Refine search
Actions for selected content:
13 results
Some guidance for the choice of priors for Bayesian structural models in economic experiments
-
- Journal:
- Journal of the Economic Science Association ,
- Published online by Cambridge University Press:
- 18 July 2025, pp. 1-10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Unit Value Imputation Methods Using Household Scanner Data: A Case Study of Milk Purchases
-
- Journal:
- Journal of Agricultural and Applied Economics / Volume 57 / Issue 3 / August 2025
- Published online by Cambridge University Press:
- 14 May 2025, pp. 480-489
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The statistical power of individual-level risk preference estimation
-
- Journal:
- Journal of the Economic Science Association / Volume 6 / Issue 2 / December 2020
- Published online by Cambridge University Press:
- 17 January 2025, pp. 168-188
-
- Article
- Export citation
Is the Hamilton regression filter really superior to Hodrick–Prescott detrending?
-
- Journal:
- Macroeconomic Dynamics / Volume 29 / 2025
- Published online by Cambridge University Press:
- 02 May 2024, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
An article published in 2018 by J.D. Hamilton gained significant attention due to its provocative title, “Why you should never use the Hodrick-Prescott filter.” Additionally, an alternative method for detrending, the Hamilton regression filter (HRF), was introduced. His work was frequently interpreted as a proposal to substitute the Hodrick–Prescott (HP) filter with HRF, therefore utilizing and understanding it similarly as HP detrending. This research disputes this perspective, particularly in relation to quarterly business cycle data on aggregate output. Focusing on economic fluctuations in the United States, this study generates a large amount of artificial data that follow a known pattern and include both a trend and cyclical component. The objective is to assess the effectiveness of a certain detrending approach in accurately identifying the real decomposition of the data. In addition to the standard HP smoothing parameter of
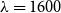 $\lambda = 1600$, the study also examines values of
$\lambda = 1600$, the study also examines values of 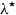 $\lambda ^{\star }$ from earlier research that are seven to twelve times greater. Based on three unique statistical measures of the discrepancy between the estimated and real trends, it is evident that both versions of HP significantly surpass those of HRF. Additionally, HP with
$\lambda ^{\star }$ from earlier research that are seven to twelve times greater. Based on three unique statistical measures of the discrepancy between the estimated and real trends, it is evident that both versions of HP significantly surpass those of HRF. Additionally, HP with 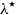 $\lambda ^{\star }$ consistently outperforms HP-1600.
$\lambda ^{\star }$ consistently outperforms HP-1600.
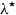
Wine rankings and the Borda method
-
- Journal:
- Journal of Wine Economics / Volume 18 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 11 May 2023, pp. 122-138
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
HAPPINESS AND AGE—RESOLVING THE DEBATE
-
- Journal:
- National Institute Economic Review / Volume 263 / Spring 2023
- Published online by Cambridge University Press:
- 12 April 2023, pp. 76-93
- Print publication:
- Spring 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Forecasting mortality rates with a coherent ensemble averaging approach
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 25 November 2022, pp. 2-28
- Print publication:
- January 2023
-
- Article
- Export citation
Tracking the wines of the Judgment of Paris over time: The case of Stag's Leap Wine Cellars’ Cabernet Sauvignon
-
- Journal:
- Journal of Wine Economics / Volume 17 / Issue 2 / May 2022
- Published online by Cambridge University Press:
- 05 September 2022, pp. 159-166
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Development, Implementation, and Evaluation of a More Efficient Method of Best-Worst Scaling Data Collection
-
- Journal:
- Agricultural and Resource Economics Review / Volume 51 / Issue 1 / April 2022
- Published online by Cambridge University Press:
- 24 January 2022, pp. 178-201
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
MORTALITY FORECASTING WITH A SPATIALLY PENALIZED SMOOTHED VAR MODEL
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 1 / January 2021
- Published online by Cambridge University Press:
- 04 November 2020, pp. 161-189
- Print publication:
- January 2021
-
- Article
- Export citation
POISSON MODELS WITH DYNAMIC RANDOM EFFECTS AND NONNEGATIVE CREDIBILITIES PER PERIOD
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 50 / Issue 2 / May 2020
- Published online by Cambridge University Press:
- 13 February 2020, pp. 585-618
- Print publication:
- May 2020
-
- Article
- Export citation
Willingness to Pay for Rose Attributes: Helping Provide Consumer Orientation to Breeding Programs
-
- Journal:
- Journal of Agricultural and Applied Economics / Volume 52 / Issue 1 / February 2020
- Published online by Cambridge University Press:
- 15 August 2019, pp. 1-15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SOLVENCY REQUIREMENT IN A UNISEX MORTALITY MODEL
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 48 / Issue 3 / September 2018
- Published online by Cambridge University Press:
- 25 April 2018, pp. 1219-1243
- Print publication:
- September 2018
-
- Article
- Export citation
