
















1. Introduction
The class of complex networks consists of large real-life networks that primarily arise from human interactions, such as social networks and the Internet, as well as from other fields like biology [Reference Albert and Barabási2]. Networks in this class exhibit four essential features: high clustering, the small-world property, sparseness, and a scale-free degree distribution [Reference Chung and Lu11]. Krioukov, Papadopoulos, Kitsak, Vahdat, and Boguñá empirically showed that these four properties naturally emerge in graphs constructed on hyperbolic spaces. This led them to introduce the random hyperbolic graph (RHG) as a model for complex networks [Reference Krioukov, Papadopoulos, Kitsak, Vahdat and Boguñá17]. Boguñá, Papadopoulos, and Krioukov further illustrated this point by providing an embedding of the Internet graph into a hyperbolic space [Reference Boguñá, Papadopoulos and Krioukov6]. For modelling purposes, the model can be tuned through a curvature parameter
 $\alpha$
and a parameter
$\alpha$
and a parameter
 $\nu$
determining the average degree.
$\nu$
determining the average degree.
It has now been rigorously proven that, in the regime
 $\alpha > \tfrac{1}{2}$
, the RHG exhibits all the properties of complex networks listed above. Sparseness is proven in [Reference Peter19], the small-world property is shown in [Reference Abdullah, Bode and Fountoulakis1], the high clustering is also fully tested [Reference Candellero and Fountoulakis10], [Reference Fountoulakis, van der Hoorn, Müller and Schepers13], [Reference Gugelmann, Panagiotou and Peter14], and the scale-free degree distribution of the RHG has been proven in [Reference Gugelmann, Panagiotou and Peter14]. In this regime, the RHG is a particular case of the geometric inhomogeneous random graph (GIRG) [Reference Bringmann, Keusch and Lengler8]. In the GIRG model, nodes are sampled on a torus and inhomogeneity is obtained via power law weights on the nodes, which determine the connection probabilities. It is established in [Reference Bringmann, Keusch and Lengler8] and [Reference Bringmann, Keusch and Lengler9] that the GIRG model possesses the main properties of complex networks listed above, thereby reproving, in a more conceptual way, that the RHG exhibits all the properties of complex networks.
$\alpha > \tfrac{1}{2}$
, the RHG exhibits all the properties of complex networks listed above. Sparseness is proven in [Reference Peter19], the small-world property is shown in [Reference Abdullah, Bode and Fountoulakis1], the high clustering is also fully tested [Reference Candellero and Fountoulakis10], [Reference Fountoulakis, van der Hoorn, Müller and Schepers13], [Reference Gugelmann, Panagiotou and Peter14], and the scale-free degree distribution of the RHG has been proven in [Reference Gugelmann, Panagiotou and Peter14]. In this regime, the RHG is a particular case of the geometric inhomogeneous random graph (GIRG) [Reference Bringmann, Keusch and Lengler8]. In the GIRG model, nodes are sampled on a torus and inhomogeneity is obtained via power law weights on the nodes, which determine the connection probabilities. It is established in [Reference Bringmann, Keusch and Lengler8] and [Reference Bringmann, Keusch and Lengler9] that the GIRG model possesses the main properties of complex networks listed above, thereby reproving, in a more conceptual way, that the RHG exhibits all the properties of complex networks.
A graph is said to have a scale-free degree distribution when its degree sequence follows a power law distribution, meaning that, for large k, the number of nodes with degree k behaves like an inverse power of k. In this case, the graph has a large number of hubs (nodes with degrees much larger than the average degree). A RHG is typically structured as follows: high-degree nodes are well connected to each other and serve as hubs for nodes with slightly lower degrees. These intermediate-degree nodes, in turn, connect to nodes with even lower degrees, and so on, forming a hierarchical, tree-like structure. In addition to this tree-like organization, there are also connections between nodes with similar angular coordinates. This structure provides an intuitive explanation for the small-world phenomenon observed in these graphs, as short paths naturally emerge by travelling from hub to hub.
In the
 $\alpha \leq \tfrac{1}{2}$
case, the RHG is no longer sparse nor scale-free. However, the model remains highly inhomogeneous in the sense that the degree distribution of a node depends heavily on its position in the hyperbolic space, leading to the presence of a large number of hubs. This regime is referred to as the dense regime. The value
$\alpha \leq \tfrac{1}{2}$
case, the RHG is no longer sparse nor scale-free. However, the model remains highly inhomogeneous in the sense that the degree distribution of a node depends heavily on its position in the hyperbolic space, leading to the presence of a large number of hubs. This regime is referred to as the dense regime. The value
 $\alpha = \tfrac{1}{2}$
is also the transition point between the connected and the non-connected regime: for
$\alpha = \tfrac{1}{2}$
is also the transition point between the connected and the non-connected regime: for
 $\alpha < \tfrac{1}{2}$
, the graph has a high probability of being connected, with connectivity being entirely ensured by a few large hubs located near the centre. Conversely, for
$\alpha < \tfrac{1}{2}$
, the graph has a high probability of being connected, with connectivity being entirely ensured by a few large hubs located near the centre. Conversely, for
 $\alpha > \tfrac{1}{2}$
, the graph has a high probability of being disconnected. In the critical phase
$\alpha > \tfrac{1}{2}$
, the graph has a high probability of being disconnected. In the critical phase
 $\alpha = \tfrac{1}{2}$
, the probability of connectivity tends to a constant that depends on the parameter
$\alpha = \tfrac{1}{2}$
, the probability of connectivity tends to a constant that depends on the parameter
 $\nu$
. This constant takes the value 1 if and only if
$\nu$
. This constant takes the value 1 if and only if
 $\nu \geq \pi$
(see [Reference Bode, Fountoulakis and Müller5]).
$\nu \geq \pi$
(see [Reference Bode, Fountoulakis and Müller5]).
1.1. Main results
In this paper we are interested in the nodes with the largest degrees, which are the most important hubs of the graph. Theorem 3.1 proves the ordering of these nodes, namely that, for k fixed, with high probability, the node with the kth largest degree is the node with the kth smallest distance to the centre of the underlying space. In the regime
 $\alpha > \tfrac{1}{2}$
, Theorem 3.2 even shows that this ordering property holds up to rank
$\alpha > \tfrac{1}{2}$
, Theorem 3.2 even shows that this ordering property holds up to rank
 $n^{1/(1+8\alpha) + o(1)}$
and fails beyond. Finally, Theorem 3.3 states the convergence in distribution of the normalised point process of the degrees towards a Poisson point process. In particular, it establishes the convergence in distribution of the normalised maximum degree of the graph for all
$n^{1/(1+8\alpha) + o(1)}$
and fails beyond. Finally, Theorem 3.3 states the convergence in distribution of the normalised point process of the degrees towards a Poisson point process. In particular, it establishes the convergence in distribution of the normalised maximum degree of the graph for all
 $\alpha > 0$
.
$\alpha > 0$
.
Node degrees in RHGs are closely related to the measures of certain regions of the underlying hyperbolic space. The exact expressions of these quantities are seldom tractable, but since we are seeking asymptotic results, we only need to approximate them. The approximations we employ depend on the value of the curvature parameter
 $\alpha$
, as the asymptotic position of the closest node to the centre is strongly influenced by this parameter. In the regime
$\alpha$
, as the asymptotic position of the closest node to the centre is strongly influenced by this parameter. In the regime
 $\alpha>\tfrac{1}{2}$
, we use the approximations from [Reference Gugelmann, Panagiotou and Peter14, Lemma 3.2] (see Lemma 5.3 for another version of this result and Lemma 8.1 for a refinement). In the two regimes
$\alpha>\tfrac{1}{2}$
, we use the approximations from [Reference Gugelmann, Panagiotou and Peter14, Lemma 3.2] (see Lemma 5.3 for another version of this result and Lemma 8.1 for a refinement). In the two regimes
 $\alpha<\tfrac{1}{2}$
and
$\alpha<\tfrac{1}{2}$
and
 $\alpha = \tfrac{1}{2}$
, we use new approximations (given by Lemmas 5.4 and 5.5, respectively).
$\alpha = \tfrac{1}{2}$
, we use new approximations (given by Lemmas 5.4 and 5.5, respectively).
1.2. Structure of the paper
Section 2 contains a presentation of the RHG model. Our main results are given in Section 3. In Section 4 we prove the convergence of the node radii. Section 5 is dedicated to estimations of the measure of the balls involved in the connection rule. The results of these two last sections are used to prove Theorem 3.1 (Section 6), Theorem 3.3 (Section 7), and Theorem 3.2 (Section 8).
2. Definition of the model
2.1. Hyperbolic geometry
Before introducing the RHG model, let us review some definitions and notation concerning hyperbolic geometry. We refer to the book of Stillwell [Reference Stillwell21] for a broader introduction to hyperbolic geometry. The Poincaré disc, denoted by
 $\mathbb{H}$
, is the open unit disc of
$\mathbb{H}$
, is the open unit disc of
 $\mathbb{C}$
equipped with the Riemannian metric
$\mathbb{C}$
equipped with the Riemannian metric
 $\textbf{g}_\mathbb{H}$
, defined at
$\textbf{g}_\mathbb{H}$
, defined at
 $w \in \mathbb{H}$
by
$w \in \mathbb{H}$
by
 \begin{align*}\textbf{g}_\mathbb{H} \;:\!=\; \frac{4\textbf{g}_{\mathbb{C}}}{(1-|w|^2)^2}, \quad \mbox{where}\;\textbf{g}_{\mathbb{C}}\; \mbox{is the Euclidean metric on}\;\mathbb{C}.\end{align*}
\begin{align*}\textbf{g}_\mathbb{H} \;:\!=\; \frac{4\textbf{g}_{\mathbb{C}}}{(1-|w|^2)^2}, \quad \mbox{where}\;\textbf{g}_{\mathbb{C}}\; \mbox{is the Euclidean metric on}\;\mathbb{C}.\end{align*}
We denote by
 $d_{\mathbb{H}}$
the distance induced by
$d_{\mathbb{H}}$
the distance induced by
 $\textbf{g}_{\mathbb{H}}$
on
$\textbf{g}_{\mathbb{H}}$
on
 $\mathbb{H}$
. Throughout this paper, we make extensive use of the polar coordinates to describe points in the Poincaré disc. The polar coordinates of a point w in
$\mathbb{H}$
. Throughout this paper, we make extensive use of the polar coordinates to describe points in the Poincaré disc. The polar coordinates of a point w in
 $\mathbb{H}$
are given by the pair
$\mathbb{H}$
are given by the pair
 $(r(w),\theta(w))$
, where r(w) denotes its hyperbolic distance to the origin and
$(r(w),\theta(w))$
, where r(w) denotes its hyperbolic distance to the origin and
 $\theta(w)$
denotes its angle in the complex plane. The quantity r(w) is also referred to as the radius of w. If x and y are two points of
$\theta(w)$
denotes its angle in the complex plane. The quantity r(w) is also referred to as the radius of w. If x and y are two points of
 $\mathbb{H}$
with respective polar coordinates
$\mathbb{H}$
with respective polar coordinates
 $(r,\theta)$
and
$(r,\theta)$
and
 $(s,\beta)$
, the hyperbolic distance between x and y is given by the celebrated hyperbolic law of cosines:
$(s,\beta)$
, the hyperbolic distance between x and y is given by the celebrated hyperbolic law of cosines:
 \begin{align}\cosh(d_{\mathbb{H}}(x,y)) = \cosh(r)\cosh(s) - \sinh(r)\sinh(s)\cos(\theta - \beta).\end{align}
\begin{align}\cosh(d_{\mathbb{H}}(x,y)) = \cosh(r)\cosh(s) - \sinh(r)\sinh(s)\cos(\theta - \beta).\end{align}
For visualization purposes, we use the native representation to draw pictures of the RHG, as done in [Reference Krioukov, Papadopoulos, Kitsak, Vahdat and Boguñá17]. This means that instead of representing the RHG directly in
 $\mathbb{H}$
, we represent its image under the mapping
$\mathbb{H}$
, we represent its image under the mapping
 $\omega \mapsto r(w)\mathrm{e}^{i\theta(w)}$
, defined from
$\omega \mapsto r(w)\mathrm{e}^{i\theta(w)}$
, defined from
 $\mathbb{H}$
to
$\mathbb{H}$
to
 $\mathbb{C}$
. This transformation dilates all distances to the origin, ensuring that every point
$\mathbb{C}$
. This transformation dilates all distances to the origin, ensuring that every point
 $(r,\theta)$
is represented with a Euclidean distance to the origin equal to its radial coordinate r.
$(r,\theta)$
is represented with a Euclidean distance to the origin equal to its radial coordinate r.
For a point x with polar coordinates
 $(r,\theta)$
in
$(r,\theta)$
in
 $\mathbb{H}$
and a radius
$\mathbb{H}$
and a radius
 $s > 0$
, we denote by
$s > 0$
, we denote by
 $\mathcal{B}_{x}(s)$
or
$\mathcal{B}_{x}(s)$
or
 $\mathcal{B}_{(r,\theta)}(s)$
the open hyperbolic ball of radius s centred at x. For
$\mathcal{B}_{(r,\theta)}(s)$
the open hyperbolic ball of radius s centred at x. For
 $0 < r_1 < r_2$
, we define
$0 < r_1 < r_2$
, we define
 $\mathcal{C}(r_1,r_2)$
as the annulus with inner radius
$\mathcal{C}(r_1,r_2)$
as the annulus with inner radius
 $r_1$
and outer radius
$r_1$
and outer radius
 $r_2$
, i.e.
$r_2$
, i.e.
 $\mathcal{C}(r_1,r_2)\;:\!=\; \mathcal{B}_{0}(r_2) \setminus \mathcal{B}_{0}(r_1)$
.
$\mathcal{C}(r_1,r_2)\;:\!=\; \mathcal{B}_{0}(r_2) \setminus \mathcal{B}_{0}(r_1)$
.
2.2. RHG
We now proceed with the formal definition of the RHG
 $\mathcal{G}_{\alpha,\nu}(n)$
, as defined in [Reference Krioukov, Papadopoulos, Kitsak, Vahdat and Boguñá17]. Fix two parameters
$\mathcal{G}_{\alpha,\nu}(n)$
, as defined in [Reference Krioukov, Papadopoulos, Kitsak, Vahdat and Boguñá17]. Fix two parameters
 $\alpha > 0$
and
$\alpha > 0$
and
 $\nu > 0$
and, for
$\nu > 0$
and, for
 $n \in \mathbb{N}^*$
, set
$n \in \mathbb{N}^*$
, set
 \begin{align}R_n \;:\!=\; 2\log\bigg(\frac{n}{\nu}\bigg).\end{align}
\begin{align}R_n \;:\!=\; 2\log\bigg(\frac{n}{\nu}\bigg).\end{align}
Define a probability measure
 $\mu_n$
on
$\mu_n$
on
 $\mathbb{H}$
such that, if a point
$\mathbb{H}$
such that, if a point
 $(r,\theta)$
(in polar coordinates) is chosen according to
$(r,\theta)$
(in polar coordinates) is chosen according to
 $\mu_n$
, then r and
$\mu_n$
, then r and
 $\theta$
are independent,
$\theta$
are independent,
 $\theta$
is uniformly distributed in
$\theta$
is uniformly distributed in
 $(-\pi,\pi]$
, and the probability distribution of r has a density function on
$(-\pi,\pi]$
, and the probability distribution of r has a density function on
 $\mathbb{R}_+$
given by
$\mathbb{R}_+$
given by
 \begin{align}\rho_n(r) \;:\!=\; \frac{\alpha \sinh(\alpha r)}{\cosh(\alpha R_n) - 1} \textbf{1}_{\{r < R_n\}}.\end{align}
\begin{align}\rho_n(r) \;:\!=\; \frac{\alpha \sinh(\alpha r)}{\cosh(\alpha R_n) - 1} \textbf{1}_{\{r < R_n\}}.\end{align}
Let
 $X_1^n,X_2^n,\dots,X_n^n$
be a sequence of n independent points sampled from the Poincaré disc according to the distribution
$X_1^n,X_2^n,\dots,X_n^n$
be a sequence of n independent points sampled from the Poincaré disc according to the distribution
 $\mu_n$
(for brevity, the superscript n in
$\mu_n$
(for brevity, the superscript n in
 $X_i^n$
will often be omitted). We denote by
$X_i^n$
will often be omitted). We denote by
 $\mathcal{G}_{\alpha,\nu}(n)$
the RHG with n nodes and parameters
$\mathcal{G}_{\alpha,\nu}(n)$
the RHG with n nodes and parameters
 $\alpha$
and
$\alpha$
and
 $\nu$
. It is defined as the undirected graph with nodes at the points
$\nu$
. It is defined as the undirected graph with nodes at the points
 $X_1^n,X_2^n,\dots,X_n^n$
, where an edge exists between two nodes if and only if their hyperbolic distance is at most
$X_1^n,X_2^n,\dots,X_n^n$
, where an edge exists between two nodes if and only if their hyperbolic distance is at most
 $R_n$
. The degree of a node
$R_n$
. The degree of a node
 $X_i$
in the graph
$X_i$
in the graph
 $\mathcal{G}_{\alpha,\nu}(n)$
is defined as the number of its direct neighbours in
$\mathcal{G}_{\alpha,\nu}(n)$
is defined as the number of its direct neighbours in
 $\mathcal{G}_{\alpha,\nu}(n)$
and is denoted by
$\mathcal{G}_{\alpha,\nu}(n)$
and is denoted by
 $\deg(X_i)$
. Since we focus on the behaviour of large graphs, the value of n will always be considered large, while the parameters
$\deg(X_i)$
. Since we focus on the behaviour of large graphs, the value of n will always be considered large, while the parameters
 $\alpha$
and
$\alpha$
and
 $\nu$
are fixed.
$\nu$
are fixed.

Figure 1. Simulations of RHGs (native representation) with
 $n = 500$
,
$n = 500$
,
 $\nu = 1$
,
$\nu = 1$
,
 $\alpha = 0.45$
(left),
$\alpha = 0.45$
(left),
 $\alpha = 0.50$
(middle), and
$\alpha = 0.50$
(middle), and
 $\alpha = 0.55$
(right). The boundary of
$\alpha = 0.55$
(right). The boundary of
 $\mathcal{B}_{0}(R_n)$
is represented by a black circle and its centre by a larger dot.
$\mathcal{B}_{0}(R_n)$
is represented by a black circle and its centre by a larger dot.
Observe that the n nodes of the graph
 $\mathcal{G}_{\alpha,\nu}(n)$
are located within
$\mathcal{G}_{\alpha,\nu}(n)$
are located within
 $\mathcal{B}_{0}(R_n)$
. Moreover, due to the choice of the measure, the points tend to concentrate near the boundary of
$\mathcal{B}_{0}(R_n)$
. Moreover, due to the choice of the measure, the points tend to concentrate near the boundary of
 $\mathcal{B}_{0}(R_n)$
. Also note that the measure
$\mathcal{B}_{0}(R_n)$
. Also note that the measure
 $\mu_n(\mathcal{B}_{(r,\theta)}(s))$
of a ball centred at
$\mu_n(\mathcal{B}_{(r,\theta)}(s))$
of a ball centred at
 $(r,\theta)$
is independent of
$(r,\theta)$
is independent of
 $\theta$
. Therefore, we omit the angle
$\theta$
. Therefore, we omit the angle
 $\theta$
to shorten notation and instead write
$\theta$
to shorten notation and instead write
 $\mu_n(\mathcal{B}_{r}(s))$
. Likewise, we write
$\mu_n(\mathcal{B}_{r}(s))$
. Likewise, we write
 $\mu_n(\mathcal{B}_{r}(s) \setminus \mathcal{B}_{0}(s'))$
instead of
$\mu_n(\mathcal{B}_{r}(s) \setminus \mathcal{B}_{0}(s'))$
instead of
 $\mu_n(\mathcal{B}_{(r,\theta)}(s) \setminus \mathcal{B}_{0}(s'))$
.
$\mu_n(\mathcal{B}_{(r,\theta)}(s) \setminus \mathcal{B}_{0}(s'))$
.
In the special case
 $\alpha = 1$
,
$\alpha = 1$
,
 $\mu_n$
is the uniform measure on
$\mu_n$
is the uniform measure on
 $\mathcal{B}_{0}(R_n)$
associated with the Riemannian metric
$\mathcal{B}_{0}(R_n)$
associated with the Riemannian metric
 $\textbf{g}_\mathbb{H}$
. In the general case
$\textbf{g}_\mathbb{H}$
. In the general case
 $\alpha > 0$
,
$\alpha > 0$
,
 $\mu_n$
corresponds to a uniform measure on the hyperbolic plane
$\mu_n$
corresponds to a uniform measure on the hyperbolic plane
 $\mathbb{H}_\alpha$
of curvature
$\mathbb{H}_\alpha$
of curvature
 $-\alpha^2$
. More precisely, for fixed
$-\alpha^2$
. More precisely, for fixed
 $\alpha > 0$
, multiplying the differential form in the Poincaré disc model by a factor
$\alpha > 0$
, multiplying the differential form in the Poincaré disc model by a factor
 ${1}/{\alpha^2}$
, we obtain a hyperbolic plane of curvature
${1}/{\alpha^2}$
, we obtain a hyperbolic plane of curvature
 $-\alpha^2$
. Choosing a point according to the measure
$-\alpha^2$
. Choosing a point according to the measure
 $\mu_n$
amounts to choosing a point uniformly in the ball of radius
$\mu_n$
amounts to choosing a point uniformly in the ball of radius
 $R_n$
of
$R_n$
of
 $\mathbb{H}_\alpha$
and projecting it on
$\mathbb{H}_\alpha$
and projecting it on
 $\mathbb{H}$
, by keeping the same polar coordinates. The measure of a ball of radius r in
$\mathbb{H}$
, by keeping the same polar coordinates. The measure of a ball of radius r in
 $\mathbb{H}_\alpha$
is
$\mathbb{H}_\alpha$
is
 \begin{align*}\frac{2\pi}{\alpha^2}(\!\cosh(\alpha r) - 1);\end{align*}
\begin{align*}\frac{2\pi}{\alpha^2}(\!\cosh(\alpha r) - 1);\end{align*}
thus, the larger
 $\alpha$
is, the faster it increases with r. Therefore, the larger
$\alpha$
is, the faster it increases with r. Therefore, the larger
 $\alpha$
is, the more the points of the graph
$\alpha$
is, the more the points of the graph
 $\mathcal{G}_{\alpha,\nu}(n)$
concentrate near the boundary of
$\mathcal{G}_{\alpha,\nu}(n)$
concentrate near the boundary of
 $\mathcal{B}_{0}(R_n)$
. Thus, the maximum degree is expected to decrease with
$\mathcal{B}_{0}(R_n)$
. Thus, the maximum degree is expected to decrease with
 $\alpha$
(see Figure 1). The degree distribution is also influenced by the parameter
$\alpha$
(see Figure 1). The degree distribution is also influenced by the parameter
 $\nu$
. Increasing
$\nu$
. Increasing
 $\nu$
makes the domain smaller, which limits the concentration of the nodes near the boundary of the domain, resulting in a higher expected degree. In the sparse regime
$\nu$
makes the domain smaller, which limits the concentration of the nodes near the boundary of the domain, resulting in a higher expected degree. In the sparse regime
 $\alpha > \tfrac{1}{2}$
, the expected degree evolves linearly with
$\alpha > \tfrac{1}{2}$
, the expected degree evolves linearly with
 $\nu$
[Reference Gugelmann, Panagiotou and Peter14].
$\nu$
[Reference Gugelmann, Panagiotou and Peter14].
The Poissonised RHG
 $\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
is obtained by choosing the nodes according to a Poisson point process with intensity measure
$\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
is obtained by choosing the nodes according to a Poisson point process with intensity measure
 $n\mu_n$
, instead of choosing n points according to the measure
$n\mu_n$
, instead of choosing n points according to the measure
 $\mu_n$
. All the results proved in this paper also hold for the Poissonised model. In the proof of the non-ordering result (3.2), the use of a classical Poissonisation/de-Poissonisation procedure allows us to avoid some technicalities by using the properties of Poisson processes.
$\mu_n$
. All the results proved in this paper also hold for the Poissonised model. In the proof of the non-ordering result (3.2), the use of a classical Poissonisation/de-Poissonisation procedure allows us to avoid some technicalities by using the properties of Poisson processes.
3. Results
3.1. Ordering of large degrees
We denote by
 $X_{(1)}^n,X_{(2)}^n,\dots,X_{(n)}^n$
a reordering of the nodes of
$X_{(1)}^n,X_{(2)}^n,\dots,X_{(n)}^n$
a reordering of the nodes of
 $\mathcal{G}_{\alpha,\nu}(n)$
by increasing radius, i.e.
$\mathcal{G}_{\alpha,\nu}(n)$
by increasing radius, i.e.
 $r(X_{(1)}^n) \leq r(X_{(2)}^n) \leq \cdots \leq r(X_{(n)}^n)$
. To shorten notation, we often omit the superscript n. Our first result shows that this ranking of the nodes coincide with the ranking of the nodes by decreasing degree, at least up to any constant rank. We say that an event occurs with high probability if its probability tends to 1 as
$r(X_{(1)}^n) \leq r(X_{(2)}^n) \leq \cdots \leq r(X_{(n)}^n)$
. To shorten notation, we often omit the superscript n. Our first result shows that this ranking of the nodes coincide with the ranking of the nodes by decreasing degree, at least up to any constant rank. We say that an event occurs with high probability if its probability tends to 1 as
 $n \to \infty$
.
$n \to \infty$
.
Theorem 3.1. For fixed
 $\alpha > 0$
,
$\alpha > 0$
,
 $\nu > 0$
, and
$\nu > 0$
, and
 $k \in \mathbb{N}^*$
, the following event occurs with high probability:
$k \in \mathbb{N}^*$
, the following event occurs with high probability:
 \begin{align*}\deg(X_{(1)}^n) > \deg(X_{(2)}^n) > \cdots > \deg(X_{(k)}^n) > \deg(X_{(i)}^n) \quad\textit{for all }i > k.\end{align*}
\begin{align*}\deg(X_{(1)}^n) > \deg(X_{(2)}^n) > \cdots > \deg(X_{(k)}^n) > \deg(X_{(i)}^n) \quad\textit{for all }i > k.\end{align*}
In the regime
 $\alpha > \tfrac{1}{2}$
, we will even prove the following result, which provides an estimate of the rank at which the ranking of the nodes by increasing radius and the ranking of the nodes by decreasing degree cease to coincide. We believe that similar polynomial rank orderings hold in the other regimes, but we choose to present this refined result only for the case
$\alpha > \tfrac{1}{2}$
, we will even prove the following result, which provides an estimate of the rank at which the ranking of the nodes by increasing radius and the ranking of the nodes by decreasing degree cease to coincide. We believe that similar polynomial rank orderings hold in the other regimes, but we choose to present this refined result only for the case
 $\alpha > \tfrac{1}{2}$
to avoid additional computations.
$\alpha > \tfrac{1}{2}$
to avoid additional computations.
Theorem 3.2. Let us fix
 $\alpha > \tfrac{1}{2}$
,
$\alpha > \tfrac{1}{2}$
,
 $\nu > 0$
, and a sequence
$\nu > 0$
, and a sequence
 $a_n \to \infty$
. Define
$a_n \to \infty$
. Define
 \begin{align*}\beta \;:\!=\; \frac{1}{1+8\alpha} \quad {\textit{and}} \quad k_n &\;:\!=\; n^{\beta} \log(n)^{-2\alpha}.\end{align*}
\begin{align*}\beta \;:\!=\; \frac{1}{1+8\alpha} \quad {\textit{and}} \quad k_n &\;:\!=\; n^{\beta} \log(n)^{-2\alpha}.\end{align*}
We have, with high probability,
 \begin{align}\deg(X_{(1)}^n) > \deg(X_{(2)}^n) &> \cdots > \deg(X_{(k_n)}^n) > \deg(X_{(i)}^n) \quad \text{for all }i>k_n,\end{align}
\begin{align}\deg(X_{(1)}^n) > \deg(X_{(2)}^n) &> \cdots > \deg(X_{(k_n)}^n) > \deg(X_{(i)}^n) \quad \text{for all }i>k_n,\end{align}
and there exists
 $i \in [n^{\beta},n^{\beta}a_n]$
such that
$i \in [n^{\beta},n^{\beta}a_n]$
such that
 \begin{align}\deg(X_{(i)}^n) < \deg(X_{(i+1)}^n).\end{align}
\begin{align}\deg(X_{(i)}^n) < \deg(X_{(i+1)}^n).\end{align}
If we choose
 $a_n = \log(n)$
, the result shows that, with high probability, the ordering of the degrees holds up to rank
$a_n = \log(n)$
, the result shows that, with high probability, the ordering of the degrees holds up to rank
 $n^{\beta-o(1)}$
and fails before rank
$n^{\beta-o(1)}$
and fails before rank
 $n^{\beta + o(1)}$
. This proves the optimality of the exponent
$n^{\beta + o(1)}$
. This proves the optimality of the exponent
 $\beta$
as the ordering exponent.
$\beta$
as the ordering exponent.
The ordering results above show that the position of a node in the underlying hyperbolic space is a precise estimate of its position in the hierarchy of hubs. This is natural, as the degrees of the k closest nodes to the centre stochastically dominate the degrees of the
 $n-k$
following nodes. However, this observation alone is insufficient to prove our ordering results, since having more connections than these
$n-k$
following nodes. However, this observation alone is insufficient to prove our ordering results, since having more connections than these
 $n-k$
nodes requires competing with a polynomial number of nodes. For example, in the random recursive tree model, similar ordering results do not hold: the root has the highest expected degree but does not necessarily have the highest degree (see [Reference Devroye and Lu12]). In RHGs we use the fast decay of degree with distance to the centre to show that the k (or
$n-k$
nodes requires competing with a polynomial number of nodes. For example, in the random recursive tree model, similar ordering results do not hold: the root has the highest expected degree but does not necessarily have the highest degree (see [Reference Devroye and Lu12]). In RHGs we use the fast decay of degree with distance to the centre to show that the k (or
 $k_n$
) closest nodes to the centre can compete with the remaining
$k_n$
) closest nodes to the centre can compete with the remaining
 $n-k$
(or
$n-k$
(or
 $n-k_n$
) nodes.
$n-k_n$
) nodes.
3.2. Convergence of large degrees
For every subspace E of the compactified real line
 $[\!-\!\infty,\infty]$
, we denote by
$[\!-\!\infty,\infty]$
, we denote by
 $M_p(E)$
the space of locally finite point measures on E. A point process on E is a random element of
$M_p(E)$
the space of locally finite point measures on E. A point process on E is a random element of
 $M_p(E)$
(see [Reference Brémaud7], [Reference Kallenberg15], and [Reference Resnick20] for details on point processes). We denote by ‘
$M_p(E)$
(see [Reference Brémaud7], [Reference Kallenberg15], and [Reference Resnick20] for details on point processes). We denote by ‘
 ${\xrightarrow{d}}$
’ the convergence in distribution (or weak convergence) of point processes in
${\xrightarrow{d}}$
’ the convergence in distribution (or weak convergence) of point processes in
 $M_p(E)$
. We also use the notation ‘
$M_p(E)$
. We also use the notation ‘
 $\xrightarrow{d}$
’ for the convergence in distribution of random variables or random vectors. For
$\xrightarrow{d}$
’ for the convergence in distribution of random variables or random vectors. For
 $x \in [\!-\!\infty,\infty]$
, we write
$x \in [\!-\!\infty,\infty]$
, we write
 $\delta_x$
for the Dirac measure at x.
$\delta_x$
for the Dirac measure at x.
We want to describe the asymptotic behaviour of the point process of node degrees
 $\sum_{i=1}^n \delta_{\deg(X_i^n)}$
. We consider this point process as an element of
$\sum_{i=1}^n \delta_{\deg(X_i^n)}$
. We consider this point process as an element of
 $M_p((0,\infty])$
. Since the interval includes
$M_p((0,\infty])$
. Since the interval includes
 $+\infty$
, this point process captures information about the largest degrees of the graph. Given that the expected value of the maximum degree goes to
$+\infty$
, this point process captures information about the largest degrees of the graph. Given that the expected value of the maximum degree goes to
 $\infty$
with n, we normalise the degree process by a quantity depending on the expected value of the maximum degree. This quantity heavily depends on the curvature parameter
$\infty$
with n, we normalise the degree process by a quantity depending on the expected value of the maximum degree. This quantity heavily depends on the curvature parameter
 $\alpha$
. As with connectivity, a transition occurs at
$\alpha$
. As with connectivity, a transition occurs at
 $\alpha = \tfrac{1}{2}$
: for
$\alpha = \tfrac{1}{2}$
: for
 $\alpha < \tfrac{1}{2}$
, the maximum degree is of order
$\alpha < \tfrac{1}{2}$
, the maximum degree is of order
 $n - O(n^{\alpha + 1/2})$
, whereas for
$n - O(n^{\alpha + 1/2})$
, whereas for
 $\alpha \geq \tfrac{1}{2}$
, the maximum degree is of order
$\alpha \geq \tfrac{1}{2}$
, the maximum degree is of order
 $n^{1/(2\alpha)}$
. This compels us to treat the three regimes
$n^{1/(2\alpha)}$
. This compels us to treat the three regimes
 $\alpha<\tfrac{1}{2}$
,
$\alpha<\tfrac{1}{2}$
,
 $\alpha=\tfrac{1}{2}$
, and
$\alpha=\tfrac{1}{2}$
, and
 $\alpha > \tfrac{1}{2}$
separately. The result below states the convergence in distribution of the normalised point process. We recall that, for
$\alpha > \tfrac{1}{2}$
separately. The result below states the convergence in distribution of the normalised point process. We recall that, for
 $\beta > 0$
, a random variable Z follows the distribution
$\beta > 0$
, a random variable Z follows the distribution
 $\mbox{Weibull}(\beta)$
if, for all
$\mbox{Weibull}(\beta)$
if, for all
 $z \geq 0$
,
$z \geq 0$
,
 $\mathbb{P}[Z \leq z] = 1 - \mathrm{e}^{-z^\beta}$
and it follows the distribution
$\mathbb{P}[Z \leq z] = 1 - \mathrm{e}^{-z^\beta}$
and it follows the distribution
![]() if, for all
if, for all
 $z \geq 0$
,
$z \geq 0$
,
 $\mathbb{P}[Z \leq z] = \mathrm{e}^{-z^{-\beta}}$
.
$\mathbb{P}[Z \leq z] = \mathrm{e}^{-z^{-\beta}}$
.
Theorem 3.3. Let us fix
 $\alpha,\nu > 0$
and denote by
$\alpha,\nu > 0$
and denote by
![]() the maximum degree of the graph
the maximum degree of the graph
 $\mathcal{G}_{\alpha,\nu}(n)$
. We have the following convergences.
$\mathcal{G}_{\alpha,\nu}(n)$
. We have the following convergences.
-
• For
 $\alpha < \tfrac{1}{2}$
,
(3.3)where
\begin{align}\sum_{i=1}^n \delta_{n^{-(\alpha + 1/2)}(\!\deg(X_i^n)-n)} \xrightarrow[n\to\infty]{d} \eta_{g_1}\quad {\textit{in}}\;M_p((\!-\!\infty,0]),\end{align}
$\eta_{g_1}$
is the Poisson process whose intensity measure has density
$g_1$
, given by
In particular,
\begin{align*}g_1(y) = 2 \pi^2 \nu^{2\alpha} |y| \quad\textit{for all }y \in (\!-\!\infty,0].\end{align*}
$\alpha < \tfrac{1}{2}$
,
(3.3)where
\begin{align}\sum_{i=1}^n \delta_{n^{-(\alpha + 1/2)}(\!\deg(X_i^n)-n)} \xrightarrow[n\to\infty]{d} \eta_{g_1}\quad {\textit{in}}\;M_p((\!-\!\infty,0]),\end{align}
$\eta_{g_1}$
is the Poisson process whose intensity measure has density
$g_1$
, given by
In particular,
\begin{align*}g_1(y) = 2 \pi^2 \nu^{2\alpha} |y| \quad\textit{for all }y \in (\!-\!\infty,0].\end{align*}
-
• For
$\alpha = \tfrac{1}{2}$
,
(3.4)where
\begin{align}\sum_{i=1}^n \delta_{n^{-1}\deg(X_i^n)} \xrightarrow[n\to\infty]{d} \eta_{g_2} \quad {\textit{in}}\;M_p((0,1]),\end{align}
$\eta_{g_2}$
is the Poisson process whose intensity measure has density
$g_2$
, given by
where
\begin{align*}g_2(y) = \nu |(V_{1/2}^{-1})'(y)| \sinh\bigg(\frac{V_{1/2}^{-1}(y)}{2}\bigg) \quad \textit{for all } y \in (0,1],\end{align*}
$V_{1/2}$
is the diffeomorphism from
$[0,\infty)$
to (0, 1] defined by
In particular,
\begin{align*}V_{1/2}(r) \;:\!=\; \frac{1}{\pi}\int_0^1 \arccos\bigg(\max\bigg(-1,\frac{\cosh(r) - x^{-2}}{\sinh(r)}\bigg)\bigg) \,\textrm{d}x \quad \textit{for all }r > 0.\end{align*}
-
• For
$\alpha > \tfrac{1}{2}$
,
(3.5)where
\begin{align}\sum_{i=1}^n \delta_{n^{-1/(2\alpha)}\deg(X_i^n)} \xrightarrow[n\to\infty]{d} \eta_{g_3} \quad {\textit{in} }\; M_p((0,\infty]),\end{align}
$\eta_{g_3}$
is the Poisson process whose intensity measure has density
$g_3$
, given by
where
\begin{align*}g_3(y) = 2\alpha (C_{\alpha} \nu)^{2\alpha} y^{-2\alpha-1}\quad \textit{for all } y \in (0,\infty],\end{align*}
$C_{\alpha} \;:\!=\; {2\alpha}/{\pi(\alpha-\tfrac12)}$
. In particular,



















Remark 3.1. Convergence in distribution of a sequence of point processes
 $(\mathcal{P}_n)_{n \in \mathbb{N}}$
towards a point process
$(\mathcal{P}_n)_{n \in \mathbb{N}}$
towards a point process
 $\mathcal{P}$
in
$\mathcal{P}$
in
 $M_p((a,b])$
(with
$M_p((a,b])$
(with
 $a,b \in [\!-\!\infty,\infty]$
) is equivalent to the convergence in distribution of the vectors
$a,b \in [\!-\!\infty,\infty]$
) is equivalent to the convergence in distribution of the vectors
 $(Y_1^n,Y_2^n,\ldots,Y_k^n)$
towards
$(Y_1^n,Y_2^n,\ldots,Y_k^n)$
towards
 $(Y_1,Y_2,\ldots,Y_k)$
in
$(Y_1,Y_2,\ldots,Y_k)$
in
 $\mathbb{R}^k$
for every positive integer k, where
$\mathbb{R}^k$
for every positive integer k, where
 $Y_1^n \geq Y_2^n \geq \cdots \geq Y_k^n$
are the k largest points of
$Y_1^n \geq Y_2^n \geq \cdots \geq Y_k^n$
are the k largest points of
 $\mathcal{P}_n$
and
$\mathcal{P}_n$
and
 $Y_1 \geq Y_2 \geq \cdots \geq Y_k$
are the k largest points of
$Y_1 \geq Y_2 \geq \cdots \geq Y_k$
are the k largest points of
 $\mathcal{P}$
(assuming that
$\mathcal{P}$
(assuming that
 $\mathcal{P}$
almost surely has infinitely many points). One gets a similar characterisation of convergence in distribution in
$\mathcal{P}$
almost surely has infinitely many points). One gets a similar characterisation of convergence in distribution in
 $M_p([a,b))$
by inverting the order. Convergence in distribution in
$M_p([a,b))$
by inverting the order. Convergence in distribution in
 $M_p(E)$
can be characterised in many other ways, such as via the convergence of evaluation functions or the convergence of Laplace transforms (see [Reference Brémaud7], [Reference Kallenberg15], and [Reference Resnick20]).
$M_p(E)$
can be characterised in many other ways, such as via the convergence of evaluation functions or the convergence of Laplace transforms (see [Reference Brémaud7], [Reference Kallenberg15], and [Reference Resnick20]).
In the regime
 $\alpha > \tfrac{1}{2}$
, Theorem 3.3 refines the estimate of
$\alpha > \tfrac{1}{2}$
, Theorem 3.3 refines the estimate of
 $n^{1/(2\alpha)+o(1)}$
for the maximum degree given in [Reference Gugelmann, Panagiotou and Peter14]. It also supplements the description of the scale-free degree sequence presented in the same paper by describing precisely the sequence of the k largest degrees for k fixed. Also note that, in the regime
$n^{1/(2\alpha)+o(1)}$
for the maximum degree given in [Reference Gugelmann, Panagiotou and Peter14]. It also supplements the description of the scale-free degree sequence presented in the same paper by describing precisely the sequence of the k largest degrees for k fixed. Also note that, in the regime
 $\alpha > \tfrac{1}{2}$
, a more general result can be found in [Reference Bhattacharjee and Schulte3], where the convergence towards a Poisson point process with a power law intensity is proven for a general class of scale-free inhomogeneous random graphs. By refining the proof of the representation of the RHG as a GIRG from [Reference Bringmann, Keusch and Lengler8], it can be shown that the RHG in the regime
$\alpha > \tfrac{1}{2}$
, a more general result can be found in [Reference Bhattacharjee and Schulte3], where the convergence towards a Poisson point process with a power law intensity is proven for a general class of scale-free inhomogeneous random graphs. By refining the proof of the representation of the RHG as a GIRG from [Reference Bringmann, Keusch and Lengler8], it can be shown that the RHG in the regime
 $\alpha > \tfrac{1}{2}$
is indeed part of the more general model considered in [Reference Bhattacharjee and Schulte3]. This provides an alternative proof of Theorem 3.3 for
$\alpha > \tfrac{1}{2}$
is indeed part of the more general model considered in [Reference Bhattacharjee and Schulte3]. This provides an alternative proof of Theorem 3.3 for
 $\alpha > \tfrac{1}{2}$
. Note that this result would not hold directly for GIRGs, even with unspecified limit distributions, because the O notation appearing in the definition of the edge probabilities may allow large degrees to oscillate instead of converging. Also note that, in the present paper, we propose proof strategies that work for both the sparse regime
$\alpha > \tfrac{1}{2}$
. Note that this result would not hold directly for GIRGs, even with unspecified limit distributions, because the O notation appearing in the definition of the edge probabilities may allow large degrees to oscillate instead of converging. Also note that, in the present paper, we propose proof strategies that work for both the sparse regime
 $\alpha > \tfrac{1}{2}$
and the dense regime
$\alpha > \tfrac{1}{2}$
and the dense regime
 $\alpha \leq \tfrac{1}{2}$
.
$\alpha \leq \tfrac{1}{2}$
.
In the
 $\alpha < \tfrac{1}{2}$
and
$\alpha < \tfrac{1}{2}$
and
 $\alpha > \tfrac{1}{2}$
cases, we obtain extreme value distribution limits for the maximum degree
$\alpha > \tfrac{1}{2}$
cases, we obtain extreme value distribution limits for the maximum degree
![]() . This is not surprising, as
. This is not surprising, as
![]() is the maximum of a weakly correlated sequence of variables. However, a difficulty in proving a formal result using a standard extreme value theorem (see, for example, [Reference Leadbetter and Rootzén18] and [Reference Resnick20]) arises from the fact that the distribution of the typical degree depends on n. Nevertheless, we can still use extreme value theory to give an intuitive explanation of the limit distributions of
is the maximum of a weakly correlated sequence of variables. However, a difficulty in proving a formal result using a standard extreme value theorem (see, for example, [Reference Leadbetter and Rootzén18] and [Reference Resnick20]) arises from the fact that the distribution of the typical degree depends on n. Nevertheless, we can still use extreme value theory to give an intuitive explanation of the limit distributions of
![]() as follows. In the regime
as follows. In the regime
 $\alpha > \tfrac{1}{2}$
, the limit distribution is easy to interpret since the degree of a typical node converges to a power law with exponent
$\alpha > \tfrac{1}{2}$
, the limit distribution is easy to interpret since the degree of a typical node converges to a power law with exponent
 $2\alpha +1$
, which belongs to the domain of attraction of
$2\alpha +1$
, which belongs to the domain of attraction of
![]() . In the regime
. In the regime
 $\alpha < \tfrac{1}{2}$
, the degree distribution does not converge, but since the largest degrees are attained by nodes that are close to the centre, we can focus on a variable
$\alpha < \tfrac{1}{2}$
, the degree distribution does not converge, but since the largest degrees are attained by nodes that are close to the centre, we can focus on a variable
 $D_n$
distributed as the degree of a typical node in the annulus
$D_n$
distributed as the degree of a typical node in the annulus
 $\mathcal{C}(0,n^{\alpha-1/2 + \varepsilon})$
, with
$\mathcal{C}(0,n^{\alpha-1/2 + \varepsilon})$
, with
 $\varepsilon > 0$
small. A direct computation using Lemma 5.4 shows that
$\varepsilon > 0$
small. A direct computation using Lemma 5.4 shows that
 $(n-D_n)n^{-(1/2+\alpha+\varepsilon)}$
converges in distribution towards the inverse of a power law with exponent 1, which belongs to the domain of attraction of
$(n-D_n)n^{-(1/2+\alpha+\varepsilon)}$
converges in distribution towards the inverse of a power law with exponent 1, which belongs to the domain of attraction of
 $\mbox{Weibull}(2)$
. Similar arguments using polynomial normalisations cannot hold in the regime
$\mbox{Weibull}(2)$
. Similar arguments using polynomial normalisations cannot hold in the regime
 $\alpha = \tfrac{1}{2}$
as, in this regime, the highest degrees are too much influenced by the geometry of the model. The influence of the geometry can be seen in the function
$\alpha = \tfrac{1}{2}$
as, in this regime, the highest degrees are too much influenced by the geometry of the model. The influence of the geometry can be seen in the function
 $V_{\scriptscriptstyle 1/2}(2\textrm{arcosh}(\cdot+1))$
appearing in the limit and explains why we do not obtain an extreme value distribution in this case.
$V_{\scriptscriptstyle 1/2}(2\textrm{arcosh}(\cdot+1))$
appearing in the limit and explains why we do not obtain an extreme value distribution in this case.
In a soft version of the RHG model [Reference Boguñá, Papadopoulos and Krioukov6], the threshold rule for connection is replaced by the following connection rule: conditionally on their positions, the two nodes
 $X_i$
and
$X_i$
and
 $X_j$
are connected with probability
$X_j$
are connected with probability
 \begin{align*}p_{ij} = \frac{1}{1 + \exp((d_{\mathbb{H}}(X_i,X_j) - R_n)/(2T))},\end{align*}
\begin{align*}p_{ij} = \frac{1}{1 + \exp((d_{\mathbb{H}}(X_i,X_j) - R_n)/(2T))},\end{align*}
where
 $T>0$
is a temperature parameter. We recover our initial model by taking the limit
$T>0$
is a temperature parameter. We recover our initial model by taking the limit
 $T \to 0$
in the soft model. We believe that the results of Theorems 3.1 and 3.3 remain valid in the soft model (with different limit distributions in Theorem 3.3), as the expected degrees of the nodes should stay of the same order in the soft model. In the
$T \to 0$
in the soft model. We believe that the results of Theorems 3.1 and 3.3 remain valid in the soft model (with different limit distributions in Theorem 3.3), as the expected degrees of the nodes should stay of the same order in the soft model. In the
 $\alpha > \tfrac{1}{2}$
case, this can be proven by combining [Reference Bhattacharjee and Schulte3] and [Reference Bringmann, Keusch and Lengler8]. The computation of the limit measures in the soft case would require replacing volume estimates with estimates of the integrals of the connection probability, so as to approximate the expected degrees of the nodes under the new connection rule.
$\alpha > \tfrac{1}{2}$
case, this can be proven by combining [Reference Bhattacharjee and Schulte3] and [Reference Bringmann, Keusch and Lengler8]. The computation of the limit measures in the soft case would require replacing volume estimates with estimates of the integrals of the connection probability, so as to approximate the expected degrees of the nodes under the new connection rule.
3.2.1. Landau’s notation.
In this paper, we use the Landau notation o and O to describe the asymptotic behaviour of certain quantities as the number of nodes n tends to
 $\infty.$
Specifically, we use a version of this notation that allows us to express uniformity in some other variables
$\infty.$
Specifically, we use a version of this notation that allows us to express uniformity in some other variables
 $y_1,y_2,\ldots,y_d$
. More precisely, for
$y_1,y_2,\ldots,y_d$
. More precisely, for
 $(J_n)_{n \in \mathbb{N}}$
, a sequence of subsets of
$(J_n)_{n \in \mathbb{N}}$
, a sequence of subsets of
 $\mathbb{R}^d$
and two functions
$\mathbb{R}^d$
and two functions
 $f,g\colon\mathbb{N} \times \mathbb{R}^d \to \mathbb{R}$
, we write
$f,g\colon\mathbb{N} \times \mathbb{R}^d \to \mathbb{R}$
, we write
 \begin{align*}g(n,y) = o_{y \in J_n}(f(n,y)) \quad \mbox{if} \quad \forall \varepsilon > 0, \exists n_0, \forall n \geq n_0, \forall y \in J_n,\, |g(n,y)| \leq \varepsilon |f(n,y)|,\end{align*}
\begin{align*}g(n,y) = o_{y \in J_n}(f(n,y)) \quad \mbox{if} \quad \forall \varepsilon > 0, \exists n_0, \forall n \geq n_0, \forall y \in J_n,\, |g(n,y)| \leq \varepsilon |f(n,y)|,\end{align*}
and we write
 \begin{align*}g(n,y) = O_{y \in J_n}(f(n,y)) \quad \mbox{if} \quad \exists c > 0, \exists n_0, \forall n \geq n_0, \forall y \in J_n,\, |g(n,y)| \leq c |f(n,y)|.\end{align*}
\begin{align*}g(n,y) = O_{y \in J_n}(f(n,y)) \quad \mbox{if} \quad \exists c > 0, \exists n_0, \forall n \geq n_0, \forall y \in J_n,\, |g(n,y)| \leq c |f(n,y)|.\end{align*}
Note that the subscript ‘
 $y \in J_n$
’ indicates that the comparison holds uniformly for y in the set
$y \in J_n$
’ indicates that the comparison holds uniformly for y in the set
 $J_n$
as n tends to
$J_n$
as n tends to
 $\infty.$
To simplify notation, this subscript is specified beforehand and omitted in most cases. When f and g are functions of the variable n only, we keep the same definitions.
$\infty.$
To simplify notation, this subscript is specified beforehand and omitted in most cases. When f and g are functions of the variable n only, we keep the same definitions.
4. Convergence of the radii
The particularity of RHGs, compared with graphs constructed in Euclidean spaces, is that the degree of a node strongly depends on its position in the underlying space, specifically on its radius. In this section we study the asymptotic behaviour of the radii of the closest points to the centre by proving the convergence of the point process of the radii
 $\sum_{i=1}^n \delta_{r(X_i^n)}$
in
$\sum_{i=1}^n \delta_{r(X_i^n)}$
in
 $M_p([0,\infty))$
. Since the interval includes 0, this point process captures information about the smallest degrees of the graph (see Remark 3.1). As in Theorem 3.1, normalisation by the expected value of the smallest radius is required.
$M_p([0,\infty))$
. Since the interval includes 0, this point process captures information about the smallest degrees of the graph (see Remark 3.1). As in Theorem 3.1, normalisation by the expected value of the smallest radius is required.
Proposition 4.1. We have the following convergences.
-
• For
$\alpha < \tfrac{1}{2}$
,
where
\begin{align*}\sum\limits_{i=1}^n \delta_{n^{1/2-\alpha}r(X_i^n)} \xrightarrow[n\to\infty]{d} \eta_{\gamma_1} \quad {\textit{in}}\;M_p([0,\infty)),\end{align*}
$\eta_{\gamma_1}$
is the Poisson process whose intensity measure has density
$\gamma_1$
, given by
\begin{align*}\gamma_1(u) = 2 \alpha^2 \nu^{2\alpha} u\quad\textit{for all } u \in [0,\infty).\end{align*}
-
• For
$\alpha = \tfrac{1}{2}$
,
where
\begin{align*}\sum_{i=1}^n \delta_{r(X_i^n)} \xrightarrow[n\to\infty]{d} \eta_{\gamma_2} \quad {\textit{in}}\;M_p([0,\infty)),\end{align*}
$\eta_{\gamma_2}$
is the Poisson process whose intensity measure has density
$\gamma_2$
, given by
\begin{align*}\gamma_2(u) = \nu \sinh\bigg(\frac{u}{2}\bigg) \quad\textit{for all } u \in [0, \infty).\end{align*}
-
• For
$\alpha > \tfrac{1}{2}$
,
where
\begin{align*}\sum\limits_{i=1}^n \delta_{r(X_i^n) - (1-1/(2\alpha))R_n} \xrightarrow[n\to\infty]{d} \eta_{\gamma_3} \quad {\textit{in}}\;M_p([\!-\!\infty,\infty)),\end{align*}
$\eta_{\gamma_3}$
is the Poisson process whose intensity measure has density
$\gamma_3$
, given by
\begin{align*}\gamma_3(u) = \alpha \nu \mathrm{e}^{\alpha u} \quad\textit{for all } u \in [\!-\!\infty, \infty).\end{align*}















Proof. We introduce the functions
 $\gamma_1$
,
$\gamma_1$
,
 $\gamma_2$
, and
$\gamma_2$
, and
 $\gamma_3$
exactly like in the statement of Proposition 4.1. For E a subspace of
$\gamma_3$
exactly like in the statement of Proposition 4.1. For E a subspace of
 $[\!-\!\infty,\infty]$
, let us write
$[\!-\!\infty,\infty]$
, let us write
 $C_K^+(E)$
for the set of continuous, real-valued and non-negative functions on E with compact support. We begin with the
$C_K^+(E)$
for the set of continuous, real-valued and non-negative functions on E with compact support. We begin with the
 $\alpha < \tfrac{1}{2}$
case. Fix
$\alpha < \tfrac{1}{2}$
case. Fix
 $\varphi \in C_K^+([0,\infty))$
. By a simple change of variables, we get
$\varphi \in C_K^+([0,\infty))$
. By a simple change of variables, we get
 \begin{align*}n \mathbb{E}[\varphi(n^{1/2-\alpha}r(X_1^n))]&= n \int_0^\infty \varphi(n^{1/2-\alpha}r) \rho_n(r) \,\textrm{d}r\\&= \int_0^\infty \varphi(u) \frac{\alpha \sinh(\alpha u n^{\alpha-1/2})}{\cosh(\alpha R_n) - 1} n^{1/2+\alpha} \textbf{1}_{\{u \leq n^{1/2-\alpha} R_n\}} \,\textrm{d}u.\end{align*}
\begin{align*}n \mathbb{E}[\varphi(n^{1/2-\alpha}r(X_1^n))]&= n \int_0^\infty \varphi(n^{1/2-\alpha}r) \rho_n(r) \,\textrm{d}r\\&= \int_0^\infty \varphi(u) \frac{\alpha \sinh(\alpha u n^{\alpha-1/2})}{\cosh(\alpha R_n) - 1} n^{1/2+\alpha} \textbf{1}_{\{u \leq n^{1/2-\alpha} R_n\}} \,\textrm{d}u.\end{align*}
Using the fact that
 $\sinh(x) \sim x$
for x close to 0 and that
$\sinh(x) \sim x$
for x close to 0 and that
 $\cosh(\alpha R_n) \sim \frac{1}{2}(n/\nu)^{2 \alpha}$
for large n, we get by the dominated convergence theorem,
$\cosh(\alpha R_n) \sim \frac{1}{2}(n/\nu)^{2 \alpha}$
for large n, we get by the dominated convergence theorem,
 \begin{align}n \mathbb{E}[\varphi(n^{1/2-\alpha}r(X_1^n))] \xrightarrow[n\to\infty]{} \int_0^\infty \varphi(u) \gamma_1(u) \,\textrm{d}u.\end{align}
\begin{align}n \mathbb{E}[\varphi(n^{1/2-\alpha}r(X_1^n))] \xrightarrow[n\to\infty]{} \int_0^\infty \varphi(u) \gamma_1(u) \,\textrm{d}u.\end{align}
Note that the above states that the measures
 $n \mathbb{P}[n^{1/2-\alpha}r(X_1^n) \in \cdot]$
converge vaguely on
$n \mathbb{P}[n^{1/2-\alpha}r(X_1^n) \in \cdot]$
converge vaguely on
 $[0,\infty)$
towards a measure with density
$[0,\infty)$
towards a measure with density
 $\gamma_1$
with respect to the Lebesgue measure. For all
$\gamma_1$
with respect to the Lebesgue measure. For all
 $n \in \mathbb{N}^*$
, we denote by
$n \in \mathbb{N}^*$
, we denote by
 $\Psi_n$
the Laplace functional associated with the point process
$\Psi_n$
the Laplace functional associated with the point process
 $\sum_{i=1}^n \delta_{n^{1/2-\alpha}r(X_i^n)}$
and we denote by
$\sum_{i=1}^n \delta_{n^{1/2-\alpha}r(X_i^n)}$
and we denote by
 $\Psi$
the Laplace functional associated with
$\Psi$
the Laplace functional associated with
 $\eta_{\gamma_1}$
. Since the variables
$\eta_{\gamma_1}$
. Since the variables
 $r(X_1^n),\ldots,r(X_n^n)$
are independent, it follows from (4.1) and a classical computation that, for all
$r(X_1^n),\ldots,r(X_n^n)$
are independent, it follows from (4.1) and a classical computation that, for all
 $f \in C_K^+([0,\infty))$
,
$f \in C_K^+([0,\infty))$
,
 $\Psi_n(f) \to \Psi(f)$
(see [Reference Resnick20, Proposition 3.21] for a detailed computation). This is sufficient to establish the desired convergence in distribution for
$\Psi_n(f) \to \Psi(f)$
(see [Reference Resnick20, Proposition 3.21] for a detailed computation). This is sufficient to establish the desired convergence in distribution for
 $\alpha < \tfrac{1}{2}$
.
$\alpha < \tfrac{1}{2}$
.
In the
 $\alpha = \tfrac{1}{2}$
case, for
$\alpha = \tfrac{1}{2}$
case, for
 $\varphi \in C_K^+([0,\infty))$
, we have
$\varphi \in C_K^+([0,\infty))$
, we have
 \begin{align*}n \mathbb{E}[\varphi(r(X_1^n))]&= n \int_0^\infty \varphi(r) \frac{\sinh(r/2)}{2(\!\cosh(R_n/2) - 1)}\textbf{1}_{\{r \leq R_n\}}\,\textrm{d}r\\&\xrightarrow[n\to\infty]{} \int_0^\infty \varphi(r) \gamma_2(r) \,\textrm{d}r,\end{align*}
\begin{align*}n \mathbb{E}[\varphi(r(X_1^n))]&= n \int_0^\infty \varphi(r) \frac{\sinh(r/2)}{2(\!\cosh(R_n/2) - 1)}\textbf{1}_{\{r \leq R_n\}}\,\textrm{d}r\\&\xrightarrow[n\to\infty]{} \int_0^\infty \varphi(r) \gamma_2(r) \,\textrm{d}r,\end{align*}
where the convergence follows from approximating
 $\cosh(R_n/2)$
by
$\cosh(R_n/2)$
by
 $n/(2\nu)$
and applying the dominated convergence theorem. Thus, we can conclude exactly like in the
$n/(2\nu)$
and applying the dominated convergence theorem. Thus, we can conclude exactly like in the
 $\alpha < \tfrac{1}{2}$
case.
$\alpha < \tfrac{1}{2}$
case.
In the
 $\alpha > \tfrac{1}{2}$
case, a simple change of variables gives, for
$\alpha > \tfrac{1}{2}$
case, a simple change of variables gives, for
 $\varphi \in C_K^+([\!-\!\infty,\infty))$
,
$\varphi \in C_K^+([\!-\!\infty,\infty))$
,
 \begin{align}n \mathbb{E}\bigg[\varphi\bigg(r(X_1^n) - \bigg(1-\frac{1}{2\alpha}\bigg)R_n\bigg)\bigg]&= n \int_0^\infty \varphi\bigg(r - \bigg(1-\frac{1}{2\alpha}\bigg)R_n\bigg) \rho_n(r) \,\textrm{d}r \notag\\&= \int_{-(1-{1}/{2\alpha}) R_n}^{R_n / (2\alpha)} \varphi(u) \frac{\alpha n \sinh(\alpha (u + (1-{1}/{2\alpha})R_n))}{\cosh(\alpha R_n) - 1} \,\textrm{d}u.\end{align}
\begin{align}n \mathbb{E}\bigg[\varphi\bigg(r(X_1^n) - \bigg(1-\frac{1}{2\alpha}\bigg)R_n\bigg)\bigg]&= n \int_0^\infty \varphi\bigg(r - \bigg(1-\frac{1}{2\alpha}\bigg)R_n\bigg) \rho_n(r) \,\textrm{d}r \notag\\&= \int_{-(1-{1}/{2\alpha}) R_n}^{R_n / (2\alpha)} \varphi(u) \frac{\alpha n \sinh(\alpha (u + (1-{1}/{2\alpha})R_n))}{\cosh(\alpha R_n) - 1} \,\textrm{d}u.\end{align}
Moreover, there exists
 $K > 0$
such that, for all sufficiently large
$K > 0$
such that, for all sufficiently large
 $n \in \mathbb{N}^*$
and all
$n \in \mathbb{N}^*$
and all
 $u \in \mathbb{R}$
,
$u \in \mathbb{R}$
,
 \begin{align*}\varphi(u) \frac{\alpha n \sinh(\alpha (u + (1-{1}/{2\alpha})R_n))}{\cosh(\alpha R_n) - 1} \leq K \varphi(u) \exp(\alpha u).\end{align*}
\begin{align*}\varphi(u) \frac{\alpha n \sinh(\alpha (u + (1-{1}/{2\alpha})R_n))}{\cosh(\alpha R_n) - 1} \leq K \varphi(u) \exp(\alpha u).\end{align*}
The bound above is integrable on
 $\mathbb{R}$
. Applying the dominated convergence theorem to (4.2) and using the fact that
$\mathbb{R}$
. Applying the dominated convergence theorem to (4.2) and using the fact that
 $\cosh(x) \sim \mathrm{e}^{x}/2$
and
$\cosh(x) \sim \mathrm{e}^{x}/2$
and
 $\sinh(x) \sim \mathrm{e}^{x}/2$
for large x, we get
$\sinh(x) \sim \mathrm{e}^{x}/2$
for large x, we get
 \begin{align*}n \mathbb{E}\bigg[\varphi\bigg(r(X_1^n) - \bigg(1-\frac{1}{2\alpha}\bigg)R_n\bigg)\bigg] \xrightarrow[n\to\infty]{} \int_{-\infty}^{\infty} \varphi(u) \gamma_3(u) \,\textrm{d}u.\end{align*}
\begin{align*}n \mathbb{E}\bigg[\varphi\bigg(r(X_1^n) - \bigg(1-\frac{1}{2\alpha}\bigg)R_n\bigg)\bigg] \xrightarrow[n\to\infty]{} \int_{-\infty}^{\infty} \varphi(u) \gamma_3(u) \,\textrm{d}u.\end{align*}
We conclude exactly like in the
 $\alpha < \tfrac{1}{2}$
case.
$\alpha < \tfrac{1}{2}$
case.
5. Measures of the connection balls
A node in the RHG
 $\mathcal{G}_{\alpha,\nu}(n)$
is connected to all other nodes that are at a distance smaller than
$\mathcal{G}_{\alpha,\nu}(n)$
is connected to all other nodes that are at a distance smaller than
 $R_n$
from it. Thus, conditionally on the position of the node X, the degree of X follows a binomial distribution with
$R_n$
from it. Thus, conditionally on the position of the node X, the degree of X follows a binomial distribution with
 $n-1$
trials and success probability
$n-1$
trials and success probability
 $\mu_n(\mathcal{B}_{r(X)}(R_n))$
. The previous section gives a good understanding of the radii of the closest nodes to the centre
$\mu_n(\mathcal{B}_{r(X)}(R_n))$
. The previous section gives a good understanding of the radii of the closest nodes to the centre
 $r(X_{(1)})$
. In order to obtain information about the degrees of the closest nodes to the centre, we now study
$r(X_{(1)})$
. In order to obtain information about the degrees of the closest nodes to the centre, we now study
 $\mu_n(\mathcal{B}_{r}(R_n))$
as a function of r. Unfortunately, this quantity cannot be expressed by a tractable closed-form formula. However, since we are principally concerned with the asymptotic behaviour of
$\mu_n(\mathcal{B}_{r}(R_n))$
as a function of r. Unfortunately, this quantity cannot be expressed by a tractable closed-form formula. However, since we are principally concerned with the asymptotic behaviour of
 $\mathcal{G}_{\alpha,\nu}(n)$
as
$\mathcal{G}_{\alpha,\nu}(n)$
as
 $n \to \infty$
, it is sufficient to provide approximations of this quantity.
$n \to \infty$
, it is sufficient to provide approximations of this quantity.

Figure 2. Depiction of a ball
 $\mathcal{B}_{X}(R_n)$
(native representation).
$\mathcal{B}_{X}(R_n)$
(native representation).
Before dealing with quantitative results, we state the following lemma, which gives an intuitive inclusion between hyperbolic balls. Its proof follows readily from [Reference Bode, Fountoulakis and Müller4, Lemma 2.3]. The fact that
 $\mu_n(\mathcal{B}_{r}(R_n))$
decreases with r shows that the expected degree of a node X is a decreasing function of r(X). Indeed, we can see in Figure 1 that the ball
$\mu_n(\mathcal{B}_{r}(R_n))$
decreases with r shows that the expected degree of a node X is a decreasing function of r(X). Indeed, we can see in Figure 1 that the ball
 $\mathcal{B}_{X}(R_n)$
is not entirely contained in the domain
$\mathcal{B}_{X}(R_n)$
is not entirely contained in the domain
 $\mathcal{B}_{0}(R_n)$
. If we let r(X) increase, then more mass is lost outside the domain
$\mathcal{B}_{0}(R_n)$
. If we let r(X) increase, then more mass is lost outside the domain
 $\mathcal{B}_{0}(R_n)$
, leading to a smaller expected degree. This strongly suggests that the nodes with the highest degrees are likely to be located near the origin of the underlying space.
$\mathcal{B}_{0}(R_n)$
, leading to a smaller expected degree. This strongly suggests that the nodes with the highest degrees are likely to be located near the origin of the underlying space.
Lemma 5.1 (Lemma 2.3 of [Reference Bode, Fountoulakis and Müller4].) For all
 $\alpha,\nu > 0$
,
$\alpha,\nu > 0$
,
 $n \in \mathbb{N}^*$
, and
$n \in \mathbb{N}^*$
, and
 $0\leq r \leq r' \leq R_n$
, the following holds:
$0\leq r \leq r' \leq R_n$
, the following holds:
 \begin{align*}\mathcal{B}_{(r',0)}(R_n) \cap \mathcal{B}_{0}(R_n) \subset \mathcal{B}_{(r,0)}(R_n) \cap \mathcal{B}_{0}(R_n).\end{align*}
\begin{align*}\mathcal{B}_{(r',0)}(R_n) \cap \mathcal{B}_{0}(R_n) \subset \mathcal{B}_{(r,0)}(R_n) \cap \mathcal{B}_{0}(R_n).\end{align*}
In particular, the function
 $r \mapsto \mu_n(\mathcal{B}_{r}(R_n))$
is decreasing.
$r \mapsto \mu_n(\mathcal{B}_{r}(R_n))$
is decreasing.
Now, to get quantitative results on
 $\mu_n(\mathcal{B}_{r(X)}(R_n))$
, we first give an integral expression of
$\mu_n(\mathcal{B}_{r(X)}(R_n))$
, we first give an integral expression of
 $\mu_n(\mathcal{B}_{r}(R_n))$
for
$\mu_n(\mathcal{B}_{r}(R_n))$
for
 $r \in [0,R_n)$
. In the following definitions, we take
$r \in [0,R_n)$
. In the following definitions, we take
 $\alpha >0$
and we fix an integer
$\alpha >0$
and we fix an integer
 $n \in \mathbb{N}^*$
. We also take r and y in
$n \in \mathbb{N}^*$
. We also take r and y in
 $[0,R_n)$
. Using polar coordinates for points in the Poincaré disc, we define the set
$[0,R_n)$
. Using polar coordinates for points in the Poincaré disc, we define the set
 $I_y(r)$
by
$I_y(r)$
by
 \begin{align*}I_y(r) \;:\!=\; \{\theta \in [0,\pi]\colon (y,\theta) \in \mathcal{B}_{(r,0)}(R_n)\}.\end{align*}
\begin{align*}I_y(r) \;:\!=\; \{\theta \in [0,\pi]\colon (y,\theta) \in \mathcal{B}_{(r,0)}(R_n)\}.\end{align*}
It follows from a direct use of the hyperbolic law of cosines (2.1) that
 $I_y(r)$
is a non-empty interval containing 0. Thus, defining
$I_y(r)$
is a non-empty interval containing 0. Thus, defining
 $\theta_r(y)$
by
$\theta_r(y)$
by
 \begin{align*}\theta_r(y) \;:\!=\; \sup I_y(r),\end{align*}
\begin{align*}\theta_r(y) \;:\!=\; \sup I_y(r),\end{align*}
we get
 \begin{align}\mu_n(\mathcal{B}_{r}(R_n)) = \frac{1}{\pi}\int_0^{R_n}\theta_r(y) \rho_n(y) \,\textrm{d}y.\end{align}
\begin{align}\mu_n(\mathcal{B}_{r}(R_n)) = \frac{1}{\pi}\int_0^{R_n}\theta_r(y) \rho_n(y) \,\textrm{d}y.\end{align}
Figure 3 provides a graphical representation of the angle
 $\theta_r(y)$
(in a Euclidean setting to ease the representation). Let us fix
$\theta_r(y)$
(in a Euclidean setting to ease the representation). Let us fix
 $r \in [0,R_n)$
. We want to compute
$r \in [0,R_n)$
. We want to compute
 $\theta_r(y)$
for
$\theta_r(y)$
for
 $y \in [0,R_n)$
. It is clear that
$y \in [0,R_n)$
. It is clear that
 $\mathcal{B}_{0}(R_n-r) \subset \mathcal{B}_{(r,0)}(R_n)$
, so
$\mathcal{B}_{0}(R_n-r) \subset \mathcal{B}_{(r,0)}(R_n)$
, so
 \begin{align}\theta_r(y) = \pi \quad\text{for all }y \in [0,R_n - r].\end{align}
\begin{align}\theta_r(y) = \pi \quad\text{for all }y \in [0,R_n - r].\end{align}
When
 $y \geq R_n - r$
, the point
$y \geq R_n - r$
, the point
 $(y,\theta_r(y))$
is at a distance
$(y,\theta_r(y))$
is at a distance
 $R_n$
from the point (r,0), so by the hyperbolic law of cosines (2.1), we get
$R_n$
from the point (r,0), so by the hyperbolic law of cosines (2.1), we get
 \begin{align}\cos(\theta_r(y)) = \frac{\cosh(r)\cosh(y) - \cosh(R_n)}{\sinh(r) \sinh(y)} \quad\text{for all } y \in [R_n - r,R_n).\end{align}
\begin{align}\cos(\theta_r(y)) = \frac{\cosh(r)\cosh(y) - \cosh(R_n)}{\sinh(r) \sinh(y)} \quad\text{for all } y \in [R_n - r,R_n).\end{align}
One may check that (5.2) and (5.3) can be rewritten as
 \begin{align}\theta_r(y) = \arccos\bigg(\max\bigg(-1,\frac{\cosh(r)\cosh(y) - \cosh(R_n)}{\sinh(r) \sinh(y)}\bigg)\bigg) \quad\text{for all } r,y \in [0,R_n).\end{align}
\begin{align}\theta_r(y) = \arccos\bigg(\max\bigg(-1,\frac{\cosh(r)\cosh(y) - \cosh(R_n)}{\sinh(r) \sinh(y)}\bigg)\bigg) \quad\text{for all } r,y \in [0,R_n).\end{align}
To estimate the degrees of the closest nodes to the centre
 $(X_{(1)},X_{(2)},\dots,X_{(k)})$
(with k fixed), we need an estimate of
$(X_{(1)},X_{(2)},\dots,X_{(k)})$
(with k fixed), we need an estimate of
 $\mu_n(\mathcal{B}_{r}(R_n))$
that holds for r in intervals containing the radii of these nodes with high probability. The convergence of the radii given in Proposition 4.1 shows that the choice of this interval highly depends on the value of
$\mu_n(\mathcal{B}_{r}(R_n))$
that holds for r in intervals containing the radii of these nodes with high probability. The convergence of the radii given in Proposition 4.1 shows that the choice of this interval highly depends on the value of
 $\alpha$
: going from small radii when
$\alpha$
: going from small radii when
 $\alpha < \tfrac{1}{2}$
to large radii for
$\alpha < \tfrac{1}{2}$
to large radii for
 $\alpha > \tfrac{1}{2}$
. This requires treating the three regimes separately.
$\alpha > \tfrac{1}{2}$
. This requires treating the three regimes separately.

Figure 3. Representation of
 $\theta_r(y)$
(in a Euclidean setting).
$\theta_r(y)$
(in a Euclidean setting).
In the
 $\alpha > \tfrac{1}{2}$
case, we recall the following crucial estimate for the angle
$\alpha > \tfrac{1}{2}$
case, we recall the following crucial estimate for the angle
 $\theta_r(y)$
from [Reference Gugelmann, Panagiotou and Peter14, Lemma 3.1].
$\theta_r(y)$
from [Reference Gugelmann, Panagiotou and Peter14, Lemma 3.1].
Lemma 5.2. Suppose that
 $\alpha > \tfrac{1}{2}$
. For
$\alpha > \tfrac{1}{2}$
. For
 $r \in [0,R_n)$
and
$r \in [0,R_n)$
and
 $y \in [R_n - r,R_n)$
,
$y \in [R_n - r,R_n)$
,
 \begin{align*}\theta_r(y) = 2\mathrm{e}^{(R_n-r-y)/2} (1+O(\mathrm{e}^{R_n-r-y})).\end{align*}
\begin{align*}\theta_r(y) = 2\mathrm{e}^{(R_n-r-y)/2} (1+O(\mathrm{e}^{R_n-r-y})).\end{align*}
It is shown in [Reference Gugelmann, Panagiotou and Peter14] how this estimate can be combined with (5.1) to approximate quantities related to the measure of the ball
 $\mathcal{B}_{r}(R_n)$
. In the following lemma, the first estimate is a weaker but more convenient version of the approximation of the quantity
$\mathcal{B}_{r}(R_n)$
. In the following lemma, the first estimate is a weaker but more convenient version of the approximation of the quantity
 $\mu_n(\mathcal{B}_{r}(R_n)\setminus \mathcal{B}_{0}(x))$
given in [Reference Gugelmann, Panagiotou and Peter14, Lemma 3.2]. The second estimate shows that most of the mass of
$\mu_n(\mathcal{B}_{r}(R_n)\setminus \mathcal{B}_{0}(x))$
given in [Reference Gugelmann, Panagiotou and Peter14, Lemma 3.2]. The second estimate shows that most of the mass of
 $\mathcal{B}_{r}(R_n)$
is contained in the part of the ball that is outside of the disc of radius
$\mathcal{B}_{r}(R_n)$
is contained in the part of the ball that is outside of the disc of radius
 $(1-\varepsilon)R_n$
. This is in line with the fact that most of the nodes of
$(1-\varepsilon)R_n$
. This is in line with the fact that most of the nodes of
 $\mathcal{G}_{\alpha,\nu}(n)$
concentrate near the boundary of
$\mathcal{G}_{\alpha,\nu}(n)$
concentrate near the boundary of
 $\mathcal{B}_{0}(R_n)$
.
$\mathcal{B}_{0}(R_n)$
.
Lemma 5.3. Suppose that
 $\alpha > \tfrac{1}{2}$
and set
$\alpha > \tfrac{1}{2}$
and set
 $C_{\alpha} \;:\!=\; {2\alpha}/{\pi(\alpha-\tfrac12)}$
. Fix
$C_{\alpha} \;:\!=\; {2\alpha}/{\pi(\alpha-\tfrac12)}$
. Fix
 $\eta > 0$
and a sequence
$\eta > 0$
and a sequence
 $(u_n)$
that diverges to
$(u_n)$
that diverges to
 $+\infty$
. For
$+\infty$
. For
 $r \in [u_n,R_n)$
and
$r \in [u_n,R_n)$
and
 $x \in [0,(1-\eta)R_n]$
, we have
$x \in [0,(1-\eta)R_n]$
, we have
 \begin{align}\mu_n(\mathcal{B}_{r}(R_n)\setminus \mathcal{B}_{0}(x)) &= C_{\alpha} \mathrm{e}^{-r/2}(1+o(1)).\end{align}
\begin{align}\mu_n(\mathcal{B}_{r}(R_n)\setminus \mathcal{B}_{0}(x)) &= C_{\alpha} \mathrm{e}^{-r/2}(1+o(1)).\end{align}
Fix
 $\varepsilon \in (0,1)$
and set
$\varepsilon \in (0,1)$
and set
 $R_n^{\varepsilon} \;:\!=\; (1-\varepsilon)R_n$
, we have, for
$R_n^{\varepsilon} \;:\!=\; (1-\varepsilon)R_n$
, we have, for
 $r \in [\varepsilon R_n,R_n)$
,
$r \in [\varepsilon R_n,R_n)$
,
 \begin{align}\mu_n(\mathcal{B}_{r}(R_n) \cap \mathcal{B}_{0}(R_n^{\varepsilon})) = O(\mathrm{e}^{-r/2 - \varepsilon (\alpha - 1/2)R_n}).\end{align}
\begin{align}\mu_n(\mathcal{B}_{r}(R_n) \cap \mathcal{B}_{0}(R_n^{\varepsilon})) = O(\mathrm{e}^{-r/2 - \varepsilon (\alpha - 1/2)R_n}).\end{align}
Proof. Since the measure
 $\mu_n$
is supported on the ball
$\mu_n$
is supported on the ball
 $\mathcal{B}_{0}(R_n)$
, the estimates of [Reference Gugelmann, Panagiotou and Peter14, Lemma 3.2] can be rewritten as follows.
$\mathcal{B}_{0}(R_n)$
, the estimates of [Reference Gugelmann, Panagiotou and Peter14, Lemma 3.2] can be rewritten as follows.
-
• For
$x \leq R_n - r$
,
(5.7)
\begin{align}\mu_n(\mathcal{B}_{r}(R_n) \setminus \mathcal{B}_{0}(x)) = C_{\alpha} \mathrm{e}^{-r/2} (1 + O(\mathrm{e}^{-(\alpha - 1/2)r} + \mathrm{e}^{-r})).\end{align}
-
• For
$x \geq R_n - r$
,
(5.8)
\begin{multline}\mu_n(\mathcal{B}_{r}(R_n) \setminus \mathcal{B}_{0}(x)) = C_{\alpha} \mathrm{e}^{-r/2}\bigg(1-\bigg(1+\frac{\alpha-1/2}{\alpha+1/2}\mathrm{e}^{-2\alpha x}\bigg)\mathrm{e}^{-(\alpha-1/2)(R_n-x)}\bigg)\\(1+O(\mathrm{e}^{-r}+\mathrm{e}^{-r-(R_n-x)(\alpha-3/2)})).\end{multline}




The proof of (5.5) follows by observing that, for
 $r \in [u_n,R_n)$
and
$r \in [u_n,R_n)$
and
 $x \in [0,(1-\eta)R_n]$
, the O terms and the term
$x \in [0,(1-\eta)R_n]$
, the O terms and the term
 $\mathrm{e}^{-(\alpha-1/2)(R_n-x)}$
appearing in (5.7) and (5.8) are of order o(1).
$\mathrm{e}^{-(\alpha-1/2)(R_n-x)}$
appearing in (5.7) and (5.8) are of order o(1).
For the proof of (5.6), we begin with the following equation, which is obtained in a similar fashion to (5.1) and is valid for all
 $r \in [0,R_n)$
,
$r \in [0,R_n)$
,
 \begin{align*}\mu_n(\mathcal{B}_{r}(R_n) \cap \mathcal{B}_{0}(R_n^{\varepsilon}))&= \frac{1}{\pi}\int_0^{R_n^{\varepsilon}}\theta_{r}(y) \rho_n(y) \,\textrm{d}y.\end{align*}
\begin{align*}\mu_n(\mathcal{B}_{r}(R_n) \cap \mathcal{B}_{0}(R_n^{\varepsilon}))&= \frac{1}{\pi}\int_0^{R_n^{\varepsilon}}\theta_{r}(y) \rho_n(y) \,\textrm{d}y.\end{align*}
Using (5.2), it follows that, for
 $r \in [\varepsilon R_n,R_n)$
,
$r \in [\varepsilon R_n,R_n)$
,
 \begin{align*}\mu_n(\mathcal{B}_{r}(R_n) \cap \mathcal{B}_{0}(R_n^{\varepsilon}))&= \mu_n(\mathcal{B}_{0}(R_n-r)) + \frac{1}{\pi}\int_{R_n-r}^{R_n^{\varepsilon}}\theta_{r}(y) \rho_n(y) \,\textrm{d}y.\end{align*}
\begin{align*}\mu_n(\mathcal{B}_{r}(R_n) \cap \mathcal{B}_{0}(R_n^{\varepsilon}))&= \mu_n(\mathcal{B}_{0}(R_n-r)) + \frac{1}{\pi}\int_{R_n-r}^{R_n^{\varepsilon}}\theta_{r}(y) \rho_n(y) \,\textrm{d}y.\end{align*}
For the first term, we have, for
 $r \in [\varepsilon R_n,R_n)$
,
$r \in [\varepsilon R_n,R_n)$
,
 \begin{align*}\mu_n(\mathcal{B}_{0}(R_n-r)) = \frac{\cosh(\alpha (R_n-r)) - 1}{\cosh(\alpha R_n) - 1}= O(\mathrm{e}^{-\alpha r}) = O(\mathrm{e}^{- r/2 - \varepsilon (\alpha - 1/2)R_n})\end{align*}
\begin{align*}\mu_n(\mathcal{B}_{0}(R_n-r)) = \frac{\cosh(\alpha (R_n-r)) - 1}{\cosh(\alpha R_n) - 1}= O(\mathrm{e}^{-\alpha r}) = O(\mathrm{e}^{- r/2 - \varepsilon (\alpha - 1/2)R_n})\end{align*}
and for the second term, Lemma 5.2 yields, for
 $r \in [\varepsilon R_n,R_n)$
,
$r \in [\varepsilon R_n,R_n)$
,
 \begin{align*}\frac{1}{\pi}\int_{R_n-r}^{R_n^{\varepsilon}}\theta_{r}(y) \rho_n(y) \,\textrm{d}y = O\Bigg(\int_{R_n-r}^{R_n^{\varepsilon}} \mathrm{e}^{(R_n-r-y)/2} \mathrm{e}^{\alpha(y-R_n)} \,\textrm{d}y\Bigg) = O(\mathrm{e}^{- r/2 - \varepsilon (\alpha - 1/2)R_n}).\end{align*}
\begin{align*}\frac{1}{\pi}\int_{R_n-r}^{R_n^{\varepsilon}}\theta_{r}(y) \rho_n(y) \,\textrm{d}y = O\Bigg(\int_{R_n-r}^{R_n^{\varepsilon}} \mathrm{e}^{(R_n-r-y)/2} \mathrm{e}^{\alpha(y-R_n)} \,\textrm{d}y\Bigg) = O(\mathrm{e}^{- r/2 - \varepsilon (\alpha - 1/2)R_n}).\end{align*}
We conclude that (5.6) holds in the regime
 $r \in [\varepsilon R_n,R_n)$
.
$r \in [\varepsilon R_n,R_n)$
.
In the
 $\alpha < \tfrac{1}{2}$
case, we give the following approximation of
$\alpha < \tfrac{1}{2}$
case, we give the following approximation of
 $\mu_n(\mathcal{B}_{r}(R_n))$
. Our estimate holds for r in intervals
$\mu_n(\mathcal{B}_{r}(R_n))$
. Our estimate holds for r in intervals
 $J_n$
whose bounds tend to 0 more slowly than
$J_n$
whose bounds tend to 0 more slowly than
 $n^{-1}$
. By the convergence result of Proposition 4.1, the radii of the closest nodes to the centre are of order
$n^{-1}$
. By the convergence result of Proposition 4.1, the radii of the closest nodes to the centre are of order
 $n^{\alpha-1/2}$
, so the approximation is valid in an appropriate regime for estimating the expected degree of the closest node to the centre. Since we look at small values of r, it is not surprising that
$n^{\alpha-1/2}$
, so the approximation is valid in an appropriate regime for estimating the expected degree of the closest node to the centre. Since we look at small values of r, it is not surprising that
 $\mu_n(\mathcal{B}_{r}(R_n))$
is close to 1. Here, we provide additional information on the rate at which this quantity decreases with r. The result is stated for all possible values of
$\mu_n(\mathcal{B}_{r}(R_n))$
is close to 1. Here, we provide additional information on the rate at which this quantity decreases with r. The result is stated for all possible values of
 $\alpha$
, as this comes without extra cost.
$\alpha$
, as this comes without extra cost.
Lemma 5.4. Fix
 $\alpha > 0$
and define a sequence of intervals
$\alpha > 0$
and define a sequence of intervals
 $(J_n)$
by
$(J_n)$
by
 $J_n \;:\!=\; [a_n,b_n]$
, with
$J_n \;:\!=\; [a_n,b_n]$
, with
 $na_n \to \infty$
and
$na_n \to \infty$
and
 $b_n \to 0$
. Then, for
$b_n \to 0$
. Then, for
 $r \in J_n$
, we have
$r \in J_n$
, we have
 \begin{align*}\mu_n(\mathcal{B}_{r}(R_n)) = 1 - \frac{\alpha r}{\pi} + o(r).\end{align*}
\begin{align*}\mu_n(\mathcal{B}_{r}(R_n)) = 1 - \frac{\alpha r}{\pi} + o(r).\end{align*}
Proof. Let
 $r \in J_n$
. By (5.1) and (5.2) we get
$r \in J_n$
. By (5.1) and (5.2) we get
 \begin{align} \mu_n(\mathcal{B}_{r}(R_n)) = 1 - \frac{1}{\pi}\int_{R_n-r}^{R_n} (\pi - \theta_r(y)) \rho_n(y) \,\textrm{d}y.\end{align}
\begin{align} \mu_n(\mathcal{B}_{r}(R_n)) = 1 - \frac{1}{\pi}\int_{R_n-r}^{R_n} (\pi - \theta_r(y)) \rho_n(y) \,\textrm{d}y.\end{align}
Now, to find a good approximation of
 $\theta_r(y)$
, we use (5.3). Note that
$\theta_r(y)$
, we use (5.3). Note that
 $b_n \to 0$
, so we can approximate all the hyperbolic terms in r that appear in the identity given by (5.3). This yields, for
$b_n \to 0$
, so we can approximate all the hyperbolic terms in r that appear in the identity given by (5.3). This yields, for
 $r \in J_n$
and
$r \in J_n$
and
 $y \in [R_n - r,R_n)$
,
$y \in [R_n - r,R_n)$
,
 \begin{align}\cos(\theta_r(y)) &= \frac{(1+O(r^2))(1+\mathrm{e}^{-2y}) - (\mathrm{e}^{R_n-y} + \mathrm{e}^{-R_n-y})}{(r+O(r^3))(1-\mathrm{e}^{-2y})}. \end{align}
\begin{align}\cos(\theta_r(y)) &= \frac{(1+O(r^2))(1+\mathrm{e}^{-2y}) - (\mathrm{e}^{R_n-y} + \mathrm{e}^{-R_n-y})}{(r+O(r^3))(1-\mathrm{e}^{-2y})}. \end{align}
Moreover, it holds that
 \begin{align*}\mathrm{e}^{-y} &\leq \mathrm{e}^{-R_n+b_n} = O(n^{-2}).\end{align*}
\begin{align*}\mathrm{e}^{-y} &\leq \mathrm{e}^{-R_n+b_n} = O(n^{-2}).\end{align*}
Since
 $n a_n \to +\infty$
, it follows that
$n a_n \to +\infty$
, it follows that
 \begin{align*}\mathrm{e}^{-y} = o(r^2).\end{align*}
\begin{align*}\mathrm{e}^{-y} = o(r^2).\end{align*}
Substituting this in (5.10) yields, for
 $r \in J_n$
and
$r \in J_n$
and
 $y \in [R_n - r,R_n)$
,
$y \in [R_n - r,R_n)$
,
 \begin{align}\cos(\theta_r(y)) &= -\frac{R_n-y}{r} + O(r).\end{align}
\begin{align}\cos(\theta_r(y)) &= -\frac{R_n-y}{r} + O(r).\end{align}
For
 $r \in J_n$
, we define
$r \in J_n$
, we define
 \begin{align}U_n(r) \;:\!=\; 1 - \frac{1}{\pi}\int_{R_n-r}^{R_n} \Bigg(\pi - \arccos\Bigg(-\frac{R_n-y}{r}\Bigg)\Bigg) \rho_n(y) \,\textrm{d}y. \end{align}
\begin{align}U_n(r) \;:\!=\; 1 - \frac{1}{\pi}\int_{R_n-r}^{R_n} \Bigg(\pi - \arccos\Bigg(-\frac{R_n-y}{r}\Bigg)\Bigg) \rho_n(y) \,\textrm{d}y. \end{align}
Let us show that
 $U_n(r)$
is a good approximation of
$U_n(r)$
is a good approximation of
 $\mu_n(\mathcal{B}_{r}(R_n))$
. Since the function
$\mu_n(\mathcal{B}_{r}(R_n))$
. Since the function
 $\arccos$
is
$\arccos$
is
 $\tfrac{1}{2}$
-Hölder, it follows from (5.11) that, for
$\tfrac{1}{2}$
-Hölder, it follows from (5.11) that, for
 $r \in J_n$
and for
$r \in J_n$
and for
 $y \in [R_n - r,R_n)$
,
$y \in [R_n - r,R_n)$
,
 \begin{align*}\theta_r(y) = \arccos\Bigg(-\frac{R_n-y}{r}\Bigg) + O\big(\sqrt{r}\big).\end{align*}
\begin{align*}\theta_r(y) = \arccos\Bigg(-\frac{R_n-y}{r}\Bigg) + O\big(\sqrt{r}\big).\end{align*}
Combining this estimate of
 $\theta_r(y)$
with (5.9) yields, for
$\theta_r(y)$
with (5.9) yields, for
 $r \in J_n$
,
$r \in J_n$
,
 \begin{align}\mu_n(\mathcal{B}_{r}(R_n)) &= U_n(r) + O\bigg(\sqrt{r} \int_{R_n-r}^{R_n} \rho_n(y) \,\textrm{d}y \bigg) \notag\\ &= U_n(r) + O(r^{3/2} ).\end{align}
\begin{align}\mu_n(\mathcal{B}_{r}(R_n)) &= U_n(r) + O\bigg(\sqrt{r} \int_{R_n-r}^{R_n} \rho_n(y) \,\textrm{d}y \bigg) \notag\\ &= U_n(r) + O(r^{3/2} ).\end{align}
Now, it remains to estimate
 $U_n(r)$
. Let
$U_n(r)$
. Let
 $n \in \mathbb{N}^*$
and
$n \in \mathbb{N}^*$
and
 $r \in J_n$
. Integrating (5.12) by parts gives
$r \in J_n$
. Integrating (5.12) by parts gives
 \begin{align*}U_n(r) &=1 - \frac{1}{\pi} \int_0^1 \frac{1}{\sqrt{1-z^2}\,}\frac{\cosh(\alpha R_n) - \cosh(\alpha (R_n - rz))}{\cosh(\alpha R_n)-1} \,\textrm{d}z.\end{align*}
\begin{align*}U_n(r) &=1 - \frac{1}{\pi} \int_0^1 \frac{1}{\sqrt{1-z^2}\,}\frac{\cosh(\alpha R_n) - \cosh(\alpha (R_n - rz))}{\cosh(\alpha R_n)-1} \,\textrm{d}z.\end{align*}
Furthermore, the mean value theorem yields, for
 $r \in J_n$
and
$r \in J_n$
and
 $z \in [0,1]$
,
$z \in [0,1]$
,
 \begin{align*}\frac{\cosh(\alpha R_n) - \cosh(\alpha (R_n - rz))}{\cosh(\alpha R_n)-1} = \alpha r z (1+o(1)),\end{align*}
\begin{align*}\frac{\cosh(\alpha R_n) - \cosh(\alpha (R_n - rz))}{\cosh(\alpha R_n)-1} = \alpha r z (1+o(1)),\end{align*}
so
 \begin{align*}U_n(r) &= 1 - \frac{\alpha r}{\pi} \int_0^1 \frac{z}{\sqrt{1-z^2}\,} ( 1 + o_{r \in J_n, z \in [0,1]}(1)) \,\textrm{d}z \\ &= 1 - \frac{\alpha r}{\pi} + o_{r \in J_n}(r).\end{align*}
\begin{align*}U_n(r) &= 1 - \frac{\alpha r}{\pi} \int_0^1 \frac{z}{\sqrt{1-z^2}\,} ( 1 + o_{r \in J_n, z \in [0,1]}(1)) \,\textrm{d}z \\ &= 1 - \frac{\alpha r}{\pi} + o_{r \in J_n}(r).\end{align*}
Combining this with (5.13) yields
 \begin{align*}\mu_n(\mathcal{B}_{r}(R_n)) = 1 - \frac{\alpha r}{\pi} + o_{r \in J_n}(r).\end{align*}
\begin{align*}\mu_n(\mathcal{B}_{r}(R_n)) = 1 - \frac{\alpha r}{\pi} + o_{r \in J_n}(r).\end{align*}
This completes the proof.
In the
 $\alpha = \tfrac{1}{2}$
case, the radii of the closest nodes to the centre (without normalisation) converge in distribution (see Proposition 4.1); thus, we need to approximate
$\alpha = \tfrac{1}{2}$
case, the radii of the closest nodes to the centre (without normalisation) converge in distribution (see Proposition 4.1); thus, we need to approximate
 $\mu_n(\mathcal{B}_{r}(R_n))$
for fixed r. This is the purpose of the following lemma.
$\mu_n(\mathcal{B}_{r}(R_n))$
for fixed r. This is the purpose of the following lemma.
Lemma 5.5. Suppose that
 $\alpha > 0$
is fixed. Then,
$\alpha > 0$
is fixed. Then,
 \begin{align*}\mu_n(\mathcal{B}_{r}(R_n)) \xrightarrow[n\to\infty]{} V_\alpha(r) \quad {\textit{uniformly for}}\;r \in [0,\infty),\end{align*}
\begin{align*}\mu_n(\mathcal{B}_{r}(R_n)) \xrightarrow[n\to\infty]{} V_\alpha(r) \quad {\textit{uniformly for}}\;r \in [0,\infty),\end{align*}
where
 $V_\alpha$
is a decreasing diffeomorphism from
$V_\alpha$
is a decreasing diffeomorphism from
 $[0,\infty)$
to (0, 1] defined by
$[0,\infty)$
to (0, 1] defined by
 \begin{align}V_\alpha(r) \;:\!=\; \frac{1}{\pi}\int_0^1 \arccos\bigg(\max\bigg(-1,\frac{\cosh(r) - x^{-1/\alpha}}{\sinh(r)}\bigg)\bigg) \,\textrm{d}x \quad\textit{for all }r > 0.\end{align}
\begin{align}V_\alpha(r) \;:\!=\; \frac{1}{\pi}\int_0^1 \arccos\bigg(\max\bigg(-1,\frac{\cosh(r) - x^{-1/\alpha}}{\sinh(r)}\bigg)\bigg) \,\textrm{d}x \quad\textit{for all }r > 0.\end{align}
Proof. Let us fix
 $\alpha > 0$
and
$\alpha > 0$
and
 $r > 0$
. For all
$r > 0$
. For all
 $n \in \mathbb{N}^*$
and
$n \in \mathbb{N}^*$
and
 $x \in (0,1)$
, we define
$x \in (0,1)$
, we define
 $h_n(x)$
as the only positive real number such that
$h_n(x)$
as the only positive real number such that
 \begin{align*}\frac{\cosh(\alpha h_n(x)) - 1}{\cosh(\alpha R_n) - 1} = x.\end{align*}
\begin{align*}\frac{\cosh(\alpha h_n(x)) - 1}{\cosh(\alpha R_n) - 1} = x.\end{align*}
By the change of variable
 $x = {(\!\cosh(\alpha y) - 1)}/{(\!\cosh(\alpha R_n) - 1)}$
in (5.1), we obtain
$x = {(\!\cosh(\alpha y) - 1)}/{(\!\cosh(\alpha R_n) - 1)}$
in (5.1), we obtain
 \begin{align}\mu_n(\mathcal{B}_{r}(R_n)) = \frac{1}{\pi} \int_0^1 \theta_{r}(h_n(x)) \,\textrm{d}x.\end{align}
\begin{align}\mu_n(\mathcal{B}_{r}(R_n)) = \frac{1}{\pi} \int_0^1 \theta_{r}(h_n(x)) \,\textrm{d}x.\end{align}
Let us fix
 $x \in (0,1)$
. By the definition of
$x \in (0,1)$
. By the definition of
 $h_n$
, we have
$h_n$
, we have
 \begin{align*}h_n(x) = R_n + \frac{\log(x)}{\alpha} + o(1).\end{align*}
\begin{align*}h_n(x) = R_n + \frac{\log(x)}{\alpha} + o(1).\end{align*}
Combining this with the expression of
 $\theta_r(y)$
given by (5.4) yields
$\theta_r(y)$
given by (5.4) yields
 \begin{align*}\theta_{r}(h_n(x)) \xrightarrow[n\to\infty]{} \arccos\bigg(\max\bigg(-1,\frac{\cosh(r) - x^{-1/\alpha}}{\sinh(r)}\bigg)\bigg).\end{align*}
\begin{align*}\theta_{r}(h_n(x)) \xrightarrow[n\to\infty]{} \arccos\bigg(\max\bigg(-1,\frac{\cosh(r) - x^{-1/\alpha}}{\sinh(r)}\bigg)\bigg).\end{align*}
Thus, by dominated convergence, the functions
 $r \mapsto \mu_n(\mathcal{B}_{r}(R_n))$
converge pointwise towards the function
$r \mapsto \mu_n(\mathcal{B}_{r}(R_n))$
converge pointwise towards the function
 $V_\alpha$
defined by (5.14). The fact that
$V_\alpha$
defined by (5.14). The fact that
 $V_\alpha$
is a decreasing diffeomorphism from
$V_\alpha$
is a decreasing diffeomorphism from
 $[0,+\infty)$
to (0, 1] follows directly from its expression. Combining this with the fact that the functions
$[0,+\infty)$
to (0, 1] follows directly from its expression. Combining this with the fact that the functions
 $r \mapsto \mu_n(\mathcal{B}_{r}(R_n))$
are decreasing and take values in (0, 1], we conclude that the convergence is necessarily uniform on
$r \mapsto \mu_n(\mathcal{B}_{r}(R_n))$
are decreasing and take values in (0, 1], we conclude that the convergence is necessarily uniform on
 $[0,\infty)$
.
$[0,\infty)$
.
We conclude this section by providing estimates for the volume of balls centred at the origin. These volumes are much easier to obtain than those of the balls studied earlier, as integrating the density
 $\rho_n$
directly gives, for all
$\rho_n$
directly gives, for all
 $r \in (0,R_n)$
,
$r \in (0,R_n)$
,
 \begin{align*}\mu_n(\mathcal{B}_{0}(r)) = \frac{\cosh(\alpha r) - 1}{\cosh(\alpha R_n) - 1}.\end{align*}
\begin{align*}\mu_n(\mathcal{B}_{0}(r)) = \frac{\cosh(\alpha r) - 1}{\cosh(\alpha R_n) - 1}.\end{align*}
Approximating the hyperbolic terms, we get the following estimates.
Lemma 5.6. Let us fix
 $\alpha > 0$
and a sequence
$\alpha > 0$
and a sequence
 $u_n \to 0$
. We have, for
$u_n \to 0$
. We have, for
 $r \in [0,u_n]$
,
$r \in [0,u_n]$
,
 \begin{align}\mu_n(\mathcal{B}_{0}(r)) &= (\alpha r)^2\mathrm{e}^{-\alpha R_n}(1+o(1)). \end{align}
\begin{align}\mu_n(\mathcal{B}_{0}(r)) &= (\alpha r)^2\mathrm{e}^{-\alpha R_n}(1+o(1)). \end{align}
Let us fix
 $\alpha > 0$
and a sequence
$\alpha > 0$
and a sequence
 $v_n \to \infty$
. We have, for
$v_n \to \infty$
. We have, for
 $r \in [v_n,R_n)$
,
$r \in [v_n,R_n)$
,
 \begin{align}\mu_n(\mathcal{B}_{0}(r)) &= \mathrm{e}^{\alpha(r-R_n)}(1+o(1)). \end{align}
\begin{align}\mu_n(\mathcal{B}_{0}(r)) &= \mathrm{e}^{\alpha(r-R_n)}(1+o(1)). \end{align}
6. Constant rank ordering (proof of Theorem 3.1)
The results of the two previous sections give enough information on the degrees of the closest nodes to the centre to proceed with the proof of Theorem 3.1. Indeed, the convergence of the (normalised) point process of the radii, as stated in Proposition 4.1, also gives estimates for the radius gap between consecutive nodes,
 $r(X_{(i+1)}) - r(X_{(i)})$
. This, combined with the volume estimates of the previous part allows us to get a lower bound on the difference of the expected degrees of the nodes
$r(X_{(i+1)}) - r(X_{(i)})$
. This, combined with the volume estimates of the previous part allows us to get a lower bound on the difference of the expected degrees of the nodes
 $X_{(i)}$
and
$X_{(i)}$
and
 $X_{(j)}$
with
$X_{(j)}$
with
 $i < j$
. The following lemma provides a way to translate this information into a bound on the probability that
$i < j$
. The following lemma provides a way to translate this information into a bound on the probability that
 $X_{(i)}$
has a smaller degree than
$X_{(i)}$
has a smaller degree than
 $X_{(j)}$
. Note that the two variables A and B are not required to be independent. Thus, A and B may be legitimately replaced by two node degrees that we want to compare. In the following, we denote by
$X_{(j)}$
. Note that the two variables A and B are not required to be independent. Thus, A and B may be legitimately replaced by two node degrees that we want to compare. In the following, we denote by
 $\mbox{Bin}(m,p)$
the binomial distribution with parameters
$\mbox{Bin}(m,p)$
the binomial distribution with parameters
 $m \in \mathbb{N}^*$
and
$m \in \mathbb{N}^*$
and
 $p \in [0,1]$
.
$p \in [0,1]$
.
Lemma 6.1. Let
 $A \sim {\rm Bin}(n,a)$
and
$A \sim {\rm Bin}(n,a)$
and
 $B \sim {\rm Bin}(n,b)$
. If
$B \sim {\rm Bin}(n,b)$
. If
 $0 < b \leq a$
then
$0 < b \leq a$
then
 \begin{align*}\mathbb{P}[A \leq B] \leq 2\exp\bigg(-\frac{(a-b)^2n}{8a}\bigg).\end{align*}
\begin{align*}\mathbb{P}[A \leq B] \leq 2\exp\bigg(-\frac{(a-b)^2n}{8a}\bigg).\end{align*}
Proof. By splitting at
 $n{(a+b)}/{2}$
, we get
$n{(a+b)}/{2}$
, we get
 \begin{align*}\mathbb{P}[A \leq B]&\leq \mathbb{P}\bigg[B \geq n\frac{a+b}{2}\bigg] + \mathbb{P}\bigg[A \leq n\frac{a+b}{2}\bigg]\\&= \mathbb{P}\bigg[B \geq \bigg(1+\frac{a-b}{2b}\bigg)nb\bigg] + \mathbb{P}\bigg[A \leq \bigg(1-\frac{a-b}{2a}\bigg)na\bigg].\end{align*}
\begin{align*}\mathbb{P}[A \leq B]&\leq \mathbb{P}\bigg[B \geq n\frac{a+b}{2}\bigg] + \mathbb{P}\bigg[A \leq n\frac{a+b}{2}\bigg]\\&= \mathbb{P}\bigg[B \geq \bigg(1+\frac{a-b}{2b}\bigg)nb\bigg] + \mathbb{P}\bigg[A \leq \bigg(1-\frac{a-b}{2a}\bigg)na\bigg].\end{align*}
For
 $Z \sim \mbox{Bin}(n,p)$
and
$Z \sim \mbox{Bin}(n,p)$
and
 $\mu = np$
, we recall the multiplicative Chernoff bounds
$\mu = np$
, we recall the multiplicative Chernoff bounds
 \begin{gather*}\mathbb{P}[Z \geq (1+\delta)\mu] \leq \mathrm{e}^{-{\mu\delta^2}/{(2+\delta)}} \quad\text{for all } \delta \geq 0,\\\mathbb{P}[Z \leq (1-\delta)\mu] \leq \mathrm{e}^{-\mu \delta^2/2} \quad\text{for all } \delta \in [0,1).\end{gather*}
\begin{gather*}\mathbb{P}[Z \geq (1+\delta)\mu] \leq \mathrm{e}^{-{\mu\delta^2}/{(2+\delta)}} \quad\text{for all } \delta \geq 0,\\\mathbb{P}[Z \leq (1-\delta)\mu] \leq \mathrm{e}^{-\mu \delta^2/2} \quad\text{for all } \delta \in [0,1).\end{gather*}
Since
 ${(a-b)}/{2b} \geq 0$
and
${(a-b)}/{2b} \geq 0$
and
 $0 \leq {(a-b)}/{2a} < 1$
, we can use these bounds to obtain
$0 \leq {(a-b)}/{2a} < 1$
, we can use these bounds to obtain
 \begin{align*}\mathbb{P}[A \leq B]&\leq \exp\bigg(-\frac{(a-b)^2n}{2(a+3b)}\bigg) + \exp\bigg(-\frac{(a-b)^2n}{8a}\bigg)\\&\leq 2\exp\bigg(-\frac{(a-b)^2n}{8a}\bigg).\end{align*}
\begin{align*}\mathbb{P}[A \leq B]&\leq \exp\bigg(-\frac{(a-b)^2n}{2(a+3b)}\bigg) + \exp\bigg(-\frac{(a-b)^2n}{8a}\bigg)\\&\leq 2\exp\bigg(-\frac{(a-b)^2n}{8a}\bigg).\end{align*}
This proves our claim.
We are now ready to prove Theorem 3.1.
Proof of Theorem
3.1. Let us fix
 $k \in \mathbb{N}^*$
and define the ordering event
$k \in \mathbb{N}^*$
and define the ordering event
 $O_n$
as
$O_n$
as
 \begin{align*}\deg(X_{(1)}) > \deg(X_{(2)}) > \dots > \deg(X_{(k)}) > \deg(X_{(i)}) \quad\text{for all } i > k.\end{align*}
\begin{align*}\deg(X_{(1)}) > \deg(X_{(2)}) > \dots > \deg(X_{(k)}) > \deg(X_{(i)}) \quad\text{for all } i > k.\end{align*}
We want to show that the complementary
 $O_n^c$
of this event has probability converging to 0. We start with the
$O_n^c$
of this event has probability converging to 0. We start with the
 $\alpha < \tfrac{1}{2}$
case. The
$\alpha < \tfrac{1}{2}$
case. The
 $\alpha > \tfrac{1}{2}$
case can be handled in a similar fashion, but we do not present it here, since the result in this case follows from the stronger statement of Theorem 3.2 (proved without using Theorem 3.1). We deal with the
$\alpha > \tfrac{1}{2}$
case can be handled in a similar fashion, but we do not present it here, since the result in this case follows from the stronger statement of Theorem 3.2 (proved without using Theorem 3.1). We deal with the
 $\alpha = \tfrac{1}{2}$
case at the end of the proof.
$\alpha = \tfrac{1}{2}$
case at the end of the proof.
Define the localisation event
 $L_n$
and the gap event
$L_n$
and the gap event
 $G_n$
by
$G_n$
by
 \begin{align*}L_n &\;:\!=\; \{t_n \leq r(X_{(1)}) \; \mbox{and} \; r(X_{(k)}) \leq r_n\},\\G_n &\;:\!=\; \{\text{for all } i \leq k,\, r(X_{(i+1)}) - r(X_{(i)}) \geq \lambda_n\},\end{align*}
\begin{align*}L_n &\;:\!=\; \{t_n \leq r(X_{(1)}) \; \mbox{and} \; r(X_{(k)}) \leq r_n\},\\G_n &\;:\!=\; \{\text{for all } i \leq k,\, r(X_{(i+1)}) - r(X_{(i)}) \geq \lambda_n\},\end{align*}
where the sequences
 $(t_n)$
,
$(t_n)$
,
 $(r_n)$
, and
$(r_n)$
, and
 $(\lambda_n)$
are defined for
$(\lambda_n)$
are defined for
 $n \in \mathbb{N}^*$
by
$n \in \mathbb{N}^*$
by
 \begin{align*}t_n \;:\!=\; n^{\alpha - 1/2} \log(n)^{-1}, \qquad r_n \;:\!=\; n^{\alpha - 1/2} \log(n), \qquad \lambda_n \;:\!=\; n^{\alpha - 1/2}\log(n)^{-1} .\end{align*}
\begin{align*}t_n \;:\!=\; n^{\alpha - 1/2} \log(n)^{-1}, \qquad r_n \;:\!=\; n^{\alpha - 1/2} \log(n), \qquad \lambda_n \;:\!=\; n^{\alpha - 1/2}\log(n)^{-1} .\end{align*}
By the convergence result stated in Proposition 4.1 and the characterisation of convergence in distribution in
 $M_p([a,b))$
given in Remark 3.1, we know that the vector
$M_p([a,b))$
given in Remark 3.1, we know that the vector
 $(n^{1/2-\alpha}r(X_{(i)}), i \leq k+1)$
converges in distribution in
$(n^{1/2-\alpha}r(X_{(i)}), i \leq k+1)$
converges in distribution in
 $\mathbb{R}^k$
towards the vector of the k first points of the point process
$\mathbb{R}^k$
towards the vector of the k first points of the point process
 $\eta_{\gamma_1}$
. In particular, the normalised variables
$\eta_{\gamma_1}$
. In particular, the normalised variables
 $n^{1/2-\alpha}r(X_{(1)})$
and
$n^{1/2-\alpha}r(X_{(1)})$
and
 $n^{1/2-\alpha}r(X_{(k)})$
, as well as the differences
$n^{1/2-\alpha}r(X_{(k)})$
, as well as the differences
 $n^{1/2-\alpha}(r(X_{(i+1)}) - r(X_{(i)}))$
, for
$n^{1/2-\alpha}(r(X_{(i+1)}) - r(X_{(i)}))$
, for
 $1 \leq i \leq k$
, converge in distribution. Since
$1 \leq i \leq k$
, converge in distribution. Since
 $t_n = o(n^{\alpha-1/2})$
,
$t_n = o(n^{\alpha-1/2})$
,
 $n^{\alpha-1/2} = o (r_n)$
, and
$n^{\alpha-1/2} = o (r_n)$
, and
 $\lambda_n = o(n^{\alpha-1/2})$
, it follows that
$\lambda_n = o(n^{\alpha-1/2})$
, it follows that
 \begin{align*}\mathbb{P}[L_n \cap G_n] \xrightarrow[n\to\infty]{} 1.\end{align*}
\begin{align*}\mathbb{P}[L_n \cap G_n] \xrightarrow[n\to\infty]{} 1.\end{align*}
Thus, it suffices to show that
 \begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n] \xrightarrow[n\to\infty]{} 0.\end{align}
\begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n] \xrightarrow[n\to\infty]{} 0.\end{align}
If the event
 $O_n^c$
occurs then there must exist two indices
$O_n^c$
occurs then there must exist two indices
 $i<j$
such that
$i<j$
such that
 $i \leq k$
and
$i \leq k$
and
 $\deg(X_{(i)}) \leq \deg(X_{(j)})$
. If the event
$\deg(X_{(i)}) \leq \deg(X_{(j)})$
. If the event
 $L_n \cap G_n$
also occurs, these indices also satisfy
$L_n \cap G_n$
also occurs, these indices also satisfy
 \begin{align*}t_n \leq r(X_{(i)}) \leq r_n \quad \mbox{and} \quad r(X_{(j)}) - r(X_{(i)}) \geq \lambda_n.\end{align*}
\begin{align*}t_n \leq r(X_{(i)}) \leq r_n \quad \mbox{and} \quad r(X_{(j)}) - r(X_{(i)}) \geq \lambda_n.\end{align*}
Thus, the probability to control can be bounded as follows (note that the bound does not refer to the reordering of the nodes):
 \begin{align*}&\mathbb{P}[O_n^c \cap L_n \cap G_n]\\&\qquad\leq \mathbb{P}[\exists i \neq j,\, t_n \leq r(X_i) \leq r_n,\, r(X_j) - r(X_i) \geq \lambda_n,\, \deg(X_i) \leq \deg(X_j)].\end{align*}
\begin{align*}&\mathbb{P}[O_n^c \cap L_n \cap G_n]\\&\qquad\leq \mathbb{P}[\exists i \neq j,\, t_n \leq r(X_i) \leq r_n,\, r(X_j) - r(X_i) \geq \lambda_n,\, \deg(X_i) \leq \deg(X_j)].\end{align*}
Using a union bound and writing
 $\mathbb{P}_{(X_1,X_2)}[\cdot]$
for the conditional probability with respect to
$\mathbb{P}_{(X_1,X_2)}[\cdot]$
for the conditional probability with respect to
 $(X_1,X_2)$
, we finally get
$(X_1,X_2)$
, we finally get
 \begin{align*}&\mathbb{P}[O_n^c \cap L_n \cap G_n]\\&\qquad\leq n^2\mathbb{E}[ \mathbb{P}_{(X_1,X_2)}[\deg(X_1) \leq \deg(X_2)] \textbf{1}_{\{t_n \leq r(X_1) \leq r_n, \; r(X_2) - r(X_1) \geq \lambda_n\}} ].\end{align*}
\begin{align*}&\mathbb{P}[O_n^c \cap L_n \cap G_n]\\&\qquad\leq n^2\mathbb{E}[ \mathbb{P}_{(X_1,X_2)}[\deg(X_1) \leq \deg(X_2)] \textbf{1}_{\{t_n \leq r(X_1) \leq r_n, \; r(X_2) - r(X_1) \geq \lambda_n\}} ].\end{align*}
Conditionally on the couple
 $(X_1,X_2)$
, the variables
$(X_1,X_2)$
, the variables
 $\deg(X_1)$
and
$\deg(X_1)$
and
 $\deg(X_2)$
have binomial distributions with
$\deg(X_2)$
have binomial distributions with
 $n-2$
trials and probabilities
$n-2$
trials and probabilities
 $\mu_n(\mathcal{B}_{r(X_1)}(R_n))$
and
$\mu_n(\mathcal{B}_{r(X_1)}(R_n))$
and
 $\mu_n(\mathcal{B}_{r(X_2)}(R_n))$
, respectively (we neglect the potential connection between
$\mu_n(\mathcal{B}_{r(X_2)}(R_n))$
, respectively (we neglect the potential connection between
 $X_1$
and
$X_1$
and
 $X_2$
since it does not contribute to the inequality between their degrees). Given that
$X_2$
since it does not contribute to the inequality between their degrees). Given that
 $\mu_n(\mathcal{B}_{r(X_1)}(R_n))$
is larger than
$\mu_n(\mathcal{B}_{r(X_1)}(R_n))$
is larger than
 $\mu_n(\mathcal{B}_{r(X_2)}(R_n))$
(see Lemma 5.1), we can apply Lemma 6.1 to bound the conditional probability of the previous display. It follows that
$\mu_n(\mathcal{B}_{r(X_2)}(R_n))$
(see Lemma 5.1), we can apply Lemma 6.1 to bound the conditional probability of the previous display. It follows that
 \begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n]\leq \max_{(s_1,s_2)} 2n^2 \exp\bigg(- \frac{(n-2)(\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n)))^2}{8\mu_n(\mathcal{B}_{s_1}(R_n))}\bigg),\end{align}
\begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n]\leq \max_{(s_1,s_2)} 2n^2 \exp\bigg(- \frac{(n-2)(\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n)))^2}{8\mu_n(\mathcal{B}_{s_1}(R_n))}\bigg),\end{align}
where the maximum is taken over the couples
 $(s_1,s_2)$
belonging to the set
$(s_1,s_2)$
belonging to the set
 \begin{align*}E_n \;:\!=\; \{(s_1,s_2) \in [0,R_n)^2\colon t_n \leq s_1 \leq r_n,\, s_2 - s_1 \geq \lambda_n\}.\end{align*}
\begin{align*}E_n \;:\!=\; \{(s_1,s_2) \in [0,R_n)^2\colon t_n \leq s_1 \leq r_n,\, s_2 - s_1 \geq \lambda_n\}.\end{align*}
Using Lemma 5.4 to approximate the volume of the balls
 $\mu_n(\mathcal{B}_{s_j}(R_n))$
for
$\mu_n(\mathcal{B}_{s_j}(R_n))$
for
 $j=1,2$
, we get
$j=1,2$
, we get
 $K > 0$
such that, for large n and
$K > 0$
such that, for large n and
 $(s_1,s_2) \in E_n$
,
$(s_1,s_2) \in E_n$
,
 \begin{align*}\frac{(n-2)(\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n)))^2}{8\mu_n(\mathcal{B}_{s_1}(R_n))} \geq K n\lambda_n^2 = K n^{2\alpha} \log(n)^{-2}.\end{align*}
\begin{align*}\frac{(n-2)(\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n)))^2}{8\mu_n(\mathcal{B}_{s_1}(R_n))} \geq K n\lambda_n^2 = K n^{2\alpha} \log(n)^{-2}.\end{align*}
Substituting this in (6.2) yields
 \begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n]&\leq 2n^2 \mathrm{e}^{-K n^{2\alpha} \log(n)^{-2}} \xrightarrow[n\to\infty]{} 0.\end{align}
\begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n]&\leq 2n^2 \mathrm{e}^{-K n^{2\alpha} \log(n)^{-2}} \xrightarrow[n\to\infty]{} 0.\end{align}
This proves (6.1) and concludes the proof of this case.
Now, let us proceed with the
 $\alpha = \tfrac{1}{2}$
case. We take
$\alpha = \tfrac{1}{2}$
case. We take
 $\varepsilon > 0$
and for all
$\varepsilon > 0$
and for all
 $\delta,\lambda > 0$
, we introduce the set
$\delta,\lambda > 0$
, we introduce the set
 \begin{align*}\mathcal{L}(\lambda,\delta) \;:\!=\; \{r \geq 0\colon V_\alpha(r)- V_\alpha(r+\lambda) > \delta\},\end{align*}
\begin{align*}\mathcal{L}(\lambda,\delta) \;:\!=\; \{r \geq 0\colon V_\alpha(r)- V_\alpha(r+\lambda) > \delta\},\end{align*}
where
 $V_\alpha$
is the function defined in Lemma 5.5. In the present case, we define the localisation event
$V_\alpha$
is the function defined in Lemma 5.5. In the present case, we define the localisation event
 $L_n$
and the gap event
$L_n$
and the gap event
 $G_n$
by
$G_n$
by
 \begin{align*}L_n &\;:\!=\; \{\text{for all }i \leq k,\, r(X_{(i)}) \in \mathcal{L}(\lambda,\delta)\},\\G_n &\;:\!=\; \{\text{for all }i \leq k,\, r(X_{(i+1)}) - r(X_{(i)}) \geq \lambda\}.\end{align*}
\begin{align*}L_n &\;:\!=\; \{\text{for all }i \leq k,\, r(X_{(i)}) \in \mathcal{L}(\lambda,\delta)\},\\G_n &\;:\!=\; \{\text{for all }i \leq k,\, r(X_{(i+1)}) - r(X_{(i)}) \geq \lambda\}.\end{align*}
The convergence stated in Proposition 4.1, together with the characterisation of convergence in distribution in
 $M_p([a,b))$
, given in Remark 3.1, implies that the vector
$M_p([a,b))$
, given in Remark 3.1, implies that the vector
 $(r(X_{(i)}),\, i \leq k+1)$
converges in distribution towards the k first points of the point process
$(r(X_{(i)}),\, i \leq k+1)$
converges in distribution towards the k first points of the point process
 $\eta_{\gamma_2}$
. In particular, the differences
$\eta_{\gamma_2}$
. In particular, the differences
 $r(X_{(i+1)}) - r(X_{(i)})$
for
$r(X_{(i+1)}) - r(X_{(i)})$
for
 $1 \leq i \leq k$
, also converge in distribution. Therefore, by choosing
$1 \leq i \leq k$
, also converge in distribution. Therefore, by choosing
 $\lambda > 0$
small enough, we can ensure that, for large enough n,
$\lambda > 0$
small enough, we can ensure that, for large enough n,
 \begin{align*}\mathbb{P}[G_n^c] \leq \varepsilon.\end{align*}
\begin{align*}\mathbb{P}[G_n^c] \leq \varepsilon.\end{align*}
Since the function
 $V_{\alpha}$
is strictly decreasing, we find that, for every
$V_{\alpha}$
is strictly decreasing, we find that, for every
 $\lambda > 0$
, the set
$\lambda > 0$
, the set
 $\bigcup_{\delta > 0} \mathcal{L}(\lambda,\delta)$
covers the entire interval
$\bigcup_{\delta > 0} \mathcal{L}(\lambda,\delta)$
covers the entire interval
 $[0,+\infty)$
. Hence, if
$[0,+\infty)$
. Hence, if
 $\delta > 0$
is also chosen sufficiently small, the probability that the k first points of the limit process
$\delta > 0$
is also chosen sufficiently small, the probability that the k first points of the limit process
 $\eta_{\gamma_2}$
are not in
$\eta_{\gamma_2}$
are not in
 $\mathcal{L}(\lambda,\delta)$
is less than
$\mathcal{L}(\lambda,\delta)$
is less than
 $\varepsilon$
. It follows that, for large enough n,
$\varepsilon$
. It follows that, for large enough n,
 \begin{align*}\mathbb{P}[L_n^c] \leq 2\varepsilon.\end{align*}
\begin{align*}\mathbb{P}[L_n^c] \leq 2\varepsilon.\end{align*}
Therefore, it remains to prove that
 \begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n] \xrightarrow[n\to\infty]{} 0.\end{align}
\begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n] \xrightarrow[n\to\infty]{} 0.\end{align}
Proceeding exactly as we did for proving (6.2) in the previous case, we get
 \begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n]&\leq \max\limits_{(s_1,s_2)} 2n^2 \exp\bigg(- \frac{(n-2)(\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n)))^2}{8\mu_n(\mathcal{B}_{s_1}(R_n))}\bigg),\end{align}
\begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n]&\leq \max\limits_{(s_1,s_2)} 2n^2 \exp\bigg(- \frac{(n-2)(\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n)))^2}{8\mu_n(\mathcal{B}_{s_1}(R_n))}\bigg),\end{align}
where the maximum is taken over the couples
 $(s_1,s_2)$
belonging to the set
$(s_1,s_2)$
belonging to the set
 \begin{align*}E_n \;:\!=\; \{(s_1,s_2) \in [0,R_n)^2\colon s_1 \in \mathcal{L}(\lambda,\delta),\, s_2 - s_1 \geq \lambda\}.\end{align*}
\begin{align*}E_n \;:\!=\; \{(s_1,s_2) \in [0,R_n)^2\colon s_1 \in \mathcal{L}(\lambda,\delta),\, s_2 - s_1 \geq \lambda\}.\end{align*}
By the definition of
 $\mathcal{L}(\lambda,\delta)$
and the uniform convergence of
$\mathcal{L}(\lambda,\delta)$
and the uniform convergence of
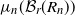 $\mu_n(\mathcal{B}_{r}(R_n))$
towards
$\mu_n(\mathcal{B}_{r}(R_n))$
towards
 $V_{\alpha}(r)$
(see Lemma 5.5), it follows that, for sufficiently large n,
$V_{\alpha}(r)$
(see Lemma 5.5), it follows that, for sufficiently large n,
 \begin{align*}\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n)) \geq \frac{\delta}{2} \quad\text{for all } (s_1,s_2) \in E_n.\end{align*}
\begin{align*}\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n)) \geq \frac{\delta}{2} \quad\text{for all } (s_1,s_2) \in E_n.\end{align*}
Substituting this in (6.5) and bounding
 $\mu_n(\mathcal{B}_{s_1}(R_n))$
by 1 proves (6.4) and concludes the proof of this case.
$\mu_n(\mathcal{B}_{s_1}(R_n))$
by 1 proves (6.4) and concludes the proof of this case.
7. Convergence of the degrees (proof of Theorem 3.3)
The key to proving the convergence of the largest degrees is to show that the degrees of the closest nodes to the centre concentrate around their conditional expected values, given the positions of the corresponding nodes. This implies that the point process of the degrees is comparable to the image of the point process of the radii under the mapping
 $r \mapsto \mu_n(\mathcal{B}_{r}(R_n))$
. The conclusion then follows from the convergence of the point process of the radii.
$r \mapsto \mu_n(\mathcal{B}_{r}(R_n))$
. The conclusion then follows from the convergence of the point process of the radii.
Proof of Theorem
3.3. Let us begin with the
 $\alpha > \tfrac{1}{2}$
case. The convergence of the normalised degree process towards a point process
$\alpha > \tfrac{1}{2}$
case. The convergence of the normalised degree process towards a point process
 $\mathcal{P}$
will be stated if we prove that, for all k, the normalised vector of the k highest degrees converges in distribution to the vector of the k largest points of
$\mathcal{P}$
will be stated if we prove that, for all k, the normalised vector of the k highest degrees converges in distribution to the vector of the k largest points of
 $\mathcal{P}$
(see Remark 3.1). By Theorem 3.1, with high probability, the vector of the k highest degrees is the vector of the degrees of the k closest points to the centre (in the same order). Thus, to prove the convergence of the normalised degree process towards a point process
$\mathcal{P}$
(see Remark 3.1). By Theorem 3.1, with high probability, the vector of the k highest degrees is the vector of the degrees of the k closest points to the centre (in the same order). Thus, to prove the convergence of the normalised degree process towards a point process
 $\mathcal{P}$
, it suffices to prove that, for all k,
$\mathcal{P}$
, it suffices to prove that, for all k,
 \begin{align}n^{-1/(2\alpha)}(\!\deg(X_{(1)}),\deg(X_{(2)}), \dots \deg(X_{(k)})) \xrightarrow[n\to\infty]{d} (Y_1,Y_2,\dots,Y_k),\end{align}
\begin{align}n^{-1/(2\alpha)}(\!\deg(X_{(1)}),\deg(X_{(2)}), \dots \deg(X_{(k)})) \xrightarrow[n\to\infty]{d} (Y_1,Y_2,\dots,Y_k),\end{align}
where the variables
 $Y_1 \geq \dots \geq Y_k$
are the k largest points of the point process
$Y_1 \geq \dots \geq Y_k$
are the k largest points of the point process
 $\mathcal{P}$
. For all
$\mathcal{P}$
. For all
 $s \in \mathbb{R}$
, we set
$s \in \mathbb{R}$
, we set
 \begin{align*}p_n(s) \;:\!=\; \frac{\mu_n(\mathcal{B}_{s}(R_n) \setminus \mathcal{B}_{0}(s))}{1 - \mu_n(\mathcal{B}_{0}(s))} \textbf{1}_{\{s \in [0,R_n)\}}\end{align*}
\begin{align*}p_n(s) \;:\!=\; \frac{\mu_n(\mathcal{B}_{s}(R_n) \setminus \mathcal{B}_{0}(s))}{1 - \mu_n(\mathcal{B}_{0}(s))} \textbf{1}_{\{s \in [0,R_n)\}}\end{align*}
and we define the vectors
 $\Delta_k^n$
,
$\Delta_k^n$
,
 $\widetilde{\Delta_k^n}$
, and
$\widetilde{\Delta_k^n}$
, and
 $W_k^n$
by
$W_k^n$
by
 \begin{align*}\Delta_k^n &\;:\!=\; (\!\deg(X_{(1)}),\deg(X_{(2)}) \dots ,\deg(X_{(k)})), \\\widetilde{\Delta_k^n} &\;:\!=\; (\widetilde{\deg}(X_{(1)}),\widetilde{\deg}(X_{(2)}) \dots ,\widetilde{\deg}(X_{(k)})),\\W_k^n &\;:\!=\; ((n-i) p_n(r(X_{(i)})),\, 1 \leq i \leq k),\end{align*}
\begin{align*}\Delta_k^n &\;:\!=\; (\!\deg(X_{(1)}),\deg(X_{(2)}) \dots ,\deg(X_{(k)})), \\\widetilde{\Delta_k^n} &\;:\!=\; (\widetilde{\deg}(X_{(1)}),\widetilde{\deg}(X_{(2)}) \dots ,\widetilde{\deg}(X_{(k)})),\\W_k^n &\;:\!=\; ((n-i) p_n(r(X_{(i)})),\, 1 \leq i \leq k),\end{align*}
where
 $\widetilde{\deg}(X_{(k)})$
denotes the number of neighbours of the point
$\widetilde{\deg}(X_{(k)})$
denotes the number of neighbours of the point
 $X_{(k)}$
that are in the annulus
$X_{(k)}$
that are in the annulus
 $\mathcal{C}(r(X_{(k)}),R_n)$
. We first show that
$\mathcal{C}(r(X_{(k)}),R_n)$
. We first show that
 $n^{-1/(2\alpha)}\Delta_k^n$
can be approximated by
$n^{-1/(2\alpha)}\Delta_k^n$
can be approximated by
 $n^{-1/(2\alpha)}W_k^n$
and in a second step we prove the convergence of
$n^{-1/(2\alpha)}W_k^n$
and in a second step we prove the convergence of
 $n^{-1/(2\alpha)}W_k^n$
.
$n^{-1/(2\alpha)}W_k^n$
.
Since the difference
 $\Delta_k^n - \widetilde{\Delta_k^n}$
is bounded by k, it is clear that
$\Delta_k^n - \widetilde{\Delta_k^n}$
is bounded by k, it is clear that
 \begin{align}n^{-1/(2\alpha)}(\Delta_k^n - \widetilde{\Delta_k^n}) \xrightarrow[n\to\infty]{\mathbb{P}} 0.\end{align}
\begin{align}n^{-1/(2\alpha)}(\Delta_k^n - \widetilde{\Delta_k^n}) \xrightarrow[n\to\infty]{\mathbb{P}} 0.\end{align}
For all i, conditionally on
 $X_{(i)}$
, the
$X_{(i)}$
, the
 $n-i$
nodes with radius larger than
$n-i$
nodes with radius larger than
 $r(X_{(i)})$
are independently and identically distributed according to the restriction of
$r(X_{(i)})$
are independently and identically distributed according to the restriction of
 $\mu_n$
to the annulus
$\mu_n$
to the annulus
 $\mathcal{C}(r(X_{(i)}),R_n)$
. Thus, conditionally on
$\mathcal{C}(r(X_{(i)}),R_n)$
. Thus, conditionally on
 $X_{(i)}$
, the variable
$X_{(i)}$
, the variable
 $\widetilde{\deg}(X_{(i)})$
is distributed according to the binomial distribution
$\widetilde{\deg}(X_{(i)})$
is distributed according to the binomial distribution
 \begin{align}\mbox{Bin}(n-i,p_n(r(X_{(i)}))).\end{align}
\begin{align}\mbox{Bin}(n-i,p_n(r(X_{(i)}))).\end{align}
Let us fix
 $K > 0$
and denote by
$K > 0$
and denote by
 $L_n$
the event that all the variables
$L_n$
the event that all the variables
 $r(X_{(i)}),\, i \leq k$
belong to the interval
$r(X_{(i)}),\, i \leq k$
belong to the interval
 $[(1-{1}/{2\alpha})R_n - K,(1-{1}/{2\alpha})R_n + K]$
. Let us fix
$[(1-{1}/{2\alpha})R_n - K,(1-{1}/{2\alpha})R_n + K]$
. Let us fix
 $\varepsilon > 0$
. By the convergence of the radii stated in Proposition 4.1, we can choose
$\varepsilon > 0$
. By the convergence of the radii stated in Proposition 4.1, we can choose
 $K > 0$
such that, for sufficiently large n, the event
$K > 0$
such that, for sufficiently large n, the event
 $L_n$
occurs with probability greater than
$L_n$
occurs with probability greater than
 $1 - \varepsilon$
. By the volume estimates (5.5) and (5.17), we know that there exists
$1 - \varepsilon$
. By the volume estimates (5.5) and (5.17), we know that there exists
 $K' > 1$
such that, on the event
$K' > 1$
such that, on the event
 $L_n$
, for large n and
$L_n$
, for large n and
 $i \leq k$
, we have
$i \leq k$
, we have
 \begin{align}\frac{1}{K'}n^{1/(2\alpha)} \leq \mathbb{E}[\widetilde{\deg}(X_{(i)}) \,\mid\, X_{(i)}] \leq K'n^{1/(2\alpha)}.\end{align}
\begin{align}\frac{1}{K'}n^{1/(2\alpha)} \leq \mathbb{E}[\widetilde{\deg}(X_{(i)}) \,\mid\, X_{(i)}] \leq K'n^{1/(2\alpha)}.\end{align}
Let us fix
 $\delta > 0$
. Denoting by
$\delta > 0$
. Denoting by
 $\mathbb{P}_{L_n}$
the probability measure conditioned on the event
$\mathbb{P}_{L_n}$
the probability measure conditioned on the event
 $L_n$
, it follows from (7.3) and (7.4) that, for large n and
$L_n$
, it follows from (7.3) and (7.4) that, for large n and
 $i \leq k$
,
$i \leq k$
,
 \begin{align*}&\mathbb{P}_{\scriptscriptstyle L_n}[|\widetilde{\deg}(X_{(i)}) - (n-i)p_n(r(X_{(i)}))| \geq n^{1/(2\alpha)} \delta ]\\&\qquad\leq \mathbb{P}_{\scriptscriptstyle L_n}\bigg[|\widetilde{\deg}(X_{(i)}) - \mathbb{E}[\widetilde{\deg}(X_{(i)})\,\mid\,X_{(i)}]| \geq \frac{\delta \mathbb{E}\big[\widetilde{\deg}(X_{(i)})\,\mid\,X_{(i)}\big]}{K'}\bigg].\end{align*}
\begin{align*}&\mathbb{P}_{\scriptscriptstyle L_n}[|\widetilde{\deg}(X_{(i)}) - (n-i)p_n(r(X_{(i)}))| \geq n^{1/(2\alpha)} \delta ]\\&\qquad\leq \mathbb{P}_{\scriptscriptstyle L_n}\bigg[|\widetilde{\deg}(X_{(i)}) - \mathbb{E}[\widetilde{\deg}(X_{(i)})\,\mid\,X_{(i)}]| \geq \frac{\delta \mathbb{E}\big[\widetilde{\deg}(X_{(i)})\,\mid\,X_{(i)}\big]}{K'}\bigg].\end{align*}
Combining this with a Chernoff bound and using (7.4) again yields
 \begin{align*}&\mathbb{P}_{\scriptscriptstyle L_n}[|\widetilde{\deg}(X_{(i)}) - (n-i)p_n(r(X_{(i)}))| \geq n^{1/(2\alpha)} \delta] \xrightarrow[n\to\infty]{} 0.\end{align*}
\begin{align*}&\mathbb{P}_{\scriptscriptstyle L_n}[|\widetilde{\deg}(X_{(i)}) - (n-i)p_n(r(X_{(i)}))| \geq n^{1/(2\alpha)} \delta] \xrightarrow[n\to\infty]{} 0.\end{align*}
From this and (7.2) we conclude that
 \begin{align}n^{-1/(2\alpha)}(\Delta_k^n - W_k^n) \xrightarrow[n\to\infty]{\mathbb{P}} 0.\end{align}
\begin{align}n^{-1/(2\alpha)}(\Delta_k^n - W_k^n) \xrightarrow[n\to\infty]{\mathbb{P}} 0.\end{align}
Now, it remains to prove the convergence in distribution of the vector
 $n^{-1/(2\alpha)} W_k^n$
. For this purpose, we remark that
$n^{-1/(2\alpha)} W_k^n$
. For this purpose, we remark that
 \begin{align}n^{-1/(2\alpha)} W_k^n = \varphi_n\bigg(r(X_{(i)}) - \left(1-\frac{1}{2\alpha}\right)R_n,\, 1 \leq i \leq k\bigg),\end{align}
\begin{align}n^{-1/(2\alpha)} W_k^n = \varphi_n\bigg(r(X_{(i)}) - \left(1-\frac{1}{2\alpha}\right)R_n,\, 1 \leq i \leq k\bigg),\end{align}
where for all n, the application
 $\varphi_n$
is defined from
$\varphi_n$
is defined from
 $\mathbb{R}^k$
to
$\mathbb{R}^k$
to
 $\mathbb{R}^k$
by
$\mathbb{R}^k$
by
 \begin{align*}\varphi_n(z_i, 1 \leq i \leq k) \;:\!=\; \bigg(n^{-1/(2\alpha)}(n-i)p_n\left(z_i+\left(1-\frac{1}{2\alpha}\right)R_n\right),\, 1 \leq i \leq k\bigg).\end{align*}
\begin{align*}\varphi_n(z_i, 1 \leq i \leq k) \;:\!=\; \bigg(n^{-1/(2\alpha)}(n-i)p_n\left(z_i+\left(1-\frac{1}{2\alpha}\right)R_n\right),\, 1 \leq i \leq k\bigg).\end{align*}
By the volume estimates (5.5) and (5.17), the applications
 $\varphi_n$
converges uniformly on every compact of
$\varphi_n$
converges uniformly on every compact of
 $\mathbb{R}^k$
towards the function
$\mathbb{R}^k$
towards the function
 $\varphi$
defined by
$\varphi$
defined by
 \begin{align*}\varphi(z_i, 1 \leq i \leq k) \;:\!=\; (T(z_i),\, 1 \leq i \leq k),\end{align*}
\begin{align*}\varphi(z_i, 1 \leq i \leq k) \;:\!=\; (T(z_i),\, 1 \leq i \leq k),\end{align*}
where the application T is a diffeomorphism from
 $[\!-\!\infty,\infty)$
to
$[\!-\!\infty,\infty)$
to
 $(0,\infty]$
given by
$(0,\infty]$
given by
 \begin{align*}T(z) \;:\!=\; C_{\alpha} \nu^{1-1/(2\alpha)} \mathrm{e}^{-z/2}.\end{align*}
\begin{align*}T(z) \;:\!=\; C_{\alpha} \nu^{1-1/(2\alpha)} \mathrm{e}^{-z/2}.\end{align*}
Let us denote by
 $Z_1 \leq \dots \leq Z_k$
the k smallest points of the point process
$Z_1 \leq \dots \leq Z_k$
the k smallest points of the point process
 $\eta_{\gamma_3}$
(see Proposition 4.1 for the definition of
$\eta_{\gamma_3}$
(see Proposition 4.1 for the definition of
 $\gamma_3$
). By the convergence of the radii stated in Proposition 4.1, the vector
$\gamma_3$
). By the convergence of the radii stated in Proposition 4.1, the vector
 $(r(X_{(i)}) - (1-{1}/{2\alpha})R_n, 1 \leq i \leq k)$
converges in distribution to
$(r(X_{(i)}) - (1-{1}/{2\alpha})R_n, 1 \leq i \leq k)$
converges in distribution to
 $(Z_i, 1 \leq i \leq k)$
. Consequently, from (7.6) and the continuous mapping theorem (see, for example, [Reference Kallenberg16, Theorem 5.27] for a version of the continuous mapping theorem with mappings depending on n), we obtain
$(Z_i, 1 \leq i \leq k)$
. Consequently, from (7.6) and the continuous mapping theorem (see, for example, [Reference Kallenberg16, Theorem 5.27] for a version of the continuous mapping theorem with mappings depending on n), we obtain
 \begin{align}n^{-1/(2\alpha)}W_k^n \xrightarrow[n\to\infty]{d} \varphi(Z_i,\, 1 \leq i \leq k).\end{align}
\begin{align}n^{-1/(2\alpha)}W_k^n \xrightarrow[n\to\infty]{d} \varphi(Z_i,\, 1 \leq i \leq k).\end{align}
Combining (7.5) and (7.7) with Slutsky theorem finally gives
 \begin{align*}n^{-1/(2\alpha)}\Delta_k^n \xrightarrow[n\to\infty]{d} \varphi(Z_i,\, 1 \leq i \leq k).\end{align*}
\begin{align*}n^{-1/(2\alpha)}\Delta_k^n \xrightarrow[n\to\infty]{d} \varphi(Z_i,\, 1 \leq i \leq k).\end{align*}
This proves that (7.1) holds for all k, with the limit measure
 $\eta_{\gamma_3} \circ T^{-1}$
. Thus,
$\eta_{\gamma_3} \circ T^{-1}$
. Thus,
 \begin{align*}\sum\limits_{i=1}^n \delta_{n^{-1/(2\alpha)}\deg(X_i^n)} \xrightarrow[n\to\infty]{d} \eta_{\gamma_3} \circ T^{-1} \quad \mbox{in } M_p((0,\infty]).\end{align*}
\begin{align*}\sum\limits_{i=1}^n \delta_{n^{-1/(2\alpha)}\deg(X_i^n)} \xrightarrow[n\to\infty]{d} \eta_{\gamma_3} \circ T^{-1} \quad \mbox{in } M_p((0,\infty]).\end{align*}
By classical results on transformations of Poisson processes, the point process
 $\eta_{\gamma_3} \circ T^{-1}$
is a Poisson process with an intensity measure whose density
$\eta_{\gamma_3} \circ T^{-1}$
is a Poisson process with an intensity measure whose density
 $g_3$
with respect to the Lebesgue measure is given by
$g_3$
with respect to the Lebesgue measure is given by
 \begin{align*}g_3(y) = \frac{\gamma_3(T^{-1}(y))}{|T'(T^{-1}(y))|} = 2\alpha (C_{\alpha} \nu)^{2\alpha} y^{-2\alpha-1} \quad\text{for all } y \in (0,\infty].\end{align*}
\begin{align*}g_3(y) = \frac{\gamma_3(T^{-1}(y))}{|T'(T^{-1}(y))|} = 2\alpha (C_{\alpha} \nu)^{2\alpha} y^{-2\alpha-1} \quad\text{for all } y \in (0,\infty].\end{align*}
This concludes the proof of (3.5). Now to state the convergence of the maximum degree
, observe that, for all
 $z > 0$
,
$z > 0$
,

where the last convergence follows from the convergence in
 $M_p((0,\infty])$
stated in (3.5). A straightforward computation allows us to compute the limit above. This gives the limit of the cumulative distribution function of
$M_p((0,\infty])$
stated in (3.5). A straightforward computation allows us to compute the limit above. This gives the limit of the cumulative distribution function of
and yields
This concludes the proof of this case.
The proofs for the two other regimes follow the same method. We omit the parts that are too much similar to the proof of the previous case.
In the
 $\alpha = \tfrac{1}{2}$
case, we are interested in proving convergence in distribution of the vector
$\alpha = \tfrac{1}{2}$
case, we are interested in proving convergence in distribution of the vector
 \begin{align*}n^{-1}(\!\deg(X_{(1)}),\deg(X_{(2)}) \dots \deg(X_{(k)})).\end{align*}
\begin{align*}n^{-1}(\!\deg(X_{(1)}),\deg(X_{(2)}) \dots \deg(X_{(k)})).\end{align*}
We define the functions
 $p_n$
and the vectors
$p_n$
and the vectors
 $\Delta_k^n$
and
$\Delta_k^n$
and
 $W_k^n$
as in the previous case. Using the convergence of the radii stated in Proposition 4.1, along with the volume estimates given by (5.17) and Lemma 5.5, we fint that, conditionally on the position of
$W_k^n$
as in the previous case. Using the convergence of the radii stated in Proposition 4.1, along with the volume estimates given by (5.17) and Lemma 5.5, we fint that, conditionally on the position of
 $X_{(i)}$
, with high probability, the expected value of
$X_{(i)}$
, with high probability, the expected value of
 $\widetilde{\deg}(X_{(i)})$
is comparable to n. Thus, by copying the proof of (7.5), we get in this case
$\widetilde{\deg}(X_{(i)})$
is comparable to n. Thus, by copying the proof of (7.5), we get in this case
 \begin{align*}n^{-1}(\Delta_k^n - W_k^n) \xrightarrow[n\to\infty]{\mathbb{P}} 0.\end{align*}
\begin{align*}n^{-1}(\Delta_k^n - W_k^n) \xrightarrow[n\to\infty]{\mathbb{P}} 0.\end{align*}
It remains to prove the convergence in distribution of the vector
 $n^{-1}W_k^n$
. For this purpose, we remark that
$n^{-1}W_k^n$
. For this purpose, we remark that
 \begin{align}n^{-1} W_k^n = \varphi_n(r(X_{(i)}),\, 1 \leq i \leq k),\end{align}
\begin{align}n^{-1} W_k^n = \varphi_n(r(X_{(i)}),\, 1 \leq i \leq k),\end{align}
where the application
 $\varphi_n$
is defined from
$\varphi_n$
is defined from
 $\mathbb{R}_+^k$
to
$\mathbb{R}_+^k$
to
 $\mathbb{R}_+^k$
by
$\mathbb{R}_+^k$
by
 \begin{align*}\varphi_n(z_i,\, 1 \leq i \leq k) \;:\!=\; (p_n(z_i), 1 \leq i \leq k).\end{align*}
\begin{align*}\varphi_n(z_i,\, 1 \leq i \leq k) \;:\!=\; (p_n(z_i), 1 \leq i \leq k).\end{align*}
By the volume estimates given by (5.17) and Lemma 5.5, the applications
 $\varphi_n$
converges uniformly on every compact of
$\varphi_n$
converges uniformly on every compact of
 $\mathbb{R}_+^k$
towards the function
$\mathbb{R}_+^k$
towards the function
 $\varphi$
defined by
$\varphi$
defined by
 \begin{align*}\varphi(z_i, 1 \leq i \leq k) \;:\!=\; (V_{\scriptscriptstyle 1/2}(z_i),\, 1 \leq i \leq k).\end{align*}
\begin{align*}\varphi(z_i, 1 \leq i \leq k) \;:\!=\; (V_{\scriptscriptstyle 1/2}(z_i),\, 1 \leq i \leq k).\end{align*}
Thus, combining (7.8) with the convergence of the radii to
 $\eta_{\gamma_2}$
exactly as we did in the
$\eta_{\gamma_2}$
exactly as we did in the
 $\alpha > \tfrac{1}{2}$
case, we obtain
$\alpha > \tfrac{1}{2}$
case, we obtain
 \begin{align*}\sum\limits_{i=1}^n \delta_{n^{-1}\deg(X_i^n)} \xrightarrow[n\to\infty]{d} \eta \quad \mbox{in } M_p((0,1]),\end{align*}
\begin{align*}\sum\limits_{i=1}^n \delta_{n^{-1}\deg(X_i^n)} \xrightarrow[n\to\infty]{d} \eta \quad \mbox{in } M_p((0,1]),\end{align*}
where
 $\eta$
is a Poisson process with an intensity measure whose density
$\eta$
is a Poisson process with an intensity measure whose density
 $g_2$
with respect to the Lebesgue measure is given by
$g_2$
with respect to the Lebesgue measure is given by
 \begin{align*}g_2(y) = \frac{\gamma_2(V_{\scriptscriptstyle 1/2}^{-1}(y))}{|V_{ 1/2}'(V_{ 1/2}^{-1}(y))|} = \nu |(V_{ 1/2}^{-1})'(y)| \sinh\bigg(\frac{V_{1/2}^{-1}(y)}{2}\bigg) \quad\text{for all }y \in (0,1].\end{align*}
\begin{align*}g_2(y) = \frac{\gamma_2(V_{\scriptscriptstyle 1/2}^{-1}(y))}{|V_{ 1/2}'(V_{ 1/2}^{-1}(y))|} = \nu |(V_{ 1/2}^{-1})'(y)| \sinh\bigg(\frac{V_{1/2}^{-1}(y)}{2}\bigg) \quad\text{for all }y \in (0,1].\end{align*}
This concludes the proof of (3.4). The convergence of the normalised maximum degree
![]() follows by a direct computation exactly like in the
follows by a direct computation exactly like in the
 $\alpha > \tfrac{1}{2}$
case.
$\alpha > \tfrac{1}{2}$
case.
In the
 $\alpha < \tfrac{1}{2}$
case, we are interested in proving convergence in distribution of the vector
$\alpha < \tfrac{1}{2}$
case, we are interested in proving convergence in distribution of the vector
 \begin{align*}n^{-(\alpha + 1/2)}(\!\deg(X_{(1)})-n,\deg(X_{(2)})-n, \dots \deg(X_{(k)})-n).\end{align*}
\begin{align*}n^{-(\alpha + 1/2)}(\!\deg(X_{(1)})-n,\deg(X_{(2)})-n, \dots \deg(X_{(k)})-n).\end{align*}
Because of the additional normalisation by n, we shall define the vectors
 $\Delta_k^n$
and
$\Delta_k^n$
and
 $W_k^n$
in a different manner in this case, by letting
$W_k^n$
in a different manner in this case, by letting
 \begin{align*}\Delta_k^n &\;:\!=\; (\!\deg(X_{(1)})-n,\deg(X_{(2)})-n \dots \deg(X_{(k)})-n), \\W_k^n &\;:\!=\; ((n-i) (p_n(r(X_{(i)}))-1),\, 1 \leq i \leq k).\end{align*}
\begin{align*}\Delta_k^n &\;:\!=\; (\!\deg(X_{(1)})-n,\deg(X_{(2)})-n \dots \deg(X_{(k)})-n), \\W_k^n &\;:\!=\; ((n-i) (p_n(r(X_{(i)}))-1),\, 1 \leq i \leq k).\end{align*}
Using the convergence of the radii stated in Proposition 4.1, together with the volume estimates given by (5.16) and Lemma 5.4, we find that, conditionally on the position of
 $X_{(i)}$
, with high probability, the expected value of
$X_{(i)}$
, with high probability, the expected value of
 $\widetilde{\deg}(X_{(i)}) - n$
is comparable to
$\widetilde{\deg}(X_{(i)}) - n$
is comparable to
 $-n^{\alpha + 1/2}$
. Thus, by copying the proof of (7.5), we get in this case
$-n^{\alpha + 1/2}$
. Thus, by copying the proof of (7.5), we get in this case
 \begin{align*}n^{-(\alpha + 1/2)}(\Delta_k^n - W_k^n) \xrightarrow[n\to\infty]{\mathbb{P}} 0.\end{align*}
\begin{align*}n^{-(\alpha + 1/2)}(\Delta_k^n - W_k^n) \xrightarrow[n\to\infty]{\mathbb{P}} 0.\end{align*}
It remains to prove the convergence in distribution of the vector
 $n^{-(\alpha+1/2)}W_k^n$
. For this purpose, we remark that
$n^{-(\alpha+1/2)}W_k^n$
. For this purpose, we remark that
 \begin{align}n^{-(\alpha + 1/2)} W_k^n = \varphi_n(n^{1/2-\alpha}r(X_{(i)}),\, 1 \leq i \leq k),\end{align}
\begin{align}n^{-(\alpha + 1/2)} W_k^n = \varphi_n(n^{1/2-\alpha}r(X_{(i)}),\, 1 \leq i \leq k),\end{align}
where, the application
 $\varphi_n$
is defined from
$\varphi_n$
is defined from
 $\mathbb{R}_+^k$
to
$\mathbb{R}_+^k$
to
 $\mathbb{R}_-^k$
by
$\mathbb{R}_-^k$
by
 \begin{align*}\varphi_n(z_i, 1 \leq i \leq k) \;:\!=\; (n^{-(\alpha+1/2)}(n-i) (p_n(n^{\alpha-1/2} z_i)-1),\, 1 \leq i \leq k).\end{align*}
\begin{align*}\varphi_n(z_i, 1 \leq i \leq k) \;:\!=\; (n^{-(\alpha+1/2)}(n-i) (p_n(n^{\alpha-1/2} z_i)-1),\, 1 \leq i \leq k).\end{align*}
By the volume estimates given by (5.16) and Lemma 5.4, the applications
 $\varphi_n$
converge uniformly on every compact of
$\varphi_n$
converge uniformly on every compact of
 $\mathbb{R}_+^k$
towards the function
$\mathbb{R}_+^k$
towards the function
 $\varphi$
defined by
$\varphi$
defined by
 \begin{align*}\varphi(z_i, 1 \leq i \leq k) \;:\!=\; (T(z_i),\, 1 \leq i \leq k),\end{align*}
\begin{align*}\varphi(z_i, 1 \leq i \leq k) \;:\!=\; (T(z_i),\, 1 \leq i \leq k),\end{align*}
where T is a diffeomorphism from
 $[0,+\infty)$
to
$[0,+\infty)$
to
 $(\!-\!\infty,0]$
given by
$(\!-\!\infty,0]$
given by
 \begin{align*}T(z) \;:\!=\; - \frac{\alpha z}{\pi}.\end{align*}
\begin{align*}T(z) \;:\!=\; - \frac{\alpha z}{\pi}.\end{align*}
Thus, proceeding exactly as in the
 $\alpha > \tfrac{1}{2}$
case, we obtain
$\alpha > \tfrac{1}{2}$
case, we obtain
 \begin{align*}\sum\limits_{i=1}^n \delta_{n^{-(\alpha + 1/2)}(\!\deg(X_i^n)-n)} \xrightarrow[n\to\infty]{d} \eta \quad \mbox{in } M_p((\!-\!\infty,0]),\end{align*}
\begin{align*}\sum\limits_{i=1}^n \delta_{n^{-(\alpha + 1/2)}(\!\deg(X_i^n)-n)} \xrightarrow[n\to\infty]{d} \eta \quad \mbox{in } M_p((\!-\!\infty,0]),\end{align*}
where
 $\eta$
is a Poisson process with an intensity measure whose density
$\eta$
is a Poisson process with an intensity measure whose density
 $g_1$
with respect to the Lebesgue measure is given by
$g_1$
with respect to the Lebesgue measure is given by
 \begin{align*}g_1(y) = \frac{\gamma_1(T^{-1}(y))}{|T'(T^{-1}(y))|} = 2 \pi^2 \nu^{2\alpha} |y| \quad\text{for all } y \in (\!-\!\infty,0].\end{align*}
\begin{align*}g_1(y) = \frac{\gamma_1(T^{-1}(y))}{|T'(T^{-1}(y))|} = 2 \pi^2 \nu^{2\alpha} |y| \quad\text{for all } y \in (\!-\!\infty,0].\end{align*}
This concludes the proof of (3.3). The convergence of the normalised maximum degree follows by a direct computation exactly like in the
 $\alpha > \tfrac{1}{2}$
case.
$\alpha > \tfrac{1}{2}$
case.
8. Ordering/non-ordering transition (proof of Theorem 3.2)
From the proof of Theorem 3.1, we observe that the key quantities determining the ordering properties of the node degrees are the differences between the volumes of successive balls,
 $\mu_n(\mathcal{B}_{X_{(i)}}(R_n))-\mu_n(\mathcal{B}_{X_{(i+1)}}(R_n))$
. We expect the ordering to break around the first i for which this difference is sufficiently small. The following lemma is a refinement of Lemma 5.3 that allows us to obtain fine estimates on these differences.
$\mu_n(\mathcal{B}_{X_{(i)}}(R_n))-\mu_n(\mathcal{B}_{X_{(i+1)}}(R_n))$
. We expect the ordering to break around the first i for which this difference is sufficiently small. The following lemma is a refinement of Lemma 5.3 that allows us to obtain fine estimates on these differences.
Lemma 8.1. For
 $\alpha > \tfrac{1}{2}$
, there exists
$\alpha > \tfrac{1}{2}$
, there exists
 $r_0 > 0$
such that, for
$r_0 > 0$
such that, for
 $r \in (r_0,R_n)$
,
$r \in (r_0,R_n)$
,
 \begin{align*}\frac{\partial}{\partial r} \mu_n(\mathcal{B}_{r}(R_n)) = - \frac{C_{\alpha}}{2} \mathrm{e}^{-r/2} (1 + O(\mathrm{e}^{-(\alpha-1/2)r} + r \mathrm{e}^{-r})),\end{align*}
\begin{align*}\frac{\partial}{\partial r} \mu_n(\mathcal{B}_{r}(R_n)) = - \frac{C_{\alpha}}{2} \mathrm{e}^{-r/2} (1 + O(\mathrm{e}^{-(\alpha-1/2)r} + r \mathrm{e}^{-r})),\end{align*}
where
 $C_{\alpha} \;:\!=\; {2\alpha}/{\pi(\alpha-\tfrac12)}$
(as in Lemma 5.3).
$C_{\alpha} \;:\!=\; {2\alpha}/{\pi(\alpha-\tfrac12)}$
(as in Lemma 5.3).
We explain in Remark 8.1 why this estimate is necessary for proving Theorem 3.2 when
 $\alpha$
is close to
$\alpha$
is close to
 $\tfrac{1}{2}$
. We defer the proof of this lemma to the end of the section and proceed directly with the proof of Theorem 3.2.
$\tfrac{1}{2}$
. We defer the proof of this lemma to the end of the section and proceed directly with the proof of Theorem 3.2.
Proof of Theorem
3.2. In this proof K stands for a positive constant (depending only on
 $\alpha$
and
$\alpha$
and
 $\nu$
) whose value may change throughout the proof. We define the sequence
$\nu$
) whose value may change throughout the proof. We define the sequence
 $(k_n)$
, as in the statement of the theorem, by
$(k_n)$
, as in the statement of the theorem, by
 $k_n \;:\!=\; n^{\beta} \log(n)^{-2\alpha}$
, where
$k_n \;:\!=\; n^{\beta} \log(n)^{-2\alpha}$
, where
 $\beta \;:\!=\; 1/(1+8\alpha)$
. The proof of the two assertions (3.1) and (3.2) are done separately.
$\beta \;:\!=\; 1/(1+8\alpha)$
. The proof of the two assertions (3.1) and (3.2) are done separately.
8.1. Ordering up to rank
$k_n$
(proof of (3.1))

The proof of (3.1) follows the same general idea as the proof of Theorem 3.1, but in a more precise form. The argument is divided into three steps. The first two steps consist in localising the
 $k_n$
first nodes and showing that there are large gaps between their radii. Actually, this is done by proving that two specific events,
$k_n$
first nodes and showing that there are large gaps between their radii. Actually, this is done by proving that two specific events,
 $L_n$
and
$L_n$
and
 $G_n$
, occur with high probability. In the third step, we show that, under the event
$G_n$
, occur with high probability. In the third step, we show that, under the event
 $L_n \cap G_n$
, there are large differences between the expected degrees of the
$L_n \cap G_n$
, there are large differences between the expected degrees of the
 $k_n$
first nodes. The conclusion then follows from a Chernoff bound.
$k_n$
first nodes. The conclusion then follows from a Chernoff bound.
Step 1: Localisation of the
 $k_n$
first nodes. Let
$k_n$
first nodes. Let
 $w_n \;:\!=\; \log(\log(n))$
and define the localisation event
$w_n \;:\!=\; \log(\log(n))$
and define the localisation event
 $L_n$
by
$L_n$
by
 \begin{align*}L_n \;:\!=\; \{t_n \leq r(X_{(1)}) \; \mbox{and} \; r(X_{(k_n)}) \leq r_n\},\end{align*}
\begin{align*}L_n \;:\!=\; \{t_n \leq r(X_{(1)}) \; \mbox{and} \; r(X_{(k_n)}) \leq r_n\},\end{align*}
where
 \begin{align*}t_n \;:\!=\; \bigg(1-\frac{1}{2\alpha}\bigg)R_n - w_n \quad \mbox{and} \quad r_n \;:\!=\; t_n + \frac{\beta}{\alpha}\log(n).\end{align*}
\begin{align*}t_n \;:\!=\; \bigg(1-\frac{1}{2\alpha}\bigg)R_n - w_n \quad \mbox{and} \quad r_n \;:\!=\; t_n + \frac{\beta}{\alpha}\log(n).\end{align*}
Let us prove that, with this choice of
 $t_n$
and
$t_n$
and
 $r_n$
, the event
$r_n$
, the event
 $L_n$
is realised with high probability. We already know from Proposition 4.1 that
$L_n$
is realised with high probability. We already know from Proposition 4.1 that
 $t_n \leq r(X_{(1)})$
holds with high probability. On the other hand, we note that
$t_n \leq r(X_{(1)})$
holds with high probability. On the other hand, we note that
 $r(X_{(k_n)}) \leq r_n$
holds if and only if the number of nodes in the ball
$r(X_{(k_n)}) \leq r_n$
holds if and only if the number of nodes in the ball
 $\mathcal{B}_{0}(r_n)$
is larger than
$\mathcal{B}_{0}(r_n)$
is larger than
 $k_n$
. The number of points falling in this ball has a binomial distribution with expected value
$k_n$
. The number of points falling in this ball has a binomial distribution with expected value
 \begin{align*}n \mu_n(\mathcal{B}_{0}(r_n)) \underset{n \to \infty}{\sim} \nu n^{\beta}\log(n)^{-\alpha} \gg k_n.\end{align*}
\begin{align*}n \mu_n(\mathcal{B}_{0}(r_n)) \underset{n \to \infty}{\sim} \nu n^{\beta}\log(n)^{-\alpha} \gg k_n.\end{align*}
Using a Chernoff bound it follows that
 $r(X_{(k_n)}) \leq r_n$
holds with high probability, so
$r(X_{(k_n)}) \leq r_n$
holds with high probability, so
 \begin{align*}\mathbb{P}[L_n] \xrightarrow[n\to\infty]{} 1.\end{align*}
\begin{align*}\mathbb{P}[L_n] \xrightarrow[n\to\infty]{} 1.\end{align*}
Step 2: Proving the existence of large gaps between the
 $k_n$
first nodes. We define the gap event
$k_n$
first nodes. We define the gap event
 $G_n$
by
$G_n$
by
 \begin{align*}G_n \;:\!=\; \{\text{for all }i \leq k_n,\, r(X_{(i+1)}) - r(X_{(i)}) \geq \lambda_n(r(X_{(i)})) \},\end{align*}
\begin{align*}G_n \;:\!=\; \{\text{for all }i \leq k_n,\, r(X_{(i+1)}) - r(X_{(i)}) \geq \lambda_n(r(X_{(i)})) \},\end{align*}
where, for all n, the function
 $\lambda_n$
is defined by
$\lambda_n$
is defined by
 \begin{align*}\lambda_n(s) \;:\!=\; \mathrm{e}^{\alpha(R_n - s)} n^{-(\beta+1)}\quad\text{for all }s \geq 0.\end{align*}
\begin{align*}\lambda_n(s) \;:\!=\; \mathrm{e}^{\alpha(R_n - s)} n^{-(\beta+1)}\quad\text{for all }s \geq 0.\end{align*}
Let us prove that with this choice of
 $\lambda_n$
, the event
$\lambda_n$
, the event
 $G_n$
is realised with high probability, which will prove that the radius gaps between the
$G_n$
is realised with high probability, which will prove that the radius gaps between the
 $n^{\beta}$
first nodes are relatively large.
$n^{\beta}$
first nodes are relatively large.
The first
 $k_n+1$
nodes (i.e.
$k_n+1$
nodes (i.e.
 $X_{(1)},X_{(2)},\dots,X_{(k_n+1)}$
) can be sampled in the following way. First, sample n nodes in
$X_{(1)},X_{(2)},\dots,X_{(k_n+1)}$
) can be sampled in the following way. First, sample n nodes in
 $\mathcal{B}_{0}(R_n)$
according to the distribution
$\mathcal{B}_{0}(R_n)$
according to the distribution
 $\mu_n$
, select the closest to the centre as
$\mu_n$
, select the closest to the centre as
 $X_{(1)}$
and erase the
$X_{(1)}$
and erase the
 $(n-1)$
other points. Next, sample
$(n-1)$
other points. Next, sample
 $(n-1)$
points according to the restriction of
$(n-1)$
points according to the restriction of
 $\mu_n$
to the annulus
$\mu_n$
to the annulus
 $\mathcal{C}(r(X_{(1)}),R_n)$
, choose the closest to the centre as
$\mathcal{C}(r(X_{(1)}),R_n)$
, choose the closest to the centre as
 $X_{(2)}$
and erase the other ones. Repeat this process until the
$X_{(2)}$
and erase the other ones. Repeat this process until the
 $(k_n + 1)$
first nodes have been sampled (at step
$(k_n + 1)$
first nodes have been sampled (at step
 $(i+1)$
sample
$(i+1)$
sample
 $(n-i)$
points in the annulus
$(n-i)$
points in the annulus
 $\mathcal{C}(r(X_{(i)}),R_n)$
, choose the closest to the centre as
$\mathcal{C}(r(X_{(i)}),R_n)$
, choose the closest to the centre as
 $X_{(i+1)}$
and erase the other ones). Considering this process, we get
$X_{(i+1)}$
and erase the other ones). Considering this process, we get
 \begin{align*}\mathbb{P}[G_n^c,\,L_n] &\leq \sum\limits_{i = 1}^{k_n} \mathbb{P}[Z_i^n \neq 0,\,L_n],\end{align*}
\begin{align*}\mathbb{P}[G_n^c,\,L_n] &\leq \sum\limits_{i = 1}^{k_n} \mathbb{P}[Z_i^n \neq 0,\,L_n],\end{align*}
where the random variable
 $Z_i^n$
counts the number of points falling in the annulus
$Z_i^n$
counts the number of points falling in the annulus
 $\mathcal{C}(r(X_{(i)}), r(X_{(i)}) + \lambda_n(r(X_{(i)})))$
at step
$\mathcal{C}(r(X_{(i)}), r(X_{(i)}) + \lambda_n(r(X_{(i)})))$
at step
 $(i+1)$
. Conditionally on the position of
$(i+1)$
. Conditionally on the position of
 $X_{(i)}$
, the variable
$X_{(i)}$
, the variable
 $Z_i^n$
follows a binomial distribution with
$Z_i^n$
follows a binomial distribution with
 $(n-i)$
trials and probability
$(n-i)$
trials and probability
 $p_i^n$
given by
$p_i^n$
given by
 \begin{align*}p_i^n&\;:\!=\; \frac{\mu_n(\mathcal{C}(r(X_{(i)}),r(X_{(i)})+\lambda_n(r(X_{(i)}))))}{\mu_n(\mathcal{C}(r(X_{(i)}),R_n))}\\&= \frac{\cosh(\alpha (r(X_{(i)})+\lambda_n(r(X_{(i)})))) - \cosh(\alpha r(X_{(i)}))}{\cosh(\alpha R_n) - \cosh(\alpha r(X_{(i)}))}.\end{align*}
\begin{align*}p_i^n&\;:\!=\; \frac{\mu_n(\mathcal{C}(r(X_{(i)}),r(X_{(i)})+\lambda_n(r(X_{(i)}))))}{\mu_n(\mathcal{C}(r(X_{(i)}),R_n))}\\&= \frac{\cosh(\alpha (r(X_{(i)})+\lambda_n(r(X_{(i)})))) - \cosh(\alpha r(X_{(i)}))}{\cosh(\alpha R_n) - \cosh(\alpha r(X_{(i)}))}.\end{align*}
For
 $r(X_{(i)}) \leq r_n$
and as
$r(X_{(i)}) \leq r_n$
and as
 $n \to \infty$
, the denominator is asymptotically equivalent to
$n \to \infty$
, the denominator is asymptotically equivalent to
 $\mathrm{e}^{\alpha R_n}/2$
. Moreover, for
$\mathrm{e}^{\alpha R_n}/2$
. Moreover, for
 $r(X_{(i)}) \geq t_n$
, we have
$r(X_{(i)}) \geq t_n$
, we have
 $\lambda_n(r(X_{(i)})) = o(1)$
. Applying the mean value theorem to the numerator, it follows that, for large enough n and
$\lambda_n(r(X_{(i)})) = o(1)$
. Applying the mean value theorem to the numerator, it follows that, for large enough n and
 $t_n \leq r(X_{(i)}) \leq r_n$
,
$t_n \leq r(X_{(i)}) \leq r_n$
,
 \begin{align*}p_i^n &\leq K \lambda_n(r(X_{(i)})) \exp(\alpha (r(X_{(i)}) - R_n)) = K n^{-(\beta+1)}.\end{align*}
\begin{align*}p_i^n &\leq K \lambda_n(r(X_{(i)})) \exp(\alpha (r(X_{(i)}) - R_n)) = K n^{-(\beta+1)}.\end{align*}
Writing
 $\mathbb{P}_{\scriptscriptstyle \scriptscriptstyle X_{(i)}}[\cdot]$
for conditional probability with respect to the variable
$\mathbb{P}_{\scriptscriptstyle \scriptscriptstyle X_{(i)}}[\cdot]$
for conditional probability with respect to the variable
 $X_{(i)}$
, we get
$X_{(i)}$
, we get
 \begin{align*}\mathbb{P}[G_n^c \cap L_n] &\leq \sum_{i = 1}^{k_n} \mathbb{E}[\mathbb{P}_{\scriptscriptstyle \scriptscriptstyle X_{(i)}}[Z_i^n \neq 0] \textbf{1}_{\{t_n \leq r(X_{(i)}) \leq r_n\}}]\\&\leq k_n (1 - (1-K n^{-(\beta+1)})^{n})\\&\underset{n \to \infty}{\sim} K \log(n)^{-2\alpha}\\&\xrightarrow[n\to\infty]{} 0.\end{align*}
\begin{align*}\mathbb{P}[G_n^c \cap L_n] &\leq \sum_{i = 1}^{k_n} \mathbb{E}[\mathbb{P}_{\scriptscriptstyle \scriptscriptstyle X_{(i)}}[Z_i^n \neq 0] \textbf{1}_{\{t_n \leq r(X_{(i)}) \leq r_n\}}]\\&\leq k_n (1 - (1-K n^{-(\beta+1)})^{n})\\&\underset{n \to \infty}{\sim} K \log(n)^{-2\alpha}\\&\xrightarrow[n\to\infty]{} 0.\end{align*}
Since
 $L_n$
occurs with high probability, we conclude that
$L_n$
occurs with high probability, we conclude that
 \begin{align*}\mathbb{P}[G_n] \xrightarrow[n\to\infty]{} 1.\end{align*}
\begin{align*}\mathbb{P}[G_n] \xrightarrow[n\to\infty]{} 1.\end{align*}
Step 3: Comparing the successive expected values of the degrees. Let us denote by
 $O_n$
the ordering event described in (3.1). By the previous two steps, it remains to prove that
$O_n$
the ordering event described in (3.1). By the previous two steps, it remains to prove that
 \begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n] \xrightarrow[n\to\infty]{} 0.\end{align}
\begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n] \xrightarrow[n\to\infty]{} 0.\end{align}
Proceeding as we did for proving (6.2) in the proof of Theorem 3.1, we get the upper bound
 \begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n]&\leq \max\limits_{(s_1,s_2)} 2n^2 \exp\bigg(- \frac{(n-2)(\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n)))^2}{8\mu_n(\mathcal{B}_{s_1}(R_n))}\bigg),\end{align}
\begin{align}\mathbb{P}[O_n^c \cap L_n \cap G_n]&\leq \max\limits_{(s_1,s_2)} 2n^2 \exp\bigg(- \frac{(n-2)(\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n)))^2}{8\mu_n(\mathcal{B}_{s_1}(R_n))}\bigg),\end{align}
where the maximum is taken over the couples
 $(s_1,s_2)$
belonging to the set
$(s_1,s_2)$
belonging to the set
 \begin{align*}E_n \;:\!=\; \{(s_1,s_2) \in [0,R_n)^2\colon t_n \leq s_1 \leq r_n,\, s_2 - s_1 \geq \lambda_n(s_1)\}.\end{align*}
\begin{align*}E_n \;:\!=\; \{(s_1,s_2) \in [0,R_n)^2\colon t_n \leq s_1 \leq r_n,\, s_2 - s_1 \geq \lambda_n(s_1)\}.\end{align*}
We are now interested in bounding the fraction appearing in the exponential term. For
 $(s_1,s_2) \in E_n$
and n large, we have
$(s_1,s_2) \in E_n$
and n large, we have
 \begin{align*}\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n))&= - \int_{s_1}^{s_2} \frac{\partial}{\partial r} \mu_n(\mathcal{B}_{r}(R_n)) \,\textrm{d}r\\&\geq K (1 + O(\mathrm{e}^{-(\alpha-1/2)t_n} + t_n \mathrm{e}^{-t_n})) \int_{s_1}^{s_2} \mathrm{e}^{-r/2}\,\textrm{d}r\\&= K \mathrm{e}^{-s_1/2}(1 - \mathrm{e}^{-(s_2-s_1)/2}),\end{align*}
\begin{align*}\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n))&= - \int_{s_1}^{s_2} \frac{\partial}{\partial r} \mu_n(\mathcal{B}_{r}(R_n)) \,\textrm{d}r\\&\geq K (1 + O(\mathrm{e}^{-(\alpha-1/2)t_n} + t_n \mathrm{e}^{-t_n})) \int_{s_1}^{s_2} \mathrm{e}^{-r/2}\,\textrm{d}r\\&= K \mathrm{e}^{-s_1/2}(1 - \mathrm{e}^{-(s_2-s_1)/2}),\end{align*}
where the second line follows from Lemma 8.1. Using (5.5) to estimate the denominator in the expression below, it follows that, for
 $(s_1,s_2) \in E_n$
and large n,
$(s_1,s_2) \in E_n$
and large n,
 \begin{align}\frac{(n-2)(\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n)))^2}{8\mu_n(\mathcal{B}_{s_1}(R_n))}&\geq K n\mathrm{e}^{-s_1/2}(1-\mathrm{e}^{-(s_2-s_1)/2})^2 \notag\\&\geq K n\mathrm{e}^{-r_n/2}\lambda_n(r_n)^2, \end{align}
\begin{align}\frac{(n-2)(\mu_n(\mathcal{B}_{s_1}(R_n)) - \mu_n(\mathcal{B}_{s_2}(R_n)))^2}{8\mu_n(\mathcal{B}_{s_1}(R_n))}&\geq K n\mathrm{e}^{-s_1/2}(1-\mathrm{e}^{-(s_2-s_1)/2})^2 \notag\\&\geq K n\mathrm{e}^{-r_n/2}\lambda_n(r_n)^2, \end{align}
Moreover, straightforward computations give
 \begin{align*}n\mathrm{e}^{-r_n/2} = K n^{{(1-\beta)}/{2\alpha}} \log(n)^{1/2} \quad \mbox{and} \quad \lambda_n(r_n)= K n^{-2\beta} \log(n)^\alpha.\end{align*}
\begin{align*}n\mathrm{e}^{-r_n/2} = K n^{{(1-\beta)}/{2\alpha}} \log(n)^{1/2} \quad \mbox{and} \quad \lambda_n(r_n)= K n^{-2\beta} \log(n)^\alpha.\end{align*}
By choice of
 $\beta$
, we have
$\beta$
, we have
 ${(1-\beta)}/{2\alpha} = 4\beta$
. Thus, substituting the above in (8.3) and combining with (8.2) gives
${(1-\beta)}/{2\alpha} = 4\beta$
. Thus, substituting the above in (8.3) and combining with (8.2) gives
 \begin{align*}\mathbb{P}[O_n^c \cap L_n \cap G_n]&\leq 2n^2\exp(\!- K \log(n)^{1/2+2\alpha}) \xrightarrow[n\to\infty]{} 0.\end{align*}
\begin{align*}\mathbb{P}[O_n^c \cap L_n \cap G_n]&\leq 2n^2\exp(\!- K \log(n)^{1/2+2\alpha}) \xrightarrow[n\to\infty]{} 0.\end{align*}
This proves (8.1) and concludes the proof of (3.1).
Remark 8.1. Instead of using Lemma 8.1 to bound the numerator in (8.3), one might consider using the volume estimate of
 $\mu_n(\mathcal{B}_{r}(R_n))$
from [Reference Gugelmann, Panagiotou and Peter14, Lemma 3.2], which is recalled in (5.2). However, for
$\mu_n(\mathcal{B}_{r}(R_n))$
from [Reference Gugelmann, Panagiotou and Peter14, Lemma 3.2], which is recalled in (5.2). However, for
 $\alpha \in ({1}/{2},{(7 + \sqrt{33})}/{16})$
, the error terms appearing in this estimate are larger than
$\alpha \in ({1}/{2},{(7 + \sqrt{33})}/{16})$
, the error terms appearing in this estimate are larger than
 $\lambda_n(r_n)$
, which is not sufficiently precise for our purposes. The estimate of the differential of
$\lambda_n(r_n)$
, which is not sufficiently precise for our purposes. The estimate of the differential of
 $\mu_n(\mathcal{B}_{r}(R_n))$
in r, given by Lemma 8.1, is more suitable for measuring volume differences of balls with close radii.
$\mu_n(\mathcal{B}_{r}(R_n))$
in r, given by Lemma 8.1, is more suitable for measuring volume differences of balls with close radii.
8.2. No ordering beyond rank
$n^\beta$
(proof of (3.2))

The proof is divided into four main steps. Before proceeding with these, we first introduce some notation and a Poissonised version of (3.2), which will serve as an intermediate result. Fix an arbitrary sequence
 $(a_n)$
diverging to
$(a_n)$
diverging to
 $+\infty$
. Observe that if (3.2) holds for a given sequence
$+\infty$
. Observe that if (3.2) holds for a given sequence
 $(a_n)$
then it also holds for any sequence larger than
$(a_n)$
then it also holds for any sequence larger than
 $(a_n)$
. Thus, without loss of generality, we may assume that
$(a_n)$
. Thus, without loss of generality, we may assume that
 $a_n \leq \log(n)$
. This assumption on
$a_n \leq \log(n)$
. This assumption on
 $(a_n)$
will be used implicitly in the proof when establishing certain bounds. Let
$(a_n)$
will be used implicitly in the proof when establishing certain bounds. Let
 $w_n' \;:\!=\; \log(a_n)$
and define
$w_n' \;:\!=\; \log(a_n)$
and define
 \begin{align*}t_n' &\;:\!=\; \bigg(1-\frac{1}{2\alpha}\bigg)R_n + \frac{\beta}{\alpha}\log(n) + w_n' \quad \mbox{and} \quad r_n' \;:\!=\; t_n' + w_n'.\end{align*}
\begin{align*}t_n' &\;:\!=\; \bigg(1-\frac{1}{2\alpha}\bigg)R_n + \frac{\beta}{\alpha}\log(n) + w_n' \quad \mbox{and} \quad r_n' \;:\!=\; t_n' + w_n'.\end{align*}
Recall that we aim at finding an index
 $i \in [n^\beta,n^\beta a_n]$
such that
$i \in [n^\beta,n^\beta a_n]$
such that
 $\deg(X_{(i)}^n) < \deg(X_{(i+1)}^n)$
. In order to gain some independence between the degrees of the nodes, we first prove an analogue of (3.2) for the Poissonised model
$\deg(X_{(i)}^n) < \deg(X_{(i+1)}^n)$
. In order to gain some independence between the degrees of the nodes, we first prove an analogue of (3.2) for the Poissonised model
 $\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
. It turns out that, for
$\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
. It turns out that, for
 $i \in [n^\beta,n^\beta a_n]$
, the nodes
$i \in [n^\beta,n^\beta a_n]$
, the nodes
 $X_{(i)}$
and
$X_{(i)}$
and
 $X_{(i+1)}$
have radii that are approximately located in the interval
$X_{(i+1)}$
have radii that are approximately located in the interval
 $[t_n',r_n']$
. Thus, the counterpart of the non-ordering event (3.2) for the Poissonised model
$[t_n',r_n']$
. Thus, the counterpart of the non-ordering event (3.2) for the Poissonised model
 $\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
can be written as follows.
$\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
can be written as follows.
-
• With high probability, there exist two nodes v and v ′ in the graph
$\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
, such that
(8.4)where the sequence
\begin{align}t_n' \leq r(v) \leq r(v') \leq r_n' \quad \mbox{and} \quad \deg(v) + \delta_n \leq \deg(v'),\end{align}
$(\delta_n)$
is defined by
$\delta_n \;:\!=\; \sqrt{n\mathrm{e}^{-r_n'/2}} = K n^{2 \beta} \mathrm{e}^{-w_n'/2}$
.




In the first three steps of the proof, we work within the Poissonised model
 $\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
to establish the Poissonised statement. The final step of the proof is a de-Poissonisation procedure that gives the result for
$\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
to establish the Poissonised statement. The final step of the proof is a de-Poissonisation procedure that gives the result for
 $\mathcal{G}_{\alpha,\nu}(n)$
from the result for
$\mathcal{G}_{\alpha,\nu}(n)$
from the result for
 $\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
. The extra gap of size
$\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
. The extra gap of size
 $\delta_n$
that appears in the Poissonised statement is crucial for this de-Poissonisation step.
$\delta_n$
that appears in the Poissonised statement is crucial for this de-Poissonisation step.
Let us fix a small
 $\varepsilon \in (0,1)$
and set
$\varepsilon \in (0,1)$
and set
 $R_n^{\varepsilon} \;:\!=\; (1-\varepsilon)R_n$
. For
$R_n^{\varepsilon} \;:\!=\; (1-\varepsilon)R_n$
. For
 $x \in \mathcal{B}_{0}(R_n)$
, we denote by
$x \in \mathcal{B}_{0}(R_n)$
, we denote by
 $\mathcal{B}^{\varepsilon}_{x}(R_n)$
the part of the ball
$\mathcal{B}^{\varepsilon}_{x}(R_n)$
the part of the ball
 $\mathcal{B}_{x}(R_n)$
that lies beyond the circle of radius
$\mathcal{B}_{x}(R_n)$
that lies beyond the circle of radius
 $R_n^{\varepsilon}$
, i.e.
$R_n^{\varepsilon}$
, i.e.
 \begin{align*}\mathcal{B}^{\varepsilon}_{x}(R_n) \;:\!=\; \mathcal{B}_{x}(R_n) \cap \mathcal{C}(R_n^{\varepsilon},R_n).\end{align*}
\begin{align*}\mathcal{B}^{\varepsilon}_{x}(R_n) \;:\!=\; \mathcal{B}_{x}(R_n) \cap \mathcal{C}(R_n^{\varepsilon},R_n).\end{align*}
The
 $\varepsilon$
degree of a node X is the number of nodes (excluding X itself) contained in
$\varepsilon$
degree of a node X is the number of nodes (excluding X itself) contained in
 $\mathcal{B}^{\varepsilon}_{X}(R_n)$
. It is denoted by
$\mathcal{B}^{\varepsilon}_{X}(R_n)$
. It is denoted by
 $\deg_{\varepsilon}(X)$
. Since the nodes of
$\deg_{\varepsilon}(X)$
. Since the nodes of
 $\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
are concentrated near the boundary of
$\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
are concentrated near the boundary of
 $\mathcal{B}_{0}(R_n)$
, the
$\mathcal{B}_{0}(R_n)$
, the
 $\varepsilon$
degrees provide good estimates of the actual degrees of the nodes. Therefore, we first focus on the
$\varepsilon$
degrees provide good estimates of the actual degrees of the nodes. Therefore, we first focus on the
 $\varepsilon$
degree rather than degrees directly, as it is easier to get independence results concerning the
$\varepsilon$
degree rather than degrees directly, as it is easier to get independence results concerning the
 $\varepsilon$
degrees.
$\varepsilon$
degrees.
We can now proceed with the four steps of the proof. The first step consists in finding a number
 $c_n \to \infty$
of pairs of points (v, v
′) in the Poissonised graph
$c_n \to \infty$
of pairs of points (v, v
′) in the Poissonised graph
 $\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
that have a positive probability of satisfying (8.4). In the second step, we use the independence property of the Poissonised model
$\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
that have a positive probability of satisfying (8.4). In the second step, we use the independence property of the Poissonised model
 $\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
to show that, with high probability, at least one of these candidate pairs satisfies a version of (8.4) in which the degree is replaced by the
$\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
to show that, with high probability, at least one of these candidate pairs satisfies a version of (8.4) in which the degree is replaced by the
 $\varepsilon$
degree. In the third step, we show that the error induced by replacing the degree with the
$\varepsilon$
degree. In the third step, we show that the error induced by replacing the degree with the
 $\varepsilon$
degree is sufficiently small. It follows that (8.4) holds with high probability. The fourth and final step is the de-Poissonisation procedure.
$\varepsilon$
degree is sufficiently small. It follows that (8.4) holds with high probability. The fourth and final step is the de-Poissonisation procedure.

Figure 4. Depiction of the closeness event
 $C_n$
. By condition (8.5), for all i, the radius gap
$C_n$
. By condition (8.5), for all i, the radius gap
 $r(v_i') - r(v_i)$
is small, ensuring that
$r(v_i') - r(v_i)$
is small, ensuring that
 $\deg_{\varepsilon}(v_i) \leq \deg_{\varepsilon}(v_i')$
holds with a probability bounded away from 0. By condition (8.6), the portions of the balls
$\deg_{\varepsilon}(v_i) \leq \deg_{\varepsilon}(v_i')$
holds with a probability bounded away from 0. By condition (8.6), the portions of the balls
 $\mathcal{B}_{v_i}(R_n)$
and
$\mathcal{B}_{v_i}(R_n)$
and
 $\mathcal{B}_{v_i'}(R_n)$
that lie beyond the circle of radius
$\mathcal{B}_{v_i'}(R_n)$
that lie beyond the circle of radius
 $R_n^{\varepsilon}$
are all disjoints, ensuring the independence of the corresponding
$R_n^{\varepsilon}$
are all disjoints, ensuring the independence of the corresponding
 $\varepsilon$
degrees.
$\varepsilon$
degrees.
Step 1: Finding good pairs of candidates for the couple (v,v’). For all n, set
 $\lambda_n' \;:\!=\; n^{-2\beta} \mathrm{e}^{- \alpha w_n'}$
and denote by
$\lambda_n' \;:\!=\; n^{-2\beta} \mathrm{e}^{- \alpha w_n'}$
and denote by
 $C_n$
the following event (see Figure 4).
$C_n$
the following event (see Figure 4).
-
• There exist two sequences
$(v_i)_{\scriptscriptstyle 1 \leq i \leq c_n}$
and
$(v_i')_{\scriptscriptstyle 1 \leq i \leq c_n}$
each containing
$c_n$
nodes of
$\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
, such that
$v_1,\dots,v_{c_n},v_1',\dots,v_{c_n}'$
are pairwise distinct and, for all i,
(8.5)We also require that, for all x and y distinct in
\begin{align}t_n' \leq r(v_i) \leq r(v_i') \leq r(v_i)+\lambda_n' \leq r_n'.\end{align}
$\{v_1,\dots,v_{c_n},v_1',\dots,v_{c_n}'\}$
,
(8.6)
\begin{align}\mathcal{B}^{\varepsilon}_{x}(R_n) \cap \mathcal{B}^{\varepsilon}_{y}(R_n) = \emptyset .\end{align}








Let us prove that this event is realised with high probability. We prove in the following two steps of the proof that, when this event occurs, there is a high probability of finding two nodes satisfying (8.4). We define
 $m_n \;:\!=\; w_n' n^{2\beta}$
and take
$m_n \;:\!=\; w_n' n^{2\beta}$
and take
 $c_n = o(w_n')$
such that
$c_n = o(w_n')$
such that
 $c_n \to \infty$
. For all
$c_n \to \infty$
. For all
 $1 \leq j \leq m_n$
, let
$1 \leq j \leq m_n$
, let
 $I_j^n \;:\!=\; [t_n' + j \lambda_n', t_n' + (j+1)\lambda_n')$
. Note that all of these intervals are contained in
$I_j^n \;:\!=\; [t_n' + j \lambda_n', t_n' + (j+1)\lambda_n')$
. Note that all of these intervals are contained in
 $[t_n',r_n']$
. We denote by
$[t_n',r_n']$
. We denote by
 $A_j^n$
the event that there exist at least two nodes of
$A_j^n$
the event that there exist at least two nodes of
 $\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
with radial coordinates in the interval
$\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
with radial coordinates in the interval
 $I_j^n$
. The number of nodes having a radial coordinate in the interval
$I_j^n$
. The number of nodes having a radial coordinate in the interval
 $I_j^n$
follows a Poisson distribution with parameter
$I_j^n$
follows a Poisson distribution with parameter
 $n p_j^n$
, with
$n p_j^n$
, with
 $p_j^n$
given by
$p_j^n$
given by
 \begin{align*}p_j^n = \frac{\cosh(\alpha (t_n' + (j+1) \lambda_n')) - \cosh(\alpha (t_n' + j \lambda_n'))}{\cosh(\alpha R_n) - 1} \geq K \lambda_n' \mathrm{e}^{\alpha (t_n' - R_n)} = K n^{-(\beta + 1)}.\end{align*}
\begin{align*}p_j^n = \frac{\cosh(\alpha (t_n' + (j+1) \lambda_n')) - \cosh(\alpha (t_n' + j \lambda_n'))}{\cosh(\alpha R_n) - 1} \geq K \lambda_n' \mathrm{e}^{\alpha (t_n' - R_n)} = K n^{-(\beta + 1)}.\end{align*}
It follows that
 \begin{align*}\mathbb{P}[A_j^n] \geq Kn^{-2\beta}.\end{align*}
\begin{align*}\mathbb{P}[A_j^n] \geq Kn^{-2\beta}.\end{align*}
Moreover, the events
 $A_j^n$
are independent, so the number of indices
$A_j^n$
are independent, so the number of indices
 $1 \leq j \leq m_n$
for which the event
$1 \leq j \leq m_n$
for which the event
 $A_j^n$
occurs dominates a binomial distribution with
$A_j^n$
occurs dominates a binomial distribution with
 $m_n$
trials and an expected value equivalent to
$m_n$
trials and an expected value equivalent to
 $Kw_n'$
. Since
$Kw_n'$
. Since
 $c_n = o(w_n')$
, it follows that, with high probability, we can find
$c_n = o(w_n')$
, it follows that, with high probability, we can find
 $c_n$
indices j for which the event
$c_n$
indices j for which the event
 $A_j^n$
is realised. We conclude that, with high probability, there exist two sequences made of distinct nodes
$A_j^n$
is realised. We conclude that, with high probability, there exist two sequences made of distinct nodes
 $(v_i)_{1 \leq i \leq c_n}$
and
$(v_i)_{1 \leq i \leq c_n}$
and
 $(v_i')_{1 \leq i \leq c_n}$
satisfying condition (8.5) of the event
$(v_i')_{1 \leq i \leq c_n}$
satisfying condition (8.5) of the event
 $G_n$
.
$G_n$
.
Let us prove that these nodes also have a high probability of satisfying condition (8.6). First remark that, by the estimate of
 $\theta_r(y)$
(given in Lemma 5.2), if
$\theta_r(y)$
(given in Lemma 5.2), if
 $\varepsilon$
is small enough then
$\varepsilon$
is small enough then
 \begin{align*}\theta_{t_n'}(R_n^{\varepsilon})= 2\exp\bigg(\frac{R_n-t_n' - R_n^{\varepsilon}}{2}\bigg) (1 + O(\mathrm{e}^{R_n - t_n' - R_n^{\varepsilon}})) \xrightarrow[n\to\infty]{} 0.\end{align*}
\begin{align*}\theta_{t_n'}(R_n^{\varepsilon})= 2\exp\bigg(\frac{R_n-t_n' - R_n^{\varepsilon}}{2}\bigg) (1 + O(\mathrm{e}^{R_n - t_n' - R_n^{\varepsilon}})) \xrightarrow[n\to\infty]{} 0.\end{align*}
Thus, we may assume that
 $c_n$
was chosen such that
$c_n$
was chosen such that
 $c_n^2 \theta_{t_n'}(R_n^{\varepsilon}) \to 0$
.
$c_n^2 \theta_{t_n'}(R_n^{\varepsilon}) \to 0$
.
Sample all the nodes appearing in
 $\mathcal{C}(t_n',r_n')$
and suppose that there exist two sequences made of distinct nodes
$\mathcal{C}(t_n',r_n')$
and suppose that there exist two sequences made of distinct nodes
 $(v_i)_{1 \leq i \leq c_n}$
and
$(v_i)_{1 \leq i \leq c_n}$
and
 $(v_i')_{1 \leq i \leq c_n}$
in
$(v_i')_{1 \leq i \leq c_n}$
in
 $\mathcal{C}(t_n',r_n')$
that satisfy condition (8.5) of the event
$\mathcal{C}(t_n',r_n')$
that satisfy condition (8.5) of the event
 $C_n$
. Suppose that the angular coordinates of the nodes of these sequences have not been sampled yet. Note that it is valid to suppose this as condition (8.5) only concerns the radial coordinates of the nodes. We now sample the angular coordinates of these nodes one by one. Each time we sample a new angular coordinate, the probability that it differs by less than
$C_n$
. Suppose that the angular coordinates of the nodes of these sequences have not been sampled yet. Note that it is valid to suppose this as condition (8.5) only concerns the radial coordinates of the nodes. We now sample the angular coordinates of these nodes one by one. Each time we sample a new angular coordinate, the probability that it differs by less than
 $2\theta_{t_n'}(R_n^{\varepsilon})$
with an already sampled angular coordinate is upper bounded by
$2\theta_{t_n'}(R_n^{\varepsilon})$
with an already sampled angular coordinate is upper bounded by
 $({2c_n}/{\pi}) \theta_{t_n'}(R_n^{\varepsilon})$
. Thus, the probability of getting a pair of angular coordinates that differ by less than
$({2c_n}/{\pi}) \theta_{t_n'}(R_n^{\varepsilon})$
. Thus, the probability of getting a pair of angular coordinates that differ by less than
 $2\theta_{t_n'}(R_n^{\varepsilon})$
is upper bounded by
$2\theta_{t_n'}(R_n^{\varepsilon})$
is upper bounded by
 $({4c_n^2}/{\pi})\theta_{t_n'}(R_n^{\varepsilon})$
, which tends to 0 by our choice of
$({4c_n^2}/{\pi})\theta_{t_n'}(R_n^{\varepsilon})$
, which tends to 0 by our choice of
 $c_n$
. Thus, with high probability, all the angular coordinates of the nodes
$c_n$
. Thus, with high probability, all the angular coordinates of the nodes
 $v_1,\dots,v_{c_n},v_1',\dots,v_{c_n}'$
differ by more than
$v_1,\dots,v_{c_n},v_1',\dots,v_{c_n}'$
differ by more than
 $2\theta_{t_n'}(R_n^{\varepsilon})$
.
$2\theta_{t_n'}(R_n^{\varepsilon})$
.
For
 $1 \leq i \leq c_n$
, the angle of the smallest cone (with apex at 0) containing
$1 \leq i \leq c_n$
, the angle of the smallest cone (with apex at 0) containing
 $\mathcal{B}^{\varepsilon}_{v_i}(R_n)$
is
$\mathcal{B}^{\varepsilon}_{v_i}(R_n)$
is
 $2\theta_{r(v_i)}(R_n^{\varepsilon})$
. Since
$2\theta_{r(v_i)}(R_n^{\varepsilon})$
. Since
 $t_n' \leq r(v_i)$
, Lemma 5.1 implies that this angle is at most
$t_n' \leq r(v_i)$
, Lemma 5.1 implies that this angle is at most
 $2\theta_{t_n'}(R_n^{\varepsilon})$
. The same holds for the nodes
$2\theta_{t_n'}(R_n^{\varepsilon})$
. The same holds for the nodes
 $v_i'$
. It follows that the sequences
$v_i'$
. It follows that the sequences
 $(v_i)$
and
$(v_i)$
and
 $(v_i')$
also satisfy condition (8.6), with high probability. Thus,
$(v_i')$
also satisfy condition (8.6), with high probability. Thus,
 \begin{align}\mathbb{P}[C_n] \xrightarrow[n\to\infty]{} 1.\end{align}
\begin{align}\mathbb{P}[C_n] \xrightarrow[n\to\infty]{} 1.\end{align}
Step 2: Finding a pair of nodes (V,V’) with
 $r(V) \leq r(V')$
such that
$r(V) \leq r(V')$
such that
 $\deg_{\varepsilon}(V)$
is small and
$\deg_{\varepsilon}(V)$
is small and
 $\deg_{\varepsilon}(V')$
is large. Let us sample all the nodes that fall in the annulus
$\deg_{\varepsilon}(V')$
is large. Let us sample all the nodes that fall in the annulus
 $\mathcal{C}(t_n',r_n')$
. Since the event
$\mathcal{C}(t_n',r_n')$
. Since the event
 $C_n$
depends only on the point process of the nodes restricted to this region, we can suppose that the points in this annulus are such that the event
$C_n$
depends only on the point process of the nodes restricted to this region, we can suppose that the points in this annulus are such that the event
 $C_n$
occurs. We denote by
$C_n$
occurs. We denote by
 $\mathbb{P}_{\scriptscriptstyle C_n}$
the probability measure conditioned on the event
$\mathbb{P}_{\scriptscriptstyle C_n}$
the probability measure conditioned on the event
 $C_n$
.
$C_n$
.
For all
 $K > 0$
, we define
$K > 0$
, we define
 $\eta(K)$
by
$\eta(K)$
by
 \begin{align*}\eta(K) = \liminf\limits_{n \in \mathbb{N}^*} \inf\limits_{a \, \geq \, n \mu_n(\mathcal{B}^{\varepsilon}_{r_n'}(R_n))} \mathbb{P}[\mbox{Poi}(a) \geq a + K \sqrt{a}],\end{align*}
\begin{align*}\eta(K) = \liminf\limits_{n \in \mathbb{N}^*} \inf\limits_{a \, \geq \, n \mu_n(\mathcal{B}^{\varepsilon}_{r_n'}(R_n))} \mathbb{P}[\mbox{Poi}(a) \geq a + K \sqrt{a}],\end{align*}
where
 $\mbox{Poi}(a)$
denotes a Poisson variable with parameter a. Using (5.5) and (5.6), one checks that, if
$\mbox{Poi}(a)$
denotes a Poisson variable with parameter a. Using (5.5) and (5.6), one checks that, if
 $\varepsilon$
is chosen sufficiently small, then
$\varepsilon$
is chosen sufficiently small, then
 $n \mu_n(\mathcal{B}^{\varepsilon}_{r_n'}(R_n)) \to \infty$
as
$n \mu_n(\mathcal{B}^{\varepsilon}_{r_n'}(R_n)) \to \infty$
as
 $n \to \infty$
. By the central limit theorem,
$n \to \infty$
. By the central limit theorem,
 $\eta(K)$
is then equal to the probability that a standard normal random variable exceeds K. In particular,
$\eta(K)$
is then equal to the probability that a standard normal random variable exceeds K. In particular,
 $\eta(K) > 0$
.
$\eta(K) > 0$
.
Select two sequences
 $(v_i)_{1 \leq i \leq c_n}$
and
$(v_i)_{1 \leq i \leq c_n}$
and
 $(v_i')_{1 \leq i \leq c_n}$
as provided by the event
$(v_i')_{1 \leq i \leq c_n}$
as provided by the event
 $C_n$
(choose them according to a fixed rule to ensure measurability). For
$C_n$
(choose them according to a fixed rule to ensure measurability). For
 $1 \leq i \leq c_n$
, since
$1 \leq i \leq c_n$
, since
 $r(v_i) \leq r_n'$
, it follows from Lemma 5.1 that
$r(v_i) \leq r_n'$
, it follows from Lemma 5.1 that
 \begin{align}n\mu_n(\mathcal{B}^{\varepsilon}_{v_i}(R_n))\geq n\mu_n(\mathcal{B}^{\varepsilon}_{r_n'}(R_n)) = n (\mu_n(\mathcal{B}_{r_n'}(R_n)) - \mu_n(\mathcal{B}_{r_n'}(R_n) \cap \mathcal{B}_{0}(R_n^{\varepsilon}))).\end{align}
\begin{align}n\mu_n(\mathcal{B}^{\varepsilon}_{v_i}(R_n))\geq n\mu_n(\mathcal{B}^{\varepsilon}_{r_n'}(R_n)) = n (\mu_n(\mathcal{B}_{r_n'}(R_n)) - \mu_n(\mathcal{B}_{r_n'}(R_n) \cap \mathcal{B}_{0}(R_n^{\varepsilon}))).\end{align}
If
 $\varepsilon$
is chosen small enough then
$\varepsilon$
is chosen small enough then
 $r_n' \geq \varepsilon R_n$
. Thus, we can use the approximations given by (5.5) and (5.6) to get, uniformly in
$r_n' \geq \varepsilon R_n$
. Thus, we can use the approximations given by (5.5) and (5.6) to get, uniformly in
 $1 \leq i \leq c_n$
,
$1 \leq i \leq c_n$
,
 \begin{align*}n\mu_n(\mathcal{B}^{\varepsilon}_{v_i'}(R_n)) \geq K n \mathrm{e}^{-r_n'/2} = K \delta_n^2\end{align*}
\begin{align*}n\mu_n(\mathcal{B}^{\varepsilon}_{v_i'}(R_n)) \geq K n \mathrm{e}^{-r_n'/2} = K \delta_n^2\end{align*}
(the sequence
 $(\delta_n)$
is defined below (8.4)). It follows that, for a possibly different constant
$(\delta_n)$
is defined below (8.4)). It follows that, for a possibly different constant
 $K > 0$
, we have, for all
$K > 0$
, we have, for all
 $1 \leq i \leq c_n$
,
$1 \leq i \leq c_n$
,
 \begin{align}&\mathbb{P}_{\scriptscriptstyle \scriptscriptstyle C_n}[\deg_{\varepsilon}(v_i') \geq n\mu_n(\mathcal{B}^{\varepsilon}_{v_i'}(R_n)) + 2\delta_n]\nonumber\\&\qquad\geq \mathbb{P}_{\scriptscriptstyle \scriptscriptstyle C_n}\big[\deg_{\varepsilon}(v_i') \geq n\mu_n(\mathcal{B}^{\varepsilon}_{v_i'}(R_n)) + K \sqrt{n\mu_n(\mathcal{B}^{\varepsilon}_{v_i'}(R_n))}\big].\end{align}
\begin{align}&\mathbb{P}_{\scriptscriptstyle \scriptscriptstyle C_n}[\deg_{\varepsilon}(v_i') \geq n\mu_n(\mathcal{B}^{\varepsilon}_{v_i'}(R_n)) + 2\delta_n]\nonumber\\&\qquad\geq \mathbb{P}_{\scriptscriptstyle \scriptscriptstyle C_n}\big[\deg_{\varepsilon}(v_i') \geq n\mu_n(\mathcal{B}^{\varepsilon}_{v_i'}(R_n)) + K \sqrt{n\mu_n(\mathcal{B}^{\varepsilon}_{v_i'}(R_n))}\big].\end{align}
Moreover, for all
 $1 \leq i \leq c_n$
, conditionally on the event
$1 \leq i \leq c_n$
, conditionally on the event
 $C_n$
and on the position of
$C_n$
and on the position of
 $v_i'$
, the variable
$v_i'$
, the variable
 $\deg_{\varepsilon}(v_i')$
follows a Poisson distribution with parameter
$\deg_{\varepsilon}(v_i')$
follows a Poisson distribution with parameter
 $n\mu_n(\mathcal{B}^{\varepsilon}_{v_i'}(R_n))$
. Since
$n\mu_n(\mathcal{B}^{\varepsilon}_{v_i'}(R_n))$
. Since
 $r(v_i') \leq r_n'$
and
$r(v_i') \leq r_n'$
and
 $\mu_n(\mathcal{B}_{r}(R_n))$
is decreasing in r, this parameter is at least
$\mu_n(\mathcal{B}_{r}(R_n))$
is decreasing in r, this parameter is at least
 $n\mu_n(\mathcal{B}^{\varepsilon}_{r_n'}(R_n))$
. Thus, combining (8.8) with (8.9) provides a constant
$n\mu_n(\mathcal{B}^{\varepsilon}_{r_n'}(R_n))$
. Thus, combining (8.8) with (8.9) provides a constant
 $K > 0$
such that, for large enough n and for all
$K > 0$
such that, for large enough n and for all
 $1 \leq i \leq c_n$
,
$1 \leq i \leq c_n$
,
 \begin{align}\mathbb{P}_{\scriptscriptstyle \scriptscriptstyle C_n}[\deg_{\varepsilon}(v_i') \geq n\mu_n(\mathcal{B}^{\varepsilon}_{v_i'}(R_n)) + 2\delta_n] \geq \frac{\eta(K)}{2}.\end{align}
\begin{align}\mathbb{P}_{\scriptscriptstyle \scriptscriptstyle C_n}[\deg_{\varepsilon}(v_i') \geq n\mu_n(\mathcal{B}^{\varepsilon}_{v_i'}(R_n)) + 2\delta_n] \geq \frac{\eta(K)}{2}.\end{align}
With a similar argument, we get
 $\hat{\eta} > 0$
such that, for large enough n and
$\hat{\eta} > 0$
such that, for large enough n and
 $1 \leq i \leq c_n$
,
$1 \leq i \leq c_n$
,
 \begin{align}\mathbb{P}_{\scriptscriptstyle C_n}[\deg_{\varepsilon}(v_i) \leq n\mu_n(\mathcal{B}^{\varepsilon}_{v_i}(R_n))] \geq \hat{\eta} .\end{align}
\begin{align}\mathbb{P}_{\scriptscriptstyle C_n}[\deg_{\varepsilon}(v_i) \leq n\mu_n(\mathcal{B}^{\varepsilon}_{v_i}(R_n))] \geq \hat{\eta} .\end{align}
Conditionally on the event
 $C_n$
and on the positions of the nodes
$C_n$
and on the positions of the nodes
 $(v_i)_{1\leq i \leq c_n}$
and
$(v_i)_{1\leq i \leq c_n}$
and
 $(v_i')_{1 \leq i \leq c_n}$
, the variables
$(v_i')_{1 \leq i \leq c_n}$
, the variables
 $\deg_{\varepsilon}(v_1),\dots,\deg_{\varepsilon}(v_{c_n}),\deg_{\varepsilon}(v_i'),\dots,\deg_{\varepsilon}(v_{c_n}')$
are independent. Indeed, once these nodes are fixed, their
$\deg_{\varepsilon}(v_1),\dots,\deg_{\varepsilon}(v_{c_n}),\deg_{\varepsilon}(v_i'),\dots,\deg_{\varepsilon}(v_{c_n}')$
are independent. Indeed, once these nodes are fixed, their
 $\varepsilon$
degrees correspond to the number of points of a Poisson point process in
$\varepsilon$
degrees correspond to the number of points of a Poisson point process in
 $\mathcal{B}_{0}(R_n) \setminus \mathcal{B}_{0}(R_n^\varepsilon)$
falling into certain predetermined regions: by condition (8.6) of the event
$\mathcal{B}_{0}(R_n) \setminus \mathcal{B}_{0}(R_n^\varepsilon)$
falling into certain predetermined regions: by condition (8.6) of the event
 $C_n$
, these regions are disjoint (see Figure 4). Since
$C_n$
, these regions are disjoint (see Figure 4). Since
 $c_n \to \infty$
and both
$c_n \to \infty$
and both
 $\eta(K)$
and
$\eta(K)$
and
 $\hat{\eta}$
are positive, it follows that, with high probability, there exists an index
$\hat{\eta}$
are positive, it follows that, with high probability, there exists an index
 $1 \leq i \leq c_n$
for which the events in (8.10) and (8.11) occur simultaneously. Define
$1 \leq i \leq c_n$
for which the events in (8.10) and (8.11) occur simultaneously. Define
 $i_0$
as the smallest such index and set
$i_0$
as the smallest such index and set
 $(V,V') = (v_{i_0},v_{i_0}')$
. We verify that this defines a random vector (V, V
′) on an event of high probability. The definition of (V, V
′) out of this event is not relevant.
$(V,V') = (v_{i_0},v_{i_0}')$
. We verify that this defines a random vector (V, V
′) on an event of high probability. The definition of (V, V
′) out of this event is not relevant.
Step 3: From
 $\deg_{\varepsilon}$
to
$\deg_{\varepsilon}$
to
 $\deg$
. The previous step would allow us to conclude immediately if we were comparing the
$\deg$
. The previous step would allow us to conclude immediately if we were comparing the
 $\varepsilon$
degrees
$\varepsilon$
degrees
 $\deg_{\varepsilon}$
of the nodes instead of their actual degrees
$\deg_{\varepsilon}$
of the nodes instead of their actual degrees
 $\deg$
. Thus, it remains to show that
$\deg$
. Thus, it remains to show that
 $\deg_{\varepsilon}$
is very close to
$\deg_{\varepsilon}$
is very close to
 $\deg$
. To achieve this, we introduce the following subsets of the ball
$\deg$
. To achieve this, we introduce the following subsets of the ball
 $\mathcal{B}_{x}(R_n)$
:
$\mathcal{B}_{x}(R_n)$
:
 \begin{align}\mathcal{B}'_{x}(R_n) &\;:\!=\; \mathcal{B}_{x}(R_n) \setminus (\mathcal{C}(t_n',r_n') \cup \mathcal{C}(R_n^{\varepsilon},R_n)),\end{align}
\begin{align}\mathcal{B}'_{x}(R_n) &\;:\!=\; \mathcal{B}_{x}(R_n) \setminus (\mathcal{C}(t_n',r_n') \cup \mathcal{C}(R_n^{\varepsilon},R_n)),\end{align}
 \begin{align}\mathcal{B}''_{x}(R_n) &\;:\!=\; \mathcal{B}_{x}(R_n) \cap \mathcal{C}(t_n',r_n'). \end{align}
\begin{align}\mathcal{B}''_{x}(R_n) &\;:\!=\; \mathcal{B}_{x}(R_n) \cap \mathcal{C}(t_n',r_n'). \end{align}
For a node X, we write
 $\deg'(X)$
(respectively
$\deg'(X)$
(respectively
 $\deg''(X)$
) for the number of nodes (excluding X) that are contained in
$\deg''(X)$
) for the number of nodes (excluding X) that are contained in
 $\mathcal{B}'_{X}(R_n)$
(respectively
$\mathcal{B}'_{X}(R_n)$
(respectively
 $\mathcal{B}''_{X}(R_n)$
). Note that, for any point x, the ball
$\mathcal{B}''_{X}(R_n)$
). Note that, for any point x, the ball
 $\mathcal{B}_{x}(R_n)$
is the union of the balls
$\mathcal{B}_{x}(R_n)$
is the union of the balls
 $\mathcal{B}^{\varepsilon}_{x}(R_n)$
,
$\mathcal{B}^{\varepsilon}_{x}(R_n)$
,
 $\mathcal{B}'_{x}(R_n)$
, and
$\mathcal{B}'_{x}(R_n)$
, and
 $\mathcal{B}''_{x}(R_n)$
. Thus, the degree of X can be decomposed as follows:
$\mathcal{B}''_{x}(R_n)$
. Thus, the degree of X can be decomposed as follows:
 \begin{align*}\deg(X) = \deg_{\varepsilon}(X) + \deg'(X) + \deg''(X).\end{align*}
\begin{align*}\deg(X) = \deg_{\varepsilon}(X) + \deg'(X) + \deg''(X).\end{align*}
Let us first estimate the error induced by the term
 $\deg'$
. If
$\deg'$
. If
 $\varepsilon$
is small enough, we can use (5.6) and get
$\varepsilon$
is small enough, we can use (5.6) and get
 $\varepsilon' > 0$
such that, for large enough n,
$\varepsilon' > 0$
such that, for large enough n,
 \begin{align*}n\mu_n(\mathcal{B}'_{V}(R_n)) \leq n\mu_n(\mathcal{B}_{V}(R_n) \cap \mathcal{B}_{0}(R_n^{\varepsilon})) \leq n^{-5\varepsilon'} n\mathrm{e}^{-t_n'/2} \leq n^{-4\varepsilon'} \delta_n^2\end{align*}
\begin{align*}n\mu_n(\mathcal{B}'_{V}(R_n)) \leq n\mu_n(\mathcal{B}_{V}(R_n) \cap \mathcal{B}_{0}(R_n^{\varepsilon})) \leq n^{-5\varepsilon'} n\mathrm{e}^{-t_n'/2} \leq n^{-4\varepsilon'} \delta_n^2\end{align*}
(the sequence
 $(\delta_n)$
is defined below (8.4)). Since
$(\delta_n)$
is defined below (8.4)). Since
 $\mathcal{B}'_{V}(R_n)$
does not intersect the annulus
$\mathcal{B}'_{V}(R_n)$
does not intersect the annulus
 $\mathcal{C}(t_n',r_n')$
, we find that, conditionally on
$\mathcal{C}(t_n',r_n')$
, we find that, conditionally on
 $C_n$
and on the position of the node V, the variable
$C_n$
and on the position of the node V, the variable
 $\deg'(V)$
follows a Poisson distribution with parameter
$\deg'(V)$
follows a Poisson distribution with parameter
 $n\mu_n(\mathcal{B}'_{V}(R_n)) $
. Thus, by Chebyshev’s inequality,
$n\mu_n(\mathcal{B}'_{V}(R_n)) $
. Thus, by Chebyshev’s inequality,
 \begin{align}\mathbb{P}_{\scriptscriptstyle C_n}[\!\deg'(V) \leq n\mu_n(\mathcal{B}'_{V}(R_n)) + n^{-\varepsilon'}\delta_n] \xrightarrow[n\to\infty]{} 1.\end{align}
\begin{align}\mathbb{P}_{\scriptscriptstyle C_n}[\!\deg'(V) \leq n\mu_n(\mathcal{B}'_{V}(R_n)) + n^{-\varepsilon'}\delta_n] \xrightarrow[n\to\infty]{} 1.\end{align}
With a similar argument, we also prove that
 \begin{align}\mathbb{P}_{\scriptscriptstyle C_n}[\deg'(V') \geq n\mu_n(\mathcal{B}'_{V'}(R_n)) - n^{-\varepsilon'}\delta_n] \xrightarrow[n\to\infty]{} 1.\end{align}
\begin{align}\mathbb{P}_{\scriptscriptstyle C_n}[\deg'(V') \geq n\mu_n(\mathcal{B}'_{V'}(R_n)) - n^{-\varepsilon'}\delta_n] \xrightarrow[n\to\infty]{} 1.\end{align}
Now, concerning
 $\deg''$
, a direct computation gives, for
$\deg''$
, a direct computation gives, for
 $r \in [0,R_n)$
,
$r \in [0,R_n)$
,
 \begin{align}n\mu_n(\mathcal{C}(t_n',r_n')) = o(n^{\beta} \log(n)^{3\alpha}).\end{align}
\begin{align}n\mu_n(\mathcal{C}(t_n',r_n')) = o(n^{\beta} \log(n)^{3\alpha}).\end{align}
Since
 $\deg''(V)$
is smaller than the number of nodes that fall in the annulus
$\deg''(V)$
is smaller than the number of nodes that fall in the annulus
 $\mathcal{C}(t_n',r_n')$
, it follows from Chebyshev’s inequality that
$\mathcal{C}(t_n',r_n')$
, it follows from Chebyshev’s inequality that
 \begin{align}\mathbb{P}_{\scriptscriptstyle C_n}[\deg''(V) \leq n^\beta \log(n)^{3\alpha}] \xrightarrow[n\to\infty]{} 1.\end{align}
\begin{align}\mathbb{P}_{\scriptscriptstyle C_n}[\deg''(V) \leq n^\beta \log(n)^{3\alpha}] \xrightarrow[n\to\infty]{} 1.\end{align}
Combining the definition of V with (8.14) and (8.17), it follows that, with high probability,
 \begin{align*}\deg(V)&= \deg_{\varepsilon}(V) + \deg'(V) + \deg''(V) \\&\leq n \mu_n(\mathcal{B}^{\varepsilon}_{V}(R_n)) + n \mu_n(\mathcal{B}'_{V}(R_n)) + n^{-\varepsilon'}\delta_n + n^{\beta}\log(n)^{3 \alpha}.\end{align*}
\begin{align*}\deg(V)&= \deg_{\varepsilon}(V) + \deg'(V) + \deg''(V) \\&\leq n \mu_n(\mathcal{B}^{\varepsilon}_{V}(R_n)) + n \mu_n(\mathcal{B}'_{V}(R_n)) + n^{-\varepsilon'}\delta_n + n^{\beta}\log(n)^{3 \alpha}.\end{align*}
Since
 $\mathcal{B}^{\varepsilon}_{V}(R_n)$
and
$\mathcal{B}^{\varepsilon}_{V}(R_n)$
and
 $\mathcal{B}'_{V}(R_n)$
are disjoint subsets of
$\mathcal{B}'_{V}(R_n)$
are disjoint subsets of
 $\mathcal{B}_{V}(R_n)$
and since
$\mathcal{B}_{V}(R_n)$
and since
 $\delta_n = n^{2 \beta + o(1)}$
, we finally obtain, with high probability,
$\delta_n = n^{2 \beta + o(1)}$
, we finally obtain, with high probability,
 \begin{align}\deg(V) &\leq n \mu_n(\mathcal{B}_{V}(R_n)) + o(\delta_n).\end{align}
\begin{align}\deg(V) &\leq n \mu_n(\mathcal{B}_{V}(R_n)) + o(\delta_n).\end{align}
Likewise, combining the definition of V
′ with (8.15) and (8.16) and using the fact that
 $\mathcal{B}_{V'}(R_n)$
is the union of the balls
$\mathcal{B}_{V'}(R_n)$
is the union of the balls
 $\mathcal{B}^{\varepsilon}_{V'}(R_n)$
,
$\mathcal{B}^{\varepsilon}_{V'}(R_n)$
,
 $\mathcal{B}'_{V'}(R_n)$
, and
$\mathcal{B}'_{V'}(R_n)$
, and
 $\mathcal{B}''_{V'}(R_n)$
, it follows that, with high probability,
$\mathcal{B}''_{V'}(R_n)$
, it follows that, with high probability,
 \begin{align*}\deg(V')&\geq \deg_{\varepsilon}(V') + \deg'(V') \\&\geq n \mu_n(\mathcal{B}^{\varepsilon}_{V'}(R_n)) + 2\delta_n + n\mu_n(\mathcal{B}'_{V'}(R_n)) - n^{-\varepsilon'}\delta_n \\&\geq n \mu_n(\mathcal{B}_{V'}(R_n)) - n \mu_n(\mathcal{B}''_{V'}(R_n)) + 2\delta_n - n^{-\varepsilon'}\delta_n .\end{align*}
\begin{align*}\deg(V')&\geq \deg_{\varepsilon}(V') + \deg'(V') \\&\geq n \mu_n(\mathcal{B}^{\varepsilon}_{V'}(R_n)) + 2\delta_n + n\mu_n(\mathcal{B}'_{V'}(R_n)) - n^{-\varepsilon'}\delta_n \\&\geq n \mu_n(\mathcal{B}_{V'}(R_n)) - n \mu_n(\mathcal{B}''_{V'}(R_n)) + 2\delta_n - n^{-\varepsilon'}\delta_n .\end{align*}
It follows from (8.13) and (8.16) that
 $n \mu_n(\mathcal{B}''_{V'}(R_n)) = o(\delta_n)$
, so we finally obtain, with high probability,
$n \mu_n(\mathcal{B}''_{V'}(R_n)) = o(\delta_n)$
, so we finally obtain, with high probability,
 \begin{align}\deg(V')&\geq n \mu_n(\mathcal{B}_{V'}(R_n)) + 2\delta_n + o(\delta_n).\end{align}
\begin{align}\deg(V')&\geq n \mu_n(\mathcal{B}_{V'}(R_n)) + 2\delta_n + o(\delta_n).\end{align}
On the other hand, using the fact that
 $r(V') - r(V) \leq \lambda_n'$
, Lemma 8.1 yields
$r(V') - r(V) \leq \lambda_n'$
, Lemma 8.1 yields
 \begin{align*}n\mu_n(\mathcal{B}_{V}(R_n)) - n\mu_n(\mathcal{B}_{V'}(R_n)) \leq Kn \mathrm{e}^{-t_n'/2} \lambda_n' = o(\delta_n).\end{align*}
\begin{align*}n\mu_n(\mathcal{B}_{V}(R_n)) - n\mu_n(\mathcal{B}_{V'}(R_n)) \leq Kn \mathrm{e}^{-t_n'/2} \lambda_n' = o(\delta_n).\end{align*}
Combining this with (8.18) and (8.19) proves that, with high probability,
 \begin{align}\deg(V) + \delta_n \leq \deg(V').\end{align}
\begin{align}\deg(V) + \delta_n \leq \deg(V').\end{align}
Since
 $t_n' \leq r(V) \leq r(V') \leq r_n'$
, this concludes the proof of (8.4).
$t_n' \leq r(V) \leq r(V') \leq r_n'$
, this concludes the proof of (8.4).
Step 4: de-Poissonisation. Let us now explain how to transfer the result from the Poissonised model
 $\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
to the original model
$\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
to the original model
 $\mathcal{G}_{\alpha,\nu}(n)$
. We use a standard procedure that consists in coupling the original model with the Poissonised model by sampling the points of
$\mathcal{G}_{\alpha,\nu}(n)$
. We use a standard procedure that consists in coupling the original model with the Poissonised model by sampling the points of
 $\mathcal{G}_{\alpha,\nu}(n)$
in the following manner: sample the graph
$\mathcal{G}_{\alpha,\nu}(n)$
in the following manner: sample the graph
 $\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
and call
$\mathcal{G}^{\scriptscriptstyle{\text{Poi}}}_{\alpha,\nu}(n)$
and call
 $N_n$
the number of nodes in this graph. If
$N_n$
the number of nodes in this graph. If
 $N_n > n$
, randomly remove
$N_n > n$
, randomly remove
 $(N_n - n)$
nodes from the graph. If
$(N_n - n)$
nodes from the graph. If
 $N_n < n$
, add
$N_n < n$
, add
 $(n - N_n)$
nodes, independently sampled from
$(n - N_n)$
nodes, independently sampled from
 $\mathcal{B}_{0}(R_n)$
according to
$\mathcal{B}_{0}(R_n)$
according to
 $\mu_n$
and connect all pairs of nodes that are within distance
$\mu_n$
and connect all pairs of nodes that are within distance
 $R_n$
. The resulting graph follows the same distribution as
$R_n$
. The resulting graph follows the same distribution as
 $\mathcal{G}_{\alpha,\nu}(n)$
and is referred to as the de-Poissonised graph.
$\mathcal{G}_{\alpha,\nu}(n)$
and is referred to as the de-Poissonised graph.
For a node x that appears in both the Poissonised and de-Poissonised graph, we denote its degree in each graph by
 $\deg(x)$
and
$\deg(x)$
and
 $\widetilde{\deg}(x)$
, respectively. Fix
$\widetilde{\deg}(x)$
, respectively. Fix
 $\varepsilon > 0$
small enough. The random variable
$\varepsilon > 0$
small enough. The random variable
 $N_n$
follows a Poisson distribution with parameter n. Thus,
$N_n$
follows a Poisson distribution with parameter n. Thus,
 \begin{align*}\mathbb{P}[|N_n - n| \geq n^{1/2+\varepsilon}] \xrightarrow[n\to\infty]{} 0.\end{align*}
\begin{align*}\mathbb{P}[|N_n - n| \geq n^{1/2+\varepsilon}] \xrightarrow[n\to\infty]{} 0.\end{align*}
From this, it follows that, with high probability, the nodes V and V
′ are not removed during the de-Poissonisation procedure. For the remainder of the proof, we work on the event that V and V
′ are not removed. In the case where
 $N_n < n$
, conditionally on the position of V, the variable
$N_n < n$
, conditionally on the position of V, the variable
 $\widetilde{\deg}(V) - \deg(V)$
follows a binomial distribution with
$\widetilde{\deg}(V) - \deg(V)$
follows a binomial distribution with
 $(n - N_n)$
trials and probability parameter
$(n - N_n)$
trials and probability parameter
 $\mu_n(\mathcal{B}_{V}(R_n))$
. Thus, with high probability,
$\mu_n(\mathcal{B}_{V}(R_n))$
. Thus, with high probability,
 \begin{align*}\widetilde{\deg}(V) - \deg(V) \leq n^{1/2+2\varepsilon} \mu_n(\mathcal{B}_{r_n'}(R_n)) \leq K n^{2\beta + 2\varepsilon - 1/2} \mathrm{e}^{-w_n'/2} \delta_n = o(\delta_n),\end{align*}
\begin{align*}\widetilde{\deg}(V) - \deg(V) \leq n^{1/2+2\varepsilon} \mu_n(\mathcal{B}_{r_n'}(R_n)) \leq K n^{2\beta + 2\varepsilon - 1/2} \mathrm{e}^{-w_n'/2} \delta_n = o(\delta_n),\end{align*}
where the last equality holds if
 $\varepsilon$
is chosen sufficiently small (because
$\varepsilon$
is chosen sufficiently small (because
 $\beta < \tfrac{1}{5}$
). In the
$\beta < \tfrac{1}{5}$
). In the
 $N_n > n$
case, we can also prove with similar arguments that the de-Poissonisation reduces the degree of V
′ by at most
$N_n > n$
case, we can also prove with similar arguments that the de-Poissonisation reduces the degree of V
′ by at most
 $o(\delta_n)$
. Therefore, we finally conclude from (8.20) that
$o(\delta_n)$
. Therefore, we finally conclude from (8.20) that
 $\widetilde{\deg}(V) < \widetilde{\deg}(V')$
holds with high probability. In addition, straightforward estimates, using the fact that
$\widetilde{\deg}(V) < \widetilde{\deg}(V')$
holds with high probability. In addition, straightforward estimates, using the fact that
 $t_n' \leq r(V) \leq r(V') \leq r_n'$
, show that in the de-Poissonised graph the ranks of the nodes V and V
′ in the ranking of the nodes by increasing radii are in the interval
$t_n' \leq r(V) \leq r(V') \leq r_n'$
, show that in the de-Poissonised graph the ranks of the nodes V and V
′ in the ranking of the nodes by increasing radii are in the interval
 $[n^{\beta},n^{\beta} a_n^{3\alpha}]$
, with high probability. It follows that (3.2) holds with high probability (the power
$[n^{\beta},n^{\beta} a_n^{3\alpha}]$
, with high probability. It follows that (3.2) holds with high probability (the power
 $3\alpha$
is not problematic, as the sequence
$3\alpha$
is not problematic, as the sequence
 $(a_n)$
is an arbitrary sequence diverging to
$(a_n)$
is an arbitrary sequence diverging to
 $+\infty$
).
$+\infty$
).
Let us conclude by proving Lemma 8.1.
Proof of Lemma
8.1. We recall the integral expression (5.1) of
 $\mu_n(\mathcal{B}_{r}(R_n))$
:
$\mu_n(\mathcal{B}_{r}(R_n))$
:
 \begin{align*}\mu_n(\mathcal{B}_{r}(R_n)) = \frac{1}{\pi}\int_0^{R_n}\theta_r(y) \rho_n(y) \,\textrm{d}y.\end{align*}
\begin{align*}\mu_n(\mathcal{B}_{r}(R_n)) = \frac{1}{\pi}\int_0^{R_n}\theta_r(y) \rho_n(y) \,\textrm{d}y.\end{align*}
Using the expression of
 $\theta_r(y)$
given by (5.4), we get
$\theta_r(y)$
given by (5.4), we get
 \begin{align*}\frac{\partial}{\partial r} \mu_n(\mathcal{B}_{r}(R_n)) = \frac{1}{\pi}\int_{R_n-r}^{R_n} f_{n,r}(y) \rho_n(y) \,\textrm{d}y,\end{align*}
\begin{align*}\frac{\partial}{\partial r} \mu_n(\mathcal{B}_{r}(R_n)) = \frac{1}{\pi}\int_{R_n-r}^{R_n} f_{n,r}(y) \rho_n(y) \,\textrm{d}y,\end{align*}
where
 $f_{n,r}(y) \;:\!=\; ({\partial}/{\partial r}) \arccos(c_{n,r}(y))$
, with
$f_{n,r}(y) \;:\!=\; ({\partial}/{\partial r}) \arccos(c_{n,r}(y))$
, with
 $c_{n,r}(y) \;:\!=\; {(\!\cosh(r)\cosh(y) -\cosh(R_n))}/{\sinh(r) \sinh(y)}$
. Since the angle
$c_{n,r}(y) \;:\!=\; {(\!\cosh(r)\cosh(y) -\cosh(R_n))}/{\sinh(r) \sinh(y)}$
. Since the angle
 $\theta_r(y)$
is decreasing in r (see Lemma 5.1), the integral above is always well defined in
$\theta_r(y)$
is decreasing in r (see Lemma 5.1), the integral above is always well defined in
 $\mathbb{R} \cup \{-\infty\}$
. The contribution of the integral over
$\mathbb{R} \cup \{-\infty\}$
. The contribution of the integral over
 $(R_n-r,R_n-r+r_0)$
requires special treatment, because the quantity
$(R_n-r,R_n-r+r_0)$
requires special treatment, because the quantity
 $f_{n,r}(y)$
diverges as y approaches
$f_{n,r}(y)$
diverges as y approaches
 $(R_n-r)$
. We show at the end of the proof that this contribution is
$(R_n-r)$
. We show at the end of the proof that this contribution is
 $O(\mathrm{e}^{-\alpha r})$
(which can be incorporated into the first error term of the formula given in the statement). More precisely, we prove at the end of the proof that, for
$O(\mathrm{e}^{-\alpha r})$
(which can be incorporated into the first error term of the formula given in the statement). More precisely, we prove at the end of the proof that, for
 $r \in (r_0,R_n)$
,
$r \in (r_0,R_n)$
,
 \begin{align}\frac{\partial}{\partial r} \mu_n(\mathcal{B}_{r}(R_n)) = \frac{1}{\pi}\int_{R_n-r+r_0}^{R_n} f_{n,r}(y) \rho_n(y) \,\textrm{d}y + O(\mathrm{e}^{-\alpha r}).\end{align}
\begin{align}\frac{\partial}{\partial r} \mu_n(\mathcal{B}_{r}(R_n)) = \frac{1}{\pi}\int_{R_n-r+r_0}^{R_n} f_{n,r}(y) \rho_n(y) \,\textrm{d}y + O(\mathrm{e}^{-\alpha r}).\end{align}
For now, let us estimate the integrand for
 $r \in (r_0,R_n)$
and
$r \in (r_0,R_n)$
and
 $y \in (R_n-r+r_0,R_n)$
. A direct computation gives
$y \in (R_n-r+r_0,R_n)$
. A direct computation gives
 \begin{align*}f_{n,r}(y)&= -\frac{\cosh(R_n)\cosh(r)-\cosh(y)}{\sinh(r)^2\sinh(y) \sqrt{1-c_{n,r}(y)^2}\,}.\end{align*}
\begin{align*}f_{n,r}(y)&= -\frac{\cosh(R_n)\cosh(r)-\cosh(y)}{\sinh(r)^2\sinh(y) \sqrt{1-c_{n,r}(y)^2}\,}.\end{align*}
Using
 $\cosh(x) = \mathrm{e}^x(1/2+O(\mathrm{e}^{-2x}))$
and
$\cosh(x) = \mathrm{e}^x(1/2+O(\mathrm{e}^{-2x}))$
and
 $\sin(x) = \mathrm{e}^x(1/2+O(\mathrm{e}^{-2x}))$
, it follows that
$\sin(x) = \mathrm{e}^x(1/2+O(\mathrm{e}^{-2x}))$
, it follows that
 \begin{align}f_{n,r}(y)&= -\frac{2\mathrm{e}^{R_n-r-y}(1+O(\mathrm{e}^{-2r})+O(\mathrm{e}^{y-R_n-r}))}{(1+O(\mathrm{e}^{-2r} + \mathrm{e}^{-2y})) \sqrt{1-c_{n,r}(y)^2}}.\end{align}
\begin{align}f_{n,r}(y)&= -\frac{2\mathrm{e}^{R_n-r-y}(1+O(\mathrm{e}^{-2r})+O(\mathrm{e}^{y-R_n-r}))}{(1+O(\mathrm{e}^{-2r} + \mathrm{e}^{-2y})) \sqrt{1-c_{n,r}(y)^2}}.\end{align}
If
 $r_0$
is chosen large enough, using
$r_0$
is chosen large enough, using
 $1/(1+x) = 1+O(x)$
for
$1/(1+x) = 1+O(x)$
for
 $|x| < \tfrac{1}{2}$
, we get
$|x| < \tfrac{1}{2}$
, we get
 \begin{align}f_{n,r}(y)&= -\frac{2\mathrm{e}^{R_n-r-y}(1+O(\mathrm{e}^{y-R_n-r}) + O(\mathrm{e}^{-2y}))}{\sqrt{1-c_{n,r}(y)^2} }.\end{align}
\begin{align}f_{n,r}(y)&= -\frac{2\mathrm{e}^{R_n-r-y}(1+O(\mathrm{e}^{y-R_n-r}) + O(\mathrm{e}^{-2y}))}{\sqrt{1-c_{n,r}(y)^2} }.\end{align}
Note that we used the fact that
 $y-R_n-r \geq -2r$
to get rid of the
$y-R_n-r \geq -2r$
to get rid of the
 $O(\mathrm{e}^{-2r})$
term. A similar computation gives, for
$O(\mathrm{e}^{-2r})$
term. A similar computation gives, for
 $r \in (r_0,R_n)$
and
$r \in (r_0,R_n)$
and
 $y \in (R_n-r+r_0,R_n)$
,
$y \in (R_n-r+r_0,R_n)$
,
 \begin{align*}c_{n,r}(y)&= 1-2\mathrm{e}^{R_n-r-y}+O(\mathrm{e}^{-2r}+\mathrm{e}^{-2y}) .\end{align*}
\begin{align*}c_{n,r}(y)&= 1-2\mathrm{e}^{R_n-r-y}+O(\mathrm{e}^{-2r}+\mathrm{e}^{-2y}) .\end{align*}
Thus, if
 $r_0$
is chosen large enough, we have
$r_0$
is chosen large enough, we have
 \begin{align*}\frac{1}{\sqrt{1-c_{n,r}(y)^2}\,}&= \frac{\mathrm{e}^{-(R_n-r-y)/2}}{2}(1+O(\mathrm{e}^{R_n-r-y})).\end{align*}
\begin{align*}\frac{1}{\sqrt{1-c_{n,r}(y)^2}\,}&= \frac{\mathrm{e}^{-(R_n-r-y)/2}}{2}(1+O(\mathrm{e}^{R_n-r-y})).\end{align*}
Substituting this into (8.23) yields, for
 $r \in (r_0,R_n)$
and
$r \in (r_0,R_n)$
and
 $y \in (R_n-r+r_0,R_n)$
,
$y \in (R_n-r+r_0,R_n)$
,
 \begin{align*}f_{n,r}(y)&= -\mathrm{e}^{(R_n-r-y)/2}(1 + O(\mathrm{e}^{R_n-r-y})).\end{align*}
\begin{align*}f_{n,r}(y)&= -\mathrm{e}^{(R_n-r-y)/2}(1 + O(\mathrm{e}^{R_n-r-y})).\end{align*}
Estimating the hyperbolic terms in
 $\rho_n(y)$
, it follows that
$\rho_n(y)$
, it follows that
 \begin{align}f_{n,r}(y)\rho_n(y)&= - \alpha \mathrm{e}^{(1/2-\alpha)R_n-r/2}\mathrm{e}^{(\alpha-1/2)y}(1 + O(\mathrm{e}^{R_n-r-y}) + O(\mathrm{e}^{-\alpha R_n})).\end{align}
\begin{align}f_{n,r}(y)\rho_n(y)&= - \alpha \mathrm{e}^{(1/2-\alpha)R_n-r/2}\mathrm{e}^{(\alpha-1/2)y}(1 + O(\mathrm{e}^{R_n-r-y}) + O(\mathrm{e}^{-\alpha R_n})).\end{align}
Solving the integral in (8.21) using (8.24), without taking into account the error terms, gives
 \begin{align*}-\frac{\alpha}{\pi} \int_{R_n-r+r_0}^{R_n} \mathrm{e}^{(1/2-\alpha)R_n-r/2}\mathrm{e}^{(\alpha-1/2)y} \,\textrm{d}y&= -\frac{C_{\alpha}}{2} \mathrm{e}^{-r/2} (1 + O(\mathrm{e}^{-(\alpha - 1/2)r})).\end{align*}
\begin{align*}-\frac{\alpha}{\pi} \int_{R_n-r+r_0}^{R_n} \mathrm{e}^{(1/2-\alpha)R_n-r/2}\mathrm{e}^{(\alpha-1/2)y} \,\textrm{d}y&= -\frac{C_{\alpha}}{2} \mathrm{e}^{-r/2} (1 + O(\mathrm{e}^{-(\alpha - 1/2)r})).\end{align*}
If
 $\alpha \neq \tfrac32$
then the integral over the first error term gives
$\alpha \neq \tfrac32$
then the integral over the first error term gives
 \begin{align*}O\Bigg(\int_{R_n-r+r_0}^{R_n} \mathrm{e}^{(1/2-\alpha)R_n-r/2}\mathrm{e}^{(\alpha-1/2)y} \mathrm{e}^{R_n-r-y} \,\textrm{d}y \Bigg)&= O(\mathrm{e}^{-3r/2}) + O(\mathrm{e}^{-\alpha r}).\end{align*}
\begin{align*}O\Bigg(\int_{R_n-r+r_0}^{R_n} \mathrm{e}^{(1/2-\alpha)R_n-r/2}\mathrm{e}^{(\alpha-1/2)y} \mathrm{e}^{R_n-r-y} \,\textrm{d}y \Bigg)&= O(\mathrm{e}^{-3r/2}) + O(\mathrm{e}^{-\alpha r}).\end{align*}
In the
 $\alpha = \tfrac32$
case, the addition of the error term
$\alpha = \tfrac32$
case, the addition of the error term
 $r\mathrm{e}^{-r}$
in the statement makes it correct. The integral over the second error term (corresponding to the
$r\mathrm{e}^{-r}$
in the statement makes it correct. The integral over the second error term (corresponding to the
 $O(\mathrm{e}^{-\alpha R_n})$
term of (8.24)) is of order
$O(\mathrm{e}^{-\alpha R_n})$
term of (8.24)) is of order
 $O(\mathrm{e}^{-r/2 - \alpha R_n})$
, which can be incorporated into the first error term of the result. Thus, the computation of the integral appearing in (8.21) yields the correct estimate.
$O(\mathrm{e}^{-r/2 - \alpha R_n})$
, which can be incorporated into the first error term of the result. Thus, the computation of the integral appearing in (8.21) yields the correct estimate.
It remains to prove (8.21). This requires a bound on the speed of divergence of the function
 $f_{n,r}(y)$
, as y approaches
$f_{n,r}(y)$
, as y approaches
 $(R_n-r)$
. To obtain this bound, we first need to bound
$(R_n-r)$
. To obtain this bound, we first need to bound
 $c_{n,r}(y)$
, for y in the neighbourhood of
$c_{n,r}(y)$
, for y in the neighbourhood of
 $(R_n -r)$
. In the following, K stands for a positive constant whose value depends only on
$(R_n -r)$
. In the following, K stands for a positive constant whose value depends only on
 $\alpha, \nu$
, and
$\alpha, \nu$
, and
 $r_0$
and may change throughout the proof. For two functions f and g, we denote by
$r_0$
and may change throughout the proof. For two functions f and g, we denote by
 $f \wedge g$
(respectively
$f \wedge g$
(respectively
 $f \vee g$
) the minimum (respectively maximum) of f and g. Using the formula
$f \vee g$
) the minimum (respectively maximum) of f and g. Using the formula
 $\cosh(a+b) = \cosh(a)\cosh(b) + \sinh(a)\sinh(b)$
and the mean value theorem to bound the difference
$\cosh(a+b) = \cosh(a)\cosh(b) + \sinh(a)\sinh(b)$
and the mean value theorem to bound the difference
 $\cosh(r+y) - \cosh(R_n)$
, we obtain, for
$\cosh(r+y) - \cosh(R_n)$
, we obtain, for
 $y \in (R_n-r,R_n-r+r_0)$
,
$y \in (R_n-r,R_n-r+r_0)$
,
 \begin{align*}c_{n,r}(y)&= \frac{\cosh(r+y)- \sinh(r)\sinh(y) - \cosh(R_n)}{\sinh(r)\sinh(y)}\\&\geq K(y-(R_n-r))\,\mathrm{e}^{(R_n-r)-y} - 1.\end{align*}
\begin{align*}c_{n,r}(y)&= \frac{\cosh(r+y)- \sinh(r)\sinh(y) - \cosh(R_n)}{\sinh(r)\sinh(y)}\\&\geq K(y-(R_n-r))\,\mathrm{e}^{(R_n-r)-y} - 1.\end{align*}
Since
 $(R_n-r) - y \geq -r_0$
, we finally get
$(R_n-r) - y \geq -r_0$
, we finally get
 \begin{align*}c_{n,r}(y)&\geq (K(y-(R_n-r)) - 1) \wedge 0.\end{align*}
\begin{align*}c_{n,r}(y)&\geq (K(y-(R_n-r)) - 1) \wedge 0.\end{align*}
On the other hand, for
 $r_0$
and large enough n, approximating the hyperbolic terms by exponentials gives, for
$r_0$
and large enough n, approximating the hyperbolic terms by exponentials gives, for
 $y \in (R_n-r,R_n-r+r_0)$
,
$y \in (R_n-r,R_n-r+r_0)$
,
 \begin{align*}c_{n,r}(y)&\leq 1 - K.\end{align*}
\begin{align*}c_{n,r}(y)&\leq 1 - K.\end{align*}
Thus, for
 $y \in (R_n-r,R_n-r+r_0)$
,
$y \in (R_n-r,R_n-r+r_0)$
,
 \begin{align*}\frac{1}{\sqrt{1-c_{n,r}(y)^2}\,} \leq \frac{1}{\sqrt{1-(1-K)^2}\,} \vee \frac{1}{\sqrt{1-((K(y-(R_n-r)) - 1) \wedge 0)^2}\,}.\end{align*}
\begin{align*}\frac{1}{\sqrt{1-c_{n,r}(y)^2}\,} \leq \frac{1}{\sqrt{1-(1-K)^2}\,} \vee \frac{1}{\sqrt{1-((K(y-(R_n-r)) - 1) \wedge 0)^2}\,}.\end{align*}
It follows that the function
 ${1}/{\sqrt{1-c_{n,r}(y)^2}\,}$
is integrable over the interval
${1}/{\sqrt{1-c_{n,r}(y)^2}\,}$
is integrable over the interval
 $(R_n-r,R_n-r+r_0)$
and the integral is bounded by a constant that does not depend on n. From this and the approximation of
$(R_n-r,R_n-r+r_0)$
and the integral is bounded by a constant that does not depend on n. From this and the approximation of
 $f_{n,r}(y)$
given in (8.22) (which also holds for
$f_{n,r}(y)$
given in (8.22) (which also holds for
 $y \in [R_n-r,R_n-r+r_0]$
), we get
$y \in [R_n-r,R_n-r+r_0]$
), we get
 \begin{align*}\int_{R_n-r}^{R_n-r+r_0} f_{n,r}(y) \rho_n(y) \,\textrm{d}y = O(\rho_n(R_n-r+r_0)) = O(\mathrm{e}^{-\alpha r}).\end{align*}
\begin{align*}\int_{R_n-r}^{R_n-r+r_0} f_{n,r}(y) \rho_n(y) \,\textrm{d}y = O(\rho_n(R_n-r+r_0)) = O(\mathrm{e}^{-\alpha r}).\end{align*}
This completes the proof.
Acknowledgements
The author wishes to thank Pierre Calka for suggesting the topic and providing inspiring support. Many ideas presented in this paper would not have been developed as thoroughly without his suggestions and encouragement. The author also thanks the Laboratoire de Mathématiques Raphaël Salem (Université de Rouen, France) for its hospitality during the early stages of the project.
Funding information
The topic fits into the objectives of the French grant GrHyDy (Dynamic Hyperbolic Graphs) ANR-20-CE40-0002.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.




















 Open access
Open access