Refine search
Actions for selected content:
16 results
Nudging and boosting reasonable use of public products: two experiments from China
-
- Journal:
- Behavioural Public Policy , First View
- Published online by Cambridge University Press:
- 24 November 2025, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
12 - Regression and Classification
-
- Book:
- Probability and Statistics for Data Science
- Published online:
- 19 June 2025
- Print publication:
- 03 July 2025, pp 495-598
-
- Chapter
- Export citation
Moving from nudging to boosting: empowering behaviour change to address global challenges
-
- Journal:
- Behavioural Public Policy / Volume 9 / Issue 4 / October 2025
- Published online by Cambridge University Press:
- 15 April 2025, pp. 874-885
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prediction and Classification in Nonlinear Data Analysis: Something Old, Something New, Something Borrowed, Something Blue
-
- Journal:
- Psychometrika / Volume 68 / Issue 4 / December 2003
- Published online by Cambridge University Press:
- 01 January 2025, pp. 493-517
-
- Article
- Export citation
7 - Interventions to Combat Misinformation
- from Part III - Countering Misinformation
-
- Book:
- The Psychology of Misinformation
- Published online:
- 28 March 2024
- Print publication:
- 04 April 2024, pp 98-115
-
- Chapter
- Export citation
Boosted Poisson regression trees: a guide to the BT package in R
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 3 / November 2024
- Published online by Cambridge University Press:
- 15 January 2024, pp. 605-625
-
- Article
- Export citation
9 - Advanced Examples: Semi-supervised, Ensembles, Deep Learning Model Deployment
- from Part III - Machine Learning for Big Data
-
- Book:
- Large-Scale Data Analytics with Python and Spark
- Published online:
- 15 December 2023
- Print publication:
- 23 November 2023, pp 305-368
-
- Chapter
- Export citation
Chapter 4 - Governmental and Technological Paternalism
- from Part I - The War on Intuition
-
- Book:
- The Intelligence of Intuition
- Published online:
- 28 September 2023
- Print publication:
- 12 October 2023, pp 68-88
-
- Chapter
- Export citation
9 - Predictor Importance and Model Selection in Multiple Regression Models
-
- Book:
- Experimental Design and Data Analysis for Biologists
- Published online:
- 04 September 2023
- Print publication:
- 07 September 2023, pp 174-193
-
- Chapter
- Export citation
Systematic metacognitive reflection helps people discover far-sighted decision strategies: A process-tracing experiment
-
- Journal:
- Judgment and Decision Making / Volume 18 / 2023
- Published online by Cambridge University Press:
- 18 May 2023, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Short-sighted decisions can have devastating consequences, and teaching people to make their decisions in a more far-sighted way is challenging. Previous research found that reflecting on one’s behavior can boost learning from success and failure. Here, we explore the potential benefits of guiding people to reflect on whether and how they thought about what to do (i.e., systematic metacognitive reflection). We devised a series of Socratic questions that prompt people to reflect on their decision-making and tested their effectiveness in a process-tracing experiment with a 5-step planning task (
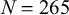 $N=265$). Each participant went through several cycles of making a series of decisions and then either reflecting on how they made those decisions, answering unrelated questions, or moving on to the next decision right away. We found that systematic metacognitive reflection helps people discover adaptive, far-sighted decision strategies faster. Our results suggest that systematic metacognitive reflection is a promising approach to boosting people’s decision-making competence.
$N=265$). Each participant went through several cycles of making a series of decisions and then either reflecting on how they made those decisions, answering unrelated questions, or moving on to the next decision right away. We found that systematic metacognitive reflection helps people discover adaptive, far-sighted decision strategies faster. Our results suggest that systematic metacognitive reflection is a promising approach to boosting people’s decision-making competence.
14 - Decision Trees, Random Forests and Boosting
-
- Book:
- Introduction to Environmental Data Science
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023, pp 473-493
-
- Chapter
- Export citation
Improving hand hygiene in hospitals: comparing the effect of a nudge and a boost on protocol compliance
-
- Journal:
- Behavioural Public Policy / Volume 6 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 03 May 2021, pp. 52-74
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Variable selection methods for identifying predictor interactions in data with repeatedly measured binary outcomes
-
- Journal:
- Journal of Clinical and Translational Science / Volume 5 / Issue 1 / 2021
- Published online by Cambridge University Press:
- 16 November 2020, e59
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A NEURAL NETWORK BOOSTED DOUBLE OVERDISPERSED POISSON CLAIMS RESERVING MODEL
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 50 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 17 December 2019, pp. 25-60
- Print publication:
- January 2020
-
- Article
- Export citation
Comparing Random Forest with Logistic Regression for Predicting Class-Imbalanced Civil War Onset Data: A Comment
-
- Journal:
- Political Analysis / Volume 27 / Issue 1 / January 2019
- Published online by Cambridge University Press:
- 31 December 2018, pp. 107-110
-
- Article
-
- You have access
- HTML
- Export citation
Boosted Hybrid Method for Solving Chemical Reaction Systems with Multiple Scales in Time and Population Size
-
- Journal:
- Communications in Computational Physics / Volume 12 / Issue 4 / October 2012
- Published online by Cambridge University Press:
- 20 August 2015, pp. 981-1005
- Print publication:
- October 2012
-
- Article
- Export citation
