Refine search
Actions for selected content:
23 results
Public Interest in Dermatological Issues After the 2023 Türkiye Earthquake: A Comparative Google Trends Analysis
-
- Journal:
- Disaster Medicine and Public Health Preparedness / Volume 19 / 2025
- Published online by Cambridge University Press:
- 03 June 2025, e136
-
- Article
- Export citation
8 - Conclusion
-
- Book:
- Regulating Access and Transfer of Data
- Published online:
- 06 April 2023
- Print publication:
- 13 April 2023, pp 239-250
-
- Chapter
- Export citation
3 - Competition Law
-
- Book:
- Regulating Access and Transfer of Data
- Published online:
- 06 April 2023
- Print publication:
- 13 April 2023, pp 68-94
-
- Chapter
- Export citation
4 - General and Sector-Specific Regulations
-
- Book:
- Regulating Access and Transfer of Data
- Published online:
- 06 April 2023
- Print publication:
- 13 April 2023, pp 95-150
-
- Chapter
- Export citation
2 - The Data-Driven Economy
-
- Book:
- Regulating Access and Transfer of Data
- Published online:
- 06 April 2023
- Print publication:
- 13 April 2023, pp 6-67
-
- Chapter
- Export citation
A Capabilities Framework for Dynamic Competition: Assessing the Relative Chances of Incumbents, Start-Ups, and Diversifying Entrants
-
- Journal:
- Management and Organization Review / Volume 19 / Issue 1 / February 2023
- Published online by Cambridge University Press:
- 16 December 2022, pp. 141-156
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
9 - Open-Source AI Platforms and the Cyber Security Law
- from Part II - Impact on Artificial Intelligence
-
- Book:
- AI Development and the ‘Fuzzy Logic' of Chinese Cyber Security and Data Laws
- Published online:
- 16 December 2021
- Print publication:
- 16 December 2021, pp 260-328
-
- Chapter
- Export citation
1 - The Cult of Dual-Class Stock in the Era of Big Tech
- from Part I - Putting Dual-Class Stock into Context
-
- Book:
- Founders without Limits
- Published online:
- 29 October 2021
- Print publication:
- 11 November 2021, pp 15-69
-
- Chapter
- Export citation
The hidden impacts of the ICC: An innovative assessment using Google data
-
- Journal:
- Leiden Journal of International Law / Volume 34 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 14 May 2021, pp. 729-747
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
From Google Doodles to Facebook: Nostalgia and Visual Reconstructions of the Past in Nigeria
-
- Journal:
- African Studies Review / Volume 64 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 14 April 2021, pp. 498-522
-
- Article
- Export citation
3 - Alphabet
- from Part I - The Birth of a Megacorporation
-
- Book:
- Megacorporation
- Published online:
- 06 April 2021
- Print publication:
- 08 April 2021, pp 43-68
-
- Chapter
- Export citation

Megacorporation
- The Infinite Times of Alphabet
-
- Published online:
- 06 April 2021
- Print publication:
- 08 April 2021
Suicide and the agent–host–environment triad: leveraging surveillance sources to inform prevention
-
- Journal:
- Psychological Medicine / Volume 51 / Issue 4 / March 2021
- Published online by Cambridge University Press:
- 05 March 2021, pp. 529-537
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Community movement and COVID-19: a global study using Google's Community Mobility Reports
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 13 November 2020, e284
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Lawless
- The Secret Rules That Govern our Digital Lives
-
- Published online:
- 22 June 2019
- Print publication:
- 18 July 2019
Testing the Validity of Automatic Speech Recognition for Political Text Analysis
-
- Journal:
- Political Analysis / Volume 27 / Issue 3 / July 2019
- Published online by Cambridge University Press:
- 19 February 2019, pp. 339-359
-
- Article
- Export citation
-
The analysis of political texts from parliamentary speeches, party manifestos, social media, or press releases forms the basis of major and growing fields in political science, not least since advances in “text-as-data” methods have rendered the analysis of large text corpora straightforward. However, a lot of sources of political speech are not regularly transcribed, and their on-demand transcription by humans is prohibitively expensive for research purposes. This class includes political speech in certain legislatures, during political party conferences as well as television interviews and talk shows. We showcase how scholars can use automatic speech recognition systems to analyze such speech with quantitative text analysis models of the “bag-of-words” variety. To probe results for robustness to transcription error, we present an original “word error rate simulation” (WERSIM) procedure implemented in
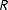 $R$. We demonstrate the potential of automatic speech recognition to address open questions in political science with two substantive applications and discuss its limitations and practical challenges.
$R$. We demonstrate the potential of automatic speech recognition to address open questions in political science with two substantive applications and discuss its limitations and practical challenges.
WWGD (What would Gwyneth do?)
-
- Journal:
- Canadian Journal of Emergency Medicine / Volume 20 / Issue 6 / November 2018
- Published online by Cambridge University Press:
- 10 October 2018, p. 1
- Print publication:
- November 2018
-
- Article
-
- You have access
- HTML
- Export citation
Part XXVIII - Shakespeare and Media History
-
-
- Book:
- The Cambridge Guide to the Worlds of Shakespeare
- Published online:
- 17 August 2019
- Print publication:
- 21 January 2016, pp 1907-1974
-
- Chapter
- Export citation
277 - Shakespeare and Online Video
- from Part XXVIII - Shakespeare and Media History
-
-
- Book:
- The Cambridge Guide to the Worlds of Shakespeare
- Published online:
- 17 August 2019
- Print publication:
- 21 January 2016, pp 1970-1974
-
- Chapter
- Export citation
Chinese Internet Business and Human Rights
-
- Journal:
- Business and Human Rights Journal / Volume 1 / Issue 1 / January 2016
- Published online by Cambridge University Press:
- 13 November 2015, pp. 139-144
-
- Article
-
- You have access
- HTML
- Export citation
