Refine search
Actions for selected content:
51 results
Bayes factor hypothesis testing in meta-analyses: Practical advantages and methodological considerations
-
- Journal:
- Research Synthesis Methods ,
- Published online by Cambridge University Press:
- 04 December 2025, pp. 1-35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The distribution of the minimum observation until a stopping time, with an application to the minimal spacing in a Renewal process
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 21 November 2025, pp. 1-20
-
- Article
- Export citation
-
Let
 $\{X_{i}\}_{i\geq1}$ be a sequence of independent and identically distributed random variables and
$\{X_{i}\}_{i\geq1}$ be a sequence of independent and identically distributed random variables and  $T\in\{1,2,\ldots\}$ a stopping time associated with this sequence. In this paper, the distribution of the minimum observation,
$T\in\{1,2,\ldots\}$ a stopping time associated with this sequence. In this paper, the distribution of the minimum observation,  $\min\{X_{1},X_{2},\ldots,X_{T}\}$, until the stopping time T is provided by proposing a methodology based on an appropriate change of the initial probability measure of the probability space to a truncated (shifted) one on the
$\min\{X_{1},X_{2},\ldots,X_{T}\}$, until the stopping time T is provided by proposing a methodology based on an appropriate change of the initial probability measure of the probability space to a truncated (shifted) one on the  $X_{i}$. As an application of the aforementioned general result, the random variables
$X_{i}$. As an application of the aforementioned general result, the random variables  $X_{1},X_{2},\ldots$ are considered to be the interarrival times (spacings) between successive appearances of events in a renewal counting process
$X_{1},X_{2},\ldots$ are considered to be the interarrival times (spacings) between successive appearances of events in a renewal counting process  $\{Y_{t},t\geq0\}$, while the stopping time T is set to be the number of summands until the sum of the
$\{Y_{t},t\geq0\}$, while the stopping time T is set to be the number of summands until the sum of the  $X_{i}$ exceeds t for the first time, i.e.
$X_{i}$ exceeds t for the first time, i.e.  $T=Y_{t}+1$. Under this setup, the distribution of the minimal spacing,
$T=Y_{t}+1$. Under this setup, the distribution of the minimal spacing,  $D_{t}=\min\{X_{1},X_{2},\ldots,X_{Y_{t}+1}\}$, that starts in the interval [0, t] is investigated and a stochastic ordering relation for
$D_{t}=\min\{X_{1},X_{2},\ldots,X_{Y_{t}+1}\}$, that starts in the interval [0, t] is investigated and a stochastic ordering relation for  $D_{t}$ is obtained. In addition, bounds for the tail probability of
$D_{t}$ is obtained. In addition, bounds for the tail probability of  $D_{t}$ are provided when the interarrival times have the increasing failure rate / decreasing failure rate property. In the special case of a Poisson process, an exact formula, as well as closed-form bounds and an asymptotic result, are derived for the tail probability of
$D_{t}$ are provided when the interarrival times have the increasing failure rate / decreasing failure rate property. In the special case of a Poisson process, an exact formula, as well as closed-form bounds and an asymptotic result, are derived for the tail probability of  $D_{t}$. Furthermore, for renewal processes with Erlang and uniformly distributed interarrival times, exact and approximation formulae for the tail probability of
$D_{t}$. Furthermore, for renewal processes with Erlang and uniformly distributed interarrival times, exact and approximation formulae for the tail probability of  $D_{t}$ are also proposed. Finally, numerical examples are presented to illustrate the aforementioned exact and asymptotic results, and practical applications are briefly discussed.
$D_{t}$ are also proposed. Finally, numerical examples are presented to illustrate the aforementioned exact and asymptotic results, and practical applications are briefly discussed.













6 - Applications for a Single Network
- from Part III - Applications
-
- Book:
- Hands-On Network Machine Learning with Python
- Published online:
- 23 September 2025
- Print publication:
- 18 September 2025, pp 259-310
-
- Chapter
- Export citation
19 - Analyzing Quantitative Data: Exploring Key Concepts in Inferential Statistics
- from Part V - Quantitative Research: Data Analysis and Interpretation
-
- Book:
- Applied Linguistics Research
- Published online:
- 12 December 2025
- Print publication:
- 11 September 2025, pp 531-555
-
- Chapter
- Export citation
Nonparametric Tests of Differences in Medians: Comparison of the Wilcoxon-Mann-Whitney and Robust Rank-Order Tests
-
- Journal:
- Experimental Economics / Volume 6 / Issue 3 / November 2003
- Published online by Cambridge University Press:
- 14 March 2025, pp. 273-297
-
- Article
- Export citation
Testing for the Presence of a Tremble in Economic Experiments
-
- Journal:
- Experimental Economics / Volume 4 / Issue 3 / December 2001
- Published online by Cambridge University Press:
- 14 March 2025, pp. 221-228
-
- Article
- Export citation
1 - Asymptotics of Polynomial Time Trend Estimation and Hypothesis Testing under Rank Deficiency
- from Part I - Trend Determination, Asset Price Bubbles, and Factor-Augmented Regressions
-
- Book:
- Financial Econometrics
- Published online:
- 20 February 2025
- Print publication:
- 27 February 2025, pp 3-29
-
- Chapter
-
- You have access
- Export citation
6 - Treatment with Data from Statistically Imprecise Trials
- from Part II - Analyses of Planning Problems
-
- Book:
- Discourse on Social Planning under Uncertainty
- Published online:
- 02 January 2025
- Print publication:
- 09 January 2025, pp 131-150
-
- Chapter
- Export citation
31 - Lower Bounds via Reduction to Hypothesis Testing
- from Part VI - Statistical Applications
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp 608-616
-
- Chapter
- Export citation
Tests for Equality of Several Alpha Coefficients when their Sample Estimates are Dependent
-
- Journal:
- Psychometrika / Volume 51 / Issue 3 / September 1986
- Published online by Cambridge University Press:
- 01 January 2025, pp. 393-413
-
- Article
- Export citation
Diagnostic Classification Models for Testlets: Methods and Theory
-
- Journal:
- Psychometrika / Volume 89 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 851-876
-
- Article
- Export citation
Objective Bayesian Comparison of Constrained Analysis of Variance Models
-
- Journal:
- Psychometrika / Volume 82 / Issue 3 / September 2017
- Published online by Cambridge University Press:
- 01 January 2025, pp. 589-609
-
- Article
- Export citation
-
In the social sciences we are often interested in comparing models specified by parametric equality or inequality constraints. For instance, when examining three group means \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\{ \mu _1, \mu _2, \mu _3\}$$\end{document}
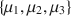 through an analysis of variance (ANOVA), a model may specify that \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mu _1<\mu _2<\mu _3$$\end{document}
through an analysis of variance (ANOVA), a model may specify that \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mu _1<\mu _2<\mu _3$$\end{document}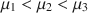 , while another one may state that \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\{ \mu _1=\mu _3\} <\mu _2$$\end{document}
, while another one may state that \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\{ \mu _1=\mu _3\} <\mu _2$$\end{document}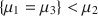 , and finally a third model may instead suggest that all means are unrestricted. This is a challenging problem, because it involves a combination of nonnested models, as well as nested models having the same dimension. We adopt an objective Bayesian approach, requiring no prior specification from the user, and derive the posterior probability of each model under consideration. Our method is based on the intrinsic prior methodology, suitably modified to accommodate equality and inequality constraints. Focussing on normal ANOVA models, a comparative assessment is carried out through simulation studies. We also present an application to real data collected in a psychological experiment.
, and finally a third model may instead suggest that all means are unrestricted. This is a challenging problem, because it involves a combination of nonnested models, as well as nested models having the same dimension. We adopt an objective Bayesian approach, requiring no prior specification from the user, and derive the posterior probability of each model under consideration. Our method is based on the intrinsic prior methodology, suitably modified to accommodate equality and inequality constraints. Focussing on normal ANOVA models, a comparative assessment is carried out through simulation studies. We also present an application to real data collected in a psychological experiment.
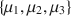
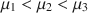
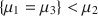
A Dual Scaling Analysis for Paired Compositions
-
- Journal:
- Psychometrika / Volume 36 / Issue 2 / June 1971
- Published online by Cambridge University Press:
- 01 January 2025, pp. 135-154
-
- Article
- Export citation
Maximum Likelihood Estimation in Multidimensional Scaling
-
- Journal:
- Psychometrika / Volume 42 / Issue 2 / June 1977
- Published online by Cambridge University Press:
- 01 January 2025, pp. 241-266
-
- Article
- Export citation
Hypothesis Testing of the Q-matrix
-
- Journal:
- Psychometrika / Volume 83 / Issue 3 / September 2018
- Published online by Cambridge University Press:
- 01 January 2025, pp. 515-537
-
- Article
- Export citation
A Model and Algorithm for Multidimensional Scaling with External Constraints on the Distances
-
- Journal:
- Psychometrika / Volume 45 / Issue 1 / March 1980
- Published online by Cambridge University Press:
- 01 January 2025, pp. 25-38
-
- Article
- Export citation
Statistical Consistency and Hypothesis Testing for Nonmetric Multidimensional Scaling
-
- Journal:
- Psychometrika / Volume 50 / Issue 4 / December 1985
- Published online by Cambridge University Press:
- 01 January 2025, pp. 509-537
-
- Article
- Export citation
6 - Hypothesis Testing
-
- Book:
- Social Behavioral Statistics
- Published online:
- 13 January 2025
- Print publication:
- 28 November 2024, pp 116-148
-
- Chapter
- Export citation
3 - Statistical Hydrology
-
- Book:
- Applied Hydrology
- Published online:
- 09 July 2024
- Print publication:
- 04 July 2024, pp 36-92
-
- Chapter
- Export citation
Chapter 11 - Explore and explain: statistics for network data
- from Part II - Applications, tools, and tasks
-
- Book:
- Working with Network Data
- Published online:
- 06 June 2024
- Print publication:
- 13 June 2024, pp 137-164
-
- Chapter
- Export citation
