Refine search
Actions for selected content:
69 results
13 - Validation of Models
-
- Book:
- Multivariable Analysis
- Published online:
- 09 October 2025
- Print publication:
- 23 October 2025, pp 238-243
-
- Chapter
- Export citation
2 - The Discovery of Quarks
-
- Book:
- Discovering Quarks
- Published online:
- 06 November 2025
- Print publication:
- 16 October 2025, pp 14-34
-
- Chapter
- Export citation
6 - Multivariate and Correlated Experimental Data
-
- Book:
- Probability Theory for Quantitative Scientists
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025, pp 161-187
-
- Chapter
- Export citation
5 - Statistical Inference and Experimental Data Analysis
-
- Book:
- Probability Theory for Quantitative Scientists
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025, pp 117-160
-
- Chapter
- Export citation
9 - Estimation of Population Parameters
-
- Book:
- Probability and Statistics for Data Science
- Published online:
- 19 June 2025
- Print publication:
- 03 July 2025, pp 325-389
-
- Chapter
- Export citation
Multiple hypothesis testing in experimental economics
-
- Journal:
- Experimental Economics / Volume 22 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 14 March 2025, pp. 773-793
-
- Article
- Export citation
Factor Analysis for Non-Normal Variables
-
- Journal:
- Psychometrika / Volume 50 / Issue 3 / September 1985
- Published online by Cambridge University Press:
- 01 January 2025, pp. 323-342
-
- Article
- Export citation
Analytic Smoothing for Equipercentile Equating Under the Common Item Nonequivalent Populations Design
-
- Journal:
- Psychometrika / Volume 52 / Issue 1 / March 1987
- Published online by Cambridge University Press:
- 01 January 2025, pp. 43-59
-
- Article
- Export citation
Comparing One-Step M-Estimators of Location when there are More than Two Groups
-
- Journal:
- Psychometrika / Volume 58 / Issue 1 / March 1993
- Published online by Cambridge University Press:
- 01 January 2025, pp. 71-78
-
- Article
- Export citation
Comparing Latent Means Without Mean Structure Models: A Projection-Based Approach
-
- Journal:
- Psychometrika / Volume 81 / Issue 3 / September 2016
- Published online by Cambridge University Press:
- 01 January 2025, pp. 802-829
-
- Article
- Export citation
Pairwise Comparisons of Trimmed Means for Two or More Groups
-
- Journal:
- Psychometrika / Volume 66 / Issue 3 / September 2001
- Published online by Cambridge University Press:
- 01 January 2025, pp. 343-356
-
- Article
- Export citation
Comparing Variances of Correlated Variables
-
- Journal:
- Psychometrika / Volume 51 / Issue 3 / September 1986
- Published online by Cambridge University Press:
- 01 January 2025, pp. 379-391
-
- Article
- Export citation
Comparing the Variances of Dependent Groups
-
- Journal:
- Psychometrika / Volume 54 / Issue 2 / June 1989
- Published online by Cambridge University Press:
- 01 January 2025, pp. 305-315
-
- Article
- Export citation
Problems with Bootstrapping Pearson Correlations in Very Small Bivariate Samples
-
- Journal:
- Psychometrika / Volume 47 / Issue 4 / December 1982
- Published online by Cambridge University Press:
- 01 January 2025, pp. 529-530
-
- Article
- Export citation
Resampling-Based Inference Methods for Comparing Two Coefficients Alpha
-
- Journal:
- Psychometrika / Volume 83 / Issue 1 / March 2018
- Published online by Cambridge University Press:
- 01 January 2025, pp. 203-222
-
- Article
- Export citation
-
The two-sample problem for Cronbach’s coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _C$$\end{document}
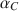 , as an estimate of test or composite score reliability, has attracted little attention compared to the extensive treatment of the one-sample case. It is necessary to compare the reliability of a test for different subgroups, for different tests or the short and long forms of a test. In this paper, we study statistical procedures of comparing two coefficients \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _{C,1}$$\end{document}
, as an estimate of test or composite score reliability, has attracted little attention compared to the extensive treatment of the one-sample case. It is necessary to compare the reliability of a test for different subgroups, for different tests or the short and long forms of a test. In this paper, we study statistical procedures of comparing two coefficients \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _{C,1}$$\end{document}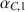 and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _{C,2}$$\end{document}
and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _{C,2}$$\end{document}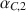 . The null hypothesis of interest is \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$H_0 : \alpha _{C,1} = \alpha _{C,2}$$\end{document}
. The null hypothesis of interest is \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$H_0 : \alpha _{C,1} = \alpha _{C,2}$$\end{document}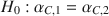 , which we test against one-or two-sided alternatives. For this purpose, resampling-based permutation and bootstrap tests are proposed for two-group multivariate non-normal models under the general asymptotically distribution-free (ADF) setting. These statistical tests ensure a better control of the type-I error, in finite or very small sample sizes, when the state-of-affairs ADF large-sample test may fail to properly attain the nominal significance level. By proper choice of a studentized test statistic, the resampling tests are modified in order to be valid asymptotically even in non-exchangeable data frameworks. Moreover, extensions of this approach to other designs and reliability measures are discussed as well. Finally, the usefulness of the proposed resampling-based testing strategies is demonstrated in an extensive simulation study and illustrated by real data applications.
, which we test against one-or two-sided alternatives. For this purpose, resampling-based permutation and bootstrap tests are proposed for two-group multivariate non-normal models under the general asymptotically distribution-free (ADF) setting. These statistical tests ensure a better control of the type-I error, in finite or very small sample sizes, when the state-of-affairs ADF large-sample test may fail to properly attain the nominal significance level. By proper choice of a studentized test statistic, the resampling tests are modified in order to be valid asymptotically even in non-exchangeable data frameworks. Moreover, extensions of this approach to other designs and reliability measures are discussed as well. Finally, the usefulness of the proposed resampling-based testing strategies is demonstrated in an extensive simulation study and illustrated by real data applications.
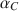
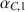
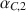
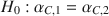
Accurate Confidence and Bayesian Interval Estimation for Non-centrality Parameters and Effect Size Indices
-
- Journal:
- Psychometrika / Volume 88 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 253-273
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Distance-Based Variety of Nonlinear Multivariate Data Analysis, Including Weights for Objects and Variables
-
- Journal:
- Psychometrika / Volume 64 / Issue 2 / June 1999
- Published online by Cambridge University Press:
- 01 January 2025, pp. 169-186
-
- Article
- Export citation
Testing Whether Independent Treatment Groups have Equal Medians
-
- Journal:
- Psychometrika / Volume 56 / Issue 3 / September 1991
- Published online by Cambridge University Press:
- 01 January 2025, pp. 381-395
-
- Article
- Export citation
Application of the Bootstrap Methods in Factor Analysis
-
- Journal:
- Psychometrika / Volume 60 / Issue 1 / March 1995
- Published online by Cambridge University Press:
- 01 January 2025, pp. 77-93
-
- Article
- Export citation
Comparing One-Step M-Estimators of Location Corresponding to Two Independent Groups
-
- Journal:
- Psychometrika / Volume 57 / Issue 1 / March 1992
- Published online by Cambridge University Press:
- 01 January 2025, pp. 141-154
-
- Article
- Export citation
