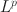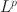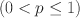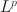Refine search
Actions for selected content:
128 results
Association between tomato consumption and prehypertension among Korean adults: finding from the Korean Genome and Epidemiology Study
-
- Journal:
- British Journal of Nutrition , First View
- Published online by Cambridge University Press:
- 19 November 2025, pp. 1-7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hepcidin is low in children with moderate acute malnutrition and asymptomatic malaria: secondary analysis of a 2×2×3 factorial randomised trial in Burkina Faso
-
- Journal:
- British Journal of Nutrition , First View
- Published online by Cambridge University Press:
- 17 November 2025, pp. 1-11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Assessing the Predictive Value of mREMS in Patients with Trauma from the Syrian Civil War: A Retrospective Epidemiological Study
-
- Journal:
- Prehospital and Disaster Medicine / Volume 40 / Issue 5 / October 2025
- Published online by Cambridge University Press:
- 07 October 2025, pp. 243-250
- Print publication:
- October 2025
-
- Article
- Export citation
Prehospital Aspirin Delivery: Emergency Medical Dispatcher-Directed versus Emergency Medical Services Field Provider-Directed Aspirin Administration
-
- Journal:
- Prehospital and Disaster Medicine / Volume 40 / Issue 5 / October 2025
- Published online by Cambridge University Press:
- 04 November 2025, pp. 251-258
- Print publication:
- October 2025
-
- Article
- Export citation
Relative associations of coffee, tea and plain water with all-cause and cause-specific mortality: a prospective cohort study
-
- Journal:
- British Journal of Nutrition , First View
- Published online by Cambridge University Press:
- 22 September 2025, pp. 1-10
-
- Article
- Export citation
Simple imputation method for meta-analysis of survival rates when precision information is missing
-
- Journal:
- Research Synthesis Methods / Volume 16 / Issue 6 / November 2025
- Published online by Cambridge University Press:
- 11 September 2025, pp. 937-952
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Evaluation of patients’ satisfaction with food services and assessment of plate waste in Cypriot hospitals
-
- Journal:
- Journal of Nutritional Science / Volume 14 / 2025
- Published online by Cambridge University Press:
- 15 August 2025, e57
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Malnutrition among students with visual impairment studying in integrated public schools of Nepal
-
- Journal:
- Journal of Nutritional Science / Volume 14 / 2025
- Published online by Cambridge University Press:
- 06 August 2025, e56
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Novel approaches for random-effects meta-analysis of a small number of studies under normality
-
- Journal:
- Research Synthesis Methods / Volume 16 / Issue 6 / November 2025
- Published online by Cambridge University Press:
- 10 July 2025, pp. 922-936
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A reverse J-shaped association between adherence to planetary health diet and all-cause and cause-specific mortality in Japan: a cross-sectional prefecture-level ecological study
-
- Journal:
- Journal of Nutritional Science / Volume 14 / 2025
- Published online by Cambridge University Press:
- 02 July 2025, e45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A cross-sectional study on the relationship between dietary magnesium intake and periodontitis in different body mass index and waist circumference groups: National Health and Nutrition Examination Survey, 2009–2014
-
- Journal:
- Journal of Nutritional Science / Volume 14 / 2025
- Published online by Cambridge University Press:
- 08 May 2025, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Estimating sodium and potassium intakes in a Portuguese adult population: can first-morning void urine replace 24-hour urine samples?
-
- Journal:
- Journal of Nutritional Science / Volume 14 / 2025
- Published online by Cambridge University Press:
- 26 March 2025, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Zinc ion dyshomeostasis in autism spectrum disorder
-
- Journal:
- Nutrition Research Reviews / Volume 38 / Issue 2 / December 2025
- Published online by Cambridge University Press:
- 13 March 2025, pp. 661-681
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cross-sectional associations between healthy and unhealthy plant-based diets and metabolic syndrome in three distinct French populations: a meta-analysis
-
- Journal:
- British Journal of Nutrition / Volume 133 / Issue 7 / 14 April 2025
- Published online by Cambridge University Press:
- 03 March 2025, pp. 949-965
- Print publication:
- 14 April 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Lifestyle risk factors for overweight and obesity among rural Indian adults: a community-based prospective cohort study
-
- Journal:
- Journal of Nutritional Science / Volume 14 / 2025
- Published online by Cambridge University Press:
- 11 February 2025, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prevalence of daily fruit and vegetable intake by socio-economic characteristics, women’s empowerment, and climate zone: an ecological study in Latin American cities
-
- Journal:
- Journal of Nutritional Science / Volume 14 / 2025
- Published online by Cambridge University Press:
- 15 January 2025, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Differential Item Functioning Analysis Without A Priori Information on Anchor Items: QQ Plots and Graphical Test
-
- Journal:
- Psychometrika / Volume 86 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 345-377
-
- Article
- Export citation
Generalized Sample Size Determination Formulas for Investigating Contextual Effects by a Three-Level Random Intercept Model
-
- Journal:
- Psychometrika / Volume 82 / Issue 1 / March 2017
- Published online by Cambridge University Press:
- 01 January 2025, pp. 133-157
-
- Article
- Export citation
Frequentist Model Averaging in Structure Equation Model With Ordinal Data
-
- Journal:
- Psychometrika / Volume 87 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1130-1145
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In practice, it is common that a best fitting structural equation model (SEM) is selected from a set of candidate SEMs and inference is conducted conditional on the selected model. Such post-selection inference ignores the model selection uncertainty and yields too optimistic inference. Using the largest candidate model avoids model selection uncertainty but introduces a large variation. Jin and Ankargren (Psychometrika 84:84–104, 2019) proposed to use frequentist model averaging in SEM with continuous data as a compromise between model selection and the full model. They assumed that the true values of the parameters depend on \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$n^{-1/2}$$\end{document}
 with n being the sample size, which is known as a local asymptotic framework. This paper shows that their results are not directly applicable to SEM with ordinal data. To address this issue, we prove consistency and asymptotic normality of the polychoric correlation estimators under the local asymptotic framework. Then, we propose a new frequentist model averaging estimator and a valid confidence interval that are suitable for ordinal data. Goodness-of-fit test statistics for the model averaging estimator are also derived.
with n being the sample size, which is known as a local asymptotic framework. This paper shows that their results are not directly applicable to SEM with ordinal data. To address this issue, we prove consistency and asymptotic normality of the polychoric correlation estimators under the local asymptotic framework. Then, we propose a new frequentist model averaging estimator and a valid confidence interval that are suitable for ordinal data. Goodness-of-fit test statistics for the model averaging estimator are also derived.

Rotation to Sparse Loadings Using Lp\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}
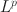 Losses and Related Inference Problems
Losses and Related Inference Problems
-
- Journal:
- Psychometrika / Volume 88 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 527-553
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Researchers have widely used exploratory factor analysis (EFA) to learn the latent structure underlying multivariate data. Rotation and regularised estimation are two classes of methods in EFA that they often use to find interpretable loading matrices. In this paper, we propose a new family of oblique rotations based on component-wise \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}
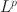 loss functions \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(0 < p\le 1)$$\end{document}
loss functions \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(0 < p\le 1)$$\end{document}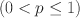 that is closely related to an \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}
that is closely related to an \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}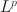 regularised estimator. We develop model selection and post-selection inference procedures based on the proposed rotation method. When the true loading matrix is sparse, the proposed method tends to outperform traditional rotation and regularised estimation methods in terms of statistical accuracy and computational cost. Since the proposed loss functions are nonsmooth, we develop an iteratively reweighted gradient projection algorithm for solving the optimisation problem. We also develop theoretical results that establish the statistical consistency of the estimation, model selection, and post-selection inference. We evaluate the proposed method and compare it with regularised estimation and traditional rotation methods via simulation studies. We further illustrate it using an application to the Big Five personality assessment.
regularised estimator. We develop model selection and post-selection inference procedures based on the proposed rotation method. When the true loading matrix is sparse, the proposed method tends to outperform traditional rotation and regularised estimation methods in terms of statistical accuracy and computational cost. Since the proposed loss functions are nonsmooth, we develop an iteratively reweighted gradient projection algorithm for solving the optimisation problem. We also develop theoretical results that establish the statistical consistency of the estimation, model selection, and post-selection inference. We evaluate the proposed method and compare it with regularised estimation and traditional rotation methods via simulation studies. We further illustrate it using an application to the Big Five personality assessment.