbb{Z}}}}_{(\varphi_N \otimes \tilde \varphi_N) \tilde m_{N,\mathbb{R}}}(F,G) )_{N \in \mathbb{I}}, \end{align} $$
where
 $F,G$
are again some Fourier localizations of
$F,G$
are again some Fourier localizations of
 $f,g$
to major arcs and
$f,g$
to major arcs and
 $\mathrm {B}^{l_1, l_2, m_{\hat {\mathbb {Z}}}}_{(\varphi _N \otimes \tilde \varphi _N) \tilde m_{N,\mathbb {R}}}$
is a certain bilinear Fourier multiplier adapted to major arcs; see [Reference Krause, Mirek and Tao13, Proposition 7.13] for a precise statement. At this stage, it became necessary to split the set
$\mathrm {B}^{l_1, l_2, m_{\hat {\mathbb {Z}}}}_{(\varphi _N \otimes \tilde \varphi _N) \tilde m_{N,\mathbb {R}}}$
is a certain bilinear Fourier multiplier adapted to major arcs; see [Reference Krause, Mirek and Tao13, Proposition 7.13] for a precise statement. At this stage, it became necessary to split the set
 $\mathbb {I}$
of spatial averaging scales into the small scales
$\mathbb {I}$
of spatial averaging scales into the small scales
 $\mathbb {I}_{\leq }$
and large scales
$\mathbb {I}_{\leq }$
and large scales
 $\mathbb {I}_{>}$
. For the small scales, one could reduce matters to controlling another tuple
$\mathbb {I}_{>}$
. For the small scales, one could reduce matters to controlling another tuple
 $$ \begin{align*} (\mathrm{B}^{l_1,l_2, m_{\hat {\mathbb{Z}}}}_{m_*}(\mathrm{T}^{l_1}_{\varphi_{N,t,j_1}} F, \mathrm{T}^{l_2}_{\tilde{\varphi}_{N,t,j_2}} G ))_{N \in \mathbb{I}_{\leq}} \end{align*} $$
$$ \begin{align*} (\mathrm{B}^{l_1,l_2, m_{\hat {\mathbb{Z}}}}_{m_*}(\mathrm{T}^{l_1}_{\varphi_{N,t,j_1}} F, \mathrm{T}^{l_2}_{\tilde{\varphi}_{N,t,j_2}} G ))_{N \in \mathbb{I}_{\leq}} \end{align*} $$
for another bilinear Fourier multiplier
 $B^{l_1,l_2, m_{\hat {\mathbb {Z}}}}_{m_*}$
and Fourier multipliers
$B^{l_1,l_2, m_{\hat {\mathbb {Z}}}}_{m_*}$
and Fourier multipliers
 $T^{l_1}_{\varphi _N,t,j_1}$
,
$T^{l_1}_{\varphi _N,t,j_1}$
,
 $T^{l_2}_{\tilde {\varphi }_N,t,j_2}$
, while for the large scales, one instead considered tuples of the form
$T^{l_2}_{\tilde {\varphi }_N,t,j_2}$
, while for the large scales, one instead considered tuples of the form
 $$ \begin{align*} (\mathrm{B}_{1 \otimes m_{\hat {\mathbb{Z}}}}( \mathrm{T}_{\varphi_{N,t,j_1} \otimes 1} F_{\mathbb{A}}, \mathrm{T}_{\tilde{\varphi}_{N,t,j_2} \otimes 1} G_{\mathbb{A}} ))_{N \in \mathbb{I}_{>}}, \end{align*} $$
$$ \begin{align*} (\mathrm{B}_{1 \otimes m_{\hat {\mathbb{Z}}}}( \mathrm{T}_{\varphi_{N,t,j_1} \otimes 1} F_{\mathbb{A}}, \mathrm{T}_{\tilde{\varphi}_{N,t,j_2} \otimes 1} G_{\mathbb{A}} ))_{N \in \mathbb{I}_{>}}, \end{align*} $$
where
 $F_{\mathbb {A}}, G_{\mathbb {A}}$
were now defined on the ring
$F_{\mathbb {A}}, G_{\mathbb {A}}$
were now defined on the ring
 $\mathbb {A}_{\mathbb {Z}} = \mathbb {R} \times \hat {\mathbb {Z}}$
of adelic integers rather than on the integers
$\mathbb {A}_{\mathbb {Z}} = \mathbb {R} \times \hat {\mathbb {Z}}$
of adelic integers rather than on the integers
 $\mathbb {Z}$
. See [Reference Krause, Mirek and Tao13, Theorem 7.28] for a precise statement of the estimates required on these tuples.
$\mathbb {Z}$
. See [Reference Krause, Mirek and Tao13, Theorem 7.28] for a precise statement of the estimates required on these tuples.
In the small-scale case, it was possible to apply a general two-parameter Radamacher– Menshov inequality [Reference Krause, Mirek and Tao13, Corollary 8.2] followed by some shifted Calderón–Zygmund theory [Reference Krause, Mirek and Tao13, Theorem B.1] to reduce matters to obtaining a good
 $\ell ^{p_1}(\mathbb {Z}) \times \ell ^{p_2}(\mathbb {Z}) \to \ell ^p(\mathbb {Z})$
estimate for the bilinear multiplier
$\ell ^{p_1}(\mathbb {Z}) \times \ell ^{p_2}(\mathbb {Z}) \to \ell ^p(\mathbb {Z})$
estimate for the bilinear multiplier
 $\mathrm {B}^{l_1,l_2, m_{\hat {\mathbb {Z}}}}_{m_*}$
(see [Reference Krause, Mirek and Tao13, Lemma 8.6]), which was ultimately proven with the assistance of the minor arc estimate in equation (1.2) and the approximation result in [Reference Krause, Mirek and Tao13, Proposition 7.13].
$\mathrm {B}^{l_1,l_2, m_{\hat {\mathbb {Z}}}}_{m_*}$
(see [Reference Krause, Mirek and Tao13, Lemma 8.6]), which was ultimately proven with the assistance of the minor arc estimate in equation (1.2) and the approximation result in [Reference Krause, Mirek and Tao13, Proposition 7.13].
In the large-scale case, some interpolation and factorization arguments, together with a version of equation (1.2) on the profinite integers
 $\hat {\mathbb {Z}}$
, reduced matters to establishing
$\hat {\mathbb {Z}}$
, reduced matters to establishing
 $L^2(\mathbb {Z}_p) \times L^2(\mathbb {Z}_p) \to L^q(\mathbb {Z}_p)$
bounds on the p-adic averaging operator
$L^2(\mathbb {Z}_p) \times L^2(\mathbb {Z}_p) \to L^q(\mathbb {Z}_p)$
bounds on the p-adic averaging operator
for all primes p and some
 $q>2$
, with the operator norm required to be bounded by
$q>2$
, with the operator norm required to be bounded by
 $1$
for p large enough; see [Reference Krause, Mirek and Tao13, equations (10.3), (10.4)] for a precise statement. The boundedness ultimately came from some distributional analysis of the level sets of P on the p-adics (see [Reference Krause, Mirek and Tao13, Corollary C.2]); getting the bound of
$1$
for p large enough; see [Reference Krause, Mirek and Tao13, equations (10.3), (10.4)] for a precise statement. The boundedness ultimately came from some distributional analysis of the level sets of P on the p-adics (see [Reference Krause, Mirek and Tao13, Corollary C.2]); getting the bound of
 $1$
for large p required some additional refined analysis in which one again uses (a p-adic version of) the minor arc estimate in equation (1.2).
$1$
for large p required some additional refined analysis in which one again uses (a p-adic version of) the minor arc estimate in equation (1.2).
1.2 Möbius-weighted ergodic averages
More recently, another one of us [Reference Teräväinen26] considered the non-conventional averaging operators
 $\mathrm {A}_{N,\mu ;X}$
weighted by the Möbius function
$\mathrm {A}_{N,\mu ;X}$
weighted by the Möbius function
 $\mu $
instead of
$\mu $
instead of
 $1$
. Perhaps counter-intuitively, the convergence of ergodic averages weighted by
$1$
. Perhaps counter-intuitively, the convergence of ergodic averages weighted by
 $\mu $
is actually better than that of the unweighted case, especially in light of the recent progress on quantitative Gowers uniformity of the Möbius function [Reference Green and Tao7, Reference Krause, Mirek and Tao14–Reference Leng, Sah and Sawhney16, Reference Tao and Teräväinen25]. For instance, as a special case of [Reference Teräväinen26, Theorem 1.2], the following result was shown.
$\mu $
is actually better than that of the unweighted case, especially in light of the recent progress on quantitative Gowers uniformity of the Möbius function [Reference Green and Tao7, Reference Krause, Mirek and Tao14–Reference Leng, Sah and Sawhney16, Reference Tao and Teräväinen25]. For instance, as a special case of [Reference Teräväinen26, Theorem 1.2], the following result was shown.
Theorem 1.2. (Möbius-weighted ergodic theorem)
Let X have finite measure,
 ${f \in L^{p_1}(X)}$
,
${f \in L^{p_1}(X)}$
,
 $g \in L^{p_2}(X)$
with
$g \in L^{p_2}(X)$
with
 $({1}/{p_1}) + ({1}/{p_2}) < 1$
, and let
$({1}/{p_1}) + ({1}/{p_2}) < 1$
, and let
 $A>0$
. Then,
$A>0$
. Then,
 $$ \begin{align} \lim_{N \to\infty} (\log^A N) \mathrm{A}_{N,\mu;X}(f,g) = 0 \end{align} $$
$$ \begin{align} \lim_{N \to\infty} (\log^A N) \mathrm{A}_{N,\mu;X}(f,g) = 0 \end{align} $$
pointwise almost everywhere.
The ingredients used to prove Theorem 1.2 are somewhat different from those used to prove Theorem 1.1; a key input was [Reference Teräväinen26, Theorem 4.1], which, in our context, establishes the bound
 $$ \begin{align} | \mathbb{E}_{x \in [-CN^d, CN^d]} \mathrm{A}_{N,\theta;\mathbb{Z}}(f,g)(x) h(x) | \lesssim_{C,P} (N^{-1} + \|\theta\|_{u^{d+1}[N]})^{1/K} \end{align} $$
$$ \begin{align} | \mathbb{E}_{x \in [-CN^d, CN^d]} \mathrm{A}_{N,\theta;\mathbb{Z}}(f,g)(x) h(x) | \lesssim_{C,P} (N^{-1} + \|\theta\|_{u^{d+1}[N]})^{1/K} \end{align} $$
for all
 $1$
-bounded
$1$
-bounded
 $f,g,h, \theta $
and some
$f,g,h, \theta $
and some
 $1 \leq K \lesssim _d 1$
, where the ‘little’ Gowers uniformity norm
$1 \leq K \lesssim _d 1$
, where the ‘little’ Gowers uniformity norm
 $\|\theta \|_{u^{d+1}[N]}$
is defined as
$\|\theta \|_{u^{d+1}[N]}$
is defined as
where Q ranges over all polynomials of degree at most d with real coefficients and ![]() . The results of [Reference Green and Tao7] show that
. The results of [Reference Green and Tao7] show that
 $\|\mu \|_{u^{d+1}[N]}$
decays faster than any power of
$\|\mu \|_{u^{d+1}[N]}$
decays faster than any power of
 $\log N$
, and the claim then follows by standard sparsification and transference arguments.
$\log N$
, and the claim then follows by standard sparsification and transference arguments.
1.3 Prime-weighted ergodic averages
In this paper, we combine the methods of [Reference Krause, Mirek and Tao13, Reference Teräväinen26], together with some additional arguments, to obtain a non-conventional ergodic theorem in which the weight is selected to be the von Mangoldt function
 $\Lambda $
, defined by
$\Lambda $
, defined by
 $$ \begin{align*} \Lambda(n)=\begin{cases}\log p& n \text{ is a power of a prime } p,\\ 0&\text{otherwise}.\end{cases} \end{align*} $$
$$ \begin{align*} \Lambda(n)=\begin{cases}\log p& n \text{ is a power of a prime } p,\\ 0&\text{otherwise}.\end{cases} \end{align*} $$
More specifically, we show the following.
Theorem 1.3. (Main theorem)
Let
 $(X,\nu ,T)$
be a measure-preserving system and let
$(X,\nu ,T)$
be a measure-preserving system and let
 $f \in L^{p_1}(X)$
,
$f \in L^{p_1}(X)$
,
 $g \in L^{p_2}(X)$
for some
$g \in L^{p_2}(X)$
for some
 $1 < p_1,p_2 < \infty $
with
$1 < p_1,p_2 < \infty $
with
 $({1}/{p_1}) + ({1}/{p_2}) \leq 1$
. Then, the averages
$({1}/{p_1}) + ({1}/{p_2}) \leq 1$
. Then, the averages
 $\mathrm {A}_{N,\Lambda ;X}(f,g)$
converge pointwise almost everywhere. In fact, one has the variational estimate
$\mathrm {A}_{N,\Lambda ;X}(f,g)$
converge pointwise almost everywhere. In fact, one has the variational estimate
 $$ \begin{align} \| (\mathrm{A}_{N,\Lambda;X}(f,g))_{N \in \mathbb{D}} \|_{L^p(X; \mathbf{V}^r)} \lesssim_{p_1,p_2,p,r,P,\unicode{x3bb}} \|f\|_{L^{p_1}(X)} \|g\|_{L^{p_2}(X)} \end{align} $$
$$ \begin{align} \| (\mathrm{A}_{N,\Lambda;X}(f,g))_{N \in \mathbb{D}} \|_{L^p(X; \mathbf{V}^r)} \lesssim_{p_1,p_2,p,r,P,\unicode{x3bb}} \|f\|_{L^{p_1}(X)} \|g\|_{L^{p_2}(X)} \end{align} $$
whenever
 $\unicode{x3bb}> 1$
,
$\unicode{x3bb}> 1$
,
 $p \geq 1$
and
$p \geq 1$
and
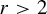 $r>2$
with
$r>2$
with
 $({1}/{p_1}) + ({1}/{p_2}) = ({1}/{p})$
, and
$({1}/{p_1}) + ({1}/{p_2}) = ({1}/{p})$
, and
 $\mathbb {D}\subset [1,+\infty )$
is finite and
$\mathbb {D}\subset [1,+\infty )$
is finite and
 $\unicode{x3bb} $
-lacunary.
$\unicode{x3bb} $
-lacunary.
The range of r here is optimal, as will be mentioned in §6.4. It is possible to extend the range of
 $(p_1,p_2)$
slightly beyond duality, see the discussion in §6.3.
$(p_1,p_2)$
slightly beyond duality, see the discussion in §6.3.
Using the fact that
 $\log n=\log N+O(\log M)$
for
$\log n=\log N+O(\log M)$
for
 $n\in [N/M,N]$
and the prime number theorem, we have the following immediate corollary to Theorem 1.3.
$n\in [N/M,N]$
and the prime number theorem, we have the following immediate corollary to Theorem 1.3.
Corollary 1.4. Let the assumptions be as in Theorem 1.3. Then, the prime-weighted averages
 $$ \begin{align*} \frac{1}{N/\log N} \sum_{p \leq N} f(T^p x) g(T^{P(p)} x) \end{align*} $$
$$ \begin{align*} \frac{1}{N/\log N} \sum_{p \leq N} f(T^p x) g(T^{P(p)} x) \end{align*} $$
converge pointwise almost everywhere.
Previously, the pointwise convergence of ergodic averages over the primes was known only in the case of a single polynomial iterate. This case was established by Bourgain [Reference Bourgain2] and Wierdl [Reference Wierdl27] for linear polynomials (with the latter work allowing
 $L^q$
functions for any
$L^q$
functions for any
 $q>1$
), and the case of an arbitrary single polynomial iterate was handled by Nair [Reference Nair21, Reference Nair22]. We also mention that the problem of pointwise convergence of ergodic averages with more than one iterate was discussed by Frantzikinakis in [Reference Frantzikinakis3, Problem 12]; the specific problem there about two linear iterates however remains open.
$q>1$
), and the case of an arbitrary single polynomial iterate was handled by Nair [Reference Nair21, Reference Nair22]. We also mention that the problem of pointwise convergence of ergodic averages with more than one iterate was discussed by Frantzikinakis in [Reference Frantzikinakis3, Problem 12]; the specific problem there about two linear iterates however remains open.
Let us also mention that the norm convergence of non-conventional ergodic averages is now known for any number of polynomial iterates, thanks to the works of Frantzikinakis, Host and Kra [Reference Frantzikinakis, Host and Kra4], and Wooley and Ziegler [Reference Wooley and Ziegler28].
1.4 Methods of proof
From a high-level perspective, Theorem 1.3 is proven by combining the methods used in [Reference Krause, Mirek and Tao13] to prove Theorem 1.1 with the methods used in [Reference Teräväinen26] to prove Theorem 1.2. However, several technical difficulties make the analysis delicate in places, as we shall now discuss.
The first issue arises when trying to approximate various frequency-localized averages (analogous to equation (1.3), but with the weight
 $1$
replaced by
$1$
replaced by
 $\Lambda $
) by certain bilinear model operators (analogous to equation (1.4), but with the symbol
$\Lambda $
) by certain bilinear model operators (analogous to equation (1.4), but with the symbol
 $m_{\hat {\mathbb {Z}}}$
replaced by a variant
$m_{\hat {\mathbb {Z}}}$
replaced by a variant
 $m_{\hat {\mathbb {Z}}^\times }$
). It is important for the arguments in [Reference Krause, Mirek and Tao13] that the error in this approximation gains a polynomial factor
$m_{\hat {\mathbb {Z}}^\times }$
). It is important for the arguments in [Reference Krause, Mirek and Tao13] that the error in this approximation gains a polynomial factor
 $N^{-c}$
in N, or at least a quasipolynomial factor
$N^{-c}$
in N, or at least a quasipolynomial factor
 $\exp (-\log ^c N)$
. Using the von Mangoldt function as a weight, this is possible in the absence of Siegel zeroes (and, in particular, assuming the generalized Riemann hypothesis); however, the presence of a Siegel zero near a given scale N requires one to add a scale-dependent correction term to the bilinear symbol
$\exp (-\log ^c N)$
. Using the von Mangoldt function as a weight, this is possible in the absence of Siegel zeroes (and, in particular, assuming the generalized Riemann hypothesis); however, the presence of a Siegel zero near a given scale N requires one to add a scale-dependent correction term to the bilinear symbol
 $m_{\hat {\mathbb {Z}}}$
to obtain a satisfactory approximation at small scales. While this correction term is ultimately manageable because of the Landau–Page theorem, it significantly complicates the analysis, in that one cannot simply repeat arguments from [Reference Krause, Mirek and Tao13] verbatim. See §6 for further discussion.
$m_{\hat {\mathbb {Z}}}$
to obtain a satisfactory approximation at small scales. While this correction term is ultimately manageable because of the Landau–Page theorem, it significantly complicates the analysis, in that one cannot simply repeat arguments from [Reference Krause, Mirek and Tao13] verbatim. See §6 for further discussion.
To avoid this issue, we adapt some ideas from [Reference Tao and Teräväinen25] and swap the von Mangoldt weight
 $\Lambda $
early in the argument with an approximant
$\Lambda $
early in the argument with an approximant
 $\Lambda _N$
that is not sensitive to Siegel zeroes. The arguments used in [Reference Teräväinen26] to establish Theorem 1.2 allow one to do so provided that one has good control of the little Gowers uniformity norm in the sense that
$\Lambda _N$
that is not sensitive to Siegel zeroes. The arguments used in [Reference Teräväinen26] to establish Theorem 1.2 allow one to do so provided that one has good control of the little Gowers uniformity norm in the sense that
 $$ \begin{align*} \|\Lambda - \Lambda_N\|_{u^{d+1}[N]} \lesssim \langle \operatorname{Log} N \rangle^{-A} \end{align*} $$
$$ \begin{align*} \|\Lambda - \Lambda_N\|_{u^{d+1}[N]} \lesssim \langle \operatorname{Log} N \rangle^{-A} \end{align*} $$
for some large A. One available choice of approximant is the Cramér(–Granville) approximant
for a suitable parameter w and
 $W=\prod _{p\leq w}p$
(we end up selecting
$W=\prod _{p\leq w}p$
(we end up selecting ![]() for some large constant
for some large constant
 $C_0$
); the required bounds follow, for instance, from the results in [Reference Matomäki, Shao, Tao and Teräväinen18] (which even extend to shorter intervals). A useful fact, first observed in [Reference Tao and Teräväinen25] and refined further here, is that these approximants are stable in Gowers uniformity norms with respect to the w parameter; see Lemma 4.5 for a precise statement.
$C_0$
); the required bounds follow, for instance, from the results in [Reference Matomäki, Shao, Tao and Teräväinen18] (which even extend to shorter intervals). A useful fact, first observed in [Reference Tao and Teräväinen25] and refined further here, is that these approximants are stable in Gowers uniformity norms with respect to the w parameter; see Lemma 4.5 for a precise statement.
After using the arguments from [Reference Teräväinen26] to replace
 $\Lambda $
by
$\Lambda $
by
 $\Lambda _N$
, most of the arguments of [Reference Krause, Mirek and Tao13] proceed with only minor changes; in particular, the analogue of the approximation of equation (1.3) by equation (1.4) is fairly routine, thanks in large part to the fundamental lemma of sieve theory; see the proof of Proposition 3.4 in §5. We remark that Siegel zeroes play no role whatsoever in establishing this proposition, in contrast to what would have occurred if we retained the original weight
$\Lambda _N$
, most of the arguments of [Reference Krause, Mirek and Tao13] proceed with only minor changes; in particular, the analogue of the approximation of equation (1.3) by equation (1.4) is fairly routine, thanks in large part to the fundamental lemma of sieve theory; see the proof of Proposition 3.4 in §5. We remark that Siegel zeroes play no role whatsoever in establishing this proposition, in contrast to what would have occurred if we retained the original weight
 $\Lambda $
instead of
$\Lambda $
instead of
 $\Lambda _N$
. However, three components of the argument of Theorem 1.3 still require some additional care. The first is a polynomial improving estimate
$\Lambda _N$
. However, three components of the argument of Theorem 1.3 still require some additional care. The first is a polynomial improving estimate
 $$ \begin{align*} \bigg( \sum_{x\in \mathbb{Z}} |\mathbb{E}_{n\in [N]} (\Lambda(n)+\Lambda_N(n))f(x+P(n)) |^2 \bigg)^{1/2} \lesssim N^{d(1/2-1/p)} \|f\|_{\ell^p(\mathbb{Z})} \end{align*} $$
$$ \begin{align*} \bigg( \sum_{x\in \mathbb{Z}} |\mathbb{E}_{n\in [N]} (\Lambda(n)+\Lambda_N(n))f(x+P(n)) |^2 \bigg)^{1/2} \lesssim N^{d(1/2-1/p)} \|f\|_{\ell^p(\mathbb{Z})} \end{align*} $$
for
 $p\in (2-c_P,2]$
, with
$p\in (2-c_P,2]$
, with
 $c_P>0$
small (see Lemma 5.1). This is eventually reduced to the analogous unweighted improving estimate using some properties of the Cramér approximant, in particular, Corollary 4.4.
$c_P>0$
small (see Lemma 5.1). This is eventually reduced to the analogous unweighted improving estimate using some properties of the Cramér approximant, in particular, Corollary 4.4.
The second component is the p-adic estimates, in which the averaging operator in equation (1.5) ends up being replaced by the variant
It is necessary to bound the
 $L^2(\mathbb {Z}_p) \times L^2(\mathbb {Z}_p) \to L^q(\mathbb {Z}_p)$
norm of this operator by exactly the constant
$L^2(\mathbb {Z}_p) \times L^2(\mathbb {Z}_p) \to L^q(\mathbb {Z}_p)$
norm of this operator by exactly the constant
 $1$
when
$1$
when
 $q>2$
is close to
$q>2$
is close to
 $2$
and p is large; losing a multiplicative factor such as
$2$
and p is large; losing a multiplicative factor such as
 $1+O(1/p)$
would not be acceptable as one needs to multiply these constants over all primes p. Fortunately, the effect of restricting to the invertible elements
$1+O(1/p)$
would not be acceptable as one needs to multiply these constants over all primes p. Fortunately, the effect of restricting to the invertible elements
 $\mathbb {Z}_p^\times $
of
$\mathbb {Z}_p^\times $
of
 $\mathbb {Z}_p$
is not too severe and the arguments from [Reference Krause, Mirek and Tao13] can be adapted with only a modest amount of effort to avoid any losses of
$\mathbb {Z}_p$
is not too severe and the arguments from [Reference Krause, Mirek and Tao13] can be adapted with only a modest amount of effort to avoid any losses of
 $O(1/p)$
in the constants.
$O(1/p)$
in the constants.
The most delicate step is to adapt the single-scale estimate in equation (1.2) to the weighted setting. As the Peluse–Prendiville theory is somewhat complicated, our approach is to use the approximation theory from [Reference Teräväinen26] to try to replace the approximant
 $\Lambda _N$
with an approximant closer to the constant weight
$\Lambda _N$
with an approximant closer to the constant weight
 $1$
. With the theory of the Cramér approximant from [Reference Tao and Teräväinen25], it is not too difficult to replace
$1$
. With the theory of the Cramér approximant from [Reference Tao and Teräväinen25], it is not too difficult to replace
 $\Lambda _N$
by a Cramér approximant
$\Lambda _N$
by a Cramér approximant
 $\Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}$
for a smaller parameter w, with error terms polynomial in w. However, a technical problem then arises: this approximant is not a pure ‘Type I’ sum of the form
$\Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}$
for a smaller parameter w, with error terms polynomial in w. However, a technical problem then arises: this approximant is not a pure ‘Type I’ sum of the form
 $\sum _{d\mid n} \unicode{x3bb} _d$
for certain well-behaved weights
$\sum _{d\mid n} \unicode{x3bb} _d$
for certain well-behaved weights
 $\unicode{x3bb} _d$
, preventing one from removing the weight entirely. To resolve this, we appeal to the theory from [Reference Teräväinen26] once more to replace the Cramér approximant
$\unicode{x3bb} _d$
, preventing one from removing the weight entirely. To resolve this, we appeal to the theory from [Reference Teräväinen26] once more to replace the Cramér approximant
 $\Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}$
with a more Fourier-analytic approximant, which we call the Heath-Brown approximant (as it was introduced by him in [Reference Heath-Brown9]). This approximant is defined by
$\Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}$
with a more Fourier-analytic approximant, which we call the Heath-Brown approximant (as it was introduced by him in [Reference Heath-Brown9]). This approximant is defined by

where Q is a parameter of similar size to w and
 $c_q$
is a Ramanujan sum; roughly speaking, this approximant is the main term in the Fourier restriction of the von Mangoldt function to major arcs. By using the analysis of the little Gowers uniformity norms of Type I sums from [Reference Matomäki and Shao17], we are able to show that
$c_q$
is a Ramanujan sum; roughly speaking, this approximant is the main term in the Fourier restriction of the von Mangoldt function to major arcs. By using the analysis of the little Gowers uniformity norms of Type I sums from [Reference Matomäki and Shao17], we are able to show that
 $\Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}$
is close in these norms to
$\Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}$
is close in these norms to
 $\Lambda _{\operatorname {HB},w}$
and then, by the theory from [Reference Teräväinen26] (and a dyadic decomposition), one can replace the former by the latter, at least for the purposes of proving an ‘
$\Lambda _{\operatorname {HB},w}$
and then, by the theory from [Reference Teräväinen26] (and a dyadic decomposition), one can replace the former by the latter, at least for the purposes of proving an ‘
 $\ell ^\infty $
’ Peluse–Prendiville inverse theorem for weighted averages. As in [Reference Krause, Mirek and Tao13], it is also necessary to obtain a more delicate ‘
$\ell ^\infty $
’ Peluse–Prendiville inverse theorem for weighted averages. As in [Reference Krause, Mirek and Tao13], it is also necessary to obtain a more delicate ‘
 $\ell ^2$
’ inverse theorem, which requires a weighted version of the
$\ell ^2$
’ inverse theorem, which requires a weighted version of the
 $\ell ^p$
improving inequality from [Reference Han, Kovač, Lacey, Madrid and Yang8], but this can be achieved by a variant of the arguments just presented.
$\ell ^p$
improving inequality from [Reference Han, Kovač, Lacey, Madrid and Yang8], but this can be achieved by a variant of the arguments just presented.
Remark 1.5. The proof of Theorem 1.3 quickly yields a version of Peluse’s inverse theorem [Reference Peluse23, Theorem 3.3] with prime weights. This was not needed for proving Theorem 1.3 (what we did need was in essence a version with the weight function
 $\Lambda _N$
; see Proposition 5.3), but we believe such a result may be of independent interest, so we record it as Theorem 6.1. Some combinatorial applications of this result will be investigated in a future work.
$\Lambda _N$
; see Proposition 5.3), but we believe such a result may be of independent interest, so we record it as Theorem 6.1. Some combinatorial applications of this result will be investigated in a future work.
Remark 1.6. We expect the methods of this paper to be applicable also to pointwise convergence of bilinear polynomial ergodic averages weighted by some other weights of arithmetic interest. The exact requirements for the weight are not so easy to axiomatize, but we need the weight to satisfy analogues of equations (3.1)–(3.4), as well as a suitable ‘local-to-global’ factorization over the primes to be able to pass to the adeles. In particular, we expect the methods to be applicable to ergodic averages weighted by the divisor function
 $\tau $
, but we will not pursue this problem here.
$\tau $
, but we will not pursue this problem here.
2 Notation
2.1 General notation
Our notation largely follows [Reference Krause, Mirek and Tao13], though somewhat abridged, as some of the notation in [Reference Krause, Mirek and Tao13] is only used to establish results or arguments that we are treating here as ‘black boxes’.
We use ![]() to denote the positive integers and
to denote the positive integers and ![]() to denote the natural numbers.
to denote the natural numbers.
We use ![]() to denote the indicator function of a set E. Similarly, if S is a statement, we use
to denote the indicator function of a set E. Similarly, if S is a statement, we use ![]() to denote its indicator, equal to
to denote its indicator, equal to
 $1$
if S is true and
$1$
if S is true and
 $0$
if S is false. Thus, for instance,
$0$
if S is false. Thus, for instance, ![]() . We use
. We use
 $|E|$
to denote the cardinality of a set E and adopt for
$|E|$
to denote the cardinality of a set E and adopt for
 $f\colon E\to \mathbb {C}$
the averaging notation
$f\colon E\to \mathbb {C}$
the averaging notation

if E is finite and non-empty. We similarly define
 $L^p$
norms
$L^p$
norms

for
 $0 < p < \infty $
, with the usual convention that
$0 < p < \infty $
, with the usual convention that
 $\|f\|_{L^\infty (E)}$
is the (essential) supremum of f on E. One can extend these averaging conventions to other measurable spaces E of positive finite measure (such as a p-adic group
$\|f\|_{L^\infty (E)}$
is the (essential) supremum of f on E. One can extend these averaging conventions to other measurable spaces E of positive finite measure (such as a p-adic group
 $\mathbb {Z}_p$
equipped with Haar probability measure), if f (or
$\mathbb {Z}_p$
equipped with Haar probability measure), if f (or
 $|f|^p$
) is absolutely integrable, in the obvious fashion. When X is equipped with counting measure, we will write
$|f|^p$
) is absolutely integrable, in the obvious fashion. When X is equipped with counting measure, we will write
 $\ell ^p(X)$
or just
$\ell ^p(X)$
or just
 $\ell ^{p}$
in place of
$\ell ^{p}$
in place of
 $L^p(X)$
.
$L^p(X)$
.
Throughout,
 $p'$
denotes the dual exponent of
$p'$
denotes the dual exponent of
 $p\in [1,\infty ]$
, so
$p\in [1,\infty ]$
, so
 $1/p+1/p'=1$
.
$1/p+1/p'=1$
.
If
 $f \colon X \to \mathbb {C}$
,
$f \colon X \to \mathbb {C}$
,
 $g \colon Y \to \mathbb {C}$
are functions, we use
$g \colon Y \to \mathbb {C}$
are functions, we use
 $f \otimes g \colon X \times Y \to \mathbb {C}$
to denote the tensor product
$f \otimes g \colon X \times Y \to \mathbb {C}$
to denote the tensor product
2.2 Magnitudes and asymptotic notation
We use the Japanese bracket notation
for any real or complex x. We use
 $\lfloor x \rfloor $
to denote the greatest integer less than or equal to x. For any
$\lfloor x \rfloor $
to denote the greatest integer less than or equal to x. For any
 $N \geq 1$
, we define the logarithmic scale
$N \geq 1$
, we define the logarithmic scale
 $\operatorname {Log} N$
of N by the formula
$\operatorname {Log} N$
of N by the formula
thus
 $\operatorname {Log} N$
is the unique natural number such that
$\operatorname {Log} N$
is the unique natural number such that
 $2^{\operatorname {Log} N} \leq N < 2^{\operatorname {Log} N+1}$
.
$2^{\operatorname {Log} N} \leq N < 2^{\operatorname {Log} N+1}$
.
For any two quantities
 $A, B$
, we will write
$A, B$
, we will write
 $A \lesssim B$
,
$A \lesssim B$
,
 $B \gtrsim A$
or
$B \gtrsim A$
or
 $A = O(B)$
to denote the bound
$A = O(B)$
to denote the bound
 $|A| \leq CB$
for some absolute constant C. If we need the implied constant C to depend on additional parameters, we will denote this by subscripts; thus, for instance,
$|A| \leq CB$
for some absolute constant C. If we need the implied constant C to depend on additional parameters, we will denote this by subscripts; thus, for instance,
 $A \lesssim _\rho B$
denotes the bound
$A \lesssim _\rho B$
denotes the bound
 $|A| \leq C_\rho B$
for some
$|A| \leq C_\rho B$
for some
 $C_\rho $
depending on
$C_\rho $
depending on
 $\rho $
. We write
$\rho $
. We write
 $A \sim B$
for
$A \sim B$
for
 $A \lesssim B \lesssim A$
. To abbreviate the notation, we will sometimes explicitly permit the implied constant to depend on certain fixed parameters (such as the polynomial P) when the issue of uniformity with respect to such parameters is not of relevance. Due to our reliance in some places on tools based on Siegel’s theorem (specifically, Siegel’s theorem is used in [Reference Matomäki, Shao, Tao and Teräväinen18], and we will use results from that paper to establish equation (3.1)), several of the implied constants in our arguments will be ineffective, but we will not track the effectivity of constants explicitly in this paper.
$A \lesssim B \lesssim A$
. To abbreviate the notation, we will sometimes explicitly permit the implied constant to depend on certain fixed parameters (such as the polynomial P) when the issue of uniformity with respect to such parameters is not of relevance. Due to our reliance in some places on tools based on Siegel’s theorem (specifically, Siegel’s theorem is used in [Reference Matomäki, Shao, Tao and Teräväinen18], and we will use results from that paper to establish equation (3.1)), several of the implied constants in our arguments will be ineffective, but we will not track the effectivity of constants explicitly in this paper.
2.3 Algebraic notation
If R is a commutative ring, we use
 $R^\times $
to denote the multiplicatively invertible elements of R.
$R^\times $
to denote the multiplicatively invertible elements of R.
2.4 Number theoretic notation
For any
 $N> 0$
,
$N> 0$
,
 $[N]$
denotes the discrete interval
$[N]$
denotes the discrete interval ![]() . If
. If
 $q_1,q_2 \in \mathbb {Z}_+$
, we write
$q_1,q_2 \in \mathbb {Z}_+$
, we write
 $q_1\mid q_2$
if
$q_1\mid q_2$
if
 $q_1$
divides
$q_1$
divides
 $q_2$
. If
$q_2$
. If
 $a,q \in \mathbb {Z}_+$
, we let
$a,q \in \mathbb {Z}_+$
, we let
 $(a,q)$
denote the greatest common divisor of a and q, and
$(a,q)$
denote the greatest common divisor of a and q, and
 $[a,q]$
the least common multiple.
$[a,q]$
the least common multiple.
All sums and products over the symbol p will be understood to be over primes; other sums will be understood to be over positive integers unless otherwise specified.
In addition to the von Mangoldt function
 $\Lambda (n)$
and Möbius function
$\Lambda (n)$
and Möbius function
 $\mu (n)$
already introduced, we will also use the divisor function
$\mu (n)$
already introduced, we will also use the divisor function ![]() and the Euler totient function
and the Euler totient function ![]() .
.
2.5 Fourier analytic notation
We write ![]() for any real
for any real
 $\theta $
, and also
$\theta $
, and also
 $\|\theta \|_{\mathbb {R}/\mathbb {Z}}$
for the distance from
$\|\theta \|_{\mathbb {R}/\mathbb {Z}}$
for the distance from
 $\theta $
to the nearest integer.
$\theta $
to the nearest integer.
For a prime p, we let
 $\mathbb {Z}_p$
be the ring of p-adic integers, defined as the inverse limit of the cyclic groups
$\mathbb {Z}_p$
be the ring of p-adic integers, defined as the inverse limit of the cyclic groups
 $\mathbb {Z}/p^j\mathbb {Z}$
for
$\mathbb {Z}/p^j\mathbb {Z}$
for
 $j \in \mathbb {N}$
; this is a compact abelian group equipped with a Haar probability measure. Similarly, let
$j \in \mathbb {N}$
; this is a compact abelian group equipped with a Haar probability measure. Similarly, let
 $\hat {\mathbb {Z}}$
be the ring of profinite integers, defined as the inverse limit of the cyclic groups
$\hat {\mathbb {Z}}$
be the ring of profinite integers, defined as the inverse limit of the cyclic groups
 $\mathbb {Z}/Q\mathbb {Z}$
for all positive integers Q; this is again a compact abelian group with a Haar probability measure, being the direct product of the
$\mathbb {Z}/Q\mathbb {Z}$
for all positive integers Q; this is again a compact abelian group with a Haar probability measure, being the direct product of the
 $\mathbb {Z}_p$
. We use
$\mathbb {Z}_p$
. We use
 $\mathbb {E}_{\mathbb {Z}_p}$
or
$\mathbb {E}_{\mathbb {Z}_p}$
or
 $\mathbb {E}_{\hat {\mathbb {Z}}}$
to denote averaging with respect to these compact abelian groups. Finally, we let
$\mathbb {E}_{\hat {\mathbb {Z}}}$
to denote averaging with respect to these compact abelian groups. Finally, we let ![]() denote the ring of adelic integers, which is a locally compact abelian group.
denote the ring of adelic integers, which is a locally compact abelian group.
We define some Fourier transforms on various locally compact abelian groups.
-
(i) Given a summable function
$f \colon \mathbb {Z} \to \mathbb {C}$
, the Fourier transform
$\mathcal {F}_{\mathbb {Z}} f \colon \mathbb {R}/\mathbb {Z} \to \mathbb {C}$
is defined by the formula -
(ii) Given a Schwartz function
$f \colon \mathbb {R} \to \mathbb {C}$
, the Fourier transform
$\mathcal {F}_{\mathbb {R}} f \colon \mathbb {R} \to \mathbb {C}$
is defined by the formula -
(iii) Given a function
$f \colon \hat {\mathbb {Z}} \to \mathbb {C}$
which is Schwartz–Bruhat in the sense that it factors through a function
$f_Q \colon \mathbb {Z}/Q\mathbb {Z} \to \mathbb {C}$
on a cyclic group, we define the Fourier transform
$\mathcal {F}_{\hat {\mathbb {Z}}} f \colon \mathbb {Q}/\mathbb {Z} \to \mathbb {C}$
by the formula for any integer a. -
(iv) Given a function
$f \colon \mathbb {A}_{\mathbb {Z}} \to \mathbb {C}$
which is Schwartz–Bruhat in the sense that it factors through a function
$f_Q \colon \mathbb {R} \times \mathbb {Z}/Q\mathbb {Z}$
which is Schwartz in the first variable, we define the Fourier transform
$\mathcal {F}_{\mathbb {A}} f \colon \mathbb {R} \times \mathbb {Q}/\mathbb {Z} \to \mathbb {C}$
by the formula for integer a and
$\xi \in \mathbb {R}$
, and
$\mathcal {F}_{\hat {\mathbb {A}}}$
vanishing otherwise.














We refer the reader to [Reference Krause, Mirek and Tao13, §4] for a further discussion of the Fourier transform on such locally compact abelian groups as
 $\mathbb {Z}$
,
$\mathbb {Z}$
,
 $\mathbb {R}$
,
$\mathbb {R}$
,
 $\mathbb {Z}_p$
,
$\mathbb {Z}_p$
,
 $\hat {\mathbb {Z}}$
,
$\hat {\mathbb {Z}}$
,
 $\mathbb {Z}/Q\mathbb {Z}$
or
$\mathbb {Z}/Q\mathbb {Z}$
or
 $\mathbb {A}_{\mathbb {Z}}$
, and the various intertwining relationships among these transforms.
$\mathbb {A}_{\mathbb {Z}}$
, and the various intertwining relationships among these transforms.
Given a Schwartz symbol
 $m \colon \mathbb {R}/\mathbb {Z} \to \mathbb {C}$
, we define the Fourier multiplier
$m \colon \mathbb {R}/\mathbb {Z} \to \mathbb {C}$
, we define the Fourier multiplier
 $\mathrm {T}_m$
on
$\mathrm {T}_m$
on
 $\ell ^2(\mathbb {Z})$
by the formula
$\ell ^2(\mathbb {Z})$
by the formula

and, similarly, given a bilinear Schwartz symbol
 $m \colon \mathbb {R}/\mathbb {Z} \times \mathbb {R}/\mathbb {Z} \to \mathbb {C}$
, define the bilinear Fourier multiplier
$m \colon \mathbb {R}/\mathbb {Z} \times \mathbb {R}/\mathbb {Z} \to \mathbb {C}$
, define the bilinear Fourier multiplier
 $\mathrm {B}_m$
by the formula
$\mathrm {B}_m$
by the formula

Linear and bilinear multipliers are defined similarly for the other locally compact abelian groups defined here, and obey a certain operator calculus; again, we refer the reader to [Reference Krause, Mirek and Tao13, §4] for details, as we shall largely use facts and arguments about these operators from [Reference Krause, Mirek and Tao13] as ‘black boxes’.
We will need the Ionescu–Wainger Fourier multipliers on major arcs. Again, we shall mostly be using these tools as ‘black boxes’, so their definition and properties are not of critical importance in this paper; however, for sake of completeness, we recall the main definitions from [Reference Krause, Mirek and Tao13]. Given a small parameter
 $\rho $
, it is possible to assign a Ionescu–Wainger height
$\rho $
, it is possible to assign a Ionescu–Wainger height
 $\mathrm {h}(\alpha )=\mathrm {h}_{\rho }(\alpha ) \in 2^{\mathbb {N}}$
for each
$\mathrm {h}(\alpha )=\mathrm {h}_{\rho }(\alpha ) \in 2^{\mathbb {N}}$
for each
 $\alpha \in \mathbb {Q}/\mathbb {Z}$
; see [Reference Krause, Mirek and Tao13, Appendix A]. Using this height, we define the Ionescu–Wainger arithmetic frequency sets
$\alpha \in \mathbb {Q}/\mathbb {Z}$
; see [Reference Krause, Mirek and Tao13, Appendix A]. Using this height, we define the Ionescu–Wainger arithmetic frequency sets
and the Ionescu–Wainger major arcs
thus,
 ${\mathcal M}_{\leq l, \leq k}$
is the union of arcs
${\mathcal M}_{\leq l, \leq k}$
is the union of arcs
 $[\alpha -2^k, \alpha +2^k]$
for
$[\alpha -2^k, \alpha +2^k]$
for
 $\alpha \in (\mathbb {Q}/\mathbb {Z})_{\leq l}$
; we will be focused on the regime where k is sufficiently small that these arcs are disjoint, which happens whenever
$\alpha \in (\mathbb {Q}/\mathbb {Z})_{\leq l}$
; we will be focused on the regime where k is sufficiently small that these arcs are disjoint, which happens whenever
 $k \leq -C_\rho 2^{\rho l}$
. We also use the variants
$k \leq -C_\rho 2^{\rho l}$
. We also use the variants
and
with the convention that
 $(\mathbb {Q}/\mathbb {Z})_{\leq -1}$
and
$(\mathbb {Q}/\mathbb {Z})_{\leq -1}$
and
 ${\mathcal M}_{\leq -1,k}$
are empty.
${\mathcal M}_{\leq -1,k}$
are empty.
The Ionescu–Wainger Fourier projection operator
 $\Pi _{\leq l, \leq k}$
for any
$\Pi _{\leq l, \leq k}$
for any
 $(l,k) \in \mathbb {N} \times \mathbb {Z}$
is defined by the formula
$(l,k) \in \mathbb {N} \times \mathbb {Z}$
is defined by the formula
 $$ \begin{align*} \Pi_{\leq l, \leq k} f(x) = \sum_{\alpha \in (\mathbb{Q}/\mathbb{Z})_{\leq l}} \int_{\mathbb{R}} \eta(\theta/2^k) \mathcal{F}_{\mathbb{Z}} f(\alpha+\theta) e(-x(\alpha+\theta))\, d\theta,\end{align*} $$
$$ \begin{align*} \Pi_{\leq l, \leq k} f(x) = \sum_{\alpha \in (\mathbb{Q}/\mathbb{Z})_{\leq l}} \int_{\mathbb{R}} \eta(\theta/2^k) \mathcal{F}_{\mathbb{Z}} f(\alpha+\theta) e(-x(\alpha+\theta))\, d\theta,\end{align*} $$
where
 $\eta $
is a smooth even function supported on
$\eta $
is a smooth even function supported on
 $[-1,1]$
that equals
$[-1,1]$
that equals
 $1$
on
$1$
on
 $[-1/2,1/2]$
. We then define
$[-1/2,1/2]$
. We then define
We refer the reader to [Reference Krause, Mirek and Tao13, §5, Appendix A] for the key properties of these projections, which can be viewed as analogues of Littlewood–Paley projection operators for major arcs.
2.6 Variational norms
A sequence
 $1 \leq N_1 < \cdots < N_k$
of positive reals is said to be
$1 \leq N_1 < \cdots < N_k$
of positive reals is said to be
 $\unicode{x3bb} $
-lacunary for some
$\unicode{x3bb} $
-lacunary for some
 $\unicode{x3bb} \geq 1$
if
$\unicode{x3bb} \geq 1$
if
 $$ \begin{align*} N_{j+1}/N_j> \unicode{x3bb}\end{align*} $$
$$ \begin{align*} N_{j+1}/N_j> \unicode{x3bb}\end{align*} $$
for all
 $1 \leq j < k$
.
$1 \leq j < k$
.
For any finite dimensional normed vector space
 $(B,\|\cdot \|_B)$
and any sequence
$(B,\|\cdot \|_B)$
and any sequence
 $(\mathfrak a_t)_{t\in \mathbb {I}}$
of elements of B indexed by a totally ordered set
$(\mathfrak a_t)_{t\in \mathbb {I}}$
of elements of B indexed by a totally ordered set
 $\mathbb {I}$
, and any exponent
$\mathbb {I}$
, and any exponent
 $1 \leq r < \infty $
, the r-variation seminorm is defined by the formula
$1 \leq r < \infty $
, the r-variation seminorm is defined by the formula

where the supremum is taken over all finite increasing sequences in
 $\mathbb {I}$
and is set by convention to equal zero if
$\mathbb {I}$
and is set by convention to equal zero if
 $\mathbb {I}$
is empty.
$\mathbb {I}$
is empty.
The r-variation norm for
 $1 \leq r < \infty $
is defined by
$1 \leq r < \infty $
is defined by
This clearly defines a norm on the space of functions from
 $\mathbb {I}$
to B. If
$\mathbb {I}$
to B. If
 $B=\mathbb {C}$
, then we will abbreviate
$B=\mathbb {C}$
, then we will abbreviate
 $V^r(\mathbb {I};X)$
to
$V^r(\mathbb {I};X)$
to
 $V^r(\mathbb {I})$
or
$V^r(\mathbb {I})$
or
 $V^r$
, and
$V^r$
, and
 $\mathbf {V}^r(\mathbb {I};X)$
to
$\mathbf {V}^r(\mathbb {I};X)$
to
 $ \mathbf {V}^r(\mathbb {I})$
or
$ \mathbf {V}^r(\mathbb {I})$
or
 $\mathbf {V}^r$
.
$\mathbf {V}^r$
.
2.7 Gowers norms
In addition to the little Gowers uniformity norm
 $u^{d+1}[N]$
defined in equation (1.8), we will also need the full Gowers norm
$u^{d+1}[N]$
defined in equation (1.8), we will also need the full Gowers norm
 $U^{d+1}[N]$
defined for functions
$U^{d+1}[N]$
defined for functions
 $f \colon \mathbb {Z} \to \mathbb {C}$
as
$f \colon \mathbb {Z} \to \mathbb {C}$
as
where the
 $U^{d+1}(\mathbb {Z})$
norm is defined for finitely supported functions by the formula
$U^{d+1}(\mathbb {Z})$
norm is defined for finitely supported functions by the formula

where
 $\omega = (\omega _1,\ldots ,\omega _{d+1})$
and
$\omega = (\omega _1,\ldots ,\omega _{d+1})$
and
 ${\mathcal C}$
denotes the complex conjugation operator. It is well known that
${\mathcal C}$
denotes the complex conjugation operator. It is well known that
 $$ \begin{align} \| f\|_{u^{d+1}[N]} \lesssim_d \|f\|_{U^{d+1}[N]}; \end{align} $$
$$ \begin{align} \| f\|_{u^{d+1}[N]} \lesssim_d \|f\|_{U^{d+1}[N]}; \end{align} $$
see, e.g. [Reference Green and Tao5, equation (2.2)].
Similar uniformity norms
 $u^{d+1}(I)$
,
$u^{d+1}(I)$
,
 $U^{d+1}(I)$
can then be defined for other intervals
$U^{d+1}(I)$
can then be defined for other intervals
 $I \subset \mathbb {R}$
than
$I \subset \mathbb {R}$
than
 $[N]$
in the obvious fashion.
$[N]$
in the obvious fashion.
3 High-level proof of theorem
We now describe the high-level proof of Theorem 1.3, reducing it to two key statements (Theorem 3.2 and Proposition 3.4) that we will prove in §5. The arguments here will closely follow those of [Reference Krause, Mirek and Tao13], and some familiarity with the arguments in that paper would be highly recommended to follow the text in this section.
In the next section, we shall introduce an approximant
 $\Lambda _N \colon \mathbb {N} \to \mathbb {R}$
to
$\Lambda _N \colon \mathbb {N} \to \mathbb {R}$
to
 $\Lambda $
(depending on a parameter
$\Lambda $
(depending on a parameter
 $C_0$
) which enjoys the bound
$C_0$
) which enjoys the bound
 $$ \begin{align} \|\Lambda - \Lambda_N\|_{u^{d+1}[N]} \lesssim_{A,C_0} \langle \operatorname{Log} N \rangle^{-A} \end{align} $$
$$ \begin{align} \|\Lambda - \Lambda_N\|_{u^{d+1}[N]} \lesssim_{A,C_0} \langle \operatorname{Log} N \rangle^{-A} \end{align} $$
for any
 $A>0$
, as well as the pointwise bound
$A>0$
, as well as the pointwise bound
 $$ \begin{align} \Lambda_N(n) \lesssim_{C_0} \langle \operatorname{Log} N \rangle^{O(1)}, \end{align} $$
$$ \begin{align} \Lambda_N(n) \lesssim_{C_0} \langle \operatorname{Log} N \rangle^{O(1)}, \end{align} $$
the
 $L^1$
bound
$L^1$
bound
 $$ \begin{align} \mathbb{E}_{n \in [N]} |\Lambda_N(n)| \lesssim_{C_0} 1 \end{align} $$
$$ \begin{align} \mathbb{E}_{n \in [N]} |\Lambda_N(n)| \lesssim_{C_0} 1 \end{align} $$
and finally the polynomial improving bound
 $$ \begin{align} \| \mathbb{E}_{n \in [N]} (\Lambda(n)+|\Lambda_N(n)|) |g(\cdot-P(n)+n)| \|_{\ell^{p'}(\mathbb{Z})} \lesssim_{C_0} N^{d (1/p' - 1/p)} \|g\|_{\ell^p(\mathbb{Z})} \end{align} $$
$$ \begin{align} \| \mathbb{E}_{n \in [N]} (\Lambda(n)+|\Lambda_N(n)|) |g(\cdot-P(n)+n)| \|_{\ell^{p'}(\mathbb{Z})} \lesssim_{C_0} N^{d (1/p' - 1/p)} \|g\|_{\ell^p(\mathbb{Z})} \end{align} $$
for all
 $u_P< p \leq 2$
and
$u_P< p \leq 2$
and
 $g \in \ell ^p(\mathbb {Z})$
, with
$g \in \ell ^p(\mathbb {Z})$
, with
 $u_P < 2$
an exponent depending only on P, and
$u_P < 2$
an exponent depending only on P, and
 $C>0$
a constant also depending only on P.
$C>0$
a constant also depending only on P.
We shall also require further properties of
 $\Lambda _N$
in the following as needed. (Our choice of approximant
$\Lambda _N$
in the following as needed. (Our choice of approximant
 $\Lambda _N$
will in fact be non-negative and, although this is not crucial, it makes it easier to establish the
$\Lambda _N$
will in fact be non-negative and, although this is not crucial, it makes it easier to establish the
 $L^1$
bound in equation (3.3) and the improving bound in equation (3.4).)
$L^1$
bound in equation (3.3) and the improving bound in equation (3.4).)
Arguing as in the proof of [Reference Krause, Mirek and Tao13, Proposition 3.2(i)] (inserting the non-negative weight
 $\Lambda $
as necessary), we see that the pointwise convergence claim of Theorem 1.3 follows from the ‘Hölder variational estimate’ in equation (1.9), so we focus now on this estimate. Henceforth, we fix
$\Lambda $
as necessary), we see that the pointwise convergence claim of Theorem 1.3 follows from the ‘Hölder variational estimate’ in equation (1.9), so we focus now on this estimate. Henceforth, we fix
 $p_1,p_2,p,d,P,r,\unicode{x3bb} $
, as well as the finite
$p_1,p_2,p,d,P,r,\unicode{x3bb} $
, as well as the finite
 $\unicode{x3bb} $
-lacunary set
$\unicode{x3bb} $
-lacunary set
 $\mathbb {D}$
. We allow all constants to depend on
$\mathbb {D}$
. We allow all constants to depend on
 $p_1, p_2, p, d, P, r, \unicode{x3bb} $
(but not on
$p_1, p_2, p, d, P, r, \unicode{x3bb} $
(but not on
 $\mathbb {D}$
). As in [Reference Krause, Mirek and Tao13, §5], we now select sufficiently large parameters
$\mathbb {D}$
). As in [Reference Krause, Mirek and Tao13, §5], we now select sufficiently large parameters
 $$ \begin{align*} 1 \lesssim C_0 \lesssim C_1 \lesssim C_2 \lesssim C_3. \end{align*} $$
$$ \begin{align*} 1 \lesssim C_0 \lesssim C_1 \lesssim C_2 \lesssim C_3. \end{align*} $$
By a routine application of Calderón’s transference principle [Reference Krause, Mirek and Tao13, Theorem 3.2(ii)], adapted to this weighted setting, it suffices to prove equation (1.9) for the integer shift system
 $(\mathbb {Z}, |\cdot |, x \mapsto x-1)$
, endowed with counting measure
$(\mathbb {Z}, |\cdot |, x \mapsto x-1)$
, endowed with counting measure
 $|\cdot |$
. Thus, our task is now to show that
$|\cdot |$
. Thus, our task is now to show that
 $$ \begin{align*} \| (\mathrm{A}_{N,\Lambda;\mathbb{Z}}(f,g))_{N \in \mathbb{D}} \|_{\ell^p(\mathbb{Z}; \mathbf{V}^r)} \lesssim \|f\|_{\ell^{p_1}(\mathbb{Z})} \|g\|_{\ell^{p_2}(\mathbb{Z})} \end{align*} $$
$$ \begin{align*} \| (\mathrm{A}_{N,\Lambda;\mathbb{Z}}(f,g))_{N \in \mathbb{D}} \|_{\ell^p(\mathbb{Z}; \mathbf{V}^r)} \lesssim \|f\|_{\ell^{p_1}(\mathbb{Z})} \|g\|_{\ell^{p_2}(\mathbb{Z})} \end{align*} $$
for all
 $f \in \ell ^{p_1}(\mathbb {Z})$
and
$f \in \ell ^{p_1}(\mathbb {Z})$
and
 $g \in \ell ^{p_2}(\mathbb {Z})$
. Arguing as in the proof of [Reference Krause, Mirek and Tao13, Proposition 3.2(iii)] (inserting the weight
$g \in \ell ^{p_2}(\mathbb {Z})$
. Arguing as in the proof of [Reference Krause, Mirek and Tao13, Proposition 3.2(iii)] (inserting the weight
 $\Lambda $
as needed), it suffices to prove the ‘upper half’
$\Lambda $
as needed), it suffices to prove the ‘upper half’
 $$ \begin{align} \| (\tilde {\mathrm{A}}_{N,\Lambda}(f,g))_{N \in \mathbb{D}} \|_{\ell^p(\mathbb{Z}; \mathbf{V}^r)} \lesssim \|f\|_{\ell^{p_1}(\mathbb{Z})} \|g\|_{\ell^{p_2}(\mathbb{Z})} \end{align} $$
$$ \begin{align} \| (\tilde {\mathrm{A}}_{N,\Lambda}(f,g))_{N \in \mathbb{D}} \|_{\ell^p(\mathbb{Z}; \mathbf{V}^r)} \lesssim \|f\|_{\ell^{p_1}(\mathbb{Z})} \|g\|_{\ell^{p_2}(\mathbb{Z})} \end{align} $$
of this estimate, where the averaging operators
 $\tilde {\mathrm {A}}_{N,w}$
were defined in equation (1.1).
$\tilde {\mathrm {A}}_{N,w}$
were defined in equation (1.1).
The next step is to replace the von Mangoldt weight
 $\Lambda $
by the approximant
$\Lambda $
by the approximant
 $\Lambda _N$
.
$\Lambda _N$
.
Lemma 3.1. (From
$\Lambda $
to
$\Lambda _N$
)


To prove equation (3.5) (and hence, equation (1.9)), it suffices to show that
 $$ \begin{align} \| (\tilde {\mathrm{A}}_{N,\Lambda_N}(f,g))_{N \in \mathbb{D}} \|_{\ell^{p}(\mathbb{Z}; \mathbf{V}^r)} \lesssim_{C_3} \|f\|_{\ell^{p_1}(\mathbb{Z})} \|g\|_{\ell^{p_2}(\mathbb{Z})}. \end{align} $$
$$ \begin{align} \| (\tilde {\mathrm{A}}_{N,\Lambda_N}(f,g))_{N \in \mathbb{D}} \|_{\ell^{p}(\mathbb{Z}; \mathbf{V}^r)} \lesssim_{C_3} \|f\|_{\ell^{p_1}(\mathbb{Z})} \|g\|_{\ell^{p_2}(\mathbb{Z})}. \end{align} $$
Proof. Assuming equation (3.6), from the triangle inequality and the lacunarity of
 $\mathbb {D}$
, we see that equation (3.5) reduces to the single-scale estimate
$\mathbb {D}$
, we see that equation (3.5) reduces to the single-scale estimate
 $$ \begin{align*} \| \tilde {\mathrm{A}}_{N,\Lambda - \Lambda_N}(f,g) \|_{\ell^{p}(\mathbb{Z})} \lesssim_{C_3} \langle \operatorname{Log} N \rangle^{-2} \| f \|_{\ell^{p_1}(\mathbb{Z})} \| g \|_{\ell^{p_2}(\mathbb{Z})} \end{align*} $$
$$ \begin{align*} \| \tilde {\mathrm{A}}_{N,\Lambda - \Lambda_N}(f,g) \|_{\ell^{p}(\mathbb{Z})} \lesssim_{C_3} \langle \operatorname{Log} N \rangle^{-2} \| f \|_{\ell^{p_1}(\mathbb{Z})} \| g \|_{\ell^{p_2}(\mathbb{Z})} \end{align*} $$
for each
 $N \in \mathbb {D}$
.
$N \in \mathbb {D}$
.
Using the triangle and Hölder inequalities, the prime number theorem and the hypothesis in equation (3.3), we may bound
 $$ \begin{align*} \| \tilde {\mathrm{A}}_{N,\Lambda - \Lambda_N}(f,g) \|_{\ell^{p}(\mathbb{Z})} \lesssim_{C_0} \| f \|_{\ell^{p_1}(\mathbb{Z})} \| g \|_{\ell^{p_2}(\mathbb{Z})}, \end{align*} $$
$$ \begin{align*} \| \tilde {\mathrm{A}}_{N,\Lambda - \Lambda_N}(f,g) \|_{\ell^{p}(\mathbb{Z})} \lesssim_{C_0} \| f \|_{\ell^{p_1}(\mathbb{Z})} \| g \|_{\ell^{p_2}(\mathbb{Z})}, \end{align*} $$
so by interpolation (modifying the exponents
 $p_1,p_2,p$
as needed), it suffices to prove the
$p_1,p_2,p$
as needed), it suffices to prove the
 $\ell ^2 \times \ell ^2 \to \ell ^1$
bound
$\ell ^2 \times \ell ^2 \to \ell ^1$
bound
 $$ \begin{align} \| \tilde {\mathrm{A}}_{N,\Lambda - \Lambda_N}(f,g) \|_{\ell^{1}(\mathbb{Z})} \lesssim_{A,C_3} \langle \operatorname{Log} N \rangle^{-A} \| f \|_{\ell^2(\mathbb{Z})} \| g \|_{\ell^2(\mathbb{Z})} \end{align} $$
$$ \begin{align} \| \tilde {\mathrm{A}}_{N,\Lambda - \Lambda_N}(f,g) \|_{\ell^{1}(\mathbb{Z})} \lesssim_{A,C_3} \langle \operatorname{Log} N \rangle^{-A} \| f \|_{\ell^2(\mathbb{Z})} \| g \|_{\ell^2(\mathbb{Z})} \end{align} $$
for any
 $A>0$
.
$A>0$
.
We claim that it suffices to prove equation (3.7) when
 $f,g$
are supported on intervals of length
$f,g$
are supported on intervals of length
 $N^d$
. Write
$N^d$
. Write
Let
 $C=C_P$
be such that
$C=C_P$
be such that
 $\{P(n)\colon n\in [N]\}$
is contained in an interval of length
$\{P(n)\colon n\in [N]\}$
is contained in an interval of length
 $CN^d$
. Supposing that equation (3.7) holds whenever
$CN^d$
. Supposing that equation (3.7) holds whenever
 $f,g$
are supported on intervals of length
$f,g$
are supported on intervals of length
 $N^d$
, by the triangle inequality and Cauchy–Schwarz, we have
$N^d$
, by the triangle inequality and Cauchy–Schwarz, we have
 $$ \begin{align*} \| \tilde {\mathrm{A}}_{N,\Lambda - \Lambda_N}(f,g) \|_{\ell^{1}(\mathbb{Z})} &\lesssim_{A,C_3} \langle \operatorname{Log} N \rangle^{-A} \sum_{\substack{i,j\in \mathbb{Z}\\|i-j|\leq C+1}} \| f_i \|_{\ell^2(\mathbb{Z})} \| g_j \|_{\ell^2(\mathbb{Z})}\\ &\lesssim_C \langle \operatorname{Log} N \rangle^{-A}\max_{k\in \mathbb{Z}}\sum_{i\in \mathbb{Z}}\| f_i \|_{\ell^2(\mathbb{Z})} \| g_{i+k} \|_{\ell^2(\mathbb{Z})}\\ &\leq \langle \operatorname{Log} N\rangle^{-A} \max_{k\in \mathbb{Z}}\bigg(\sum_{i\in \mathbb{Z}}\| f_i \|_{\ell^2(\mathbb{Z})}^2\bigg)^{1/2} \bigg(\sum_{i\in \mathbb{Z}}\| g_{i+k} \|_{\ell^2(\mathbb{Z})}^2\bigg)^{1/2}\\ &\leq \langle \operatorname{Log} N \rangle^{-A}\|f\|_{\ell^2(\mathbb{Z})}\|g\|_{\ell^2(\mathbb{Z})}. \end{align*} $$
$$ \begin{align*} \| \tilde {\mathrm{A}}_{N,\Lambda - \Lambda_N}(f,g) \|_{\ell^{1}(\mathbb{Z})} &\lesssim_{A,C_3} \langle \operatorname{Log} N \rangle^{-A} \sum_{\substack{i,j\in \mathbb{Z}\\|i-j|\leq C+1}} \| f_i \|_{\ell^2(\mathbb{Z})} \| g_j \|_{\ell^2(\mathbb{Z})}\\ &\lesssim_C \langle \operatorname{Log} N \rangle^{-A}\max_{k\in \mathbb{Z}}\sum_{i\in \mathbb{Z}}\| f_i \|_{\ell^2(\mathbb{Z})} \| g_{i+k} \|_{\ell^2(\mathbb{Z})}\\ &\leq \langle \operatorname{Log} N\rangle^{-A} \max_{k\in \mathbb{Z}}\bigg(\sum_{i\in \mathbb{Z}}\| f_i \|_{\ell^2(\mathbb{Z})}^2\bigg)^{1/2} \bigg(\sum_{i\in \mathbb{Z}}\| g_{i+k} \|_{\ell^2(\mathbb{Z})}^2\bigg)^{1/2}\\ &\leq \langle \operatorname{Log} N \rangle^{-A}\|f\|_{\ell^2(\mathbb{Z})}\|g\|_{\ell^2(\mathbb{Z})}. \end{align*} $$
Assume henceforth that
 $f,g$
are supported on intervals of length
$f,g$
are supported on intervals of length
 $N^d$
in equation (3.7). By translation, we can further assume that g is supported on
$N^d$
in equation (3.7). By translation, we can further assume that g is supported on
 $[N^d]$
.
$[N^d]$
.
By duality, for some function
 $h\in \ell ^{\infty }(\mathbb {Z})$
with
$h\in \ell ^{\infty }(\mathbb {Z})$
with
 $|h|\leq 1$
, we have
$|h|\leq 1$
, we have
 $$ \begin{align} \| \tilde {\mathrm{A}}_{N,\Lambda - \Lambda_N}(f,g) \|_{\ell^{1}(\mathbb{Z})} \kern1.2pt{=}\kern1.2pt\bigg|\!\sum_{x\in \mathbb{Z}} h(x) \tilde A_{N,\Lambda-\Lambda_N}(f,g)(x)\bigg| \kern1.2pt{=}\kern1.2pt \bigg|\!\sum_{x\in \mathbb{Z}} f(x) \tilde A_{N,\Lambda-\Lambda_N}^*(h,g)(x)\bigg|, \end{align} $$
$$ \begin{align} \| \tilde {\mathrm{A}}_{N,\Lambda - \Lambda_N}(f,g) \|_{\ell^{1}(\mathbb{Z})} \kern1.2pt{=}\kern1.2pt\bigg|\!\sum_{x\in \mathbb{Z}} h(x) \tilde A_{N,\Lambda-\Lambda_N}(f,g)(x)\bigg| \kern1.2pt{=}\kern1.2pt \bigg|\!\sum_{x\in \mathbb{Z}} f(x) \tilde A_{N,\Lambda-\Lambda_N}^*(h,g)(x)\bigg|, \end{align} $$
where
is one of the adjoint averaging operators. By Cauchy–Schwarz, the desired estimate in equation (3.7) follows from equation (3.8) if we show that
 $$ \begin{align*} \|\tilde A_{N,\Lambda-\Lambda_N}^*(h,g)(x)\|_{\ell^2(\mathbb{Z})} \lesssim_{A,C_3} \langle \operatorname{Log} N \rangle^{-A} \|g\|_{\ell^2(\mathbb{Z})}. \end{align*} $$
$$ \begin{align*} \|\tilde A_{N,\Lambda-\Lambda_N}^*(h,g)(x)\|_{\ell^2(\mathbb{Z})} \lesssim_{A,C_3} \langle \operatorname{Log} N \rangle^{-A} \|g\|_{\ell^2(\mathbb{Z})}. \end{align*} $$
By equation (3.4) and the triangle inequality, for all
 $u_P<q\leq 2$
, we have
$u_P<q\leq 2$
, we have
 $$ \begin{align} \|\tilde A_{N,\Lambda-\Lambda_N}^*(h,g)\|_{\ell^{q'}(\mathbb{Z})}\leq \|\tilde A_{N,\Lambda-\Lambda_N}^*(1,|g|)\|_{\ell^{q'}(\mathbb{Z})}\lesssim N^{d(1/q'-1/q)}\|g\|_{\ell^q(\mathbb{Z})}. \end{align} $$
$$ \begin{align} \|\tilde A_{N,\Lambda-\Lambda_N}^*(h,g)\|_{\ell^{q'}(\mathbb{Z})}\leq \|\tilde A_{N,\Lambda-\Lambda_N}^*(1,|g|)\|_{\ell^{q'}(\mathbb{Z})}\lesssim N^{d(1/q'-1/q)}\|g\|_{\ell^q(\mathbb{Z})}. \end{align} $$
However, [Reference Teräväinen26, Theorem 4.1] (i.e. equation (1.7)), the assumption on the support of g and the hypotheses in equations (3.1) and (3.2), we have
 $$ \begin{align} \| \tilde {\mathrm{A}}^*_{N,\Lambda - \Lambda_N}(h,g) \|_{\ell^{1}(\mathbb{Z})} \lesssim_{A,C_3} \langle \operatorname{Log} N \rangle^{-A} N^d \| g \|_{\ell^\infty(\mathbb{Z})} \end{align} $$
$$ \begin{align} \| \tilde {\mathrm{A}}^*_{N,\Lambda - \Lambda_N}(h,g) \|_{\ell^{1}(\mathbb{Z})} \lesssim_{A,C_3} \langle \operatorname{Log} N \rangle^{-A} N^d \| g \|_{\ell^\infty(\mathbb{Z})} \end{align} $$
for any
 $A>0$
. Interpolating equations (3.9) and (3.10), the claim in equation (3.7) follows.
$A>0$
. Interpolating equations (3.9) and (3.10), the claim in equation (3.7) follows.
With this lemma, we can now pass to the approximant
 $\Lambda _N$
.
$\Lambda _N$
.
We are left with showing equation (3.6). Note from equation (3.3) and the triangle and Hölder inequalities that
 $\tilde {\mathrm {A}}_{N,\Lambda _N}$
is bounded from
$\tilde {\mathrm {A}}_{N,\Lambda _N}$
is bounded from
 $\ell ^{p_1}(\mathbb {Z}) \times \ell ^{p_2}(\mathbb {Z})$
to
$\ell ^{p_1}(\mathbb {Z}) \times \ell ^{p_2}(\mathbb {Z})$
to
 $\ell ^{p}(\mathbb {Z})$
whenever
$\ell ^{p}(\mathbb {Z})$
whenever
 ${1}/{p_1} + {1}/{p_2} = {1}/{p}$
; the challenge is to estimate all the scales N in
${1}/{p_1} + {1}/{p_2} = {1}/{p}$
; the challenge is to estimate all the scales N in
 $\mathbb {D}$
simultaneously in
$\mathbb {D}$
simultaneously in
 $\mathbf {V}^r$
norm. We can restrict attention to scales
$\mathbf {V}^r$
norm. We can restrict attention to scales
 $N \geq C_3$
, since the contribution of the case
$N \geq C_3$
, since the contribution of the case
 $N < C_3$
can be handled just from the Hölder and triangle inequalities. The fact that the weight function
$N < C_3$
can be handled just from the Hölder and triangle inequalities. The fact that the weight function
 $\Lambda _N$
now depends on N will not significantly impact the arguments that follow.
$\Lambda _N$
now depends on N will not significantly impact the arguments that follow.
As in [Reference Krause, Mirek and Tao13, §5], we introduce the Ionescu–Wainger parameter
We use c to denote various small positive constants that can depend on the fixed quantities
 $p_1, p_2, d, P, r$
, but do not depend on
$p_1, p_2, d, P, r$
, but do not depend on
 $C_0,C_1,C_2,C_3$
(or
$C_0,C_1,C_2,C_3$
(or
 $\rho $
). As reviewed in §2.5, this allows us to create major arc sets
$\rho $
). As reviewed in §2.5, this allows us to create major arc sets
 $\mathcal {M}_{\leq l, \leq k}$
,
$\mathcal {M}_{\leq l, \leq k}$
,
 $\mathcal {M}_{l,\leq k}$
for
$\mathcal {M}_{l,\leq k}$
for
 $l \in \mathbb {N}$
,
$l \in \mathbb {N}$
,
 $k \in \mathbb {Z}$
, as well as associated Ionescu–Wainger multipliers
$k \in \mathbb {Z}$
, as well as associated Ionescu–Wainger multipliers
 $\Pi _{\leq l, \leq k}$
,
$\Pi _{\leq l, \leq k}$
,
 $\Pi _{l,\leq k}$
. As in [Reference Krause, Mirek and Tao13, equation (5.8)], we say that the pair
$\Pi _{l,\leq k}$
. As in [Reference Krause, Mirek and Tao13, equation (5.8)], we say that the pair
 $(l,k)$
has good major arcs if
$(l,k)$
has good major arcs if
 $$ \begin{align*} k \leq -C_\rho 2^{\rho l}\end{align*} $$
$$ \begin{align*} k \leq -C_\rho 2^{\rho l}\end{align*} $$
for some sufficiently large
 $C_\rho $
depending only on
$C_\rho $
depending only on
 $\rho $
. This condition will always be satisfied in practice and will ensure that the intervals
$\rho $
. This condition will always be satisfied in practice and will ensure that the intervals
 $[\alpha -2^k, \alpha +2^k]$
that comprise
$[\alpha -2^k, \alpha +2^k]$
that comprise
 $\mathcal {M}_{\leq l, \leq k}$
in equation (2.2) are disjoint; thus, avoiding any difficulties arising from ‘aliasing’.
$\mathcal {M}_{\leq l, \leq k}$
in equation (2.2) are disjoint; thus, avoiding any difficulties arising from ‘aliasing’.
In §5, we shall establish the following crucial variant of [Reference Krause, Mirek and Tao13, Theorem 5.12].
Theorem 3.2. (Single scale minor arc estimate)
Let
 $N \geq 1$
,
$N \geq 1$
,
 $l \in \mathbb {N}$
, and suppose that
$l \in \mathbb {N}$
, and suppose that
 $f,g \in \ell ^2(\mathbb {Z})$
obey one of the following two properties:
$f,g \in \ell ^2(\mathbb {Z})$
obey one of the following two properties:
-
(i)
$\mathcal {F}_{\mathbb {Z}} f$
vanishes on
$\mathcal {M}_{\leq l, \leq -\operatorname {Log} N+l}$
; -
(ii)
$\mathcal {F}_{\mathbb {Z}} g$
vanishes on
$\mathcal {M}_{\leq l, \leq -d\operatorname {Log} N + dl}$
.




Then, one has
 $$ \begin{align*} \| \tilde {\mathrm{A}}_{N, \Lambda_N}(f,g)\|_{\ell^1(\mathbb{Z})} \lesssim_{C_1} (2^{-cl} + \langle \operatorname{Log} N \rangle^{-cC_1}) \|f\|_{\ell^2(\mathbb{Z})} \|g\|_{\ell^2(\mathbb{Z})}.\end{align*} $$
$$ \begin{align*} \| \tilde {\mathrm{A}}_{N, \Lambda_N}(f,g)\|_{\ell^1(\mathbb{Z})} \lesssim_{C_1} (2^{-cl} + \langle \operatorname{Log} N \rangle^{-cC_1}) \|f\|_{\ell^2(\mathbb{Z})} \|g\|_{\ell^2(\mathbb{Z})}.\end{align*} $$
As in [Reference Krause, Mirek and Tao13, equation (5.22)], we introduce the scales
and repeat the arguments in [Reference Krause, Mirek and Tao13, §5] all the way to [Reference Krause, Mirek and Tao13, equation (5.25)], inserting the weight
 $\Lambda _N$
as needed, to reduce to establishing the bound
$\Lambda _N$
as needed, to reduce to establishing the bound
 $$ \begin{align*} &\| (\tilde {\mathrm{A}}_{N, \Lambda_N}(\Pi_{l_1, \leq -\operatorname{Log} N + l_{(N)}} f, \Pi_{l_2, \leq -d\operatorname{Log} N + dl_{(N)}} g))_{N \in \mathbb{D}; l_1, l_2 \leq l_{(N)}}\|_{\ell^{p_0}(\mathbb{Z};\mathbf{V}^r)}\\ &\quad\lesssim_{C_3} 2^{-\rho l} \|f\|_{\ell^2(\mathbb{Z})} \|g\|_{\ell^2(\mathbb{Z})}\end{align*} $$
$$ \begin{align*} &\| (\tilde {\mathrm{A}}_{N, \Lambda_N}(\Pi_{l_1, \leq -\operatorname{Log} N + l_{(N)}} f, \Pi_{l_2, \leq -d\operatorname{Log} N + dl_{(N)}} g))_{N \in \mathbb{D}; l_1, l_2 \leq l_{(N)}}\|_{\ell^{p_0}(\mathbb{Z};\mathbf{V}^r)}\\ &\quad\lesssim_{C_3} 2^{-\rho l} \|f\|_{\ell^2(\mathbb{Z})} \|g\|_{\ell^2(\mathbb{Z})}\end{align*} $$
for all
 $l_1,l_2 \in \mathbb {N}$
, where
$l_1,l_2 \in \mathbb {N}$
, where ![]() .
.
Now, we fix
 $l_1,l_2$
, and (as in [Reference Krause, Mirek and Tao13, equation (5.26)]) introduce the quantity
$l_1,l_2$
, and (as in [Reference Krause, Mirek and Tao13, equation (5.26)]) introduce the quantity
As in [Reference Krause, Mirek and Tao13, equations (5.27), (5.28)], we introduce the frequency-localized functions

and

for any integers
 $-u \leq s_1, s_2 \leq l_{(N)}$
. Arguing as in the text up to [Reference Krause, Mirek and Tao13, Theorem 5.30], inserting the weight
$-u \leq s_1, s_2 \leq l_{(N)}$
. Arguing as in the text up to [Reference Krause, Mirek and Tao13, Theorem 5.30], inserting the weight
 $\Lambda _N$
as necessary, it now suffices to establish the following.
$\Lambda _N$
as necessary, it now suffices to establish the following.
Theorem 3.3. (Variational paraproduct estimates)
Let
 $l_1, l_2 \in \mathbb {N}$
,
$l_1, l_2 \in \mathbb {N}$
, ![]() , let
, let
 $f,g \colon \mathbb {Z} \to \mathbb {C}$
be finitely supported and define u by equation (3.11). Let
$f,g \colon \mathbb {Z} \to \mathbb {C}$
be finitely supported and define u by equation (3.11). Let
 $s_1,s_2 \geq -u$
, and then let
$s_1,s_2 \geq -u$
, and then let ![]() ,
, ![]() ,
, ![]() be defined respectively by equations (3.12) and (3.13) and
be defined respectively by equations (3.12) and (3.13) and
Then,

Repeating the proof of [Reference Krause, Mirek and Tao13, Proposition 5.33], inserting the weight
 $\Lambda _N$
as needed, we see that Theorem 3.3 already holds in the ‘high-high’ case where
$\Lambda _N$
as needed, we see that Theorem 3.3 already holds in the ‘high-high’ case where
 $s_1,s_2> -u$
and
$s_1,s_2> -u$
and
 ${p_1=p_2=2}$
. Thus, we may assume that at least one of the statements
${p_1=p_2=2}$
. Thus, we may assume that at least one of the statements
 $s_1=-u$
,
$s_1=-u$
,
 $s_2=-u$
or
$s_2=-u$
or
 $(p_1,p_2) \neq (2,2)$
holds.
$(p_1,p_2) \neq (2,2)$
holds.
We now begin the arguments in [Reference Krause, Mirek and Tao13, §7]. We introduce the functions
and note that
 $$ \begin{align*} F_N = T^{l_1}_{\varphi_N} F, \quad G_N = T^{l_2}_{\tilde \varphi_N} G,\end{align*} $$
$$ \begin{align*} F_N = T^{l_1}_{\varphi_N} F, \quad G_N = T^{l_2}_{\tilde \varphi_N} G,\end{align*} $$
where

and

Repeating the arguments up to [Reference Krause, Mirek and Tao13, equation (7.7)], we thus see that it suffices to show that the tuple
 $$ \begin{align*} (\tilde A_{N,\Lambda_N}( T^{l_1}_{\varphi_N} F, T^{l_2}_{\tilde{\varphi}_N} G ))_{N \in \mathbb{I}}\end{align*} $$
$$ \begin{align*} (\tilde A_{N,\Lambda_N}( T^{l_1}_{\varphi_N} F, T^{l_2}_{\tilde{\varphi}_N} G ))_{N \in \mathbb{I}}\end{align*} $$
is ‘acceptable’ in the sense that it has an
 $\ell ^{p_0}(\mathbb {Z};\mathbf {V}^r)$
norm of
$\ell ^{p_0}(\mathbb {Z};\mathbf {V}^r)$
norm of
We introduce the arithmetic symbol
 $m_{\hat {\mathbb {Z}}^\times } \colon (\mathbb {Q}/\mathbb {Z})^2 \to \mathbb {C}$
by the formula
$m_{\hat {\mathbb {Z}}^\times } \colon (\mathbb {Q}/\mathbb {Z})^2 \to \mathbb {C}$
by the formula
 $$ \begin{align} m_{\hat {\mathbb{Z}}^\times}\bigg( \frac{a_1}{q}\,\mod 1, \frac{a_2}{q}\,\mod 1 \bigg) = \mathbb{E}_{n \in (\mathbb{Z}/q\mathbb{Z})^\times} e\bigg( \frac{a_1 n + a_2 P(n)}{q} \bigg) \end{align} $$
$$ \begin{align} m_{\hat {\mathbb{Z}}^\times}\bigg( \frac{a_1}{q}\,\mod 1, \frac{a_2}{q}\,\mod 1 \bigg) = \mathbb{E}_{n \in (\mathbb{Z}/q\mathbb{Z})^\times} e\bigg( \frac{a_1 n + a_2 P(n)}{q} \bigg) \end{align} $$
for any
 $q \in \mathbb {Z}_+$
and
$q \in \mathbb {Z}_+$
and
 $a_1,a_2 \in \mathbb {Z}$
; this differs from the corresponding symbol
$a_1,a_2 \in \mathbb {Z}$
; this differs from the corresponding symbol
 $m_{\hat {\mathbb {Z}}}$
in [Reference Krause, Mirek and Tao13] by restricting n to the primitive residue classes of
$m_{\hat {\mathbb {Z}}}$
in [Reference Krause, Mirek and Tao13] by restricting n to the primitive residue classes of
 $\mathbb {Z}/q\mathbb {Z}$
rather than all residue classes, which is a key effect of weighting by
$\mathbb {Z}/q\mathbb {Z}$
rather than all residue classes, which is a key effect of weighting by
 $\Lambda $
. It is easy to see from the Chinese remainder theorem that
$\Lambda $
. It is easy to see from the Chinese remainder theorem that
 $m_{\hat {\mathbb {Z}}^\times }$
is well defined, in the sense that replacing
$m_{\hat {\mathbb {Z}}^\times }$
is well defined, in the sense that replacing
 $a_1, a_2, q$
by
$a_1, a_2, q$
by
 $k a_1, ka_2, kq$
for any positive integer k does not affect the right-hand side of equation (3.17). Given any Schwartz function
$k a_1, ka_2, kq$
for any positive integer k does not affect the right-hand side of equation (3.17). Given any Schwartz function
 $m \colon \mathbb {R}^2 \to \mathbb {C}$
, we then define the twisted bilinear multiplier operator
$m \colon \mathbb {R}^2 \to \mathbb {C}$
, we then define the twisted bilinear multiplier operator
 $\mathrm {B}^{l_1,l_2,m_{\hat {\mathbb {Z}}^\times }}_{m}(f,g)$
for rapidly decreasing
$\mathrm {B}^{l_1,l_2,m_{\hat {\mathbb {Z}}^\times }}_{m}(f,g)$
for rapidly decreasing
 $f,g \colon \mathbb {Z} \to \mathbb {C}$
by the formula
$f,g \colon \mathbb {Z} \to \mathbb {C}$
by the formula

As in [Reference Krause, Mirek and Tao13, equation (7.9)], we also introduce the continuous symbol
 $\tilde m_{N,\mathbb {R}} \colon \mathbb {R}^2 \to \mathbb {C}$
by the formula
$\tilde m_{N,\mathbb {R}} \colon \mathbb {R}^2 \to \mathbb {C}$
by the formula

and also the cutoff functions
for any integer k and frequency
 $\xi \in \mathbb {R}$
, where
$\xi \in \mathbb {R}$
, where
 $\eta \colon \mathbb {R} \to [0,1]$
is a fixed smooth even function supported on
$\eta \colon \mathbb {R} \to [0,1]$
is a fixed smooth even function supported on
 $[-1,1]$
that equals one on
$[-1,1]$
that equals one on
 $[-1/2,1/2]$
.
$[-1/2,1/2]$
.
In §5, we will prove the following analogue of [Reference Krause, Mirek and Tao13, Proposition 7.13].
Proposition 3.4. (Major arc approximation of
$\tilde A_{N,\Lambda _N}$
)

For any
 $N \geq 1$
and
$N \geq 1$
and
 $s \in \mathbb {N}$
with
$s \in \mathbb {N}$
with
 $-\operatorname {Log} N+s \leq -u$
, we have
$-\operatorname {Log} N+s \leq -u$
, we have
 $$ \begin{align} &\| \tilde A_{N,\Lambda_N}( \Pi_{l_1, \leq -\operatorname{Log} N+s} \tilde F, \Pi_{l_2, \leq -d\operatorname{Log} N+ds} \tilde G )\nonumber\\ &\qquad- \mathrm{B}^{l_1, l_2, m_{\hat {\mathbb{Z}}^\times}}_{(\eta_{\leq -\operatorname{Log} N+s} \otimes \eta_{\leq -d\operatorname{Log} N+ds})\tilde m_{N,\mathbb{R}} }(\tilde F,\tilde G) \|_{\ell^p(\mathbb{Z})} \nonumber\\ &\quad \lesssim_{C_3} 2^{O(\max(2^{\rho l},s))} \exp(-\operatorname{Log}^c N) \| \tilde F \|_{\ell^{p_1}(\mathbb{Z})} \|\tilde G\|_{\ell^{p_2}(\mathbb{Z})} \end{align} $$
$$ \begin{align} &\| \tilde A_{N,\Lambda_N}( \Pi_{l_1, \leq -\operatorname{Log} N+s} \tilde F, \Pi_{l_2, \leq -d\operatorname{Log} N+ds} \tilde G )\nonumber\\ &\qquad- \mathrm{B}^{l_1, l_2, m_{\hat {\mathbb{Z}}^\times}}_{(\eta_{\leq -\operatorname{Log} N+s} \otimes \eta_{\leq -d\operatorname{Log} N+ds})\tilde m_{N,\mathbb{R}} }(\tilde F,\tilde G) \|_{\ell^p(\mathbb{Z})} \nonumber\\ &\quad \lesssim_{C_3} 2^{O(\max(2^{\rho l},s))} \exp(-\operatorname{Log}^c N) \| \tilde F \|_{\ell^{p_1}(\mathbb{Z})} \|\tilde G\|_{\ell^{p_2}(\mathbb{Z})} \end{align} $$
for all
 $\tilde F \in \ell ^{p_1}(\mathbb {Z}), \tilde G \in \ell ^{p_2}(\mathbb {Z})$
.
$\tilde F \in \ell ^{p_1}(\mathbb {Z}), \tilde G \in \ell ^{p_2}(\mathbb {Z})$
.
This is a slightly weaker type of bound than the corresponding result in [Reference Krause, Mirek and Tao13], as the polynomial gain of
 $N^{-1}$
has been reduced to the quasipolynomial gain of
$N^{-1}$
has been reduced to the quasipolynomial gain of
 $\exp (-\operatorname {Log}^c N)$
. However, this is still good enough to dominate the
$\exp (-\operatorname {Log}^c N)$
. However, this is still good enough to dominate the
 $2^{O(\max (2^{\rho l},s))}$
terms, since from [Reference Krause, Mirek and Tao13, equation (7.1)], one has
$2^{O(\max (2^{\rho l},s))}$
terms, since from [Reference Krause, Mirek and Tao13, equation (7.1)], one has
 $$ \begin{align} N \geq \max(2^{2^{\max(l,s_1,s_2)/2}}, C_3) \end{align} $$
$$ \begin{align} N \geq \max(2^{2^{\max(l,s_1,s_2)/2}}, C_3) \end{align} $$
for all
 $N \in \mathbb {I}$
. Because of this, we can repeat the Fourier-analytic arguments in [Reference Krause, Mirek and Tao13, §7] down to [Reference Krause, Mirek and Tao13, Theorem 7.23] with the obvious changes, and reduce to showing the acceptability of the small-scale model tuple
$N \in \mathbb {I}$
. Because of this, we can repeat the Fourier-analytic arguments in [Reference Krause, Mirek and Tao13, §7] down to [Reference Krause, Mirek and Tao13, Theorem 7.23] with the obvious changes, and reduce to showing the acceptability of the small-scale model tuple
 $$ \begin{align} \bigg( \int_{1/2}^1 \mathrm{B}^{l_1,l_2,m_{\hat {\mathbb{Z}}^\times}}_{m_*}( \mathrm{T}^{l_1}_{\varphi_{N,t}} F, \mathrm{T}^{l_2}_{\tilde \varphi_{N,t}} G)\, dt \bigg)_{N \in \mathbb{I}_{\leq}} \end{align} $$
$$ \begin{align} \bigg( \int_{1/2}^1 \mathrm{B}^{l_1,l_2,m_{\hat {\mathbb{Z}}^\times}}_{m_*}( \mathrm{T}^{l_1}_{\varphi_{N,t}} F, \mathrm{T}^{l_2}_{\tilde \varphi_{N,t}} G)\, dt \bigg)_{N \in \mathbb{I}_{\leq}} \end{align} $$
and the large-scale model tuple
 $$ \begin{align} \bigg(\int_{1/2}^1 \mathrm{B}_{1 \otimes m_{\hat {\mathbb{Z}}^\times}}(\mathrm{T}_{\varphi_{N,t} \otimes 1} F_{\mathbb{A}},\mathrm{T}_{\tilde \varphi_{N,t} \otimes 1} G_{\mathbb{A}}) \bigg)_{N \in \mathbb{I}_{>}}, \end{align} $$
$$ \begin{align} \bigg(\int_{1/2}^1 \mathrm{B}_{1 \otimes m_{\hat {\mathbb{Z}}^\times}}(\mathrm{T}_{\varphi_{N,t} \otimes 1} F_{\mathbb{A}},\mathrm{T}_{\tilde \varphi_{N,t} \otimes 1} G_{\mathbb{A}}) \bigg)_{N \in \mathbb{I}_{>}}, \end{align} $$
where:
-
(i)
and ; -
(ii)
; -
(iii)
, ; -
(iv) the adelic model functions
$F_{\mathbb {A}} \in L^{p_1}(\mathbb {A}_{\mathbb {Z}})$
,
$G_{\mathbb {A}} \in L^{p_2}(\mathbb {A}_{\mathbb {Z}})$
are defined by the formulae (3.22)and(3.23)for
$x \in \mathbb {R}, y \in \hat {\mathbb {Z}}$
.





We can then repeat the integration by parts arguments in the remainder of [Reference Krause, Mirek and Tao13, §7] (replacing
 $m_{\hat {\mathbb {Z}}}$
by
$m_{\hat {\mathbb {Z}}}$
by
 $m_{\hat {\mathbb {Z}}^\times }$
) and reduce to establishing the small-scale model estimate
$m_{\hat {\mathbb {Z}}^\times }$
) and reduce to establishing the small-scale model estimate

and the large-scale model estimate

whenever
 $1/2 \leq t \leq 1$
and
$1/2 \leq t \leq 1$
and
 $j_1,j_2 \in \{-1,0,+1\}$
are such that
$j_1,j_2 \in \{-1,0,+1\}$
are such that
 $$ \begin{align} (s_1,j_1), (s_2,j_2) \neq (-u,-1), \end{align} $$
$$ \begin{align} (s_1,j_1), (s_2,j_2) \neq (-u,-1), \end{align} $$
where
and
To prove the small-scale argument in equation (3.25), we use the two-dimensional Radamacher–Menshov inequality [Reference Krause, Mirek and Tao13, Corollary 8.2] by repeating the arguments of [Reference Krause, Mirek and Tao13, §8] (replacing
 $m_{\hat {\mathbb {Z}}}$
by
$m_{\hat {\mathbb {Z}}}$
by
 $m_{\hat {\mathbb {Z}}^\times }$
), reducing matters to establishing the following single-scale estimate.
$m_{\hat {\mathbb {Z}}^\times }$
), reducing matters to establishing the following single-scale estimate.
Lemma 3.5. (Single-scale estimate)
If
 $\tilde F \in \ell ^{p_1}(\mathbb {Z}), \tilde G \in \ell ^{p_2}(\mathbb {Z})$
have Fourier support on
$\tilde F \in \ell ^{p_1}(\mathbb {Z}), \tilde G \in \ell ^{p_2}(\mathbb {Z})$
have Fourier support on
 ${\mathcal M}_{l_1, \leq -3u}$
and
${\mathcal M}_{l_1, \leq -3u}$
and
 ${\mathcal M}_{l_2, \leq -3du}$
, respectively, then
${\mathcal M}_{l_2, \leq -3du}$
, respectively, then
However, this can be proven by repeating the proof of [Reference Krause, Mirek and Tao13, Lemma 8.6], using Proposition 3.4 in place of [Reference Krause, Mirek and Tao13, Proposition 7.13]; the replacement of
 $m_{\hat {\mathbb {Z}}}$
with
$m_{\hat {\mathbb {Z}}}$
with
 $m_{\hat {\mathbb {Z}}^\times }$
makes no difference here, and the slight reduction in strength of Proposition 3.4 from a polynomial gain in N to a quasipolynomial gain in N is similarly manageable.
$m_{\hat {\mathbb {Z}}^\times }$
makes no difference here, and the slight reduction in strength of Proposition 3.4 from a polynomial gain in N to a quasipolynomial gain in N is similarly manageable.
It remains to establish the large-scale estimate in equation (3.25). We repeat the arguments in [Reference Krause, Mirek and Tao13, §9], replacing
 $m_{\hat {\mathbb {Z}}}$
by
$m_{\hat {\mathbb {Z}}}$
by
 $m_{\hat {\mathbb {Z}}^\times }$
, and noting that
$m_{\hat {\mathbb {Z}}^\times }$
, and noting that
 $\mathrm {B}_{1 \otimes m_{\hat {\mathbb {Z}}^\times }}$
is the tensor product of the identity and the bilinear operator
$\mathrm {B}_{1 \otimes m_{\hat {\mathbb {Z}}^\times }}$
is the tensor product of the identity and the bilinear operator
 $\mathrm {A}_{\hat {\mathbb {Z}}^\times }$
on the profinite integers defined for
$\mathrm {A}_{\hat {\mathbb {Z}}^\times }$
on the profinite integers defined for
 $f \colon \mathbb {Z}/Q\mathbb {Z} \to \mathbb {C}$
,
$f \colon \mathbb {Z}/Q\mathbb {Z} \to \mathbb {C}$
,
 $g \colon \mathbb {Z}/Q\mathbb {Z} \to \mathbb {C}$
for any Q (which one can also view as functions on
$g \colon \mathbb {Z}/Q\mathbb {Z} \to \mathbb {C}$
for any Q (which one can also view as functions on
 $\hat {\mathbb {Z}}$
in the obvious fashion) by the formula
$\hat {\mathbb {Z}}$
in the obvious fashion) by the formula
These arguments reduce matters to establishing the following analogue of [Reference Krause, Mirek and Tao13, Theorem 9.9].
Theorem 3.6. (Arithmetic bilinear estimate)
Let
 $l \in \mathbb {N}$
and let
$l \in \mathbb {N}$
and let
 $f, g \in L^2(\hat {\mathbb {Z}})$
obey one of the following hypotheses:
$f, g \in L^2(\hat {\mathbb {Z}})$
obey one of the following hypotheses:
-
(i)
$\mathcal {F}_{\hat {\mathbb {Z}}} f$
vanishes on
$(\mathbb {Q}/\mathbb {Z})_{\leq l}$
; -
(ii)
$\mathcal {F}_{\hat {\mathbb {Z}}} g$
vanishes on
$(\mathbb {Q}/\mathbb {Z})_{\leq l}$
.




Then, for any
 $1 \leq r < ({2d}/({d-1}))$
, one has
$1 \leq r < ({2d}/({d-1}))$
, one has
 $$ \begin{align*} \| \mathrm{A}_{\hat {\mathbb{Z}}^\times}(f,g) \|_{L^r(\hat {\mathbb{Z}})} \lesssim_{C_3,r} 2^{-c_r l} \| f\|_{L^2(\hat {\mathbb{Z}})} \| g \|_{L^2(\hat {\mathbb{Z}})}.\end{align*} $$
$$ \begin{align*} \| \mathrm{A}_{\hat {\mathbb{Z}}^\times}(f,g) \|_{L^r(\hat {\mathbb{Z}})} \lesssim_{C_3,r} 2^{-c_r l} \| f\|_{L^2(\hat {\mathbb{Z}})} \| g \|_{L^2(\hat {\mathbb{Z}})}.\end{align*} $$
Repeating the arguments in [Reference Krause, Mirek and Tao13, §10] up to [Reference Krause, Mirek and Tao13, equations (10.3), (10.4)], using
 $\mathrm {A}_{\hat {\mathbb {Z}}^\times }$
in place of
$\mathrm {A}_{\hat {\mathbb {Z}}^\times }$
in place of
 $\mathrm {A}_{\hat {\mathbb {Z}}}$
and Theorem 3.2 in place of [Reference Krause, Mirek and Tao13, Theorem 5.12], we see that it suffices to establish the p-adic bound
$\mathrm {A}_{\hat {\mathbb {Z}}}$
and Theorem 3.2 in place of [Reference Krause, Mirek and Tao13, Theorem 5.12], we see that it suffices to establish the p-adic bound
 $$ \begin{align} \| \mathrm{A}_{\mathbb{Z}_p^\times} \|_{L^2(\mathbb{Z}_p) \times L^2(\mathbb{Z}_p) \to L^q(\mathbb{Z}_p)} \lesssim_q 1 \end{align} $$
$$ \begin{align} \| \mathrm{A}_{\mathbb{Z}_p^\times} \|_{L^2(\mathbb{Z}_p) \times L^2(\mathbb{Z}_p) \to L^q(\mathbb{Z}_p)} \lesssim_q 1 \end{align} $$
for all primes p, together with the improvement
 $$ \begin{align} \| \mathrm{A}_{\mathbb{Z}_p^\times} \|_{L^2(\mathbb{Z}_p) \times L^2(\mathbb{Z}_p) \to L^q(\mathbb{Z}_p)} \leq 1 \end{align} $$
$$ \begin{align} \| \mathrm{A}_{\mathbb{Z}_p^\times} \|_{L^2(\mathbb{Z}_p) \times L^2(\mathbb{Z}_p) \to L^q(\mathbb{Z}_p)} \leq 1 \end{align} $$
whenever
 $1 \leq q < ({2d}/({d-1}))$
and p is sufficiently large depending on q, where the averaging operator
$1 \leq q < ({2d}/({d-1}))$
and p is sufficiently large depending on q, where the averaging operator
 $\mathrm {A}_{\mathbb {Z}_p^\times }$
is defined as
$\mathrm {A}_{\mathbb {Z}_p^\times }$
is defined as
Because
 $\mathbb {Z}_p^\times $
has density
$\mathbb {Z}_p^\times $
has density
 $({p-1})/{p}$
in
$({p-1})/{p}$
in
 $\mathbb {Z}_p$
, we have the pointwise bound
$\mathbb {Z}_p$
, we have the pointwise bound
 $$ \begin{align} |\mathrm{A}_{\mathbb{Z}_p^\times}(f,g)(x)| \leq \frac{p}{p-1} \mathrm{A}_{\mathbb{Z}^p}(|f|, |g|)(x) \end{align} $$
$$ \begin{align} |\mathrm{A}_{\mathbb{Z}_p^\times}(f,g)(x)| \leq \frac{p}{p-1} \mathrm{A}_{\mathbb{Z}^p}(|f|, |g|)(x) \end{align} $$
from the triangle inequality, where
Hence, equation (3.29) is immediate from [Reference Krause, Mirek and Tao13, equation (10.3)]. It remains to establish equation (3.30). As in [Reference Krause, Mirek and Tao13, §10], we may assume
 $2 < q < ({2d}/({d-1}))$
and
$2 < q < ({2d}/({d-1}))$
and
 $\|f\|_{L^2(\mathbb {Z}_p)} = \|g\|_{L^2(\mathbb {Z}_p)} = 1$
with
$\|f\|_{L^2(\mathbb {Z}_p)} = \|g\|_{L^2(\mathbb {Z}_p)} = 1$
with
 $f,g$
non-negative, in which case, our task is to show that
$f,g$
non-negative, in which case, our task is to show that
 $$ \begin{align*} \mathbb{E}_{n \in \mathbb{Z}_p} |\mathrm{A}_{\mathbb{Z}_p^\times}(f,g)(x)|^q \leq 1.\end{align*} $$
$$ \begin{align*} \mathbb{E}_{n \in \mathbb{Z}_p} |\mathrm{A}_{\mathbb{Z}_p^\times}(f,g)(x)|^q \leq 1.\end{align*} $$
Applying equation (3.31) and the bound
 $\|\mathrm {A}_{\mathbb {Z}_p}(|f|,|g|)\|_{L^q(\mathbb {Z}_p)}\leq 1$
from [Reference Krause, Mirek and Tao13, §10] would cost a factor of
$\|\mathrm {A}_{\mathbb {Z}_p}(|f|,|g|)\|_{L^q(\mathbb {Z}_p)}\leq 1$
from [Reference Krause, Mirek and Tao13, §10] would cost a factor of
 $({p}/({p-1}))^q$
, which is not acceptable here (the product
$({p}/({p-1}))^q$
, which is not acceptable here (the product
 $\prod _p ({p}/({p-1}))$
diverges). Instead, we follow the arguments in [Reference Krause, Mirek and Tao13, §10], decomposing
$\prod _p ({p}/({p-1}))$
diverges). Instead, we follow the arguments in [Reference Krause, Mirek and Tao13, §10], decomposing
 $f = a + f_0$
,
$f = a + f_0$
,
 $g = b + g_0$
, where
$g = b + g_0$
, where
 $0 \leq a,b \leq 1$
,
$0 \leq a,b \leq 1$
,
 $f_0, g_0$
have mean zero, and the ‘energies’
$f_0, g_0$
have mean zero, and the ‘energies’
obey
 $0 \leq E_f, E_g \leq 1$
and
$0 \leq E_f, E_g \leq 1$
and
 $$ \begin{align*} |a| = (1 - E_f)^{1/2}, \quad |b| = (1 - E_g)^{1/2}.\end{align*} $$
$$ \begin{align*} |a| = (1 - E_f)^{1/2}, \quad |b| = (1 - E_g)^{1/2}.\end{align*} $$
In the case of
 $\mathrm {A}_{\mathbb {Z}_p}$
, we clearly have
$\mathrm {A}_{\mathbb {Z}_p}$
, we clearly have
 $$ \begin{align*} \mathrm{A}_{\mathbb{Z}_p}(a,b) = ab, \quad \mathrm{A}_{\mathbb{Z}_p}(f_0,b) = 0\end{align*} $$
$$ \begin{align*} \mathrm{A}_{\mathbb{Z}_p}(a,b) = ab, \quad \mathrm{A}_{\mathbb{Z}_p}(f_0,b) = 0\end{align*} $$
(was observed in [Reference Krause, Mirek and Tao13, §10]) so that by linearity, we have
 $$ \begin{align*} \mathrm{A}_{\mathbb{Z}_p}(f,g) = ab + \mathrm{A}_{\mathbb{Z}_p}(f,g_0).\end{align*} $$
$$ \begin{align*} \mathrm{A}_{\mathbb{Z}_p}(f,g) = ab + \mathrm{A}_{\mathbb{Z}_p}(f,g_0).\end{align*} $$
For the averaging operator
 $\mathrm {A}_{\mathbb {Z}_p^\times }$
, the situation is slightly more complicated; we have
$\mathrm {A}_{\mathbb {Z}_p^\times }$
, the situation is slightly more complicated; we have
 $$ \begin{align*} \mathrm{A}_{\mathbb{Z}_p^\times}(a,b) = ab, \quad \mathrm{A}_{\mathbb{Z}_p^\times}(f_0,b) = -\frac{p}{p-1} b h,\end{align*} $$
$$ \begin{align*} \mathrm{A}_{\mathbb{Z}_p^\times}(a,b) = ab, \quad \mathrm{A}_{\mathbb{Z}_p^\times}(f_0,b) = -\frac{p}{p-1} b h,\end{align*} $$
where
 $h \colon \mathbb {Z}_p \to \mathbb {R}$
is the function
$h \colon \mathbb {Z}_p \to \mathbb {R}$
is the function
Since
 $f_0$
has mean zero, h has mean zero as well. Furthermore, from Young’s convolution inequality, one has the bounds
$f_0$
has mean zero, h has mean zero as well. Furthermore, from Young’s convolution inequality, one has the bounds

where
 $1/q + 1 = 1/2 + 1/r$
.
$1/q + 1 = 1/2 + 1/r$
.
We now have the decomposition
 $$ \begin{align*} \mathrm{A}_{\mathbb{Z}_p^\times}(f,g) = ab + \mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0) - \frac{p}{p-1} b h\end{align*} $$
$$ \begin{align*} \mathrm{A}_{\mathbb{Z}_p^\times}(f,g) = ab + \mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0) - \frac{p}{p-1} b h\end{align*} $$
and hence by the Taylor expansion
 $(x+y)^q=x^q+qx^{q-1}y+O(q^2x^{q-2}y^2)$
(as in [Reference Krause, Mirek and Tao13, §10]), we have
$(x+y)^q=x^q+qx^{q-1}y+O(q^2x^{q-2}y^2)$
(as in [Reference Krause, Mirek and Tao13, §10]), we have
 $$ \begin{align*} |\mathrm{A}_{\mathbb{Z}_p^\times}(f,g)|^q &= |ab|^q + q |ab|^{q-1} \bigg(\mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0) - \frac{p}{p-1} b h\bigg) \\ &\quad + O_q( |\mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0)|^2 + |\mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0)|^q + |h|^2 + |h|^q ). \end{align*} $$
$$ \begin{align*} |\mathrm{A}_{\mathbb{Z}_p^\times}(f,g)|^q &= |ab|^q + q |ab|^{q-1} \bigg(\mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0) - \frac{p}{p-1} b h\bigg) \\ &\quad + O_q( |\mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0)|^2 + |\mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0)|^q + |h|^2 + |h|^q ). \end{align*} $$
Since
 $a,b\in [0,1]$
, we can bound
$a,b\in [0,1]$
, we can bound
 $|ab|^q\leq |ab|^2 = (1-E_f)(1-E_g)$
. Furthermore,
$|ab|^q\leq |ab|^2 = (1-E_f)(1-E_g)$
. Furthermore,
 ${p}/({p-1}) b h$
has mean zero and
${p}/({p-1}) b h$
has mean zero and
 $\mathrm {A}_{\mathbb {Z}_p^\times }(f,g_0)$
has a mean of at most
$\mathrm {A}_{\mathbb {Z}_p^\times }(f,g_0)$
has a mean of at most
 $\| \mathrm {A}_{\mathbb {Z}_p^\times }(f_0,g_0)\|_{L^1(\mathbb {Z}_p)}$
since
$\| \mathrm {A}_{\mathbb {Z}_p^\times }(f_0,g_0)\|_{L^1(\mathbb {Z}_p)}$
since
 $\mathrm {A}_{\mathbb {Z}_p^\times }(a,g_0)$
has mean zero. We conclude that
$\mathrm {A}_{\mathbb {Z}_p^\times }(a,g_0)$
has mean zero. We conclude that
 $$ \begin{align*} \|\mathrm{A}_{\mathbb{Z}_p^\times}(f,g)\|_{L^q(\mathbb{Z}_p)}^q &\leq (1-E_f) (1-E_g) + O_q( \| \mathrm{A}_{\mathbb{Z}_p^\times}(f_0,g_0) \|_{L^1(\mathbb{Z}_p)} \\ &\ \ \ +\! \| \mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0) \|_{L^2(\mathbb{Z}_p)}^2 \!+ \| \mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0) \|_{L^q(\mathbb{Z}_p)}^q \!+\! p^{-2} E_f \!+ p^{-q/2-1} E_f^{q/2}). \end{align*} $$
$$ \begin{align*} \|\mathrm{A}_{\mathbb{Z}_p^\times}(f,g)\|_{L^q(\mathbb{Z}_p)}^q &\leq (1-E_f) (1-E_g) + O_q( \| \mathrm{A}_{\mathbb{Z}_p^\times}(f_0,g_0) \|_{L^1(\mathbb{Z}_p)} \\ &\ \ \ +\! \| \mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0) \|_{L^2(\mathbb{Z}_p)}^2 \!+ \| \mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0) \|_{L^q(\mathbb{Z}_p)}^q \!+\! p^{-2} E_f \!+ p^{-q/2-1} E_f^{q/2}). \end{align*} $$
By arguing as in [Reference Krause, Mirek and Tao13, §10] (using Theorem 3.2 in place of [Reference Krause, Mirek and Tao13, Theorem 5.12]), we see that if l is any large integer and p is sufficiently large depending on q, we have the estimates
 $$ \begin{align*} \| \mathrm{A}_{\mathbb{Z}_p^\times}(f_0,g_0) \|_{L^1(\mathbb{Z}_p)} &\lesssim 2^{-c_q l} E_f^{1/2} E_g^{1/2}, \\ \| \mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0) \|_{L^2(\mathbb{Z}_p)}^2 &\lesssim 2^{-c_q l} E_g, \\ \| \mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0) \|_{L^q(\mathbb{Z}_p)}^q &\lesssim 2^{-c_q l} E_g^{q/2} \end{align*} $$
$$ \begin{align*} \| \mathrm{A}_{\mathbb{Z}_p^\times}(f_0,g_0) \|_{L^1(\mathbb{Z}_p)} &\lesssim 2^{-c_q l} E_f^{1/2} E_g^{1/2}, \\ \| \mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0) \|_{L^2(\mathbb{Z}_p)}^2 &\lesssim 2^{-c_q l} E_g, \\ \| \mathrm{A}_{\mathbb{Z}_p^\times}(f,g_0) \|_{L^q(\mathbb{Z}_p)}^q &\lesssim 2^{-c_q l} E_g^{q/2} \end{align*} $$
for some
 $c_q>0$
depending only on q, and hence, by the arithmetic mean-geometric mean inequality and the hypothesis
$c_q>0$
depending only on q, and hence, by the arithmetic mean-geometric mean inequality and the hypothesis
 $q> 2$
, we have
$q> 2$
, we have
 $$ \begin{align*} \|\mathrm{A}_{\mathbb{Z}_p^\times}(f,g)\|_{L^q(\mathbb{Z}_p)}^q &\leq (1-E_f) (1-E_g) + O_q( (2^{-c_q l} + p^{-2}) (E_f+E_g) )\\ &\leq (1-E_f) (1-E_g) + O_q( (2^{-c_q l} + p^{-2})), \end{align*} $$
$$ \begin{align*} \|\mathrm{A}_{\mathbb{Z}_p^\times}(f,g)\|_{L^q(\mathbb{Z}_p)}^q &\leq (1-E_f) (1-E_g) + O_q( (2^{-c_q l} + p^{-2}) (E_f+E_g) )\\ &\leq (1-E_f) (1-E_g) + O_q( (2^{-c_q l} + p^{-2})), \end{align*} $$
and the right-hand side is bounded by
 $1$
for l and p large enough, as required.
$1$
for l and p large enough, as required.
To summarize, to complete the proof of Theorem 1.3, we need to select an approximant
 $\Lambda _N$
to the weight
$\Lambda _N$
to the weight
 $\Lambda $
at each scale N that obeys the estimates in equations (3.1), (3.2), (3.3) and (3.4), as well as the single scale minor arc estimate in Theorem 3.2 and the major arc approximation in Proposition 3.4. This will be the focus of the next sections.
$\Lambda $
at each scale N that obeys the estimates in equations (3.1), (3.2), (3.3) and (3.4), as well as the single scale minor arc estimate in Theorem 3.2 and the major arc approximation in Proposition 3.4. This will be the focus of the next sections.
4 Approximants to the von Mangoldt function
As seen in the previous section, the arguments rely on using an approximant
 $\Lambda _N$
to the von Mangoldt function
$\Lambda _N$
to the von Mangoldt function
 $\Lambda $
at scale N. There are several plausible candidates for such approximants, including the following.
$\Lambda $
at scale N. There are several plausible candidates for such approximants, including the following.
-
(i)
$\Lambda $
itself. -
(ii) A Cramér (or Cramér–Granville) approximant
whereand
$w \geq 1$
is a parameter.
-
(iii) A Heath-Brown approximant
(4.1)where
$Q \geq 1$
is a parameter and
$c_q(n)$
are the Ramanujan sums (4.2)






Other possibilities for approximants exist, including Goldston–Pintz–Yıldırım type approximants
 $(\log R) \sum _{\ell \mid n} \mu (\ell ) \eta (\log \ell /\log R)$
and
$(\log R) \sum _{\ell \mid n} \mu (\ell ) \eta (\log \ell /\log R)$
and
 $(\log R) (\sum _{\ell \mid n} \mu (\ell ) \eta (\log \ell /\log R))^2$
for suitable level parameters R and smooth cutoffs
$(\log R) (\sum _{\ell \mid n} \mu (\ell ) \eta (\log \ell /\log R))^2$
for suitable level parameters R and smooth cutoffs
 $\eta $
, Selberg sieve approximants
$\eta $
, Selberg sieve approximants
 $(\sum _{\ell \mid n} \unicode{x3bb} _{\ell })^2$
, or adjustments to several of the previous approximants by a correction term arising from a Siegel zero, but we will not discuss these other options further here.
$(\sum _{\ell \mid n} \unicode{x3bb} _{\ell })^2$
, or adjustments to several of the previous approximants by a correction term arising from a Siegel zero, but we will not discuss these other options further here.
The choice of option (i) (that is, setting ![]() ) is tempting, particularly in view of recent advances in quantitative understanding of functions such as
) is tempting, particularly in view of recent advances in quantitative understanding of functions such as
 $\Lambda $
in [Reference Leng15, Reference Tao and Teräväinen25]. However, it turns out that the presence of a Siegel zero would distort the asymptotics of
$\Lambda $
in [Reference Leng15, Reference Tao and Teräväinen25]. However, it turns out that the presence of a Siegel zero would distort the asymptotics of
 $\Lambda $
to such an extent that the desired approximation in Proposition 3.4 no longer holds with quasipolynomial error terms in N, which turns out to significantly complicate the analysis (particularly in the small-scale regime, in which one has to modify the Radamacher–Menshov type arguments significantly). See §6 for further discussion.
$\Lambda $
to such an extent that the desired approximation in Proposition 3.4 no longer holds with quasipolynomial error terms in N, which turns out to significantly complicate the analysis (particularly in the small-scale regime, in which one has to modify the Radamacher–Menshov type arguments significantly). See §6 for further discussion.
The choice of option (ii) has the advantage of being non-negative, reasonably well controlled in
 $\ell ^\infty $
and also relatively easy to control in Gowers uniformity norms, and so we shall take such a choice for our approximant
$\ell ^\infty $
and also relatively easy to control in Gowers uniformity norms, and so we shall take such a choice for our approximant
 $\Lambda _N$
; specifically, we will set
$\Lambda _N$
; specifically, we will set
 $$ \begin{align} \Lambda_N = \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, \exp(\operatorname{Log}^{1/C_0} N)}. \end{align} $$
$$ \begin{align} \Lambda_N = \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, \exp(\operatorname{Log}^{1/C_0} N)}. \end{align} $$
However, there is one aspect in which this approximant
 $\Lambda _N(n)$
is not ideal: it is not exactly equal to a ‘Type I sum’
$\Lambda _N(n)$
is not ideal: it is not exactly equal to a ‘Type I sum’
 $\sum _{\ell \mid n} \unicode{x3bb} _{\ell }$
, where
$\sum _{\ell \mid n} \unicode{x3bb} _{\ell }$
, where
 $\unicode{x3bb} _{\ell }$
are weights supported on relatively small values of d. The Heath-Brown approximants
$\unicode{x3bb} _{\ell }$
are weights supported on relatively small values of d. The Heath-Brown approximants
 $\Lambda _{\operatorname {HB},Q}$
introduced in option (iii) are precisely Type I sums, and so we will switch to those approximants at a certain point in the proof.
$\Lambda _{\operatorname {HB},Q}$
introduced in option (iii) are precisely Type I sums, and so we will switch to those approximants at a certain point in the proof.
To achieve these goals, we will need to collect some basic facts about the Cramér approximants
 $\Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}$
and the Heath-Brown approximants
$\Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}$
and the Heath-Brown approximants
 $\Lambda _{\operatorname {HB},Q}$
, which may be of independent interest.
$\Lambda _{\operatorname {HB},Q}$
, which may be of independent interest.
4.1 Bounds on the Cramér approximant
We begin with the Cramér approximant. First, we record an easy uniform bound.
Lemma 4.1. (Uniform bound on Cramér model)
If
 $w \geq 1$
, then
$w \geq 1$
, then
 $$ \begin{align*} 0 \leq \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) \lesssim \langle \operatorname{Log} w\rangle \end{align*} $$
$$ \begin{align*} 0 \leq \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) \lesssim \langle \operatorname{Log} w\rangle \end{align*} $$
for all
 $n \in \mathbb {Z}$
.
$n \in \mathbb {Z}$
.
Proof. This is immediate from the Mertens theorem bound
 $$ \begin{align*}\frac{W}{\varphi(W)} = \prod_{p \leq w} \frac{p}{p-1} \lesssim \langle \operatorname{Log} w\rangle.\\[-46pt]\end{align*} $$
$$ \begin{align*}\frac{W}{\varphi(W)} = \prod_{p \leq w} \frac{p}{p-1} \lesssim \langle \operatorname{Log} w\rangle.\\[-46pt]\end{align*} $$
The Cramér approximant is not easily expressible as an exact Type I sum once w is reasonably large (in particular, larger than
 $\operatorname {Log} N$
), but thanks to the fundamental lemma of sieve theory, it can be approximated by such a sum.
$\operatorname {Log} N$
), but thanks to the fundamental lemma of sieve theory, it can be approximated by such a sum.
Lemma 4.2. (Fundamental lemma of sieve theory)
If
 $2 \leq w \leq y \leq N^{1/10}$
, then there exist weights
$2 \leq w \leq y \leq N^{1/10}$
, then there exist weights
 $\unicode{x3bb} ^\pm _{\ell } \in [-1,1]$
, supported on
$\unicode{x3bb} ^\pm _{\ell } \in [-1,1]$
, supported on
 $1\leq \ell \leq y$
, such that
$1\leq \ell \leq y$
, such that
 $$ \begin{align*} \sum_{\ell\mid n} \unicode{x3bb}^-_{\ell} \leq \frac{\varphi(W)}{W} \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) \leq \sum_{\ell\mid n} \unicode{x3bb}^+_{\ell}\end{align*} $$
$$ \begin{align*} \sum_{\ell\mid n} \unicode{x3bb}^-_{\ell} \leq \frac{\varphi(W)}{W} \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) \leq \sum_{\ell\mid n} \unicode{x3bb}^+_{\ell}\end{align*} $$
for all n, and also
 $$ \begin{align*} \mathbb{E}_{n \in I} \sum_{\ell\mid n} \unicode{x3bb}^\pm_{\ell} = \frac{\varphi(W)}{W} (1 + O( \exp( -\!\log y/ \log w ))) \end{align*} $$
$$ \begin{align*} \mathbb{E}_{n \in I} \sum_{\ell\mid n} \unicode{x3bb}^\pm_{\ell} = \frac{\varphi(W)}{W} (1 + O( \exp( -\!\log y/ \log w ))) \end{align*} $$
for any interval I of length N. In particular,
 $$ \begin{align*} \mathbb{E}_{n \in I} \bigg|\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) - \frac{W}{\varphi(W)} \sum_{\ell\mid n} \unicode{x3bb}^\pm_{\ell}\bigg| \lesssim \exp(-\!\log y /\log w ).\end{align*} $$
$$ \begin{align*} \mathbb{E}_{n \in I} \bigg|\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) - \frac{W}{\varphi(W)} \sum_{\ell\mid n} \unicode{x3bb}^\pm_{\ell}\bigg| \lesssim \exp(-\!\log y /\log w ).\end{align*} $$
Proof. This follows easily from [Reference Iwaniec and Kowalski11, Lemma 6.3].
The fundamental lemma can then be used to give many good estimates for the Cramér model.
Proposition 4.3. (Linear equations in the Cramér model)
Let
 $t,m \geq 1$
be integers and let
$t,m \geq 1$
be integers and let
 $N \geq 100$
. Let
$N \geq 100$
. Let
 $\Omega \subset [-N,N]^d$
be convex, and let
$\Omega \subset [-N,N]^d$
be convex, and let
 $\psi _1,\ldots ,\psi _t \colon \mathbb {Z}^m \to \mathbb {Z}$
be linear forms
$\psi _1,\ldots ,\psi _t \colon \mathbb {Z}^m \to \mathbb {Z}$
be linear forms
 $$ \begin{align*} \psi_i(\vec n) = \vec n \cdot \dot \psi_i + \psi_i(0) \end{align*} $$
$$ \begin{align*} \psi_i(\vec n) = \vec n \cdot \dot \psi_i + \psi_i(0) \end{align*} $$
for some
 $\dot \psi _i \in \mathbb {Z}^m$
and
$\dot \psi _i \in \mathbb {Z}^m$
and
 $\psi _i(0) \in \mathbb {Z}$
. Assume that the linear coefficients
$\psi _i(0) \in \mathbb {Z}$
. Assume that the linear coefficients
 $\dot \psi _1,\ldots ,\dot \psi _t \in \mathbb {Z}^m$
are all pairwise linearly independent and have magnitude at most
$\dot \psi _1,\ldots ,\dot \psi _t \in \mathbb {Z}^m$
are all pairwise linearly independent and have magnitude at most
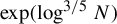 $\exp (\log ^{3/5} N)$
. Suppose that
$\exp (\log ^{3/5} N)$
. Suppose that
 $1 \leq z_i \leq \exp (\operatorname {Log}^{1/10} N)$
for all
$1 \leq z_i \leq \exp (\operatorname {Log}^{1/10} N)$
for all
 $i=1,\ldots ,t$
. Then, one has
$i=1,\ldots ,t$
. Then, one has
 $$ \begin{align*} \sum_{\vec n \in \Omega \cap \mathbb{Z}^m} \prod_{i=1}^t \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r},z_i}(\psi_i(\vec n)) = \mathrm{vol}(\Omega) \prod_p \beta_p + O_{t,m}( N^m \exp(-c \operatorname{Log}^{4/5} N))\end{align*} $$
$$ \begin{align*} \sum_{\vec n \in \Omega \cap \mathbb{Z}^m} \prod_{i=1}^t \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r},z_i}(\psi_i(\vec n)) = \mathrm{vol}(\Omega) \prod_p \beta_p + O_{t,m}( N^m \exp(-c \operatorname{Log}^{4/5} N))\end{align*} $$
for some
 $c>0$
depending only on
$c>0$
depending only on
 $t,m$
, where for each p,
$t,m$
, where for each p,
 $\beta _p$
is the local factor
$\beta _p$
is the local factor

where
 $\psi _i$
is also viewed as a map from
$\psi _i$
is also viewed as a map from
 $(\mathbb {Z}/p\mathbb {Z})^m$
to
$(\mathbb {Z}/p\mathbb {Z})^m$
to
 $\mathbb {Z}/p\mathbb {Z}$
in the obvious fashion. Furthermore,
$\mathbb {Z}/p\mathbb {Z}$
in the obvious fashion. Furthermore,
 $\beta _p$
obeys the bounds
$\beta _p$
obeys the bounds
 $$ \begin{align} \beta_p = 1 + O_{t,m}(1/p^2) \end{align} $$
$$ \begin{align} \beta_p = 1 + O_{t,m}(1/p^2) \end{align} $$
for all primes p (and
 $\beta _p=1$
if
$\beta _p=1$
if
 $p> \max (z_1,\ldots ,z_t)$
).
$p> \max (z_1,\ldots ,z_t)$
).
Proof. This is essentially [Reference Tao and Teräväinen25, Proposition 5.2] (which relies to a large extent on the fundamental lemma of sieve theory). Strictly speaking, this proposition only covered the case where the
 $z_i$
were equal to a single parameter z which was also assumed to be at least
$z_i$
were equal to a single parameter z which was also assumed to be at least
 $2$
, but an inspection of the argument shows that it applies without significant difficulty to variable
$2$
, but an inspection of the argument shows that it applies without significant difficulty to variable
 $z_i$
as well, even if some of the
$z_i$
as well, even if some of the
 $z_i$
are as small as
$z_i$
are as small as
 $1$
. The bound in equation (4.4) follows from [Reference Tao and Teräväinen25, equations (5.2), (5.5)] (a slightly weaker bound, which also suffices for our application, can be found in [Reference Green and Tao6, Lemma 1.3]).
$1$
. The bound in equation (4.4) follows from [Reference Tao and Teräväinen25, equations (5.2), (5.5)] (a slightly weaker bound, which also suffices for our application, can be found in [Reference Green and Tao6, Lemma 1.3]).
Specializing to the
 $t=m=1$
case (and noting that the constant coefficients of
$t=m=1$
case (and noting that the constant coefficients of
 $\psi _i$
can be large in Proposition 4.3), we immediately obtain the following corollary.
$\psi _i$
can be large in Proposition 4.3), we immediately obtain the following corollary.
Corollary 4.4. (Mean value of Cramér)
Let
 $N \geq 100$
and
$N \geq 100$
and
 $1 \leq z \leq \exp (\operatorname {Log}^{1/10} N)$
, then
$1 \leq z \leq \exp (\operatorname {Log}^{1/10} N)$
, then
 $$ \begin{align*} \mathbb{E}_{n \in I} \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z}(n) = 1 + O(\exp(-c \operatorname{Log}^{4/5} N))\end{align*} $$
$$ \begin{align*} \mathbb{E}_{n \in I} \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z}(n) = 1 + O(\exp(-c \operatorname{Log}^{4/5} N))\end{align*} $$
for any interval I of length N. In particular, since
 $\Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r},z}(n)$
is non-negative, we also have
$\Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r},z}(n)$
is non-negative, we also have
 $$ \begin{align*} \mathbb{E}_{n \in I} |\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z}(n)| = 1 + O(\exp(-c \operatorname{Log}^{4/5} N)).\end{align*} $$
$$ \begin{align*} \mathbb{E}_{n \in I} |\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z}(n)| = 1 + O(\exp(-c \operatorname{Log}^{4/5} N)).\end{align*} $$
More generally, if
 $1 \leq q \leq z$
and
$1 \leq q \leq z$
and
 $a\ (q)$
is a residue class, then
$a\ (q)$
is a residue class, then
As a more sophisticated application of Proposition 4.3, we record the following improvement of [Reference Tao and Teräväinen25, Proposition 1.2].
Lemma 4.5. (Improved stability of the Cramér model)
If
 $1 \leq z,w \leq \exp (\operatorname {Log}^{1/10} N)$
, for any
$1 \leq z,w \leq \exp (\operatorname {Log}^{1/10} N)$
, for any
 $d \ge 1$
, one has
$d \ge 1$
, one has
 $$ \begin{align*} \| \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z} \|_{U^{d+1}(I)} \lesssim_{d} w^{-c} + z^{-c}\end{align*} $$
$$ \begin{align*} \| \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z} \|_{U^{d+1}(I)} \lesssim_{d} w^{-c} + z^{-c}\end{align*} $$
for any interval I of length N. In particular, by equation (2.5),
 $$ \begin{align*} \| \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z} \|_{u^{d+1}(I)} \lesssim_{d} w^{-c} + z^{-c}.\end{align*} $$
$$ \begin{align*} \| \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z} \|_{u^{d+1}(I)} \lesssim_{d} w^{-c} + z^{-c}.\end{align*} $$
In fact, one can take
 $c = 1/2^{d+1}$
in these estimates.
$c = 1/2^{d+1}$
in these estimates.
The result in [Reference Tao and Teräväinen25, Proposition 1.2] had an additional term of
 $\operatorname {Log}^{-c} N$
on the right-hand side. The removal of this term was already conjectured in [Reference Tao and Teräväinen25, Remark 5.4].
$\operatorname {Log}^{-c} N$
on the right-hand side. The removal of this term was already conjectured in [Reference Tao and Teräväinen25, Remark 5.4].
Proof. Without loss of generality, we may assume that
 $z \leq w$
. Expanding out the expression
$z \leq w$
. Expanding out the expression
 $\| \Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z} \|_{U^{d+1}(I)}^{2^{d+1}}$
into an alternating sum of
$\| \Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z} \|_{U^{d+1}(I)}^{2^{d+1}}$
into an alternating sum of
 $2^{d+1}$
terms, it suffices to show that
$2^{d+1}$
terms, it suffices to show that

for all choices of parameters
 $w_\epsilon \in \{w,z\}$
, where
$w_\epsilon \in \{w,z\}$
, where
 $\epsilon = (\epsilon _1,\ldots ,\epsilon _{d+1})$
and X is a quantity that is independent of the choice of parameters
$\epsilon = (\epsilon _1,\ldots ,\epsilon _{d+1})$
and X is a quantity that is independent of the choice of parameters
 $w_\epsilon $
. Applying Proposition 4.3, the left-hand side is
$w_\epsilon $
. Applying Proposition 4.3, the left-hand side is
 $$ \begin{align*} \mathrm{vol}(\Omega) \prod_p \beta_p + O_d( N^{d+2} \exp(-c \operatorname{Log}^{4/5} N)),\end{align*} $$
$$ \begin{align*} \mathrm{vol}(\Omega) \prod_p \beta_p + O_d( N^{d+2} \exp(-c \operatorname{Log}^{4/5} N)),\end{align*} $$
where
 $\Omega $
is a certain explicit convex polytope of volume
$\Omega $
is a certain explicit convex polytope of volume
 $\beta _\infty N^{d+2}$
for some constant
$\beta _\infty N^{d+2}$
for some constant
 $\beta _\infty $
depending only on d, and the local factors
$\beta _\infty $
depending only on d, and the local factors
 $\beta _p$
are defined by the formula
$\beta _p$
are defined by the formula

The local factors
 $\beta _p$
are independent of the
$\beta _p$
are independent of the
 $w_\epsilon $
if
$w_\epsilon $
if
 $p \leq w$
or
$p \leq w$
or
 $p> z$
. Thus, by equation (4.4), the product
$p> z$
. Thus, by equation (4.4), the product
 $\prod _p \beta _p$
can be written as
$\prod _p \beta _p$
can be written as
 $Y(1+O(1/z))$
for some Y that is independent of the
$Y(1+O(1/z))$
for some Y that is independent of the
 $w_\epsilon $
parameters, and the claim follows.
$w_\epsilon $
parameters, and the claim follows.
4.2 Bounds on the Heath-Brown approximant
We now turn to the Heath-Brown approximants
 $\Lambda _{\operatorname {HB},Q}$
. The nice bounds in
$\Lambda _{\operatorname {HB},Q}$
. The nice bounds in
 $\ell ^\infty $
or
$\ell ^\infty $
or
 $\ell ^1$
one has in Lemma 4.1 or Corollary 4.4 are unfortunately not available for this approximant. However, we have reasonable control in other norms such as
$\ell ^1$
one has in Lemma 4.1 or Corollary 4.4 are unfortunately not available for this approximant. However, we have reasonable control in other norms such as
 $\ell ^2$
, in large part due to a good Type I representation.
$\ell ^2$
, in large part due to a good Type I representation.
Lemma 4.6. (Moment bounds for Heath-Brown approximant)
For any
 $Q \geq 1$
, one has the Type I representation
$Q \geq 1$
, one has the Type I representation

for some weights
 $\unicode{x3bb} _{\ell }$
with
$\unicode{x3bb} _{\ell }$
with
In particular, we have the pointwise bound
 $$ \begin{align} \Lambda_Q(n) \lesssim \tau(n,Q) \langle \operatorname{Log} Q \rangle, \end{align} $$
$$ \begin{align} \Lambda_Q(n) \lesssim \tau(n,Q) \langle \operatorname{Log} Q \rangle, \end{align} $$
where
 $\tau (n,Q)$
is the truncated divisor function
$\tau (n,Q)$
is the truncated divisor function

Furthermore, we have the moment bounds
 $$ \begin{align} \mathbb{E}_{n \in [N]} |\Lambda_Q(n)|^k \lesssim_k \langle \operatorname{Log} Q\rangle^{2^k+k} \end{align} $$
$$ \begin{align} \mathbb{E}_{n \in [N]} |\Lambda_Q(n)|^k \lesssim_k \langle \operatorname{Log} Q\rangle^{2^k+k} \end{align} $$
for any positive integer k and
 $N \geq 1$
.
$N \geq 1$
.
Proof. Applying the standard identity
 $c_q(n)=\sum _{\ell \mid (q,n)}\ell \mu (q/\ell )$
and then writing
$c_q(n)=\sum _{\ell \mid (q,n)}\ell \mu (q/\ell )$
and then writing
 $q=\ell r$
, we have
$q=\ell r$
, we have
 $$ \begin{align*} \Lambda_Q(n) &= \sum_{q<Q} \frac{\mu(q)}{\varphi(q)}\sum_{\ell\mid (q,n)}\ell\mu(q/\ell) \\ &= \sum_{\substack{\ell\mid n\\ \ell<Q}} \frac{\mu(\ell) \ell }{\varphi(\ell)} \sum_{\substack{r < Q/\ell\\ (\ell,r)=1}} \frac{\mu^2(r)}{\varphi(r)}. \end{align*} $$
$$ \begin{align*} \Lambda_Q(n) &= \sum_{q<Q} \frac{\mu(q)}{\varphi(q)}\sum_{\ell\mid (q,n)}\ell\mu(q/\ell) \\ &= \sum_{\substack{\ell\mid n\\ \ell<Q}} \frac{\mu(\ell) \ell }{\varphi(\ell)} \sum_{\substack{r < Q/\ell\\ (\ell,r)=1}} \frac{\mu^2(r)}{\varphi(r)}. \end{align*} $$
We then take

From Rankin’s trick and Mertens’s theorem, for any
 $1\leq d\leq Q$
, one has
$1\leq d\leq Q$
, one has
 $$ \begin{align*} \sum_{\substack{r \leq Q/\ell\\ (d,\ell)=1}} \frac{\mu^2(r)}{\varphi(r)} &\lesssim \sum_{\substack{r\geq 1\\ (\ell,r)=1}} \frac{\mu^2(r)}{\varphi(r) r^{1/\langle \operatorname{Log} Q\rangle}} \\ &\lesssim \prod_{\substack{p\\ p \nmid \ell}} \bigg(1+\frac{1}{(p-1) p^{1/\langle \operatorname{Log} Q\rangle}}\bigg) \\ &\lesssim \frac{\varphi(\ell)}{\ell} \prod_p \bigg(1 + \frac{1}{p^{1+1/\langle \operatorname{Log} Q\rangle}} + O\bigg(\frac{1}{p^2}\bigg)\bigg) \\ &\lesssim \frac{\varphi(\ell)}{\ell} \langle \operatorname{Log} Q\rangle, \end{align*} $$
$$ \begin{align*} \sum_{\substack{r \leq Q/\ell\\ (d,\ell)=1}} \frac{\mu^2(r)}{\varphi(r)} &\lesssim \sum_{\substack{r\geq 1\\ (\ell,r)=1}} \frac{\mu^2(r)}{\varphi(r) r^{1/\langle \operatorname{Log} Q\rangle}} \\ &\lesssim \prod_{\substack{p\\ p \nmid \ell}} \bigg(1+\frac{1}{(p-1) p^{1/\langle \operatorname{Log} Q\rangle}}\bigg) \\ &\lesssim \frac{\varphi(\ell)}{\ell} \prod_p \bigg(1 + \frac{1}{p^{1+1/\langle \operatorname{Log} Q\rangle}} + O\bigg(\frac{1}{p^2}\bigg)\bigg) \\ &\lesssim \frac{\varphi(\ell)}{\ell} \langle \operatorname{Log} Q\rangle, \end{align*} $$
where we used the Euler product formula and the standard bound
 $\zeta (\sigma )\sim {1}/{(\sigma -1)}$
for
$\zeta (\sigma )\sim {1}/{(\sigma -1)}$
for
 $\sigma>1$
to estimate the product over the primes. This gives equation (4.6). The bound in equation (4.7) then follows from the triangle inequality.
$\sigma>1$
to estimate the product over the primes. This gives equation (4.6). The bound in equation (4.7) then follows from the triangle inequality.
Now, we turn to equation (4.8). We may assume that
 $Q \geq 100$
, as the claim is trivial otherwise. We allow all implied constants to depend on k. In view of equation (4.7), it suffices to establish the bound
$Q \geq 100$
, as the claim is trivial otherwise. We allow all implied constants to depend on k. In view of equation (4.7), it suffices to establish the bound
 $$ \begin{align*} \sum_{n \in [N]} \tau(n,Q)^k \lesssim N \langle \operatorname{Log} Q\rangle^{2^k}.\end{align*} $$
$$ \begin{align*} \sum_{n \in [N]} \tau(n,Q)^k \lesssim N \langle \operatorname{Log} Q\rangle^{2^k}.\end{align*} $$
We expand
 $$ \begin{align*} \sum_{n \in [N]} \tau(n,Q)^k = \sum_{n \in [N]} \bigg(\sum_{\substack{\ell\mid n\\d<Q}}1\bigg)^k = \sum_{n \in [N]} \sum_{\ell_1,\ldots, \ell_k<Q} 1 = \sum_{\ell_1,\ldots, \ell_k<Q} \frac{N}{[\ell_1,\ldots, \ell_k]}, \end{align*} $$
$$ \begin{align*} \sum_{n \in [N]} \tau(n,Q)^k = \sum_{n \in [N]} \bigg(\sum_{\substack{\ell\mid n\\d<Q}}1\bigg)^k = \sum_{n \in [N]} \sum_{\ell_1,\ldots, \ell_k<Q} 1 = \sum_{\ell_1,\ldots, \ell_k<Q} \frac{N}{[\ell_1,\ldots, \ell_k]}, \end{align*} $$
where
 $[a_1,\ldots , a_k]$
is the least common multiple of
$[a_1,\ldots , a_k]$
is the least common multiple of
 $a_1,\ldots , a_k$
.
$a_1,\ldots , a_k$
.
Now, we apply Rankin’s trick. For
 $\ell _i<Q$
, we have
$\ell _i<Q$
, we have
 $\ell _i^{1/\langle \operatorname {Log} Q\rangle } = O(1)$
, and thus,
$\ell _i^{1/\langle \operatorname {Log} Q\rangle } = O(1)$
, and thus,
 $$ \begin{align*} \mathbb{E}_{n \in [N]} \tau(n,Q)^k &\lesssim \sum_{\ell_1,\ldots, \ell_k} \frac{1}{\ell_1^{1/\log Q}\cdots \ell_k^{1/\langle \operatorname{Log} Q\rangle}[\ell_1,\ldots, \ell_k]}. \end{align*} $$
$$ \begin{align*} \mathbb{E}_{n \in [N]} \tau(n,Q)^k &\lesssim \sum_{\ell_1,\ldots, \ell_k} \frac{1}{\ell_1^{1/\log Q}\cdots \ell_k^{1/\langle \operatorname{Log} Q\rangle}[\ell_1,\ldots, \ell_k]}. \end{align*} $$
Factorizing into an Euler product, we conclude that
 $$ \begin{align*} \mathbb{E}_{n \in [N]} \tau(n,Q)^k \lesssim \prod_{p}\bigg(1+\sum_{\substack{a_1,\ldots, a_k\in \{0,1\}\\ (a_1,\ldots,a_k)\neq \mathbf{0}}}\frac{1}{p^{1+(a_1+\cdots a_k)/\langle \operatorname{Log} Q\rangle}} +O\bigg(\frac{1}{p^2}\bigg)\bigg), \end{align*} $$
$$ \begin{align*} \mathbb{E}_{n \in [N]} \tau(n,Q)^k \lesssim \prod_{p}\bigg(1+\sum_{\substack{a_1,\ldots, a_k\in \{0,1\}\\ (a_1,\ldots,a_k)\neq \mathbf{0}}}\frac{1}{p^{1+(a_1+\cdots a_k)/\langle \operatorname{Log} Q\rangle}} +O\bigg(\frac{1}{p^2}\bigg)\bigg), \end{align*} $$
where ![]() . Hence, on taking logarithms, it will suffice to show that
. Hence, on taking logarithms, it will suffice to show that
 $$ \begin{align*} \sum_p \sum_{\substack{a_1,\ldots,a_k\in \{0,1\}\\ (a_1,\ldots, a_k)\neq \mathbf{0}}}p^{-1- ({a_1+\cdots+ a_k})/{\langle \operatorname{Log} Q\rangle}} \leq 2^k \log\log Q + O(1). \end{align*} $$
$$ \begin{align*} \sum_p \sum_{\substack{a_1,\ldots,a_k\in \{0,1\}\\ (a_1,\ldots, a_k)\neq \mathbf{0}}}p^{-1- ({a_1+\cdots+ a_k})/{\langle \operatorname{Log} Q\rangle}} \leq 2^k \log\log Q + O(1). \end{align*} $$
From partial summation and the prime number theorem, we have
 $$ \begin{align*} &\sum_{\substack{a_1,\ldots,a_k\in \{0,1\}\\ (a_1,\ldots, a_k)\neq \mathbf{0}}}\sum_{p\geq Q}p^{-1- ({a_1+\cdots+ a_k})/{\langle \log Q\rangle}}\\ &\quad\leq \sum_{\substack{a_1,\ldots,a_k\in \{0,1\}\\ (a_1,\ldots, a_k)\neq \mathbf{0}}} \int_{Q}^{\infty}\frac{t^{-1-({a_1+\cdots+a_k})/{\langle \operatorname{Log} Q\rangle}}}{\log t}\, dt+O(1)\\ &\quad\leq 2^k \cdot \int_{Q}^{\infty} t^{-{1}/{\langle \log Q\rangle}} \ \frac{dt}{t \log t} +O(1) \lesssim 2^k + O(1). \end{align*} $$
$$ \begin{align*} &\sum_{\substack{a_1,\ldots,a_k\in \{0,1\}\\ (a_1,\ldots, a_k)\neq \mathbf{0}}}\sum_{p\geq Q}p^{-1- ({a_1+\cdots+ a_k})/{\langle \log Q\rangle}}\\ &\quad\leq \sum_{\substack{a_1,\ldots,a_k\in \{0,1\}\\ (a_1,\ldots, a_k)\neq \mathbf{0}}} \int_{Q}^{\infty}\frac{t^{-1-({a_1+\cdots+a_k})/{\langle \operatorname{Log} Q\rangle}}}{\log t}\, dt+O(1)\\ &\quad\leq 2^k \cdot \int_{Q}^{\infty} t^{-{1}/{\langle \log Q\rangle}} \ \frac{dt}{t \log t} +O(1) \lesssim 2^k + O(1). \end{align*} $$
Moreover, we can use Mertens’s theorem to estimate
 $$ \begin{align*} \sum_{\substack{a_1,\ldots,a_k\in \{0,1\}\\ (a_1,\ldots, a_k)\neq \mathbf{0}}}\sum_{p<Q}p^{-1- ({a_1+\cdots+ a_k})/{\langle \operatorname{Log} Q\rangle}} \leq 2^k\log \langle \operatorname{Log} Q \rangle +O(1). \end{align*} $$
$$ \begin{align*} \sum_{\substack{a_1,\ldots,a_k\in \{0,1\}\\ (a_1,\ldots, a_k)\neq \mathbf{0}}}\sum_{p<Q}p^{-1- ({a_1+\cdots+ a_k})/{\langle \operatorname{Log} Q\rangle}} \leq 2^k\log \langle \operatorname{Log} Q \rangle +O(1). \end{align*} $$
Combining these bounds gives the result.
4.3 Comparing the Cramér and Heath-Brown approximants
We have a useful comparison theorem between the Cramér and Heath-Brown approximants.
Proposition 4.7. (Comparison between Cramér and Heath-Brown)
Let
 $N \geq 1$
and
$N \geq 1$
and
 $1 \leq w, Q \leq \exp (\operatorname {Log}^{1/20} N)$
, and let
$1 \leq w, Q \leq \exp (\operatorname {Log}^{1/20} N)$
, and let
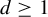 $d \geq 1$
be an integer. Then,
$d \geq 1$
be an integer. Then,
 $$ \begin{align*} \| \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\operatorname{HB},Q} \|_{u^{d+1}(I)} \lesssim_d w^{-c} + Q^{-c}\end{align*} $$
$$ \begin{align*} \| \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\operatorname{HB},Q} \|_{u^{d+1}(I)} \lesssim_d w^{-c} + Q^{-c}\end{align*} $$
for any interval I of length N. As a consequence, from Lemma 4.5 and the triangle inequality, we also have
 $$ \begin{align*} \| \Lambda_{\operatorname{HB},Q_1} - \Lambda_{\operatorname{HB},Q_2} \|_{u^{d+1}(I)} \lesssim_d Q_1^{-c} + Q_2^{-c}\end{align*} $$
$$ \begin{align*} \| \Lambda_{\operatorname{HB},Q_1} - \Lambda_{\operatorname{HB},Q_2} \|_{u^{d+1}(I)} \lesssim_d Q_1^{-c} + Q_2^{-c}\end{align*} $$
whenever
 $1 \leq Q_1,Q_2 \leq \exp (\operatorname {Log}^{1/20} N)$
.
$1 \leq Q_1,Q_2 \leq \exp (\operatorname {Log}^{1/20} N)$
.
Proof. We allow all implied constants to depend on d. In view of Lemma 4.5 and the triangle inequality, it suffices to establish the bound
 $$ \begin{align*} \| \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r},Q} - \Lambda_{\operatorname{HB},Q} \|_{u^{d+1}(I)} \lesssim Q^{-c}\end{align*} $$
$$ \begin{align*} \| \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r},Q} - \Lambda_{\operatorname{HB},Q} \|_{u^{d+1}(I)} \lesssim Q^{-c}\end{align*} $$
for any interval I of length N, that is to say, it suffices to show that
 $$ \begin{align*} |\mathbb{E}_{n \in I} (\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r},Q}(n) - \Lambda_{\operatorname{HB},Q}(n)) e(R(n)) | \lesssim Q^{-c}\end{align*} $$
$$ \begin{align*} |\mathbb{E}_{n \in I} (\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r},Q}(n) - \Lambda_{\operatorname{HB},Q}(n)) e(R(n)) | \lesssim Q^{-c}\end{align*} $$
for any polynomial
 $R(n) = \sum _{j=0}^d \alpha _j (n-n_I)^d$
of degree at most d with some real coefficients
$R(n) = \sum _{j=0}^d \alpha _j (n-n_I)^d$
of degree at most d with some real coefficients
 $\alpha _j$
, where
$\alpha _j$
, where
 $n_I$
denotes the midpoint of I. By subdividing I into smaller intervals and using the triangle inequality (adjusting the coefficients
$n_I$
denotes the midpoint of I. By subdividing I into smaller intervals and using the triangle inequality (adjusting the coefficients
 $\alpha _j$
as necessary), we may assume without loss of generality that
$\alpha _j$
as necessary), we may assume without loss of generality that
 $$ \begin{align*} N \sim \exp(\operatorname{Log}^{20} Q).\end{align*} $$
$$ \begin{align*} N \sim \exp(\operatorname{Log}^{20} Q).\end{align*} $$
We can then also assume that Q (and hence N) are large, as the claim is trivial otherwise. In particular,
 $\operatorname {Log} N = \operatorname {Log}^{O(1)} Q$
, which in practice will permit us to absorb all logarithmic factors of N in the analysis below.
$\operatorname {Log} N = \operatorname {Log}^{O(1)} Q$
, which in practice will permit us to absorb all logarithmic factors of N in the analysis below.
Fix the polynomial R. We may of course assume without loss of generality that
 $$ \begin{align*} |\mathbb{E}_{n \in I} (\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r},Q}(n) - \Lambda_{\operatorname{HB},Q}(n)) e(R(n)) |\geq Q^{-1}.\end{align*} $$
$$ \begin{align*} |\mathbb{E}_{n \in I} (\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r},Q}(n) - \Lambda_{\operatorname{HB},Q}(n)) e(R(n)) |\geq Q^{-1}.\end{align*} $$
Applying Lemma 4.2 (with
 $w=Q$
and
$w=Q$
and
 $y = \exp (\operatorname {Log}^{1/10} N)$
) as well as Lemma 4.6, we thus have
$y = \exp (\operatorname {Log}^{1/10} N)$
) as well as Lemma 4.6, we thus have

for some weights
 $\unicode{x3bb} _{\ell }$
of size
$\unicode{x3bb} _{\ell }$
of size
 $O(\operatorname {Log}^{O(1)} N) = O(\operatorname {Log}^{O(1)} Q)$
. Applying [Reference Matomäki and Shao17, Proposition 2.1] (after shifting the summation variable by
$O(\operatorname {Log}^{O(1)} N) = O(\operatorname {Log}^{O(1)} Q)$
. Applying [Reference Matomäki and Shao17, Proposition 2.1] (after shifting the summation variable by
 $n_I$
), we conclude that the polynomial R is major arc in the sense that there exists an integer
$n_I$
), we conclude that the polynomial R is major arc in the sense that there exists an integer
 $1 \leq q \lesssim Q^{O(1)}$
such that
$1 \leq q \lesssim Q^{O(1)}$
such that
 $$ \begin{align*} \| q \alpha_j \|_{\mathbb{R}/\mathbb{Z}} \lesssim Q^{O(1)} / N^j\end{align*} $$
$$ \begin{align*} \| q \alpha_j \|_{\mathbb{R}/\mathbb{Z}} \lesssim Q^{O(1)} / N^j\end{align*} $$
for all
 $1 \leq j \leq d$
. We may assume that
$1 \leq j \leq d$
. We may assume that
 $q\geq Q$
by multiplying q by an integer of size Q if necessary. Thus, one can write
$q\geq Q$
by multiplying q by an integer of size Q if necessary. Thus, one can write
 $R(n) = R_0(n) + E(n)$
, where
$R(n) = R_0(n) + E(n)$
, where
 $R_0$
is a polynomial of degree at most d that is periodic with period q and the error E satisfies
$R_0$
is a polynomial of degree at most d that is periodic with period q and the error E satisfies
 $\sup _{n\in I}|E(n+1)-E(n)|=O( Q^{O(1)}/N)$
.
$\sup _{n\in I}|E(n+1)-E(n)|=O( Q^{O(1)}/N)$
.
Set
and thus,
 $Q \leq w \lesssim Q^{O(1)}$
. By Lemma 4.5 and the triangle inequality, it will suffice to show that
$Q \leq w \lesssim Q^{O(1)}$
. By Lemma 4.5 and the triangle inequality, it will suffice to show that
 $$ \begin{align*} |\mathbb{E}_{n \in I} (\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) - \Lambda_{\operatorname{HB},Q}(n)) e(R(n)) | \lesssim Q^{-c}.\end{align*} $$
$$ \begin{align*} |\mathbb{E}_{n \in I} (\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) - \Lambda_{\operatorname{HB},Q}(n)) e(R(n)) | \lesssim Q^{-c}.\end{align*} $$
Breaking up I into intervals J of length
 $\sqrt {N}$
and using the slowly varying nature of
$\sqrt {N}$
and using the slowly varying nature of
 $E(n)$
, it suffices to show that
$E(n)$
, it suffices to show that
 $$ \begin{align*} |\mathbb{E}_{n \in J} (\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) - \Lambda_{\operatorname{HB},Q}(n)) e(R_0(n)) |\lesssim Q^{-c}\end{align*} $$
$$ \begin{align*} |\mathbb{E}_{n \in J} (\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) - \Lambda_{\operatorname{HB},Q}(n)) e(R_0(n)) |\lesssim Q^{-c}\end{align*} $$
for any interval J of length
 $\sqrt {N}$
.
$\sqrt {N}$
.
From Corollary 4.4 and the q-periodicity of
 $R_0$
, we have
$R_0$
, we have
 $$ \begin{align*} \mathbb{E}_{n \in J} \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) e(R_0(n)) = \mathbb{E}_{n \in (\mathbb{Z}/q\mathbb{Z})^\times} e(R_0(n)) + O(Q^{-c})\end{align*} $$
$$ \begin{align*} \mathbb{E}_{n \in J} \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) e(R_0(n)) = \mathbb{E}_{n \in (\mathbb{Z}/q\mathbb{Z})^\times} e(R_0(n)) + O(Q^{-c})\end{align*} $$
(in fact, the error term is significantly better than this). Using the multiplicativity of the Ramanujan sums
 $c_q(\cdot )$
and the fact that
$c_q(\cdot )$
and the fact that ![]() , we have
, we have

We thus have
 $$ \begin{align*} \mathbb{E}_{n \in J} \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) e(R_0(n)) = \sum_{\ell\mid q} \frac{\mu(\ell)}{\varphi(\ell)} \mathbb{E}_{n \in [q]} e(R_0(n)) c_{\ell}(n) + O(Q^{-c}).\end{align*} $$
$$ \begin{align*} \mathbb{E}_{n \in J} \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}(n) e(R_0(n)) = \sum_{\ell\mid q} \frac{\mu(\ell)}{\varphi(\ell)} \mathbb{E}_{n \in [q]} e(R_0(n)) c_{\ell}(n) + O(Q^{-c}).\end{align*} $$
Note that for any natural numbers
 $\ell ,a,q$
with
$\ell ,a,q$
with
 $\ell \nmid q$
, by the geometric sum formula, we have
$\ell \nmid q$
, by the geometric sum formula, we have
 $$ \begin{align*} \mathbb{E}_{n\in J}c_{\ell}(n)1_{n\equiv a\pmod q}=\sum_{r\in (\mathbb{Z}/\ell\mathbb{Z})^{\times}}\mathbb{E}_{n\in J}e\bigg(\frac{rn}{\ell}\bigg)1_{n\equiv a\pmod q}\ll \ell^2/\sqrt{N}. \end{align*} $$
$$ \begin{align*} \mathbb{E}_{n\in J}c_{\ell}(n)1_{n\equiv a\pmod q}=\sum_{r\in (\mathbb{Z}/\ell\mathbb{Z})^{\times}}\mathbb{E}_{n\in J}e\bigg(\frac{rn}{\ell}\bigg)1_{n\equiv a\pmod q}\ll \ell^2/\sqrt{N}. \end{align*} $$
Therefore, from equation (4.1) and the q-periodicity of
 $e(R_0(n))$
, we have
$e(R_0(n))$
, we have
 $$ \begin{align*} \mathbb{E}_{n \in J} \Lambda_{\operatorname{HB},Q}(n) e(R_0(n)) = \sum_{\substack{\ell\mid q\\ \ell < Q}} \frac{\mu(\ell)}{\varphi(\ell)} \mathbb{E}_{n \in [q]} e(R_0(n)) c_{\ell}(n) + O(Q^{-c})\end{align*} $$
$$ \begin{align*} \mathbb{E}_{n \in J} \Lambda_{\operatorname{HB},Q}(n) e(R_0(n)) = \sum_{\substack{\ell\mid q\\ \ell < Q}} \frac{\mu(\ell)}{\varphi(\ell)} \mathbb{E}_{n \in [q]} e(R_0(n)) c_{\ell}(n) + O(Q^{-c})\end{align*} $$
(again, a better error term is available here). Thus, by the triangle inequality, it suffices to show that
 $$ \begin{align*} \sum_{\substack{\ell\mid q\\ \ell\geq Q}} \frac{\mu^2(\ell)}{\varphi(\ell)} |\mathbb{E}_{n \in [q]} e(R_0(n)) c_{\ell}(n)| \lesssim Q^{-c}.\end{align*} $$
$$ \begin{align*} \sum_{\substack{\ell\mid q\\ \ell\geq Q}} \frac{\mu^2(\ell)}{\varphi(\ell)} |\mathbb{E}_{n \in [q]} e(R_0(n)) c_{\ell}(n)| \lesssim Q^{-c}.\end{align*} $$
By the divisor bound, q has at most
 $Q^{o(1)}$
factors, so it will suffice to establish the bound
$Q^{o(1)}$
factors, so it will suffice to establish the bound
 $$ \begin{align*} |\mathbb{E}_{n \in [q]} e(R_0(n)) c_{\ell}(n)| \lesssim \varphi(\ell) Q^{-c}\end{align*} $$
$$ \begin{align*} |\mathbb{E}_{n \in [q]} e(R_0(n)) c_{\ell}(n)| \lesssim \varphi(\ell) Q^{-c}\end{align*} $$
for each square-free
 $\ell \mid q$
with
$\ell \mid q$
with
 $\ell \geq Q$
. By the triangle inequality, it suffices to show that
$\ell \geq Q$
. By the triangle inequality, it suffices to show that
 $$ \begin{align*} \sum_{r \in (\mathbb{Z}/\ell\mathbb{Z})^\times} |\mathbb{E}_{n \in \mathbb{Z}/q\mathbb{Z}} e(R_0(n) - rn/\ell)| \lesssim \varphi(\ell) Q^{-c}.\end{align*} $$
$$ \begin{align*} \sum_{r \in (\mathbb{Z}/\ell\mathbb{Z})^\times} |\mathbb{E}_{n \in \mathbb{Z}/q\mathbb{Z}} e(R_0(n) - rn/\ell)| \lesssim \varphi(\ell) Q^{-c}.\end{align*} $$
However, from the Plancherel identity (or Bessel inequality) and the fact that
 $\ell \leq q$
, one has
$\ell \leq q$
, one has
 $$ \begin{align*} \sum_{r \in (\mathbb{Z}/\ell\mathbb{Z})^\times} |\mathbb{E}_{n \in \mathbb{Z}/q\mathbb{Z}} e(R_0(n) - rn/\ell)|^2 \leq \frac{\ell}{q}\leq 1,\end{align*} $$
$$ \begin{align*} \sum_{r \in (\mathbb{Z}/\ell\mathbb{Z})^\times} |\mathbb{E}_{n \in \mathbb{Z}/q\mathbb{Z}} e(R_0(n) - rn/\ell)|^2 \leq \frac{\ell}{q}\leq 1,\end{align*} $$
and the claim follows from Cauchy–Schwarz (noting from the hypothesis
 $\ell \geq Q$
that
$\ell \geq Q$
that
 $\varphi (\ell ) \gtrsim Q^{1/2}$
, say, so that
$\varphi (\ell ) \gtrsim Q^{1/2}$
, say, so that
 $\varphi (\ell )^{1/2} \lesssim \varphi (\ell ) Q^{-1/4}$
).
$\varphi (\ell )^{1/2} \lesssim \varphi (\ell ) Q^{-1/4}$
).
5 Verifying the properties of the approximant
Recall the definition of
 $\Lambda _N$
from equation (4.3). In this section, we verify the properties in equations (3.1), (3.2), (3.3) and (3.4) for
$\Lambda _N$
from equation (4.3). In this section, we verify the properties in equations (3.1), (3.2), (3.3) and (3.4) for
 $\Lambda _N$
, and prove Proposition 3.4 and Theorem 3.2 concerning it.
$\Lambda _N$
, and prove Proposition 3.4 and Theorem 3.2 concerning it.
Verifying equations (3.1), (3.2) and (3.3). The bound in equation (3.3) follows from Corollary 4.4, while the bound in equation (3.2) follows from Lemma 4.1. The bound in equation (3.1) follows, for instance, from [Reference Matomäki, Shao, Tao and Teräväinen18, Theorem 1.1(ii)] (and could also be extracted from the earlier arguments in [Reference Matomäki and Shao17]). (Strictly speaking, the results in [Reference Matomäki, Shao, Tao and Teräväinen18] were stated only for
 $C_0=10$
, but an inspection of the arguments reveal that they also apply for larger choices of
$C_0=10$
, but an inspection of the arguments reveal that they also apply for larger choices of
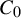 $C_0$
.)
$C_0$
.)
Verifying equation (3.4). We need the following weighted analogue of [Reference Krause, Mirek and Tao13, Proposition 6.21].
Lemma 5.1. (
$L^p$
improving)

Let
 $Q \in \mathbb {Z}[\mathrm {n}]$
be of degree
$Q \in \mathbb {Z}[\mathrm {n}]$
be of degree
 $d\geq 1$
. If
$d\geq 1$
. If
 $2-c_d < p \leq 2$
for some sufficiently small
$2-c_d < p \leq 2$
for some sufficiently small
 $c_d>0$
, then
$c_d>0$
, then
 $$ \begin{align*} \|\mathbb{E}_{n\in [N]}(\Lambda(n)+\Lambda_N(n))f(\cdot+Q(n))\|_{\ell^{2}(\mathbb{Z})}\lesssim_Q N^{d/2 - d/p} \|f\|_{\ell^p(\mathbb{Z})}\end{align*} $$
$$ \begin{align*} \|\mathbb{E}_{n\in [N]}(\Lambda(n)+\Lambda_N(n))f(\cdot+Q(n))\|_{\ell^{2}(\mathbb{Z})}\lesssim_Q N^{d/2 - d/p} \|f\|_{\ell^p(\mathbb{Z})}\end{align*} $$
and also for the dual exponent
 $p'=p/(p-1)$
, we have
$p'=p/(p-1)$
, we have
 $$ \begin{align} \|\mathbb{E}_{n\in [N]}(\Lambda(n)+\Lambda_N(n))f(\cdot+Q(n))\|_{\ell^{p'}(\mathbb{Z})}\lesssim_Q N^{d/p' - d/p} \|f\|_{\ell^p(\mathbb{Z})}. \end{align} $$
$$ \begin{align} \|\mathbb{E}_{n\in [N]}(\Lambda(n)+\Lambda_N(n))f(\cdot+Q(n))\|_{\ell^{p'}(\mathbb{Z})}\lesssim_Q N^{d/p' - d/p} \|f\|_{\ell^p(\mathbb{Z})}. \end{align} $$
The value of
 $c_d$
here could be explicitly computed, but we do not attempt to optimize it here. After Lemma 5.1 has been proven, equation (5.1) together with the non-negativity of
$c_d$
here could be explicitly computed, but we do not attempt to optimize it here. After Lemma 5.1 has been proven, equation (5.1) together with the non-negativity of
 $\Lambda _N$
immediately implies the required estimate in equation (3.4).
$\Lambda _N$
immediately implies the required estimate in equation (3.4).
Proof. By interpolation (adjusting
 $c_d$
as necessary), it suffices to show the second estimate in equation (5.1).
$c_d$
as necessary), it suffices to show the second estimate in equation (5.1).
For any polynomial
 $Q(\mathrm {n}) \in \mathbb {Z}[\mathrm {n}]$
, we define the averaging operators
$Q(\mathrm {n}) \in \mathbb {Z}[\mathrm {n}]$
, we define the averaging operators
 $\mathrm {A}^{Q,0}_N, \ \mathrm {A}^Q_N \colon \ell ^p(\mathbb {Z}) \to \ell ^p(\mathbb {Z})$
by the formulae
$\mathrm {A}^{Q,0}_N, \ \mathrm {A}^Q_N \colon \ell ^p(\mathbb {Z}) \to \ell ^p(\mathbb {Z})$
by the formulae
First, the operators
 $\mathrm {A}^Q_N, \mathrm {A}^{Q,0}_N$
are bounded on every
$\mathrm {A}^Q_N, \mathrm {A}^{Q,0}_N$
are bounded on every
 $\ell ^p(\mathbb {Z})$
thanks to equation (3.3) and the triangle inequality. With this notation, it suffices to show that
$\ell ^p(\mathbb {Z})$
thanks to equation (3.3) and the triangle inequality. With this notation, it suffices to show that
 $$ \begin{align}\begin{split} \| \mathrm{A}^Q_N f \|_{\ell^{p'}(\mathbb{Z})} &\lesssim_Q N^{d/p' - d/p} \|f\|_{\ell^p(\mathbb{Z})},\\ \| \mathrm{A}^{Q,0}_N f \|_{\ell^{p'}(\mathbb{Z})} &\lesssim_Q N^{d/p' - d/p} \|f\|_{\ell^p(\mathbb{Z})}. \end{split} \end{align} $$
$$ \begin{align}\begin{split} \| \mathrm{A}^Q_N f \|_{\ell^{p'}(\mathbb{Z})} &\lesssim_Q N^{d/p' - d/p} \|f\|_{\ell^p(\mathbb{Z})},\\ \| \mathrm{A}^{Q,0}_N f \|_{\ell^{p'}(\mathbb{Z})} &\lesssim_Q N^{d/p' - d/p} \|f\|_{\ell^p(\mathbb{Z})}. \end{split} \end{align} $$
We can write
 $\mathrm {A}^Q_N = \mathrm {A}^Q_{N, \exp (\operatorname {Log}^{1/C_0} N)}$
, where
$\mathrm {A}^Q_N = \mathrm {A}^Q_{N, \exp (\operatorname {Log}^{1/C_0} N)}$
, where
On the one hand, from Lemma 4.1 and the results in [Reference Han, Kovač, Lacey, Madrid and Yang8] (see also [Reference Krause, Mirek and Tao13, Proposition 6.21]), we have
 $$ \begin{align}\| \mathrm{A}^Q_{N,w} f \|_{\ell^{p'}(\mathbb{Z})} \lesssim_Q N^{d/p' - d/p} \langle \operatorname{Log} w\rangle \|f\|_{\ell^p(\mathbb{Z})} \end{align} $$
$$ \begin{align}\| \mathrm{A}^Q_{N,w} f \|_{\ell^{p'}(\mathbb{Z})} \lesssim_Q N^{d/p' - d/p} \langle \operatorname{Log} w\rangle \|f\|_{\ell^p(\mathbb{Z})} \end{align} $$
for any
 $2-c < p \leq 2$
(where
$2-c < p \leq 2$
(where
 $c>0$
depends on d and can vary from line to line). On the other hand, from Lemma 4.5, we have
$c>0$
depends on d and can vary from line to line). On the other hand, from Lemma 4.5, we have
 $$ \begin{align} \mathbb{E}_{n \in [N]} (\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z})(n) e(Q(n)) \lesssim_d z^{-c} \end{align} $$
$$ \begin{align} \mathbb{E}_{n \in [N]} (\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z})(n) e(Q(n)) \lesssim_d z^{-c} \end{align} $$
for any
 $1 \leq z \leq w \leq \exp (\operatorname {Log}^{1/C_0} N)$
.
$1 \leq z \leq w \leq \exp (\operatorname {Log}^{1/C_0} N)$
.
By the Plancherel theorem, this implies that
 $$ \begin{align*} \| \mathrm{A}^Q_{N,w} f - \mathrm{A}^Q_{N,z} f \|_{\ell^2(\mathbb{Z})}&=\bigg(\int_{0}^1\bigg|\!\sum_{x\in \mathbb{Z}}(\mathrm{A}^Q_{N,w} f - \mathrm{A}^Q_{N,z} f)(x)e(\theta x)\bigg|^2\, d\theta\bigg)^{1/2}\\ & \lesssim_d z^{-c} \bigg(\int_{0}^1\bigg|\!\sum_{x\in \mathbb{Z}}f(x)e(\theta x)\bigg|^2\, d\theta\bigg)^{1/2}\\ & \lesssim_d z^{-c} \|f\|_{\ell^2(\mathbb{Z})}. \end{align*} $$
$$ \begin{align*} \| \mathrm{A}^Q_{N,w} f - \mathrm{A}^Q_{N,z} f \|_{\ell^2(\mathbb{Z})}&=\bigg(\int_{0}^1\bigg|\!\sum_{x\in \mathbb{Z}}(\mathrm{A}^Q_{N,w} f - \mathrm{A}^Q_{N,z} f)(x)e(\theta x)\bigg|^2\, d\theta\bigg)^{1/2}\\ & \lesssim_d z^{-c} \bigg(\int_{0}^1\bigg|\!\sum_{x\in \mathbb{Z}}f(x)e(\theta x)\bigg|^2\, d\theta\bigg)^{1/2}\\ & \lesssim_d z^{-c} \|f\|_{\ell^2(\mathbb{Z})}. \end{align*} $$
Interpolating (and reducing c as necessary), we see that if
 $2-c \leq p \leq 2$
, then
$2-c \leq p \leq 2$
, then
 $$ \begin{align*} \| \mathrm{A}^Q_{N,w} f - \mathrm{A}^Q_{N,z} f \|_{\ell^{p'}(\mathbb{Z})} \lesssim_Q N^{d/p' - d/p} z^{-c} \|f\|_{\ell^p(\mathbb{Z})}\end{align*} $$
$$ \begin{align*} \| \mathrm{A}^Q_{N,w} f - \mathrm{A}^Q_{N,z} f \|_{\ell^{p'}(\mathbb{Z})} \lesssim_Q N^{d/p' - d/p} z^{-c} \|f\|_{\ell^p(\mathbb{Z})}\end{align*} $$
if
 $1 \leq z \leq w \leq \exp (\operatorname {Log}^{1/C_0} N)$
is such that
$1 \leq z \leq w \leq \exp (\operatorname {Log}^{1/C_0} N)$
is such that
 $w^{1/2} \leq z$
. Summing this bound telescopically for suitable values of
$w^{1/2} \leq z$
. Summing this bound telescopically for suitable values of
 $z, w$
, we conclude from the triangle inequality that
$z, w$
, we conclude from the triangle inequality that
 $$ \begin{align*} \| \mathrm{A}^Q_{N} f - \mathrm{A}^Q_{N,1} f \|_{\ell^{p'}(\mathbb{Z})} \lesssim_Q N^{d/p' - d/p} \|f\|_{\ell^p(\mathbb{Z})}.\end{align*} $$
$$ \begin{align*} \| \mathrm{A}^Q_{N} f - \mathrm{A}^Q_{N,1} f \|_{\ell^{p'}(\mathbb{Z})} \lesssim_Q N^{d/p' - d/p} \|f\|_{\ell^p(\mathbb{Z})}.\end{align*} $$
Combining this with the
 $w=1$
case of equation (5.3), we obtain the first estimate in equation (5.2).
$w=1$
case of equation (5.3), we obtain the first estimate in equation (5.2).
The second estimate in equation (5.2) follows similarly, except that in the proof, we replace equation (5.3) with
 $$ \begin{align*} \| \mathrm{A}^{Q,0}_N f \|_{\ell^{p'}(\mathbb{Z})} \lesssim_Q N^{d/p' - d/p} \langle \operatorname{Log} N\rangle \|f\|_{\ell^p(\mathbb{Z})} \end{align*} $$
$$ \begin{align*} \| \mathrm{A}^{Q,0}_N f \|_{\ell^{p'}(\mathbb{Z})} \lesssim_Q N^{d/p' - d/p} \langle \operatorname{Log} N\rangle \|f\|_{\ell^p(\mathbb{Z})} \end{align*} $$
and replace equation (5.4) with
 $$ \begin{align*} \mathbb{E}_{n \in [N]} (\Lambda - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z})(n) e(Q(n)) \lesssim_d z^{-c} \end{align*} $$
$$ \begin{align*} \mathbb{E}_{n \in [N]} (\Lambda - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z})(n) e(Q(n)) \lesssim_d z^{-c} \end{align*} $$
and use the first estimate in equation (5.2).
Proof of Proposition 3.4
Arguing as in the proof of [Reference Krause, Mirek and Tao13, Proposition 7.13], Proposition 3.4 reduces to establishing the symbol estimates
 $$ \begin{align*} \bigg|\frac{\partial^{j_1}}{\partial \xi_1^{j_1}} \frac{\partial^{j_2}}{\partial \xi_2^{j_2}} M_0( (\alpha_1,\xi_1), (\alpha_2,\xi_2))\bigg| \lesssim_{C_3} 2^{O(\max(2^{\rho l},s))} N^{j_1+dj_2} \exp(-\operatorname{Log}^c N)\end{align*} $$
$$ \begin{align*} \bigg|\frac{\partial^{j_1}}{\partial \xi_1^{j_1}} \frac{\partial^{j_2}}{\partial \xi_2^{j_2}} M_0( (\alpha_1,\xi_1), (\alpha_2,\xi_2))\bigg| \lesssim_{C_3} 2^{O(\max(2^{\rho l},s))} N^{j_1+dj_2} \exp(-\operatorname{Log}^c N)\end{align*} $$
for
 $0 \leq j_1,j_2 \leq 2$
,
$0 \leq j_1,j_2 \leq 2$
,
 $\alpha _1 \in (\mathbb {Q}/\mathbb {Z})_{l_1}$
,
$\alpha _1 \in (\mathbb {Q}/\mathbb {Z})_{l_1}$
,
 $\alpha _2 \in (\mathbb {Q}/\mathbb {Z})_{l_2}$
and
$\alpha _2 \in (\mathbb {Q}/\mathbb {Z})_{l_2}$
and
 $\xi _1 = O( 2^{s}/N)$
,
$\xi _1 = O( 2^{s}/N)$
,
 $\xi _2 = O( 2^{ds}/N^d)$
, where the symbol
$\xi _2 = O( 2^{ds}/N^d)$
, where the symbol
 $M_0$
is defined by the formula
$M_0$
is defined by the formula

As in the proof of [Reference Krause, Mirek and Tao13, Proposition 7.13], the function
 $n \mapsto e(\alpha _1 n + \alpha _2 P(n))$
is periodic of some period
$n \mapsto e(\alpha _1 n + \alpha _2 P(n))$
is periodic of some period
 $$ \begin{align} q = O_\rho(2^{O(2^{\rho l})}). \end{align} $$
$$ \begin{align} q = O_\rho(2^{O(2^{\rho l})}). \end{align} $$
In particular, from equation (3.19), one has
 $$ \begin{align*} q \leq \exp(\operatorname{Log}^{c_0} N)\end{align*} $$
$$ \begin{align*} q \leq \exp(\operatorname{Log}^{c_0} N)\end{align*} $$
and hence q divides W. So the function
 $\Lambda _N(n)$
vanishes outside of the primitive residue classes modulo q. Meanwhile, we have
$\Lambda _N(n)$
vanishes outside of the primitive residue classes modulo q. Meanwhile, we have
 $$ \begin{align*} m_{\hat {\mathbb{Z}}^\times}(\alpha_1,\alpha_2) = \mathbb{E}_{a \in (\mathbb{Z}/q\mathbb{Z})^\times} e(\alpha_1 a + \alpha_2 P(a)).\end{align*} $$
$$ \begin{align*} m_{\hat {\mathbb{Z}}^\times}(\alpha_1,\alpha_2) = \mathbb{E}_{a \in (\mathbb{Z}/q\mathbb{Z})^\times} e(\alpha_1 a + \alpha_2 P(a)).\end{align*} $$
By the triangle inequality, it thus suffices to show for each
 $a \in (\mathbb {Z}/q\mathbb {Z})^\times $
that
$a \in (\mathbb {Z}/q\mathbb {Z})^\times $
that

Evaluating the derivatives, it suffices to show that

where
The function w is smooth with a total variation of
 $O( 2^{O(\max (2^{\rho l},s))} N^{j_1+2j_2})$
. Summing (or integrating) by parts as in [Reference Matomäki, Shao, Tao and Teräväinen18, Lemma 2.2(iii)], it suffices to show that
$O( 2^{O(\max (2^{\rho l},s))} N^{j_1+2j_2})$
. Summing (or integrating) by parts as in [Reference Matomäki, Shao, Tao and Teräväinen18, Lemma 2.2(iii)], it suffices to show that

for all intervals I in
 $[N,2N]$
. However, this follows from Corollary 4.4.
$[N,2N]$
. However, this follows from Corollary 4.4.
Proof of Theorem 3.2
The last remaining task is to establish the single-scale estimate in Theorem 3.2. We first recall an application of the Peluse–Prendiville theory.
Proposition 5.2. (Unweighted inverse theorem)
Let
 $N \geq 1$
and
$N \geq 1$
and
 $0 < \delta \leq 1$
, and let
$0 < \delta \leq 1$
, and let
 $N_0$
be a quantity with
$N_0$
be a quantity with
 $N_0 \sim N^d$
. Let
$N_0 \sim N^d$
. Let
 $f,g,h \colon \mathbb {Z} \to \mathbb {C}$
be supported on
$f,g,h \colon \mathbb {Z} \to \mathbb {C}$
be supported on
 $[-N_0,N_0]$
with
$[-N_0,N_0]$
with
 $$ \begin{align} \|f\|_{\ell^\infty(\mathbb{Z})}, \|g\|_{\ell^\infty(\mathbb{Z})}, \|h\|_{\ell^\infty(\mathbb{Z})} \leq 1, \end{align} $$
$$ \begin{align} \|f\|_{\ell^\infty(\mathbb{Z})}, \|g\|_{\ell^\infty(\mathbb{Z})}, \|h\|_{\ell^\infty(\mathbb{Z})} \leq 1, \end{align} $$
obeying the lower bound
 $$ \begin{align} |\langle \tilde {\mathrm{A}}_{N,1}(f,g), h \rangle| \geq \delta N^d. \end{align} $$
$$ \begin{align} |\langle \tilde {\mathrm{A}}_{N,1}(f,g), h \rangle| \geq \delta N^d. \end{align} $$
Then, there exists a function
 $F \in \ell ^2(\mathbb {Z})$
with
$F \in \ell ^2(\mathbb {Z})$
with
 $$ \begin{align} \|F\|_{\ell^\infty(\mathbb{Z})} \lesssim 1, \quad \|F\|_{\ell^1(\mathbb{Z})} \lesssim N^d \end{align} $$
$$ \begin{align} \|F\|_{\ell^\infty(\mathbb{Z})} \lesssim 1, \quad \|F\|_{\ell^1(\mathbb{Z})} \lesssim N^d \end{align} $$
and with
 $\mathcal {F}_{\mathbb {Z}}F$
supported in the
$\mathcal {F}_{\mathbb {Z}}F$
supported in the
 $O(\delta ^{-O(1)}/N)$
-neighbourhood of some rational
$O(\delta ^{-O(1)}/N)$
-neighbourhood of some rational
 $a/b \mod 1 \in \mathbb {Q}/\mathbb {Z}$
with
$a/b \mod 1 \in \mathbb {Q}/\mathbb {Z}$
with
 $b = O(\delta ^{-O(1)})$
such that
$b = O(\delta ^{-O(1)})$
such that
 $$ \begin{align} |\langle f, F \rangle| \gtrsim \delta^{O(1)} N^d. \end{align} $$
$$ \begin{align} |\langle f, F \rangle| \gtrsim \delta^{O(1)} N^d. \end{align} $$
Here, we use the inner product ![]() .
.
Proof. See [Reference Krause, Mirek and Tao13, Proposition 6.6].
We now transfer this to the weighted setting, under an additional (mild) largeness hypothesis on
 $\delta $
.
$\delta $
.
Proposition 5.3. (Weighted inverse theorem)
Let
 $N \geq 1$
and
$N \geq 1$
and
 $\exp (-\operatorname {Log}^{1/C_0} N) \leq \delta \leq 1$
, and let
$\exp (-\operatorname {Log}^{1/C_0} N) \leq \delta \leq 1$
, and let
 $N_0$
be a quantity with
$N_0$
be a quantity with
 $N_0 \sim N^d$
. Let
$N_0 \sim N^d$
. Let
 $f,g,h \colon \mathbb {Z} \to \mathbb {C}$
be supported on
$f,g,h \colon \mathbb {Z} \to \mathbb {C}$
be supported on
 $[-N_0,N_0]$
, obeying equation (5.6) and the lower bound
$[-N_0,N_0]$
, obeying equation (5.6) and the lower bound
 $$ \begin{align} |\langle \tilde {\mathrm{A}}_{N,\Lambda_N}(f,g), h \rangle| \geq \delta N^d. \end{align} $$
$$ \begin{align} |\langle \tilde {\mathrm{A}}_{N,\Lambda_N}(f,g), h \rangle| \geq \delta N^d. \end{align} $$
Then, the conclusions of Proposition 5.2 hold.
Proof. We may assume that N is sufficiently large depending on the fixed polynomial P, as the claim is easy to establish otherwise.
For any
 $1 \leq z \leq w \leq \exp (\operatorname {Log}^{1/C_0} N)$
, we have from Lemmas 4.5, 4.1 and [Reference Teräväinen26, Theorem 4.1] (that is, equation (1.7)) that
$1 \leq z \leq w \leq \exp (\operatorname {Log}^{1/C_0} N)$
, we have from Lemmas 4.5, 4.1 and [Reference Teräväinen26, Theorem 4.1] (that is, equation (1.7)) that
 $$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z}}(f,g), h \rangle| \lesssim z^{-c} \langle \operatorname{Log} w\rangle N^d.\end{align*} $$
$$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z}}(f,g), h \rangle| \lesssim z^{-c} \langle \operatorname{Log} w\rangle N^d.\end{align*} $$
In particular, we have
 $$ \begin{align} |\langle \tilde {\mathrm{A}}_{N,\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z}}(f,g), h \rangle| \lesssim z^{-c} N^d \end{align} $$
$$ \begin{align} |\langle \tilde {\mathrm{A}}_{N,\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z}}(f,g), h \rangle| \lesssim z^{-c} N^d \end{align} $$
for
 $z \in [w/2,w]$
; summing dyadically using the triangle inequality, we conclude that
$z \in [w/2,w]$
; summing dyadically using the triangle inequality, we conclude that
 $$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,\Lambda_N - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}}(f,g), h \rangle| \lesssim w^{-c} N^d\end{align*} $$
$$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,\Lambda_N - \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}}(f,g), h \rangle| \lesssim w^{-c} N^d\end{align*} $$
for any
 $1 \leq w \leq \exp (\operatorname {Log}^{1/C_0} N)$
.
$1 \leq w \leq \exp (\operatorname {Log}^{1/C_0} N)$
.
The weight
 $\Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r},w}$
is not quite of Type I form, so we now aim to swap it with the Heath-Brown weight
$\Lambda _{\mathrm{Cram}\acute{\rm e}\mathrm{r},w}$
is not quite of Type I form, so we now aim to swap it with the Heath-Brown weight
 $\Lambda _{\operatorname {HB},w}$
. From Lemma 4.7, we have
$\Lambda _{\operatorname {HB},w}$
. From Lemma 4.7, we have
 $$ \begin{align} \| \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\operatorname{HB},w} \|_{u^{d+1}[N]} \lesssim w^{-c}. \end{align} $$
$$ \begin{align} \| \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda_{\operatorname{HB},w} \|_{u^{d+1}[N]} \lesssim w^{-c}. \end{align} $$
We would like to apply [Reference Teräväinen26, Theorem 4.1] again, but we have the technical issue that
 $\Lambda _{\operatorname {HB},w}$
does not quite have a good uniform bound, but is instead only controlled in the
$\Lambda _{\operatorname {HB},w}$
does not quite have a good uniform bound, but is instead only controlled in the
 $\ell ^k$
norm for arbitrarily large but finite k. However, from Lemma 4.6 (applied with sufficiently large k) and Chebyshev’s inequality, for any small
$\ell ^k$
norm for arbitrarily large but finite k. However, from Lemma 4.6 (applied with sufficiently large k) and Chebyshev’s inequality, for any small
 $\kappa> 0$
and
$\kappa> 0$
and
 $\varepsilon>0$
, we can find an approximation
$\varepsilon>0$
, we can find an approximation
 $\Lambda ^{\prime }_{\operatorname {HB},w}$
to
$\Lambda ^{\prime }_{\operatorname {HB},w}$
to
 $\Lambda _{\operatorname {HB},w}$
with
$\Lambda _{\operatorname {HB},w}$
with
 $$ \begin{align} \| \Lambda_{\operatorname{HB},w} - \Lambda^{\prime}_{\operatorname{HB},w}\|_{\ell^1[N]} \leq \kappa\quad\text{and}\quad \Lambda^{\prime}_{\operatorname{HB},w}(n)=O_\varepsilon( \kappa^{-\varepsilon} \langle \operatorname{Log} w\rangle^{O_\varepsilon(1)}). \end{align} $$
$$ \begin{align} \| \Lambda_{\operatorname{HB},w} - \Lambda^{\prime}_{\operatorname{HB},w}\|_{\ell^1[N]} \leq \kappa\quad\text{and}\quad \Lambda^{\prime}_{\operatorname{HB},w}(n)=O_\varepsilon( \kappa^{-\varepsilon} \langle \operatorname{Log} w\rangle^{O_\varepsilon(1)}). \end{align} $$
We can use the
 $\ell ^1$
norm to control the
$\ell ^1$
norm to control the
 $u^{d+1}$
norm; hence, by equation (5.12) and the triangle inequality,
$u^{d+1}$
norm; hence, by equation (5.12) and the triangle inequality,
 $$ \begin{align} \| \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda^{\prime}_{\operatorname{HB},w} \|_{u^{d+1}[N]} \lesssim \kappa + w^{-c}. \end{align} $$
$$ \begin{align} \| \Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda^{\prime}_{\operatorname{HB},w} \|_{u^{d+1}[N]} \lesssim \kappa + w^{-c}. \end{align} $$
Now, we can apply [Reference Teräväinen26, Theorem 4.1] (and Lemma 4.1) to conclude that
 $$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda^{\prime}_{\operatorname{HB},w}}(f,g), h \rangle| \lesssim_\varepsilon \langle \operatorname{Log} w\rangle^{O_{\varepsilon}(1)}(\kappa^c + \kappa^{-\varepsilon} w^{-c}) N^d.\end{align*} $$
$$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w} - \Lambda^{\prime}_{\operatorname{HB},w}}(f,g), h \rangle| \lesssim_\varepsilon \langle \operatorname{Log} w\rangle^{O_{\varepsilon}(1)}(\kappa^c + \kappa^{-\varepsilon} w^{-c}) N^d.\end{align*} $$
Finally, from the triangle inequality and Cauchy–Schwarz, we can crudely bound
 $$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,\Lambda^{\prime}_{\operatorname{HB},w} - \Lambda_{\operatorname{HB},w}}(f,g), h \rangle| \lesssim \kappa N^d.\end{align*} $$
$$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,\Lambda^{\prime}_{\operatorname{HB},w} - \Lambda_{\operatorname{HB},w}}(f,g), h \rangle| \lesssim \kappa N^d.\end{align*} $$
Putting this all together, choosing
 $\varepsilon $
to be sufficiently small and
$\varepsilon $
to be sufficiently small and
 $\kappa $
to be a small multiple of
$\kappa $
to be a small multiple of
 $w^{-c}$
for a suitable c, we conclude that
$w^{-c}$
for a suitable c, we conclude that
 $$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,\Lambda_N - \Lambda_{\operatorname{HB},w}}(f,g), h \rangle| \lesssim w^{-c} N^d\end{align*} $$
$$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,\Lambda_N - \Lambda_{\operatorname{HB},w}}(f,g), h \rangle| \lesssim w^{-c} N^d\end{align*} $$
for any
 $1 \leq w \leq \exp (\operatorname {Log}^{1/C_0} N)$
. In particular, from equation (5.10), we now have
$1 \leq w \leq \exp (\operatorname {Log}^{1/C_0} N)$
. In particular, from equation (5.10), we now have
 $$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,\Lambda_{\operatorname{HB},w}}(f,g), h \rangle| \gtrsim \delta N^d\end{align*} $$
$$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,\Lambda_{\operatorname{HB},w}}(f,g), h \rangle| \gtrsim \delta N^d\end{align*} $$
for some
 $1 \leq w \lesssim \delta ^{-O(1)}$
. Expanding equation (4.1) and using the triangle inequality and crude bounds, we conclude that
$1 \leq w \lesssim \delta ^{-O(1)}$
. Expanding equation (4.1) and using the triangle inequality and crude bounds, we conclude that
 $$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,e(-r\cdot/q)}(f,g), h \rangle| \gtrsim \delta^{O(1)} N^d\end{align*} $$
$$ \begin{align*}|\langle \tilde {\mathrm{A}}_{N,e(-r\cdot/q)}(f,g), h \rangle| \gtrsim \delta^{O(1)} N^d\end{align*} $$
for some
 $1 \leq r \leq q \lesssim \delta ^{-O(1)}$
. However, observe the identity
$1 \leq r \leq q \lesssim \delta ^{-O(1)}$
. However, observe the identity
 $$ \begin{align*} \langle \tilde {\mathrm{A}}_{N,e(-r\cdot/q)}(f,g), h \rangle = \langle \tilde {\mathrm{A}}_{N,1}(e(-r\cdot/q)f,g), e(-r\cdot/q) h \rangle.\end{align*} $$
$$ \begin{align*} \langle \tilde {\mathrm{A}}_{N,e(-r\cdot/q)}(f,g), h \rangle = \langle \tilde {\mathrm{A}}_{N,1}(e(-r\cdot/q)f,g), e(-r\cdot/q) h \rangle.\end{align*} $$
We can thus apply Proposition 5.2 to conclude that
 $$ \begin{align*} |\langle e(-r\cdot/q) f, F \rangle| \gtrsim \delta^{O(1)} N^d\end{align*} $$
$$ \begin{align*} |\langle e(-r\cdot/q) f, F \rangle| \gtrsim \delta^{O(1)} N^d\end{align*} $$
for some function F obeying the conclusions of that proposition. Transferring the plane wave
 $e(-r\cdot / q)$
from f to F, we obtain the claim (noting that the denominator b will remain acceptably under control since
$e(-r\cdot / q)$
from f to F, we obtain the claim (noting that the denominator b will remain acceptably under control since
 $q \lesssim \delta ^{-O(1)}$
).
$q \lesssim \delta ^{-O(1)}$
).
If we now repeat the arguments of [Reference Krause, Mirek and Tao13, §6.1], using Proposition 5.3 and Lemma 5.1 in place of [Reference Krause, Mirek and Tao13, Proposition 6.6] and [Reference Krause, Mirek and Tao13, Proposition 6.21], respectively, inserting the weights
 $\Lambda _N$
in the averaging operators in the obvious fashion, we obtain case (i) of Theorem 3.2. To handle case (ii), we need the following variant of Proposition 5.3.
$\Lambda _N$
in the averaging operators in the obvious fashion, we obtain case (i) of Theorem 3.2. To handle case (ii), we need the following variant of Proposition 5.3.
Proposition 5.4. (Weighted inverse theorem for g)
Under the hypotheses of Proposition 5.3, there exists a function
 $G \in \ell ^2(\mathbb {Z})$
with
$G \in \ell ^2(\mathbb {Z})$
with
 $$ \begin{align} \|G\|_{\ell^\infty(\mathbb{Z})} \lesssim 1, \quad \|G\|_{\ell^1(\mathbb{Z})} \lesssim N^d \end{align} $$
$$ \begin{align} \|G\|_{\ell^\infty(\mathbb{Z})} \lesssim 1, \quad \|G\|_{\ell^1(\mathbb{Z})} \lesssim N^d \end{align} $$
and with
 $\mathcal {F}_{\mathbb {Z}}G$
supported in the
$\mathcal {F}_{\mathbb {Z}}G$
supported in the
 $O(\delta ^{-O(1)}/N^d)$
-neighbourhood of some rational
$O(\delta ^{-O(1)}/N^d)$
-neighbourhood of some rational
 $a/b \mod 1 \in \mathbb {Q}/\mathbb {Z}$
with
$a/b \mod 1 \in \mathbb {Q}/\mathbb {Z}$
with
 $b=O(\delta ^{-O(1)})$
such that
$b=O(\delta ^{-O(1)})$
such that
 $$ \begin{align} |\langle g, G \rangle| \gtrsim \delta^{O(1)} N^d. \end{align} $$
$$ \begin{align} |\langle g, G \rangle| \gtrsim \delta^{O(1)} N^d. \end{align} $$
However, this can be derived from [Reference Krause, Mirek and Tao13, Proposition 6.26] in precisely the same way Proposition 5.3 was derived from [Reference Krause, Mirek and Tao13, Proposition 6.6]. By repeating the remaining arguments of [Reference Krause, Mirek and Tao13, §6.2], one obtains case (ii) of Theorem 3.2.
6 Remarks
6.1 Peluse’s inverse theorem for the primes
As is clear from the previous sections, Peluse’s inverse theorem [Reference Peluse23] was an important ingredient in the proof of the unweighted bilinear ergodic theorem in [Reference Krause, Mirek and Tao13]. In the course of proving Theorem 1.3, we essentially needed a version of this inverse theorem where one of the variables was weighted by the approximant
 $\Lambda _N$
; see Proposition 5.3. It is natural to ask if one can also obtain a version of Peluse’s inverse theorem with the von Mangoldt weight
$\Lambda _N$
; see Proposition 5.3. It is natural to ask if one can also obtain a version of Peluse’s inverse theorem with the von Mangoldt weight
 $\Lambda $
. We record here how such a result quickly follows from the arguments used to prove Proposition 5.3.
$\Lambda $
. We record here how such a result quickly follows from the arguments used to prove Proposition 5.3.
Theorem 6.1. (Peluse’s inverse theorem with prime weight)
Let
 $k,d\in \mathbb {N}$
and
$k,d\in \mathbb {N}$
and
 $A>0$
. Let
$A>0$
. Let
 $N\geq 2$
,
$N\geq 2$
,
 $(\log N)^{-A}\leq \delta \leq 1$
and
$(\log N)^{-A}\leq \delta \leq 1$
and
 $N_0\sim N^d$
. Let
$N_0\sim N^d$
. Let
 $P_1,\ldots , P_k$
be polynomials with integer coefficients of distinct degrees, with maximal degree d. Let
$P_1,\ldots , P_k$
be polynomials with integer coefficients of distinct degrees, with maximal degree d. Let
 $h,f_1,\ldots , f_k\colon \mathbb {Z}\to \mathbb {C}$
be functions bounded in modulus by
$h,f_1,\ldots , f_k\colon \mathbb {Z}\to \mathbb {C}$
be functions bounded in modulus by
 $1$
and supported on
$1$
and supported on
 $[-N_0,N_0]$
. Suppose that
$[-N_0,N_0]$
. Suppose that
 $$ \begin{align} \bigg|\!\sum_{x\in \mathbb{Z}}\mathbb{E}_{n\in [N]}\Lambda(n)h(x)f_1(x+P_1(n))\cdots f_k(x+P_k(n))\bigg| \geq \delta N^d. \end{align} $$
$$ \begin{align} \bigg|\!\sum_{x\in \mathbb{Z}}\mathbb{E}_{n\in [N]}\Lambda(n)h(x)f_1(x+P_1(n))\cdots f_k(x+P_k(n))\bigg| \geq \delta N^d. \end{align} $$
Then, either
 $N_0\lesssim _{P_1,\ldots , P_k} \delta ^{-O_d(1)}$
or there exists a positive integer
$N_0\lesssim _{P_1,\ldots , P_k} \delta ^{-O_d(1)}$
or there exists a positive integer
 $q\lesssim _{P_1,\ldots , P_k} \delta ^{-O_d(1)}$
and
$q\lesssim _{P_1,\ldots , P_k} \delta ^{-O_d(1)}$
and
 $\delta ^{O_d(1)}N\lesssim _{P_1,\ldots , P_k} N'\leq N$
such that
$\delta ^{O_d(1)}N\lesssim _{P_1,\ldots , P_k} N'\leq N$
such that
 $$ \begin{align*} \frac{1}{N^d}\bigg|\!\sum_{x\in \mathbb{Z}}\mathbb{E}_{m\in [N']}f_1(x+qm)\bigg|\gtrsim_{A,P_1,\ldots, P_k}\delta^{O_d(1)}. \end{align*} $$
$$ \begin{align*} \frac{1}{N^d}\bigg|\!\sum_{x\in \mathbb{Z}}\mathbb{E}_{m\in [N']}f_1(x+qm)\bigg|\gtrsim_{A,P_1,\ldots, P_k}\delta^{O_d(1)}. \end{align*} $$
Proof. Fix
 $P_1,\ldots , P_k$
; we allow all implied constants to depend on them. Define the polynomial averaging operator
$P_1,\ldots , P_k$
; we allow all implied constants to depend on them. Define the polynomial averaging operator
Let
 $w_0=\delta ^{-C_d}$
for a large enough constant
$w_0=\delta ^{-C_d}$
for a large enough constant
 $C_d$
. We claim that
$C_d$
. We claim that
 $$ \begin{align} T_{N,\Lambda-\Lambda_N}(h,f_1,\ldots, f_k)\lesssim_A (\log N)^{-A}, \end{align} $$
$$ \begin{align} T_{N,\Lambda-\Lambda_N}(h,f_1,\ldots, f_k)\lesssim_A (\log N)^{-A}, \end{align} $$
and
 $$ \begin{align} T_{N,\Lambda_N-\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r},w_0}}(h,f_1,\ldots, f_k)\lesssim \delta^2 \end{align} $$
$$ \begin{align} T_{N,\Lambda_N-\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r},w_0}}(h,f_1,\ldots, f_k)\lesssim \delta^2 \end{align} $$
and
 $$ \begin{align} T_{N,\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r},w_0}-\Lambda_{\operatorname{HB},w_0}}(h,f_1,\ldots, f_k)\lesssim \delta^2. \end{align} $$
$$ \begin{align} T_{N,\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r},w_0}-\Lambda_{\operatorname{HB},w_0}}(h,f_1,\ldots, f_k)\lesssim \delta^2. \end{align} $$
After we have these three estimates, we conclude from equation (6.1) and linearity that
 $$ \begin{align*} |T_{N,\Lambda_{\operatorname{HB},w_0}}(h,f_1,\ldots, f_k)|\gtrsim \delta. \end{align*} $$
$$ \begin{align*} |T_{N,\Lambda_{\operatorname{HB},w_0}}(h,f_1,\ldots, f_k)|\gtrsim \delta. \end{align*} $$
By equations (4.1) and (4.2), the function
 $\Lambda _{\operatorname {HB},w_0}$
is a linear combination, with
$\Lambda _{\operatorname {HB},w_0}$
is a linear combination, with
 $1$
-bounded coefficients, of
$1$
-bounded coefficients, of
 $O(w_0^3)$
indicators of arithmetic progressions of common difference at most
$O(w_0^3)$
indicators of arithmetic progressions of common difference at most
 $w_0$
. Hence, crudely using the triangle inequality, we obtain
$w_0$
. Hence, crudely using the triangle inequality, we obtain
for some
 $1\leq a\leq q'\lesssim \delta ^{-O_d(1)}$
. However, now the claim of the theorem follows from [Reference Peluse23, Theorem 3.3] after making a change of variables.
$1\leq a\leq q'\lesssim \delta ^{-O_d(1)}$
. However, now the claim of the theorem follows from [Reference Peluse23, Theorem 3.3] after making a change of variables.
We are left with showing equations (6.2), (6.3) and (6.4). The estimate in equation (6.2) follows immediately from [Reference Teräväinen26, Theorem 4.1] and equation (3.1). The estimate in equation (6.3) follows by using Lemmas 4.5, 4.1 and [Reference Teräväinen26, Theorem 4.1] to obtain
 $$ \begin{align*} T_{N,\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}-\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z}}(h,f_1,\ldots, f_k)\lesssim w^{-c_d} \end{align*} $$
$$ \begin{align*} T_{N,\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w}-\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, z}}(h,f_1,\ldots, f_k)\lesssim w^{-c_d} \end{align*} $$
for some
 $c_d>0$
and any
$c_d>0$
and any
 $z\in [w/2,w]$
,
$z\in [w/2,w]$
,
 $1\leq w\leq \exp ((\log N)^{1/10})$
, and then summing this dyadically. For proving equation (6.4), note that from equation (5.14) and [Reference Teräväinen26, Theorem 4.1], we have for any
$1\leq w\leq \exp ((\log N)^{1/10})$
, and then summing this dyadically. For proving equation (6.4), note that from equation (5.14) and [Reference Teräväinen26, Theorem 4.1], we have for any
 $\kappa>0, \varepsilon >0$
, the bound
$\kappa>0, \varepsilon >0$
, the bound
 $$ \begin{align*} T_{N,\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w_0}-\Lambda^{\prime}_{\operatorname{HB},w_0}}(h,f_1,\ldots, f_k) \lesssim_\varepsilon \langle \operatorname{Log} w_0\rangle^{O_{\varepsilon}(1)}(\kappa^{c_d^{\prime}} + \kappa^{-\varepsilon} w_0^{-c_d^{\prime}}) N^d, \end{align*} $$
$$ \begin{align*} T_{N,\Lambda_{\mathrm{Cram}\acute{\rm e}\mathrm{r}, w_0}-\Lambda^{\prime}_{\operatorname{HB},w_0}}(h,f_1,\ldots, f_k) \lesssim_\varepsilon \langle \operatorname{Log} w_0\rangle^{O_{\varepsilon}(1)}(\kappa^{c_d^{\prime}} + \kappa^{-\varepsilon} w_0^{-c_d^{\prime}}) N^d, \end{align*} $$
with
 $\Lambda ^{\prime }_{\operatorname {HB},w_0}$
obeying equation (5.13). However, from equation (5.13) and the triangle inequality, we now obtain equation (6.4) by taking
$\Lambda ^{\prime }_{\operatorname {HB},w_0}$
obeying equation (5.13). However, from equation (5.13) and the triangle inequality, we now obtain equation (6.4) by taking
 $\varepsilon>0$
small enough and
$\varepsilon>0$
small enough and
 $\kappa =w_0^{-c}$
for a small enough constant c (depending on d). This was enough to complete the proof.
$\kappa =w_0^{-c}$
for a small enough constant c (depending on d). This was enough to complete the proof.
6.2 Siegel zeroes
In this subsection, we mention an alternative approach to Theorem 1.3 based on working with Siegel zeroes. This approach is somewhat more complicated than that implemented above and we shall only sketch it very briefly, leaving the details to the interested reader.
The place in the proof of Theorem 1.3 where passing from the von Mangoldt function
 $\Lambda $
to the approximant
$\Lambda $
to the approximant
 $\Lambda _N$
avoided dealing with Siegel zeroes is Proposition 3.4, so we begin by sketching how a variant of Proposition 3.4 can be proven for the weight
$\Lambda _N$
avoided dealing with Siegel zeroes is Proposition 3.4, so we begin by sketching how a variant of Proposition 3.4 can be proven for the weight
 $\Lambda $
.
$\Lambda $
.
We say that a modulus
 $q\geq 2$
is exceptional if there exists a non-principal real Dirichlet character
$q\geq 2$
is exceptional if there exists a non-principal real Dirichlet character
 $\chi _q\pmod q$
such that
$\chi _q\pmod q$
such that
 $L(s,\chi _q)$
has a real zero
$L(s,\chi _q)$
has a real zero
 $\beta _q>1-c_0/(\log q)$
, where
$\beta _q>1-c_0/(\log q)$
, where
 $c_0$
is some small absolute constant. We call the corresponding character
$c_0$
is some small absolute constant. We call the corresponding character
 $\chi _q$
an exceptional character and we call
$\chi _q$
an exceptional character and we call
 $\beta _q$
a Siegel zero. For any given exceptional q, the character
$\beta _q$
a Siegel zero. For any given exceptional q, the character
 $\chi _q$
and Siegel zero
$\chi _q$
and Siegel zero
 $\beta _q$
are uniquely determined.
$\beta _q$
are uniquely determined.
For exceptional characters
 $\chi _q$
, we define the arithmetic symbol
$\chi _q$
, we define the arithmetic symbol

and the (weighted) continuous multiplier

where
 $\beta _q\in (0,1)$
is the Siegel zero. Then, if we replace in equation (3.18),
$\beta _q\in (0,1)$
is the Siegel zero. Then, if we replace in equation (3.18),
 $$ \begin{align*} &\mathrm{B}^{l_1, l_2, m_{\hat {\mathbb{Z}}^\times}}_{(\eta_{\leq -\operatorname{Log} N+s} \otimes \eta_{\leq -d\operatorname{Log} N+ds})\tilde m_{N,\mathbb{R}} } \\ & \qquad \longrightarrow \mathrm{B}^{l_1, l_2, m_{\hat {\mathbb{Z}}^\times}}_{(\eta_{\leq -\operatorname{Log} N+s} \otimes \eta_{\leq -d\operatorname{Log} N+ds})\tilde m_{N,\mathbb{R}} } + \sum_{q \text{ exceptional}} \mathrm{B}^{l_1, l_2, m_{\hat {\mathbb{Z}}^\times,\chi_q}}_{(\eta_{\leq -\operatorname{Log} N+s} \otimes \eta_{\leq -d\operatorname{Log} N+ds})\tilde m_{N,\mathbb{R},\chi_q} }, \end{align*} $$
$$ \begin{align*} &\mathrm{B}^{l_1, l_2, m_{\hat {\mathbb{Z}}^\times}}_{(\eta_{\leq -\operatorname{Log} N+s} \otimes \eta_{\leq -d\operatorname{Log} N+ds})\tilde m_{N,\mathbb{R}} } \\ & \qquad \longrightarrow \mathrm{B}^{l_1, l_2, m_{\hat {\mathbb{Z}}^\times}}_{(\eta_{\leq -\operatorname{Log} N+s} \otimes \eta_{\leq -d\operatorname{Log} N+ds})\tilde m_{N,\mathbb{R}} } + \sum_{q \text{ exceptional}} \mathrm{B}^{l_1, l_2, m_{\hat {\mathbb{Z}}^\times,\chi_q}}_{(\eta_{\leq -\operatorname{Log} N+s} \otimes \eta_{\leq -d\operatorname{Log} N+ds})\tilde m_{N,\mathbb{R},\chi_q} }, \end{align*} $$
the conclusion of Proposition 3.4 holds with the von Mangoldt weight
 $\Lambda $
in place of
$\Lambda $
in place of
 $\Lambda _N$
. This follows from essentially the same proof as in §5, but using the Landau–Page theorem [Reference Montgomery and Vaughan20, Corollary 11.10] in place of Corollary 4.4.
$\Lambda _N$
. This follows from essentially the same proof as in §5, but using the Landau–Page theorem [Reference Montgomery and Vaughan20, Corollary 11.10] in place of Corollary 4.4.
In the large-scale regime, the error bounds arising from the Siegel–Walfisz theorem remove the need for the above approximation; in the small-scale regime,
 $$ \begin{align*}\{ N \in \mathbb{D}\colon 2^{u^{O(1/(C_0 \rho))}} \leq N \leq 3^{C_0 \cdot 2^u} \},\end{align*} $$
$$ \begin{align*}\{ N \in \mathbb{D}\colon 2^{u^{O(1/(C_0 \rho))}} \leq N \leq 3^{C_0 \cdot 2^u} \},\end{align*} $$
further analysis is required to reduce matters to the two-parameter Rademacher–Menshov inequality.
The first observation is the classical fact that there is at most one exceptional character at each dyadic scale:
 $$ \begin{align} |\{q\in (2^j,2^{j+1}]\colon q \text{ exceptional} \}| \leq 1. \end{align} $$
$$ \begin{align} |\{q\in (2^j,2^{j+1}]\colon q \text{ exceptional} \}| \leq 1. \end{align} $$
We let
 $q_j$
denote the unique exceptional modulus in
$q_j$
denote the unique exceptional modulus in
 $(2^j,2^{j+1}]$
and abbreviate
$(2^j,2^{j+1}]$
and abbreviate
 $\beta _j = \beta _{q_j}$
.
$\beta _j = \beta _{q_j}$
.
We then introduce a dyadic decomposition
 $$ \begin{align*} \sum_{q \text{ exceptional}} \mathrm{B}^{l_1, l_2, m_{\hat {\mathbb{Z}}^\times,\chi_q}}_{(\eta_{\leq -\operatorname{Log} N+s} \otimes \eta_{\leq -d\operatorname{Log} N+ds})\tilde m_{N,\mathbb{R},\chi_q}} = \sum_{j \leq 2^{\rho l}} C_{N,j}(f,g),\end{align*} $$
$$ \begin{align*} \sum_{q \text{ exceptional}} \mathrm{B}^{l_1, l_2, m_{\hat {\mathbb{Z}}^\times,\chi_q}}_{(\eta_{\leq -\operatorname{Log} N+s} \otimes \eta_{\leq -d\operatorname{Log} N+ds})\tilde m_{N,\mathbb{R},\chi_q}} = \sum_{j \leq 2^{\rho l}} C_{N,j}(f,g),\end{align*} $$
where
 $$ \begin{align*} &C_{N,j}(f,g)(x) \\ & = \int_{1/2}^1 \bigg( \int_{\mathbb{T}^2} \sum_{(a_1/q_j,a_2/q_j)\colon \mathrm{h}(a_i/q_j) = 2^{l_i}} m_{\hat{\mathbb{Z}}^{\times},\chi_{q_j}}(a_1/q_j,a_2/q_j) e(a_1 x/q_j + a_2 x/q_j) \\ & \quad\times ( \hat{f}(\xi_1 + a_1/q_j) \cdot \varphi(2^u \xi_1) \cdot e(\xi_1 N t) ) \\ & \quad\times ( \hat{g}(\xi_2 + a_2/q_j) \cdot \varphi(2^{du} \xi_2) \cdot e( \xi_2 P(Nt)) ) e(\xi_1 x + \xi_2 x) \cdot N^{\beta_{j} - 1} t^{\beta_{j} - 1} \ d\xi_1 d\xi_2 \bigg) \, dt. \end{align*} $$
$$ \begin{align*} &C_{N,j}(f,g)(x) \\ & = \int_{1/2}^1 \bigg( \int_{\mathbb{T}^2} \sum_{(a_1/q_j,a_2/q_j)\colon \mathrm{h}(a_i/q_j) = 2^{l_i}} m_{\hat{\mathbb{Z}}^{\times},\chi_{q_j}}(a_1/q_j,a_2/q_j) e(a_1 x/q_j + a_2 x/q_j) \\ & \quad\times ( \hat{f}(\xi_1 + a_1/q_j) \cdot \varphi(2^u \xi_1) \cdot e(\xi_1 N t) ) \\ & \quad\times ( \hat{g}(\xi_2 + a_2/q_j) \cdot \varphi(2^{du} \xi_2) \cdot e( \xi_2 P(Nt)) ) e(\xi_1 x + \xi_2 x) \cdot N^{\beta_{j} - 1} t^{\beta_{j} - 1} \ d\xi_1 d\xi_2 \bigg) \, dt. \end{align*} $$
The key novelty then derives from proving the following modified Rademacher– Menshov-type inequality, similar to [Reference Krause, Mirek and Tao13, Lemma 8.2].
Lemma 6.2. Let
 $V,W$
be normed vector spaces,
$V,W$
be normed vector spaces,
 $K,J$
be two positive integers and let
$K,J$
be two positive integers and let
 $0<q<\infty $
. Let
$0<q<\infty $
. Let
 $B_j\colon V\times W\rightarrow L^q(X)$
be a family of bilinear operators for
$B_j\colon V\times W\rightarrow L^q(X)$
be a family of bilinear operators for
 $j\in [J]$
. Let
$j\in [J]$
. Let
 $\{f_{k}^j\}, \{g_k^j\}$
be sets of functions with
$\{f_{k}^j\}, \{g_k^j\}$
be sets of functions with
 $f_k^j\in V$
and
$f_k^j\in V$
and
 $g_k^j\in W$
for
$g_k^j\in W$
for
 $k\in [K]$
and
$k\in [K]$
and
 $j\in [J]$
. Then,
$j\in [J]$
. Then,
 $$ \begin{align*}&\bigg\|V^2\bigg(\sum_{j\in [J]}B_j(f_k^j,g_k^j)\colon k \in [K]\bigg)\bigg\|_{L^q(X)} \\ &\ \lesssim_{q} \langle \operatorname{Log} K\rangle^{O_q(1)} \kern-3pt\sup_{\epsilon_{k}^{j}, {\varepsilon}_k^j \in \{ \pm 1 \}}\kern-1pt \bigg\|\kern-1pt \sum_{j\in [J]}\kern-2pt B_j\bigg(\kern-1pt\sum_{k\in [K]} \epsilon_k^j (f_k^j- f_{k-1}^j), \kern-2pt\sum_{k\in [K]}\kern-1.3pt {\varepsilon}_k^j (g_k^j- g_{k-1}^j)\kern-1.2pt\bigg)\bigg\|_{L^q(X)}\!. \end{align*} $$
$$ \begin{align*}&\bigg\|V^2\bigg(\sum_{j\in [J]}B_j(f_k^j,g_k^j)\colon k \in [K]\bigg)\bigg\|_{L^q(X)} \\ &\ \lesssim_{q} \langle \operatorname{Log} K\rangle^{O_q(1)} \kern-3pt\sup_{\epsilon_{k}^{j}, {\varepsilon}_k^j \in \{ \pm 1 \}}\kern-1pt \bigg\|\kern-1pt \sum_{j\in [J]}\kern-2pt B_j\bigg(\kern-1pt\sum_{k\in [K]} \epsilon_k^j (f_k^j- f_{k-1}^j), \kern-2pt\sum_{k\in [K]}\kern-1.3pt {\varepsilon}_k^j (g_k^j- g_{k-1}^j)\kern-1.2pt\bigg)\bigg\|_{L^q(X)}\!. \end{align*} $$
This result may be of independent interest, so we provide a brief proof.
Proof. Set
 $a_{k_1,k_2}= \sum _{j \in [J]} B_j(f_{k_1}^j,g_{k_2}^j)$
. By [Reference Krause, Mirek and Tao13, Lemma 8.1], we have
$a_{k_1,k_2}= \sum _{j \in [J]} B_j(f_{k_1}^j,g_{k_2}^j)$
. By [Reference Krause, Mirek and Tao13, Lemma 8.1], we have
 $$ \begin{align*} V^2\bigg(\sum_{j \in [J]} B_j(f_k^j,g_k^j)\colon k\in [K]\bigg) \lesssim \sum_{\substack{M_1,M_2<K\\ \mathcal{M}_1,M_2\colon \text{dyadic}}} \bigg\| \Delta \sum_{j \leq J} B_j(f_{M_1n_1}^j,g_{M_2n_2}^j)\bigg\|_{\ell^2(n_1,n_2)}, \end{align*} $$
$$ \begin{align*} V^2\bigg(\sum_{j \in [J]} B_j(f_k^j,g_k^j)\colon k\in [K]\bigg) \lesssim \sum_{\substack{M_1,M_2<K\\ \mathcal{M}_1,M_2\colon \text{dyadic}}} \bigg\| \Delta \sum_{j \leq J} B_j(f_{M_1n_1}^j,g_{M_2n_2}^j)\bigg\|_{\ell^2(n_1,n_2)}, \end{align*} $$
where
 $$ \begin{align*} \Delta \sum_{j \in [J]} B_j(f_{M_1n_1}^j,g_{M_2n_2}^j) =& \sum_{ j \in [J]} B_j(f_{M_1n_1}^j,g_{M_2n_2}^j) - \sum_{j\in [J]} B_j(f_{(n_1-1)M_1}^j,g_{M_2n_2}^j)\\ &- \sum_{j \in [J]} B_j(f_{M_1n_1}^j,g_{(n_2-1)M_2}^j) + \kern-2pt\sum_{j \in [J]}\kern-2pt B_j(f_{(n_1-1)M_1}^j,g_{(n_2-1)M_2}^j). \end{align*} $$
$$ \begin{align*} \Delta \sum_{j \in [J]} B_j(f_{M_1n_1}^j,g_{M_2n_2}^j) =& \sum_{ j \in [J]} B_j(f_{M_1n_1}^j,g_{M_2n_2}^j) - \sum_{j\in [J]} B_j(f_{(n_1-1)M_1}^j,g_{M_2n_2}^j)\\ &- \sum_{j \in [J]} B_j(f_{M_1n_1}^j,g_{(n_2-1)M_2}^j) + \kern-2pt\sum_{j \in [J]}\kern-2pt B_j(f_{(n_1-1)M_1}^j,g_{(n_2-1)M_2}^j). \end{align*} $$
Taking
 $$ \begin{align*} \tilde f_{M_1n_1} = f_{M_1n_1} - f_{(n_1-1)M_1},\quad \tilde g_{M_2n_2} = g_{M_2n_2} - g_{(n_2-1)M_2},\end{align*} $$
$$ \begin{align*} \tilde f_{M_1n_1} = f_{M_1n_1} - f_{(n_1-1)M_1},\quad \tilde g_{M_2n_2} = g_{M_2n_2} - g_{(n_2-1)M_2},\end{align*} $$
we need to bound
 $$ \begin{align} \langle \operatorname{Log} K\rangle^{O_q(1)} \sup_{M_1,M_2 < K \text{ dyadic}} \bigg\| \bigg(\sum_{\substack{n_1<k/M_1\\ \mathrm{n}_2<k/M_2}}\bigg| \sum_{j\in [J]} B_j(\tilde f_{M_1n_1}^j,\tilde g_{M_2n_2}^j)\bigg|^2\bigg)^{1/2}\bigg\|_{L^q(X)}. \end{align} $$
$$ \begin{align} \langle \operatorname{Log} K\rangle^{O_q(1)} \sup_{M_1,M_2 < K \text{ dyadic}} \bigg\| \bigg(\sum_{\substack{n_1<k/M_1\\ \mathrm{n}_2<k/M_2}}\bigg| \sum_{j\in [J]} B_j(\tilde f_{M_1n_1}^j,\tilde g_{M_2n_2}^j)\bigg|^2\bigg)^{1/2}\bigg\|_{L^q(X)}. \end{align} $$
Applying Khintchine’s inequality
 $$ \begin{align*} \bigg( \sum_{n} |a_n|^2 \bigg)^{1/2} = \bigg( \mathbb{E}_{\epsilon_n \in \pm 1}\bigg| \sum_n \epsilon_n a_n\bigg|^2 \bigg)^{1/2} \sim_q \bigg( \mathbb{E}_{\epsilon_n \in \pm 1}\bigg| \sum_n \epsilon_n a_n\bigg|^q \bigg)^{1/q}, \end{align*} $$
$$ \begin{align*} \bigg( \sum_{n} |a_n|^2 \bigg)^{1/2} = \bigg( \mathbb{E}_{\epsilon_n \in \pm 1}\bigg| \sum_n \epsilon_n a_n\bigg|^2 \bigg)^{1/2} \sim_q \bigg( \mathbb{E}_{\epsilon_n \in \pm 1}\bigg| \sum_n \epsilon_n a_n\bigg|^q \bigg)^{1/q}, \end{align*} $$
we arrive at the following chain of inequalities:
 $$ \begin{align*} &\bigg\| V^2\bigg(\sum_{j\in [J]}B_j(f_k^j,g_k^j)\colon k \in [K]\bigg)\bigg\|_{L^q(X)} \\ &\ \ \lesssim \langle \operatorname{Log} K\rangle^{O_q(1)} \sup_{M_1,M_2} \bigg\| \bigg(\mathbb{E}_{\varepsilon_{n_2} \in \pm 1} \sum_{\substack{n_1}}\bigg| \sum_{n_2}\sum_{j\in [J]} \varepsilon_{n_2} B_s(\tilde f_{M_1n_1}^j,\tilde g_{M_2n_2}^j)\bigg|^2\bigg)^{1/2}\bigg\|_{L^q(X)} \\ &\ \ \lesssim \langle \operatorname{Log} K\rangle^{O_q(1)} \sup_{M_1,M_2} \bigg\| \bigg(\mathbb{E}_{\epsilon_{n_1}, \varepsilon_{n_2} \in \pm 1}\bigg| \sum_{\substack{n_1}} \sum_{n_2}\sum_{j\in [J]} \epsilon_{n_1} \varepsilon_{n_2} B_j(\tilde f_{M_1n_1}^j,\tilde g_{M_2n_2}^j)\bigg|^2\bigg)^{1/2}\bigg\|_{L^q(X)} \\ &\ \ \lesssim_q \langle \operatorname{Log} K\rangle^{O_q(1)} \kern-2pt\sup_{M_1,M_2}\kern-1pt \bigg\| \bigg(\mathbb{E}_{\epsilon_{n_1}, \varepsilon_{n_2} \in \pm 1} \bigg|\sum_{\substack{n_1}} \sum_{n_2}\kern-2pt\sum_{j\in [J]} \epsilon_{n_1} \varepsilon_{n_2} B_j(\tilde f_{M_1n_1}^j,\tilde g_{M_2n_2}^j)\bigg|^q\bigg)^{1/q}\bigg\|_{L^q(X)} \\ &\ \ \lesssim_q \langle \operatorname{Log} K\rangle^{O_q(1)} \sup_{M_1,M_2, \epsilon_{n_1},\epsilon_{n_2}} \bigg\| \sum_{\substack{n_1}} \sum_{n_2}\sum_{j\in [J]} \epsilon_{n_1} \varepsilon_{n_2} B_j(\tilde f_{M_1n_1}^j,\tilde g_{M_2n_2}^j)\bigg\|_{L^q(X)}. \end{align*} $$
$$ \begin{align*} &\bigg\| V^2\bigg(\sum_{j\in [J]}B_j(f_k^j,g_k^j)\colon k \in [K]\bigg)\bigg\|_{L^q(X)} \\ &\ \ \lesssim \langle \operatorname{Log} K\rangle^{O_q(1)} \sup_{M_1,M_2} \bigg\| \bigg(\mathbb{E}_{\varepsilon_{n_2} \in \pm 1} \sum_{\substack{n_1}}\bigg| \sum_{n_2}\sum_{j\in [J]} \varepsilon_{n_2} B_s(\tilde f_{M_1n_1}^j,\tilde g_{M_2n_2}^j)\bigg|^2\bigg)^{1/2}\bigg\|_{L^q(X)} \\ &\ \ \lesssim \langle \operatorname{Log} K\rangle^{O_q(1)} \sup_{M_1,M_2} \bigg\| \bigg(\mathbb{E}_{\epsilon_{n_1}, \varepsilon_{n_2} \in \pm 1}\bigg| \sum_{\substack{n_1}} \sum_{n_2}\sum_{j\in [J]} \epsilon_{n_1} \varepsilon_{n_2} B_j(\tilde f_{M_1n_1}^j,\tilde g_{M_2n_2}^j)\bigg|^2\bigg)^{1/2}\bigg\|_{L^q(X)} \\ &\ \ \lesssim_q \langle \operatorname{Log} K\rangle^{O_q(1)} \kern-2pt\sup_{M_1,M_2}\kern-1pt \bigg\| \bigg(\mathbb{E}_{\epsilon_{n_1}, \varepsilon_{n_2} \in \pm 1} \bigg|\sum_{\substack{n_1}} \sum_{n_2}\kern-2pt\sum_{j\in [J]} \epsilon_{n_1} \varepsilon_{n_2} B_j(\tilde f_{M_1n_1}^j,\tilde g_{M_2n_2}^j)\bigg|^q\bigg)^{1/q}\bigg\|_{L^q(X)} \\ &\ \ \lesssim_q \langle \operatorname{Log} K\rangle^{O_q(1)} \sup_{M_1,M_2, \epsilon_{n_1},\epsilon_{n_2}} \bigg\| \sum_{\substack{n_1}} \sum_{n_2}\sum_{j\in [J]} \epsilon_{n_1} \varepsilon_{n_2} B_j(\tilde f_{M_1n_1}^j,\tilde g_{M_2n_2}^j)\bigg\|_{L^q(X)}. \end{align*} $$
By bilinearity, we may consolidate
 $$ \begin{align*} \sum_{\substack{n_1}} \sum_{n_2}\sum_{j\in [J]} \epsilon_{n_1} \varepsilon_{n_2} B_j(\tilde f_{M_1n_1}^j,\tilde g_{M_2n_2}^j) = \sum_{j\in [J]} B_j\bigg(\sum_{n_1} \epsilon_{n_1} \tilde f_{M_1 n_1}^j, \sum_{n_2} \varepsilon_{n_2}\tilde g_{M_2n_2}^j\bigg);\end{align*} $$
$$ \begin{align*} \sum_{\substack{n_1}} \sum_{n_2}\sum_{j\in [J]} \epsilon_{n_1} \varepsilon_{n_2} B_j(\tilde f_{M_1n_1}^j,\tilde g_{M_2n_2}^j) = \sum_{j\in [J]} B_j\bigg(\sum_{n_1} \epsilon_{n_1} \tilde f_{M_1 n_1}^j, \sum_{n_2} \varepsilon_{n_2}\tilde g_{M_2n_2}^j\bigg);\end{align*} $$
putting everything together,
 $$ \begin{align*} &\bigg\| {V}^2\bigg(\sum_{j\in [J] }B_j(f_k^j,g_k^j)\colon k \in [K]\bigg)\bigg\|_{L^q(X)} \\ &\quad\lesssim \langle \operatorname{Log} K\rangle^{O_q(1)} \sup_{\substack{M_1,M_2\\ \epsilon_{n_1}, \varepsilon_{n_2}}} \bigg\| \sum_{j \in [J]} B_j\bigg( \sum_{n_1} \epsilon_{n_1} ( f_{M_1n_1}^j- f_{(n_1-1)M_1}^j),\\ &\quad\qquad\sum_{n_2}\varepsilon_{n_2} (g_{M_2n_2}^j-g_{(n_2-1)M_2}^j)\bigg)\bigg\|_{L^q(X)}, \end{align*} $$
$$ \begin{align*} &\bigg\| {V}^2\bigg(\sum_{j\in [J] }B_j(f_k^j,g_k^j)\colon k \in [K]\bigg)\bigg\|_{L^q(X)} \\ &\quad\lesssim \langle \operatorname{Log} K\rangle^{O_q(1)} \sup_{\substack{M_1,M_2\\ \epsilon_{n_1}, \varepsilon_{n_2}}} \bigg\| \sum_{j \in [J]} B_j\bigg( \sum_{n_1} \epsilon_{n_1} ( f_{M_1n_1}^j- f_{(n_1-1)M_1}^j),\\ &\quad\qquad\sum_{n_2}\varepsilon_{n_2} (g_{M_2n_2}^j-g_{(n_2-1)M_2}^j)\bigg)\bigg\|_{L^q(X)}, \end{align*} $$
and so we get the result upon telescoping e.g.

6.3 Breaking duality
We briefly remark that one may establish Theorem 1.3 with r-variation restricted to the range
 $r> 2 + \epsilon $
for exponents
$r> 2 + \epsilon $
for exponents
 $p_1,p_2>1$
that satisfy
$p_1,p_2>1$
that satisfy
where
 $\epsilon '> 0$
is sufficiently small in terms of
$\epsilon '> 0$
is sufficiently small in terms of
 $\epsilon $
; hence, going beyond the duality range.
$\epsilon $
; hence, going beyond the duality range.
The single-scale estimate
 $$ \begin{align} \| A_{N;\Lambda;X}(f,g) \|_{L^p(X)} \lesssim \| f \|_{L^{p_1}(X)} \| g \|_{L^{p_2}(X)} \end{align} $$
$$ \begin{align} \| A_{N;\Lambda;X}(f,g) \|_{L^p(X)} \lesssim \| f \|_{L^{p_1}(X)} \| g \|_{L^{p_2}(X)} \end{align} $$
anchors the argument; equation (6.7) follows from Hölder’s inequality and the improving estimate Lemma 5.1, as per [Reference Krause, Mirek and Tao13, Lemma 11.1]. With equation (6.7) in hand, the proof of [Reference Krause, Mirek and Tao13, Proposition 11.4] can be formally reproduced, with only notational changes arising. We leave the details to the interested reader.
6.4 Sharpness of the variational result
The unboundedness of the quadratic variation along polynomial orbits, namely [Reference Krause, Mirek and Tao13, Proposition 12.1], extends to our context.
Proposition 6.3. Let
 $P \in \mathbb {Z}[\mathrm {n}]$
be a non-constant polynomial and let
$P \in \mathbb {Z}[\mathrm {n}]$
be a non-constant polynomial and let
 $0 < p \leq \infty $
. Let
$0 < p \leq \infty $
. Let
 $I \subset \mathbb {N}$
be an infinite set. Then, for every
$I \subset \mathbb {N}$
be an infinite set. Then, for every
 $C> 0$
, there exists a measure-preserving system
$C> 0$
, there exists a measure-preserving system
 $(X,\mu ,T)$
of total measure 1 and a
$(X,\mu ,T)$
of total measure 1 and a
 $1$
-bounded
$1$
-bounded
 $f \in L^{\infty }(X)$
so that
$f \in L^{\infty }(X)$
so that
 $$ \begin{align*} \| ( \mathbb{E}_{p \in [N]} T^{P(p)} f )_{N \in I} \|_{L^p(X;V^2)} \geq C. \end{align*} $$
$$ \begin{align*} \| ( \mathbb{E}_{p \in [N]} T^{P(p)} f )_{N \in I} \|_{L^p(X;V^2)} \geq C. \end{align*} $$
We shall leave the details of the proof of this proposition to the interested reader as it is similar to the proof of [Reference Krause, Mirek and Tao13, Proposition 12.1]. The key additional observation is the equidistribution of
 $$ \begin{align*} p \mapsto ( \alpha_1 \cdot P(p),\ldots,\alpha_K \cdot P(p) ) \subset \mathbb{T}^K \end{align*} $$
$$ \begin{align*} p \mapsto ( \alpha_1 \cdot P(p),\ldots,\alpha_K \cdot P(p) ) \subset \mathbb{T}^K \end{align*} $$
over the primes whenever
 $\alpha _1,\ldots ,\alpha _K$
are
$\alpha _1,\ldots ,\alpha _K$
are
 $\mathbb {Q}$
-linearly independent and
$\mathbb {Q}$
-linearly independent and
 $P \in \mathbb {Z}[\mathrm {n}]$
is a non-constant polynomial (which follows from Weyl’s criterion and a standard exponential sum estimate for polynomials of primes; see e.g. [Reference Matomäki and Shao17, Theorem 1.3]).
$P \in \mathbb {Z}[\mathrm {n}]$
is a non-constant polynomial (which follows from Weyl’s criterion and a standard exponential sum estimate for polynomials of primes; see e.g. [Reference Matomäki and Shao17, Theorem 1.3]).
To see why this implies the sharpness of the range of the variational estimate in Theorem 1.3, one may employ the convexity arguments of [Reference Mirek, Trojan and Zorin-Kranich19, §5], taking into account [Reference Mirek, Trojan and Zorin-Kranich19, Proposition 4.1], to obtain the lower bound
 $$ \begin{align*} \| ( \mathbb{E}_{p \in [N]} T^{P(p)} f )_{N \in I} \|_{L^p(X;V^2)} \leq \| ( \mathbb{E}_{n \in [N]} \Lambda(n) \cdot T^{P(n)} f )_{N \in I} \|_{L^p(X;V^2)} + O(1). \end{align*} $$
$$ \begin{align*} \| ( \mathbb{E}_{p \in [N]} T^{P(p)} f )_{N \in I} \|_{L^p(X;V^2)} \leq \| ( \mathbb{E}_{n \in [N]} \Lambda(n) \cdot T^{P(n)} f )_{N \in I} \|_{L^p(X;V^2)} + O(1). \end{align*} $$
6.5 Continuous extensions
From the perspective of density, the primes are ‘full/dimensional’, with a very ‘Fourier-uniform’ measure,
 $\Lambda $
. A natural question concerns establishing a continuous analogue of Theorem 1.3, namely the existence of a measure
$\Lambda $
. A natural question concerns establishing a continuous analogue of Theorem 1.3, namely the existence of a measure
 $\nu $
supported on
$\nu $
supported on
 $[0,1]$
, with (say) full Fourier dimension,
$[0,1]$
, with (say) full Fourier dimension,
 $$ \begin{align*} |\hat{\nu}(\xi)| \lesssim (1 + |\xi|)^{o(1)-1/2}\end{align*} $$
$$ \begin{align*} |\hat{\nu}(\xi)| \lesssim (1 + |\xi|)^{o(1)-1/2}\end{align*} $$
so that
 $$ \begin{align*} \lim_{N \to \infty} \frac{1}{N} \int_0^N f(x-t) g(x-P(t)) \, d\nu(t), \quad d = \text{deg}(P) \geq 2 \end{align*} $$
$$ \begin{align*} \lim_{N \to \infty} \frac{1}{N} \int_0^N f(x-t) g(x-P(t)) \, d\nu(t), \quad d = \text{deg}(P) \geq 2 \end{align*} $$
exists almost everywhere whenever
 $f \in L^{p_1}(\mathbb {R})$
and
$f \in L^{p_1}(\mathbb {R})$
and
 $g \in L^{p_2}(\mathbb {R})$
with
$g \in L^{p_2}(\mathbb {R})$
with
 $p_1,p_2> 1$
and
$p_1,p_2> 1$
and
 ${1}/{p_1} + {1}/{p_2} \leq 1$
. The key point is establishing a suitable Sobolev inequality, namely
${1}/{p_1} + {1}/{p_2} \leq 1$
. The key point is establishing a suitable Sobolev inequality, namely
 $$ \begin{align*} \bigg\| \frac{1}{N} \int_0^N f(x-t) g(x-P(t)) \ d\nu(t) \bigg\|_{L^1([0,CN^d])} \lesssim (2^{-cl} + O_A(\langle \log N \rangle^{-A} )) N^d\end{align*} $$
$$ \begin{align*} \bigg\| \frac{1}{N} \int_0^N f(x-t) g(x-P(t)) \ d\nu(t) \bigg\|_{L^1([0,CN^d])} \lesssim (2^{-cl} + O_A(\langle \log N \rangle^{-A} )) N^d\end{align*} $$
for some
 $c> 0$
, whenever
$c> 0$
, whenever
 $|f|, |g| \leq 1$
, and
$|f|, |g| \leq 1$
, and
 $\hat {f}$
vanishes on
$\hat {f}$
vanishes on
 $\{ |\xi | \lesssim 2^{l}/N \}$
and/or
$\{ |\xi | \lesssim 2^{l}/N \}$
and/or
 $\hat {g}$
vanishes on
$\hat {g}$
vanishes on
 $\{ |\xi | \lesssim 2^l/N^d\}$
.
$\{ |\xi | \lesssim 2^l/N^d\}$
.
Estimates of this form in the unweighted setting go back to [Reference Bourgain1], with the strongest estimates recently established by one of us as part of a much more general phenomenon, see [Reference Krause, Mirek, Peluse and Wright12]. This approach relies on PET induction, which suggests that certain Gowers-uniformity conditions might need to be imposed on
 $\nu $
; it is unclear how this might interact with dimension, so we leave the problem to the interested reader.
$\nu $
; it is unclear how this might interact with dimension, so we leave the problem to the interested reader.
Acknowledgments
We thank the referee for careful reading of the paper. B.K. is supported by an EPSRC New Investigators grant and an ERC Starting grant. T.T. is supported by NSF grant DMS-2347850. J.T. is supported by European Union’s Horizon Europe research and innovation programme under Marie Skłodowska-Curie grant agreement No. 101058904 and ERC grant agreement No. 101162746, and Academy of Finland grant No. 362303.




 Open access
Open access